Machine learning methods for multimedia information retrieval
B\'alint Zolt\'an Dar\'oczy

TL;DR
This thesis explores multimodal feature extraction and similarity kernels for multimedia retrieval and classification, demonstrating their effectiveness across various datasets and proposing future enhancements with complex graph models.
Contribution
It introduces similarity kernel methods for multimedia retrieval, showing their competitive performance and suggesting their applicability to diverse generative models and complex graph structures.
Findings
Similarity kernel improves over state-of-the-art in multimedia retrieval
Generative models based on instance similarities are broadly applicable
Fisher kernel is a powerful tool for classification and regression
Abstract
In this thesis we examined several multimodal feature extraction and learning methods for retrieval and classification purposes. We reread briefly some theoretical results of learning in Section 2 and reviewed several generative and discriminative models in Section 3 while we described the similarity kernel in Section 4. We examined different aspects of the multimodal image retrieval and classification in Section 5 and suggested methods for identifying quality assessments of Web documents in Section 6. In our last problem we proposed similarity kernel for time-series based classification. The experiments were carried over publicly available datasets and source codes for the most essential parts are either open source or released. Since the used similarity graphs (Section 4.2) are greatly constrained for computational purposes, we would like to continue work with more complex, evolving…
Click any figure to enlarge with its caption.
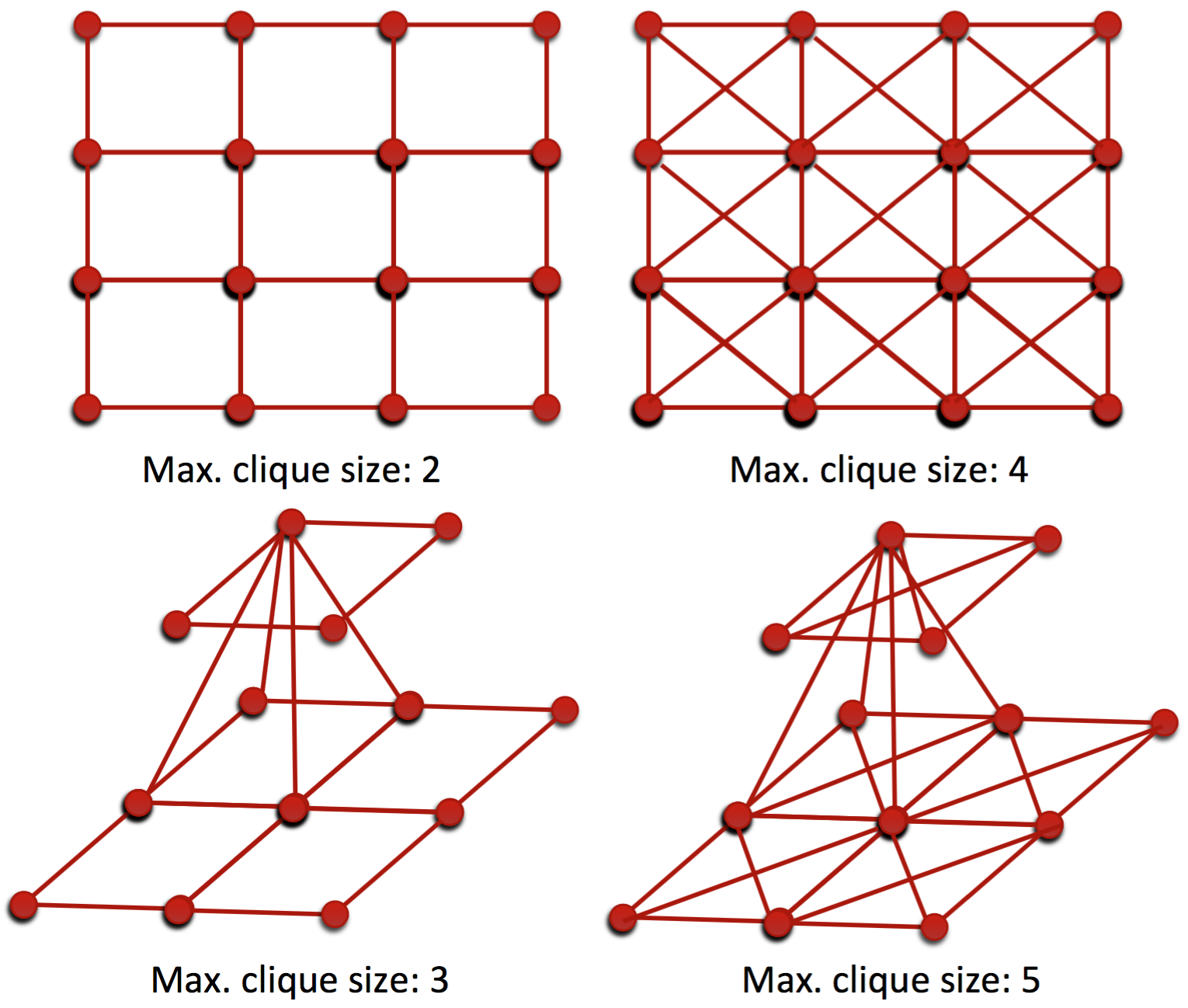 Figure 1
Figure 1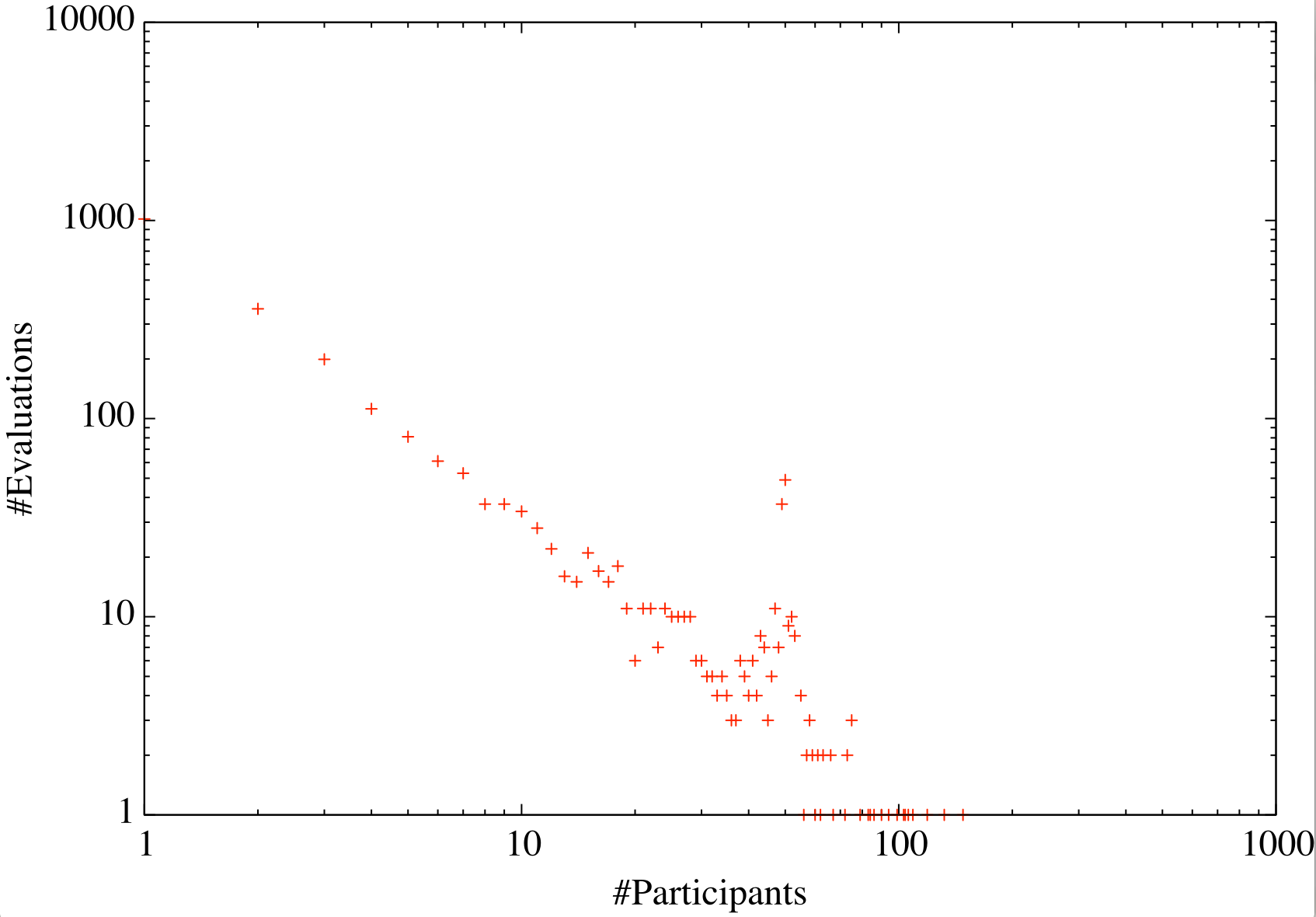 Figure 2
Figure 2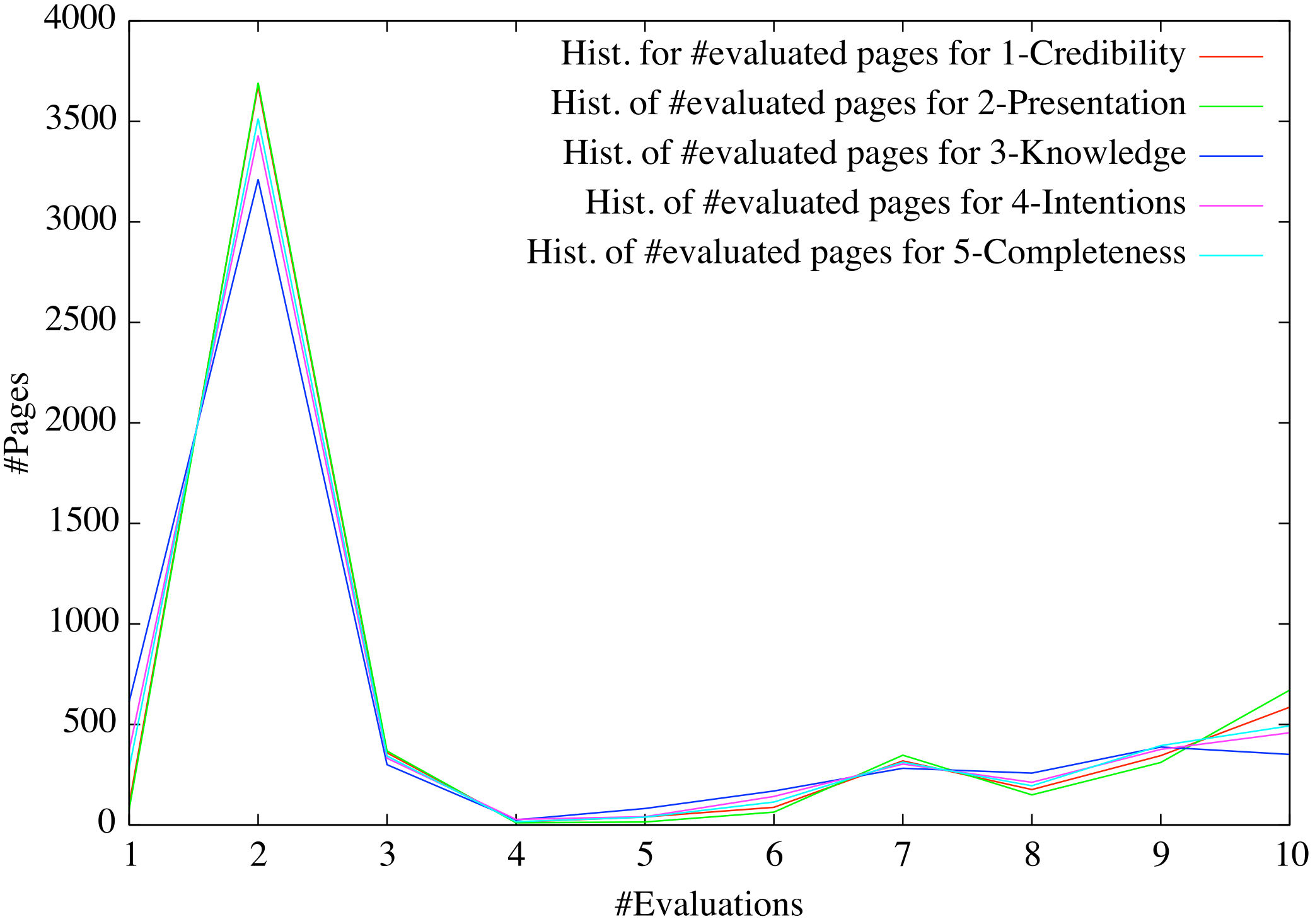 Figure 3
Figure 3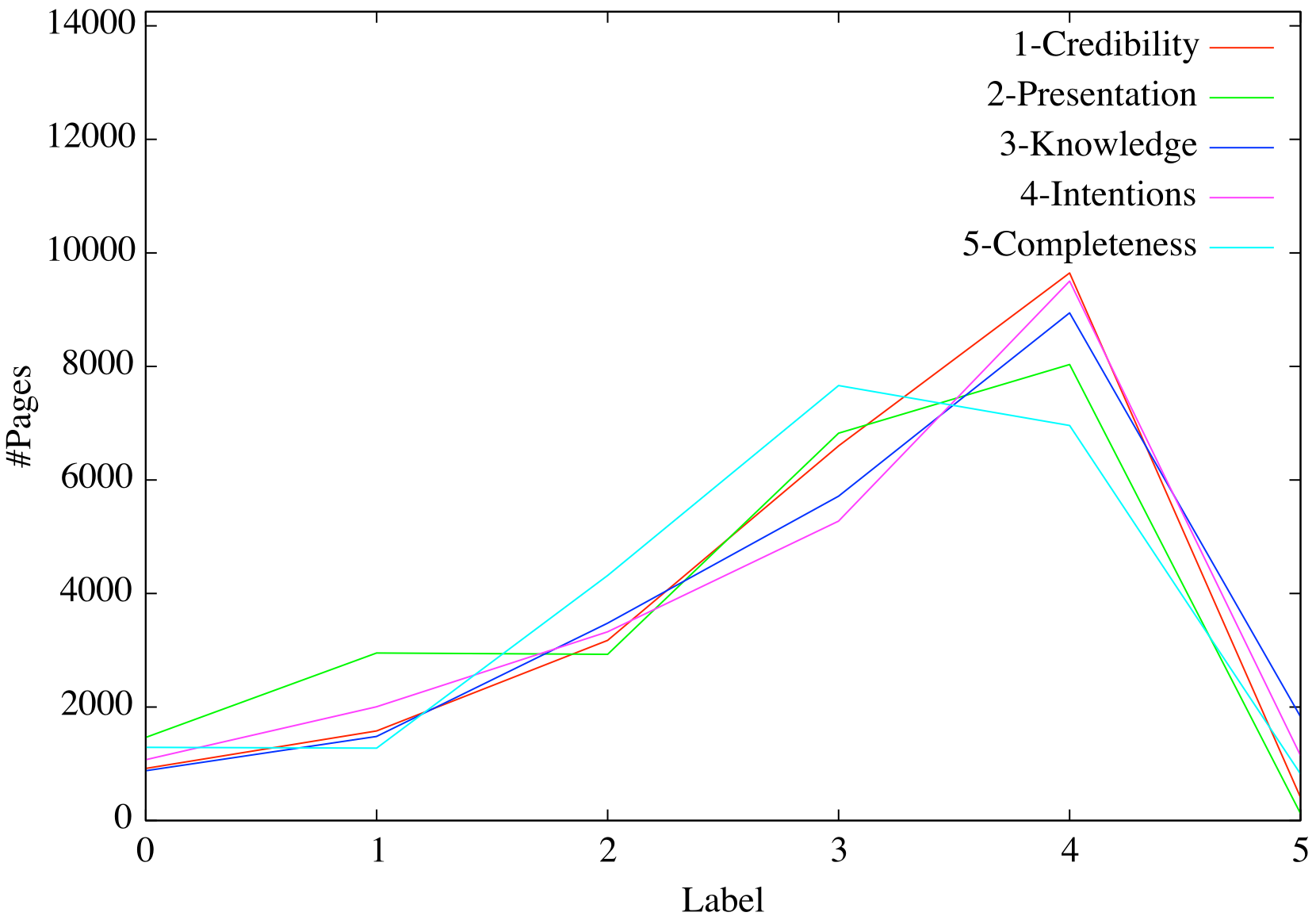 Figure 4
Figure 4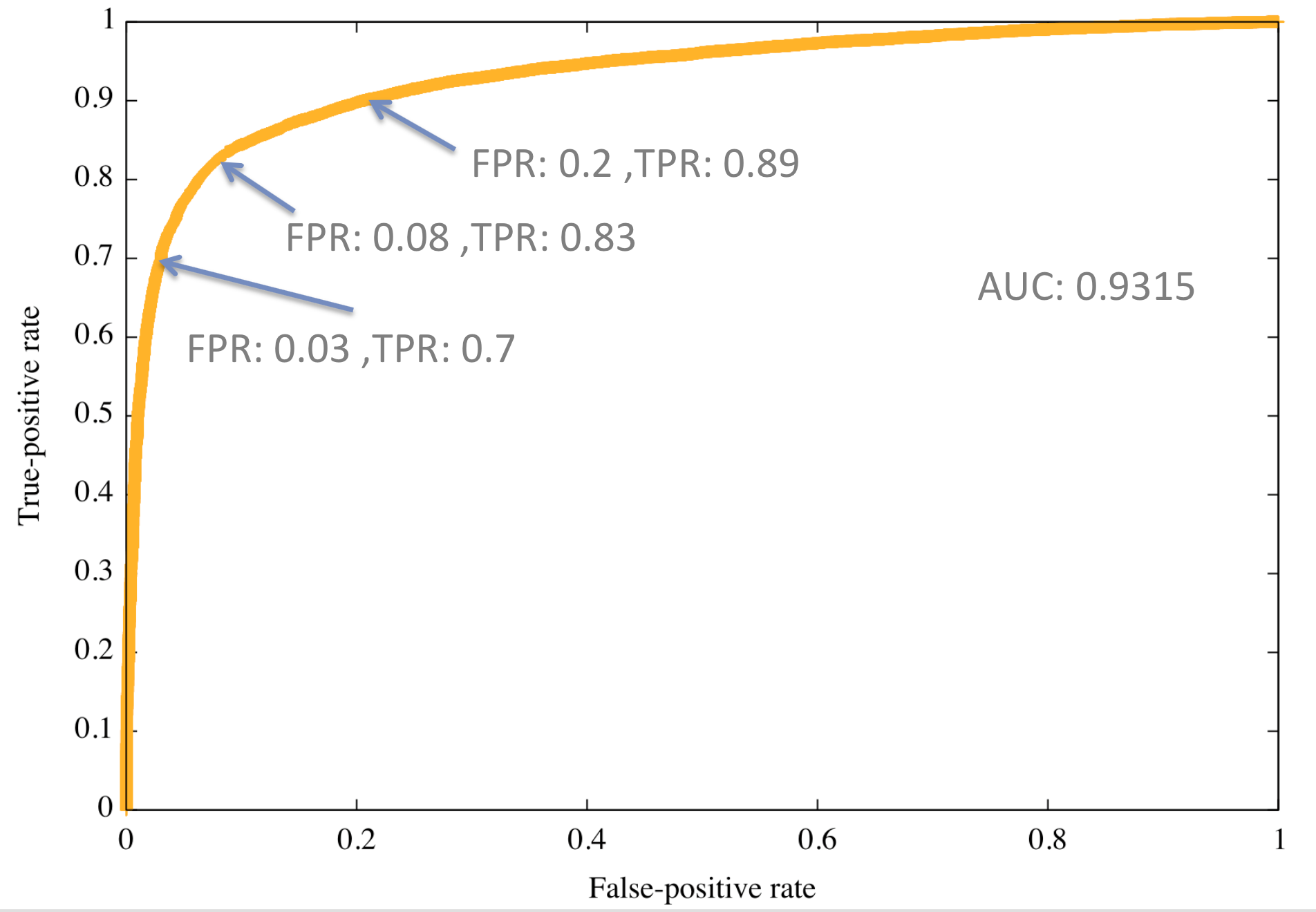 Figure 5
Figure 5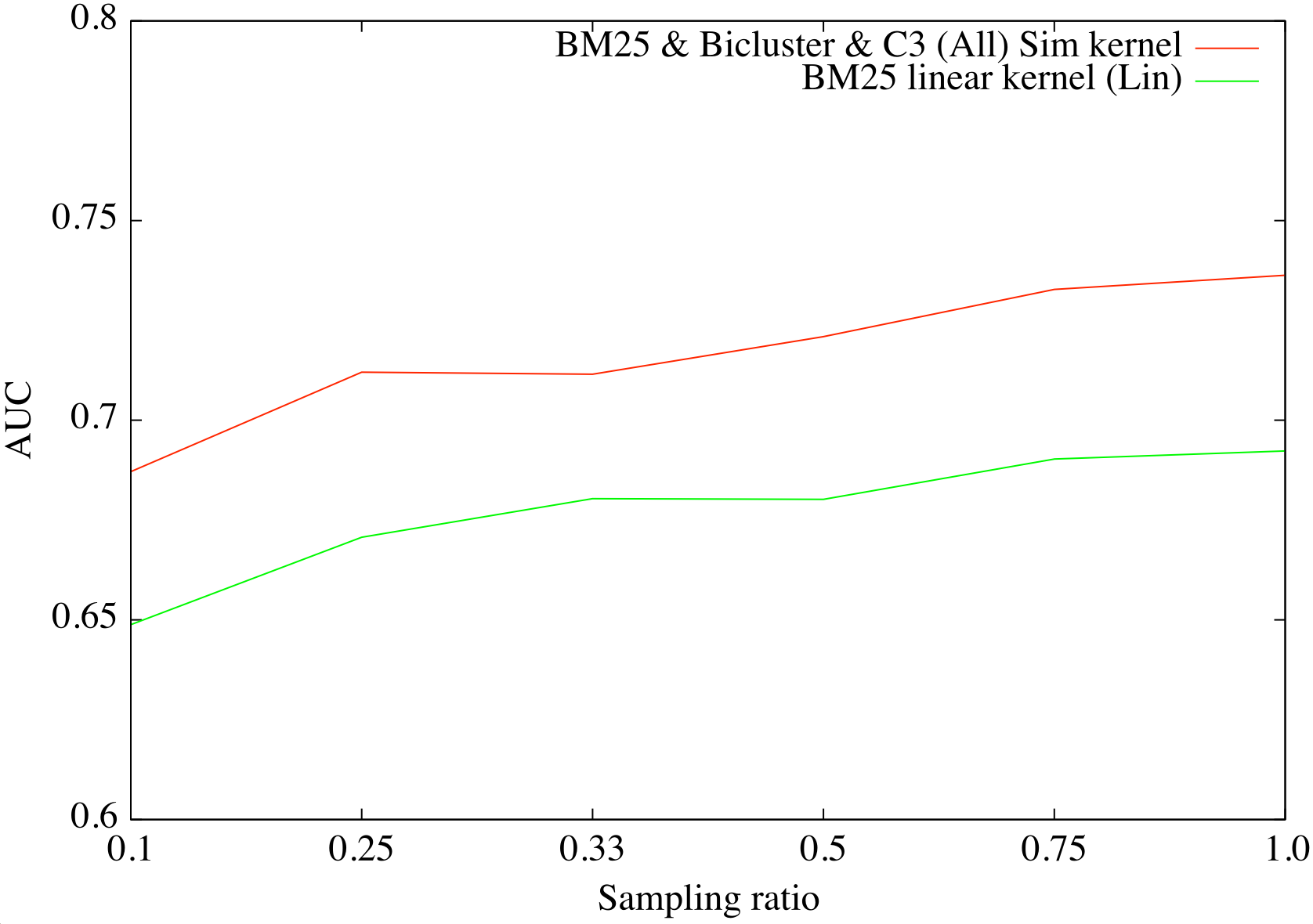 Figure 6
Figure 6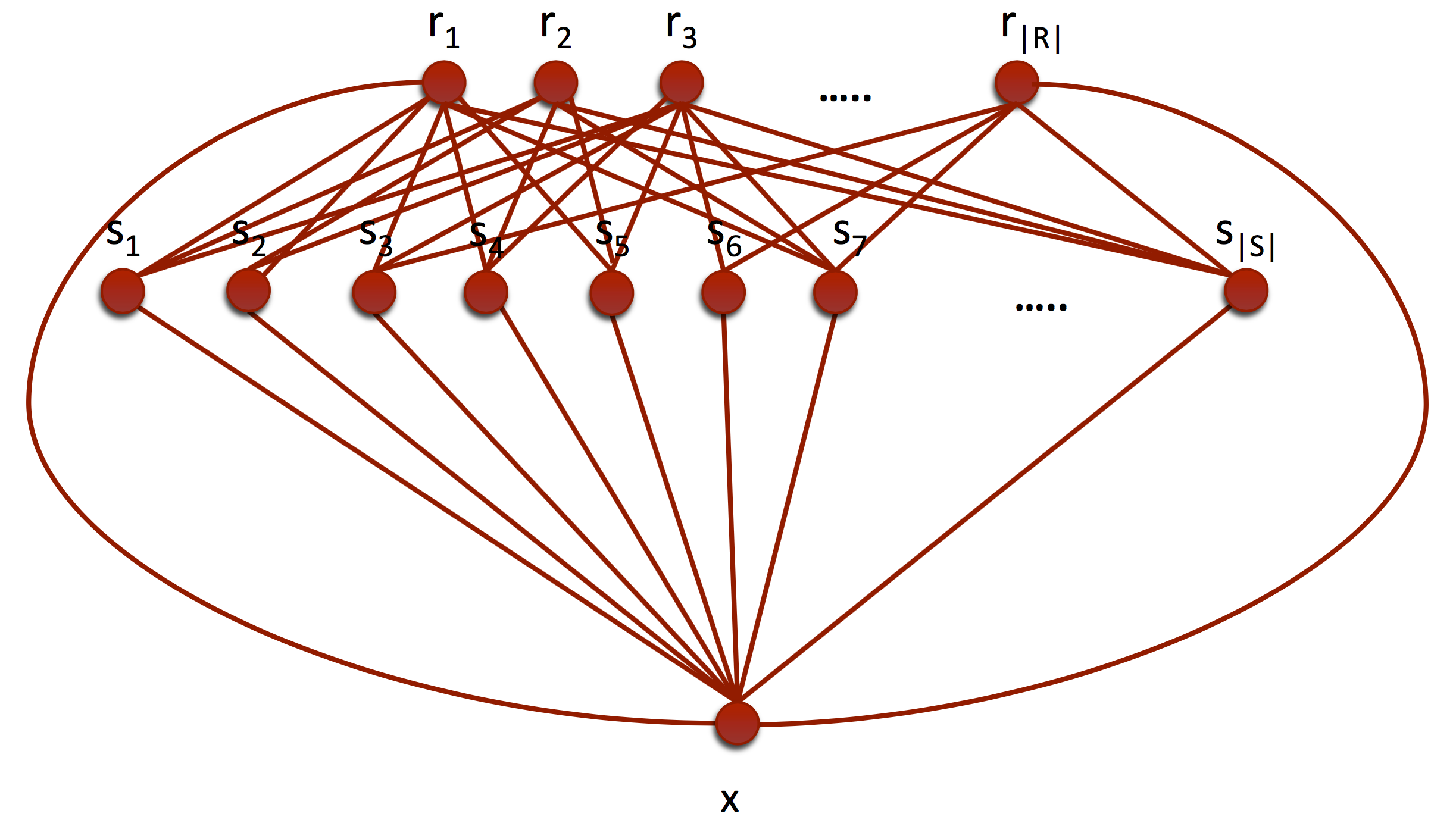 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9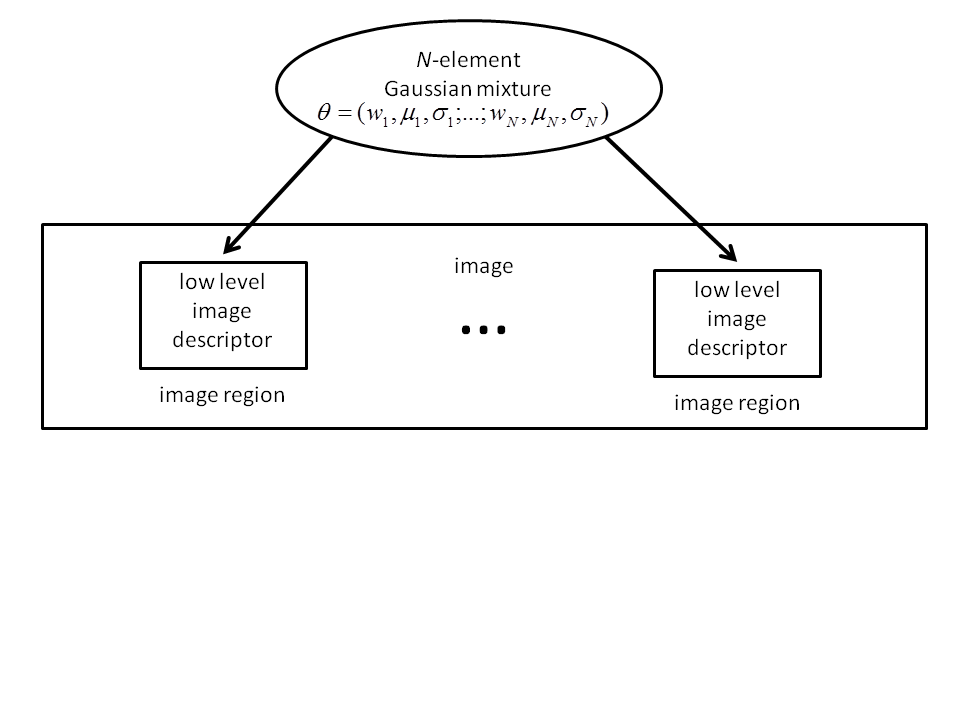 Figure 10
Figure 10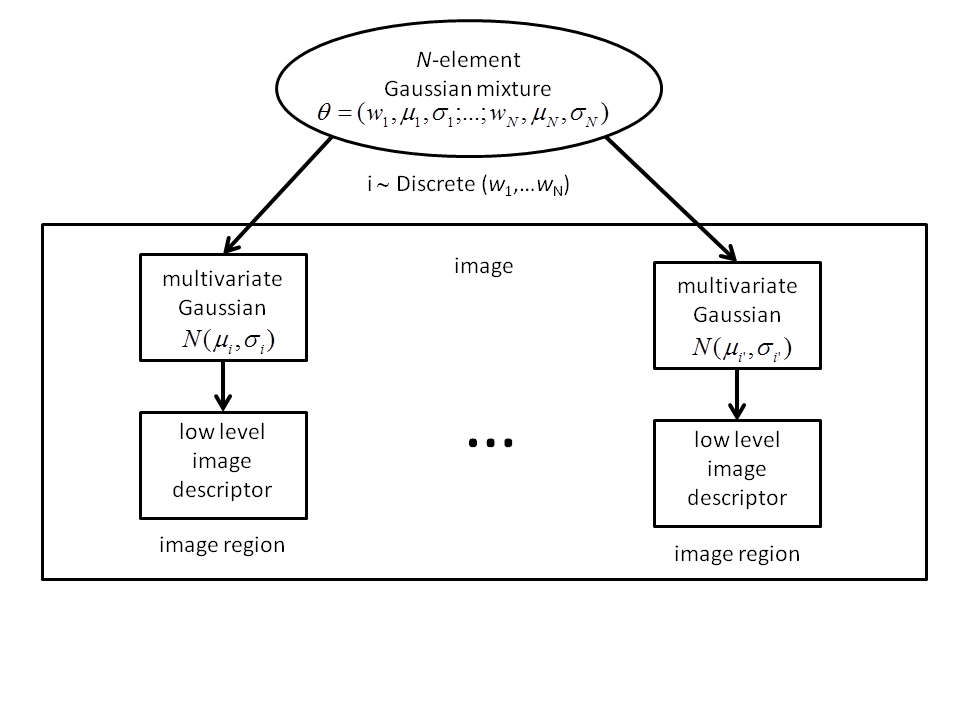 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13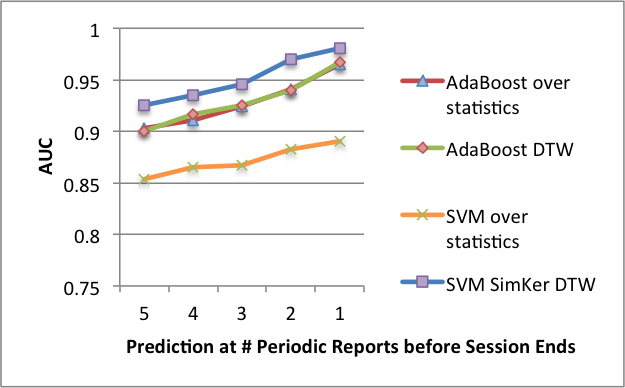 Figure 14
Figure 14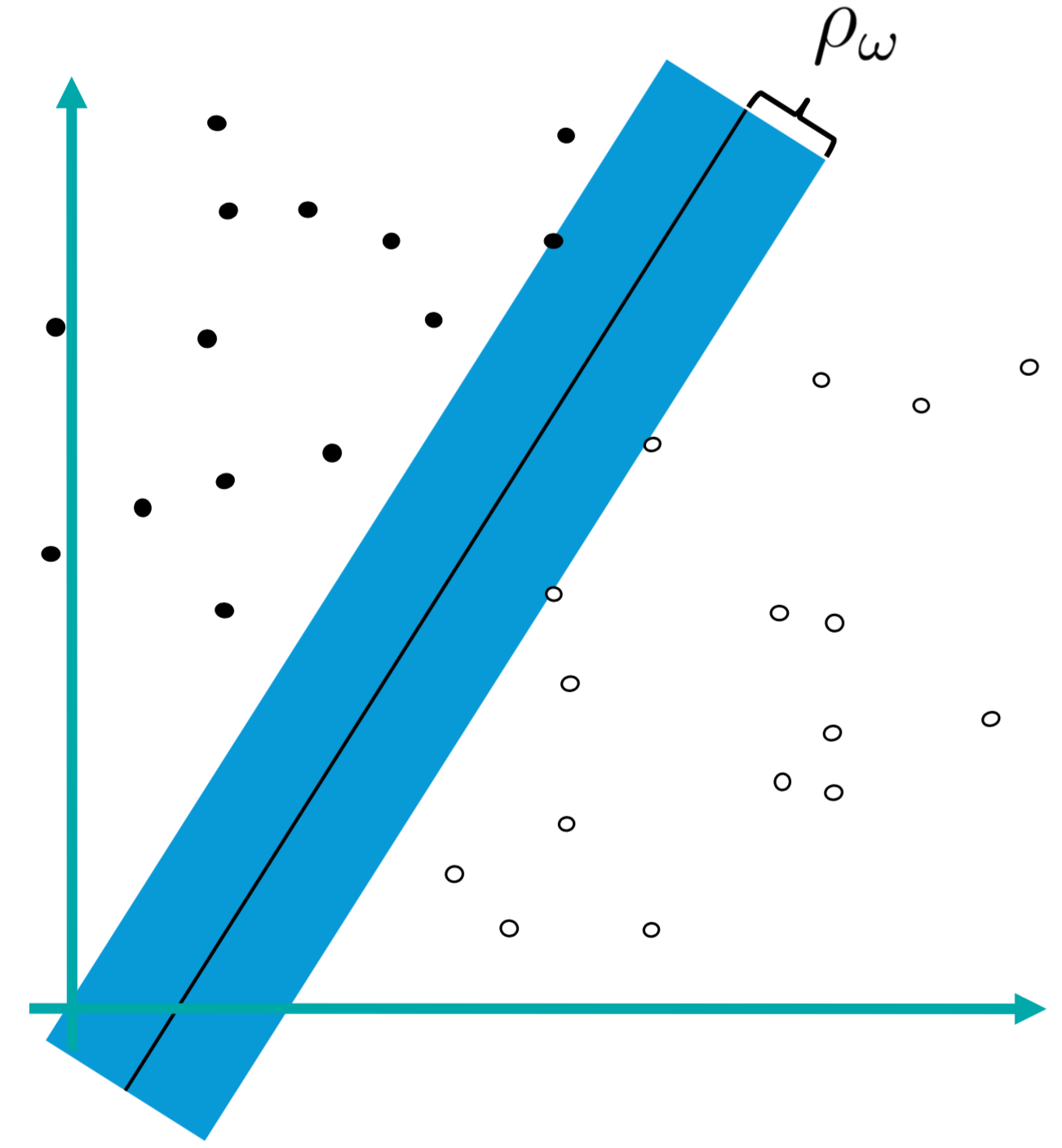 Figure 15
Figure 15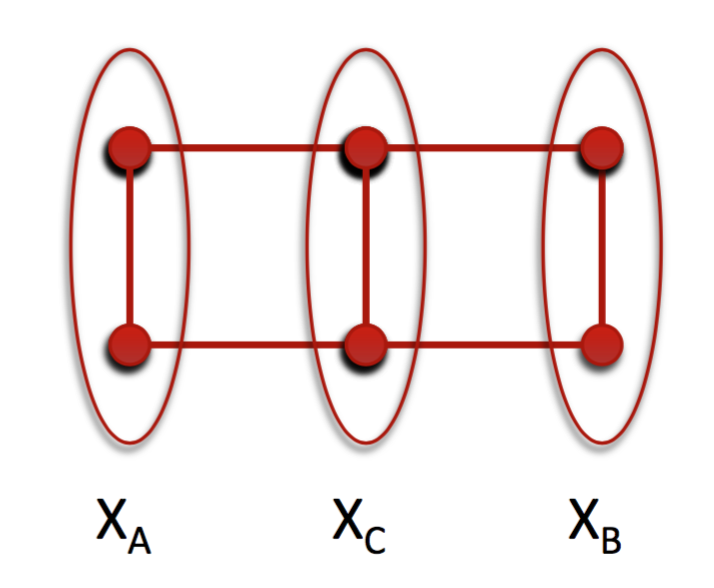 Figure 16
Figure 16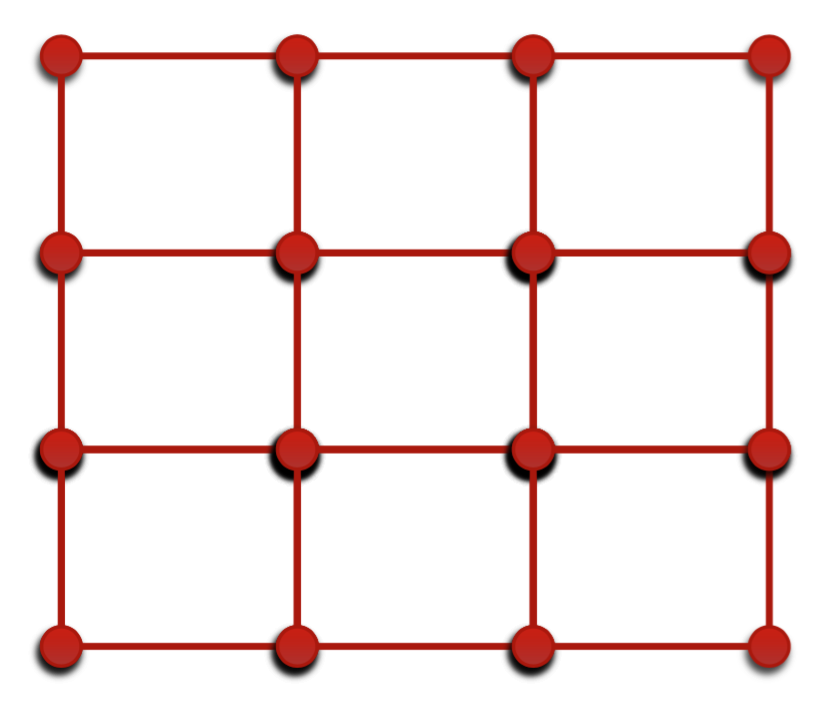 Figure 17
Figure 17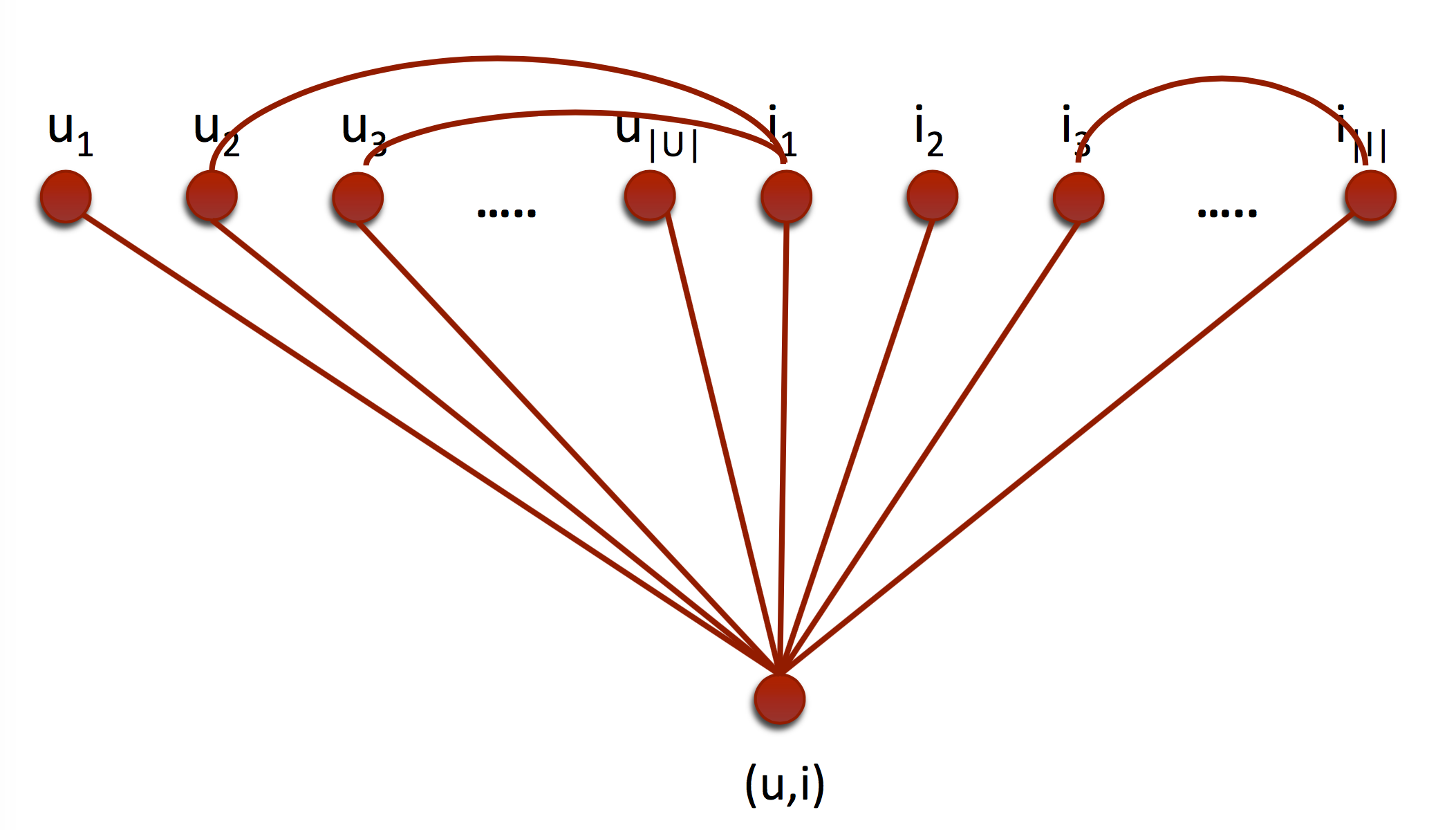 Figure 18
Figure 18 Figure 19
Figure 19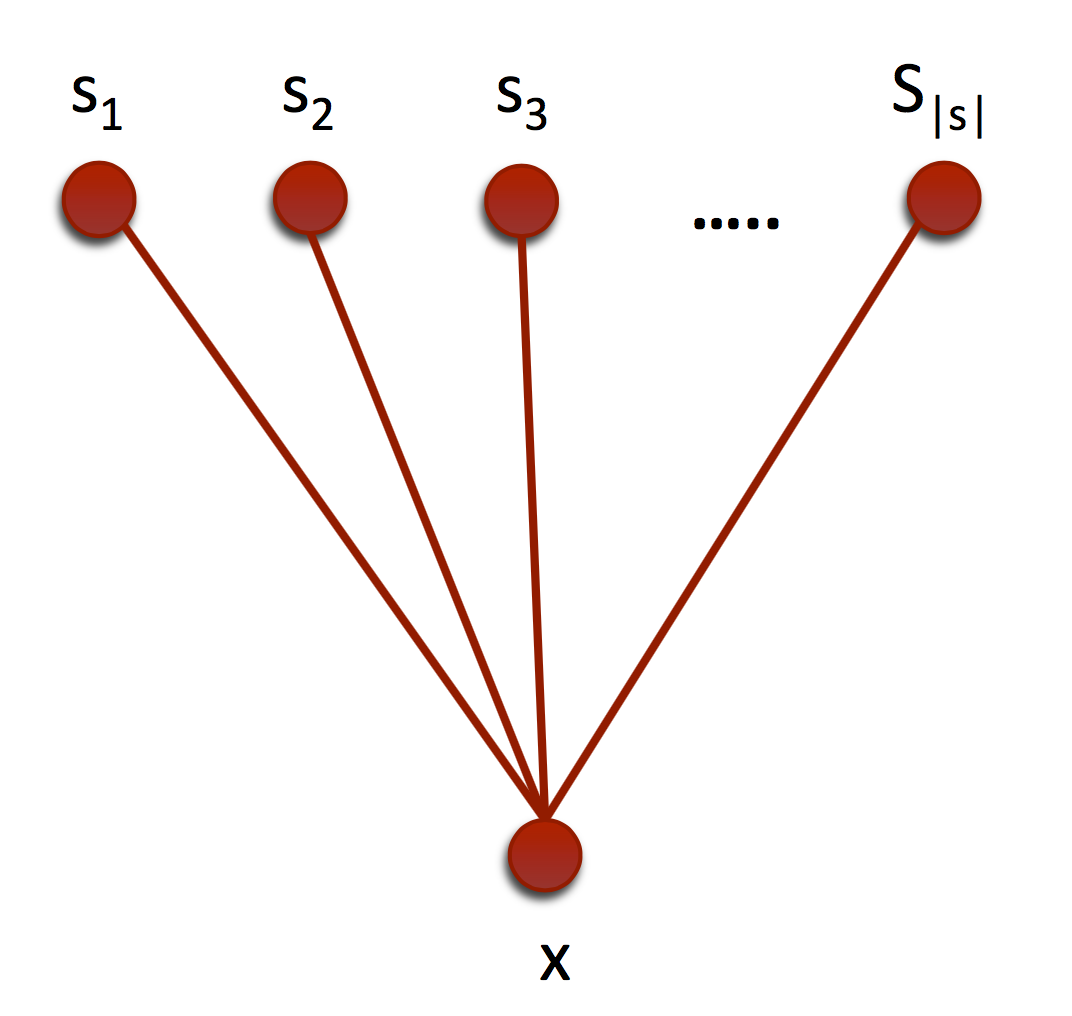 Figure 20
Figure 20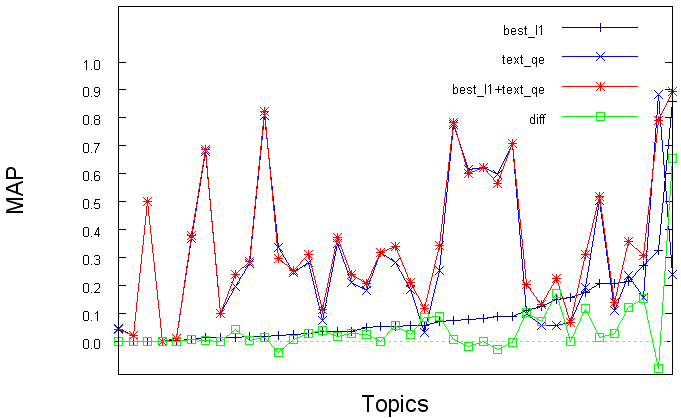 Figure 1
Figure 1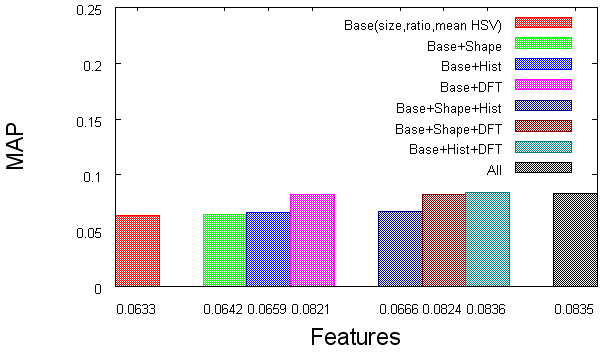 Figure 2
Figure 2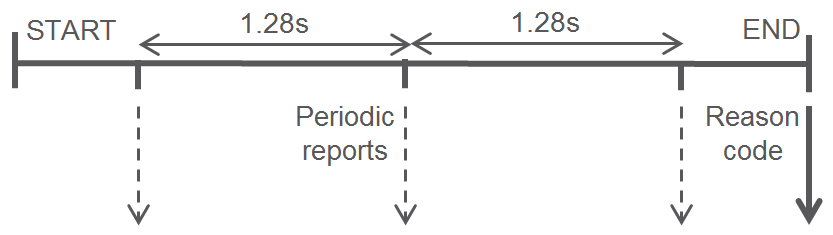 Figure 23
Figure 23 Figure 24
Figure 24 Figure 25
Figure 25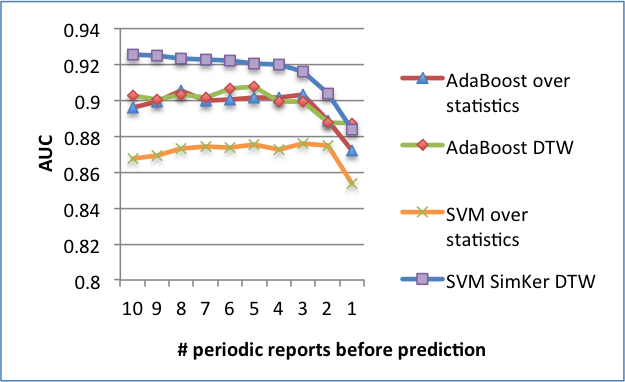 Figure 26
Figure 26|
Fine sampling |
Descriptor |
Codebook size |
Spatial Pooling |
Dimension |
MAP |
|
|---|---|---|---|---|---|---|
| LLC [Chatfield et al., 2011] | yes | SIFT | 25k | yes | 200k | .573 |
| SV [Chatfield et al., 2011] | yes | SIFT | 1024 | yes | 1048k | .582 |
| IFK [Perronnin et al., 2010a] | no | SIFT | 256 | no | 41k | .553 |
| IFK [Perronnin et al., 2010a] | no | SIFT | 256 | yes | 327k | .583 |
| IFK [Chatfield et al., 2011] | yes | SIFT | 256 | yes | 327k | .617 |
| IFK GMM Exp. 1 | yes | HOG | 63 | no | 12k | .512 |
| IFK GMM Exp. 2 | yes | HOG | 507 | no | 97k | .558 |
| IFK GMM Exp. 3 | yes | HOG | 507 | no | 97k | .579 |
| IFK GMM Exp. 4 | very | HOG | 507 | no | 97k | .588 |
| IFK GMM Exp. 5 | very | HOG | 507 | yes | 97k | .625 |
| IFK GMM Exp. 6 | very | ColHOG | 512 | yes | 655k | .641 |
| Method |
1 |
1 |
1 |
1 |
1 |
1 |
| bility | tation | ledge | tions | ness | ||
| Gradient Boosted Tree (GBT) | 0.6492 | 0.6558 | 0.6179 | 0.6368 | 0.7845 | 0.6688 |
| Factorization Machine (LibFM) | 0.6563 | 0.6744 | 0.6452 | 0.6481 | 0.7234 | 0.6695 |
| Marix Factorization (MF) | 0.5687 | 0.5613 | 0.5966 | 0.5700 | 0.5854 | 0.5764 |
| TF linear kernel | 0.6484 | 0.6962 | 0.6239 | 0.6767 | 0.6205 | 0.6531 |
| TF polynomial degree=2 SVM | 0.6481 | 0.6934 | 0.6374 | 0.6230 | 0.6472 | 0.6498 |
| TF polynomial degree=3 SVM | 0.6571 | 0.7024 | 0.6394 | 0.6234 | 0.6426 | 0.6530 |
| TF.IDF linear kernel | 0.6571 | 0.7020 | 0.5935 | 0.6824 | 0.6128 | 0.6496 |
| TF.IDF polynomial d=2 SVM | 0.6666 | 0.7065 | 0.6080 | 0.6023 | 0.6304 | 0.6428 |
| TF.IDF polynomial d=3 SVM | 0.6596 | 0.7020 | 0.6234 | 0.6174 | 0.6298 | 0.6464 |
| BM25 linear kernel (Lin) | 0.7236 | 0.7480 | 0.6278 | 0.6987 | 0.6633 | 0.6923 |
| BM25 polynomial degree=2 SVM | 0.7109 | 0.7479 | 0.6477 | 0.6268 | 0.6795 | 0.6826 |
| BM25 polynomial degree=3 SVM | 0.6855 | 0.7247 | 0.6558 | 0.6150 | 0.6761 | 0.6714 |
| Bicluster linear kernel | 0.6402 | 0.7467 | 0.5796 | 0.6482 | 0.6382 | 0.6506 |
| Bicluster Sim kernel | 0.6744 | 0.7718 | 0.6379 | 0.6830 | 0.6560 | 0.6846 |
| C3 attributes Sim kernel | 0.6267 | 0.7706 | 0.6327 | 0.6408 | 0.6149 | 0.6571 |
| TF J–S Sim kernel | 0.6902 | 0.7404 | 0.6758 | 0.7047 | 0.6778 | 0.6978 |
| TF L2 Sim kernel | 0.6335 | 0.6882 | 0.6200 | 0.6585 | 0.6300 | 0.6460 |
| TF.IDF J–S Sim kernel | 0.7006 | 0.7546 | 0.6552 | 0.7073 | 0.6791 | 0.6994 |
| TF.IDF L2 Sim kernel | 0.6461 | 0.7152 | 0.6013 | 0.6902 | 0.6353 | 0.6576 |
| BM25 J–S Sim kernel | 0.6956 | 0.7473 | 0.6351 | 0.6529 | 0.6222 | 0.6706 |
| BM25 L2 Sim kernel | 0.7268 | 0.7715 | 0.6741 | 0.7081 | 0.6898 | 0.7141 |
| BM25 L2 & J–S Sim kernel (BM25) | 0.7313 | 0.7761 | 0.6926 | 0.7141 | 0.7003 | 0.7229 |
| BM25 & C3 Sim kernel | 0.7449 | 0.8029 | 0.7009 | 0.7148 | 0.6993 | 0.7326 |
| BM25 & Bicluster & C3 (All) Sim kernel | 0.7457 | 0.8086 | 0.7063 | 0.7158 | 0.7052 | 0.7363 |
| Lin + GBT | 0.7296 | 0.8056 | 0.6589 | 0.6783 | 0.6939 | 0.7133 |
| Lin + LibFM | 0.7400 | 0.7769 | 0.6622 | 0.6733 | 0.6975 | 0.7100 |
| All Sim kernel + Lin + GBT | 0.7549 | 0.8179 | 0.6916 | 0.7098 | 0.7123 | 0.7373 |
| Method |
1 |
1 |
1 |
1 |
1 |
1 |
|
| bility | tation | ledge | tions | ness | |||
| Gradient Boosted Tree (GBT) | MAE | 1.5146 | 1.3067 | 1.2250 | 1.2737 | 1.4438 | 1.3528 |
| RMSE | 1.6483 | 1.4510 | 1.3658 | 1.4132 | 1.6021 | 1.4961 | |
| Factorization Machine (LibFM) | MAE | 1.5313 | 1.3213 | 1.2303 | 1.2632 | 1.4984 | 1.3689 |
| RMSE | 1.6725 | 1.4745 | 1.3744 | 1.4073 | 1.6759 | 1.5209 | |
| Matrix Factorization (MF) | MAE | 1.7450 | 1.4093 | 1.3676 | 1.2905 | 1.5794 | 1.4784 |
| RMSE | 1.9174 | 1.5912 | 1.5540 | 1.4636 | 1.7583 | 1.6569 | |
| BM25 linear kernel (Lin) | MAE | 0.5562 | 0.7230 | 0.6052 | 0.5979 | 0.5896 | 0.6144 |
| RMSE | 0.7085 | 0.9072 | 0.7784 | 0.7910 | 0.7724 | 0.7915 | |
| BM25 L2 Sim kernel | MAE | 0.5678 | 0.7083 | 0.6228 | 0.5946 | 0.6045 | 0.6196 |
| RMSE | 0.7321 | 0.9307 | 0.8038 | 0.7878 | 0.7930 | 0.8095 | |
| Bicluster Sim kernel | MAE | 0.5340 | 0.6868 | 0.6039 | 0.5883 | 0.5813 | 0.5989 |
| RMSE | 0.6958 | 0.8906 | 0.7861 | 0.7778 | 0.7624 | 0.7825 | |
| BM25 & Bicluster & C3 All Sim kernel | MAE | 0.5403 | 0.6324 | 0.5946 | 0.5952 | 0.5829 | 0.5891 |
| RMSE | 0.7106 | 0.8357 | 0.7763 | 0.7879 | 0.7661 | 0.7753 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Doktori értekezés
Daróczy Bálint Zoltán
2016
Machine learning methods for multimedia information retrieval
Bálint Zoltán Daróczy
Supervisor: András Benczúr Ph.D.
Eötvös Loránd University
Faculty of Informatics
Department of Information Systems
Ph.D. School of Computer Science
Erzsébet Csuhaj-Varjú D.Sc.
Ph.D. Program of “Basics and Methodology of Informatics”
János Demetrovics D.Sc.
A dissertation submitted for the degree of
Philosophiae Doctor (PhD)
Budapest, 2016.
DOI: 10.15476/ELTE.2016.086
Contents
-
3 Probabilistic models for unsupervised and supervised learning
-
4.3.4 Practical approximation of the Fisher Kernel over Gibbs distribution
-
5.1 Ad-hoc photographic retrieval: a segmentation based CBIR over the IAPR TC-12 dataset
-
5.3 Visual concept detection over the Yahoo! MIR Flickr dataset
-
5.3.7 Experiments and results over the ImageCLEF 2012 Photo Annotation challenge
-
6 Web document classification based on text, link and content features
-
7 Mobile Radio Session drop prediction via Similarity kernel
List of Figures
- 1 An example for the Receiver Operating Characteristic curve.
- 2 A simple 2d layout of an image.
- 3 There are no path between sets and without at least one point from set .
- 4 Margin of a hyperplane.
- 5 Pairwise similarity graph with two type of agents.
- 6 Class similarity graph
- 7 Multi-agent similarity graph with two type of agents.
- 8 In the naive independence model, image regions are conditionally independent, exchangeable of each other according to the Gaussian mixture .
- 9 In this variant of the naive independence model, image regions are generated by first selecting one component of the mixture from a discrete distribution and then the low level descriptors are given by the selected multivariate Gaussian .
- 10 Performance of different methods by topic. The diff line denotes the improvement of the CBIR over text retrieval with query expansion.
- 11 Performance of different feature combinations.
- 12 Maximal clique size of image layouts.
- 13 Our classification procedure
- 14 Examples of relevant segments from the highest ranked test segments in the Pascal VOC 2007 dataset. Categories from top left: First row: 1-bicycle, 1-bicycle, 2-bird. Second row: 6-car, 11-dog, 14-person. Third row: 13-motorbike, 10-diningtable, 16-sheep.
- 15 Examples of relevant segments from the highest ranked test segments in the MIR Flickr dataset. Categories from top left: First row: 11-weather fog/mist, 24-scape rural, 29-water lake. Second row: 30-water riverstream, 30-flora tree, 41-fauna spider. Third row: 50-quantity biggroup, 66-style picture in picture, 91-transport rail
- 16 The distribution of the scores for the five evaluation dimensions.
- 17 The distribution of the number of evaluations given by the same site (left) and for the same evaluator (right).
- 18 The number of pairs of ratings given by different assessors for the same aspect of the same page.
- 19 AUC as the function of the size of the training set, given as percent of the full3040, for the baseline BM25 with linear kernel and All with similarity kernel.
- 20 User session and reporting.
- 21 Typical examples for time evolution of drop (left) and no-drop scenarios (right).
- 22 Performance of early prediction (left )and dependence of prediction performance on the number of observations (right).
List of Tables
- 1 Description and number of visual features used to characterize a single image segment.
- 2 ImageCLEF 2008 Ad Hoc Photograhic Retrieval performance of different methods (left) with explanation on the right.
- 3 Performance of the various segmentation methods
- 4 Average MAP on Pascal VOC 2007
- 5 MAP on Pascal VOC 2007 data set
- 6 MAP results of the Spatial Fisher kernel over Pascal VOC 2007 dataset
- 7 Experimenting on visual descriptors, both the training set and the validation set contained 5k images
- 8 Reference set selection
- 9 Biclustering of Flickr tags and images
- 10 Dimension of the basic representations
- 11 MiAP, GMiAP and F-ex results of basic runs
- 12 Experiments on the MIR Flickr dataset where T - text only, V - visual only and M means the run is multimodal.
- 13 Detailed performance over the C3 labels in terms of AUC
- 14 Detailed performance over the C3 labels in terms of RMSE and MAE
- 15 Web Spam detection over ClueWeb09.
- 16 Overview of a Session Record.
- 17 Size of the session drop experimental data set.
- 18 Prediction quality at 5 periodic reports before the end of the session over the small dataset with at least 15 measurement point per session.
- 19 Best features returned by AdaBoost.
Acknowledgement
During my years working on the presented thesis I have had the chance to meet with wonderful people who helped and supported me in a lot of ways. I am eternally grateful for the humanity, the brilliance and complete support of my supervisor, András Benczúr. Without his teachings, endless help and patience toward me I could not finish this thesis.
I would like to express my gratitude to professors János Demetrovics and Lajos Rónyai for their limitless guidance and kindness.
I am grateful to my co-authors and the members of the Data Mining and Search Group at the Institute for Computer Science and Control, a part of the Hungarian Academy of Sciences (MTA SZTAKI), especially to the people I closely worked with: Dávid Siklósi, Miklós Kurucz, István Petrás, Frederick Ayala-Gómez, Zsolt Fekete, Róbert Pálovics, Levente Kocsis, Péter Vaderna, Dávid Nemeskey, Tamás Kiss, András Garzó, Róbert Pethes and Matthias Brendel.
I cannot be thankful enough the support of my family and my friends. Their friendship, kindness and inspiration and the endless conversations helped me ineffably. I would like to thank especially my father for his profound thoughts, ideas, advices and endless patience.
To my little daughter, Sári.
1 Introduction
Text and image classification or retrieval are well-known challenging problems. Textual content is usually represented as a set of occurring terms (bag-of-words) while images can be described as a set of regions (segment or an environment of a keypoint [Lowe, 1999, Dalal and Triggs, 2005, Csurka et al., 2004]). The chosen feature extraction methods highly affect the quality of the retrieval or the classification in both cases. One of the interesting cases is, when both modalities are present at the same time, giving us the opportunity to increase the quality of the classification and retrieval. In my thesis I will examine several feature extraction and learning methods for retrieval and classification purposes and give examples where the combination of them increase the quality. As a final result we introduce a general probabilistic model for joining at first sight incompatible feature spaces, the Fisher kernel based similarity kernel [Daróczy et al., 2015, Daróczy et al., 2015] in Section 4. We use it as a basis for various problems such as multi-modal image annotation [Daróczy et al., 2012] in Section 5, for session drop detection [Daróczy et al., 2015] in Section 7 or in Section 6 for web based document quality prediction[Daróczy et al., 2015].
The current state-of-the-art image representations, including the Convolutional Neural Networks (CNN [LeCun et al., 1998, Krizhevsky et al., 2012, He et al., 2015]) are modelling the image as a set of regions instead of extracting global statistics [Csurka et al., 2004, Chatfield et al., 2011]. We can either extract features around the environment of the detected keypoints (e.g. SIFT [Lowe, 1999]) or describe previously determined coherent image parts (e.g. graph-cut based segmentation [Felzenszwalb and Huttenlocher, 2004, Shi and Malik, 2000]).
In Section 5.1 we will describe a model for multimedia image retrieval. In [Daróczy et al., 2009a] we elaborated on the importance of choices in the segmentation procedure for retrieval with emphasis on edge detection and pyramidal segmentation. Evaluation was performed on the ImageCLEF IAPRTC-12 dataset. We measured 6-12% increase in MAP (Mean Average Precision) and Precision over the original graph-cut based segmentation suggested by Felzenswalb et al. [Felzenszwalb and Huttenlocher, 2004] with the same features. Beside determining the proper regions, we investigated the relative importance of the visual features as well as the right choice of the distance function between segment descriptors. Our experiments showed 31.9% increase over a simple color statistic. We also suggested a method, that for parametric optimization of the parameters by measuring how well the similarity measures separate sample images of the same topic from those of different topics increased the quality of retrieval by 16.1%. We used a simplified version of the segmentation algorithm for object recognition in [Deselaers et al., 2008] measuring the similarity between the non-artificial sample object and the actual test images with re-segmentation.
For retrieval, in [Benczúr et al., 2008] we suggested a novel method consists of biclustering image segments and annotation words. Given the query words, it is possible to select the image segment clusters that have strongest co-occurrence with the corresponding word clusters. These image segment clusters act as the selected segments relevant to a query.
In [Daróczy et al., 2013] we overviewed the theoretical foundations of the Fisher kernel method. In most cases, the Gaussian Mixture Modelling (GMM) with a Fisher information based distance over the mixtures yields the most accurate classification results out of the keypoint based method [Perronnin et al., 2010a, Perronnin and Dance, 2007, Chatfield et al., 2011, Thomee and Popescu, 2012]. We indicated that it yields a natural metric over images characterized by low level content descriptors generated from a Gaussian mixtures. We justified the theoretical observations by reproducing standard measurements over the Pascal VOC 2007 data and showing the importance of dense sampling with an efficient GPU based implementation. The resulted image classification system is comparable to the best performing PASCAL VOC systems using SIFT descriptors, in some categories outperforming the best published Fisher vector based systems [Perronnin et al., 2010a, Chatfield et al., 2011] without Spatial Pooling [S. Lazebnik and Ponce., 2006] and with 3.3 times lower dimension. We suggested that a further improvement could be a better approximation of the Fisher information and a generative model capturing the intra image structure. The latter issue is quite serious. If we rearrange the samples (patches of a particular image) in an arbitrary way, then the Fisher vector of the resulting image will be the same as before, while the new image may be radically different. To overcome this we will introduce a model based on Markov Random Fields in Section 5.2.
In [Daróczy et al., 2010] we showed that the segmentation based feature extraction method in [Daróczy et al., 2009a] and the Fisher vector representation complement each other in some cases.
In Section 5.3 we will examine the problem of multimodal image classification. One of the key points of multimodal image classification is how to handle the increasing number of different representations of the same image such as spatial pooling, keypoint detection and dense sampling, different color and grayscale descriptors or textual context (e.g. Flickr tags). In [Daróczy et al., 2011] we suggested an efficient fusion method using different similarity measures. By this method we were able combine, before the classification by Support Vector Machine (SVM [Cortes and Vapnik, 1995]), a large variety of representations to improve the classification quality. This descriptor is a combination of several visual (Fisher vectors per modality and per pooling/sampling) and textual similarity values (Jensen-Shannon divergence) between the actual image and a reference image set (a subset of the training images). Our experiments showed near zero loss in performance with a reference set sized less than half of the training set [Daróczy et al., 2012] while the optimized combination resulted 4.5% increase in MAP over a simple averaging of similarities [Daróczy et al., 2011]. As an alternative fusion method, we suggested a novel method in [Daróczy et al., 2012] by biclustering the images. The algorithm calculates the similarity of the entities (particularly images) by Jensen-Shannon divergence of their Flickr tags combined with the visual similarity.
As an extension we describe a high quality method to exploit cross-media tags for image indexing and classification. The suggested algorithm learns the mapping between free text annotation and the visual content. Our method exploits image tags of unrestricted vocabulary composed not necessary of objects only, without the need for explicit labelled regions in the training data. By our method, content based image indexing can be done by assigning text to image regions and at the same time we improved the visual model by the text annotation. Key in our solution is the use of our highly efficient GPU based generative image modelling algorithms. We train Gaussian Mixture Models to define a generative model for low-level descriptors extracted from the training set using a very dense grid that enables us to obtain a high quality model of individual image segments. The final model arises by biclustering a combined matrix of the uniform representation and annotation text distance that yields clusters of features and words representing image segments. In addition to solving the new, double ambiguous labelling task, our method performed very well for the standard MIR Flickr classification data outperforming results in the literature by 2.99% in MAP [Liu et al., 2014, Thomee and Popescu, 2012].
In Section 4 we will expand the idea of the fusion method we used in [Daróczy et al., 2011, Daróczy et al., 2012] and define the similarity kernel, a theoretically justified probabilistic model based on Markov Random Fields and the Fisher Information [Daróczy et al., 2015, Daróczy et al., 2015] with various approximations.
In Section 6 we will suggest a method for web document classification. Similarly to images, web pages are often contain additional modalities besides the main modality, the text. While in [Siklósi et al., 2012] we examined different kernel based methods to detect english web spam based on the text, link and content features of the web pages, in [Garzó et al., 2013] we also investigated cross-lingual web spam detection based on pure English models. In [Daróczy et al., 2015] we predicted quality aspects of web pages beside spamicity. We gave methods for automatically assessing the credibility, presentation, knowledge, intention and completeness. We used both regression and classification based models over the evaluator, site, evaluation triplets and their metadata combined with the textual representation of the page. In our experiments best results can be reached by the similarity kernel based on various feature sets including distances extracted from the clusters of the bicluster.
As our final application, in Section 7 we examine an interesting problem related to cellular telecommunication networks. The abnormal bearer session release (i.e. bearer session drop) in cellular telecommunication networks may seriously impact the quality of experience of mobile users. The latest mobile technologies enable high granularity real-time reporting of all conditions of individual sessions, which gives rise to use data analytic methods to process and monetize this data for network optimization. One such example for analytic is classification to predict session drops well before the end of session. In [Daróczy et al., 2015] we presented a novel method based on Dynamic-time warping [Keogh, 2006] that is able to predict session drops with higher accuracy than traditional models such as AdaBoost [Freund and Schapire, 1995] used in recent publications [Zhou et al., 2013]. Interestingly, the predictor can be part of a SON (Self-organizing Network) function in order to eliminate the session drops or mitigate their effects.
The thesis is organized as follows. As a starting point we will overview briefly several theoretical fundamentals of learning in Section 2 and review some supervised and unsupervised models in Section 3. After joining the generative and discriminative probabilistic models with Fisher Information in Section 4, we will review the results for Gaussian Mixtures and introduce a novel Markov Random Field based model. After a detailed description of the similarity kernel in Section 4 we will suggest models for above mentioned problems. Finally, in the last chapters we will describe various representations and models for images (Section 5), web documents (Section 6) and time-series (Section 7).
2 Brief introduction to learning theory
Statistical learning was inspired by the work of Fisher [Fisher et al., 1960] in the first half of the 20th century. Sir Ronald A. Fisher’s “Lady tasting tea" problem introduced the basics of the statistical decision making and the evaluation of such a procedure. He showed the importance of the underlying distribution (randomization) in decision making and suggested various tests and methods. His famous experiment based on actual events in Fisher’s life. He met with a Lady (Dr. Muriel Bristol-Roach) who declared “that by tasting a cup of tea made with milk she can discriminate whether the milk or the tea infusion was first added to the cup"[Fisher et al., 1960]. Fisher’s initial hypothesis (the null hypothesis) was that the Lady cannot tell it. To prove it he prepared four cups for both cases randomly and asked the Lady to choose the ones which were filled first with tea. He showed that the probability of selecting correctly all the four cups is 1 to 70 and choosing four incorrect cups is exactly as rare. His pioneer experiment and reasoning opened a new field in statistics which based validity of any procedure on randomization.
2.1 Generalisation theory
A more general theoretical contribution was given by Vapnik and Chervonenkis in the early 1970s [Vapnik and Chervonenkis, 1971, Vapnik and Vapnik, 1998]. The Vapnik-Chervonenkis theorem explains the connection between generalisation, training set selection and model selection. Let us define the empirical risk as
[TABLE]
where in is a set of examples with know target and is a loss function given a previously chosen model function . The theorem states that if we optimize for a binary loss function (0 if and 1 if not) over a set of independent samples from a fixed distribution with known labels (the training set) than the true risk (the expected value of the loss function over ) is upper bounded by the empirical risk plus an additional value depending on the chosen function’s capabilities. The VC-theorem [Vapnik and Chervonenkis, 1971] tells us about the worst case scenario, formally for binary classification with a binary loss function and a chosen function class the generalisation (the difference between the true and the empirical risk) is bounded as follows
[TABLE]
and
[TABLE]
The theory shows that the bound is depending only on the size of the training set and the separating capability of the chosen function class measured by the shattering coefficient , the maximum number of different labellings the function class can realize over samples. For binary labels the maximum and the ideal would be but in practice usually it is not the case. To capture this amount, they defined the so called Vapnik-Chervonenkis dimension (VC-dimension) that is independent from the size of the training set. The VC-dimension of a function class is the cardinality of the largest set in the d-dimensional space which can be separated correctly (or shattered) with any label set. According to Sauer’s lemma [Sauer, 1972] the shattering coefficient is upper bounded as . For example, as a consequence of the Radon theorem the VC-dimension of the linear separator (a hyperplane which separates the space into two half-spaces) is in -dimensional space (but not a sharp bound, imagine three points on a line in ). Let us consider a linear separator capable of separating with low empirical risk. If the number of examples in the training set were high, the feature space may had been high dimensional according to the theory. This suggests a high shattering coefficient and high upper bound. Another example is the class of the polynomial functions in with degree . It can be viewed as a mapping into a higher, dimensional space (for example if and , the transformed feature space is dimensional). Since is finite by definition we can always find a polynomial function with a high enough degree to exceed in dimension the number of the training examples to minimize the empirical risk to zero at the cost of a high shattering coefficient and higher expected generalisation error.
Interestingly, this means that optimization for low true risk is a balance between low empirical risk and low VC-dimension or as Hopcroft and Kannan wrote “The concept of VC-dimension is fundamental and the backbone of learning theory." [Hopcroft and Kannan, 2012]. The VC-theorem suggests a key role for the empirical risk optimization to achieve low overall risk. Although the result is independent from the distribution (distribution free), it presumes a fixed distribution. This limitation is particularly painful in case of machine learning problems such as recommender systems or social networks analysis where the distribution is changing rapidly. An example for the seriousness of this issue is the problem of predicting the retweet cascade size of a twitter message, where even the labels of the known tweets have to be approximated because of the short time period of significance among others [Daroczy et al., 2015].
In the proof of the VC-theorem by [Devroye et al., 1996] the main idea is to take advantage of the size of the training set and examine the difference between the empirical (in practice computable) risk taken over two disjoint sets, the training set and a same, finite sized sample set drawn independently from the fixed distribution, . It can be proven that the left hand size of the inequality (eq. 2) is upper bounded as
[TABLE]
According to this, lowering the difference between the empirical risk taken over the training set and an independent, but same sized set will most likely reduce the difference between the empirical and the overall risk. In some cases we will refer the additional set as the validation set or simply as the test set. In practice we can split the known set of observations into two subsets. The first we use to lower the empirical risk by searching for a well enough element in the chosen function class while the second part justifies our decision.
At this point it may seem that the problem of binary classification is almost impossible to solve and more dependent on our initial choices (training set, function class selection, optimisation method and test set selection) than not. We could not be any closer to the reality. But before we go into the details about model selection and other very interesting questions we revise the measurement of the quality. So far we measured the quality of a model with a simple loss function (binary), but in practice there can be very diverse motivations why we want to classify. Since we no longer measure the quality over the training set we are free to define any suitable evaluational method. Next we review several widely used evaluational methods.
2.2 Evaluation methods
In practice we can measure in many different ways the quality of a model on any set (such as the evaluation set ) with known labels and known classification outcome (prediction)[Tan et al., 2005]. The first and most obvious measure is the binary loss function or the misclassification error. If we measure the ratio of the correctly classified samples to the cardinality of the evaluation set we get the accuracy:
[TABLE]
Notice how misleading it could be. Let us consider an evaluation set with three points with label “+" and 997 points with label “-". If the predicted class is “-" for all, the accuracy will be still very high, not far from the perfect. In contrast a model that predicts the three “+" examples correctly and three negative samples as “+", the accuracy is the same. To overcome this we can define other measures based on the four basic measures in the confusion matrix:
- •
True positive (TP): the number of correctly classified positive samples
- •
True negative (TN): the number of correctly classified negative samples
- •
False positive (FN): the number of incorrectly classified positive samples
- •
False negative (FP): the number of incorrectly classified negative samples.
With this notation the Accuracy is equal to (TP+TN)/(TP+TN+FP+FN). One of the useful measures is the precision for a class, particularly for “+",
[TABLE]
or in other words the ratio of the correctly classified samples with a “+" label to the number of positively classified examples. As a shortage, the Precision ignores the misclassified positive examples, therefore if we measure the precision we can also measure the recall by replacing the denominator with the number of positive examples:
[TABLE]
The importance of the recall or the precision depends on the problem. Imagine a medical screening to detect spreading of a disease. In this case our goal is to classify correctly any patient who has the disease or have maximal recall rate. In general a good balance between the two may be a useful indicator about the performance of the model. A common way is to calculate the harmonic mean of the precision and the recall,
[TABLE]
Reasonably if there are no correctly classified positive examples (both precision and recall are zero) we define the F-measure as zero. In our original example the accuracy is very misleading. If a model classifies all the examples as “-" both the precision and the recall will be zero and therefore the F-measure too. If the model classifies the three positive samples correctly and predicts only three negative samples as “+", the precision, recall and F-measure will be 0.5, 1 and respectively, clearly distinguishing the second model from the first. Nonetheless the F-measure has shortcomings too. Suppose we have two models both predicting only “-" class labels because of a high threshold. Lowering the threshold could result a better decision if the predictions for the positive samples are surpassing the predictions for the negative samples. The main drawback of all class confusion based measures is their dependence on the classification threshold. If in an application we may relieve certain amount of the samples that are most likely positive, the threshold and hence the recall and precision change dynamically with the available budget for relieving positive samples. A solution for it is to define a threshold independent evaluation score based on the actual continuous predictions.
There are many ranking based models of quality but the most popular are still the Receiver Operating Characteristic Area Under Curve (ROC AUC)[Fogarty et al., 2005], the Average Precision (AP) [Tan et al., 2005] and the normalized Discounted Cumulative Gain (nDCG) [Järvelin and Kekäläinen, 2002]. They are only slightly different in general, but for particular problems each of them is more suitable than the others. The ROC and AP are only for binary classification while the nDCG can be used for regression type of problems such as rating prediction (recommendation). The ROC Curve plots the True Positive Rate (TPR, equal to Recall) as the function of the False Positive Rate (FPR = FP/(FP+TN)) by varying the decision threshold. An example ROC curve is shown in Fig. 1. The Area Under the ROC curve (AUC) is a stable metric to compare different machine learning methods since it does not depend on the decision threshold:
[TABLE]
where is the at , the Recall rate if the highest ranked samples are classified as a positive instance. is the number of negative samples in the evaluation set and is if the -th ranked element has positive label, zero otherwise. As an intuitive interpretation, AUC is the probability that a uniformly selected positive sample is ranked higher in the prediction than a uniformly selected negative sample.
If we replace the axis of the ROC curve to precision/recall and measure the area under curve similarly to ROC we get the Average Precision:
[TABLE]
where is the precision at and is the number of positive samples. Despite the similarities they are a bit different. Both are monotone increasing and scale between zero and one. The main difference is how they handle random lists. The AUC of the ROC curve will be around the diagonal, a meaningful . This cannot be said about the AP, where the random point varies with the ratio of the negative and positive samples. Both indicate if the value is lower than the random point an invert list will perform better than random.
By nDCG the relevance of a sample plays also a key part. The nDCG does not constrain the labels to be binary instead we assume to have a relevance value to each sample. The DCG of a ranked list is
[TABLE]
and the normalized DCG is the DCG divided by the ideal DCG (IDCG), formally
[TABLE]
In the next chapter we focus mainly on the empirical optimisation and examine some generative and discriminative probabilistic learning methods.
3 Probabilistic models for unsupervised and supervised learning
In statistical analysis empirical methods are well-known for estimating the parameters of a distribution. By classification type of problems we can, among others, estimate the underlying distribution of the samples (generative models) or directly estimate the probability of labelling with a conditional probability (discriminative models). Either way, we can define them as a learning process. The main difference is the target variable, by generative models the samples and by discriminative models the label. Since the generative models are assumed to ignore the labels with reason, we call them as label independent, unsupervised models. Similarly, the discriminative models are called supervised models. Important to mention, the VC-theorem is only valid for the supervised case with binary class label, therefore the theorem indicates different treatment. We will see in the next chapter that despite the differences there is a natural connection between the generative and discriminative models.
3.1 Generative models
As we mentioned briefly previously, one of the main problems of the statistical analysis is to determine a probabilistic model to fit a known set of observations. More formally, we have a set of observations in and a probability density function (pdf) as
[TABLE]
where is the parameter set of the density function. Now let us define the likelihood function to be equal to the probability of observing our sample set :
[TABLE]
Our main goal is to estimate the parameter set which maximizing the likelihood function or the natural logarithm of it (log-likelihood) over , formally
[TABLE]
where we think of as a constant.
This optimization problem is the so-called Maximum Likelihood Estimation (MLE). If our density function is simple enough, we can calculate the parameters analytically by setting the derivative of the log-likelihood to zero. Unfortunately, there are important and widely used models where we cannot solve the derivative directly and therefore we need more refined methods to estimate the parameters. One of them is the Expectation-Maximization [Dempster et al., 1977].
3.1.1 Expectation-Maximization
By the EM algorithm we assume that either our set of known observations or our model parameter set has missing latent variables or values. The EM method is an iterative algorithm with two steps. In each iteration, first we calculate the expected value of the latent variables (E-step) using the current estimation of the parameters, while in the second step (M-step) we calculate the parameters which maximize the estimated likelihood over the known observations. We usually think of the known observations (or the training set) as independent samples drawn from the same distribution, thus the joint probability is
[TABLE]
Now, let us assume that the missing set of random variables exists thus we define the complete pdf and therefore the complete likelihood as
[TABLE]
With the left side and the first part of the right side we assume a joint relationship between the missing, latent variables and the known observations. If we think of as a random variable drawn from an underlying distribution, we can define the following supplementary function:
[TABLE]
the expected value of the complete log-likelihood over drawn from a distribution parametrized by the previous (thus a constant) estimation of the parameters () and , another constant. With we have a more manageable function to calculate the next estimation of the parameters:
[TABLE]
Now we start again with the estimation of the latent variable and repeat the E- and M-steps until we stop for some reason. It can be proven that this two-step procedure is guaranteed not to decrease the original likelihood and converge to an unfortunately local maximum. For a detailed explanation about the theoretical background and applications of Expectation-Maximization see [Dempster et al., 1977, McLachlan and Krishnan, 2007].
In the next sections we will examine two, for the latter chapters very important generative models, first the Gaussian Mixture Model [McLachlan and Krishnan, 2007], then the Markov Random Field [Geman and Graffigne, 1986].
3.1.2 Gaussian Mixture Model
Approximation with a single multivariate normal distribution results regularly not only poor approximation error over the sub-population but it can prefer observations not in the original sample population. We have multiple options to overcome this disadvantage. One of them is expanding to mixture distributions. If we are mixing only finite number of Gaussian distributions our model will be a Gaussian Mixture Model (GMM). Formally, let N be the number of Gaussian distributions, each in and their positive mixing weights with . The probability density function of our mixture distribution is
[TABLE]
where are the parameters of the mixture and the -th -dimensional multivariate normal distribution is
[TABLE]
Unfortunately, in practice the number of parameters of our mixture distribution could be really huge. If we assume a -dimensional underlying vector space, our parameter set has three parts:
is an -dimensional real vector 2. 2.
is a set of -dimensional mean vectors 3. 3.
is a set of covariance matrices each with elements.
Although we can reduce the latter item practically to with diagonal covariance matrices (isotropic Gaussian), overall the number of parameters to estimate is still high: . Worth to mention, it is not rare to describe high dimensional feature spaces with large number of parameters. For example, one of the well known and simplest clustering algorithm, the k-Means has a similarly large parameter set with parameters [Tan et al., 2005].
Unfortunately, for GMM the analytical way, directly solving the derivative of the log-likelihood, is not suitable to determine the parameters of the model. On the other hand there is a method which works particularly well for Gaussian Mixtures, the EM [Dempster et al., 1977, McLachlan and Krishnan, 2007].
First, we define an adjuvant proportion (the latent variable as in EM), namely the membership probability for a sample and the -th Gaussian as
[TABLE]
It can be interpreted as the probability that sample was generated by the -th Gaussian distribution, due to the fact that for all . During the E-step we estimate the membership probabilities for the observations using the actual parameters.
In the next step we will use these expected values to determine a better estimation of the parameters (the M-step). The smoothness property of the Gaussian Mixtures (and for all the density functions) allow us to optimize over the natural logarithm of the likelihood instead of the likelihood:
[TABLE]
This yields us to an interesting gradient:
[TABLE]
Now, let us start the calculation of the gradient with the weight parameter:
[TABLE]
There is a straightforward connection between the membership probability and our gradient, as
[TABLE]
The rest of the gradient vector respect to the mean and variance vectors, under assumption of diagonal covariance matrices (isotropic Gaussian), can be calculated similarly, as
[TABLE]
and
[TABLE]
Next we sketch the exact procedure of the EM algorithm. In the first iteration we set the parameters of the GMM randomly. During the -th iteration we estimate the membership probabilities (E-step) considering the parameters estimated during the last iteration:
[TABLE]
where is . Because we think of this probabilities as already estimated values, we can use them to analytically compute the parameters. If we set the expressions (eq. 25) and (eq. 26) to zero, we get very intuitive formulas:
[TABLE]
and
[TABLE]
The mixture parameter is a bit more trickier, because setting (eq. 24) to zero wont help us, for more details see [McLachlan and Krishnan, 2007]. Ultimately, the formula to update the mixture weights is just as illustrative as the above expressions:
[TABLE]
or in other words, the mean of the membership probabilities for the -th Gaussian.
The EM algorithm will alternate between the two steps and as we mentioned in the previous section there are theoretical guarantees of convergence, hence a direct implementation will not work or will be slow in particular cases. The main reason is that the denominator in the definition of the membership probability (eq. 21) can easily underflow even in fp64 (64 bit precision, aka double) and especially in large dimensional spaces. One solution is to modify the expression. Let us reformulate the value as where . If we put it back to (eq. 21) we get
[TABLE]
where . Because one of the exponent is equal to this maximum, at least this element in the summation will be equal to and therefore the membership probability for this Gaussian will be non zero for sample . With this trick we may avoid having zero membership probabilities in practice for all the samples. This recognition can also help us to decrease the number of calculations during the optimization. If one of the membership probabilities of the -th Gaussian for a sample is equal to (in our available precision) we could avoid including the particular sample during the maximization step for other Gaussians and decrease the obligatory calculations. In the latter chapters we will see that this approximation of the membership probability is not even rare in practice.
3.1.3 Markov Random Fields
As we mentioned in the previous section the Gaussian Mixture is powerful method to model the prior distribution of a single observation. Nevertheless there we can easily think of structures over the samples (for example a website) or samples originated from a complicated structure of sub-samples, such as words or image patches. In such a case we can model the overall observation (a set of samples) as a set of random variables each drawn from a prior probability distribution. If our underlying prior model is a Gaussian Mixture we assume exchangeability for the inner samples of the sample [Perronnin and Dance, 2007]. This conditional independence gives us the advantage of variability in the layout of the sub-samples, although there are some structures where the composition is significant [Daróczy et al., 2013].
Now let us capture the relation between the samples with a graphical model or Random Field: the vertices are the set of samples (random variables) and we connect samples if there is a known connection between them. There are several kinds of Random Fields, among them are the Gaussian and the Markov Random Field. One of the main characteristics of the Gaussian Random Field is the assumption of conditional independence between the random variables (rough interpretation is a graph without edges). In comparison, by the Markov Random Field we can also capture connections between samples with an undirected graph whilst following both local and global Markov property.
Formally, let be an observation with corresponding observations: . In this section we will focus on problems where we have a structural observation containing finite number of observations, for example an image with a set of keypoints, regions or pixels [Geman and Graffigne, 1986, Szirányi et al., 2000]. In this case, the Random Field has vertices and we connect two vertices with an edge if they are neighbours according to our knowledge (see Fig. 2). The local Markov property means that an observation is conditionally independent of the non-neighbour observations:
[TABLE]
where is the neighbourhood of , the set of nodes adjacent to . The global Markov property denotes that any two disjoint subsets are conditionally independent given a non-empty separate set so that any path between each node from to any node in will include at least one node from or in other words if we remove from the graph there will be no paths connecting and (see Fig 3). The smallest set of nodes for a node, which is making the node conditionally independent from all other nodes in the graph, is called the Markov blanket of the node. This set is equivalent with the neighbourhood of the node. The last property is the pairwise Markov property, namely if two separate nodes are not immediate neighbours then they are conditionally independent given the rest of the nodes in the graph [Hammersley and Clifford, 1971].
The Hammersly-Clifford theorem [Hammersley and Clifford, 1971] states that the joint probability has a Gibbs distribution form,
[TABLE]
where called as the energy function and is the partition function (or normalization constant), the expected value of the energy function over our generative model. Worth to mention, if we define the energy function as the natural logarithm of a pdf, is trivially equal to and therefore we get back the original as expected.
According to [Hammersley and Clifford, 1971, Besag, 1974] if our MRF can be factorized over the set of cliques () in the graph than our has a from of
[TABLE]
Compared to GMM the difficulty of estimation of the parameters rather depends on the energy function and consequently on the normalization constant. Despite a wide variety of methods can be used to determine the parameters with inference (though the Maximum-a-Posteriori inference is -hard [Taskar et al., 2004]) or approximation with simulated annealing [Geman and Graffigne, 1986]. There are some type of energy functions where the simple Maximum Likelihood estimation is also an option. For more details about the Markov Random Fields and their theoretical background please check out [Li, 2009].
In the latter chapters we will discuss some concrete graphs considering the main perspective (the classification) and focus on the necessity of determination of the parameters. Now, let us look at the discriminative models starting with a simple classifier, the logistic regression.
3.2 Discriminative models
Classification of instances is one of the main problems of machine learning, but the discriminative models also include regression problems. By both our goal is to assign a value to any sample we can observe like decide whether a tree is present at a photograph or not. The main difference between classification and regression is the properties of the target variable. As by the generative models we assume a known set of observations (or training set) in now with an additional continuous variable for each of the observations, namely our target . In a probabilistic sense our goal is to maximize the likelihood of the original target given the known observations:
[TABLE]
If our target is a nominal variable (it is from a finite set) we call the problem as classification otherwise regression. It is very common that even if our original target variable is neither nominal or nominal but not binary we disassemble it into binary problems. The main reason is the large variety of methods which are mainly for binary problems and the VC-theorem. Therefore in this chapter we will focus only on binary classification.
3.2.1 Logistic regression
Let us start with a simple assumption about our distribution. In binary case first we pick one of the classes arbitrary. Then we seek for the distribution for the chosen class (for example “+" or “1") and for the other one (“-" or “0"). Since the name of the classes has no meaning, we will refer the chosen class as “+".
At first we would like to define a linear, thus easily differentiable function of the given random variables:
[TABLE]
where and is a scalar.
The linear regression (LR), a simple linear combination of the input variables, is very well known and studied as one of the basic regression models [Cristianini and Shawe-Taylor, 2000, Tan et al., 2005] but as approximation of the conditional distribution it is not suitable because unbounded. One of the common solutions is a modification of the original distribution with the logit transformation into an unbounded function, which we approximate with a linear combination:
[TABLE]
Solving the equation for the original probability will result the sigmoid function, formally for a sample
[TABLE]
This function has a lot of good properties: it is differentiable, strict monotone increasing, symmetric to zero and has finite limits ( in the limit is zero and in the limit is ). By classification our goal is to minimize a predefined error function over the training set. In our case we want to maximize the probability of class “+" for observations with class label “+" and minimize for observations with class label “-". Formally, if we think of the training set as an independent set of samples, we want to maximize
[TABLE]
where is the set of observations with class label “+" (or “+1") and similarly is the set of observations with class label “-" (or “0"). The derivation of the log-likelihood in case of leads us to
[TABLE]
where is the class label respectively. The derivative respect to can be derived with an expansion of the sample space with (an expansion to dimensional space) without altering the result. During the calculation we used the fact that the derivative of the sigmoid function is . Similarly to the Gaussian Mixtures we cannot solve it analytically, but we can use gradient descent or Newton’s method to find a local optimum [Cristianini and Shawe-Taylor, 2000].
As one of the basic discriminative models, the Logistic Regression has some interesting advantages. The end model is a hyperplane which separates the samples from each other. If we look into the sigmoid function, we can see that as we move away from the hyperplane the probability (the value of sigmoid) will be closer to or zero depending on the halfspace we are in and it is iff we are on the hyperplane (undecided). In short, the probability and therefore the gradient largely depends on the distance from the hyperplane and during optimization we prefer hyperplanes as far as possible from the training samples while correctly classify. Despite this, we greatly constrained ourselves with linearity. There are many possible ways for extensions, but before we approach the problem, we examine an important model, the Support Vector Machines to find a bit different, but also good separating hyperplanes not necessary in the original feature space.
3.2.2 Maximal margin and kernel models
We discussed previously that we want to push the hyperplane away from the training samples as possible while predict the proper class labels. In this Section we reformulate the problem by introducing the margin of a hyperplane (, see Fig. 4) [Boser et al., 1992] defined as
[TABLE]
The maximum margin problem is to maximize the margin while solving the original labeling problem:
[TABLE]
where the class label is . Because of the monotonicity of the sigmoid function we can explain the maximal margin problem in a probabilistic sense too with
[TABLE]
i.e. maximizing the minimum uncertainty (difference from the undecided probability).
By definition
[TABLE]
for all and therefore we can define a new hyperplane with for which holds (for simplicity we will refer as ). The original maximization problem is equivalent to minimization of the norm of the new normal vector with a new constrain, formally
[TABLE]
where we take the square of the norm and multiply it with a positive constant for a simpler derivative.
This convex, quadratic optimisation problem cannot be solved directly because of the constraints. Fortunately, we can treat it as a Lagrangian problem [Cristianini and Shawe-Taylor, 2000] since both the constraint and the value function are continuously differentiable. Formally let be the set of primal variables of the Lagrangian (multipliers) then the Lagrangian function is
[TABLE]
and the derivative respect to will be zero at points where the original optimisation has usually an optimum (note, not all cases).
After a simple derivation we get an interesting stationary point,
[TABLE]
thus we can claim that the normal vector is a linear combination of the training samples, . Worth to mention, if there is a orthogonal component of the normal vector to all the training samples, the scalar product will not change for any therefore this claim does not violate the above inequalities. If we put back the results, we obtain the primal form as
[TABLE]
and the final optimisation (as a dual form) will be
[TABLE]
The second constraint is originating from the derivative of the Lagrangian respect to the bias () since . We know from the Karush-Kuhn-Tucker conditions (KKT [Kuhn and Tucker, 1951, Karush, 1939]) that the optimum solution for the above problem includes positive Lagrangian multipliers such that
[TABLE]
It follows interesting consequences. First, this condition for the multipliers means that if a training example is not on the hyperplane parallel to the optimal hyperplane with a distance of the margin then the example has to have zero as a multiplier. Cortes and Vapnik [Cortes and Vapnik, 1995] named the training points with non-zero multipliers as Support vectors (SV). Therefore there are unnecessary points since their coefficient in the linear combination is also zero,
[TABLE]
So far we discussed methods to find ideal separating hyperplanes for linearly separable problems although in practice it is rarely the case. We can handle non-separable situations with two ideas. First with an additional variable called the slackness variable introduced by Cortes and Vapnik [Cortes and Vapnik, 1995] and then with transformation of the features. Let us measure the penalty for a training example inside the margin with the distance from the margin then we can reformulate the optimization into a 1-Norm Soft Margin problem as
[TABLE]
where is a previously determined constant and the Lagrangian function is
[TABLE]
with as the additional Lagrangian multiplier for the second constraint. As previously we set the gradients to zero
[TABLE]
Interestingly, the gradient respect to does not include neither nor and identical to gradient in case of non-soft margin (eq. 42). Since both and are positive, the gradient respect to lead us to an interesting upper bound for , namely . Therefore the KKT conditions are also similar, but not the same as
[TABLE]
The latter suggests that if a sample is inside the margin then the corresponding is equal to . At the end we will end up with the same maximization as before only with an additional constraint about the upper bound of the Lagrangian multipliers [Cortes and Vapnik, 1995]
[TABLE]
Since the derivatives are very simple as
[TABLE]
we can maximize with gradient ascend or taking advantage of the sparsity of [Cristianini and Shawe-Taylor, 2000].
We discussed previously that the VC dimension of the linear separator is which is very low in comparison to other kind of separators such as polynomial where we can always find a degree to surpass the size of a fixed sized training set. Notice, both the optimisation (eq. 45) and the prediction (eq. 37) can be reformulated with only inner products over the training samples. Cortes and Vapnik [Cortes and Vapnik, 1995] suggested to replace the original inner product with a kernel function over a given feature mapping. In many cases the kernel can actually be viewed as an inner product: where the feature vectors are obtained via a fixed, problem specific map which describes the examples in terms of a real vector of length . The really interesting part if we have a closed formula to calculate the inner product (the kernel values) without computing the transformation we can use very large dimensional mappings (such as the polynomial) or even infinite dimensional transformations in practice.
More interesting that any positive semi-definite matrix may be used as a kernel function (for proof see [Hopcroft and Kannan, 2012]). The simple algorithm for 1-Norm Soft Margin with a predetermined kernel function can be seen below.
**Algorithm 1-Norm Soft Margin SVM
**Given a training set with , a positive real valued constant C, a positive real valued learning rate and a kernel function
repeat
for to
if then
else
if then
end for
until we reach a stopping criterion
return
In the next chapter we will discuss a special kernel function, the Similarity kernel, a special case of Fisher kernel, which we will use for various problems in the latter chapters.
4 Similarity kernel
Kernel methods [Shawe-Taylor and Cristianini, 2004] are popular in various fields of data mining and knowledge discovery such as classification, regression, clustering or dimensionality reduction. While kernel methods are well-founded from the theoretical point of view, as we discussed in the previous section, the selection of the appropriate kernel (e.g. polynomial, Radial Basis Function or application specific ones, for more see [Cristianini and Shawe-Taylor, 2000]) is essential in many real-world tasks.
Learning optimal hyperparameters of these kernels may be computationally prohibitive in case of large datasets. Furthermore, even if the best hyperparameters have been found, the resulting kernel may not completely reflect the true structure of the data, which is likely to manifest in suboptimal results, regardless of the particular analysis task.
The selection of feature set dependent distance or similarity metrics is crucial for learning. Although selecting and in some cases computing the potential metrics may constitute a challenging task, once metrics are defined, they can often be used to transform the original complex optimization problem to a less challenging one (see Section 3.2.2). Since SVM convergence mainly depends on the metric, certain results address kernel selection for convergence considerations [Rakotomamonjy et al., 2008] and some of the SVM solvers are taking advantage of knowing the exact kernel function reaching faster convergence times such as the dual coordinate descent method for large scale linear kernel based maximal margin [Hsieh et al., 2008]. In this section, however, we focus on classification accuracy and seek for the kernel that best characterizes the data set, decoupled from the actual SVM optimization procedure.
An additional and interesting opportunity arise from the freedom of selecting similarity or distance metrics to define kernel functions. In a number of practical applications such as image or document classification, we have to learn over multiple representations, often with different kernel functions. Images are often enriched by text description or other non-visual metadata such as geo-location or date, yielding a multimodal classification task with visual, text, and geospatial modes. Another example is Web classification [Castillo et al., 2007], where text and linkage can be considered as two independent modalities.
In order to address the kernel selection problem, we define a principled meta-kernel learning approach based on Fisher information theory. As we will see in the next section, the Fisher Information matrix is the foundation of a “natural" kernel function over generative models [C̆encov, 1982]. The approach is computationally inexpensive and needs no wrapper methods for learning a kernel over multiple modalities. The section is organized as follows: first, in 4.1 we discuss the related literature of multimodal learning and describe the factor graph of the similarity kernel in Section 4.2. Next, in 4.3 we review the theoretic background of the Fisher kernel, than we introduce a suitable Fisher kernel over our graph.
4.1 Related work and problem
In many cases, one single kernel may perform suboptimally. In the last decade, this issue has primarily been addressed in the framework of multiple kernel learning (MKL [Bach et al., 2004, Lanckriet et al., 2004, Sonnenburg et al., 2006, Gönen and Alpaydın, 2011]). The method we describe is substantially different from MKL in several respects. First, in comparison to Bach et al. [Rakotomamonjy et al., 2008] we will assume that all of representations are conducive to the training procedure. Second, in order to devise a computationally efficient approach, we only calculate the distance between each instance and a small set of sample instances. Last, but not least, our approach runs only one SVM optimization procedure while most MKL approaches are wrapper approaches and therefore they execute large amount of SVM optimization.
Selecting the appropriate kernel under multiple modalities can be seen as a special case of the MKL problems where the kernels are computed on different feature sets. Having multiple number of kernels due the representations via different modalities with previously selected kernel functions, we can modify the SVM dual form (eq. 45) into a multiple kernel learning problem:
[TABLE]
where is the number of the basic kernels and is the th kernel function with as weight.
In [Rakotomamonjy et al., 2008] the MKL problem is solved with an iterative, wrapper like, sparse algorithm where in each iteration they solve a standard SVM dual problem and update the weights of the basic kernels. Instead of optimizing multiple times over the training set with a combination of kernel functions, we will define a novel kernel function combining all the representations into a single feature space. The method is wrapper-free and is hence scalable for large data sets as well.
Late fusion approaches, see e.g. [Ye et al., 2012, Liu et al., 2014], combine the outputs of various kernel methods. Usually, they take an estimated certainty of each kernel method into account. In contrast to late fusion, our approach learns a kernel over various modalities instead of combining the outputs of different kernel methods.
Let be our starting point simply a set of modalities with proper metrics (distance functions). In other worlds, without any exact considerations about our underlying generative model, our goal is to determine a suitable probabilistic density function based on our set of modalities and a set of known observations (), more formally
[TABLE]
where is the set of parameters of our model. As our model approximate the probabilistic density function according a set of known observations, we will refer the set of observations as “sample set".
Our goal is to define a unified kernel function with the following properties:
A single kernel should include all modalities to avoid the computational complexity of the multiple kernel learning problem and in particular the need for wrapper methods. 2. 2.
The kernel should be based on an underlying probabilistic model that captures the connection and dependencies between the modalities or the multiple representations. 3. 3.
Data points should posses a generative model so that the Fisher Information matrix can be used to define a mathematically justified optimal kernel.
4.2 Random Field representation
As the main idea of the similarity kernel method, we define a Random Field generative model by using pairwise similarities. In this model, a new instance is generated based on its distance from certain selected instances as distribution parameters. To select , we have the options to select all the training set, or a subset in case it is too large, or even an arbitrary sample of labelled or unlabelled instances.
We will consider our instances as random variables forming a Markov Random Field (Section 3.1.3) described by an undirected graph. We define a generative model of based on its similarity or distance to elements of . By the Hammersley–Clifford theorem [Ripley and Kelly, 1977], the joint distribution of the generative model for is a Gibbs distribution.
Our choice for the generative model was also driven by the invariance properties of Fisher kernels. We will show in Theorem 1 that for the Markov Random Field with the proposed energy functions, we can even spare the expensive parameter selection procedure for classification.
In the next subsections, first we derive this distribution via an appropriate energy function. Then we define three new factor graphs suitable for defining kernels for classification and regression. Given a Markov Random Field defined by a graph, a wide variety of proper energy functions can be used to define a Gibbs distribution. The weak but necessary restrictions are that the energy function has to be positive real valued, additive over the maximal cliques of the graph, and more probable configurations (specific sets of parameters) have to have lower energy.
Pairwise similarity factor graph
Our first and least complex factor graph is a bipartite graph connecting only the actual observations and a finite set of previously known observations (see fig. 5). For simplicity, first we will assume that only a single, unimodal distance is defined across the instances. In the bipartite factor graph, the maximal cliques are the pairs of the actual observation and , therefore our energy function has the simple form
[TABLE]
where is the set of hyperparameters and is the th sample.
For modalities with different distance functions between the instances, the energy function has the form
[TABLE]
where is the number of different distance functions and is the set of hyperparameters. For simplicity, from now on we omit and use for the hyperparameters.
Class similarity factor graph
Although the labels of the training set are of primary importance for classification, we do not use the labels in equations (53) and (54). In our next factor graph, we add class representative points, set , uniformly sampled from the positive and negative training samples from each of the classes (see fig. 6). These points are connected to the samples and to the actual observation but not to each other. If the class representatives and the samples are disjoint, the maximal and only clique size is three, composed of the actual observation, a class representative and a sample. To capture the joint energy, we can use the pseudo-likelihood heuristic of [Besag, 1975] who approximates the joint distribution additively from the individual ones, as follows:
[TABLE]
At first glance, the additive approximation seems to oversimplify the potential to the pairwise potential (eq. 53). However, in practice, the effect of the clique in the potential is apparently captured by the clique hyperparameter .
Multi-agent similarity factor graph
So far we assumed that the samples are only dividable through modality, but in certain problems such as the recommender systems even the observations are multiple agents. To capture the known connections betweens the elements, we can define a bit different factor graph. Let be any point in the graph an agent (e.g. items and users, see fig. 7), than we can define an energy function as
[TABLE]
where is the number of agent types and is the set of k-cliques between the different type of agents.
4.2.1 Gibbs distribution
Given the potential function over the maximal cliques, by the Hammersley–Clifford theorem (Section 3.1.3), the joint distribution of the generative model for is a Gibbs distribution
[TABLE]
where
[TABLE]
is the expected value of the energy function over our generative model, a normalization term called the partition function. If the model parameters are previously determined, is a constant. Now, let us examine the Fisher Information matrix.
4.3 Fisher kernel: natural kernel over generative models
In this section, we review the theorems of [Jaakkola and Haussler, 1999, Amari, 1996, C̆encov, 1982, Cencov, 2000] and substitute our generative models to obtain the form of the natural kernel function, whose existence based on the Fisher information matrix follows from the theorems. We previously discussed (see Section 3) that the generative probability models (such as Markov models) and discriminative approaches (such as support vector machines) are very important tools in the area of statistical classification of various types of data. Jaakkola and Haussler [Jaakkola and Haussler, 1999] proposed a remarkable and highly successful approach to combine the two, somewhat complementary approaches. As we seen in the previous section, kernel methods for discriminative classification employ a real valued kernel function to measure the similarity of two examples (they could be a set of samples as in images) in terms of the value . By following [Jaakkola and Haussler, 1999], we may employ the Fisher information to obtain the kernel function directly from a generative probability model. We may consider a parametric class of probability models , where for some positive integer .
For example in Fig. 8 the image content generative model is given by GMM (Section 3.1.2) with isotropic Gaussians with weights for ,…,.
Provided that the dependence on is sufficiently smooth, the collection of models with parameters from can then be viewed as a (statistical) manifold . can be turned into a Riemannian manifold [Jost, 2011] or in other words into a smooth real manifold, where for each point there is an inner product defined on the tangent space of . This inner product varies smoothly with . One can define the length of a tangent vector via this inner product on the tangent space. This makes possible to define the length of a curve on by integrating the length of the tangent vector . The distance between two points and is just the length of the shortest curve on from to . The notion of the inner product in turn allows to define a metric on . The significance of Fisher metric is highlighted by a fundamental result of N. N. C̆encov [C̆encov, 1982] stating that it exhibits an invariance property under some maps which are quite natural in the context of probability. These maps are congruent embeddings by Markov morphisms. Moreover it is essentially the unique Riemannian metric with this property. This invariance property is discussed by Campbell [Campbell, 1985, Campbell, 1986], Amari [Amari, 1996] and it is extended by Petz and Sudár to a quantum setting [Petz and Sudar, 1999]. Thus, one can view the use of Fisher kernel as an attempt to introduce a natural comparison of the examples on the basis of the generative model (see Section 4 in [Jaakkola and Haussler, 1999]).
In other words, this means that we obtain a metric that maintains the original distances and hence defines a “natural” metric of the data instances of the generative model.
Next we formally compute the metric over the manifold. Precisely, we can get the Riemann manifold by giving a scalar product at the tangent space of each point via a positive semidefinite matrix , which varies smoothly with the base point . Such positive semidefinite matrices are provided by the Fisher information matrix
[TABLE]
where the gradient vector is
[TABLE]
and the expectation is taken over . In particular, if is a probability density function, then the -th entry of is
[TABLE]
The kernel can actually be viewed as an inner product
[TABLE]
where the feature vectors are obtained via a fixed, problem specific map which describes the examples in terms of a real vector of length .
The vector is called the Fisher score of the example . Now the mapping of examples to feature vectors can be (we suppressed here the dependence on ), the Fisher vector. Thus, to capture the generative process, the gradient space of the model space is used to derive a meaningful feature vector. The corresponding kernel function
[TABLE]
is called the Fisher kernel.
An intuitive interpretation is that gives the direction where the parameter vector should be changed to fit best the data [Perronnin and Dance, 2007].
Before we deeply examine the Fisher metric over particular distributions, we prove a theorem for the similarity kernel on a crucial reparametrization invariance property that typically holds for Fisher kernels [Janke et al., 2004]. By the theorem, we do not require an expensive parameter selection procedure for the similarity kernel with energy function in Section 4.2.
Theorem 1**.**
For all for a continuously differentiable function , is identical.
Proof.
The Fisher score is
[TABLE]
and therefore
[TABLE]
∎
As a consequence, if our optimisation procedure yields only changes trough continuously differentiable reparametrization of an already found parametrization we can stop since it will never alter our kernel value. We will see in a latter chapter that for several distributions the whole optimisation is an unnecessary step due the nice properties of the Fisher score.
4.3.1 Fisher distance: a univariate Gaussian example
The question arises why we use the Fisher metric on instead of e.g. the Euclidean distance inherited from the ambient space ? As a first step in discussing this issue, we follow [Costa et al., 2014] to consider the family of univariate Gaussian probability density functions
[TABLE]
parameterized by the points of the upper half-plane of points with . Fix values and . The Euclidean distance of and is , the same as the distance of and . At the same time, an inspection of the graphs of the density functions shows111Let be the density functions corresponding to and let be a small interval close to . Then will be smaller than . that the dissimilarity of the distributions attached to and is smaller than the dissimilarity of the distributions with parameters and . This suggests that a distance reflecting the dissimilarity of the distributions is not the Euclidean one. It turns out that the Fisher distance reflects dissimilarity much better in this case. In fact, the Fisher distance of two points and is related nicely to the hyperbolic distance measured in the Poincaré half-plane model of hyperbolic geometry (formula (4) in [Costa et al., 2014]):
[TABLE]
4.3.2 The Fisher metric over general distributions
The Fisher metric over the Riemannian space
[TABLE]
of finite probability distributions has a beautiful connection to the metric of the sphere of points with . This goes back to Sir Ronald Fisher and is discussed in [Campbell, 1985, Gromov, 2012] and [Petz and Sudar, 1999]. A point of the probability simplex corresponds to a unique point of the positive “quadrant” of of via , . This is actually an isometry if one considers the spherical metric on . In fact, let be a curve on . Then the squared length of the tangent vector to is
[TABLE]
[TABLE]
which is the squared length of in the Fisher metric on . The Fisher distance between probability distributions and can then be calculated along a great circle of . It will be
[TABLE]
4.3.3 An example: Fisher over Gaussian Mixtures
For classification tasks Perronnin and Dance [Perronnin and Dance, 2007] proposed the Fisher metric over the Gaussian mixture image content generative model as a content based distance between two images. Let be a set of samples extracted from a particular image . In the naive independence model (see Section 3.1.2), the probability density function of is equal to
[TABLE]
We obtain that the Fisher score of is a sum over the Fisher scores of the samples of
[TABLE]
The GMM assumption means (for more details see Section 3.1.2) that
[TABLE]
where is a finite probability distribution and is the density of , a dimensional Gaussian distribution with mean vector and diagonal covariance matrix with diagonal .
In Section (3.1.2) we already discussed the derivative for the loglikelihood of the GMM. Note, Perronnin and Dance in [Perronnin and Dance, 2007] refer the membership probability (eq. 21) as occupancy probability.
Despite the compact form of the derivatives, the computation of the Fisher information remains a challenging problem. To overcome this difficulty, Perronnin and Dance further simplified the naive independence model of Fig. 8 as follows. In the model illustrated in Fig. 9, they assume that the sample for image region is generated by first selecting one Gaussian from the mixture according to the distribution and then considering as a sample from . In other words, they assume that the distribution of the membership probability is sharply peaked [Perronnin and Dance, 2007], resulting in only one Gaussian per sample with non-zero () membership probability. They also assume that , the number of regions generated for an image, is constant. Worth to mention, that the assumptions on sharp peaks and a constant are not entirely valid in some cases and we will discuss it in a latter section during the experiments.
Nevertheless the final representation of image is
[TABLE]
For this computation in practice a diagonal approximation of is used as suggested in [Jaakkola and Haussler, 1999, Perronnin and Dance, 2007]. The diagonal terms of this approximation (for details see [Perronnin and Dance, 2007]) are
[TABLE]
For images , and the Fisher kernel is the following bilinear kernel over the Fisher vectors and :
[TABLE]
The dimension of the Fisher vector is (equal to the number of parameters of the model), where is the dimension of the samples. Since this value depends on , the number of Gaussians in the mixture, one has to find a good balance between the accuracy of the mixture model and the computational cost. The Vapnik-Chervonenkis theorem (Section 2) is also suggest less complex Gaussian Mixtures since the Fisher kernel is a linear kernel. Interestingly, the Gaussian Mixtures used in [Perronnin et al., 2010b, Chatfield et al., 2011] result significantly high dimensional Fisher scores () learning over a small training set (Pascal VOC with training images). This experiments (and the experiments with the similarity kernel) suggest us that the Fisher kernel has good generalisation properties despite the high dimensional underlying space. As our similarity graphs are not Gaussian Mixtures, next, we calculate the Fisher score over the graphs introduced in Section 4.2.
4.3.4 Practical approximation of the Fisher Kernel over Gibbs distribution
Without reasoning about the lattice (and therefore about the energy function), let us calculate the Fisher score based on our general generative model derived from (eq. 32),
[TABLE]
As we set our model fixed, is a constant and our formula can be simplified as
[TABLE]
since
[TABLE]
The first part of the formula can be calculated from the observation while the expected value (the mean of the gradient of the potential function) is hard to compute. Worth to mention, if there exists a probability density function such that
[TABLE]
then the expected term of eq. (69) is zero trivially.
The computational complexity of the Fisher information matrix is where is the size of the training set. The linearization of the Fisher kernel through Cholesky decomposition is also an expensive procedure depending only on the size of the parameter set.
To reduce the complexity to we can approximate the Fisher information matrix again with the diagonal.
Focusing on the diagonal of the Fisher information matrix, we get
[TABLE]
For the energy functions of equations (53) and (54), the diagonal of the Fisher kernel is the standard deviation of the distances from the samples. We give the Fisher vector of for (53):
[TABLE]
The above formula can be directly computed from the distance matrix of the sample and the training and testing instances . We note that here we make another heuristic approximation: instead of computing the expected values in (73) e.g. by simulation, we substitute the mean and variance of the distances from the training data. For the equations (55) and (56) the derivation is similar and therefore the kernel values does not depend on the parameters of the random graph.
Because of Theorem 1, the equation is independent of the hyperparameters , hence it is less sensitive to the heuristic approximation. Note that the earlier results of [Jaakkola and Haussler, 1999, Perronnin and Dance, 2007] use the same heuristic, however their models are not known satisfy Theorem 1: for example they need to learn the Gaussian mixture model parameters, and their method is, at least theoretically, more sensitive to the hyperparameters and the heuristic approximation as well.
The dimensionality of the Fisher vector (the normalized Fisher score) is equal to the size of the parameter set of our joint distribution. In our case it depends only on the size of the sample sets and and the number of modalities (), for eq. (53) and for eq. (55). In case of the Multi-agent graph (eq. (55)) the dimension depends on the edges between the agent sets, particularly for agent sets the dimension is .
By the pairwise similarity graph, if we use the whole training set as sample the dimension of the underlying euclidean space is equal to the size of the training set almost reaching the separability limit (Section 3). This limit can be reached with a significantly smaller sample set in the class similarity kernel.
4.4 Summary and my contribution
From a generative model based on instance similarities, we derived a similarity kernel applicable for classification and regression. The method is capable of defining a single unified kernel even in the case of rich data types. The final kernel does not depend on the parameters of the random graph and therefore we do not need to determine the relative importance of the basic modalities. In the next sections we will show experiments over various datasets such as images (see Section 5.2,5.3), web classification (Section 6) and time-series typed problems (Section 7). As a summary and the main contribution:
- From a generative model based on instance similarities, we derived various kernels applicable for classification and regression. The method is capable of defining a single unified kernel even in the case of rich data types.
The theoretical background of the similarity kernel and some of the experiments were presented in various publications [Daróczy et al., 2013, Daróczy et al., 2015, Daróczy et al., 2015]. My contribution were mainly the idea and the definition of the similarity graphs (Section 4.2) and the derivation of the practical approximation of the Fisher Information (Section 4.3.4). For the particular problems I will mention at the end of the experiment sections which basic distance metrics and experiments were done by me.
5 Multimodal image classification and retrieval
Efficient representation of images is still a widely researched and open problem. The selection of the ideal, better performing feature extraction method depends greatly on the aim of the application where we want to utilize it. While the challenge seems different for content based information retrieval (CBIR) and visual concept detection, they are closely related. By image retrieval the main objective is to rank images in a corpus by their relevance to a set of query images. Traditional text based information retrieval is a very well studied area with robust methods. The most common solution is to map the images into so called sets of “visual" words and treat them as documents [Csurka et al., 2004, Chen and Wang, 2004, Prasad et al., 2004, Carson et al., 2002, Lv et al., 2004]. Interestingly, normalized term frequency values are very applicable features for classification of images and textual documents as well. One of the main questions is the mapping or translation of the visual content. In a way, direct mapping or detection of textual concepts would be an ideal solution, but let us consider the differences between the visual and textual concepts. Since there is no unambiguous translation between them, so we may consider a different kind of finite dictionary for the image concepts as for natural languages [Csurka et al., 2004]. They considered to assign a “visual word" from a finite codebook to each of the patches extracted from the image, describing the image with the histogram of the occurrence of the “visual words". This representation of the images results a sparse and finite description of the images in comparison to the matching based similarity measure, which is also a common method in content based image retrieval [Chen and Wang, 2004, Prasad et al., 2004, Carson et al., 2002, Lv et al., 2004]. Although they described local keypoint based “visual words", the method is applicable for any type of segmentation of the image. One of the key parts of the method are the detection and description of local the patches and the codebook generation.
In Section 5.1 we examine an image retrieval system based on segmented query images [Daróczy et al., 2009a, Benczúr et al., 2008, Deselaers et al., 2008, Daróczy et al., 2009b]. focusing on a hierarchical graph-cut based segmentation algorithm and feature extraction. Afterwords, in Section 5.2 we introduce a generative model to capture the structural layout of the images. Lastly, in Section 5.3 we discuss several models for multimodal image classification [Daróczy et al., 2011, Daróczy et al., 2012] and introduce a method for classifying image segments based on Fisher vectors and biclustering.
5.1 Ad-hoc photographic retrieval: a segmentation based CBIR over the IAPR TC-12 dataset
The ImageCLEF Photo Retrieval [Arni et al., 2009] challenges targeted towards image processing and visual and textual feature generation over the IAPR TC-12 benchmark collection [Grubinger et al., 2006, Arni et al., 2009] with 20,000 still natural images with textual meta information and querys with three sample images and a textual descriptions. The collection was used in three consecutive challenges at the ImageCLEF 2007, ImageCLEF 2008 and ImageCLEF 2009 campaigns. Our main goal at the ImageCLEF Ad-hoc photographic retrieval task was an analysis of the strength of various elements of segmentation. This section is based mainly on our solution to the ImageCLEF 2008 Ad-hoc Photographic Retrieval task [Daróczy et al., 2009a] with additional remarks [Benczúr et al., 2008, Deselaers et al., 2008, Daróczy et al., 2009b].
The main components of our model are the segmentation based visual retrieval ranking and the textual search engine. The segmentation procedure consists of a novel combination of the Felzenszwalb–Huttenlocher graph cut method [Felzenszwalb and Huttenlocher, 2004] with smoothing over the scale-space [Witkin, 1984]. All image segments are mapped into a roughly 400-dimensional space with features describing the color, shape and texture of the segment (see Table 1). Since the number of query images were limited at the challenge, the relative importance of the features considering a distance function were considered hard to determine yet we made an excessive analysis of the feature weights as well as gave a method to learn these weights based solely on the sample images of the photo retrieval topics. We used the Hungarian Academy of Sciences search engine [Benczúr et al., 2003] as our textual information retrieval system that is based on Okapi BM25 [Robertson and Jones, 1976] and the original automatic query expansion formula of [Xu and Croft, 1996].
5.1.1 Hierarchical graph-cut image segmentation
Image segmentation is a widely researched and open problem. There are both supervised and unsupervised algorithms based on Markov Random Fields [Geman and Graffigne, 1986, Kato and Pong, 2006], Gaussian Mixtures [Belongie et al., 1998] or spectral clustering [Shi and Malik, 2000]. Since the original task permitted external knowledge and the majority of the queries was not based on object type concepts we choose an unsupervised but efficient algorithm as a basic segmentation algorithm. Felzenszwalb and Huttenlocher [Felzenszwalb and Huttenlocher, 2004] defined an undirected graph over where corresponds to a pixel in the image, and the edges in connect certain pairs of neighbouring pixels. This graph-based representation of images reduces the original proposition into a graph cutting challenge. They made a very efficient and linear algorithm that yields a result near to the optimal normalized cut which is one of the NP-full graph problems [Felzenszwalb and Huttenlocher, 2004, Shi and Malik, 2000].
Our segmentation procedure is based on the scale space [Witkin, 1984] that enables a gradual refinement of the segments starting out from a coarse segmentation on the top level of the pyramid. Given a coarser segmentation on a higher level, we first try to replace each segment pixel by pixel with the four lower level pixels if their similarity based on the their color is within a threshold. If the four pixels of the finer resolution are dissimilar, we remove those pixels from the segment. The remaining segments are kept together as starting segments for the lower level procedure while the removed pixels can join existing segments or form new ones.
On the lower levels of the pyramid the images are segmented by a modified Felzenszwalb–Huttenlocher graph cut method [Felzenszwalb and Huttenlocher, 2004]. On lower levels, we simply continue to grow the segments obtained on the higher level. Our main improvement over the original method is the use of Canny edge detection [Canny, 1986] and HSV values to weight the connection between neighbouring pixels. The original method only uses distances in the RGB space as weight that we add to the edge detection weight. We chose the Canny despite the computational complexity of the method. Our choice was driven by the fine details of edge structure. Additionally, we experimented with dynamic thresholds.
We also require a similar number of segments in the images that are large enough to be meaningful for retrieval or classification purposes. The original Felzenszwalb–Huttenlocher method builds a minimum spanning forest where the addition of a new pixel to the component is constrained by the weight of the connection with the next pixel and the size of the existing component. We test two post-processing rules that reject the smallest segments. The pixels of rejected segments are then redistributed by the same minimum spanning forest method but now without any further restriction on the growth of the existing large segments. The two different rules are as follows:
- •
Segments of size below a threshold are rejected.
- •
All segments are rejected except for the prescribed number of largest ones.
The segmentation algorithm on a single scale is based on dynamic thresholds over the edge weights. Let be the segment of pixel , a function over the inner edge weights of and a similarity function between and based on their border edges. The simplest function is the minimal weight of the border edges.
During the experiments we set to 10 (the minimal edge weight), to 100 (the minimal segment size) and to 20. The dynamic thresholds increase the possibility for smaller segments to join neighbouring segments.
After segmentation we map each segment into a feature space characterizing its color, shape and texture with description and dimensionality shown in Table 1. Given a pair of a sample and a target image, for each sample segment we compute the distance of the closest segment in the target image. The final (asymmetric) distance arises by simply averaging over all sample image segments, formally
[TABLE]
where is the set of query images and is an image in the corpus.
5.1.2 Learning feature weights for image similarity search
The system ranks the images in the corpus based on the target image segments with the sample image segments. Unlike image classification where classifiers may be capable of learning the relative importance of the features, when considering distances in the feature space, we cannot distinguish between directions relevant or irrelevant with respect to image retrieval.
When we apply feature weight optimization to our particular task, we have to face three serious problems. First, training data consists solely of the three sample images of the topics. Second, relevance to certain topics are based on aspects other than image similarity such as the location of the scene. Third, the three sample images of the same topic are sometimes not even similar to one another.
Our method for training the image processing weights is based on a test for topic separation. We select those topics manually where the three sample images are similar to one another. For the ImageCLEF 2008 Photo challenge we selected 20 topics: 01, 02, 04, 07, 14, 15, 17, 22, 24, 27, 33, 36, 41, 43, 45, 51, 53, 55, 58, 60 (see [Arni et al., 2009]).
The training data consists of image pairs with an identical number of pairs from the same topic and from different topics. Since our distance is asymmetric, we have six pairs for each topic that results in 120 positive pairs. The negative pairs are formed by selecting two random pairs from a different topic for each of the 60 sample images.
We optimize weights for AUC (Section 2.2) of the two-class classification. Since the task at hand is computationally very inexpensive, we simply performed a brute force parameter search.
Given the post-campaign evaluation data, we could perform another manual parameter search to find the best performing weights in terms of the MAP of the retrieval system. As shown in Section 5.1.3 we could reach very close to the best settings we found manually, a result that is in fact overfitted due to the use of all evaluation data.
5.1.3 Experiments
As a common evaluation metric for retrieval the quality of the systems are measured in Mean Average Precision and Precision at the top of the ranked list ( see Section 2.2).
We combine the scores of our text retrieval system (with or without query expansion) with the following visual relevance score. For a target image to be ranked we take each segment of a given topic sample image and find the closest segment in the target image. We average distances over all these segments. Finally among the three sample images we use the smallest value that corresponds to the closest, most similar one.
When combining the lower quality visual scores with the text retrieval scores, we use a method that basically optimizes for early precision but reaches very good improvement in MAP as well. Due to the lower quality of the visual scores, lower ranked images carry little information and act as noise when combining with text retrieval. Hence we replace all except the highest scores by the same largest value among them, i.e. after some position , for all we let scorescorei. During our experiment we choose to be the first value where scorescorei+1.
Our results are summarized in Table 2 for a choice of 100 segments per image with the best segmentation method that uses a 7-level scale pyramid and Canny edge detection. We experimented with and distances between the segments, the previous performed better in all cases. As we expected, better CBIR scores translated into better combined scores. Our weight selection method based on topic separation (Section 5.1.2) finds weights that perform nearly as well as the overfitted best weight setting that we were only able to compute given all relevance assessment data and by far outperforms the uniform weight case.
In Table 3 we compare some variations of the segmentation method and the extracted features. In general the HSV color space is better than RGB but RGB yields additional improvement in combination. The use of both the scale pyramid and the Canny edge weight in the Felzenszwalb-Huttenlocher segmentation algorithm results significantly higher performance. As we can see in Fig. 11, even simple features (mean HSV values, segment size ratio and aspect ratio) are feasible due the relatively large number of segments per image. Out of the rest of the features the DFT gives the largest additional improvement while refined color histograms and shape add very little increase in MAP.
Figure 10 shows the performance of the best methods on the different topics. As it can be seen, the visual result improves text result in most of the topics with the exception of four topics (31, 60, 17 and 15) only. Interestingly, for four topics (23, 59, 50 and 53) the MAP improvement is higher than the visual MAP itself.
5.1.4 Summary
In comparison to other participants at the challenge, our best text only submission ranked third out of 21 teams while our best automatic visual run would be the third best out of 12 teams (see [Arni et al., 2009] and http://www.imageclef.org/2008/results-photo). The best results [Ah-Pine et al., 2008] were given by the team XRCE (Xerox Research Center Europe). Their solution based on Fisher vectors over Gaussian Mixtures (see Section 4.3.3) of local Histogram of Oriented Gradients [Dalal and Triggs, 2005] and RGB statistics, a complementary model to our segmentation based representation. In [Daróczy et al., 2010] we showed that even with a simple linear combination the two method complement each other. The segment matching model use relatively large number of segments per image based on our findings in [Deselaers et al., 2008], where we showed that an automatic, finer re-segmentation of hand-made sample images significantly increase the quality of image matching.
As a summary and the main statement of this section:
- We described a modified, multi-scale Felzenszwalb-Huttenlocher graph-cut segmentation. The suggested segment matching based ranking increased the retrieval performance.
This section based mainly on our approaches to the ImageCLEF 2007-2009 campaigns [Daróczy et al., 2009a, Benczúr et al., 2008, Deselaers et al., 2008, Daróczy et al., 2009b] where my contribution included the models and development of the visual retrieval system, particularly the segmentation, the feature extraction methods and the segment matching.
5.2 Fisher kernel over 2d lattices
In this section we describe a generative model for image classification based on Markov Random Fields over the local patches. As we discussed in Section 4.3.3, the Gaussian Mixtures perform well as an underlying generative approach for images, but exchangeability could be an issue if the layout matters. If we rearrange the samples (patches of a particular image) in an arbitrary way, then the Fisher vector of the resulting image will be the same as before, while the new image may be radically different. To overcome this we may model the layout as a Markov Random Field. Perronnin et al. [Perronnin and Dance, 2007] suggested to model an image as Gaussian Mixture over a set of detected keypoints (see Scale-Invariant Feature Transform [Lowe, 1999]) without considering their spatial relationship. It was extended later with a dense sampling instead of detected corner points and with multiple descriptors (e.g. Histogram of Oriented Gradients [Dalal and Triggs, 2005] or color moments) over the neighbourhood of the sample points [Perronnin et al., 2010b, Chatfield et al., 2011] but still without describing the fine structure of the layout. The most common method to include the layout, in a shallow and rigid way, is the Spatial Pyramid Matching (SPM [S. Lazebnik and Ponce., 2006]), which can be easily adopted to any kind of Bag-of-Features model (BoF [Csurka et al., 2004]) even for the model proposed in this section. Another interesting extension of the common BoF is the Ordered Bag-of-Features [Cao et al., 2010], a generalization of the SPM. In comparison to this methods, where the layout is considered only over a previously determined high-level structure, we would like to introduce a generative model over the samples to capture their spatial structure and compute Fisher kernel. The most similar result to ours is the visual phrases [Zhang et al., 2009] where they consider the co-occurrence of visual words for image retrieval using k-means to generate a hard visual codebook.
5.2.1 The underlying generative model
One option to include the layout into the generative model is to define a Markov Random Field (see Section 3.1.3) over the samples (in our case local patches and not pixels). If we restrict the possible connections to nearest neighbours, the maximal clique size will be small, four. As an example in Fig. 12 we can see several possible spatial layouts over samples on a 2d lattice (e.g. images). If we expand the model with more refined structures based on scale pyramids (Section 5.1.1), depending on the pyramid the maximal clique size can increase to five.
Let us define the energy function (Section 3.1.3) of an unknown lattice over a finite set of samples in as
[TABLE]
where is the set of maximal cliques and is a positive, real function. We will call as clique parameters. Following the BoF type image model we can assume an underlying model for individual samples based on either a simple k-means or a Gaussian Mixture, formally
[TABLE]
where is the number of clusters and is positive, real function measuring the probability of cluster assignments for the samples in the actual clique.
Since the Gaussian Mixtures are proved to be one of the best performing generative models over images, we may approximate by assuming conditional independence between the cliques and the individual cluster assignments:
[TABLE]
where is the membership probability (see Section 3.1.2). The assumption of the Gaussian Mixture as prior probability suggest us to expand the energy function with an additional term,
[TABLE]
Before calculating the partial derivatives for the Fisher kernel, let us consider the connection between the lattice and the size of the parameter set. The second part of the energy function is a Gaussian Mixture thus (see Section 3.1.2) while the first part depends on the size of the cliques and the number of the Gaussians. With constant sized cliques () and shared parameters over the cliques the dimension of is suggesting a careful consideration about the lattice and the number of Gaussians in the mixture.
Derivation of the Fisher Information
We will derive that with a simply assumption (sharply peaked membership probabilities by GMM, as in Section 4.3.3) the Fisher score by Gaussian Mixture is independent of the clique parameters in case of (eq. 78).
Formally, let be a finite 2-dimensional lattice over samples in and a Markov Random Field with energy function (eq. 78). The partial derivative according to any parameter of the GMM, is
[TABLE]
Let use denote the Gaussian Mixture model as . Since \mathbf{E_{\theta}}\bigg{[}\frac{\partial\log p(X\mid\theta)}{\partial\theta_{i}}\bigg{]}=0 we only need to prove that or equivalently
[TABLE]
Because of the summation, let us calculate the derivatives for a single element of a clique:
[TABLE]
Due the peakness property of the membership probability the above equation is either zero (at least one of the probability values is zero) or equal to . Furthermore, by definition the derivatives according to the weight parameters of the GMM are
[TABLE]
and similarly to the mean and the variance of the Gaussians:
[TABLE]
Since both and are zero if we assume peak membership probabilities, we are done.
The partial gradients according to the clique parameters (eq. 77) is similar to the gradients in Section 4.3.3 and do not depend on the values of the parameter set. Therefore we can derive the Fisher score as a straightforward formula:
[TABLE]
If we assume again peak membership probabilities, the Fisher score is
[TABLE]
The final Fisher vector has two parts. The first part is the gradient according to the parameters of the Gaussian Mixture and a second part based on the clique parameters. In the next section we discuss some experiments based on the Gaussian-only model and the spatial model.
5.2.2 Experiments over the Pascal VOC dataset
We carried out our experiments by using the Pascal VOC 2007 data set [Everingham et al., 2010], one of the most popular benchmark for image categorization. The Pascal VOC 2007 task uses 5011 training images and a test set with 4952 images, each image annotated manually into predefined object classes such as cat, bus, person or airplane. Our choice of dataset gave us an opportunity to compare our experiments to the winner methods (without detection) of later challenges including the SuperVector coding (SV, [Zhou et al., 2010a]) and Locality-constrained Linear Coding (LLC, [Wang et al., 2010]). To justify our experiments, we compare them to the Improved Fisher Kernel (IFK) results in [Perronnin et al., 2010a] and [Chatfield et al., 2011]. We do not include models based on deep convolutional networks [Krizhevsky et al., 2012, He et al., 2015], where the spatial layout are concerned naturally. The main reasons are the scalability of the high-dimensional BoF models and the necessity of the large training set to learn a deep network.
We extracted multiple feature vectors per images to describe the visual content. We employed two different fine sampling procedures, the very dense sampling (Exp. 4,5,6 in Table 4) resulting in approximately 300,000 while the other (Exp. 1,2,3) about 72,000 (step size is equal to 3, similarly to [Chatfield et al., 2011]) keypoints (regions) per image. To describe the keypoints, we calculated grayscale HOG (Histogram of Oriented Gradients) with different sub-block sizes (4x4, 8x8, 12x12, 16x16 for Exp. 4,5,6 and 4x4, 6x6, 8x8, 10x10 for Exp. 1,2,3 as suggested in [Chatfield et al., 2011]) on a five layer scale pyramid. We reduced the original dimension (144) of the samples (low-level descriptors) to 96 by Principal Component Analysis (PCA). Additionally, we experimented with a color HOG variant where we concatenated RGB moments [T. Mensink et al., 2010] with HOG and compressed into a 160 dimensional local descriptor by PCA (ColHOG, Exp. 6). The Gaussian Mixture Model (GMM) was trained on a sample set of 3 million descriptors with 512 and 64 Gaussians. Due the dimensionality of the spatial model (see 5.2) we omit the connections between the layers and set to a simple Random Field with a maximal clique size of two (see lattice a) in 12). Our overall procedure is shown in Fig. 13.
We used the resulting kernels after applying the normalizations suggested in [Perronnin et al., 2010a] with different exponents () for training linear SVM models by the LibSVM package [Chang and Lin, 2001] for each of the 20 Pascal VOC 2007 concepts independently.
We trained a GMM over a very dense sample by using our highly efficient GPU based algorithm. Our source code along with previously trained GMM models for different patch descriptors and codes for Fisher vector calculation is available free for research use at https://dms.sztaki.hu/en/project/gaussian-mixture-modeling-gmm-and-fisher-vector-toolkit.
5.2.3 Evaluation
Although spatial pooling is a widely used and effective extension to naive bag-of-words models [S. Lazebnik and Ponce., 2006, Perronnin et al., 2010a, Chatfield et al., 2011], we applied a reduced spatial pooling only to the very fine sampling models (the dimension of the Fisher vector is sampling independent). Our consideration is based on the fact that the standard spatial pooling methods (split the images into 1x1, 3x1, 2x2 regions) contribute a huge increase in the dimension of the representation per image (8 times in [Perronnin et al., 2010a, Chatfield et al., 2011]). Despite the 3.3 times lower dimension of Exp. 4 the results are comparable to IFK fine SP with Spatial Pooling [Chatfield et al., 2011] in five categories (within 5 percent range) and are better in four categories (airplane, boat, car and dog, Table 5). In our experiments the densely sampled joint Color HOG descriptor with reduced spatial pooling performed best.
For the spatial model we omitted the very dense sampling due the closeness of the samples. We extracted the samples on five scales in the spatial pyramid. The spatial model outperformed the baseline methods by (Table 6).
5.2.4 Summary
In this section we described a spatial bag-of-words model based on local rigid descriptors. Additionally, we showed that very dense sampling over a scale pyramid and the Color HOG descriptor may increase the performance of the traditional GMM based Fisher vector. We reviewed the Fisher kernel method for images and described the very fine sampling in [Daróczy et al., 2013] while the efficient GPU implementation was introduced in [Daróczy et al., 2012].
As a summary and the main statement of this section:
- The Fisher scores according to the Gaussian Mixture parameters are independent of the clique parameters if the membership probabilities are sharply peaked and the proposed energy function over the lattice is multiplicative. Therefore we can derive an approximated Fisher kernel.
My contribution included the implementation and evaluation of the methods and the theoretical part of the spatial model. The spatial model is an unpublished joint work with Levente Kocsis, István Petrás and András Benczúr.
5.3 Visual concept detection over the Yahoo! MIR Flickr dataset
Images are rarely being present alone, usually we can extract some content related textual or other non-visual information such as geo-location or date from their context. Besides non visual meta features we can think of any visual representation as an individual modality. Altogether we can easily define a set of very diverse distance functions over images.
In this section we describe our approach to the ImageCLEF 2012 Photo Annotation task [Daróczy et al., 2012] and additionally we experiment with a segmentation based model. The main challenge is to select proper image processing and feature extraction methods for given classification and pre-processing framework. Our image descriptors included spatial pooling based Fisher vectors [Perronnin and Dance, 2007, S. Lazebnik and Ponce., 2006] calculated on point descriptors [Dalal and Triggs, 2005, Mikolajczyk et al., 2005, Harris and Stephens, 1988] such as Histogram of Oriented Gradients and Color moments [Dalal and Triggs, 2005, T. Mensink et al., 2010]. We adopted several different methods to measure the similarity of images based on their Flickr tags. Beside Jensen-Shannon divergence, we used a modified version of Dhillon’s biclustering algorithm [Dhillon et al., 2003] to explore deeper connections between the images and the Flickr tags. The annotation method for segments based on an improved version of the hierarchical graph-cut segmentation (Section 5.1.1).
The section is organized as follows. First, we discuss the problem of image and segment labelling. Next, we describe our visual feature extraction method and the combination of multiple modalities via biclustering before the experiments.
5.3.1 Related results
Image segment labelling [Jeon et al., 2003, He et al., 2004, Shotton et al., 2006, Duygulu et al., 2006, Li and Fei-Fei, 2010] typically relies on small data sets such as the Corel image database where regions and contours are labeled. For example Duygulu et al. solve a task very similar to ours by considering image labelling as a machine translation task, however they use a small text vocabulary of 80 words. ImageNet, the largest image ontology [Deng et al., 2009] consists of 1000 synsets with SIFT features at present.
Object detection methods are capable of learning the bounding box or the shape of the object [Vedaldi et al., 2009]. These methods learn specific object models with specific training sets. In these results, models are trained for a predefined list of a few dozen of objects only. Our goal is to label by a much richer vocabulary (in our case Flickr tags) such that object specific methods are infeasible both on the human annotation and on the machine learning side.
Closer to our task is the so-called (single) ambiguous setting when images are annotated by objects from a predefined set, however the location of the objects is not given. Multiple Instance Learning [Galleguillos et al., 2008] is a framework for learning from data with ambiguous labels and can be used for example to localize the objects. Flickr tags (or any implicit Web annotation), however, follow no clear notion of objects, as observed by [Schroff et al., 2011] who use Web annotation to harvest images of a few predefined classes. Compared to both object localization and image harvesting, our task can be considered double ambiguous.
Another method for exploiting cross-media relations is blind feedback for retrieval [Zhou and Huang, 2003] that is also used for automatic labelling [Jeon et al., 2003]. This latter result however considers a fixed set of annotation terms. In addition, the scalability of blind feedback for batch processing large open vocabularies remains unclear.
Unlike other labelling approaches such as [Jeon et al., 2003, Galleguillos et al., 2008], we overcome the computational bottleneck by running modelling over GPUs to build a generative model for annotation. We consider the use of dense BoF models crucial (see Section 5.2.2).
5.3.2 Visual feature extraction
As we discussed previously in Section 5.2, among a large number of BoF models (super vector [Zhou et al., 2010b], kernel codebook [van Gemert et al., 2008], locality-constrained [Wang et al., 2010] to name a few), GMM based Fisher kernel [Perronnin et al., 2010b] appears best by the evaluation work of [Chatfield et al., 2011], hence we choose the same method. Regarding the spatial image descriptors used, the spatial pyramid matching (SPM) kernel have been highly successful [Yang et al., 2009, Lin et al., 2011]. Our patch sampling strategy included a dense grid and a Harris-Laplace point detection. Similarly to the previous section we calculated HOG and RBG color statistics for each patch. We also calculated a separate Fisher vector on the Harris-Laplacian detected corner descriptors. As by our GMM implementation we were able to compute all the membership probabilities (see Section 3.1.2) for each descriptor without significant loss of time, which resulted a strongly dense Fisher vector even in fp32 due the density of the sampling.
Our starting point for the segmentation based annotation is the Fisher kernel over spatial pooling that we replaced by also using image segments via very dense sampling, of importance for the image indexing application. Since our main objective is to classify images and their regions using a bag of features model, we do not need to perfectly separate objects and the background. Instead, by experimentation we determine the optimal number of segments (around ten) that improves the overall system the best. Our segmentation method is a modified version of the hierarchical graph-cut based algorithm (Section 5.1.1). The main difference is that the condition of the join method depends also on the average weights of the detected edges inside the regions and the average RGB statistics of the regions.
5.3.3 Biclustering algorithm
Since adopting Jensen-Shannon divergence on probability distributions using Flickr tags is an excellent image similarity measure [Daróczy et al., 2011] our goal was to expand it with determining deeper interrelations between the tags and the documents.
Our assumption is that biclusters indicate connection between the features and the text such as blue color and “pool”, white color and “snow”, black and white histogram and “black and white” that can be used to select relevant segments of the sample image. Hence we compute an interrelated segment and word clustering together with a weight for each pair of a segment and a word cluster.
We apply biclustering an expanded version of Dhillon’s information theoretic co-clustering algorithm. Dhillon’s biclustering method [Dhillon et al., 2003] is a bidirectional clustering algorithm that is capable of clustering along multiple aspects at the same time by switching between clustering along two axis. Biclustering explores a deeper connection between instances and attributes than the usual one-directional clustering methods. The basic idea is to consider the data as a joint distribution and maximize the mutual information of row and column clusters.
Formally, let and be discrete random variables that take values in the sets of instances and attributes respectively. Let denote the joint probability distribution of and . Let the clusters of be , , …,, and let the clusters of be , , …, . We are interested in finding maps and ,
[TABLE]
For brevity we write and where and are random variables that are a deterministic function of and , respectively. The algorithm of [Dhillon et al., 2003] iterates between computing row and column clusters.
In comparison to Dhillon’s algorithm we measure document similarity with a combination of visual and textual similarity values. We chose to adopt Jensen-Shannon divergence instead of Kullback-Leibler used in the original article. Our choice was inspired by our experiences with other datasets where Jensen-Shannon divergence resulted a significantly better clustering quality instead of Kullback-Leibler [Siklósi et al., 2012]. In order to refine the clustering with non-textual information we added a similarity measure based on the visual features.
Translation is not literally, complex visual objects such as person, vehicle, building or landscape are characterized by single terms: girl, bicycle, hotel, hill. The corresponding visual feature translation will be a fuzzy set of several likely regions, color or texture. On the other hand simple visual features such as large blue regions may correspond to water (lake, sea, swimming pool), sky and grass, woods, forest or hill.
Our method is a co-learning procedure of features and words that extends the soft clustering process for defining the visual features. Two popular clustering methods are k-means [Tan et al., 2005] and Gaussian Mixtures (Section 3.1.2). The direct combination with tag text would be Gaussian Mixture co-learning, however this method is computationally unfeasible since GMM itself incurs a very high computational cost.
Instead we take a two-layer procedure. First we build a complete Fisher vector over the image descriptors. Given the Fisher vector, we may compute the distance between two images, segments, or a segment and an image. Next we construct a matrix with rows corresponding to images (or segments) and part of the columns to the same segments and another part to the terms appearing in the tag of the image.
We slightly modify the procedure for computing the new cluster index of image (or segment) by using the content. We normalize both the Jensen-Shannon divergence over the word incidence matrix and the similarity values into and take a weighted combination:
[TABLE]
where is the average distance of from the cluster elements under the Fisher vector. We resolve ties arbitrarily.
Since Dhillon’s [Dhillon et al., 2003] method is based on information theoretic distances, the raw tf values give best performance for biclustering. Normalized versions such as tf.idf or the BM25 weighting scheme performs significantly worse and is omitted for further consideration.
5.3.4 Uniform representation
Efficient combination of different feature sets based on a wide range of visual modalities is one of the main problems of image classification. This problem becomes more complex if we have additional non-visual features such as Flickr tags. Our starting point was a widely used technique: learning SVM models on textual and visual Bag-of-Words models [Van de Sande et al., 2010, Csurka et al., 2004, Nowak, 2010]. The selection of the ideal kernel depends on both of the original feature space and the class variable. Therefore the selection procedure is computationally expensive.
We used a dense uniform representation of the basic representations considering to avoid the MKL problem combining modality adaptive similarity based feature transforms, a model closely related to the similarity kernel (Section 4.3.4). Adopting distance based feature transform for classification using the training set is a well-known technique. Schölkopf [Schölkopf, 2000] showed that a class of kernels can be represented as norm-based distances in Hilbert spaces and Ah-Pine et al. [Ah-Pine et al., 2008] applied L1-norm based feature transformation measuring the distance from the Fisher vectors of the training set for image classification with excellent results.
Let us consider a reference set of documents and their corresponding representations . We define the final uniform representation of a document over the set of representations of a reference set as
[TABLE]
where with , denotes the selected similarity measure on basic representation . The define the normalized representation as
[TABLE]
where the expected value is taken over the training set, The dimensionality of this uniform representation is the cardinality of the reference set. Note, if we constrain the model to a single modality, the uniform representation with negative weights is the same as the energy function in the pairwise similarity although the normalization in the similarity kernel is not present.
5.3.5 Reference set selection and weight determination
Considering the properties of the SVM the proper selection of the reference set could decrease significantly the demanding computational time of solving the standard dual problem. In addition, we had the ability to combine textual and visual content before the classification without increasing the dimension of the learning problem against the standard MKL methods. Although the obvious reference set is the training set, but it is not necessary. The transformed feature space captures the relation between the document and a set of documents in various aspects. Our initial assumption was, if we choose a set of documents various enough to be as samples for a concept, this set of documents should be informative enough to use them as reference documents. In other words, we are seeking for the minimal set of documents without affecting significantly the quality of the learning procedure.
To determine the reference set we defined a ranking for the images according to their annotations. The rarer in the training set a concept is, the higher the score of its specimens will be. We cut the list where the selected documents contained at least a specified quantity of positive samples for all categories. We set the minimal amount of positive samples to where N is the number of training images. If a category did not have the minimal amount of positive instances all the samples were included. The resulted subset of training images using (%) contained only images out of the original training images. Since the dimension of the combined representation equals with the number of images in the reference set this selection reduced the dimension by more than %.
To identify the weight vector of the basic representations per class we sampled the training set. We used totally images for training and images for validation. We trained binary SVM classifiers separately for each representation and used a grid search method to find the optimal linear combination per class.
5.3.6 The Yahoo! MIR Flickr dataset
In our experiments we used the Yahoo! MIR Flickr dataset containing images as the training set and images as a test set [Thomee and Popescu, 2012]. The dataset was used for various challenges such as ImageCLEF 2012 Photo Annotation task [Thomee and Popescu, 2012] and in recent articles [Liu et al., 2014, Binder et al., 2013, Thomee et al., 2013]. The aim is to detect the presence of categories (a wide variety of concepts not limited to objects, e.g. daylight, indoor, underwater or citylife) in terms of their visual and textual features. First, we discuss our experiments at the challenge [Daróczy et al., 2012] then we expand with new results.
5.3.7 Experiments and results over the ImageCLEF 2012 Photo Annotation challenge
All of our submissions for the ImageCLEF 2012 Photo Annotation challenge used both visual and textual features. The main differences were the number of training images used for classification and the size of the reference set. All the runs included the following basic representations: HOG based Fisher vectors (extracted on full image, splitted into 3x1 and Harris-Laplacian detected points), Color moment based Fisher vectors (extracted on full image, splitted into 3x1 and Harris-Laplacian) and Jensen-Shannon divergence using Flickr tags as probability distributions (Table 11). By biclustering we computed 2000 document (image) and 1000 terms clusters. As in [Siklósi et al., 2012] with web pages we described images by distances from image clusters determined by biclustering.
In order to determine the parameters of the combined representation we experimented on the basic features using a subset of the training set. It can be seen in Table 7 that color moment and HOG descriptors are complement each other. Although the number of corner detected keypoints was considerably less than at both the full and the 3x1 poolings, we measured small performance differences between them. For Flickr tags we tested three methods (Table 9). As noise reduction we selected the top 25,000 Flickr tags as vocabulary. The refined biclustering using visual similarity and Jensen-Shannon divergence outperformed the Jensen-Shannon divergence and the purely tag based biclustering. We experimented with the parameter for proper reference set selection. The best uniform representation included all visual similarity values and Jensen-Shannon divergence. It can be seen in Table 8 that the performance loss was negligible even using less than half of the training set as reference set. If we left only the 11.9% () to construct the reference set the performance dropped significantly.
During the challenge we submitted only multimodal results. In we used the ranked reference set with images and adopted an annotation category based weighting scheme for the combination ( different weight vectors). We trained binary SVM classifiers per class using a reduced training set containing only images.
Additionally to , in we added a refined biclustering representation with clusters to the common representations. Notice that by biclustering the dimension of the representation was significantly the lowest of all (Table 10).
Our best performing method at challenge ( in Table 11) used the total training set as reference set and the binary SVM models were trained on the whole training set () per class. The adopted weight vector were the same for each class. In comparison to other teams our best run achieved the second highest MAP, MiAP, GMiAP (interpolated versions of MAP) and F-measure scores among participants [Thomee and Popescu, 2012].
5.3.8 Additional experiments and segment annotation
The model we used at the challenge to describe the images visually handled the HOG and color based descriptors independently till the learning. To fit our segmentation based biclustering model, we modify the image feature extraction part. We compute a single, ColHOG based Fisher vector per segment (as in Section 5.2) with Gaussians. To describe the segments properly, we increase the density of the sampling grid by upscaling the images to avoid Fisher scores based on too small amount of local descriptors. For the segmentation based bicluster we increased the number of document (image) clusters from to .
Our main experiment measures the quality of the distance vectors obtained by biclustering. The performance of our three baseline models is seen in the first three rows of Table 12. The first method (CH) uses very dense sampling and computes the Fisher kernel over the combined HOG and color descriptors obtained from the full image, as described in Section 5.2. Note with the reduced spatial pooling the performance increases to in MiAP, but even without spatial pooling the Fisher based on joint Color HOG outperforms the best visual run at challenge (0.3481 in MiAP [Thomee and Popescu, 2012]). The second kernel (JS) is simply unified vector based only on the Jensen-Shannon divergence of the Flickr tags. Finally the third method is our ImageCLEF 2012 submission [Daróczy et al., 2012]. Next we show two multimodal results where the modalities are combined by biclustering only. The difference in the two methods is that the first one considers the entire image only while the second one takes each segment as a row. In spite of the promising results on the Pascal VOC 2007 dataset, the segmentation did not improve the classification. However with the same classification quality we obtain segment labels by the method. Sample segment labels for Pascal VOC 2007 are shown in Fig. 14 and for MIR Flickr in Fig. 15.
Our best submission at the challenge combined lately with biclustering (Bic) performs similar to the winner method, the Selective Weighted Late Fusion (LIRIS), despite the low dimension of both representations ( for the uniform vector and for the Bic). We also experimented with several combinations of the runs using late fusion. As expected, the basic modalities complement each other. Despite both the uniform representation and biclustering use visual and textual content, they can be improved by the basic runs. We achieved the best results with fusing the predictions of the multimodal methods and the single modalities. In comparison to recent results, our method outperforms the Selective Weighted Late Fusion [Liu et al., 2014] by , the best result published to our knowledge over the MIR Flickr dataset.
5.3.9 Summary
Our approach for ImageCLEF 2012 Photo Annotation task employed various representations of the images based on different visual and textual modalities. We extracted several Fisher vectors using a grayscale and a color patch descriptor. We adopted a biclustering method to cluster the images and their Flickr tags. We combined the different descriptors and representations before the classification. This combination procedure included a transformation, a feature aggregation and a selection step. As a summary and the main statement of this section:
- We proposed a dense uniform and a biclustering representation of the basic representations considering modality adaptive similarity based feature transforms based on a sample set. The model is feasible to combine different descriptors and representations before the classification.
We also described a method to determine the connection between the visual content of the images and their Flickr tags. We gave a solution to the double ambiguous labeling task:
- We proposed a multimodal biclustering method to exploit cross-media relations. The method results a low dimensional representation of images and segments.
The method without segmentation was published in [Daróczy et al., 2011, Daróczy et al., 2012]. My contribution was the idea and development of the visual feature extraction and the multimodal fusion. The biclustering method was developed by Dávid Siklósi.
6 Web document classification based on text, link and content features
Identifying the quality aspects of Web documents turned out to be a more challenging problem than the more traditional topic or genre classification. The first results on automatic Web quality classification focus on Web spam [Castillo et al., 2006]. Additionally, there are various aspects and problems related to the quality of the web documents. Mining opinion from the Web and assessing its quality and credibility became also a well-studied area [Dave et al., 2003]. Known results typically mine Web data on the micro level, analyzing individual comments and reviews. Recently, several attempts were made to manually label and automatically assess the credibility of Web content [Olteanu et al., 2013, Papaioannou et al., 2012]. Microsoft created, among others, a reference data set [Schwarz and Morris, 2011]. Classifying various aspects of quality on the Web host level were, to our best knowledge, first introduced as part of the ECML/PKDD Discovery Challenge 2010 tasks [Siklósi et al., 2012].
Classification for quality aspects of Web pages or hosts turned out to be very hard. For example, the ECML/PKDD Discovery Challenge 2010 participants stayed with AUC values near 0.5 for classifying trust, bias and neutrality.
In this chapter we address opinion mining through the C3 dataset 222http://ugc.webquality.org/datasets/ and Web spam detection over the ClueWeb corpus [Cormack et al., 2011]. First, we review the literature and discuss the application of the similarity kernel (Section 4.2) for the particular problems and compare our model with various baselines.
6.1 Related Results
Existing results for Web credibility fall in four categories: Bag of Words; language statistical, syntactic, semantic features; numeric indicators of quality such as social media activity; and assessor-page based collaborative filtering.
It has already been known from the early results on text classification that “obtaining classification labels is expensive” [Nigam et al., 2000].
Web users usually lack evidence about author expertise, trustworthiness and credibility [Castillo et al., 2006]. The first results on automatic Web quality classification focus on Web spam. In the area of the so-called Adversarial Information Retrieval workshop series ran for five years [Fetterly and Gyöngyi, 2009] and evaluation campaigns, the Web Spam Challenges [Castillo et al., 2008] were organized. Over different Web spam and quality corpora [Erdélyi et al., 2011], the bag-of-words classifiers based on the top few 10,000 terms performed best and significantly improved the traditional Web spam features [Castillo et al., 2006]. The ECML/PKDD Discovery Challenge 2010 extended the scope by introducing labels for genre and in particular for three quality aspects. In our work [Siklósi et al., 2012], we improved over the best results of the participants by using new text classification methods. Our method with biclustering and various MKL methods reach 0.634 in AUC for neutrality, bias and trust, while the best method at the challenge performed 0.561 on average for quality classes. With the suggested normalization in Section 5.3.4 over the cluster distances we measured 0.661 in AUC. In [Garzó et al., 2013] we extended the MKL model for cross-lingual spam detection without translating the pages. As our main conclusion, Web spam can be classified purely based on the terms used.
Recent results on Web credibility assessment [Olteanu et al., 2013] use content quality and appearance features combined with social and general popularity and linkage. After feature selection, they use 10 features of content and 12 of popularity by standard machine learning methods of the scikit-learn toolkit.
If sufficiently many evaluators assess the same Web page, one may consider evaluator and page-based collaborative filtering [Papaioannou et al., 2012] for credibility assessment. In this setting, we face a dyadic prediction task where rich metadata is associated with both the evaluator and especially with the page. The Netflix Prize competition [Bennett and Lanning, 2007] put recommender algorithms through a systematic evaluation on standard data [Bell and Koren, 2007]. The final best results blended a very large number of methods whose reproduction is out of the scope of our experiment. Therefore among the basic recommender methods, we use matrix factorization [Koren et al., 2009, Takács et al., 2008]. In our experiments we also use the factorization machine [Rendle et al., 2011] as a very general toolkit for expressing relations within side information. Note, the RecSys Challenge 2014 run a similar dyadic prediction task where Gradient Boosted Trees [Zheng et al., 2008] performed very well [Pálovics et al., 2014].
6.2 Similarity kernel over Web documents
As we discussed in Section (4.2), with the similarity kernel we can move from terms as features to content similarity as features. On one hand, content similarity is more general and it can be defined by using the attributes other than term frequencies as well. Similarity based description is also scalable since we may select the size of sample set as large as it remains computationally feasible.
Our goal is to define Web pages in a general way according to any modality we can assign to them. Similarity may be based on the distribution of terms, content features, distances over the hyperlink structure or distances from clusters as we defined in [Siklósi et al., 2012].
Our most important feature set is the bag of words representation of the text over the Web host. Let there be hosts consisting of an average terms. Given a term of frequency over a given host that contains terms and documents include the term in the corpus, we used the BM25 [Robertson and Walker, 1994] term weighting scheme, where the weight of in the host becomes
[TABLE]
where and are free parameters. Low means very quick saturation of the term frequency function while large downweights content from very large Web hosts.
Besides BM25, we experimented with two additional term frequency normalization schemes:
- •
Term frequency (tf): simply , for all terms in the documents of .
- •
Term frequency times inverse document frequency (tf.idf):
[TABLE]
6.3 Quality assessment prediction over the C3 dataset
The C3 data set consists of 22325 Web page evaluations in five dimensions (credibility, presentation, knowledge, intentions, completeness) of 5704 pages given by 2499 people. Ratings are similar to the dataset built by Microsoft for assessing Web credibility [Schwarz and Morris, 2011], on a scale of four values 0-4, with 5 indicating no rating. The distribution of the scores for the five evaluation dimensions can be seen in Fig. 16. Since multiple values may be assigned to the same aspect of a page, we simply average the human evaluations per page. We may also consider binary classification problems by assigning 1 for above 2.5 and 0 for below 2.5.
Since earlier results [Papaioannou et al., 2012] suggest the use of collaborative filtering along the page and evaluator dimensions, we measure the distribution of the number of evaluations given by the same evaluator and for the same site in Fig. 17.
Distribution of the variance of the ratings is shown by heatmap of all pairs of ratings given for the same page and same dimension by pairs of different evaluators in Fig. 18.
Note that 65% of the C3 URLs returned “OK HTTP" status but 7% of them could no longer be crawled. Redirects reached over 20% that we followed and substituted for the original page.
The C3 data set contains numeric attributes for the evaluator, the page, and the evaluation itself, which can be considered as triplets in a recommender system. The majority of the evaluators however rated only one Web page and hence we expect low performance of the recommender methods over this data set. Most important elements of our classifier ensemble will hence use the bag of words representation of the page content.
Our classifier ensemble consists of the following components:
- •
Gradient Boosted Trees and recommender methods that reached us second place at the RecSys Challenge 2014 [Pálovics et al., 2014].
- •
Standard text classifiers, including our biclustering based method (Section 5.3.3) that performed best over the DC2010 data set [Siklósi et al., 2012].
- •
The similarity kernel (Section 4.3.4) that may work over arbitrarily defined similarity measures over pairs of pages, using not only the text but also the C3 attributes.
In order to perform text classification, we crawled the pages listed in the C3 data set.
6.3.1 Kernel methods
The classification power of Support Vector Machine (Section 3.2.2) over bag of words representations has been shown in [Abernethy et al., 2008, Castillo et al., 2006]. The models rely on term and inverse document frequency values (TF and IDF): aggregated as TF.IDF and BM25. The BM25 scheme turned out to perform best in our earlier results [Erdélyi et al., 2014, Siklósi et al., 2012, Garzó et al., 2013], where we applied SVM with various linear and polynomial kernel functions and their combinations.
In our earlier experiments, biclustering (Section 5.3.3) performed best for assessing the quality aspects of the DC2010 data [Siklósi et al., 2012]. As for images we use Jensen-Shannon divergence instead of Kullback-Leibler divergence and describe pages by distances from page clusters. To exploit the similarity kernel we can think of this page clusters as additional samples with a specific distance function. In case of the pairwise factor graph (Section 4.2), this results sparsity in the energy function
[TABLE]
where corresponds to the th cluster, therefore the clusters behave as a secondary sample set on a cost of expanded dimension.
Since kernel methods are feasible for regression [Platt, 1998, Schölkopf et al., 1999], we also use the methods of this subsection for predicting the numeric evaluation scores.
6.3.2 Gradient Boosted Trees and Matrix factorization
We apply Gradient Boosting Trees [Zheng et al., 2008] and matrix factorization on the user and C3 data features. We used two different matrix factorization techniques. The first one is a traditional matrix factorization method [Koren et al., 2009], while the second one is a simplified version of Steffen Rendle’s LibFM algorithm [Rendle et al., 2011]. Both techniques use stochastic gradient descent to optimize for mean-square error on the training set. LibFM is particularly designed to use the side information of the evaluators and the pages.
6.3.3 Evaluation metrics and results
First, we consider binary classification problems by simply averaging the human evaluations per page and assign them 1 for above 2.5 and 0 for below 2.5. The standard evaluation metrics since the Web Spam Challenges [Castillo et al., 2008] is the area under the ROC curve (AUC) (Section 2.2). The use of Precision, Recall and F-measure are discouraged by experiences of the Web spam challenges.
Unlike spam classification, the translation of quality assessments into binary values is not so obvious. Therefore we also test regression methods evaluated by Mean Absolute Error (MAE) and Root Mean Squared Error (RMSE).
We measure the accuracy of various methods and their combinations. The detailed results can be seen in Table 13, in four groups. The first group gives the baseline methods. Below, we apply the similarity kernel separate for the corresponding attributes. In the third group we combine multiple similarity functions by the similarity kernel. Finally, in the last group, we average after standardizing the predictions. In Table 14 part of the methods are tested for regression.
For user and item features we experiment with GraphLab Create333http://graphlab.com/products/create/ [Low et al., 2012] implementation of Gradient Boosted Tree and matrix factorization techniques. In case of the gradient boosted tree algorithm (GBT) we set the maximum depth of the trees 4, and enabled maximum 18 iterations. To determine the advantage of additional side information over the original matrix factorization technique (MF) we use factorization machine (LibFM) for user and item feature included collaborative filtering prediction. As seen from the tables, matrix factorization (MF) fails due to the too low number of ratings by user and by document but LibFM can already take advantage of the website metadata with performance similar to GBT.
Our Bag of words models use the top stemmed terms. For TF, TF.IDF and BM25, we show results for linear kernel SVM as it outperforms the RBF and polynomial kernels. We use LibSVM [Chang and Lin, 2001] for classification the Weka implementation of SMOReg [Platt, 1998] for regression.
Out of the unimodal methods, the similarity kernel gives the best results both for classification and for regression. For distance, we use L2 for the C3 attributes as well as TF, TF.IDF and BM25. For the last three, we also use the Jensen–Shannon divergence (J–S). While the similarity kernel over the bi-cluster performs weak for classification, it is the most accurate single method for regression. In the similarity kernel, we may combine multiple distance measures by Equation (54). The All Sim method fuses four representations: J–S and L2 over BM25 and L2 for C3 and the bi-cluster representation.
The best non-Fisher method is the average of the linear kernel over BM25 (Lin) and GBT. The performance is similar to the BM25 L2 similarity kernel. As a remarkable feature of the similarity kernel, we may combine multiple distance functions in a single kernel. The best method (All Sim) outperforms the best combination not using the similarity kernel (Lin + GBT) by . The difference is for classifying “knowledge”. The same method performs bests for regression too.
Our best results reach the AUC of 0.74 for credibility, 0.81 for Presentation, 0.70 for Knowledge, 0.71 for Intentions and 0.70 for Completeness. We may hence say that all results reach the level of practical usability. Text classification is the main component: alone it reaches 0.73, 0.77, 0.69, 0.71 and 0.70, respectively, for the five quality dimensions.
The similarity kernel method can also resist noise and learn from small training sets. If we add 10% noise in the training set, the combination of all similarity kernels deteriorates only to an average AUC of 0.7241 from 0.7363 (1.7%). In contrast, the best BM25 SVM result 0.6923 degrades to 0.6657 (3.85%), both with variance 0.004 for ten independent samples. The robustness of the similarity kernel for small training sets is similar to BM25 with linear kernel, as seen in Fig. 19.
6.4 Web Spam detection over ClueWeb09
In this section, we show experiments over the Waterloo Spam Rankings [Cormack et al., 2011] of the ClueWeb09 corpus. Detection of spam hosts can be seen as a binary classification task. As a baseline we use the same bag-of-words classifiers as for the C3 dataset.
Since the C3 features are not available, we use the public feature set by [Castillo et al., 2007] that includes the following values computed for the home page, page with the maximum pagerank and average over the entire host:
Number of words in the page, title; 2. 2.
Average word length, average word trigram likelihood; 3. 3.
Compression rate, entropy; 4. 4.
Fraction of anchor text, visible text; 5. 5.
Corpus and query precision and recall.
Feature classes 1–4 can be normalized by using the average and standard deviation values while class 4 is likely domain and language independent.
Corpus precision and recall are defined over the most frequent words in the dataset, excluding stopwords. Corpus precision is the fraction of words in a page that appear in the set of popular terms while corpus recall is the fraction of popular terms that appear in the page. This class of features is language independent but rely on different lists of most frequent terms for the two data sets.
Results for spam detection in Table 15 show improvement for the multimodal Similarity kernel over the linear combination of the predictions of the BM25 based SVM and the content feature based SVM. Note, the similarity kernel with class similarity graph performed better than the simpler pairwise similarity graph, although both of them outperformed the baseline.
6.5 Summary
As a summary of this section, we form the following statement:
- We defined Web pages via the similarity kernel in a general way according to any modality we can assign to them. The similarity kernel for Web documents can also resist noise and learn from small training sets.
The results were published in [Daróczy et al., 2015] while biclustering was introduced for trust and bias classification in [Siklósi et al., 2012]. My contribution was mainly the idea and development of the similarity kernel and the experiments. Dávid Siklósi developed the biclustering, crawled the web pages and calculated the BM25 features while Róbert Pálovics calculated the Matrix Factorization models with GraphLab.
7 Mobile Radio Session drop prediction via Similarity kernel
Management of Mobile Telecommunication Networks (MTN) is a complex task. Setting up, operation and optimization of MTNs such as those defined by the 3rd Generation Partnership Project (3GPP) need high-level expert knowledge. Therefore it is important for network operators that as many processes in network deployment and operation are automated as possible, thus reducing the cost of operation.
MTNs consist of network elements connected to each other with standard interfaces and communicating via standard protocols. MTNs are managed by Network Management System (NMS) running separately from the network elements. NMS provides functions for network configuration via Configuration Management (CM) and operation supervision via Performance Management (PM) and Fault Management (FM). There are specific functions in the CM, PM and FM systems providing automatic configuration and optimization, usually called self-configuration, self-optimization or self-healing. The common name of these functions in the 3GPP standard is Self-Organizing Network (SON) functions. In this section we focus on performance management and performance optimization.
With the evolution of the generations of the radio and core networks ranging from 2G to 4G, PM reporting functions of the network elements have become higher granularity and more detailed, thus providing better observability. In 2G systems performance management relies mostly on counters providing aggregated measurements over a given Reporting Output Period (ROP, usually 15 minutes) within a certain node, in 3G systems it is possible to get higher granularity measurements where per-user events (e.g. Radio Resource Control connection setup, sending handover request, paging, etc.) and periodic per-user measurement reports (sent from the User Equipment to the nodeB indicating the current radio signal strength and interference conditions) might appear in node logs. In LTE the granularity grows even higher with the possibility of frequent periodic (ROP=1.28 second) measurements per-user and/or per-cell in eNodeBs. Moreover, it is also possible to get the event reports and periodic reports as a data stream, making it possible to process the incoming measurements real-time. The detailed, frequent, high-granularity, real-time reporting enables further processing and analyzing the data and applying them in data-driven techniques to be used in network functions, especially in SON functions.
In LTE in order to enable communication between the user equipment and the eNodeB a radio bearer is established. The main metric of interest is retainability in LTE systems which is defined as the ability of a User Equipment to retain the bearer once connected, for the desired duration. The release of radio bearers between the User Equipment and the eNodeB can have multiple reasons. There are normal cases such as release due to user inactivity (after expiry of an inactivity timer), release initiated by the user, release due to successful handover to another radio cell or successful Inter Radio Access Technology handover, etc. However, there can be abnormal releases (also called drops) due to e.g. low radio quality either in downlink or uplink direction, transport link problems in the eNodeB, failed handover, etc. Unexpected session drops may seriously impact the quality of experience of mobile users, especially those using real-time services such as Voice-over-IP (VoIP).
The aim of our work [Daróczy et al., 2015] was to introduce and evaluate a method to predict session drops before the end of session and investigate how it can be applied in SON.
7.1 Related work
As we mentioned, frequent periodic reports were introduced first in 3G systems. The authors in [Zhou et al., 2013, Theera-Ampornpunt et al., 2013] use traditional machine learning models, AdaBoost [Freund and Schapire, 1995] and Support Vector Machine (Section 3.2.2), to predict call drops in 3G network and use the prediction result to either avoid them or mitigate their effects. The features of the models in these studies are aggregated values of certain radio events and reports in a fixed time window preceding the drop. While the settings greatly differ in these studies, the accuracy of our results is much better than in [Theera-Ampornpunt et al., 2013] and comparable to [Zhou et al., 2013]. In both papers, prediction is only made where the session is dropped in the next second. In comparison, we address the SON aspects by evaluating the power of our methods for predicting several seconds before session termination.
We provide an improved machine learning methodology where the high granularity of the performance reports is exploited and the time evolution of the main features is used as extra information to increase prediction accuracy. We deploy and extend techniques of time series classification [Ding et al., 2008]. For single parameter series, nearest neighbour classifiers perform the best for time series classification where the distance between two time series is defined by Dynamic Time Warping (DTW) [Berndt and Clifford, 1994]. For session drop prediction, however, we have six simultaneous data sets and hence nearest neighbour methods cannot be directly applied. The size of the data sets are also a concern. To overcome the scalability issue while take advantage of the DTW distance we use the similarity kernel with a small sized sample set.
7.2 Network measurements
The analysis is based on raw logs of multiple eNodeBs from a live network containing elementary signaling events indicating e.g. RRC connection setup, user equipment context release, successful handover to/from the cell, and periodic reports having per-user radio and traffic measurements. The basic unit of information is a Radio Bearer session within a cell. The session is constituted from the elementary signaling events (see Fig. 20). The session is started with setting up an RRC connection or successful handover into the cell from an adjacent cell, and it is ended with a user equipment context release or successful handover out of the cell. At the end of the session the reason code of the release is reported. Periodic reports are logged during the session every 1.28s containing various radio quality and traffic descriptors.
7.2.1 Session records
Except the cause of release (our target variable), all of the essential variables can be collected from the session records (Table 16) however the cause of the release can be derived easily from the unique release reason code after the end of the session. There are 20 different reason codes, half of them indicating normal release and the other half indicating abnormal release (drop). The describing variables are contained in the periodic reports and have a time evolution within the session.
The variable to predict is release category that is a binary variable indicating session drop. The variables contributing most to the session drops are selected from a larger set. It contains downlink and uplink parameters. Channel Quality Index (CQI) ranging from 1 to 15 characterizes the quality of the radio channel in downlink direction. Error correction and retransmission mechanisms are operating on different layers of the radio protocols. The retransmission ratio of hybrid automatic repeat request (HARQ) and radio link control (RLC) protocols are reported periodically for both downlink and uplink direction. Signal to Interference plus Noise Ratio on Uplink Shared/Control Channel (sinr_pusch/sinr_pucch) characterizes the quality of the uplink shared/control channel. The sinr_pucch having a constant value in almost the whole dataset, therefore it has been removed from the analysis.
7.2.2 Time evolution of the variables
The values of the essential variables preceding the end of session have most impact on the release category. However, 1 or 2 seconds before the drop the session is already in a state where the quality is extremely low, making the service unusable. Fig. 21 shows examples for sessions with normal and abnormal release. In the dropped session the sinr_pusch decreases and the HARQ NACK ratio increases, indicating uplink problem.
Our objective is to predict the release category (drop or no-drop) of the session based not only on the features measured directly preceding the end of session but also the time evolution of the features. We consider each session record as a set of time series for the six technical parameters, along with the target variable of drop or no-drop. As baseline features, for each of the time series, we compute five statistical attributes (similarly to [Zhou et al., 2013]): minimum, maximum, most frequent item (mode), mean, variance and for each, we compute the statistical attributes over the gradient. Overall, we obtain a statistical descriptor for a session with 60 attributes: for six time series, we have five statistics and for each, we also have the gradient.
7.3 Classification methods
In this section we first give an overview of AdaBoost [Freund and Schapire, 1995], our baseline method also used in [Zhou et al., 2013]. Then we describe the Similarity kernel over the Dynamic Time Warping time series distance [Keogh, 2006] of the six measurement series corresponding to each radio bearer session.
7.3.1 AdaBoost
AdaBoost [Freund and Schapire, 1995] is a machine learning meta-algorithm that “boosts” base learners by computing their weighted sum. In each iteration, subsequent weak learners are trained by increasing the importance of the LTE session samples that were misclassified previously.
Our base learners consist of single attributes with a threshold called decision stump. For example, a stump can classify sessions with maximum uplink RLC NACK ratio above certain value as drop, otherwise no drop. In an iteration , the new stump is selected along with a weight to minimize the error of the predictor with an exponential cost function where is an instance (session) and is its label, 1 for drop and -1 for no-drop.
We use the AdaBoost implementation of Weka [Witten and Frank, 2005] for performing the experiments.
7.3.2 Time Series
By an extensive comparative study of time series classification methods [Ding et al., 2008], the overall best performing time series distance measure is the Euclidean distance of the optimal “dynamic” time warping (DTW) of the two series [Berndt and Clifford, 1994].
Let our time series consist of discrete periodic reports. If the length of two series , …, and , …, is identical, we can define their Euclidean distance as
[TABLE]
By Dynamic Time Warping (DTW), we may define the distance of series of different length. In addition, DTW warps the series by mapping similar behaviour to the same place. For example, peaks and valleys can be matched along the two series and the optimal warping will measure similarity in trends instead of in the actual pairs of measured values. For illustrations of DTW and Euclidean distance, see [Berndt and Clifford, 1994, Ding et al., 2008].
The optimal warping is found by dynamic programming. Let the distance of two single-point series be their difference, DTW. The DTW of longer series is defined recursively as the minimum of warping either one or no endpoint,
[TABLE]
[TABLE]
The DTW distance can be used for classifying time series by any distance based method, e.g. nearest neighbours [Ding et al., 2008]. In our problem of predicting mobile sessions, however, we have six time series and for a pair of sessions, six distance values need to be aggregated. In addition, we would also like to combine time series similarities with similarity in the statistical features.
In order to combine the six distance functions and the statistical features for classification, we may use both the multimodal pairwise or the class similarity graph (Section 4.2). To determine the sample set we randomly select a set of reference sessions, thus for each session , we obtain distances from the pairs of the six measurement time series for and the elements of . By considering the statistical parameters, we may obtain additional Euclidean distance values between the statistical parameters of and elements of , resulting in distances overall.
As before, we used LibSVM [Chang and Lin, 2001] for training the SVM model. Our main metric for evaluation is ROC AUC (Section 2.2).
7.4 Experimental Results
Our data consists of 210K dropped and 27.2M normal sessions. To conduct our experiments over the same data for all parameter settings, we consider sessions with at least 15 periodic reports as summarized in Table 17. Part of our experiments are conducted over a sample of the normal sessions.
We consider the number of periodic report measurements both before and after the prediction. Data before prediction may constitute in building better descriptors. On the other hand, if we take the last periodic reports before drop or normal termination, the prediction model is required to look farther ahead in time, hence we expect deterioration in quality. Another parameter of the session is the duration till prediction: very short sessions will have too few data to predict.
Overall, we observe best performance by the DTW based similarity kernel method, followed by the baseline AdaBoost over statistical descriptors. For all practically relevant parameters, similarity kernel with pairwise similarity graph improves the accuracy of AdaBoost around by 5% over the sample as in Table 17. Over the full data set, performance is similar: AUC 0.891 for AdaBoost and 0.908 for DTW, with five periodic reports before session termination and at least ten before the prediction.
The possible typical physical phenomenon behind drop can be explained by considering the output model parameters. The best features returned by AdaBoost are seen in Table 19. We observe that the most important factor is the increased number of packets retransmitted, most importantly over the uplink control channel followed by HARQ over the downlink. Other natural measures as the CQI or even SINR play less role.
In order to see how early the prediction can be made, the performance as the function of the number of periodic reports before session drop or normal termination is given in Fig. 22. The figure shows the accuracy of early prediction: we observe that we can already with fairly high quality predict drop five measurements, i.e. more than 7 seconds ahead. Regarding the necessary number of observations before prediction we can see that already the first measurement point gives an acceptable level of accuracy. Beyond three reporting periods, most methods saturate and only the DTW based similarity kernel shows additional moderate improvement.
Interestingly, each descriptor needs its own machine learning method: time series with AdaBoost and statistical descriptors with SVM perform poor (Table 18). Additionally, we experiment with the similarity graph. If we replace the pairwise similarity graph with the class similarity graph (Section 4.2), the performance increases significantly achieving in AUC.
The computational time of feature extraction and the prediction depends typically linearly on the number of parameters of the methods, in the range of 1–5 ms, a small fraction of ROP per session. This enables a SON function for online sessions using the predictor to balance between how accurate or how early the prediction is performed.
7.5 Summary
In this section we gave a method to classify complex time-series. The method is based on the similarity kernel over DTW. We experimented with a cellular data sets. In both cases the method outperformed by a large margin the existing methods, achieving more than increase in AUC.
The main statement of this section:
- We predicted session drops in LTE networks more than 5 seconds before the end of the session. The model based on multi-dimensional time-series described by the class similarity graph with multiple statistical features and DTW.
The method and experiments without the class similarity graph was published in [Daróczy et al., 2015]. My contribution was mainly the idea and development of the similarity kernel and the experiments.
8 Conclusions and future work
In this thesis we examined several multimodal feature extraction and learning methods for retrieval and classification purposes. We reread briefly some theoretical results of learning in Section 2 and reviewed several generative and discriminative models in Section 3 while we described the similarity kernel in Section 4.
We examined different aspects of the multimodal image retrieval and classification in Section 5 and suggested methods for identifying quality assessments of Web documents in Section 6. In our last problem we proposed similarity kernel for time-series based classification. The experiments were carried over publicly available datasets and source codes for the most essential parts are either open source or released.
Since the used similarity graphs (Section 4.2) are greatly constrained for computational purposes, we would like to continue work with more complex, evolving and capable graphs and apply for different problems such as capturing the rapid change in the distribution (e.g. session based recommendation) or complex graphs of the literature work.
The similarity kernel with the proper metrics reaches and in many cases improves over the state-of-the-art. Hence we may conclude generative models based on instance similarities with multiple modes is a generally applicable model for classification and regression tasks ranging over various domains, including but not limited to the ones presented in this thesis. More generally, the Fisher kernel is not only unique in many ways but one of the most powerful kernel functions. Therefore we may exploit the Fisher kernel in the future over widely used generative models, such as Boltzmann Machines [Hinton et al., 1984], a particular subset, the Restricted Boltzmann Machines and Deep Belief Networks [Hinton et al., 2006]), Latent Dirichlet Allocation [Blei et al., 2003] or Hidden Markov Models [Baum and Petrie, 1966] to name a few.
References
- [Abernethy et al., 2008]
Abernethy, J., Chapelle, O., and Castillo, C. (2008).
WITCH: A New Approach to Web Spam Detection.
In Proceedings of the 4th International Workshop on Adversarial Information Retrieval on the Web (AIRWeb).
- [Ah-Pine et al., 2008]
Ah-Pine, J., Cifarelli, C., Clinchant, S., Csurka, G., and Renders, J. (2008).
XRCEs Participation to ImageCLEF 2008.
In Working Notes of the 2008 CLEF Workshop.
- [Amari, 1996]
Amari, S.-i. (1996).
Neural learning in structured parameter spaces-natural riemannian gradient.
In NIPS, pages 127–133. Citeseer.
- [Arni et al., 2009]
Arni, T., Clough, P., Sanderson, M., and Grubinger, M. (2008 (printed in 2009)).
Overview of the ImageCLEFphoto 2008 photographic retrieval task.
In Peters, C., Giampiccol, D., Ferro, N., Petras, V., Gonzalo, J., Peñas, A., Deselaers, T., Mandl, T., Jones, G., and Kurimo, M., editors, Evaluating Systems for Multilingual and Multimodal Information Access – 9th Workshop of the Cross-Language Evaluation Forum, Lecture Notes in Computer Science, Aarhus, Denmark.
- [Bach et al., 2004]
Bach, F. R., Lanckriet, G. R., and Jordan, M. I. (2004).
Multiple kernel learning, conic duality, and the smo algorithm.
In Proceedings of the twenty-first international conference on Machine learning, page 6. ACM.
- [Baum and Petrie, 1966]
Baum, L. E. and Petrie, T. (1966).
Statistical inference for probabilistic functions of finite state markov chains.
The annals of mathematical statistics, pages 1554–1563.
- [Bell and Koren, 2007]
Bell, R. M. and Koren, Y. (2007).
Lessons from the netflix prize challenge.
ACM SIGKDD Explorations Newsletter, 9(2):75–79.
- [Belongie et al., 1998]
Belongie, S., Carson, C., Greenspan, H., and Malik, J. (1998).
Color-and texture-based image segmentation using em and its application to content-based image retrieval.
In Computer Vision, 1998. Sixth International Conference on, pages 675–682. IEEE.
- [Benczúr et al., 2003]
Benczúr, A. A., Csalogány, K., Friedman, E., Fogaras, D., Sarlós, T., Uher, M., and Windhager, E. (2003).
Searching a small national domain—preliminary report.
In Proceedings of the 12th World Wide Web Conference (WWW), Budapest, Hungary.
- [Bennett and Lanning, 2007]
Bennett, J. and Lanning, S. (2007).
The netflix prize.
In KDD Cup and Workshop in conjunction with KDD 2007.
- [Berndt and Clifford, 1994]
Berndt, D. J. and Clifford, J. (1994).
Using dynamic time warping to find patterns in time series.
In KDD workshop, volume 10, pages 359–370. Seattle, WA.
- [Besag, 1974]
Besag, J. (1974).
Spatial interaction and the statistical analysis of lattice systems.
Journal of the Royal Statistical Society. Series B (Methodological), pages 192–236.
- [Besag, 1975]
Besag, J. (1975).
Statistical analysis of non-lattice data.
The statistician, pages 179–195.
- [Binder et al., 2013]
Binder, A., Samek, W., Müller, K.-R., and Kawanabe, M. (2013).
Enhanced representation and multi-task learning for image annotation.
Computer Vision and Image Understanding, 117(5):466–478.
- [Blei et al., 2003]
Blei, D. M., Ng, A. Y., and Jordan, M. I. (2003).
Latent dirichlet allocation.
the Journal of machine Learning research, 3:993–1022.
- [Boser et al., 1992]
Boser, B. E., Guyon, I. M., and Vapnik, V. N. (1992).
A training algorithm for optimal margin classifiers.
In Proceedings of the fifth annual workshop on Computational learning theory, pages 144–152. ACM.
- [Campbell, 1986]
Campbell, L. (1986).
An extended čencov characterization of the information metric.
Proceedings of the American Mathematical Society, 98(1):135–141.
- [Campbell, 1985]
Campbell, L. L. (1985).
The relation between information theory and the differential geometry approach to statistics.
Information sciences, 35(3):199–210.
- [Canny, 1986]
Canny, J. (1986).
A computational approach to edge detection.
IEEE Trans. Pattern Anal. Mach. Intell., 8(6):679–698.
- [Cao et al., 2010]
Cao, Y., Wang, C., Li, Z., Zhang, L., and Zhang, L. (2010).
Spatial-bag-of-features.
In Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on, pages 3352–3359. IEEE.
- [Carson et al., 2002]
Carson, C., Belongie, S., Greenspan, H., and Malik, J. (2002).
Blobworld: Image segmentation using expectation-maximization and its application to image querying.
IEEE Trans. Pattern Anal. Mach. Intell., 24(8):1026–1038.
- [Castillo et al., 2008]
Castillo, C., Chellapilla, K., and Denoyer, L. (2008).
Web spam challenge 2008.
In Proceedings of the 4th International Workshop on Adversarial Information Retrieval on the Web (AIRWeb).
- [Castillo et al., 2006]
Castillo, C., Donato, D., Becchetti, L., Boldi, P., Leonardi, S., Santini, M., and Vigna, S. (2006).
A reference collection for web spam.
SIGIR Forum, 40(2):11–24.
- [Castillo et al., 2007]
Castillo, C., Donato, D., Gionis, A., Murdock, V., and Silvestri, F. (2007).
Know your neighbors: web spam detection using the web topology.
Proceedings of the 30th annual international ACM SIGIR conference on Research and development in information retrieval, pages 423–430.
- [Cencov, 2000]
Cencov, N. N. (2000).
Statistical decision rules and optimal inference.
Number 53. American Mathematical Soc.
- [Chang and Lin, 2001]
Chang, C.-C. and Lin, C.-J. (2001).
LIBSVM: a library for support vector machines.
Software available at http://www.csie.ntu.edu.tw/~cjlin/libsvm.
- [Chatfield et al., 2011]
Chatfield, K., Lempitsky, V., Vedaldi, A., and Zisserman, A. (2011).
The devil is in the details: an evaluation of recent feature encoding methods.
In British Machine Vision Conference.
- [Chen and Wang, 2004]
Chen, Y. and Wang, J. Z. (2004).
Image categorization by learning and reasoning with regions.
J. Mach. Learn. Res., 5:913–939.
- [Cormack et al., 2011]
Cormack, G., Smucker, M., and Clarke, C. (2011).
Efficient and effective spam filtering and re-ranking for large web datasets.
Information retrieval, 14(5):441–465.
- [Cortes and Vapnik, 1995]
Cortes, C. and Vapnik, V. (1995).
Support-vector networks.
Machine Learning, 20.
- [Costa et al., 2014]
Costa, S. I., Santos, S. A., and Strapasson, J. E. (2014).
Fisher information distance: a geometrical reading.
Discrete Applied Mathematics.
- [Cristianini and Shawe-Taylor, 2000]
Cristianini, N. and Shawe-Taylor, J. (2000).
An introduction to support vector machines and other kernel-based learning methods.
Cambridge university press.
- [Csurka et al., 2004]
Csurka, G., Dance, C., Fan, L., Willamowski, J., and Bray, C. (2004).
Visual categorization with bags of keypoints.
In Workshop on Statistical Learning in Computer Vision, ECCV, volume 1, page 22. Citeseer.
- [Dalal and Triggs, 2005]
Dalal, N. and Triggs, B. (2005).
Histograms of oriented gradients for human detection.
In Computer Vision and Pattern Recognition (CVPR), 2005 IEEE Conference on.
- [Dave et al., 2003]
Dave, K., Lawrence, S., and Pennock, D. (2003).
Mining the peanut gallery: Opinion extraction and semantic classification of product reviews.
In Proceedings of the 12th international conference on World Wide Web, pages 519–528. ACM.
- [Dempster et al., 1977]
Dempster, A. P., Laird, N. M., and Rubin, D. B. (1977).
Maximum likelihood from incomplete data via the em algorithm.
Journal of the royal statistical society. Series B (methodological), pages 1–38.
- [Deng et al., 2009]
Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., and Fei-Fei, L. (2009).
Imagenet: A large-scale hierarchical image database.
In Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on, pages 248–255. IEEE.
- [Devroye et al., 1996]
Devroye, L., Györfi, L., and Lugosi, G. (1996).
A Probabilistic Theory of Pattern Recognition, volume 31.
Springer Science & Business Media.
- [Dhillon et al., 2003]
Dhillon, I., Mallela, S., and Modha, D. (2003).
Information-theoretic co-clustering.
Proceedings of the Ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 89–98.
- [Ding et al., 2008]
Ding, H., Trajcevski, G., Scheuermann, P., Wang, X., and Keogh, E. (2008).
Querying and mining of time series data: experimental comparison of representations and distance measures.
Proceedings of the VLDB Endowment, 1(2):1542–1552.
- [Duygulu et al., 2006]
Duygulu, P., Barnard, K., de Freitas, J. F., and Forsyth, D. A. (2006).
Object recognition as machine translation: Learning a lexicon for a fixed image vocabulary.
In Computer Vision—ECCV 2002, pages 97–112. Springer.
- [Erdélyi et al., 2011]
Erdélyi, M., Garzó, A., and Benczúr, A. A. (2011).
Web spam classification: a few features worth more.
In Joint WICOW/AIRWeb Workshop on Web Quality (WebQuality 2011) In conjunction with the 20th International World Wide Web Conference in Hyderabad, India. ACM Press.
- [Everingham et al., 2010]
Everingham, M., Van Gool, L., Williams, C. K., Winn, J., and Zisserman, A. (2010).
The pascal visual object classes (voc) challenge.
International journal of computer vision, 88(2):303–338.
- [Felzenszwalb and Huttenlocher, 2004]
Felzenszwalb, P. F. and Huttenlocher, D. P. (2004).
Efficient graph-based image segmentation.
International Journal of Computer Vision, 59.
- [Fetterly and Gyöngyi, 2009]
Fetterly, D. and Gyöngyi, Z. (2009).
Fifth international workshop on adversarial information retrieval on the web (AIRWeb 2009).
- [Fisher et al., 1960]
Fisher, S. R. A., Genetiker, S., Fisher, R. A., Genetician, S., Fisher, R. A., and Généticien, S. (1960).
The design of experiments, volume 12.
Oliver and Boyd Edinburgh.
- [Fogarty et al., 2005]
Fogarty, J., Baker, R. S., and Hudson, S. E. (2005).
Case studies in the use of roc curve analysis for sensor-based estimates in human computer interaction.
In Proceedings of Graphics Interface 2005, GI ’05, pages 129–136, School of Computer Science, University of Waterloo, Waterloo, Ontario, Canada. Canadian Human-Computer Communications Society.
- [Freund and Schapire, 1995]
Freund, Y. and Schapire, R. E. (1995).
A decision-theoretic generalization of on-line learning and an application to boosting.
In Computational learning theory, pages 23–37. Springer.
- [Galleguillos et al., 2008]
Galleguillos, C., Babenko, B., Rabinovich, A., and Belongie, S. (2008).
Weakly supervised object localization with stable segmentations.
In Computer Vision–ECCV 2008, pages 193–207. Springer.
- [Geman and Graffigne, 1986]
Geman, S. and Graffigne, C. (1986).
Markov random field image models and their applications to computer vision.
In Proceedings of the International Congress of Mathematicians, volume 1, page 2.
- [Gönen and Alpaydın, 2011]
Gönen, M. and Alpaydın, E. (2011).
Multiple kernel learning algorithms.
The Journal of Machine Learning Research, 12:2211–2268.
- [Gromov, 2012]
Gromov, M. (2012).
In a search for a structure, part 1: On entropy.
Proc ECM6, Krakow.
- [Grubinger et al., 2006]
Grubinger, M., Clough, P., M ller, H., and Deselears, T. (2006).
The IAPR TC-12 benchmark - a new evaluation resource for visual information systems.
In OntoImage, pages 13–23.
- [Hammersley and Clifford, 1971]
Hammersley, J. M. and Clifford, P. (1971).
Markov fields on finite graphs and lattices.
seminar, unpublished.
- [Harris and Stephens, 1988]
Harris, C. and Stephens, M. (1988).
A combined corner and edge detector.
In Alvey vision conference, volume 15, page 50. Citeseer.
- [He et al., 2015]
He, K., Zhang, X., Ren, S., and Sun, J. (2015).
Delving deep into rectifiers: Surpassing human-level performance on imagenet classification.
arXiv preprint arXiv:1502.01852.
- [He et al., 2004]
He, X., Zemel, R. S., and Carreira-Perpinán, M. A. (2004).
Multiscale conditional random fields for image labeling.
In Computer Vision and Pattern Recognition, 2004. CVPR 2004. Proceedings of the 2004 IEEE Computer Society Conference on, volume 2, pages II–695. IEEE.
- [Hinton et al., 2006]
Hinton, G. E., Osindero, S., and Teh, Y.-W. (2006).
A fast learning algorithm for deep belief nets.
Neural computation, 18(7):1527–1554.
- [Hinton et al., 1984]
Hinton, G. E., Sejnowski, T. J., and Ackley, D. H. (1984).
Boltzmann machines: Constraint satisfaction networks that learn.
Carnegie-Mellon University, Department of Computer Science Pittsburgh, PA.
- [Hopcroft and Kannan, 2012]
Hopcroft, J. and Kannan, R. (2012).
Computer Science Theory for the Information Age.
draft.
- [Hsieh et al., 2008]
Hsieh, C.-J., Chang, K.-W., Lin, C.-J., Keerthi, S. S., and Sundararajan, S. (2008).
A dual coordinate descent method for large-scale linear svm.
In Proceedings of the 25th international conference on Machine learning, pages 408–415. ACM.
- [Jaakkola and Haussler, 1999]
Jaakkola, T. S. and Haussler, D. (1999).
Exploiting generative models in discriminative classifiers.
Advances in neural information processing systems, pages 487–493.
- [Janke et al., 2004]
Janke, W., Johnston, D., and Kenna, R. (2004).
Information geometry and phase transitions.
Physica A: Statistical Mechanics and its Applications, 336(1):181–186.
- [Järvelin and Kekäläinen, 2002]
Järvelin, K. and Kekäläinen, J. (2002).
Cumulated gain-based evaluation of ir techniques.
ACM Transactions on Information Systems (TOIS), 20(4):422–446.
- [Jeon et al., 2003]
Jeon, J., Lavrenko, V., and Manmatha, R. (2003).
Automatic image annotation and retrieval using cross-media relevance models.
In Proceedings of the 26th annual international ACM SIGIR conference on Research and development in informaion retrieval, pages 119–126. ACM.
- [Jost, 2011]
Jost, J. (2011).
Riemannian geometry and geometric analysis.
Springer.
- [Karush, 1939]
Karush, W. (1939).
Minima of functions of several variables with inequalities as side constraints.
PhD thesis, Master’s thesis, Dept. of Mathematics, Univ. of Chicago.
- [Kato and Pong, 2006]
Kato, Z. and Pong, T.-C. (2006).
A markov random field image segmentation model for color textured images.
Image and Vision Computing, 24(10):1103–1114.
- [Keogh, 2006]
Keogh, E. (2006).
A decade of progress in indexing and mining large time series databases.
In Proceedings of the 32nd international conference on Very large data bases, pages 1268–1268. VLDB Endowment.
- [Koren et al., 2009]
Koren, Y., Bell, R., and Volinsky, C. (2009).
Matrix factorization techniques for recommender systems.
Computer, 42(8):30–37.
- [Krizhevsky et al., 2012]
Krizhevsky, A., Sutskever, I., and Hinton, G. E. (2012).
Imagenet classification with deep convolutional neural networks.
In Advances in neural information processing systems, pages 1097–1105.
- [Kuhn and Tucker, 1951]
Kuhn, H. and Tucker, A. (1951).
Nonlinear programming. sid 481–492 i proc. of the second berkeley symposium on mathematical statistics and probability.
- [Lanckriet et al., 2004]
Lanckriet, G. R., Cristianini, N., Bartlett, P., Ghaoui, L. E., and Jordan, M. I. (2004).
Learning the kernel matrix with semidefinite programming.
The Journal of Machine Learning Research, 5:27–72.
- [LeCun et al., 1998]
LeCun, Y., Bottou, L., Bengio, Y., and Haffner, P. (1998).
Gradient-based learning applied to document recognition.
Proceedings of the IEEE, 86(11):2278–2324.
- [Li and Fei-Fei, 2010]
Li, L.-J. and Fei-Fei, L. (2010).
Optimol: automatic online picture collection via incremental model learning.
International journal of computer vision, 88(2):147–168.
- [Li, 2009]
Li, S. Z. (2009).
Markov random field modeling in image analysis.
Springer Science & Business Media.
- [Lin et al., 2011]
Lin, Y., Lv, F., Zhu, S., Yang, M., Cour, T., Yu, K., Cao, L., and Huang, T. (2011).
Large-scale image classification: fast feature extraction and svm training.
In Computer Vision and Pattern Recognition (CVPR), 2011 IEEE Conference on, pages 1689–1696. IEEE.
- [Liu et al., 2014]
Liu, N., Dellandrea, E., Tellez, B., and Chen, L. (2014).
A selective weighted late fusion for visual concept recognition.
In Fusion in Computer Vision, pages 1–28. Springer.
- [Low et al., 2012]
Low, Y., Bickson, D., Gonzalez, J., Guestrin, C., Kyrola, A., and Hellerstein, J. M. (2012).
Distributed graphlab: a framework for machine learning and data mining in the cloud.
Proceedings of the VLDB Endowment, 5(8):716–727.
- [Lowe, 1999]
Lowe, D. (1999).
Object recognition from local scale-invariant features.
In International Conference on Computer Vision, volume 2, pages 1150–1157.
- [Lv et al., 2004]
Lv, Q., Charikar, M., and Li, K. (2004).
Image similarity search with compact data structures.
In CIKM ’04: Proceedings of the Thirteenth ACM International Conference on Information and Knowledge Management, pages 208–217, New York, NY, USA. ACM Press.
- [McLachlan and Krishnan, 2007]
McLachlan, G. and Krishnan, T. (2007).
The EM algorithm and extensions, volume 382.
John Wiley & Sons.
- [Mikolajczyk et al., 2005]
Mikolajczyk, K., Tuytelaars, T., Schmid, C., Zisserman, A., Matas, J., Schaffalitzky, F., Kadir, T., and Van Gool, L. (2005).
A comparison of affine region detectors.
International journal of computer vision, 65(1-2):43–72.
- [Nigam et al., 2000]
Nigam, K., McCallum, A., Thrun, S., and Mitchell, T. (2000).
Text classification from labeled and unlabeled documents using em.
Machine learning, 39(2):103–134.
- [Nowak, 2010]
Nowak, S. (2010).
New Strategies for Image Annotation: Overview of the Photo Annotation Task at ImageCLEF 2010.
In Cross Language Evaluation Forum , ImageCLEF Workshop, 2010.
- [Olteanu et al., 2013]
Olteanu, A., Peshterliev, S., Liu, X., and Aberer, K. (2013).
Web credibility: Features exploration and credibility prediction.
In Advances in Information Retrieval, pages 557–568. Springer.
- [Papaioannou et al., 2012]
Papaioannou, T. G., Ranvier, J.-E., Olteanu, A., and Aberer, K. (2012).
A decentralized recommender system for effective web credibility assessment.
In Proceedings of the 21st ACM international conference on Information and knowledge management, pages 704–713. ACM.
- [Perronnin and Dance, 2007]
Perronnin, F. and Dance, C. (2007).
Fisher kernels on visual vocabularies for image categorization.
In IEEE Conference on Computer Vision and Pattern Recognition, 2007. CVPR’07, pages 1–8.
- [Perronnin et al., 2010a]
Perronnin, F., Sánchez, J., and Mensink, T. (2010a).
Improving the fisher kernel for large-scale image classification.
In ECCV (4), pages 143–156.
- [Perronnin et al., 2010b]
Perronnin, F., Sánchez, J., and Mensink, T. (2010b).
Improving the fisher kernel for large-scale image classification.
In Computer Vision–ECCV 2010, pages 143–156. Springer.
- [Petz and Sudar, 1999]
Petz, D. and Sudar, C. (1999).
Extending the fisher metric to density matrices.
Geometry of Present Days Science, pages 21–34.
- [Platt, 1998]
Platt, J. C. (1998).
Sequential minimal optimization: A fast algorithm for training support vector machines.
Technical report, ADVANCES IN KERNEL METHODS - SUPPORT VECTOR LEARNING.
- [Prasad et al., 2004]
Prasad, B. G., Biswas, K. K., and Gupta, S. K. (2004).
Region-based image retrieval using integrated color, shape, and location index.
Comput. Vis. Image Underst., 94(1-3):193–233.
- [Rakotomamonjy et al., 2008]
Rakotomamonjy, A., Bach, F., Canu, S., and Grandvalet, Y. (2008).
simplemkl.
Journal of Machine Learning Research, 9:2491–2521.
- [Rendle et al., 2011]
Rendle, S., Gantner, Z., Freudenthaler, C., and Schmidt-Thieme, L. (2011).
Fast context-aware recommendations with factorization machines.
In Proceedings of the 34th international ACM SIGIR conference on Research and development in Information Retrieval, pages 635–644. ACM.
- [Ripley and Kelly, 1977]
Ripley, B. D. and Kelly, F. P. (1977).
Markov point processes.
Journal of the London Mathematical Society, 2(1):188–192.
- [Robertson and Jones, 1976]
Robertson, S. E. and Jones, K. S. (1976).
Relevance weighting of search terms.
Journal of the American Society for Information science, 27(3):129–146.
- [Robertson and Walker, 1994]
Robertson, S. E. and Walker, S. (1994).
Some simple effective approximations to the 2-poisson model for probabilistic weighted retrieval.
In In Proceedings of SIGIR’94, pages 232–241. Springer-Verlag.
- [S. Lazebnik and Ponce., 2006]
S. Lazebnik, C. S. and Ponce., J. (2006).
Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories.
In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New York, June 2006.
- [Sauer, 1972]
Sauer, N. (1972).
On the density of families of sets.
Journal of Combinatorial Theory, Series A, 13(1):145–147.
- [Schölkopf, 2000]
Schölkopf, B. (2000).
The kernel trick for distances.
MIT Press, pages 301–307.
- [Schölkopf et al., 1999]
Schölkopf, B., Burges, C. J. C., and Smola, A. J., editors (1999).
Advances in kernel methods: support vector learning.
MIT Press, Cambridge, MA, USA.
- [Schroff et al., 2011]
Schroff, F., Criminisi, A., and Zisserman, A. (2011).
Harvesting image databases from the web.
Pattern Analysis and Machine Intelligence, IEEE Transactions on, 33(4):754–766.
- [Schwarz and Morris, 2011]
Schwarz, J. and Morris, M. (2011).
Augmenting web pages and search results to support credibility assessment.
In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, pages 1245–1254. ACM.
- [Shawe-Taylor and Cristianini, 2004]
Shawe-Taylor, J. and Cristianini, N. (2004).
Kernel methods for pattern analysis.
Cambridge university press.
- [Shi and Malik, 2000]
Shi, J. and Malik, J. (2000).
Normalized cuts and image segmentation.
IEEE Transactions on Pattern and Machine Intelligence, 22:888–905.
- [Shotton et al., 2006]
Shotton, J., Winn, J., Rother, C., and Criminisi, A. (2006).
Textonboost: Joint appearance, shape and context modeling for multi-class object recognition and segmentation.
In Computer Vision–ECCV 2006, pages 1–15. Springer.
- [Sonnenburg et al., 2006]
Sonnenburg, S., Rätsch, G., Schäfer, C., and Schölkopf, B. (2006).
Large scale multiple kernel learning.
The Journal of Machine Learning Research, 7:1531–1565.
- [Szirányi et al., 2000]
Szirányi, T., Zerubia, J., Czúni, L., Geldreich, D., and Kato, Z. (2000).
Image segmentation using markov random field model in fully parallel cellular network architectures.
Real-Time Imaging, 6(3):195–211.
- [T. Mensink et al., 2010]
T. Mensink, G. C., Perronnin, F., Sánchez, J., and Verbeek, J. (2010).
LEAR and XRCEs participation to Visual Concept Detection Task at ImageCLEF 2010.
In Working Notes for the CLEF 2010 Workshop.
- [Takács et al., 2008]
Takács, G., Pilászy, I., Németh, B., and Tikk, D. (2008).
Investigation of various matrix factorization methods for large recommender systems.
In Proceedings of the 2nd KDD Workshop on Large-Scale Recommender Systems and the Netflix Prize Competition, pages 1–8. ACM.
- [Tan et al., 2005]
Tan, P.-N., Steinbach, M., and Kumar, V. (2005).
Introduction to Data Mining, (First Edition).
Addison-Wesley Longman Publishing Co., Inc., Boston, MA, USA.
- [Taskar et al., 2004]
Taskar, B., Chatalbashev, V., and Koller, D. (2004).
Learning associative markov networks.
In Proceedings of the twenty-first international conference on Machine learning, page 102. ACM.
- [Theera-Ampornpunt et al., 2013]
Theera-Ampornpunt, N., Bagchi, S., Joshi, K. R., and Panta, R. K. (2013).
Using big data for more dependability: a cellular network tale.
In Proceedings of the 9th Workshop on Hot Topics in Dependable Systems, page 2. ACM.
- [Thomee et al., 2013]
Thomee, B., Huiskes, M., and S. Lew, M. (2013).
Special issue on visual concept detection in the mirflickr/imageclef benchmark.
Computer Vision and Image Understanding, 117:451–452.
- [Thomee and Popescu, 2012]
Thomee, B. and Popescu, A. (2012).
Overview of the imageclef 2012 flickr photo annotation and retrieval task.
Working Notes of CLEF 2012, Rome, Italy, 2012.
- [C̆encov, 1982]
C̆encov, N. N. (1982).
Statistical decision rules and optimal inference.
American Mathematical Society, 53.
- [Van de Sande et al., 2010]
Van de Sande, K. E. A., Gevers, T., and Snoek, C. G. M. (2010).
Evaluating color descriptors for object and scene recognition.
IEEE Transactions on Pattern Analysis and Machine Intelligence, 32(9):1582–1596.
- [van Gemert et al., 2008]
van Gemert, J. C., Geusebroek, J.-M., Veenman, C. J., and Smeulders, A. W. (2008).
Kernel codebooks for scene categorization.
In Computer Vision–ECCV 2008, pages 696–709. Springer.
- [Vapnik and Chervonenkis, 1971]
Vapnik, V. N. and Chervonenkis, A. Y. (1971).
On the uniform convergence of relative frequencies of events to their probabilities.
Theory of Probability & Its Applications, 16(2):264–280.
- [Vapnik and Vapnik, 1998]
Vapnik, V. N. and Vapnik, V. (1998).
Statistical learning theory, volume 1.
Wiley New York.
- [Vedaldi et al., 2009]
Vedaldi, A., Gulshan, V., Varma, M., and Zisserman, A. (2009).
Multiple kernels for object detection.
In Computer Vision, 2009 IEEE 12th International Conference on, pages 606–613. IEEE.
- [Wang et al., 2010]
Wang, J., Yang, J., Yu, K., Lv, F., Huang, T., and Gong, Y. (2010).
Locality-constrained linear coding for image classification.
In Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on, pages 3360–3367. IEEE.
- [Witkin, 1984]
Witkin, A. P. (1984).
Scale-space filtering: A new approach to multi-scale description.
In Acoustics, Speech, and Signal Processing, IEEE International Conference on ICASSP’84., volume 9, pages 150–153. IEEE.
- [Witten and Frank, 2005]
Witten, I. H. and Frank, E. (2005).
Data Mining: Practical Machine Learning Tools and Techniques.
Morgan Kaufmann Series in Data Management Systems. Morgan Kaufmann, second edition.
- [Xu and Croft, 1996]
Xu, J. and Croft, W. (1996).
Query expansion using local and global document analysis.
Proceedings of the 19th annual international ACM SIGIR conference on Research and development in information retrieval, pages 4–11.
- [Yang et al., 2009]
Yang, J., Yu, K., Gong, Y., and Huang, T. (2009).
Linear spatial pyramid matching using sparse coding for image classification.
In Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on, pages 1794–1801. IEEE.
- [Ye et al., 2012]
Ye, G., Liu, D., Jhuo, I.-H., and Chang, S.-F. (2012).
Robust late fusion with rank minimization.
In Computer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on, pages 3021–3028. IEEE.
- [Zhang et al., 2009]
Zhang, S., Tian, Q., Hua, G., Huang, Q., and Li, S. (2009).
Descriptive visual words and visual phrases for image applications.
In Proceedings of the 17th ACM international conference on Multimedia, pages 75–84. ACM.
- [Zheng et al., 2008]
Zheng, Z., Zha, H., Zhang, T., Chapelle, O., Chen, K., and Sun, G. (2008).
A general boosting method and its application to learning ranking functions for web search.
In Advances in neural information processing systems, pages 1697–1704.
- [Zhou et al., 2013]
Zhou, S., Yang, J., Xu, D., Li, G., Jin, Y., Ge, Z., Kosseifi, M. B., Doverspike, R., Chen, Y., and Ying, L. (2013).
Proactive call drop avoidance in umts networks.
In INFOCOM, 2013 Proceedings IEEE, pages 425–429. IEEE.
- [Zhou et al., 2010a]
Zhou, X., Yu, K., Zhang, T., and Huang, T. S. (2010a).
Image classification using super-vector coding of local image descriptors.
In Computer Vision–ECCV 2010, pages 141–154. Springer.
- [Zhou et al., 2010b]
Zhou, X., Yu, K., Zhang, T., and Huang, T. S. (2010b).
Image classification using super-vector coding of local image descriptors.
In Proceedings of the 11th European conference on Computer vision: Part V, ECCV’10, pages 141–154, Berlin, Heidelberg. Springer-Verlag.
- [Zhou and Huang, 2003]
Zhou, X. S. and Huang, T. S. (2003).
Relevance feedback in image retrieval: A comprehensive review.
Multimedia systems, 8(6):536–544.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[Benczúr et al., 2008] Benczúr, A., Bíró, I., Brendel, M., Csalogány, K., Daróczy, B., and Siklósi, D. (2008). Multimodal retrieval by text–segment biclustering. Advances in Multilingual and Multimodal Information Retrieval, Lecture Notes in Computer Science (LNCS) 5152 , pages 518–521.
- 2[Daróczy et al., 2013] Daróczy, B., Benczúr, A. A., and Rónyai, L. (2013). Fisher kernels for image descriptors: a theoretical overview and experimental results. Annales Universitatis Scientiarum Budapestinensis de Rolando Eőtvős Nominatae. Sectio Computatorica .
- 3[Daróczy et al., 2009 a] Daróczy, B., Fekete, Z., Brendel, M., Rácz, S., Benczúr, A., Siklósi, D., and Pereszlényi, A. (2009 a). Sztaki@ imageclef 2008: visual feature analysis in segmented images. Evaluating Systems for Multilingual and Multimodal Information Access, Lecture Notes in Computer Science (LNCS) 5706 , pages 644–651.
- 4[Daroczy et al., 2015] Daroczy, B., Palovics, R., Wieszner, V., Farkas, R., and Benczur (2015). Predicting user-specific temporal retweet count. In Proceedings of the 3rd International Workshop on News Recommendation and Analytics (INRA 2015) in conjunction with ACM Rec Sys 2015 .
- 5[Daróczy et al., 2011] Daróczy, B., Pethes, R., and Benczúr, A. A. (2011). Sztaki@ imageclef 2011. In CLEF (Notebook Papers/Labs/Workshop) Amsterdam, The Netherlands, 2011 .
- 6[Daróczy et al., 2010] Daróczy, B., Petrás, I., Benczúr, A., Fekete, Z., Nemeskey, D., Siklósi, D., and Weiner, Z. (2010). Interest point and segmentation-based photo annotation. Multilingual Information Access Evaluation II. Multimedia Experiments, Lecture Notes in Computer Science (LNCS 6242) , pages 340–347.
- 7[Daróczy et al., 2009 b] Daróczy, B., Petrás, I., Benczúr, A., Fekete, Z., Nemeskey, D. M., Siklósi, D., and Weiner, Z. (2009 b). Sztaki@ imageclef 2009. CLEF (Notebook Papers/Labs/Workshop) Corfu, Greece 2009 .
- 8[Daróczy et al., 2012] Daróczy, B., Siklósi, D., and Benczúr, A. A. (2012). Sztaki@ imageclef 2012 photo annotation. In CLEF (Notebook Papers/Labs/Workshop) Rome, Italy, 2012 .