Discovering Reliable Approximate Functional Dependencies
Panagiotis Mandros, Mario Boley, Jilles Vreeken

TL;DR
This paper introduces a new information-theoretic method for reliably discovering approximate functional dependencies in data, addressing bias, efficiency, and optimality in dependency mining.
Contribution
It presents a bias-corrected score and an optimistic estimator enabling efficient, reliable discovery of approximate dependencies with guarantees of optimality.
Findings
Score effectively balances bias and variance.
Algorithm efficiently discovers meaningful dependencies.
Method remains reliable with sparse data.
Abstract
Given a database and a target attribute of interest, how can we tell whether there exists a functional, or approximately functional dependence of the target on any set of other attributes in the data? How can we reliably, without bias to sample size or dimensionality, measure the strength of such a dependence? And, how can we efficiently discover the optimal or -approximate top- dependencies? These are exactly the questions we answer in this paper. As we want to be agnostic on the form of the dependence, we adopt an information-theoretic approach, and construct a reliable, bias correcting score that can be efficiently computed. Moreover, we give an effective optimistic estimator of this score, by which for the first time we can mine the approximate functional dependencies from data with guarantees of optimality. Empirical evaluation shows that the derived score achieves a…
Click any figure to enlarge with its caption.
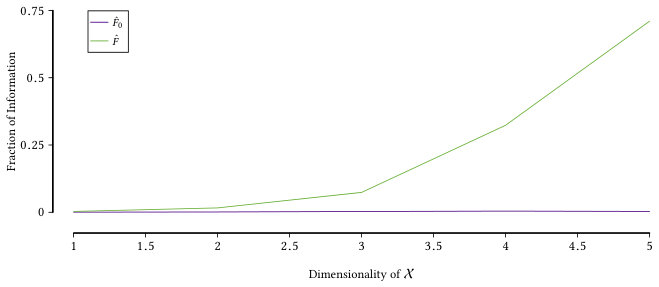 Figure 1
Figure 1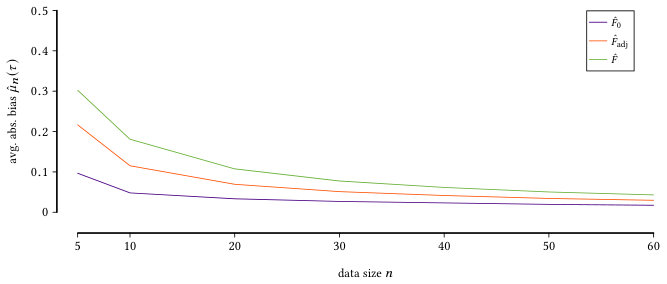 Figure 2
Figure 2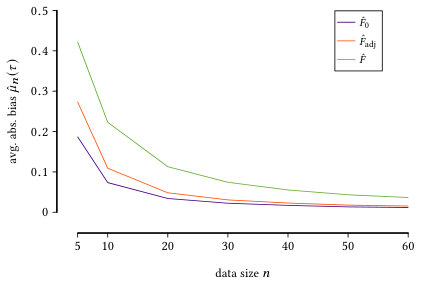 Figure 3
Figure 3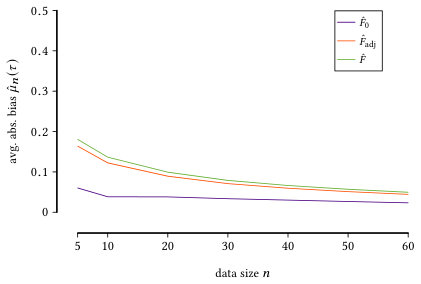 Figure 4
Figure 4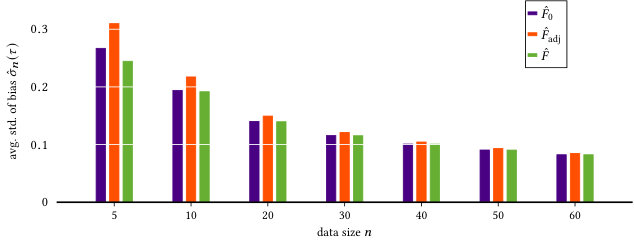 Figure 5
Figure 5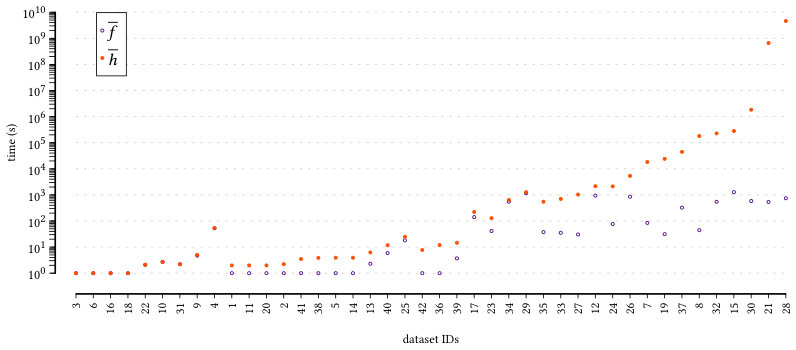 Figure 6
Figure 6 Figure 7
Figure 7 Figure 0
Figure 0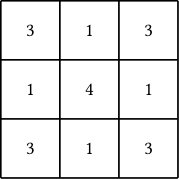 Figure 1
Figure 1| ID | Name | #rows | #attrs. | #clases | time(s) | max dep. | sol. dep. | prune | |
|---|---|---|---|---|---|---|---|---|---|
| 1 | abalone | 4174 | 8 | 28 | 1 | 2.1 | 8 | 3 | 0.00 |
| 2 | appendicitis | 106 | 7 | 2 | 1 | 1.0 | 6 | 3 | 50.00 |
| 3 | tic | 958 | 9 | 2 | 1 | 1.0 | 7 | 5 | 1.95 |
| 4 | australian | 690 | 14 | 2 | 1 | 3.7 | 11 | 5 | 75.01 |
| 5 | bupa | 345 | 6 | 2 | 1 | 1.0 | 1 | 1 | 96.88 |
| 6 | car | 1728 | 6 | 4 | 1 | 1.0 | 5 | 4 | 1.56 |
| 7 | chess | 3196 | 36 | 2 | 0.7 | 84.8 | 7 | 4 | 99.99 |
| 8 | coil2000 | 9822 | 85 | 2 | 0.1 | 44.5 | 5 | 4 | 99.99 |
| 9 | contraceptive | 1473 | 9 | 3 | 1 | 1.0 | 7 | 4 | 75.00 |
| 10 | ecoli | 336 | 7 | 8 | 1 | 1.0 | 6 | 4 | 50.00 |
| 11 | flare | 1066 | 11 | 6 | 1 | 2.7 | 11 | 3 | 0.00 |
| 12 | german | 1000 | 20 | 2 | 1 | 76.9 | 11 | 7 | 97.29 |
| 13 | glass | 214 | 9 | 7 | 1 | 1.0 | 7 | 4 | 75.00 |
| 14 | heart | 270 | 13 | 2 | 1 | 1.0 | 9 | 5 | 75.34 |
| 15 | ionosphere | 351 | 33 | 2 | 1 | 1272.7 | 11 | 4 | 99.98 |
| 16 | led7digit | 500 | 7 | 10 | 1 | 1.0 | 7 | 5 | 0.00 |
| 17 | lymphography | 148 | 18 | 4 | 1 | 41.2 | 11 | 5 | 71.79 |
| 18 | monk | 432 | 6 | 2 | 1 | 1.0 | 4 | 3 | 10.94 |
| 19 | movement-libras | 360 | 90 | 15 | 0.4 | 31.2 | 5 | 3 | 99.99 |
| 20 | nursery | 12690 | 8 | 5 | 1 | 2.2 | 7 | 5 | 0.78 |
| 21 | optdigits | 5620 | 64 | 10 | 0.5 | 538.1 | 10 | 3 | 99.99 |
| 22 | page | 5472 | 10 | 5 | 1 | 4.7 | 8 | 4 | 7.23 |
| 23 | penbased | 10992 | 16 | 10 | 1 | 141.2 | 5 | 3 | 93.33 |
| 24 | ring | 7400 | 20 | 2 | 0.6 | 944.4 | 7 | 3 | 94.24 |
| 25 | saheart | 462 | 9 | 2 | 1 | 1.0 | 5 | 4 | 93.75 |
| 26 | satimage | 6435 | 36 | 7 | 0.9 | 850.9 | 5 | 3 | 99.99 |
| 27 | segment | 2310 | 19 | 7 | 1 | 35.3 | 8 | 2 | 98.37 |
| 28 | sonar | 208 | 60 | 2 | 1 | 744.7 | 13 | 6 | 99.99 |
| 29 | spambase | 4597 | 57 | 2 | 0.5 | 30.4 | 4 | 3 | 99.99 |
| 30 | spectfheart | 267 | 44 | 2 | 0.5 | 583.1 | 10 | 5 | 99.99 |
| 31 | splice | 3190 | 60 | 3 | 0.6 | 52.5 | 3 | 3 | 99.99 |
| 32 | texture | 5500 | 40 | 11 | 0.8 | 546.4 | 7 | 3 | 99.99 |
| 33 | thyroid | 7200 | 21 | 3 | 0.9 | 37.5 | 7 | 3 | 99.35 |
| 34 | twonorm | 7400 | 20 | 2 | 0.9 | 1160.2 | 6 | 4 | 94.74 |
| 35 | vehicle | 846 | 18 | 4 | 1 | 547.2 | 13 | 4 | 15.44 |
| 36 | vowel | 990 | 13 | 11 | 1 | 18.1 | 10 | 3 | 27.69 |
| 37 | wdbc | 569 | 30 | 2 | 1 | 326.1 | 10 | 4 | 99.96 |
| 38 | wine | 178 | 13 | 3 | 1 | 1.0 | 6 | 3 | 77.37 |
| 39 | winequality red | 1599 | 11 | 11 | 1 | 1.0 | 8 | 6 | 87.50 |
| 40 | winequality white | 4898 | 11 | 11 | 1 | 5.9 | 10 | 9 | 50.00 |
| 41 | yeast | 1484 | 8 | 10 | 1 | 1.0 | 7 | 7 | 50.00 |
| 42 | zoo | 101 | 15 | 7 | 1 | 2.3 | 9 | 5 | 84.41 |
| Average | 2800.0 | 24.0 | 5.6 | 0.89 | 194.0 | 7.5 | 4.0 | 67.9 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Discovering Reliable Approximate Functional Dependencies
Panagiotis Mandros
Max Planck Institute for Informatics and Saarland University, Germany
,
Mario Boley
Max Planck Institute for Informatics and Saarland University, Germany
and
Jilles Vreeken
Max Planck Institute for Informatics and Saarland University, Germany
(2017)
Abstract.
Given a database and a target attribute of interest, how can we tell whether there exists a functional, or approximately functional dependence of the target on any set of other attributes in the data? How can we reliably, without bias to sample size or dimensionality, measure the strength of such a dependence? And, how can we efficiently discover the optimal or -approximate top- dependencies? These are exactly the questions we answer in this paper.
As we want to be agnostic on the form of the dependence, we adopt an information-theoretic approach, and construct a reliable, bias correcting score that can be efficiently computed. Moreover, we give an effective optimistic estimator of this score, by which for the first time we can mine the approximate functional dependencies from data with guarantees of optimality. Empirical evaluation shows that the derived score achieves a good bias for variance trade-off, can be used within an efficient discovery algorithm, and indeed discovers meaningful dependencies. Most important, it remains reliable in the face of data sparsity.
Pattern discovery, Information theory
††copyright: rightsretained††doi: 10.475/123_4††isbn: 123-4567-24-567/08/06††conference: ACM SIGKDD conference; August 2017; Halifax, Canada††journalyear: 2017††price: 15.00††ccs: Information systems Data mining††ccs: Mathematics of computing Probability and statistics
1. introduction
Discovering dependencies is an important and well-studied topic in data mining. Most proposals, however, focus specifically on symmetric dependencies. That is, they aim to find variable sets that strongly correlate or associate with a target variable. In many applications, however, asymmetric, or targeted dependencies are of particular interest. When anonymizing a dataset, for example, we need to be certain a private attribute cannot be reconstructed given the public attribute, while we do not care for the opposite direction. Similarly, in scientific applications we want to hypothesize whether a certain target variable, say an effect, can be explained by the observed variables, the potential causes, and not the other way around. Generally, an effective procedure to detect functional dependencies from data allows us to rule out alternate theories about our domain and to determine whether finding concrete models, e.g., by statistical learning, is worthwhile, or if we rather should acquire more data or enrich our feature space first (Ghiringhelli et al., 2015).
More formally, given a target variable and a set of attributes , we want to measure the degree at which has a functional, or an approximate functional dependence on , i.e., if . Additionally, we want to efficiently discover whether any such exists in our data. The database community studied how to infer exact functional dependencies, as these allow for normalization, i.e., reducing redundancy. These methods are not suited to our end, however, as they do not measure the approximation in terms of an intuitive score, and in addition, make implicit closed-world assumptions based on the schema of the data (Huhtala et al., 1999; Liu et al., 2012; Giannella and Robertson, 2004).
On the contrary, information theory provides an intuitive and interpretable measure to address these issues. The fraction of information quantifies functional dependence in terms of proportional reduction of uncertainty about when observing (Cavallo and Pittarelli, 1987; Dalkilic and Roberston, 2000; Reimherr and Nicolae, 2013). Information-theoretic measures, however, are sensitive to data sparsity and as a result, the fraction of information overestimates the amount of dependence (Romano et al., 2016). For large dimensionalities of , it is even possible that a functional dependence is indicated when and are actually independent. This makes it a non-reliable score. In addition, maximizing it is NP-hard (Krause and Guestrin, 2012).
In this paper we propose a reliable measure for approximate functional dependencies based on the fraction of information. Even in extreme cases of data sparsity, it does not show dependence. In addition, we derive an effective optimistic estimator for this score, that allows for an admissible branch-and-bound algorithm to discover the top- optimal, or -approximate optimal strongest dependencies. Empirical evaluation shows that the derived score achieves a good bias for variance trade-off, and in addition, it does not favor spurious dependencies. The corresponding optimistic estimator is a data-dependent quantity, and by exploiting the structure of the data, leads to an effective search algorithm. Lastly, concrete findings in two exemplary application domains, AI and Materials Science, reproduce sensible domain information.
The main contributions of this paper are the following. We
- (i)
propose a consistent estimator for the fraction for information score that is not prone to spurious dependencies,
- (ii)
provide an efficient branch-and-bound algorithm for the discovery of optimal, and -approximate optimal top- dependencies, and
- (iii)
provide empirical evaluation on a wide range of real and synthetic datasets.
The paper is structured as follows. We formally introduce the two problems we consider in Section 2. Next, in Section 3 we propose our fraction of information score, and in Section 4 we detail how to optimize it by deriving a bounding function for a branch-and-bound search scheme. Following, in Section 5 we evaluate the performance on a variety of tasks. Finally, we round up with conclusions in Section 6.
2. Problem Definition
We consider a discrete sample space governed by some probability mass function for which we have defined discrete random variables with domains , and , respectively. Subsets are identified with vector-valued random variables in the usual way with domain . We consider the variable as the output variable and the remaining variables as the input variables, and our goal is to discover subsets of the input variables that approximately determine . In particular, we are interested in approximations to the concept of functional dependencies, i.e., the case when there is a function such that for all it holds that
[TABLE]
Relaxing this rather strict concept is necessary because it is rare that such a completely deterministic relationship exists—if the random variables correspond to measurements of real-world quantities there are usually unobserved subtle effects or noise that cause Eq. (1) to not hold exactly.
One traditional approach to relax Eq. (1) is to use instead the condition if , for some fixed value , i.e., to allow a certain fraction of events to not obey the functional relation. However, as with any parameterization based on a hard threshold, this parameter is difficult to set in practice and additionally only provides a qualitative and not a quantitative relaxation (Giannella and Robertson, 2004). That is, it does not allow us to express “how far” is from being determined by . In order to address these issues one can quantify the degree of functional dependence through information theoretic measures. A particularly useful way of doing this is to use the concept of fraction of information () (Cavallo and Pittarelli, 1987; Reimherr and Nicolae, 2013; Dalkilic and Roberston, 2000), which is defined as
[TABLE]
where denotes the Shannon entropy and the conditional Shannon entropy (Shannon, 1948). The numerator is referred to as mutual information . The entropy measures the uncertainty about , while the conditional entropy measures the uncertainty about after observing . The fraction of information then represents the proportional reduction of uncertainty about by knowing . Moreover, the extreme values, and , correspond to a functional dependence and statistical independence, respectively. With this notion, we can go about discovering approximate functional dependencies from data.
For that we assume that a dataset is given consisting of i.i.d. samples generated according to the joint distribution . Such a dataset induces empirical probability estimates for all our random variables given by with the empirical counts
[TABLE]
(where is the entry in corresponding to variable ). In turn, these empirical probabilities give rise to empirical estimators for our quantities of interest, , , and . However, trying to directly discover approximate functional dependence using the empirical fraction of information is bound to fail, because this estimator is not unbiased, i.e., we have for finite , as it is the case with many dependence measures (Vinh et al., 2010; Romano et al., 2014; Hubert and Arabie, 1985; Dobra and Gehrke, 2001; White and Liu, 1994; Kononenko, 1995; Nguyen et al., 2016; Wang et al., 2017). This holds in particular also for the case when , i.e., when contains no information about . This situation, which is referred to as the (lack of) zero-baseline property (Romano et al., 2016), can be misleading in practice. Even worse, independent of the true value , the bias depends on the number of attainable distinct values for , and favors larger attribute sets over smaller ones (which follows from the bias of the empirical mutual information, see, e.g., (Roulston, 1999)). See Fig. 1 for a quantitative demonstration of both of these facts.
Even if a more suitable estimator was available, the challenge of which variable sets to test for high functional dependence scores remains—naively considering all options is practically infeasible. Thus, to derive a useful method for the reliable discovery of functional dependencies from data, we have to solve the following two problems:
- (i)
Find a more reliable empirical estimator for ; in particular one that satisfies the zero-baseline property and obtains better dimensionality bias.
- (ii)
Identify structural properties of that allow to derive an effective search algorithm for discovering the variable sets with the highest functional dependence scores.
We will present solutions to each of these problems in turn, in Sections 3 and 4, respectively.
3. Reliable fraction of information
Intuitively, the reason why is unreliable as an estimator for is that it does not take into account the confidence in the empirical estimates . This is especially obvious in the extreme case when the empirical count is equal to . In this situation exactly for one value of and, hence, is trivially equal to [math] independent of the true distribution . Moreover, if the data size is small compared to the observed domain of , this case is likely to occur for many of the sampled values for —even when , which coincides with the highest error, because then .
This last observation suggests a path to a more reasonable estimator: while it is hard to determine the bias in the general case, it is likely much easier under the assumption of independence , which, as pointed out above, corresponds exactly to the case of highest estimation error when the empirical observations are sparse. More concretely, let us denote by the bias under independence defined as
[TABLE]
where the expectation is taken w.r.t. the random dataset of size . Let us assume that we have a good estimator for this quantity. With this we can define a corrected estimator, let us refer to it as reliable fraction of information , as follows:
[TABLE]
This approach essentially trades the bias of with that of when . We have:
[TABLE]
A non-parametric choice for , which we use in this paper, corresponds to the permutation model (Lancaster (1969, Chap. 11.2)), i.e., considering all possible datasets resulting from independently permuting the -values associated to the -values in the given empirical data . Formally, let denote the symmetric group of degree , i.e., consists of all bijections . For a bijection , let denote the permuted version of , i.e., the variable with data entries . With this we can define the permutation model as the probabilities (and corresponding expectations ) resulting from permuting the empirical data of by a uniform random permutation from . Using this model, the expectation of the empirical mutual information under independence, , is estimated as
[TABLE]
Clearly, a naive evaluation of this expression is computationally infeasible (order of ). However, one can dramatically reduce the complexity by reformulating the above expression as a function of contingency table cell values and exploiting its symmetries (Vinh et al., 2009). More precisely, let the observed domains of and be and , respectively. Moreover, we define shortcuts for the observed marginal counts and as well as for the joint counts . The complete joint count configuration we refer to as contingency table. Noting that is a function of the contingency table resulting from the random permutation, the estimator can be rewritten as
[TABLE]
where is the set of all possible contingency tables indexed by the values and (note that only for resulting in the observed marginal counts ).
As this expression is still infeasible, Vinh et al. (2009) propose to re-order the terms of the sum according to the possible count values that can be found in individual table cells. The permutation model implies that the empirical counts for the joint events are generated according to the probabilities
[TABLE]
where is the probability mass function of the hypergeometric distribution with the number of successes, the number of draws, the number of total successes, and the population size. This allows us to group terms according to their count values for a specific table cell, which can be systematically enumerated from the support of the hypergeometric distribution, i.e., . We can then compute as
[TABLE]
Using the recurrence relation of the hypergeometric distribution, the computational complexity can be further reduced to the order of (Romano et al., 2014). Moreover, it is easily parallelizable. Hence, we end up with an efficiently computable estimator for the bias under independence .
In addition to being computationally efficient, the resulting reliable functional dependence score satisfies several other properties. First of all, it is indeed a consistent estimator of . One can show (Vinh et al., 2010) that , which implies together with the consistency of that
[TABLE]
Moreover, remains upper-bounded by , although this value is only attainable in the limit case (for true functional dependencies). Most importantly, in contrast to the naive estimator, approaches zero111It fact, it is principally not lower bounded by [math] since the empirical fraction of information can be less than the correction term. However, these are rare cases, which strongly indicate independence. as the data size relative to the empirical domain approaches one. In other words, penalizes spurious dependencies that can easily appear for high dimensional —justifying the name reliable fraction of information.
4. Search scheme
After deriving a suitably corrected empirical estimator for the fraction of information, we can now turn to the problem of using it for the discovery of approximate functional dependencies from a given dataset. Essentially, this is a combinatorial optimization problem where, given a dataset , the problem is to find a subset with maximal value of . However, as usual in pattern discovery, we are not just interested in one but several score maximizers—to produce more diverse insights into the data domain and to provide alternatives in subsequent applications. Hence, we end up with a top- pattern search formulation:
Given* a dataset consisting of i.i.d. samples of random variables and and a number , find a family of variable sets such that no variable set outside has a higher -score than any of the sets in , i.e., for all and it holds that . *
In the search for an algorithm solving the above problem, it is first important to note that maximizing mutual information is NP-hard (Krause and Guestrin, 2012)—even approximately and even in the restricted case when all are conditionally independent given . While it is an open question whether this result implies hardness of -maximization (the correction term changes maximization order), this is a substantial indication that no polynomial time algorithm for our problem exists (even with constant ). On the other hand, the branch-and-bound framework (see, e.g., Mehlhorn and Sanders (2008, Chap. 12.4)), while not efficient in terms of the worst-case complexity, can often yield algorithms for hard optimization problems that are very effective in practice—particularly in the best-first search variant.
In a nutshell, best-first branch-and-bound maximizes an objective function defined on some abstract search space with the help of a branch operator and a matching auxiliary selection and bounding function . The role of the branch operator is to non-redundantly generate the search space from some designated root element , i.e., for all there must be a unique sequence such that for . The bounding function must guarantee the property
[TABLE]
where denotes the set of all that can be generated from by multiple applications of . Based on these ingredients, a branch-and-bound algorithm simply enumerates starting from , but uses to avoid expanding elements that cannot yield an improvement over the best solution found so far.
For our problem the search space is , for which a suitable branch operator is simply given by
[TABLE]
i.e., we ensure non-redundant generation by creating a lexicographical order on the power set of the input variables and only enumerate lexicographically larger elements from a given set . In order to derive a bounding function for our objective function , we first need to establish another central property of the correction term .
Theorem 4.1.
Given two sets of variables then , i.e., the correction term is monotonically increasing with respect to the subset relation.
Proof.
It is sufficient to consider the case for some , i.e. the cardinality differs by one variable. The general case follows inductively. Following the notation of Eq. (4), let the marginals of , and be for , for , and for , respectively. Note that . We need to show that , i.e., per definition .
In order to do this, we first define a relation between the contingency tables of and . Let be the projection of values from to values of defined by . We can extend this projection to the sets of contingency tables by finding the counts in the column corresponding to of as the sum of the columns in corresponding to . We will prove the claim by showing that for all we have .
First, it follows from the chain rule of information and from mutual information being non-negative (Cover and Thomas, 1991) that for . Next we show that , which concludes the proof. For any contingency table let denote the set of permutations that result in . Let . This means that for at least one cell . Denoting by
[TABLE]
the set of all indices of values of that are projected down to , it follows by the definition of that
[TABLE]
So for at least one it is , and, thus we also have that and can conclude
[TABLE]
Now let with and assume for a contradiction that , i.e., there is an . Let us denote . Since , we know that . However, it follows from Eq. (5) that —a contradiction, and, hence . Thus, as desired
[TABLE]
∎
With this theorem (and the fact that the conditional entropy is bounded from below by 0), it follows for all that
[TABLE]
Hence, since for , we can use as valid bounding function for the branch-and-bound search. Besides the features mentioned above, the search scheme also provides the option of relaxing the required result guarantee to that of an -approximation for accuracy parameter . This means that the resulting family of variable sets will satisfy the relaxed condition that for all and it holds that . Hence, using -values of less than allows to trade accuracy for computation time.
The pseudocode in Algorithm 1 summarizes the resulting method for the discovery of approximate functional dependencies. The algorithm maintains a priority queue that holds the search frontier and a current result set throughout the search. In the beginning of each iteration, it checks whether the search has terminated, which is the case either when the frontier is empty or the potential of top-potential element from the frontier (w.r.t. the bounding function) is less than the -th best -value of the current result. As long as this condition is not satisfied, the search continuous by expanding the top-potential variable set (line 5), and using its successors to update the current result set (line 6), as well as the priority queue (line 7).
5. Empirical Evaluation
In this section, we study the empirical performance of discovering approximate functional dependencies based on . This includes, the bias of as an estimator of the true functional, the performance of the bounding function in branch-and-bound search, and two concrete examples of functional dependencies in real datasets.
5.1. Estimation Bias
In this section we evaluate the bias and variance of our corrected estimator . It is instructive to see the behavior of the bias for various amounts of dependence, and not in the particular case of independence, i.e., , where aims to be unbiased (see Fig. 1 for an empirical confirmation of this fact). For that let us denote by the set of all joint probability mass functions over two random variables and with , and by all such probability mass functions for which we have a functional dependence score of . We are interested in the behavior of the estimation bias over under a distribution that puts equal weight on the four different regimes “weak” (), “low” (), “high” (), and “strong” ().
More specifically, let be the result of the -estimator computed on data and the bias of when fixing the underlying pmf to , i.e.,
[TABLE]
To estimate the expected value and standard variation of the absolute bias for the pmfs from , we uniformly sample pmfs in equal proportions from the four different regimes, i.e., each from , , , and . For each pmf we can calculate the true value directly from its definition. To compute it then only remains to empirically estimate the expectation term in Eq. (6), for which we sample per pmf a total of datasets of size . By averaging over all , we end up with the desired estimates and for the absolute bias of estimator with sample size .
Equipped with this procedure we can go ahead and compare the performance of to other estimators. In addition to the naive uncorrected estimator we also introduce an alternative correction resulting from the application of the quantification adjustment framework proposed by Romano et al. (Romano et al., 2016). This correction, which we denote by , is defined as
[TABLE]
Thus, we consider . For each estimator, we compute and for data sizes . We focus on small data sizes, because any consistent estimator converges to for . Furthermore, we can expect the small data sizes for the small domain size of this experiment to behave similar to larger data sizes combined with the potentially huge domains occurring during the algorithmic search (resulting from the complex random variables ).
In Figure 2 we present the results for the estimated absolute bias of estimators , , and the reliable fraction of information , averaged over all 100 pmfs across different data sizes . We observe that our estimator achieves a lower bias for all compared to and , and converges fast to a bias close to zero after 10 samples. The differences in bias are apparent in the cases of and samples. These are cases where the insufficient data samples cause to approach 0, independent of the true distribution . In such scenarios, the estimators and start to show functional dependence, while is designed to show independence for reliability reasons. So it is useful to see that this design, also offers a better bias.
We can further draw conclusions about the behavior of by considering only the “weak” and “strong” dependencies, i.e., where is closer to independence and functional dependence respectively. As such, we present in Figure 3 the estimated absolute bias , averaged over (left), and (right). We see that in both cases, i.e., when there is low and high functional dependence, achieves a lower bias, as it was the case with . Since our score aims to be unbiased under the null hypothesis, we observe a high correction over the for weak dependencies. Even for high dependencies, where one could expect to have less correction, we see that is practically unbiased across all .
For the standard deviation , we present in Figure 4 the results after averaging over all 100 pmfs across different data sizes . We observe that has an almost equal for all in comparison with , and a lower one with . Estimators achieve better bias by trading variance, and from Figures 2, 3, and 4, we see that in comparison with and , we trade very little variance for a large bias correction. With the previous observations, we can conclude that is a suitable estimator for the fraction of information , as desired.
5.2. Optimization performance
In this section, we investigate the performance of the branch-and-bound algorithm combined with our optimistic estimator . Specifically, we are interested in the effects of having a data dependent quantity in our bounding function, i.e., , which in addition, acts as a penalty for non-reliable dependencies.
For this experiment we utilize the KEEL data repository.222http://www.keel.es/ We use all classification datasets with , , without missing values, resulting in 42 datasets with an average number of 2800 data samples and 24 attributes.333Some attributes with obviously wrong type declarations were corrected, e.g., ’sex’ was often corrected to be categoric and not metric. All metric attributes are discretized using the method of Fayyad and Irani (1993). The datasets are summarized in Table 1. All experiments were executed on a dedicated Intel Xeon E5-2643 v3 machine with 256 GB memory. We make our code available online for research purposes.444http://eda.mmci.uni-saarland.de/dora/
We employ the algorithm to retrieve the top dependence, and individually set the for each dataset, such that the algorithm terminates in less than 30 minutes. We report time, used, pruning percentage of the search space, depth of the solution, and the maximum depth the algorithm had to explore in Table 1.
The percentage of the datasets where , i.e., 30 out of 42, show that an optimal solution can be discovered in under 30 minutes for the majority of the cases considered. In 28 datasets it takes a maximum of 6 minutes. For the rest, reasonable approximations to the optimal solution can be achieved, e.g., .
We observe that our bounding function , is effective in pruning a considerable amount of the search space, i.e., on average. In addition, an average of maximum depth combined with an average solution depth of , show that is not simply pruning on set cardinality, but it is a data dependent quantity that selectively explores the search space based on the structure of the data. That is, it can potentially go to higher levels for promising candidates.
To further corroborate on the previous observation, we consider a hypothetical optimistic estimator that prunes based solely on the cardinality of . For a meaningful comparison, we provide an oracle to this method and restrict the search space to the maximum depth that had to explore, and not the complete space of size nodes. For example, if the maximum depth is , then the branch-and-bound with as bounding function will visit nodes. The estimated time for every dataset is then , where is a node processing time estimated by dividing the completion time of branch-and-bound with , with the number of nodes visited. We plot the computation time for both estimators in Figure 5. The datasets are sorted in ascending order of speed-up.
We see that in the majority of the datasets, taking into account the structure of the data is of crucial importance. This is most evident in the last two datasets, where it would take 20 and 146 years respectively to find the solution based on cardinality alone. This plot shows the potential of a data dependent optimistic estimator, as opposed to a simple function evaluating statistics as cardinality, in a potentially hard optimization problem.
Regarding reliability, useful conclusions can be drawn from the average solution dimensionality of , which is a reasonable number for the size of the data considered. Trying to maximize other estimators for example, such as or , would result in very large dimensionalities.
5.3. Exemplary discoveries
After investigating the statistical properties of and its algorithmic performance, we close this section with examples of concrete approximate functional dependencies discovered in two different applications: determining the winner of a tic-tac-toe configuration and predicting the preferred crystal structure of octet binary semi-conductors. Both settings are examples of problems where elementary input features are available, but to correctly represent the input/output relation either non-linear models have to be used or—if interpretable models are sought—complex auxiliary feature have to be constructed from the given elementary features.
The tic-tac-toe application (Matheus and Rendell, 1989) is one of the earliest examples of this complex feature construction problem. Tic-tac-toe is a game of two players where each player picks a symbol from and, taking turns, marks his symbol in an unoccupied cell of a game board. A player wins the game if he marks 3 consecutive cells in a row, column, or diagonal. A game can end in draw, if the board configuration does not allow for any winning move. The dataset consists of 958 end game, winning configurations (i.e., there are no draws). The 9 input variables represent the cells of the board, and can have 3 values , where denotes an empty cell (see Fig. 6). The output variable with is the outcome of the game for player .
Searching for approximate functional dependencies reveals as top pattern with empirical fraction of information and corrected score the variable set
[TABLE]
i.e., the four corner cells and the middle one. This is a sensible discovery as these cells correspond exactly to those involved in the highest number of winning combinations (see Fig. 6). Knowing the state of these cell provides, therefore, a high amount of information about the outcome of the game. Moreover, removing a variable results in a loss of a considerable amount of information, while adding a variable would provide more information, but also redundancy. That is, the increase of fraction of information would not be higher than the increase of .
Our second example is a classical problem from Materials Science (Van Vechten, 1969), which has meanwhile become a canonical example for the challenge of the automatic discovery of interpretable and “physically meaningful” prediction models of material properties (Ghiringhelli et al., 2015; Goldsmith et al., 2017). The task is to predict the symmetry or crystal structure, in which a given binary compound semi-conductor material will crystalize. That is, each of the material involved consist of two atom types (A and B) and the output variable describes the crystal structure it prefers energetically. The input variables are 14 electro-chemical features of the two atom types considered in isolation: the radii of the three different electron orbitals shapes , , and of atom type A denoted as as well as four important energy quantities that determine its chemical properties (electron affinity, ionization potential, HOMO and LUMO energy levels); the same variables are defined for component B.
For this dataset the top approximate functional dependency with and uncorrected empirical fraction of information is
[TABLE]
i.e., the atomical and radii of component A. Again, this is a sensible finding, since these two variables constitute two out of three variables contained in the best structure prediction model that can be identified using the non-linear subgroup discovery approach (Goldsmith et al., 2017). Also both features are involved in the best linear LASSO model based on systematically constructed non-linear combinations of the elementary input variables (Ghiringhelli et al., 2015). The fact that not all variables of those models are identified by the functional dependency discovery algorithm can likely be explained by the facts that (a) the continuous input variables had to be discretized and (b) the dataset is extremely small with only 82 entries, which renders the discovery of reliable patterns with more than two variables very challenging.
6. conclusion
We considered the dual problem of measuring and efficiently discovering approximate functional dependencies from data. We adopted an information theoretic approach, and proposed a fraction of information score that is reliable and achieves a good bias. In addition, we proposed an efficient optimistic estimator that allows for the effective discovery of the optimal, or -approximate top- dependencies of the target variable.
Although we carefully constructed the proposed correction term such that bias under those regimes that are most problematic for searching for high-dimensional functional dependencies is removed, other scores could potentially be found that estimate the fraction of information with even less bias.
Other correction terms could also lead to other algorithms. The computational complexity for finding reliable functional dependencies is still open. Hence, polynomial time algorithm for this or adapted problem variants are a possibility. Similarly so, efficient tight(er) optimistic estimators would improve the runtime of branch-and-bound, as fewer nodes would have to be expanded to discover the optimal solution.
Both our score and optimistic estimator are specifically defined for discrete data. While in this paper we only considered univariate discrete targets, our scores can be trivially extended to multivariate discrete variables. Clearly, it is also of interest to discover approximate functional dependencies from continuous real-valued data. As entropy has been defined for such data, e.g. differential entropy (Shannon, 1948) and cumulative entropy (Rao et al., 2004), it is possible to instantiate fraction of information scores. It will be interesting to see whether we can also efficiently correct these scores for chance, and whether optimistic estimators exist that allow for effective search.
Acknowledgements.
The authors wish to thank Luca Ghiringhelli and Brian Goldsmith for insightful discussions. Panagiotis Mandros is supported by the International Max Planck Research School for Computer Science (IMPRS-CS). The authors are supported by the Cluster of Excellence “Multimodal Computing and Interaction” within the Excellence Initiative of the German Federal Government.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1(1)
- 2Cavallo and Pittarelli (1987) Roger Cavallo and Michael Pittarelli. 1987. The Theory of Probabilistic Databases. In Proceedings of the 13th International Conference on Very Large Data Bases (VLDB), Brighton, UK . 71–81.
- 3Cover and Thomas (1991) Thomas M. Cover and Joy A. Thomas. 1991. Elements of Information Theory . Wiley-Interscience, New York, NY, USA.
- 4Dalkilic and Roberston (2000) Mehmet M. Dalkilic and Edward L. Roberston. 2000. Information Dependencies. In Proceedings of the 19th ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems . ACM, 245–253.
- 5Dobra and Gehrke (2001) Alin Dobra and Johannes Gehrke. 2001. Bias Correction in Classification Tree Construction. In Proceedings of the 18th International Conference on Machine Learning (ICML), Williams College, MA . Morgan Kaufmann, 90–97.
- 6Fayyad and Irani (1993) Usama M. Fayyad and Keki B. Irani. 1993. Multi-Interval Discretization of Continuous-Valued Attributes for Classification Learning. In Proceedings of the 13th International Joint Conference on Artificial Intelligence (IJCAI), Chambéry, France . 1022–1029.
- 7Ghiringhelli et al . (2015) Luca M Ghiringhelli, Jan Vybiral, Sergey V Levchenko, Claudia Draxl, and Matthias Scheffler. 2015. Big data of materials science: Critical role of the descriptor. Physical review letters 114, 10 (2015), 105503.
- 8Giannella and Robertson (2004) Chris Giannella and Edward L. Robertson. 2004. On approximation measures for functional dependencies. Information Systems 29, 6 (2004), 483–507.