Finding Robust Solutions to Stable Marriage
Begum Genc, Mohamed Siala, Barry O'Sullivan, Gilles Simonin

TL;DR
This paper introduces a new robustness concept for stable matchings, defines the most robust stable matching, and compares algorithms to find it, with local search performing best on large instances.
Contribution
It defines (a,b)-supermatches for robustness in stable matchings and develops algorithms including local search to efficiently find the most robust solution.
Findings
Local search outperforms other methods on large instances.
Checking robustness as a (1,b)-supermatch is polynomial-time solvable.
The approach effectively identifies highly robust stable matchings.
Abstract
We study the notion of robustness in stable matching problems. We first define robustness by introducing (a,b)-supermatches. An -supermatch is a stable matching in which if pairs break up it is possible to find another stable matching by changing the partners of those pairs and at most other pairs. In this context, we define the most robust stable matching as a -supermatch where b is minimum. We show that checking whether a given stable matching is a -supermatch can be done in polynomial time. Next, we use this procedure to design a constraint programming model, a local search approach, and a genetic algorithm to find the most robust stable matching. Our empirical evaluation on large instances show that local search outperforms the other approaches.
Click any figure to enlarge with its caption.
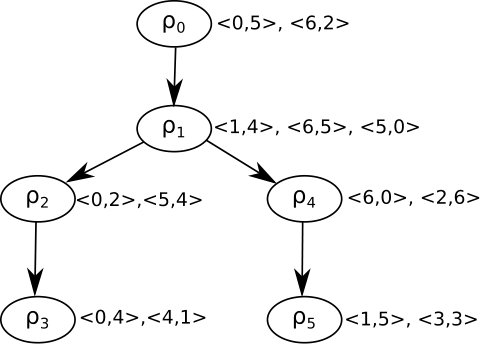 Figure 1
Figure 1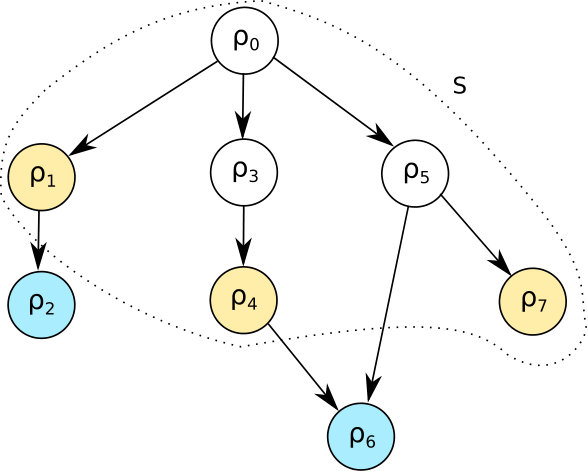 Figure 2
Figure 2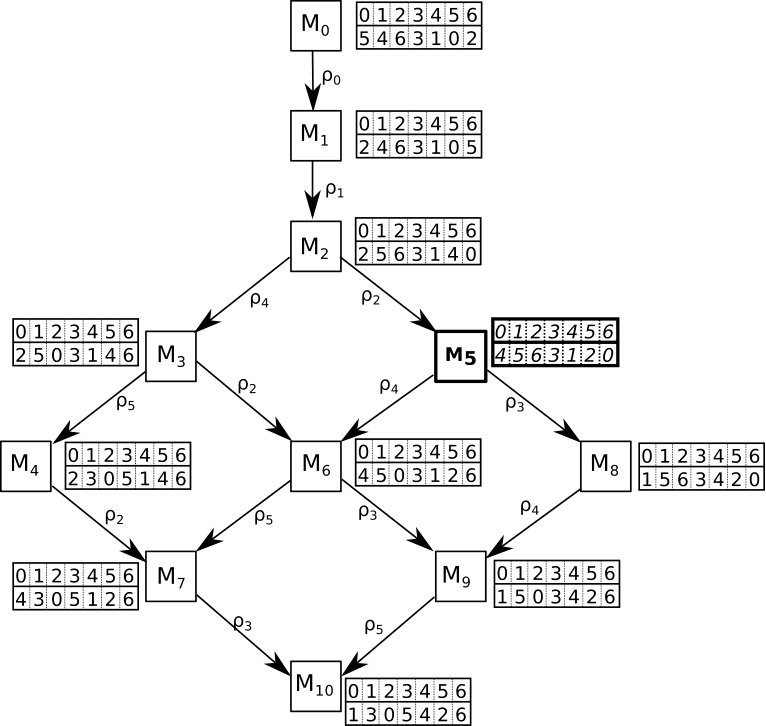 Figure 3
Figure 3| 0 6 5 2 4 1 3 | 2 1 6 4 5 3 0 | |||
| 6 1 4 5 0 2 3 | 0 4 3 5 2 6 1 | |||
| 6 0 3 1 5 4 2 | 2 5 0 4 3 1 6 | |||
| 3 2 0 1 4 6 5 | 6 1 2 3 4 0 5 | |||
| 1 2 0 3 4 5 6 | 4 6 0 5 3 1 2 | |||
| 6 1 0 3 5 4 2 | 3 1 2 6 5 4 0 | |||
| 2 5 0 6 4 3 1 | 4 6 2 1 3 0 5 |
| , | , , , | |||
| , , , , | ||||
| - | - | , , , | ||
| - | - | , , , , | ||
| - | - | ,, , | ||
| - | , | - | ||
| } | , , , |
| 2 | 2 | 1 | ||
| 4 | 4 | 3 | ||
| - | 2 | 1 | ||
| - | 4 | 3 | ||
| - | 2 | 1 | ||
| - | 2 | 1 | ||
| 4 | 2 | 1 |
| SM | Closed Subset | Robustness |
|---|---|---|
| 5 | ||
| 4 | ||
| 3 | ||
| 2 | ||
| 3 | ||
| 3 | ||
| 1 | ||
| 3 | ||
| 3 | ||
| 2 | ||
| 3 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsGender, Labor, and Family Dynamics
Finding Robust Solutions to Stable Marriage
Begum Genc1, Mohamed Siala1, Gilles Simonin2, Barry O’Sullivan1
1 Insight, Centre for Data Analytics, Department of Computer Science, University College Cork, Ireland
2 TASC, Institut Mines Telecom Atlantique, LS2N UMR 6004, Nantes, France
{begum.genc, mohamed.siala, barry.osullivan}@insight-centre.org, [email protected]
Abstract
We study the notion of robustness in stable matching problems. We first define robustness by introducing (a,b)-supermatches. An -supermatch is a stable matching in which if any pairs break up it is possible to find another stable matching by changing the partners of those pairs and the partners of at most other pairs. In this context, we define the most robust stable matching as a -supermatch where b is minimum. We first show that checking whether a given stable matching is a -supermatch can be done in polynomial time. Next, we use this procedure to design a constraint programming model, a local search approach, and a genetic algorithm to find the most robust stable matching. Our empirical evaluation on large instances shows that local search outperforms the other approaches.
1 Introduction
Heraclitus, the Greek philosopher is quoted as saying that “Change is the only constant”. Therefore, it is essential to build robust systems that can be repaired by only minor changes in case of an unforeseen event Sussman (2007). Although it is usually difficult to provide robustness to a complex problem, as it may be computationally expensive, a robust solution reduces the cost of future repairs.
This paper focuses on matching problems under preferences, where the aim is to find an assignment between two disjoint sets of agents while respecting an optimality criterion. Each agent has an ordinal preference ranking over agents of the other set. These types of problems have been widely studied by different research communities such as computer scientists and economists over the years; in fact, the 2012 Nobel Prize for Economics was awarded to Shapley and Roth for their work on stable allocations. Some of the variants can be listed as assigning residents to hospitals (HR), matching men and women to find stable marriages (SM) Gale and Shapley (1962); Gusfield and Irving (1989), and finding donors for kidney patients Roth et al. (2005).
Stable Marriage (SM) Gale and Shapley (1962) is the first and the most studied variant of these problems. In SM, the sets of agents correspond to men and woman. The goal is to find a matching between men and women where each person is matched to at most one partner from the opposite sex such that there is no man and woman that prefers each other to their situations in . Such a matching is called stable. We primarily work on the Stable Marriage problem, but the problem is also meaningful in the context of other matching problem variants.
We introduce the notion of -supermatches as a measure of robustness for SM. Informally, a stable matching is called an -supermatch if any agents decide to break their matches in , thereby breaking pairs, it is possible to “repair” (i.e., find another stable matching) by changing the assignments of those agents and the assignments of at most others. This concept is inspired by the notion of -supermodels in boolean satisfiability Ginsberg et al. (1998) and super solutions in constraint programming Hebrard et al. (2004a, b); Hebrard (2007). Note that, if one agent wants to break his/her current match, the match of the partner breaks also. Therefore, when we mention (or ) as the number of agents, we always refer to the agents from the same set.
There exist different definitions for robustness that leads researchers to ambiguity Climent (2015). We take the definitions of supermodels and super solutions as reference and use the term robust for characterising repairable stable matchings Ginsberg et al. (1998); Hebrard et al. (2004b).
In order to give additional insight into the problem, we motivate robustness on the Hospital/Residents (HR) problem. The HR problem is a one-to-many generalization of SM. In HR, each hospital has a capacity and a preference list in which they rank the residents. Similarly, each resident has a preference list over the hospitals. A -supermatch means that if a resident wants to leave his assigned hospital or a hospital does not want to have one of its current residents, it is possible to move that resident to another hospital by also moving at most other residents to other hospitals. By minimising , we can ensure that the required number of additional relocations to provide a repair is minimal and therefore the solution is robust. In practice, the most robust matching minimises the cost for recovering from unwanted and unforeseen events.
The first contribution of this paper is a polynomial time procedure to verify whether a given stable matching is a -supermatch. Next, based on this procedure, we design a constraint programming (CP) model, as well as local search (LS) and genetic algorithm (GA) to find the most robust stable matching. Last, we give empirical evidence that the local search algorithm is by far the most efficient approach to tackle this problem.
The structure of the paper is as follows: in Section 2, the basics of the Stable Marriage problem and the different notations are introduced. In Section 3, our polynomial-time method is proposed. Next, we give the CP model in Section 4 and the two meta-heuristic algorithms in Section 5. Finally, we give our experimental study in Section 6.
2 Stable Marriage
The Stable Marriage problem takes as input a set of men and a set of woman where each person has an ordinal preference list over people of the opposite sex. For the sake of simplicity we suppose in the rest of the paper that (denoted by n), and that each person expresses a complete preference ranking over the set of opposite sex. In the rest of the paper we interchangeably use to denote man in or similarly to denote woman in .
A matching is a one-to-one correspondence between and . For each man , is called the partner of in matching . In the latter case, we denote by . We shall sometimes abuse notation by considering as a set of pairs. In that case, a pair iff . A pair is said to be blocking a matching if prefers to and prefers to . A matching is called stable if there exists no blocking pairs for . A pair is said to be stable if it appears in a stable matching. Also, a pair is fixed if appears in every stable matching.
The structure that represents all stable matchings forms a lattice . In this lattice, the man-optimal matching is denoted by and the woman-optimal (man-pessimal) matching is denoted by . A stable matching dominates a stable matching , denoted by , if every man prefer their matches in to or indifferent between them. The size of a lattice can be exponential as the number of all stable matchings can be exponential Irving and Leather (1986). Therefore, making use of this structure for measuring the robustness of a stable matching is not practical.
Table 1 gives an example of a Stable Marriage instance with men/women. For the sake of clarity, we denote each man with and each woman with .
Let be a stable matching. A rotation (where ) is an ordered list of pairs in such that changing the partner of each man to the partner of the next man , where and the operation +1 is modulo , in the list leads to a stable matching . The latter is said to be obtained after eliminating from . In this case, we say that is eliminated by , is produced by , and that is exposed in .
For each pair , we say (or ) is involved in . Additionally, for each such that , there exists a unique rotation that produces . Similarly, if there is a unique rotation that eliminates . Note that it is always the case that (strictly) dominates .
There exists a partial order for rotations. A rotation is said to precede another rotation (denoted by ), if is eliminated in every sequence of eliminations that starts at and ends at a stable matching in which is exposed Gusfield and Irving (1989). Note that this relation is transitive, that is, . Two rotations are said to be incomparable if one does not precede the other. The structure that represents all rotations and their partial order is a directed graph called rotation poset denoted by . Each rotation corresponds to a vertex in and there exists an edge from to if precedes . The number of rotations is bounded by and the number of arcs is Gusfield and Irving (1989). It should be noted that the construction of can be done in .
Predecessors of a rotation in a rotation poset are denoted by and successors are denoted by . Later, we shall need transitivity to complete these lists. Therefore, we denote by (respectively ) the predecessors (respectively successors) of a rotation including transitivity.
In Figure 1, we give the lattice of all stable matchings of the instance given in Table 1. There exists two vectors for each stable matching. The first vector represents the set of men and the second vector represents the partner of each man in the matching. Each edge of the form to on the lattice is labeled with the rotation such that is obtained after exposing on . All the rotations are given in Figure 2. The latter represents the rotation poset of this instance.
A closed subset is a set of rotations such that for any rotation in , if there exists a rotation that precedes then is also in . By Theorem 1, every closed subset in the rotation poset corresponds to a stable matching. We denote by the set of men that are included in at least one of the rotations in .
Below is a theorem and a corollary from Gusfield and Irving (1989) mainly used in some proofs in the next section.
Theorem 1** (Theorem 2.5.7).**
*i) There is a one-one correspondence between the closed subsets of and the stable matchings of .
ii) S is the closed subset of rotations of corresponding to a stable matching if and only if is the (unique) set of rotations on every -chain in ending at . Further, can be generated from by eliminating the rotations in their order along any of these paths, and these are the only ways to generate by rotation eliminations starting from .
iii) If and are the unique sets of rotations corresponding to distinct stable matchings and , then dominates if and only if .*
Corollary 1** (Corollary 3.2.1).**
Every man-woman pair is in at most one rotation. Hence there are at most rotations in an instance of the Stable Marriage problem of size n.
We introduce here a notion that is important to measure robustness. Let and be two stable matchings. The distance is the number of men that have different partners in and . A matching is closer to than if . We give in Definition1 a formal definition of -supermatch.
Definition 1**.**
*-supermatch
A stable matching is said to be -supermatch if for any set of stable pairs that are not fixed, there exists a stable matching such that and .*
In this paper, we focus on the -supermatch case. Notice that for any stable matching , there exists a value such that is a -supermatch. In this case, we say that is the robustness value of . The most robust stable matching is a -supermatch with the minimum robustness value.
3 Checking -supermatch in Polynomial Time
A preliminary version of this section appeared in Genc et al. (2017).
In this section, we first recall the basics, and then show how to find or verify the closest stable matching of a given stable matching with an unwanted couple. Throughout this section, we suppose that is a given stable matching, its corresponding closed subset, and is a non-fixed (stable) pair to remove from .
The closest stable matching to that does not include is a matching in which either was eliminated or not produced in any sequence of rotation eliminations starting from leading to . Hence, if then exists, and there is a set of stable matchings , where each of them dominates and does not include the . Similarly, if then exists, and there is a set of stable matchings , where each of them is dominated by and does not include the pair .
If , we define a specific set of rotations as follows111The brackets in Equations 1 and 2 are used to give the priority between the operators.:
[TABLE]
If , we define a specific set of rotations as follows:
[TABLE]
Observe first that and are in fact closed subsets since is a closed subset. Let (respectively ) be the stable matching corresponding to (respectively ). By construction, we have and . We show later that any stable matching that does not include the pair cannot be closer to than or .
For illustration, consider the stable matching of the previous example and its closed subset . Table 2 shows for each pair the matchings and if they exist.
Table 3 shows the stable matchings corresponding to the closed subsets given in Table 2 and the distances between the current stable matching to each one of them. The distances are denoted as and in the table, where for each man , and , respectively. If does not exist for a man , then is denoted by (the same value is used when does not exist). Last, represents the repair cost of each man. The reason for extraction of is because we are considering only -supermatches (see Definition 1).
The robustness of a stable matching is equal to the repair cost of the non-fixed man that has the worst repair cost . For the follow-up example, is labelled as a -supermatch. Moreover, Table 4 shows the -robustness measures for each stable matching of the given sample. The most robust stable matching for the sample is identified as since it has the smallest value.
We give few lemmas in order to show that the closest stable matching to when breaking the pair is either or .
Lemma 1**.**
Given two incomparable rotations and , .
Proof.
By definition of incomparability, if two rotations are incomparable, it means that they modify a set of men who do not require modifications from the other first. Therefore the sets of men are distinct. ∎
Lemma 2**.**
Given three stable matchings and such that , then and .
Proof.
Using the properties of domination and the closed subsets in Theorem 1, we can infer .
Assume to the contrary that . This situation occurs only if a set of pairs that are present in are eliminated to obtain and then re-matched with the same partners they had in to get . However, this contradicts Corollary 1. For similar reasons, . ∎
The case where stable matchings have the same distance such as , if the rotation set in the difference sets , , and modify the same set of men. We can demonstrate the case where we have equal distance between the three matchings on a Stable Marriage instance of size given in Manlove’s book on page 91 Manlove (2013). It can be verified that , where:
,
,
.
In this case, due to the fact that , the distances of all three matchings will be equal to each other .
Lemma 3**.**
If there exists a stable matching that does not contain , dominates and different from , then dominates .
Proof.
by definition. Suppose by contradiction that there exists an such that and . It implies that . In this case, (S_{x}\setminus S_{\textsc{UP}}^{*i})\subset\Big{\{}\{\rho_{{p_{{i},{j}}}}\}\cup\{{{N}_{t}^{+}}(\rho_{{p_{{i},{j}}}})\cap S\}\Big{\}}. However, this set contains and the rotations preceded by . Adding any rotation from this set to results in a contradiction by either adding to the matching, thereby not breaking that couple, or because the resulting set is not a closed subset. ∎
Lemma 4**.**
If there exists an that does not contain dominated by but different from , then dominates .
Proof.
Similar to the proof above, suppose that there exists an such that and . We have . It implies (S_{x}\setminus S)\subset\Big{\{}\{\rho_{{e_{{i},{j}}}}\}\cup\{{{N}_{t}^{-}}(\rho_{{e_{{i},{j}}}})\setminus S\}\Big{\}}. This set contains the rotation that eliminates the pair and the rotations preceding . In order to add all other rotations must be added to form a closed subset. If all rotations are added, which results in a contradiction. ∎
Lemma 5**.**
For any stable matching incomparable with such that does not contain the pair , is closer to than .
Proof.
Let be the closed subset corresponding to , and be that corresponding to .
First, we consider the case in which . If the closed subsets have no rotations in common the rotations in these sets are incomparable. Using Lemma 1, . Therefore, , whereas .
Second, we consider the case in which . Let be the closest dominating stable matching of both and , along with as its corresponding closed subset. Using Lemma 2 we know that , where .
Using Lemma 1 we know that . Therefore, . By substituting the formula above, . Using the fact that from the definition of , we can conclude that . ∎
The following theorem is a direct consequence of Lemmas 3, 4, 5.
Theorem 2**.**
The closest stable matching of a stable matching given the unwanted pair is either or .
We show that checking if a stable matching is a -supermatch can be performed in time after a preprocessing step. First, the pre-processing step consists of building: the poset graph (in time); the lists , for each rotation (in time); and and for each pair whenever applicable (in time). Next, we compute and for each man. Note that and can be constructed in time (by definition of and ) for each man . Note that is equal to the number of men participating in the rotations that are eliminated from to obtain . Similarly, is equal to the number of men participating in the rotations that are added to obtain . Last, if and , we know that it is impossible to repair when needs to change his partner with at most other changes. Otherwise, is a -supermatch.
The constraint programming (CP) formulation and the metaheuristic approaches that we propose in the following sections to find the most robust stable matching are essentially based on this procedure.
4 A Constraint Programming Formulation
Constraint programming (CP) is a powerful technique for solving combinatorial search problems by expressing the relations between decision variables as constraints Rossi et al. (2006). We give in this section a CP formulation for finding the most robust stable matching, that is, the -supermatch with the minimum b. The idea is to formulate the stable matching problem using rotations, then extend that formulation in order to compute the two values and (where M is the solution) for each man so that is always greater or equal to one of them. Using rotations to model stable matching problems has been used in Gusfield and Irving (1989) (page 194), and in Feder (1992); Fleiner et al. (2007); Siala and O’Sullivan (2017).
Let be the set of all stable pairs that are not fixed and be the set of all men that are at least in one of the pairs in . Let the set of rotations be and for each , is the unique rotation that produces . Moreover, for each , denotes the unique rotation that eliminates the pair . Notice that . We use to denote the set of rotations in which man is involved.
In our model, we assume that a pre-processing step is performed to compute , , , , the poset graph, , and for every pair whenever applicable. We also need to compute the lists , for each rotation (in time).
We start by giving the different sets of variables, then we show the constraints. Let denote man ’s partner in , and denote his partner in . There exists a boolean variable for every pair to indicate if is part of the solution . Therefore, is a boolean variable related to a pair in . There exists also a boolean variable for each rotation , where to indicate if is in the closed subset of the solution. Moreover, we use an integer variable with as an initial domain to represent the objective. That is, the solution is a -supermatch with the minimum .
For each man , we define the following variables:
- •
(respectively ): a boolean variable to indicate if (respectively ) is a part of the solution.
- •
(respectively ): a boolean variable for every to know if is in the difference set (respectively ) where S is the closed subset of the solution, (respectively ) corresponds to the closed subset of the nearest stable matchings dominating (respectively dominated by) S when then pair defined by man and his partner is to be eliminated.
- •
(respectively ): a boolean variable for each man to know if the partner of needs to be changed to find a repair when man breaks up with his partner to obtain (respectively ) from the solution.
A pair is a part of a solution if and only if it is produced by a rotation (if it is not a part of ) and not eliminated by another (if it is not a part of ). Moreover, a set of rotations corresponds to a closed subset (or a solution) if and only if all the parents of each rotation in the set are also in the set. Hence, the following constraints are required to keep track of the pairs that are in the solutions and also to make sure the solution is a stable matching.
More specifically, let denote the closed subset of the solution. Without loss of generality, the first constraints ensure that if a pair is in the solution, the rotation that produces must be in and the rotation that eliminates it should not be in . The second constraints enforce the set of rotations assigned to true to form a closed subset. This model was used in the many-to-many setting in Siala and O’Sullivan (2017).
:
- (a)
If , 2. (b)
Else if , 3. (c)
Otherwise 2. 2.
: . 3. 3.
The following set of constraints are required to build the difference set :
- (a)
: This constraint handles the special case when man is matched to his partner in . 2. (b)
:
- i.
, where : .
This constraint is used to know the rotation that produces the partner of in the solution. 2. ii.
- •
: to make sure if this pair is not produced by a rotation, then there does not exist an set.
- •
,: to build the difference set.
- •
There are two cases to distinguish:
- –
If produces the pair : s_{up_{v}}^{i}\rightarrow s_{v}\wedge\big{(}x_{{{i}},{{j}}}\vee\bigvee_{\rho_{v*}\in{{N}^{-}}(\rho_{v})}(s_{up_{v*}}^{i}\big{)}.
- –
Else : s_{up_{v}}^{i}\rightarrow s_{v}\wedge\big{(}\bigvee_{\rho_{v*}\in{{N}^{-}}(\rho_{v})}(s_{up_{v*}}^{i}\big{)}. 4. 4.
Following the same intuition above, we use the following constraints to represent the difference set .
- (a)
. 2. (b)
:
- i.
, where : 2. ii.
:
- •
: to handle the particular case of having a partner in .
- •
.
- •
There are two cases to distinguish:
- –
If eliminates the pair : s_{down_{v}}^{i}\!\!\!\rightarrow\!\neg s_{v}\wedge\!\big{(}x_{{{i}},{{j}}}\!\vee\bigvee_{\rho_{v*}\in{{N}^{+}}(\rho_{v})}s_{down_{v*}}^{i}\big{)}.
- –
Else: s_{down_{v}}^{i}\!\!\!\rightarrow\!\neg s_{v}\wedge\!\big{(}\bigvee_{\rho_{v*}\in{{N}^{+}}(\rho_{v})}s_{down_{v*}}^{i}\big{)}. 5. 5.
Last, we define the following constraints to count exactly how many men must be modified to repair the solution by using and :
- (a)
The following two constraints are required to keep track if man has to change his partner to obtain (or ) upon the break-up of man with his current partner. :
- i.
2. ii.
2. (b)
The next two constraints are required to count the number of men that needs to change their partners to obtain the closest stable matchings. :
- i.
and 2. ii.
and 3. (c)
To constrain b:
, \big{(}\neg\alpha_{i}\rightarrow(b\geq d_{up}^{i})\big{)}\vee\big{(}\neg\beta_{i}\rightarrow(b\geq d_{down}^{i})\big{)} 4. (d)
The objective is to minimise . We can easily improve the initial upper bound by taking the minimum value between the maximum number of men required to repair any (non-fixed) pair from and from .
5 Metaheuristics
For finding the -supermatch with minimal , we provide solutions using two different mono-objective metaheuristics: genetic algorithm (GA) and iterated local search (LS) Boussaïd et al. (2013). The intuition behind using those approaches is that they are mostly based on finding neighbour solutions and are easy to adapt to our problem. In this section, we will describe how to apply those two methods to find -supermatches and subsequently the most robust stable matching.
The two metaheuristic models described in the following sections are also based on the assumption that a pre-processing step is performed to compute , , the poset graph, the lists , for each rotation (in time).
5.1 Genetic Algorithm
Genetic algorithms are being used extensively in optimization problems as an alternative to traditional heuristics. They are compelling robust search and optimization tools, which work on the natural concept of evolution, based on natural genetics and natural selection. Holland introduced the GAs and he has also shown how to apply the process to various computationally difficult problems Holland (1975, 1992); Bäck (1996).
Our approach is based on the traditional GA, where evolutions are realised after the initialisation of a random set of solutions (population). The process finishes either when an acceptable solution is found or the search loop reaches a predetermined limit, i.e. maximum iteration count or time limit.
The genetic algorithm that we propose to find the most robust stable matching is detailed below with a follow-up example for one iteration.
5.1.1 Initialization
The purpose of initialization step is to generate a number of random stable matchings for constructing the initial population set, denoted by . Recall that each closed subset in the rotation poset corresponds to a stable matching. The random stable matching generation is performed by selecting a random rotation from the rotation poset and adding all of its predecessors to the rotation set to construct a closed subset , therefore a stable matching as detailed in Algorithm 1. In Line 6, the method is responsible from converting the given closed subset to its corresponding matching by exposing all the rotations in in order on .
Then, randomly created stable matchings are added to the population set as described in Algorithm 2.
Let us illustrate the procedure on a sample for the Stable Marriage instance given in Table 1. Assume that the population size is 3. In order to generate the 3 initial stable matchings, 3 random rotations are selected from the rotation poset, namely: . Since has no predecessors, the stable matching that corresponds is obtained by exposing on , resulting in . Similarly, the closed subset obtained by adding all predecessors of corresponds to and the closed subset for corresponds to . Thus, the current population is: .
5.1.2 Evaluation
For each stable matching , we denote by its robustness value for (1,b)-supermatch. At the evaluation step, we compute the value of each stable matching . Then, a fitness value is assigned to each in the population. This is to indicate that a stable matching with a lower b value is more fit. Then, the values are normalised in the interval .
Let denote the maximum b value in the population. The first thing required is to get the complements of the numbers with to indicate that a stable matching with a smaller b is a more fit solution. In the meantime, a small constant is added to each to make sure even the least fit stable matching , where , is still an eligible solution (Equation 3). Then, the normalization is applied as shown in Equation 4. For normalization, an integer variable is used to keep track of the sum of the total fitness values in the population.
[TABLE]
[TABLE]
The steps are detailed in Algorithm 3.
The b values for the stable matchings given in our example, where are calculated as , , by the polynomial procedure defined in Section 3. Given these values, . Let us fix to . Then, the fitness values are calculated as , , and the sum of the fitness values is . By normalizing the fitness values, we obtain the following values: indicating that and are the fittest stable matchings in .
5.1.3 Evolution
The evolution step consists in selecting stable matchings from the population using a selection method, then applying crossover and mutation on the selected matchings.
We use the roulette wheel selection in our procedure. Because it is a method favouring more fit solutions to be selected and therefore useful for the convergence of the population to a fit state Goldberg (1989). Algorithm 4 gives details of the roulette wheel selection procedure we used. First, a random double number is generated. Then, the fitness values of the stable matchings in the population are visited. At each step, a sum of the fitness values seen so far are recorded in a variable named . This procedure continues until a stable matching is found, where the recording up to satisfies the criterion at line 5 in Algorithm 4.
The evolution step is then continued by applying crossover and mutation on selected stable matchings. First, two stable matchings are selected, namely and . If these matchings are different from each other, crossover is applied (between Lines 2 and 5 in Algorithm 5).
After applying the crossover on and obtaining the resulting stable matchings , we refine the population. Refinement is applied for adding adding more fit solutions to the population and removing the least fit solutions. The overall procedure is detailed in Algorithm 6. In the refinement procedure, are immediately added to the population . Then, the worst two solutions, in other words the two least fit stable matchings and are found and removed from the population. Note that after the refinement procedure in line 7 in Algorithm 5, the evaluation must be repeated to properly evaluate the current fitness values in the population.
Subsequently, between the lines 8 and 11 of Algorithm 5, a stable matching is selected for mutation. If is different from the fittest stable matching , the mutation is applied. Mutation step may result in producing either better or worse solutions. We do not apply a refinement procedure after the mutations, instead directly apply the mutation on . Next, we go into the details of the crossover and mutation operations.
Crossover.
The procedure for crossover is detailed in Algorithm 7. Given two stable matchings and their corresponding closed subsets and , one random rotation is selected from each subset. Let and denote the randomly selected rotations. Between the lines 4 and 7, the procedure for creating a new closed subset from the closed subset is shown. The method is, if already contains the rotation , then is constructed by removing and all its successor rotations that are in from the set . We denote this removal process by the method ) in lines 5 and 9 in Algorithm 7. However, if , then and all its predecessors that are not included in are added to with the rotations that are already in to form the new closed subset . Similarly, we denote the addition process by the method ) in lines 7 and 11. This new closed subset corresponds to one of the stable matchings produced by crossover, . Similarly, the same process is repeated for by constructing , and another stable matching is obtained.
For the sake of the example, assume that and are selected for crossover by the roulette wheel selection from the current population . One random rotation is selected from each set: and . Then, the produced stable matchings are since and , and by removing all rotations from . After adding new stable matchings, the population becomes . Then the population is refined by removing the least two fit stable matchings, which are in this case and . Hence, the refined population after crossover is: .
Mutation.
At this step, the mutation method is given a stable matching . Let denote its corresponding closed subset. The procedure starts by selecting a random rotation from the rotation poset . Then, similar to the crossover procedure above, if , and all its required predecessors to form a closed subset are added to . However, if , then and all its successors in are removed from . Algorithm 8 defines this procedure.
In order to demonstrate this step on the example population, assume that has been selected for mutation and is randomly selected from the rotation poset. Since , and all its predecessors are added to , resulting in . The new stable matching is is added to the population and the mutated stable matching, is deleted. The final population is: .
The procedure for the overall algorithm is given in Algorithm 9. The evolution step is repeated until either a solution is found or the termination criteria are met. In our case, we have two termination criteria: a time limit and an iteration limit to cut-off the process if there is no improved solution for the specified number of iterations . For cut-off termination criterion, we keep a counter to count the number of iterations with no improvement, i.e. more fit solution than the current fittest solution. This counter is increased at each unimproved iteration until it reaches the cut-off limit. If a more fit solution is generated, is restarted as .
In order to compute the b values of the stable matchings, we use the method described in the Section 3 for each stable matching. Recall that this procedure takes time after a preprocessing step. In order to speed up this process from a practical point of view, in our experiments an extra data structure is used to memorize the fitness value of already generated stable matchings. In both crossover and mutation, the worst case time complexity for one call is bounded by since the set of all predecessors (respectively successors) of a given node is (respectively ).
5.2 Local Search
In our local search model, we use the well-known iterated local search with restarts Stützle (1998); Lourenço et al. (2010). The first step of the algorithm is to find a random solution to start with. A random stable matching is created by using the Initialization method detailed in Algorithm 2 in Section 5.1. Then, a neighbour stable match set is created using the properties of rotation poset.
A neighbour in this context is defined as a stable matching that differs only by one rotation from the closed subset of the matching . Let denote the set of leaf rotations of . Removing one rotation from corresponds to a different dominating neighbour of . Similarly, let denote the set of rotations that are not included in and either they have an in-degree of 0 or all of their predecessors are in . In the same manner, adding a rotation from to at a time corresponds to a different dominated neighbour of .
Figure 3 illustrates a sample rotation poset, where the closed subset is . Then, the set of leaf rotations in this set is identified as . Similarly, the set of neighbour rotations is since all their predecessors are included in the closed subset .
These two sets correspond to rotations, where removal of any rotation from at a time does not require removal of any other rotations in order to obtain another closed subset, i.e. a neighbour. Likewise, adding any rotation to does not require adding any additional rotations to obtain a closed subset. Algorithm 10 expands on the procedure for identifying the set of neighbour stable matchings of a given stable matching . The lines between 3 and 11 details the procedure of finding the rotations in Similarly, the lines between 12 and 19 defines the procedure for identifying the leaf nodes in . The neighbour stable matchings are denoted by . In this procedure, a variable called is used to count the number of incoming edges of , where the source node is not in and then to count the number of outgoing edges whose target node is a member of .
The general procedure is detailed in Algorithm 11. At each iteration, if a neighbour has lower b than , in other words, it is a more robust solution, the search continues by finding the neighbours of the new solution. A variable is used to keep track of the best solution found so far in the whole search process. We denote the best stable matching in set by and the function N is used to find the stable matching with the lowest b in set . Also a counter is used to count the number of iterations with no improved solutions. The cut-off limit is bounded by a variable denoted by in the algorithm. There is an iteration limit that indicates the depth of searching for neighbours of a randomly created stable matching. After the iteration limit is met, a new random stable matching is generated and the neighbour search continues from that stable matching.
Let us illustrate the neighbourhood search on the Stable Marriage instance given in Table 1. Assume that the search starts with a randomly generated stable matching, , where . The sets and are identified as follows: , . Thus the current stable matching has 3 neighbours:
.
Next step is to calculate the robustness of each stable matching. Using the method described in Section 3, the b values are calculated as follows: . Since is the most robust stable matching in the neighbourhood and better than the current stable matching , the neighbourhood search for the next step expands from .
Notice that there can be at most neighbours of a stable matching. Thus, creating neighbours and finding their respective values is .
6 Experiments
We experimentally evaluate the three models for finding the most robust stable matching. The CP model is implemented in Choco 4.0.1 Prud’homme et al. (2016) and the two meta-heuristics are implemented in Java. All experiments were performed on DELL M600 with 2.66 Ghz processors under Linux.
We ran each model with different randomization seeds for each instance. The time limit is fixed to 20 minutes for every run. An additional cut-off is used for local search (LS) and genetic algorithm (GA) as follows: if the solution quality does not improve for 10000 iterations, we terminate the search. The genetic algorithm applies a crossover at each iteration unless the roulette wheel selection selects the fittest stable matching from the population. Additionally, the probability of applying mutation on a randomly selected stable matching is fixed as . For local search, we chose to restart the local search with a randomly generated stable matching every 50 iterations. Last, the CP model (CP) uses the weighted degree heuristic Boussemart et al. (2004) with geometric restarts.
We use two sets of random instances. The first set contains instances. The number of men for this set is in the set where . The second set contains large instances of size where . We generated instances for each size for both benchmarks.
In Figures 4 and 5 we plot the normalized objective value of the best solution found by the search model (-axis) after a given time (-axis). Let be the objective value of the best solution found using model on instance and (resp. ) the lowest (resp. highest) objective value found by any model on . The formula below gives a normalized score in the interval :
[TABLE]
The value of is equal to if has found the best solution for this instance among all models, decreases as gets further from the optimal objective value, and is equal to [math] if and only if did not find any solution for .
Note that the CP model runs out of memory for large instances. Therefore, we do not plot it in Figure 5.
The outcome from both figures is clear. Local search is extremely efficient both in the quality of the solutions, and in runtime. Indeed, in the first plot, the best solutions are found by LS and CP. However, CP takes much longer time. Note that in Figure 4, CP and LS both find almost always the same objective, and in fact CP claims that the solution is optimal in all instances except one.
The GA model does not seem to be well suited for this problem. In the first data set it does not find the best solutions in all instances. Moreover, it clearly takes much longer time than CP and LS for finding good quality solutions.
The results in Figure 5 are more spectacular for local search. Local search does not always find the best solutions since the normalised objective ratio does not exceed . However, the overall performance is clearly better than GA in both quality and runtime.
7 Conclusions
We studied the notion of robustness in stable matching problems by using the notion of -supermatch. We first showed that the problem of finding a stable matching that is closest to a given stable matching if a pair (man,woman) decides to break their match in can be found in polynomial time. Then, we used essentially this procedure to model the problem of finding the most robust stable matching using a CP formulation, local search, and genetic algorithm. Last, we empirically evaluated these models on randomly generated instances and showed that local search is by far the best model to find robust solutions.
To the best of our knowledge, this notion of robustness in stable matchings has never been proposed before. We hope that the proposed problem will get some attention in the future as it represents a challenge in real-world settings.
Acknowledgments
This publication has emanated from research conducted with the financial support of Science Foundation Ireland (SFI) under Grant Number SFI/12/RC/2289.
Appendix A CP Model
Below is an overview of the CP model for the Stable Marriage instance provided in Table 1.
As an example, find below the full CP model of the sample Stable Marriage instance given in Table 1. The set of stable pairs, .
The constraints ensuring if a pair is a part of the solution by checking the existence of the rotations that produces and eliminates each pair:
The constraints to make sure the solution forms a closed subset by requiring all predecessors of each rotation:
The constraints that handle the case if a man is matched to his best possible partner:
The constraints to state if a couple is no longer wanted, the rotation that produces the couple must be removed from the solution closed subset:
The constraints that ensure there does not exist a repair matching for man if he is matched to his best possible partner:
The constraints that require if a rotation is in the difference set , then all successors of that rotation that are a part of solution is also in the difference set when :
when
when
when
when
when
when
The constraints that ensure if a rotation is in the difference set , they must be a part of the solution and they are either the rotation that produces the couple in the solution or they have a predecessor that produces the couple. For :
For :
For :
For :
For :
For :
The constraints for construction of the difference set can also be generated similar to the difference set constraints above. We do not include those constraints here for space limitations.
For the counting constraints, following are for counting which other men are required to change their couples in order to repair man for difference set , when :
when :
when :
when :
when :
when :
when :
For difference set , the constraints are the same except the boolean variables is replaced with and is replaced with .
The constraints for counting how many other men are required to change their partners in order to provide a repair stable matching that dominates the current matching:
true , else
true , else
true , else
true , else
true , else
true , else
true , else
Similarly, the repairs required for the dominated stable matching: true , else
true , else
true , else
true , else
true , else
true , else
true , else
The constraint for measuring the robustness of the solution:
\big{(}\neg(\alpha_{0})\rightarrow(b\geq d_{up}^{0})\big{)}\vee\big{(}\neg(\beta_{0})\rightarrow(b\geq d_{down}^{0})\big{)}
\big{(}\neg(\alpha_{1})\rightarrow(b\geq d_{up}^{1})\big{)}\vee\big{(}\neg(\beta_{1})\rightarrow(b\geq d_{down}^{1})\big{)}
\big{(}\neg(\alpha_{2})\rightarrow(b\geq d_{up}^{2})\big{)}\vee\big{(}\neg(\beta_{2})\rightarrow(b\geq d_{down}^{2})\big{)}
\big{(}\neg(\alpha_{3})\rightarrow(b\geq d_{up}^{3})\big{)}\vee\big{(}\neg(\beta_{3})\rightarrow(b\geq d_{down}^{3})\big{)}
\big{(}\neg(\alpha_{4})\rightarrow(b\geq d_{up}^{4})\big{)}\vee\big{(}\neg(\beta_{4})\rightarrow(b\geq d_{down}^{4})\big{)}
\big{(}\neg(\alpha_{5})\rightarrow(b\geq d_{up}^{5})\big{)}\vee\big{(}\neg(\beta_{5})\rightarrow(b\geq d_{down}^{5})\big{)}
\big{(}\neg(\alpha_{6})\rightarrow(b\geq d_{up}^{6})\big{)}\vee\big{(}\neg(\beta_{6})\rightarrow(b\geq d_{down}^{6})\big{)}
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Bäck (1996) Thomas Bäck. Evolutionary Algorithms in Theory and Practice: Evolution Strategies, Evolutionary Programming, Genetic Algorithms . Oxford University Press, Oxford, UK, 1996.
- 2Boussaïd et al. (2013) Ilhem Boussaïd, Julien Lepagnot, and Patrick Siarry. A survey on optimization metaheuristics. Information Sciences , 237:82 – 117, 2013. Prediction, Control and Diagnosis using Advanced Neural Computations.
- 3Boussemart et al. (2004) Frédéric Boussemart, Fred Hemery, Christophe Lecoutre, and Lakhdar Sais. Boosting systematic search by weighting constraints. In Proceedings of the 16th European Conference on Artificial Intelligence – ECAI , pages 146–150, 2004.
- 4Climent (2015) Laura Climent. Robustness and stability in dynamic constraint satisfaction problems. Constraints , 20(4):502–503, 2015.
- 5Feder (1992) Tomás Feder. A new fixed point approach for stable networks and stable marriages. J. Comput. Syst. Sci. , 45(2):233–284, 1992.
- 6Fleiner et al. (2007) Tamás Fleiner, Robert W. Irving, and David Manlove. Efficient algorithms for generalized stable marriage and roommates problems. Theor. Comput. Sci. , 381(1-3):162–176, 2007.
- 7Gale and Shapley (1962) D. Gale and L. S. Shapley. College Admissions and the Stability of Marriage. The American Mathematical Monthly , 69(1):9–15, January 1962.
- 8Genc et al. (2017) Begum Genc, Mohamed Siala, Barry O’Sullivan, and Gilles Simonin. Robust stable marriage. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, February 4-9, 2017, San Francisco, California, USA. , pages 4925–4926, 2017.