Exploiting the Pruning Power of Strong Local Consistencies Through Parallelization
Minas Dasygenis, Kostas Stergiou

TL;DR
This paper introduces a parallelization approach for applying strong local consistencies in CSP solving, balancing pruning benefits and runtime penalties through synchronized and asynchronous algorithms, leading to improved performance.
Contribution
It proposes two novel parallel algorithms for applying strong local consistencies, enhancing efficiency by reducing runtime penalties and preserving pruning power.
Findings
Parallel algorithms improve CSP solving efficiency.
Synchronous and asynchronous methods outperform traditional approaches.
Experimental results show significant performance gains.
Abstract
Local consistencies stronger than arc consistency have received a lot of attention since the early days of CSP research. %because of the strong pruning they can achieve. However, they have not been widely adopted by CSP solvers. This is because applying such consistencies can sometimes result in considerably smaller search tree sizes and therefore in important speed-ups, but in other cases the search space reduction may be small, causing severe run time penalties. Taking advantage of recent advances in parallelization, we propose a novel approach for the application of strong local consistencies (SLCs) that can improve their performance by largely preserving the speed-ups they offer in cases where they are successful, and eliminating the run time penalties in cases where they are unsuccessful. This approach is presented in the form of two search algorithms. Both algorithms consist of a…
Click any figure to enlarge with its caption.
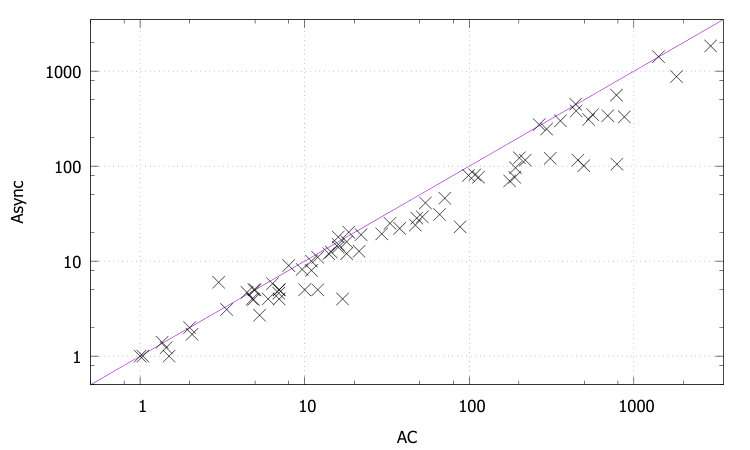 Figure 1
Figure 1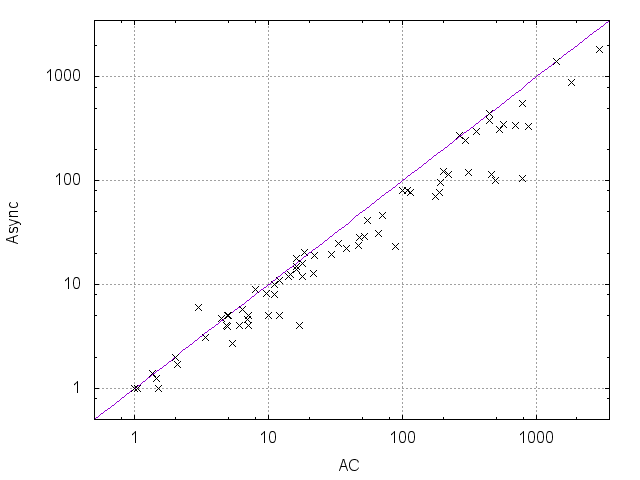 Figure 2
Figure 2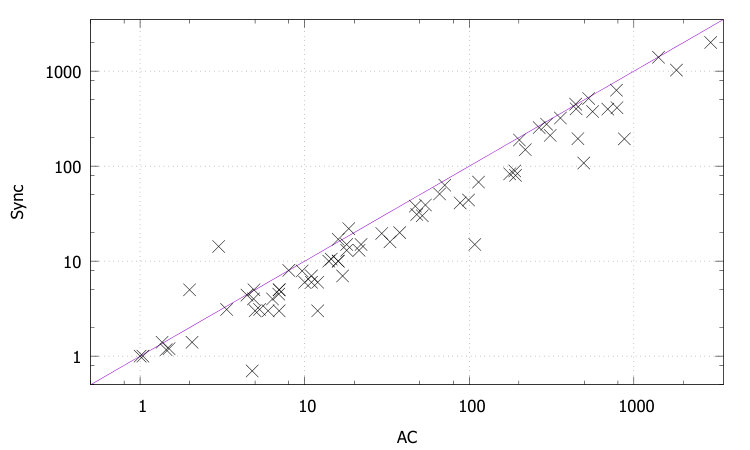 Figure 3
Figure 3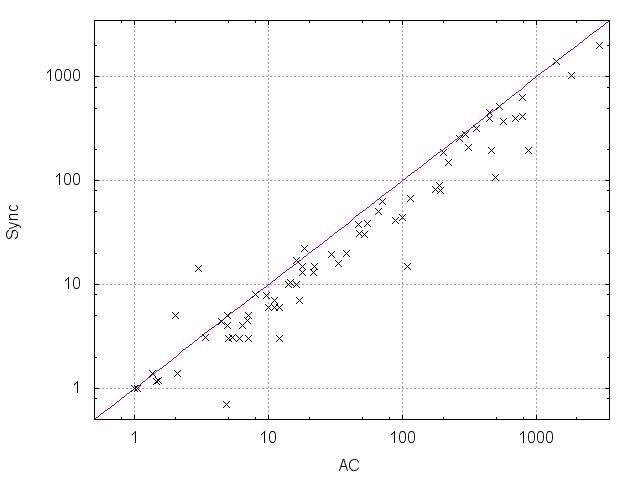 Figure 4
Figure 4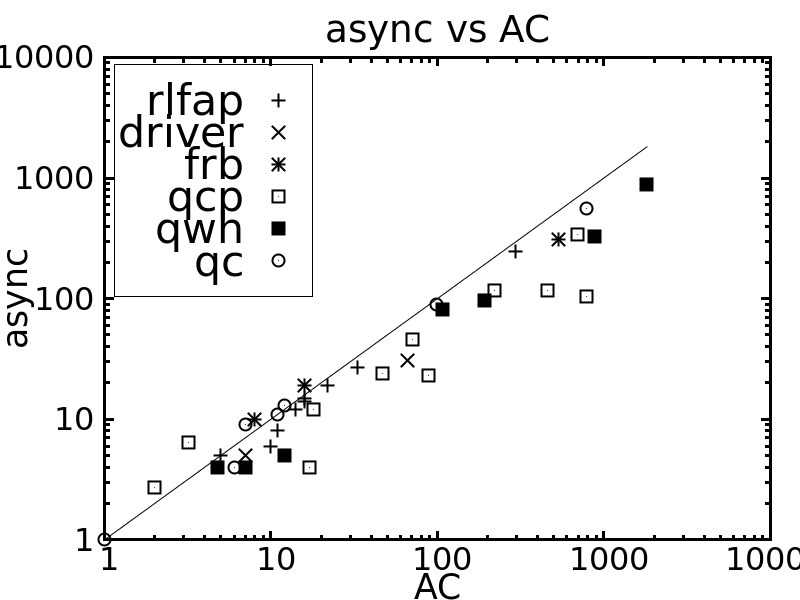 Figure 5
Figure 5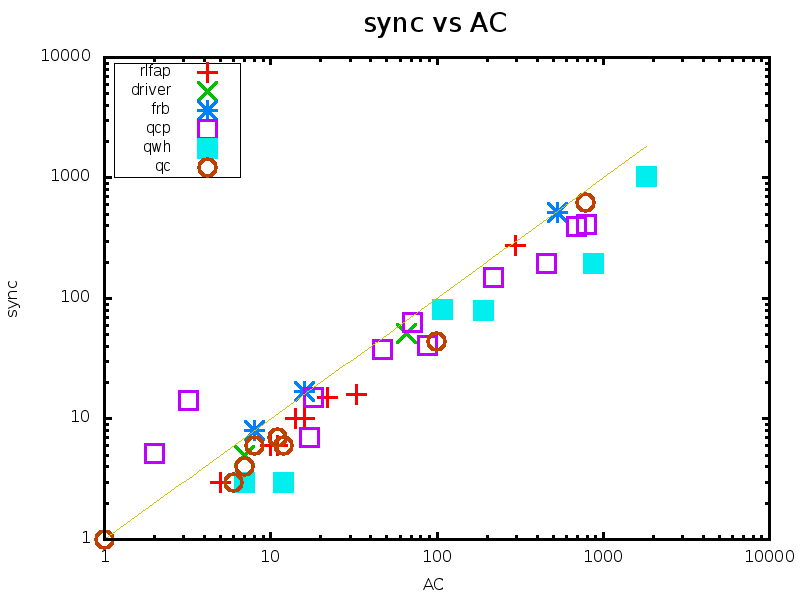 Figure 6
Figure 6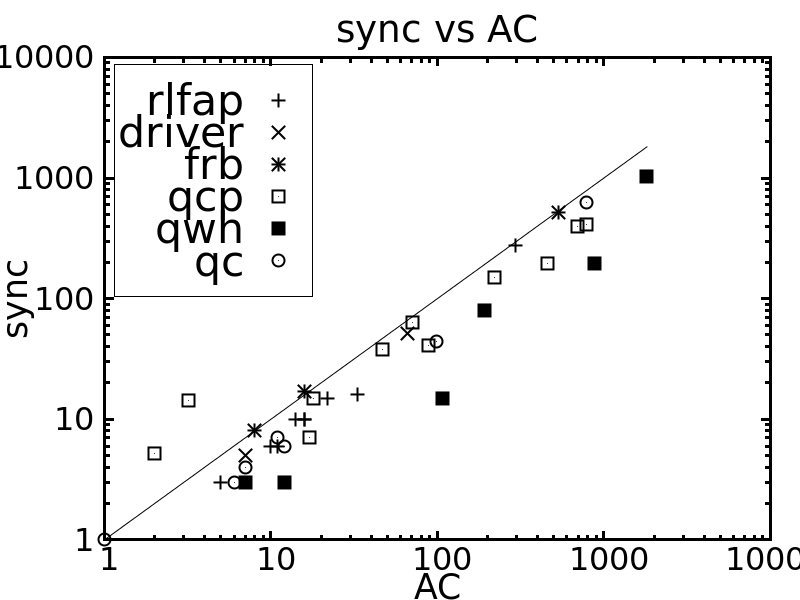 Figure 7
Figure 7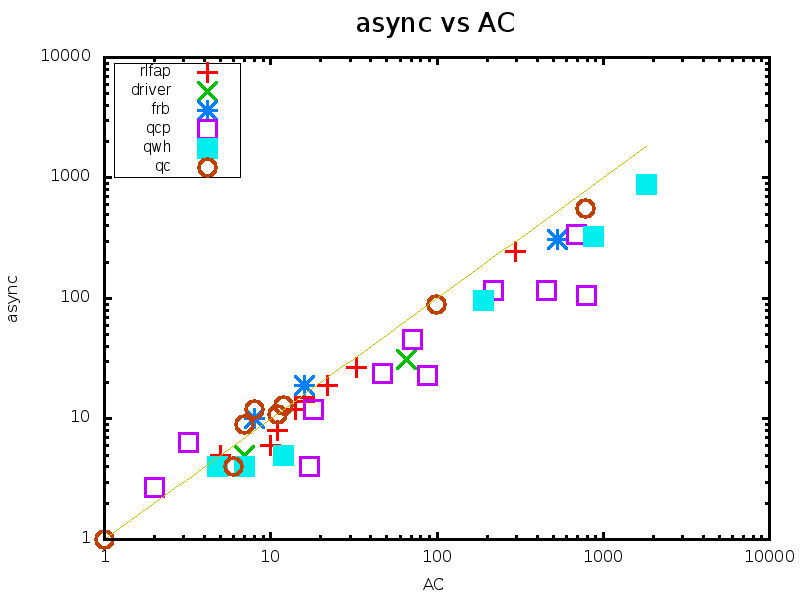 Figure 8
Figure 8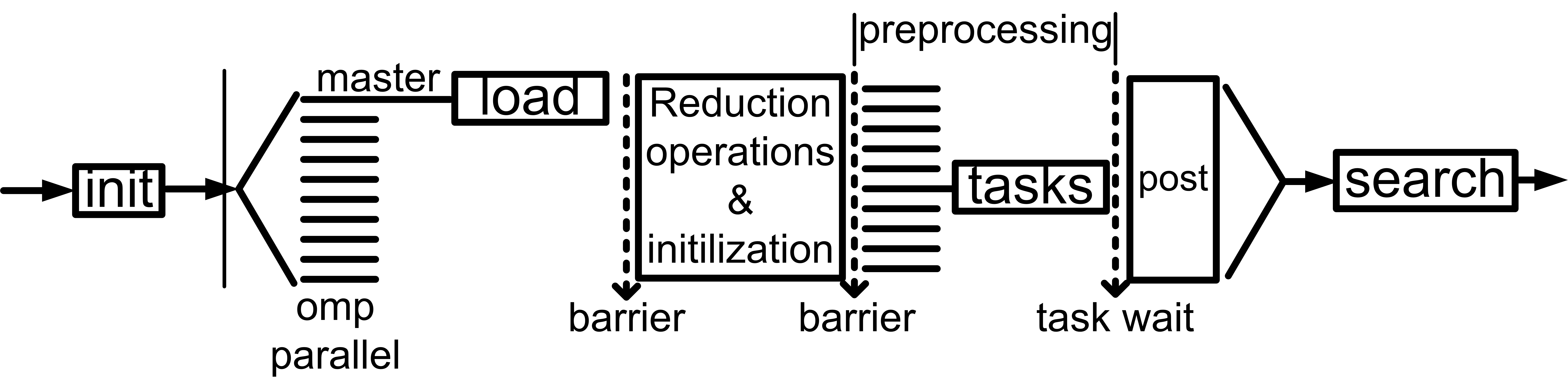 Figure 9
Figure 9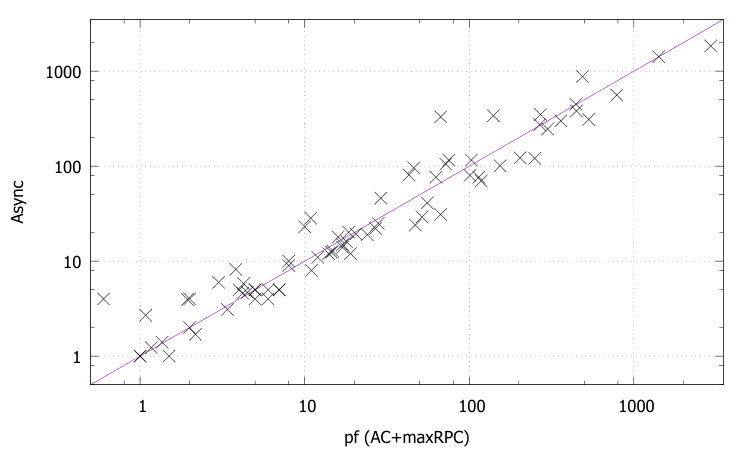 Figure 10
Figure 10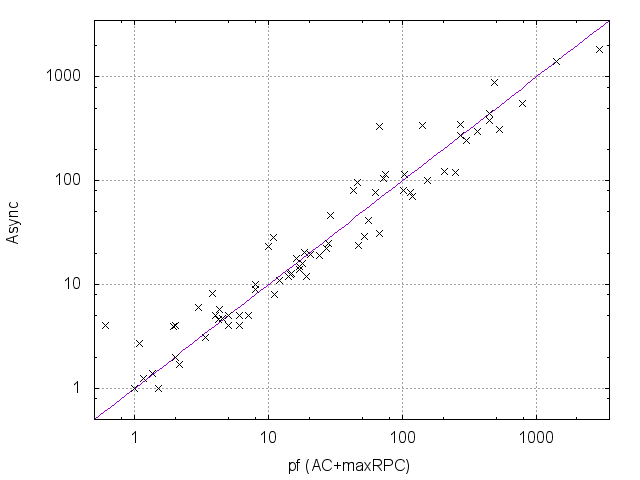 Figure 11
Figure 11 Figure 12
Figure 12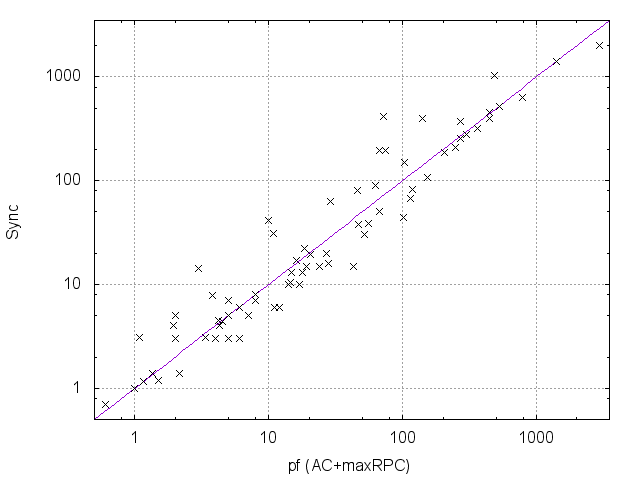 Figure 13
Figure 13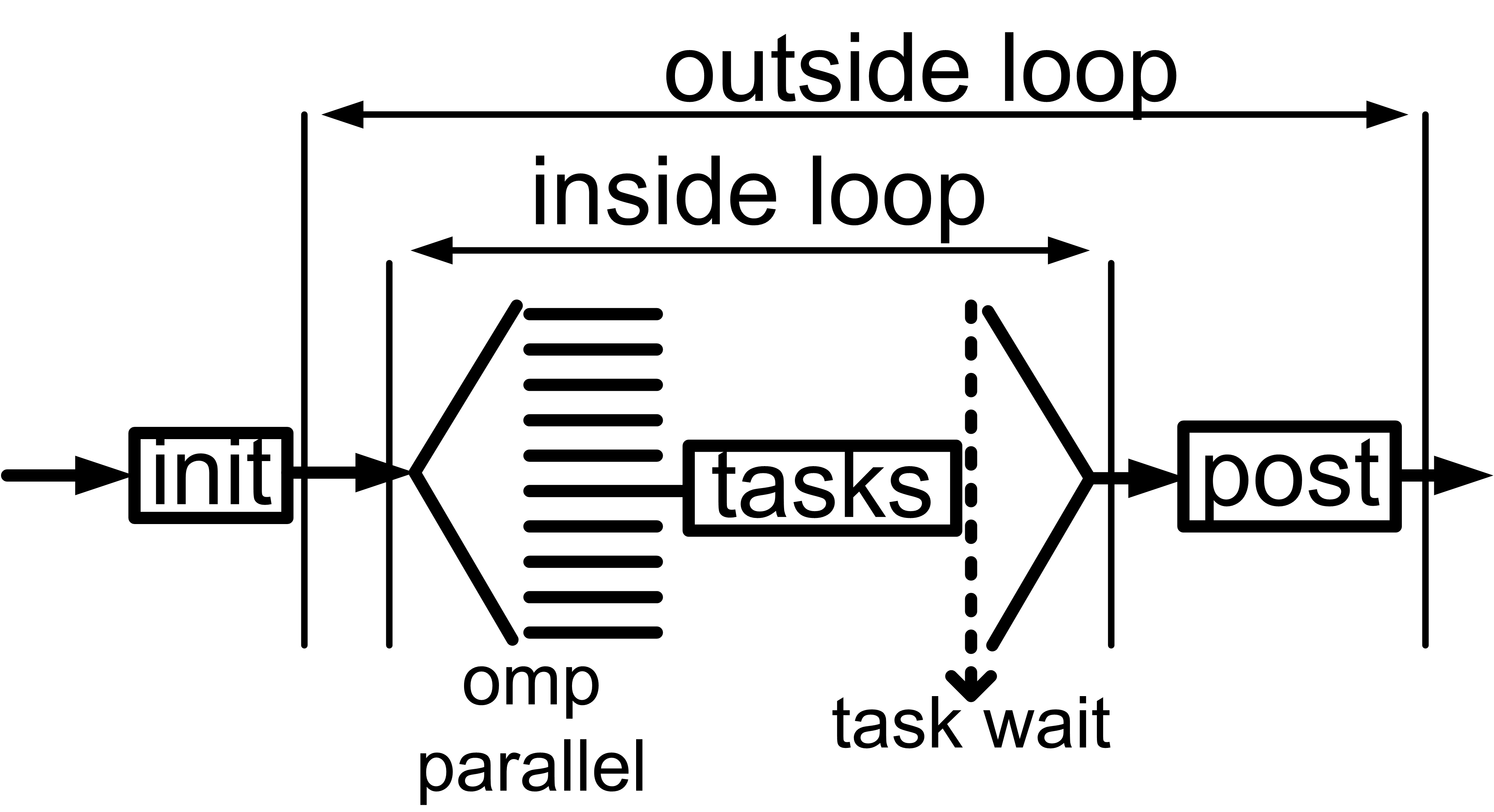 Figure 14
Figure 14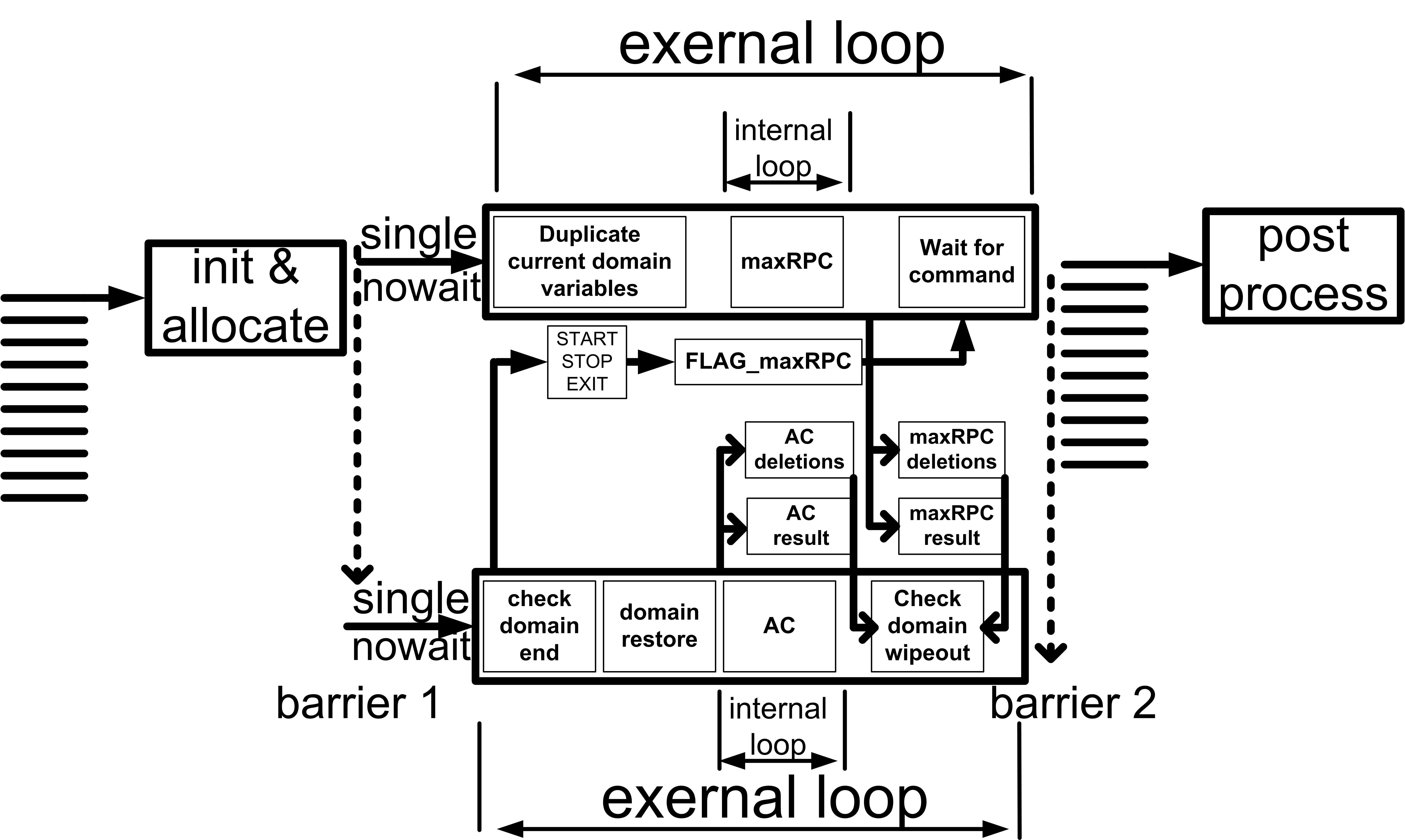 Figure 15
Figure 15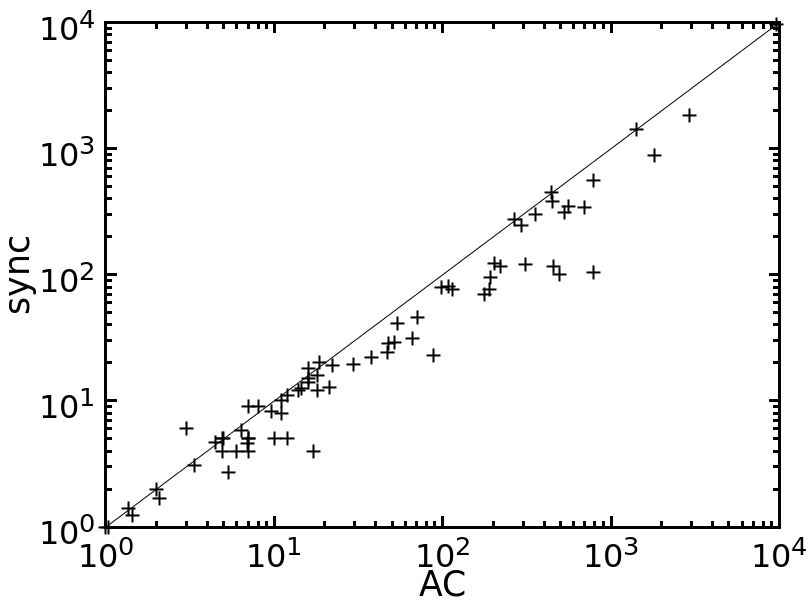 Figure 16
Figure 16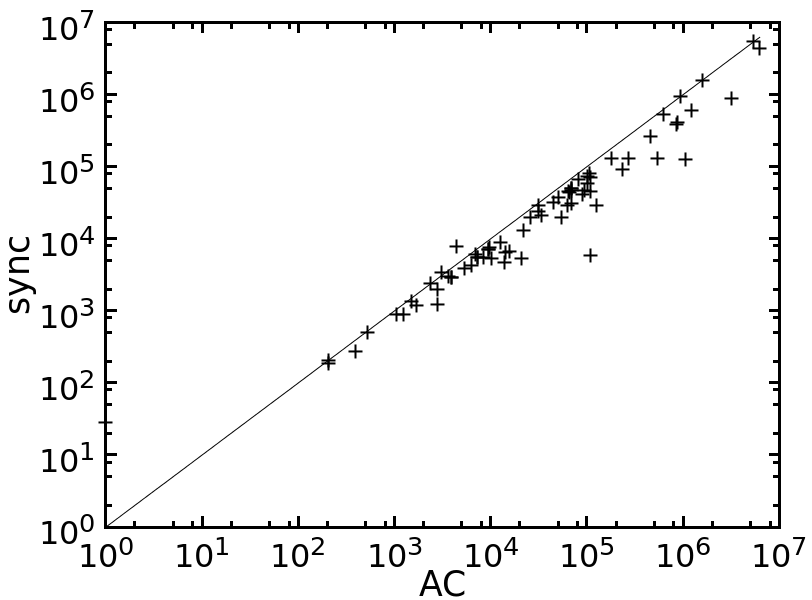 Figure 17
Figure 17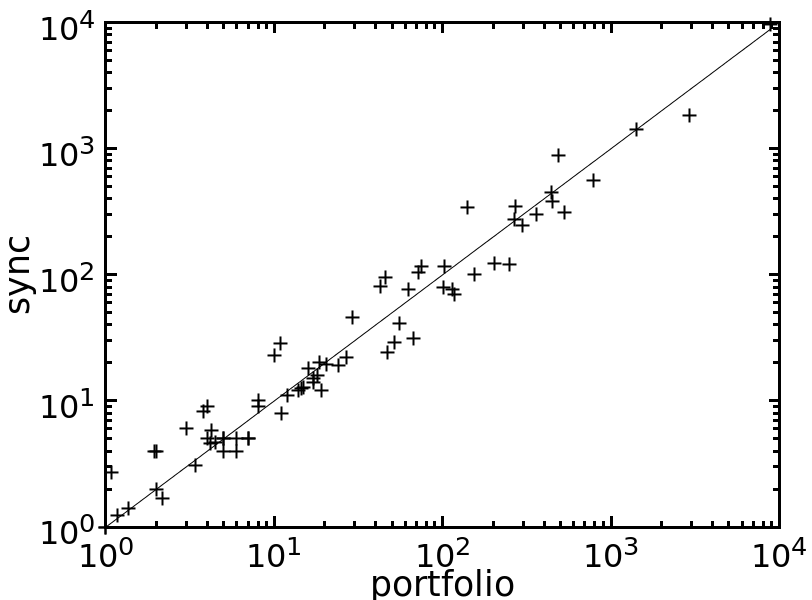 Figure 18
Figure 18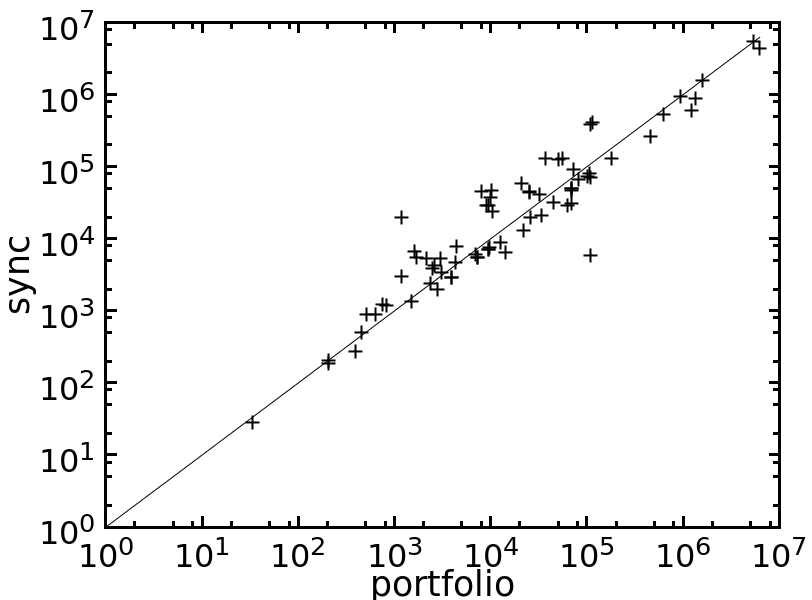 Figure 19
Figure 19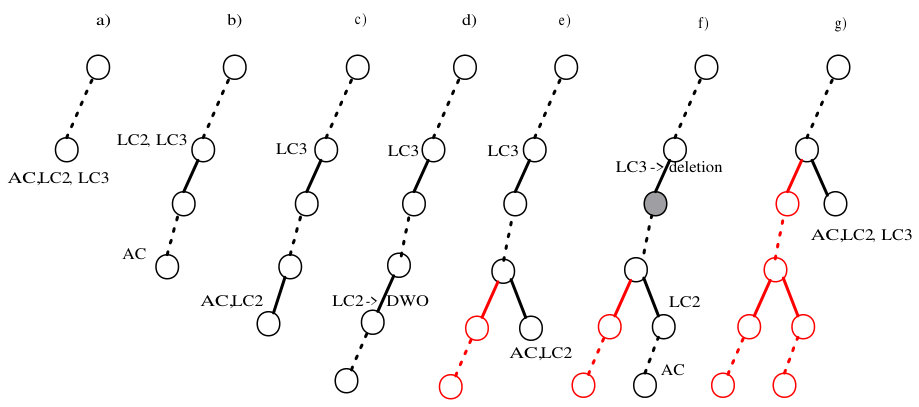 Figure 20
Figure 20 Figure 21
Figure 21| instance | AC | pfAC+maxRPC | Async | Sync | pfall | |||||
| (n) | (t) | (n) | (t) | (n) | (t) | (n) | (t) | (n) | (t) | |
| rlfap | ||||||||||
| s11-f12 | 7349 | 16 | 7349 | 17 | 5521 | 14 | 3983 | 10 | 3983 | 10 |
| s11-f10 | 9601 | 22 | 9601 | 24 | 7518 | 19 | 6198 | 15 | 6198 | 15 |
| s11-f09 | 101K | 295 | 101K | 299 | 73K | 246 | 80K | 277 | 73K | 248 |
| s02-f25 | 12688 | 11 | 12688 | 11 | 9024 | 8 | 5056 | 6 | 5056 | 6 |
| s03-f11 | 9486 | 14 | 9486 | 14 | 7082 | 12 | 5293 | 10 | 5293 | 10 |
| g08-f10 | 19590 | 33 | 8808 | 28 | 9715 | 25 | 7199 | 16 | 7199 | 16 |
| g14-f27 | 13833 | 10 | 4326 | 6 | 4869 | 6 | 4697 | 5 | 4697 | 5 |
| graph coloring | ||||||||||
| anna-8 | 69K | 18 | 69K | 18 | 46K | 16 | 30K | 10 | 30K | 10 |
| homer-8 | 69K | 99 | 69K | 101 | 50K | 80 | 29K | 44 | 29K | 45 |
| ga120-7 | 65K | 7 | 25K | 4 | 45K | 9 | 29K | 4 | 29K | 4 |
| ga120-8 | 3208K | 310 | 1352K | 250 | 887K | 121 | 1999K | 211 | 887K | 122 |
| lei-450-8 | 107K | 784 | 107K | 787 | 80K | 560 | 86K | 630 | 80K | 562 |
| driver,frb | ||||||||||
| driver-8 | 3872 | 7 | 3872 | 7 | 2919 | 5 | 2742 | 5 | 2742 | 5 |
| driver-9 | 14129 | 66 | 14129 | 67 | 6534 | 31 | 11546 | 51 | 6534 | 31 |
| frb-35 | 26K | 8 | 26K | 8 | 20K | 9 | 24K | 8 | 24K | 8 |
| frb-40 | 45K | 16 | 45K | 16 | 32K | 18 | 39K | 17 | 45K | 16 |
| frb-45 | 1207K | 531 | 1207K | 532 | 601K | 310 | 1001K | 517 | 601K | 313 |
| qcp,qwh | ||||||||||
| qcp-15-0 | 102K | 71 | 21K | 29 | 58K | 46 | 85K | 63 | 21K | 29 |
| qcp-15-1 | 20988 | 17 | 3025 | 5 | 5325 | 4 | 8893 | 7 | 5325 | 4 |
| qcp-15-5 | 536K | 457 | 37K | 75 | 131K | 116 | 222K | 195 | 37K | 76 |
| qcp-15-6 | 62K | 47 | 62K | 47 | 29K | 24 | 49K | 38 | 29K | 24 |
| qcp-15-8 | 22K | 18 | 22K | 19 | 13K | 12 | 17K | 15 | 13K | 12 |
| qcp-15-13 | 269K | 219 | 55K | 103 | 129K | 116 | 174K | 149 | 55K | 105 |
| qwh-20-0 | 94K | 191 | 10K | 46 | 46K | 96 | 39K | 80 | 10K | 46 |
| qwh-20-2 | 869K | 1813 | 113K | 487 | 407K | 878 | 501K | 1025 | 113K | 490 |
| qwh-20-4 | 231K | 496 | 72K | 154 | 91K | 101 | 183K | 209 | 91K | 102 |
| qwh-20-5 | 89K | 176 | 32K | 118 | 41K | 70 | 67K | 124 | 41K | 69 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsConstraint Satisfaction and Optimization · Algorithms and Data Compression · Data Management and Algorithms
Exploiting the Pruning Power of Strong Local Consistencies Through Parallelization
Minas Dasygenis and Kostas Stergiou
Department of Informatics and Telecommunications Engineering
University of Western Macedonia
Kozani, Greece
Abstract
Local consistencies stronger than arc consistency have received a lot of attention since the early days of CSP research. However, they have not been widely adopted by CSP solvers. This is because applying such consistencies can sometimes result in considerably smaller search tree sizes and therefore in important speed-ups, but in other cases the search space reduction may be small, causing severe run time penalties. Taking advantage of recent advances in parallelization, we propose a novel approach for the application of strong local consistencies (SLCs) that can improve their performance by largely preserving the speed-ups they offer in cases where they are successful, and eliminating the run time penalties in cases where they are unsuccessful. This approach is presented in the form of two search algorithms. Both algorithms consist of a master search process, which is a typical CSP solver, and a number of slave processes, with each one implementing a SLC method. The first algorithm runs the different SLCs synchronously at each node of the search tree explored in the master process, while the second one can run them asynchronously at different nodes of the search tree. Experimental results demonstrate the benefits of the proposed method.
1 Introduction
Constraint propagation is at the core of Constraint Programming (CP) and constitutes one the main reasons for its success. Constraint propagation algorithms typically enforce some local consistency property such as (generalized) arc consistency (G)AC or bounds consistency (BC) on the constraints of the problem, and in this way prune inconsistent values from the domains of the variables. Hence, algorithms for GAC and BC have been widely studied and applied.
Local consistencies stronger than (G)AC have also received attention since they can offer even stronger pruning. Studies on such consistencies cover both binary constraints (e.g. the works by Berlandier (1995); Freuder & Elfe (1996); Debruyne & Bessiere (1997, 2001)) and non-binary constraints (e.g. the works by Janssen et al. (1989); Jégou (1993); van Beek & Dechter (1995); Bessiere at al. (2008); Karakashian et al. (2010); Lecoutre et al. (2011)). Despite the wealth of research on strong local consistencies, and the recent advances in algorithms for such consistencies made among others by Bessiere et al. (2011); Balafoutis et al. (2011); Woodward et al. (2012), they have not been widely adopted by CSP solvers. This is because applying such consistencies can sometimes result in considerably smaller search tree sizes and therefore in important speed-ups, but in other cases the search space reduction may be small, causing severe run time penalties.
One inherent shortcoming of all such methods is that they have been designed for a sequential processing mode and therefore cannot exploit the very important recent advances in multicore parallel computing. These advances have triggered increasing interest in parallel constraint solving methods. But since local consistency algorithms are by nature sequential, meaning that their parallelization is quite challenging and requires very careful synchronization, there is limited, mainly theoretical, work on parallelizing such algorithms.
In this paper we explore new ways to exploit the filtering offered by strong local consistencies through parallelization while keeping the complexity of synchronization manageable. Our goal is to exploit the extra filtering offered by strong local consistencies without penalizing the run time in cases where they are unsuccessful. Instead of trying to parallelize local consistency algorithms, we propose novel ways to apply different (strong) local consistencies during search in parallel to the main solver. The proposed approaches are presented in the form of search algorithms that consist of a master search process, which is a typical CSP solver, and a number of slave processes, which can implement strong local consistency algorithms.
In the first algorithm, after each branching decision is made, the master process applies standard propagation (e.g. AC), while at the same time the slave processes are initiated. Each one of them applies some strong local consistency algorithm on a copy of the problem and is charged with delivering any value deletions that this algorithm makes back to the master process. All slave processes are terminated once propagation in the master process terminates, or alternatively, if a failure is detected by some slave process before propagation in the master process stops. In this way, even if a strong local consistency algorithm is not allowed to reach a fixpoint, it may still make many value deletions (or even discover failures) that the main propagation method, being weaker, cannot make. This method guarantees that the resulting solver will never be noticeably slower than a standard solver, even if the strong local consistencies employed do not offer any extra pruning.
The second method we propose again uses slave processes to run strong local consisteny algorithms. However, this method can run these algorithms asynchronously at different nodes of the search tree. The intuition behind this algorithm is the following: If the subtree rooted at some node of the search tree does not contain a solution then this can be verified either by searching the subtree or by applying a strong inference (e.g. local consistency) method at that node. We propose to apply both of them at the same time on different processes. Once a node is visited, the master process is responsible for running propagation and searching the subtree of the node if propagation does not fail, while the slave processes run strong local consistency algorithms at that node. If some slave process detects a failure then the master process is notified and a backtrack, which may be a large non-chronological one, occurs.
Experiments with benchmark binary problems that were performed as a case study demonstrate that our algorithms outperform a standard CSP solver, sometimes by large margins, even when only one strong local consistency, i.e. maxRPC, is employed in addition to the standard AC propagation. Also, our algorithms outperform in quite a few cases a portfolio of two solvers running in parallel, where the first solver applies AC and the second maxRPC throughout search, but they are also outperformed in other cases. As a result, by adding our algorithms to this portfolio, we can build a method that outperforms the portfolio of AC and maxRPC since on any given problem it is at least as good as any single solver or the portfolio of two solvers.
This paper is structured as follows. Section 2 gives the necessary background. Sections 3 and 4 present the two proposed algorithms and discuss possible extensions. In Section 5 we give experimental results, while in Section 6 we discuss related work. Finally, in Section 7 we conclude.
2 Background
A Constraint Satisfaction Problem (CSP) is defined as a triple where:
- •
is a set of variables.
- •
is a set of ordered finite domains. Each domain , with , contains the possible values for variable .
- •
is a set of constraints. Each constraint is a pair , where is an ordered subset of , and contains the allowed combinations of values for the variables in . For simplicity, a binary constraint between two variables and will be denoted by .
The concept of local consistency (LC) is central to CP. LCs are used prior to and during search through what is known as constraint propagation to filter domains and discover inconsistencies early. The most widely studied LC is arc consistency. A binary CSP is Arc Consistent (AC) iff for all , is non-empty and all values of are AC. A value is AC iff for any constraint , there exists at least one value s.t. the assignments and are consistent (i.e. they satisfy ). In this case is called a support for . The generalization of AC to non-binary constraints is known as GAC.
Apart from AC and GAC, numerous other LCs have been proposed for binary and non-binary constraints. Here we are particularly interested in LCs that are stronger, i.e. can achieve stronger pruning, than AC. In the following we will simply refer to such LCs as strong LCs.
Since the experiments included in this paper concern binary problems, we will focus on LCs for binary constraints hereafter. However, the algorithms presented below are generic and do not depend on the arity of the constraints.
LCs that only prune values from domains and do not add new constraints or alter existing ones are called domain filtering consistencies by Debruyne & Bessiere (2001). One of the most efficient such LCs that was proposed by Debruyne & Bessiere (1997) is maxRPC. A binary CSP is max Restricted Path Consistent (maxRPC) iff it is AC and for each value and variable constrained with , there is a support for in s.t. the pair of values is path consistent. That is, for any third variable constrained with and there exists a value that is consistent with both and .
Singleton Arc Consistent (SAC) is another strong LC that was proposed by Debruyne & Bessiere (2001). A binary CSP is SAC iff it has non-empty domains and for any assignment of a variable , the resulting subproblem, denoted by , can be made AC. If cannot be made AC, SAC removes from .
Backtracking tree search is the standard complete method for solving CSPs. This method interleaves branching decisions (e.g. variable assignments) with constraint propagation. A backtracking algorithm searches for a solution in the space of possible variable assignments by gradually extending a partial assignment until it becomes a solution or proves that no solution exists.
The description of the algorithms in the next section follows a classical d-way branching scheme where the values of any variable are tried one by one111This is not a requirement of the algorithms since they are equally applicable with any other branching scheme.. Given d-way branching, the root of the search tree that the algorithm builds corresponds to the initial empty assignment (typically preprocessing is applied at the root) and thereafter, level i of the tree corresponds to the i**th selected variable. Each node of the tree at level i corresponds to a partial assignment starting from the first selected variable down to the i**th variable.
After each variable assignment, a constraint propagation phase follows. Typically, this consists of applying LC algorithms on the constraints of the problem (e.g. AC on binary constraints). CP solvers usually implement constraint propagation using a queue where entities of the problem (i.e. variables, or constraints, or propagators) are inserted once an event such as a value removal occurs. Then the elements of the queue are iteratively removed and domains are revised (i.e. values that are no longer consistent are removed from domains). This may cause new queue insertions and so on, until the queue becomes empty or a failure occurs. The latter takes place when propagation removes all values from the domain of a variable. This is known as a domain wipeout (DWO). If a DWO is detected then the algorithm rejects the latest assignment and tries the next available one. The search algorithm which applies AC after the branching decisions is known as Maintaining Arc Consistency (MAC).
Algorithms such as MAC employ chronological backtracking. That is, if all possible assignments of the currently selected variable at search tree level i have been tried and failed, in which case we have a dead-end, then the algorithm moves back to the previously selected variable at level i-1 and tries its next value. A non-chronological bakcktrack, or backjump, occurs when after a dead-end is encountered the search algorithm moves further up the search tree, instead of moving to level i-1. A number of algorithms that allow for backjumps were proposed in the past (e.g. CBJ by Prosser (1993)), and although backjumping had been neglected for quite a few years, it has recently gathered attention again through ideas such as lazy clause learning by Ohrimenko et al. (2009). As we will explain, one of the methods we propose allows for backjumps in a novel way by exploiting the pruning power of strong LCs and parallelization.
3 A Synchronous Algorithm
We now describe our first search algorithm that incorporates the parallel application of different LCs. We assume that there are k LCs available (LC1,LC2,...,LCk) and that LC1, i.e. the default propagation method of the solver, is AC. The search process of the solver, i.e. variable assignments, domain updates, backtracks, and AC propagation, runs on a single thread (the main or master thread). This means that the search algorithm explores a single search tree. As we will explain, strong LCs are used to cut down the size of the search tree and hence speed up the solving process.
Algorithm 1 describes a synchronous method for applying strong LCs in parallel. This method aims at exploiting the filtering power offered by strong LCs, to some extent, without slowing down the solver in cases where there is little or no extra pruning. This is done by applying the main propagation method and the strong LCs synchronously at each node of the search tree. In the following we will call this algorithm Sync.
Specifically, Algorithm 1 implements the following simple idea: In addition to the application of AC after each branching decision, the remaining k-1 LCs are also applied by running them on different threads in parallel. As soon as AC reaches a fixpoint, or any of the LCs detects a DWO, all threads where the LCs are executed are stopped. Given that the LCs applied are stronger than AC, and therefore the algorithms that enforce them are more expensive than a typical AC algorithm, in most of their invocations they will not be allowed to reach a fixpoint since AC will reach a fixpoint earlier. Despite this, it is quite possible that during the available run time they will prune some values that AC cannot prune, and they may even discover DWOs that AC cannot detect.
Algorithm Sync is based on a standard iterative description of a MAC-like search algorithm. treelevel denotes the current level of the search tree. The algorithm iteratively searches the space of possible variable assignments, through the while loop in line 10, until a solution is found or it is proved that none exists.
The parallel invocations of the different LCs occur in lines 1-3 (preprocessing) and 14-16 (after each branching decision). Hence, all the LCs are run in parallel at each node of the search tree, starting from the root. Note that any LC other than AC operates on a copy of the variables’ domains. Importantly, if the threads running the LCs are stopped without having detected a DWO then all value deletions caused by the different LCs are merged (lines 7 and 21). That is, they are carried over from the copies to the domains of the main thread where AC is run.
Sync starts by preprocessing the given CSP instance (lines 1-7). This is done by running all the available LCs in parallel. If some LC detects a DWO then all threads are stopped since the problem has been proved to be insoluble (line 4). Otherwise, the threads are terminated once AC has been applied on the problem, and the value deletions made by the various LCs are carried over to the domains of the main thread (line 7).
Thereafter, search commences by setting treelevel is set to 1 (line 8) and asking the variable ordering heuristic to make its first choice of variable (line 9). The loop of line 10 iterates over the variables, while the loop of line 11 iterates over the values of the selected variable x. After making a value assignment (lines 12-13), the algorithm enters the constraint propagation phase. At this point the variables’ domains are copied and the various LC algorithms are run on different threads on these copies (line 15). Constraint propagation stops when AC has been applied on the main thread or when a DWO is detected in any of the threads. In the first case the value deletions made by the various LC algorithms are copied to the main thread (line 21), while in the latter case the current value assignment is rejected and a new value is tried for the current variable x in the next iteration of the inner while loop.
If the propagation of all value assignments for the current variable fail then a chronological backtrack to the immediately preceding variable is triggered (lines 23-24). Otherwise, if a value assignment is successfully propagated then the algorithm moves forward by selecting one of the unassigned variables (lines 26-28).
Significantly, the synchronization process is trivial to implement and the overheads for copying domains are negligible. Hence, the algorithm will not be noticeably slower than a standard sequential solver even if the strong LCs do not offer any extra pruning.
4 An Asynchronous Algorithm
Algorithm 2 describes an asynchronous method for applying strong LCs, , where “asynchronous” refers to the simultaneous application of LC algorithms at different nodes of the tree. In the following we will call this algorithm Async. The main difference with Algorithm 1 is that LC algorithms that run on different processes are allowed to reach their fixpoints and can run at different nodes of the search tree at the same time. This can utilize the filtering power of strong LCs to a greater extent.
In each call to some LCi we pass as an argument treeleveli: the level of the search tree where the call is made. Since LC1 is AC, treelevel1 will always denote the current level of the search tree for the master process where the search mechanism of the solver operates. There is also a variable statei associated with each strong LCi. This variable can take values RUNNING and IDLE. If statei=RUNNING then a process applying LCi is currently running. Otherwise, if statei=IDLE then no process applying LCi is currently running. Once the application of some LCi terminates then statei is automatically set to IDLE.
Algorithm Async starts by applying all the LCs simultaneously at the root of the search tree (preprocessing at lines 1-5). As in Sync, all LCs apart from AC operate on copies of the variables’ domains. But in contrast to Sync, the threads running the strong LCs are not stopped once AC reaches a fixpoint but they continue their execution. Once AC finishes with preprocessing, the algorithm checks if any LC algorithm has detected a DWO (line 6). In such a case, the problem has been proved to be insoluble. If no DWO is detected, then search, which is running on the master process, kicks off (lines 9-10). In the meantime, some or all of the processes running strong LCs at the root of the tree will continue their execution until they reach a fixpoint.
Before a new variable assignment is made, the algorithm checks if any strong LC algorithms have finished processing and if so, whether a backtrack can be initiated. This is done by calling Function ForceBT with the current partial assignment as an argument. There are two cases where a (non-chronological) backtrack can be forced:
Some LC algorithms that were called at levels shallower than the current level have detected a DWO. 2. 2.
Some LC algorithms that were called at levels shallower than the current level have deleted a value that is part of the current partial assignment.
If any of these cases, which we call reasons for failure, occurs, Function ForceBT compares the levels of the search tree where the relevant LC algorithms were called (lines 3-4 and 6-7) and the shallowest level (i.e. the one closest to the root) is returned in line 8. This will then trigger a non-chronological backtrack of the search mechanism running on the master process. If none of the two cases occurs then the current search level treelevel1 is returned.
If ForceBT returns treelevel1 then the selected variable assignment is temporarily made (line 18). Then AC propagation is run on the master process and at the same time, any LC that is at an IDLE state is set to RUNNING and is run in parallel to AC (lines 19-21). Once AC finishes, the algorithm checks if any of these LCs has also terminated. For any LC that has terminated, including AC, the algorithm then checks if it has detected a DWO or not (line 22). If a DWO has been detected, the current variable assignment is rejected and if there are no values left for the current variable, BTlevel is set to the current level minus 1 to cause a chronological backtrack. Otherwise, the algorithm exits the inner while loop of line 11 and proceeds to make the currently tried assignment, move to the next level of the search tree, and select the next variable (lines 35-38).
The way reasons for failure are handled after DWOs or deletions from the partial assignment occur (lines 29-34) is where we gain from the application of the strong LCs. There are three cases:
None of the strong LCs that finished running within the current iteration detected a reason for failure at a level shallower than the current one. This means that the failure was detected by AC or another LC in line 22. If there are still values left for the current variable x{}_{\texttt{tree\_level{}{1}}} then BTlevel will be set to treelevel1 (from the call to ForceBT) and therefore the algorithm will not backtrack and will proceed to try the next value of x{}_{\texttt{tree\_level{}{1}}} in the next iteration. 2. 2.
The failure was detected by AC or another LC in line 22 but no values are left for the current variable. In this case a chronological backtrack will take place since BTlevel will be set to treelevel1 - 1 (from line 26). 3. 3.
Some of the strong LCs that finished running within the current iteration detected a reason for failure at a level shallower than the current one. In this case a non-chronological backtrack (i.e. a backjump) may take place since ForceBT will set BTlevel to the shallowest level where a reason for failure was detected.
After the backtrack point BTlevel has been determined, a crucial step follows. Namely, all slave processes running a strong LC at a level equal or greater than BTlevel are stopped and their state is set to IDLE (lines 32-34). This is because the subtree below the node where they were called has been proved not to contain a solution (hence the backtrack). Therefore, continuing their execution is fruitless.
The following example illustrates the algorithm.
Example 1
Assume that two strong LCs, LC2 and LC3, are utilized in addition to AC by Algorithm 2. In Figure 1a) the algorithm initiates the master and slave processes for the application of the three LCs at some node of the search tree. In Figure 1b) LC2 and LC3 are still running but search on the master process has moved on and AC is applied at a node further down the search tree. In Figure 1c) LC2 has terminated without disovering a reason for failure before the next assignment is made. Hence, after the next assigment is made, AC and LC2 are applied simultaneously. In Figure 1d) search has moved further down the search tree but before applying AC at the current node, LC2 terminates by detecting a DWO. At this point a non-chronological backtrack is initiated, and as Figure 1e) illustrates, AC and LC2 are applied in parallel at the sibling of the node where the DWO was detected. In Figure 1f) LC2 is still being applied at that node while search has moved on and AC is applied at a node further down. But at this time LC3 terminates having deleted a value that belongs to the partial assignment (the shaded node). Hence, in Figure 1g) a non-chronological backtrack up to the level where this assignment was made will occur. Then all three LCs will be again applied.
4.1 Extensions of the algorithms
One shortcoming of the algorithms, as they are describe above, is that only a portion of the parallelization power offered by modern machines is utilized by them. This is because the algorithms dedicate one core to each different LC, and realistically there will only be a few LCs available in any CSP solver. Even in the case of binary constraints, where quite a few different LCs have been proposed, typical solvers only include a basic propagation mechanism (e.g. AC) and perhaps one or two stronger methods such as SAC and maxRPC.
We now briefly discuss two ideas, one for each algorithm, that can be exploited to overcome this limitation. We intend to implement and test them in the future.
4.1.1 Sync
Regarding algorithm Sync, the full potential of multithreading can be exploited using different orderings of the propagation queue. Such orderings can be generated through randomization as we will explain. First of all, it is well known that the order in which elements of the propagation queue (e.g. variables or constraints) are processed has an impact on the cpu time that propagation takes. There have been quite a few studies on this and a number of heuristics for efficiently ordering the elements of the queue, mainly in the case of arc consistency, have been proposed by Wallace & Freuder (1992); Boussemart et al. (2004); Balafoutis & Stergiou (2011). Of course, any different ordering of the queue results in exactly the same value deletions if the particular propagation algorithm is run to completion (i.e. until its fixpoint is reached). However, if the algorithm is not run to completion, as is the case for strong LC algorithms in the framework of Sync, different queue orderings may result in different value deletions.
For example, assume that an algorithm that applies maxRPC removes a variable from the queue. Then all values of all variables constrained with must be checked for maxRPC. In our framework, if this algorithm is run in parallel to the main AC propagation mechanism, it will be stopped once AC terminates. Therefore, it is likely that only some of the variables constrained with may have been processed until the algorithm is stopped. If these variables are handled in parallel threads, in different orderings, then potentially different value deletions may be made in each thread.
To summarize, each time the application of a strong LC is initiated on some thread within algorithm Sync, we can additionally allocate any number of available threads where the same LC is run under different (randomized) queue orderings. Once constraint propagation on the main thread terminates, all the threads are stopped and any value deletions made are merged.
4.1.2 Async
Assuming that k-1 strong LC are available in addition to the standard propagation mechanism, algorithm Async will utilize at most k threads as at any time during search. One way to utilize all of the available threads is the following: At lines 19-21 of Algorithm 2, instead of initiating the application only of those LCs whose state is IDLE, we can initiate the application of all LCs as long as there are available resources. This will mean that at any time during search the same LC may run simultaneously at many different nodes of the search tree.
For example, consider a case where there is only one strong LC available (say maxRPC). Async will start by applying AC and maxRPC at the root of the search tree. Once the AC algorithm terminates, and assuming no DWO occurs, search on the main thread will start by assigning a variable and again applying AC, while at the same time the maxRPC algorithm may still be running at the root node. The extension of Async discussed here will initiate the application of maxRPC on one of the avaiable threads, in addition to AC, after the assignment of . Hence, the maxRPC algorithm may now be running at two different nodes at the same time.
This extension of Async should result in faster search, but on the other hand a greater effort for synchronization will be required.
5 Experimental Results
As a case study, we have experimented with benchmark binary CSPs taken from Christophe Lecoutre’s XCSP repository and used in CSP solvers competitions. Specifically, we experimented with 300 instances belonging to the following classes: radio links frequency assignment (rlfap), graph coloring (gc), driver (dr), forced random (frb), quasigroup completion (qcp), quasigroups with holes (qwh).
All experiments were performed in a multiprocessor shared memory system consisting of 8 cores (the total number with hyperthreading is 16) of Intel(R) Xeon(R) CPU E5520 at 2.27GHz and with 78GB of memory, under the operating system Ubuntu Linux 12.04. The framework that we used for the implementation was the OpenMP 3.0 OpenMP (2008) API extensions on the GCC 4.6.3 compiler , without any compiler optimization parameters. To assess the performance we used the practical execution time (or wall clock) as a measure. The practical execution time (or wall clock) is the total time that a process requires in order to complete its computation. The execution time is obtained by calling the C POSIX.1-2001 function clockgettime() and it is measured in nano seconds, with the highest available timer accuracy.
We used a standard MAC algorithm as the baseline solver, and in addition we implemented and applied maxRPC within the context of the proposed framework. Specifically, the two algorithms presented in Section 3 (denoted Sync and Async hereafter) apply maxRPC in slave processes parallel to the master process which applies AC. We compare Sync and Async to: 1) the baseline solver, i.e. MAC (denoted AC), and 2) a simple portfolio of two search algorithms that are run in parallel independently from one another. These algorithms respectively apply AC and maxRPC throughout search. For any given problem, the portfolio (denoted pfAC+maxRPC) terminates once one of the algorithms finds a solution (or proves that none exists). Hence, for any given instance the portfolio gives the same result as either AC or maxRPC, depending on which of the two is better for the specific instance. Finally, we integrated Sync and Async within the portfolio resulting in a new portfolio that consists of four algorithms (denoted pfall).
All algorithms used the dom/wdeg heuristic for variable ordering and lexicographical value ordering. Our algorithms were run 50 times on each instance and the median cpu times and node visits are reported222The mean values are quite close in general but are heavily influenced by a few outliers in some cases of soluble instances.. A time limit of 1 hour was set.
Table 1 compares the performance of all the tested methods on various problem instances. Figures 2 and 3 give pairwise comparisons between our algorithms and AC (resp. pfAC+maxRPC) by showing cpu times in log scale. We exclude very easy instances that are solvable by all methods in less than a second and very hard ones where the time limit was reached by all methods. Any point above (resp. below) the diagonal corresponds to an instance where AC/pfAC+maxRPC was better (resp. worse) than Sync/Async.
The results demonstrate the validity of the motivation behind this work. As Figures 2 and 3 demonstrate, our algorithms are able to almost always outperform AC by taking advantage of the extra filtering offered by maxRPC without slowing down search, since this strong LC is applied in parallel to the main solver. Considering each problem class separately, we can note the following:
- •
The rlfap is a class where AC dominates maxRPC as can been by the results of pfAC+maxRPC in Table 1, which usually follow those of AC. In this class both Async and Sync outperform AC, and therefore also pfAC+maxRPC, with the latter algorithm being more efficient. Specifically, Sync can be up to twice as fast as AC and pfAC+maxRPC.
- •
In gc problems AC is again better on average than maxRPC, but there are quite a few cases where the opposite occurs. In these problems Async and Sync are in most cases more efficient than AC and pfAC+maxRPC, and there is no clear winner between them.
- •
AC is clearly better than maxRPC on driver and frb problems. The performance of Sync and Async is usually close to that of AC, but there are instances where they clearly outperform it.
- •
In the qcp and qwh classes maxRPC is typically by far faster than AC, very often by exponential margins. This is because of the considerable extra pruning it achieves. In most cases Sync and Async cannot match the performance of maxRPC and are therefore less efficient than pfAC+maxRPC. However, the pruning achieved by the application of maxRPC inside Sync and Async is enough to make them clearly more efficient than AC. Also, there are some instances where our algorithms, and especially Async, are able to outperform maxRPC.
Overall, we can say that the performance of Sync is perhaps surprising. Despite the limited time given to maxRPC while AC runs on the master process, it is able to achieve considerable extra pruning. This is reflected on cpu times where Sync is often twice as fast as AC, while it is rarely outperformed. Regarding the portfolio pfAC+maxRPC, Sync is usually better on problems where the winner among the portfolio’s solvers is AC (rlfap, gc, dr, frb). On problems where the winner is maxRPC (qcp, qwh) pfAC+maxRPC is in most cases better than Sync.
Regarding Async, which has the greater potential for further development, results demonstrate that its performance follows that of maxRPC in terms of search space reduction, but without penalizing cpu times on problems where maxRPC is not successful. That is, while Async is faster than AC in most cases, it performs much better in problem classes where maxRPC excells. In qcp it can be up to 7 times faster than AC while being always better than Sync. On the other hand, the differences between Async and AC are not very significant on rlfap, while on graph coloring AC is slightly better on some instances.
These results are explained by looking at the backjumps that take place in each problem when solved by Async. The number of backjumps, as well as the mean and maximum numbers of search tree levels that are jumped over, are considerably higher in quasigroup instances compared to some other classes. For example, on qcp15-5 there were 7547 backjumps on average, and their mean and maximum lengths (i.e. levels jumped over) were 2.38 and 17.35 respectively. On driver-9, where Async is also very successful, there were only 52 backjumps on average but their mean and maximum lengths were 4.8 and 42.1. In contrast, on s11-f09 there were 2113 backjumps on average, and their mean and maximum lengths were 1.26 and 2.75.
Finally, it is clear from Table 1 that the portfolio pfall which includes all four methods outperforms each individual method, as well as the portfolio pfAC+maxRPC. For each given instance, pfall matches the performance of the algorithm that performs best on this instance among AC, maxRPC, Sync, and Async. Therefore, it is the clear winner overall. It is well known that when building portfolios using different solvers or a single solver under different parameter settings, a very important desired attribute is variability. That is, in order for the portfolio to be successful the solvers included in the portfolio should display dissimilar behavior. This is achieved by pfall because, as demonstrated in Table 1, any method among pfAC+maxRPC, Sync, and Async can be the winner on different instances and problem classes. Hence, they display variability in their performance, and this is why their integration into pfall is very successful.
6 Related Work
Obviously, the proposed framework for the efficient application of strong LCs requires the availability of machines with more than one processor (core). Since such machines are the norm nowadays, this is by no means a prohibitive requirement. In addition, the implementation effort required is very small, given already implemented algorithms for strong LCs.
There is a quite extensive body of work on parallel constraint solving which aims at exploiting the increasing number of available processors to speed up computation. A review can be found in the paper by Gent at al. (2011). Such works are relevant to our framework since they also exploit multiple processors, but at the same time they are quite different. Parallel CSP (and SAT) solving has mainly focused on search space splitting (i.e. allocating different branches of the search tree to different processors), e.g. the works by Perron (1999); Jaffar et al. (2004); Michel et al. (2009); Chu (2009); Bordeaux et al. (2009); Régin et al. (2013), and solver portfolios, e.g. the works by Hamadi et al. (2009); Hyvärinen et al. (2009); Audemard & Simon (2014); Yun & Epstein (2012); Dasygenis & Stergiou (2014), and to a lesser extent, on the parallelization of propagation, e.g. the works by Kasif (1990); Ruiz-Andino et al. (1998); Rolf & Kuchcinski (2010).
Regarding the latter direction, which is closer to our work, parallelizing constraint propagation algorithms is a challenging task since most such algorithms are sequential by nature, as demonstrated by Kasif (1990). Hence, this approach has not been explored as much as the other ones, and it is quite different to our work where each LC algorithm runs on a single processor. Another common perception that has resulted in limited research on constraint propagation parallelization is that the scalability of this approach is limited by Amdahl’s law: ”if propagation consumes 80 of the runtime, then by parallelizing it, even with a massive number of processors, the speed-up that can be obtained will be under 5”, as Bordeaux et al. (2009) explains.
Existing works on parallel constraint propagation have focused on AC and have either been purely theoretical, or any experiments that were conducted, e.g. by Ruiz-Andino et al. (1998) and Nguyen & Deville (2011) either failed to show significant speed-ups or were limited to very few processors. Rolf & Kuchcinski (2010) consider the parallelization of a modern CP solvers’ constraint propagation engine and shows that problems with a large number of (expensive to propagate) global constraints can benefit from parallelization of the propagation mechanism. Since this approach is orthogonal to ours, their combination is an interesting avenue for research.
Our work is orthogonal to search space splitting methods since our algorithms explore a single search tree, on the master processor, and use a number of slaves to help speed up the exploration of this tree. However, it is feasible to combine our approach with search space splitting by first allocating different branches to different processors and then committing a number of slaves to each of these processors, along the lines of our framework.
Running a portfolio of solvers where each one applies a different LC is not the same as using these LCs within our framework, as our experimental results demonstrate. For example, consider a simple portfolio of two solvers where the first maintains AC and the second a stronger LC. It is quite likely that on some problem the first solver thrashes while the second explores a much smaller tree but spends too much time applying the strong LC at every node. In contrast, algorithm Sync may exploit the applications of the strong LC, even if its fixpoint is not reached, to remove some extra values and quickly direct search on the master process to a fruitful area of the search tree. Also, the application the strong LC within algorithm Async may result in large backjumps and thus avoid thrashing.
Finally, we need to note that through the use of strong local consistencies for propagation the scalability limitation posed by Amdahl’s law can be overcome. This is because such consistencies we can achieve significantly stronger pruning than standard methods (such as AC), and therefore in many cases we can result in exponentially smaller search trees and corresponding run times.
7 Conclusions
We presented two novel ways to exploit the filtering power of strong LCs without paying a severe cpu time cost when they are not successful. Algorithm Sync applies strong LCs in parallel to the main propagation mechanism of the solver at each node of the search tree. The LC algorithms are stopped once propagation on the main process terminates, or if some LC algorithm detects a failure. Algorithm Async can apply different LCs at different nodes of the search tree at the same time. This can result in non-chronological backtracks of the main solver. Initial experimental results demonstrate the potential of our methods. We believe that the work presented here can open up numerous possibilities of parallelizing constraint propagation. Another important contribution of this study is to further motivate research on strong local consistencies and propagation methods.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Audemard & Simon (2014) Audemard, G. & Simon, L., Lazy clause exchange policy for parallel SAT solvers . In Theory and Applications of Satisfiability Testing - SAT 2014 - 17th International Conference , pages 197–205, 2014.
- 2Balafoutis et al. (2011) Balafoutis, T., Paparrizou, A., Stergiou, K., Walsh, T., New algorithms for max restricted path consistency, Constraints , 16(4):372–406, 2011.
- 3Balafoutis & Stergiou (2011) Balafoutis, T., Stergiou, K., Exploiting constraint weights for revision ordering in Arc Consistency Algorithms, ECAI-2008 Workshop on Modeling and Solving Problems with Constraints , 2008.
- 4Berlandier (1995) Berlandier, P., Improving Domain Filtering Using Restricted Path Consistency, In Proceedings of IEEE CAIA’95 , pages 32–37, 1995.
- 5Bessiere et al. (2011) Bessiere, C., Cardon, S., Debruyne, R., Lecoutre, C., Efficient Algorithms for Singleton Arc Consistency, Constraints , 16:25–53, 2011.
- 6Bessiere at al. (2008) Bessiere, C., Stergiou, K., Walsh, T., Domain Filtering Consistencies for Non-binary Constraints, Artificial Intelligence , 172(6-7):800–822, 2008.
- 7Bordeaux et al. (2009) Bordeaux, L., Hamadi, Y., Samulowitz, H., Experiments with Massively Parallel Constraint Solving, In Proceedings of IJCAI-2009 , pages 443–448, 2009.
- 8Boussemart et al. (2004) Boussemart, F., Hemery, F., Lecoutre, C., Revision ordering heuristics for the Constraint Satisfaction Problem, In CP’04 Workshop on Constraint Propagation and Implementation , 2004.