Responsive Action-based Video Synthesis
Corneliu Ilisescu, Halil Aytac Kanaci, Matteo Romagnoli and, Neill D. F. Campbell, Gabriel J. Brostow

TL;DR
This paper introduces an interactive system for creating and editing videos by converting static-camera footage into loopable sequences, allowing users to easily synthesize and manipulate video content with semantic-level control.
Contribution
It presents an end-to-end human-in-the-loop framework for converting videos into reusable, loopable segments, enabling intuitive and iterative video synthesis and editing.
Findings
User interface facilitates creative control over video synthesis.
Artists successfully used trigger interfaces for video authoring.
System enables previewing and easy iteration of synthesized videos.
Abstract
We propose technology to enable a new medium of expression, where video elements can be looped, merged, and triggered, interactively. Like audio, video is easy to sample from the real world but hard to segment into clean reusable elements. Reusing a video clip means non-linear editing and compositing with novel footage. The new context dictates how carefully a clip must be prepared, so our end-to-end approach enables previewing and easy iteration. We convert static-camera videos into loopable sequences, synthesizing them in response to simple end-user requests. This is hard because a) users want essentially semantic-level control over the synthesized video content, and b) automatic loop-finding is brittle and leaves users limited opportunity to work through problems. We propose a human-in-the-loop system where adding effort gives the user progressively more creative control. Artists…
Click any figure to enlarge with its caption.
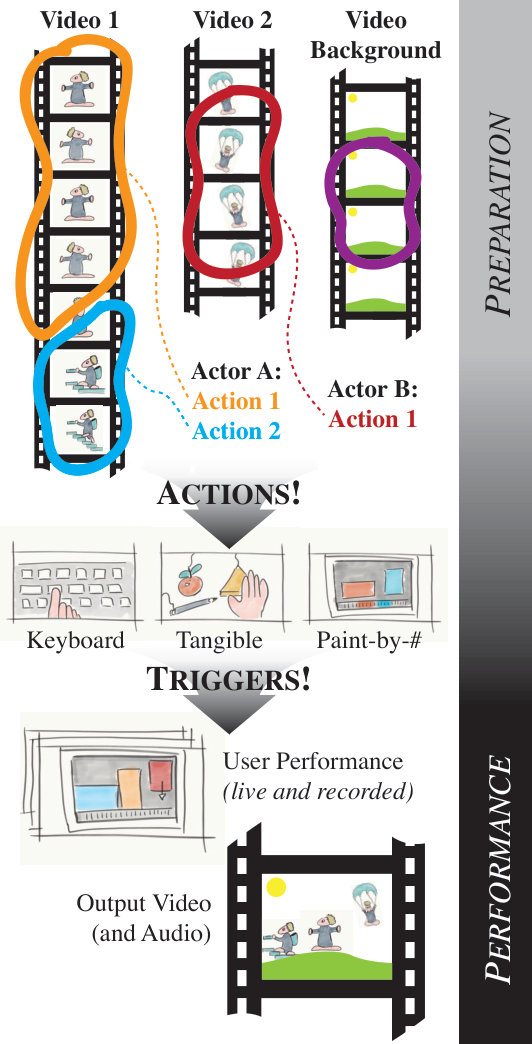 Figure 2
Figure 2 Figure 2
Figure 2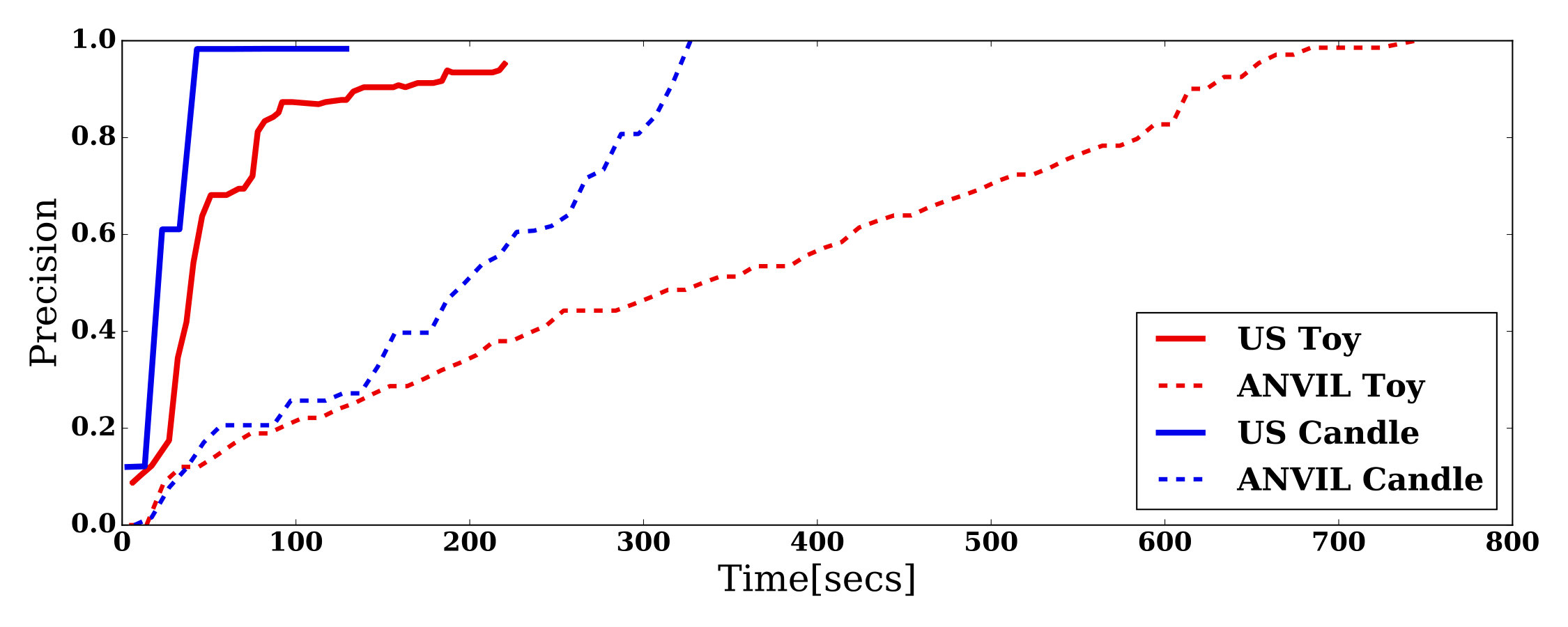 Figure 3
Figure 3 Figure 4
Figure 4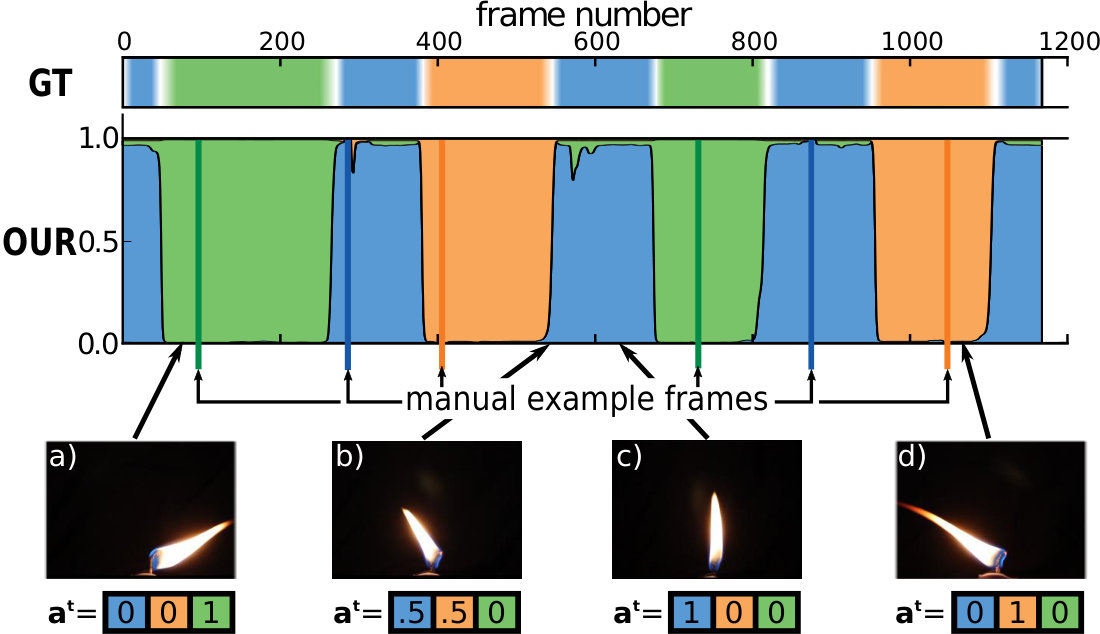 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21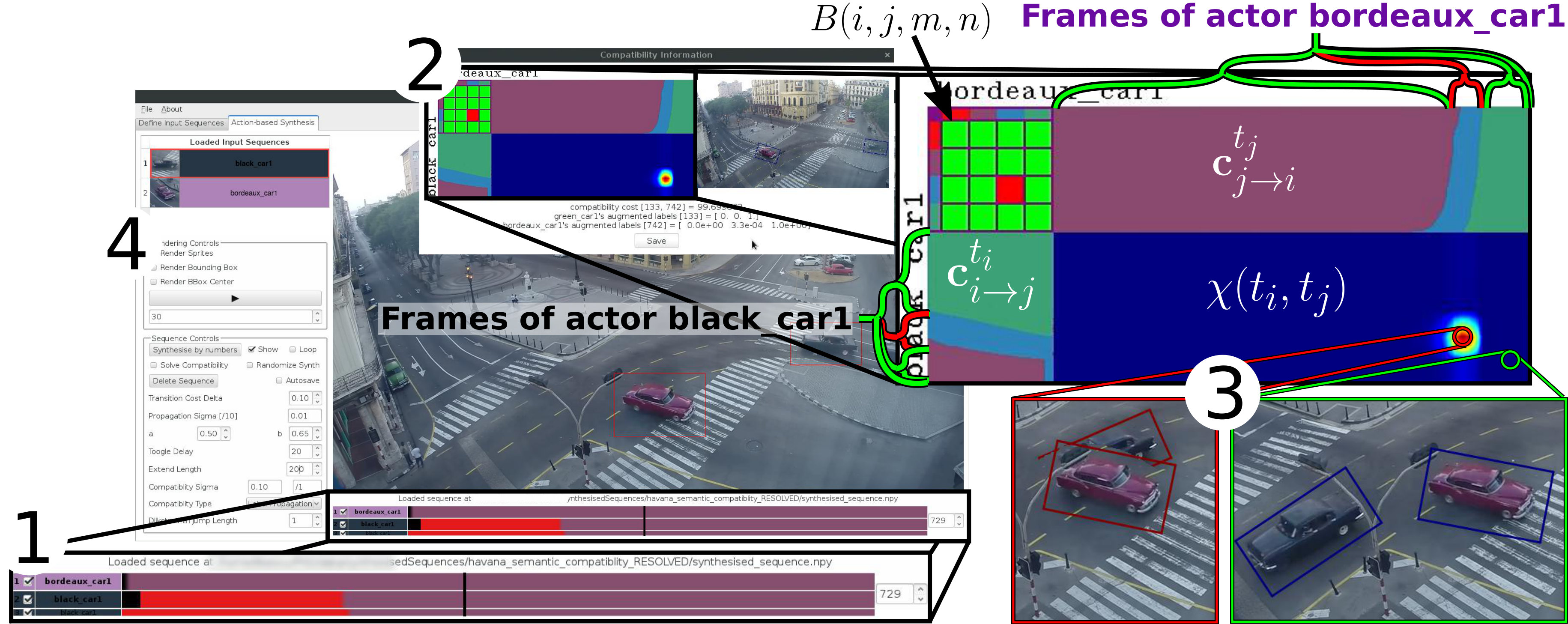 Figure 22
Figure 22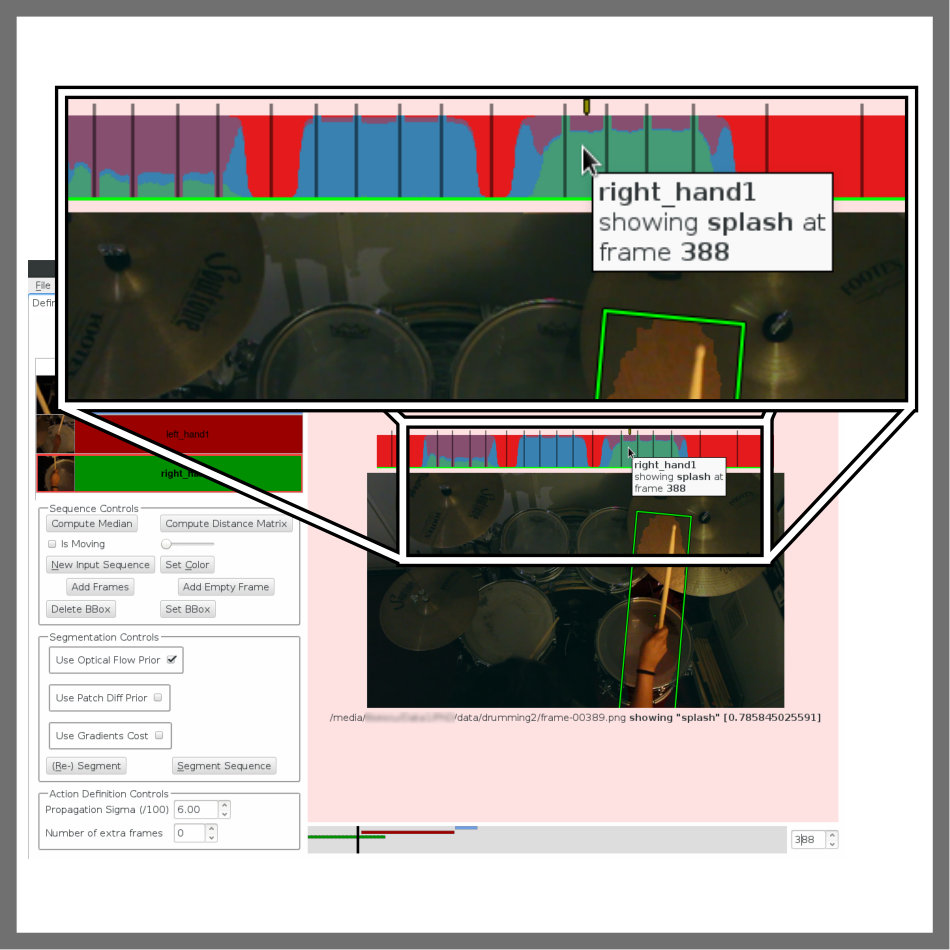 Figure 23
Figure 23 Figure 24
Figure 24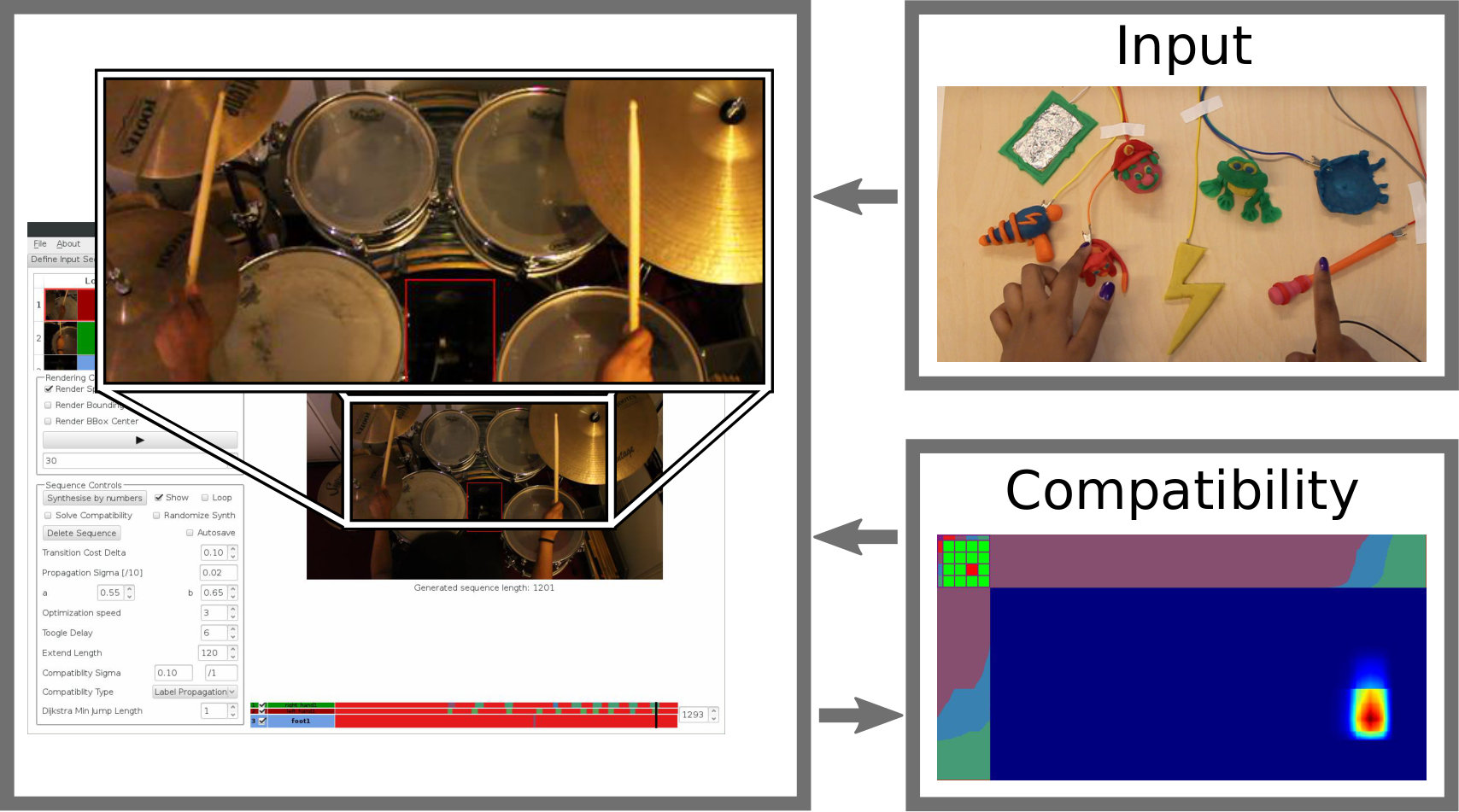 Figure 25
Figure 25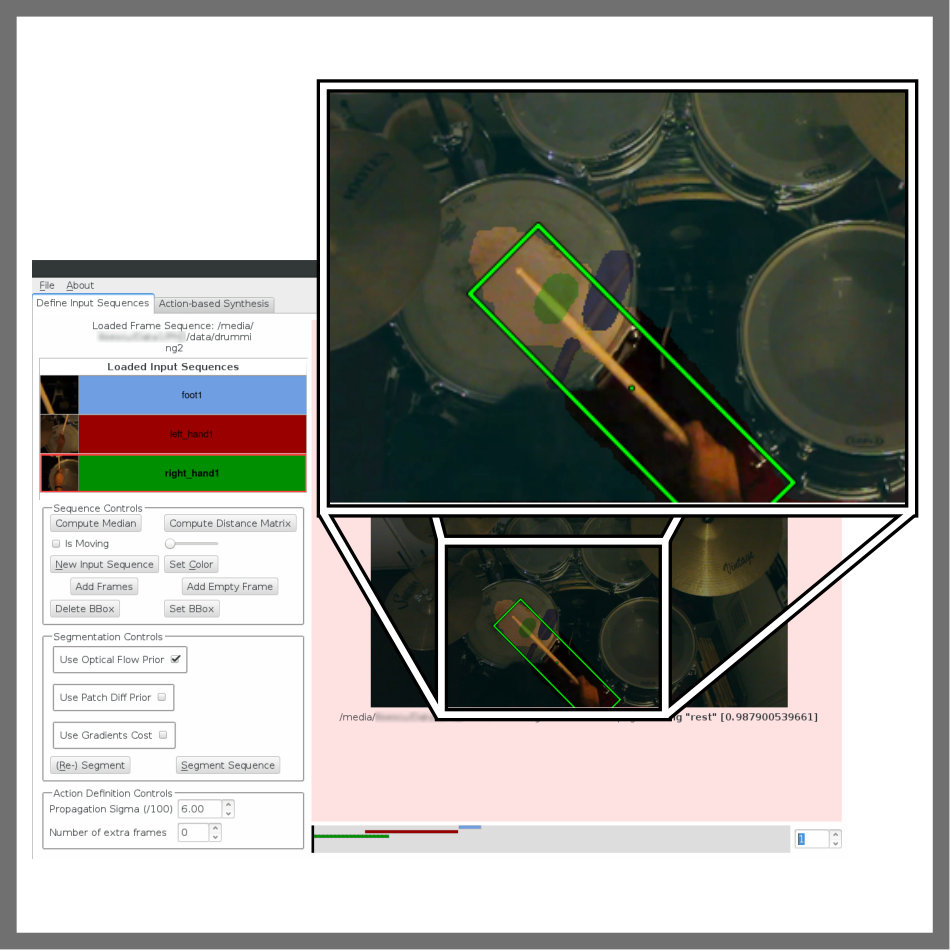 Figure 26
Figure 26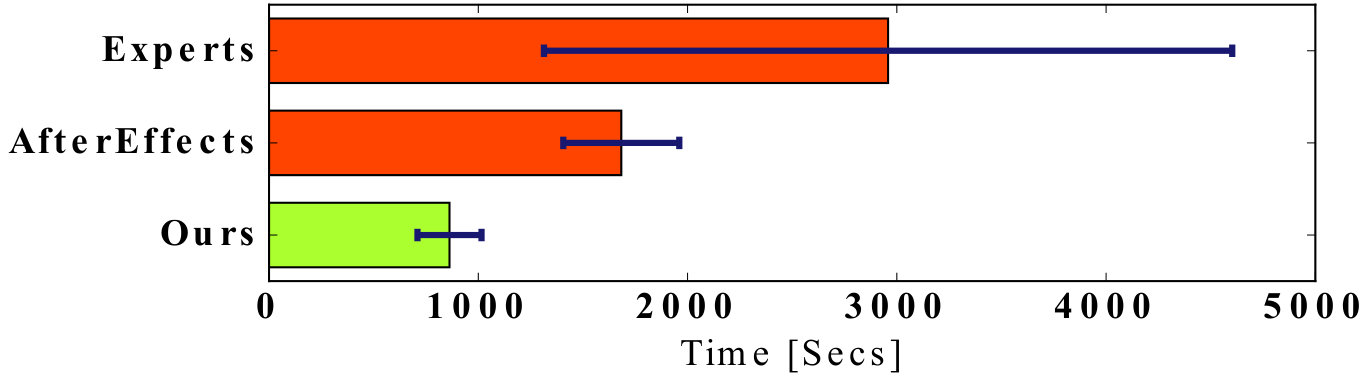 Figure 27
Figure 27 Figure 28
Figure 28| Dataset | Actors | Actions |
|
|
|
||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Candle | 1 | {3} | 1168 | 60 | 8 | ||||||
| Toy | 1 | {9} | 702 | 210 | 1 | ||||||
| Wave | 18 | {2} | 1124 | 1320 | 15 | ||||||
| Havana | 13 | {2} | 587 | 1257 | |||||||
| Theme Park | 13 | {1, 2} | 630 | 820 | 21 | ||||||
| Digger | 2 | {2} | 160 | 405 | 2 | ||||||
| Windows | 23 | {2} | 115 | 60 | 54 | ||||||
| Planes | 7 | {2} | 105 | 917 | 10 | ||||||
| Drumming | 3 | {2, 4, 5} | 506 | 2440 | 3 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
\toappear
This is an author-prepared print that includes the errata mentioned on the project page at \hrefhttp://visual.cs.ucl.ac.uk/pubs/actionVideo/visual.cs.ucl.ac.uk/pubs/actionVideo/. The original published version appears in the ACM Digital Library (\hrefhttp://dx.doi.org/10.1145/3025453.3025880dx.doi.org/10.1145/3025453.3025880).
Responsive Action-based Video Synthesis
Corneliu Ilisescu
Halil Aytac Kanaci
Matteo Romagnoli
Neill D. F. Campbell
Gabriel J. Brostow
University College London
University College London
Testaluna srl
University of Bath
University College London
Abstract
We propose technology to enable a new medium of expression, where video elements can be looped, merged, and triggered, interactively. Like audio, video is easy to sample from the real world but hard to segment into clean reusable elements. Reusing a video clip means non-linear editing and compositing with novel footage. The new context dictates how carefully a clip must be prepared, so our end-to-end approach enables previewing and easy iteration.
We convert static-camera videos into loopable sequences, synthesizing them in response to simple end-user requests. This is hard because a) users want essentially semantic-level control over the synthesized video content, and b) automatic loop-finding is brittle and leaves users limited opportunity to work through problems. We propose a human-in-the-loop system where adding effort gives the user progressively more creative control. Artists help us evaluate how our trigger interfaces can be used for authoring of videos and video-performances.
category:
H.5.2 Information Interfaces and Presentation User interfaces - Prototyping
keywords:
Video Editing; Video Textures; Sprites; Cinemagraphs; Interactive Machine Learning.
1 Introduction
In a SIGCHI acceptance speech [22], Dan Olsen outlined the three properties that characterize a great medium of expression: Range, Empowerment, and a Balanced Structure. Good range indicates a wide variety of possible expressions, empowering mediums lower the required skills and cost to reach excellent results while a balanced structure constrains the user to make new outputs possible. By these measures, we find Live Looping [24], where music is recorded and played back in real-time, to be an inspirational medium for authoring music. Present-day musicians like Reggie Watts111https://youtu.be/0gKWfvd-chA?t=123s and Kimbra222https://youtu.be/DgmoHtnoi7k?t=27 can easily accumulate simple sounds, faithful to the original audio-clips, yet they have the flexibility and precise control to overlay and repeat clips to compose complex music that transcends their solo-musician appearance. We want to make a “cousin” of Live Looping for the video domain333YouTube’s MysteryGuitarMan uses labor-intensive methods and has almost 3M followers: https://youtu.be/EQXA7ErL708, as illustrated in Fig. 1.
Presently, technologies for video-authoring have good Range [22], meaning that they are flexible and accurate in depicting many subjects. But they lack a Balanced Structure and Empowerment, which require confining flexibility to ensure even novices succeed, without curtailing what experts can create. Our goal is to develop a tool that enables a medium of expression characterized by all of these three properties. In particular, we aim to a) “lower the floor” so that novices can participate, b) “raise the ceiling” so that a single artist can compose expressive pieces and performances while c) catering for the widest range of inputs possible.
We achieve this by adapting looping concepts to video in a prepare- and perform-structure (see Fig. 1).
In the preparation stage, we treat all moving elements as video sprites, i.e. a bendy tube of pixels in a stack of sequenced images, like Lu et al. [20]. We call these actors. If a video features only one actor, this is simply a whole-frame sprite. Each tube is then manipulated in time, while maintaining the original spatial properties, to create the output. This is done by splitting a sprite’s frames into clusters of actions, and allowing artists to choose which subset of frames to show during the second part of our approach: the live performance. A user requests actions through a wide range of trigger interfaces, such as tangible widgets, keyboard, or paint-by-numbers, while our system ensures smooth loops within clusters and transitions between them. Artists can also edit synthesis constraints to ensure sensible actor behavior.
In this paper, we present the following contributions:
a constrained optimization algorithm wrapped inside an expressive new interface, that allows users, for the first time, to control actors in video by high level interactions; 2. 2.
an end-to-end system to create, iteratively repair, and control video sprites: artists can quickly improve clips that are hard to segment or loop, and check their quality live without jumping between disjoint tool-chains; 3. 3.
a responsive new medium of expression, that enables artists to merge video assets they made and rehearsed earlier in a live performance.
We assume the input videos to our system adhere to the following criteria: a) the camera is stationary, b) there are no large differences in lighting over the sequence, c) the background is mostly stationary, d) the filmed actors are mostly well separated from each other and e) the actions they perform are visually distinct. We show how, despite these assumptions, our system can cater for widely different videos featuring various types of actors and actions and produce rich and diverse results. We also present interviews with several video-artists and evaluate the triggering interfaces to understand the pros and cons of this new medium of expression and adjust the underlying technology.
2 Related work
In this work, we are inspired by methods for direct video manipulation [9] and navigation [6, 13]. Eventually, we aim to make interactive synthesis of new videos as fun as the manipulation and non-sequential playback of existing videos is in the above methods. We simultaneously tackle the problems of looping arbitrary videos and influencing synthesis of novel content through user annotation. We now highlight works related to those problems and interesting interfaces for video editing.
Video looping and animation
With their pioneering work on Video Textures, Schödl et al. [29] tackled the problem of indefinitely playing back a finite length video without visible transitions. It worked by finding interchangeable pairs of frames, for single subject videos depicting repetitive or stochastic motion, but struggled with videos containing multiple independent subjects or complex motions.
Kwatra et al. [16] treat video looping as a texture synthesis problem, solved using an energy minimization approach. Extensions for panoramic videos and stereo panoramic videos were proposed in [2] and [5] respectively. Liao et al. [18, 17] model motion on a per-pixel basis and segment the input video into spatio-temporal regions of similar motion automatically. Finally, Sevilla-Lara et al. [30] focus on videos exhibiting camera motion which significantly increases the looping complexity and thus limit themselves to single dominant subjects.
In contrast to the above, our technique enables more meaningful synthesis by introducing additional knowledge rather than simply focusing on loop finding and disguising transitions.
Video-based animation
There are many examples of methods to create novel animations from filmed footage found in the literature. The original Video Textures paper by Schödl et al. [29] and follow-up work [28], allows segmented sprites of animals, annotated with velocity vectors, to be controlled interactively using the mouse pointer. In contrast, Bhat et al. [4] create animations of stochastic elements, such as smoke and water, by leveraging user-defined flow patterns to loop and re-position them. Flagg et al. [8] introduce a specialized technique for human video textures that can create animations of human motions from a database.
The systems described above do not have any knowledge about what is taking place in the input video. Therefore, synthesized video elements look plausible, but random. Some indirect user control is possible by making some assumptions and devising custom energy functions (such as looping through more or less heterogeneous frames [18]). In contrast, we generalize by giving users the tools to interactively define their subjects and how to control them “by example”.
Video editing
A cinemagraph is a traditionally hand-made medium of expression that combines still and moving imagery. In recent years, much effort [3, 11, 18, 32] has gone into automating this time-consuming process. Users can decide what areas to animate in [32], combine small looped clips called cliplets in [11] or scribble over patches to automatically animate or de-animate them [3, 18]. Similar to these works, we reduce the degrees of freedom of captured footage by dividing it into disjoint patches. Unlike them, however, we do not restrict users to a binary decision of “(not) animate” and allow them to easily decide how to animate through our object-action mapping.
Related to our method, video re-timing allows one to re-order filmed events for new and interesting effects. Shah et al. [25] focus on condensing large amounts of video into short animations but often result in disturbing artifacts such as ghosting. Users are given tools to cut and re-arrange trajectories in a spatio-temporal 3D volume in [20, 31]. In DuctTake [27], events filmed in the same scene at different times are composed together using a graph-cut energy optimization, while Liao et al. [19] build on this by allowing music to drive event re-ordering. Finally, Rav-Acha et al. [26] bend time for image patches by projecting their pixels onto evolving time fronts.
In contrast to the above techniques, which do not natively support looping, our method can re-arrange frames arbitrarily. Additionally, unlike in our approach, users must synchronize events manually to avoid incompatibilities, e.g. colliding cars [31]; outputs are limited to ones where filmed interactions are preserved [20], or they are not supported altogether [26].
3 System Overview
We design our end-to-end interface to allow content-creators to quickly prototype their ideas. The more effort they are willing to invest, the higher the quality and complexity their results can achieve. Through discussions with six different technical artists, interactivity (as opposed to automation) and responsiveness were identified as stand-out characteristics of this medium of expression; we emphasize these aspects in our prototype system.
Broadly, videos are prepared before being used in one or more performances. With this in mind, we start by providing the necessary tools to define elements of interest which we call actors. These can be full-frame video sequences, such as our Toy and Candle datasets (see Fig. 11 and Tab. 1), or localized objects, such as the cars in Havana or hands in Drumming.
For the objects, we provide semi-automatic tracking and segmentation capabilities (Fig. 2(a)). We enable the user to correct any mistakes in the bounding box tracks interactively. Similarly, for separating the tracked object from the background, our tool provides previews of generated action video clips, together or in isolation. Users can then correct and influence the quality of the final segmentation by scribbling over the resulting masks.
The next step is the most critical and represents the core of our new medium of expression. Using our simple UI (Fig. 2(b)), users associate a set of actions to each actor, specifying the moment in the video timeline. For instance, each musical note in Toy, or drum hit in Drumming, represents semantically and visually distinct actions. Users define these by tagging a few example frames while the remaining ones are labeled automatically, based on visual similarity, using a machine learning approach. This reduces the required user input and provides almost instant feedback, allowing users to validate the automatic action association and, if necessary, refine it by tagging more examples.
A new video performance synthesizes a number of output layers, each of which corresponds to an actor. Without further guidance, our algorithm can seamlessly loop through the actor input frames by finding visually smooth transitions (similar to [29]). Users can, however, guide the live video performance by pressing keys mapped to actors’ actions (Fig. 2(c)), requesting what to see and when. As we show later, this simple but powerful interaction mechanism enables more creative input methods such as MakeyMakey [12], synthesis-by-numbers [10] or custom game logic.
Our novel and fast synthesis algorithm balances the importance of meeting users’ requests with maintaining the visual quality of loop transitions, to create a new video interactively. Users can further refine the output by tagging incompatible frames or actions, so that actors interact only in desirable ways; for example, diggers should only load parked trucks (see Digger in Fig. 7). Our synthesis algorithm uses this information to improve the resulting output, completing the human-machine feedback loop that makes results possible, in response to high level triggers.
Finally, we can perform an optional post-processing step (Fig. 2(d)) to improve the quality of the output sequence recorded during the interactive phase described above, producing the final results shown in the supplemental video. We use seamless blending to remove artifacts due to illumination changes and then merge the actor patches together with the background ensuring that the overlapping regions are handled correctly.
The following sections provide the technical and implementation details required to reproduce our system; these are followed by the results and evaluation.
4 Actor Preparation
We now describe the steps and tools used to prepare a raw video for use during a live performance. The result of this stage is a set of actor sequences: video sprites associated to actions that can be interactively triggered during synthesis. Optionally, actors can be tracked and segmented to improve looping and increase output variability.
Tracking and segmentation
Critical to looping algorithms is the ability to find similar frames or patches, at different points in the timeline, that can be used interchangeably to “jump” between different parts of the video. This is impossible for complex videos, such as ones with multiple, independently moving objects (see Havana). Methods such as [18] partially address this problem by adapting their patch shape to best suit looping, but are prone to cutting objects, introducing visible seams. We choose to let users decide interactively which elements they may want at showtime.
First, users track bounding boxes around objects. In our system, we chose to use the CMT tracker [21] because a) it is easy and quick to correct in an interactive setting (see our UI in Fig. 5) and b) it estimates both scale and orientation along with the position of the bounding box.
We then use the bounding box to constrain our custom, graphcut-based foreground (FG) segmentation algorithm. Unlike traditional approaches, we aim to composite the patches on their original background (BG). We therefore allow BG pixels to belong to the FG patch as long as all FG pixels are correctly classified (see Fig. 3(a)). To ensure this, users can correct any errors in the labeling by interactively scribbling over patches (the colored strokes in (2) in Fig. 5).
Segmentation algorithm
After estimating the static background as the per-pixel median of all input frames, we use the seam-finding algorithm in Graphcut textures [16] to separate FG from BG pixels. We use their pairwise term to conceal seams, and a novel unary term that enforces seam consistency over time and FG pixels to be within the bounding box. Formally, the unary term for pixel at position belonging to the FG in frame is defined as
[TABLE]
where are the coordinates of the center of the bounding box in image space, is the optical flow function that maps a pixel to its location in the previous frame [7] and is the pixel mask (FG/BG) of the previous frame . We use against a fixed cost to the BG. User-defined scribbles fix pixels’ unary cost depending on their association; see Fig. 3 for an example output.
Action definition
The main innovation of our paper is the direct mapping between arbitrary, user-defined, semantic actions and video synthesis commands. Users quickly and intuitively guide our synthesis algorithm towards their goal by issuing these commands; for instance, requesting a candle flame to flicker to the right.
In contrast, traditional approaches expect users to manipulate the timelines of several clips by cutting, re-arranging and synchronizing them [11, 20]; we believe this makes for far less intuitive and powerful video synthesis.
Action recognition is a well studied problem in the literature. However, existing methods focus on specific use cases, e.g. human actions [33]. Not wanting to impose restrictions, we allow users to indicate actions of interest “by example”, using our responsive interactive tool (Fig. 5). To define actions, users inspect actor sequences (potentially tracked and segmented) and indicate example frames for each action with the press of a button. Users receive immediate feedback on the quality of the frame-to-action association of the remaining input frames, as they are automatically compared to the user-given examples.
We can view this as a fuzzy clustering problem, where each action (e.g. “sit” and “stand” for Wave in Fig. 5) is a cluster. In practice, we represent the action visible in frame of actor sequence for which distinct actions have been defined as an -dimensional vector . It represents a probability distribution over the action space, so . Intuitively, the higher the value of the element of , the more representative is frame of the action. For frames indicated as examples of a given action, takes the form of a binary vector with a for the specified action and [math]’s elsewhere. For instance, given the actions defined for Candle (i.e. “rest”, “left” and “right” in Fig. 4), a confident example frame showing the flame flickering to the left would be associated the action vector (Fig. 4d).
We then quickly propagate the user-given information to the remaining frames using [34]. Action vectors , with , are assigned to all frames, softly clustering them into different actions based on similarity to example frames. The distance between each frame pair is defined as
[TABLE]
where we take the distance between color intensities \mathbf{I}\big{(}t,\mathbf{X}(n)\big{)} and \mathbf{I}\big{(}t^{\prime},\mathbf{X}(n)\big{)} of every pixel . If the actor sequence has been tracked, we first place the frame’s segmented patch onto the static background as shown in Fig. 3(a). This ensures Eq. 2 can be used for both tracked and full frame sequences, and spatial relationships are preserved. To avoid bias due to camera-related effects, such as foreshortening, we normalize the distance measure by the number of overlapping pixels between each frame’s bounding box. We set to the whole frame area if no bounding box is defined. For space reasons we do not discuss the propagation further. Please see [34] and specifically their Eq.(5) for more details.
Each input frame is associated to an action-cluster “softly” as shown in Fig. 4. This is critical, as frames for which no clear association exists (e.g. (Fig. 4b)), are used as in-between transitions by our synthesis algorithm. In contrast, traditional video annotation tools, such as ANVIL [14], enable a similar partitioning of video sequences but with hard boundaries between manually defined intervals (see Fig. 4 GT), losing the expressiveness of fuzzy assignments in the process.
Moreover, as shown in Fig. 6, we experienced a to speed-up in reaching the accuracy permitted by ANVIL (and ignoring in-between frames) thanks to the automatic label propagation from [34].
5 Video Performance
In this section, we show how we synthesize a live video performance given a set of input actor sequences. First, users interactively define the frame compatibility measure, which is later used to avoid implausible outputs. Second, we present our optimization strategy that balances user commands, frame compatibility and transition quality information to synthesize new videos.
Frame compatibility
As we will see later, users guide the video synthesis by requesting when actors should perform actions. When multiple actors are present in the same frame however, outputs can exhibit implausible situations depending on when users issue their commands (see Havana cars or Candle flames). For instance, Candle flames could flicker in different directions at the same time (Fig. 11(a)), a digger could start loading a moving truck (Fig. 7(a)) or cars could collide in Havana (Fig. 8). In our system, these incompatibilities take the form of two actors’ frames being composited together onto the output background.
In essence, we again want to assign frames to a set of clusters fuzzily, as we did for our action definition. These clusters further decompose the actions into sub-sequences. Users mark them as (in)compatible w.r.t. the sub-sequences of other actors, indicating which sets of frames should be allowed to co-exist in the output video. Given actor sequences and , we define the compatibility between their respective clusters and as
[TABLE]
Initially, there is one sub-sequence cluster for each user-defined action, so and are in the range . Later, we discuss how users marking (in)compatibilities changes the number of clusters. We initialize for all combinations of and . We use to denote the vector containing the probability that frame of actor belongs to clusters compatible with actor . Similarly, we define for frames of actor . We initialize as it provides an initial division of the input frames, the combination of which could be incompatible. The compatibility between frame of and frame of is then defined as
[TABLE]
where denotes the element of . Intuitively, the higher the probability that two frames belong to two compatible clusters, the lower the value of \chi\big{(}t_{i},t_{j}\big{)}, denoting a low compatibility cost.
Using our GUI (Fig. 8) at synthesis time, users can tag pairs of frames as compatible or incompatible. Given the pair we allow two options, which we illustrate for only, as they are analogous for :
specialize the compatibility by using as an example for a new cluster , re-running label propagation using the extended set of examples to compute (the now 1D larger) for all frames of , extending by one row, setting and according to the user input; 2. 2.
refine the compatibility measure by leaving unchanged, setting as a new example for the cluster m=\underset{m}{\arg\!\max}\big{[}\mathbf{c}^{t_{i}}_{i\rightarrow j}\big{]} it most likely belongs to and, again, re-running label propagation to re-compute .
If the compatibility of is changed, we assume option 1, otherwise, the user is asked to decide.
Intuitively, using the example of the two cars at the crossing in Fig. 8, if one chooses to specialize, each cluster will contain frames showing the car in different parts of the intersection. All frames showing the cars in the middle of the crossing can then be marked as incompatible and avoided in the output, making our synthesis continuously smarter.
Action-based video synthesis
An output video is composed of the frames of one or more actor sequences, re-arranged to infinitely loop showing specific actions and the transitions between them. We phrase our synthesis process as a labeling problem over a two-dimensional graph with rows and columns. Each row is an output layer that contains the frames of a specific actor sequence , re-arranged to adapt to the user’s commands. Each column represents a final output frame as the union of the frames chosen for each layer. For instance, the Toy result has one row with output frames straight from the input, while the Havana output has as many rows as controllable cars. The label assigned to each node is the index of an actor’s frame.
Users control the output video by selecting one output layer at a time (see output timeline in Fig. 8) and pressing the key associated to the action they want the actor to perform. This in turn defines for each output frame a -dimensional requested action vector , . We use a smooth-step function to automatically switch from the currently shown action to the one associated to the user-pressed key stroke.
Formally, our optimization strategy minimizes the energy function
[TABLE]
where and are action, compatibility and transition costs respectively. Intuitively, the higher the value of , the more responsive the synthesis is to the requested actions (as counts more towards total energy) at the expense of looping quality. This is in turn controlled by the other two terms, balanced by . The higher its value, the more important it is to show compatible frames () at the expense of smooth transitions (). Both parameters are user-tuned.
We now define the three components of our energy function. For output layer , is the cost of showing a frame of actor sequence , in output frame k, based on whether the action it shows matches the requested action and is defined as
[TABLE]
is the cost of showing a pair of frames and , from output layers and respectively, in the same output frame based on the compatibility cost from Eq. 4 and is defined as
[TABLE]
Finally, is the cost of showing actor ’s frame in output frame after showing a frame in the previous output frame and is defined as
[TABLE]
where is defined in Equation 2.
Real-time performance
The objective in Eq. 5 can be solved using any discrete energy minimization solver that supports multi-label nodes and arbitrary cost functions, e.g. TRW-S [15]. Unfortunately, TRW-S fails to converge in our experiments and our system requires immediate feedback to enable live performances.
Instead, we propose an iterative approach that minimizes our objective function locally. We define the new energy function
[TABLE]
and solve it using dynamic programming, one row at a time, to synthesize output frames showing the actor associated to the given row. The only inter-row energy is (Eq. 7), that ensures compatibility between frames of different actors, which we “bake” into the unary term . We define it and pairwise term as
[TABLE]
respectively. At each iteration we minimize Eq. 9 for each row in the order the output layers are defined and update to consider the already computed rows. We have found that, one iteration is enough to satisfy our three constraints and enables real-time synthesis. Note that, the result seen during a live performance might differ from the one synthesized using the full set of action requests recorded during it. This is due to the fact that, we can better optimize frame compatibilities and transitions between actions, once we exactly know what each actor will be requested to do and when. In our experiments, even long (see Table 1) actor sequences such as the people in Wave or the flame in Candle never require more than to synthesize 400 frames. We further drastically reduce these timings ( to ) by using our compression strategy described below. Typically, we synthesize less than 100 frames in every 2-3 seconds in a live performance scenario, making our system very reactive.
Optimization Compression
Jumps are rarely perfect, as pointed out by [29], so higher quality outputs involve fewer jumps (i.e. the original timeline is followed for as long as possible). With this insight, we speed up our optimization further by synthesizing a subset of the output frames using a subset of the input frames, and “filling in the blanks” using subsequent frames. For instance, we can optimize for half the output frames using only every other input frame and gain a speed-up. We experimented with up to compression, meaning we optimize for every frame, with no visible quality penalty.
Post-Processing Rendering
Our optional post-process first uses seamless cloning by Pérez et al. [23], to merge each patch to the static background and remove artifacts (red arrows in Fig. 3(a)) due to illumination changes. Then, our custom compositing algorithm resolves occlusions between overlapping segmented actor patches.
As shown in Fig. 3(a), our segmented patches often contain background pixels. This was deliberate as it allows us to retain small details such as soft shadows, and works well when patches are placed on their original background. When patches of different actors overlap in the synthesized frame (Fig. 3(b)), BG pixels may obscure FG pixels. For each pixel where this happens, we dynamically decide which patch is most likely to be FG based on its color intensity difference to the BG. This approach is more flexible and gives better results than setting a global threshold on the background difference, as shown in Fig. 3(c). It is also more suited to our problem than the “mixed seamless cloning” in [23] which does not perform well with complex backgrounds or occlusions, and introduces ghosting (Fig. 3(d)).
6 Creative synthesis
In contrast to existing tools, our system accepts high-level, user-defined commands that guide our video synthesis algorithm. Users need simply request when they want an actor to perform an action, enabling many alternative and fun ways of creating videos, which we now present.
Keyboard and MakeyMakey
The simplest way to create a video with our system is by using a keyboard. An action for each actor can be mapped to a specific key stroke which, when pressed, signals our synthesis algorithm to show frames from that category. Given the simplicity of our mapping process, we can use more creative input methods too. For instance, in Fig. 9(a) and in our supplemental video, an artist uses MakeyMakey [12] and some Play-doh figurines to create a video using our Drumming dataset, where specific drums or cymbals are hit when the associated figurine is touched.
Synthesis by numbers
Our system enables creation of video analogous to image synthesis [10]. We associate actions to solid colors, and create an animated control sequence showing those colors using any paint tool. Actions are then triggered according to the colors shown by the control sequence. For instance, Fig. 9(b), shows an animated black bar crossing the screen from left to right. At each output frame, people in Wave are asked to “stand” if they are under the black bar and “sit” otherwise. This allows us to quickly create a Mexican Wave. In our supplemental video we show that we can easily change the control sequence to quickly synthesize completely different waves.
Game Logic
Our system also allows external factors to drive video synthesis. In particular, custom video-game logic can be programmed to issue commands to our synthesis algorithm based on dynamic game-related events. For instance, we have embedded a pre-computed set of outputs of our controllable Candle into a game level (see Fig. 9(c) and supplemental video). Then, the game logic decides how the candle should react to its own wind simulation, by for instance, making it flicker to the left or to the right.
7 Results
The new medium of expression described in this paper enables the creation of a wide variety of video performances. To stimulate the reader’s creativity, we and our users have produced a number of output videos using the system. They can be seen in our supplemental video444Visit our website http://visual.cs.ucl.ac.uk/pubs/actionVideo/, as stills in Fig. 11, and are briefly described here. In Table 1, we provide information about the actors defined for each dataset and the needed user effort.
We use Candle as a didactic example. After segmenting the flame using pixel intensity, we define three actions (“left”, “right”, “rest”) and thus are able to have it react according to a hypothetical breeze. Given multiple copies of a candle, as shown in our supplemental video, we also tag pairs of frames showing distinct actions as incompatible, such that our synthesis algorithm can ensure they all react to the breeze randomly, but in the same manner, without having to manually ensure it for each flame. Similar results are achieved from within a videogame level, as shown in Fig. 9(c).
Range
Havana and Theme Park show the flexibility of our method and its ability to avoid incompatibilities. These and the subsequent examples differ from Candle because they cannot or would be very hard to make using existing tools. Multiple moving elements were tracked and segmented, and associated to the actions “visible” and “invisible”. Thanks to our frame compatibility measure, we are able to avoid collisions between cars and people when they are visible at the same time in the output video. Similarly, in Digger the user ensured a digger only loads a truck when it is parked, by tagging a few incompatible pairs of actor-frames where the truck is moving while the digger tries to load it.
With the remaining datasets, we showcase further creative interactions with our system. Using Wave, we create a Mexican Wave simply by creating a control animation as seen in Fig. 9(b). We can then quickly alter the result by simply changing the control sequence, to add a second subsequent wave, one in the opposite direction, or even an interlaced one. In Drumming, we can control a drummer playing his instrument by simply touching play doh figurines representing funny sounds, while with Toy we can create a video showing specific songs being played onto a colorful xylophone after filming random notes being hit. Windows allows us to map windows on a building facade to pixels in a grid, and render a compelling game of Tetris by manipulating the light switches. With Planes, airplanes take off in sync with a user hitting the spacebar to the rhythm of a well known videogame theme-song. Finally, a game-developer used Havana to create the CounterLoop videogame (see project webpage). All these outputs and use-cases are prepared with the same workflow, qualitatively demonstrating its range.
8 Empowerment Evaluation
As they are our closest competitors, we aim to replicate our Mexican Wave output (Fig. 11(c)) using either of [18, 20, 11]. Liao et al. [18] can deal with complicated scenes but it merely finds the best possible looping patches. It does not allow the user to choose where to loop or when people should sit and when to stand. The system of Lu et al. [20] can allow us to splice together different sub-clips and re-arrange them. However, they create unnatural speed-ups or slow-downs when people need to sit for longer or less than the input video, because of their time scaling algorithm, and do not account for transitions between the clips as our looping does automatically.
We informally compare our system to Cliplets [11] by recreating an 8-actor Mexican Wave (see supplemental video) and one candle flame using Candle. Similar to [20], Cliplets works by defining, manipulating, and arranging layers of video clips to create the output. Each layer shows one looping animation (e.g. an actor performing one action) or input frames as captured (which we used to transition between actions of the same actor). For instance, a video of a flame flickering left and then right, requires three layers: a) “loop flame left”, b) “playback flame going from left to right”, c) “loop flame right”. Users must manually define when to show each loop and its length and find transition frames in b) such that there is no visible jump when hiding layer a) to show b) and when hiding b) to show c). This very time consuming process is slowed further if the result needs changes, as changing looping time or animation order requires carefully re-arranging layers and redefining transitions, effectively starting over. In contrast, our system enables live performances after a one-off preparation stage. The output is created as an endless stream and the user is free to play-act and improvise in real time, an invaluable ability unique to our system. Using Cliplets, it took us and longer to recreate Wave and Candle respectively. This is mainly due to manually inspecting the video to find the right subset of frames to loop through or use as transitions between animations.
For reasons discussed above, several methods [11, 18, 20] were not able to successfully recreate our outputs. Separately from range, we want to assess whether our action-based synthesis empowers users’ creativity [22] and helps express it better and faster than baselines. We therefore compare against Adobe After Effects (AE) because, with proper training, it gives users commercially-accepted tools that should reproduce our results. We gathered 6 novice users, that had never used either system, and asked them to recreate the Mexican Wave sequence. In particular, they were instructed to create a left-to-right wave, some idle animation in the middle (i.e. sitting people) and a final right-to-left wave. After relevant training, half of the users used our system while the remaining half performed the same task using AE. Both sets of users were given the same 7 sprites as input that had already been tracked and segmented.
Fig. 12 shows that users of our system were roughly twice as fast, indicating that our system is indeed easy to use. In their words, they really enjoyed the simplicity with which actions are defined, the responsive visualization (Fig. 5), and the immediate video feedback that comes with action requests during synthesis. In the supplemental video, we qualitatively show that the AE results are inferior to ours. This is because our system automatically finds the best transitions between actions, while the AE users need to manually align the clips showing the sitting and standing actions and decide when to transition between them. Finally, we also asked three expert Nuke Studio, Blender, and AE users to recreate the same sequence. Their timings (also in Fig. 12) show a larger variability depending on their willingness to find optimal-looking jumps. In fact, they were given the same inputs and task as the novice AE users, but no further instructions, and their results are of varying quality.
9 Discussions with artists
To assess the balanced structure [22] of our system, we informally interviewed three digital artists, mostly involved with game development or live performance design, and introduced them to our system (see Fig. 13 using Drumming). They agreed that our system takes a large step toward making “video composition more like playing a musical instrument”, enabling live performances with immediate video feedback, such as seen in Drumming. We were surprised that one asked to sacrifice video quality for better responsiveness, especially if sound feedback is present. As shown in our supplemental video, we were able to cater to this request by favoring (Eq. 5) at the expense of good looking transitions. The result can then be improved, immediately after recording the user commands, by re-synthesizing the sequence with the default video settings.
Interestingly, artists saw our system as a “sketching tool” for quick prototyping, such as seen using synthesis by numbers to create the variations of the Mexican Wave. In fact, experimenting with choreographies was a suggested use case, such as filming dancers improvising and re-arranging their moves using our system after the fact. They also expressed the desire to have the synthesis algorithm as part of game engines, as they feel it gives them important control over sprite synthesis. When shown our Candle video, they immediately recognized its value for game development and suggested further content, such as water drops into puddles. Finally, they suggested a number of “shared experiences” for teaching and training that our system would make possible. For example, a trainer could decide which exercises people should perform and give them live video tutorials, or could trigger traffic scenarios.
10 Conclusion
We presented a system that facilitates a new medium of expression, where videos are created much like live looping is composed. Users define actors, optionally tracking and segmenting them, and associate actions to triggers, which can take the form of multiple interfaces. Our workflow helps both novices and advanced users to prepare their footage and, for the first time, turn it into interactive live performances.
Limitations
The quality of our results, ultimately depends on the input videos and the users’ willingness to invest the necessary effort to process them. The longer the actor sequences, the greater the variability and coverage of situations. For instance, there are no clean transitions between hitting some notes in Toy and the rest position, because the mallet hand rarely leaves the view in the input video, resulting in occasional jumpy animation. In general, this holds for short videos where there is too much variability but not enough coverage. This problem could be tackled with interpolation and morphing techniques similar in spirit to [30]. Additionally, there is always a trade-off between how quickly the synthesis shows the desired action, and how smooth the transition looks. Being able to successfully camouflage bad jumps would reduce the time necessary to transition between actions. It would also remove the input lag between the button press and the on-screen response, critical for live performances such as Drumming.
11 Acknowledgments
We would like to thank Mike Terry for his invaluable feedback. Thanks to all the volunteers and artists for their availability during our validation phase, especially Tobias Noller, Evan Raskob and Ralph Wiedemeier. The authors are grateful for the support of EU project CR-PLAY (no 611089) www.cr-play.eu and EPSRC grants EP/K023578/1, EP/K015664/1 and EP/M023281/1.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1]
- 2[2] Aseem Agarwala, Ke Colin Zheng, Chris Pal, Maneesh Agrawala, Michael Cohen, Brian Curless, David Salesin, and Richard Szeliski. 2005. Panoramic Video Textures. In ACM SIGGRAPH 2005 Papers (SIGGRAPH ’05) . ACM, New York, NY, USA, 821–827. DOI: http://dx.doi.org/10.1145/1186822.1073268 · doi ↗
- 3[3] Jiamin Bai, Aseem Agarwala, Maneesh Agrawala, and Ravi Ramamoorthi. 2012. Selectively De-Animating Video. ACM Transactions on Graphics (2012). http://graphics.berkeley.edu/papers/Bai-SDV-2012-08/
- 4[4] Kiran S. Bhat, Steven M. Seitz, Jessica K. Hodgins, and Pradeep K. Khosla. 2004. Flow-based Video Synthesis and Editing. In ACM SIGGRAPH 2004 Papers (SIGGRAPH ’04) . ACM, New York, NY, USA, 360–363. DOI: http://dx.doi.org/10.1145/1186562.1015729 · doi ↗
- 5[5] V. Couture, M.S. Langer, and S. Roy. 2011. Panoramic stereo video textures. In Computer Vision (ICCV), 2011 IEEE International Conference on . 1251–1258. DOI: http://dx.doi.org/10.1109/ICCV.2011.6126376 · doi ↗
- 6[6] Pierre Dragicevic, Gonzalo Ramos, Jacobo Bibliowitcz, Derek Nowrouzezahrai, Ravin Balakrishnan, and Karan Singh. 2008. Video browsing by direct manipulation. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems . 237–246.
- 7[7] Gunnar Farnebäck. 2003. Two-frame motion estimation based on polynomial expansion. In Image Analysis . Springer, 363–370.
- 8[8] Matthew Flagg, Atsushi Nakazawa, Qiushuang Zhang, Sing Bing Kang, Young Kee Ryu, Irfan Essa, and James M. Rehg. 2009. Human Video Textures. In Proceedings of the 2009 Symposium on Interactive 3D Graphics and Games (I 3D ’09) . ACM, New York, NY, USA, 199–206. DOI: http://dx.doi.org/10.1145/1507149.1507182 · doi ↗