Reducing the Top Quark Mass Uncertainty with Jet Grooming
Anders Andreassen, Matthew D. Schwartz

TL;DR
This paper investigates how jet grooming techniques can significantly reduce the systematic uncertainties in top quark mass measurements, especially when calibrated to the W boson mass, thereby improving measurement precision.
Contribution
The study demonstrates that applying jet grooming procedures like soft-drop and trimming can substantially lower the Monte Carlo mass ambiguity and associated uncertainties in top quark mass measurements.
Findings
Jet grooming reduces top mass uncertainty by up to 60%.
Calibration to W mass further decreases systematic errors.
Jet grooming enhances robustness against underlying event effects.
Abstract
The measurement of the top quark mass has large systematic uncertainties coming from the Monte Carlo simulations that are used to match theory and experiment. We explore how much that uncertainty can be reduced by using jet grooming procedures. We estimate the inherent ambiguity in what is meant by Monte Carlo mass to be around 530 MeV without any corrections. This uncertainty can be reduced by 60% to 200 MeV by calibrating to the W mass and a further 33% to 140 MeV by applying soft-drop jet grooming (or by 20% more to 170 MeV with trimming). At e+e- colliders, the associated uncertainty is around 110 MeV, reducing to 50 MeV after calibrating to the W mass. By analyzing the tuning parameters, we conclude that the importance of jet grooming after calibrating to the W mass is to reduce sensitivity to the underlying event.
Click any figure to enlarge with its caption.
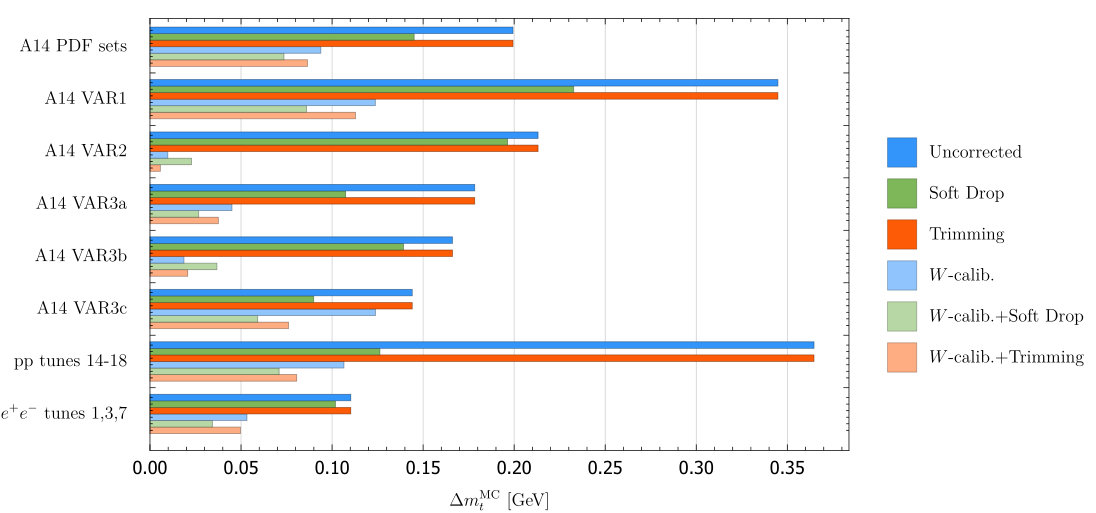 Figure 1
Figure 1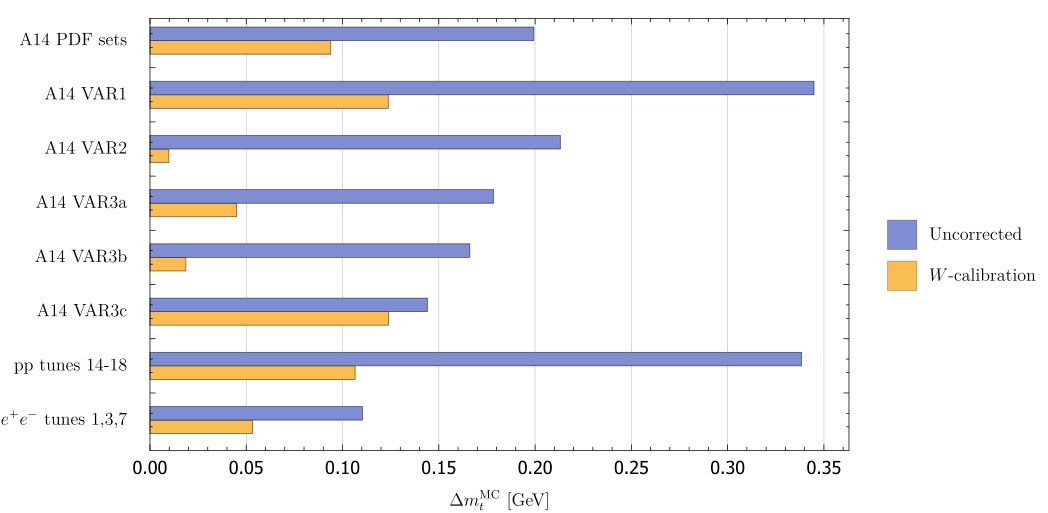 Figure 2
Figure 2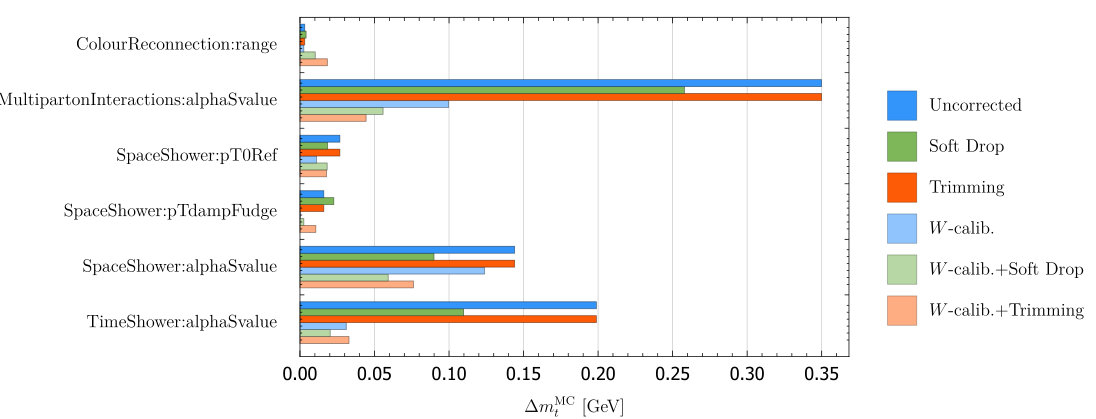 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6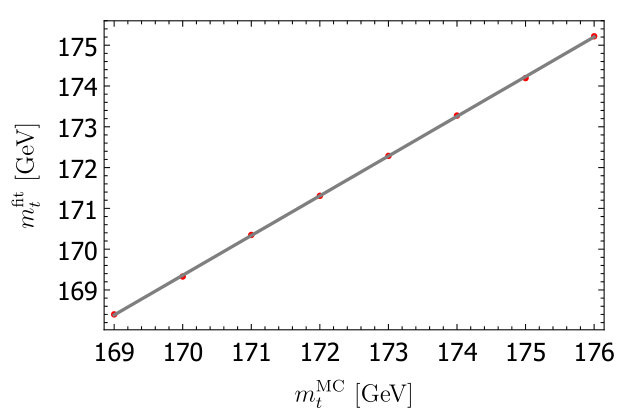 Figure 7
Figure 7 Figure 8
Figure 8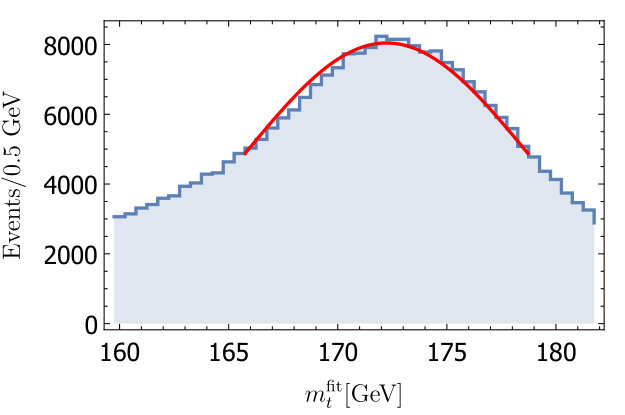 Figure 9
Figure 9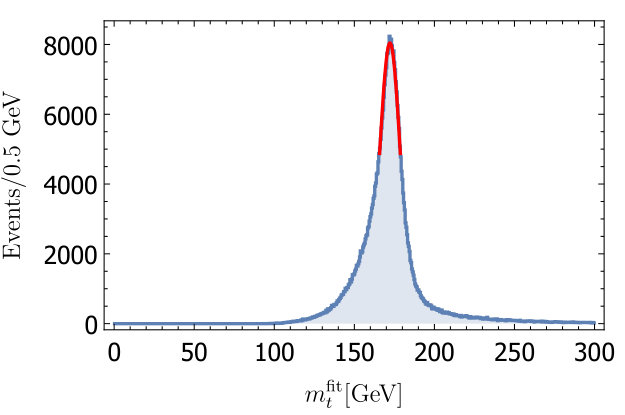 Figure 10
Figure 10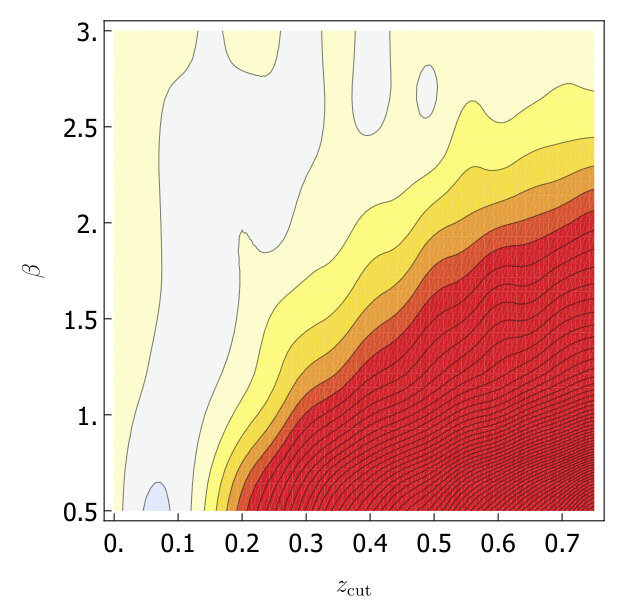 Figure 11
Figure 11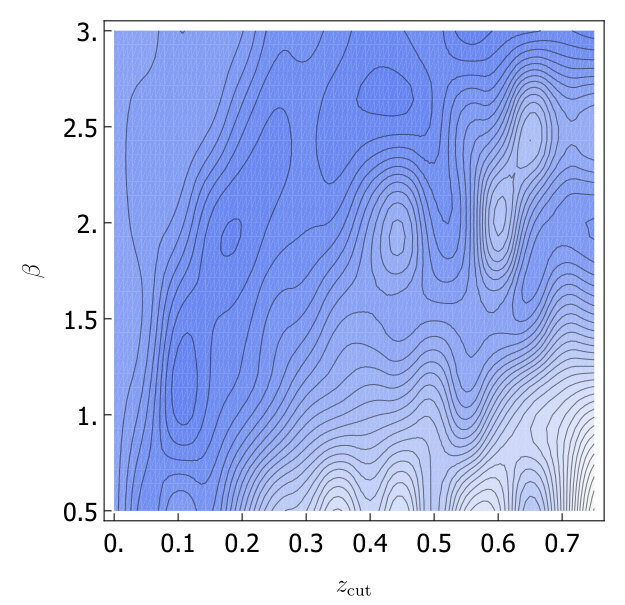 Figure 12
Figure 12 Figure 13
Figure 13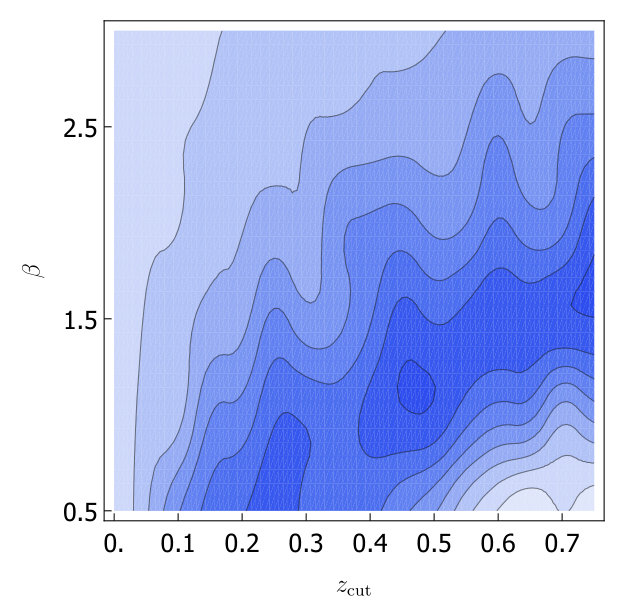 Figure 14
Figure 14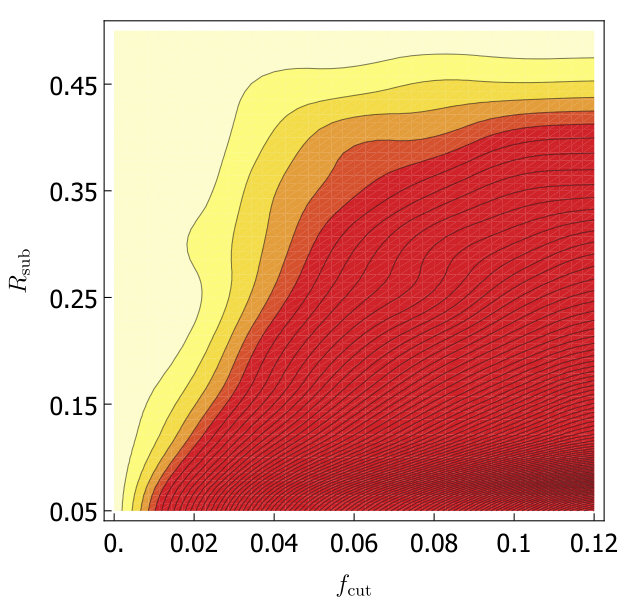 Figure 15
Figure 15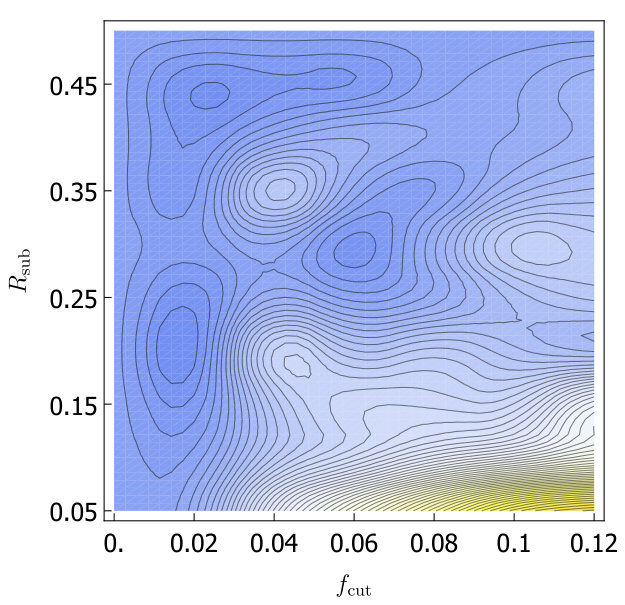 Figure 16
Figure 16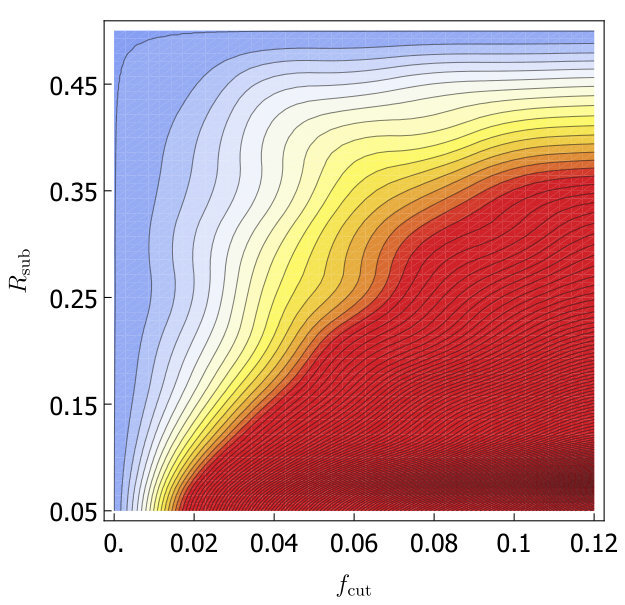 Figure 17
Figure 17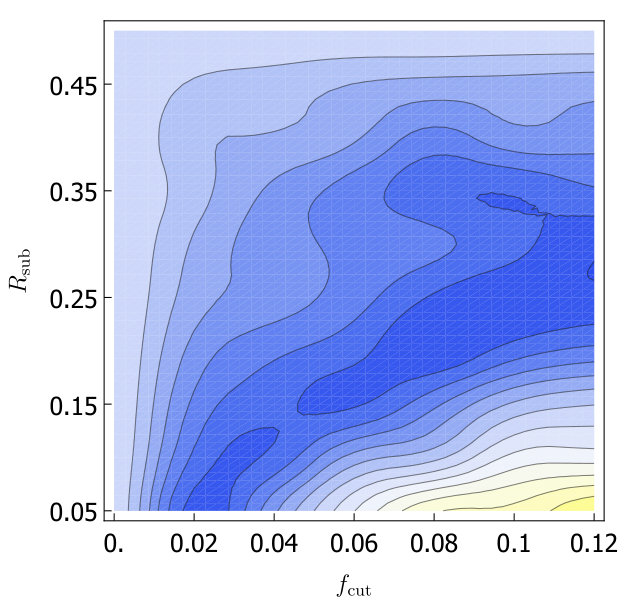 Figure 18
Figure 18 Figure 19
Figure 19| Trimming | Soft Drop | |
|---|---|---|
| without -calibration | – | (0.05,0.5) |
| with -calibration | (0.02,0.2) | (0.1,1.0) |
| without calibration | with W-calibration | |||
|---|---|---|---|---|
| No grooming | ||||
| Trimming | ||||
| Soft drop | ||||
| Setting | VAR1 | VAR2 | VAR3a | VAR3b | VAR3c | Min-Max |
|---|---|---|---|---|---|---|
| ColourReconnection:range | 1.69-1.73 | 1.69-1.73 | ||||
| MPI:alphaSvalue | 0.121-0.131 | 0.127-0.125 | 0.121-0.131 | |||
| SpaceShower:pT0Ref | 1.50-1.60 | 1.51-1.67 | 1.50-1.67 | |||
| SpaceShower:pTdampFudge | 1.08-1.04 | 0.93-1.36 | 1.07-1.04 | 0.93-1.36 | ||
| SpaceShower:pTmaxFudge | 0.88-0.98 | 0.83-1.00 | 0.83-1.00 | |||
| SpaceShower:alphaSvalue | 0.126-0.129 | 0.115-0.140 | 0.115-0.140 | |||
| TimeShower:alphaSvalue | 0.111-0.139 | 0.124-0.136 | 0.138-0.114 | 0.111-0.139 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Reducing the Top Quark Mass Uncertainty
with Jet Grooming
Anders Andreassen [email protected] Department of Physics, Harvard University, Cambridge, MA 02138, USA
Matthew D. Schwartz [email protected] Department of Physics, Harvard University, Cambridge, MA 02138, USA
Abstract
The measurement of the top quark mass has large systematic uncertainties coming from the Monte Carlo simulations that are used to match theory and experiment. We explore how much that uncertainty can be reduced by using jet grooming procedures. We estimate the inherent ambiguity in what is meant by Monte Carlo mass to be around 530 MeV without any corrections. This uncertainty can be reduced by 60% to 200 MeV by calibrating to the mass and by 70% to 140 MeV by additionally applying soft-drop jet grooming (or to 170 MeV using trimming). At colliders, the associated uncertainty is around 110 MeV, reducing to 50 MeV after calibrating to the mass. By analyzing the tuning parameters, we conclude that the importance of jet grooming after calibrating to the -mass is to reduce sensitivity to the underlying event.
1 Introduction
The top quark mass is a fundamental parameter in the Standard Model (SM). Its value, and the associated uncertainty, are of great importance for predictions at the Large Hadron Collider (LHC). In the top quark discovery papers from 1995, the CDF [1] collaboration measured and DØ [2] measured . Since then measurements have come a long way, with a recent CMS combination [3] using 7 and 8 TeV data giving and a recent ATLAS combination [4] giving . Further reducing the uncertainty on the top quark mass is important both for checking self-consistency of the SM and for new physics searches. For example, because of its order-one coupling to the Higgs, the top quark is a dominant contributor to the Higgs effective potential, with implications for baryogenesis and vacuum stability. Indeed, the top quark mass uncertainty is currently the limiting factor in determining whether the Standard Model (SM) is stable or meta-stable [5, 6, 7]. If , our universe is unstable, if it is rapidly unstable. For intermediate values, the universe should last at least as long is it currently has. If is measured precisely enough to confidently claim the Standard Model is in the unstable region this would be compelling evidence for physics beyond the Standard Model.
For a precision measurement of the top quark mass, we need a precision definition of the top quark mass. Since the quark carries color charge, we cannot observe an isolated top quark and measure its mass directly. Instead we have to construct observables that depend on a top-quark mass parameter in a particular scheme, such as the pole mass, mass, mass [8, 9], potential-subtracted mass [10], Monte-Carlo mass, MSR mass [11], etc. (for reviews, see [12, 13, 14]). Then we can fit the experimental data to a theoretical calculation. Some of these schemes, like the mass, are short-distance mass schemes, meaning they are free of renormalon ambiguities and are more stable to the order in perturbation theory at which they are used. For the precision in the top-quark mass measurements to continue to improve, understanding the interplay between scheme choice and experimental uncertainty will be crucial.
The most theoretically sensible way to measure the top quark mass is through an inclusive quantity, like the total cross section [15] or the cross section differential in the top [16]. Such calculations can be performed in perturbative QCD using an unambiguous short-distance mass scheme like . Unfortunately, extractions using cross sections are unlikely to produce a top-quark-mass uncertainty below 1 GeV, even at the high-luminosity LHC [17]. Another approach under good theoretical control is to look at the production cross section scanning over the energy of the incoming particles, as in [18, 19, 20]. This method requires a new collider. Using the Large Hadron Collider, the best top quark mass extractions will come from measurements involving the top quark’s hadronic decay products, and therefore it is imperative to get an accurate assesement of the uncertainty on these methods.
So far, the most precise measurements of the top quark mass have involved fitting the reconstructed top decay products to a theoretical curve. These curves are usually produced using Monte Carlo (MC) event generators so that the mass scheme used is a Monte-Carlo mass, . This Monte-Carlo mass is by definition the value of a parameter in the simulation. It is often assumed to be the same as the pole mass. To make a precision top-mass measurement, one cannot just assume that , and indeed these two schemes cannot be the same since depends on which Monte-Carlo is used and which tune, while has a precise field-theoretic definition (up to a renormalon ambiguity of around 70 MeV [21]). Early estimates put the uncertainty in translating from to a well defined short-distance mass scheme like is of order [11], although it seems like the uncertainty may in fact be reducible, perhaps below 100 MeV [22, 23].
One approach to translating the MC mass into a short-distance mass scheme was proposed in [23]. The idea in this paper is to do a precision calculation of an observable related to the top-quark decay products, such as the mass of a highly-boosted top-jet. The calculation should involve a short-distance scheme, and the MSR scheme was preferred [22, 23]. Then one can fit the distributions from the MC event generators to the theory curves and extract the map from to . Ideally, one could do these fit in a relatively clean environment, like events, and the extracted relation between and could be applied to values of extracted from fits to data at hadron colliders. That is, the program involves two maps: data and . The second map seems to be under systematically improvable theoretical control, assuming that the first map exists, that is, that is well-defined.
In order to use for precision mass measurements, one must understand the inherent ambiguity in the definition of . This ambiguity, related to tuning and limitations of the Monte Carlo programs, contributes to the uncertainty on the extracted top mass and may be the limiting factor in top mass measurements. In this paper, we explore how the uncertainty on can be reduced, particularly with the use of the jet grooming techniques trimming [24] and soft-drop [25].
The uncertainty we are concerned with is that the extracted value of can depend on the various parameters of the simulation. The MC generator has to simulate not only the top quark production and decay, but initial- and final-state radiation (ISR/FSR), hadronization, secondary interactions in the colliding protons known as either underlying event (UE) or multiparton interactions (MPI). There is the additional problem of contamination from collisions of other nearby hadrons known as pileup. Pileup is a stochastic process, uncorrelated with tunings related to , so we do not consider it here. By varying the various MC tuning parameters associated with these effects, the same curve (either experimental or theoretical) would match to different values of , thus we can estimate the uncertainty on by varying the tunes. Most experimental top mass measurements provide some estimate of this uncertainty. For example, the 7 TeV ATLAS top quark mass measurement in the lepton-plus-jets channel [4] has , a substantial part of their 1030 MeV total systematic uncertainty from this run. In [3] combining 7 TeV and 8 TeV data, CMS estimates an analogous uncertainty of around 300 MeV. There has also been some theoretical work on understanding how different MC parameters, such as the color-reconnection model, effect [26].
In recent years, a number of jet grooming algorithms have been developed to help clean up jets or events in some way. Some example groomers are mass-drop filtering [27], trimming [24], pruning [28], modified mass drop [29] and soft drop [25]. A typical application is to help resolve subjects in a highly-boosted decay object, like a boosted top quark [30, 31] or boosted boson [32, 33]. Another application is to remove radiation from underlying event or pileup so that peaks or shapes in invariant mass distributions are sharper [34, 35]. These techniques have shown to be successful in improving signal over background significance. Such applications do not require precision theory: one can find a bump in groomed data without theory input. Recently, there has been progress in understanding what the groomers are doing from perturbative QCD[29, 36, 37], and it seems promising that precision groomed jet observables might be compared directly to theory without using MC simulations at all [38, 39].
In this paper, we explore the interplay of jet grooming at the uncertainty on . In Section 2 we describe the setup of our analysis and describe the method used for estimating the uncertainty on the top mass. In Section 3 we show that forcing the reconstructed mass to be exactly is extremely helpful in stabilizing over different tunes. Then, in Section 4, we study how grooming techniques trimming and soft-drop can further help reduce uncertainty. In Section 4.2, we explore the parameter space of the groomers and try to get a feel for which parameters are most sensitive to grooming. Our conclusions and a brief discussion is presented in Section 5.
2 Monte Carlo Top Mass Extraction
The basic idea for how we extract the uncertainty on is to generate events for each tune for different values of . Then we fit those distributions to extract a fit mass . The fit mass will not be the same as the MC mass, but the two are linearly related to an excellent approximation in the regimes we fit: for some . Different tunes give different values of which then translate to an uncertainty on . More details on the simulation and this extraction procedure are given in this section.
2.1 Generation of Events
For our simulated top quark mass measurement we have used the pythia 8.219 [40, 41] event generator to generate lepton-plus-jet top events, at where . All final state particles (except the neutrinos) with pseudorapidity are clustered using FastJet 3.2.1 [42] with [43] with (as used by CMS [3]). We require exactly one isolated lepton and at least 4 jets with , and that the two -tagged jets are among the 4 jets with highest . Only jets with are included in the top reconstruction. The lepton and -jets are tagged by matching the four-momentum after the hard interaction to the four-momentum of the jet. If the distance between the four-momentum of the jet and the hard interaction, or if one jet is tagged multiple times, the event is thrown out.
The events are generated such that and . With the and jets tagged, we iterate over all pairs of untagged jets to find the pair with invariant mass closest to . Only events with the reconstructed mass between are kept. The invariant mass of the four-momenta of this pair together with the -jet gives us our reconstructed top quark mass.
For each run, we generate events of which around 4% pass our cuts. The reconstructed top quark mass for all events passing the cuts are then put in a histogram with bin size that is used for fitting. One such histogram is shown in Fig. 1.
2.2 Fitting
The fitting procedure we used is similar to that implemented by Skands and Wicke in [26]. We fit the simulated data to a 3 parameter () Gaussian
[TABLE]
We use a fit range of . This relatively narrow window is chosen to avoid sensitivity to the tails of the distribution. The fit is done multiple times, each time changing the central value and window, until the fit is symmetric around the peak. A typical distribution and fit is shown in Fig. 1. The fit is clearly not perfect, but it does not have to be. One could get better fits with more parameters, but doing so does not improve extracted uncertainty on . Indeed, after trying more complicated examples, we concluded that a simpler fit gives equivalent results with less statistical variation.
The goal is to know what the uncertainty on is if two tunes give the same value of . In the right part of Fig. 1, we show the extraction form this procedure for event distributions for a fixed tuning with different values of . One can see the relation between and is linear to an excellent approximation. . If one tune gives and another gives then the uncertainty on is .
Conveniently, using the linear relation between and , we can skip the the step of varying and simply estimate from a single value. Suppose for a given tune 1 gives and tune 2 gives . Then we can conclude the second tune would have also given if if . Thus the uncertainty on is simply
[TABLE]
In the following we use this formula we use to estimate uncertainty. Note that the factor of can be large. For example, for aggressive grooming, we might find .
We estimate the uncertainty on this procedure from varying fit shapes and statistical uncertainty in our simulations to be . The effect of assuming a linear relation between and is negligible.
2.3 Tunes
The parameters in pythia are not all independent. In fact, changing parameters separately can result in much more unrealistic events than changing a handful of parameters in a coordinated way. The recommended way to change simulation parameters is to vary the tune. Each tune in pythia represents values of the simulation parameters coordinated to give realistic events.
Choosing which tunes to vary to get a realistic estimate of the MC uncertainty is notoriously subjective. One can choose a subset of tunes and take the envelope of those variations, or one can include the variations from 30 tunes and add the uncertainties in quadrature. The first procedure might underestimate the uncertainty, and the latter probably overestimates it. It is not even clear if all the available tunes span the possible forms that events could have [44]. Alternatively, one could vary the simulation itself, comparing pythia to hewig or to sherpa to estimate uncertainties.
For concreteness, we have chosen to focus our attention on a collection of recent pythia tunes made by ATLAS [45], , known as the A14 tunes. The starting point for these tunes is the Monash 2013 tune [46], which is the default tune in pythia 8.219. The A14 tunes are divided into six groups (Tune:pp numbers in parenthesis): PDF set variations (19-22), VAR1 (23-24), VAR2 (25-26), VAR3a (27-28), VAR3b (29-30) and VAR3c (31-32). The PDF set variations correspond to the four different tunes using different PDF sets: CTEQL1 [47], MSTW2008LO [48], NNPDF2.3LO [49] and HERAPDF1.5LO [50]. The remaining VAR1-3abc tunes come in pairs with a “” and a “” systematic variations of the NNPDF tune [45]. These tunes provides us with a fixed set of tunes that is supposed to cover the range of uncertainties in the MC. Our overall uncertainty is computed by adding the uncertainty from the six groups of tunes in quadrature.
In addition to using the A14 tunes, we also look at tunes . In some plots, we will show the uncertainty from the envelope over these tunes. We include this as a cross check only; tunes 14-18 are not used to to calculate our overall uncertainty. We find the relative reduction in uncertainty using grooming is fairly insensitive to which set of tunes are used, although obviously the absolute size of the reduction does depend on which tunes are chosen. We did not look at the comparison with hewig or any other generator, since the procedure for combining the hewig uncertainty with the pythia one is arbitrary.
For , we estimate uncerainty by looking at the envelope over tunes and .
To be clear, our main concern is the relative improvement in the uncertainty from using grooming. This relative improvement is largely independent of the absolute size of the uncertainty (e.g. soft-drop reduces the uncertainty by 26%). We quote absolute uncertainties for concreteness, but a proper estimate must be done in the context of the experimental measurement which is beyond the scope of, and not the point of, this paper.
3 -calibration
One of the biggest systematic uncertainties in top mass measurements is due to jet energy scale (JES). For this paper, we define JES as the uncertainty on how much energy and momentum is in a jet given a particular detector response, although other definitions are sometimes used. One way to calibrate JES is through a standard reference whose energy is known. For events with top quarks a natural reference is the -boson mass, which is known to precision of a few MeV. Thus one can demand on an event-by-event basis that the boson is always reconstructed correctly by rescaling the energy of all particles by some factor [26, 44]. We call this -calibration.
-calibration corrects for a lot of issues associated with detector response, so it is common used as a JES correction in experiment. Note however that -calibration also corrects for contamination in the decay products coming from underlying event, pileup, ISR going into the decay products and FSR going out of the decay products. Thus by putting the reconstructed exactly at the right mass, more than just JES is corrected for. Thus it is meaningful, and indeed very useful as we will see, to use -calibration even for MC-only top mass studies, as we are doing here.
For our implementation of -calibration, we calculate from the invariant mass of the decay products, and then we rescale the fit top quark mass by , with .
For each group of A14 tunes, as described in the previous section, we calculate where is taken to be half the difference between the maximum and minimum value of within the group. The result of with and without the -calibration is shown in Fig. 2. We find that -calibration significantly reduces the sensitivity to the tune variations, which is what we expected based on the literature of measurements of the top quark mass.111Skands and Wicke [26] found that -calibration (which they call JES corrections) gave a slight increase of . This is in contradiction to our findings. Details of the variations being studied and improvements in the Monte Carlo simulations over the last ten years make it difficult to reproduce their analysis exactly and may explain the difference.
Adding the A14 uncertainties in quadrature, , we find that with no -calibration , and with -calibration we find . In other words, the combined uncertainty from the A14 tunes is reduced by by including the -calibration.
In addition to the -calibration, we also tried applying jet area corrections [51]. This did not lead to any additional improvement.
In Fig. 2 we also show the uncertainty coming from the envelope over five other tunes. This uncertainty is smaller than the envelope over the A14 tunes.
We also show in in Fig. 2 the variations of three tunes. The uncertainty at colliders is significantly smaller than the largest uncertainties from the tunes (by a factor of 3 without -calibration and a factor of 2 with -calibration). Numerically, the uncertainty is 110 MeV without -calibration and 50 MeV with -calibration. Keeping in mind that we have estimated around a 50 MeV uncertainty in our fitting procedure, the -calibration has saturated the improvement we can expect for at colliders without a more comprehensive study (involving detector simulation, systematic uncertainty and so on, all of which are well beyond the scope of our study).
4 Grooming
In a top mass measurement based on hadronic decay products of the top quark, the reconstructed four-momentum of the top is sensitive to the underlying event and initial- and final-state radiation. More underlying event activitiy will typically give a large contribution to the top quark four-momentum, which will directly affect the reconstructed top mass. To mitigate these effects, many different jet grooming algorithms have been introduced to remove wide-angle and/or soft radiation, as mentioned in the introduction. In this section we study how the application of jet grooming techniques can reduce the uncertainty on . We focus our attention on two groomers, trimming [24] and soft drop [25]. Based on the improvements on the systematic uncertainty with -calibration, as seen in the previous section, we will consider both groomed jets with and without the calibration applied.
4.1 Optimizing Groomer Parameters
Every grooming algorithm is defined in terms of some set of parameters that we can optimize based on our application. Trimming reclusters each jet using the algorithm [52, 53] with characteristic radius , and it discards contributions from subjets which carry less than a fraction of the transverse momentum of the original jet. Soft drop reclusters the jet using the Cambridge-Aachen (A/C) algorithm [54, 55], and depends on two parameters, the soft threshold and an angular exponent . It breaks the jet into two subjets (labeled 1 and 2) by undoing the last stage of the C/A clustering, then checks the soft drop condition . If the subjets pass this condition, the jet is the final soft-dropped jet, otherwise the subjet with smaller is thrown out, and the procedure is iterated.
For both trimming and soft drop, we would like to know which grooming parameters minimize as we look at the variations within the A14 tunes. As in Section 3, we will consider the 6 subgroups of the A14 tunes: PDF set variations, VAR1, VAR2, VAR3a, VAR3b and VAR3c. For each group we calculate for each set of groomer parameters, and the uncertainties from the six groups is added in quadrature and plotted in Fig. 3. Without -calibration we find trimming does not help and for soft-drop is optimal. With -calibration we find for the optimum is at , while for soft drop the optimum is at . We will call these values our optimized parameters in the rest of this paper.
After optimizing the grooming parameters, we study the effect of grooming for each of the A14 groups of tunes. In Fig. 4 we show a comparison of the calculated with soft drop, trimming and no grooming, both with and without -calibration. Our results are summarized in Table 2. In Fig. 4 we also include the uncertainty coming from envelope over tunes (using the A14 optimized groomer parameters). That the uncertainty is in the range of the other tunes indicates that improvements from grooming does not crucially depend on fine tuning of groomer parameters. We also show the envelope over tunes for events.
For trimming, we see that without -calibration, trimming only makes the uncertainty worse. After -calibration, trimming helps in almost all of the tunes. Adding the A14 tune uncertainties in quadrature, we find that in conjunction with -calibration, the uncertainty is reduced by (compared to 62% using only -calibration).
Soft drop helps even without -calibration. With -calibration, it gives an improvement in all variations except VAR2 and VAR3b, whose uncertainties are small anyway. Adding the uncertainties in quadrature, we find that soft drop gives an improvement of and with and without calibration, respectively. These results are summarized in Table 2.
As a cross check, it is informative to look at the shapes of the reconstructed mass distribution in the different cases. These are shown in Fig 5. The -calibration seems to clean up the tails of the distribution. The additional improvement from soft drop seems to improve the peak region slightly, although it is hard to see by eye the origin of the improvement.
4.2 Changing Individual Parameters
The A14 tunes contain systematic variations based on the A14 NNPDF tune. The parameters that are changed in each tune and the full range of each setting used by these tunes is listed in Table 3. In Fig. 6 we show the calculated value for when we compare the maximum vs. minimum value for each individual setting in Table 3. Since the variation tunes are based on the A14 NNPDF tune, we set all other parameters to the values described by this tune. Note that changing each setting separately does not give us a good physics description, but it will give us a direct measure of how sensitive the top quark mass measurement is to each of the MC parameters of interest.
Looking at the results in Fig. 6 we find that the dominant uncertainty is coming from the variations of in the multiparton interactions (underlying event), timelike shower (final state radiation) and spacelike shower (initial state radiation).
By comparing the results in Fig. 4 and 6 while referencing Table 3 to see which parameters were varied for each tune, we can understand which settings is most sensitive to. It is straighforward to see which tuning parameters dominate the uncertainty on the different tunes:
- •
VAR1 is very clearly dominated by MultipartonInteractions:alphaSvalue.
- •
VAR2, VAR3a and VAR3b are dominated by TimeShower:alphaSvalue, and the size of for each pair of tunes is nicely correlated with the absolute variation of TimeShower:alphaSvalue for the corresponding pair.
- •
VAR3c is domianted by SpaceShower:alphaSvalue, since this is the only parameter changed.
In Fig. 7 we show the calculation of (without -calibration) obtained by varying MultipartonInteractions:alphaSvalue and TimeShower:alphaSvalue in the minimum and maximum range listed in Table 3 for different grooming parameters. For both trimming and soft drop, the grooming is more aggressive as we move towards the lower right corner. Trimming will create many small subjets, and with a higher it will throw out more and more of them. Looking at the soft drop criterion , we see that higher makes it harder to pass the test, and more particles will be thrown out. Also, since , smaller will similarly increase the number multiplying , which will make the soft drop condition more difficult to pass.
First consider the case without -calibration. To explain the difference between the MPI and FSR plots, consider the case where we increase . In the final state shower, a particle is more likely to split into two (as determined by the splitting functions), and with more aggressive grooming we are more likely to throw out one (or maybe both) of these particles, and hence giving a less accurate reconstruction of the top quark four-momentum. For the multiparton interactions, higher gives more particles produced in the underlying event which in turn contaminate our reconstructed top quark four-momentum. More aggressive grooming (to a certain degree) will hence remove more of the contamination.
Fig. 7 therefore confirms our intuition about grooming: aggressive grooming helps remove contamination from the underlying event, but it comes at the expense of throwing out particles that came from the actual decay of the top quark. The optimized grooming parameters strike a balance between the two effects to give the maximal overall improvement of .
We can see how things change when including -calibration from Fig. 6. By putting the on-shell, problems with aggressive grooming are automatically compensated for. For example, when we increase for FSR, so that a particle is more likely to split into two smaller subjets and get removed by the groomer, the mass will also be reduced. Thus the -calibration will compensate for the aggressive groomer in estimating the top mass. Indeed, looking at Fig. 6, we see that with -calibration included, sensitivity to TimeShower:alphaSvalue in essentially removed, whether or not grooming is additionally applied. MultipartonInteractions:alphaSvalue on the other hand is somewhat reduced, but it is in no way eliminated by the additional calibration. Thus, Fig. 6 shows that with -calibration, the importance of grooming is to correct for contamination by the underlying event.
5 Conclusions
In this paper we have studied the systematic uncertainty of the definition of the top quark Monte-Carlo mass, . This is the parameter extracted from experimental fits which so far has given the best top-quark mass measurements. In order to convert to a short-distance mass scheme like , which can be used in precision calculations, one must understand the extent to which is even well-defined. First, there is the question of, for a given MC and a given tune, what short-distance scheme is closest to. The traditional answer to this question has been the pole mass , since appears in hard scattering matrix elements and phase space restrictions just as the pole mass would. Recently, it has been suggested that in fact should be identified with the MSR mass, at a particular scale [11, 22]. Independent of the conversion to a short-distance scheme, there is the question of the simulation dependence of . It is the uncertainty on this simulation-dependence that we address in this paper.
Although corresponds to a parameter in the Monte Carlo event generator, its extracted value depends on what generator is used and what tune is used within that generator. By varying the tunes, we found that fluctuates by around 530 MeV. A standard experimental procedure to reduce the jet-energy-scale uncertainty is to rescale the energies of the particles so that the -mass is reconstructed exactly. We call this -calibration. In addition to mitigating experimental uncertainties associated with detector response, -calibration also removes theoretical uncertainties, such as sensitivity to the amount of final-state radiation and underlying event in an event. We find that by calibrating to the -mass, the uncertainty on shrinks to 200 MeV.
To reduce the uncertainty further, we considered two grooming methods, trimming and soft-drop. We find that on top of -calibration, trimming reduces the uncertainty to 170 MeV while soft drop reduces it to 140 MeV. By looking at the parameters in the different tunes, we saw that the dominant effect corrected by the groomers, but not by the -calibration, is contamination from underlying event. That is, -calibration largely eradicates sensitivity to a dominant source of uncertainty, the amount of final-state-radiation, even before grooming. In addition, we estimate around a 50 MeV ambiguity on our uncertainties due to the fitting procedure.
Our estimates were based on adding in quadrature the uncertainties from a set of pythia tunes developed by ATLAS, the A14 tunes. The procedure for calculating theoretical uncertainty is always subjective. Using a different set of tunes, or taking the envelope over the variations rather than adding them in quadrature, or using different MC generators, will all give different absolute numbers. Nevertheless, we believe the relative improvement from -calibration, reducing the uncertainty by about 60%, and from grooming, an additional 15-30% improvement, should be fairly insensitive to the absolute size of the uncertainties. An absolute error estimate is only possible in the context of a particular measurement, including experimental systematic uncertainties, detector effects, and other issues beyond the scope of our study.
We also looked at the analogous uncertainty estimate at colliders. We find without any correction, the uncertainty is around 110 MeV and with -calibration, it reduces to 50 MeV. Since 50 MeV is the same as our estimate of the ambiguity on our fitting procedure, there is no need to consider the effect of grooming on top of -calibration.
There are two implications of our work. First, we recommend that experimental top mass measurements consider jet grooming in addition to their jet-energy scale corrections. This has the potential to reduce the uncertainty on by an additional 30%. Second, in the pursuit of understanding how to convert to a short-distance scheme, like , it will be important to understand the effect of -calibration on theoretical predictions.
Acknowledgments
The authors would like to thank P. Agrawal, C. Frye, A Hoang, V. Mateu and P. Skands for helpful discussions. This research was supported in part by the Department of Energy under grant DE-SC.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] CDF Collaboration, F. Abe et al. , “Observation of top quark production in p ¯ p ¯ 𝑝 𝑝 \bar{p}p collisions,” Phys. Rev. Lett. 74 (1995) 2626–2631 , ar Xiv:hep-ex/9503002 [hep-ex] . · doi ↗
- 2[2] D 0 Collaboration, S. Abachi et al. , “Observation of the top quark,” Phys. Rev. Lett. 74 (1995) 2632–2637 , ar Xiv:hep-ex/9503003 [hep-ex] . · doi ↗
- 3[3] CMS Collaboration, V. Khachatryan et al. , “Measurement of the top quark mass using proton-proton data at ( s ) 𝑠 {\sqrt{(s)}} = 7 and 8 Te V,” Phys. Rev. D 93 no. 7, (2016) 072004 , ar Xiv:1509.04044 [hep-ex] . · doi ↗
- 4[4] ATLAS Collaboration, M. Aaboud et al. , “Measurement of the top quark mass in the t t ¯ → → 𝑡 ¯ 𝑡 absent t\bar{t}\to dilepton channel from s = 8 𝑠 8 \sqrt{s}=8 Te V ATLAS data,” Phys. Lett. B 761 (2016) 350–371 , ar Xiv:1606.02179 [hep-ex] . · doi ↗
- 5[5] G. Degrassi, S. Di Vita, J. Elias-Miro, J. R. Espinosa, G. F. Giudice, G. Isidori, and A. Strumia, “Higgs mass and vacuum stability in the Standard Model at NNLO,” JHEP 08 (2012) 098 , ar Xiv:1205.6497 [hep-ph] . · doi ↗
- 6[6] A. Andreassen, W. Frost, and M. D. Schwartz, “Consistent Use of the Standard Model Effective Potential,” Phys. Rev. Lett. 113 no. 24, (2014) 241801 , ar Xiv:1408.0292 [hep-ph] . · doi ↗
- 7[7] J. R. Espinosa, G. F. Giudice, E. Morgante, A. Riotto, L. Senatore, A. Strumia, and N. Tetradis, “The cosmological Higgstory of the vacuum instability,” JHEP 09 (2015) 174 , ar Xiv:1505.04825 [hep-ph] . · doi ↗
- 8[8] A. H. Hoang, Z. Ligeti, and A. V. Manohar, “B decays in the upsilon expansion,” Phys. Rev. D 59 (1999) 074017 , ar Xiv:hep-ph/9811239 [hep-ph] . · doi ↗