Asynchronous parallel primal-dual block coordinate update methods for affinely constrained convex programs
Yangyang Xu

TL;DR
This paper introduces an asynchronous parallel primal-dual block coordinate update method for convex problems with nonseparable linear constraints, demonstrating convergence and improved speed-up over synchronous methods.
Contribution
It proposes a novel randomized primal-dual BCU method with adaptive stepsize for multi-block affinely constrained problems, extending async-parallel optimization to nonseparable constraints.
Findings
Convergence in probability to the optimal value and zero constraint residual.
Ergodic $O(1/k)$ convergence rate established.
Numerical experiments show superior speed-up compared to synchronous methods.
Abstract
Recent several years have witnessed the surge of asynchronous (async-) parallel computing methods due to the extremely big data involved in many modern applications and also the advancement of multi-core machines and computer clusters. In optimization, most works about async-parallel methods are on unconstrained problems or those with block separable constraints. In this paper, we propose an async-parallel method based on block coordinate update (BCU) for solving convex problems with nonseparable linear constraint. Running on a single node, the method becomes a novel randomized primal-dual BCU with adaptive stepsize for multi-block affinely constrained problems. For these problems, Gauss-Seidel cyclic primal-dual BCU needs strong convexity to have convergence. On the contrary, merely assuming convexity, we show that the objective value sequence generated by the proposed algorithm…
Click any figure to enlarge with its caption.
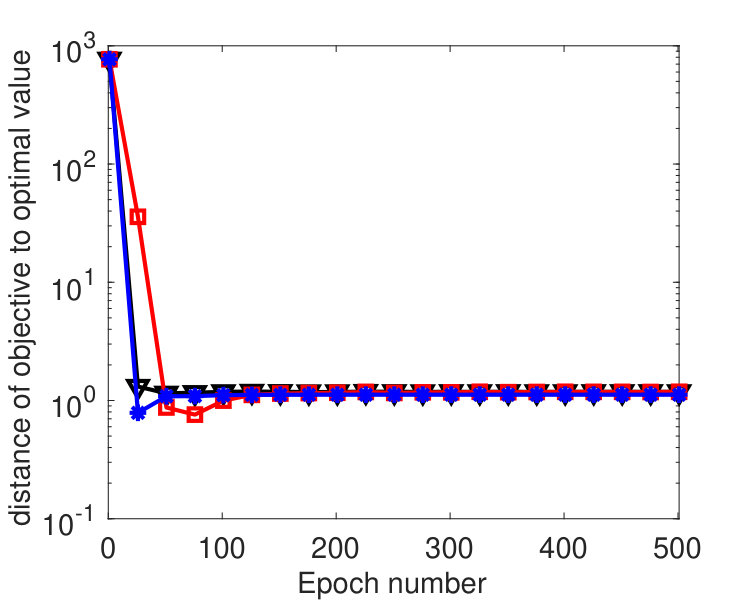 Figure 1
Figure 1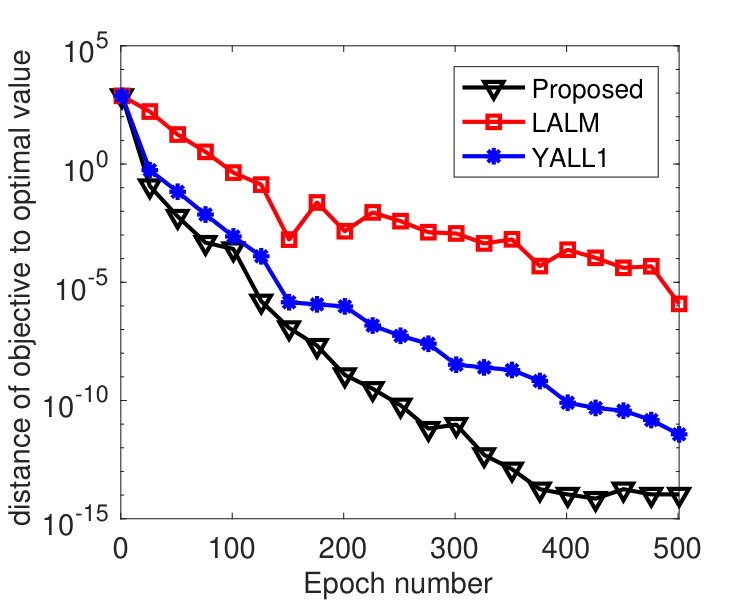 Figure 2
Figure 2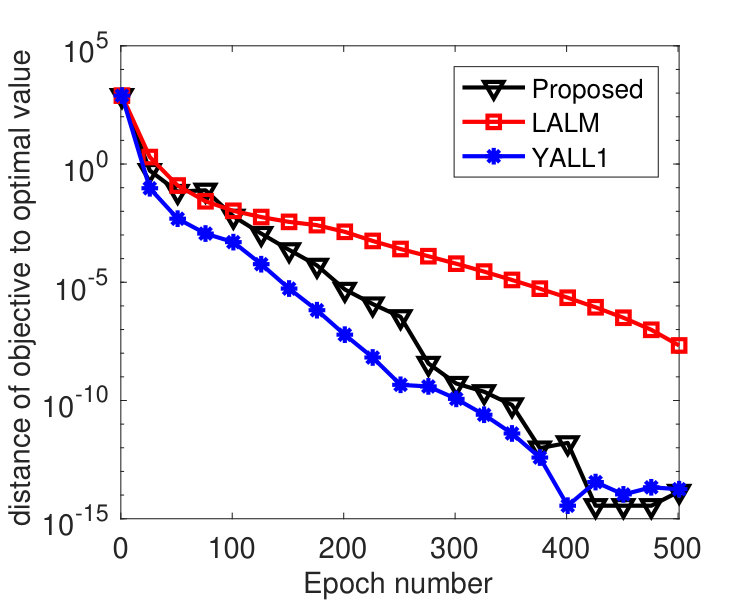 Figure 3
Figure 3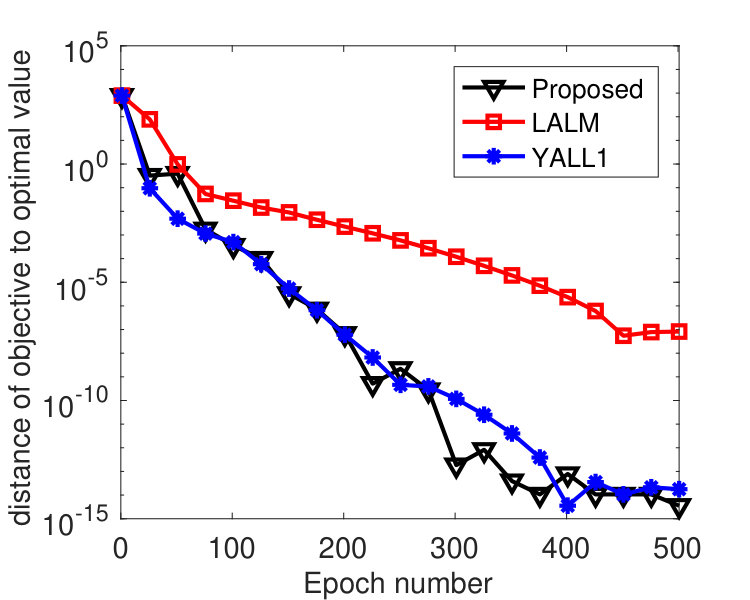 Figure 4
Figure 4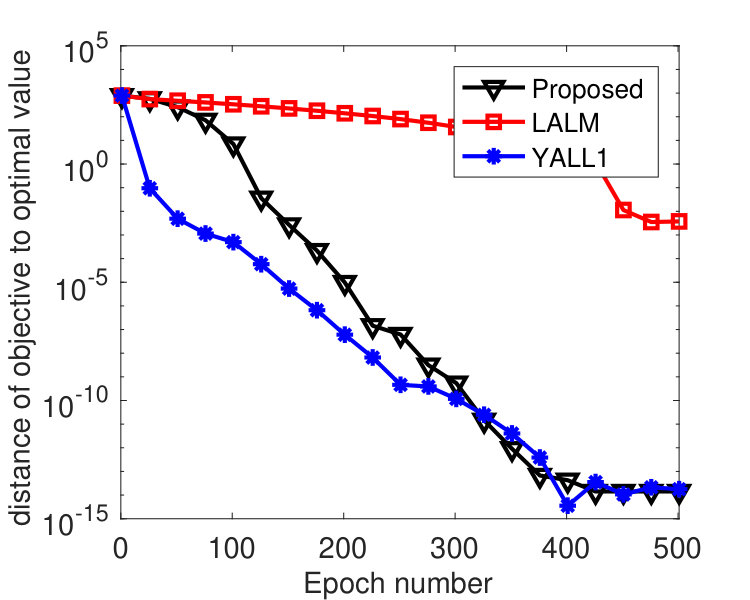 Figure 5
Figure 5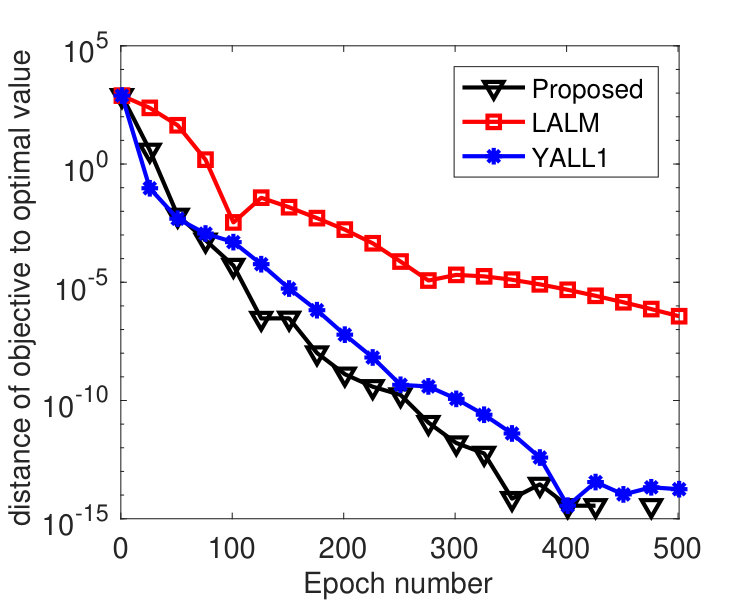 Figure 6
Figure 6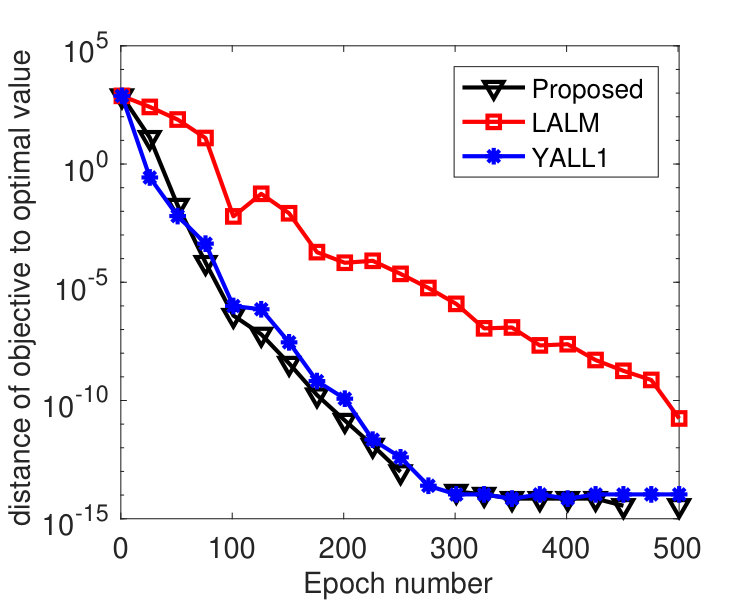 Figure 7
Figure 7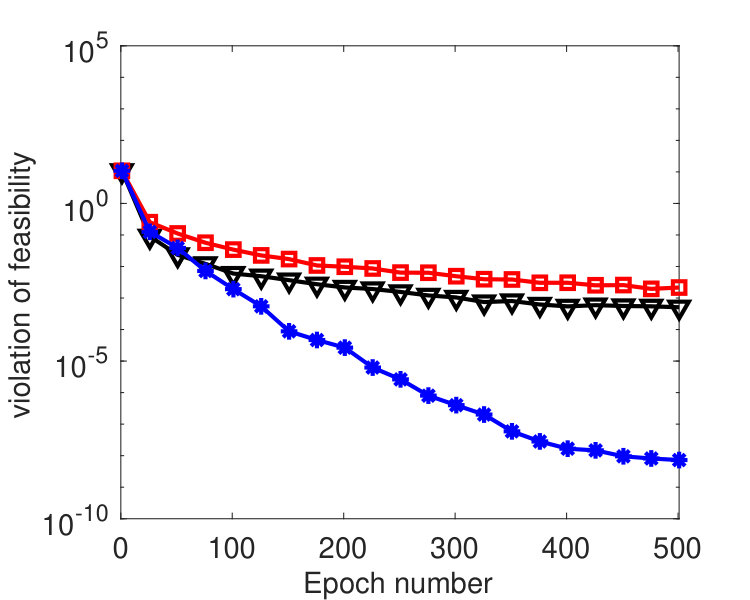 Figure 8
Figure 8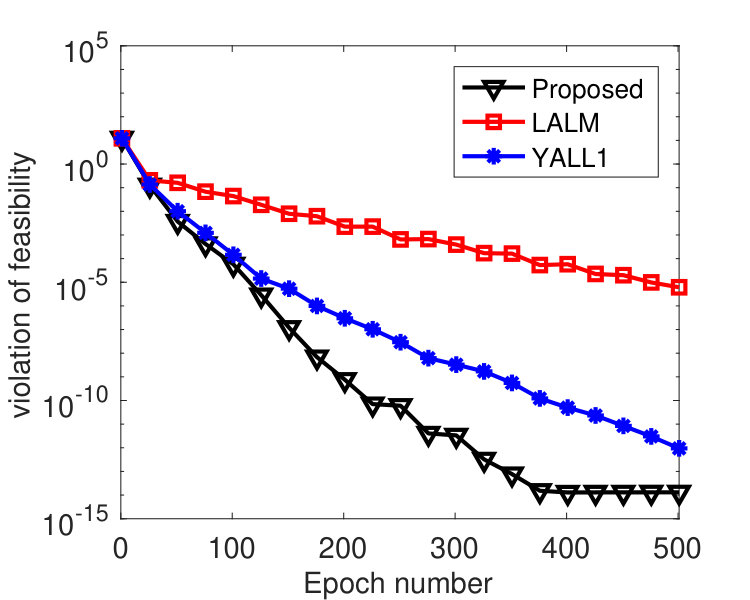 Figure 9
Figure 9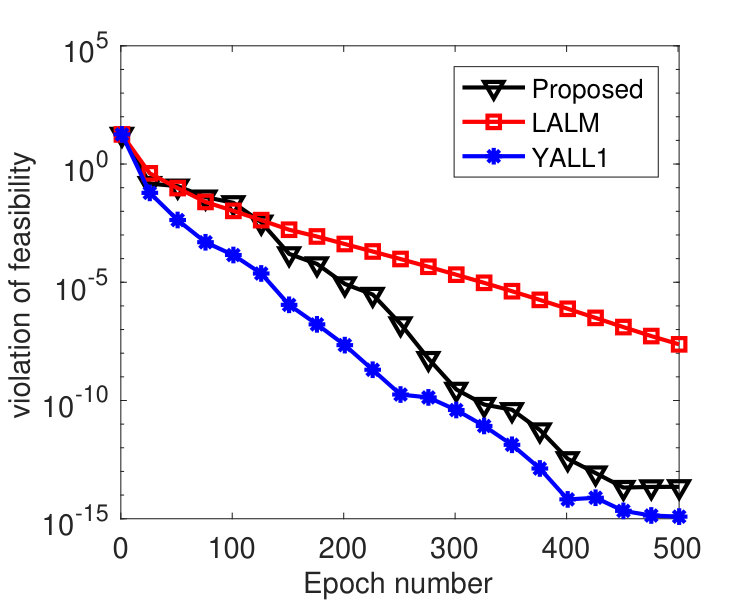 Figure 10
Figure 10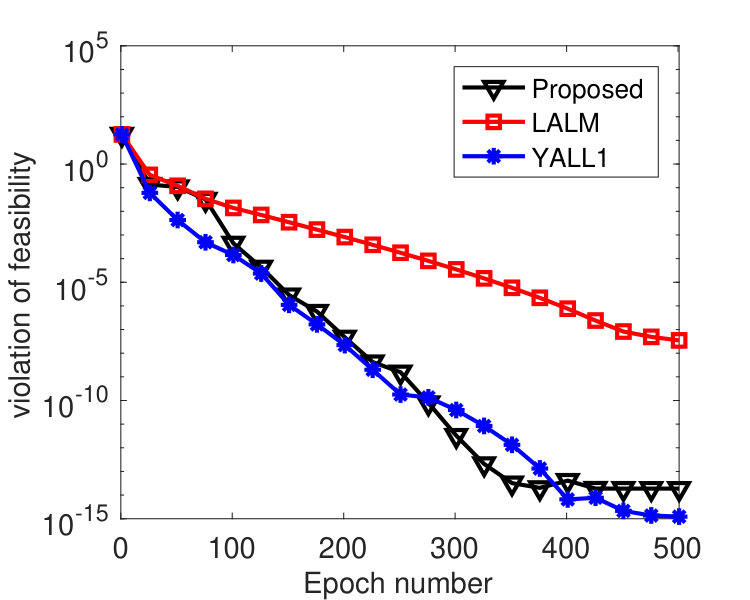 Figure 11
Figure 11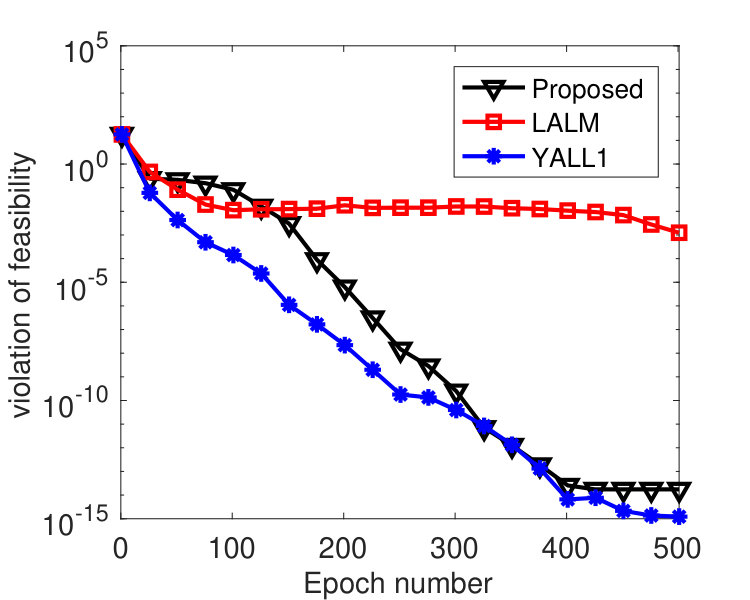 Figure 12
Figure 12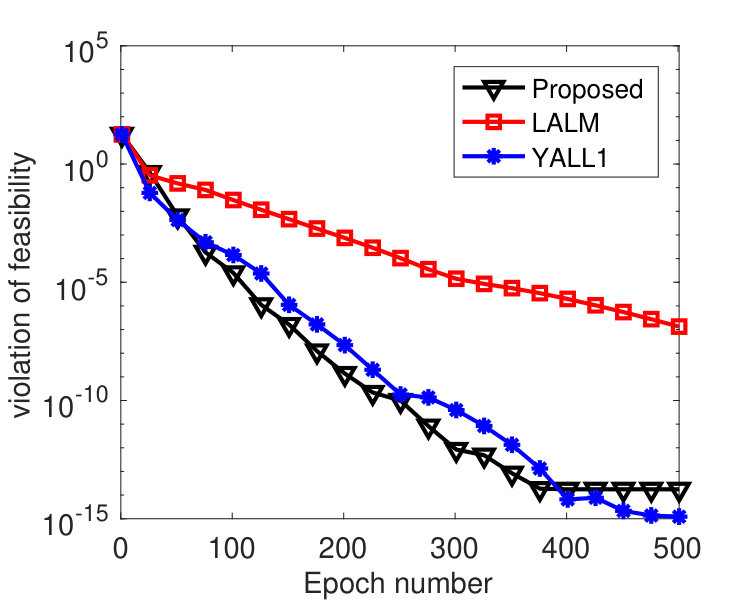 Figure 13
Figure 13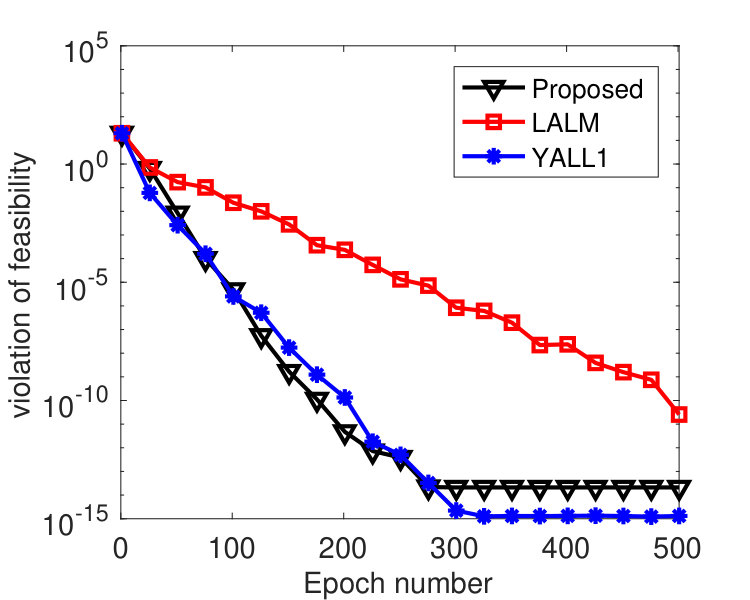 Figure 14
Figure 14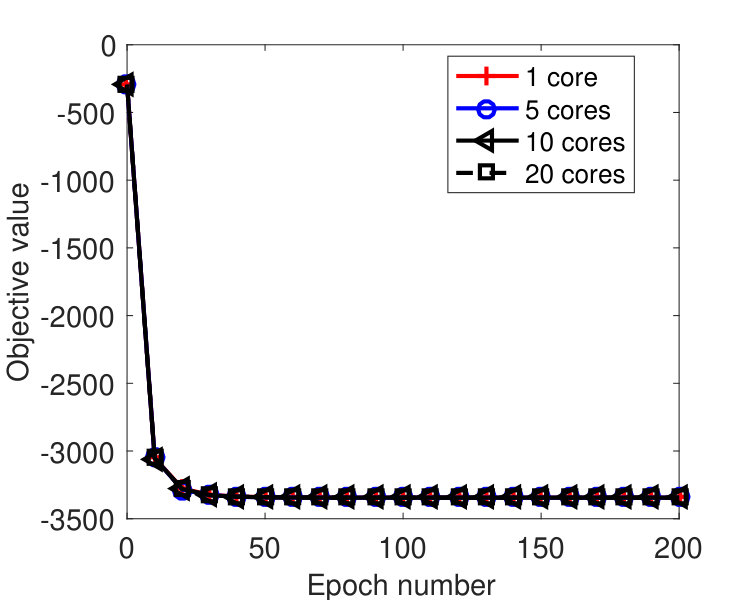 Figure 15
Figure 15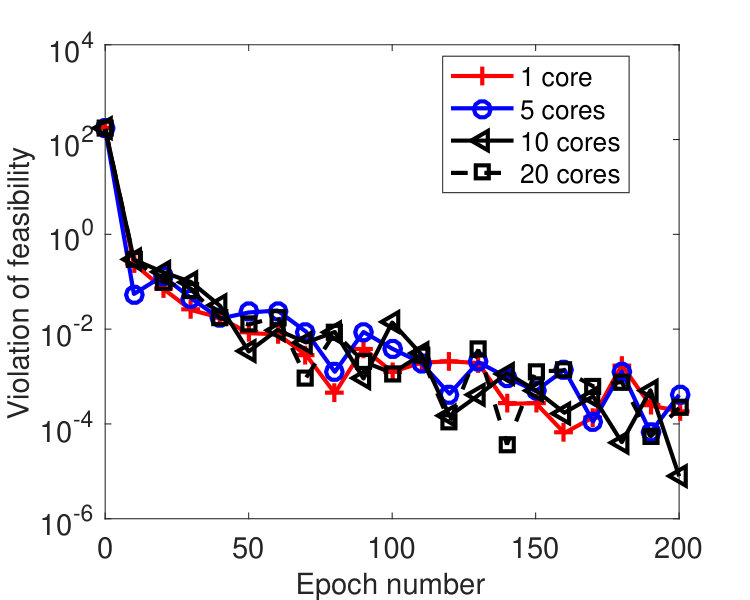 Figure 16
Figure 16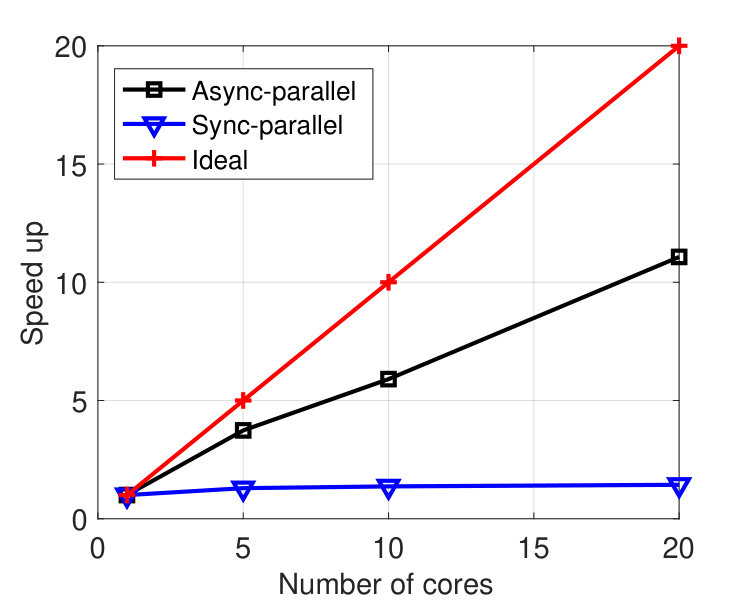 Figure 17
Figure 17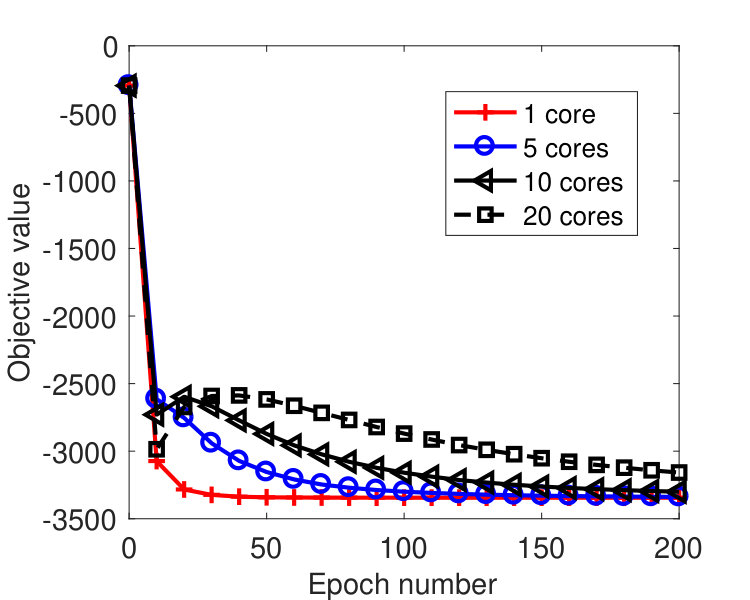 Figure 18
Figure 18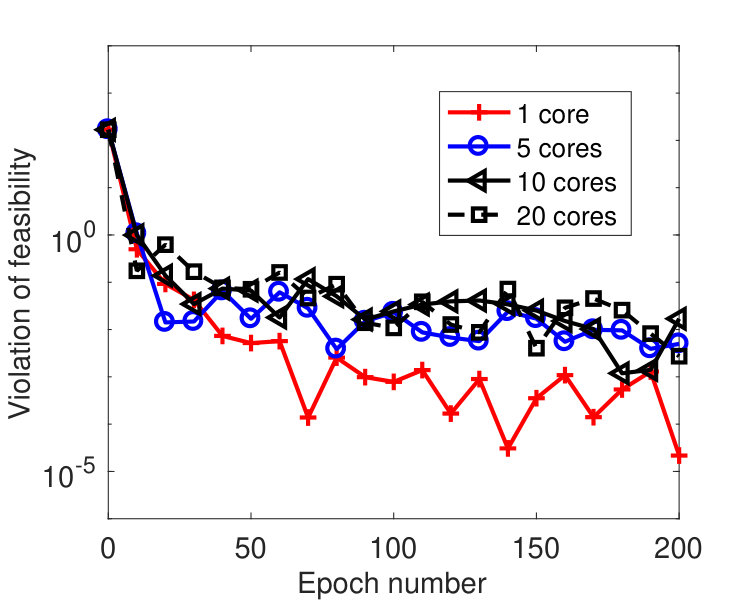 Figure 19
Figure 19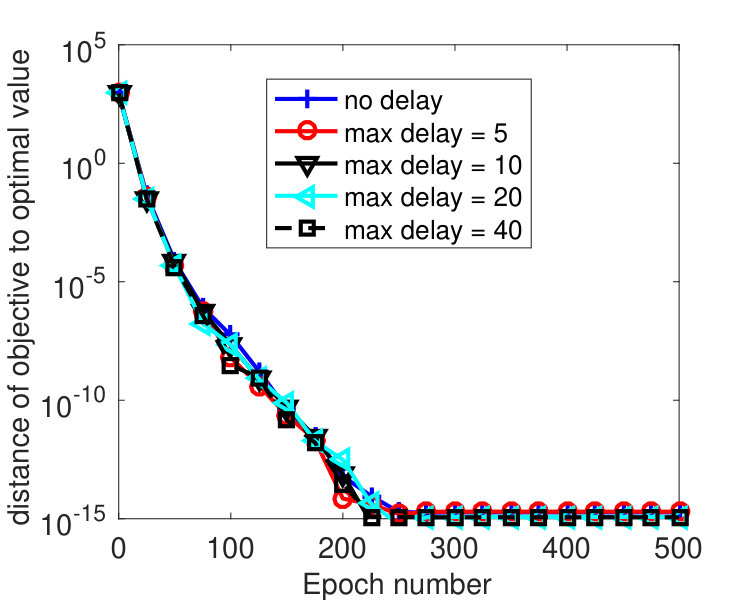 Figure 20
Figure 20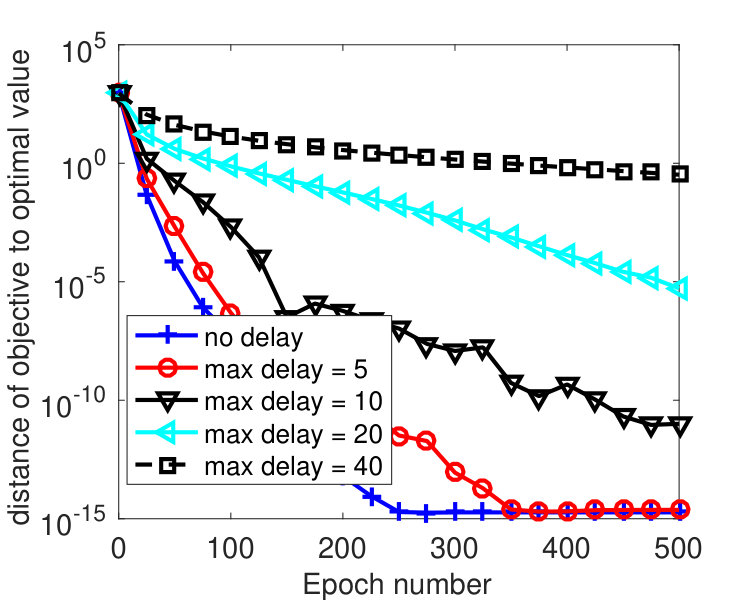 Figure 21
Figure 21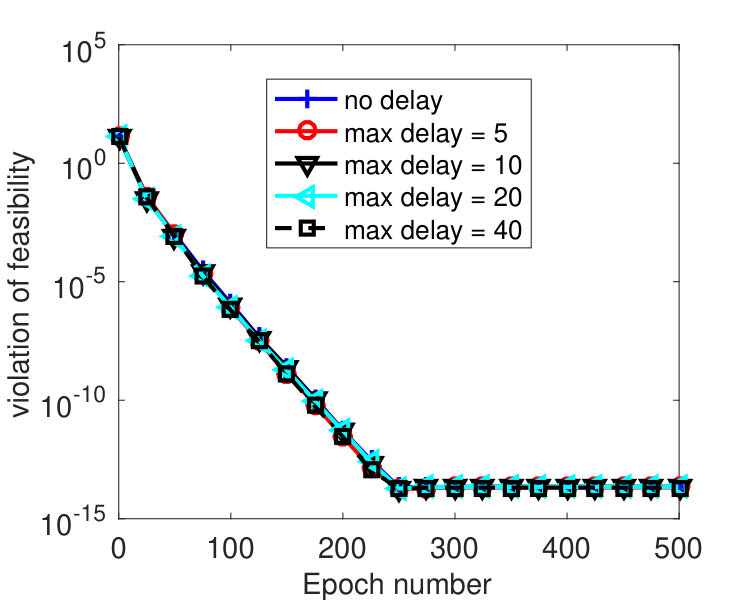 Figure 22
Figure 22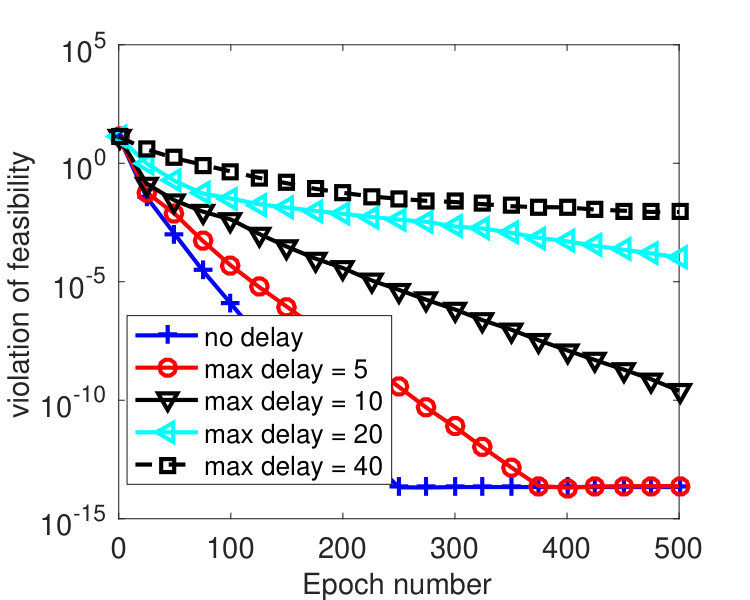 Figure 23
Figure 23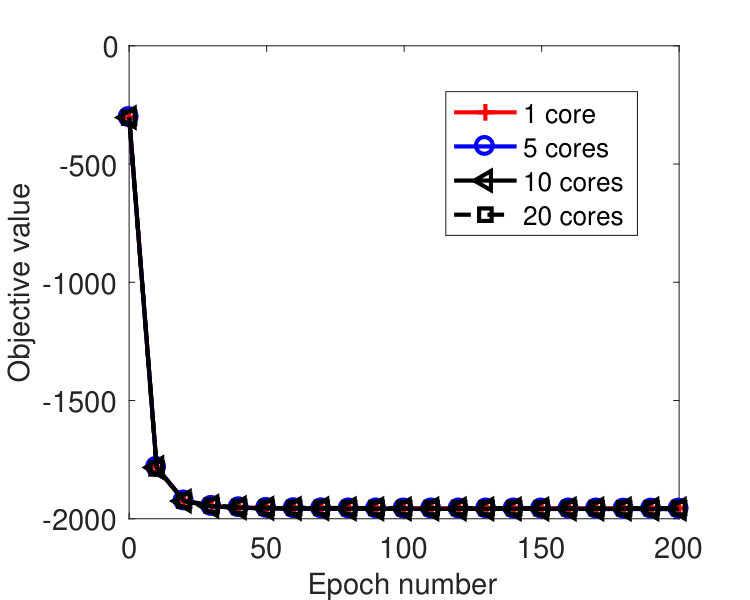 Figure 24
Figure 24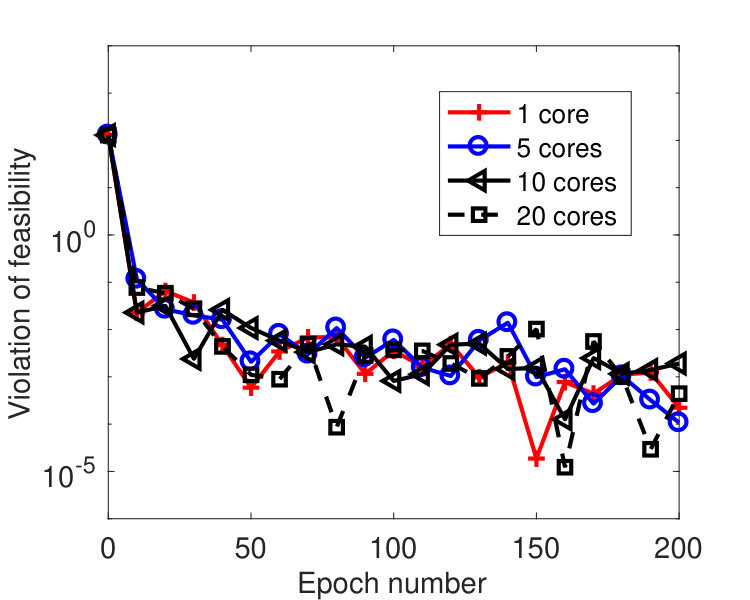 Figure 25
Figure 25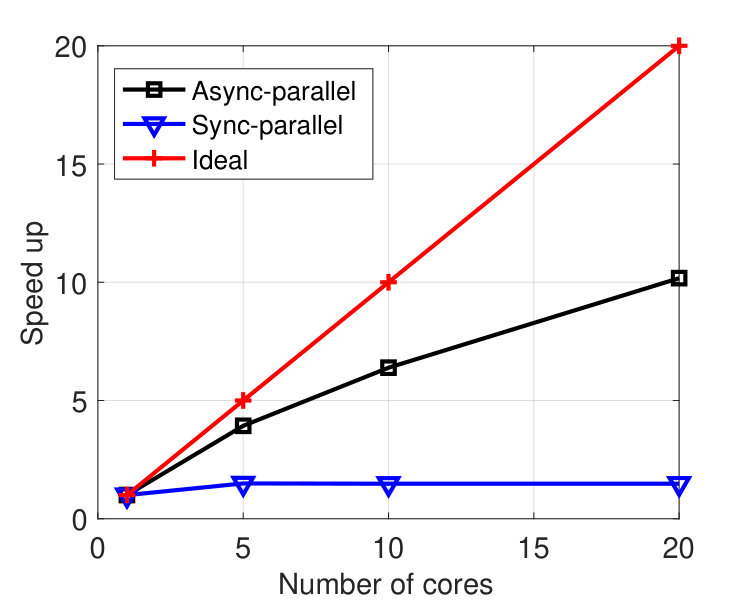 Figure 26
Figure 26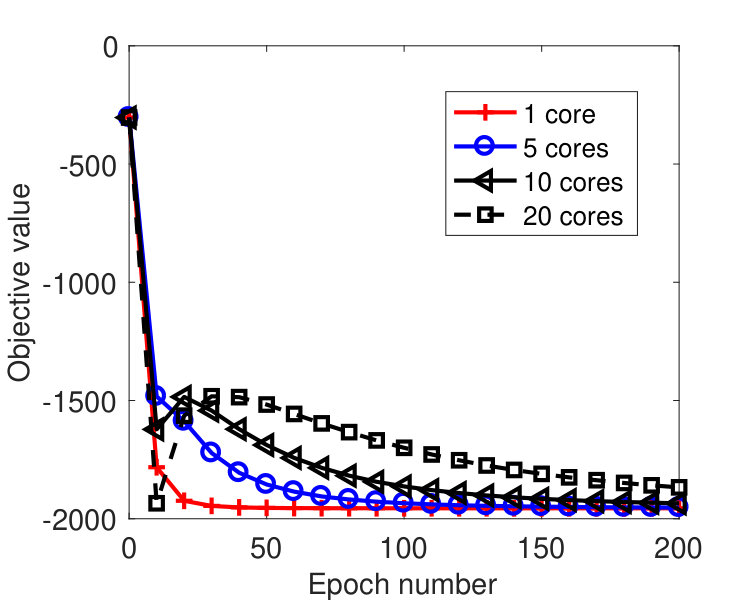 Figure 27
Figure 27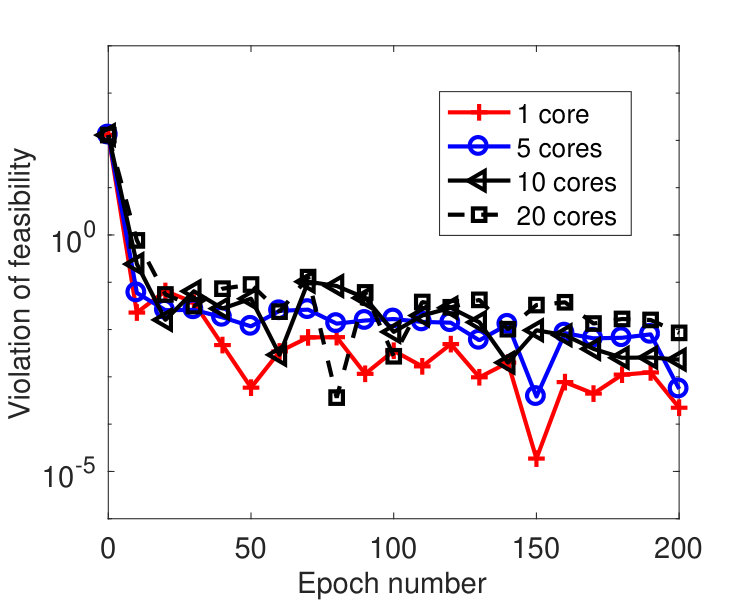 Figure 28
Figure 28| Name | #samples | #features | #nonzeros |
|---|---|---|---|
| rcv1 | 20,242 | 47,236 | 1,498,952 |
| news20 | 19,996 | 1,355,191 | 9,097,916 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Asynchronous parallel primal-dual block coordinate update methods for affinely constrained convex programs††thanks: This work is partly supported by NSF grant DMS-1719549.
Yangyang Xu [email protected]. Department of Mathematical Sciences, Rensselaer Polytechnic Institute, Troy, NY
Abstract
Recent several years have witnessed the surge of asynchronous (async-) parallel computing methods due to the extremely big data involved in many modern applications and also the advancement of multi-core machines and computer clusters. In optimization, most works about async-parallel methods are on unconstrained problems or those with block separable constraints.
In this paper, we propose an async-parallel method based on block coordinate update (BCU) for solving convex problems with nonseparable linear constraint. Running on a single node, the method becomes a novel randomized primal-dual BCU for multi-block affinely constrained problems. For these problems, Gauss-Seidel cyclic primal-dual BCU is not guaranteed to converge to an optimal solution if no additional assumptions, such as strong convexity, are made. On the contrary, assuming convexity and existence of a primal-dual solution, we show that the objective value sequence generated by the proposed algorithm converges in probability to the optimal value and also the constraint residual to zero. In addition, we establish an ergodic convergence result, where is the number of iterations. Numerical experiments are performed to demonstrate the efficiency of the proposed method and significantly better speed-up performance than its sync-parallel counterpart.
Keywords: asynchronous parallel, block coordinate update, primal-dual method
Mathematics Subject Classification: 90C06, 90C25, 68W40, 49M27.
1 Introduction
Modern applications in various data sciences and engineering can involve huge amount of data and/or variables [43]. Driven by these very large-scale problems and also the advancement of multi-core computers, parallel computing has gained tremendous attention in recent years. In this paper, we consider the affinely constrained multi-block structured problem:
[TABLE]
where the variable is partitioned into multiple disjoint blocks , is a continuously differentiable and convex function, and each is a lower semi-continuous extended-valued convex but possibly non-differentiable function. Besides the nonseparable affine constraint, (1) can also include certain block separable constraint by letting part of be an indicator function of a convex set, e.g., nonnegativity constraint.
We will present a novel asynchronous (async-) parallel primal-dual method (see Algorithm 2) towards finding a solution to (1). Suppose there are multiple nodes (or cores, CPUs). We let one node (called master node) update both primal and dual variables and all the remaining ones (called worker nodes) compute and provide block gradients of to the master node. We assume each is proximable (see the definition in (5) below). When there is a single node, our method reduces to a novel serial primal-dual BCU for solving (1); see Algorithm 1.
1.1 Motivating examples
Problems in the form of (1) arise in many areas including signal processing, machine learning, finance, and statistics. For example, the basis pursuit problem [8] seeks a sparse solution on an affine subspace through solving the linearly constrained program:
[TABLE]
Partitioning into multiple disjoint blocks in an arbitrary way, one can formulate (2) into the form of (1) with and each .
Another example is the portfolio optimization [29]. Suppose we have a unit of capital to invest on assets. Let be the fraction of capital invested on the -th asset and be the expected return rate of the -th asset. The goal is to minimize the risk measured by subject to total unit capital and minimum expected return , where and is the covariance matrix. To find the optimal , one can solve the problem:
[TABLE]
Introducing slack variables to the first two inequalities, one can easily write (3) into the form of (1) with a quadratic and each being an indicator function of the nonnegativity constraint set.
In addition, (1) includes as a special case the dual support vector machine (SVM) [10]. Given training data set with , let and . The dual form of the linear SVM can be written as
[TABLE]
where , and is a given number relating to the soft margin size. It is easy to formulate (4) into the form of (1) with being the quadratic objective function and each the indicator function of the set .
Finally, the penalized and constrained (PAC) regression problem [22] is also one example of (1) with and linear constraint of equations. As (that often holds for problems with massive training data), the PAC regression satisfies Assumption ‣ 2.2. In addition, if and , both (3) and (4) satisfy the assumption, and thus the proposed async-parallel method will be efficient when applied to these problems. Although Assumption ‣ 2.2 does not hold for (2) as , our method running on a single node can still outperform state-of-the-art non-parallel solvers; see the numerical results in section 4.1.
1.2 Block coordinate update
The block coordinate update (BCU) method breaks possibly very high-dimensional variable into small pieces and renews one at a time while all the remaining blocks are fixed. Although the problem (1) can be extremely large-scale and complicated, BCU solves a sequence of small-sized and easier subproblems. As (1) owns nice structures, e.g., coordinate friendly [31], BCU can not only have low per-update complexity but also enjoy faster overall convergence than the method that updates the whole variable every time. BCU has been applied to many unconstrained or block-separably constrained optimization problems (e.g., [40, 41, 30, 34, 45, 36, 46, 21]), and it has also been used to solve affinely constrained separable problems, i.e., in the form of (1) without term (e.g., [13, 12, 17, 18, 19]). However, only a few existing works (e.g., [20, 15, 14]) have studied BCU on solving affinely constrained problems with a nonseparable objective function.
1.3 Asynchronization
Parallel computing methods distribute computation over and collect results from multiple nodes. Synchronous (sync) parallel methods require all nodes to keep in the same pace. Upon all nodes finish their own computation, they altogether proceed to the next step. This way, the faster node has to wait for the slowest one, and that wastes a lot of waiting time. On the contrary, async-parallel methods keep all nodes continuously working and eliminate the idle waiting time. Numerous works (e.g., [35, 27, 28, 32]) have demonstrated that async-parallel methods can achieve significantly better speed-up than their sync-parallel counterparts.
Due to lack of synchronization, the information used by a certain node may be outdated. Hence the convergence of an async-parallel method cannot be easily inherited from its non-parallel counterpart but often requires a new tool of analysis. Most existing works only analyze such methods for unconstrained or block-separably constrained problems. Exceptions include [42, 48, 4, 5] that consider separable problems with special affine constraint.
1.4 Related works
Recent several years have witnessed the surge of async-parallel methods partly due to the increasingly large scale of data/variable involved in modern applications. However, only a few existing works discuss such methods for affinely constrained problems. Below we review the literature of async-parallel BCU methods in optimization and also primal-dual BCU methods for affinely constrained problems.
It appears that the first async-parallel method was proposed by Chazan and Miranker [6] for solving linear systems. Later, such methods have been applied in many others fields. In optimization, the first async-parallel BCU method was due to Bertsekas and Tsitsiklis [1] for problems with a smooth objective. It was shown that the objective gradient sequence converges to zero. Tseng [39] further analyzed its convergence rate and established local linear convergence by assuming isocost surface separation and a local Lipschitz error bound on the objective. Recently, [28, 27] developed async-parallel methods based on randomized BCU for convex problems with possibly block separable constraints. They established convergence and also rate results by assuming a bounded delay on the outdated block gradient information. The results have been extended to the case with unbounded probabilistic delay in [33], which also shows convergence of the async-parallel BCU methods for nonconvex problems. On solving problems with convex separable objective and linear constraints, [42] proposed to apply the alternating direction method of multipliers (ADMM) in an asynchronous and distributive way. Assuming a special structure on the linear constraint, it established ergodic convergence result, where is the total number of iterations. In [48, 4, 5, 2], the async-ADMM is applied to distributed multi-agent optimization, which can be equivalently formulated into (1) with and consensus constraint. Among them, [2] proved an almost sure convergence result, [48] showed sublinear convergence of the async-ADMM for convex problems, and [5] established its linear convergence for strongly convex problems. Besides convex problems, [4] also considered nonconvex cases. Assuming certain structure on the problem and choosing appropriate parameters, it showed that any limit point of the iterates satisfies first-order optimality conditions. The works [32, 9] developed async-parallel BCU methods for fixed-point or monotone inclusion problems. Although these settings are more general (including convex optimization as a special case), no convergence rate results have been shown under monotonicity assumption111In [32], a linear convergence result is established under strong monotonicity assumption, which is similar to strong convexity in optimization. (similar to convexity in optimization).
Running on a single node, the proposed async-parallel method reduces to a serial randomized primal-dual BCU. In the literature, various Gauss-Seidel (GS) cyclic BCU methods have been developed for solving separable convex programs with linear constraints. Although a cyclic primal-dual BCU can empirically work well, in general it may diverge [13, 7, 44]. By an example of linear system, [7] showed that the direct extension of ADMM could diverge on solving problems with more than 2 blocks. The works [13, 44] showed that even with proximal terms, the cyclic primal-dual BCU can still diverge. Hence, to guarantee convergence, additional assumptions besides convexity must be made, such as strong convexity on part of the objective [16, 3, 23, 26, 25, 11] and orthogonality properties of block matrices in the linear constraint [7]. Assuming strong convexity of each block component function and choosing the penalty parameter within a region, [16] showed the convergence of ADMM to an optimal solution for solving problems with multiple blocks. For 3-block problems, [3, 23, 11] established the convergence of ADMM and/or its variant by assuming strong convexity of one block component function. For general -block problems, [26] showed that if block component functions are strongly convex, then ADMM with appropriate penalty parameter is guaranteed to converge. Without these assumptions, modifications to the algorithm are necessary for convergence. For example, [18, 19] performed a correction step after each cycle of updates. On solving linear system or quadratic programming, [38] proposed, at each iteration, to first randomly permute all block variables and then perform a cyclic update. Jacobi-type update together with proximal terms was used in [12, 17] to ensure the convergence of the algorithm, which turns out to be a linearized augmented Lagrange method (ALM). In addition, a hybrid Jacobi-GS update was performed in [37, 24, 44]. Different from these modifications, our algorithm simply employs randomization in selecting block variable and can perform significantly better than Jacobi-type methods. In addition, convergence is guaranteed with convexity assumption and thus better than those results for GS-type methods.
1.5 Contributions
The contributions are summarized as follows.
- –
We propose an async-parallel BCU method for solving multi-block structured convex programs with linear constraint. The algorithm is the first async-parallel primal-dual method for affinely constrained problems with nonseparable objective. When there is only one node, it reduces to a novel serial primal-dual BCU method.
- –
With convexity and existence of a primal-dual solution, convergence of the proposed method is guaranteed. We first establish convergence of the serial BCU method. We show that the objective value converges in probability to the optimal value and also the constraint residual to zero. In addition, we establish an ergodic convergence rate result. Then through bounding a cross term involving delayed block gradient, we prove that similar convergence results hold for the async-parallel BCU method if a delay-dependent stepsize is chosen.
- –
We implement the proposed algorithm and apply it to the basis pursuit, quadratic programming, and also the support vector machine problems. Numerical results demonstrate that the serial BCU is comparable to or better than state-of-the-art methods. In addition, the async-parallel BCU method can achieve significantly better speed-up performance than its sync-parallel counterpart.
1.6 Notation and Outline
We use bold small letters for vectors and bold capital letters for matrices. denotes the integer set . represents a vector with for its -th block and zero for all other blocks. denotes a block diagonal matrix with on the diagonal blocks. We denote as the Euclidean norm of and for a symmetric positive semidefinite matrix . We reserve for the identity matrix, and its size is clear from the context. stands for the expectation about conditional on previous history . We use for convergence in probability of a random vector sequence to .
For ease of notation, we let , , and . Denote
[TABLE]
Then is a saddle point of (1) if and .
The proximal operator of a function is defined as
[TABLE]
If has a closed-form solution or is easy to compute, we call proximable.
Outline. The rest of the paper is organized as follows. In section 2, we present the serial and also async-parallel primal-dual BCU methods for (1). Convergence results of the algorithms are shown in section 3. Section 4 gives experimental results, and finally section 5 concludes the paper.
2 Algorithm
In this section, we propose an async-parallel primal-dual method for solving (1). Our algorithm is a BCU-type method based on the augmented Lagrangian function of (1):
[TABLE]
where is the multiplier (or augmented Lagrangian dual variable), and is a penalty parameter.
2.1 Non-parallel method
For ease of understanding, we first present a non-parallel method in Algorithm 1. At every iteration, the algorithm chooses one out of block uniformly at random and renews it by (6) while fixing all the remaining blocks. Upon finishing the update to , it immediately changes the multiplier . The linearization to possibly complicated smooth term greatly eases the -subproblem. Depending on the form of , we can choose appropriate to make (6) simple to solve. Since each is proximable, one can always easily find a solution to (6) if . For even simpler such as -norm and indicator function of a box constraint set, we can set to a diagonal matrix and have a closed-form solution to (6). Note that the algorithm is a special case of Algorithm 1 in [14] with only one group of variables. We include it here for ease of understanding our parallel method.
Randomly choosing a block to update has advantages over the cyclic way in both theoretical and empirical perspectives. We will show that this randomized BCU has guaranteed convergence with convexity other than strong convexity assumed by the cyclic primal-dual BCU. In addition, randomization enables us to parallelize the algorithm in an efficient way as shown in Algorithm 2.
2.2 Async-parallel method
Assume there are nodes. Let the data and variables be stored in a global memory accessible to every node. We let one node (called master node) update both primal variable and dual variable and the remaining ones (called worker nodes) compute block gradients of and provide them to the master node. The method is summarized in Algorithm 2.
To achieve nice practical speed-up performance, we make the following assumption:
Assumption 0
The cost of computing is roughly at least times of that of updating , , and respectively by (9), (7) and (8) for all , where is the number of nodes.
Note that our theoretical analysis does not require this assumption. Roughly speaking, the above assumption means that the worker nodes compute block gradients no faster than the master node can use them. When it holds, the master node can quickly digest the block gradient information fed by all worker nodes. Without this assumption, Algorithm 2 may not perform well in terms of parallel efficiency. For example, if , and computing takes similar time as updating , and , then until the -th iteration, there would be roughly partial gradients that have been sent to but not used by the master node. In this case, a lot of computation will be wasted.
We make a few remarks on Algorithm 2 as follows.
- –
Special case: If there is only one node (i.e., ), the algorithm simply reduces to the non-parallel Algorithm 1. In this case, Assumption ‣ 2.2 trivially holds.
- –
Iteration number: Only the master node increases the iteration number , which counts the times is updated and also the number of used block gradients. The sync-parallel method (e.g., in [14]) chooses to update multiple blocks every time, and the computation is distributed over multiple nodes. It generally requires larger weight in the proximal term for convergence. Hence, even if , Algorithm 2 does not reduce to its sync-parallel counterpart.
- –
Delayed information: Since all worker nodes provide block gradients to the master node, we cannot guarantee every computed block gradient will be immediately used to update . Hence, in (9), may not equal but can be a delayed (i.e., outdated) block gradient. The delay is usually in the same order of and can affect the stepsize, but the affect is negligible as the block number is greater than the delay in an order (see Theorem 3.8).
Because -blocks are computed in the master node, the values of and used in the update are always up-to-date. One can let worker nodes compute new ’s and then feed them (or also the changes in ) to the master node. That way, and will also be outdated when computing -blocks.
- –
Load balance: Under Assumption ‣ 2.2, if (9) is easy to solve (e.g., ) and all nodes have similar computing power, the master node will have used all received block gradients before a new one comes. We let the master node itself also compute block gradient if there is no new one sent from any worker node. This way, all nodes work continuously without idle wait. Compared to its sync-parallel counterpart that typically suffers serious load imbalance, the async-parallel can achieve better speed-up; see the numerical results in section 4.3.
3 Convergence analysis
In this section, we present convergence results of the proposed algorithm. First, we analyze the non-parallel Algorithm 1. We show that the objective value and the residual converge to the optimal value and zero respectively in probability. In addition, we establish a sublinear convergence rate result based on an averaged point. Then, through bounding a cross term involving the delayed block gradient, we establish similar results for the async-parallel Algorithm 2.
Throughout our analysis, we make the following assumptions.
Assumption 1** (Existence of a solution)**
There exists one pair of primal-dual solution such that and .
Assumption 2** (Gradient Lipschitz continuity)**
There exist constants ’s and such that for any and ,
[TABLE]
and
[TABLE]
Denote . Then under the above assumption, it holds that
[TABLE]
3.1 Convergence results of Algorithm 1
Although Algorithm 1 is a special case of the method in [14], its convergence analysis is easier and can be made more succinct. In addition, our analysis for Algorithm 2 is based on that for Algorithm 1. Hence, we provide a complete convergence analysis for Algorithm 1. First, we establish several lemmas, which will be used to show our main convergence results.
Lemma 3.1
Let be the sequence generated from Algorithm 1. Then for any independent of , it holds that
[TABLE]
Proof. We write . For the first term, we use the uniform distribution of on and the convexity of to have
[TABLE]
and for the second term, we use (10) to have
[TABLE]
Combining the above two inequalities gives the desired result.
Lemma 3.2
For any independent of such that , it holds
[TABLE]
Proof. Let . Then
[TABLE]
Note and . In addition, from , we have . Hence,
[TABLE]
Noting
[TABLE]
we complete the proof by plugging (16) into (13).
Lemma 3.3
For any independent of , it holds
[TABLE]
where denotes a subgradient of at .
Proof. From the convexity of and definition of subgradient, it follows that
[TABLE]
Writing and taking the conditional expectation give
[TABLE]
We obtain the desired result by plugging the above equation into (17).
Using the above three lemmas, we show an inequality after each iteration of the algorithm.
Theorem 3.4** (Fundamental result)**
Let be the sequence generated from Algorithm 1. Then for any such that , it holds
[TABLE]
where .
Proof. Since is one solution to (6), there is a subgradient of at such that
[TABLE]
Hence,
[TABLE]
In the above equation, using Lemmas 3.1 through 3.3 and noting
[TABLE]
we have the desired result.
Now we are ready to show the convergence results of Algorithm 1.
Theorem 3.5** (Global convergence in probability)**
Let be the sequence generated from Algorithm 1. If and , then
[TABLE]
Before proving the theorem, we make a remark here. The dual stepsize can be up to , so it could be much smaller than as is big. However, note that is renewed more frequently than . It is updated once immediately after one change to . Hence, if , after one epoch of -update, the dual variable has been updated times and moved a step of size . That is why we can still observe fast convergence of the algorithm to the optimal solution even though a small is used; see the numerical results in section 4.
Proof. Note that
[TABLE]
Hence, taking expectation over both sides of (18) and summing up from through yield
[TABLE]
Since , it follows from Young’s inequality that
[TABLE]
In addition,
[TABLE]
Plugging (24) and (25) into (3.1) and using , we have
[TABLE]
Letting in the above equality, we have from and that
[TABLE]
which together with implies that
[TABLE]
For any , it follows from the Markov’s inequality that
[TABLE]
and
[TABLE]
where in the first inequality, we have used the fact , and the last equation follows from (28) and the Markov’s inequality. This completes the proof.
Given any and , we can also estimate the number of iterations for the algorithm to produce a solution satisfying an error bound with probability no less than .
Definition 3.1** (-solution)**
Given and , a random vector is called an -solution to (1) if and
Theorem 3.6** (Ergodic convergence rate)**
Let be the sequence generated from Algorithm 1. Assume and . Let and
[TABLE]
Then
[TABLE]
In addition, given any and , if
[TABLE]
then is an -solution to (1).
Proof. Since is convex, it follows from (3.1) that
[TABLE]
which with and implies the second inequality in (34). From and Cauchy-Schwartz inequality, we have that
[TABLE]
Letting and in (37) and using (38) give (35), where we have used the convention . By Markov’s inequality,
[TABLE]
and thus to have , it suffices to let
[TABLE]
Similarly, letting and in (37) and using (38) give
[TABLE]
which together with (38) implies the first inequality in (34). Through the same arguments that show (29), we have
[TABLE]
Hence, to have , it suffices to let
[TABLE]
which together with (39) gives the desired result and thus completes the proof.
3.2 Convergence results of Algorithm 2
The key difference between Algorithms 1 and 2 is that used in (9) may not equal the block gradient of at but another outdated vector, which we denote as . This delayed vector may not be any iterate that ever exists in the memory, i.e., inconsistent read can happen [27]. Besides Assumptions 1 and 2, we make an additional assumption on the delayed vector.
Assumption 3** (Bounded delay)**
The delay is uniformly bounded by an integer , and can be related to by the equation
[TABLE]
where is a subset of .
The boundedness of the delay holds if there is no “dead” node. The relation between and in (41) is satisfied if the read of each block variable is consistent, which can be guaranteed by a dual memory approach; see [32].
Similar to (21), we have from the optimality condition of (9) that
[TABLE]
where we have used . Except , all the other terms in (42) can be bounded in the same ways as those in section 3.1. We first show how to bound this term and then present the convergence results of Algorithm 2.
Lemma 3.7
Under Assumptions 2 and 3, we have for any that
[TABLE]
where , and denotes the condition number.
Proof. We split into four terms:
[TABLE]
and we bound each of the four cross terms in (46). The first is bounded in (11). Secondly, from the convexity of , we have
[TABLE]
For the other two terms, we use the relation between and in (41). From the result in [28, pp.306], it holds that
[TABLE]
Hence by Young’s inequality, we have for any that
[TABLE]
Let and order the elements in as . Define and Then we have
[TABLE]
Since , it follows from (10) that
[TABLE]
Note . Thus, by the Cauchy-Schwarz inequality and the Young’s inequality, we have
[TABLE]
Plugging (59) and (60) into (55) gives
[TABLE]
Noting , we have the desired result by plugging (11), (49), (51), and (64) into (46).
From Lemmas 3.2, 3.3, and 3.7, and also the equation (22), we can easily have the following result.
[TABLE]
Regard . Hence,
[TABLE]
Using (65) and following the same arguments in the proofs of Theorems 3.5 and 3.6, we obtain the two theorems below.
Theorem 3.8** (Global convergence in probability)**
Let be the sequence generated from Algorithm 2 with and ’s satisfying
[TABLE]
for , then
[TABLE]
Theorem 3.9** (Ergodic convergence rate)**
Under the assumptions of Theorem 3.8, let and
[TABLE]
Then we have the same results as those in (34) and (35). In addition, given any and , if satisfies (36), then is an -solution to (1).
Remark 3.1
Comparing the settings of ’s in Theorems 3.5 and 3.8, we see that they are only weakly affected by the delay if , which holds for problems involving extremely many variables. If all nodes compute at the same rate, is in the same order of [33], and thus Theorem 3.8 indicates that nearly linear speed-up can be achieved on nodes. Even without the nonseparable affine constraint, this quantity is better than that required in [27]. In addition, as , Algorithm 2 reduces to Algorithm 1, and their convergence results coincide.
4 Numerical experiments
In this section, we test the proposed methods on the basis pursuit problem (2), the nonnegativity constrained quadratic programming, and also the dual SVM (4). We demonstrate their efficacy by comparing to several other existing algorithms.
4.1 Basis pursuit
The tests in this subsection compare Algorithm 1 to the linearized augmented Lagrangian method (LALM) and the open-source solver YALL1 [49] on the basis pursuit problem (2). Putting all variables into a single block, we can regard LALM as a special case of Algorithm 1 with , and YALL1 is a linearized ADMM with penalty parameter adaptively updated based on primal and dual residuals.
The matrix in (2) was randomly generated with varying among , and its entries independently follow standard Gaussian distribution. We normalized each row of . A sparse vector was then generated with 30 nonzero entries that follow standard Gaussian distribution and whose locations are chosen uniformly at random. The vector . We evenly partitioned the variable into 100 blocks, and we set and , where denotes the spectral norm of . For LALM, we treated it as a special case of Algorithm 1 with a single block and set and . The same values of were used for both Algorithm 1 and LALM. The parameters of YALL1 were set to the default values.
To compare the performance of the three algorithms, we plot their values of and with respect to , where denotes the epoch number.222Each epoch is equivalent to updating -blocks. Since the three algorithms have roughly the same per-epoch complexity, the plot in terms of running time will be similar. In Figure 1, we fixed and varied among . From the results, we see that the proposed algorithm perform significantly better than LALM and comparably as well as YALL1. In addition, the parameter affected both Algorithm 1 and LALM but the former was only weakly affected. In Figure 2, we set and varied among . Again we see that the proposed algorithm is significantly better than LALM. For , Algorithm 1 is slightly better than YALL1, and for and , they perform equally well.
4.2 Quadratic programming
In this subsection, we simulate the performance of Algorithm 2 with different delays on solving the nonnegativity constrained quadratic programming (NCQP):
[TABLE]
where is a positive semidefinite matrix. We set with randomly generated from standard Gaussian distribution, and the vector was generated from Gaussian distribution. The matrix with the entries of independently following standard Gaussian distribution, and was generated from uniform distribution on . This way, we guarantee the feasibility of (69).
We partitioned into 2,000 blocks, namely, every coordinate was treated as one block. To see how the algorithm is affected by delayed block gradients, most recent iterates were kept, and was set to one of these iterates that was chosen uniformly at random. We varied among . was tuned to , was used, and ’s were set in two different ways. Figure 3 plots the results by Algorithm 2 with ’s set according to (68) with . Note that for this instance, we have , i.e., the -th diagonal entry of for each , and where denotes the -th column of . From the figure, we see that the convergence speed of the algorithm is affected by the delays. Larger gives smaller stepsize and leads to slower convergence. However, the algorithm is hardly affected by delayed block gradient if the same ’s were used, as shown in Figure 4. Practically, the maximum delay is unknown, but the results in Figure 4 indicate that we can simply set ’s according to Theorem 3.5 regardless of the delay. This implies that our analysis may not be tight.
4.3 Support vector machine
In this subsection, we compare the performance of the async-parallel Algorithm 2 and its sync-parallel counterpart on solving the dual SVM (4). Another way of parallel computing on solving (4) is to directly distribute computation of an algorithm (that may not be BCU type) over multiple nodes, such as the method in [47]. In the test, we used two LIBSVM datasets:333The data can be downloaded from https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/ rcv1 and news20, whose characteristics are listed in Table 1.
We partitioned the variable into blocks of size 50 or 51. For both sync and async-parallel methods, and were set, where is the number of blocks. As suggested in section 4.2, for the async-parallel method, we set according to Theorem 3.5. For the sync-parallel method, if there are cores, we selected a set of blocks at every iteration and set for all . We also used ’s the same as those by the async-parallel method but noticed that the sync-parallel method diverged. The larger weight matrices are also suggested in [14] to be proportional to the number of blocks. Note that in the dual SVM (4), if we let and contain the data points and labels corresponding to the -th block variable, then equals the spectral norm of the matrix . Since every block only has 50 or 51 coordinates, it is easy to compute ’s.
We ran the tests on a machine with 20 cores. Figure 5 plots the results by the sync and async-parallel algorithms on the rcv1 dataset. From the figure, we see that in terms of epoch number, the sync-parallel method converges slower if more cores are used, while the async-parallel one converges almost the same with different number of cores. As shown in Figure 6, similar results were observed for the news20 dataset. We also measured the speed-up of the two parallel methods in terms of running time. The results are plotted in Figure 7. From the results, we see that the async-parallel method achieves significantly better speed-up than the sync-parallel one, and that is because synchronization at every iteration wastes much waiting time.
5 Conclusions
We have proposed an async-parallel primal-dual BCU method for convex programming with nonseparable objective and arbitrary linear constraint. As a special case on a single node, the method reduces to a randomized primal-dual BCU for multi-block linearly constrained problems. Convergence and also rate results in probability have been established under convexity assumption. We have also numerically compared the proposed algorithm to several existing methods. The experimental results demonstrate the superior performance of our algorithm over other ones.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] D. P. Bertsekas and J. N. Tsitsiklis. Parallel and distributed computation: numerical methods , volume 23. Prentice hall Englewood Cliffs, NJ, 1989.
- 2[2] P. Bianchi, W. Hachem, and F. Iutzeler. A coordinate descent primal-dual algorithm and application to distributed asynchronous optimization. IEEE Transactions on Automatic Control , 61(10):2947–2957, 2016.
- 3[3] X. Cai, D. Han, and X. Yuan. On the convergence of the direct extension of admm for three-block separable convex minimization models with one strongly convex function. Computational Optimization and Applications , 66(1):39–73, 2017.
- 4[4] T.-H. Chang, M. Hong, W.-C. Liao, and X. Wang. Asynchronous distributed admm for large-scale optimization — part i: Algorithm and convergence analysis. IEEE Transactions on Signal Processing , 64(12):3118–3130, 2016.
- 5[5] T.-H. Chang, W.-C. Liao, M. Hong, and X. Wang. Asynchronous distributed admm for large-scale optimization — part ii: Linear convergence analysis and numerical performance. IEEE Transactions on Signal Processing , 64(12):3131–3144, 2016.
- 6[6] D. Chazan and W. Miranker. Chaotic relaxation. Linear Algebra and its Applications , 2(2):199–222, 1969.
- 7[7] C. Chen, B. He, Y. Ye, and X. Yuan. The direct extension of admm for multi-block convex minimization problems is not necessarily convergent. Mathematical Programming , 155(1-2):57–79, 2016.
- 8[8] S. S. Chen, D. L. Donoho, and M. A. Saunders. Atomic decomposition by basis pursuit. SIAM review , 43(1):129–159, 2001.