Inference for Differential Equation Models using Relaxation via Dynamical Systems
Kyoungjae Lee, Jaeyong Lee, Sarat C. Dass

TL;DR
This paper introduces a fast Bayesian inference framework for ODE-based models by relaxing the ODE system with numerical methods like Runge-Kutta and Gaussian noise, enabling efficient parameter estimation.
Contribution
It proposes a novel, computationally efficient Bayesian approach for parameter inference in ODE models using numerical relaxation and provides theoretical convergence guarantees.
Findings
Method is at least 14 times faster than existing approaches
Theoretical convergence of the posterior is established
Explicit relations between numerical method parameters and convergence rate
Abstract
Statistical regression models whose mean functions are represented by ordinary differential equations (ODEs) can be used to describe phenomenons dynamical in nature, which are abundant in areas such as biology, climatology and genetics. The estimation of parameters of ODE based models is essential for understanding its dynamics, but the lack of an analytical solution of the ODE makes the parameter estimation challenging. The aim of this paper is to propose a general and fast framework of statistical inference for ODE based models by relaxation of the underlying ODE system. Relaxation is achieved by a properly chosen numerical procedure, such as the Runge-Kutta, and by introducing additive Gaussian noises with small variances. Consequently, filtering methods can be applied to obtain the posterior distribution of the parameters in the Bayesian framework. The main advantage of the proposed…
Click any figure to enlarge with its caption.
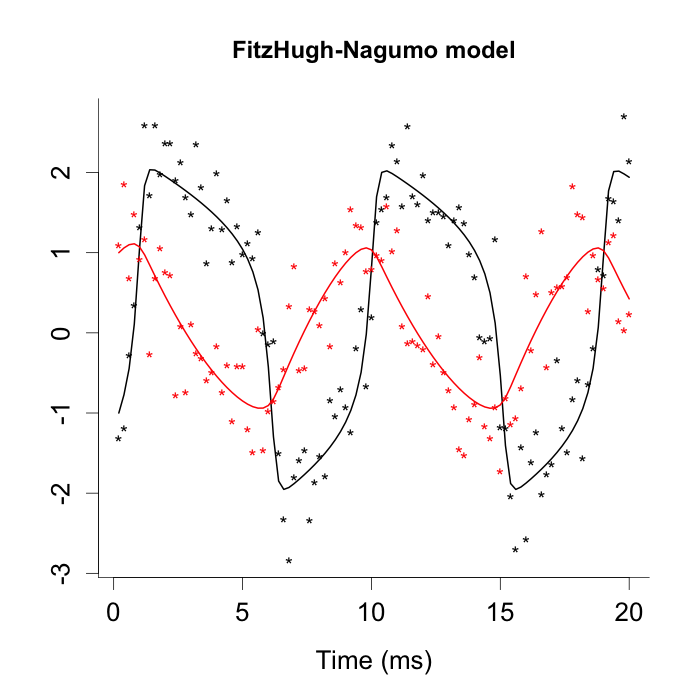 Figure 1
Figure 1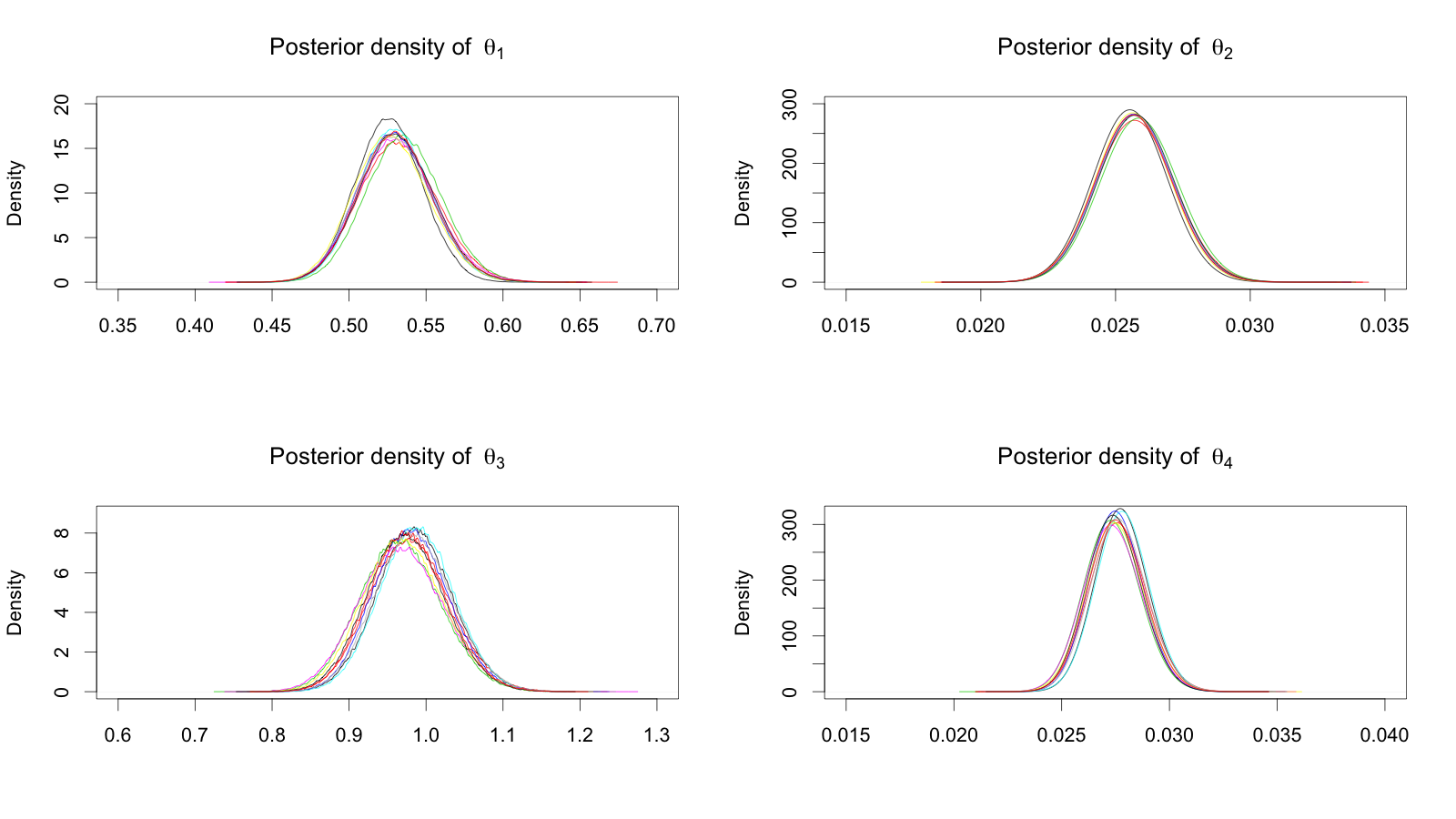 Figure 2
Figure 2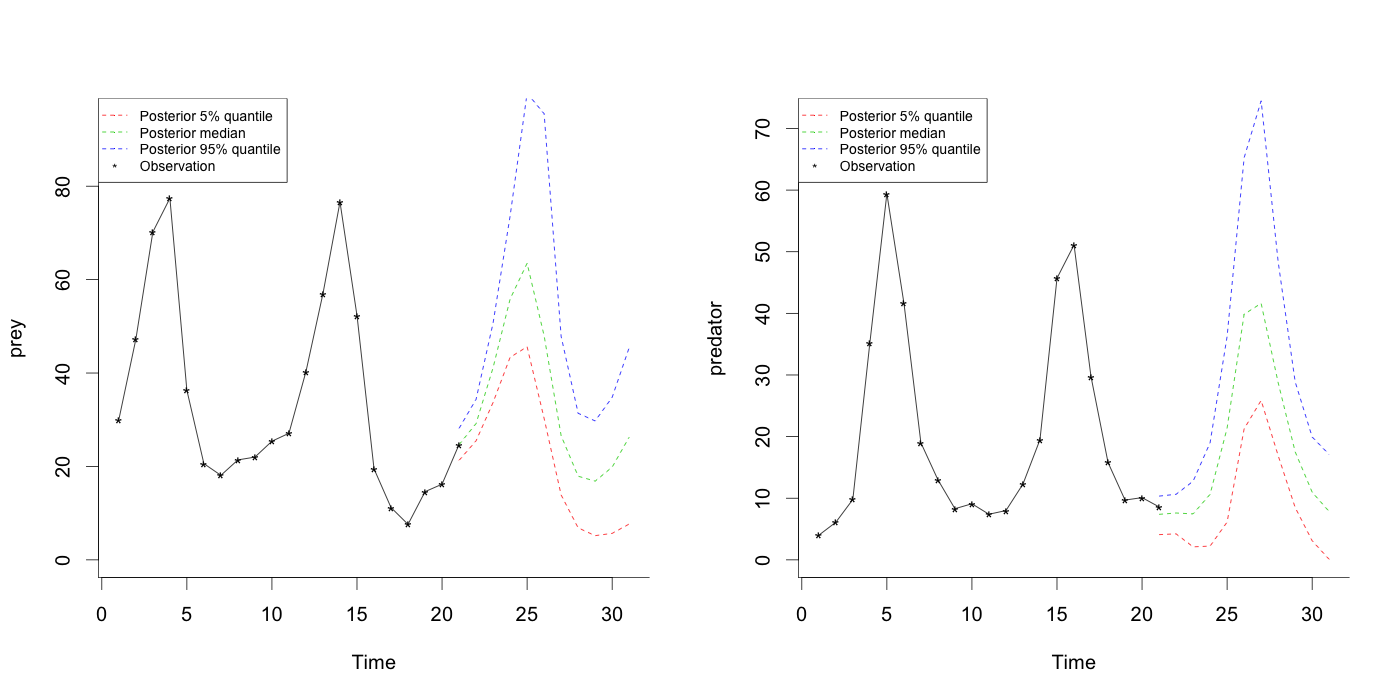 Figure 3
Figure 3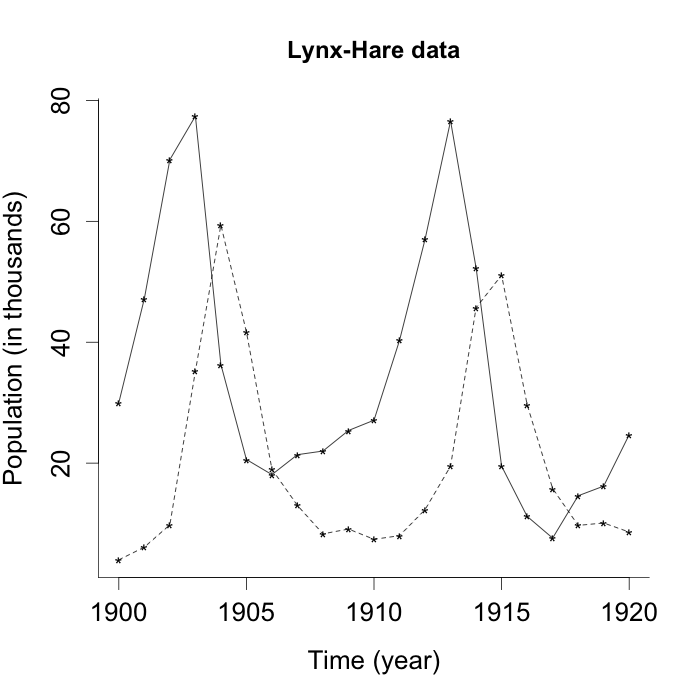 Figure 4
Figure 4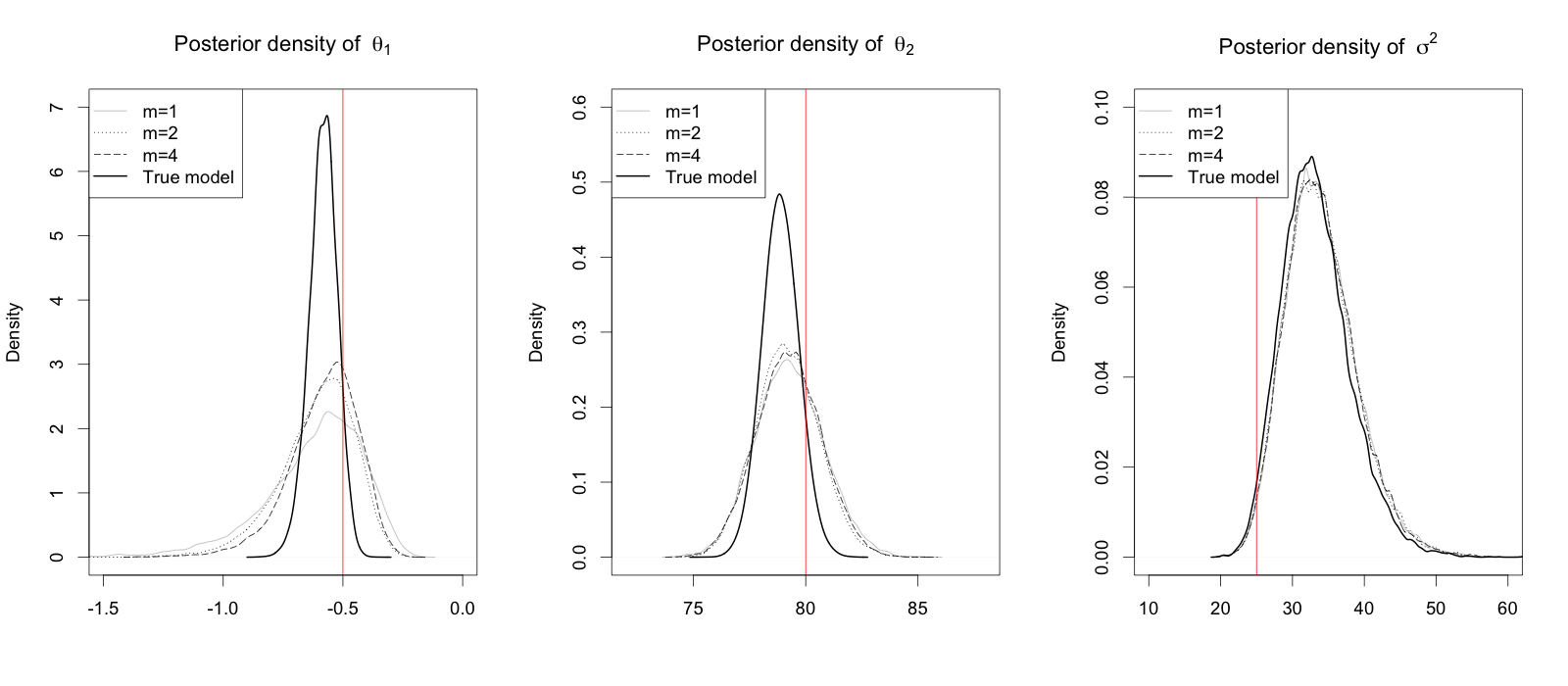 Figure 5
Figure 5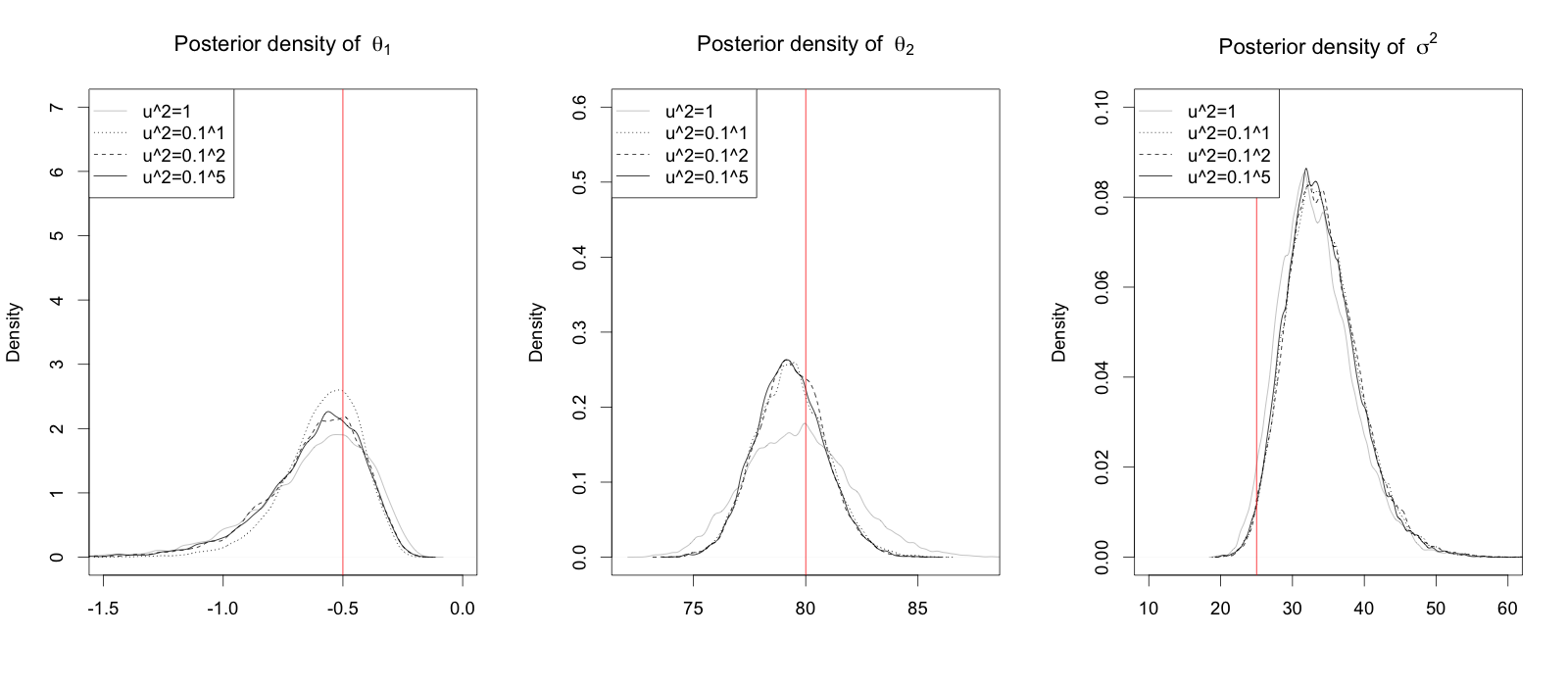 Figure 6
Figure 6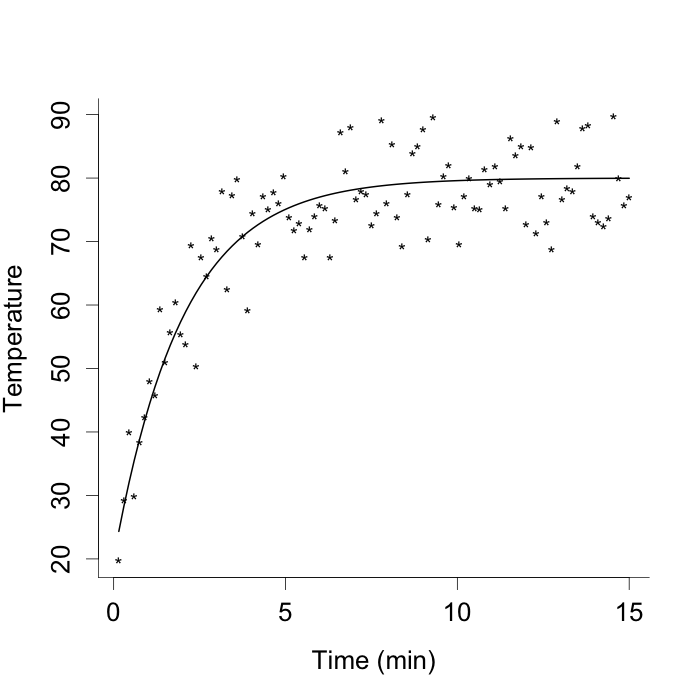 Figure 7
Figure 7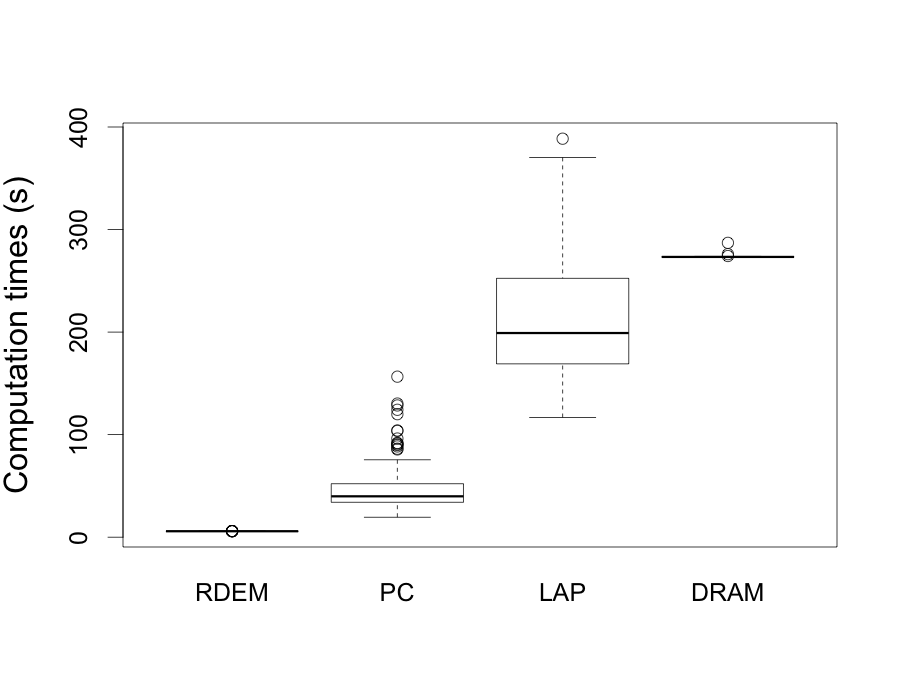 Figure 8
Figure 8| RDEM | PC | LAP | DRAM | ||
|---|---|---|---|---|---|
| Absolute bias | 0.051 | 0.024 | 0.024 | 0.024 | |
| 0.135 | 0.106 | 0.099 | 0.100 | ||
| 0.108 | 0.039 | 0.044 | 0.047 | ||
| Standard deviation | 0.063 | 0.027 | 0.027 | 0.028 | |
| 0.130 | 0.123 | 0.117 | 0.119 | ||
| 0.194 | 0.060 | 0.056 | 0.059 | ||
| rmse | 0.084 | 0.038 | 0.038 | 0.040 | |
| 0.198 | 0.171 | 0.161 | 0.164 | ||
| 0.233 | 0.076 | 0.075 | 0.079 | ||
| Mean | Median | 90% credible interval | |
|---|---|---|---|
| 0.526 | 0.525 | (0.491, 0.562) | |
| 0.026 | 0.026 | (0.024, 0.027) | |
| 0.986 | 0.985 | (0.906, 1.067) | |
| 0.028 | 0.028 | (0.026, 0.030) | |
| 4.087 | 3.818 | (2.018, 7.065) |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Inference for Differential Equation Models using Relaxation via Dynamical Systems
Kyoungjae Lee
Department of Applied and Computational Mathematics and Statistics, The University of Notre Dame
Jaeyong Lee
Department of Statistics, Seoul National University
Sarat Dass
Department of Fundamental and Applied Sciences, Universiti Teknologi PETRONAS
Abstract
Statistical regression models whose mean functions are represented by ordinary differential equations (ODEs) can be used to describe phenomenons dynamical in nature, which are abundant in areas such as biology, climatology and genetics. The estimation of parameters of ODE based models is essential for understanding its dynamics, but the lack of an analytical solution of the ODE makes the parameter estimation challenging. The aim of this paper is to propose a general and fast framework of statistical inference for ODE based models by relaxation of the underlying ODE system. Relaxation is achieved by a properly chosen numerical procedure, such as the Runge-Kutta, and by introducing additive Gaussian noises with small variances. Consequently, filtering methods can be applied to obtain the posterior distribution of the parameters in the Bayesian framework. The main advantage of the proposed method is computation speed. In a simulation study, the proposed method was at least 14 times faster than the other methods. Theoretical results which guarantee the convergence of the posterior of the approximated dynamical system to the posterior of true model are presented. Explicit expressions are given that relate the order and the mesh size of the Runge-Kutta procedure to the rate of convergence of the approximated posterior as a function of sample size.
Key words: Ordinary differential equation, Dynamic model, Runge-Kutta Method, Extended Liu and West filter
1 Introduction
Many dynamical phenomenons in the real world can be represented mathematically by ordinary differential equations (ODEs). Common examples include Newton’s law of cooling, Lotka-Volterra equations for predator-prey populations (Alligood et al., 1997) and Lorenz equation for atmospheric convection (Lorenz, 1963). There are many other popular examples describing physical, chemical and biological phenomenons using ODEs. Although observing the data sets from an ODE systems is common, estimating the parameters of ODE models (ODEMs) can be challenging because of lack of an analytical solution to ODE. Here, we give a brief review of previous works on the ODEMs.
There are several frequentist methods in the literature for parameter estimation of ODEMs. Bard (1974) used numerical integration to approximate the solution of ODEs and minimized the objective function based on a gradient method. Varah (1982) suggested a two step estimation method using the cubic spline approximation. The two steps consist of estimation of the regression function and estimation of the parameters in the ODEM. Ramsay and Silverman (2005) modified the first step of Varah by adding the roughness penalty function which measures the difference between the ODE and the mean function. The parameter cascading method was proposed by Ramsay et al. (2007). They grouped the parameters into the regression coefficients, structural parameters, and regularization parameters. The parameters in each group are estimated in turn in a cascading fashion.
Bayesian inference of ODEMs is more challenging because naive application of Markov Chain Monte Carlo (MCMC) methods would require calculation of the numerical solution of ODE whenever parameters are sampled from the proposal distribution. Gelman et al. (1996) and Huang et al. (2006) proposed a Bayesian computation method for parameter inference of pharmacokinetic models and the longitudinal HIV dynamic system, respectively. Campbell (2007) combined the parallel tempering (Geyer, 1991) and collocation method (Ramsay et al., 2007) to get over the rough surface of the posterior, but this slows down the speed of computations significantly. Arnold et al. (2013) used particle filter framework for the inference of ODEMs with linear multistep methods for the numerical integration. Dass et al. (2017) suggested a Bayesian inference with Laplace approximation for a fast computation when the dimension of is moderate.
In this paper, we propose a Bayesian inference method for the ODEMs using a relaxation technique via dynamical systems and associated dynamic models. Relaxation is achieved by a properly chosen numerical procedure, such as the Runge-Kutta, and by introducing additive Gaussian noise variables with variance tending to zero. The variance of the additive noise variables works as a measure of fidelity to the original ODEM and by letting it tend to zero, we recover the original model. The relaxation introduces inefficiency of the inference, but we gain the speed of the computation in return.
For a fast computation, a filtering method is applied for inferring posterior distributions of parameters in a Bayesian framework. The relaxation technique provides a dynamical system and model to which a fast inference tool based on sequential Monte Carlo can be applied to. With these sequential methods, we do not need to calculate the whole path of the numerical solution for each realization of the new parameter. It reduces the computation time significantly compared to other standard Bayesian procedures and enables us to deal with the ODEM in reasonable computing time. In subsection 5.2, to emphasize its fast computation the proposed method is compared with the other methods: the parameter cascading, the delayed rejection adaptive Metropolis algorithm and the Bayesian inference with the Laplace approximation. In the simulation study, the proposed method is from 14 times to 78 times faster than other methods.
We also derive convergence results for the approximated posteriors under suitable regularity conditions. We present a guideline for the choice of the model parameters which give a reasonable relative error rate, and provide its theoretical basis. Theoretical results which guarantee the convergence of the posterior of the approximated dynamical system to the posterior of true model are presented. Explicit expressions are given that relate the order and the mesh size of the Runge-Kutta procedure and guarantee the rate of convergence of the approximated posterior to the true posterior.
The rest of the paper is organized as follows. In section 2, we describe a differential equation model and its corresponding relaxed dynamic model counterpart as well as prior choices. The method of posterior inference is described in section 3. Some theoretical support for the proposed method are given in section 4. In section 5, we give two simulated data examples to demonstrate the speed and performance of the proposed method. A real data set, the Lynx-Hare data set, is analyzed in section 6. The discussion is given in section 7. The proofs of theorems are given in the appendix.
2 Ordinary Differential Equation Models and Nonlinear Dynamic Models
2.1 Ordinary Differential Equation Models (ODEMs)
The ODEM is the regression model with regression function described by an ODE. The regression function is the solution of the differential equation
[TABLE]
where is a -dimensional smooth function, is a deterministic input function, is the unknown parameter, and denotes the first derivative of with respect to time . Since the input function does not affect the general ideas of inference in this paper, it is not considered subsequently. The data are observed at points in the time interval , given by . Thus,
[TABLE]
where is a -dimensional observation vector at time , the error is drawn independently from the multivariate normal distribution with unknown , and is the underlying regression function measured at time .
The regression model is given by
[TABLE]
where . The covariate is determined by the initial value of , , and the parameter . In the rest of the paper, we call the model (2) as the regression model or the true model.
In most cases, ODE (1) does not have a closed form solution, so there is a need to approximate numerically. We will use the Runge-Kutta method which is a standard numerical method for ODE. While there are many types of Runge-Kutta methods, we will only consider the 4th order method in this paper. However, our proposed method can be extended to the other approximation methods for ODE as well as other Runge-Kutta methods with different orders easily. Letting , the form of 4th order Runge-Kutta approximation for (2) is as follows:
[TABLE]
where
[TABLE]
In the above equation, all ’s indicate the approximated values. For more details, see Spijker (1996).
With this approximation, we have the following model
[TABLE]
In the remainder of this paper, we call the model (4) as a differential equation model (DEM). Sometimes to obtain better approximation of , we divide the interval into small subintervals and apply the Runge-Kutta method for the subintervals. In this case, we will call the corresponding ODE model the step ODE model and the step size.
2.2 Nonlinear Dynamic Models
In practice, estimating the parameter from DEM can pose a significant computational challenge if the ODE does not have an analytical solution. Dass et al. (2017) marginalized out using Laplace approximation and conducted grid sampling to get posterior samples of . Their method is fast and accurate when the dimension of is small; however, the methodology suffers from heavy computations when the dimension of is large. The computation time increases exponentially as the dimension of increases due to the grid sampling. The griddy Gibbs sampler can be used on , but practical problems such as dependencies and slow convergence may arise.
In this paper, in order to make posterior inference on , we adopt a nonlinear dynamic model relaxation of the DEM in (4) given in terms of the model below with unknown initial condition :
[TABLE]
where and with . The error term reflects the fact that the approximation of is made with uncertainty. In the remainder of the paper, we call model (5) as the approximate dynamic model obtained as a relaxation of the DEM in (4) via the relaxation parameter . The quantities in (5) are not the same as given in (4) since the former are quantities that are observed with error whereas the latter are not. However, note that the two models (4) and (5) become equivalent as the relaxation parameter .
In the above model (5), there are four unknown quantities, namely, and . The Bayesian approach proceeds by considering priors for these quantities. We do not consider a prior for the relaxation parameter since it is artificially introduced to control the quality of the approximation. We fix to be a small positive quantity in the subsequent numerical computations. The priors on and are taken as
[TABLE]
where and represents the Gamma distribution with mean and variance . The prior for , , is taken independently of the rest of the unknown quantities above.
2.3 Sequential Monte Carlo
Sequential Monte Carlo (SMC) is a simulation-based method for estimating the states and the parameters of the nonlinear dynamic model. The basic idea of SMC is using the importance samples to approximate posterior at each state and updating the samples sequentially through a proper kernel. There exists an extensive literature on SMC which includes sequential importance sampling (Handschin and Mayne, 1969), bootstrap filter (Gordon et al., 1993), auxiliary particle filter (Pitt and Shephard, 1999), Rao-Blackwellised particle filter (Doucet et al., 2000), sequential Monte Carlo sampler (Del Moral et al., 2006), Liu and West filter (Liu and West, 2001), particle learning (Carvalho et al., 2010), multilevel sequential Monte Carlo sampler (Beskos et al., 2016), to name just a few. For an extensive review of SMC, see Doucet et al. (2001), Kantas et al. (2009), Lopes and Tsay (2011) or Särkkä (2013).
The SMC has advantages over other alternative posterior computation methods such as Kalman filter, extended Kalman filter and Markov chain Monte Carlo (MCMC). The Kalman filter and the extended Kalman filter are applicable to the linear dynamic model, while the SMC can be applied to the nonlinear dynamic model as well. The SMC has advantages over MCMC. First, SMC methods are much faster than MCMC methods. Whenever the new parameter is propagated in each stage of SMC, we only calculate the next step of the numerical solution. Fast computation is the biggest advantage of our method. Second, they are able to be implemented in an on-line learning scenario. When a new data point is observed, SMC just need to update one step of the algorithm, while MCMC must implement the whole algorithm again to get the new posterior samples. Due to these advantages, we choose SMC for the posterior computation of the nonlinear dynamic model, which approximates the ODE model.
3 Posterior Computations for the Approximate Dynamic Model via Sequential Monte Carlo
To obtain inference for based on the approximated dynamic model of (5), we will use the extended Liu and West (ELW) filter to estimate parameters and states (Rios and Lopes, 2013). We call the proposed method of computation relaxed DEM with ELW filter (RDEM-ELW) or simply RDEM. The ELW filter uses the idea of auxiliary particle filter to sample the states, and it divides the parameters into two sets, and , representing parameters with and without sufficient statistic, respectively. The parameters denoted by (i.e., without the sufficient statistic) is the same set of parameters denoted by in (5). For the -set, the ELW filter introduces artificial random errors onto the static parameter , thus converting and combining it with the other evolving parameters which are the states (see Liu and West, 2001). Furthermore, in the ELW filter, the marginal posterior of at each time point is approximated by a finite mixture of normal distributions. The mean and variance of the evolution distribution are determined so that the mixture of normals does not increase the posterior variance. For the posterior update of the -set of parameters, the idea of Storvik (2002) and Fearnhead (2002) is used. For the idea of ELW to be successfully applied, the posterior of , , needs to be tractable, that is from which samples can be drawn directly. In particular, we assume depends on a sufficient statistic .
Incorporating the evolution of into (5) according to the ELW methodology creates a further relaxation of the former model. The ELW model for the approximate dynamical model in (5) is given by
[TABLE]
for with and distributed according to its prior specification in (6). In (8), is as defined in (3), and is a small fixed positive real number representing the relaxation parameter. In (9), represents the posterior mean of given at time , where , is a discounting factor usually taken to be a high value such as or , and is the covariance matrix corresponding to the evolution equation of . Equation (9) is the further relaxation and evolution model for prescribed by the ELW methodology (see Liu and West, 2001). The selection of the parameters and guarantees that the posterior variance of remains stable (i.e., does not increase) with the progression of the time index .
Several posterior distributions will be needed for the subsequent discussion and we derive their forms here. Consider , the inverse of the variance of observation error. ELW methodology requires the distribution be tractable and easily sampled from. In our case, the posterior distribution for , conditional on observations , states and , is given by
[TABLE]
which is a tractable distribution. Note also from the above equation that the distribution of depends on and through the sufficient statistic , where and are all fixed and known hyperparameters (see (6)). Next, the two distributions, that is (i) the conditional distribution of given , , and , and (ii) the marginal distribution of given , and , can be obtained by considering the joint density of and , conditional on , and , from (7) and (8). From these two equations, it follows that is jointly normal, and thus, the conditional density of given is
[TABLE]
whereas the marginal distribution of given and , obtained by integrating out , is given by
[TABLE]
We now give the ELW algorithm for obtaining inference for based on the approximate dynamic model (5) and the posteriors defined above. Let the notation denote the conditional density of random entities (either scalars or vectors) conditional on either random or fixed constant entities . The ELW model of (7)-(9) can be written based on this notation as
[TABLE]
Equation (13)-(15) gives the joint distribution of conditional on the observations, states and -values at previous time points, that is,
[TABLE]
based on (13)-(15). The auxiliary particle filter (APF) technique rewrites this joint density as
[TABLE]
The first term on the right hand side of (16) is given by (11), thus available in closed form for sampling in our examples. The second term on the right hand side of (16) is given by (12), which is again available in closed form for evaluation in our examples. The third term in (16) is the Liu and West filter for given by (15), which can be easily sampled from. We give our sampling methodology to sample from the posteriors using sequential Monte Carlo. Suppose for are samples from the posterior . The subscript on does not imply any evolution equation for . It just denotes the random variable for marginal realizations of from the posterior . Similarly, denotes realizations of the sufficient statistic at time point based on its functional equation, namely, when and are samples from the posterior .
The steps of our sampling algorithm is as follows:
- •
First, sample according to (9) for .
- •
Compute weights for .
- •
Obtain resamples by sampling from the collection according to the weights .
- •
Sample for .
- •
Compute for .
- •
Sample for .
Then, it follows that the samples for are realizations from the posterior . As the tuning parameter , the posterior of at every time point from the approximate dynamic model becomes closer to the true posterior from the DEM.
As mentioned earlier, in the above algorithm, the subscripts on and do not imply any kind of evolution over time. They just represent the update of the parameter and statistic, respectively, as new data become available. The tuning parameter determines the extent of shrinkage of the normal mixture through its mean. It also controls the smoothness through the variance term . It is usually prescribed to be chosen around the value . The tuning parameter was fixed at throughout the rest of examples. This corresponds to taking and . For the covariance matrix , we chose .
The initial proposal density affects the performance of the algorithm. The proposal density which is concentrated around the true parameter has a better performance than the other proposal densities even with relatively small number of particles. In practice, we suggest that one run the ELW filter with initial particles and from and rerun with the particles and from the first inference. It is equivalent to consider the proposal density
[TABLE]
We call the resulting particles the refined particles. It was used throughout the rest of examples.
4 Convergence of the Posterior
4.1 Convergence of the Posterior as the relaxiation parameter decreases
In this subsection, we show that as the relaxation parameter converges to [math], the posterior density of from the approximate dynamic model converges to the posterior from the DEM, i.e.
[TABLE]
converges to
[TABLE]
as , where ,
[TABLE]
with . Note that is the posterior of DEM.
Theorem 4.1
Consider model (5) and prior (6). Suppose is continuous in . Then, the posterior density of the dynamic model (5) converges to that of the differential equation model (4), i.e.
[TABLE]
for all as .
4.2 Convergence of the Posterior as the step size increases
We have shown that the posterior of the dynamic model (5) converges to that of the differential equation model (4) as . In this subsection, we will prove that the posterior of the differential equation model converges to that of the true model.
If the step size is , each time interval is divided into segments of length , and the Runge-Kutta method is applied to each subinterval to obtain . To clarify the difference, let be the approximated solution of the differential equation by the fourth-order Runge-Kutta method with segments. Similarly, let and be the posterior distributions corresponding to and the true , respectively. Note for all .
Theorem 4.2
Consider model (4) and prior (6). Suppose satisfies Lipschitz condition in , i.e. there exists the constant such that
[TABLE]
for any and . Then, the posterior density of the differential equation model (4) converges that of the true model, i.e.
[TABLE]
for all as .
This result guarantees that the differential equation model works well with a reasonable segments parameter under the Lipschitz condition.
4.3 Choice of the relaxation parameter and the step size
In practice, the choice of and can affect the performance of the approximation. The approximate posterior distribution may vary by different choice of these values. Theoretically, the smaller the relaxation parameter is, the closer the approximate posterior is to the true posterior. But in practice we may need moderately large value of to get stable posterior approximation. We suggest following strategy for choosing the variance of state . Consider various values from large to small values in turn. For each value, check the stability of posteriors by running two or three ELW filters simultaneously. Here, the stability means that all posterior densities based on ELW runs are closed enough to each other. Finally, use the smallest value for the inference which gives the stable result.
For convenience, let for all . For the choice of , we assume . Theoretically, the larger value of gives more accurate inference, but it would require heavier computation. In the following theorem, we relate the step size to the approximation error rate of the posterior, and based on the theorem we suggest values of for computation according to the acceptable error rate. The theorem requires the following assumptions.
- A1.
is a compact subset of ;
- A2.
is a bounded subset of ; and
- A3.
the th order derivative of with respect to exists and is continuous in and , where is the order of the numerical method .
Theorem 4.3
Consider model (4) and prior (6). Suppose satisfies Lipschitz condition (19) in , and suppose hold. Let be the order of the numerical method and . If , the error rate of the posterior approximation is for sufficiently large , i.e.,
[TABLE]
for all , then is sufficient.
Note that the order of Runge-Kutta method is 4, and the rate of is because we consider a bounded time interval with . By the above theorem, if we want to get the error rate or larger, we know that it can be achieved by for large . However, in practice, one should notice that the additional error from the SMC sampling may arise. In such case, we may need to use bigger than .
5 Simulated Data Examples
5.1 Newton’s law of Cooling
5.1.1 Description of model and data generation step
Newton’s law of cooling, made by English physicist Isaac Newton, is a model describing the temperature change of an object. According to the model, the temperature of an object changes proportional to the temperature difference between the object and its surroundings. This notion is given by the following ODE form
[TABLE]
where is the temperature of the object at time , is a negative constant and is the temperature of the surroundings. All of the temperature are in Celcius. For more details, see Incropera (2006).
We chose this model as a testbed for our method. Since the solution of (20) is known as
[TABLE]
where , we can calculate the true posterior directly. The data was generated with the true mean function (21) and we set the model parameters as , , and time points for where the sample size and the step size . The simulated data and the true mean function are shown in Figure 1.
The priors were set by
[TABLE]
where and . The values of are in the interval after 50th observation, and the temperature of the surroundings, , must be the around the interval. The prior of is set by whose support includes . With a similar reasoning, we set .
The true posterior of and can be obtained as follows:
[TABLE]
where
[TABLE]
5.1.2 Assessment of the convergence of the posteriors
We assessed the convergence of posteriors which is described at Theorem 4.1. To show that the posterior of dynamic model converges to that of DEM, we got the simulation results for RDEM with and . The DEM was treated as a dynamic model with small value of . We ran the ELW filter based on 20,000 particles and fixed the number of segments at 1. For all of the settings, the ELW filter takes less than 3 seconds for 20,000 particles. The histogram of the marginal posterior distributions are drawn at Figure 2. It seems that the posterior of dynamic model approaches that of the DEM as decreases to zero. Thus, it supports the theoretical result, Theorem 4.1.
To show that the posterior of DEM converges to that of true model, we got the simulation results for the DEM with the number of segments and the true model. We approximated DEM by the dynamic model with . For the true model, we used a grid sampling algorithm for the true posterior (22). For each setting, the ELW filter takes less than 3 seconds for 20,000 particles. The grid set was chosen by , and each axis was divided into 50 equal length intervals resulting 51 points. 20,000 posterior samples were drawn. The histograms of the marginal posterior distributions are drawn at Figure 3. The posterior densities of DEM are quite similar to each other, but they have the larger variation than the true posterior densities.
5.2 FitzHugh-Nagumo model
5.2.1 Description of model and data generation step
FitzHugh-Nagumo model (FitzHugh, 1961; Nagumo et al. 1962) describes the action of spike potential in the giant axon of squid neurons by an ODE with two state variables and three parameters:
[TABLE]
where and . The two state variables, and , are the voltage across an membrane and outward currents at time , respectively.
Using the FitzHugh-Nagumo model, we compare the proposed method with the parameter cascading method (Ramsay et al., 2007), the delayed rejection adaptive Metropolis (DRAM) algorithm (Soetaert and Petzoldt, 2010) and the Laplace approximated posterior (LAP) method (Dass et al., 2017). The data was generated from DEM (4) with the model parameters , and time points for , where the sample size and the step size , . The simulated data and the true mean function are shown in Figure 4. The priors were set by
[TABLE]
where , and .
5.2.2 Comparison with other methods
To compare the proposed method (RDEM-ELW) with other methods, the parameter cascading (PC) method, DRAM algorithm and LAP method were applied to the same data set. We used the R packages CollocInfer and FME for the parameter cascading and DRAM, respectively.
The PC method is one of the popular frequentist methods for estimating the parameters in ODE. It uses the collocation method which represents the state vector as a series of basis expansion. The penalized likelihood criterion has three components: the matrix of coefficients of basis expansions , the unknown parameter and the smoothing parameter . PC optimizes the penalized likelihood by two steps. In the inner optimization, the criterion is optimized with respect to the coefficient while and are fixed. After that, in the outer optimization, the penalized likelihood is optimized with respect to while is kept fixed. The smoothing parameter is chosen based on the appropriate criteria such as the numerical stability of parameter estimates or the forward prediction error (Hooker et al., 2000). For more details about PC method, see Ramsay et al. (2007). For the PC method, we used the third-order B-spline basis and equally spaced knots on . The smoothing parameter was set by . The initial parameter were drawn from where is the true parameter value.
The DRAM algorithm, a variant of the standard Metropolis-Hastings algorithm (Metropolis et al., 1953; Hastings, 1970), is chosen as a benchmark in the Bayesian side. With the R package FME (Soetaert and Petzoldt, 2010), one can infer the DEM with DRAM algorithm for the parameters and numerical integration for the state variables. We applied the DRAM algorithm with the initial parameter as the maximum likelihood estimate using modFit() function and the maximal number of tries 1. The parameter covariance was updated in every 100 iteration. We got 20,000 posterior samples for the inference.
LAP method is another benchmark in the Bayesian side. It is fast when the dimension of parameter is small and empirically has comparable or better performance than PC method and DRAM algorithm (Dass et al., 2017). Since the dimension of parameter is small, the grid sampling method for was chosen. For each parameter , the grid range was chosen by where is the parameter estimate for from the PC method. Each axis was divided into intervals of equal length, and the step size for numerical integration was set at . The priors for parameters were set as in subsection 5.2.1, and 20,000 posterior samples were obtained.
For the RDEM-ELW, the step size for numerical integration and the variance for the state were chosen by and , respectively. The priors for parameters were set as described in subsection 5.2.1, the number of particles was chosen by . We generated 100 simulated data set using the 4th order Runge-Kutta. The model parameters were set as described in subsection 5.2.1.
For RDEM, PC and DRAM methods, R and C/C were used for implementation. R and Fortran90 were used for LAP method. On average based on 100 simulations, it took only 3.523 seconds for estimation, while the PC method, DRAM algorithm and LAP method took 49.152, 276.700 and 215.591 seconds, respectively. The boxplot of computation times for each method is given at Figure 5. The proposed RDEM method significantly reduced the computation time. It was even faster than the frequentist method, the PC method. Thus, the RDEM method has an enormous advantage in computation speed over other methods. Table 1 represents the absolute biases, standard deviations for and root mean squared errors (rmse) for in the FitzHugh-Nagumo model. It seems RDEM method provides reasonable estimates in terms of bias, but larger standard deviation than others.
6 Lynx-hare data: Lotka-Volterra equation
There are large number of models to express predator-prey relationships because predation is often direct, conspicuous and easy to study. Lotka-Volterra model is one of the simplest model of predator-pray interactions. Lotka (1925) and Volterra (1926) independently developed the model of the form:
[TABLE]
where denotes the number of preys, and denotes the number of their predators. The model parameters and are the intrinsic rate of prey population increase, the predation rate, the predator mortality rate and the offspring rate of the predator, respectively.
Lynx-hare data is a popular data set representing the number of captured lynx and snowshoe hares in North Canada which was collected by Hudson Bay company. It contains the number of furs of lynx and hares, so it implies the actual populations of them. We obtained the annual data between 1900 and 1920 recorded in thousands from Li (2012) which is given at Figure 6. The Lotka-Volterra equation, the equation (23), is fitted to the data set and used to predict the future values of trapped lynxes and hares.
The same model and prior in subsection 5.2 were used. As we mentioned in subsection 4.3, we ran the ELW filter 10 times based on particles with and , in turn. In this case, values smaller than lead somewhat unstable approximation even with 3,000,000 particles. Finally, the state variance was chosen by based on the criterion in subsection 4.3, because it gives stable posterior densities for each ELW run. The other model parameters were chosen as the subsection 5.2. On average, it took approximately 17 seconds for each run.
The marginal posterior densities of parameters are given at Figure 7. Posterior summary statistics for the first run are represented at Table 2. Figure 8 contains the scatter plots of the observations and 90% posterior credible lines for prediction values at 10 future time points when and . The predicted values of trapped lynxes and hares follow oscillation patterns. The size of prediction interval gets wider as the prediction time gets further ahead and also the predicted value become larger.
7 Discussion
A lot of biological or physical systems are given by a set of differential equations. To understand these processes, estimation of their parameters is essential. However, especially in Bayesian literature, there is no standard framework to analyze differential equation model. In many cases, the posterior of parameter does not belong a well-known family, so grid sampling or MCMC methods are used to get posterior samples. They usually suffer from heavy computation. We propose a general framework to analyze DEM using relaxation via dynamical systems. The dynamic model enables a fast inference for DEM and provides convenient sampling methods. Among the sampling algorithms for dynamic models, we adopted the ELW filter suggested by Rios and Lopes (2013). We argue that our method can be an alternative to the existing inference methods when one needs a fast and reasonable result. This argument is supported by the example in subsection 5.2. Section 4 guarantees the convergence of the approximated posterior to the true posterior. However, the theoretical results in this paper does not consider the additional error from the SMC sampling. The proposed method may be improved if a better SMC algorithm is developed.
Appendix
The following lemma shows that each given converges to in probability as .
Lemma 7.1
Consider model (5). Then, for , given and converges to in probability as .
- Proof of Lemma 7.1
Note that for all . If we denote as a moment generating function (mgf) of random variable , then for any ,
[TABLE]
as , for . Note that (24) is mgf of . Since the convergence of mgf implies the convergence of distribution, it implies
[TABLE]
for any . Hence, by the Cramer-Wold theorem (Billingsley, 1995), it implies that converges to in distribution, as . Note that given and , is a constant. Thus, by Portmanteau theorem (Dudley, 2002), it implies the convergence in probability.
With the continuity condition of in , Lemma 7.1 can be extended to the joint convergence in probability using the mathematical induction. Lemma 7.2 describes the result.
Lemma 7.2
Consider model (5). Suppose is continuous in . Then, converges to in probability as .
- Proof of Lemma 7.2
Let and where
[TABLE]
by the relation (3) where is defined recursively. We want to show
[TABLE]
for given . It suffices to prove
[TABLE]
for given and . We use the mathematical induction.
When , we can check
[TABLE]
by Lemma 7.1. Suppose (26) holds for . Note
[TABLE]
By assumption, is continuous in . Thus, (28) converges to 0 as because (26) holds for . Also note that (27) is
[TABLE]
Since and Lemma 7.1, (27) converges to 0 as by the bounded convergence theorem.
- Proof of Theorem 4.1
Note that we need to prove
[TABLE]
as where .
To show (29), we only need to prove
[TABLE]
as . Since , it suffices to prove
[TABLE]
By Lemma 7.2, we have
[TABLE]
as . Note that the right hand side of (31) is the expectation of with respect to . Also note that is bounded by 1 and is continuous in . Thus, the Portmanteau theorem implies (29).
Since we have proved (29), it suffices for (30) to show that is dominated by an integrable random variable. It is easy to check because
[TABLE]
and is integrable with respect to . The dominated convergence theorem gives the desired result.
- Proof of Theorem 4.2
Denote the likelihood of approximated with the number of segments as , and let be the likelihood of true . We should prove that
[TABLE]
converges to
[TABLE]
for any and . It is well known that if satisfies Lipschitz condition in , then Runge-Kutta method converges to the true solution, i.e.
[TABLE]
See Cartwright and Piro (1992) for the proof. The convergence (32) implies that converges to for all and because an exponential function is continuous. It implies the convergence of numerator part.
For the denominator part, recall that
[TABLE]
and is integrable with respect to . Again, the dominated convergence theorem gives the desired result.
- Proof of Theorem 4.3
At first, we want to show that under , for sufficiently large . Since we assume the Lipschitz continuity of , the ODE has a unique solution with initial condition . Assumptions A1 and A3 implies
[TABLE]
for some constants . The local errors of the th order numerical method are given by
[TABLE]
for some , which depends only on (Palais and Palais, 2009). Thus, the local errors are uniformly bounded. It implies the global errors uniformly bounded by
[TABLE]
for some constant . Thus,
[TABLE]
where , for sufficiently large .
By the above inequality, for fixed ,
[TABLE]
because for sufficiently small . It implies
[TABLE]
for sufficiently large . If , then we have .
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] K.T. Alligood, T.D. Sauer, and J.A. Yorke. Chaos: An Introduction to Dynamical Systems . Chaos: An Introduction to Dynamical Systems. Springer, 1997.
- 2[2] Andrea Arnold, Daniela Calvetti, and Erkki Somersalo. Linear multistep methods, particle filtering and sequential monte carlo. Inverse Problems , 29(8):085007, 2013.
- 3[3] Yonathan Bard. Nonlinear parameter estimation . Academic Press [A subsidiary of Harcourt Brace Jovanovich, Publishers], New York-London, 1974.
- 4[4] Alexandros Beskos, Ajay Jasra, Kody Law, Raul Tempone, and Yan Zhou. Multilevel sequential monte carlo samplers. Stochastic Processes and their Applications , 2016.
- 5[5] P. Billingsley. Probability and Measure . Wiley Series in Probability and Statistics. Wiley, 1995.
- 6[6] D.A. Campbell. Bayesian Collocation Tempering and Generalized Profiling for Estimation of Parameters from Differential Equation Models . Canadian theses. Mc Gill University (Canada), 2007.
- 7[7] Julyan H. E. Cartwright and Oreste Piro. The dynamics of runge-kutta methods. Int. J. Bifurcation and Chaos , 2:427–49, 1992.
- 8[8] Carlos M. Carvalho, Michael Johannes, Hedibert F. Lopes, and Nicholas Polson. Particle learning and smoothing. Statistical Science , pages 88–106, 2010.