Rejection-Cascade of Gaussians: Real-time adaptive background subtraction framework
B Ravi Kiran, Arindam Das, Senthil Yogamani

TL;DR
This paper introduces a real-time adaptive background subtraction framework called Rejection-Cascade of Gaussians (CoG), which significantly improves speed and accuracy over traditional GMM methods by employing a cascade approach inspired by Viola-Jones.
Contribution
The paper proposes a novel cascade decomposition of Gaussian Mixture Models for background subtraction, achieving faster processing and higher accuracy, and demonstrates its application to deep learning models like VAE.
Findings
Achieved 4-5x speed-up over baseline GMM.
Realized 17% average accuracy improvement on Wallflowers datasets.
Demonstrated applicability to deep architectures with initial results on CDW-2014.
Abstract
Background-Foreground classification is a well-studied problem in computer vision. Due to the pixel-wise nature of modeling and processing in the algorithm, it is usually difficult to satisfy real-time constraints. There is a trade-off between the speed (because of model complexity) and accuracy. Inspired by the rejection cascade of Viola-Jones classifier, we decompose the Gaussian Mixture Model (GMM) into an adaptive cascade of Gaussians(CoG). We achieve a good improvement in speed without compromising the accuracy with respect to the baseline GMM model. We demonstrate a speed-up factor of 4-5x and 17 percent average improvement in accuracy over Wallflowers surveillance datasets. The CoG is then demonstrated to over the latent space representation of images of a convolutional variational autoencoder(VAE). We provide initial results over CDW-2014 dataset, which could speed up background…
Click any figure to enlarge with its caption.
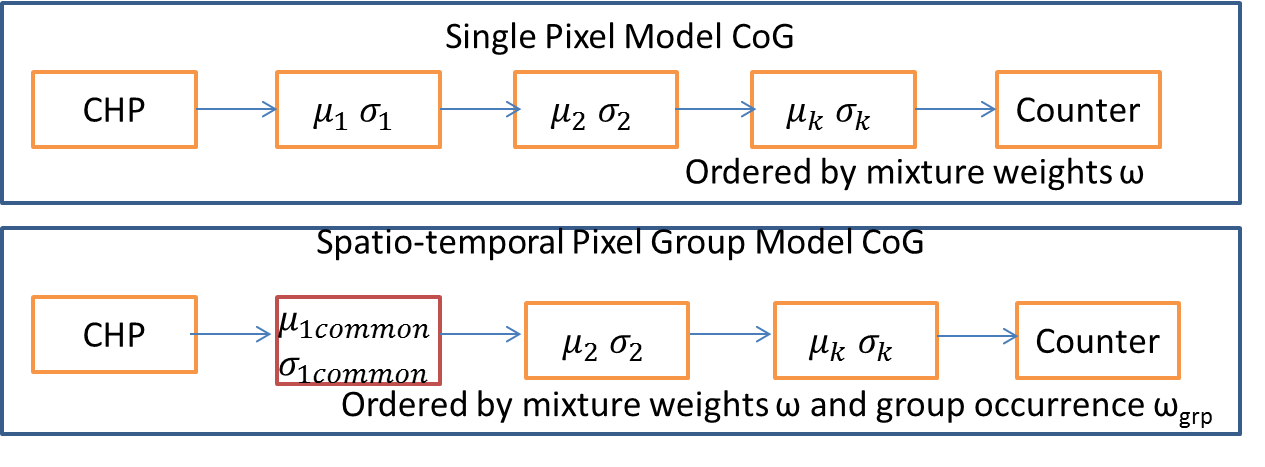 Figure 1
Figure 1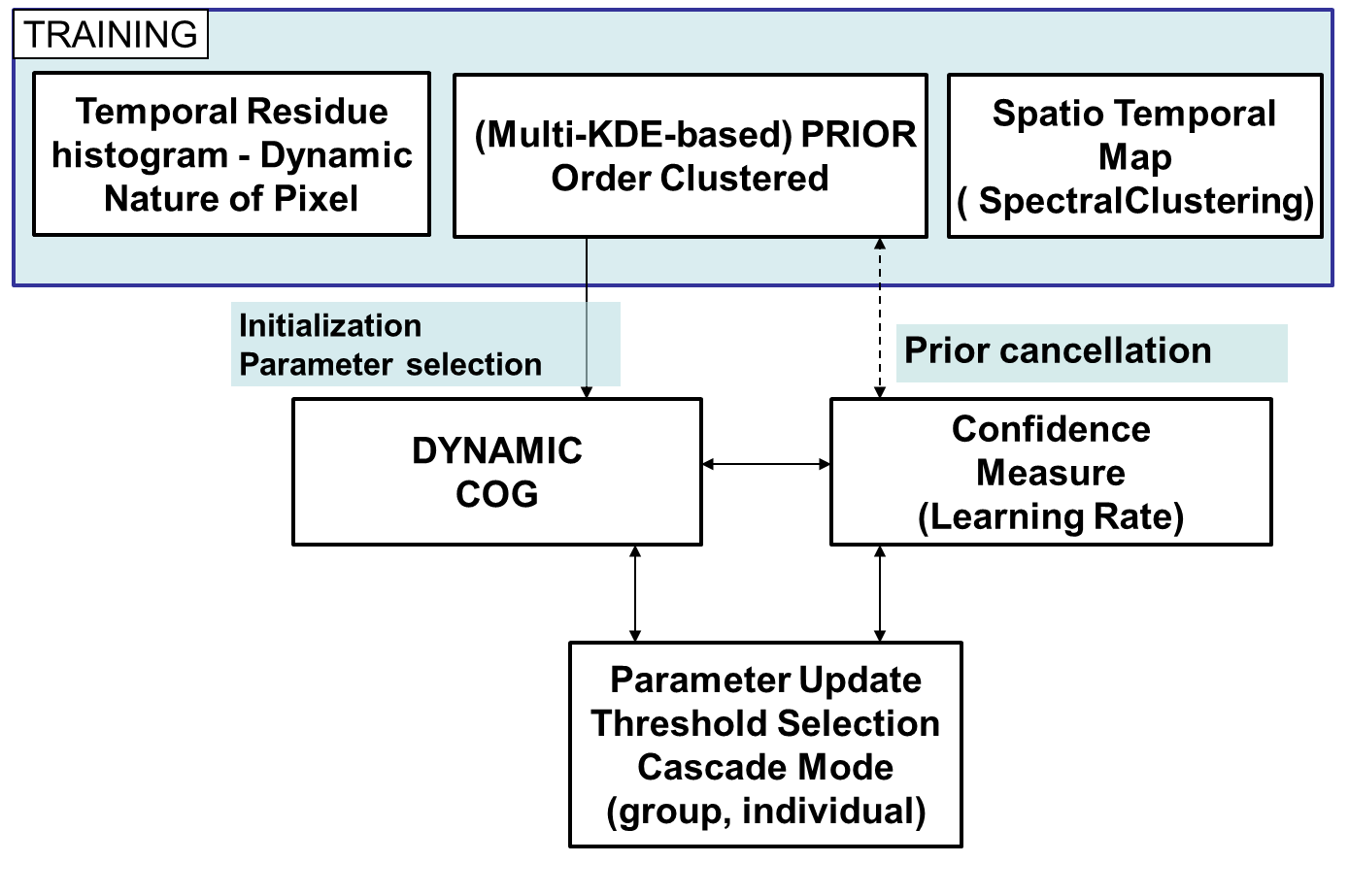 Figure 2
Figure 2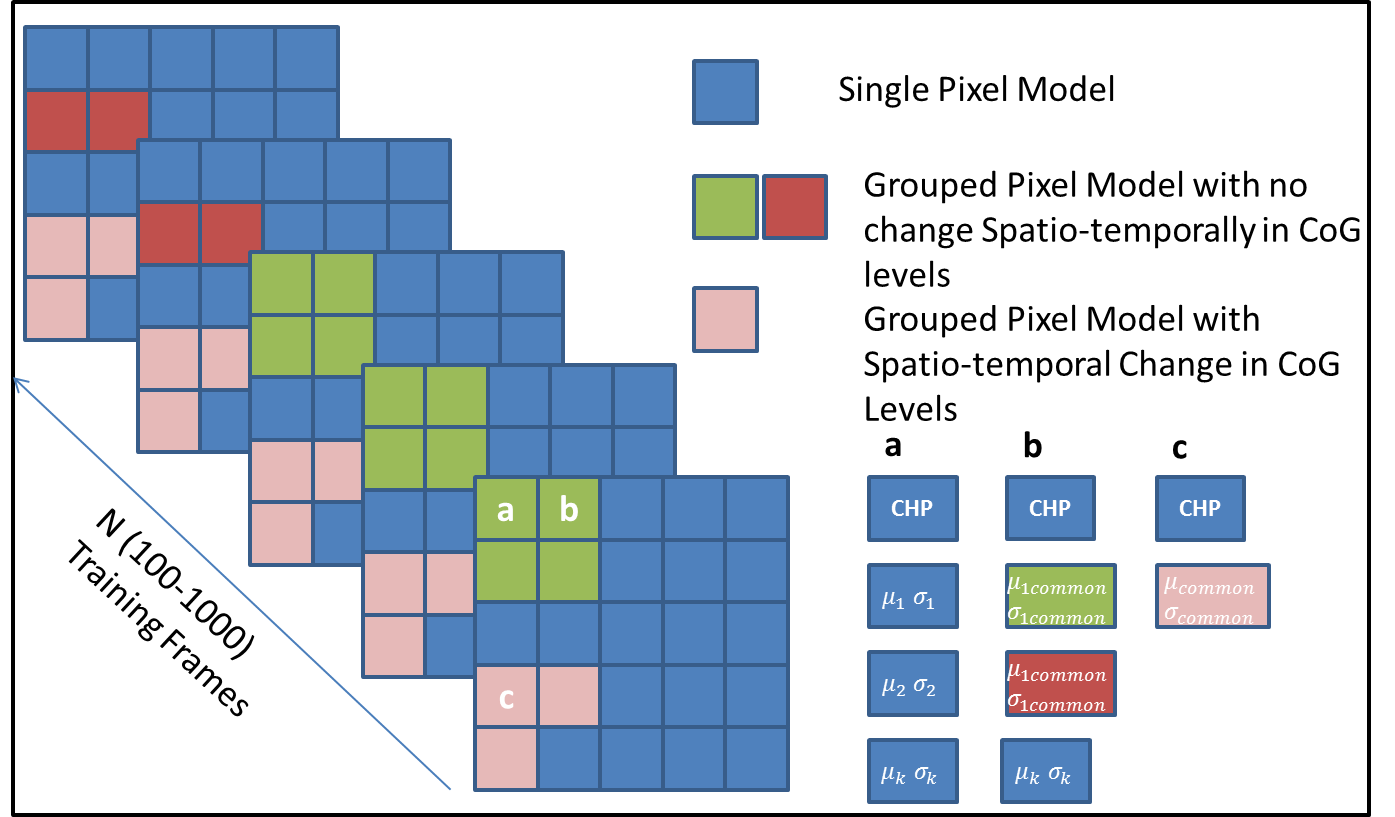 Figure 3
Figure 3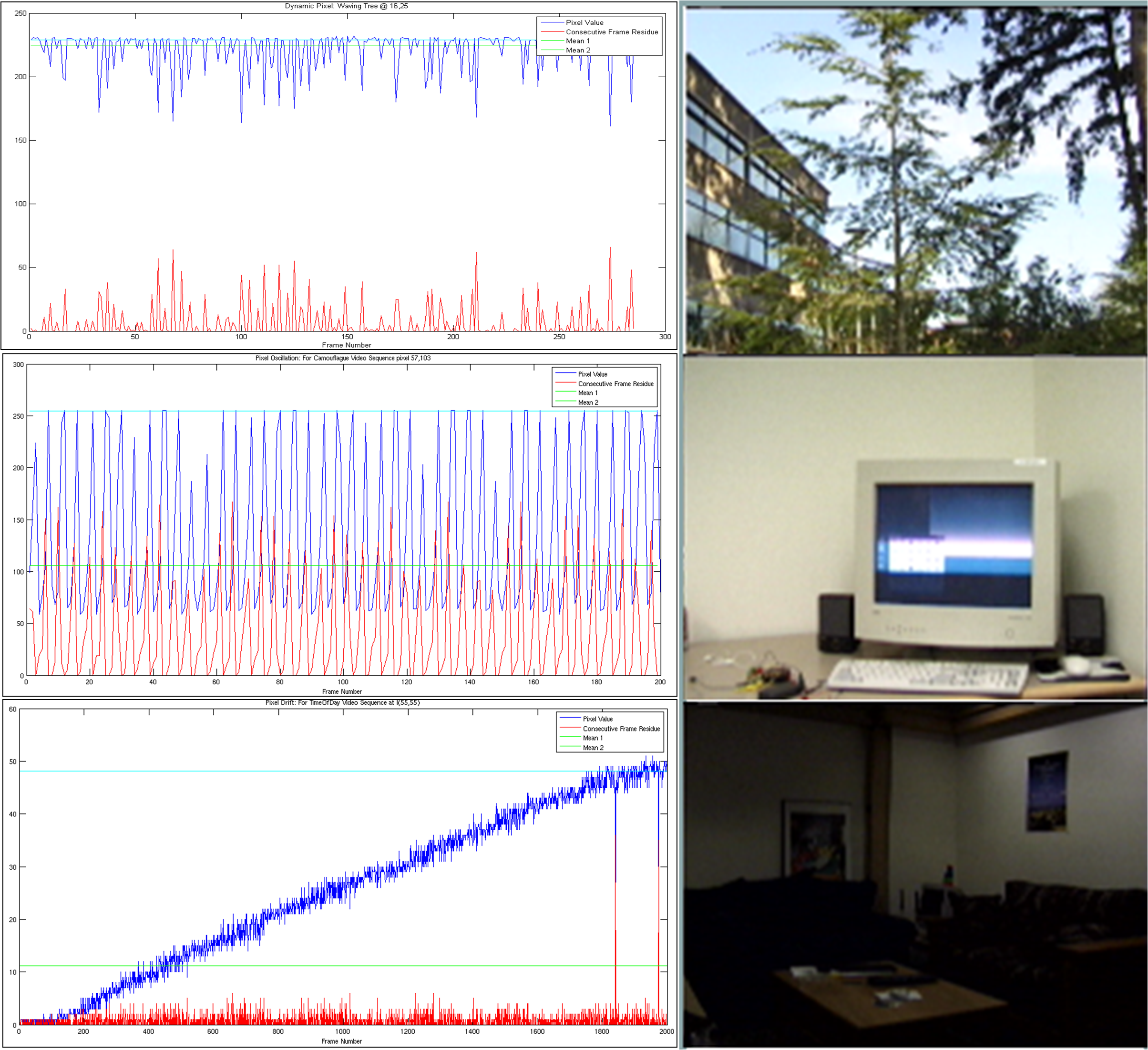 Figure 4
Figure 4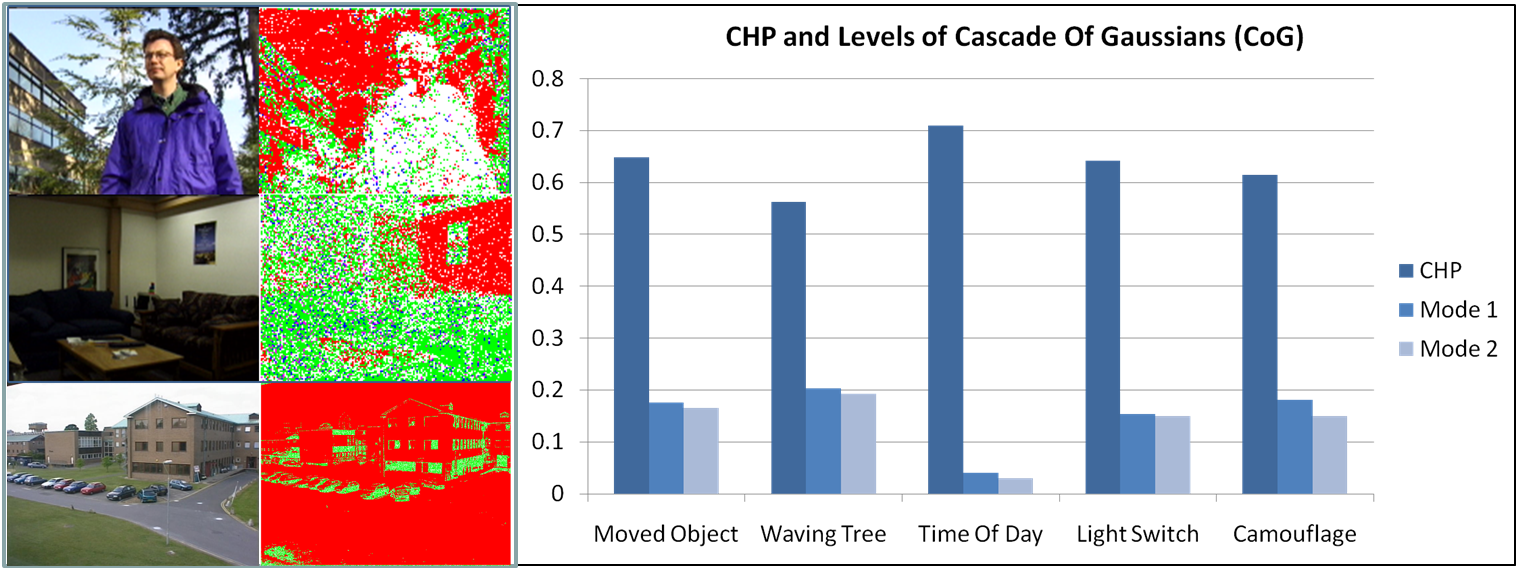 Figure 5
Figure 5 Figure 6
Figure 6Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsVideo Surveillance and Tracking Methods · Image Enhancement Techniques · Human Pose and Action Recognition
MethodsSPEED: Separable Pyramidal Pooling EncodEr-Decoder for Real-Time Monocular Depth Estimation on Low-Resource Settings
11institutetext: Navya, Paris, France
22institutetext: Detection Vision Systems, Valeo India
33institutetext: Valeo Vision Systems, Galway, Ireland
33email: [email protected], {arindam.das,senthil.yogamani}@valeo.com
Rejection-Cascade of Gaussians: Real-time adaptive background subtraction framework
B Ravi Kiran1
Arindam Das2
Senthil Yogamani3
Abstract
Background-Foreground classification is a well-studied problem in computer vision. Due to the pixel-wise nature of modeling and processing in the algorithm, it is usually difficult to satisfy real-time constraints. There is a trade-off between the speed (because of model complexity) and accuracy. Inspired by the rejection cascade of Viola-Jones classifier, we decompose the Gaussian Mixture Model (GMM) into an adaptive cascade of Gaussians(CoG). We achieve a good improvement in speed without compromising the accuracy with respect to the baseline GMM model. We demonstrate a speed-up factor of 4-5x and 17 percent average improvement in accuracy over Wallflowers surveillance datasets. The CoG is then demonstrated to over the latent space representation of images of a convolutional variational autoencoder(VAE). We provide initial results over CDW-2014 dataset, which could speed up background subtraction for deep architectures.
Keywords:
Background Subtraction Rejection Cascade Real-time
1 Introduction
Background subtraction is critical component of surveillance applications (indoor and outdoor), action recognition, human computer interactions, tracking, experimental chemical procedures that require significant change detection. Work on background subtraction started since the 1970s and even today it is an active open problem. There have been a host of methods which have been developed and below is a short review which will serve to aid understanding our algorithm. A survey by [5] provides an overview of common methods which includes Frame differencing (FD), Running Gaussian average (RGA), Gaussian Mixture Model (GMM) and Kernel Density Estimation (KDE). We employ these basic methods in a structured methodology to develop our algorithm.
A survey of variants of GMM, issues and analysis are presented in [2]. In our work, we focus on solving the variable-rate adaptation problem and improving the performance. Abstractly, our work tries to fuse several algorithms to achieve speed and accuracy and we list similar methods here. Similar attempts have been made by the following researchers. [7] and [3] used a Hierarchical background subtraction method that operates in different scales over the image : namely pixel, region and image level, while their models themselves are not hierarchical. Authors [14] switch between GMM and RGA models, while choosing a complex model for complicated backgrounds and simple model for simpler backgrounds. They use an entropy based measure to switch between the different models. We briefly describe our observations and improvement over the standard GMM from [6]. We observe in most cases, background subtraction is an asymmetric classification problem with probability of foreground pixel being much lesser than that of background. This assumption fails in the case of scenes like highways, a busy street, etc. In our work, we focus mainly on surveillance scenarios where there is very low foreground occupancy. Our framework exploits this fact and at the same time handles variable rate changes in background and improves accuracy. Our key contributions in this paper include:
- Decomposition of GMM to form an adaptive cascade of classifiers - Cascade of Gaussians (CoG) which handles complex scenes in an efficient way to obtain real-time performance. 2. A confidence estimate for each pixel’s classification which would be used to vary the learning rate and thresholds for the classifiers and adaptive sampling. 3. Learning a time windowed KDE from the training data-set which would act as a prior to the Adaptive Rejection Cascade and also help the confidence estimate.
The decomposition of the GMM into the cascade is similar to the increasing true positive detection rate inspired by the Viola Jones Rejection Cascade [9]. Authors [8] provided an optimized lookup for highly probable colors in the incoming background pixels thus providing speedup in the access.
2 Components of the Cascade
This section describes the different components of the rejection cascade and how they were determined. The rejection cascade is accompanied by the confidence measure to make an accurate background classification at each level of the cascade.
Scene Prior in Background Model: The process of distinguishing linearly varying background and noisy pixels is a challenge and critical since the background subtraction model intrinsically has no additional attribute to separate them. For this scenario, in our approach we introduce a prior probability for every pixel (eqn 1). The non-parametric probability distribution for the pixels assuming independent R,G,B channels is now given too. The Scene prior basically provides an non-parametric estimate of pixel-values value over frames during training. The choice of is empirical and depends on how much dynamic background and foreground is present in the training frames. To obtain complete variability we choose as large N as possible. Henceforth we refer to Scene Prior as the prior. In the training phase we estimate the underlying temporal distribution of pixels by calculating the kernel function that approximates the said distribution. Our case primarily concentrates on long surveillance videos with sufficient information (minimal foreground) available in the training sequence that decides . For the standard GMM model(assuming the covariance matrix is diagonal) the updates of the parameters include:
[TABLE]
Where , represents the gaussian kernel and the scale or bandwidth. This Kernel function is calculated to provide the modes of the different pixels. Where represents the pixel mode distribution obtained in equation 1, where represents the ratio of the component i in the distribution of pixel , and , are the parameters of the component, represents 0 or 1 based on a component match and finally represents the learning rate of the pixel model. The is intialised for all pixels usually, there has been work in adapting it based on the pixel entropy. We use the pixel gradient value distribution to do the same.
Determining Learning Rate Hyper-parameters: Besides the kernel density, we also estimate the dynamic nature of the pixels in the scene. This is obtained by the clustering the residue between consecutive frames into 3 categories : into static/drifting, oscillating and dynamic pixels (Fig 1 top right). This helps resolve a pixel drift versus a pixel jump as shown in example below in figure. Once we have the residue , we evaluate the normalized histogram over the residue values. We select bins intervals to extract the 3 classes based on the dynamic nature of pixels. A peaky first bin implies near zero residue, thus a drift or static pixels. A peaky second bin implies oscillating pixels and the other cases are considered as dynamic pixels. Based on these values we choose the weights for the confidence measure (explained in the next section). This frequency over each bin sets the learning rate for the pixel. The process of obtaining the right learning rates(confidence function) from the normalized binned histogram values to determine and test for the learning rates have determined empirically by shape matching the histograms.
Clustering Similar Background - Spatio-Temporal Grouping: The next step in the training phase is to determine background regions of pixels, in the frame that behave similarly in terms of adapted variance, number of modes, and optimally use fewer parameters and lesser instructions to update this specific region’s, pixel models. The problem definition can be formalized as: We are given pixels and for each pixel we have a set of matches of the form , which means that pixel correlated with pixel at frame number . From these N matches, we construct a discrete time series by clustering pixel at time interval frames. A time series of the pixel values at frame . Intuitively, measures the correlation in behavior of pixels over time window . For convenience we assume that time series have the same length. We group together pixel value time series so that similar behavior is captured by similarity of the time series . This way we can infer which pixels have a similar temporal pattern variances and modalities, and we can then consider the center of each cluster as the representative common pattern of the group. This helps us cluster similar behaving pixels together. This is can be seen a spectral clustering problem as described in [1]. We try a simpler approach here first by clustering the adapted pixel variances(matrix V) and weights(matrix R) of first dominant mode of pixels within a mixture model.
Get N frames & estimate pixel-wise 2. 2.
Form matrix whose rows are adapted variance and ranked weight observations, while columns are variables and , 3. 3.
Obtain covariance matrices 4. 4.
Perform K-means clustering with K=3 (for temporal pixel residue due to dynamic, oscillating, or drifting BG). 5. 5.
Threshold for pixels within 6. 6.
Calculate the KDE of given cluster & the joint occurrence distribution and associated weight , and
where is first dominant common cascade level at grouped pixels. This suffers from the setback that the variances chosen temporally do not correspond to mean values associated with the maximum eigen value as obtained in case of Spectral Clustering. So we have the pixel variance and adapted weight (dominant mode) covariance matrices and . A single gaussian is fit over thresholded covariance matrices (Adapted variance and first dominant mode weight).
[TABLE]
The parameters , and , represent the mean and standard deviation of the cluster of pixel variances and adapted weights of the first dominant modes. The fundamental clustering algorithm requires Data set and , number of clusters - quantization of the adapted weights or variances, Gram matrix [1]. One critical point to note here is that, when we do not choose to employ spatio-temporal grouping, and reduce the number of parameters and consequent updates, we can use the Scene Prior covariance estimation to increase the accuracy of the foreground detection. This is very similar to the background subtraction based on Co-occurrence of Image Variations.
Confidence Measure : The confidence measure is a latent variable use to aid the Rejection Cascade to obtain a measure of fitness for the classification of a pixel based on various criteria. The Confidence for a pixel is given by .
Here, represents the difference between the current pixel value and the parameters of the model occurring at the top of the ordered Rejection cascade described below, while . As seen in the ordered tree, the first set of parameters would be the first dominant mode - . This is carried out based on the level in which the pixel gets successfully classified. represents the probability of occurrence of the pixel from the KDE. The values of and are determined by the normalized temporal residue distribution (explained above). The physical significance and implications of and - says how confident the region is and regions that are stable (for example from the segments from clustering adapted variances and weights of training phase pixel models) would have high values. While the value of determines how fast the pixel would need to adapt to new incoming values and this would mean a lower effect of the prior distribution. The final parameter determines the consistency of the pixel belonging to a model and this would change whenever the pixels behavior is much more dynamic (as opposed to a temporal residue weighting it).
Confidence based temporal sampling: Applying multiple modes of background classifiers and observing the consistency in their model parameters (mean, variance, and connectivity) we predict the future values of these pixels. A threshold on confidence function value determined by using stable regions(using region growing) as a reference is used to select the pixels both spatially and temporally. The description of the confidence measure is given in more detail in section 2.3. The pixels with low confidence reflect regions R over the frame with activity and thus a high probability of finding pixels whose label are in transition (FG-BG). Thus by thresholding the confidence function we sub-sample the incoming pixels spatio-temporally. This intuition is when pixel values arriving now are within the first dominant mode’s region, and even more so within the CHP level for a large number of frames, the confidence value saturates. The Region is just a thresholded binary map of this confidence value. This is demonstrated in the analysis in section 3.
Cascade of Gaussians CoG The proposed method can be viewed as a decomposition of the GMM in an adaptive framework so as to reduce complexity and improve accuracy using a strong prior to determine the scenarios under which said gains can be achieved. The prior is used to determine the modality of the pixels distribution and any new value is treated as a new mean with variance model. The Cascade can be seen to consist of K Gaussians which are ordered based on the successful classification of the pixel. During steady state the ordered cascade conforms to the Viola Jones Rejection Cascade with decreasing positive detection rates.
The cascade is first headed by a Consistent Hypothesis Propagation (CHP) classifier which basically repeats the labeling process on the current pixel if its value is equal to the previous value (previous frame). This CHP classifier is then followed by an ordered set of Gaussians including the spatio-temporally grouped parameters. The tree ordering is different for different pixel and the order is decided based on the prior distribution (KDE) of the pixel and the temporal consistency of the pixel in the different levels. When the pixel values do not belong to any of the dominant modes based on the prior, we have scenario where the beta weight and gamma weight only considered and alpha is rejected (Prior Nullified).
The rejection cascade assumes that the frequency of occurrences of foreground detections is lesser than that of the background. This idea was first introduced in the classic Viola-Jones paper [9]. For the rejection cascade the training phase produces a sequence of features with decreasing rates of negative rejections. In our case we arrange the different classifiers in increasing complexity to maximize the speed. We observe in practice that, this cascade would also produce decreasing rates of negative rejections. The critical difference in this rejection cascade is that the classifier in each level of the cascade is evolving over time. To make adaptation efficient we adapt only the active level of the cascade, thus resulting in only one active update at a time, and during a transition the parameters are updated.
The performance of different rejection cascade elements is depicted in Figure 1. It depicts cascade elements with increasing complexity (and consequently accuracy) have higher performance. These times were obtained over 4 videos from the wallflowers data set by [7] of different types of dynamic background. This by itself can stand for the possible amount of speedup that can be obtained when the Rejection Cascade is operated on pixels adaptively based on the nature of the pixel. In a similar observation we saw that the number of pixels (in each of these 4 videos) was distributed in different manner amongst the 4 levels. This is seen in figure 1. Thus we see that even though the number of pixels corresponding to dynamic nature of pixel varies with the nature of the video, there is greater number of pixels on an average corresponding to low complexity Cascade elements. The rejection cascade for BG subtraction was formed by determining (same as in [9]) the set of background pixel classifiers (or in our case models like attentional operator in Viola Jones) and is organized as a degenerate tree such that it has decreasing false positive rate as we proceed down the cascade. The performance of different rejection cascade elements are depicted in Figure 1. It depicts cascade elements with increasing complexity (and consequently accuracy) have higher performance. These times were obtained over different types of static and dynamic background. This by itself can stand for the possible amount of speedup that can be obtained when the Rejection Cascade is operated on pixels adaptively based on the nature of the pixel. In a similar observation we saw that the number of pixels (in each of these 4 videos) was distributed in different manner amongst the 4 levels. This is seen in figure 1. Thus we see that even though the number of pixels corresponding to dynamic nature of pixel varies with the nature of the video, there is greater number of pixels on an average corresponding to low complexity Cascade elements. The learning rate for the model is calculated as a function of the confidence measure of the pixels. The abrupt illumination change is detected in the final level of the rejection cascade, by adding a conditional counter. This counter measures the number of pixels that are not modeled by the penultimate cascade element. If this value is above a threshold we can assume an abrupt illumination change scenario. This threshold is around seven tenth of the total number of pixels in the frame [7].
3 Analysis & VAE-COG
3.1 Scene Prior Analysis
Here we discuss the the Scene Prior and its different components. First with regard to the clustering pixels based on their dynamic nature similarity, we show results of various clustering methods and their intuitions. The first model considers the time series of variances of said pixels in the N frames of training. The covariance matrix is calculated for the variances of the pixels. This can loosely act as the affinity matrix for the describing similar behavior of a pair of pixels. The weight of the first dominant mode is also considered to form the affinity matrix.
3.2 Cascade Analysis
The CoG is faster on two accounts : Firstly it is cascade of simple-to-complex classifiers, CHP to RGA, and averaging over the performance (seen in figure), we see an improvement in speed of operation, since the simpler cases of classification outweigh the complex ones. Secondly it models the image as a spatio-temporal group of super pixels that needs a single set of parameters to update, even more so, when the confidence of the pixel saturates, the Cascade updates are halted, providing huge speedups. Though it is necessary to mention that the window of sampling is chosen empirically and in scale with the confidence saturation values. The average speedup of the rejection tree algorithm is calculated as : where x,y go over all indices of image, refers the ratio of background pixels labeled mean or mean with variance w.r.t the total number of background pixels in the image, is the normalized ratio of the time it takes for level BG model to evaluate and label a pixel as background. The values of and were profiled over various videos for different durations. Also we show the distribution of the CHP pixels as well as the first 3 dominant modes within different frames of Waving tree and Time of Day videos with 40 frames of training each. We can see a huge occupancy of Red (CHP) for both background and foreground pixels. Here we explain the confidence measure and effect on accuracy of the GMM model. We obtain a speedup of 2x-3x with the use of the Adaptive Rejection cascade based GMM. This speedup goes up at the effectiveness of accuracy of confidence based spatio-temporal sampling to 4-5x. This is evident in the Cascade level population (in figure 1). We observe a 17% improvement in accuracy over the baseline model because of adaptive modelling to handle difficult scenarios explicitly using scene priors.
3.3 Latent space CoG with VAEs
CNNs have become become the state-of-the-art models for various computer vision tasks. Our proposed framework is generic and can be extended to CNN models. In this section, we study a possible future extension of the the Rejection cascade to the Variational AutoEncoder (VAE). There has been recent work on using auto-encoders to learn dynamic background for the subtraction task [11]. Rejection cascades have also been employed within convolutional neural networks architectures for object detection [12]. VAEs one of the most interpretable deep generative models.
VAEs are deep generative models that approximate the distribution for high-dimensional vectors that correspond to pixel values in the image domain. Like a classical auto-encoder. VAEs consists of a probabilistic encoder that reduces the input image to latent space vector and enforces a Gaussian prior, and a probabilisic decoder that reconstructs these latent vectors back to the original images. The loss function constitutes of the KL-Divergence regularization term, and the expected negative reconstruction error with an additional KL-divergence term between the latent space vector and the representation with a mean vector and a standard deviation vector, that optimizes the variational lower bound on the marginal log-likelihood of each observation [4]. The classical cascade : CHP, ordered sequence of modes of GMM (, can now be envisaged in the latent space for a multivariate 1-Gaussian . The future goal would be to create Early rejection classifiers as in [13] for classification tasks, where within each layer of the probabilistic encoder we are capable of measuring the log-likelihood of being foreground. Storing previous latent space vectors for the CHP test would require addition memory aside that assigned to the latent space mean and variance vectors. VAEs are an ideal extension to the rejection cascade since the pixel-level tests in CoG are now performed by the VAE in the latent space, over which a likelihood can be evaluated. We also gain the invariance to positions, orientations, pixel level perturbations, and deformations in mid-level features due the convolutional architecture. A convolutional VAE with latent space of 16 dimensions was trained on the CDW-2014 datasets [10], preliminary results are show in figure 3.
4 Conclusion
The CoG was evaluated on the wallflower dataset, as well as its autoencoder counterpart VAE-CoG on the CDW-2014 datasets. We observed a speedup of 4-5x, over the baseline GMM, with an average improvement of 17% in the mis-classification rate. This study has demonstrated conceptually how a GMM can be re-factored optimally into a prior scene based pixel density and rejection cascade constituent of simpler models ordered based on the probability of occurrences of each level of the cascade, the accuracy (and complexity) of each model in the cascade level.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Azran, A., Ghahramani, Z.: Spectral methods for automatic multiscale data clustering. Computer Vision and Pattern Recognition, 2006 IEEE Computer Society Conference on In Computer Vision and Pattern Recognition, 2006 IEEE Computer Society Conference on 1 , 190–197 (dec 2006). https://doi.org/10.1109/ICDM.2008.88
- 2[2] Bouwmans, T., Baf, F.E., Vachon, B.: Background modeling using mixture of gaussians for foreground detection - a survey. Recent Patents on Computer Science 1 (3), 219–237 (Nov 2008)
- 3[3] Javed, O., Shafique, K., Shah, M.: A hierarchical approach to robust background subtraction using color and gradient information. Motion and Video Computing, 2002. Proceedings. Workshop on pp. 22–27 (2002). https://doi.org/10.1109/MOTION.2002.1182209
- 4[4] Kiran, B.R., Thomas, D.M., Parakkal, R.: An overview of deep learning based methods for unsupervised and semi-supervised anomaly detection in videos. Journal of Imaging 4 (2), 36 (2018)
- 5[5] Piccardi, M.: Background subtraction techniques: a review. Systems, Man and Cybernetics, 2004 IEEE International Conference on 4 (1), 3099–3104 (2004). https://doi.org/10.1109/ICSMC.2004.1400815
- 6[6] Strauffer, C., Grimson., W.: Adaptive background mixture models for real-time tracking. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (1999)
- 7[7] Toyama, K., Krumm, J., Brumitt, B., Meyers, B.: Wallflower: Principles and practice of background maintenance. Computer Vision, 1999. The Proceedings of the Seventh IEEE International Conference on 1 (1), 255–261 (1999)
- 8[8] Valentine, B., Apewokin, S., Wills, L., Wills, S.: An efficient, chromatic clustering-based background model for embedded vision platforms. Computer Vision and Image Understanding 114 (11), 1152–1163 (Nov 2010). https://doi.org/10.1016/j.cviu.2010.03.014