Learning a bidirectional mapping between human whole-body motion and natural language using deep recurrent neural networks
Matthias Plappert, Christian Mandery, Tamim Asfour

TL;DR
This paper introduces a deep recurrent neural network model that learns a bidirectional, end-to-end mapping between human whole-body motions and natural language descriptions, eliminating the need for manual segmentation or feature engineering.
Contribution
It presents a novel generative model that jointly learns motion and language representations directly from raw data, outperforming traditional symbolic approaches.
Findings
Successfully generates realistic motions from natural language descriptions.
Accurately produces detailed natural language descriptions from human motions.
Demonstrates effectiveness on a large dataset of motions and descriptions.
Abstract
Linking human whole-body motion and natural language is of great interest for the generation of semantic representations of observed human behaviors as well as for the generation of robot behaviors based on natural language input. While there has been a large body of research in this area, most approaches that exist today require a symbolic representation of motions (e.g. in the form of motion primitives), which have to be defined a-priori or require complex segmentation algorithms. In contrast, recent advances in the field of neural networks and especially deep learning have demonstrated that sub-symbolic representations that can be learned end-to-end usually outperform more traditional approaches, for applications such as machine translation. In this paper we propose a generative model that learns a bidirectional mapping between human whole-body motion and natural language using deep…
Click any figure to enlarge with its caption.
 Figure 2
Figure 2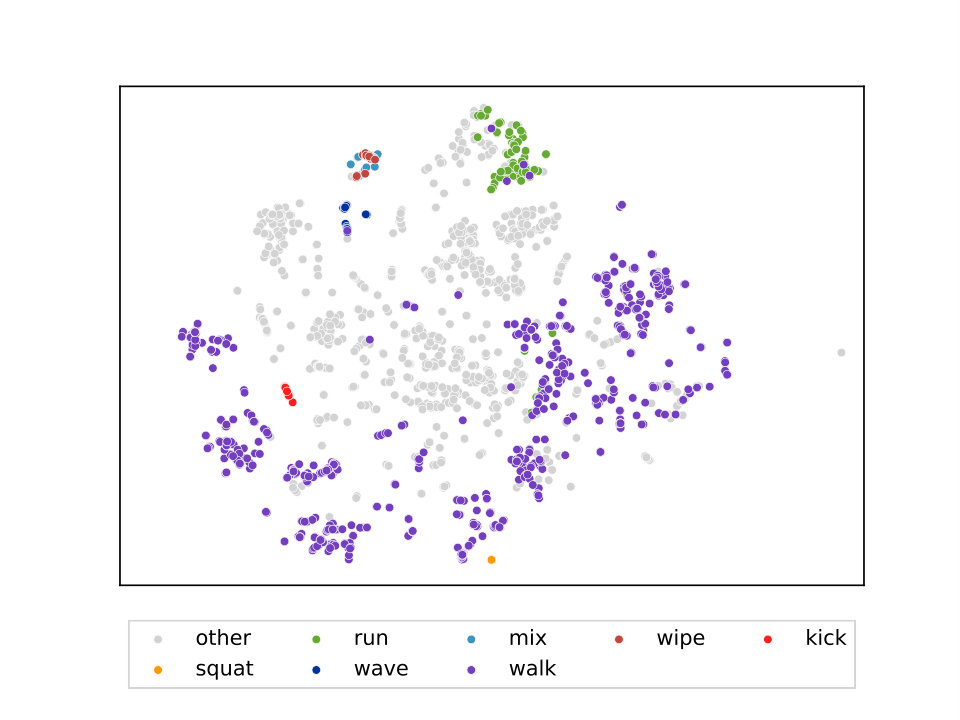 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5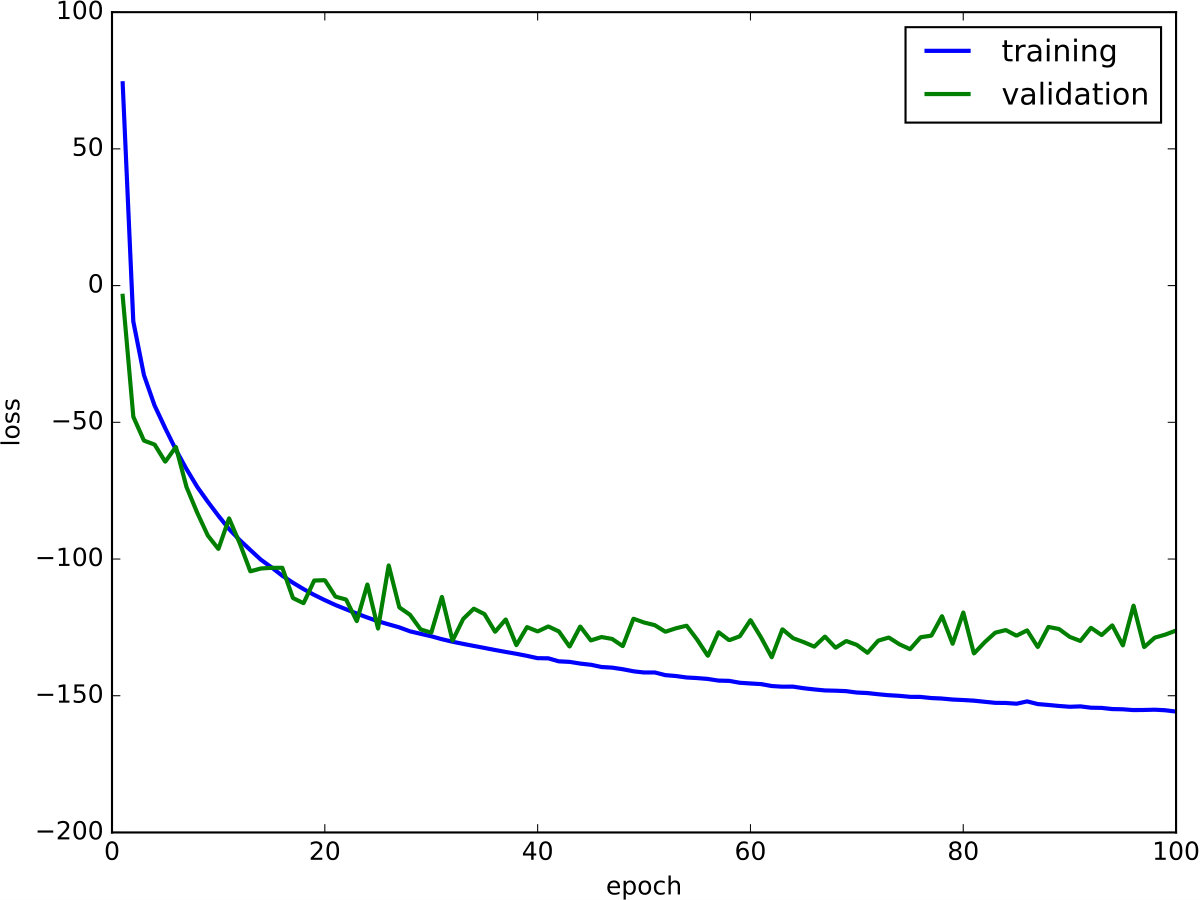 Figure 6
Figure 6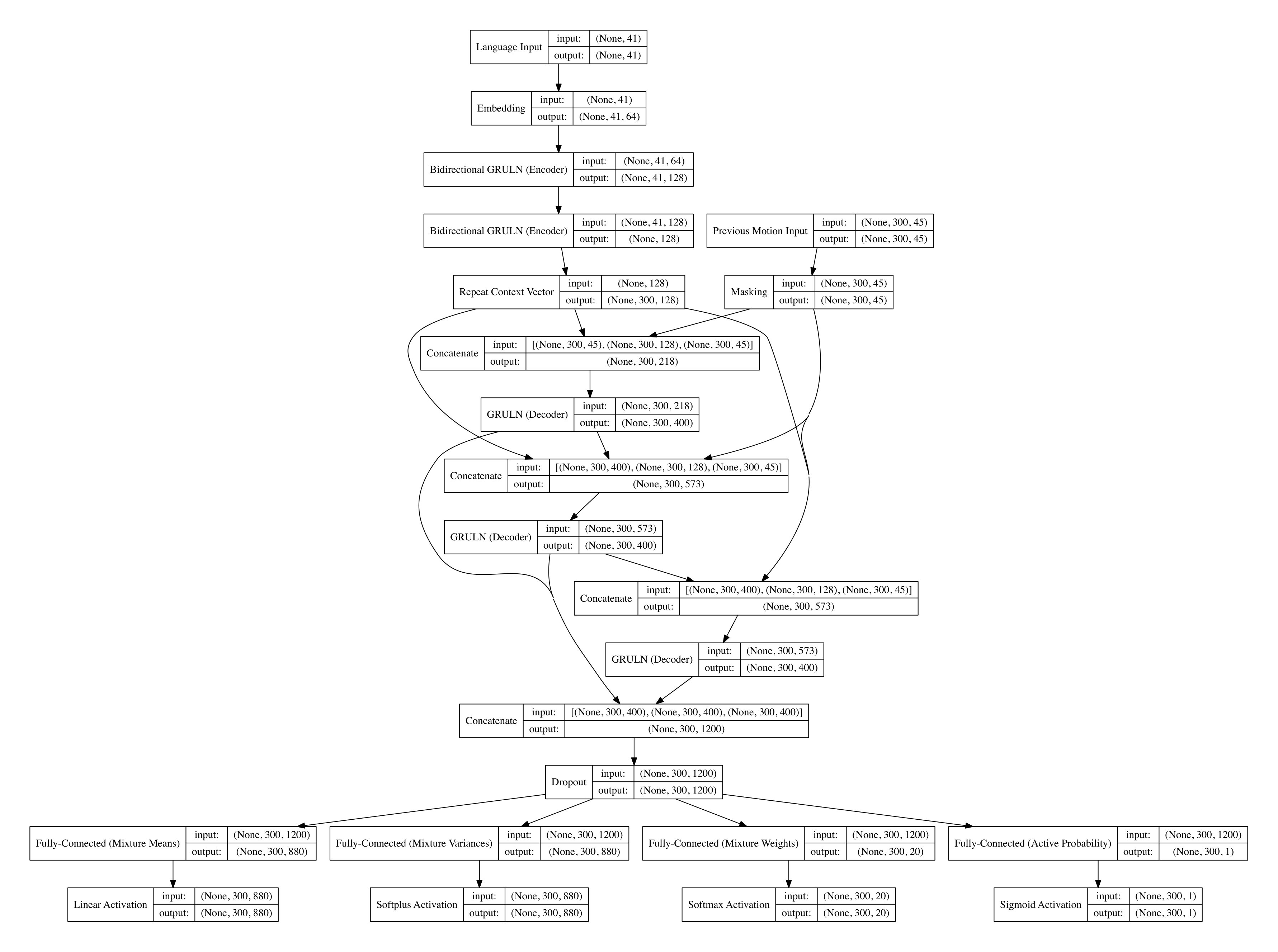 Figure 7
Figure 7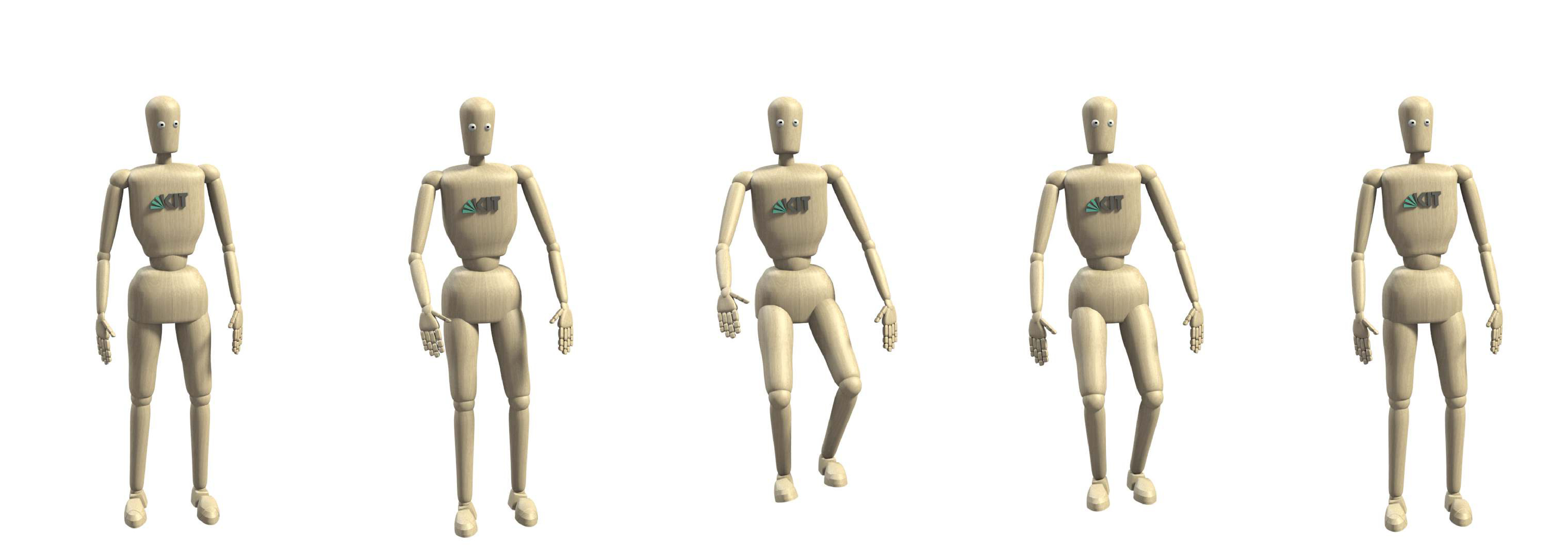 Figure 8
Figure 8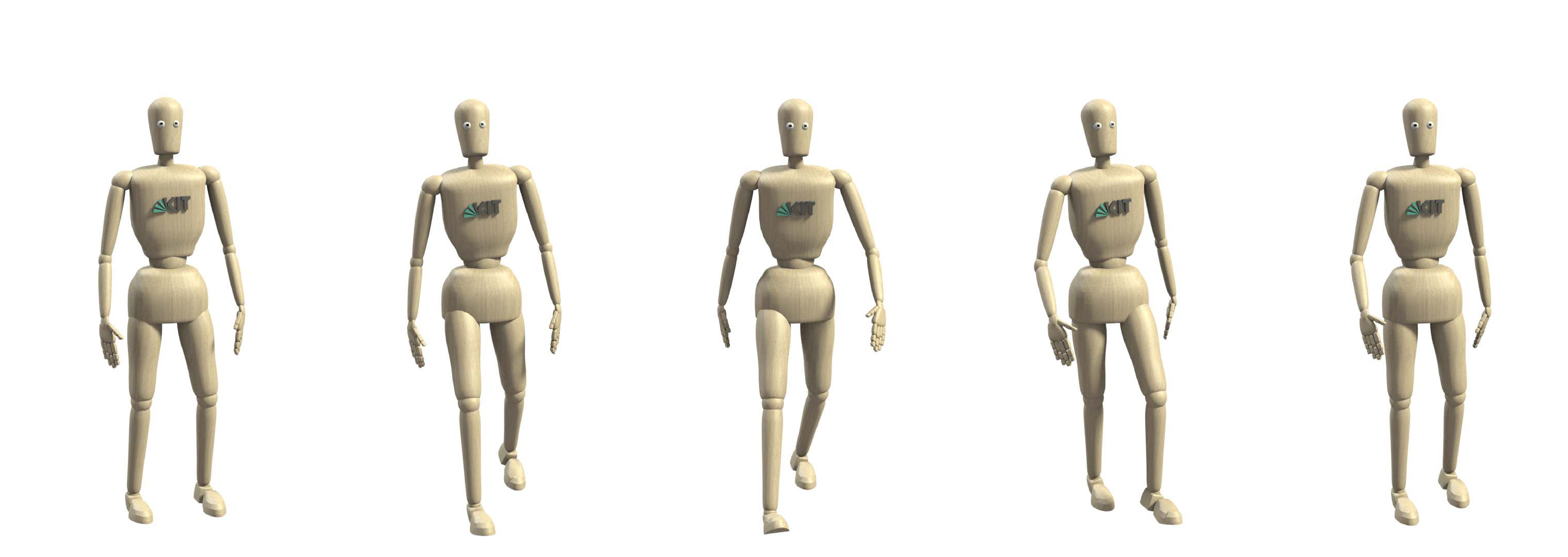 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13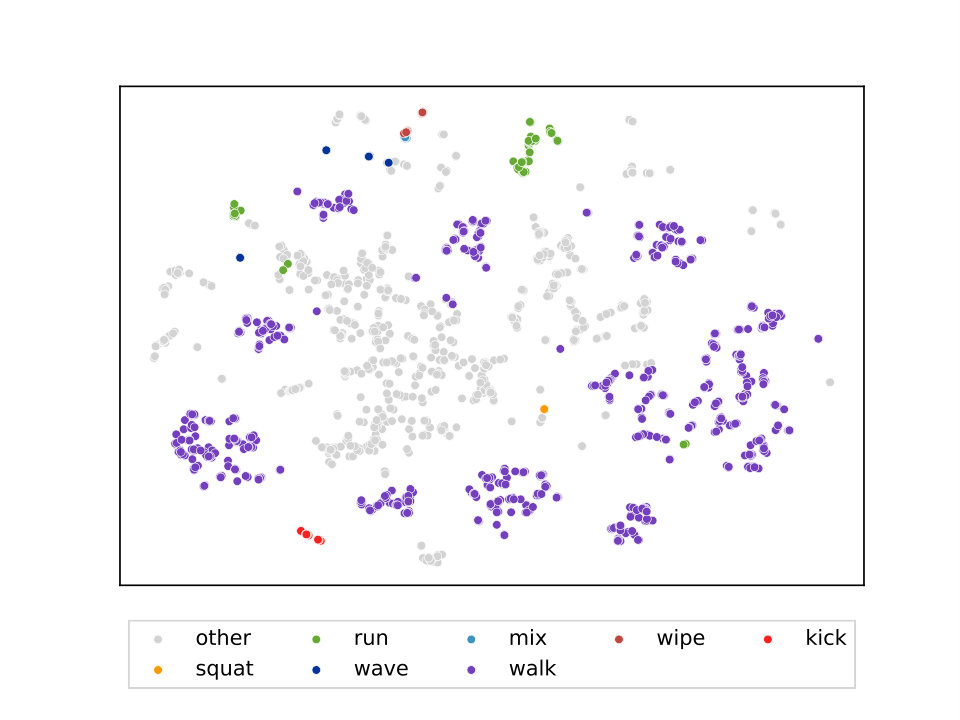 Figure 14
Figure 14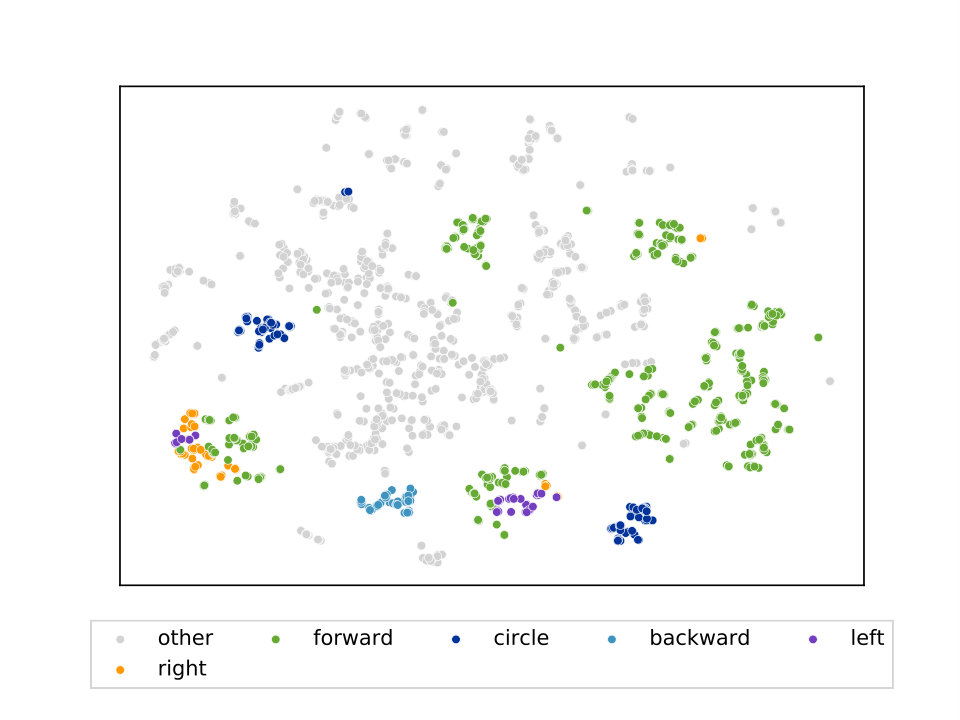 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17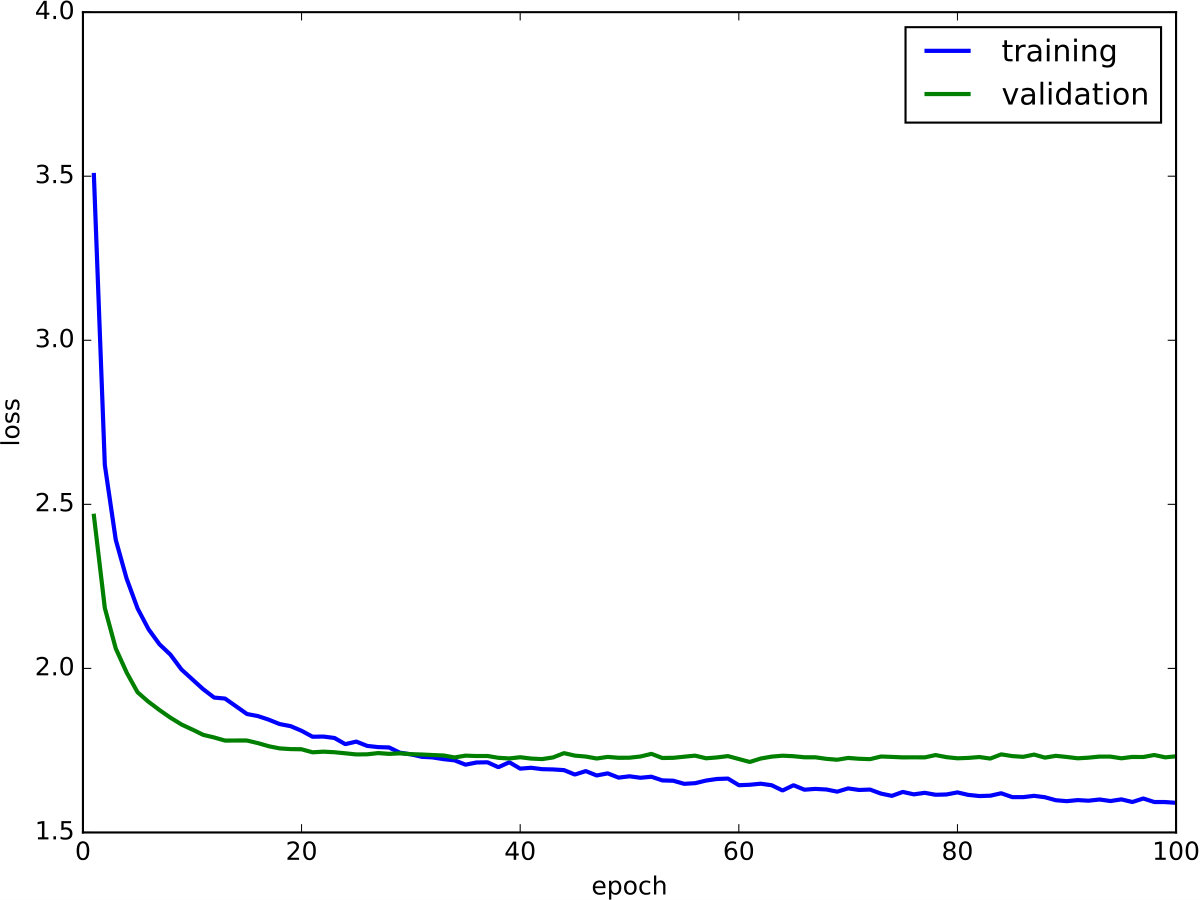 Figure 18
Figure 18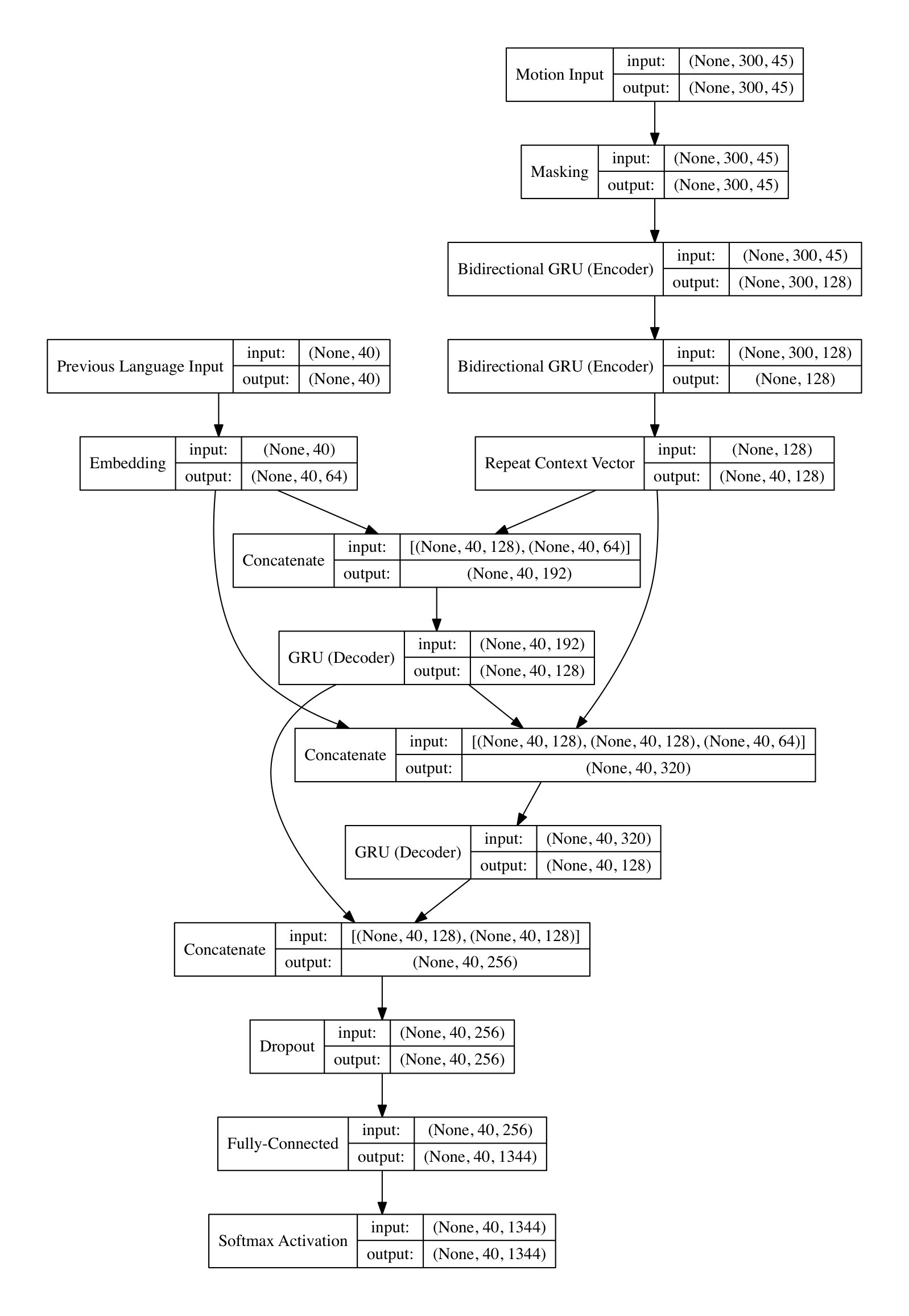 Figure 19
Figure 19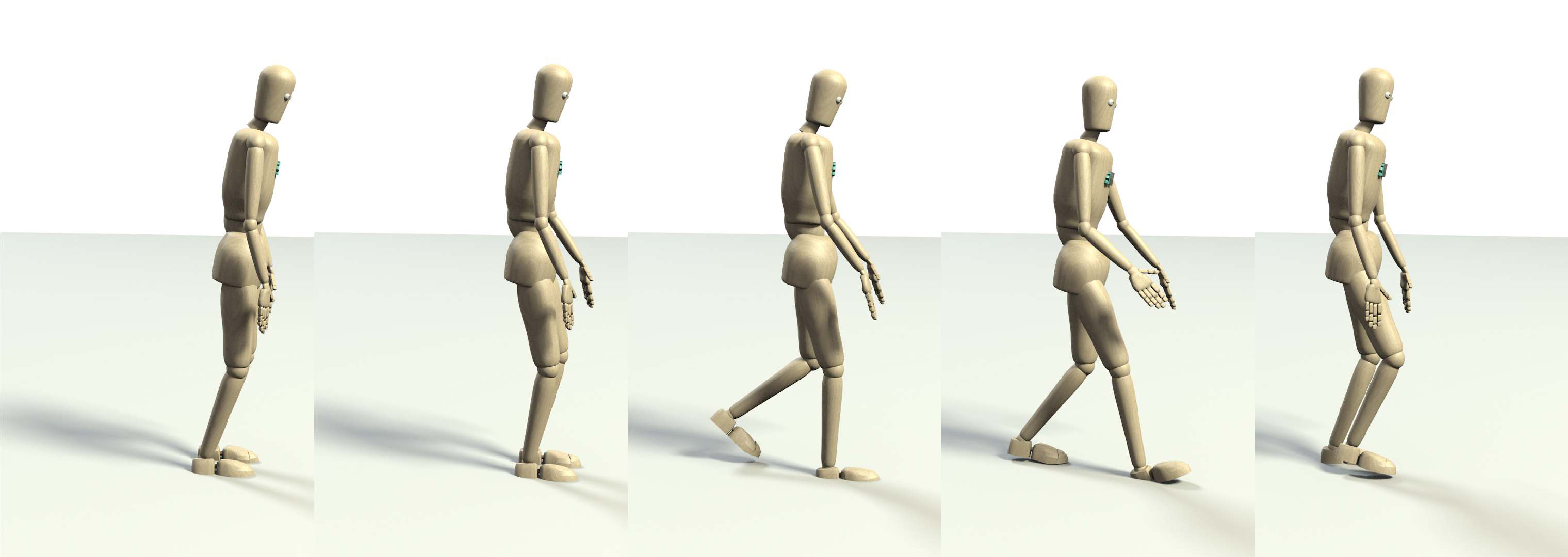 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23 Figure 24
Figure 24 Figure 25
Figure 25 Figure 26
Figure 26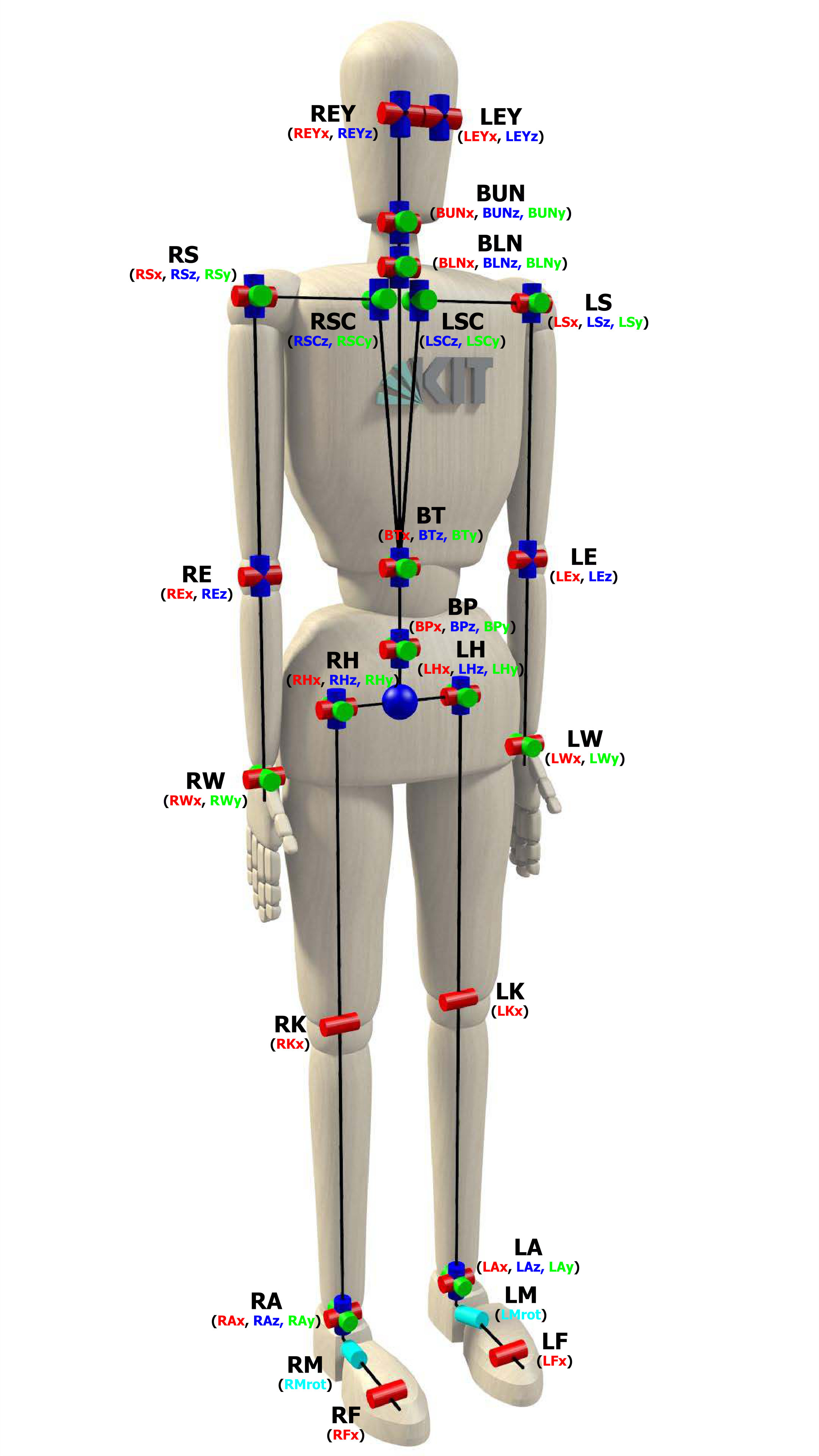 Figure 27
Figure 27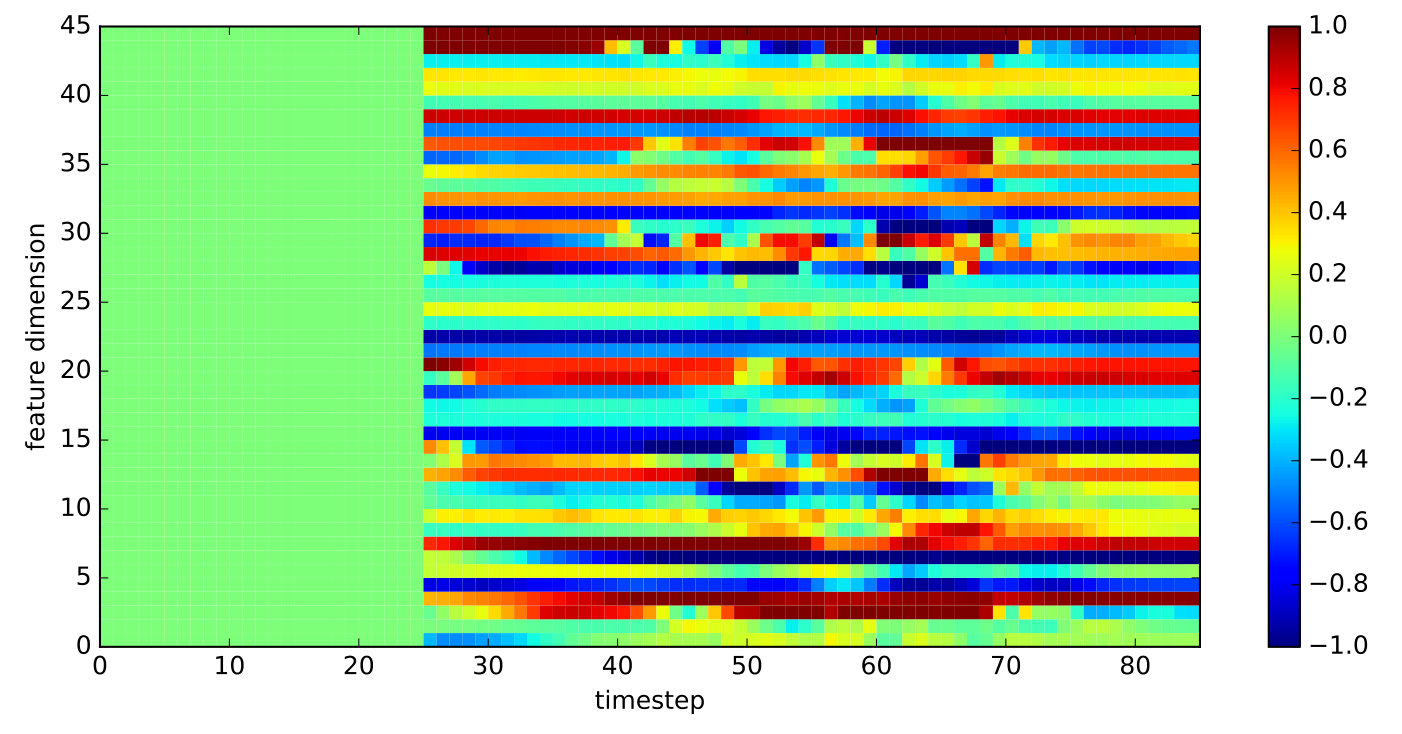 Figure 28
Figure 28 Figure 29
Figure 29| Hyperparameter | Motion-to-Language | Language-to-Motion |
|---|---|---|
| Encoder RNN type | bidirectional GRU | bidirectional GRU with layer normalization |
| Encoder layers | layers | layers |
| Decoder RNN type | GRU | GRU with layer normalization |
| Decoder layers | layers | layers |
| Embedding dimension | ||
| Dropout rate | ||
| Optimizer | Adam with Nesterov | Adam with Nesterov |
| Learning rate | ||
| Gradient clipping | ||
| Batch size | ||
| Training epochs | ||
| Vocabulary size () | ||
| Motion joints () | ||
| Mixture components | n/a | |
| Trainable parameters | ||
| excl. embedding & FC layers |
| Bleu scores | |||||
|---|---|---|---|---|---|
| 1st | 2nd | 3rd | 4th | 5th | |
| Train | 0.387 | 0.355 | 0.330 | 0.329 | 0.302 |
| Test | 0.338 | 0.283 | 0.295 | 0.277 | 0.250 |
| Bleu scores | |||||
|---|---|---|---|---|---|
| 1st | 2nd | 3rd | 4th | 5th | |
| Train | 0.256 | 0.277 | 0.289 | 0.286 | 0.278 |
| Test | 0.249 | 0.242 | 0.288 | 0.249 | 0.240 |
| Relative Performance | |||||
|---|---|---|---|---|---|
| 1st | 2nd | 3rd | 4th | 5th | |
| Train | 66.1% | 71.6% | 74.7% | 73.9% | 71.8% |
| Test | 64.3% | 62.5% | 74.4% | 64.3% | 62.0% |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Learning a bidirectional mapping between human whole-body motion and natural language using deep recurrent neural networks
Matthias Plappert
Christian Mandery
Tamim Asfour
High Performance Humanoid Technologies (H2T), Karlsruhe Institute of Technology (KIT), Adenauerring 2 (Building 50.20), 76131 Karlsruhe, Germany
Abstract
Linking human whole-body motion and natural language is of great interest for the generation of semantic representations of observed human behaviors as well as for the generation of robot behaviors based on natural language input. While there has been a large body of research in this area, most approaches that exist today require a symbolic representation of motions (e.g. in the form of motion primitives), which have to be defined a-priori or require complex segmentation algorithms. In contrast, recent advances in the field of neural networks and especially deep learning have demonstrated that sub-symbolic representations that can be learned end-to-end usually outperform more traditional approaches, for applications such as machine translation. In this paper we propose a generative model that learns a bidirectional mapping between human whole-body motion and natural language using deep recurrent neural networks (RNNs) and sequence-to-sequence learning. Our approach does not require any segmentation or manual feature engineering and learns a distributed representation, which is shared for all motions and descriptions. We evaluate our approach on 2 846 human whole-body motions and 6 187 natural language descriptions thereof from the KIT Motion-Language Dataset. Our results clearly demonstrate the effectiveness of the proposed model: We show that our model generates a wide variety of realistic motions only from descriptions thereof in form of a single sentence. Conversely, our model is also capable of generating correct and detailed natural language descriptions from human motions.
keywords:
human whole-body motion; natural language; sequence-to-sequence learning; recurrent neural network
1 Introduction
An intriguing way to instruct a robot is to first demonstrate the task at hand. In such a setup, a human teacher performs the necessary steps while the robot observes the human’s motion. This way of robot programming is commonly referred to as programming by demonstration [38, 12, 6] and has been extensively studied. However, observing only the motion of a human teacher is often not sufficient as the demonstrator will often include additional or corrective instructions to the student using natural language. In other words, the teacher-student interaction is inherently multi-modal.
Natural language presents itself as an intuitive way of communicating with the robot since it can be used to describe even rather complex motions and their parameterizations. For example, the description “A person waves with the left hand five times.” encodes the motion (waving), the body part that should perform it (left hand) and the number of repetitions (five times). Enabling a robot to combine such rich descriptions in natural language with human whole-body motion therefore facilitate a much richer human-robot communication.
In recent years, deep learning [39, 21] has proven to be very successful in computer vision [36, 27], natural language processing [57, 20, 72] and speech recognition [23]. More recently, researchers have also reported promising results when applying deep learning techniques to problems in robotics [41, 25, 40].
In this paper, we use deep learning techniques to link human whole-body motion and natural language. More specifically, we make use of sequence-to-sequence learning [57] to learn a bidirectional mapping between human whole-body motion and natural language. Human whole-body motion is represented in joint space under the Mater Motor Map (MMM) [68] framework and descriptions thereof are in the form of complete English sentences. Figure 1 illustrates the desired mapping.
On one hand, this mapping allows us to generate rich descriptions of observed human motion, which can, for example, be used in a motion database. On the other hand, our model is capable of generating a wide range of different motions only from a description thereof in natural language. Even more so, the proposed system is capable of successfully synthesizing certain variations of motion, e.g. waving with the left or the right hand as well as walking quickly or slowly simply by specifying this parametrization in the natural language description.
The remainder of this paper is organized as follows. In Section 2 we review work that is related to our approach of combining human motion and natural language. Section 3 describes in detail how we represent both modalities, human motion and natural language, for use in the proposed bidirectional mapping. The model that is used to learn this mapping is presented in Section 4. In Section 5 we show that the proposed approach is capable of learning the desired bidirectional mapping. We also analyze the model and its learned representations in depth. Finally, Section 6 summaries and discusses our results and points out promising areas for future work.
2 Related work
Different models to encode human motion have been proposed in the literature. [65], [37] and [28] use hidden Markov models (HMMs) to learn from observation. Their model can also be used to generate motion sequences by sampling from it. [67] and [66] propose conditional restricted Boltzmann machines (CRBMs) to learn from and then generate human whole-body motion. [8] use a Gaussian mixture model (GMM) to encode motion data. A different approach is proposed by [54], who uses dynamic movement primitives (DMPs) to model motion using a set differential equations. More recently, [17] and [33] have used recurrent neural networks (RNNs) to learn to generate human motion from observation. [48] have combined trajectory optimization and deep neural networks to generate complex and goal-directed movement for a diverse set of characters.
[7] use deep feed-forward neural networks and an encoder-decoder architecture to learn a lower-dimensional latent representation that can be used for classification and motion generation.
While many models have been proposed to encode human motion, less research has been conducted on the question how to combine human motion and natural language. [58] and [64] describe a system that allows to learn a mapping between human motion and word labels. The authors segment human motion and encode the resulting motion primitives into hidden Markov models, which then form the motion symbol space or proto symbol space. Similarly, the word space is constructed from the associated word labels. Finally, the authors describe a projection between the motion symbol space and word space, which allows to obtain a sequence of motion symbols from a sequence of words and vice versa.
[60, 61, 62, 63] learn a bidirectional mapping between human motion and natural language in the form of a complete sentence. The authors propose two components that, when combined, realize the desired mapping. In the motion language model, motion primitives, which are encoded into HMMs, are probabilistically related to words using latent variables. These latent variables represent non-observable properties like the semantics. The conditional probabilities that govern the association between motion and language are obtained by using the EM algorithm. The second part, the natural language model, captures the syntactical structure of natural language. Different approaches to realize this model have been described by the authors, e.g. HMMs [60, 61] or bigram models [62, 63]. Both models are finally combined to generate natural language descriptions of motion by first recognizing the motion, then obtaining an unordered set of likely words associated with that motion (using the motion language model) and finally finding a likely sequence of these words (using the natural language model). This approach is commonly referred to as bag-of-words. Similarly, the most likely motion can be obtained from a description thereof in natural language by searching for the motion symbol with maximum likelihood given the word sequence.
[46] present an approach where motion symbols in the form of motion primitives are learned using parametric hidden Markov models (PHMMs). Adverbs (e.g. slowly) are used to parametrize the PHMMs and the natural language is modeled in a similar way to aforementioned works using a bigram language model. Although their approach can enable the generation of textual representations from motions, the presented evaluation only covers the other direction of motion generation from textual descriptions. This evaluation considers a rather limited set of 7 different motion primitives and 13 words, and is based on a virtual scenario of a human-robot cooperation task with a 2 degrees of freedom haptic interface. A different approach is described by [56] and [49, 50] where the authors use a recurrent neural network with parametric bias (RNNPB) model to combine movement of simple robots (e.g. a robot platform or a robot arm) with simple commands in the form of words (e.g. push red). The authors demonstrate that their approach can generate the appropriate trajectories corresponding to a given command and vice versa. Attempts have been made to gradually increase the complexity and supported variety of the commands [1, 51].
In recent years, there has been extensive work in the field of deep learning to combine natural language with other modalities like images [34, 70] and videos [13, 69]. A recent survey on proposed solutions to the problem of visualizing natural language descriptions is given in [26].
3 Data representation
3.1 Human whole-body motion
In this work, we only consider human whole-body motion that has been recorded with an optical marker-based motion capture system. Briefly speaking, such a system observes a set of reflective markers placed on specific anatomical landmarks of the human subject using multiple cameras that are positioned around the subject. The Cartesian coordinates of each marker can then be reconstructed using triangulation. For an in-depth discussion of motion capture techniques, we refer the reader to [16].
While this approach allows for highly accurate motion acquisition, the resulting representation of motion in the form of marker trajectories has several drawbacks. First, the positions of the markers depend on the reference coordinate system, which varies across recordings and thus would require some sort of normalization to obtain an invariant representation. Second, different marker sets with a varying number of markers or different marker locations on the human body may be used. Third, the data is high-dimensional since each marker position requires three dimensions and usually more than markers are used.
We therefore use the Master Motor Map (MMM) framework [45, 68, 2] to represent human whole-body motion in joint space. This is realized by the MMM reference model, which specifies the kinematics of the human body (see Figure 2). The conversion from Cartesian to joint space is then achieved by minimizing the squared distance between the physical markers on the human subject and the virtual markers on the reference model w.r.t. to the joint angles of the kinematic model. The resulting joint representation is no longer dependent on a reference coordinate system, abstracts away the concrete marker set that was used during recording and has significantly lower dimensionality than the Cartesian representation.
Throughout this paper, we use joints of the MMM reference model to represent human motion, which are distributed over the torso, arms and legs of the model. The remainder of the degrees of freedom that the model features (e.g. individual fingers and eyes) are not used since they are less important for this work and also hard to track.
We also introduce an additional binary feature which is enabled as long as the motion is ongoing. This feature is necessary for two reasons: First, we pad all sequences to have equal length due to implementation details and the binary flag indicates the active part of the motion. Second and more importantly, the generative part of our proposed model will also predict the binary flag and thus can be used to indicate if the generation is still ongoing or if it has finished.
More formally, each motion is thus represented as a sequence of length
[TABLE]
where each timestep is defined as
[TABLE]
For the padded part of the motion, we set the first elements to zero.
Furthermore, we scale the individual joints to have zero mean and variance one. We also down-sample each motion from Hz to Hz, which results in shorter sequences that are less resource-expensive during training and evaluation of our model. However, we do not discard the remaining motion data since we split each original motion sequence into down-sampled sequences by applying a variable offset . We then treat these as additional data during training, effectively introducing noise into the training process. Since we do this for all sequences, the original distribution of different motion types in the dataset is maintained.
Figure 3 illustrates the described representation of a single human whole-body motion.
3.2 Natural language descriptions
We represent the natural language annotations on the word-level. More concretely, we first normalize by transforming each sentence to lower case letters, remove all punctuation and apply minor spelling corrections for commonly misspelled words. We also pad all sequences to have equal length by introducing a special PAD word and, similarly, use special SOS (start of sentence) and EOS (end of sentence) words to mark the start and end of a sentence, respectively. Next, we tokenize each sentence into individual words and assign each word a unique integer index.
More formally, each sentence is thus represented as a sequence of length
[TABLE]
where each word is represented as an integer . Note that, typically, (recall that denotes the motion sequence length), i.e. the motion and language sequences are not required to have equal length.
In practice, we encode each word using one-hot encoding over a vocabulary of size instead of using the integer representation (since this would imply some order):
[TABLE]
However, this representation has the problem that its dimensionality grows linearly with (the number of words in the vocabulary). Word embeddings [47] resolve this problem by projecting the one-hot encoded word to a continuous, but much lower-dimensional embedding space. Depending on the training procedure, these embeddings have also been shown to group semantically similar words closer together.
In this work, we learn this projection end-to-end when training the entire model. However, in future work we might consider to use the weights of an embedding layer that was pre-trained on a large text corpus, e.g. using the open source word2vec implementation.111https://code.google.com/archive/p/word2vec/
4 Model
We describe the two directions of the mapping between human motion and natural language separately. However, since both models share a common approach commonly referred to as sequence-to-sequence learning [57], we explain this shared mode of operation before describing each model individually.
4.1 Shared mode of operation
Sequence-to-sequence learning has been used with great success, e.g. in large-scale machine translation [72]. As the name suggests, the goal of such models is to generate a target sequence from an input sequence, where the sequences can differ in length and modality. This property makes sequence-to-sequence learning an excellent fit for the purpose of learning a mapping between human motion and natural language.
We model each direction, that is from human motion to natural language as well as from natural language to human motion, individually. Figure 4 depicts the details of both models. In both cases, the input sequence is first transformed into a latent context vector by a recurrent neural network (RNN) or a stack thereof (meaning that many recurrent layers are stacked). The output of the recurrent encoder network after the last timestep of the input sequence has been processed is used as the context vector. This context vector is then decoded by the decoder network and, therefore, acts as the coupling mechanism between encoder and decoder network. Different approaches have been proposed for this (e.g. initializing the hidden state of the decoder with the context vector) but we provide the context vector as input to the decoder network at each timestep. The decoder then produces the desired target sequence step by step.
Typically, more advanced architectures than a vanilla RNN like long short-term memory (LSTM) [29, 19] or gated recurrent units (GRUs) [9, 10] are used. The encoder often uses bidirectional RNNs (BRNNs) [24], which process the input sequence in both directions and then combine the computed latent representations, e.g. by concatenation. While we use GRUs and a bidirectional encoder in this work, the proposed model can be used with any recurrent network architecture.
We model the decoder output probabilistically, which means that the network predicts the parameters of some probability distribution instead of predicting the output value directly. This intermediate output is denoted as and its form depends on the specific mapping (i.e. motion-to-language vs. language-to-motion) and are therefore described in Section 4.2 and Section 4.3 in more detail.
The decoder222Note that the decoder is an element of the larger decoder network and the two are not the same finally decodes this probabilistic representation to a concrete deterministic instance. One way to do this would be to greedily select the instance with highest probability under the distribution. However, such a strategy does not necessarily yield the sequence with highest probability. On the other hand, expanding each possible node is computational expensive for the discrete case and intractable for the continuous case. We therefore use a common middle-ground between these two extremes: beam search [31, chapter 12]. Beam search is a modification of best-first search, where in each step, only a limited set of stored nodes is considered for expansion. Since the output of the network should depend on the decision of the decoder (which is made outside of the decoder RNNs), we feed back this decision in each timestep. The input at timestep is thus the concatenation of the decoded output from the previous timestep and the context vector, which is constant for all timesteps.
Finally, the encoder and decoder network can jointly be trained end-to-end using back-propagation through time (BPTT) [71].
4.2 Motion-to-language mapping
Having described the general sequence-to-sequence framework that is used throughout this work (depicted in 4(a)), we now explain the concrete case of mapping from human motion to natural language. To this end, the encoder network takes a motion sequence as its input and encodes it into a context vector . The decoder network then, step by step, produces the desired description in natural language from this context vector, as described in the previous section.
4.2.1 Model architecture
The architecture of the encoder network is straightforward. We use stacked bidirectional RNNs to compute the context vector given the motion sequence. More concretely, we set the context vector to be the output of the last RNN layer after it has processed all timesteps of the input sequence. In all layers, the outputs of the forward and backward processing (due to the bidirectional model) are concatenated before being passed to the next layer as input.
As mentioned before, our approach uses a probabilistic formulation of the decoder. Fortunately, this can be achieved by defining a discrete probability distribution over the entire vocabulary. This is realized in our model by a softmax layer as the final layer of the decoder network:
[TABLE]
where denotes the unnormalized activation of the -th output neuron, which corresponds to the -th item in the vocabulary. This can be interpreted as the probability of the -th item in the vocabulary conditioned on the input motion encoded by the context vector and on the previously emitted words encoded by the hidden state of the recurrent decoder network:
[TABLE]
The decoder network also uses stacked RNNs but connects them in such a way that each RNN has access to the context vector, the embedding of the previously emitted word and the output of the preceding RNN (if applicable). Finally, the fully-connected softmax layer that produces the discrete probability distribution over the vocabulary as described above has access to the output of each RNN layer. Details on the number of layers, units per layer and other hyperparameters are detailed in Section 5. A detailed schematic of the model architecture can also be found in A.
4.2.2 Training
We can train the entire model end-to-end by minimizing the categorical cross-entropy loss:
[TABLE]
denotes the ground truth at timestep in the form of a reference natural language description and denotes the corresponding prediction of the model. Note that the loss is only computed for the active part of the description and does not include the padded part. We use BPTT with mini-batches to update the network parameters. The exact hyperparameters of the training procedure are described in Section 5.
4.2.3 Decoding
During prediction, we face the problem of deciding on a concrete word given the predicted probabilities . As mentioned before, we use beam search as a middle ground between greedily selecting the word with highest probability and performing an exhaustive search in the space of possible word sequences. More concretely, we expand each of the candidate sequences by predicting different probability vectors , …, (beam search of width ) for each timestep. Given a vocabulary of size , this yields new candidates, of which we only keep around the most likely sequences under our model. This process is then repeated iteratively until each candidate has been completed as indicated by the EOS token, resulting in different descriptions.
Importantly, we also obtain the probability of each sequence by accumulating the product of all corresponding step-wise probabilities. This in turn allows us to rank the candidates according to their probability under the model.
4.3 Language-to-motion mapping
Although the approach for the language-to-motion mapping is similar to the previously describe motion-to-language mapping, the architecture of the decoder network is necessarily different since the output modality is now multi-dimensional and continuous.
4.3.1 Model architecture
The architecture of the encoder network is similar to what was already described in Section 4.2. A network of stacked bidirectional RNNs encode the input description into a context vector. The decoder uses stacked RNNs where each RNN layer has access to the context vector computed by the encoder network, the previously generated motion timestep and the output of the preceding RNN layers. The complete model is depicted in 4(b).
However, there is a significant difference in the final fully-connected layer since the problem now requires to output a multi-dimensional and continuous frame of the motion in each timestep (compared to the discrete word as in Section 4.2). Furthermore, our approach uses a probabilistic decoder network, which allows us to generate non-deterministic outputs and also provides likelihood scores under our model for each generated sequence.
Recall that each motion frame is defined as , where the first dimensions are the joint values (and therefore continuous) and the last dimension is the binary flag that indicates the active parts of the motion. We use an approach similar to [22] based on a mixture of Gaussians for the continuous part and a Bernoulli distribution for the discrete part.
More concretely, the final fully-connected layer produces the following parameters, assuming a mixture model with components and omitting time indices for better readability:
component weights produced by a softmax activation, and therefore ).
- 2.
mean vectors produced by a linear activation.
- 3.
variance vectors , assuming Gaussians with diagonal covariance matrices, produced by a softplus activation.
- 4.
The probability of being active produced by a sigmoid activation.
To summarize, at each timestep the network predicts
[TABLE]
which are the parameters for the mixture of Gaussians and Bernoulli distributions.
Given this formulation, we can define the likelihood of a given motion frame conditioned on the input description, as encoded by the context vector, as well as all previously emitted frames, encoded by the hidden state of the recurrent decoder network, as:
[TABLE]
Since we use diagonalized Gaussians, we can write the likelihood under each multivariate Gaussian as the product of one-dimensional Gaussians, one for each joint:
[TABLE]
Finally, the probability mass for the discrete Bernoulli distribution is defined as
[TABLE]
Details on the number of layers, units per layer and other hyperparameters are detailed in Section 5. A detailed schematic of the model architecture can also be found in B.
4.3.2 Training
Again, we can train the entire model end-to-end by minimizing the following loss:
[TABLE]
Note that the loss is only computed for the active part of the motion and does not include the padded part.
This loss consists of two parts. The first part describes the likelihood of the ground truth joint values (denoted as ) under the predicted mixture distribution. The second part is the binary cross-entropy between the ground truth of the active flag and the predicted parameter of the Bernoulli distribution . By minimizing the loss , we jointly maximize the likelihood of the ground truth under the mixture of Gaussians and minimize the cross-entropy.
However, in practice the formulation in Equation 11 has numerical stability issues. This is because computing the likelihood under each multi-variate Gaussian requires computing the product of individual likelihoods (compare Equation 9), which can easily be subject to both numerical under- and overflow.
We therefore define the following surrogate loss function:
[TABLE]
This re-formulation allows us to replace the product from Equation 9 with a sum of logarithms, making the computation more robust against numerical problems. We find that minimizing instead of works well and yields the desired results.
Like before, we use BPTT with mini-batches to train the network end-to-end. Again, the exact hyperparameters of the training procedure are described in Section 5.
4.3.3 Decoding
Similar to motion-to-language mapping (Section 4.2.3), we again face the problem of decoding a concrete motion frame from the prediction vector . This can be solved by sampling the joint values from the multivariate Gaussian mixture distribution (by first sampling a mixture component with probabilities and then sampling from the selected multivariate Gaussian) as well as sampling from the Bernoulli distribution for the binary active indicator. Like before we use beam search to obtain a couple of candidates at the end of the decoding process as previously described in Section 4.2.3. The key difference here is that we cannot compute the likelihood for each discrete possibility anymore. We resolve this problem by sampling a couple of candidates for each hypothesis from the respective distributions and then truncating them to keep around a fixed number of hypotheses for the next timestep.
5 Experiments
[FIGURE:]
5.1 Dataset
While large datasets for human motion exist (see also [45] for a recent review), our evaluation requires a dataset that also contains descriptions of such motion in natural language. We have recently proposed the KIT Motion-Language Dataset [53], which uses human whole-body motions from the KIT Whole-Body Human Motion Database333https://motion-database.humanoids.kit.edu/ [44] and the CMU Graphics Lab Motion Capture Database444http://mocap.cs.cmu.edu/. For each motion, a set of descriptions in the form of a single English sentence was collected using a crowd-sourcing approach.
We use the 2016-10-10 release of the KIT Motion-Language Dataset for all experiments. This version of the dataset contains recordings of human whole-body motion in the aforementioned MMM representation and annotations in natural language. The dataset is publicly available555https://motion-annotation.humanoids.kit.edu/dataset/ so that all results in this paper can be reproduced.
For our evaluation, we filter out motions that have a duration of seconds or more in order to reduce the computational overhead due to excessive padding. We have decided to discard these motions for two reasons. First, almost all motions are below seconds in duration, which means that almost no data is discarded to begin with. Second, we decided to discard motions instead of clipping them since we otherwise cannot guarantee that all important parts are visible to our model, i.e. we may remove crucial information that characterizes a motion.
This results in usable motion samples with a total duration of hours and natural language annotations that consist of words in total, with a vocabulary size of . We randomly split the remaining data into training, validation and test sets with a ratio of , and , respectively. We compute the split such that a motion and all its associated natural language descriptions are always in the same set and are not partially leaked into another set. All results are reported using the test set, if not otherwise indicated. The processing steps described in Section 3 are performed to obtain the representations suitable for training the model.
5.2 Setup
The model architectures for motion-to-language (Section 4.2) and language-to-motion (Section 4.3) have already been described. However, we have not yet described the specific hyperparameters that we used for our experimental results.
For both the encoder and decoder parts of each model, we use gated recurrent units (GRUs) [9] as the recurrent neural network architecture. We regularize all models with dropout [55, 18] in the embedding, recurrent and fully-connected layers. In both cases, we train our models using the Adam optimizer with Nesterov momentum [35, 14]. Training of the language-to-motion model proved to be more difficult, presumably due to the more complex dynamics of the recurrent model, which made it necessary to use both gradient clipping [5] as well as layer normalization [3]. We also experimented with batch normalization [32, 11] instead of layer normalization but were unable to get good results with it, presumably due to the known problems of batch normalization with padded sequences.666https://github.com/cooijmanstim/recurrent-batch-normalization/issues/2
Table 1 summaries the aforementioned and lists all other hyperparameters for both models, language-to-motion and motion-to-language. These hyperparameters were used for all experiments throughout this work. The code that was used to obtain all following results is available online: https://gitlab.com/h2t/DeepMotionLanguageMapping/
5.3 Generating language from motion
5.3.1 Training
Optimizing the model turned out to be straightforward and did not require special measures. Figure 5 depicts the change in loss during training for the training and validation split, respectively. As can be seen, both training and validation loss continuously decrease, indicating that the model does not overfit on the training data. Additionally, the validation loss seems to have converged after training epochs, indicating that our training time was sufficiently long. Training took approximately 5 hours on an Nvidia GeForce GTX 980 Ti graphics card with an Intel Core i7-6700K. After training, our model can generate approximately 12 descriptions per second.
5.3.2 Qualitative results
To provide insight into the style and quality of the natural language descriptions generated by our model, we present a few examples in Figure 6. For each depicted human whole-body motion, we compute five natural language description hypotheses (thus, we perform beam search with ) and sort them in descending order by their respective log probability under the model (depicted in the tables below each motion; due to space constraints, we only present the top three descriptions per motion). As can be seen from these examples, all descriptions are complete English sentences with valid grammatical structure. This is a pattern that we observe throughout. Interestingly, the model also produces semantically identical descriptions with varying grammatical structure. For example, when describing standing up (6(f)), the model creates a description using present simple (“a person stands up from the ground”) and another one using present continuous (“a person is standing up from the ground”).
The model also uses synonyms interchangeably. For example, the model refers to the subject in the scene as a “human”, “person” or “someone”. This is especially apparent in 6(d), where the produced sentences are identical except for this variation.
The generated natural language descriptions are also rich in detail. For example, the model successfully differentiates between wiping a surface with the right (6(h)) vs. left (6(i)) hand and creates corresponding descriptions that mention the handedness of the motion. Similar behavior can be observed for the waving motion (6(d)), stomping motion (6(e)) and pushing motion (6(c)), for which the descriptions all correctly mention the correct hand, foot and perturbation direction, respectively.
Overall, the contents of the generated descriptions are highly encouraging and demonstrate the capabilities of the model to not only generate syntactically valid descriptions, but also semantically meaningful and detailed ones.
5.3.3 Quantitative results
While the previously presented results allow us to gather some understanding of the generated descriptions, they do not necessarily represent the overall behavior of the model. Therefore, we provide in the following a quantitative evaluation of the performance of the proposed model over the training and test splits of our dataset.
We select the Bleu score [52] to measure the performance of the proposed model. Briefly speaking, the Bleu score is a metric that was initially proposed to measure the performance of machine translation systems and has also been used in work targeting the similar problem of learning a mapping between human motion and natural language [59].
The Bleu score is obtained by first counting unigrams, bigrams, …, -grams (in this work up to ) in the provided reference and then computing the -gram precision (with exhaustion) of the hypothesis. Essentially, it is this modified and weighted -gram precision with some additional smoothing. The Bleu score is defined to be between [math] and , with indicating a perfect match, i.e. the hypothesis is word for word identical to one of the references.
We compute the Bleu score on a corpus-level, in contrast to sentence-level as in other works on this problem. This is an important distinction, since sentence-level computation estimates the -gram model only on very few reference sentences, leading to bad estimates and therefore unreliable scores. In contrast, for corpus-level Bleu scores, all provided descriptions are used to compute the probabilities of the -gram model. More concretely, we generate five descriptions, that is the hypotheses, for each human motion and sort in descending order by their log probability under the model. We then compute five different Bleu scores that correspond to selecting the 1st, 2nd, …, 5th best hypothesis. In all cases, we use all available annotations, which have been created by the human annotators, as the ground truth. Bleu scores are computed separately for the training and test split. It should also be noted that the Bleu score is not without flaw when it comes to evaluations outside of the machine translation domain [30]. However, we opt to use it here since most prior work is evaluated using the Bleu score.
Table 2 lists the achieved Bleu scores. A couple of observations are noteworthy. First, the Bleu scores are lower than one would expect from a machine translation system, for example. This is because there is much more ambiguity when generating descriptions of human motion than when translating a text into a different language. In the former case, different levels of details and different styles are also semantically correct (e.g. “A human walks” vs. “Someones takes a couple of steps”), whereas the latter case is much more constrained. Second, the Bleu scores are clearly correlated with the order of the hypotheses (as defined by their log probabilities under the model) even though the loss that was used to train the model and the Bleu score are completely separate. This means that the log probability is suitable as a measure of quality and, in turn, that the model indeed captures some understanding of what an objectively high-quality (as measured by Bleu), description is.
Third, the model achieves slightly worse, but still comparable performance on the test split. This, again, demonstrates that the model does not overfit on the training data and generalizes to previously unseen motions. Additionally, the second point, that Bleu scores and their ranking as defined by the respective log probabilities of the hypotheses are correlated, still holds; however, the pattern is a bit more noisy.
5.4 Generating motion from language
5.4.1 Training
Optimizing the language-to-motion model proved to be more complex, which was presumably due to the much more complex decoder network. In order to successfully optimize the model, we found that gradient clipping and layer normalization play a crucial role. The learning curves for the training and validation splits are depicted in Figure 7. Training took approximately 24 hours on an Nvidia GeForce GTX 980 Ti graphics card with an Intel Core i7-6700K. After training, our model can generate approximately 5 motions per second.
Although the curve for the validation loss is more noisy than in the motion-to-language case, the model still appears to learn the problem at hand without overfitting on the training data.
5.4.2 Qualitative results
Similar to before, we provide some insight into the type of motion the proposed model generates by visualizing several examples in Figure 8. For each given natural language description, we compute five human whole-body motion hypotheses (thus ). Due to space constraints, we only depict the motion with the highest loglikelihood under the model.
Most interestingly, the results also demonstrate that our model is not only capable of generating the correct motion primitive, but also to adjust the generated motion to a desired parametrization, e.g. the model generates motions for waving with the right, left and both hands (8(g), 8(h) and 8(i). We observed similar behavior in other examples such as walking motions with different speed.
For periodic movements, we observed that the model does generate motions with a number of repetitions (e.g. waving seven times) that were not indeed included in the training set, suggesting that it does discover the underlying periodic structure of the motion. However, we were unable to parametrize the number of repetitions using language. We hypothesize that this is because the training data does not contain enough training examples to learn counting.
Another limitation of the proposed model is caused by the fact that we represent the motion using only joint angles. This, in turn, means that the model does not predict the pose of the human subject in space, which can be observed for the bowing, squatting and kicking motions (8(e), 8(d) and 8(c)), where the root pose of the human model remains fixed. Furthermore, since we only consider the kinematic aspects of a motion, the generated motions are not necessarily dynamically stable. Similarly, since we do not consider contact information with objects at this point, generated manipulation motions are violating constraints that would be necessary to achieve the desired outcome. This can be observed for the wiping motion (8(b)), where the wiping diverges from the (imaginary) table surface over time. Including these dynamic properties and contact information is an important area of future work.
Overall, we clearly demonstrate the capabilities of the model to generate a wide variety of realistic human whole-body motions specified only by a description in natural language. We also visualize the entirety of the generated motions in a supplementary video: https://youtu.be/2UQWOZtsg-8.
5.4.3 Quantitative results
Providing quantitative results for the performance of the language-to-motion model is complicated since defining an appropriate metric is non-trivial. The reason for this is that a motion can be performed in a large variety of different styles that can all be semantically correct for the given description but may have very different joint-level characteristics. Computing a metric like the mean squared error between reference and hypotheses is therefore ill-suited to judge how correct the motion hypothesis is semantically.
An obvious choice for evaluation would be a user study. Unfortunately, this comes with a significant cost. Our dataset contains motions and descriptions in natural language. If we generate 5 hypotheses per motion and description, we obtain descriptions (for the motions) and motions (for the descriptions). To be representative, we would need multiple users to review each of these generated motions and descriptions, which would take a significant amount of time, even if we would only evaluate a subset. Additionally, the design of such a user study is quite non-trivial due to inherent ambiguous nature of the problem. For example, consider a waving motion in which the subject waves with the left hand. It is unclear if a generated description that describes this handedness should be preferred over a description that does not describe it since both are equally valid and simply describe the same thing with varying levels of detail. Additionally, we believe that a user study alone would be problematic since it makes it almost impossible for other authors to compare their systems with ours.
Another possible way of evaluating our model would be to train a classifier to predict the type of the ground truth motion data and then use this classifier to estimate the quality of the generated motion data. The problem with this approach is that it would require labels for each motion. Even if these labels would be available, a classifier with low prediction error would need to be trained, which is in itself a non-trivial task. Even then, we would still face the problem of ambiguity. Consider, for example, a description of a waving motion that does not specify the handedness. If the generated motion does wave with the left hand, but the ground truth data was actually waving with the right hand, the motion would be counted as incorrect. However, given the available data, the generator clearly successfully generated a motion and the description was simply not detailed enough.
To resolve these problems, we exploit the fact that we already can compute a semantic description of a given motion using our previously evaluated motion-to-language model. Since we have already evaluated this model separately, we can use its performance as a baseline to judge the quality of the other direction, namely language-to-motion. Additionally, this evaluation does not require a separate system like a classifier and scales to many thousands of motion-language tuples.
More concretely, we essentially chain the two models. First, we use the language-to-motion model, which we want to evaluate here, to compute a motion given a description in natural language. Next, we use the previously trained and evaluated motion-to-language model to transform this generated motion back into a description in natural language. Finally, we can compute the Bleu score as described in Section 5.3.3 to quantitatively measure the performance of the language-to-motion model. The results of this approach are given in Table 3.
To make it easier to compare the performance, we propose to measure the language-to-motion model relative to the performance of the motion-to-language model. More formally, we relate the Bleu score of the language-to-motion model (to be evaluated, see Table 3) to the highest Bleu score of the motion-to-language model (the baseline, which is ) by dividing the two. We thus measure the percentage of performance that is retained after transforming the natural language into a motion hypothesis and then transforming this generated motion back into a description. Table 4 lists this relative performance for the language-to-motion model.
A couple of observations. First, the results clearly demonstrate that our model is capable of generating the correct human motion beyond the few examples presented in the qualitative analysis described before. Compared to the baseline, the model achieves a performance of for both the training and for the test split. As expected, the Bleu scores for the training split are slightly higher than for the test split, but still comparable. This suggests minimal overfit and generalization capabilities to previously unseen examples. Second, the ranking of hypotheses as defined by their loglikelihood under the model seems to be less correlated with the performance of the model under the proposed evaluation metric. Currently, it is difficult to identify the prime origin and cause for this since this could also be caused by the error of the motion-to-language model.
5.5 Understanding the model
Our final experiment is concerned with providing insight into the latent representations that the proposed model uses internally. In order to do so, we analyze the context vectors produced by both the motion-to-language model and language-to-motion model. Since they are extremely high-dimensional (), we use t-distributed Stochastic Neighbor Embedding (t-SNE) [42] to project all context vectors into a 2-dimensional representation. t-SNE is particular well-suited for this task since it is known to maintain the structure of the original high-dimensional vector space in the low-dimensional projection.
We then color this low-dimensional projection of the context vector space according to the type of motion performed. Due to the large variety of different motion, we select to color motions of type walking, running, waving, wiping, mixing and squatting and use a combined color for all other motions. The labels are obtained from the KIT Whole-Body Human Motion Database, which provides multiple labels for each motion record. If no labels are available or if motions have multiple conflicting labels, we discard this specific motion.777We would like to emphasize that the vast majority of motions that we used have exactly one label in each of these categories, which means that we only discard a small subset. Figure 9 depicts this visualization for both models, motion-to-language and language-to-motion.
Both visualization exhibit a clear structure and contain clusters of motions of the same type. Interestingly, the visualization of the motion-to-language model (9(a)) has denser clusters with less variance and cleaner separation between clusters than the visualization of the language-to-motion model (9(b)). This makes intuitive sense since describing a motion in natural language has far more ambiguities compared to observing the motion directly. Comparing running and walking motions, this observation is especially apparent: In the motion-to-language case, the two types of motion are nicely separated wheres in the language-to-motion case the two types often fall into the same cluster (top-most green cluster in 9(b)).
Another interesting observation is that motions of type wiping and mixing (in the sense of mixing something in a bowl) are used interchangeably in both directions. Since we do not include object information (to neither the model nor the human annotators that created the dataset), mixing and wiping appear to be the same.
We also investigate the structure within a given type of motion, in this case walking. For this purpose, we use the same projection as in the previous motion-to-language visualization. However, this time we color motions by their respective direction (left, right, forward, backward) and only those that are walking motions. The resulting 2-dimensional t-SNE projection is depicted in Figure 10, which shows that walking motions that have the same direction are grouped in the same cluster. However, the separation is often less clear than for motions of completely different type.
Overall, the analysis of the context vector space clearly suggests that our proposed models extract semantic meaning from the given input (for both cases, motion or language) and encode it into the context vector. The decoder part of the models can then generate the correct sequence using this semantic representation.
6 Conclusion
In this paper, we proposed the use of deep recurrent neural networks in a sequence-to-sequence setting to learn a bidirectional mapping between human whole-body motion and descriptions in natural language. We presented models that can be used to model each direction of the bidirectional mapping individually. An important property of our proposed models is that they are probabilistic, allowing us to produce different candidate hypotheses and ranking them accordingly. Additionally, our system makes minimal assumptions about both the natural language descriptions and human whole-body motions, requiring minimal preprocessing and no explicit motion segmentation into motion or action primitives or clusters thereof a-priori. Furthermore, each model makes use of a distributed representation, which is shared for all types of motions.
In our experiments, we clearly demonstrated the capabilities of our proposed system to generate rich and detailed descriptions of a large variety of different human whole-body motions. Conversely, we showed that our model is capable of generating a similarly large variety of realistic human whole-body motion given a description thereof in natural language. We quantified and reported the performance of our system using the Bleu score, which is well-known and frequently used in the context of machine translation. We also presented results that indicate that each model successfully learns distributed and semantically meaningful latent representations of the given input to produce the desired output.
A limitation of our proposed system is that the input sequence needs to be encoded into a single vector (the context vector ). This becomes especially problematic as the sequence length increases. To overcome this problem, attention mechanisms have been proposed in the literature[4]. Integrating such mechanisms in the future is likely going to improve the performance of our system. Similarly, hierarchical RNNs [33, 15] have been proposed and were used successfully to model human motion. Integrating these ideas into our system would likewise be an interesting experiment.
Increasing the size of the KIT Motion-Language Dataset [53] is an important area of future work as well. More data would allow us to use more complex models and reduces the risk of overfitting. Additionally, including more complex motions in which a subject performs a sequence of distinct steps (e.g. when cooking) would allow for interesting experiments to further test the generalization capabilities of our proposed system by permutating the order of the steps.
Lastly, representing human whole-body motion using only the joint values of the kinematic model is insufficient. In future work, we therefore intend to incorporate dynamic properties of the motion as well as contact information with the environment and objects that are involved in the execution of the motion. Such multi-contact motions have recently been studied by [43].
Acknowledgments
The research leading to these results has received funding from the H2T at KIT, the German Research Foundation (Deutsche Forschungsgemeinschaft: DFG) under the Priority Program on Autonomous Learning (SPP 1527), and the European Union’s Horizon 2020 Research and Innovation Programme and Seventh Framework Programme under grant agreements No. 643666 (I-Support) and No. 611832 (WALK-MAN).
Appendix A Detailed motion-to-language model architecture
Appendix B Detailed language-to-motion model architecture
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Arie et al. [2010] Arie H, Endo T, Jeong S, Lee M, Sugano S and Tani J (2010) Integrative learning between language and action: A neuro-robotics experiment. In: Artificial Neural Networks - ICANN 2010, 20th International Conference, Thessaloniki, Greece, September 15-18, 2010, Proceedings, Part II . pp. 256–265.
- 2Azad et al. [2007] Azad P, Asfour T and Dillmann R (2007) Toward an unified representation for imitation of human motion on humanoids. In: 2007 IEEE International Conference on Robotics and Automation, ICRA 2007, 10-14 April 2007, Roma, Italy . pp. 2558–2563.
- 3Ba et al. [2016] Ba LJ, Kiros R and Hinton GE (2016) Layer normalization. Co RR abs/1607.06450.
- 4Bahdanau et al. [2014] Bahdanau D, Cho K and Bengio Y (2014) Neural machine translation by jointly learning to align and translate. Co RR abs/1409.0473.
- 5Bengio et al. [2012] Bengio Y, Boulanger-Lewandowski N and Pascanu R (2012) Advances in optimizing recurrent networks. Co RR abs/1212.0901.
- 6Billard et al. [2008] Billard A, Calinon S, Dillmann R and Schaal S (2008) Robot programming by demonstration. In: Springer Handbook of Robotics . pp. 1371–1394.
- 7Bütepage et al. [2017] Bütepage J, Black MJ, Kragic D and Kjellström H (2017) Deep representation learning for human motion prediction and classification. Co RR abs/1702.07486.
- 8Calinon et al. [2007] Calinon S, Guenter F and Billard A (2007) On learning, representing, and generalizing a task in a humanoid robot. IEEE Trans. Systems, Man, and Cybernetics, Part B 37(2): 286–298.