Gaze Distribution Analysis and Saliency Prediction Across Age Groups
Onkar Krishna, Kiyoharu Aizawa, Andrea Helo, Rama Pia

TL;DR
This study investigates how visual attention and saliency prediction vary with age, analyzing eye movements across four age groups, and proposes an age-adapted computational model that improves prediction accuracy.
Contribution
It introduces an age-adapted saliency model that accounts for age-related differences in visual attention, outperforming existing models across diverse age groups.
Findings
Explorativeness varies with age, as shown by saliency map entropy.
Saliency maps of the same age group better predict fixation points within that group.
The age-adapted model outperforms existing models in saliency prediction.
Abstract
Knowledge of the human visual system helps to develop better computational models of visual attention. State-of-the-art models have been developed to mimic the visual attention system of young adults that, however, largely ignore the variations that occur with age. In this paper, we investigated how visual scene processing changes with age and we propose an age-adapted framework that helps to develop a computational model that can predict saliency across different age groups. Our analysis uncovers how the explorativeness of an observer varies with age, how well saliency maps of an age group agree with fixation points of observers from the same or different age groups, and how age influences the center bias. We analyzed the eye movement behavior of 82 observers belonging to four age groups while they explored visual scenes. Explorativeness was quantified in terms of the entropy of a…
Click any figure to enlarge with its caption.
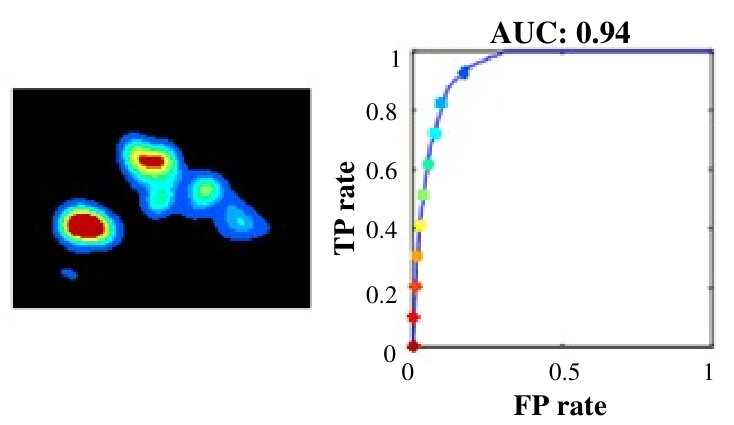 Figure 1
Figure 1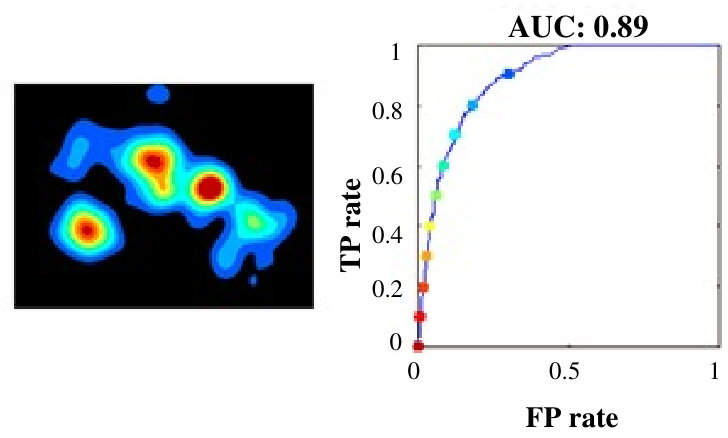 Figure 2
Figure 2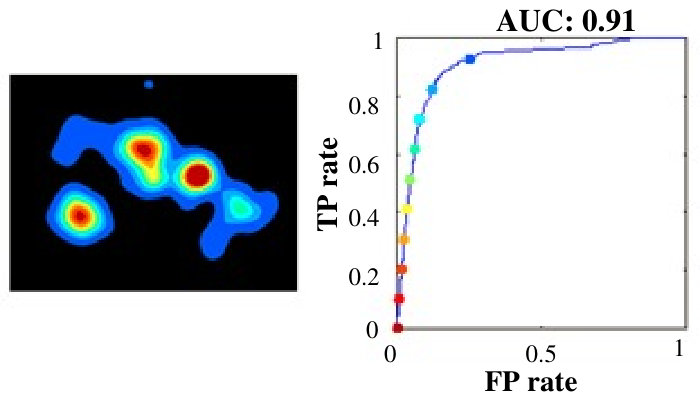 Figure 3
Figure 3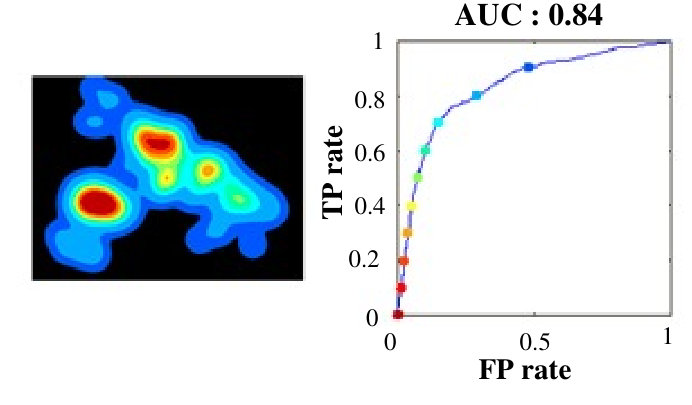 Figure 4
Figure 4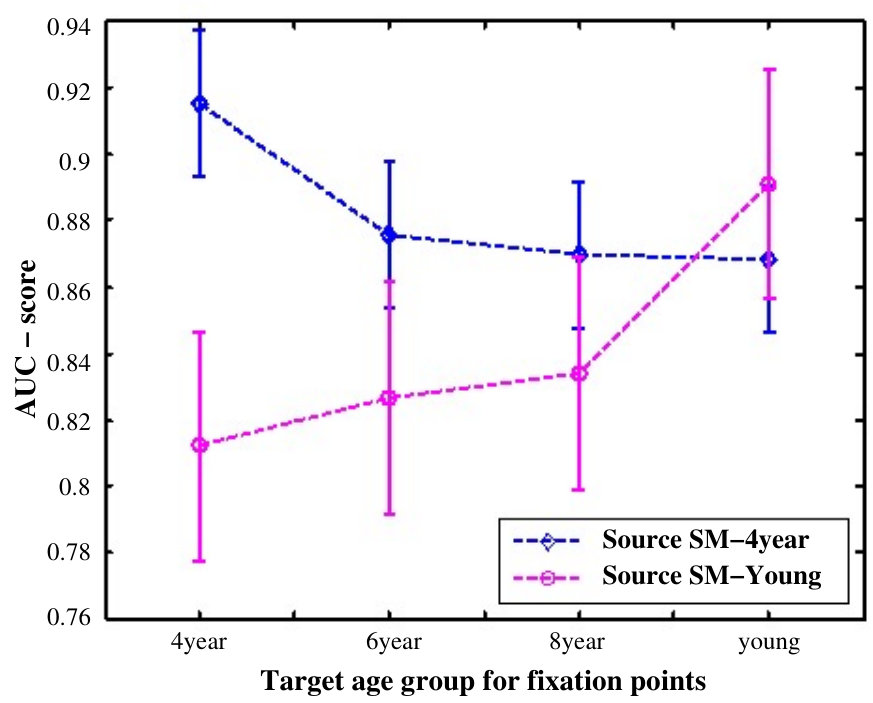 Figure 5
Figure 5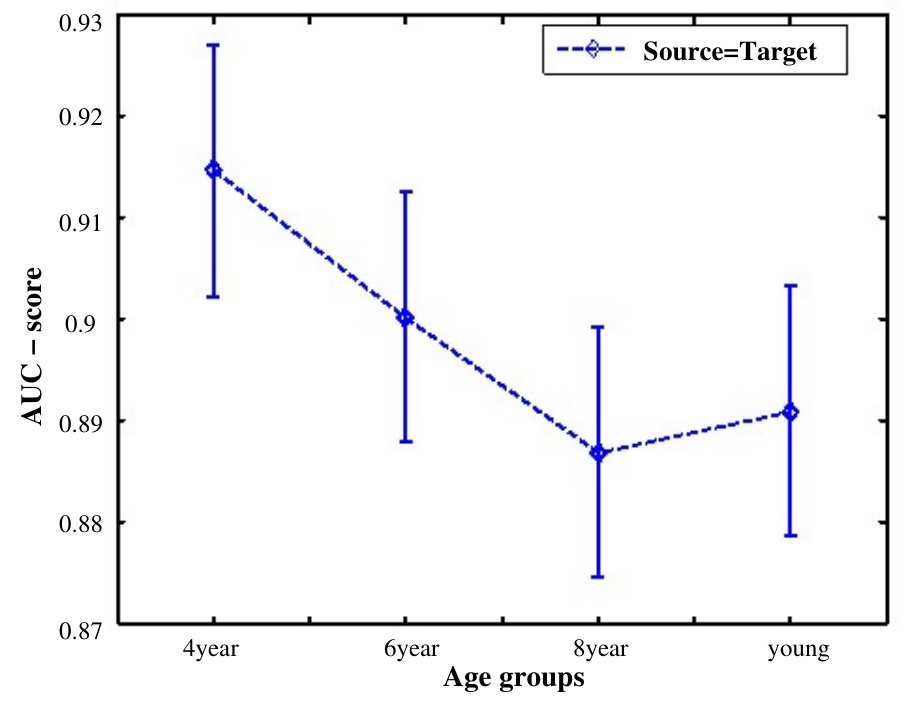 Figure 6
Figure 6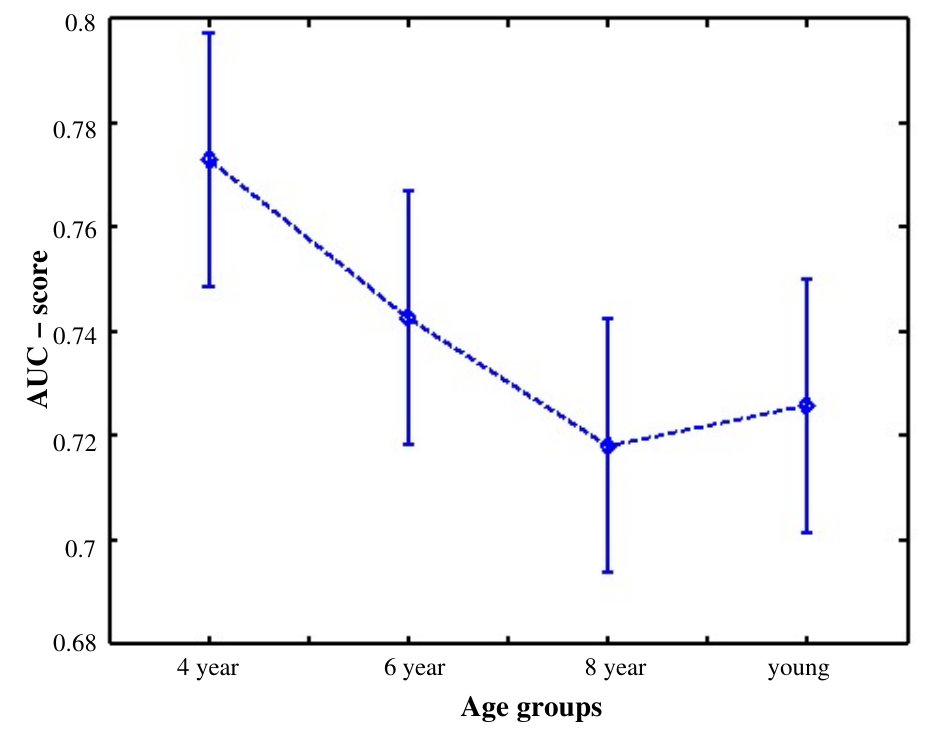 Figure 7
Figure 7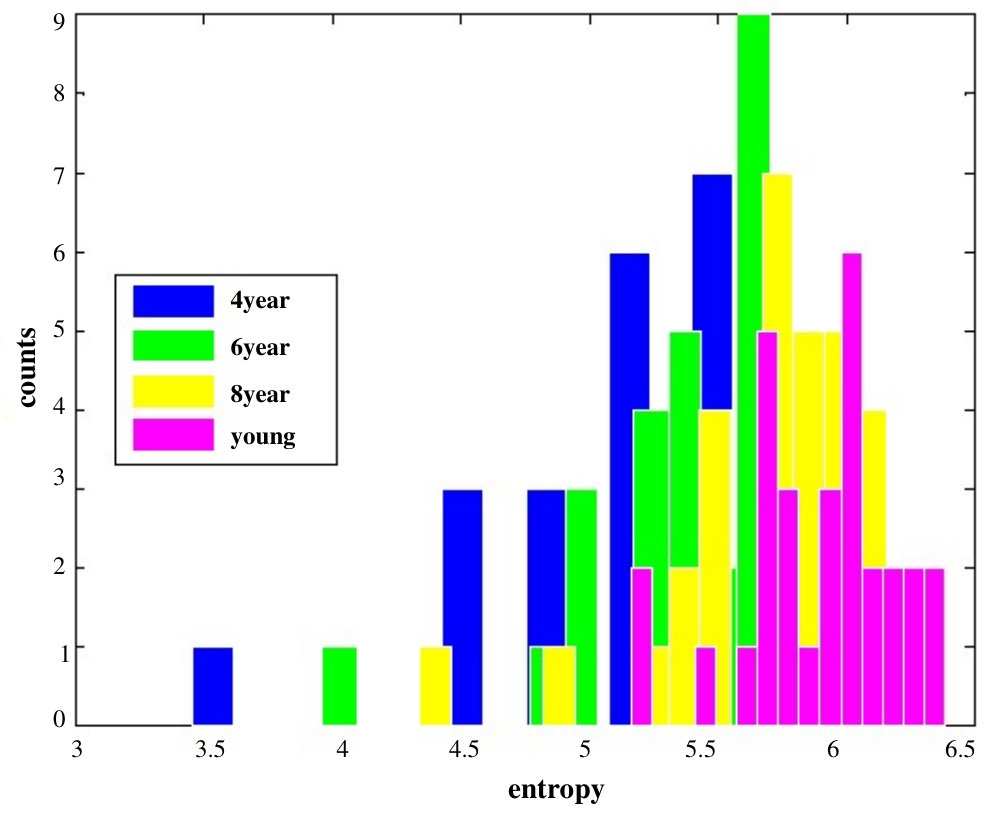 Figure 8
Figure 8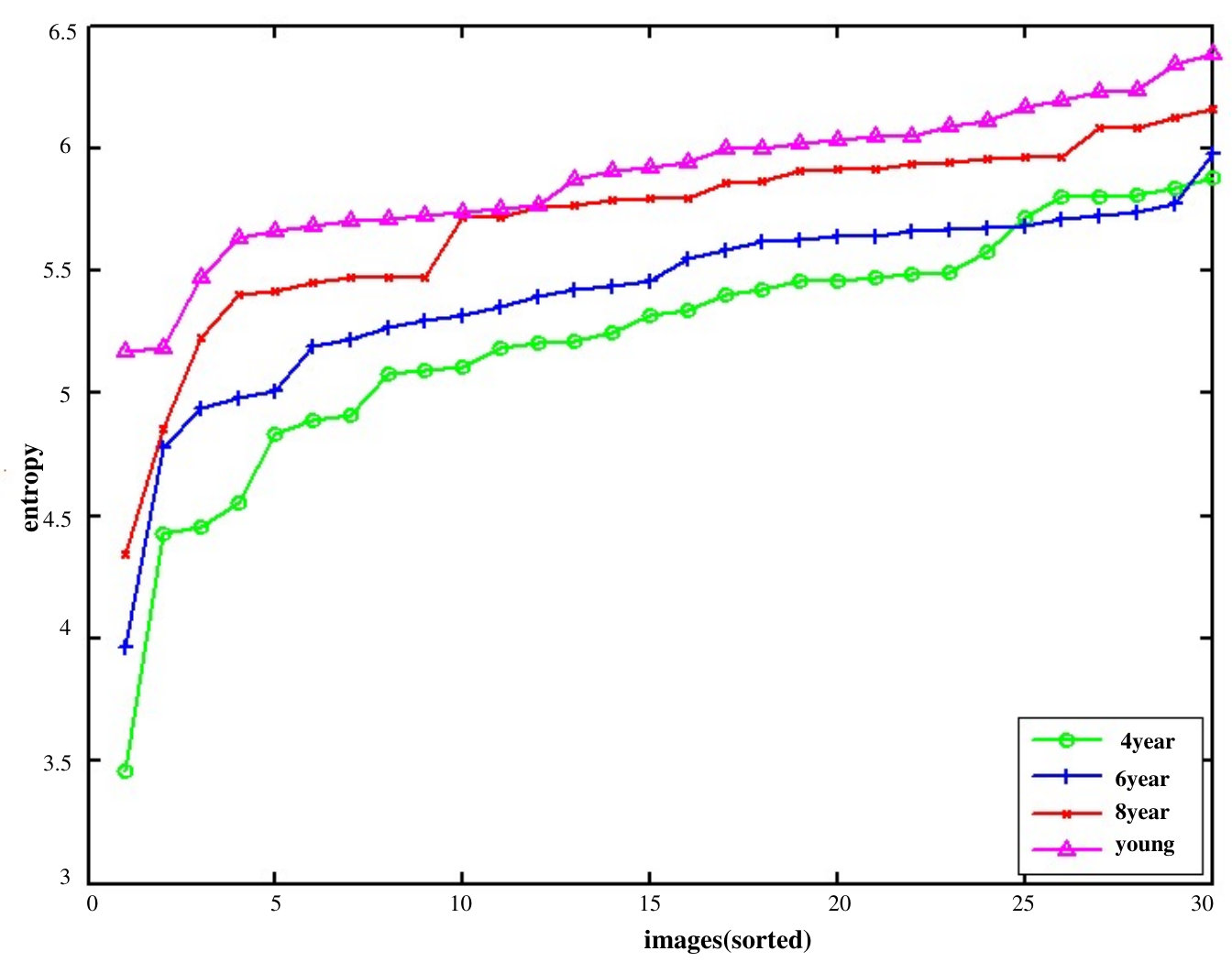 Figure 9
Figure 9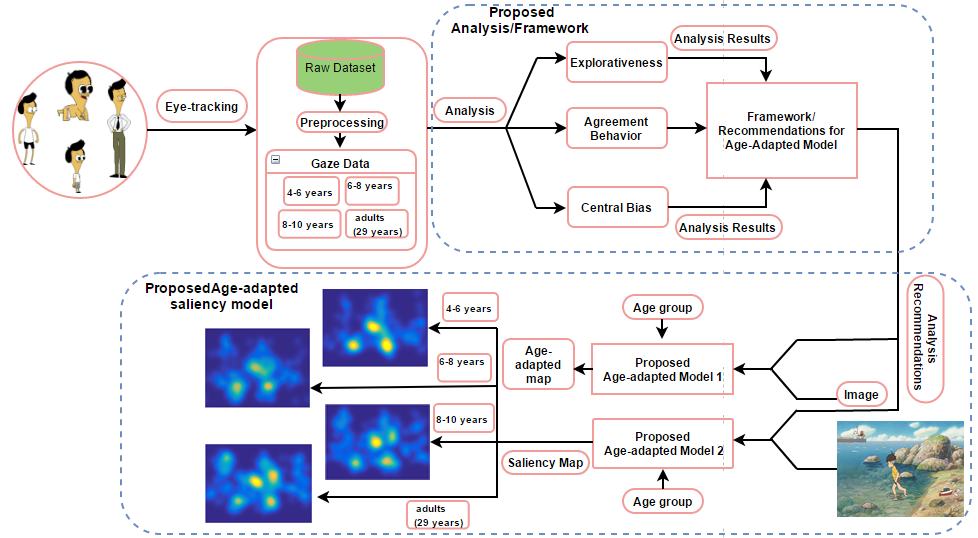 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15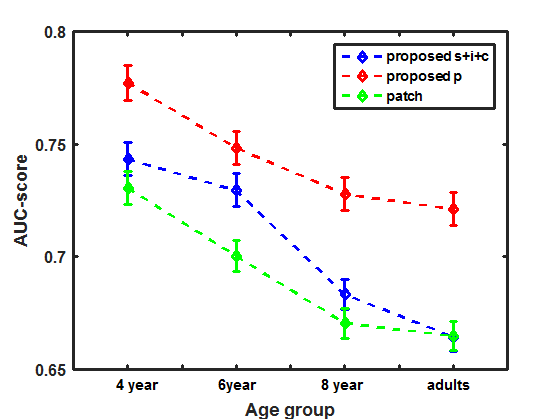 Figure 16
Figure 16Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Gaze Distribution Analysis and Saliency Prediction Across Age Groups
Onkar Krishna1, Kiyoharu Aizawa1, Andrea Helo2, Rämä Pia2; Dept. of Information and Communication Engineering, The University of Tokyo, Japan1; Laboratoire Psychologie de la Perception, Université Paris Descartes, France2
Abstract
Knowledge of the human visual system helps to develop better computational models of visual attention. State-of-the-art models have been developed to mimic the visual attention system of young adults that, however, largely ignore the variations that occur with age. In this paper, we investigated how visual scene processing changes with age and we propose an age-adapted framework that helps to develop a computational model that can predict saliency across different age groups. Our analysis uncovers how the explorativeness of an observer varies with age, how well saliency maps of an age group agree with fixation points of observers from the same or different age groups, and how age influences the center bias. We analyzed the eye movement behavior of 82 observers belonging to four age groups while they explored visual scenes. Explorativeness was quantified in terms of the entropy of a saliency map, and area under the curve (AUC) metrics was used to quantify the agreement analysis and the center bias. These results were used to develop age adapted saliency models. Our results suggest that the proposed age-adapted saliency model outperforms existing saliency models in predicting the regions of interest across age groups.
Index Terms:
Gaze, saliency, age-adapted, eye-tracking, explorativeness, saliency model.
1 Introduction
Computational models of human visual attention are becoming increasingly important, and investigations of these have driven much research by psychologists, neurobiologists and researchers in computer vision. The problem of predicting a region of a scene that attracts the observer remains a core challenge in vision research that can at present be solved in two ways: using eye-tracking devices, like the TobiiX50 [1] and Eyelink1000 [2] and, by developing a computational model [3, 4, 5, 6] to mimic human vision for scene-viewing. Although eye trackers achieve high prediction accuracy, they are not always an in-hand option [6]. Thus, the use of computational models has gained an importance in the last few decades.
The era of the development of computational models was heralded by the pioneering work of Itti et al. [5] based on Treisman’s feature integration theory (FIT) [7], where a master saliency map is obtained by combining bottom-up feature maps in parallel. A series of works [8], [9], [10], [11], [12, 13] have since investigated similar issues, where the major differences lay in the way the features were selected and maps combined. Some researchers integrated the maps linearly whereas others used non-linear techniques to combine them [11], [12]. The next set of saliency models [14], [15] were based on top-down factors, which are, the given task [16], human tendency [17], habituation and conditioning [18], and emotions [19] as these factors are closely related to visual attention during scene viewing.
Even though eye-movement control improves extensively already during early infancy, an adult-like control is reached later during childhood [21]. For example, the capability to fixate a target is acquired during the first few months of life [22, 23] but more complex aspects of the fixation system, such as steadiness of fixations and cognitive control continues to develop until adolescence [21]. Studies on development of saccade control found that the saccades were shorter and less precise when comparing children with adults [21]. Furthermore, cognitive control of saccade execution, operationalized by the performance in pro and anti-saccades tasks, reaches an adult-like performance level at around 10 to 12 years of age [24], [25], [26].
Supporting evidence from developmental studies on scene exploration [27], [28] has shown that there are remarkable differences in the scene-viewing behavior of observers across age groups. For example, local image features, such as color, intensity, luminance, etc., were shown to guide fixation landings more early in childhood, while later in childhood, fixation landings are more dominated by top-down processing [27], [28].
In spite of a few studies reporting developmental changes in scene viewing behavior, there are no studies that have systemically analyzed the gaze allocation of observers across age groups using computational models. So far, computational models have relied on the data collected in adult participants but due to significant changes in visual skills during the development, it is essential to include also age factor to the computational models
Thus, computational models that have been developed until now compromise on prediction accuracy as they do not take into account age factors. Our study aims to develop a new computational model that includes observers age in predicting salient locations for an image. Our study is divided into two part: the first part consists of quantitative analysis of the age-related differences in fixation landings during scene viewing, and the second part consists of, our proposed age-adapted computational model of saliency prediction based on the analysis results reported in the first part. The framework of the proposed study is reported in following section and shown in Fig. 1.
1.1 Framework of our study
We focused on understanding age-related changes in scene-viewing behavior and developing formal measures to quantify these differences as shown in proposed analysis part of Fig. 1. The next part of the study was to develop an age-adapted saliency model that incorporates these changes and reflects age-related differences in predicting the saliency map. The flow diagram of the proposed age-adapted saliency model is in shown Fig. 1. Our work is strategically beneficial, as most conventional models of visual attention can be easily tuned to age-related changes in observers by following the recommendations of the results of our analysis. The following framework is used in the proposed study.
Analysis We selected fixation landing locations as a main attribute to analyze the age-related differences in scene viewing behavior. The reason for this selection relies on the fact that the purpose of our analysis was to develop an age-adapted saliency model and the existing saliency models consider fixation location as a key gaze attribute in predicting salient regions. The analysis was mainly focused on three aspects of scene viewing behavior: explorativeness, agreement within and between age groups, and center bias. This selection was based on the fact that the previous studies [6], [10] have analyzed the fixation spread and center bias tendency in order to propose a better model of saliency prediction. Similarly, our analysis results of age-related differences in fixation distribution can assist in developing an age-adapted saliency model. The explorativeness index quantitatively measures the spread of fixation locations.
The second metrics, called “agreement score”, indicates how well the observers within same age group or of different age groups agrees in terms of explored locations. The center bias was used to revel the age-related differences in center bias tendency.
Age-adapted saliency model Based on our analysis, we proposed an age-adapted framework i.e. analysis recommendations, which can be used to upgrade available saliency models. This new age-adapted framework simulates the elements of a visual scene that are likely to attract the gaze of observers across age groups. As discussed earlier, most saliency models use Feature integration theory, where weighted combinations of feature maps of all scales are calculated to determine salient locations. Instead, we chose selectively the scales for different age groups depending on the level of details they observed.
1.2 Existing Saliency Models
The human vision system has been studied extensively, and several theories have been proposed to explain how our visual system process information. Feature integration theory (FIT) [7] is one of the most important psychological theories used to develop visual attention models. It suggests that the set of features for a given visual scene is processed automatically and in parallel during early stages of viewing to obtain conspicuous locations. These features are combined in late phase of viewing to help in object identification and separation.
It was subsequently found that human visual behavior is not only affected by scene-related bottom-up features, but also by top-down features. A guided search model [29] was proposed to account for the influence both of bottom-up and top-down features on human visual behavior.
In the last decade, many of image processing and computer vision researchers have used these theories [7], [29] to make computers mimic our visual system, however, all these models are developed for young adults. We briefly review some of these models according to the techniques and/or features they use.
Bottom-up features based models Itti et al.’s model [5], implemented over FIT theory is one of the most well- known models, where bottom-up features of a scene are extracted in parallel by a set of linear center-surrounded operations similar to the visual receptive field. The normalized values of the extracted features are then fused in the later stages to obtain conspicuous locations of an image.
The graph-based visual saliency model [4] also follows a similar approach in generating the activation maps of different feature channels at multiple spatial scales. Furthermore, these maps are represented as fully connected graph, where the equilibrium distribution in a Markov chain is treated as the saliency map. However, these models extract features over a fixed spatial scale, and the age-related changes in image feature-related viewing [27] were not considered while generating a master saliency map.
Combination of bottom-up and top-down features Another approach to developing visual saliency models involve combining low-level cues, i.e., bottom-up information and top-down factors to generate the conspicuity map. Torralba (2003) [8] and Torralba (2006) [9] proposed a model using a Bayesian framework that integrates the scene context with a bottom-up saliency map.
Similar to the Bayesian framework, the SUN model of saliency prediction [10] combines bottom-up features represented as self-information with top-down information, where top-down information is represented either by Difference of Gaussian (DoG) or independent component analysis (ICA) features extracted from images. Some studies have integrated scene related factors with the human tendency for top-down cues, such as face, objects detectors, and the center bias. A boolean map based model [30] was recently developed based on Gestalt psychological studies [17], and outperformed other state-of-the-art models on saliency related datasets. However, these models do not take into account developmental studies reporting that bottom-up processing is dominanting during early development while the ifluences of top-down processing increase with increasing age [27], [31], [32], [33].
Patch based models Patch based dissimilarity measures are another line of approach where saliency is estimated in terms of dissimilarity among neighbouring patches. A patch-based saliency estimation method [11] was proposed to compute saliency using dissimilarity among patches. This was measured by the average distance of regional covariance among neighbouring patches. First-order image statistics such as difference of mean value is also incorporated with this algorithm to obtain better results.
Another patch based method[12] was proposed to estimate the saliency of each patches by measuring the spatially-weighted dissimilarity among them, where the image patches were represented in reduced dimensional space by applying principal component analysis (PCA). These models are not suitable for age-adapted prediction of salient locations as the optimal patch size is selected for the highest prediction accuracy over the eyetracking data collected for young adults only.
Models based on Supervised Learning on Eye tracking datasets Supervised learning-based methods using eye-tracking data collected from young adults constitute another technique to build computational models. [6] Proposed a model that simply learns to predict saliency from an eye-tracking dataset containing over 1003 images viewed by 15 young adults.
Some of the eye-tracking datasets used for these learning methods are listed in Table 1. It can be seen from the table that the participants of these eye-tracking experiments across all datasets were adults (aged 18 to 45 years). Thus all state-of-the-art models to predict visual saliency using these datasets are inclined to reflect the scene exploration behavior of adult observers only.
1.3 Eye tracking data
Subjects and stimuli We analyzed the eye-tracking dataset collected in [28]. The eye-tracking data was obtained for 82 observers from different age groups. All observers had normal or corrected-to-normal vision. Participants were assigned to 4 different groups: four-six years, six-eight years, eight-ten years, and adults (mean age, 29 years). We use 4 year, 6 year, 8 year, and adults to refer these groups in order. The experiment was conducted on images of pixels. The images were taken from children’s books and movies, and characterized to have eventful backgrounds.
Apparatus and Procedure The remote eye-tracking system EyeLink 1000 with a sampling rate of 500 Hz was used to measure eye gaze, and provided us with the raw data that was sampled to obtain fixations and saccades. The spatial resolution of eye tracker was below , and spatial accuracy more than . The random fixations and noise were discarded by processing the raw data by fixation detection algorithm supplied by SR research (EyeLink).
The following procedures followed during eyetracking experiment:
A five point calibration and validation was performed before starting the experiment, and subjects were asked to explore the scene which was presented for 10 seconds. 2. 2.
Further the scene was subsequently replaced by an image segment and participants had to determine if the segment was part of previous scene or not. The segment recognition test was included to maintain motivation of our participants and also to understand the levels of engagement i.e. how engaged the participants were in the material. The results of the task performance reported in [28] suggests the high level of engagement for the selected stimuli for all age groups, which also confirms the age appropriateness of our selected stimuli. 3. 3.
Picture were viewed at a distance of 60 cm from a screen at a resolution of .
Data Representation For each image, fixation landings of all observers were used to generate two maps: a human fixation map and a human saliency map. The human fixation map was a binary representation of fixation locations, and the human saliency map was obtained by convolving a Gaussian filter across the fixation locations, as in [6]. The visualizations of human fixation and human saliency maps are shown in Fig. 2. These maps were used to analyze eye-movement behavior.
2 Analysis
In this section, we elaborate on our analysis to quantify the age-related differences in scene-viewing of observers. We develop measures to quantify three aspects of viewing behavior: explorativeness, agreement score within or across age groups and center bias, each of these contributes to the detailed understanding of how vision changes for scene viewing with age.
Explorativeness
To evaluate eye movement behavior during scene exploration across age groups, we conducted an explorativeness analysis. Explorativeness was used to quantify the age-related differences in the distribution of gaze locations. As shown in Fig. 3, when participants in different age groups were observing the same set of images of our dataset, the set of least explored scenes were found to be different among observers belonging to different age groups. Thus, explorative behavior depends on the observer‘s age as well.
For any scene, we observed that a human saliency map differs between age groups. Thus, we analyzed explorative behavior of an observer across age groups. We calculated first-order entropy of the human saliency map to quantify the explorativeness of observers in a group. For the image of group it is computed as,
[TABLE]
where is the human saliency map of the image from all observers in a group for which entropy is calculated and is the histogram entry of intensity value in image , and is the total number of pixels in .
In the context of viewing behavior, a higher entropy corresponds to a more explorative viewing behavior by the observer, as their saliency points are more scattered in the given scene. Similarly, a lower entropy corresponds to less explorative behavior. The average behavior of each age group over all images was analyzed based on the average entropy.
The results of the analysis suggested that:
Explorativeness increases monotonically with age, , . This can be seen in Fig. 4, which plots the entropy of all images for each age group. The histograms of entropy of all images for different age groups are illustrated in Fig. 5. 2. 2.
Adults had higher exploration tendency, which implies that during scene exploration, they tended to direct their gazes at different level of details in a given scene. On the contrary, being less explorative, children tended to direct their gazes towards fewer details of the scene. This is implied from the study in [39], which reported that decrease in image resolution i.e changing the level of detail is responded by the observers by decreasing the spread of the fixation landing i.e. entropy on the image. 3. 3.
One-way ANOVA analysis showed that explorativeness varied significantly among the age groups, , . Post-hoc analysis indicated that the changes in explorativeness score were significantly different between four to eight years, four to young adults, six to eight years, and six to young adult, all . However, no difference was found between eight-years and young adults, suggesting that from the age of eight years explorativeness behavior is adult-like.
2.1 Agreement analysis
Explorativeness reflects the difference in the scene-viewing behavior of observers from different age groups. However, explorativeness score is unable to answer questions such as: do observers belonging to the same age group explore the same spatial regions of the image? And is there any agreement among observers in terms of explored regions across age groups? Explorativeness falls short of checking for similarity of explored regions within age groups and between age groups. It should be noted that poor agreement of fixation landings between adults and children leads to imprecise prediction when using saliency models that are originally developed for adults. This motivated us to conduct an agreement analysis.
The area under the curve (AUC) is the most commonly used metric in the literature for discrete ground truth saliency maps [40], and we choose it for our analysis. The AUC-based measure analyzed how well the human saliency map of fixation points of all observers of an age group could be used to find the pooled fixation locations of all observers from the group, as well as observers from different groups. The age group of which the saliency map was used became the source group, and the group for which the fixation locations were being used as target group. Thus, under the intra-age group agreement analysis, the source and target belonged to the same group, and for inter-age group analysis, the source age group was different from the target group.
[TABLE]
[TABLE]
Where the TPR for the image is the extent to which the fixation points of observers in group agree to the thresholded saliency map of observers from source group . Similarly, FPR deals with non-fixation points that have been considered fixation points. The TPR and FPR for all -thresholded saliency maps of an image were combined into a vector of dimension. The area under the ROC curve plotted between TPR and FPR gave us the AUC-score, and an average of these scores across all stimuli of the dataset provided the agreement score of the group.
The intra-age and inter-age group agreement accuracies were then calculated in terms of AUC-score. For intra-group analysis, and were the same, whereas for inter-group analysis, they were different. For a given image, this tells us how accurately the fixation locations of all observers in the group were covered under the differently thresholded saliency maps of observers from the same or different age groups. We can visualize the intra-age and inter-age group agreement results of analysis in Fig. 6.
The key suggestions from the intra-age and inter-age group agreement analysis are as follows:
Intra-age group agreement analysis:
As shown in Fig. 7, the average agreement score of the four-year age group was highest for all images across age groups. The score started decreasing as observer’s age increased up to 8 year age group by showing a strong negative correlation, , , but, similar to the explorativeness results, the agreement score suggested that scene-viewing tendency matures at the age of eight. 2. 2.
Comparing the results of explorativeness and agreement analysis, it is interesting to note that the trend followed by the intra-group agreement analysis was opposite to exhibited by the explorativeness results. This makes sense: as explorativeness decreased, observers tended to focus on lesser details of the scene, mostly the ones that were the key areas of the image. This suggests that the fixation points of the observers of least explorative age group would mostly be consistent with one another, and would be mostly localized at key objects and, hence, the agreement score would be high. 3. 3.
One-way ANOVA test suggested the age impacted on explorativeness tendency , . As shown in Fig. 8, 8 years and adults have significantly less intra-age group agreement than 4 and 6 year olds, . This can be understood by the fact that 8 year olds and adults are the most explorative, and there salient regions may not be consistent with one another at higher level of the details.
Inter-age group agreement analysis:
Table 2 shows that the agreement scores of inter-age group experiments was lower than that of intra-age group experiments for all ages. Thus, it was even more evident that age has an impact on visual behavior as the same age group maps defined the fixations more precisely. 2. 2.
The most important contribution of the inter analysis was that the saliency map of adult subjects showed the poorest performance in predicting the fixation points of the other age groups as shown in the fifth column of Table 2: Agreement score of adults predicting all others is significantly less than the agreement scores of diagonal colored boxes of the table (prediction by same age groups). One-way ANOVA analysis indicated significant differences in performance of adults predicting 4 year, 6 year, and 8 years than the prediction by the same age-group, , . Thus, ignoring the age factor and using conventional models developed and learned over young adults can not give optimal performance for other age groups. This calls for the modification of existing models to make them adapt to age. Fig 8 shows the comparison of agreement score for saliency maps of four year olds and young adults in finding the target fixations of different age groups.
2.2 Center bias
The term “center bias” has been studied using the eye-tracking techniques, and it reflects the human tendency of looking at the center of a given image [41]. A possible explanation of this tendency lies in the fact that while taking pictures, photographers tend to keep the region of interest at the center of the frame, i.e., photographer bias. Due to the photographer’s bias, human observers develop the tendency of focusing on the center of a given scene to obtain maximum information while exploring: this is called the observer’s bias. Studies have established the existence of the center bias, but only a few scholars have considered the center bias in their computational models [6][13].
The center bias greatly influences our viewing behavior but, to the best of our knowledge no study has investigating the age related differences in tendencies toward center bias in different groups. The focus of our study is to reveal differences in center bias across age groups. We first calculated the average saliency map across all images for each age group, i.e., the center map. We then used this center map to measure agreement scores with fixation locations for all images across age groups.
As shown in Fig 9, age-related differences in center bias tendency suggested that the four year age group had the highest center bias among all age groups. It decreased with increasing age, where adult-like observation behavior was exhibited at 8 years of the age. The results of One way ANOVA analysis indicated that the any two age groups were significantly different, , . Further post hoc analysis indicated that both adults and 8 year are significantly different from 4 year and 6 year age groups,.
2.3 Results of analysis: A framework for the age-adapted model
We briefly present three main findings that helped us build the age-adapted computational model in the next section:
Results of Explorativeness anaysis suggested that children (four and six years) exhibited the least explorative behavior among the age groups. Explorativeness has a direct relation with the level of details an observer tends to explore [39]. Age associated variation in explorativeness indicates that observers of different age groups viewed different levels of detail within a scene. This helped us to choose the scales of features extracted from the images to generate a master saliency map. The features scale selection should be such that they are capable of representing age-based variations at the level of detail of the observer. 2. 2.
Intra-group agreement scores were higher than inter-group agreement scores for various combinations of groups. This suggests that while training the model, it is advisable to train the model of a particular age group by using the fixation-map data of the same age group rather than the generalized fixation map data of young adults. 3. 3.
The magnitude of the center bias was different among age groups. Thus, while including the center bias in age-adapted saliency model, we need to consider the age-related differences in center bias tendency.
3 The saliency model adapted to age
Several computational models for visual saliency have been developed in past work to provide important insights into the underlying mechanisms of the human visual system. All existing models involve learning to predict regions of interest in images by considering the gaze behavior of young adults. Thus, these models are optimized to predict fixations of young adults, but at the same time, prediction accuracy of these models are not optimal for other age groups. Given the varying viewing behavior of observers belonging to different age groups as highlighted in the last section, provide us opportunity to optimize the prediction performance of existing modes for other age groups as well.
We introduced a basic framework for age-adapted saliency models in the last section using the results of our analysis. This framework can be used to upgrade the state-of-the-art computational models to enable their predicted saliency maps to reflect the age related differences more accurately in scene-viewing behavior.
In the proposed work, our age-adapted framework was tested with two types of computational models [5], [11]. We chose these models carefully in light of the fact that they had different modeling architectures. We verified that the proposed age-adapted framework was generalizable, and could be applied to any type of existing model as, most of them follow the same basic structure with minor variations. The models chosen were the following:
The Itti’s model [5], where different visual features are extracted over multiple scales of the input image and a saliency map is obtained by linearly integrating these feature maps into one. The proposed age-adapted framework was incorporated with this model by applying the multi-scale feature subset selection mechanism with a different set of optimal weights of feature integration learned over our age specific gaze dataset. 2. 2.
A patch-based, age-adapted model was inspired by the patch-based method of saliency predictions [11], where the aim is to detect the saliency of the scene based on dissimilarity among neighbouring patches. The existing model was modified and the age-adapted framework was applied by varying patch size and the age-adapted weighting factor for the center bias.
The selection of these models relies on the fact that most of the bottom-up computational models follow this basic structure.
3.1 Age-adapted multi-scale feature subset selection and optimization based model
Most existing bottom-up models follow the basic multi-scale feature selection architecture proposed by Itti et al [5]. In these models, we observe the following basic structure: (a) Basic visual features such as color, intensity, and orientation, are extracted over multiple scales of the image, where each scale represents a different level of detail in the scene. (b) All features are investigated in parallel, to obtain the conspicuity map for each feature channel. (c) These features are integrated to obtain the saliency map.
There are three concerns in developing an age-adapted model over this basic structure of saliency prediction - First, we need to choose the appropriate set of feature scales for different age groups, as our results suggest that different age groups tend to explore different levels of detail in scenes. Second, we need to include the center bias in the proposed model by considering the fact that the strength of the center bias varies with observer age. Third, we need to combine the extracted features over an optimized set of weights for different age groups. This optimization is achieved through a supervised way of learning weights for different age groups.
**(a) Multi-scale feature subset selection: Proposed S+C
**We used the multi-scale feature extraction technique proposed in the famous Itti et al.’s saliency model [5]. The different scales represented the different levels of detail in scenes, from finer details to coarser object-level details. As stated earlier for more explorative observers, all levels of details were important and, hence, all feature scales were used to learn the model; for the less explorative observers, only coarser-level details were important and, so, only a few scales sufficed.
Observers from different age groups showed different levels of explorativenss. Thus, to make our model adapt to age-related differences in scene viewing behavior, we focused on a feature scale selection mechanism, where we identified the subsets of the feature maps that best represented the different levels of details viewed by the observers of different age groups.
We now discuss the steps to extract features for our age-adapted saliency model. For an input image, eight spatial scales were first developed using a Gaussian pyramid. The features were then extracted using the “center-surround” operations with the same settings as in [5] to yield six intensity maps , 12 color maps - six for and six for each and 24 orientation maps - i.e., sets of six maps computed for four orientation . The 6 maps for different feature represents different level of detail in scene.. The Feature maps were then combined into three “conspicuous maps”, for intensity, for color, and for orientation. However, as stated above, unlike Itti et al.’s model, this point-wise combination was not conducted over all six maps; we also chose subsets of six maps for each age group. The point wise combination of feature map was:
[TABLE]
[TABLE]
[TABLE]
where represents the normalization and is the starting index from where maps were taken.
We developed six cases by varying s to 1,2,3,4,5, and 6. If s = 1, the subset of feature scale starting from scale 1 (finer) to scale 6 (coarser) had to be combined. Similarly if s = 6, only the feature scale 6 was used. Without using the trend toward explorativeness found in the analysis section, we evaluated the model over all such possible subsets for all groups, and defined the subset for each age that best represented the gaze levels (finer to coarser) of the observers in a given age group.
As shown in prediction results in Table 3, younger age groups (4 years, 6 years, and 8 years) are performing better than adults, which makes use of all scales (16) however, the prediction accuracy of children were not optimized on the existing scale (). The predictive performance of children get optimized if used coarser scales and ignore finer ones (as in Table 3, scele , , and are optmized scale selection for 4 year, 6 year, and 8 year age groups respectively) while for young adults, prediction accuracy was higher if we chose all scales (similar to [5]). It is interesting to note that this result is consistent with our earlier results, i.e., children are less explorative than young adults and, hence, require only coarser scales to predict their fixations. Age related differences in center bias tendency was also incorporated in this model by including a differently weighted center-map as explained in following section.
(b) Training and Testing: Feature Combination Optimization: Proposed S+I+C
In this section we proposed another modifcation in existing models based on our second recommendation reported in Results of analysis: a framework for the age-adapted model section. The choice of linear integration of feature maps used in previous section was ill-suited because different features contribute differently to the final saliency map.
Some state-of-the-art models address [6] this by learning the optimal weights of feature integration in a supervised manner. These optimal weights are, however, not suitable for our age-adapted mechanism, as they are learned only over eye-tracking data collected for young adults. To fit this into our scenario, we learn these optimal weights over features extracted from age-specific subsets of the dataset. We divided the dataset into a training set with 20 images and a test set with the remaining images. Color, intensity, and orientation features were extracted for the training images. We then selected strongly positive and negative samples, each corresponding to the top and least-rated salient locations of the human saliency map of all observers generated from ground truth eye-tracking data.
Our analysis of the agreement scores of the prediction of the fixation point suggests that intra-age group fixation point prediction was better than inter-age group performance. In other words, the fixation points of the observers were better predicted by the saliency maps of observers of the same group rather than those of observers of other groups. Thus, the positive and negative samples to be chosen were age group specific, i.e., the positive and negative samples for all age groups were differently chosen for training.
We fixed value to 10; choosing more samples only involved adding redundancy and yielded no performance improvement. For a given set of features and labels (positive and negative samples) for an age group, liblinear SVM was used to learn the model parameters to predict salient locations on the training images. Thus, we obtained model parameters for predefined features over all age groups. For a given test image, we first collected its features as described in the multi-scale feature selection mechanism, and further predicted saliency values at each pixels as,
[TABLE]
where and are model parameters learned for each age group and is feature vector for the test image, this vector is composed of intensity (), color (), and orientation () features. Based on the saliency values we classified the local pixel as salient or not.
Integrating the feature maps over the optimally set weights learned over the age-specific dataset suggests further improvement in prediction accuracy for all age groups including young-adults, as shown in Table 4. Age-related differences in center bias tendency were also considered while evaluating the performance of the proposed model. The method of incorporating center bias in the age-adapted model is explained in following section. The improvement in prediction performance for our proposed S+I+C model is shown in Fig. 10.
(c) Age-adapted model for center bias
Humans have the tendency to observe at the center of a given scene. This behavior can be incorporated with existing saliency models by simply defining saliency to include weight factor , which is inversely propositional to the distance to the center of the pixel under consideration.
[TABLE]
where is the distance between the pixel under consideration and center pixel and is the maximum distance used as a normalization factor. Further center bias is updated based on the results of analysis reflect the age-related variations. is the updated center bias weight factor, where is the strength of the center bias tendency for different age groups.
3.2 Age-adapted patch based saliency model: Proposed P
Another approach that we choose to verify the generalizability of our age-adapted framework is the patch-based model for saleincy prediction [11]. This technique follows the given basic structure: (a) Image is first divided into patches of the same size. (b) The set of features are extracted from these patches. (c) Finally, the spatial dissimilarity among neighbouring patches is evaluated to generate the saliency map.
As pointed out earlier, we do not use this model as is, but introduce some modifications. For this, we represent different features extracted from a patch by using the subset of eigenvalues obtained after SVD decomposition of the feature matrix. We elaborate this before explaining how to render this newly constructed model age-adapted.
(i) SVD decomposition based representation of features
We first construct the feature matrix. The first step in feature matrix construction is to extract non-overlapping patches of size from a given image I of size . Thus, the total number of patches . Further, each patch is represented by a column vector of features , where indexes the patch. is obtained by combining three color of features () and two intesity features (). This generates a feature vector for each patch that appears as ,
. Finally, feature matrix , for the entire image is obtained by combining the feature vectors of all patches
Once the feature matrix representation is ready, we generate the covariance matrix representation of feature matrix , . Principle component analysis was used to diagonalizes covariance matrix by solving the following eigen vector problem:
[TABLE]
where are the eigen vectors of C and represents the corresponding eigenvalues. The eigenvectors are ranked in descending order of eigen values. Choosing eigenvectors corresponding to the largest eigenvalues gives us the basis along the directions of maximum variance in features. Thus, the resultant matrix can be represented as .
(ii) Saliency measurement In the final step, saliency can be measured based on the dismilarity between patches, which can be simply defined as Euclidean distance between patches in reduced dimension.
[TABLE]
where are the and patches of an image and can be defined as a weight factor to adjust the center bias.
Similarly to the previous model, the age-adapted framework is incorporated into this model by selecting a different subset of patch sizes for different age groups and incorporating the age-adapted center bias. We can select patch sizes from the set , which varies from finer to coarser scale. The result of this model is shown in Table 5. As expected, all scales are suitable for young adults, whereas children are more sensitive to fewer scales.
Table 6 lists the fixation prediction accuracies of some famous existing saliency models executed unaltered for our age specific gaze dataset over observers of different age groups. From Fig. 10 and Table 6, it is clear that our modification of Itti et al.’s model and patch-based models that leverage the age-adapted framework outperformed existing models. Our modified in patch based improves the prediction performance for adult observers as well. We believe that difference in the fixation prediction accuracies was evidence for the fact that our algorithm not only personalizes saliency models to achieve optimal performance according to the observer’s age group but also improves the prediction performance of adults.
Conclusion
In this paper, we analyzed how age influences observers’ gaze distribution during scene exploration using two computational approaches. First, we addressed the explorativeness of an observer which was quantified using the entropy of a saliency map. Our results showed that scene explorativeness increases with age. Second, we measured the average agreement score of the human saliency map of an age group and compared it with other observers of the same or different age groups. This was done by using AUC metrics. In intra-age group prediction analysis, four-year-olds were found to have the highest agreement scores whereas the adult group had the lowest. In inter-age group prediction analysis, we found that an observer from a certain age group better predicted the saliency map of an observer from the same age group. Finally, we proposed an age-adapted framework based on our data analysis for an upgraded version of existing saliency models. We proposed a multi scale feature subset selection from center-surrounded feature maps for different age groups and then learned optimal weights over it. Finally we verified our model for patch-based saliency prediction, which outperform the existing methods of saliency prediction.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Tobii eye tracker manual, retrieved from http://www.tobii.com/ .
- 2[2] Eyelink 1000-SR research manual, retrieved from http://www.sr-research.com/ .
- 3[3] L. Zhang L. Yang T. Luo, Unified saliency detection model using color and texture features, Plos One, vol. 11, no. 2, 2016.
- 4[4] J. Harel, C. Koch, and P. Perona, Graph-based visual saliency. In B. Scholkopf, J. Platt, and T. Hoffman (Eds.), Advance in Neural Information Processing Systems (NIPS), pp. 545–552. Cambridge, MA: MIT Press, 2007.
- 5[5] L. Itti, C. Koch, and E. Niebur A model of saliency-based visual attention for rapid scene analysis, IEEE Patt. Anal. Mach. Intell., 20(11): 1254-1259, November 1998.
- 6[6] T. Judd, K. Ehinger, F. Durand, and A. Torralba, Learning to predict where humans look, Proceeding International Conference Computer Vision, pp.1-7, 2009.
- 7[7] A. M. Treisman, The perception of features and objects. In Attention: Selection, awareness, and control, A. Baddeley and L. Weiskrantz, Eds. Clarendon Press, Oxford, pp.5-35. 1993.
- 8[8] A. Torralba, Modeling global scene factors in attention, Journal of the Optical Society of America A, 20(7), 1407–1418, 2003.