Multi-Scale Factor Analysis of High-Dimensional Brain Signals
Chee-Ming Ting, Hernando Ombao, Sh-Hussain Salleh

TL;DR
This paper introduces a multi-scale factor analysis method for modeling high-dimensional brain networks, capturing regional and global dependencies efficiently, and revealing hierarchical brain organization from fMRI data.
Contribution
The novel MSFA model partitions complex networks into clusters, reduces dimensionality with latent factors, and estimates connectivity at multiple scales using PCA and RV-coefficient.
Findings
Revealed modular and hierarchical brain organization during rest.
Provided a computationally efficient approach for large network analysis.
Applied to fMRI data to uncover brain connectivity patterns.
Abstract
In this paper, we develop an approach to modeling high-dimensional networks with a large number of nodes arranged in a hierarchical and modular structure. We propose a novel multi-scale factor analysis (MSFA) model which partitions the massive spatio-temporal data defined over the complex networks into a finite set of regional clusters. To achieve further dimension reduction, we represent the signals in each cluster by a small number of latent factors. The correlation matrix for all nodes in the network are approximated by lower-dimensional sub-structures derived from the cluster-specific factors. To estimate regional connectivity between numerous nodes (within each cluster), we apply principal components analysis (PCA) to produce factors which are derived as the optimal reconstruction of the observed signals under the squared loss. Then, we estimate global connectivity (between…
Click any figure to enlarge with its caption.
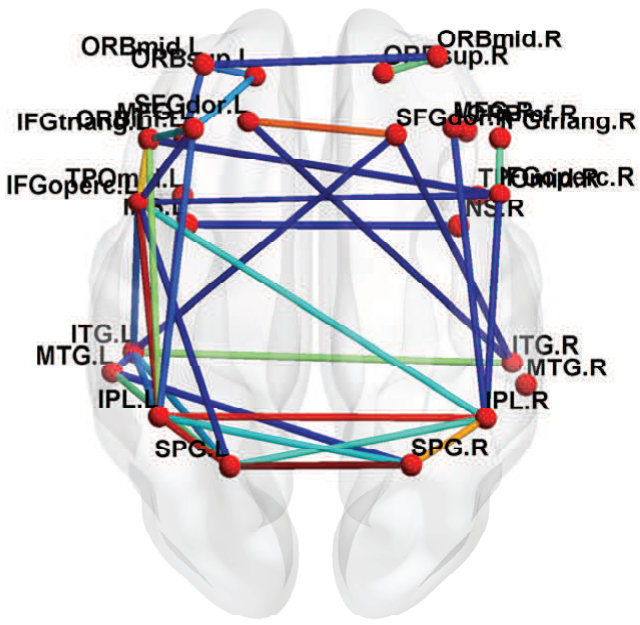 Figure 1
Figure 1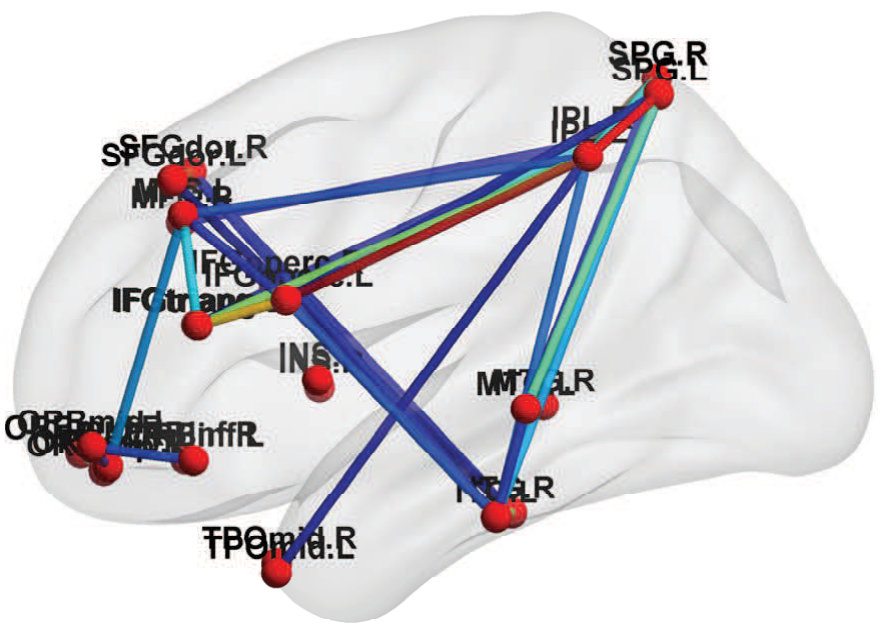 Figure 2
Figure 2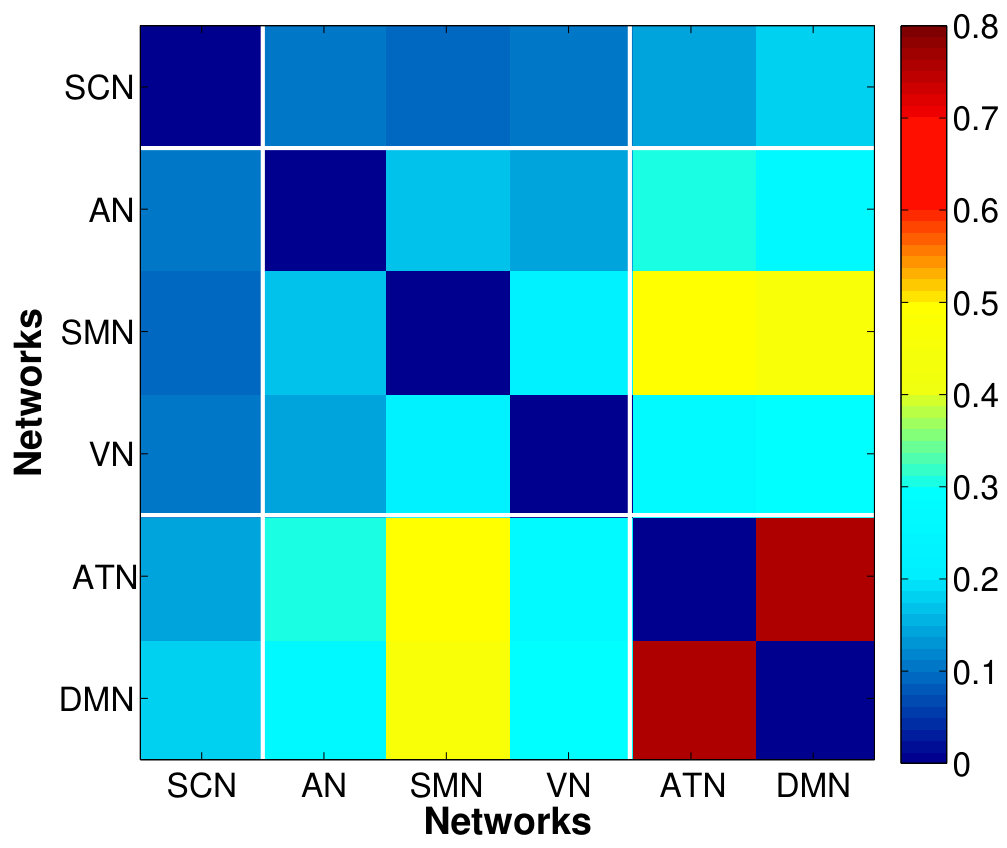 Figure 3
Figure 3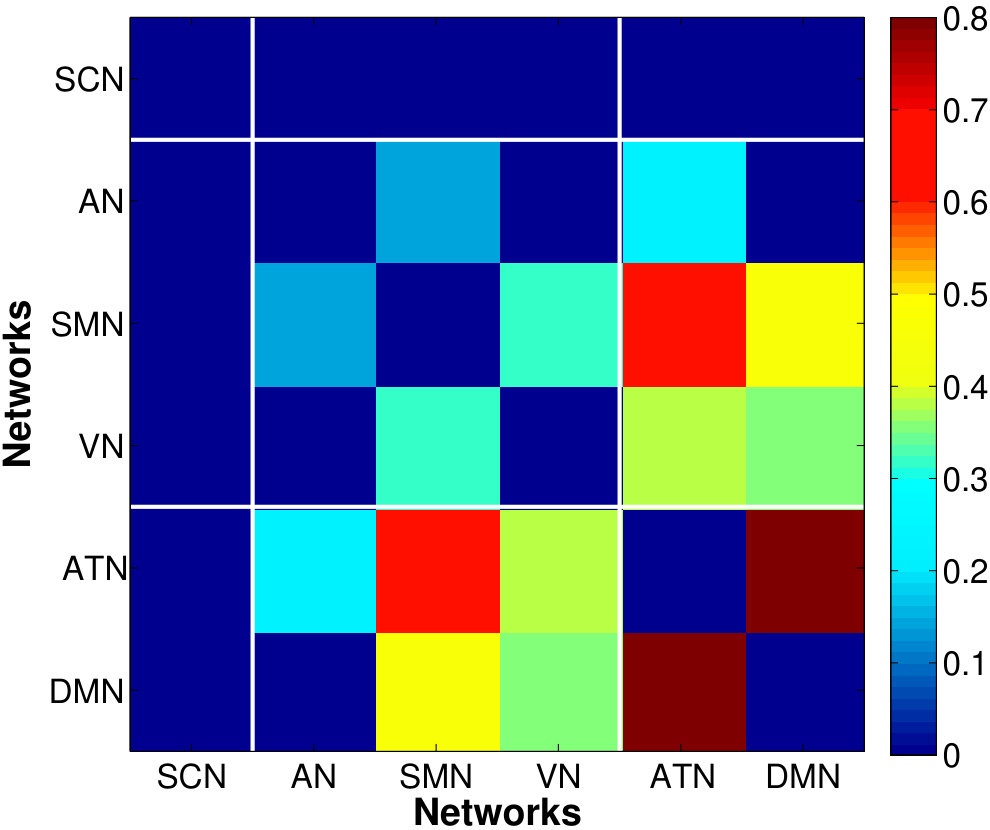 Figure 4
Figure 4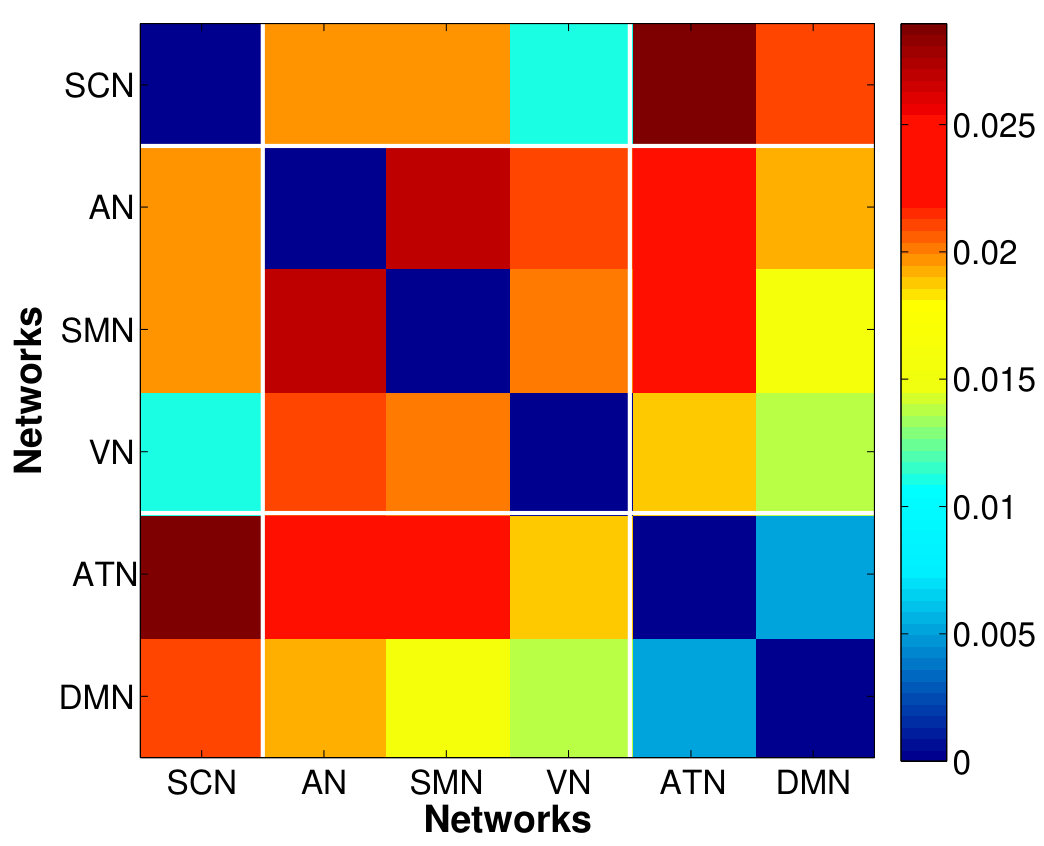 Figure 5
Figure 5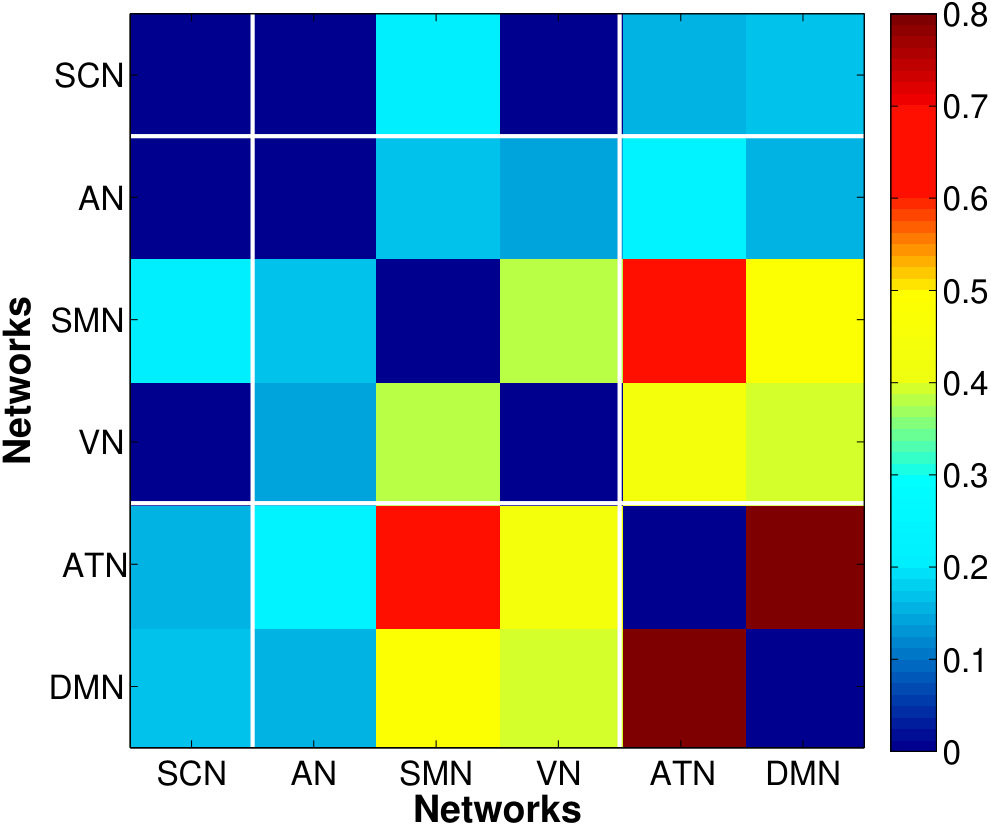 Figure 6
Figure 6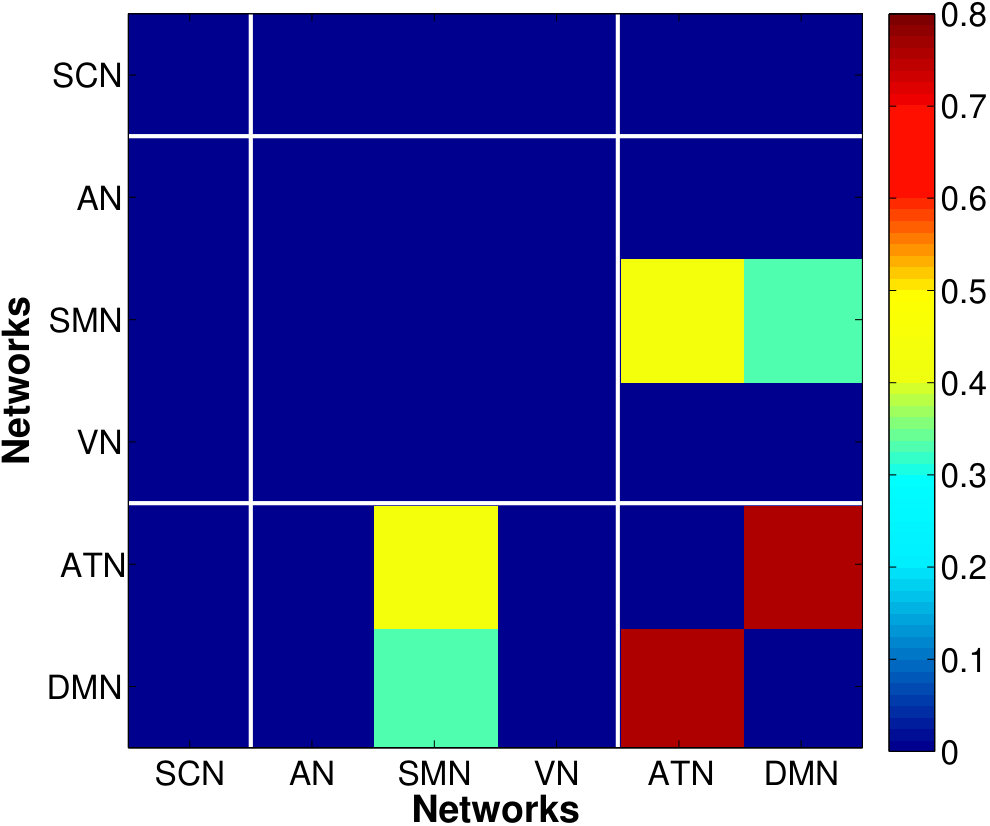 Figure 7
Figure 7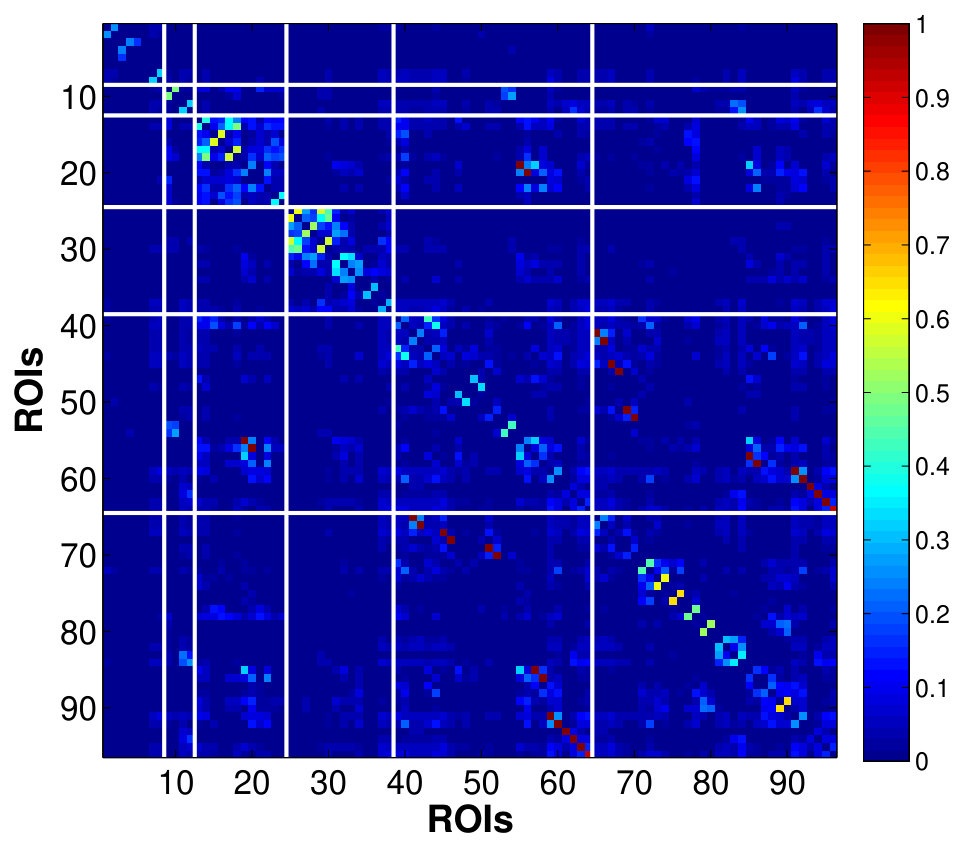 Figure 8
Figure 8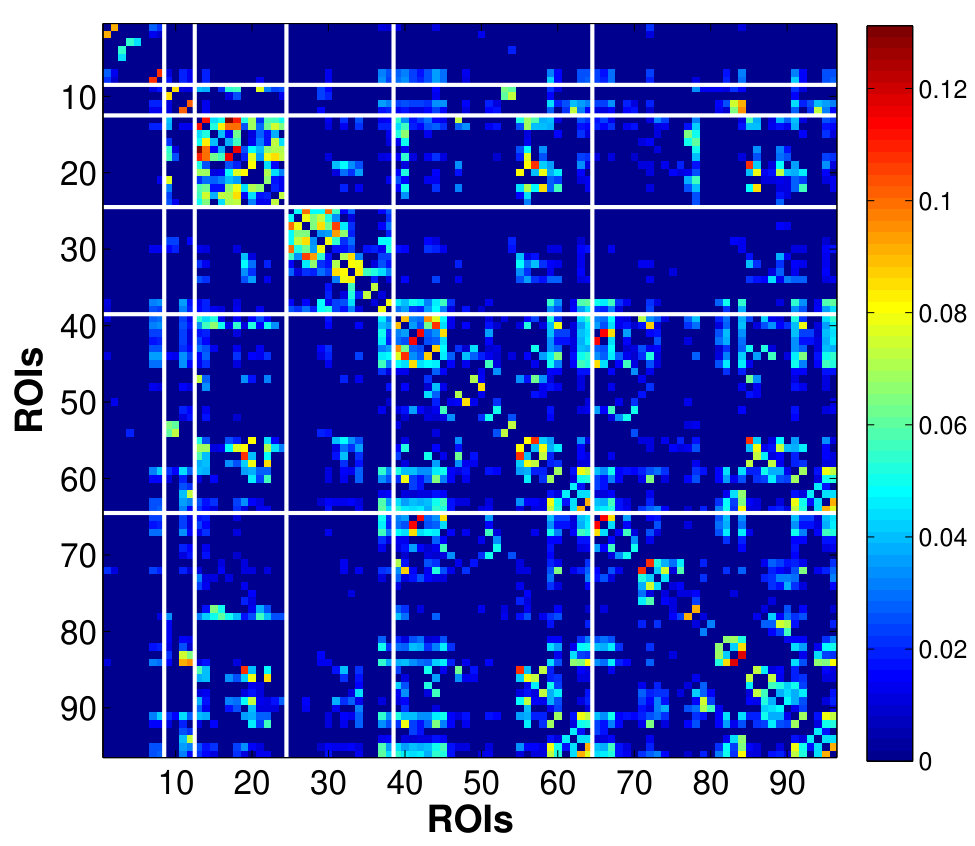 Figure 9
Figure 9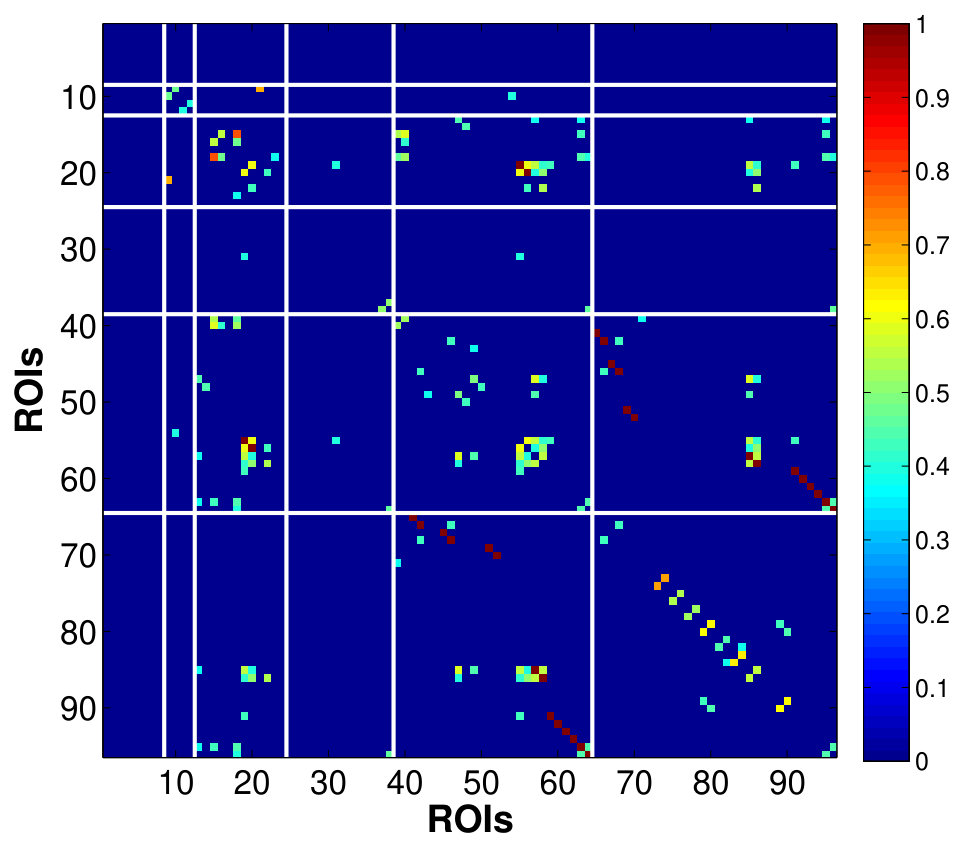 Figure 10
Figure 10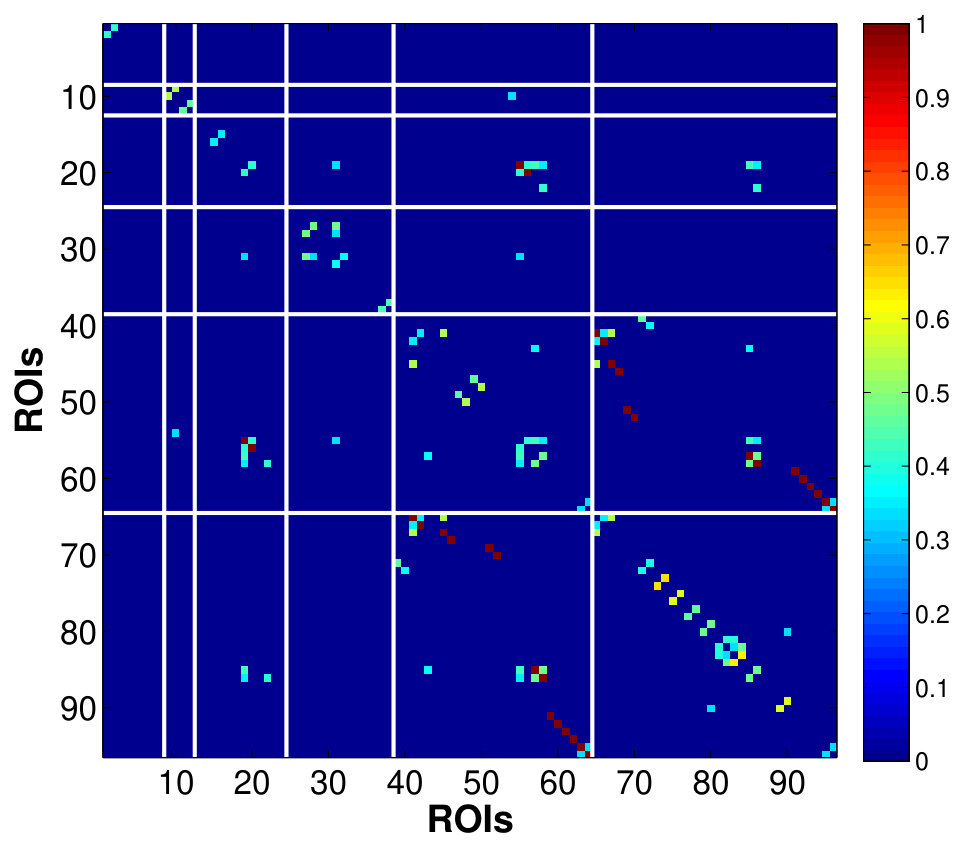 Figure 11
Figure 11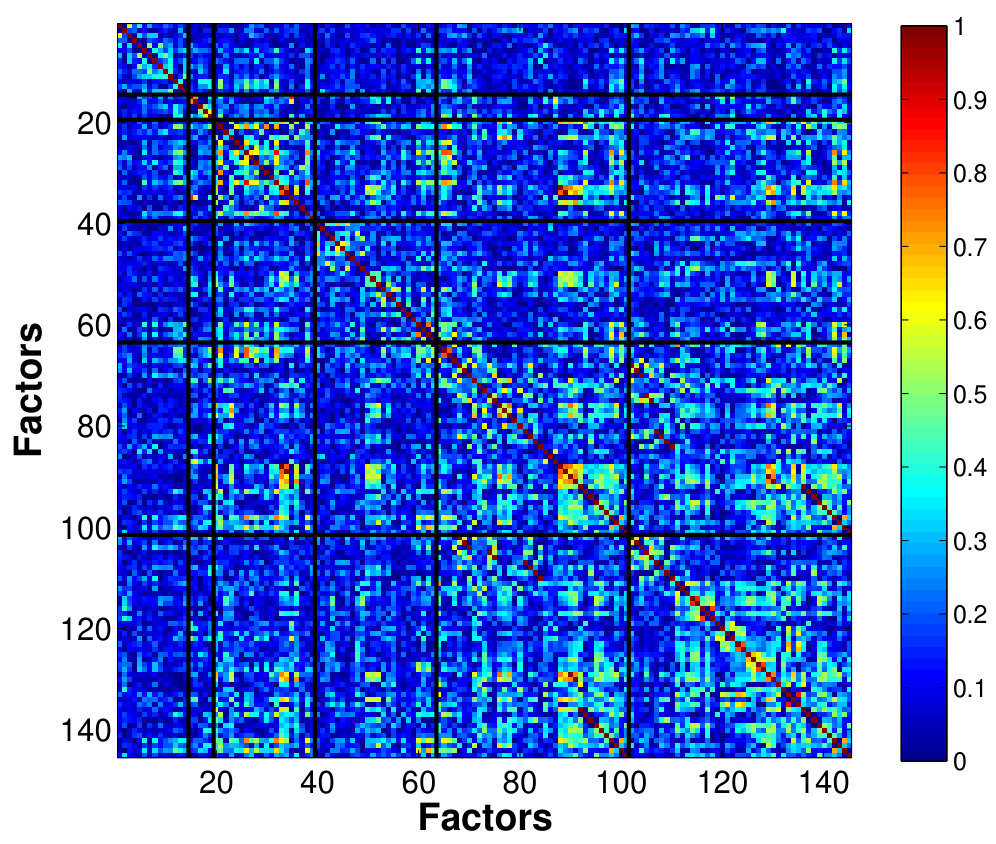 Figure 12
Figure 12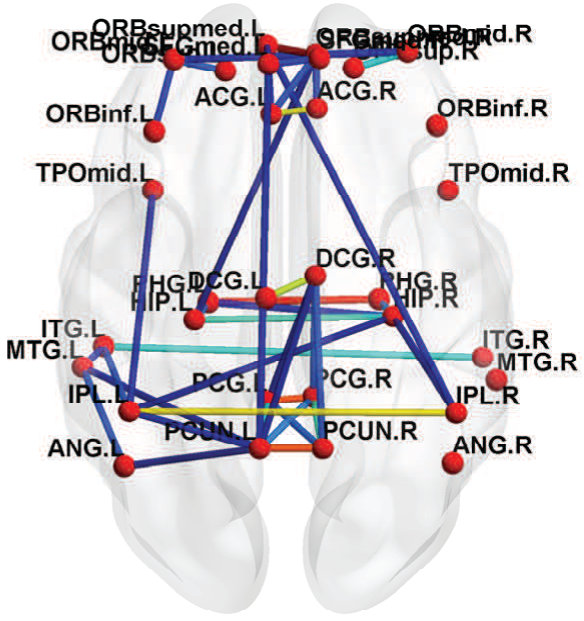 Figure 13
Figure 13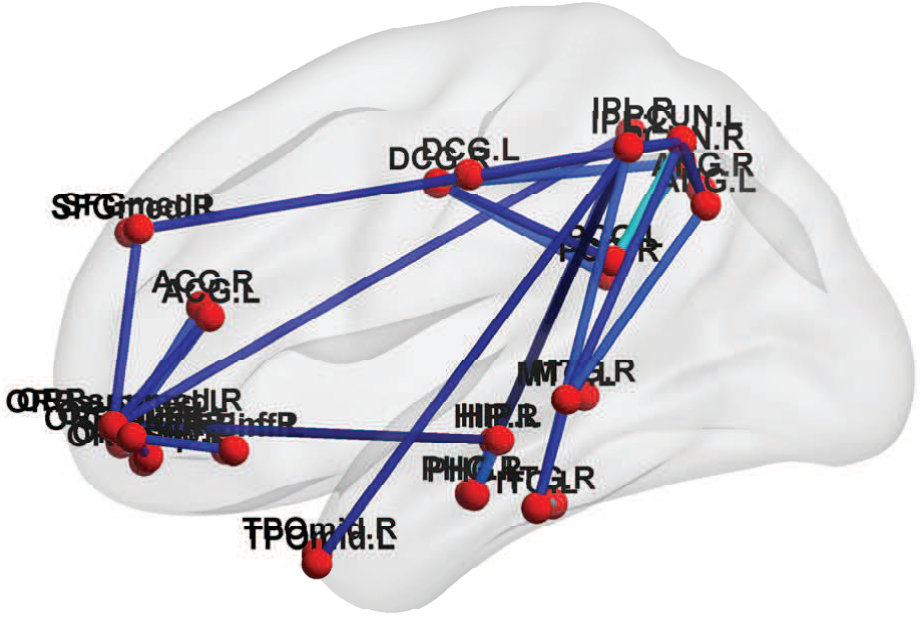 Figure 14
Figure 14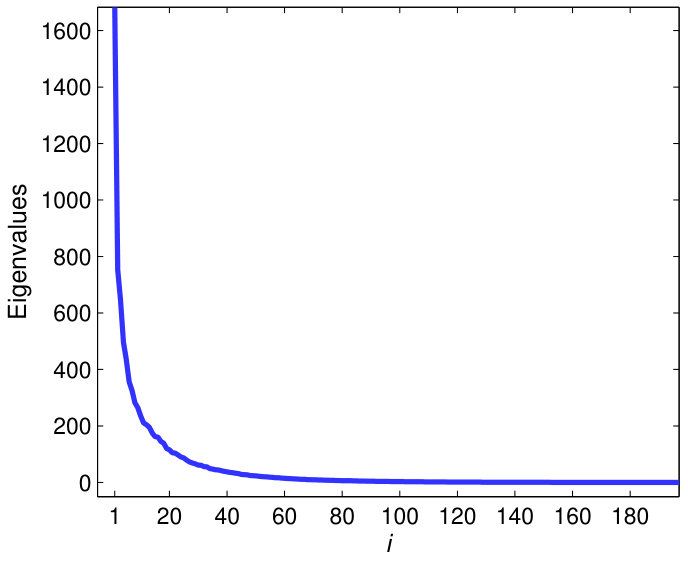 Figure 15
Figure 15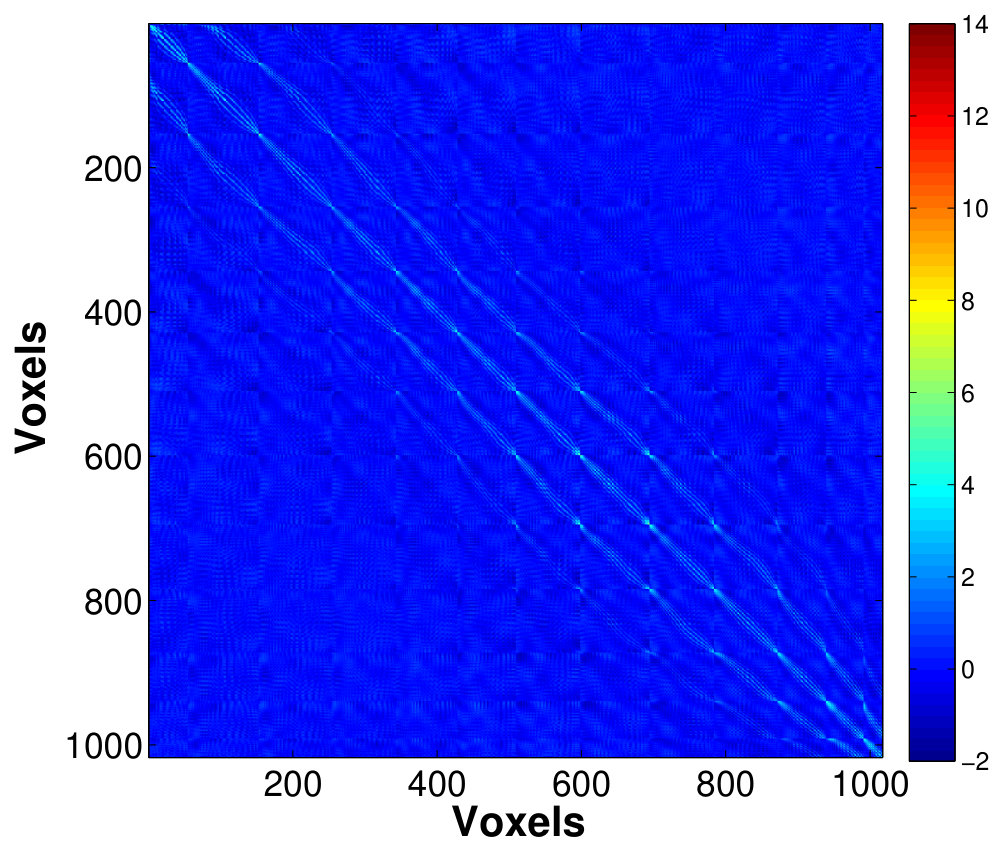 Figure 16
Figure 16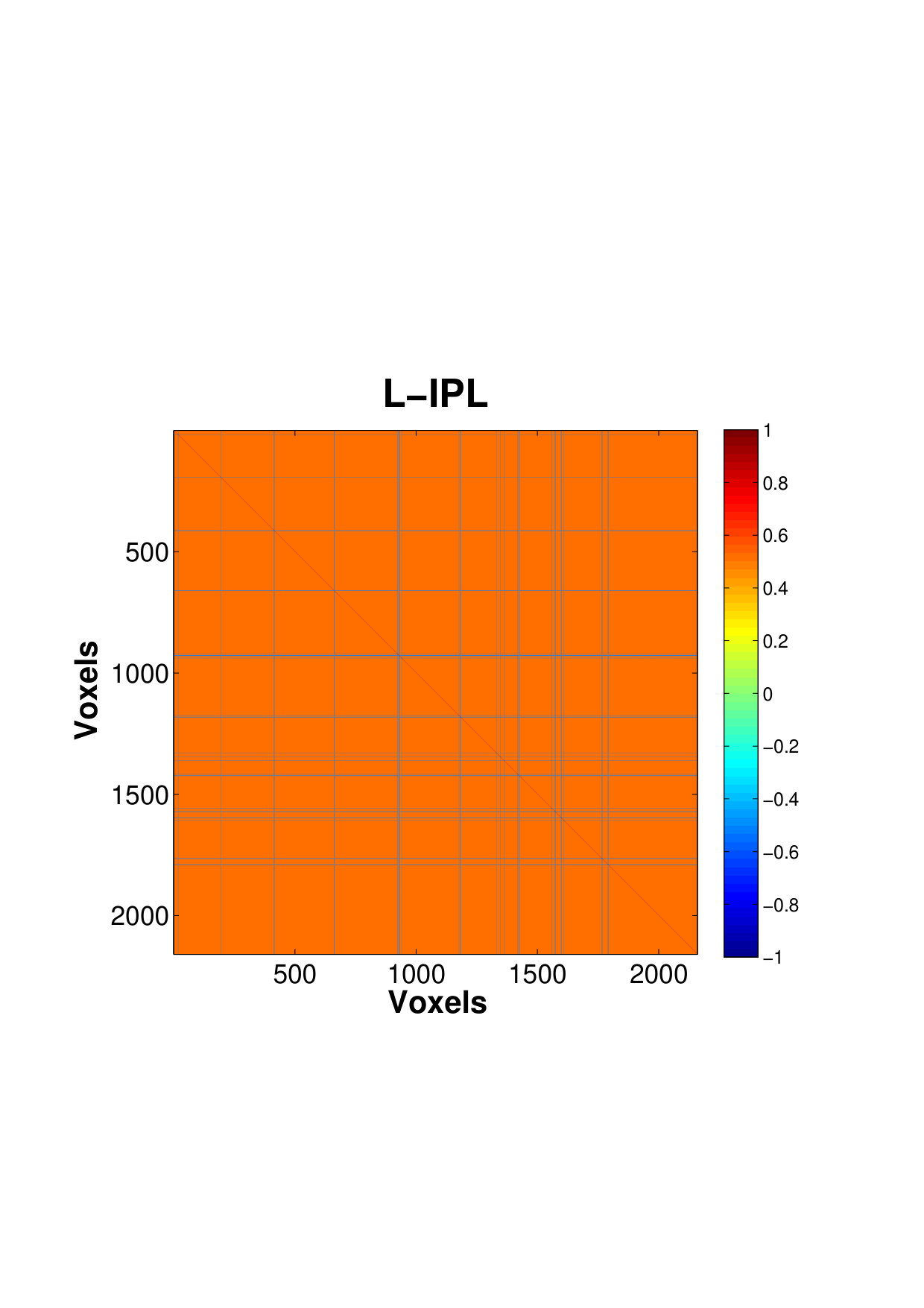 Figure 17
Figure 17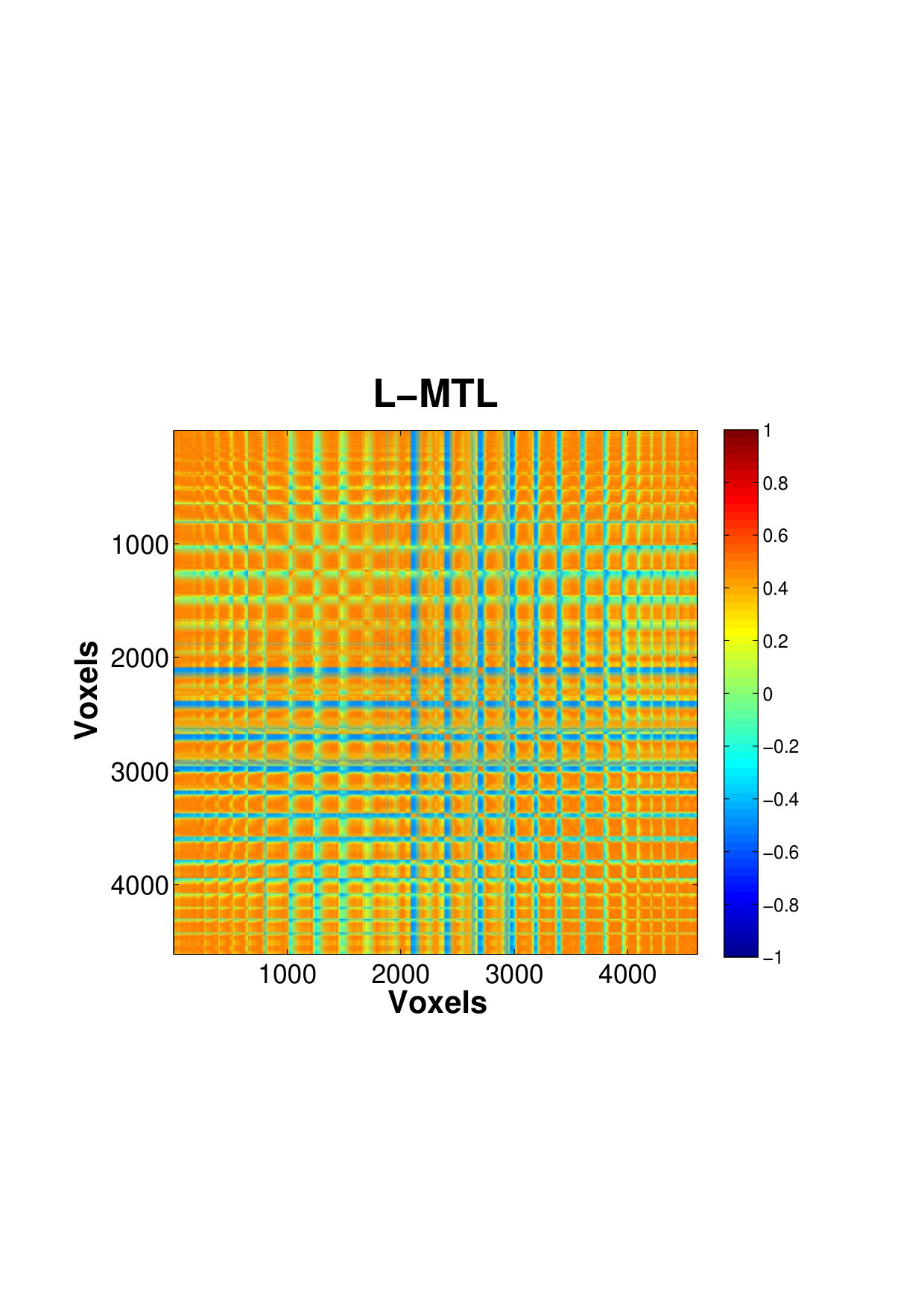 Figure 18
Figure 18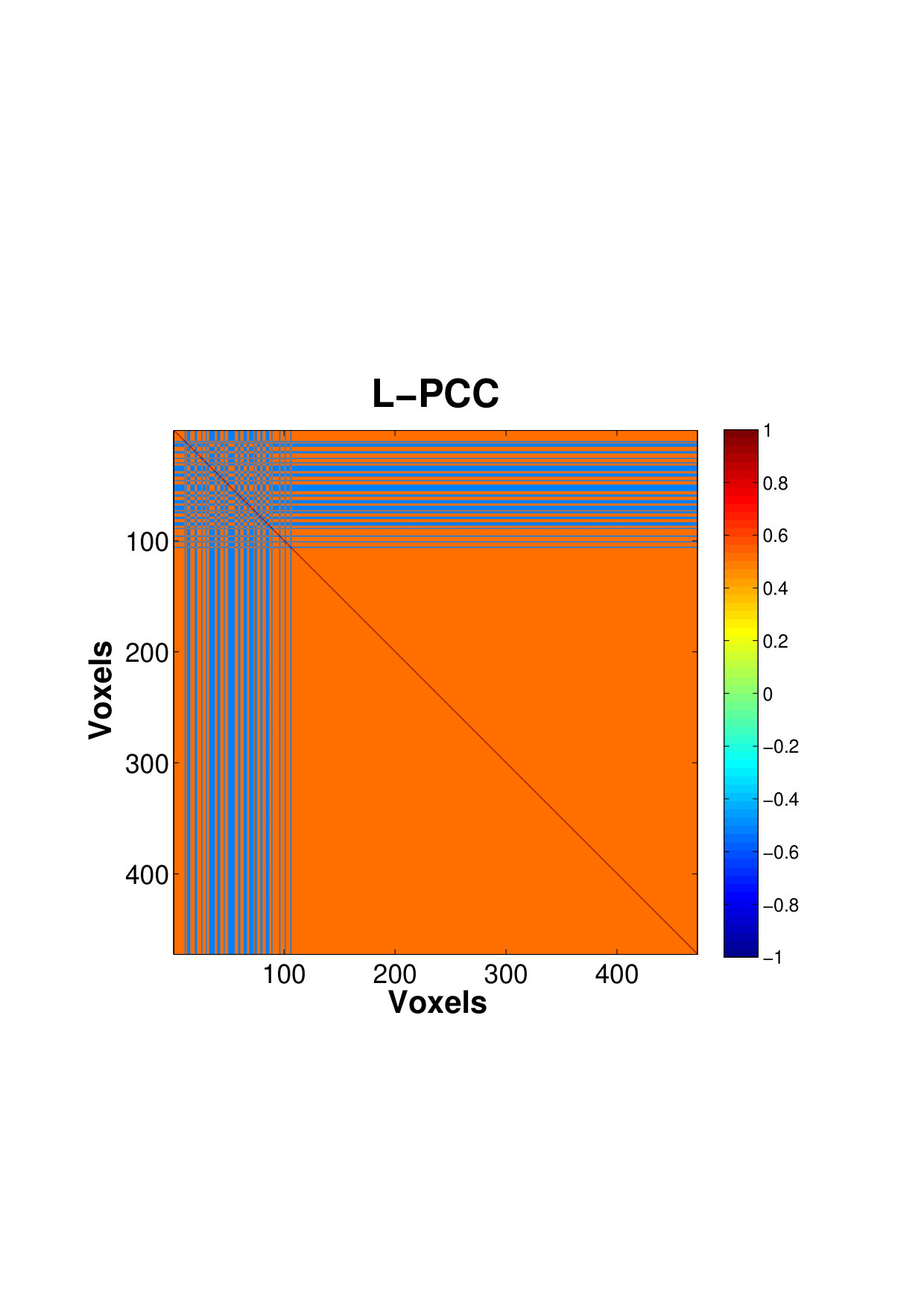 Figure 19
Figure 19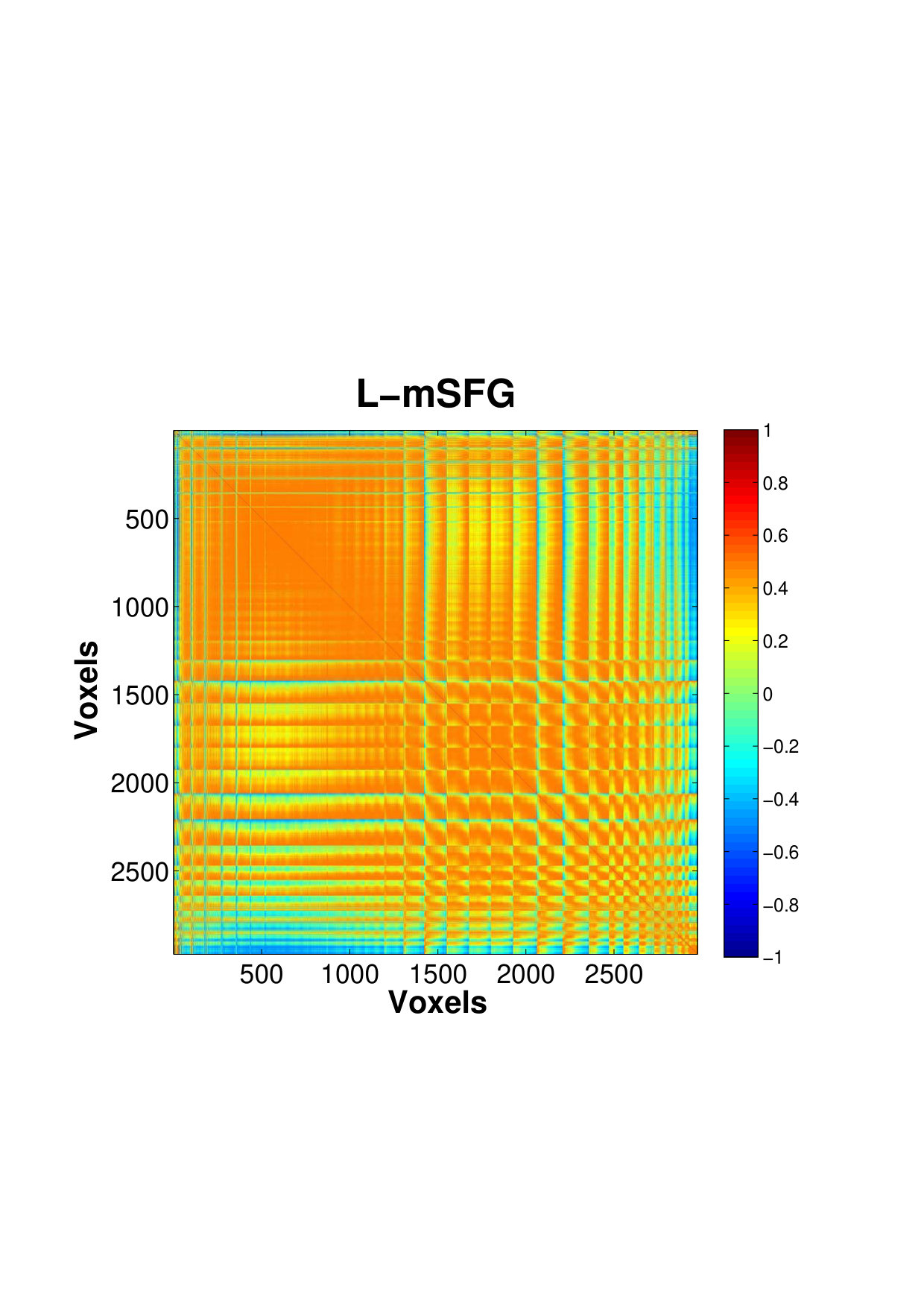 Figure 20
Figure 20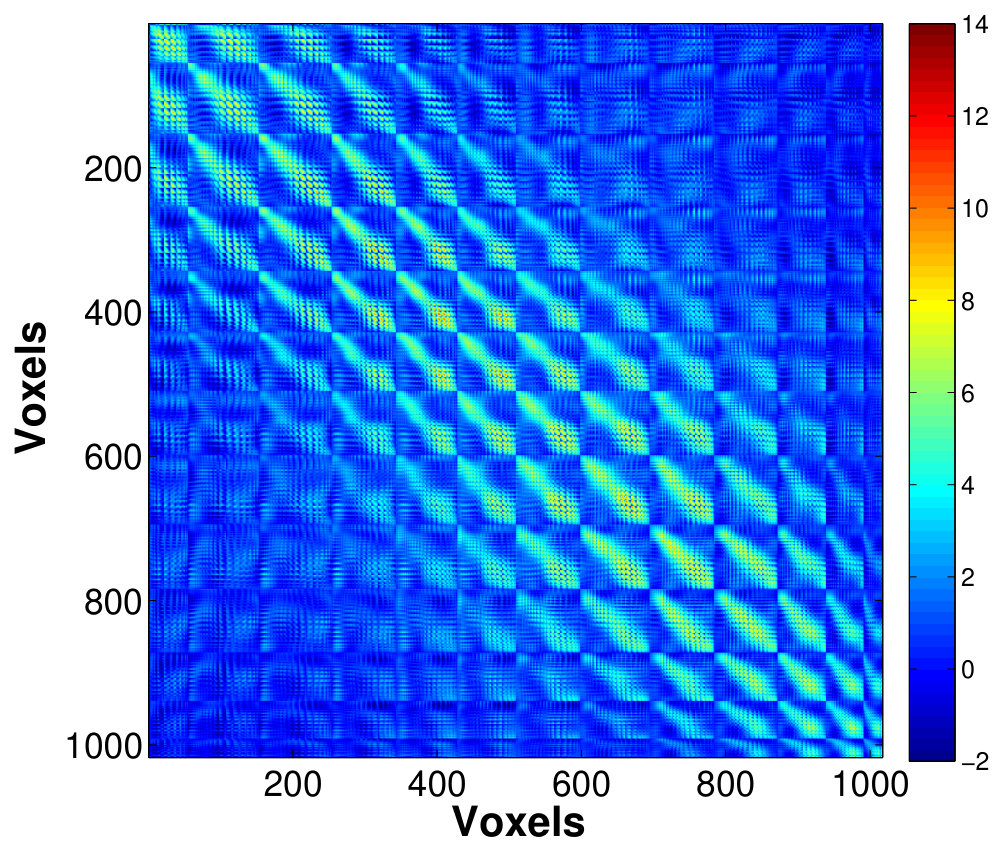 Figure 21
Figure 21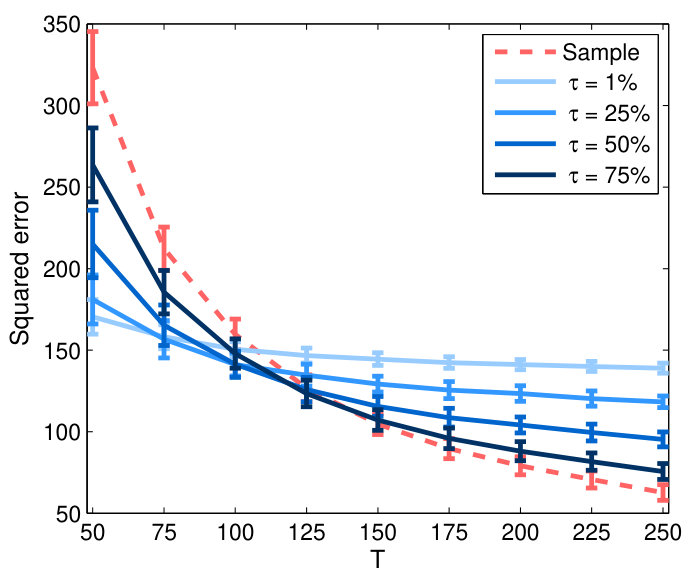 Figure 22
Figure 22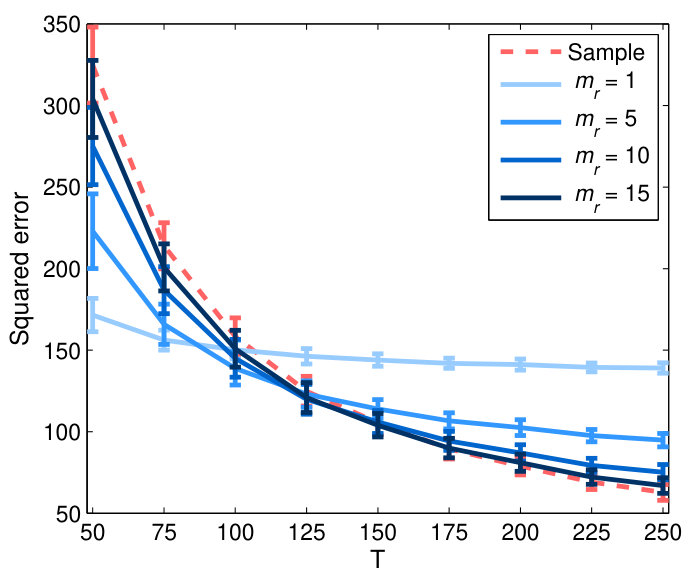 Figure 23
Figure 23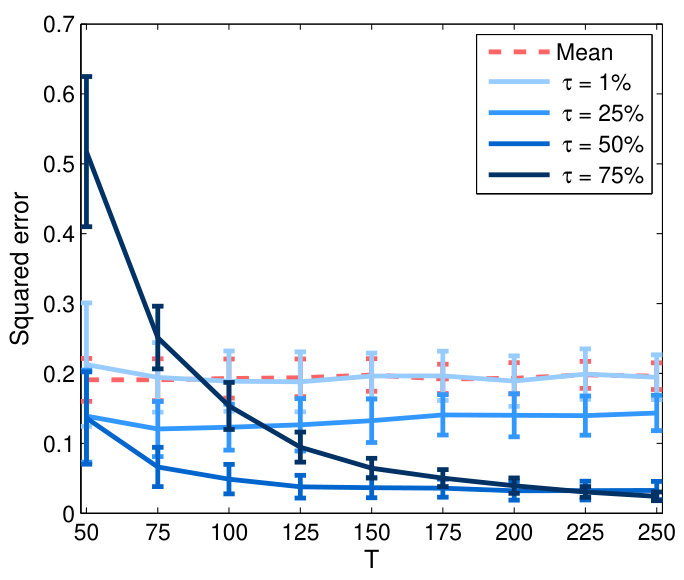 Figure 24
Figure 24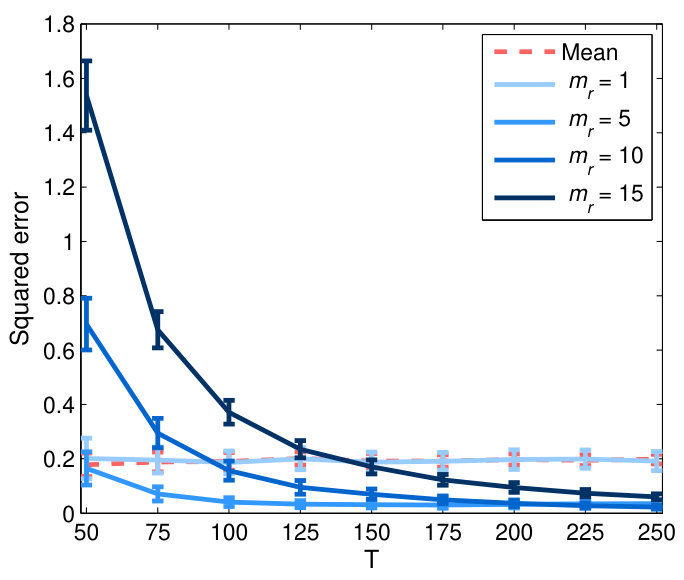 Figure 25
Figure 25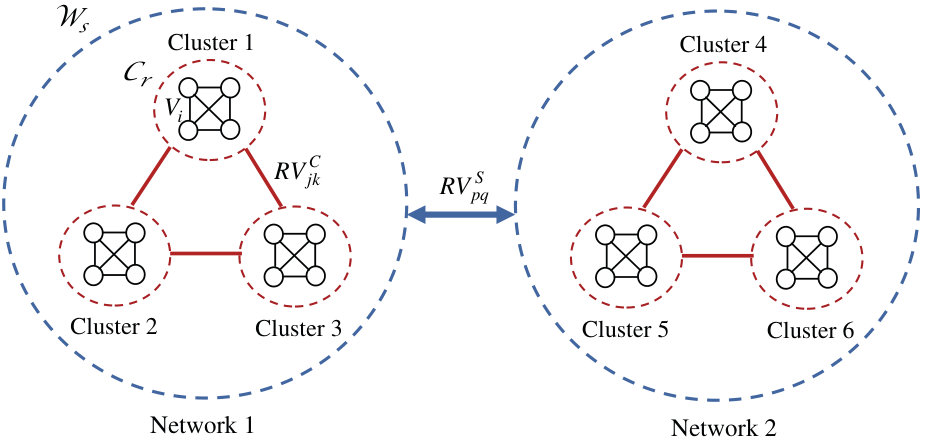 Figure 26
Figure 26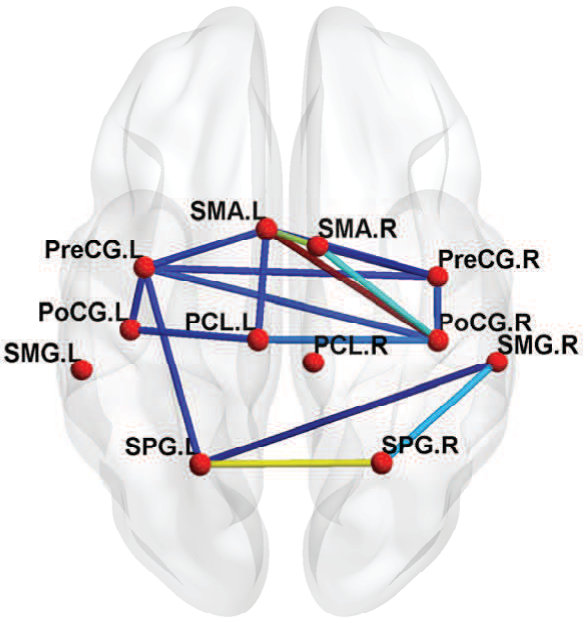 Figure 27
Figure 27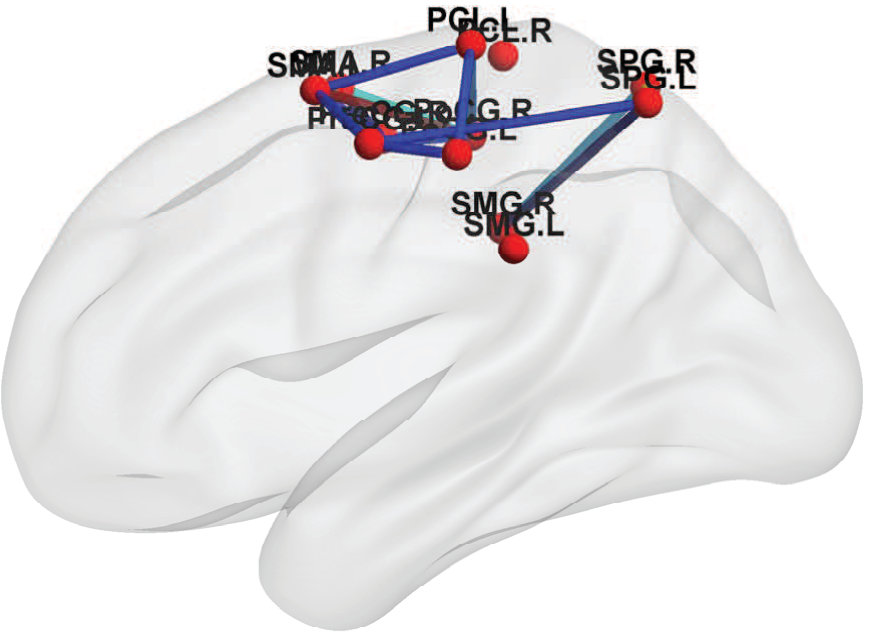 Figure 28
Figure 28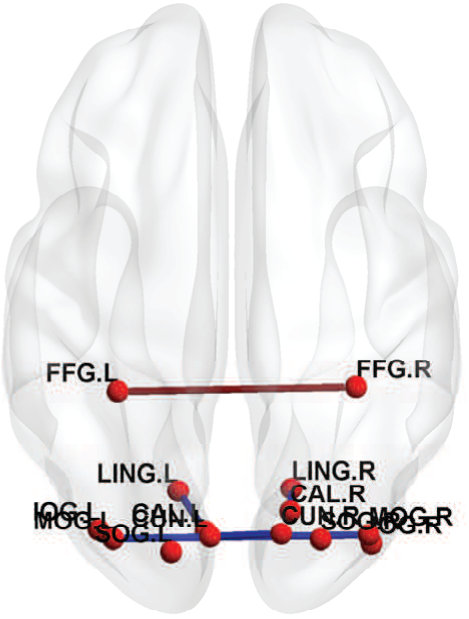 Figure 29
Figure 29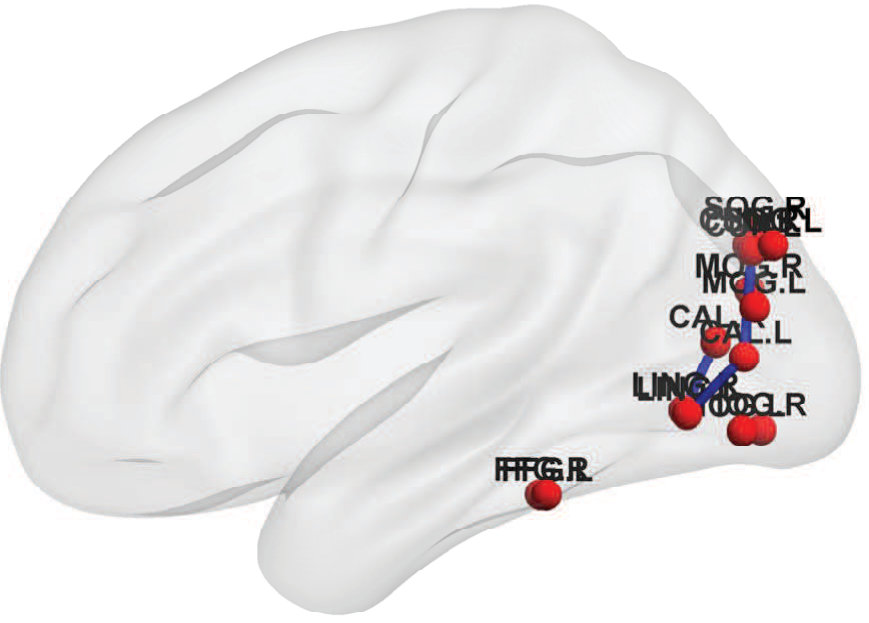 Figure 30
Figure 30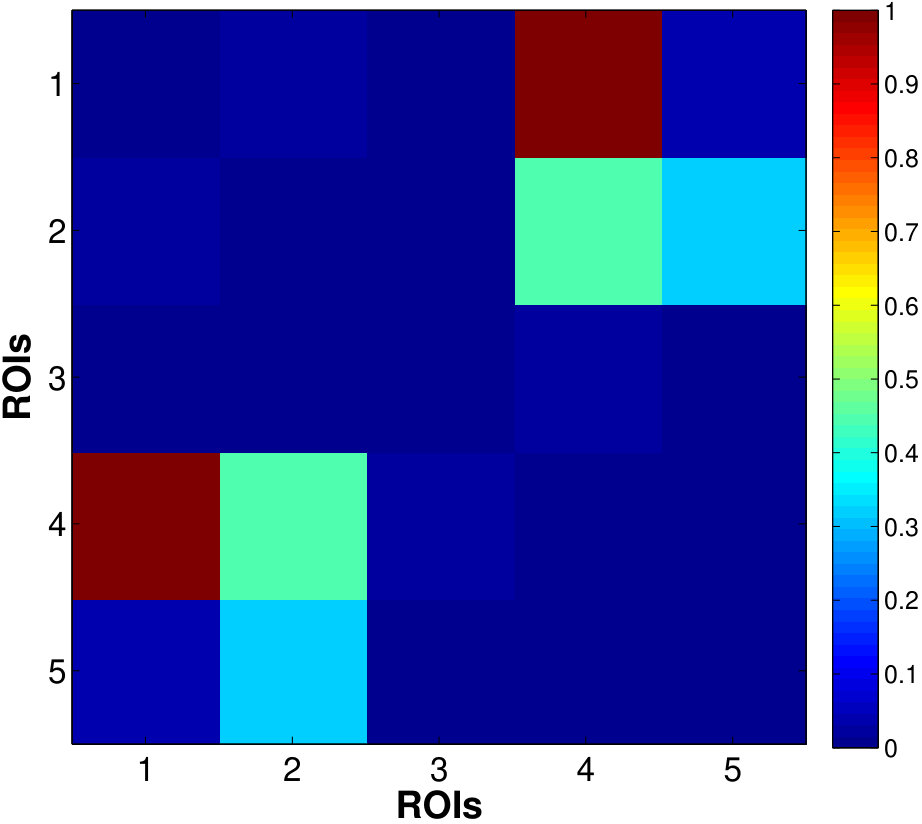 Figure 31
Figure 31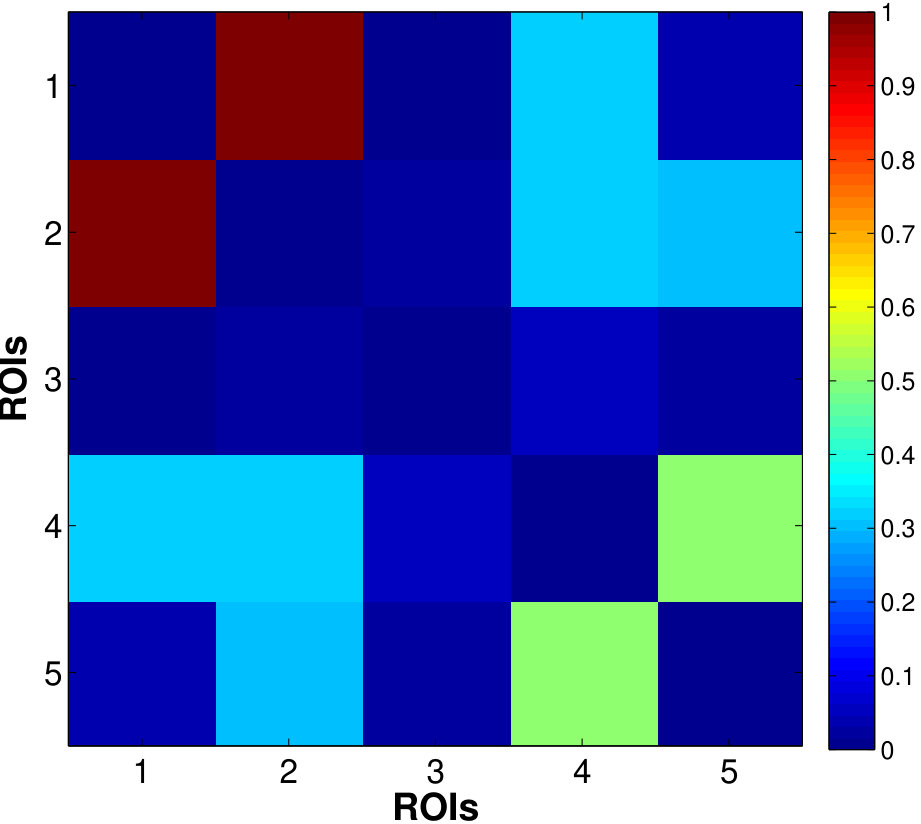 Figure 32
Figure 32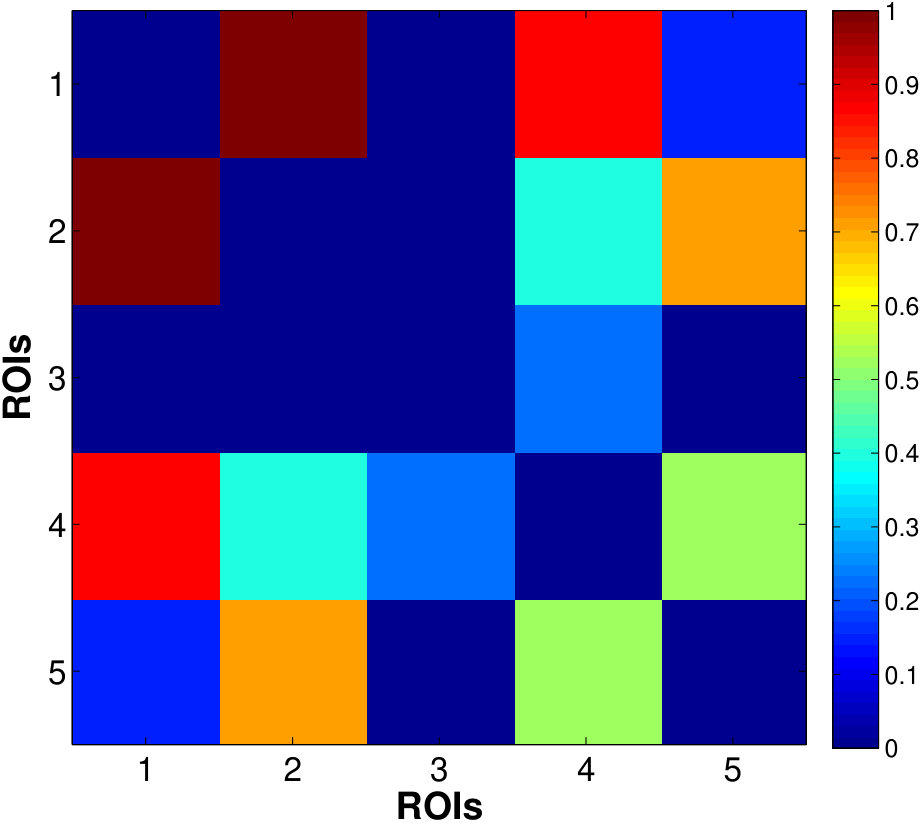 Figure 33
Figure 33| Cluster, | BIC | Percentage of variance explained | |||
|---|---|---|---|---|---|
| 1 | 1 | 1 | 2 | 4 | 9 |
| 2 | 1 | 1 | 2 | 5 | 11 |
| 3 | 1 | 1 | 2 | 6 | 12 |
| 4 | 1 | 1 | 2 | 5 | 10 |
| 5 | 1 | 1 | 2 | 5 | 11 |
| Average | 1 | 1 | 2 | 5 | 11 |
| Sample | Ledoit | Graphical | MSFA | ||
|---|---|---|---|---|---|
| Cov. | Wolf | Lasso | |||
| 50 | 323.62 (22.35) | 241.45 (10.80) | 285.85 (15.85) | 162.53 (9.37) | 156.20 (8.43) |
| 100 | 160.20 (10.86) | 209.18 (6.98) | 217.28 (7.86) | 129.67 (5.17) | 120.64 (4.24) |
| 150 | 104.33 (7.53) | 189.97 (4.61) | 197.02 (4.92) | 117.01 (3.32) | 107.75 (2.66) |
| 200 | 79.03 (6.10) | 179.19 (4.31) | 189.64 (4.90) | 110.94 (2.64) | 101.31 (2.12) |
| 250 | 62.65 (4.46) | 170.62 (3.48) | 184.73 (4.58) | 107.30 (1.96) | 97.46 (1.45) |
| RSN | Abbre | RSN | Abbre | |||||
| Subcortical Network | L inferior frontal gyrus, opercular | IFGoperc.L | 1007 | 1 | ||||
| L caudate nucleus | CAU.L | 966 | 2 | R inferior frontal gyrus, opercular | IFGoperc.R | 943 | 1 | |
| R caudate nucleus | CAU.R | 984 | 2 | L inferior frontal gyrus, triangular | IFGtriang.L | 1402 | 2 | |
| L putamen | PUT.L | 1017 | 2 | R inferior frontal gyrus, triangular | IFGtriang.R | 2237 | 1 | |
| R putamen | PUT.R | 1068 | 2 | L inferior frontal gyrus, orbital | ORBinf.L | 2167 | 2 | |
| L pallidum | PAL.L | 303 | 1 | R inferior frontal gyrus, orbital | ORBinf.R | 1671 | 2 | |
| R pallidum | PAL.R | 261 | 1 | L insula | INS.L | 1757 | 2 | |
| L thalamus | THA.L | 1117 | 2 | R insula | INS.R | 1846 | 1 | |
| R thalamus | THA.R | 1022 | 2 | L superior parietal gyrus | SPG.L | 1758 | 1 | |
| Auditory Network | R superior parietal gyrus | SPG.R | 1994 | 1 | ||||
| L superior temporal gyrus | STG.L | 2161 | 1 | L inferior parietal lobule | IPL.L | 2159 | 1 | |
| R superior temporal gyrus | STG.R | 3034 | 2 | R inferior parietal lobule | IPL.R | 1339 | 1 | |
| L temporal pole: superior temporal gyrus | TPOsup.L | 1245 | 1 | L middle temporal gyrus | MTG.L | 4614 | 2 | |
| R temporal pole: superior temporal gyrus | TPOsup.R | 1297 | 1 | R middle temporal gyrus | MTG.R | 4195 | 2 | |
| Sensorimotor Network | L temporal pole: middle temporal gyrus | TPOsup.L | 741 | 1 | ||||
| L precentral gyrus | PreCG.L | 3283 | 3 | R temporal pole: middle temporal gyrus | TPOsup.R | 1174 | 1 | |
| R precentral gyrus | PreCG.R | 3371 | 3 | L inferior temporal gyrus | ITG.L | 3088 | 2 | |
| L supplementary motor area | SMA.L | 2057 | 1 | R inferior temporal gyrus | ITG.R | 3381 | 2 | |
| R supplementary motor area | SMA.R | 2237 | 2 | Default Mode Network | ||||
| L postcentral gyrus | PoCG.L | 3495 | 3 | L superior frontal gyrus, orbital | ORBsup.L | 964 | 1 | |
| R postcentral gyrus | PoCG.R | 3770 | 1 | R superior frontal gyrus, orbital | ORBsup.R | 959 | 2 | |
| L superior parietal gyrus | SPG.L | 1994 | 1 | L middle frontal gyrus, orbital | MFG.L | 899 | 1 | |
| R superior parietal gyrus | SPG.R | 2183 | 1 | R middle frontal gyrus, orbital | MFG.R | 1007 | 1 | |
| L supramarginal gyrus | SMG.L | 1091 | 31 | L inferior frontal gyrus, orbital | ORBinf.L | 1671 | 2 | |
| R supramarginal gyrus | SMG.R | 1850 | 1 | R inferior frontal gyrus, orbital | ORBinf.R | 1757 | 2 | |
| L paracentral lobule | PCL.L | 1271 | 2 | L superior frontal gyrus, medial | SFGmed.L | 2973 | 2 | |
| R paracentral lobule | PCL.R | 795 | 1 | R superior frontal gyrus, medial | SFGmed.R | 2075 | 1 | |
| Visual Network | L superior frontal gyrus, medial orbital | ORBsupmed.L | 728 | 1 | ||||
| L calcarine gyrus | CAL.L | 2262 | 2 | R superior frontal gyrus, medial orbital | ORBsupmed.R | 827 | 1 | |
| R calcarine gyrus | CAL.R | 1843 | 2 | L anterior cingulate & paracingulate gyri | ACG.L | 1406 | 2 | |
| L cuneus | PCUN.L | 1501 | 1 | R anterior cingulate & paracingulate gyri | ACG.R | 1274 | 1 | |
| R cuneus | PCUN.R | 1405 | 1 | L median cingulate & paracingulate gyri | DCG.L | 1940 | 2 | |
| L lingual gyrus | LING.L | 2093 | 2 | R median cingulate & paracingulate gyri | DCG.R | 2089 | 2 | |
| R lingual gyrus | LING.G | 2329 | 2 | L posterior cingulate gyrus | PCC.L | 472 | 1 | |
| L superior occipital gyrus | SOG.L | 1330 | 1 | R posterior cingulate gyrus | PCC.R | 312 | 1 | |
| R superior occipital gyrus | SOG.R | 1403 | 1 | L hippocampus | HIP.L | 966 | 1 | |
| L middle occipital gyrus | MOG.L | -80.73 | 2 | R hippocampus | HIP.R | 967 | 1 | |
| R middle occipital gyrus | MOG.R | 3258 | 2 | L parahippocampal gyrus | PHG.L | 955 | 1 | |
| L inferior occipital gyrus | IOG.L | 2048 | 2 | R parahippocampal gyrus | PHG.R | 1139 | 1 | |
| R inferior occipital gyrus | IOG.R | 949 | 2 | L inferior parietal lobule | IPL.L | 2159 | 1 | |
| L fusiform gyrus | FFG.L | 1005 | 2 | R inferior parietal lobule | IPL.R | 1339 | 1 | |
| R fusiform gyrus | FFG.R | 2288 | 2 | L angular gyrus | ANG.L | 1124 | 1 | |
| Attentional Network | R angular gyrus | ANG.R | 1756 | 1 | ||||
| L superior frontal gyrus, dorsolateral | SFGdor.L | 2558 | 2 | L precuneus | PCUN.L | 3529 | 2 | |
| R superior frontal gyrus, dorsolateral | SFGdor.R | 3454 | 2 | R precuneus | PCUN.R | 3188 | 1 | |
| L superior frontal gyrus, orbital | ORBsup.L | 4002 | 1 | L middle temporal gyrus | MTG.L | 4614 | 2 | |
| R superior frontal gyrus, orbital | ORBsup.R | 964 | 2 | R middle temporal gyrus | MTG.R | 4195 | 2 | |
| L middle frontal gyrus | MFG.L | 959 | 1 | L temporal pole: middle temporal gyrus | TPOmid.L | 741 | 1 | |
| R middle frontal gyrus | MFG.R | 4593 | 2 | R temporal pole: middle temporal gyrus | TPOmid.R | 1174 | 1 | |
| L middle frontal gyrus, orbital | ORBmid.L | 5009 | 1 | L inferior temporal gyrus | ITG.L | 3088 | 2 | |
| R middle frontal gyrus, orbital | ORBmid.R | 899 | -1 | R inferior temporal gyrus | ITG.R | 3381 | 2 | |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Multi-Scale Factor Analysis of High-Dimensional Brain Signals
Chee-Ming Ting111Center for Biomedical Engineering, Universiti Teknologi Malaysia (UTM), 81310 Skudai, Johor, Malaysia;[email protected], Hernando Ombao222Computer, Electrical and Mathematical Sciences and Engineering Division, King Abdullah University of Science and Technology, Thuwal 23955, Saudi Arabia, and also the Department of Statistics, University of California, Irvine CA 92697, USA; [email protected],[email protected] and Sh-Hussain Salleh333Center for Biomedical Engineering, UTM, 81310 Skudai, Johor, Malaysia;[email protected]
Abstract
In this paper, we develop an approach to modeling high-dimensional networks with a large number of nodes arranged in a hierarchical and modular structure. We propose a novel multi-scale factor analysis (MSFA) model which partitions the massive spatio-temporal data defined over the complex networks into a finite set of regional clusters. To achieve further dimension reduction, we represent the signals in each cluster by a small number of latent factors. The correlation matrix for all nodes in the network are approximated by lower-dimensional sub-structures derived from the cluster-specific factors. To estimate regional connectivity between numerous nodes (within each cluster), we apply principal components analysis (PCA) to produce factors which are derived as the optimal reconstruction of the observed signals under the squared loss. Then, we estimate global connectivity (between clusters or sub-networks) based on the factors across regions using the RV-coefficient as the cross-dependence measure. This gives a reliable and computationally efficient multi-scale analysis of both regional and global dependencies of the large networks. The proposed novel approach is applied to estimate brain connectivity networks using functional magnetic resonance imaging (fMRI) data. Results on resting-state fMRI reveal interesting modular and hierarchical organization of human brain networks during rest.
Keywords: Multi-dimensional signals; Dimension reduction; Factor analysis; Principal components analysis; fMRI.
1 Introduction
Analysis of complex networks involves characterization and modeling of the coordinated interactions between different entities. A network can be represented as a graph, where nodes correspond to individual units and weights of edges connecting the nodes to the strength of connections. One popular measure for quantifying the connectivity in weighted networks is through statistical dependencies, such as cross-correlations between signals or data measured at each node. Correlation-based network analysis has found applications in many domains, e.g. brain functional networks (Worsley et al.,, 2005; Marrelec et al.,, 2006, 2005), gene co-expression networks (Zhang et al.,, 2005) and financial networks (Onnela et al.,, 2003). The key challenges involved in characterizing and estimating the network covariance matrix are (a.) the high-dimensionality of network data and hence a large number of connectivity parameters due to the large number of nodes in a network; and (b.) the inherent complexity of the connectivity structure between nodes in most real-world networks. The dimension of the data (refer to the number of nodes in a network) is usually comparable or even larger than the sample size (the total number of observed time points). In this high-dimensional setting, the traditional sample covariance matrix is no longer a reliable and accurate estimate of the population covariance, due to massive number of correlation coefficients (i.e. ) that have to be estimated relative to sample size. It will lead to low statistical power in detecting the true network connections. For example, in estimating a full-brain network from fMRI data, the number of voxels can be in order of but the number of scans is often of order . For gene expression data, can be up to but with is of order .
Another issue is how to quantify the network’s community structure or modularity which is an important property of real-world networks (Newman,, 2012; Girvan and Newman,, 2002). Communities (or modules) refer to sub-networks (clusters of nodes that share common properties orand roles) where nodes within the same module are densely intra-connected but relatively sparsely inter-connected with nodes at different modules. In brain networks, modules may correspond to groups of regions of interest with the same function (Bullmore and Sporns,, 2009), i.e., they respond similarly to a stimulus or are highly synchronized during resting state. It has been observed that spatially distant nodes (e.g., on different sites of the brain) may belong to the same module. Moreover, the modular structure are hierarchical, observed over multiple topological scales ranging from individual nodes as a cluster all the way to having all the nodes (or the entire network) as one cluster (Shen et al.,, 2010; Betzel and Bassett,, 2016; Song and Zhang,, 2015). At any particular scale, each of the modules can be divided into smaller sub-modules (further into sub-sub modules) (Meunier et al.,, 2010). In this paper, we address the problem of modeling and inferring correlation between nodes and modules in high-dimensional networks with a multi-scale community structure, by deriving both local and global connectivity measures based on the proposed spatio-temporal model for network data.
Various approaches have been proposed to estimate high-dimensional covariance matrix for large-scale networks. The simplest approach computes pairwise correlation matrix constructing edges between pairs of nodes, however, it ignores potential influence of other nodes in the entire network. More advanced approach is based on regularized estimation, which includes variety of methods such as thresholding (Rothman et al.,, 2009), shrinkage estimation (Fiecas and Ombao,, 2011; Beltrachini et al.,, 2013; Schneider-Luftman and Walden,, 2016) and sparse estimation (Ryali et al.,, 2012; Chen et al.,, 2016) as previously applied to analyze large-dimensional covariance in neuroimaging and genetic data. However, thresholding and imposing sparsity directly on the covariance matrix might not accurately capture the true underlying connectivity structure.
We follow the dimension-reduction approach which characterizes the connectivity structure in high-dimensional data through a small number of latent components. Two common dimension reduction methods via subspace projection are principal components analysis (PCA) and independent component analysis (ICA). These methods aim to find a projection of high-dimensional data to a low-dimensional subspace that contains independent information (thus removing data redundancy) and then extract a reduced set of latent components (or sources) for connectivity analysis. As shown in brain connectivity studies using fMRI data, ICA is capable of decomposing a network into spatial sub-networks with similar functions which are temporally correlated (Calhoun et al.,, 2008; Smith et al.,, 2009; Allen et al.,, 2011; Li et al.,, 2011). PCA has also been shown to be as effective in connectivity analyses. Signal summaries derived from PCA are more sensitive than using the mean signals in detecting Granger-causality in an ROI-based fMRI analysis (Zhou et al.,, 2009). It was able to reveal connectivity across different functional networks during rest (Carbonell et al.,, 2011; Leonardi et al.,, 2013).
In this paper, we employ the factor analysis (FA) model (Bai and Li,, 2012) and PCA for estimation of the low-dimensional projection, to produce a consistent estimator for the high-dimensional covariance structure of large networks. We now summarize the rationale for our approach. First, it is directly linked to analysis of large covariance matrix. The FA model is more general than the conventional PCA and ICA, in the sense that it includes a noise component to the common component driven by few latent factors. This model explicitly provides decomposition of a high-dimensional covariance matrix into a low-rank structure (low-dimensional subspace spanned by the factor loadings) plus a sparse noise covariance matrix. Instead of computing connectivity between reduced components obtained by the PCA or ICA, this approach allows analysis of large-dimensional connectivity matrix in the observation space based on lower-dimensional factor space. Secondly, it enables consistent and efficient estimation of high-dimensional covariance. PCA can be used to extract factors by solving the constrained linear least-squares, a well-defined criteria for the factor model structure, which minimizes the squared error between the original and projected signals based on the lower-dimensional factors. The PCA can consistently estimate the linear factor subspace, as shown in the extensive literature on estimating high-dimensional FA models (Stock and Watson,, 2002; Bai,, 2003). The large covariance estimate is only a simple construction based on these low-dimensional PC estimates. The asymptotic theory of the PCA-based FA model and covariance matrix estimators have been well established for large (Fan et al.,, 2011, 2013), which can provide insights to our proposed estimator. However, these theoretical results are still unclear for other projection methods such as ICA.
Moreover, most of the previous approaches to large network analysis produce only a single-block covariance matrix for the entire graph. The single-block covariance is ineffective for networks with ultra high dimensions mainly due to the difficulty in interpreting the results, and is unable to describe the multi-scale modularity of real networks. Motivated by the nature of dense connectivity within each network community, with high multi-collinearity (or redundant information) of activities in the same cluster of nodes, our approach applies FA to each cluster where analysis of the whole network correlation matrix is decomposed to analyzes of smaller module-specific matrices. More precisely, we propose a multi-scale factor analysis (MSFA) model for network data which allows hierarchical partition of the model cross-sectional structure to capture modular dependency at different scales in a large network. At the lowest level, the nodes (fundamental units) of the entire network domain are partitioned into a finite set of regional clusters, according to spatial proximity or functional relevance. The high-dimensional dependence between nodes is then characterized by a partitioned correlation matrix with low-dimensional sub-structures derived from the cluster-specific factors. The global dependence between clusters or collections of clusters (networks) can be measured via the correlations between cluster-specific factors. We further use the RV-coefficient (Escoufier,, 1973) as a single-valued measure to summarize these factor correlation blocks across clusters and networks. The proposed factor-based decomposable network (a.) enables more reliable and efficient estimation (lower estimation error and less computational effort) of large-scale dependency via dimension-reduction; and (b.) can capture the hierarchical, modular dependency through a factor-structured covariance matrix. We develop a two-step estimation procedure. We first apply PCA to estimate model parameters for each cluster, and then use these local estimates to construct the estimators for various global dependence measures. We apply the approach to analyze resting-state brain networks using fMRI data. It permits a multi-scale analysis of regional (within-ROI) and global (between ROIs and between networks) connectivity. While this paper covers applications only to fMRI, our proposed model and estimation procedure is broadly applicable to is broadly applicable to high-dimensional signals over other types of networks. The performance of our method was assessed via simulations and real data.
2 Multi-Scale Factor Model for Correlation Network Analysis
In this section, we propose a novel model and related correlation-based measures to characterize the hierarchical, modular dependency structure of a network at multiple topological scales, from the node-level (between fundamental units in a network) to global-level (between clusters of nodes and between larger sub-networks of clusters). The correlation networks are inferred from signals measured from nodes across the entire network.
2.1 Definitions and Notations
We consider a hierarchical network structure, as illustrated in Fig. 1. Suppose the entire network space consisting of nodes are partitioned into disjoint clusters , which are then grouped (possibly with overlapping nodes) to form larger sub-networks , such that . We define a set of nodes with indexes assigned to the cluster , for , and as a collection of clusters with indexes grouped to the network . For example in brain networks, corresponds to voxels, to anatomically-parcellated ROIs (spatially-divided clusters of voxels, and to system networks (collections of ROIs with similar functional relevance). In this paper, we represent the network as a connectivity matrix quantified with statistical dependence, i.e. the covariance between signals associated with the nodes.
We omit the index symbols for notational brevity. Let , =1, …, be the vector of signals of length (e.g. fMRI time series) measured from each node in the entire network space, and be the subset of signals from nodes in cluster , and be the signals from all clusters in network , with dimension . The total signals for the entire network can be collectively defined by . The cross-sectional dimension of the entire network (total number of nodes) is assumed to be comparable or larger than the sample size . We denote by (with dimension ), () and () the covariance matrices of , and , which describe the functional (undirected) dependence between nodes within a cluster, within a sub-network and in the whole network respectively. We assume all these covariance matrices to be time-invariant.
2.2 Modeling Local (Regional) Dependency
1) Factor model: To capture dependence between nodes within a cluster, we first specify the cluster-specific factor model. At each cluster, we assume activity across all nodes can be summarized by a finite number of latent common components, much less than the number of nodes . Specifically, the local FA model for signals of each cluster is
[TABLE]
where is a vector of latent common factors with number of factors . The covariance matrix of is assumed as , i.e. the factors within cluster are uncorrelated for any pairs of different factors , . The factor loading matrix defines the dependence between nodes through the mixing of . It satisfies the condition , where denotes a identity matrix. is a vector of white noise with and . Our approach enables dimension reduction via (1.) piece-wise partitioning of the entire high-dimensional observation space into a finite number of smaller components at each cluster, and (2.) the serial and cross-dependence within each cluster are further summarized by a much lower dimensional factor process and mixing matrix .
The components and are not separately identifiable. For any invertible matrix , with and . The model (1) is observationally equivalent to . The orthonormality of restricts to be orthonormal (imposing restrictions), together with the diagonality of (with restrictions) restricts to be a diagonal matrix with diagonal entries of (total restrictions on ). This identifies and up to a sign change.
2) Determination of clusters: In this paper, the following are assumed to be fixed and known: hierarchical partitioning of the clusters and sub-networks ; the number of clusters ; and the number of sub-networks . For fMRI analysis, clustering of brain nodes into ROIs can be defined by prior information on the anatomical parcellation (e.g. according to Anatomical Automatic Labeling (AAL) atlas (Tzourio-Mazoyer et al.,, 2002)), and the brain sub-networks by the functional similarity of the ROIs. When unknown, many algorithms for community detection in networks can be used to automatically identify the modules and their hierarchical (multi-scale) organization. See (Fortunato,, 2010) for an extensive review. Among these algorithms, we are particularly interested in spectral clustering which partitions a graph into clusters through the eigenvectors of the connectivity matrix (e.g., a simple adjacency or Laplacian matrix (Von Luxburg,, 2007) or the recently proposed correlation matrix (Shen et al.,, 2010)). These algorithms will be incorporated in the preliminary step in our future work to further refine and generalize the proposed framework.
2.3 Modeling Global (Inter-Region) Dependency
To capture dependence between the different clusters and between larger networks of these clusters, we develop the global factor model for the entire network, by concatenating the local factor models in (1) from all clusters . The global FA model has a structured form by partitioning the cross-sectional dimension, as defined by
[TABLE]
where is a global white noise process with and i.e. the off-diagonal covariance blocks for any pair of errors (), . By concatenating factor time series from all clusters in the entire network, we have a global factor process with total dimension , which has and covariance matrix . Both processes and are assumed to be uncorrelated. The global mixing matrix is a block-diagonal matrix
[TABLE]
where the diagonal blocks explains the mixing between uncorrelated factors in cluster , and the zero off-diagonals indicate that does not capture the dependence between factors of different clusters.
2.4 Measures of Dependence
Our aim of assuming factor models is to approximate large covariance matrix with a simpler, lower dimensional structure for efficient network analysis. We now describe the model parameters in (1) and (2) which quantify the network dependency at the local and global level.
1) Local (within-cluster) dependency: The between-node dependency within cluster is captured by the covariance matrix . The model (1) implies a decomposition of into a matrix of lower-rank and a diagonal matrix.
[TABLE]
assuming to be uncorrelated with .
2) Global (whole-network) dependency: The global model (2) also implies a low-rank decomposition of the whole-network covariance matrix , and a block structure
[TABLE]
with
[TABLE]
where the diagonal blocks are defined by (3) for , and the off-diagonal block for is cross-covariance matrix between the node time series and of cluster and cluster . The factor decomposition of the high-dimensional node-wise covariance matrices of and in (3) and (4) allows for massive dimension-reduction. It provides an efficient way to compute the large whole-network dependency matrix in (5), by reconstruction from smaller pair-wise between-cluster dependence blocks , which can be further approximated by lower-dimensional matrix . Moreover, the approximation using a low-rank matrix plus a diagonal matrix can produce better-conditioned estimates for the large covariance structure at the both levels. In the following, we make use of the low-dimensional factor covariance together with the RV coefficient to derive a single-valued measure to summarize the node-wise connectivity blocks across clusters and networks at the global level.
3) Global (between-cluster) dependency. The factor covariance matrix is a block matrix that model instantaneous (lag zero) dependency structure between clusters
[TABLE]
Each diagonal block is a diagonal covariance matrix that captures the total variance of factors within each cluster. While the factors within a cluster are uncorrelated, factors between different clusters may be correlated. The off-diagonal blocks for are cross-covariance matrices between factors and , satisfying , that can summarize cross-dependence between clusters and .
4) Global (between-network) dependency: The measure of dependency between the sub-networks of clusters can be conveniently derived based on the covariances between the factor time series from the clusters in different networks. Let denotes collectively the corresponding factors of all the clusters in sub-network , with a total dimension , which summarizes . The dependence within a network , can be characterized by the covariance matrix . The dependence between network and network is captured by the cross-covariance matrix between and , denoted as .
5) RV coefficients: The between-cluster and between-network connectivity above are represented by block covariance matrices between multiple factor time series (possibly of different dimensions) across clusters and networks. We propose to use the RV coefficient (Escoufier,, 1973) as a single-valued measure for the linear dependence between factors of different clusters and networks. It is a multivariate generalization of the squared correlation coefficient which measures normalized dependence between two univariate time series. The RV coefficient between factors in clusters and is defined by
[TABLE]
and between the networks and by
[TABLE]
where and are the correlation matrices. The correlations and RV coefficients provide results that are more easily interpretable than the covariances when measuring the strength of connectivity, as both , and are constrained to take values only in the unit interval . A value of close to one indicates strong connection between network and , whereas a value of zero indicates there is no connection.
2.5 Model Identifiability
We now discuss the identifiability issue of the covariance of the common component, in the global model (2). One key feature is that the mixing matrix is block diagonal. This guarantees that the cross-dependence between clusters will be captured only by the covariance matrix and not by . The dependence between the pair of clusters and is directly contained in the cross-covariance matrix . Similar to the local FA model, and are not separately identifiable, since for any invertible matrix such that , where and . However, the covariance matrix of the common component is identifiable as follows
[TABLE]
where and admit a non-unique factorization. The key question now is whether the new mixing matrix is also block diagonal as required by (2). To address this important question, we use an example of only two clusters for ease of exposition. Let ,
[TABLE]
By expanding on , we have
[TABLE]
For to be block diagonal, it is sufficient to set and . However, since , it follows that and . Thus, the factor loading matrix will be identifiable up to orthonormal transformations only within each cluster.
3 Estimation and Inference
Inferring dependence in a network between a large number of nodes involves estimating the high-dimensional covariance matrix . The traditional sample covariance matrix is no longer consistent when is large and is not invertible when . Our primary objectives are to estimate the dependence quantities: (1.) which models the dependence across all nodes in the entire network; (2.) the dependence across nodes within each cluster; (3.) and the dependence between any pairs of clusters and sub-networks of clusters.
3.1 PCA Estimation
In this section, we develop a two-step procedure to estimate the high-dimensional dependence based on the proposed MSFA model. The estimation of the whole-network covariance matrix is reduced to the estimation of sub-matrices of much smaller dimensions. The estimation procedure is summarized in Algorithm 1. In Step 1, we apply the method of PCA to estimate the parameters and in the local-level model (1) to construct the covariance estimates within each cluster. In Step 2, we integrate these local estimators to derive the estimators of the global-level dependence quantities in (2), i.e. the between-cluster and between-network factor covariance ( and ) and RV coefficients ( and ). In the local estimation, the PC estimates of and can be computed conveniently via eigenvalue-eigenvector analysis of the sample covariance matrix, for the cross-sectional covariance when [Step 1.1(a)], and on the temporal covariance when [Step 1.1(b)]. The estimator of the factor loading matrix are eigenvectors corresponding to the principal eigenvalues of the sample covariance, the factors are then estimated as . The noise covariance can be estimated based on the residuals [Step 1.2]. We then have a simple substitution estimator for the within-cluster dependence matrix in (3) using estimates from Step 1.1 - 1.2 [Step 1.3]. In the global estimation, we use the estimated factor signals to compute estimators for the pair-wise covariance sub-matrices between clusters and between networks [Step 2.1], to generate the RV coefficient estimates [Step 2.2]. In the final steps [Step 2.3 and 2.4], the parameters of the global model (2) and the whole-network dependence (5) can be constructed from the component estimators in the previous steps.
The PCA extracts latent factors that best represent the region-specific dynamics. It estimates an ordered sequence of factor series that account for most variability of signals across all nodes within a cluster, which might not sufficiently captured by a single mean signal. One of the dominant factors would possibly be the mean. However, instead of making this imposition as in most analyses, our procedure is data-driven where these factors are learned from data according to their significance. Besides, the PC estimators of factors and factor loadings are consistent under general framework of large and large , and in the presence of correlated noise in the signals (Stock and Watson,, 2002; Bai,, 2003). The FA model-based estimator of large covariance matrix and its inverse are shown to produce lower estimation errors and attain improved convergence rates under various norms, compared to the sample covariance (Fan et al.,, 2011). This can provide reliable estimation of large dependency networks.
The number of factors for a cluster can be objectively selected based on some threshold of the amount of variance of the signals within each cluster. The criterion is computed using the eigenvalues of the sample covariance matrix or , which measure the estimated variances of the individual factors. Precisely, can be estimated by
[TABLE]
where , is an evaluated candidate value of , with a bounded integer such that and is a global threshold for all clusters. The proportion of variance explained by the first components is equal to the ratio of the sum of largest sample eigenvalues to the sum of all eigenvalues. Naturally, the proportion is subjectively selected by the users via the threshold. However, once it is specified, PCA can objectively extract a number of optimal latent components.
Alternative method is via model selection using BIC (Bai,, 2003)
[TABLE]
where denotes the Euclidean norm of a vector
3.2 Asymptotic Properties of the Estimator
We first specify some regularity conditions (Assumptions 1-4 in Appendix 7.1). In following Proposition, we present the limiting distributions for the PCA estimates and for each cluster , as defined in Step 1.1 (a) of Algorithm 1. It follows from results derived in (Bai,, 2003) (Theorem 1 and 2) and (Bai and Ng,, 2013) (Theorem 1). The consistency of and can also be established based on results in (Stock and Watson,, 2002).
Proposition 1 (Asymptotic normality of and ): Suppose that Assumptions 1-4 and additional Assumptions E-G in (Bai,, 2003) hold. Let be the -th row vector of . Then as , with , we have for each
[TABLE]
Furthermore, if , for each
[TABLE]
Our proposed local (within-cluster) factor-based covariance estimator is a special case of the principal orthogonal complement thresholding (POET) estimator of Fan (Fan et al.,, 2013). The POET estimates a sparse error covariance matrix for the approximate factor model (correlated noise) by adaptive thresholding of principal orthogonal complements (i.e. remaining components of the sample covariance after taking out the first PCs), as computed by . The diagonal matrix computed in Step 1.2 is an extreme case of this sparse covariance estimate by choosing a threshold of correlation elements equal to one. Thus, we can derive the rates of convergence for our estimator for a strict factor model (uncorrelated noise) based on results in (Fan et al.,, 2013) for the POET large covariance estimator under various norms. We consider, for example, the weighted quadratic norm , as in following Proposition.
Proposition 2 (Rate of convergence for ): Under Assumptions 1-4, the within-cluster covariance estimator as defined in Step 1.3 of Algorithm 1 satisfies
[TABLE]
where
[TABLE]
and for some is the measure of sparsity condition on .
The consistency of the constructed global covariance estimator (defined in Step 2.5) for high dimensions can be implied by the consistency of estimator for each of individual component blocks at the local level. In this paper, the improved consistency is shown by simulation in Table IV (Section IV.C), as indicated by the lower estimation standard errors compared to other high-dimensional covariance estimators. The complete proof of the consistency and convergence rates for our novel estimator will be developed in future work.
3.3 Statistical Inference
To test for the statistical significance of the between-cluster and between-network dependence, as measured by the RV coefficient, we propose a formal inferential procedure for testing the null versus alternative hypotheses
[TABLE]
which denotes the absence or presence of a significant connectivity between the clusters (or networks) and .
A large value of the sample RV coefficient may not necessarily imply statistical significance in connectivity because it needs to be compared to some reference null distribution. One way of approximating null distribution of RV coefficients is by random permutation of the temporal order of factor series and computes the RVs. However, this is computationally expensive as there are possible permutations to repeat. We follow (Josse et al.,, 2008) to approximate the exact null distribution. Standardized RV (or z-score) is used as the test statistics
[TABLE]
where and are the estimates of first and second moments of null distribution of the permuted RVs (Kazi-Aoual et al.,, 1995)
[TABLE]
[TABLE]
where
[TABLE]
denotes the -th diagonal element of matrix . The test statistics has an asymptotic standard normal distribution under the null hypothesis where the true RV coefficient is zero. In practice, and are not known and hence are estimated by replacing and by their corresponding estimators and respectively. A connection is considered statistically significant if the absolute value of for the estimated RV coefficient is greater than a threshold at the -th percentile of , which is set here as with the significance level and the number of coefficients to be tested. The significance level from testing multiple connectivity entries are adjusted using the Bonferroni method. Note that in (12), the sampling distribution of sample RV coefficients even under null, depends on the sample size and the complexity of the covariance matrix for each pair of clusters, as encoded by . The RVs take high values when is small and is very high-dimensional. Modified versions of RV coefficients (jose2014) can be used in future works to solve this limitation.
4 Simulations
We evaluate the proposed MSFA model for estimating large-scale, community structure of connectivity networks at the node-cluster level, using simulated network data. We focus on comparing the performance of (1.) the MSFA model-based estimator with the sample covariance matrix and other large-dimensional covariance estimators for the whole-network (between-node) connectivity and (2.) the RV-based coefficients using the cluster-specific factor time-series with that using mean time-series for the between-cluster connectivity. The connectivity between time series from distinct network nodes typically exhibits high level of correlations (both auto- and cross-) and modularity. To emulate both these dependence structure, we used a covariance-stationary structured vector autoregressive (VAR) model of order one, to generate the node wise time-series for clusters
[TABLE]
where is a global VAR coefficient matrix that measures effective (directed) connectivity of the whole network, and with a block structure to represent the network modules. The diagonal block is the coefficient matrix which quantifies the dependence of on and measures the directed connectivity between nodes within the cluster . A non-zero element of indicates the presence of directed influence in a Granger-causality sense from node to node within cluster . The off-diagonal block , measures the directed influence from cluster to cluster . is a Gaussian white noise with and .
Under model (14), the functional connectivity in is related to its effective counterpart by
[TABLE]
where the process covariance matrix is invariant over time i.e. , which can be re-written in a vectorized form where = is a matrix. All absolute eigenvalues of are assumed to be less than one to ensure stationarity of the process and invertibility of .
We construct a synthetic network of 5 clusters each with 25 nodes. We assume following structure for the ground-truth connectivity matrix for generating process (14)
[TABLE]
The synthetic network is modular, allowing strong connections between nodes within each cluster but weak connections across different clusters. The nodes within clusters are allowed to be highly inter-connected but scarcely connected to nodes in other clusters, i.e. all diagonal-blocks have full entries and the non-zero off-diagonal blocks are sparse. All other entries of are zero. The values of the non-zero entries were randomly selected. The noise variance is set .
We used one realization of the synthetic VAR coefficient matrix and the implied covariance matrix by (15) to generate synthetic network time series data. We computed the corresponding correlation matrix and RV coefficient matrix from , as ground-truth for evaluation for the whole-network between-node and between-cluster connectivity. We compared the MSFA model-based estimator (as computed in Step 2.4 of Algorithm 1) with the sample correlation matrix, and the estimator computed by using the mean with using the factor series of each cluster. To investigate the performance of the estimators under different scenarios of dimensionality , and , we varied the number of time points from to with an increment of 25. The time series dimension is fixed as with per cluster. 100 simulations were repeated for each . To measure the estimation performance, we evaluated the total squared errors over all entries between the true and the estimated dependency matrices, defined for the whole-network between-node and between-cluster connectivity as and , where denotes Frobenius norm of matrix .
4.1 Results for Fixed
Fig. 2 plots the means and standard deviations of estimation errors under Frobenius norm for various estimators over 100 replications of simulations, as a function of sample size . In Fig. 2(top), we evaluate the factor-based estimates for different number of factors 1, 5, 10 and 15 fixed for each cluster.
For the node-wise connectivity (Fig. 2 (a)), when is small relative to dimension , the MSFA estimator of clearly outperforms the sample correlation matrix, with substantially lower estimation errors especially when . This suggests the robustness of the MSFA estimator in small-sample settings, probably due to construction of the large covariance matrix from lower-dimensional factor-based sub-matrices, which are reliably estimated by the PCA based on larger amount of data as . As expected, the sample covariance with small samples produces poor estimate, which is ill-conditioned when and becomes singular when . Using smaller number of factors tends to perform better than large when is small. This may be because the number of reliably estimated principal components is limited by the sample size and inclusion of more components when is small will probably induce noisy estimates. Another reason is that the factor-based covariance estimator using more components will converge to the sample covariance matrix as a limit.
As expected, estimation errors of both methods drop as increases. When is large, where more data is available for estimation, the sample covariance, however, performs better than factor-based estimator which basically relies on subspace approximation of the full covariance matrix. In contrast to small , factor-based estimates perform better with increase of under large , because additional components can better explain connectivity structure in the data.
For between-cluster connectivity (Fig. 2(b)), estimator based on the factors generally gives lower errors than the mean time series, especially for , suggesting that the factors can better characterize the correlations within the clusters. The first factor behaves similarly to the mean, as evident from the same errors across . Fig.3 shows the true and estimated RV-based connectivity matrices computed from the averaged correlation matrix of the mean and factor time series (with ) over 100 replications. We can see that the factor-based estimates more closely resemble the true connectivity pattern, e.g. accurately identifying the connections between clusters (-) and ( and ) which are mis-detected by estimates based on average time series.
4.2 Results for Adaptive
We also evaluated the performance of MSFA estimator with adaptively selected for each cluster according to criteria in (7) and (8). Table 1 shows the values of selected using BIC and thresholds and of variance. The results are averages over 100 realizations. As expected, more factors are selected to explain greater variability of the data. Use of and BIC select the first principal component. BIC tends to suggest low number of factors. To cover of the total variance, the first two principal components are sufficient consistently for all clusters. These most likely capture the dominant information that is shared across all the clusters. The number of additional components selected by using the higher percentage and varies for different clusters. These capture the detailed variability distinctive to individual clusters. Moreover, fewer factors are needed for clusters that are strongly and densely connected with other clusters, e.g. and as shown in Fig. 3(a), compared to clusters with few and weak connections e.g. . This is because highly correlated time series contains many redundant information and thus can be explained by only few common factors. Therefore, the optimal number of factors, which varies according to dependency structure of each cluster, should be selected adaptively rather than held fixed for the entire brain as in most PCA analyses of fMRI.
Fig. 2(bottom) plots the estimation errors obtained using obtained adaptively for the different thresholds of variance. Similar to the results for the fixed in Fig.2(top), the MSFA estimators with adaptive show improved performance over the sample correlation matrix for between-node connectivity (in Fig. 2(c)) and RV coefficient based on average time series for between-cluster connectivity (in Fig. 2(d)). To compare performance of the adaptive and the fixed fairly, we contrast the results for and (with respective average number of selected factors over all clusters = 5 and 11 as in Table 1) with that for = 5 and 10 in Fig. 2(top). The adaptive- approach generally outperforms the fixed- approach for both scales of connectivity, particularly when is small compared to . This suggests that use of adaptive which is able to capture the cluster-specific dependency structure, can improve the connectivity estimates. Based on these simulation results, we will use the MSFA estimator with adaptive to analyze real fMRI data.
4.3 Comparison with Other Covariance Estimators
In addition to the factor-based estimators, various regularization methods have been proposed in recent years for estimating a large covariance matrix and its inverse (or precision matrix). The first class of estimators are based on the shrinkage of sample covariance eigenvalues (Ledoit and Wolf,, 2004). The second includes regularizing the covariance matrix by banding, tapering and thresholding (Bickel and Levina,, 2008; Cai and Yuan,, 2012). The third imposes sparsity on the precision matrix in graphical models with penalization (Yuan and Lin,, 2007; Cai et al.,, 2011), extended to a low-rank plus sparse estimation by combining latent variable and graphical modeling (Chandrasekaran et al.,, 2012). However, the main aim of this paper is to develop a covariance modeling approach for the purpose of analyzing large dependence in networks with multi-scale structure, but not to compete with other advanced large covariance estimators. Therefore, for evaluation purposes, we compare the performance of our proposed MSFA model-based estimator only with two well-known high-dimensional covariance estimators as benchmarks: the shrinkage estimator of Ledoit and Wolf (LW) (Ledoit and Wolf,, 2004), and the graphical lasso (glasso) regularized estimator of Friedman et al. (Friedman et al.,, 2008). We focus on assessing the estimation of a single-block, high-dimensional covariance matrix i.e. the whole-network node-wise connectivity. Note that our method offers additional advantage of multi-scale covariance analysis over the above-mentioned methods which mostly estimate a single-block covariance matrix, and our framework can potentially be extended to accommodate the shrinkage and sparsity.
We performed statistical comparisons between the estimators with repeated ANOVA tests via pairwise confidence intervals, using a linear mixed effects model with the squared error as response variable. There is no significant difference in performance between a pair of estimators, if the computed confidence interval for the difference in their squared errors contains zero. The confidence intervals are adjusted using the Bonferroni’s method for multiple comparisons at a global confidence level of . The estimation errors of over 100 replications by various covariance estimators for different are reported in Table 2. For the glasso, penalty parameter is used, and the covariance estimate was obtained from the estimated inverse. As expected, both LW and glasso significantly outperform the sample covariance when , for , but fail to deliver any advantages or even perform worse when is large. Interestingly, the MSFA estimator is shown to improve substantially over the both large covariance estimators with significantly lower estimation errors for all cases of dimensionality, and only slightly underperformed relative to the sample covariance for large . This suggests that the MSFA provides a more robust and better-conditioned covariance estimator. There is also significant improvement by using as compared to for all settings.
5 Application to Connectivity in fMRI Data
In this section, we analyze a high-dimensional real resting-state fMRI data using the proposed MSFA approach. Spontaneuous fluctuations of the blood-oxygen-level-dependent (BOLD) fMRI signals during rest, are temporally correlated across distinct brain regions, revealing large-scale coherent spatial patterns called resting-state networks (RSNs) (van den Heuvel and Hulshoff,, 2010). We investigated three hierarchical levels of nested modularity in the resting-state brain functional networks, namely, (1.) voxels–ROIs; (2.) ROIs–functional systems; and (3.) systems–whole brain, in terms of within-module and between-module functional connectivity. We first partition the whole-brain network into a set of anatomically-parcellated ROIs and extract a few latent factors by PCA to summarize the massive voxel data within each ROI. The high-dimensional voxel-wise connectivity within ROIs is characterized by the low-dimensional factors. A similar approach (Sato et al.,, 2010) uses PCs from each ROI to analyze between-ROI connectivity, however, neglected the fine-scale between-voxel connectivity.
5.1 Resting-State fMRI Data
1) Data acquisition and preprocessing: We studied resting-state fMRI data of 10 subjects from a data set available at NITRC (https://www.nitrc.org/projects/nyu_trt/). A time series of BOLD functional images were acquired on a Siemens Allegra 3.0-Tesla scanner using a T2-weighted gradient-echo planar imaging (EPI) sequence (TR/TE = 2000/25 ms; voxel size = mm3; matrix = ; 39 slices). Subjects were asked to relax during scans. The data were preprocessed with motion correction, normalization and spatial smoothing.
2) Parcellation: We used the AAL atlas to obtain an anatomical parcellation of the whole brain into 90 ROIs. In this study, the ROIs were grouped into six pre-defined resting-state system networks of similar anatomical and functional properties, based on the templates in (Allen et al.,, 2011, 2012; Li et al.,, 2011). The considered RSNs include sub-cortical (SCN), auditory (AN), sensorimotor (SMN), visual (VN), attentional (ATN) and default mode network (DMN) The ROIs and their mapping to corresponding RSNs with overlapping are given in Appendix 7.2. We followed the ROI abbreviations in (Salvador et al.,, 2005).
5.2 Analysis of Voxel-wise Connectivity
Voxel-wise analysis is challenging due to low signal-to-noise ratio at individual voxels. The standard approach is to compute the average time series over each ROI. In contrast, the MSFA approach achieves dimension-reduction which leads to reliable and computationally efficient connectivity estimates. Moreover, by using PCA, the MSFA approach retains only the dominant information (components with largest eigenvalues). Those with smaller eigenvalues are considered to correspond to either measurement noise, machine noise and the weak physiological signals of non-interest. We fitted a local FA model on the voxel time series for each ROI using PCA estimation and then constructed the covariance matrix between voxels as quantified by . The number of factors, , was selected data-adaptively for each ROI based on threshold or maximum of the number of voxels. The threshold was chosen such that the number of factors are sufficient to capture the variability in the data and hence the fine dependency structure particularly at the voxel scale, while excluding fluctuations that are probably noises which could induce spurious connectivity estimates. For this data, a total of 145 factors were selected to represent brain activity from 183,348 voxels of the entire brain volume. Thus, this represents a massive reduction of the dimension of (since total number of factors is only of the total number of voxels). The number of voxel time series and the selected are given in Appendix Table 1.
Fig. 4 shows the estimated correlation matrices of voxels in four key ROIs that belongs to the DMN a for single subject. The regions of DMN, a well-known RSN, has been reported to exhibit increased activation and correlation in neuronal activities during rest compared to goal-oriented tasks, suggesting it as an important idling mode of the brain (Raichle and Snyder,, 2007). To our knowledge, our study is probably among the few reporting the voxel-level connectivity in the DMN regions. The estimates using only a small number of factors is able to reveal the existence of complex, large amount of interactions between massive voxels, within a small brain region, even during resting state. Within these regions, there appears to be a pervasively strong connectivity between many pairs of voxels. We can see that the PCC, a major hub that is strongly inter-connected with many other brain regions, also exhibits the strongest intra-connectivity within the region itself. This is followed by IPL which is another active region of the DMN.
5.3 Analysis of Between-ROI Connectivity
In this section and the next, we applied the global factor model to analyze the higher scales of functional connectivity between ROIs (and between functional system sub-networks), via the correlations between factors associated with each region. The analysis is illustrated using a single subject’s data. We further computed the RV coefficient as a single measure to summarize the strength of connectivity between the pairs of ROIs (or networks). Fig. 5 shows the correlation matrix, (absolute-valued for comparison with the non-negative RVs) of the factor time series over the entire brain, constructed form sub-blocks of correlation matrices of factors between every pair of ROIs. Note that the factors are highly correlated across different regions despite being independent within a region. This suggests that, while the intra-regional connectivity is captured mainly by the mixing matrix, the inter-regional connectivity is quantified through the dependence between factors across regions. Our method extends the roles of the factor series beyond merely explaining the variance of the data, as in the conventional factor-based connectivity analysis which is limited by the independent component assumption.
Fig. 6 shows the between-ROI RV-coefficient-based connectivity , computed from the correlations of mean and factor time series between ROIs. The results from our method have identified a markedly modular structure of the brain functional networks during rest, as reported in previous studies (Ferrarini et al.,, 2009). The ROIs within a resting-state network with similar functional relevance are more densely connected with each others, as evident particularly for the SMN, ATN and DMN. Whereas, the ROIs from different networks are sparsely connected especially between SCN, AN and VN with the other networks. However, relatively denser connections between ROIs were found across the SMN, ATN and DMN, with the strongest strength of connectivity between the ATN and DMN. Compared to our proposed method, the usual mean-time series approach gives a sparser between-ROI connectivity. A natural question here is whether the mean-time series approach has an inflated false negative (low power in detecting connectivity) or the proposed method has an inflated false positive. We believe that the former is more likely based on our simulation results.
Fig. 7 shows the topological maps of the ROI-wise connectivity within four RSNs, inferred by the estimated factor-based RV coefficients. Only significant connections with standardized coefficients greater than a threshold value of 3 are shown. The estimates by our approach shows that the ROIs are inter-connected within common functional and anatomical domains, revealing distinct spatial patterns, as identified using the spatial ICA in (Allen et al.,, 2011; Li et al.,, 2011; Allen et al.,, 2012). The sensorimotor network, centered at central sulcus, covers primary somatosensory, primary motor and supplementary motor cortex as reported by (Biswal et al.,, 1995), located in regions e.g. precentral gyrus, postcentral gyrus and supplementary motor area. The visual network involves regions in the occipital lobes (Grill-Spector and Malach,, 2004). The ATN, involved in attentional processing and monitoring, consists of few sub-networks including the dorsal and ventral systems (Vossel et al.,, 2014). The resting-state DMN consists of highly inter-correlated ROIs related to posterior cingulate cortex (PCC)/precuneus, medial prefrontal cortex and the left and right inferior parietal lobule. The PCC is correctly identified as a major hub of the DMN, strongly connected with other regions, as reported in many studies (Fransson and Marrelec,, 2008).
5.4 Analysis of Between-Network Connectivity
Fig. 8 shows the between-network RV-coefficient-based connectivity computed from the correlations between mean and factor time series across six resting-state brain networks. The mean-time series approach produced the sparsest between network connectivity. The proposed method captured a more extensive connectivity where the strength and extent is greater when there are more factors per network (higher percentage of variance explained: vs . It is appropriate to use small number of dominant factors because connectivity captured by the most factors could be spurious (due to random noise generated by the magnet and spread across the entire space) or an artifact (due to smoothing effect).
The VN, AN and SMN are related to the lower-level sensory processing while ATN and DMN to the higher-order cognitive functions. Within the cluster of low-level sensory-specific RSNs, we observe the presence of intra-dependency between these sensation networks which is consistent with the results in the similar study of directed connectivity across RSNs (Li et al.,, 2011). Using factors that explain only of the data variance, we found dependency of SMN with both AN and VN, with slightly stronger connection strength between the SMN and VN, and detected an additional VN-AN connection with the of variation, which, however, are completely missed by the estimates based on the single average time series. For the high-level cognitive RSNs, the strong dependency between the ATN and DMN, in fact the strongest among all the dependencies across RSNs, are identified consistently by both approaches, although slightly more pronounced from the factor-based estimates. This is in accordance with the recent findings of anti-correlations between the default and attentional systems in numerous studies (Fox et al.,, 2005). Using the of variance is also able to reveal the weak connections between the SCN with other networks.
The sensory-motor networks and cognitive networks are inter-dependent. The SMN exhibits strong correlation with the cognitive networks, followed by VN and AN, as detected by factor-based approach. The ATN has stronger connections with the sensory networks compared to the DMN, with the most pronounced synchrony with the SMN. The strong connection between the ATN and SMN found here is agreement with the findings using ICA (Allen et al.,, 2011), but was unable to be detected by Bayesian network model (Li et al.,, 2011). Besides, The DMN might play a pivotal roles in integrating information from all other systems, indicated by presence of connections with all networks including the subcortical network as detected using the of variation. In summary, the RSNs display modular organization where networks with similar functional relevance are densely connected, as the connectivity at the voxel and ROI levels. However, during the resting-state, the intra-connectivity among the cognitive networks are enhanced relative to that among the sensory-motor networks which are usually more correlated during active state when performing tasks, which require more interactions between the sensory and motor functions.
5.5 Multi-Subject Analysis
Fig. 9 shows the group mean (left) and variability (right) in the between-ROI and between-network functional connectivity matrices for 10 subjects. The results are averages over subject-specific estimates obtained by applying the MSFA method (with of data variance) on each subject. The average connectivity matrices demonstrate that the modular structure of the between-ROI connectivity (Fig. 9(a)), and the strong connections between the SMN with both ATN and DMN and also between the ATN and DMN (Fig. 9(c)), are stable and reproducible across subjects. The variability indicates the general deviation of the subjects from the mean. From Fig. 9(b), the major variability in the between-ROI connectivity is found within each functional network, with the highest variation in the SMN followed by the AN. Fig. 9(d) reveals the most pronounced variation across subjects in the between-network connectivity is observed between the ATN and the sensory-motor networks (AN, SMN and VN), but interestingly its connection with DMN exhibits the least variability.
6 Conclusion
We developed a multi-scale factor analysis (MSFA) model which is a statistical approach to modeling and estimating hierarchical connectivity between nodes, clusters and sub-networks in a large-dimensional network. The MSFA provides a framework for reducing dimensionality locally (within each prescribed cluster or sub-network) by estimating the principal components series separately in each cluster. These components provide a summary of localized activity that explain the most variability within the cluster or sub-network. The proposed MSFA approach gives a good representation of multi-scale dependence and thus captures connectivity at the local (within-cluster) level and global (between clusters and between networks) level. It achieves dimension reduction in each cluster and therefore has the ability to handle massive datasets such as fMRI. The approach provides statistically reliable estimation of large-dimensional covariances to measure fine-scale functional connectivity based on the factor analysis, and summarize global-scale networks using RV dependency.
The results from our simulation studies show that the factor-based estimator outperforms the conventional sample covariance matrix for high-dimensional voxel-wise connectivity and mean-based approach for inter-regional connectivity. Applications to resting-state fMRI data demonstrate the ability of the MSFA approach in identifying the modular organization of human brain networks during rest, at the three-level hierarchy of connectivity (voxel-ROI-system network), in a unified, structural and computationally efficient way. This is in contrast with many resting-state fMRI studies that analyzed only one or two levels, often of specific networks. Our procedure is able to estimate the voxel-wise correlations in a simultaneous instead of pairwise manner, providing new insights into the resting-state connectivity at a finer scale. Moreover, our method detected connectivity of major resting-state networks, in consistency with the literature, but further reveal the global interactions across these networks, i.e. between the low-level sensory-motor and high-level cognitive functions. Future works might extend the proposed method to analyzing dynamic brain connectivity (Lindquist et al.,, 2014; Samdin et al.,, 2017; Fiecas and Ombao,, 2016). Besides, this multi-scale modeling framework can be extended to handle directed dependence based on the idea of factor-based subspace VAR analysis in (Ting et al.,, 2014, 2016) by assuming the extracted factors for each cluster to follow a regional VAR model, as addressed in our recent work (Wang et al.,, 2016).
7 Appendix
7.1 Regularity Conditions
Let denotes Frobenius norm of vector or matrix . and denote the maximum and minimum eigenvalues of . We assume the following regularity conditions (used in (Bai,, 2003; Fan et al.,, 2013)) to guarantee consistent estimation of the factors, factor loadings and hence the constructed covariance matrix, for the regional FA models (1). We drop the index for notational simplicity. It can be shown that these conditions are applicable to the global model (2) which has the same form but an appended version of (1).
Assumption 1 (Covariance Structure): As ,
- (a)
There exists such that .
- (b)
There are constants such that .
Assumption 2 (Factors): and as , where with .
Assumption 3 (Factor Loadings): and as .
Assumption 4 (Moments of Errors): There exists a positive constant , such that for all and ,
- (a)
and .
- (b)
, for all , and .
- (c)
and .
- (d)
for every ().
Assumption 1(a) is the pervasiveness condition which implies the first eigenvalues of are all growing to infinity with the dimensionality . Condition 1(b) requires to be well-conditioned and its eigenvalues be uniformly bounded for all large . The decomposition (3) is then asymptotically identified as . These bounds also carry over to the covariance matrix where the largest eigenvalues of diverge fast with whereas all the remaining eigenvalues are bounded as . The Condition 1 is sufficient to imply the existence of a -factor structure in the signals . Moreover, under this condition, the eigenvectors of corresponding to the diverging eigenvalues converge to the factor loadings, suggesting the PCA on the sample covariance is appropriate for estimating the subspace structure in a high-dimensional factor analysis. Assumption 1 is reasonable for fMRI data, as indicated by the divergence of a few eigenvalues of the sample covariance for a brain ROI with large number of nodes, with the rest being close to zero (Fig. 10). This suggests the fMRI data has a factor structure.
Assumptions 2 and 3 serve as the identifiability conditions as discussed in Section II. Moreover, Assumption 2 allows to be serially correlated. Assumption 3 ensures that the factors are pervasive, i.e. having non-negligible contribution on a non-vanishing proportion of individual signal . Assumption 1 easily holds under this condition. Assumption 4 allows for weak serial and cross-sectional correlation in the error terms , as specified in the approximate factor model (Chamberlain and Rothschild,, 1983). In this paper, we assume the fMRI data to follow a strict factor structure (Bai and Li,, 2012), in which are independent across all and with a diagonal error covariance matrix . By assuming for all , with the eigenvalues of simply the diagonal elements, Condition 1 holds for this special case. Moreover, given 4(a), the remaining assumptions are also satisfied under the independence of . Since the approximate factor model is more general, the developed asymptotic results also apply to the strict model adopted here. Fig.11 shows the factor decomposition of covariance matrix for the brain ROI, where the estimated low-rank matrix (Fig. 11(a)) is dominant and accounts for most of the correlations among the voxels, whereas only a small amount of variation is picked-up by the error covariance estimated from residuals (Fig. 11(b)). Besides, most of the off-diagonal elements of the residual covariance matrix are near zero, suggesting negligible cross-correlation in the noise, and thus using strict factor model for fMRI data is not inappropriate.
7.2 ROI-RSN Mapping
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Allen et al., (2012) Allen, E. A., Damaraju, E., Plis, S. M., Erhardt, E. B., Eichele, T., and Calhoun, V. D. (2012). Tracking whole-brain connectivity dynamics in the resting state. Cerebral Cortex , 24:663–676.
- 2Allen et al., (2011) Allen, E. A., Erhardt, E. B., Damaraju, E., Gruner, W., Segall, J. M., Silva, R. F., Havlicek, M., Rachakonda, S., Fries, J., Kalyanam, R., and et al. (2011). A baseline for the multivariate comparison of resting-state networks. Front Syst Neurosci. , 5:1–23.
- 3Bai, (2003) Bai, J. (2003). Inferential theory for factor models of large dimensions. Econometrica , 71:135–171.
- 4Bai and Li, (2012) Bai, J. and Li, K. (2012). Statistical analysis of factor models of high dimension. Ann. Statist. , 40:436–465.
- 5Bai and Ng, (2013) Bai, J. and Ng, S. (2013). Principal components estimation and identification of static factors. J. Econometrics , 176(1):18–29.
- 6Beltrachini et al., (2013) Beltrachini, L., von Ellenrieder, N., and Muravchik, C. H. (2013). Shrinkage approach for spatiotemporal EEG covariance matrix estimation. IEEE Trans. Signal Process. , 61(7):1797–1808.
- 7Betzel and Bassett, (2016) Betzel, R. F. and Bassett, D. S. (2016). Multi-scale brain networks. Neuro Image .
- 8Bickel and Levina, (2008) Bickel, P. J. and Levina, E. (2008). Covariance regularization by thresholding. Ann. Statist. , 36(6):2577–2604.