Joint Sparse Recovery With Semisupervised MUSIC
Zaidao Wen, Biao Hou, Licheng Jiao

TL;DR
This paper introduces SS-MUSIC, a semisupervised approach to joint sparse recovery that enhances the classical MUSIC algorithm by leveraging unlabeled atoms, improving performance especially in rank-defective scenarios.
Contribution
It proposes a novel semisupervised MUSIC algorithm that iteratively refines classification by utilizing both labeled and unlabeled data, addressing rank deficiency issues in joint sparse recovery.
Findings
SS-MUSIC outperforms traditional MUSIC and greedy algorithms in recovery probability.
It requires fewer iterations for convergence.
It demonstrates robustness in rank-defective and coherent measurement scenarios.
Abstract
Discrete multiple signal classification (MUSIC) with its low computational cost and mild condition requirement becomes a significant noniterative algorithm for joint sparse recovery (JSR). However, it fails in rank defective problem caused by coherent or limited amount of multiple measurement vectors (MMVs). In this letter, we provide a novel sight to address this problem by interpreting JSR as a binary classification problem with respect to atoms. Meanwhile, MUSIC essentially constructs a supervised classifier based on the labeled MMVs so that its performance will heavily depend on the quality and quantity of these training samples. From this viewpoint, we develop a semisupervised MUSIC (SS-MUSIC) in the spirit of machine learning, which declares that the insufficient supervised information in the training samples can be compensated from those unlabeled atoms. Instead of constructing a…
Click any figure to enlarge with its caption.
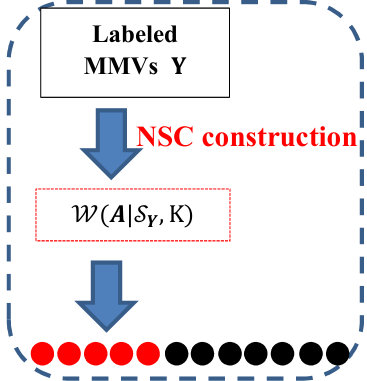 Figure 1
Figure 1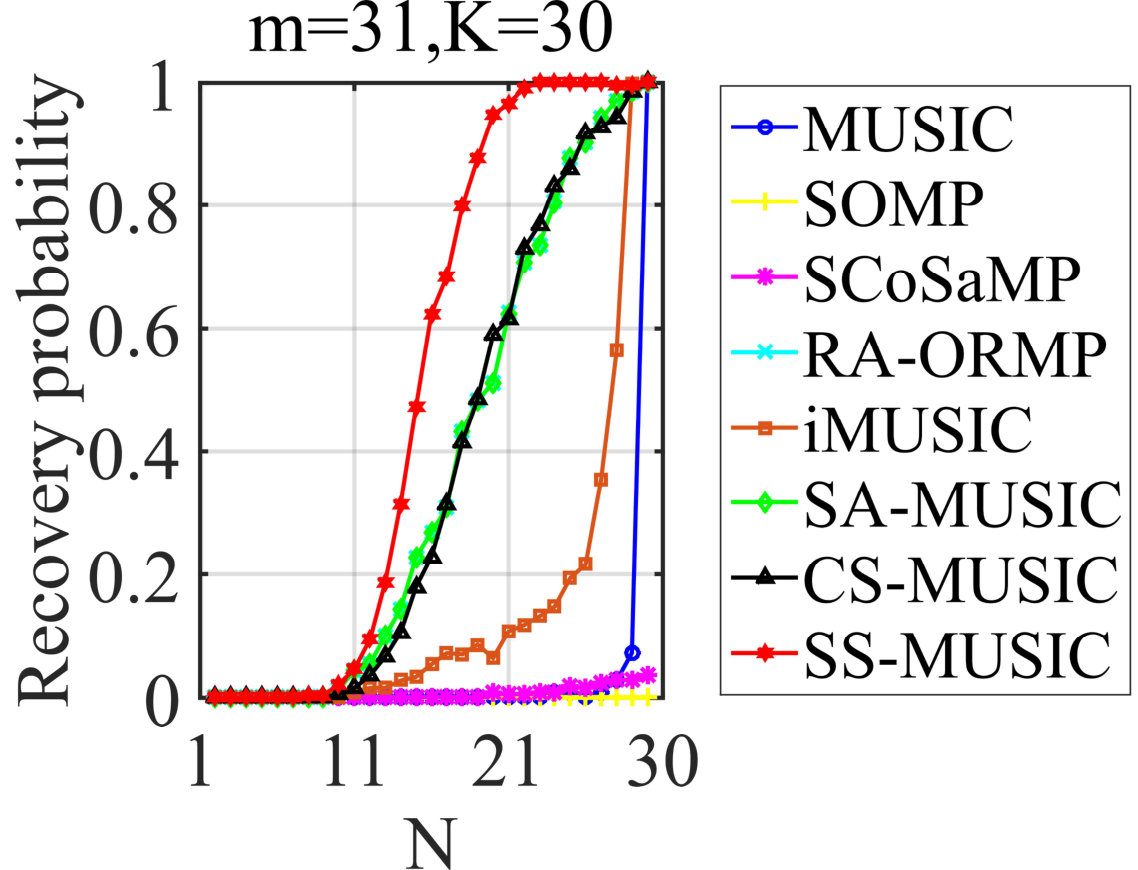 Figure 2
Figure 2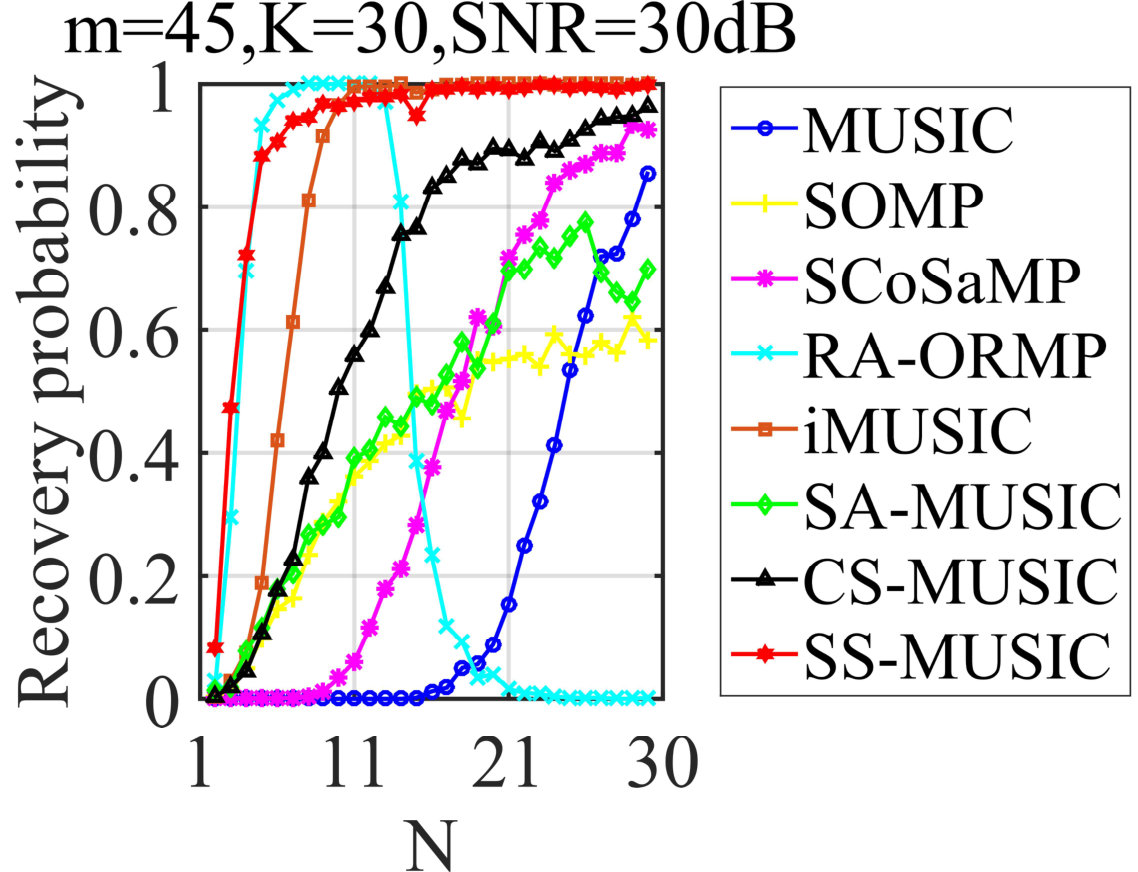 Figure 3
Figure 3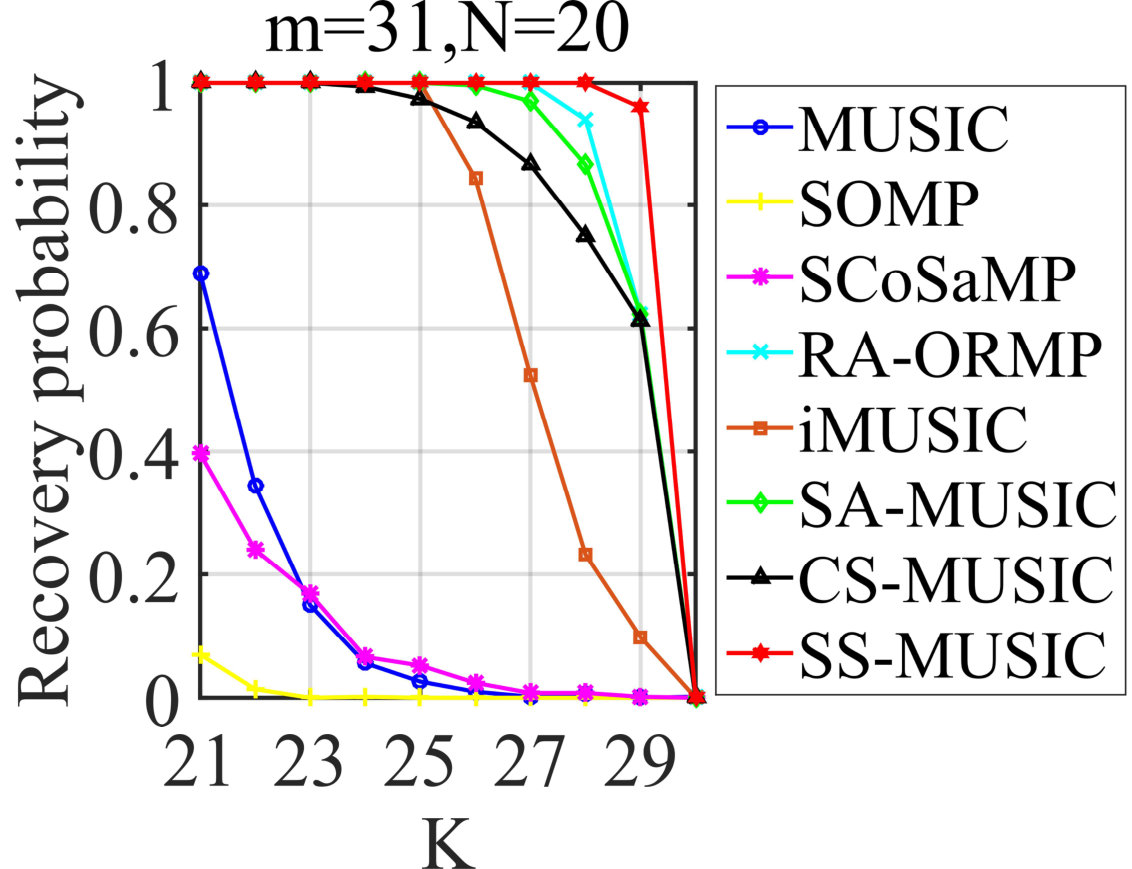 Figure 4
Figure 4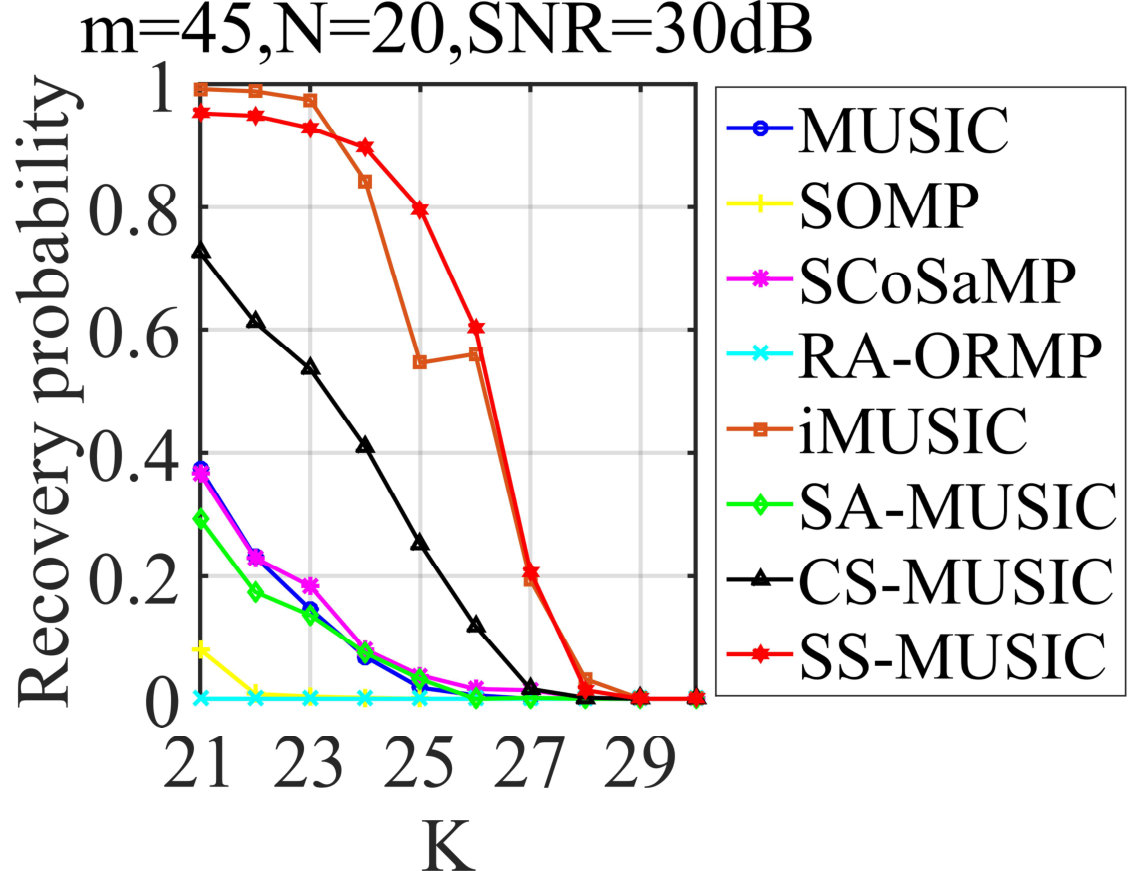 Figure 5
Figure 5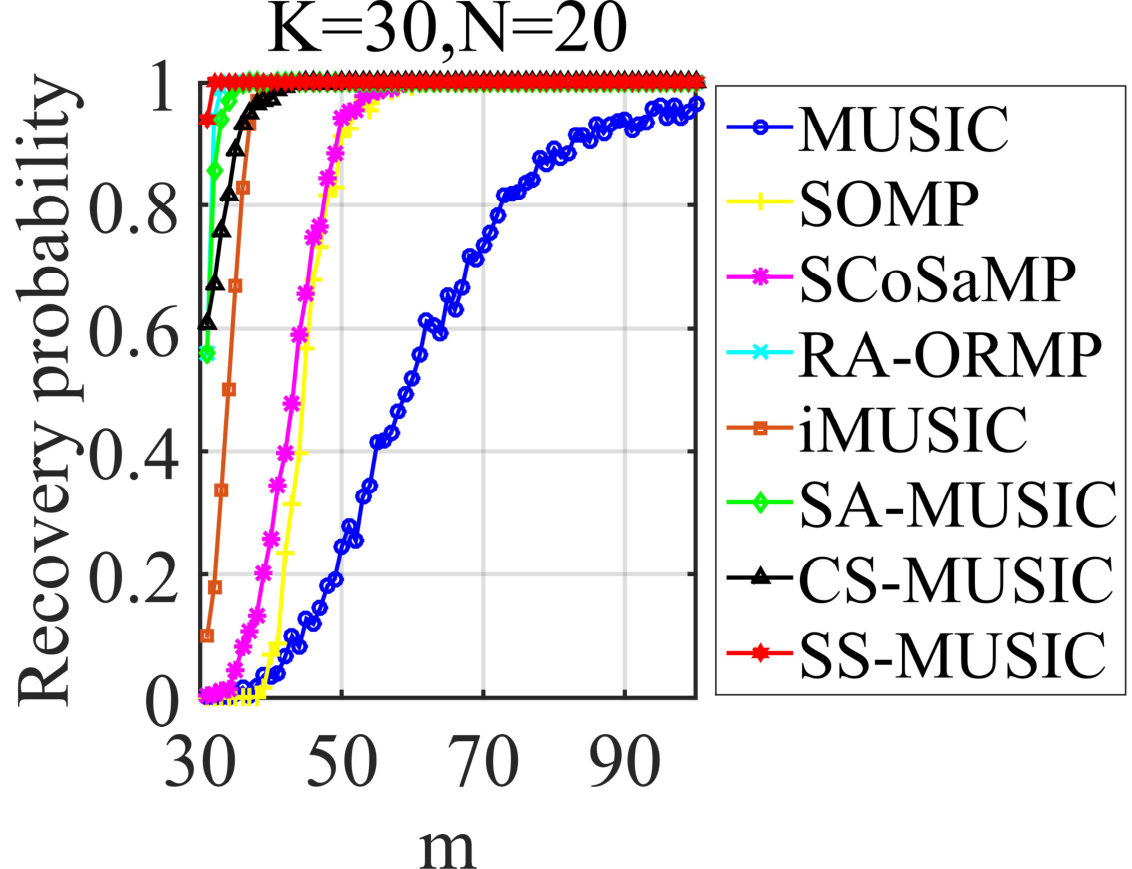 Figure 6
Figure 6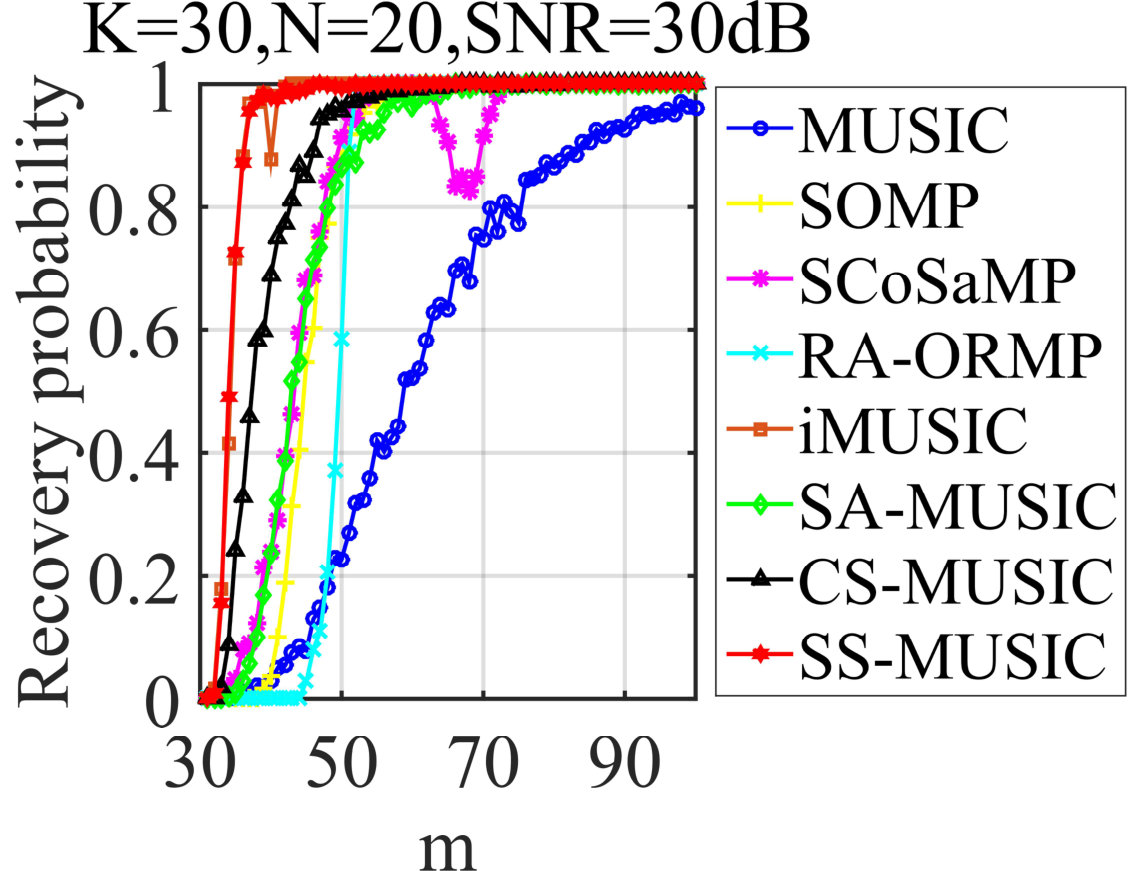 Figure 7
Figure 7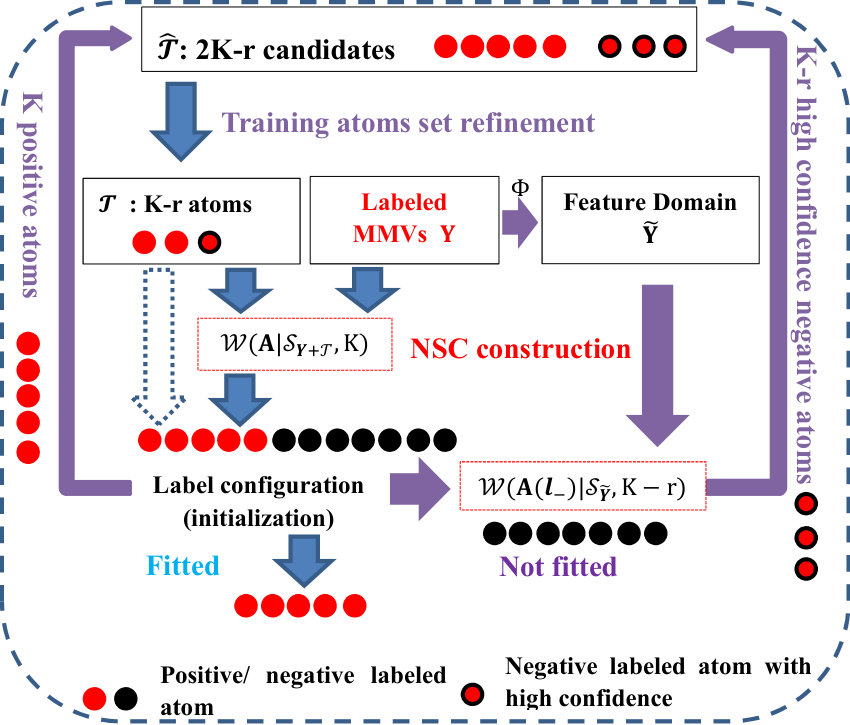 Figure 8
Figure 8 Figure 9
Figure 9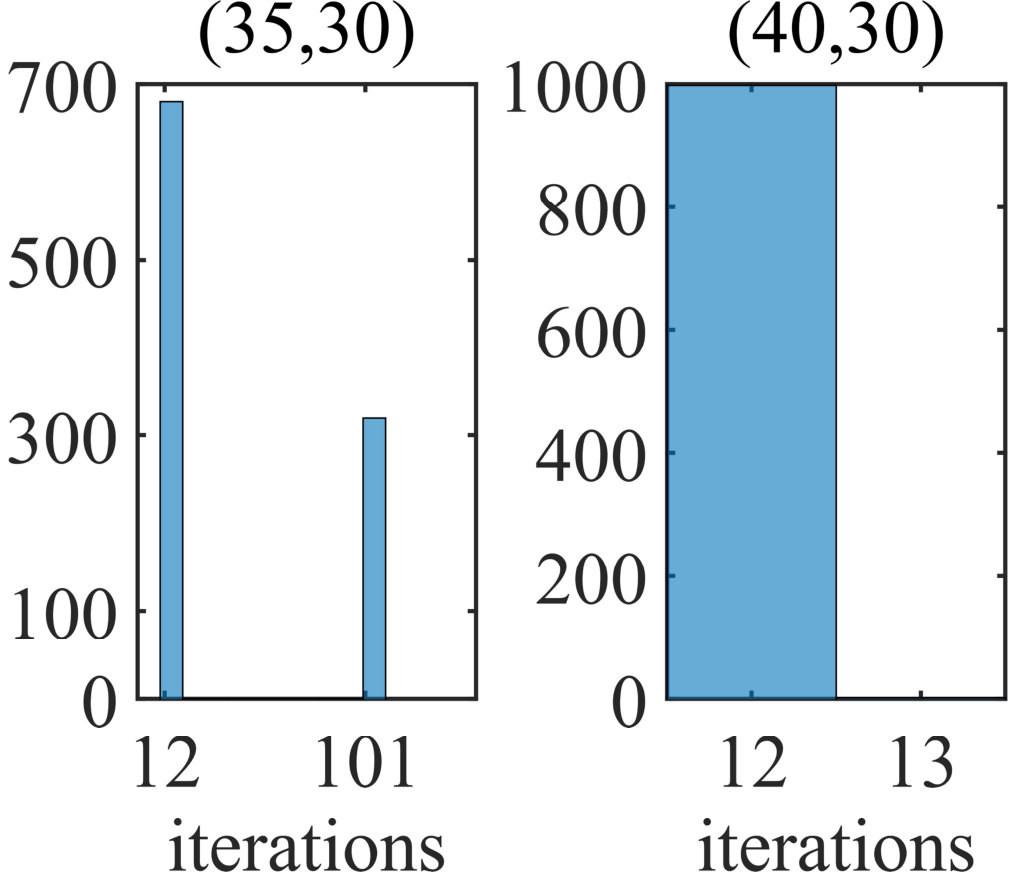 Figure 10
Figure 10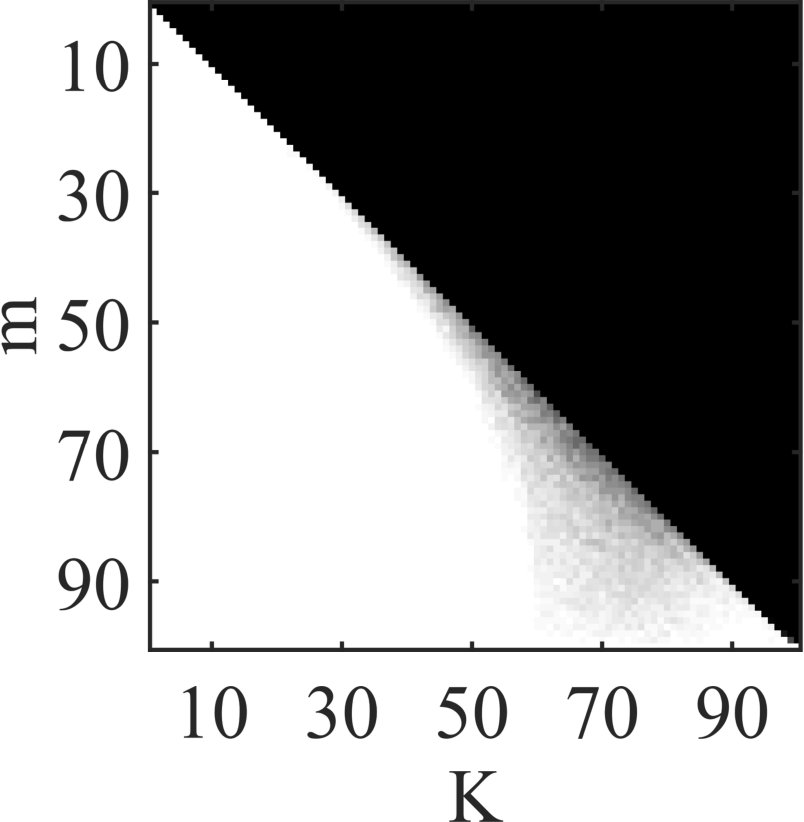 Figure 11
Figure 11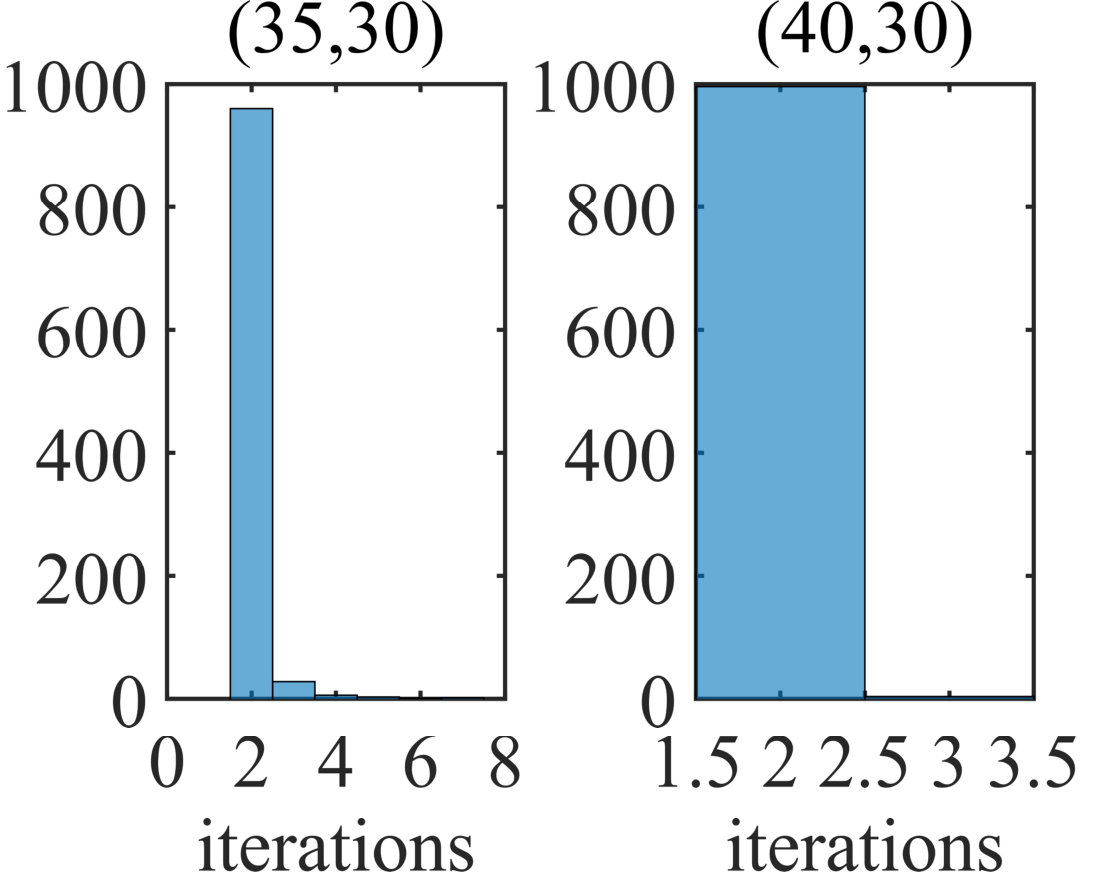 Figure 12
Figure 12Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Joint Sparse Recovery with Semi-Supervised MUSIC
Zaidao Wen, Biao Hou, Member, IEEE, Licheng Jiao, Senior Member, IEEE
Abstract
Discrete multiple signal classification (MUSIC) with its low computational cost and mild condition requirement becomes a significant non-iterative algorithm for joint sparse recovery (JSR). However, it fails in rank defective problem caused by coherent or limited amount of multiple measurement vectors (MMVs). In this paper, we provide a novel sight to address this problem by interpreting JSR as a binary classification problem with respect to atoms. Meanwhile, MUSIC essentially constructs a supervised classifier based on the labeled MMVs so that its performance will heavily depend on the quality and quantity of these training samples. From this viewpoint, we develop a semi-supervised MUSIC (SS-MUSIC) in the spirit of machine learning, which declares that the insufficient supervised information in the training samples can be compensated from those unlabeled atoms. Instead of constructing a classifier in a fully supervised manner, we iteratively refine a semi-supervised classifier by exploiting the labeled MMVs and some reliable unlabeled atoms simultaneously. Through this way, the required conditions and iterations can be greatly relaxed and reduced. Numerical experimental results demonstrate that SS-MUSIC can achieve much better recovery performances than other MUSIC extended algorithms as well as some typical greedy algorithms for JSR in terms of iterations and recovery probability. The code is available on https://github.com/wzdammy/semi_supervised_MUSIC.
Index Terms:
MUSIC, greedy pursuit, multiple measurement vectors, joint sparse recovery, semi-supervised classification.
I Introduction
The emerging theory of compressed sensing (CS) supplies a paradigm for recovering an unknown sparse signal from some compressed linear measurements and it has been devoted to many applications in signal processing as well as machine learning (ML) [1, 2, 3]. This theory primarily addresses the recovery problem of a signal from its single measurement vector (SMV) such that , where models the linear measurement matrix with . Practically, we may encounter the problem of simultaneously recovering a group of sparse signals from their multiple measurement vectors (MMVs) in many tasks, e.g., multivariate regression [4], classification [5, 6], direction of arrival estimation [7], etc. When these underlying signals share some particular sparse patterns, it will enable to reduce the condition for successful recovery. One of the most prevalent patterns expressed as joint sparse suggests that these signals will share the same support so that will contain only a few non-zero rows. In this scenario, if the row-sparsity, the number of non-zero rows of is equal to , the problem of joint sparse recovery (JSR) from a common can be formulated as
[TABLE]
where is the Frobenius norm (F-norm) and counts the non-zero rows in . Unfortunately, (1) is generally a combinatorial non-convex optimization problem due to . To solve this problem, two strategies have been developed in optimization field, namely convex relaxation with a mixed norm and greedy methods [8]. Focusing on the greedy algorithm, the central issue becomes to iteratively estimate a certain amount of atoms according to the correlations with the residual matrix so as to mostly decrease the value of objective function (1). Once a support set is determined, the recovery problem will be reduced to a standard overdetermined linear problem solved with the least square. As a consequence, numerous greedy JSR algorithms have been extended from SMV to MMVs [9], yielding the orthogonal matching pursuit (OMP) for MMVs (OMP-MMV) [10, 11] or the so-called simultaneously OMP (SOMP) [12, 13], simultaneously compressive sampling matching pursuit (SCoSaMP) [14, 9], rank aware order recursive matching pursuit (RA-ORMP) [15] etc.
Another significant algorithm referred to as discrete multiple signal classification (MUSIC) takes a different viewpoint in the field of signal processing [16]. It reveals that each measurement vector and the correct atoms should reside in the same subspace if . Under a mild condition, those atoms can be straightforward determined by singular value decomposition (SVD) without iterative process, which achieves far more remarkable performance than those greedy optimization algorithms in terms of complexity and required conditions. When caused by limited amount of MMVs or information loss due to their correlations, MUSIC will however yield a failing estimation in this rank defective case. To overcome this drawback, some MUSIC extended algorithms have been developed for rank defective problem, such as iMUSIC, compressive MUSIC (CS-MUSIC) and subspace-augmented MUSIC (SA-MUSIC) [17, 18, 19]. iMUSIC, an initial version of SA-MUSIC, involves an iterative atom refinement procedure in MUSIC so that some falsely determined atoms could be gradually refined during iterations. However, some operations in atoms refinement are not optimal so that it can only achieve a marginal improvement than MUSIC and some conventional greedy approaches in noiseless case. Later, two almost equivalent algorithms of SA-MUSIC and CS-MUSIC provide a two-stages framework, which indicates that if any atoms could be correctly estimated in the first stage with any an off the shelf algorithm, the rest atoms will be simply determined by applying MUSIC on an augmented subspace [18, 19]. It follows that the required conditions and iterations for such a combinational framework will actually depend on the algorithm in the first stage, which is usually suboptimal compared to MUSIC. How to fully exploit the advantages of MUSIC to relax the condition and reduce the iterations become two important issues.
In recent years, the field of ML attracts much more attentions because of some significant progresses in both theory and industry. If we revisit the support estimation from the perspective of ML, it can be regarded as a binary classification task with respect to atoms and MUSIC actually constructs a nearest subspace classifier (NSC) according to the positive labeled training samples in a fully supervised way [20]. Therefore, its discriminative ability will be naturally affected by the quality and quantity of these training samples. Following this novel viewpoint, we are motivated to address the rank defective problem by means of the strategy in ML.
In this paper, we present a novel semi-supervised MUSIC (SS-MUSIC) for JSR, in which both the labeled MMVs and some reliable unlabeled atoms are iteratively exploited for classifier construction [21]. Through this way, the inadequate supervised information in rank defective MMVs can be additionally compensated from those unlabeled data so as to increase the discrimination of the classifier. As a consequence, SS-MUSIC will successfully classify all atoms within iterations as long as at least one positive atom can be newly determined and preserved in each iteration. The simulation results clearly demonstrate the superiorities of SS-MUSIC, compared with the other MUSIC extended frameworks as well as some state-of-the-art greedy algorithms.
The rest paper is organised as follows. Sec. II proposes our algorithm in detail. Numerical experiments are conducted in Sec. III and Sec. IV concludes this paper.
II Semi-Supervised MUSIC
In this section, we will formally reformulate the JSR problem and MUSIC from the viewpoint of ML in the first place. Then a novel SS-MUSIC framework is developed and compared with the other algorithms in order to demonstrate its superiorities.
II-A Reformulation of JSR and MUSIC
Let contain labeled noiseless training samples drawn from the positive class. Given unlabeled atoms , the central task for JSR is classifying these atoms into two classes by assigning a proper label to such that , where is the -th row vector in , stands for the indicator function as for negative label and for positive one. Additionally, we have a prior knowledge that the amount of the positive atoms will be . Since each will reside in the subspace spanned by those positive labeled atoms, we can measure the sum of Euclidean distance from each to to evaluate the fitness of a label configuration , which is defined as following.
[TABLE]
where stands for the subset of atoms with positive labels and is the orthogonal projection operator onto subspace here and after. If is the orthogonal basis of subspace computed from truncated SVD or principal component analysis (PCA) [22], . It follows that if the classification is correct, will reach its lower bound, namely zero in a noiseless situation. In practical situation with noisy MMVs, we can exploit a threshold related to signal-to-noise ratio (SNR) to indicate the fitness of , namely .
Considering this task, one of the most prevalent strategies in ML is supervised classification, which focuses on constructing a classifier based on the training samples. Following this way, the novel MUSIC algorithm essentially constructs a NSC with and each query atom will be classified by measuring [16]. Then atoms with the closest distance will be classified into the positive class. Since this classifier will be frequently exploited in the following paper, it will be denoted by , where contains the query testing samples, is the subspace spanned by samples in set and controls the number of positive labels in the output of label configuration .
II-B Algorithm Presentation
It has been indicated that when , such a supervised classifier will produce a perfect classification result if any atoms are linearly independent [16]. However, when the number of training samples is limited or they are coherent, . In this case, supervised information in training data will be insufficient to construct a discriminative NSC so that the performance will be degraded. To overcome this deficiency, we will consider the strategy of semi-supervised classification (SSC) to develop a novel SS-MUSIC framework [21], whose central idea is to simultaneously make use of the labeled and some reliable unlabeled samples to construct a semi-supervised classifier. Then the information required for classification will be compensated from unlabeled data. For better understanding the difference between MUSIC and SS-MUSIC, two frameworks will be illustrated in Figs.1, where the notation and containing unlabeled atoms will represent the candidate and actual training set for semi-supervised classifier construction, respectively. we will address the two central issues of constructing and to explain the framework in Fig. 1 as following.
We will start from a label configuration obtained in -th iteration, . If it is not fitted according to (2), it implies that the current training set cannot provide sufficient or correct discriminative information for classifier construction, i.e., will contain some outlying atoms so as to bias the classifier or the number of involved atoms is inadequate. To address this issue, except for those atoms in current positive class, we will reappraise the confidence of each atom in the negative class so that some with high confidences will be also involved in . We suggest that if an atom is much similar to measured in a feature domain, a high confidence of being involved will be encouraged. To avoid the redundant information, the high confident atoms should have the ability of providing extra information compared with . To meet these two requirements, we will firstly project onto the orthogonal complement subspace of as with a feature extractor in order to eliminate the information of . Then NSC will be exploited to select atoms that is nearest to . Finally, the candidate set will be constructed as . The above procedures are denoted by purple flows in Fig. 1.
After we obtain containing candidates, representative and reliable atoms will be further refined to update and construct the semi-supervised classifier. This task will be simply interpreted as the following overcomplete variables selection problem [23].
[TABLE]
whose solution is given by and stands for the pseudo-inverse of . Then the atoms corresponding to the first largest will be selected into . Next, atoms in and the labeled MMVs will be simultaneously used to construct a semi-supervised classifier as . Since atoms are already devoted to classifier construction, their labels will be consequently positive and we only need to assign the rest positive labels to other atoms in . The complete SS-MUSIC is summarised in following Algorithm 1.
II-C Discussion and Comparison
To demonstrate the superiorities of SS-MUSIC to make it more convinced, some discussions and comparisons with other algorithms will be carried out in this subsection, in spite of their distinct motivations. In the first place, let us focus on the iterations. According to the principle of SA-MUSIC or CS-MUSIC, once has contained the atoms belonging to the positive class, the subsequent will generate the fitted label configuration. It follows that if one more positive atom could be newly involved and preserved in in each iteration, the upper bound on iterations will be . In fact, we will empirically show in the next section that the actual iterations will be much fewer than . On the contrary, CS-MUSIC and SA-MUSIC respectively exploit M-OMP and OSMP to determine atoms iteratively in the first stage so that their iterations will be always . Since iMUSIC also adopts M-OMP for initial atoms estimation, the lower bound on iterations will be . Accordingly, SS-MUSIC requires fewer iterations than these MUSIC extended algorithms while its computational complexity will be still comparable with that of iMUSIC. Now let us compare the required conditions for each algorithm. For SA-MUSIC and CS-MUSIC, their required conditions mainly come from the first stage that should guarantee the correctness of selecting one atom in each iteration. On the contrary, SS-MUSIC will only require at least one correct atom to be selected and preserved in , which will be reasonably much relaxed than that of SA-MUSIC and CS-MUSIC. This can be also concluded from the proof of the generalized OMP which selects a set of atoms in one iteration to relax the condition of OMP in SMV problem [24]. Additionally, SS-MUSIC involving an atom refinement process will further relax the conditions, which is similar to iMUSIC. Nevertheless, SS-MUSIC is different from iMUSIC in following implementations. 1). iMUSIC utilizes to construct , where is the number of selected atoms controlled by the condition number of . On the contrary, SS-MUSIC selects atoms based on in a different feature subspace. 2). Eq. (3) in iMUSIC is different and the resulted atoms will be directly served as the label configuration in this iteration. In SS-MUSIC, those resulted atoms will be subsequently utilized to build a semi-supervised classifier to obtain the label configuration.
Comparing SS-MUSIC with some conventional greedy optimization algorithms in CS, it will be analogous to SCoSaMP which estimates atoms and makes a refinement in each iteration. Nevertheless, SCoSaMP requires a more strict condition and more iterations for exact recovery. Ambat and Hari presented a general iterative framework for SMV problem [25], in which they introduce a regularization procedure on both atoms and measurement vector to remove the effect of the previous estimated atoms. However, they aim at estimating complete atoms in each iteration while SS-MUSIC focuses on in the spirit of SSC.
III Empirical Performance
In this section, we consider the following experimental setting to evaluate the performance for rank defective JSR problem. is drawn from the standard Gaussian distribution and rows in general position are randomly retained with other rows setting as zeros. In this case, . is also chosen as the standard Gaussian random matrix with each atom normalized. .
In the first part, the phase transition of SS-MUSIC will be evaluated in Fig. 2, where and will vary from 1 to 100, respectively and and 1000 independent recovery experiments are conducted for each pair of . We can observe from the transition map that when , SS-MUSIC will perfectly recover the signals with high probabilities for most pairs of . When , it becomes the full rank JSR problem, in which case SS-MUSIC will be the MUSIC sharing condition of . When , we however observe that the required for recovery will not greatly increase to reach the high probability performance, which empirically demonstrates a mild condition for . To evaluate the required iterations, we choose the recovery results from pair and and count the iterations for successfully recovery. For those failure trials, the iterations will be denoted by as . We plot the histograms of the iterations in Fig. 2. For comparison, the results for iMUSIC will be also illustrated in Fig. 2. It should be declared that the standard iMUSIC leverages the condition number to control the amount of involved atoms for refinement, but it will involve another parameter. Instead, a fixed number is selected which is the same with SS-MUSIC, namely . We can see from the results in Fig. 2 that SS-MUSIC can achieve perfect performances in both cases and the required iterations can reach the lower bound 2 in the most experiments among 1000 trials. On the contrary, 300 trials for iMUSIC in the case of are failed and the iterations in the rest experiments are 12.
In the next experiments, SS-MUSIC will be compared with other JSR algorithms to demonstrate its superiority in terms of required condition. For this purpose, we will vary one parameter of , and to evaluate the recovery probabilities of each algorithm with the other two fixed, respectively. In the first place, the noiseless situation is considered, yielding the results shown in Figs. 3-3 and the corresponding settings are also illustrated in the figures. From the results in Fig. 3, we can see that SS-MUSIC outperforms all competitive algorithms when we vary , followed by RA-ORMP, SA-MUSIC and CS-MUSIC. It is worth noting that when reaches its lower bound, SS-MUSIC can still achieve over probability of exact recovery, which empirically verifies a milder condition of for SS-MUSIC. Similar conclusions can be also derived from the performances in Figs. 3 and 3 and we will not discuss for the sake of space limitation.
Finally, we will evaluate their performances in noisy situation, where the measurement noise distributed from Gaussian will be considered for simplicity, namely and stands for the measurement noise matrix. Before starting, since SS-MUSIC is developed for noiseless MMVs, some operations should be modified, where the rank and the subspace of should be estimated from in the first stage. For simplicity and fair comparison, we adopt an efficient method proposed in SA-MUSIC to address this issue. Then we will exploit the estimated rank and basis of subspace to construct the semi-supervised classifier in SS-MUSIC. The comparison results are illustrated in Figs. 3-3. We can conclude that SS-MUSIC can still preserve its remarkable recovery performance to outperform the other algorithms in the most cases. It can be also observed that iMUSIC will also achieve the better performances than other algorithms due to its refinement procedure.
IV Conclusion
This paper develops a novel SS-MUSIC for rank defective JSR, which brings the strategy of ML into the optimization problem to shed a new light on this direction. We show that simultaneously exploiting the labeled MMVs and some unlabeled atoms can significantly improve the performance in terms of required iterations and conditions. In our future work, we will develop a robust framework to address the noisy JSR problem straightforwardly, in which more ML strategies will be considered and involved to avoid estimating and subspace of in the first place.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] D. L. Donoho, “Compressed sensing,” IEEE Trans. Inf. Theory , vol. 52, no. 4, pp. 1289–1306, 2006.
- 2[2] R. Baraniuk, “Compressive sensing,” IEEE Signal Process. Mag. , vol. 24, no. 4, 2007.
- 3[3] E. J. Candès and M. B. Wakin, “An introduction to compressive sampling,” IEEE Signal Process. Mag. , vol. 25, no. 2, pp. 21–30, 2008.
- 4[4] J. Peng, P. Wang, N. Zhou, and J. Zhu, “Partial correlation estimation by joint sparse regression models.” J. American Statistical Association , vol. 104, no. 486, pp. 735–746, 2009.
- 5[5] Z. Wen, B. Hou, and L. Jiao, “Discriminative dictionary learning with two-level low rank and group sparse decomposition for image classification,” IEEE Trans. Cybern. , 2016.
- 6[6] J. Li, H. Zhang, and L. Zhang, “Efficient superpixel-level multitask joint sparse representation for hyperspectral image classification,” IEEE Trans. Geosci. Remote Sens. , vol. 53, no. 10, pp. 1–14, 2015.
- 7[7] D. Malioutov, M. Cetin, and A. S. Willsky, “A sparse signal reconstruction perspective for source localization with sensor arrays.” IEEE Trans. Signal Process. , vol. 53, no. 8, pp. 3010–3022, 2005.
- 8[8] M. M. Hyder and K. Mahata, “A robust algorithm for joint-sparse recovery,” IEEE Signal Process. Lett. , vol. 16, no. 12, pp. 1091–1094, 2009.