Designs for estimating the treatment effect in networks with interference
Ravi Jagadeesan, Natesh Pillai, Alexander Volfovsky

TL;DR
This paper proposes new experimental designs for estimating causal effects in networked settings with interference, using a graph coloring approach to improve estimator properties.
Contribution
It introduces a novel quasi-coloring design inspired by matching, enhancing causal inference in networks with interference and homophily.
Findings
Classical Neymanian estimator performs well with the new designs.
Designs are easily implementable and effective in various interference scenarios.
The approach extends to networks with homophily.
Abstract
In this paper we introduce new, easily implementable designs for drawing causal inference from randomized experiments on networks with interference. Inspired by the idea of matching in observational studies, we introduce the notion of considering a treatment assignment as a quasi-coloring" on a graph. Our idea of a perfect quasi-coloring strives to match every treated unit on a given network with a distinct control unit that has identical number of treated and control neighbors. For a wide range of interference functions encountered in applications, we show both by theory and simulations that the classical Neymanian estimator for the direct effect has desirable properties for our designs. This further extends to settings where homophily is present in addition to interference.
Click any figure to enlarge with its caption.
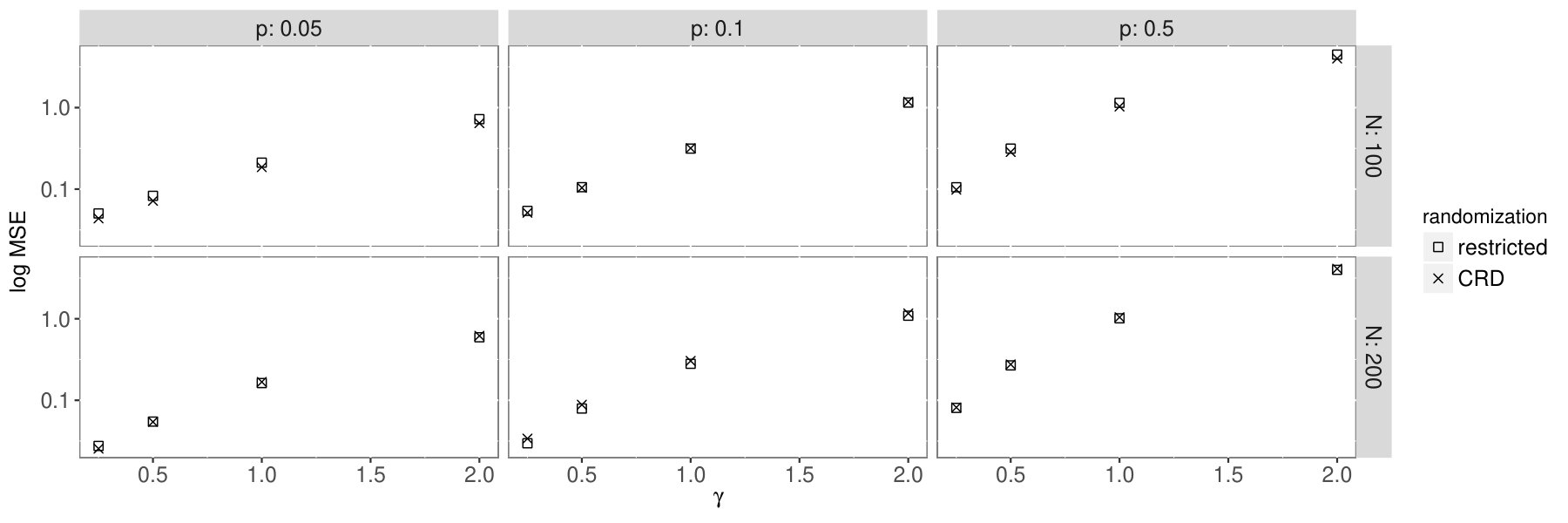 Figure 1
Figure 1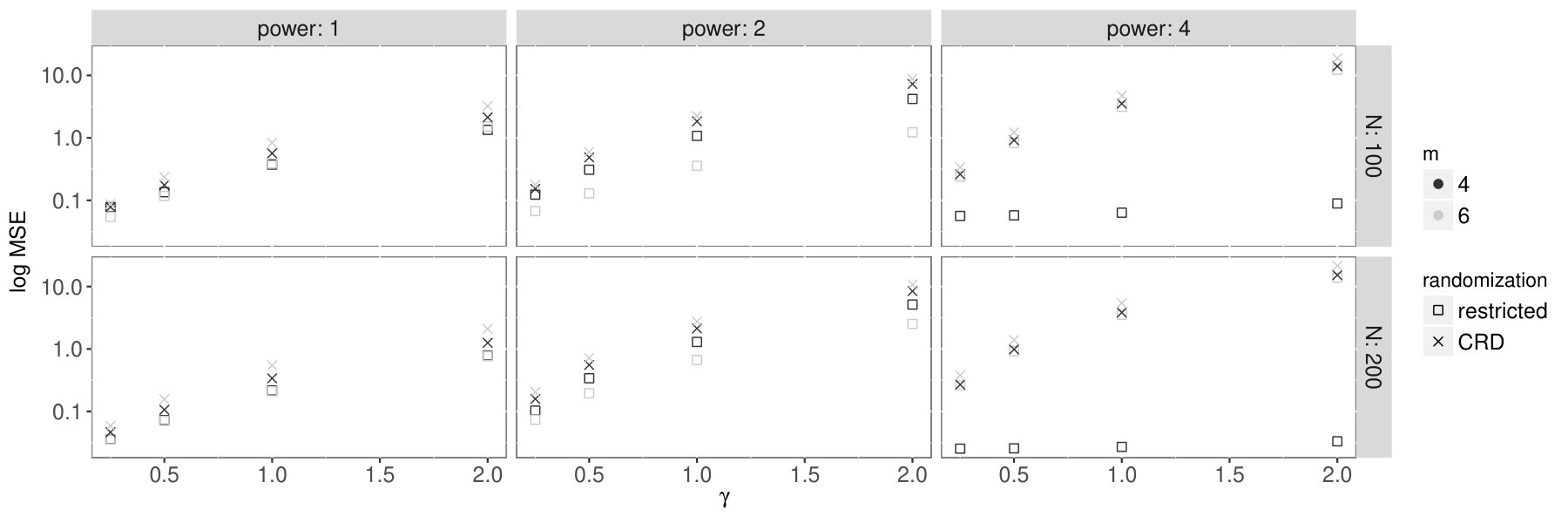 Figure 2
Figure 2Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Designs for estimating the treatment effect in Networks with
Interference
Ravi Jagadeesanlabel=e1][email protected] [
Natesh S. Pillailabel=e2][email protected] [
Alexander Volfovskylabel=e3][email protected] [
Harvard University\thanksmarkm1 and Duke University \thanksmarkm2
Abstract
In this paper we introduce new, easily implementable designs for drawing causal inference from randomized experiments on networks with interference. Inspired by the idea of matching in observational studies, we introduce the notion of considering a treatment assignment as a “quasi-coloring” on a graph. Our idea of a perfect quasi-coloring strives to match every treated unit on a given network with a distinct control unit that has identical number of treated and control neighbors. For a wide range of interference functions encountered in applications, we show both by theory and simulations that the classical Neymanian estimator for the direct effect has desirable properties for our designs. This further extends to settings where homophily is present in addition to interference.
Experimental Design,
Network Interference,
Neyman Estimator,
Symmetric Interference Model,
Homophily,
keywords:
\setattribute
journalname
and and t1Undergraduate Student, Harvard University t2Associate Professor, Department of Statistics, Harvard University t3Assistant Professor, Department of Statistical Science, Duke University
1 Introduction.
In this paper, we construct and analyze new designs for estimating treatment effects from randomized experiments in networks with interference. With the proliferation of network data and the steady increase in the number of experiments conducted on networks, understanding the behavior of individuals in a network has become an important issue in many scientific fields. Epidemiologists study the transmission of disease over social networks [1], computer scientists are interested in information diffusion in large computer networks [23, 7] and sociologists study the effects of school integration on friendship networks [15]. While much of the early statistical work on networks focussed on models for understanding network formation [8, 10], there has been a recent surge in drawing causal inference from experiments on networks [19, 6, 20, 22, 21].
A time-honored approach to performing causal inference from randomized experiments entails the following steps [9, 17, 16]: (i) define the population of units, (ii) define the treatment assignment and (iii) define the quantity, or estimand, of interest. When an experiment is conducted on a network, we must revisit each of these elements. First, the object of inference can be the network, the edges of the network or the nodes of the network. We focus on the case where the nodes are the experimental units and our population is just the observed units. Next, the treatment assignment mechanisms proposed in this paper are conditional on a given network and thus the events that any two units receive treatment are not independent. This is in stark contrast to usual Bernoulli-type randomization mechanisms where treatment is assigned to units independently or with very weak dependence. Finally, our estimand of interest is the direct treatment effect (effect of treatment on the treated unit irrespective of the treatment status of the rest of the network) discussed below.
Much of the current works on causal inference on networks study generic Bernoulli-type randomization schemes and construct various estimators for minimizing their Mean-Squared Error (MSE); a notable exception is the recent work [6]. In contrast, we fix an estimator of interest and focus on the design of treatment assignments. We study the classical Neymanian estimator that takes the difference between the means of the outcome for treated nodes and the control nodes. Our approach is motivated by two key reasons: (i) The Neymanian estimator is ubiquitously used. It is a natural estimator for the direct effect and improves on reweighted versions of it (such as Horvitz-Thompson, Hajek, etc.) due to its prima facie interpretability. (ii) It has been emphasized by many researchers that for objective causal inference, “design trumps analysis” [18]. It is known that this estimator is biased under standard designs such as Bernoulli trials (every unit has probability of treatment ) and a completely randomized design (a fraction of the units is assigned to treatment). We consider a more natural randomization scheme that works to remove the effects of interference and homophily by balancing the relevant distributions between treated and untreated nodes.
Conceptually, our main contribution is the idea of considering a treatment assignment as a “quasi-coloring” of a graph (see Definition 5.1). Roughly speaking, a treatment assignment is a perfect quasi-coloring111The word coloring is reserved for something specific in graph theory; thus we use the phrase “quasi-coloring”., if for every treated vertex (represented by black dots, say), there is a non-treated vertex (represented by gray dots) that has the same number of treated and non-treated neighbors as that of . Thus having a perfect quasi-coloring on a graph ensures that one can color the graph in such a way that for every black vertex, there exists a distinct gray vertex with identically colored neighbors. Figure 1 shows two instance of coloring a square, where one is a perfect quasi-coloring and the other is not. For multiple treatments, this definition can be naturally extended to perfect quasi-colorings with colors.
Our notion of perfect quasi-colorings is inspired by the idea of covariate balance in the context of matching in observational studies. For any given network, if a treatment assignment mechanism satisfies our notion of quasi-coloring, we prove that the Neymanian estimator for the direct treatment effect is unbiased for a wide range of families of interference effects encountered in practice. This replicates the behavior of the Neymanian estimator in classical randomized experiments. It turns out that, for many graphs, perfect quasi-colorings are not available or may be very difficult to construct. To circumvent this issue, we develop treatment assignment mechanisms that correspond to “approximately perfect quasi-colorings”. The closer an approximately perfect quasi-coloring is to a perfect quasi coloring, the smaller its bias. Based on this notion we develop a new restricted randomization design that reduces bias and variance. In networks where a perfect quasi-coloring is not possible, we give easily implementable algorithms to construct designs with desirable properties; see the “partitioning by degree” design in Definition 6.1.
We give bounds for the bias and variance of our estimator under a few different settings of approximate quasi-colorings. These results are then used to prove asymptotic consistency of our estimator in both dense and sparse asymptotic regimes for network growth. We also derive bounds for the MSE of the Neymanian estimator under homophily. We demonstrate the efficacy of our proposed randomization scheme in a series of simulations — varying both the type of interference and the network. Our proofs for the dense vs. sparse graphs are different and thus are of independent interest.
1.1 Background and literature.
We briefly survey the relevant literature, point out connections to the present paper and place our work in a broader context. In situations when the experimental units are connected in a network, some of the usual assumptions used in other settings are not likely to hold. For example, the stable unit treatment value assumption [16] requires that the outcome for a unit only depends on its own treatment, and in particular is independent of the treatment assignment mechanism. For networks this can be violated in several ways: it is likely that either the behavior of connected units is similar (homophily), that their outcomes are associated with the treatment of their network neighbors (interference) or that the treatment effect passes temporally across the network (contagion). It has been previously demonstrated that while these can affect causal inference on a network differently, they are difficult, if not impossible, to distinguish [19]. These complications lead to a difficulty in specifying an estimand of interest [11]. The four main estimands in the presence of a network are (i) the effect of treatment were it applied to the whole network versus no one in the network (total network treatment effect), (ii) the direct effect of treatment on the treated unit irrespective of the treatment status of the rest of the network (direct treatment effect), (iii) the spillover effect of treatment of the network on a single unit irrespective of its treatment (indirect treatment effect), and (iv) the sum of the direct and indirect effect (total nodal treatment effect).
Different estimands lead to different inference procedures – both from a design and an analysis point of view. We focus on the design of experiments targeting the direct treatment effect. Other recent work has targeted different estimands: In Choi [5] the author studies estimators for monotone treatment effects and constructs asymptotically consistent bounds for such estimates. Eckles, Karrer and Ugander [6] study total network effects by considering a cluster-randomized-design in conjunction with Horvitz-Thompson and Hajek estimators. In Sussman and Airoldi [20], the authors construct unbiased estimators for direct and indirect treatment effects for a fixed design.
The above works study the effects of interference on estimation and make the common assumption that the interference is limited to the immediate neighborhood of a node. We will also make this assumption but our work can be easily generalized to different patterns of interference; see Discussion for more on this point. Another simplifying assumption that is frequently made requires the interference effect to be symmetric – that is each interfering unit contributes the same indirect effect. We demonstrate results under several classes of interference patterns that generalize this assumption.
1.2 Notation.
Fix and let be a graph with . Throughout the paper, we will assume that has no isolated vertices. Let denote the set of neighbors of a vertex and let denote the degree of . Also define the minimum and maximum degrees:
[TABLE]
We will denote by , the set containing all subsets of with cardinality . Similarly, for with , define
[TABLE]
In particular, denotes the set of all partitions of into sets of size . For , the set will be denoted by . For sets , denotes the set difference.
For , let denote the indicator function:
[TABLE]
For , we will have treated units, and thus . Set . For and let
[TABLE]
1.3 Paper guide.
In Section 2 we introduce a basic model for interference and the Neymanian estimator. In Section 3 we discuss some restricted randomizations. Section 4 contains a symmetric interference model. In Section 5 we define our notion of quasi-coloring. We derive the bounds for the MSE of the Neymanian estimator in Section 6. Section 7 introduces a generalization of the symmetric interference model from Section 4. In Section 8 we study the effects of homophily on the treatment effect. The results from a simulation study are given in Section 9. We close with a short discussion. The proofs for various technical results are given in the appendices.
2 The Model and the Estimator.
For each vertex , let be constants and let be a function such that for all . We study the linear model:
[TABLE]
where denotes the treatment group. In general, the quantity can be thought of as vertex specific attributes, such as covariates. When no covariates are observed, it simply reflects the outcome for node under control. The function denotes the interference effect. For every vertex , it is only a function of its treated neighbors .
This model (without observed covariates) is a member of the class of neighborhood interference models introduced by [20]. In particular, they demonstrate that this parametrization is equivalent to the potential outcomes notation of [16] under specific assumptions on the additivity and symmetry of the effects. In particular, Equation LABEL:eqn:linmod corresponds to the additivity of main effects assumption (ANIA) — the second most general model in that paper. That is, is the baseline, is the direct treatment effect (defined as the effect of treatment on node when no one else is treated) and is the interference effect. While Sussman and Airoldi [20] construct new estimators for the average treatment effect, we focus on better designs for the Neymanian estimator defined below.
Define the average direct treatment effect as:
[TABLE]
We are interested in estimating . Throughout the paper, we will have groups of experimental units, and in each group units will receive treatment. When , define the Neymanian estimator
[TABLE]
When and , the estimator has the usual form:
[TABLE]
Define the quantity
[TABLE]
The difference222The quantity is a function of the treatment , but we suppress this dependence for notational convenience.
[TABLE]
is the “average interference effect”. Next, we show that bounds on lead to bounds on the bias of . Here, denotes that the expectation is taken over the treatment assignment mechanism.
Lemma 2.1**.**
Suppose that is selected in a fashion so that for all . Then, .
Proof.
The quantity in (LABEL:eqn:ideal) can be written as
[TABLE]
Since for all we obtain that
[TABLE]
Thus
[TABLE]
proving the lemma. ∎
3 Restricted Randomizations.
Fix a partition of the vertices into sets . Define a random vector with i.i.d. uniform on . Conditional on the partition , we define our treatment assignment mechanism to be:
[TABLE]
Thus we will give treatment to the vertex when .
The usual Completely Randomized Design (CRD) for treatment assignments is recovered when is sampled uniformly from the set . In this section, we obtain bounds for the bias of with treatment group for a fixed partition .
3.1 General upper bound on bias.
The following definition introduces a useful framework for quantifying the variability of the interference effect across the units.
Definition 3.1**.**
The function , , is called -Lipshitz if
[TABLE]
for and all .
Thus the Lipshitz constant provides an upper bound on the amount that treating a proportion of the neighbors of can affect .
Example 3.2**.**
The linear interference function for is -Lipschitz. Moreover, the normalized linear interference function is -Lipschitz.
The following lemma bounds the bias of with treatment when is Lipshitz. The idea of the proof is to apply Lemma 2.1 to reduce to bounding the expectation of . The Lipshitz condition yields a termwise bound on in (LABEL:eqn:xi). Given let
[TABLE]
Lemma 3.3**.**
Suppose the function is -Lipshitz. Then for the partition and the treatment assignment in (LABEL:eqn:tbp), we have
[TABLE]
Lemma LABEL:lem:indunbiased has the following important corollary:
Corollary 3.4**.**
If every element of is an independent set in , i.e., if whenever , and then
Proof.
Indeed, in this case, the right hand side of Lemma 3.3 has no terms in this case. Thus we have and the proof follows from Lemma 2.1. ∎
Thus Corollary 3.4 implies that if we choose clusters of independent sets and then randomize within those clusters for the treatment assignment, then will be unbiased. Thus a design principle will be to ensure that elements of do not contain too many edges of using appropriate randomizations.
3.2 Random choices of .
In this section, we assume that the function is -Lipshitz. Define the average Lipschitz constant
[TABLE]
Example 3.5**.**
Let for some . Then is -Lipshitz with . When the underlying graph has average degree , .
Choosing randomly can help reduce the bias, as the following proposition shows. As will be seen in the sequel, it will be helpful to restrict the randomization of to reduce the MSE.
Proposition 3.6**.**
When is sampled uniformly from , we have
[TABLE]
where is as in (LABEL:eqn:kbar).
The following result is immediate from Proposition 3.6.
Corollary 3.7**.**
When is sampled uniformly from , we have
[TABLE]
Corollary 3.7 generalizes the result of Karwa and Airoldi [12] for the case of and . As mentioned in Example 3.5, when has average degree , . Thus by Corollary 3.7, we obtain that .
4 Symmetric interference model.
In this section, we introduce a simple, but natural type of interference function where the interference effect on a vertex depends only on the numbers of its neighbors that are not treated. Set
[TABLE]
and define
[TABLE]
Definition 4.1**.**
The collection of functions is called a symmetric interference model without types if there is a function such that
[TABLE]
for all .
Thus in Definition 4.1, all vertices share the same interference function. In the next section, we will allow different types of vertices to have different interference functions.
Example 4.2**.**
The family of interference functions is achieved in a symmetric interference model without types when A similar related example is that is achieved in a symmetric inference model when in Definition 4.1.
Example 4.3**.**
In many natural examples, after a certain threshold, adding more number of treated neighbors does not change the interference effect. This can be modeled as (corresponding to interference only due to the first treated neighbors) and (corresponding to interference by only the first proportion of treated neighbors). Both of these functions are examples of symmetric interference model.
For and , let
[TABLE]
denote the -bidegree of . Let denote the space of finite, signed measures on of total mass 0. When , define the measure as
[TABLE]
where is as defined in (LABEL:eqn:SB). Clearly, . When the interference function is of symmetric type as in (LABEL:eqn:fsymm), the quantity in Equation (LABEL:eqn:xi) can be expressed compactly as
[TABLE]
5 Perfect quasi-colorings and designs for symmetric interference model.
In this section, we introduce our idea of perfect quasi-colorings, and use these to construct designs for the symmetric interference model. Throughout this subsection, we will assume that and so that the target treatment fraction is .
The following notion of perfect quasi-coloring lets us identify the treatment groups so that the interference effect is identically zero.
Definition 5.1**.**
A perfect quasi-coloring is a set that satisfies .
The following result implies that for the the treatment groups and when is a perfect quasi-coloring.
Proposition 5.2**.**
Let . The following are equivalent in a symmetric model.
- •
* is a perfect quasi-coloring.*
- •
* is a perfect quasi-coloring.*
- •
If , for every function of the form (LABEL:eqn:fsymm), .
- •
If , for every function of the form (LABEL:eqn:fsymm), .
- •
If the treatment is chosen uniformly and randomly between and , for every function of the form (LABEL:eqn:fsymm), .
Remark 5.3**.**
Intuitively, randomizing between and when is a perfect quasi-coloring makes unbiased because (1) interference effects cancel and (2) each vertex is treated with probability , so that each treatment effect enters the estimate with probability .
Proof.
First, we will show that is a perfect quasi-coloring then if and only if is. Define by . Let be the push forward measure of by the function . By construction, it follows that Thus we conclude that if and only if
Next, we will prove that is a perfect quasi-coloring if and only if for all when . Since, by Equation (LABEL:eqn:intxi), this assertion follows immediately. The lemma follows because the distribution with treatment chosen uniformly and randomly between and is a 50–50 mixture of point masses at the values of with and . ∎
The following example shows that highly homogeneous graphs admit perfect quasi-colorings.
Example 5.4** (Perfect quasi-colorings exist in the graph consisting of copies of a smaller graph).**
Let be an arbitrary graph with . Let . We claim that
[TABLE]
is a perfect quasi-coloring of . To see this, define an involution by
[TABLE]
Note that, for all exactly one of and is in and and have the same number of neighbors in (resp. ). It follows that
The class of graphs considered by Example 5.4 is quite specific. Unfortunately, not even -regular graphs need to admit a perfect quasi-coloring, as the following example shows.
Example 5.5** (A hexagon does not have a perfect quasi-coloring).**
Let be a hexagon. Thus with an edge drawn between and modulo 6 for all . Let .
We claim that is not perfect. Indeed, if contains three consecutive elements of then the support of contains . If does not contain any three consecutive elements of then the support of contains . In either case, we have . This example motivates studying other estimators in addition to ; see Discussion for more on this point.
Example 5.5 suggests that it might not be fruitful to search for perfect quasi-colorings in arbitrary graphs. In general, we can only hope to control the size of . Proposition 5.2 yields that for a perfect quasi-coloring. It is then natural to ask whether an “almost perfect quasi-coloring” will imply that the corresponding is close to zero. In the next section, we show that this is indeed the case, quantify this intuition and use it constructing new designs.
5.1 Quantifying the notion of perfect quasi-coloring.
Let be a metric on . For , define the Lipschitz norm
[TABLE]
For a measure , define the Wasserstein norm
[TABLE]
Since the total mass is [math] for any , we have that
[TABLE]
where denotes the total variation norm. From Equation (LABEL:eqn:intxi), we can deduce that if the interference function is Lipschitz with respect to a metric , then
[TABLE]
For a treatment assignment that is a perfect quasi-coloring, we have and thus . Equation LABEL:eqn:xiLipbd shows that is continuous in .
While (LABEL:eqn:xiLipbd) holds for any metric , we will use the following metric :
Definition 5.6**.**
Fix with and , define the metric on : for all ,
[TABLE]
where is as in (LABEL:eqn:dmin).
Remark 5.7**.**
Since we assume that does not have any isolated vertices, is indeed a metric on .
Remark 5.8**.**
The choice of a metric is crucial for our estimates. The main point here is that the chosen metric must capture the key features of the interference model. To measure the similarity of two vertices, the metric in (LABEL:eqn:nuK) just takes the differences in the fraction of the treated neighbors and the differences of the degrees between the vertices. This is justified here because, the symmetric interference model by definition depends only on these quantities. Different metrics could be used for other choices of interference functions.
For , define the constant
[TABLE]
The following proposition bounds the norm of :
Proposition 5.9**.**
Fix and let as in (LABEL:eqn:tbp). We have
[TABLE]
where is as in (LABEL:eqn:pv).
The idea behind the proof of Proposition 5.9 is to bound the contributions of each vertex to the left-hand-side, and use the fact that and are independent for where .
Proposition 5.9 and Equation (LABEL:eqn:xiLipbd) imply the following upper bound on the norm of for the treatment .
Corollary 5.10**.**
*Let the interference function be such that . Then *
[TABLE]
for all when .
Remark 5.11**.**
In the case of a complete graph on vertices, we have and hence
[TABLE]
Thus, for fixed we have .
6 New Designs and MSE for .
In this section, we will use the idea of perfect quasi-coloring and Proposition 5.9 to construct new designs for and derive bounds for its MSE. We study the dense ( as ) and sparse ( and as ) cases separately, since our methods and assumptions are different for dense vs. sparse graphs.
6.1 Dense Graphs.
A key term appearing in the right hand side of Proposition 5.9 is the constant , which is solely a function of the partition . Thus we seek for designs which will lead to smaller values for . To this end, we introduce the following new design which we call “partitioning by degree”:
Definition 6.1**.**
*Let be an enumeration of the vertices of such that whenever . Choose *
[TABLE]
for . Finally set
[TABLE]
Thus the partition is chosen by first rank ordering the vertices by degree and then pairing vertices of similar degree. The following is a key observation:
Lemma 6.2**.**
For chosen according to partitioning by degree as in Definition 6.1, we have
[TABLE]
where in the corresponding constant in Corollary 5.10.
Proof.
Breaking each appearance of in (LABEL:eqn:cp) into a sum of terms of the form we have
[TABLE]
as desired. ∎
As an immediate consequence of Lemma 6.2, Lemma 3.3, Proposition 5.9, and Corollary 5.10, we have the following bound:
Theorem 6.3**.**
When ,
[TABLE]
where is as in (LABEL:eqn:dmin). If in addition, the interference function satisfies , then
[TABLE]
Theorem 6.3 immediately yields that interference does not affect the consistency of the estimator for our randomized design when grows large and dense.
Corollary 6.4**.**
Let and fix . If as , then the mean squared error of goes to zero as .
The following example shows that the restricted randomization , where is obtained by partitioning by degree as in (LABEL:eqn:Pstar), can significantly outperform the CRD in terms of reducing the mean squared error of .
Example 6.5**.**
Let Let , and let the edges of be . Thus, is the disjoint union of a complete graph on vertices with additional vertices . Consider a symmetric linear interference model .
Fix and let . It is straightforward to verify that
[TABLE]
When is chosen uniformly and randomly from , by the CLT, we have that
[TABLE]
as . While as , it can be verified using the formulae for higher moments of normal distributions that
[TABLE]
as .
On the other hand, note that any according to (LABEL:eqn:Pstar) consists of a partition of into pairs and a partition of into pairs. Therefore, when we have and hence .
Of course in the above example, the graph contains isolated vertices . The conclusions noted above are qualitatively the same if we add some small number of edges between and , with at a sufficiently slow rate.
Example 6.5 illustrates that our treatment design can improve on the completely random design when there is a high degree of heterogeneity in the degrees of vertices.
6.2 Sparse graphs
For sparse graphs, the bias bounds implied by Theorem 6.3 is a bit weak. In this setting, it is helpful to randomize over all choices of in order to reduce bias. To this end, we introduce the following randomized version of the design introduced in Definition 6.1:
Definition 6.6**.**
Let be such that no vertices in have the same degree and the number of vertices in of each degree is divisible by . Let be sampled uniformly from the set of partitions of into sets of vertices of the same degree. Let with
[TABLE]
Let
[TABLE]
Thus the main difference between designs in Definitions 6.1 and 6.6 is that in the latter, we randomize over all vertices with same degree instead of merely fixing a partial ordering. Our MSE bounds rely on the following simple observations:
Lemma 6.7**.**
For a sequence random variables ,
[TABLE]
Proof.
For all , we have . It follows that
[TABLE]
for all . Thus, we have
[TABLE]
as desired. ∎
The following simple lemma is crucial to the proof of Proposition 7.8 below.
Lemma 6.8**.**
Let be real valued random variables. Suppose that for each there exist at most indices such that and are not independent. Then, we have
[TABLE]
Proof.
Since independent random variables are uncorrelated, for each index , there exist at most indices such that . It follows that for all . The lemma thus follows from Lemma 6.7. ∎
Now give the MSE bounds for :
Proposition 6.9**.**
If then
[TABLE]
where and is as in Definition 6.6.
Proposition 6.9 immediately yields the following MSE bounds for in the sparse regime:
Corollary 6.10**.**
When , with and , the of is
7 Interference with types.
In this section we define a generalization of the symmetric interference model discussed in Section 4 and derive the MSE bounds for under this model.
Definition 7.1**.**
The function is a symmetric interference model with types if there exists a partition of into sets of even sizes such that there are functions with
[TABLE]
for all . Here, is real-valued with domain
[TABLE]
Remark 7.2**.**
The case of recovers the symmetric interference model (without types) in Definition 4.1.
Let denote the space of finite, signed measures on of total mass 0. When is such that let
[TABLE]
7.1 Perfect quasi-colorings for interference with types.
The structure of perfect quasi-colorings extends to the setting of interference models with types. For this subsection, we assume that so that the target treatment fraction is . The analogue of Definition 5.1 is:
Definition 7.3**.**
A perfect quasi-coloring of with respect to the type partition is a set that satisfies and for all .
Definition 7.3 recovers Definition 5.1 by taking . The analogue of Proposition 5.2 is:
Proposition 7.4**.**
Let be such that for all . The following are equivalent in a symmetric model.
- •
* is a perfect quasi-coloring.*
- •
* is a perfect quasi-coloring.*
- •
* for all with treatment .*
- •
* for all with treatment .*
- •
* for all with treatment chosen uniformly and randomly between and .*
The proof of Proposition 7.4 is similar to the proof of Proposition 5.2, as
[TABLE]
Example 5.5 shows that perfect quasi-colorings need not exist in general, while the following example generalizes Example 5.4 to exhibit a class of graphs and type partitions in which perfect quasi-colorings exist.
Example 7.5** (Perfect quasi-colorings exist in the graph consisting of copies of a smaller graph).**
Let be an arbitrary graph with , and let be a partition of the vertices of . Let , and define a partition of by
[TABLE]
It is straightforward to verify that
[TABLE]
is a perfect quasi-coloring of with respect to the type partition .
7.2 Semi-restricted randomization
For each let be drawn uniformly and randomly from with independent. Define
We can represent this treatment group in terms of a restricted randomization treatment group as follows. Let be sampled uniformly from (independently of ). Then, has the same distribution as .
7.3 MSE bounds
In this section, we will use the following metric :
Definition 7.6**.**
Fix , define the metric on : for all ,
[TABLE]
where is as in (LABEL:eqn:dmin).
The analogue of Proposition 5.9 in this setting is:
Proposition 7.7**.**
For all we have
[TABLE]
when . If for all then
[TABLE]
when hence also when .
The analogue of Proposition 6.9 is:
Proposition 7.8**.**
If for all then
[TABLE]
when .
Thus, in the sparse setting, it is important that is not too large, i.e., that there are not too many different types of vertices. The condition that not be too large is analogous to the condition that not be too large implicit in the statement of Proposition 6.9.
8 Homophily and types.
In this section, we directly bound the MSE of in a model that allows homophily between vertices in a single element of .
For let
[TABLE]
be the average covariate effect and average treatment effect respectively within a type. If homophily is suspected, one expects that will be close to and will be close to within a type. To that end for let
[TABLE]
be the discrepancy between an individual node’s behavior and their type average. Then
[TABLE]
captures the sum of squared differences between nodes and their type averages within a graph. Thus has an inverse relationship with homophily. The following result, which generalizes Lemma 2.1, bounds the MSE of .
Proposition 8.1**.**
For all partitions of into sets of size divisible by , we have
[TABLE]
when .
Coupling Proposition 8.1 with bounds on yields the following bias and MSE bounds for when there is homophily.
Corollary 8.2**.**
If for all then
[TABLE]
when .
Proof.
Follows from Propositions 7.7, 7.8, and 8.1. ∎
The results of this section are closely related to the work of Basse and Airoldi [3] on optimal design with network correlated outcomes that are induced by homophily but no interference.
9 Simulations.
In this section we conduct a series of simulations to demonstrate the efficacy of the approach. We vary the following parameters: the type of the network and the strength of the interference. For each of the simulations we consider the following model:
[TABLE]
where and . That is, the baseline outcome for all of the individuals in the graph is centered at 0 with a variance of 1, while the treatment effect for everyone is centered at 2 with a variance of 0.25. We consider two treatment regimes: our approach (described in Section 6) and the completely randomized design where exactly half of all units are treated randomly. We report log mean squared errors (log MSE) for the Neymanian estimator in Figure 2 for the two sets of simulations. The MSEs are calculated over 10000 simulated randomizations for each approach.
9.1 Erdos-Renyi graphs.
In this simulation we generate a graph with nodes and overall density . This is an independent edge random graph model where an edge between node and exists with probability . We consider the symmetric linear interference function . We consider three graph sizes: , and four graph densities: , , . The parameter varies from to .
An important quality of Erdos-Renyi graphs is that they are extremely dense (expected degree is ) and the degrees of their nodes concentrate [14]. Further, this model gives rise to large cliques within the graph implying that many nodes have the exact same degree and are connected to each other [4]. Because of these traits a randomization scheme based on the degree distribution of the graph is unlikely to perform well. In fact, our proposed procedure behaves similarly to the standard Bernoulli randomization scheme. This behavior is evident in Figure 2(a) where both estimators have approximately the same log MSE with the CRD even exhibiting better behavior for denser graphs and higher levels of interference (such as ).
9.2 Preferential attachment graphs.
In this simulation we generate a graph with nodes, power of the preferential attachment (PA) and new edges at each step of the graph growth [2]. These graphs are constructed by staring with a single vertex and adding 1 new vertex at a time. The new vertex forms an edge with an existing vertex with probability . Each new vertex forms new edges. This process continues until there are vertices in the graph. These graphs have power law degree distributions and hence are sparse with many small degree nodes and a few large hubs.
It is clear that log MSE increases with power since it produces denser graphs that are more likely to have too many nodes with the same degree. However, the behavior with respect to is more complicated. In Figure 2(b) we see the log MSE of the estimator based on CRD increase in for all levels of . However, this is not the case for the restricted randomization. This behavior is likely explained by the special behavior of super-linear preferential attachment [13]. When and most graphs have four central nodes that are connected to everyone else. As such, only these central nodes induce any form of interference on the other nodes and so the restricted randomization ideally allocated treatment. The CRD does not take this structure into account and so frequently is likely to allocate all of the central nodes to treatment or control, leading to increased bias and variance. When there are enough perturbations in the system to lead to poorer performance by the restricted randomization. On the other hand, when , small frequently lead to the creation of an odd number of central nodes while a large produces a large amount of heterogeneity in the degrees. In this setting, the restricted randomization approach prefers more heterogeneity as it balances the interference among nodes. In all of these settings, the CRD performs worse than the restricted randomization.
10 Discussion.
This article provided a new approach to bounding the bias and mean squared error of the Neymanian estimator of the average treatment effect under interference and homophily. It introduced the notion of quasi-coloring to better understand the balance needed in the randomization scheme to account for interference. Based on this construct we developed a restricted randomization scheme that has good theoretical properties and performs well in simulations. There are a number of directions for future research.
The general notion of perfect quasi-coloring provides an intuition for constructing other linear unbiased estimators. For example, we can construct a partial-perfect-quasi-coloring by only treating one node. This produces the following unbiased estimator: , where is the average outcome of all the control units who are not neighbors of the treated unit. The weights associated with treated and control units are still interpretable.
It is also possible to develop the machinery in this paper for other estimands and estimators of interest. However, this requires even greater care. For example, we could be interested in the interference effect of exactly one treated neighbor — this lends itself naturally to specifying several naive Neyman-type estimators: only consider control (treated) nodes who have one treated neighbor versus control (treated) nodes who have no treated neighbors, or some combination of both. In turn, this suggests particular restrictions on the randomization scheme. More general versions of this approach can be studied for less constrained types of interference.
Acknowledgements.
The authors thank Edoardo Airoldi, Dean Eckles, Vishesh Karwa and Daniel Sussman for helpful conversations. Part of this research was conducted while RJ was an Economic Design Fellow at the Harvard Center of Mathematical Sciences and Applications. NSP was partially supported by an ONR grant. AV was partially supported by a NSF MSPRF.
Appendix A Bounds on bias
For and let
[TABLE]
denote the interference effect on , so that in (LABEL:eqn:xi) can be expressed as
[TABLE]
Given , define the weight of on as
[TABLE]
Lemma A.1**.**
*For a partition and the treatment assignment mechanism given in (LABEL:eqn:tbp), we have *
[TABLE]
The full generality of Lemma A.1 may be of use in a weighted interference model, as the formalism of weights allows one to capture the fact that different connections may have different strengths. Including a weak connection (low weight edge) in will affect the bias less than including a strong connection. The following result will imply Lemma A.1.
Lemma A.2**.**
For all and we have
[TABLE]
when
Proof.
Without loss of generality, assume that and . When define a random variable with values in by choosing uniformly from
[TABLE]
Let for Denote by (resp. ) the interference effect (resp. the interference effect on ) for the treatment group .
When we have
[TABLE]
Thus, when we have
[TABLE]
where Taking expectations with respect to , it follows that, when we have
[TABLE]
By the triangle inequality, we have
[TABLE]
Note that where denotes the law of a random variable. It follows that
[TABLE]
Combining (LABEL:eqn:xixip) and (LABEL:eqn:xisym) and using the fact that
[TABLE]
we obtain the lemma. ∎
Proof of Lemma A.1.
It follows from Lemma A.2 that
[TABLE]
Summing over we have
[TABLE]
as desired. ∎
Proof of Lemma 3.3.
From (A) and (LABEL:eqn:lip), it follows that
[TABLE]
with if . The lemma therefore follows from Lemma A.1. ∎
Proof of Proposition 3.6.
By the linearity of expectation, we have
[TABLE]
The proposition follows, by Lemma 3.3. ∎
Proof of Proposition C.1.
By the linearity of expectation, we have
[TABLE]
The proposition follows, by Lemma 3.3. ∎
Appendix B Bounds on MSE: dense case
The following bound is the key to the proofs of all of the MSE bounds.
Lemma B.1**.**
For all and all we have
[TABLE]
when
Proof.
Note that
[TABLE]
where
[TABLE]
Thus, it suffices to prove that
[TABLE]
For let
[TABLE]
It is clear that
[TABLE]
For all let
[TABLE]
Note that and that
[TABLE]
for . When , we also have
[TABLE]
for . Thus, for we have
[TABLE]
Similarly, we have
[TABLE]
for so that
[TABLE]
Since are independent (even conditioned on and ), it follows that
[TABLE]
so that
[TABLE]
Noting that and using the fact that and it follows that
[TABLE]
and the proof is finished. ∎
For define
[TABLE]
Note that
[TABLE]
Proof of Proposition 5.9.
We have
[TABLE]
By Lemma B.1, it follows that
[TABLE]
Noting that we have
[TABLE]
as claimed. ∎
Proof of Proposition 7.7.
As in the proof of Proposition 5.9, we have
[TABLE]
By Lemma B.1, it follows that
[TABLE]
Noting that we have
[TABLE]
Summing over it follows that
[TABLE]
as claimed. ∎
Appendix C Bounds on MSE: sparse case
As Proposition 3.6 shows, introducing randomness can help reduce bias. We will first need a generalization of Proposition 3.6 to a class of semi-restricted randomizations.
Given a partition of , let denote the set of partitions of into pairs such that lies in an element of for every . That is, is the set of partitions of into sets of size that refine . Assume that the function is -Lipshitz and define the quantity
[TABLE]
Proposition C.1**.**
Fix a partition of into sets of size divisible by . When is sampled uniformly from , we have
[TABLE]
when
C.1 With types
The following lemma will be used in the proof of Proposition 7.8. Recall and from Equations (LABEL:eqn:kmax) and (LABEL:eqn:dmin) respectively.
Lemma C.2**.**
When is sampled uniformly from , we have
[TABLE]
when .
Proof.
The proof of Proposition C.1 shows that
[TABLE]
We have
[TABLE]
The lemma follows, by Lemma 3.3. ∎
Proof of Proposition 7.8.
Let be sampled uniformly from and let . For define
[TABLE]
Note that if and are dependent given and , then either there is an edge between and or there exists such that there are edges between and and between and . In particular, for fixed there are at most values of such that and are dependent given . By Lemmata B.1 and 6.8, it follows that
[TABLE]
By (B.1) in the proof of Proposition 7.7
[TABLE]
Taking square-roots yields that
[TABLE]
as desired.
The bound on is given by Proposition C.1. It remains to prove the bound on . Eve’s Law, Lemma C.2, and the previous paragraph together imply that
[TABLE]
as desired. ∎
C.2 Without types
The key to the proof of Proposition 6.9 is to note that the treatment group has the same distribution as the treatment group for a suitably chosen .
Proof of Proposition 6.9.
Let . For let Define
[TABLE]
For define . For , define
[TABLE]
It is straightforward to verify that and agree on for all and
[TABLE]
for all . Define
[TABLE]
and let
[TABLE]
The discussion of the previous paragraph shows that
[TABLE]
The proposition then follows by bounding for the treatment using Proposition 7.8. ∎
Appendix D Homophily
Proof of Proposition 8.1.
The first assertion follows from Lemma 2.1 because for all .
As for all we have
[TABLE]
Note that if lie in a single part of and if and lie in different parts of . Thus, we have
[TABLE]
for all . By Lemma 6.7, it follows that
[TABLE]
as desired. ∎
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Aiello et al. [2016] {barticle} [author] \bauthor \bsnm Aiello, \bfnm Allison E \binits A. E., \bauthor \bsnm Simanek, \bfnm Amanda M \binits A. M., \bauthor \bsnm Eisenberg, \bfnm Marisa C \binits M. C., \bauthor \bsnm Walsh, \bfnm Alison R \binits A. R., \bauthor \bsnm Davis, \bfnm Brian \binits B., \bauthor \bsnm Volz, \bfnm Erik \binits E., \bauthor \bsnm Cheng, \bfnm Caroline \binits C., \bauthor \bsnm Rainey, \bfnm Jeanette J \binits J. J., \bauthor \bsnm Uzicanin, \b
- 2Barabási and Albert [1999] {barticle} [author] \bauthor \bsnm Barabási, \bfnm Albert-László \binits A.-L. and \bauthor \bsnm Albert, \bfnm Réka \binits R. ( \byear 1999). \btitle Emergence of scaling in random networks. \bjournal Science \bvolume 286 \bpages 509–512. \endbibitem
- 3Basse and Airoldi [2015] {barticle} [author] \bauthor \bsnm Basse, \bfnm Guillaume W \binits G. W. and \bauthor \bsnm Airoldi, \bfnm Edoardo M \binits E. M. ( \byear 2015). \btitle Optimal design of experiments in the presence of network-correlated outcomes. \bjournal Ar Xiv e-prints. \endbibitem
- 4Bollobás and Erdös [1976] {binproceedings} [author] \bauthor \bsnm Bollobás, \bfnm Béla \binits B. and \bauthor \bsnm Erdös, \bfnm Paul \binits P. ( \byear 1976). \btitle Cliques in random graphs. In \bbooktitle Mathematical Proceedings of the Cambridge Philosophical Society \bvolume 80 \bpages 419–427. \bpublisher Cambridge Univ Press. \endbibitem
- 5Choi [2016] {barticle} [author] \bauthor \bsnm Choi, \bfnm David \binits D. ( \byear 2016). \btitle Estimation of monotone treatment effects in network experiments. \bjournal Journal of the American Statistical Association \banumber just-accepted. \endbibitem
- 6Eckles, Karrer and Ugander [2017] {barticle} [author] \bauthor \bsnm Eckles, \bfnm Dean \binits D., \bauthor \bsnm Karrer, \bfnm Brian \binits B. and \bauthor \bsnm Ugander, \bfnm Johan \binits J. ( \byear 2017). \btitle Design and Analysis of Experiments in Networks: Reducing Bias from Interference. \bjournal Journal of Causal Inference \bvolume 5. \endbibitem
- 7Gruhl et al. [2004] {binproceedings} [author] \bauthor \bsnm Gruhl, \bfnm Daniel \binits D., \bauthor \bsnm Guha, \bfnm Ramanathan \binits R., \bauthor \bsnm Liben-Nowell, \bfnm David \binits D. and \bauthor \bsnm Tomkins, \bfnm Andrew \binits A. ( \byear 2004). \btitle Information diffusion through blogspace. In \bbooktitle Proceedings of the 13th International Conference on World Wide Web \bpages 491–501. \bpublisher ACM. \endbibitem
- 8Hoff, Raftery and Handcock [2002] {barticle} [author] \bauthor \bsnm Hoff, \bfnm Peter D. \binits P. D., \bauthor \bsnm Raftery, \bfnm Adrian E. \binits A. E. and \bauthor \bsnm Handcock, \bfnm Mark S. \binits M. S. ( \byear 2002). \btitle Latent space approaches to social network analysis. \bjournal Journal of the American Statistical Association \bvolume 97 \bpages 1090–1098. \endbibitem