PaMM: Pose-aware Multi-shot Matching for Improving Person Re-identification
Yeong-Jun Cho, Kuk-Jin Yoon

TL;DR
This paper introduces PaMM, a pose-aware multi-shot matching framework that improves person re-identification accuracy by analyzing camera viewpoints and poses, outperforming existing methods across diverse scenarios.
Contribution
The paper presents a novel pose-aware framework that robustly estimates poses and enhances multi-shot matching for person re-identification, addressing pose and viewpoint variations.
Findings
Outperforms state-of-the-art re-identification methods
Effective in diverse viewpoints and pose variations
Demonstrates robustness on public datasets
Abstract
Person re-identification is the problem of recognizing people across different images or videos with non-overlapping views. Although there has been much progress in person re-identification over the last decade, it remains a challenging task because appearances of people can seem extremely different across diverse camera viewpoints and person poses. In this paper, we propose a novel framework for person re-identification by analyzing camera viewpoints and person poses in a so-called Pose-aware Multi-shot Matching (PaMM), which robustly estimates people's poses and efficiently conducts multi-shot matching based on pose information. Experimental results using public person re-identification datasets show that the proposed methods outperform state-of-the-art methods and are promising for person re-identification from diverse viewpoints and pose variances.
Click any figure to enlarge with its caption.
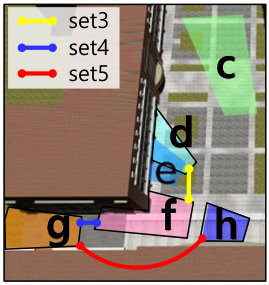 Figure 10
Figure 10 Figure 10
Figure 10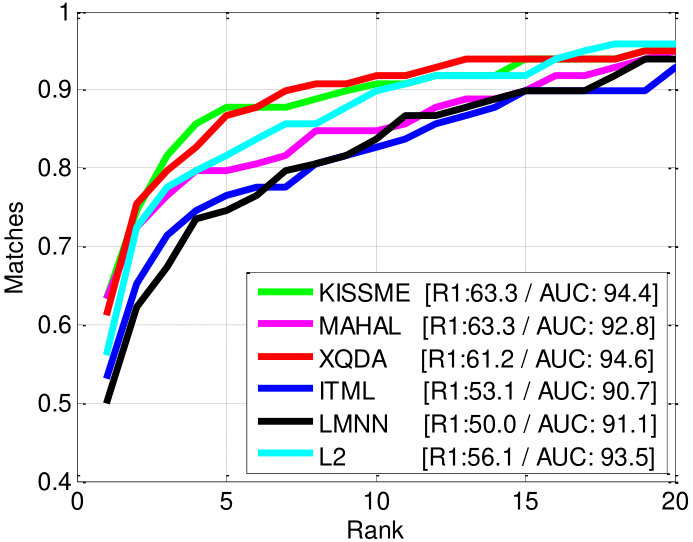 Figure 12
Figure 12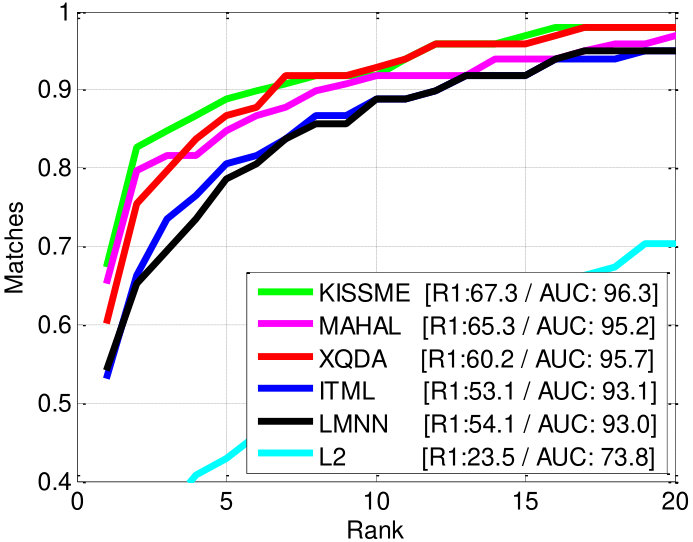 Figure 12
Figure 12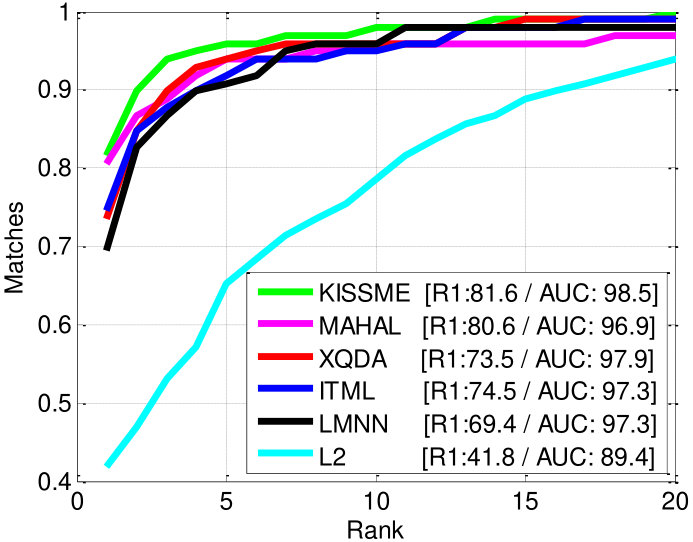 Figure 12
Figure 12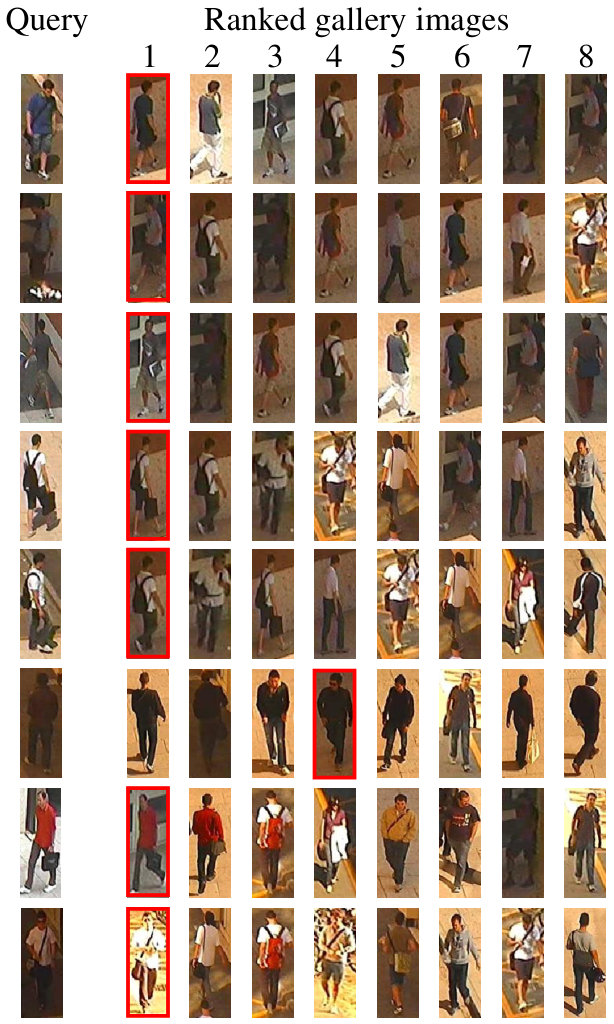 Figure 13
Figure 13 Figure 13
Figure 13 Figure 13
Figure 13 Figure 1
Figure 1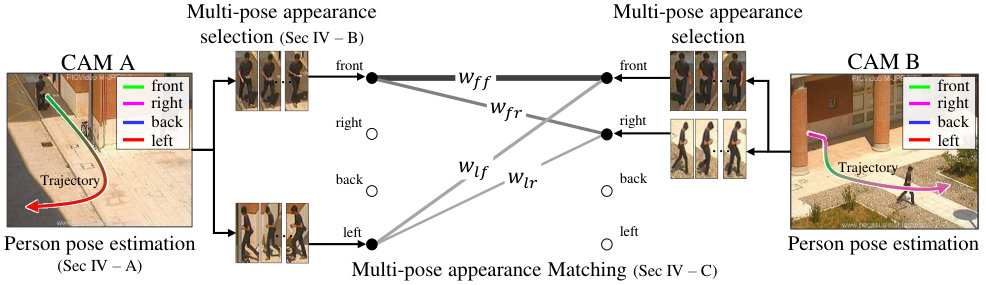 Figure 2
Figure 2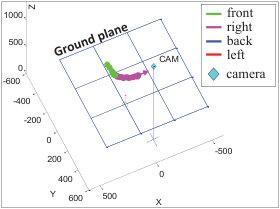 Figure 3
Figure 3 Figure 3
Figure 3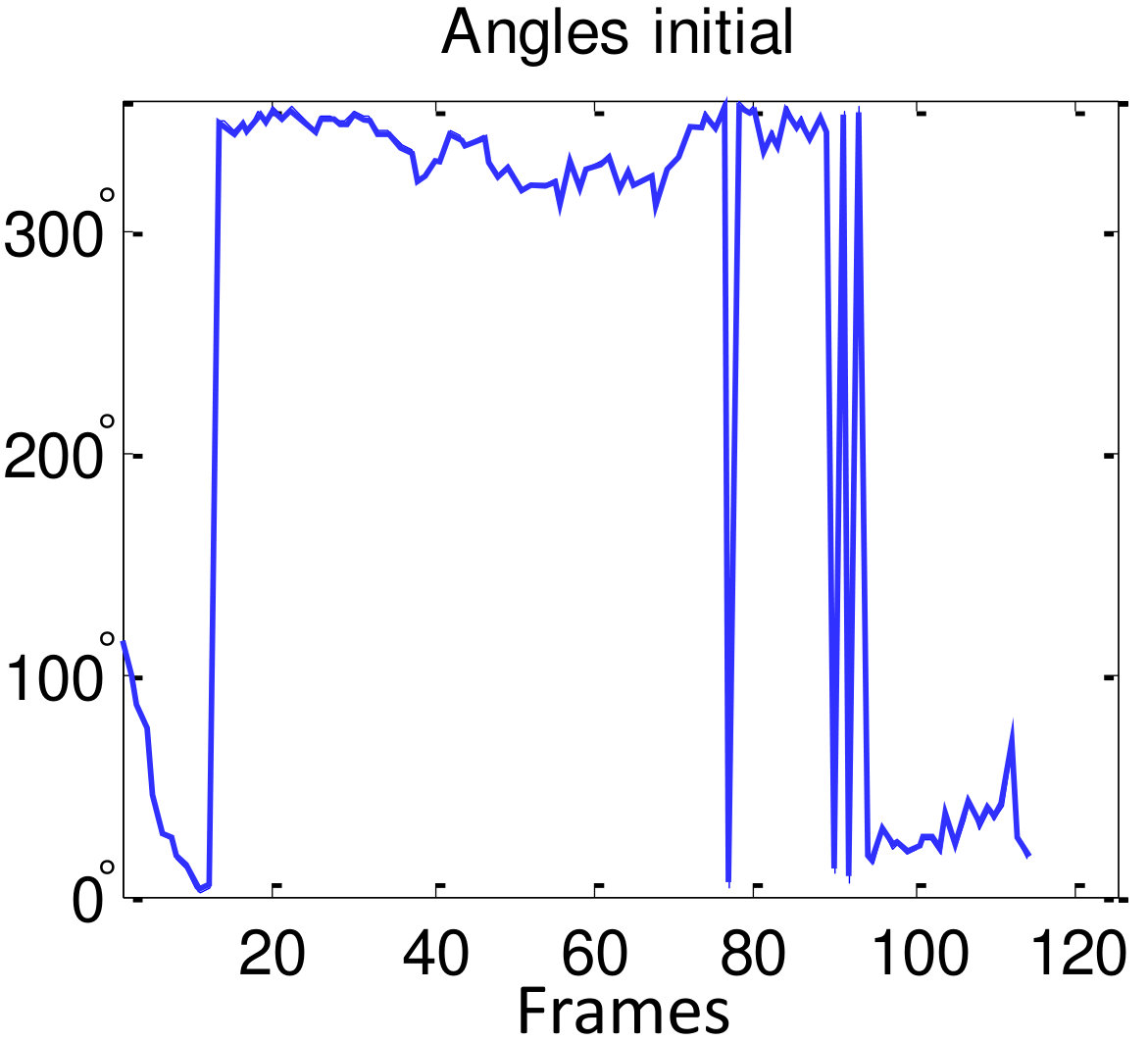 Figure 4
Figure 4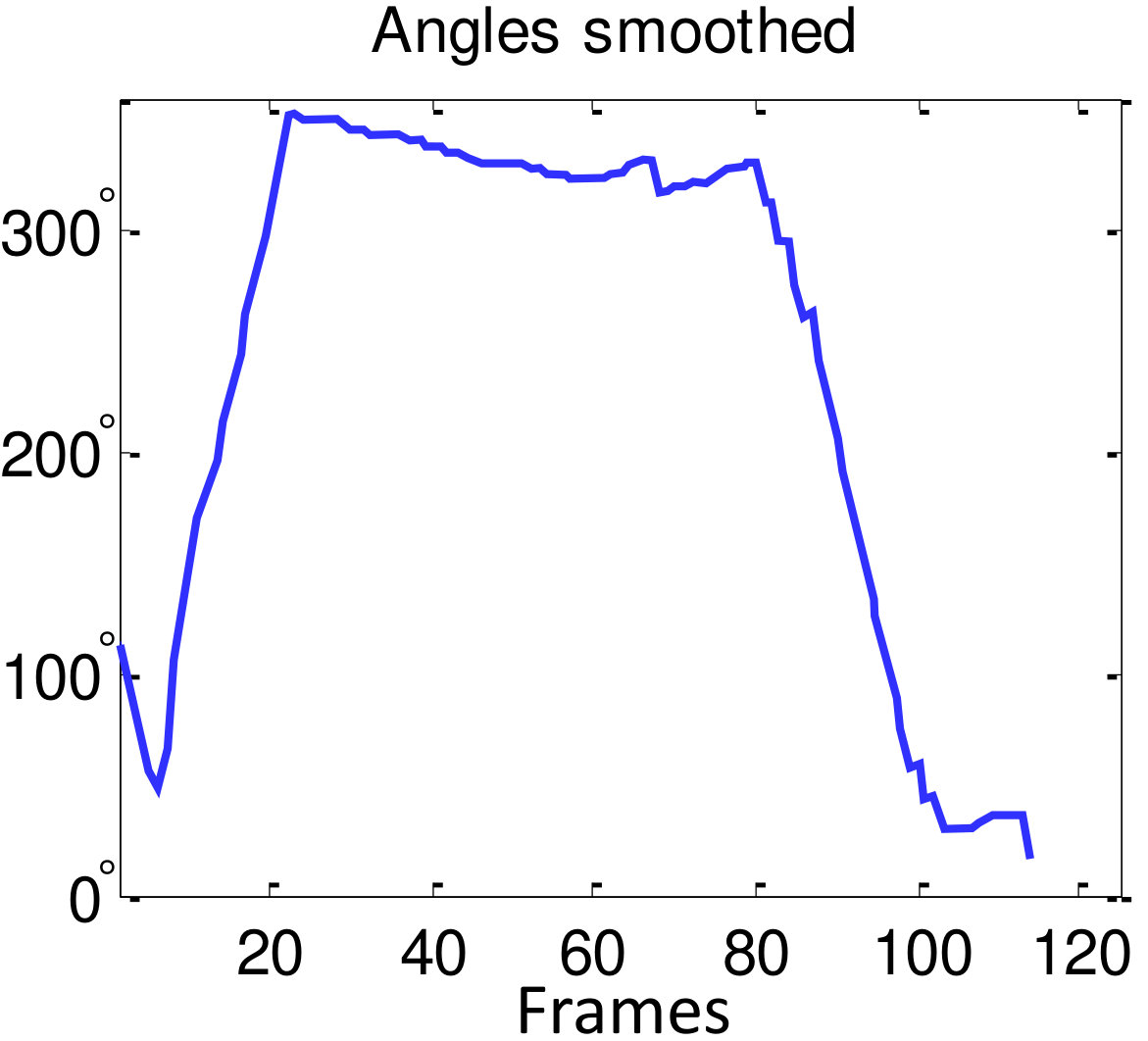 Figure 4
Figure 4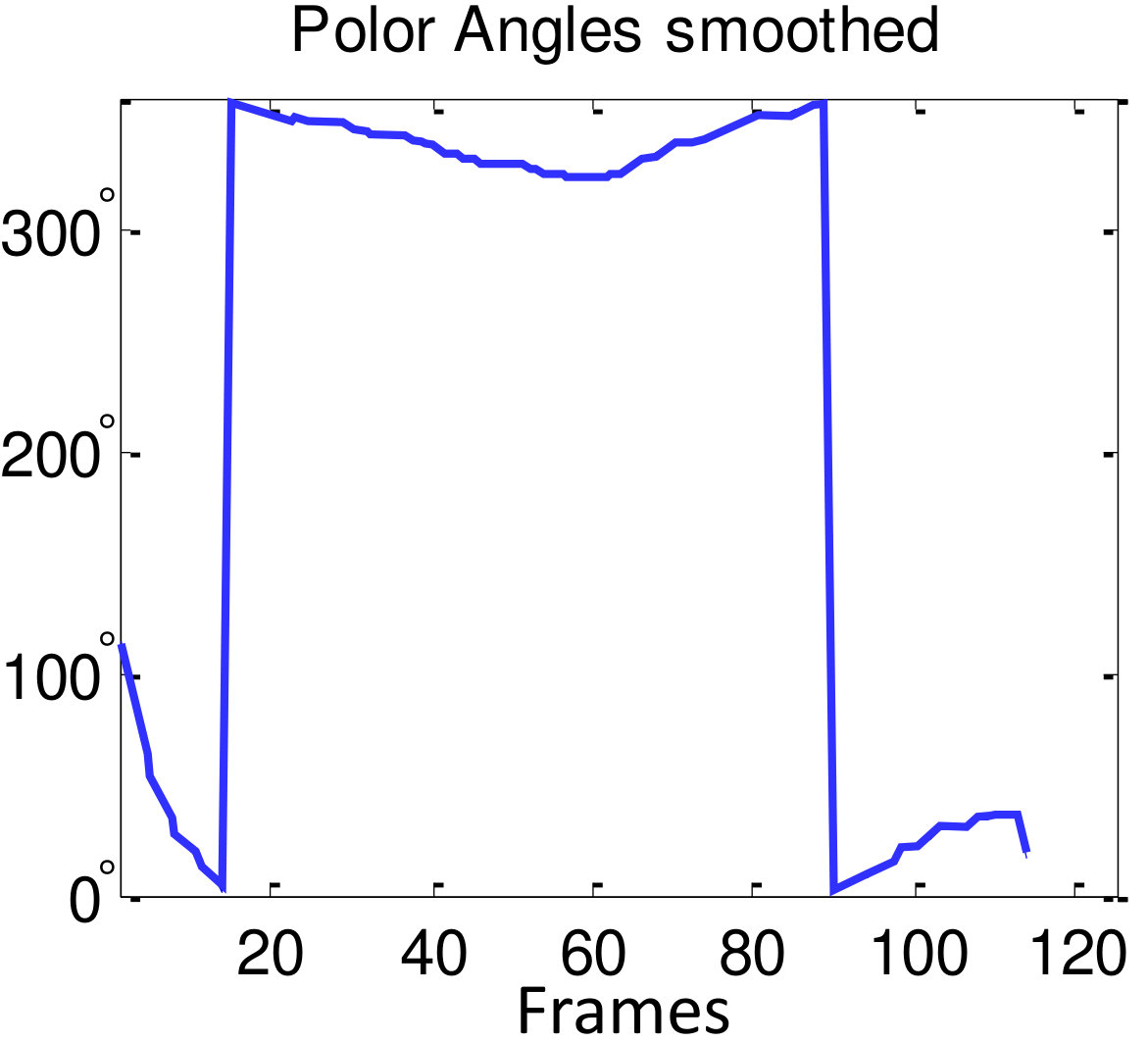 Figure 4
Figure 4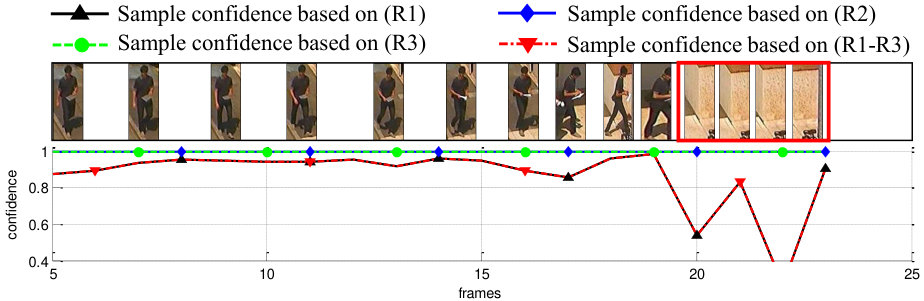 Figure 5
Figure 5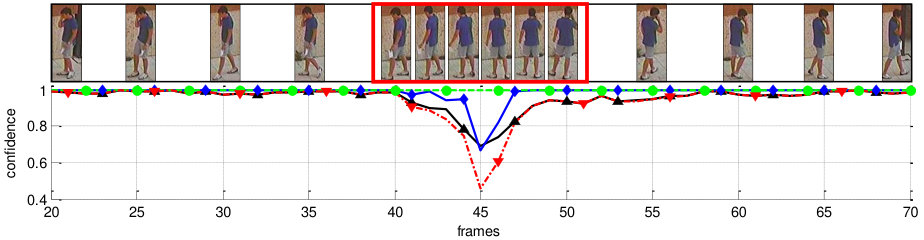 Figure 5
Figure 5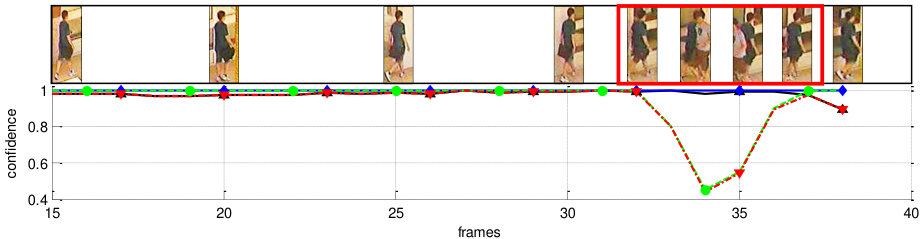 Figure 5
Figure 5 Figure 6
Figure 6 Figure 6
Figure 6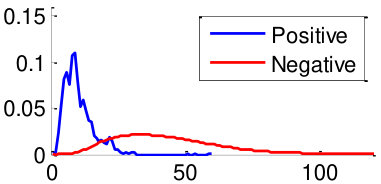 Figure 7
Figure 7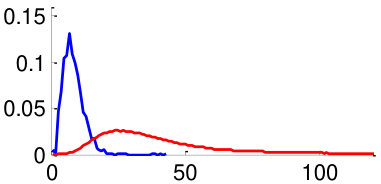 Figure 7
Figure 7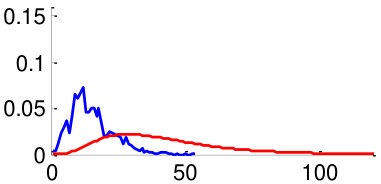 Figure 7
Figure 7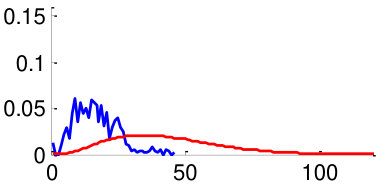 Figure 7
Figure 7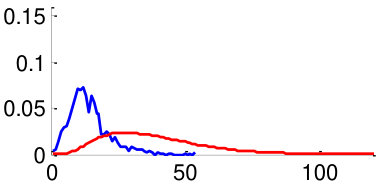 Figure 7
Figure 7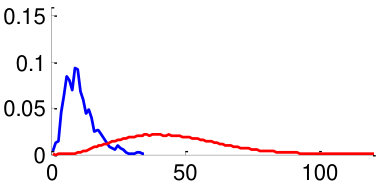 Figure 7
Figure 7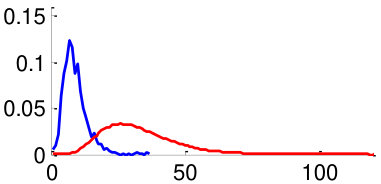 Figure 7
Figure 7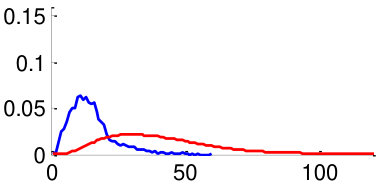 Figure 7
Figure 7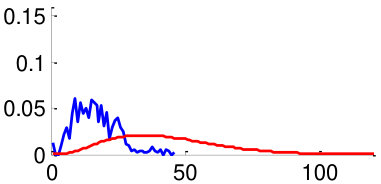 Figure 7
Figure 7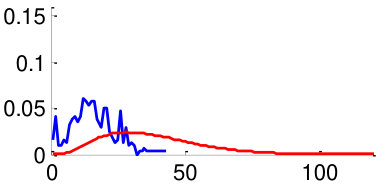 Figure 7
Figure 7 Figure 8
Figure 8 Figure 8
Figure 8 Figure 9
Figure 9| Dataset | 3DPeS - Set All [11] | ||||
|---|---|---|---|---|---|
| Baseline | KISSME [3] | ||||
| Method Rank | = 1 | = 3 | = 5 | = 10 | AUC |
| SingleMatch | 34.7 | 58.2 | 68.4 | 87.8 | 90.7 |
| MultiQ-max† | 59.2 | 75.5 | 85.7 | 93.9 | 95.4 |
| MultiQ-avg† | 80.6 | 91.8 | 94.9 | 98.0 | 98.5 |
| FullMatch-min† | 78.6 | 93.9 | 96.9 | 98.0 | 98.8 |
| FullMatch-avg† | 81.6 | 93.9 | 95.9 | 98.0 | 98.5 |
| PaMM†(ours) | 83.7 | 93.9 | 96.9 | 100 | 99.2 |
| Baseline | Mahal [4] | ||||
| Method Rank | = 1 | = 3 | = 5 | = 10 | AUC |
| SingleMatch | 39.8 | 61.2 | 75.5 | 86.7 | 91.8 |
| MultiQ-max† | 60.2 | 72.5 | 79.6 | 89.8 | 93.8 |
| MultiQ-avg† | 74.5 | 87.8 | 90.8 | 95.9 | 96.6 |
| FullMatch-min† | 75.5 | 90.8 | 92.7 | 93.9 | 97.6 |
| FullMatch-avg† | 80.6 | 88.8 | 93.9 | 95.9 | 96.9 |
| PaMM†(ours) | 81.6 | 89.8 | 93.9 | 95.9 | 97.6 |
| Baseline | XQDA [21] | ||||
| Method Rank | = 1 | = 3 | = 5 | = 10 | AUC |
| SingleMatch | 46.9 | 68.4 | 78.6 | 90.8 | 93.7 |
| MultiQ-max† | 53.1 | 71.4 | 82.7 | 91.8 | 94.2 |
| MultiQ-avg† | 75.5 | 87.8 | 93.9 | 96.9 | 97.9 |
| FullMatch-min† | 73.5 | 87.8 | 93.9 | 98.0 | 97.8 |
| FullMatch-avg† | 73.5 | 89.8 | 93.9 | 95.9 | 97.9 |
| PaMM†(ours) | 75.5 | 90.8 | 93.9 | 98.0 | 98.1 |
| Baseline | ITML [13] | ||||
| Method Rank | = 1 | = 3 | = 5 | = 10 | AUC |
| SingleMatch | 44.9 | 69.4 | 80.6 | 90.8 | 93.8 |
| MultiQ-max† | 58.2 | 70.4 | 78.6 | 88.8 | 93.6 |
| MultiQ-avg† | 75.5 | 82.7 | 89.8 | 94.9 | 96.4 |
| FullMatch-min† | 63.3 | 86.7 | 91.8 | 94.9 | 97.1 |
| FullMatch-avg† | 74.5 | 87.8 | 91.8 | 94.9 | 97.2 |
| PaMM†(ours) | 73.5 | 89.8 | 92.9 | 95.9 | 97.5 |
| Baseline | LMNN [14] | ||||
| Method Rank | = 1 | = 3 | = 5 | = 10 | AUC |
| SingleMatch | 45.9 | 68.4 | 77.6 | 90.8 | 93.6 |
| MultiQ-max† | 51.0 | 72.5 | 81.6 | 89.8 | 93.7 |
| MultiQ-avg† | 70.4 | 87.8 | 92.9 | 96.9 | 97.4 |
| FullMatch-min† | 69.4 | 86.7 | 93.9 | 96.9 | 97.8 |
| FullMatch-avg† | 69.4 | 86.7 | 90.8 | 95.9 | 97.3 |
| PaMM†(ours) | 70.4 | 87.8 | 91.8 | 98.0 | 97.8 |
| Dataset | 3DPeS - Set 3 | 3DPeS - Set 4 | 3DPeS - Set 5 | 3DPeS - Set All [11] | ||||||||||
| Method Rank | = 1 | = 3 | AUC | = 1 | = 3 | AUC | = 1 | = 3 | AUC | =1 | =3 | =5 | =10 | AUC |
| LOMO + | 47.4 | 63.2 | 85.0 | 54.2 | 79.2 | 86.8 | 41.7 | 80.6 | 90.0 | 25.5 | 39.8 | 52.0 | 71.4 | 85.9 |
| LOMO + KISSME [3] | 36.8 | 57.9 | 80.6 | 41.7 | 66.7 | 82.6 | 41.7 | 69.4 | 87.5 | 34.7 | 58.2 | 68.4 | 87.8 | 90.7 |
| LOMO + Mahal[4] | 39.5 | 60.5 | 82.3 | 37.5 | 66.7 | 83.0 | 44.4 | 72.2 | 88.1 | 39.8 | 61.2 | 75.5 | 86.7 | 91.8 |
| LOMO + XQDA[21] | 42.0 | 73.7 | 87.3 | 50.0 | 75.0 | 87.5 | 52.8 | 86.1 | 92.3 | 46.9 | 68.4 | 78.6 | 90.8 | 93.7 |
| LOMO + ITML[13] | 52.6 | 76.3 | 88.4 | 58.3 | 75.0 | 85.1 | 58.3 | 80.6 | 89.0 | 44.9 | 69.4 | 80.6 | 90.8 | 93.8 |
| LOMO + LMNN[14] | 50.0 | 73.7 | 86.8 | 58.3 | 75.0 | 85.1 | 52.8 | 69.4 | 87.3 | 45.9 | 68.4 | 77.6 | 90.8 | 93.6 |
| MultiQ-max† | 55.3 | 76.3 | 90.7 | 62.5 | 79.2 | 92.4 | 58.3 | 83.3 | 92.6 | 59.2 | 75.5 | 85.7 | 93.9 | 95.4 |
| MultiQ-avg† | 81.6 | 94.7 | 98.3 | 83.3 | 100 | 98.3 | 69.4 | 88.9 | 96.3 | 80.6 | 91.8 | 94.9 | 98.0 | 98.5 |
| FullMatch-min† | 78.9 | 90.0 | 98.1 | 83.3 | 100 | 97.9 | 69.4 | 90.0 | 96.0 | 78.6 | 93.9 | 96.9 | 98.0 | 98.8 |
| FullMatch-avg† | 84.2 | 94.7 | 98.3 | 83.3 | 100 | 97.9 | 72.2 | 90.0 | 96.3 | 81.6 | 93.9 | 95.9 | 98.0 | 98.5 |
| PaMM-ns†(ours) | 84.2 | 94.7 | 98.3 | 91.7 | 100 | 99.3 | 72.2 | 90.0 | 96.0 | 83.7 | 93.9 | 96.9 | 100 | 99.1 |
| PaMM†(ours) | 84.2 | 94.7 | 98.3 | 91.7 | 100 | 99.3 | 75.0 | 90.0 | 96.3 | 83.7 | 93.9 | 96.9 | 100 | 99.2 |
| Dataset | PRID 2011[12] | |||
|---|---|---|---|---|
| Method Rank | =1 | =5 | =10 | =20 |
| 178SDALF [1] | 4.9 | 21.5 | 30.9 | 45.2 |
| 200LOMO[21] + KISSME[3] | 22.0 | 43.0 | 55.0 | 70.0 |
| 178Salience [5] | 25.8 | 43.6 | 52.6 | 62.0 |
| 200LOMO + XQDA [21] | 39.0 | 68.0 | 83.0 | 91.0 |
| 178SDALF† [1] | 5.2 | 20.7 | 32.0 | 47.9 |
| 178DVR† [26] | 40.0 | 71.7 | 84.5 | 97.2 |
| 178DTDL† [36] | 40.6 | 69.7 | 77.8 | 85.6 |
| 178Salience+DVR† [6] | 41.7 | 64.5 | 77.5 | 88.8 |
| 178AFDA† [7] | 43.0 | 72.7 | 84.6 | 91.6 |
| 200LOMO + XQDA† [21] | 43.0 | 82.0 | 90.0 | 98.0 |
| 178TDL† [27] | 56.7 | 80.0 | 87.6 | 93.6 |
| 178STFV3D† [28] | 64.1 | 87.3 | 89.9 | 92.0 |
| 200RNN† [29] | 70.0 | 90.0 | 95.0 | 97.0 |
| 200PaMM† (Ours) | 76.0 | 94.0 | 98.0 | 99.0 |
| 178PaMM† (Ours) | 78.1 | 95.5 | 98.9 | 100 |
| Dataset | iLIDS-Vid[6] | |||
|---|---|---|---|---|
| Method Rank | =1 | =5 | =10 | =20 |
| SDALF [1] | 5.1 | 14.9 | 20.7 | 31.3 |
| Salience [5] | 10.2 | 24.8 | 35.5 | 52.9 |
| LOMO [21] + KISSME [3] | 11.3 | 27.3 | 37.3 | 49.7 |
| LOMO + XQDA [21] | 18.0 | 41.2 | 54.7 | 67.0 |
| SDALF† [1] | 6.3 | 18.8 | 27.1 | 37.3 |
| LOMO + XQDA† [21] | 20.3 | 47.0 | 63.0 | 78.7 |
| DTDL† [36] | 25.9 | 48.2 | 57.3 | 68.9 |
| Salience+DVR† [6] | 30.9 | 54.4 | 65.1 | 77.1 |
| AFDA† [7] | 37.5 | 62.7 | 73.0 | 81.8 |
| DVR† [26] | 39.5 | 61.1 | 71.7 | 81.0 |
| STFV3D† [28] | 44.3 | 71.7 | 83.7 | 91.7 |
| TDL† [27] | 56.3 | 87.6 | 95.6 | 98.3 |
| PaMM† (Ours) | 57.3 | 79.3 | 87.3 | 93.3 |
| RNN† [29] | 58.0 | 84.0 | 91.0 | 96.0 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
PaMM: Pose-aware Multi-shot Matching for Improving Person Re-identification
Yeong-Jun Cho and Kuk-Jin Yoon
Computer Vision Laboratory, GIST, South Korea Yeong-Jun Cho and Kuk-Jin Yoon are with the School of Information and Communications, Gwangju Institute of Science and Technology, South Korea.
E-mail: [email protected]
Abstract
Person re-identification is the problem of recognizing people across different images or videos with non-overlapping views. Although there has been much progress in person re-identification over the last decade, it remains a challenging task because appearances of people can seem extremely different across diverse camera viewpoints and person poses. In this paper, we propose a novel framework for person re-identification by analyzing camera viewpoints and person poses in a so-called Pose-aware Multi-shot Matching (PaMM), which robustly estimates people’s poses and efficiently conducts multi-shot matching based on pose information. Experimental results using public person re-identification datasets show that the proposed methods outperform state-of-the-art methods and are promising for person re-identification from diverse viewpoints and pose variances.
Index Terms:
Person re-identification, Person pose, Multi-shot matching, Pose-aware matching method, Non-overlapping cameras
I Introduction
Ahuge number of surveillance cameras have been installed in public places (e.g. offices, stations, airports, and streets) in recent year to closely monitor scenes and give early warnings of events such as accidents and crimes. However, dealing with large camera networks requires a lot of human effort. Automatic person re-identification tasks that can associate people across images from non-overlapping cameras have been widely utilized to reduce the required human effort.
Most previous works have generally relied on people’s appearances such as color, shape, and texture to re-identify them, since there is no continuity between non-overlapping cameras in terms of time and space. Thus, many works have focused on appearance modeling and learning such as via feature descriptor extraction [1, 2], metric learning [3, 4], and saliency learning [5] methods for efficient re-identification. Unfortunately, a person’s appearance can change considerably across images depending on a camera’s viewpoint and a person’s pose as shown in Fig. 1; thus, person re-identification tasks that only rely on appearance are very challenging. Nonetheless, many previous re-identification frameworks [3, 4, 5] have commonly adopted single-shot matching methods that utilize a single appearance for each person to measure the similarity (or difference) between a pair of person image patches. However, it is difficult to identify people with single-shot appearance matching because of the people’s aforementioned severe appearance changes. Several multi-shot matching methods [1, 6, 7] have been proposed in recent years to overcome the limitation of single-shot matching; however, the ambiguities that arise due to the viewpoint and pose variations remain.
In real world surveillance scenarios, each person provides multiple observations along a moving path. Therefore, we can exploit plenty of appearances for re-identification tasks. Furthermore, surveillance videos contain scene structures and scene contexts such as a ground plane of a scene, a person’s trajectory, etc. In practice, it is possible to estimate the camera viewpoint from the scene information via human height-based auto-calibrations [8, 9] and vanishing point-based auto-calibrations [10]; then the difficulties in person re-identification become more tractable.
This paper proposes a novel framework for person re-identification by analyzing camera viewpoints and person poses called Pose-aware Multi-shot Matching (PaMM). First camera viewpoints are calibrated and poeple’s poses are robustly estimated based on the proposed pose estimation method. We then generate a multi-pose model that contains four feature descriptor groups extracted from four image clusters grouped by person poses (i.e. front, right, back, and left). After generating multi-pose models, we calculate matching scores between multi-pose models in a weighted summation manner based on pre-trained matching weights. The proposed person re-identification framework permits the exploitation of additional cues such as person poses and 3D scene information, which makes the person re-identification problem more tractable.
To validate our methods, we extensively evaluate the performance of the proposed methods and other state-of-the-art methods that use public person re-identification datasets 3DPeS [11], PRID 2011 [12] and iLIDS-Vid [6]. Experimental results show that the proposed framework is promising for person re-identification from diverse viewpoint and pose variations and outperforms other state-of-the-art methods. For reproducibility, the PaMM code is openly available to the public at: https://cvl.gist.ac.kr/pamm/.
The main ideas of this work are simple but very effective. In addition, our method can flexibly adopt any existing person re-identification methods such as feature descriptor extraction [1, 2] and metric learning [13, 3, 14] methods as the baseline in our re-identification framework. This is the first attempt to exploit viewpoint and pose information for multi-shot person re-identification to the best of our knowledge.
The rest of the paper is organized as follows: Section II summarizes previous person re-identification works. Section III, explains the motivation behind this work. We then describe our proposed methods in Section IV. The datasets and evaluation methodology used are described in Section V. The experimental results are reported in Section VI and we conclude this paper in Section VII.
II Previous Works
We have classified previous person re-identification methods into single-shot matching methods and multi-shot matching methods and briefly reviewed them. Single-shot matching methods only use a single appearance of each person to find people correspondences between two different cameras, whereas the multi-shot matching methods exploit multiple appearances to find the correspondences.
II-A Single-shot matching methods
Most works that attempt to re-identify people across non-overlapping cameras generally rely on poeple’s appearance since there is no spatiotemporal continuity; we cannot fully utilize the motion or spatial information of a person for their re-identification. Therefore, most works have focused on appearance-based techniques such as feature descriptor extraction and metric learning methods for efficient person re-identification.
Regarding feature extraction methods, Farenzena et al. [1] proposed the symmetry-driven accumulation of local features that are extracted based on the principles of the symmetry and asymmetry of the human body. This method exploits the human body model which is robust to human pose variations. Feature extraction methods that select or weight discriminative features have been proposed in [15, 2]. These methods enable us to adaptively exploit features depending on the person’s appearance. Regarding metric learning, several methods have been proposed such as KISSME [3], LMNN-R [16], and applied to the re-identification problem. Some works [3, 4] have extensively evaluated and compared several metric learning methods (e.g. ITML [13], KISSME [3], LMNN [14] and Mahalnobis [4]) and shown the effectiveness of metric learning for re-identification. Similar to metric learning methods, a saliency learning method was also proposed by R. Zhao et al. [5] that learned saliency for handling severe appearance changes. Recently, many person re-identification methods have been proposed that are based on learning deep convolutional neural network (CNN) [17] and Siamese convolutional network [18, 19, 20] for simultaneously learning both features and metrics. In addition, [21] proposed both feature descriptor extraction and metric learning methods for re-identification.
However, a few works [22, 23] that use person pose for re-identification have been proposed very recently. Bak et al. [22] proposed learning a generic metric pool that consists of metrics, each of which are learned to match specific pairs of poses. Wu. et al. [23] proposed person re-identification involving human appearance modeling using pose priors and person-specific feature learning. Although these methods utilized pose priors for person re-identification, they consider single-shot matching that recognizes people using a single appearance, which has difficulties for handling diverse appearance changes. This paper proposes a person re-identification framework that uses pose cues for efficient multi-shot matching.
II-B Multi-shot matching methods
Several multi-shot matching methods that have sought to overcome the limitations of single-shot matching methods have been proposed in recent years. Li et al. [24] proposed a random forest-based person re-identification that exploits multiple appearances. They calculated similarity scores between two multi-shot sets and averaged them into a final similarity score. Farenzena et al. [1] also provided multi-shot matching results by comparing each possible pair of histograms between different signatures (a set of appearances) and selecting the lowest obtained distance for the final matching score. Similarly, Su et al. [17] and Zheng et al. [25] exploited multiple queries for re-identification. Instead of the multi-shot matching strategies such as [1, 24], they merged multiple queries (i.e. multi-shot) into a single query and performed re-identification using the merged queries.
Wang et al. [6, 26] proposed video ranking methods for multi-shot matching that automatically selected discriminative video fragments and learned a video ranking function. You et al. [27] proposed a top-push distance learning model for efficiently matching video features of people. Similarly, Liu et al. [28] proposed a video-based pedestrian re-identification method based on the proposed spatiotemporal body-action model. Li et al. [7] also proposed a multi-shot person re-identification method based on iterative appearance clustering and subspace learning for effective multi-shot matching. In addition, a multi-shot matching person re-identification using deep recurrent neural network (RNN) [29] was recently proposed. This implies that multi-shot matching with deep learning techniques will be a new trend in person re-identification.
Although multi-shot matching person re-identification methods have overcome the limitations of single-shot matching to some extent, ambiguities still arise from the various viewpoints and pose changes.
III Motivation and Main Ideas
As shown in Fig. 1, person re-identification is quite challenging due to camera viewpoint and person pose variations. However, what if the camera viewpoint and the pose priors of people in every non-overlapping camera are known in advance? In fact, progress in auto-calibration techniques [8, 9] has enabled the extraction of additional cues such as camera parameters, ground plane, and the 3D position of people without any offline calibration tasks [30]. Exploiting those additional cues permits the estimation of poeple’s poses, as described in Section IV-A. This paper fully exploits those additional cues for multi-shot matching and proposes the Pose-aware Multi-shot Matching (PaMM) for efficient person re-identification.
Suppose that upon estimating camera viewpoints and people’s poses, there is a simple 2 vs. 2 matching scenario that contains one same-pose matching (front–front) and three different-pose matchings (front–right, left–front, left–right) as shown in Fig. 2. The result of the same-pose matching can generally be expected to be more reliable than those of different-pose matchings, since people maintain their appearance between cameras when their poses are the same (This work excludes photometric issues such as illumination changes and camera color response differences). Then, such a multi-shot matching scenario, it is desirable that same-pose matching (front–front) plays a more important role than different-pose matchings. Hence, this work incorporates this matching idea by aggregating the matching scores of all pose matchings in a weighted summation manner, as shown in Fig. 2, where the thicknesses of the lines indicate the matching weights. We also study how to efficiently train matching weights and match between multi-shot appearances using pose information.
IV Proposed PaMM Framework
The proposed person re-identification framework, first estimates the camera viewpoint and people’s poses (Section IV-A) and then generate multi-pose models containing feature descriptors groups extracted from four image clusters obtained based on the person poses (i.e. front, right, back, left) (Section IV-B). Matching scores between multi-pose models in a weighted summation manner are calculated using the pre-trained matching weights after multi-pose models are generated (Section IV-C). The matching weight training is described in Section IV-D. Fig. 2 illustrates the overall framework for the proposed person re-identification.
IV-A Person pose estimation
Before estimating people’s poses, the camera intrinsic and extrinsic parameters (or camera pose) are estimated using auto-calibration algorithms such as [8, 9]. Then, the relationship between an image (pixel coordinates) and the real world (world coordinates) is described as
[TABLE]
where , , and represent a camera intrinsic matrix, rotation matrix, and position, respectively, and represent the image and world coordinates, respectively. Knowing the camera parameters permits the projection of every object in an image onto the ground plane (world XY plane). An object that appears in frame for camera is denoted as , where are the position, velocity, and person pose angle with respect to the camera, respectively.
Inspired by [23], the velocity of a person and camera viewpoint vector are defined to estimate person’s pose as
[TABLE]
[TABLE]
Assuming that pedestrians mostly walk forward, the pose angle of object can be estimated by ( is omitted from here for convenience),
[TABLE]
Fig. 3 shows an example of estimated person poses. However, the initially estimated is noisy as shown in Fig. 4 (a). The noise is reduced by smoothing based on a moving average algorithm in the polar coordinate system as
[TABLE]
where is the moving average parameter (here ). Although there are several discontinuities around and , the smoothing result is reliable due to the smoothing process in the polar coordinates, whereas the smoothing result in Cartesian coordinates is unreliable (Fig. 4 (b,c)).
IV-B Multi-pose appearance selection
IV-B1 Sample selection based on sample confidence
Generating good multi-pose models requires filtering out unreliable samples that have incorrect angles or polluted appearances along a moving trajectory. Thus, we define sample confidence to measure the reliability of person samples based on following requirements (R1–R3):
- •
Angle variation (R1): We assume that the angle of a walking person will not change abruptly between temporally neighboring frames. If there are rapid angle changes across consecutive frames, these are regarded as unreliable samples and filtered out. We observe that, the inaccurate localization of a person generally causes a large angle variation. This is considered by measuring the angle variation as
[TABLE]
where . Even though there is an angle discontinuity between and , is reliably calculated due to the second term of the function.
- •
Magnitude of the velocity (R2): When a person is stationary for several frames, their velocity is close to 0 and the estimated person angle based on Eq. (4) becomes unreliable111To estimate person angles, we assume that people mostly move forward in Section IV-A. However, in the case of stationary person, the assumption is not satisfied. Note that the stationary people are likely to have pure rotational motion which cannot be handled by Eq. (4).. This problem is handled by measuring the magnitude of the person’s velocity as . A sample with a small velocity magnitude is regarded as unreliable.
- •
Occlusion rate (R3): When a person is occluded by others, the sample is again considered unreliable, since person’s appearance is polluted. Occluded samples are dealt with by measuring each person’s occlusion rate as
[TABLE]
where is a 2D bounding box of an object at frame , is a 2D bounding box occluding , and is a set of object indexes occluding object . As we know the 3D position of each person , it is easy to find .
Based on the above requirements, we define the sample confidence as
[TABLE]
The sample confidence lies in [0,1]. Fig. 5 shows the sample confidences under various situations. We regard a person sample as a reliable one with high sample confidence when .
IV-B2 Generating multi-pose model
After the sample selection, we divide samples into four groups, according to their pose angles (i.e. front, right, back, left). Each group covers as follows:
[TABLE]
, are start and end frame indexes of the object , respectively. is an image sample of the object . It is worth noting that the proposed sample confidence (Eq. (8)) efficiently filters unreliable samples out as shown in Fig. 6.
We simply represent the four groups as , where . Then, an individual image that belongs to each group is represented as
[TABLE]
where is the index of each image in each group, and is the number of images in . For example, denotes a second image in the group ront of the object .
After the sample grouping, we extract feature descriptors from the four groups. Finally, the multi-pose model of object is defined as
[TABLE]
where is a function that extracts a -dimensional feature descriptor from an image. The multi-pose model consists of multiple feature descriptors grouped by their pose angles. Details of the feature extraction are described below.
Feature extraction: Our method can apply any kind of feature descriptor extraction method. In this paper, we apply several feature extraction methods such as Histogram of Oriented Gradient (HoG) [31], dcolorSIFT [5] and LOMO [21] which show promising re-identification performance. In our feature extraction process, each person image is resized to 12848 pixels. Using the resized images, we extract several feature descriptors.
HoG [31] counts occurrences of gradient orientation on a densely sampled grid and makes an orientation histogram, and it describes the overall shape of an object well. dColorSIFT [5] is a dense feature descriptor containing dense LAB-color histogram and dense SIFT. The authors pointed out that the densely sampled local features have been widely applied to matching problems due to their robustness in matching. LOMO [21] analyzes the horizontal occurrence of local features and makes a stable representation by maximizing the occurrence. In addition, it handles illumination variations by applying a Retinex transform and a scale invariant texture operator. The results of testing the various feature extraction methods are given in Section VI-A.
IV-C Multi-pose model matching
In this section, we describe the matching process of multi-pose models. Suppose that we have and , which are the multi-pose models of objects and appearing in different cameras. In order to measure the similarity between the two multi-pose models, we first calculate all pairwise feature distances between the two multi-pose models as
[TABLE]
where , , and is a positive semi-definite matrix learned by a metric learning algorithm222In practice, we first applied Principle Component Analysis (PCA) [32] to reduce the dimensions of the descriptors. We then performed metric learning on the PCA subspace. This is a conventional two-stage process for metric learning.. For metric learning, we can utilize any method, such as KISSME [3], ITML [13], or LMNN [14]. Then, the multi-pose model matching cost is computed in a weighted summation manner as
[TABLE]
is a matching weight that attaches importance to pairwise matching . Note that a high matching cost denotes low similarity between two multi-pose models. The overall algorithm of the proposed PaMM is summarized in Algorithm 1. Matching weights training process is described in the next section.
IV-D Training matching weights
When training the matching weights, we assume that every pair exists ( is eliminated). In addition, we assume that each group has a single image ( is eliminated). Then, Eq. (12) is rewritten as
[TABLE]
For convenience, we also omit several indexes and terms such as object labels , sample indexes , and a normalization term in the training step. Then, the pairwise feature distance between two multi-pose models is simply represented as , and Eq. (13) is rewritten as
[TABLE]
is a vector of pairwise feature distances and is a vector of matching weights.
In order to train matching weights , we collect training samples , where is the number of training samples and is a corresponding class of the sample. Fig. 8 shows examples of the training samples (positives: , negatives: ). Given the training set , we exploit a Support Vector Machine (SVM) [33] to find the weights by solving the following optimization problem:
[TABLE]
where is a margin tradeoff parameter and is a slack variable. The solution given by SVM ensures a maximal margin. The details and results of matching weight training are given in Section VI-B.
V Datasets and Methodology
**Datasets. ** For training matching weights, we used CUHK02 [34] and VIPeR [35]. For testing methods, we used PRID 2011 [12], iLIDS-Vid [6], and 3DPeS [11].
- •
CUHK02 [34] contains 1,816 people from five different outdoor camera pairs. The five camera pairs have 971, 306, 107, 193, and 239 people each with the size of 16060 pixels. Each person has two images per camera that were taken at different times. Most people are with burdens (e.g. backpack, handbag, or baggage). For our experiments, we manually extract all pose angles of each person in four directions (i.e. front, right, back, left), since CUHK02 does not provide the pose angles. This dataset was used for training multi-shot weights .
- •
VIPeR [35] includes 632 people and two outdoor cameras under different viewpoints and light conditions. Each person has one image per camera and each image has been scaled to be 12848 pixels. It provides the pose angle of each person as (front), (right), , and (back).
- •
PRID 2011 [12] provides multiple person trajectories recorded from two different static surveillance cameras, monitoring crosswalks and sidewalks. The dataset shows a clean background, and the people in the dataset are rarely occluded. In the dataset, 200 people appear in both views. Among the 200 people, 178 people have more than 20 appearances.
- •
iLIDS-Vid [6] was created from pedestrians in two non-overlapping cameras monitoring an airport arrival hall. It provides multiple cropped images for 300 distinct individuals and is very challenging due to clothing similarities, lighting and viewpoint variations, cluttered backgrounds, and severe occlusions.
Since the datasets (PRID [12], iLIDS[6]) do not provide full surveillance video sequences but only cropped images, we could not automatically estimate camera viewpoints and poses of targets. Therefore, to evaluate our method with the datasets, we annotated the pose of each person manually.
- •
3DPeS [11] was collected by eight non-overlapped outdoor cameras, monitoring different sections of a campus. Unlike other re-identification datasets (iLIDS, PRID), it provides full surveillance video sequences: six sets of video pairs, and uncompressed images with a resolution of 704x576 pixels at a frame rate of 15 frames per second containing hundreds of people and calibration parameters. However, this dataset provides ground-truth person identity only for selected snapshots (i.e. no ground-truth person identity for video sequences). For our experiments, we used three sets of video pairs and manually extracted ground truth labels (identities, center points, widths, heights) of video Set3,4,5. We did not use Set1,2,6 due to the small number of people, and the lack of correspondences between the two cameras. The pose of each person was estimated as described in Section IV-A. The camera layout and sample frames are given in Fig. 7.
Even though the test datasets Set3,4,5 contain people having various appearances and poses, they contain a small number of identities (Set3: 39, Set4: 24, Set5: 36). When the number of identities is small, the re-identification task becomes much easier because of the small pool of comparison targets. To show the person re-identification performance under more large scale data, we concatenate all datasets and generate 3DPeS-Set All containing 99 identity pairs. It is reasonable, since the datasets (Set3,4,5) do not share identities.
For readers, we open the pose annotations of CUHK02 [34], iLIDS[6], and PRID [12] to the public. In addition, we open the ground-truth labels of 3DPeS [11] to the public. The annotations and ground-truth labels are available online at https://cvl.gist.ac.kr/pamm/.
**Evaluation methodology. ** To compare the re-identification methods, we followed the evaluation steps described in [1]. First, we randomly split people identities in video pairs into two sets with equal numbers of identities, one set for training and the other set for testing. We learned several metrics, such as LMNN [14], ITML [13], KISSME [3], and Mahal [4], for the baseline distance functions of our person re-identification framework. After training distance metrics, we calculated all possible matches between testing video pairs. We repeated the evaluation steps 10 times. We plotted the Cumulative Match Curve (CMC) [35] representing the true match found within the first ranks to compare the performances of the different methods. Among all ranks, we mainly evaluated rank-1 accuracy which correctly finds true correspondences between two cameras. We also measured the Area Under Curve (AUC) of the CMC, which denotes the average accuracy of all ranks.
VI Experimental Results
VI-A Testing various features and metric learning methods
We first tested various combinations of feature descriptor extraction and metric learning methods for the baseline of our person re-identification framework. For the feature descriptor, we tested several feature descriptor extraction methods: Histogram of Oriented Gradient (HoG) [31], dcolorSIFT [5], and LOMO [21]. For metric learning, we tested six methods such as KISSME [3], Mahalanobis [4], XQDA [21], LMNN [14], ITML [13] and . Note that measures the Euclidean distance between two feature vectors, i.e., in Eq. (11). Therefore, we tested 18 combinations of feature descriptor extraction and metric learning methods.
Initially, we had no trained matching weight in Eq. (12); hence, we used uniform weights as for multi-shot matching called FullMatch-avg. Fig. 9 shows the re-identification performance of each combination. As we can see, the combination of the feature descriptor LOMO [21] and the metric learning method KISSME [3] shows the best re-identification performance among the 18 combinations. It shows 81.6% rank-1 accuracy and a 98.5% AUC score. In general, the LOMO feature descriptor shows promising results regardless of metric learning method (69.4% – 81.6% rank-1 accuracy).
We built several fusion feature descriptors, such as (HoG + dcolorSIFT), (dcolorSIFT + LOMO), (HoG + dcolorSIFT + LOMO), etc. by concatenating the feature descriptors. However, their performance was are lower than that of LOMO. Therefore, we utilize LOMO [21] feature as the baseline feature descriptor of our framework.
VI-B Training multi-shot matching weights
Based on Section IV-D, we train the matching weights w in this section. In practice, we consider 10 weights rather than 16 weights due to the weight symmetry. We let , where . Consequentially, we learn four same-pose matching weights and six different-pose matching weights .
As mentioned in Section V, in order to train the weights , we use two datasets: CUHK02 [34] and VIPeR [35]. By using the datasets, we generate 3,520 positive image pairs and 35,200 negative image pairs that cover diverse pose combinations as shown in Fig. 8. Here, a positive image pair is a pair of images of the same person and a negative image pair is a pair of images of different people regardless of the poses of people. We then extracted pairwise feature distances for all images pairs by following the metric learning steps described in Section V. Distributions of feature distances are plotted in Fig. 10. For example, Fig. 10 (a) shows the feature distance distribution of front-front image pairs of the same person (positive) and difference people (negative). Unfortunately, we could not make pairs using training datasets CUHK02, VIPeR, since they do not have such pairs. In order to make the distribution of , we assume that follows a similar with similar to that of . Note that a large statistical distance between positive and negative distributions implies high discriminating power. We observe that the same-pose matchings (Fig. 10 (a,b,f,g) left two columns) are more discriminative than the different-pose matchings (Fig. 10 (c-e,h-j) right three columns).
After obtaining distributions of feature distances, we generate training samples , where , by randomly selecting each from each distribution. Fig. 11 shows the result of weight training with the LOMO [21] feature descriptor and several metric learning methods. The result indicates that the weights of the same-pose matchings are generally larger than those of the different-pose matchings . The training results do not depend on the metric learning methods and show similar tendencies. For the following experiments, we use these trained matching weights for each baseline (feature descriptor and metric learning) individually.
VI-C Performance enhancements via PaMM
According to the experimental result in Section VI-A, we utilized LOMO [21] for extracting a feature descriptor from each appearance and utilized several metric learning methods (KISSME [3] and others [4][21][13][14]) as the baselines of this experiment. In this experiment, we compare the person re-identification performance based on various matching strategies (e.g. single-shot, multi-shot, and proposed) as follows:
- •
SingleMatch: performing single-shot re-identification which only uses a single appearance for each person for matching. As the appearance of each identity for SingleMatch, we randomly selected a single appearance for each identity. For unbiased selections, we repeated the appearance selection 10 times and calculated the average performance for the final result.
- •
MultiQ-max: merging multiple appearances (i.e. appearance feature vectors) into a single merged appearance based on the max-pooling approach: a merged feature vector takes the maximum value in each dimension from all feature vectors.
- •
MultiQ-avg: merging multiple appearances into a single merged appearance based on the average-pooling approach: a merged feature vector takes the average value in each dimension from all feature vectors.
Zheng et al. [25] employed MultiQ-max and MultiQ-avg to efficiently merge multiple appearances into a single appearance and performed re-identification using the merged appearances.
- •
FullMatch-min: matching all possible pairs between multiple appearances and selecting the smallest matching score for the final score as used in [1].
- •
FullMatch-avg: matching all possible pairs between multiple appearances and averaging all matching scores as used in [24].
- •
PaMM: proposed method.
For validating the performance enhancement via PaMM, we used the dataset 3DPeS Set All and followed the evaluation steps explained in Section V. As shown in Table I, all single-shot matching methods (SingleMatch) with different metric learning methods are improved considerably for all ranks (=1,3,5,10) thanks to the proposed PaMM. The performance enhancement at =1 is remarkable (achieving 24.5–49% enhancement). Compared to single-shot matching methods, multi-shot matching methods (MultiQ, FullMatch, PaMM) show better re-identification performance, since they exploit several appearances for both metric learning and appearance matching.
Among the various multi-shot matching strategies (MultiQ-max, MultiQ-avg, FullMatch-min, FullMatch-avg), the proposed PaMM shows the best performance regardless of the baseline: showing the best AUC scores for all baselines and showing the best rank-1 accuracies except for the ITML case. The result implies that the proposed PaMM, which exploits people’s pose information, can improve the re-identification performance regardless of the baseline. In the consecutive experiments, we use KISSME [3] as the baseline metric learning method for PaMM and other multi-shot matching methods (MultiQ, FullMatch).
VI-D Test results of 3DPeS dataset
In this experiment, we provide the detailed evaluation results of the 3DPeS dataset. We tested 3DPeS-Set3, 4, 5, ALL and denoted different versions of the proposed person re-identification framework as follows:
- •
PaMM: PaMM with all proposed methods.
- •
PaMM-ns: PaMM without appearance selection.
As with the experiment in Section VI-C, we tested several single-shot and multi-shot matching methods. The multi-shot matching methods (Multi-Q, FullMatch, and PaMM) utilized a LOMO [21] feature descriptor and a KISSME [3] metric learning method for their baselines.
Table II shows that our methods outperform all single-shot matching and other multi-shot matching methods. Even though FullMatch-avg and FullMatch-min also exploit all multiple appearances of targets, the performance of both methods is lower than that of PaMM. This suggests that the proposed PaMM reasonably extracts key appearances among multiple appearances (Section IV-B) and efficiently matches multi-pose models (Section IV-C). Compared to PaMM-ns, PaMM showed a slight improvement since the test dataset 3DPeS did not encounter the challenges described in Section IV-B. We expect that the proposed appearance selection method in Section IV-B would give more performance enhancement with more challenging and complex dataset. Figure 12 (a) shows several qualitative analysis results of the 3DPeS dataset. As we can see, the proposed PaMM correctly finds correspondences under diverse viewpoint variations of people.
VI-E Test results of PRID and iLIDS datasets
We also provide evaluation results and comparisons with other state-of-the-art person re-identification methods with more public datasets such as PRID [12], and iLIDS [6]. In these experiments, PaMM also utilized the LOMO feature descriptor and KISSME metric learning method for its baseline. In the PRID dataset, 200 people appear in both views. We evaluated PaMM under two different test scenarios marked as 200 and 178. Scenario 200 uses all 200 people pairs for testing. On the other hand, scenario 178 uses only 178 people pairs having more than 20 appearances. Most works [36, 6, 26, 7, 28, 27] tested under the scenario 178, since their methods needed a sufficient video length (i.e. multiple appearances) for extracting spatiotemporal features.
In Table III, PaMM shows the best performance among ten state-of-the-art methods for all ranks while significantly enhancing its baseline performance (54% enhancement at =1). Although the baseline of our method (LOMO+KISSME) showed low performance, it improved significantly and showed the best performance among the state-of-the-art methods thanks to the proposed PaMM method. Compared to other state-of-the-art methods, the rank-1 accuracies of 200PaMM and 178PaMM were 6% and 14% higher than those of 200RNN*†* [29] and 178STFV3D*†* [28].
Table IV shows the result of the performance comparison with dataset iLIDS [6]. As mentioned in Section V, iLIDS is much more challenging than PRID due to severe occlusions and lighting variations. PaMM improved its baseline performance for all ranks (46% enhancement at =1). Among ten state-of-the-art methods, the propose PaMM ranked second for rank-1 accuracy and third for other ranks unlike the result of PRID dataset. We think that the many severe occlusions of people broke the assumption of the proposed PaMM, because the assumption of the proposed multi-shot matching model is not satisfied under severe appearance variations. In particular, when the same-pose matching score is unreliable due to severe occlusions, it has a negative influence on the final multi-pose model matching score aggregation and degrades the re-identification performance.
However, even though the proposed method can be influenced by severe occlusions, PaMM shows comparable performance to RNN*†* [29], which shows the best rank-1 accuracy. The gap of rank-1 accuracy between PaMM and RNN*†* is . In addition, when we consider both benchmark datasets PRID and iLIDS, the proposed PaMM generally shows superior performance compared to the other methods. It should also be noted that PaMM can achieve better performance by adopting better baseline methods. Several qualitative analysis results of the proposed PaMM with PRID and iLIDS datasets are illustrated in Fig. 12 (b,c).
VII Conclusions
In this paper, we proposed a novel framework for person re-identification, called Pose-aware Multi-shot Matching (PaMM), which robustly estimates people’s poses and efficiently conducts multi-shot matching based on the pose information. We extensively evaluated and compared the performance of the proposed method using public person re-identification datasets such as 3DPeS, PRID 2011 and iLIDS-Vid.
The idea of this work is simple but very effective. We showed that PaMM can improve person re-identification regardless of its baseline method. In addition, PaMM can flexibly adopt any existing person re-identification method (e.g. feature extraction and metric learning methods) for computing pairwise feature distance in our framework. The results showed that the proposed methods are promising for person re-identification under diverse person pose variances and the PaMM outperforms other state-of-the-art re-identification methods. We expect that PaMM will achieve much better re-identification performance when it adopts better baseline methods.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] M. Farenzena, L. Bazzani, A. Perina, V. Murino, and M. Cristani, “Person re-identification by symmetry-driven accumulation of local features,” in CVPR . IEEE, 2010, pp. 2360–2367.
- 2[2] R. Zhao, W. Ouyang, and X. Wang, “Learning mid-level filters for person re-identification,” in CVPR . IEEE, 2014, pp. 144–151.
- 3[3] M. Koestinger, M. Hirzer, P. Wohlhart, P. M. Roth, and H. Bischof, “Large scale metric learning from equivalence constraints,” in CVPR . IEEE, 2012, pp. 2288–2295.
- 4[4] P. M. Roth, M. Hirzer, M. Köstinger, C. Beleznai, and H. Bischof, “Mahalanobis distance learning for person re-identification,” in Person Re-Identification . Springer, 2014, pp. 247–267.
- 5[5] R. Zhao, W. Ouyang, and X. Wang, “Unsupervised salience learning for person re-identification,” in CVPR . IEEE, 2013, pp. 3586–3593.
- 6[6] T. Wang, S. Gong, X. Zhu, and S. Wang, “Person re-identification by video ranking,” in ECCV . Springer, 2014, pp. 688–703.
- 7[7] Y. Li, Z. Wu, S. Karanam, R. J. Radke, and N. Troy, “Multi-shot human re-identification using adaptive fisher discriminant analysis,” BMVC , 2015.
- 8[8] W. Kusakunniran, H. Li, and J. Zhang, “A direct method to self-calibrate a surveillance camera by observing a walking pedestrian,” in DICTA . IEEE, 2009, pp. 250–255.