Doubly Robust Data-Driven Distributionally Robust Optimization
Jose Blanchet, Yang Kang, Fan Zhang, Fei He, and Zhangyi Hu

TL;DR
This paper introduces a novel doubly robust data-driven distributionally robust optimization method that improves generalization and reduces testing error by adaptively informing the transportation cost in distributional uncertainty.
Contribution
It proposes a new methodology to adaptively determine the transportation cost in DD-DRO, enhancing robustness and generalization over existing regularized estimators.
Findings
Empirically improves generalization in various datasets.
Reduces testing error compared to state-of-the-art classifiers.
Enhances robustness by adaptively informing distributional uncertainty.
Abstract
Data-driven Distributionally Robust Optimization (DD-DRO) via optimal transport has been shown to encompass a wide range of popular machine learning algorithms. The distributional uncertainty size is often shown to correspond to the regularization parameter. The type of regularization (e.g. the norm used to regularize) corresponds to the shape of the distributional uncertainty. We propose a data-driven robust optimization methodology to inform the transportation cost underlying the definition of the distributional uncertainty. We show empirically that this additional layer of robustification, which produces a method we called doubly robust data-driven distributionally robust optimization (DD-R-DRO), allows to enhance the generalization properties of regularized estimators while reducing testing error relative to state-of-the-art classifiers in a wide range of data sets.
Click any figure to enlarge with its caption.
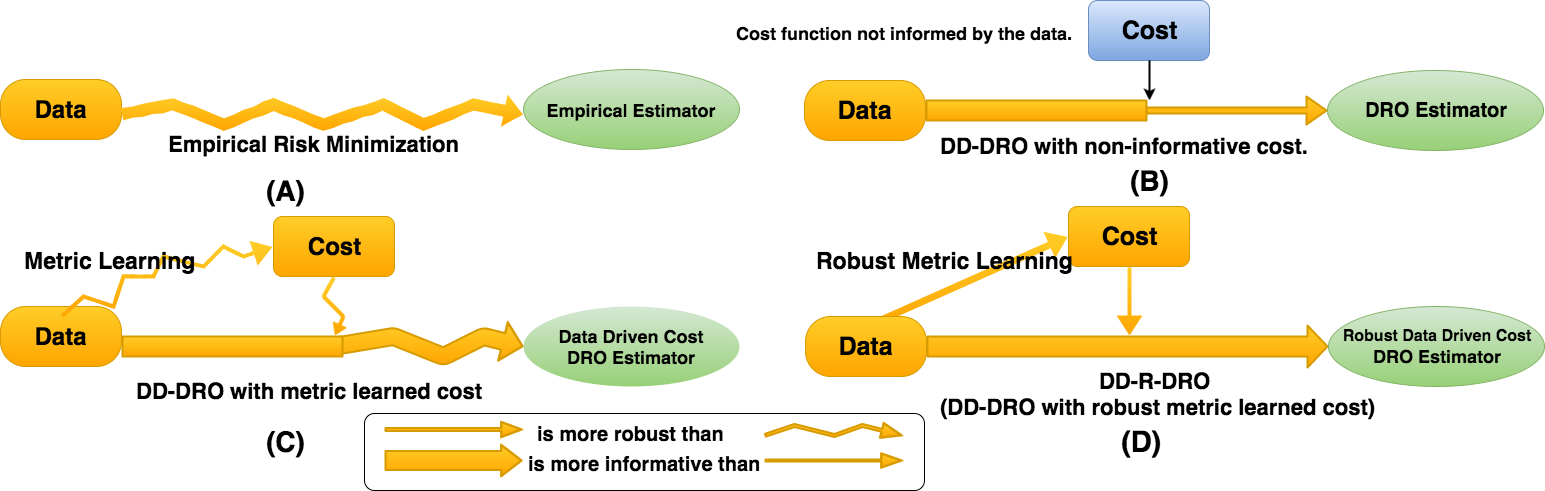 Figure 1
Figure 1| BC | BN | QSAR | Magic | MB | SB | ||
|---|---|---|---|---|---|---|---|
| LR | Train | ||||||
| Test | |||||||
| Accur | |||||||
| LRL1 | Train | ||||||
| Test | |||||||
| Accur | |||||||
| DD-DRO (absolute) | Train | ||||||
| Test | |||||||
| Accur | |||||||
| DD-R-DRO (absolute) | Train | ||||||
| Test | |||||||
| Accur | |||||||
| DD-R-DRO (absolute) | Train | ||||||
| Test | |||||||
| Accur | |||||||
| DD-DRO (relative) | Train | ||||||
| Test | |||||||
| Accur | |||||||
| DD-R-DRO (relative) | Train | ||||||
| Test | .108 | ||||||
| Accur | |||||||
| DD-R-DRO (relative) | Train | ||||||
| Test | |||||||
| Accur | |||||||
| Num Predictors | |||||||
| Train Size | |||||||
| Test Size | |||||||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Doubly Robust Data-Driven Distributionally Robust Optimization
Blanchet, J
Columbia University, Department of Statistics and Department of Industrial Engineering & Operations Research, New York, NY 10027, United States.
,
Kang, Y
Columbia University, Department of Statistics. New York, NY 10027, United States.
,
Zhang, F
Columbia University, Department of Statistics and Department of Industrial Engineering & Operations Research. New York, NY 10027, United States.
,
He, F
Columbia University, Department of Statistics and Department of Industrial Engineering & Operations Research. New York, NY 10027, United States.
and
Hu, Z
Abstract.
Data-driven Distributionally Robust Optimization (DD-DRO) via optimal transport has been shown to encompass a wide range of popular machine learning algorithms. The distributional uncertainty size is often shown to correspond to the regularization parameter. The type of regularization (e.g. the norm used to regularize) corresponds to the shape of the distributional uncertainty. We propose a data-driven robust optimization methodology to inform the transportation cost underlying the definition of the distributional uncertainty. We show empirically that this additional layer of robustification, which produces a method we called doubly robust data-driven distributionally robust optimization (DD-R-DRO), allows to enhance the generalization properties of regularized estimators while reducing testing error relative to state-of-the-art classifiers in a wide range of data sets.
1. Introduction
A wide class of popular machine learning estimators have been recently shown to be particular cases of data-driven Distributionally Robust Optimization (DD-DRO) formulations with a distributional uncertainty set centered around the empirical distribution.
For example, regularized logistic regression, support vector machines and sqrt-Lasso, among many other machine learning formulations can be exactly represented as DD-DRO problems involving an uncertainty set comprised of probability distributions which are within a distance from the empirical distribution. The distance is measured in terms of a class of suitably defined Wasserstein distances or, more generally, optimal transport distances between distributions.
Our contribution in this paper is to build an additional robustification layer on top of the DD-DRO formulation which encompasses the machine learning algorithms mentioned earlier. Because of the second layer of robustification, we call our approach DD-R-DRO.
More specifically, we consider a parametric family of optimal transport distances and formulate a data-driven Robust Optimization (RO) problem for the selection of such a distance, which in turn is used to inform the distributional uncertainty region in the type of DD-DRO mentioned in the previous paragraph. In addition, we provide an iterative algorithm for solving such RO problem.
In order to explain DD-R-DRO more precisely, let us discuss different layers of robustness that are added in our various optimization formulations and how these layers translate in terms of machine learning properties.
A DD-DRO problem takes the general form
[TABLE]
where is a decision variable, is a random element, and is a loss incurred if the decision is taken and is realized. The expectation is taken under the probability model . The set is called the distributional uncertainty set; it is centered around the empirical distribution of the data, and it is indexed by the parameter , which measures the size of the distributional uncertainty.
The min-max problem in (1) can be interpreted as a game. We (the outer player) wish to learn a task using a class of machines indexed by . An adversary (the inner player) is introduced to enhance out-of-sample performance. The adversary has a budget and can perturb the data, represented by , in a certain way – this is important and we will return to this point. By introducing the artificial adversary and the distributional uncertainty, the DD-DRO formulation provides a direct mechanism to control the generalization properties of the learning procedure.
To further connect the DD-DRO representation (1) with more mainstream machine learning mechanisms for the control of out-of-sample performance (such as regularization), we recall one of the explicit representations given in Blanchet et al., (2016).
In the context of generalized logistic regression (i.e. if the ), given an empirical sample with and a judicious choice of the distributional uncertainty , Blanchet et al., (2016) shows that
[TABLE]
where is the norm in for and .
The definition of turns out to be informed by the dual norm with . In simple words, the shape of the distributional uncertainty directly implies the type of regularization; and the size of the distributional uncertainty, , dictates the regularization parameter.
The story behind the connection to sqrt-Lasso, support vector machines and other estimators is completely analogous to that given for (2). A key point in most of the known representations, such as (2), is that they are only partially informed by data. Only the center, , and the size, (via cross validation) are informed by data, but not the shape.
In recent work, Blanchet et al., (2017) proposes using metric learning procedures to inform the shape of the distributional uncertainty. But the procedure proposed in Blanchet et al., (2017), though data-driven, is not robustified.
One of the driving points of using robust optimization techniques in machine learning is that the introduction of an adversary can be seen as a tool to control the testing error. While the data-driven procedure in Blanchet et al., (2017) is rich in the use of information, and hence it is able to improve the generalization performance, the lack of robustifiation exposes the testing error to potentially high variability. So, our contribution in this paper is to design an RO procedure for choosing the shape of using a suitable parametric family. In the context of logistic regression, for example, the parametric family that we consider includes the type of choice leading to (2) as a particular case. In turn, the choice of is applied to formulation (1) in order to obtain a doubly-robustified estimator.
Figure 1 shows the various combinations of information and robustness which have been studied in the literature so far. The figure shows four diagrams. Diagram (A) represents standard empirical risk minimization (ERM); which fully uses the information but often leads to high variability in testing error and, therefore, poor out-of-sample performance. Diagram (B) represents DD-DRO where only the center, , and the size of the uncertainty, , are data driven; this choice controls out-of-sample performance but does not use data to shape the type of perturbation, thus potentially resulting in testing error bounds which might be pessimistic. Diagram (C) represents DD-DRO with data-driven shape information for perturbation type using metric learning techniques; this construction can reduce the testing error bounds at the expense of increase in the variability of the testing error estimates. Diagram (D) represents DD-R-DRO, the shape of the perturbation allowed for the adversary player is estimated using an RO procedure; this double robustification, as we shall show in the numerical experiments is able to control the variability present in the third diagram.
In the diagrams, the straight arrows represent the use of a robustification procedure. A wide arrow represents the use of high degree of information. A wiggly arrow indicates potentially noisy testing error estimates.
The contributions of this paper can be stated, in order of importance, as follows:
-
The fourth diagram, DD-R-DRO, illustrates the main contribution of this paper, namely, a double robustification approach which reduces the generalization error, utilizes information efficiently, and controls variability.
-
An explicit RO formulation for metric learning tasks.
3) Iterative procedures for the solution of these RO problems.
2. DD-DRO, Optimal Transport, and Machine Learning
Let us consider a supervised machine learning classification problem, where we have a response and predictors . Underlying there is a general loss function and a class of classifiers indexed by the parameter . The distributional uncertainty region in (1) takes the form
[TABLE]
where is a suitably defined notion of discrepancy between and so that implies that .
Other notions of discrepancy have been considered in the DRO literaturem for example the Kullback-Leibler divergence (or another divergence notion which depends on the likelihood ratio) is utilized Hu and Hong, (2013). Unfortunately, divergence criteria which relies on the existence of the likelihood ratio between and ultimately forces to share the same support as , therefore potentially inducing undesirable out-of-sample performance.
Instead, we follow the approach in Esfahani and Kuhn, (2015), Shafieezadeh-Abadeh et al., (2015), and Blanchet et al., (2016), and define as the optimal transport discrepancy between and .
2.1. Optimal Transport Distances and Discrepancies
Assume that the cost function is lower semicontinuous. We also assume that if and only if .
Given two distributions and , with supports and , respectively, we define the optimal transport discrepancy, , via
[TABLE]
where is the set of probability distributions supported on , and and denote the marginals of and under , respectively. Because is non-negative we have that . Moreover, requiring that if and only if guarantees that if and only .
If, in addition, is symmetric (i.e. ), and there exists such that (i.e. satisfies the triangle inequality) then it can be easily verified (see Villani, (2008)) that is a metric. For example, if for (where denotes the norm in ) then is known at the Wasserstein distance of order .
Observe that (4) is obtained by solving a linear programming problem. For example, suppose that , so and assume that the support of is finite. Then, using , we have that is obtained by computing
[TABLE]
A completely analogous linear program (LP), albeit an infinite dimensional one, can be defined if has infinitely many elements. This LP has been extensively studied in great generality in the context of Optimal Transport under the name of Kantorovich’s problem (see Villani, (2008))). Requiring to be lower semicontinuous guarantees the existence of an optimal solution to Kantorovich’s problem.
Note that can be interpreted as the minimal cost of rearranging (i.e. transporting the mass of) the distribution into the distribution . The rearrangement mechanism has a transportation cost for moving a unit of mass from location in the support of to location in the support of . For instance, in the setting of (2) we have that
[TABLE]
The infinite contribution in the definition of (i.e. ) indicates that the adversary player in the DRO formulation is not allowed to perturb the response variable.
3. Data-Driven Selection of Optimal Transport Cost Function
By suitably choosing we might further improve the generalization properties of the DD-DRO estimator based on (1). To fix ideas, consider a suitably parameterized family of transportation costs as follows. Let be a positive semidefinite matrix (denoted as ) and define . Inspired by (6), consider the cost function
[TABLE]
where . Then, Blanchet et al., (2017) shows that in the generalized logistic regression setting (i.e. ), if is positive definite, we obtain
[TABLE]
If the choice of is data driven in order to impose a penalty on transportation costs whose outcomes that are highly impactful in terms of risk, then we would be able to control the risk bound induced by the DD-DRO formulation. This is the strategy studied in Blanchet et al., (2017) in which metric learning procedures have been implemented precisely to achieve such control. Our contribution, as we shall explain in the next section is the use of a robust optimization formulation to calibrate . We emphasize that once is calibrated, it can be used to multiple learning tasks and arbitrary loss functions (not only logistic regression).
3.1. Data-Driven Cost Functions via Metric Learning Procedures
We quickly review the elements of standard metric learning procedures. Our data is of the form and . The prediction variables are assumed to be standardized.
Motivated by applications such as social networks, in which there is a natural graph which can be used to connect instances in the data, we assume that one is given sets and , where is the set of the pairs that should be close (so that we can connect them) to each other, and , on contrary, is characterizing the relations that the pairs should be far away (not connected), we define them as
[TABLE]
While it is typically assumed that and are given, one may always resort to -Nearest-Neighbor (-NN) method for the generation of these sets. This is the approach that we follow in our numerical experiments. But we emphasize that choosing any criterion for the definition of and should be influenced by the learning task in order to retain both interpretability and performance. In our experiments we let belong to if, in addition to being sufficiently close (i.e. in the -NN criterion), . If , then we have that .
In addition, we consider the relative constraint set containing data triplets with relative relation defined as
[TABLE]
Let us consider the following two formulations of metric learning, the so-called Absolute Metric Learning formulation
[TABLE]
and the Relative Metric Learning formulation,
[TABLE]
Both formulations have their merits, (9) exploits both the constraint sets and , while (10) is only based on information in . Further intuition or motivation of those two formulations can be found in Xing et al., (2002) and Weinberger and Saul, (2009), respectively. We will show how to formulate and solve the robust counterpart of those two representative examples by robustifying a single constraint set or two sets simultaneously For simplicity we only discuss these two formulations, but many metric learning algorithms are based on natural generalizations of those two forms, as mentioned in the survey Bellet et al., (2013).
Once formulation (9) or (10) are considered and the matrix has been calibrated, one may then consider the cost function in (7) and solve the problem (8). This is the benchmark that we will consider in our numerical experiments. And we will contrast this approach versus a method which chooses using a robust optimization version of (9) or (10) as we shall explain next.
4. Robust Optimization for Metric Learning
In this section, we review a robust optimization method to metric learning optimization problem to learn a robust data-driven cost function. RO is a family of optimization techniques that deals with uncertainty or misspecification in the objective function and constraints. RO was first proposed in Ben-Tal et al., (2009) and has attracted increasing attentions in the recent decades El Ghaoui and Lebret, (1997) and Bertsimas et al., (2011). RO has been applied in machine learning to regularize statistical learning procedures, for example, in Xu et al., 2009a () and Xu et al., 2009b () robust optimization was employed for SR-Lasso and support vector machines. We apply RO, as we shall demonstrate, to reduce the variability in testing error when implementing DD-DRO.
4.1. Robust Optimization for Relative Metric Learning
The RO formulation that we shall use for (10) is based on the work of Huang et al., (2012). In order to motivate this formulation, suppose that we know that only level, e.g. , of the constraints are satisfied, but we do not have information on exactly which of them are ultimately satisfied. The value of may be inferred using cross validation.
Instead of optimizing over all subsets of constraints, we try to minimize the worst case loss function over all possible constraints (where is cardinality of a set) and obtain the following min-max formulation
[TABLE]
where is a robust uncertainty set of the form
[TABLE]
which is a convex and compact set.
In addition, the objective function in (10) is convex in and concave (linear) in , so we can switch the order of min-max by resorting to Sion’s min-max theorem (Terkelsen, (1973)). This important observation suggests an iterative algorithm. For a fixed , the inner maximization is linear in , and the optimal satisfy whenever ranks in the top largest values and equals otherwise.
Let us use to denote the subset of constraints satisfying that the corresponding loss function ranks at the top largest values among the corresponding loss function values of the triplets in .
For fixed , the optimization problem is convex in , we can solve this problem using sub-gradient or smoothing approximation algorithms (Nesterov, (2005)). Particularly, as we discussed above, if is the solution for fixed , we know, solving is equivalent to solving its non-robust counterpart (10), replacing by , where is a subset of that contains the constraints have top violation, i.e.
[TABLE]
We summarize the sub-gradient based sequentially update algorithm as in Algorithm 1.
As a remark, we would like to highlight the following observations. While we focus on metric learning simply as a loss minimization procedure as in (10) and (11) for simplicity, in practice people usually add a regularization term (such as ) to the loss minimization, as is common in metric learning literature (see Bellet et al., (2013)). It is easy to observe our discussion above regarding the min-max exchange uses Sion’s min-max theorem and everything else remains largely intact if we consider regularization. Likewise, one can use a more general loss functions than the hinge loss used in (10) and (11).
4.2. Robust Optimization for Absolute Metric Learning
The RO formulation that we present here for (9) appears to be novel in the literature. Note that (9) can be written into the Lagrangian form,
[TABLE]
Following similar discussion for , let us assume that the sets and are noisy or inaccurate at level (i.e. of their elements are incorrectly assigned). We can construct robust uncertainty sets and from the constraints in and as follows,
[TABLE]
Then we can write the RO counterpart for the loss minimization problem of metric learning as
[TABLE]
Note that the Cartesian product is a compact set, and the objective function is convex in and concave (linear) in pair , so we can apply Sion’s min-max Theorem again (see in Terkelsen, (1973)) to switch the order of minΛ-max (after switching maxλ and max, which can be done in general). Then we can develop a sequential iterative algorithm to solve this problem as we describe next.
At the -th step, given fixed and (it is easy to observe that optimal solution is positive, i.e. the constraint is active so we may safely assume ), the inner maximization problem, becomes,
[TABLE]
As we discussed for relative constraints case, the optimal solution for and is, is 1, if ranks top within and equals 0 otherwise; while, on the contrary, if ranks bottom within and equals 0 otherwise.
Similar as , we can define ( ) as subset of (), which contains the constraints with largest percent of within in ; and as subset of , which contains the constraints with smallest percent of within in . As we observe that the optimal if and if , thus for fixed and , we can write the optimization problem over in the constrained case as
[TABLE]
This formulation falls within the setting of the problem stated in (9) and thus it can be solved by using techniques discussed in Xing et al., (2002). We summarize the details in Algorithm 2.
Other robust methods have also been considered in the metric learning literature, see Zha et al., (2009) and Lim et al., (2013) although the connections to RO are not fully exposed.
5. Numerical Experiments
We proceed to numerical experiments to verify the performance of our DD-R-DRO method empirically using six binary classification real data sets from UCI machine learning data base Lichman, (2013).
We consider logistic regression (LR), regularized logistic regression (LRL1), DD-DRO with cost function learned using absolute constraints (DD-DRO (absolute)) and its level of doubly robust DRO (DD-R-DRO (absolute)); DD-DRO with cost function learned using relative constraints (DD-DRO (relative)) and its level of doubly robust DRO (DD-R-DRO (relative)). For each data and each experiment, we randomly split the data into training and testing and fit models on training set and evaluate on testing set.
We report the mean and standard deviation of training error, testing error, and testing accuracy via independent experiments for each data sets, and summarize the detailed results and data set information (including split setting) in Table 1.
For solving the DD-DRO and DD-R-DRO problem, we apply the smoothing approximation algorithm introduced in Blanchet et al., (2017) to solve the DRO problem directly, where the size of uncertainty is chosen via fold cross-validation.
We observe that the doubly robust DRO framework, in general, get robust improvement comparing to its non-robust counterpart with . More importantly, the robust methods tend to enjoy the variance reduction property due to RO. Also, as the robust level increases, i.e. , where we believe in higher noise in cost function learning, we can observe, the doubly robust based approach seems to shrink towards to LRL1, and benefits less from the data-driven cost structure.
6. Discussion and Conclusion
We have proposed a novel methodology, DD-R-DRO, which calibrates a transportation cost function by using a data-driven approach based on RO. In turn, DD-R-DRO uses this cost function in the description of a DRO formulation based on optimal transport uncertainty region. The overall methodology is doubly robust. On one hand, DD-DRO, which fully uses the training data to estimate the underlying transportation cost enhances out-of-sample performance by allowing an adversary to perturb the data (represented by the empirical distribution) in order to obtain bounds on the testing risk which are tight. On the other hand, the tightness of bounds might come at the cost of potentially introducing noise in the testing error performance. The second layer of robustification, as shown in the numerical examples, mitigates precisely the presence of this noise.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Bellet et al., [2013] Bellet, A., Habrard, A., and Sebban, M. (2013). A survey on metric learning for feature vectors and structured data. ar Xiv preprint ar Xiv:1306.6709 .
- 2Ben-Tal et al., [2009] Ben-Tal, A., El Ghaoui, L., and Nemirovski, A. (2009). Robust optimization . Princeton University Press.
- 3Bertsimas et al., [2011] Bertsimas, D., Brown, D. B., and Caramanis, C. (2011). Theory and applications of robust optimization. SIAM review , 53(3):464–501.
- 4Blanchet et al., [2016] Blanchet, J., Kang, Y., and Murthy, K. (2016). Robust wasserstein profile inference and applications to machine learning. ar Xiv preprint ar Xiv:1610.05627 .
- 5Blanchet et al., [2017] Blanchet, J., Kang, Y., Zhang, F., and Murthy, K. (2017). Data-driven optimal transport cost selection for distributionally robust optimization. ar Xiv preprint ar Xiv: .
- 6El Ghaoui and Lebret, [1997] El Ghaoui, L. and Lebret, H. (1997). Robust solutions to least-squares problems with uncertain data. SIAM Journal on Matrix Analysis and Applications , 18(4):1035–1064.
- 7Esfahani and Kuhn, [2015] Esfahani, P. M. and Kuhn, D. (2015). Data-driven distributionally robust optimization using the wasserstein metric: Performance guarantees and tractable reformulations. ar Xiv preprint ar Xiv:1505.05116 .
- 8Hu and Hong, [2013] Hu, Z. and Hong, L. J. (2013). Kullback-leibler divergence constrained distributionally robust optimization. Available at Optimization Online .