Error-Sensitive Proof-Labeling Schemes
Laurent Feuilloley, Pierre Fraigniaud

TL;DR
This paper introduces error-sensitive proof-labeling schemes that ensure the number of nodes detecting illegal states scales linearly with the distance from legality, improving fault detection and recovery in distributed networks.
Contribution
It provides a structural characterization of predicates with error-sensitive schemes and demonstrates that classical schemes for spanning trees are error-sensitive under certain representations.
Findings
Error-sensitive schemes exist for predicates like acyclicity and leader election.
Classical spanning tree schemes are error-sensitive with adjacency list representations.
Not all predicates, such as regular subgraphs, admit error-sensitive schemes.
Abstract
Proof-labeling schemes are known mechanisms providing nodes of networks with certificates that can be verified locally by distributed algorithms. Given a boolean predicate on network states, such schemes enable to check whether the predicate is satisfied by the actual state of the network, by having nodes interacting with their neighbors only. Proof-labeling schemes are typically designed for enforcing fault-tolerance, by making sure that if the current state of the network is illegal with respect to some given predicate, then at least one node will detect it. Such a node can raise an alarm, or launch a recovery procedure enabling the system to return to a legal state. In this paper, we introduce error-sensitive proof-labeling schemes. These are proof-labeling schemes which guarantee that the number of nodes detecting illegal states is linearly proportional to the edit-distance between…
Click any figure to enlarge with its caption.
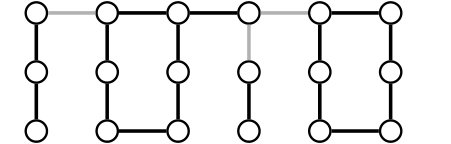 Figure 1
Figure 1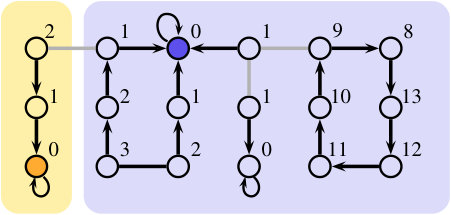 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsCryptography and Data Security · Complexity and Algorithms in Graphs · Distributed systems and fault tolerance
\hideLIPIcs\nobibliography
Univ. Lyon, Université Lyon 1, LIRIS UMR CNRS 5205, F-69621, Lyon, [email protected]://orcid.org/0000-0002-3994-0898 Institut de Recherche en Informatique Fondamentale (IRIF), Université de Paris and CNRS, [email protected]
\fundingANR ESTATE (ANR-16-CE25-0009-03), and ANR GrR (ANR-18-CE40-0032).
\ccsdesc[100]
Error-Sensitive Proof-Labeling Schemes111A preliminary version of this paper appeared in the proceedings of the 31st International Symposium on Distributed Computing (DISC), October 16-20, 2017, Vienna, Austria.
Laurent Feuilloley
Pierre Fraigniaud
Abstract
Proof-labeling schemes are known mechanisms providing nodes of networks with certificates that can be verified locally by distributed algorithms. Given a boolean predicate on network states, such schemes enable to check whether the predicate is satisfied by the actual state of the network, by having nodes interacting with their neighbors only. Proof-labeling schemes are typically designed for enforcing fault-tolerance, by making sure that if the current state of the network is illegal with respect to some given predicate, then at least one node will detect it. Such a node can raise an alarm, or launch a recovery procedure enabling the system to return to a legal state.
In this paper, we introduce error-sensitive proof-labeling schemes. These are proof-labeling schemes which guarantee that the number of nodes detecting illegal states is linearly proportional to the Hamming distance between the current state and the set of legal states. By using error-sensitive proof-labeling schemes, states which are far from satisfying the predicate will be detected by many nodes. We provide a structural characterization of the set of boolean predicates on network states for which there exist error-sensitive proof-labeling schemes. This characterization allows us to show that classical predicates such as, e.g., cycle-freeness, and leader admit error-sensitive proof-labeling schemes, while others like regular subgraphs do not. We also focus on compact error-sensitive proof-labeling schemes. In particular, we show that the known proof-labeling schemes for spanning tree and minimum spanning tree, using certificates on bits, and on bits, respectively, are error-sensitive, as long as the trees are locally represented by adjacency lists, and not just by parent pointers.
keywords:
Fault-tolerance, distributed decision, distributed property testing
1 Introduction
In the context of fault-tolerant distributed computing, it is desirable that the computing entities in the system be able to detect whether the system is in a legal state (w.r.t. some boolean predicate, potentially expressed in various forms of logics) or not. In the framework of distributed network computing, several mechanisms have been proposed to ensure such a detection (see, e.g., [1, 2, 4, 5, 31]). Among them, proof-labeling schemes [31] are mechanisms enabling failure detection based on additional information provided to the nodes. More specifically, a proof-labeling scheme is composed of a prover, and a verifier. A prover is a non-trustable oracle that assigns a certificate to each node of any given network, and a verifier is a distributed algorithm that locally checks whether the collection of certificates is a distributed proof that the network is in a legal state with respect to a given predicate – by “locally”, we essentially mean: by having each node interacting once with its neighbors.
The prover is actually an abstraction. In practice, the certificates are provided by a distributed algorithm solving some task (see, e.g., [3, 6, 31]). For instance, let us consider spanning tree construction, where every node must compute a pointer to a neighboring node such that the collection of pointers form a tree spanning all nodes in the network. In that case, the algorithm in charge of constructing a spanning tree is also in charge of constructing the certificates providing a distributed proof allowing a verifier to check that proof locally. That is, the verifier must either accept or reject at every node, under the following constraints. If the constructed set of pointers form a spanning tree, then the constructed certificates must lead the verifier to accept at every node. Instead, if the constructed set of pointers does not form a spanning tree, then, for every possible certificate assignment to the nodes, at least one node must reject. The rejecting node may then raise an alarm, or launch a recovery procedure. Abstracting the construction of the certificates thanks to a prover enables to avoid delving into the implementation details relative to the distributed construction of the certificates, for focusing attention on whether such certificates exist, and on what should be their forms. The reader is referred to [7] for more details about the connections between proof-labeling schemes and fault-tolerant computing.
One weakness of proof-labeling schemes is that they may not allow the system running the verifier to distinguish between a global state which is slightly erroneous, and a global state which is completely bogus. In both cases, it is only required that at least one node detects the illegality of the state. In the latter case though, having only one node raising an alarm, or launching a recovery procedure for bringing the whole system back to a legal state, might be quite inefficient. Instead, if many nodes would detect the errors, then bringing back the system into a legal state may be achieved by a collection of local resets running in parallel, instead of a single reset traversing the whole network sequentially.
In this paper, we aim at designing error-sensitive proof-labeling schemes, which guarantee that system states that are far from being correct can be detected by many nodes. More specifically, the distance between two global states of a distributed system is defined as the Hamming distance between these two states, i.e., the minimum number of individual states that must be modified in order to move from one global state to the other. A proof-labeling scheme is error-sensitive if there exists a constant such that, for any erroneous system state , the number of nodes detecting the error is at least , where is the shortest Hamming distance between and a correct system state. The choice of a linear dependency between the number of nodes detecting the error, and the Hamming distance to legal states is not arbitrary, but motivated by the following two observations.
- •
On the one hand, a linear dependency is somewhat the best that we may hope for in general. Indeed, let us consider a -node network in some illegal state with , for which nodes are detecting the illegality of , for some function . Think about vertex-coloring, in which one needs to modify the colors of at least nodes in order to get a proper coloring. Then, let us make copies of and of its state , potentially linked by additional edges if one insists on connectivity. In the resulting -node network , at most nodes are detecting the non legality of the global state of . However, is typically at distance from any legal state (think again about proper vertex-coloring). It follows that, essentially, , that is, the number of nodes detecting an error cannot grow faster than linearly with the distance to the legal states.
- •
On the other hand, while a sub-linear dependency may still be useful in some contexts, this would be insufficient in others. For instance, let us consider the same construction as above, with for some . As grows to infinity, the ratio between the number of nodes that are asked to detect errors in and the number of nodes in the network goes to zero. This results in significantly decreasing the impact of having more than one node detecting the illegality of the current system state, as the number of nodes detecting errors becomes negligible anyway in front of the total number of nodes, even for scenarios in which the distance to legal states grows linearly with the total number of nodes.
1.1 Our results
We consider boolean predicates on graphs with labeled nodes, as in, e.g., [35]. Given a graph , a labeling of is a function assigning binary strings to nodes. A labeled graph is a pair where is a graph, and is a labeling of . Given a boolean predicate on labeled graphs, the distributed language associated to is:
[TABLE]
It is known that every (Turing decidable) distributed language admits a proof-labeling scheme [25, 31]. We show that the situation is radically different when one is interested in error-sensitive proof-labeling schemes. In particular, not all distributed languages admit an error-sensitive proof-labeling scheme. Moreover, the existence of error-sensitive proof-labeling schemes for the solution of a distributed task is very much impacted by the way the solution is encoded. For instance, in the case of spanning tree construction, we show that asking every node to produce a single pointer to its parent in the tree cannot be certified in an error-sensitive manner, while asking every node to produce the list of its neighbors in the tree can be certified in an error-sensitive manner.
Our first main result is a structural characterization of the distributed languages for which there exist error-sensitive proof-labeling schemes. Namely, a distributed language admits an error-sensitive proof-labeling scheme if and only if it is locally stable. The notion of local stability is purely structural. Roughly, a distributed language is locally stable if a labeling resulting from copy-pasting parts of correct labelings to different subsets of nodes in a graph results in a labeled graph that is not too far from being legal. Here “not too far” means that the Hamming distance between and is proportional to the size of the boundary of the subsets in , and not to the size of these subsets. For the sake of concreteness, let us give an intuition about why a spanning tree encoded by a list of neighbors is a locally stable language. Consider a graph partitioned into connected induced subgraphs such that only a small fraction of the nodes are on the boundary of a subgraph (i.e., are having a neighboring node in another subgraph). Now, let us consider a spanning tree in each of the subgraphs. The union of these spanning trees is not a spanning tree, but it is not far from being a spanning tree. Indeed, it is acyclic, and we can simply add edges to make it connected. To do so, we only modify the adjacency list of vertices that are on the boundaries, thus the distance between the original instance and the modified one is smaller than the sum of the sizes of the boundaries. (This example is actually simplified, as it assumes that the trees in each component are correct, i.e., connected, and without cycles, which may not be the case.) Our characterization allows us to show that important distributed languages (e.g., acyclicity, leader, etc.) admit error-sensitive proof-labeling schemes, while some very basic distributed languages (e.g., regular subgraph, etc.) do not admit error-sensitive proof-labeling schemes.
Unfortunately, the error-sensitive schemes constructed for locally stable languages in the proof of our characterization result are not efficient in terms of certificate size. We investigate the question of whether it is possible to get error-sensitivity with small certificates. For this purpose, we focus on two essential languages: spanning tree, which is a building block for many proof-labeling schemes, and minimum spanning tree, which is arguably one of the most important problems in distributed network computing.
We show that the known space-optimal proof-labeling schemes for spanning tree with -bit certificates, and for minimum spanning tree (MST) with -bit certificates, are both error-sensitive, whenever the trees are encoded at each node by an adjacency list (and not by a single pointer to the parent). Hence, error-sensitivity comes at no cost for spanning tree and MST. Proving this result requires to establish some kind of matching between the erroneously labeled nodes and the rejecting nodes. Establishing this matching is difficult because, for both spanning tree and MST, the rejecting nodes might be located far away from the erroneous nodes. Indeed, the presence of certificates helps local detection of errors, but decorrelates the nodes at which the alarms take place from the nodes at which the errors take place. For example, in an erroneous spanning tree that is disconnected, it may be the case that only one node is detecting the error, and that this node is far from a place where disconnection can be fixed by adding an edge. (See Section 6 for a discussion about proximity-sensitive proof-labeling schemes). In the case of MST, the space-optimal proof-labeling schemes uses independent layers of certification, and this a challenge for error-sensitivity. Indeed, because detection and correction could happen in different places, the following scenario cannot be ruled out directly. It could be the case that: (1) every layer of certification is broken, but (2) only one vertex rejects (because all the parallel verifications reject on the same vertex), and (3) to fix the instance, we would need to modify the input of different vertices. In short, we could have one vertex rejecting but distance , which would prevent error-sensitivity. Our result demonstrates that this situation cannot appear.
1.2 Related work
As mentioned before, one important motivation for our work is fault-tolerant distributed computing, with the help of failure detection mechanisms such as proof-labeling schemes. Proof-labeling schemes were introduced in [31]. A tight bound of bits on the size of the certificates for certifying MST was established in [28, 29]. Several variants of proof-labeling schemes have been investigated in the literature, including verification at distance greater than one [25], and the design of proofs with identity-oblivious certificates [19]. Connections between proof-labeling schemes and the design of distributed (silent) self-stabilizing algorithms were studied in [7]. Extensions of proof-labeling schemes for the design of (non-silent) self-stabilizing algorithms were investigated in [30]. In all these work, the number of nodes susceptible to detect an incorrect configuration is not considered, and the only constraint imposed on the error-detection mechanism is that an erroneous configuration must be detected by at least one node. Our work requires the number of nodes detecting an erroneous configuration to grow linearly with the number of errors. As mentioned earlier, having several nodes detecting an error allows to launch a reset from several nodes at once. See [8, 11] for references on such collaborative resets. Note that taking into account how far from a correct configuration the network is, is not a new idea. Indeed there is a literature on fault-containment or fault-locality (see, e.g., [21, 32]), where the focus is on having correction algorithms that use little resources if there are just a few faults, or if these fault are grouped together somehow. In particular, [21] defines a notion of “small-scale” faults, for which the system can converge to a correct solution without modifying the states of the nodes that are far from the faulty nodes. Our work has a different objective, that is, making sure that incorrect global states resulting from many incorrect local states must be detected by many nodes, while incorrect global states resulting from just a few incorrect local states may be detected by few nodes only.
A line of work closely related to this paper is property testing. Centralized property testing for graph properties was investigated in numerous papers (see [22, 23] for an introduction to the topic). Distributed property testing has been introduced in [9], and formalized in [10] (see also, e.g., [13, 20]). In both centralized and decentralized property testing, the decision regarding whether the labeled input graph satisfies a given property (e.g., cycle-freeness) is typically relaxed: if the graph satisfies the property then all centralized queries, or all nodes must accept, and if the graph is far from satisfying the property (e.g., it contains many cycles), then at least one centralized query, or at least one node must reject. The notion of “far” depends on the context. The one adopted in the distributed setting is defined by the sparse model, specifying that a graph is -far from satisfying a property if any modification up to a fraction of the edges results in a graph that is still not satisfying the property. The goal is then to distinguish graphs that satisfy the property from graphs that are -far from satisfying the property. In some sense, property testing can be viewed as efficiently approximating the solution of a hard problem (e.g., NP-hard), while proof-labeling schemes can be viewed as establishing that the problem is complete (e.g., NP-complete). Centralized property testing was actually extended to a non-deterministic setting [26, 33] in which the centralized algorithm is provided with a centralized certificate. In error-sensitive proof-labeling schemes, we try to get the best of both worlds, that is, if the input graph is far from satisfying the property, then, whatever are the certificates provided to the nodes by the prover, a large number of nodes must reject the instance. The farness notion used in distributed property testing refers to the edges, while we use a farness notion related to the nodes, but the two notions are essentially the same in bounded-degree graphs.
From a higher perspective, our approach aims at closing the gap between local distributed computing and centralized computing in networks, by studying distributed error-detection mechanisms that perform locally, but generate individual outputs that are related to the global correctness of the system at hand. As such, it is worth mentioning other efforts in the same direction, including especially work in the context of centralized local computing, like, e.g., [14, 24, 36]. Finally, distributed property testing and proof-labeling schemes are different forms of distributed decision mechanisms (e.g., distributed interactive proofs [27, 34]), which have been investigated under various models for distributed computing. We refer to [16] for a survey on distributed decision, and to [15] for a more introductory text.
2 Model and definitions
Throughout the paper, all graphs are assumed to be connected and simple (no self-loops, and no parallel edges). Given a node of a graph , we denote by the open neighborhood of , i.e., the set of neighbors of in . In some contexts (as, e.g., MST), the considered graphs may be edge-weighted.
All results in this paper are stated in the classical local model [37] for distributed network computing, where networks are modeled by undirected graphs whose nodes model the computing entities, and edges model the communication links. Recall that the local model assumes that nodes are given distinct identities (a.k.a. IDs), and that computation proceeds in synchronous rounds. All nodes simultaneously start executing the given algorithm. At each round, nodes exchange messages with their neighbors, and perform individual computation. There are no limits placed on the message size, nor on the amount of computation performed at each round. Specifically, we are interested in proof-labeling schemes [31], which are well established mechanisms enabling to locally detect inconsistencies in the global states of networks with respect to some given boolean predicate. Such mechanisms involve a verification algorithm which performs in just a single round in the local model. In order to recall the definition of proof-labeling schemes, we first recall the definition of distributed languages [19].
A distributed language is a collection of labeled graphs, that is, a set of pairs where is a graph, and is a labeling function assigning a binary string to each node of . Such a labeling may encode just a boolean (e.g., whether the node is in a dominating set or not), or an integer (e.g., in graph coloring), or a collection of neighboring IDs (e.g., for locally encoding a subgraph). In the latter case, or whenever encodes a set of nodes at each vertex, we may slightly abuse notation by viewing as an actual set of nodes, i.e., by considering . A distributed language is said to be constructible if, for every graph , there exists such that . It is Turing decidable if there exists a (centralized) algorithm which, given returns whether or not. All distributed languages considered in this paper are always assumed to be constructible and Turing decidable.
Given a distributed language , a proof-labeling scheme for is a prover-verifier pair , where is an oracle assigning a certificate function to every labeled graph , and is a 1-round distributed algorithm222That is, every node outputs after having communicated with all its neighbors only once. taking as input at each node its identity , its label , and its certificate , such that, for every labeled graph the following two conditions are satisfied:
- •
If then outputs accept at every node of whenever all nodes of are given the certificates provided by ;
- •
If then, for every certificate function , outputs reject in at least one node of .
The first condition guarantees the existence of certificates allowing the given legally labeled graph to be globally accepted. The second condition guarantees that the verifier cannot be “cheated”, that is, an illegally labeled graph will systematically be rejected by at least one node, whatever “fake” certificates are given to the nodes. It is known that every distributed language has a proof-labeling scheme [31].
To define the novel notion of error-sensitive proof-labeling schemes, we introduce the following notion of distance between labeled graphs. Let and be two labelings of a same graph . The Hamming distance between and is the minimum number of elementary operations required to transform into , where an elementary operation consists of replacing a node label by another label. That is, the Hamming distance between and is simply
[TABLE]
The Hamming distance from a labeled graph to a language is the minimum, taken over all labelings of satisfying , of the Hamming distance between and . Note that “Hamming distance” is usually defined for words of equal length, by counting the number of characters that must be changed for moving from one word to another word. We use the same terminology in this paper as our distance measures the minimum number of nodes whose states have to be modified to transform a given global state into another global state . (Instead, distance such as the Edit distance would rather refer to the numbers of edges to be added or deleted for transforming one graph into another.)
Roughly, an error-sensitive proof-labeling scheme satisfies that the number of nodes that reject a labeled graph should be (at least) proportional to the distance between and the considered language.
Definition 2.1**.**
A proof-labeling scheme for a language is error-sensitive if there exists a constant , such that, for every labeled graph ,
- •
If then outputs accept at every node of whenever all nodes of are given the certificates provided by ;
- •
If then, for every certificate function , outputs reject in at least nodes of , where is the Hamming distance between and , i.e., \mathsf{d}=\mbox{\rm dist}\big{(}(G,\ell),{\cal L}\big{)}.
Note that the nodes rejecting a labeled graph do not need to be the same for all certificate assignments. Also note that, as far as this first study of the notion of error-sensitivity is concerned, we are mostly interested in the existence of some constant , and not much in the exact value of . However, it is worth keeping in mind that the larger , the better the error-detection mechanism is, i.e., it is desirable to design protocol for which is large. For this paper, our focus is a first attempt to explore the notion of error-sensitivity, thus we have not tried not optimize the constants. Nevertheless, we shall explicitly state what values for the sensitivity were used for establishing each of our theorems.
3 Basic properties of error-sensitive proof-labeling schemes
In this section, we explore basic properties of error-sentivity. First, we show that some proof-labeling schemes are error-sensitive (Theorem 3.1), but that some other proof-labeling schemes are not error-sensitive (Theorem 3.3). More precisely, Theorem 3.3 shows that even if a language has an error-sensitive proof-labeling scheme, not all proof-labeling schemes for that language have this property. Second, we show that if a language has an error-sensitive proof-labeling scheme, then the so-called universal scheme also has this property (Lemma 3.5). This implies that for checking whether there exists an error-sensitive scheme for a given language, we can just check whether the universal scheme for that language is error-sensitive. We use this fact for proving that there exist languages that do not have error-sensitive proof-labeling schemes (Theorems 3.7 and 3.9).
Let us first illustrate the notion of error-sensitive proof-labeling scheme by exemplifying its design for a classic example of distributed languages. Let acyclic be the following distributed language (which is a mere relaxation of spanning tree):
[TABLE]
That is, the label of a node is interpreted as a pointer to some neighboring node, or to null. Then if the subgraph of described by the set of non-null pointers is acyclic. We show that acyclic has an error-sensitive proof-labeling scheme. The proof of this result is easy, as fixing of the labels can be done locally, at the rejecting nodes. Nevertheless, its proof serves as a basic example illustrating the notion of error-sensitive proof-labeling scheme.
Theorem 3.1**.**
acyclic* has an error-sensitive proof-labeling scheme, with sensitivity 1.*
Proof 3.2**.**
Let . Every node belongs to an in-tree rooted at a node such that . The prover provides every node with its distance to the root of its in-tree (i.e., number of hops to reach the root by following the pointers specified by ). The verifier proceeds at every node as follows: first, it checks that ; second, it checks that, if then , and if then . If all these tests are passed, then accepts. Otherwise, it rejects. By construction, if is acyclic, then all nodes accept with these certificates. Conversely, if there is a cycle in , then let be a node with maximum value in . Its predecessor in (i.e., the node with ) rejects. So is a proof-labeling scheme for acyclic. We show that is error-sensitive. Suppose that rejects at nodes. Let us replace the label of each rejecting node by the label , and keep the labels of all other nodes unchanged, i.e., for every node where accepts. We have . Indeed, by construction, the label of every node in has a well-formatted label . Moreover, let us assume, for the purpose of contradiction, that there is a cycle in . By definition, every node of this cycle is pointing to . Thus for every node of , from which it follows that no nodes of was rejecting with , a contradiction with the fact that, as observed before, rejects every cycle. Therefore . Hence the Hamming distance between and acyclic is at most . It follows that is error-sensitive, with sensitivity parameter .
The definition of error-sensitiveness is based on the existence of a proof-labeling scheme for the considered language. However, two different proof-labeling schemes for the same language may have different sensitivity parameters . In fact, we show that every non-trivial language admits a proof-labeling schemes which is not error-sensitive. That is, the following result shows that demonstrating the existence of a proof-labeling scheme that is not error-sensitive for a language does not prevent that language to have another proof-labeling scheme which is error-sensitive. We say that a distributed language is trivially approximable if there exists a constant such that every labeled graph is at Hamming distance at most from .
Theorem 3.3**.**
Let be a distributed language. Unless is trivially approximable, there exists a proof-labeling scheme for that is not error-sensitive.
Proof 3.4**.**
Let be a non trivially approximable distributed language. Given a labeled graph , let be a spanning tree of . It is folklore (cf., e.g., [4, 31]) that can be certified by a proof-labeling scheme where the certificate assigned to each node consists of a pair where is the ID of a node picked as the root of , and the hop-distance in from to . The verifier checks the distances the same way as it does in the proof of Theorem 3.1 (which guarantees the absence of cycles). In addition, every node checks that it agrees with its neighbors in the graph about the ID of the root (which guarantees that is not a forest with more than one tree). At every node, if all these tests are passed at that node, then it accepts, else it rejects.
We now prove that every proof-labeling scheme for can be transformed into a proof-labeling scheme for which is not error-sensitive. On a legal instance , the prover selects a spanning tree of , and provides every node with:
the certificate that the prover would assign to for , denoted by ; 2. 2.
the local description of the tree , together with the corresponding certificate; 3. 3.
a boolean , set to .
The verifier checks the correctness of the spanning tree , and rejects if it is not correct. From now on, we assume that is correct. The verifier then outputs accept or reject according to the following rules.
At every node distinct from the root of , accepts if and only if one of the two conditions below is fulfilled:
- (a)
, and either rejects at , or a child of in satisfies ; 2. (b)
, accepts at , and for every child of in . 2. 2.
At the root of , the verifier rejects if and only if
- (a)
* rejects, or a child of satisfies .*
By construction, if then accepts at all nodes, when provided with the appropriate certificates, because, with these certificates, all booleans are , and accepts at all nodes.
If , then rejects in at least one node if the given certificates do not encode a spanning tree . Therefore, let us assume that the given certificates correctly encode a spanning tree , rooted at . Since , there exists at least one node where rejects. Let be a node where rejects, such that rejects at no other nodes on the shortest path from to in . If , then, since rejects, we get that rejects as well. So, let us assume that . Let with , , and be the shortest path from to in . For to accept at , it must be the case that . The same holds at each node along the path: For to accept at , , it must be the case that . This leads to reject at . Therefore, is a proof-labeling scheme for .
We now show that is not error-sensitive. Let . Let be a spanning tree of , rooted at node . We provide the nodes with the proper description of and the certificates to certify . We also provide the nodes with arbitrary certificates for . Then we provide the nodes with the following “fake” boolean certificates that we assign by visiting the nodes of the tree bottom-up, as follows. Let be a node:
if rejects at or a child of in satisfies , then set ; 2. 2.
else set .
In this way, only the root of can reject. Therefore, with such certificates, even instances that are arbitrarily far from will be rejected by a single node. It follows that is not error-sensitive, as claimed.
Recall that the fact that every distributed language has a proof-labeling scheme can be established by using a universal proof-labeling scheme (see [25]). Given a distributed language , the universal proof-labeling scheme is defined as follows. On a legal instance , where has vertices, the prover assigns a certificate to every node . Specifically, the prover orders the vertices from to arbitrarily, and is a vector with entries indexed from 1 to where is the ID of the -th node . Then, is the label of the -th node . Finally, is the adjacency matrix of , where the -th raw (and -th column) corresponds to the -th vertex in . The prover assigns to every node . The verifier then checks at every node that its certificate is consistent with the certificates given to its neighbors (i.e., they all have the same , , and , the indexes match with the IDs, and the actual neighborhood of is as it is specified in , and ). If this test is not passed, then outputs reject at , otherwise it outputs accept or reject according to whether the labeled graph described by is in or not. It is easy to check that is indeed a proof-labeling scheme for .
The universal scheme uses large certificates, of size . We are interested in the design of proof-labeling schemes using significantly smaller certificates.
The universal proof-labeling scheme has the following nice property, that we state as a lemma for further references in the text.
Lemma 3.5**.**
If a distributed language has an error-sensitive proof-labeling scheme, then the universal proof-labeling scheme applied to is error-sensitive.
Proof 3.6**.**
Let be an error-sensitive proof-labeling scheme for , and let be the universal proof-labeling scheme for . Let . We show that is at least as good as with respect to the number of rejecting nodes. Specifically, we show that if rejects at nodes for some certificate function , then there exists a certificate function such that rejects in at most nodes. We now describe how to construct the certificate assignment , on . Given any node , the definition of the certificate depends on the behavior of and its neighbors in the universal scheme with certificate .
- •
The first case is when accepts at , with certificate . Let be the graph described by , and be the labeling of that correspond to . Since accepts, we have is in . The certificate is the certificate that the prover would assign to if it were in .
- •
The second case is when: (1) rejects at , and (2) is adjacent to at least one node at which accepts . Note that this situation can occur only under special circumstances. The fact that accepts means that and were given the same triplet , and that this triplet corresponds to a correct instance of the language. Therefore, the fact that rejects can only come from the fact that its neighborhood does not match the description of this neighborhood in . As before, we set as the certificate assigned to node by in the labeled graph . Note that if is adjacent to two different nodes and at which accepts, then these two nodes and share the same certificates . Hence the definition of at is well defined.
- •
The third case is when none of the previous two cases apply. In this case is set to .
Let us now consider the behavior of on with certificates . We observe that for a node in which accepts, its certificate is consistent with the certificates of all its neighbors, and thus, in particular, and its neighbors share the same labeled graph representation . Therefore, the certificates assigned to and its neighbors are consistent with respect to . It follows that every node at which accepts with certificate function satisfies that accepts at with certificate function . This implies the Lemma.
While every distributed language has a proof-labeling scheme, we show, using Lemma 3.5, that there exist languages for which there are no error-sensitive proof-labeling schemes.
Theorem 3.7**.**
There exist languages that do not admit any error-sensitive proof-labeling scheme.
Proof 3.8**.**
We show that there exist languages such that, for every proof-labeling scheme for , and every , there exists a labeled graph at Hamming distance at least from , and a certificate function , such that rejects with certificate in at most a constant number of nodes. We consider labeled graphs where encodes a subgraph of as follows. The label of node is a list of neighbors of in , such that
[TABLE]
Such a labeling defines a subgraph of where every edge of is in that subgraph if and only if is in the list of . For a given , we define as the subgraph described by . Now, let us consider the language
[TABLE]
Let us assume, for the purpose of contradiction, that there exists an error-sensitive proof-labeling scheme for regular. From Lemma 3.5, it follows that the universal scheme is error-sensitive for regular. We show that this is not the case.
Let and be two distinct integers. Let be a regular graph of degree , and let be a copy of . Let , and let be the corresponding edge in . We construct the graph , obtained from and , by removing and , and adding and . By construction, is -regular. Similarly, we can construct a -regular graph from a -regular graph and its copy . We denote by and the edges connecting to its copy in . For , let be the labeling of the nodes of such that . We have
[TABLE]
Let be the graph obtained from and by removing from , removing from , and adding the edges and . Again, let us consider the labels assigned to the nodes of with . Since , we have
[TABLE]
Now, let us assign to the nodes of in the certificates assigned by to the nodes of in . Similarly, let us assign to the nodes of in the certificates assigned by to the nodes of in . With such certificates, only the four nodes , , , and , can detect an inconsistency between their certificates and the certificates of their neighborhoods. Therefore only these nodes may reject when running . Therefore, at most nodes reject. On the other hand the distance between and regular is at least as large as . This distance can be made arbitrarily large, while the number of rejecting nodes remains constant. Hence, the universal proof-labeling scheme is not error-sensitive.
Remark. The language regular used in the proof of Theorem 3.7 to establish the existence of languages that do not admit any error-sensitive proof-labeling schemes actually belongs to the class LCL of locally checkable labelings [35]. Therefore, the fact that a language is easy to check locally does not help for the design of error-sensitive proof-labeling schemes.
We complete this warmup section by some observations regarding the encoding of distributed data structures. Let us consider the following two distributed languages, both corresponding to spanning tree. The first language, , encodes the spanning trees using pointers to parents, while the second language, , encodes the spanning trees by listing all the incident edges of each node in these tree.
[TABLE]
[TABLE]
Obviously, is just a compressed version of as the latter can be constructed from the former in just one round. However, note that cannot be recover from in a constant number of rounds, because provides a consistent orientation of the edges in the tree. It follows that is an encoding of spanning trees which is actually strictly richer than . This difference between and is not anecdotal, as we shall prove later that admits an error-sensitive proof-labeling scheme, while we show hereafter that is not appropriate for the design of error-sensitive proof-labeling schemes.
Theorem 3.9**.**
* does not admit any error-sensitive proof-labeling scheme.*
Proof 3.10**.**
In this proof, we will write to denote the fact that the pointer encoded in the label of is pointing towards node . Let be the -node path with even. Let , and be labelings defined by:
- •
* for all , and ;*
- •
* for all , and ;*
- •
and for all , for all , and .
We have and . The distance from to is at least . Indeed, let us modifying to get a correct instance . Suppose, w.l.o.g., that the root of the tree described by is among the first half of the nodes. Then, to get from to , all the pointers of the second half have to be changed, which means that the certificates in at least nodes must be modified.
Let be a proof-labeling scheme for . Consider the case of where every , , is given the certificate assigned by to in , and every , , is given the certificate assigned by to in . With such certificates, all nodes for have the exact same view as in , and all nodes for have the exact same view as in . Therefore all these nodes must accept. Hence, can only be rejected by at the two nodes and .
4 Characterization
In this section, we define a notion of local stability for languages (Definition 4.4), and show that being locally stable is equivalent to the fact of having an error-sensitive scheme (Theorem 4.5). Then, we discuss a simpler but less general version of local stability, that we call strong local stability. Finally, we give several examples of application of our equivalence therorem.
Roughly, local stability captures whether a patchwork of several correct instances (with a small contact area between the instances), can be a “very incorrect” instance, or an “almost correct” instance. For example, the language regular from the previous section in non locally stable, because, by gluing together two regular graphs, one can get a graph that is very far from being regular whenever the original graphs have different degrees.
In order to define the notions of local stability, we need to formalize the notion of a “patchwork of solutions” and of “contact area”. Let be a graph, and let be a subgraph of , that is, a graph such that , and . We first define partial labelings and induced labelings (see Figure 1).
Definition 4.1** (Partial labeling).**
Given a labeling of a graph , and a subgraph of , the partial labeling denotes the labeling of induced by restricted to the nodes of :
[TABLE]
Definition 4.2** (Induced labeling).**
Let be a graph, and let be a family of connected subgraphs of such that is a partition of . For every , let us consider a labeled graph such that is a subgraph of . Let be the following labeling of : for every , where is such that . We say that such a labeled graph is induced by the labeled graphs , , via the subgraphs .
We also define a notion of boundary.
Definition 4.3** (Boundary).**
Let be a graph, and be a subgraph of . The boundary of in , denoted by is the set of nodes of that are incident to an edge in .
We are now ready to define local stability.
Definition 4.4**.**
A language is locally stable if there exists a constant , such that, for every labeled graph and for every , the following holds. For every labeled graphs , , and every subgraphs , such that is induced by the labeled graphs via the graphs , , the following holds:
[TABLE]
Intuitively the definition says that by taking pieces of labelings from different correct instances (that might not use the same underlying graph), we get a labeling whose distance to the language is at most the size of the boundary between the pieces, up to some multiplicative constant. Note that measures the size of the boundary of the -th piece in the patchwork instance, but also in the correct instance it comes from.
Our characterization is the following.
Theorem 4.5**.**
Let be a distributed language. admits an error-sensitive proof-labeling scheme if and only if is locally stable.
More precisely, we establish that a language with sensitivity is locally stable with parameter , and that a language with local stability is error-sensitive with parameter . We do not know whether these relations are tight or not.
Proof 4.6**.**
We first show that if a distributed language admits an error-sensitive proof-labeling scheme then is locally stable. So, let be a distributed language, and let be an error-sensitive proof-labeling scheme for with sensitivity parameter . Let be a labeled graph induced by labeled graphs , , via the subgraphs for some . Since, for every , , there exists a certificate function such that accepts at every node of provided with the certificate function . Now, let us consider the labeled graph , with certificate on every node for all . With such certificates, the nodes in that are not in have the same close neighborhood in and in . Therefore, they accept in the same way they accept in . It follows that the number of rejecting nodes is bounded by , and therefore is at Hamming distance at most from . Hence, is locally stable, with parameter .
It remains to show that if a distributed language is locally stable then it admits an error-sensitive proof-labeling scheme. Let be a locally stable distributed language with parameter . We prove that the universal proof-labeling scheme for (cf. Section 3) is error-sensitive for some parameter depending only on . Let , and let us fix some certificate function . The verifier rejects in at least one node. We show that if rejects at nodes, then the Hamming distance between and is at most for some constant depending only on . For this purpose, let us consider the outputs of applied to with certificate , and let us define the graph as the graph obtained from by removing all edges for which rejects at both extremities. Note that the graph may not be connected.
Let be a connected component of , with at least one node at which accepts. Recall that we used the notation for the certificates of the universal scheme (cf. Section 3). We claim that all the vertices of have received the same certificate . Indeed, if it is not the case, then, by connectivity there exist two vertices that are adjacent in , and that do not have the same certificate. This is a contradiction. Indeed, these two vertices would have detected the inconsistency, and would have both rejected, thus the edge between them would have been removed. We denote by the labeled graph described by . In addition, since accepts in at least one node , it must be that . Finally, we prove that is a subgraph of , and that the labeling and coincide on . Consider an edge of . Necessarily, at least one of its endpoints is accepting (otherwise this edge would have been removed). If the vertex accepts, it means that this edge exists in , and that both endpoints have the same label in and .
Let us now consider the other possibility: is a connected component of where all nodes reject. By construction, such a component is composed of just one isolated node. For every such isolated rejecting node , let us denote by a labeled graph composed of a unique node, with ID equal to the ID of , and with labeling such that .
Let be the set of all connected components of . Note that is a partition of the vertices of , and that we established that for every , is a subgraph of , and the labelings and coincides on . Therefore we can legally define as the graph induced by labeled graphs via the subgraphs . By local stability, we get the following:
[TABLE]
Now, let us consider the number of nodes rejecting . By construction, the nodes in are exactly the nodes that are rejecting , thus:
[TABLE]
Finally, again by construction, the Hamming distance between and is at most the number of isolated rejecting nodes, which implies:
[TABLE]
Putting all the pieces together we get:
[TABLE]
In other words, the universal proof-labeling scheme is error-sensitive, with parameter .
Theorem 3.7 can be viewed as a corollary of Theorem 4.5 as it is easy to show that regular is not locally stable. Nevertheless, local stability may not always be as easy to establish, because it is based on merging an arbitrary large number of labeled graphs. We thus consider another property, called strong local stability, which is easier to check, and which provides a sufficient condition for the existence of an error-sensitive proof-labeling scheme. Given two labeled graphs and , and a subgraph of both and , we define a third labeling of , that we call . For every node :
[TABLE]
To avoid double subscript, in the following we will sometimes use superscripts instead of subscripts for sequences, e.g., instead of .
Definition 4.7**.**
A language is strongly locally stable if there exists a constant , such that, for every graph , and every two labeled graphs and admitting as a subgraph, the labeled graph is at hamming distance at most from .
The following theorem states that strong local stability is indeed a notion that is at least as strong as local stability.
Theorem 4.8**.**
If a language is strongly locally stable, then it is locally stable.
Proof 4.9**.**
Let us consider a strongly locally stable language , with parameter , and a labeled graph induced by labeled graphs , , via the subgraphs . We will establish that , which is the condition of local stability.
For a labeling of , let be the distance between the labelings and , restricted to (in other words the label differences in do not count for ). We consider two sequences of labelings of , for , and for . They are defined iteratively in the following way. We take to be an arbitrary labeling such that . For , is a labeling such that , and:
[TABLE]
Finally, we set
[TABLE]
Note that this labeling satisfies the distance inequality, because is always zero. To prove our result, it is sufficient to show that we can indeed define the sequence , . Indeed, if we get to , then since and , Equation 1 transforms into , and because the sets are disjoint, the right-hand side is equal to , which is what we want.
By induction, suppose that we have built a proper . To define , we take and copy the labeling of on a still untouched subgraph . Therefore:
[TABLE]
We take to be a labeling such that is in , and the distance between and is minimized. By strong local stability, since and are legal labelings for , we get that:
[TABLE]
Putting the Equations 2 and 3 together, by triangle inequality, we get:
[TABLE]
That is, we get Equation 1 at index , which proves the theorem by induction.
In fact, strong local stability is a notion strictly stronger than local stability, although they coincide on bounded-degree graphs.
Theorem 4.10**.**
There are languages that are locally stable but not strongly locally stable. However, all locally stable languages on bounded degree graphs are strongly locally stable.
Proof 4.11**.**
Let us define a language to prove the first part of the theorem. As earlier in the paper (e.g., in the proof of Theorem 3.7), a proper labeling for describes a set of edges . Here, in addition, every node is also assigned a color: blue or red. The labeling is in the language if every connected component of is monochromatic.
This language has a proof-labeling scheme with empty certificates. The verifier simply checks that is well-defined, and that every neighbor in has been given the same color. In addition, this scheme is error-sensitive. This is because, for every inconsistency in the description of , or any edge of that is not monochromatic, both endpoints reject. As a consequence, if every rejecting node modifies its local description of by removing the faulty edges, the new labeling is in the language. In turn, this means that the distance from the language is upper bounded by the number of rejecting nodes. By Theorem 4.5, we know that the language is locally stable.
We show that is not strongly locally stable. Consider a graph that is a star with leaves. Now, consider two labelings and where , and all the nodes are blue in and red in . Let be a subgraph of with the center and leaves. We note that is at distance from . This is because the best we can do is to edit the labels of all the vertices of . On the other hand, contains only one node, the center. As we can make arbitrarily large, the condition of strong local checkability cannot be fulfilled.
We now show that all locally stable languages on bounded degree graphs are strongly locally stable. Let , and let be the family of graphs with maximum degree . Let be a locally stable language on graphs in . Let us consider a connected graph , and two labeled graphs and , with , and , both admitting as a subgraph. Let be the labeled graph induced by and via the subgraph . We view as induced by and via the subgraphs and . By local stability, we get that the distance from to is at most . (Note that for , is both the original graph, and the one that induces the labeling, hence there is just one border to consider.) Now, , because each edge from the cut must have an endpoint in and these endpoints have degree at most . As a consequence the distance from to is at most , and the strong local stability follows.
We do not have examples of “natural” languages that are locally stable but not strongly locally stable. In fact, the rest of this section is devoted to using strong local checkability applied to various “natural” languages. Let us give an example where strong local stability is useful for easily proving error-sensitivity. Consider the following language.
[TABLE]
Corollary 4.12**.**
leader* admits an error-sensitive proof-labeling scheme.*
Proof 4.13**.**
Consider an arbitrary graph , and two labeled graphs and in leader. On the one hand, in , there can be only 0, 1, or 2 vertices with . On the other hand, is at least 1, by connectivity. Therefore we get that is at Hamming distance at most from the language, thus that language is strongly locally stable, and the corollary follows from Theorems 4.5 and 4.8.
Also, one can show that the language of spanning trees, whenever encoded by adjacency lists, admits an error-sensitive proof-labeling scheme, in contrast to Theorem 3.9.
Corollary 4.14**.**
* admits an error-sensitive proof-labeling scheme.*
Proof 4.15**.**
We show that is strongly locally stable. Let us consider two labeled graphs and , both admitting as a subgraph. We show that is not far from . For this purpose, we aim at modifying the labels of few nodes so that to form a spanning tree of . First, for every node , we modify such that the label of becomes consistent with its neighborhood in . That is, all edges listed in the label exist in , and they match edges listed by the neighbors of in . After this modification, which impacts only nodes, the resulting labeling of the nodes in encodes a set of edges . However, may not be a spanning tree, as it may include cycles, and may even be not connected.
Let be the graph obtained from after removing all edges in , and all nodes in . Note that and . The set is equal to the union of the edges described by on , and of the edges described by on . Indeed consider an edge . If both endpoints of are in , then this edge is encoded by at its two endpoints, as the labels of these endpoints are copied from , and the modification of performed at the nodes in does not impact such nodes. If has both endpoints in then, by the same reasoning, this edge is encoded by at its two endpoints. If has both endpoints in , then the modification of performed at the nodes in this latter set did not affected edge , which implies that was originally encoded in . Finally, if has one endpoint in , and the other one outside , then, from by the modification of , the edge was present in in at least one of its extermities.
As is the labelling of a spanning tree of , restricted to is a spanning forest of . Similarly, as is a spanning tree of , restricted to is a spanning forest of . Also, since , it follows that, in both forests, every tree contains a node of . Let us denote by , , and the number of nodes, edges, and connected components of restricted to , respectively. Similarly, let us denote by , , and the same parameters for . Since the connected components of restricted to , and to , are forests, we get that:
[TABLE]
Moreover, since each connected component contains a node of the border, we get
[TABLE]
Now, let us consider the whole set , and let us define , , and as the number of nodes, edges, and connected components of , respectively. By definition, . Thus, by Eq. (4), we get that
[TABLE]
Moreover, by definition, . Therefore,
[TABLE]
We can now bound the number of edges that we need to remove from in order to get a spanning forest (with the same number of connected components). For such a forest, it must hold that its number of edges, , satisfies . Therefore,
[TABLE]
where the last equality holds by Eq. (5). Thus, by removing at most edges from , we get a spanning forest of with at most connected components. Therefore, by adding edges, one can construct a spanning tree of . So, in total, transforming into a spanning tree required to modify at most edges. This may impact the labels of at most nodes. As the labels of the nodes in were also modified at the very beginning of the construction, it follows that the number of node labels impacted by our spanning tree construction is at most . It follows that is strongly locally stable with parameter at most 9, which implies that it admit an error-sensitive proof-labeling scheme with sensitivity parameter at least , by Theorem 4.5, and Theorem 4.8.
Also, Theorem 4.5 allows us to prove that minimum-weight spanning tree (MST) is error-sensitive (whenever the tree is encoded locally by adjacency lists). More specifically, let
[TABLE]
Corollary 4.16**.**
* admits an error-sensitive proof-labeling scheme.*
Proof 4.17**.**
We show that is strongly locally testable. Let us consider a graph , and two labeled graphs and admitting as a subgraph. We show that the labeled graph is not far from . Let be the spanning tree of defined by the set of edges defined by , and let be the spanning tree of defined by the set of edges defined by . Let the edge set defined by on , after the same modification of that labeling on the nodes of as in the proof of Corollary 4.14, i.e., the labels of are modified so that the adjacency lists of these nodes in their labels match the labels of their neighbors. Let be the graph defined as in the proof of Corollary 4.14, that is, is the graph obtained from after removing all edges in , and all nodes in . Note that is obtained from the union of the two forests that came from and , on and , respectively. Hence, every connected component of contains a node in .
Recall that Kruskal algorithm constructs an MST by considering the edges in increasing order of their weights, and by adding the currently considered edge to the current set of edges if and only if this edge does not create a cycle with the previously added edges. It is known that every MST of a graph can be generated by Kruskal algorithm, by breaking ties between edges of identical weight in a way to add all edges of the desired MST. Let be the ordering of the edges of that leads to the tree , and let be the ordering of the edges of that leads to the tree . Let , be the same ordering as but restricted to the edges of .
Let be the graph obtained from by adding a new node connected to every node of by edges with weights smaller than the smallest weight in and in . Let be the ordering of obtained by concatenating to an arbitrary ordering of the edges incident to . Let be the MST of that Kruskal algorithm constructs in when it uses the ordering . Also let be a copy of , let be the MST constructed by Kruskal algorithm on using . Finally, we define the ordering of the edges of as the ordering such that the edges of appear in the same order as in , the edges of appear in the same order as in , and the edges of have priority. Let be the spanning tree defined by Kruskal algorithm on with . is necessarily equal to on the edges of because they are MST of the same graph, and because the edges of have priority in . We claim the following:
Claim 1**.**
The following inclusions hold.
[TABLE]
[TABLE]
Before proving Claim 1, let us show how to complete the proof using that Claim. By Claim 1, on , can be transformed into by changing only edges of . Moreover and are a spanning forests of with at most trees in it, because, as in the proof of Corollary 4.14, every tree contains at least a node of . We get that
[TABLE]
Therefore, restricted to the graph , the tree can be transformed into the tree by adding or removing at most edges. Now, as is equal to on , can be transformed into by changing at most edges. Thus is at Hamming distance at most from a MST of . Since the modification we made at the very beginning to ensure the consistency of the labels affected at most nodes, it follows that the Hamming distance from to the language is most , and thus the language is strongly locally stable. This completes the proof of Corollary 4.16, assuming Claim 1.
It just remains to prove Claim 1. We show the two sets of inclusion at once. Let be either or , and let be the ordering of the edges which makes Kruskal algorithm build or . Note that, by construction, , , and are consistent on the edges that they have in common, i.e., on all the edges of . Let be an ordering that is consistent with the three orderings , and . We can run Kruskal algorithm on the three instances , and with . Let , and let , and , be the subset of edges in , , and , respectively, that have been added to the current tree by Kruskal algorithm before considering the th edge in . We show, by induction on , that the three following properties hold for every :
P1:
;
P2:
if two nodes of are linked by a path in then they are linked by a path in ;
P3:
if two nodes of are linked by a path in then they are linked by a path in .
These properties are trivially true for , as all sets , and are empty. Suppose that P1, P2, and P3 hold are true for , and consider -th edge considered by Kruskal algorithm in for , and or . We consider two cases.
Consider first the case where . Then appears either only in , or only in . If appears only in , then independently of whether Kruskal algorithm takes or not, the three properties P1, P2, and P3 hold for . If appears only in , then, clearly, P1 and P2 hold for . The only scenario for which P3 may not hold for is if is added to , and this addition creates a new path between two nodes and of , while there are no paths between and in . Let us show that this does not happen. Indeed, since , such a path must pass through the border of , which is included in (this holds for both choices for , that is, either or ). In particular adding to the set of edges taken by Kruskal algorithm so far connects two nodes of the border of . Now, all the nodes of are already connected in . Indeed, the edges of have smaller weights. Therefore, all the nodes of are connected in , and thus it is not possible that there is a path created by adding in that does not already exists in .
Second, consider the case . Then appears in all the orderings. Let us consider two subcases depending on whether or not is taken in .
- •
If is taken in , then is not closing a cycle in , and thus, thanks to P2, is not closing any cycle in either. Thus is also taken in , and P1 holds. P2 still holds as well since is added to both sets. If is taken in then P3 holds. Instead if is not taken in , then its two extremities were already linked by a path, and P3 also holds.
- •
If is not taken in , then closes a cycle in . Therefore, by P3, also closes a cycle in , and thus it is not taken in either, and P1 holds. P3 still holds as we have added no edges to . If is not taken in then P2 holds. And if is taken in , then the fact that is not taken in implies that the nodes were already connected, and thus again P2 holds.
This completes the proof of Claim 1, and thus the proof of Corollary 4.16.
5 Compact error-sensitive proof-labeling schemes
The characterization of Theorem 4.5 together with Lemma 3.5 implies an upper bound of bits on the certificate size for the design of error-sensitive proof-labeling schemes for locally stable distributed languages. In this section, we show that the certificate size can be drastically reduced in certain cases. As said in the introduction, we focus on the spanning tree and minimum spanning tree problems, as they play a central role in the theory of proof-labeling schemes, and in distributed computing in general. It is known that these languages have proof-labeling schemes using respectively certificates of bits [4, 31], and bits [29]. We show that these schemes are actually error-sensitive.
Recall that Theorem 3.9 proved that the language of spanning trees encoded at each node by a pointer to its parent does not admit any error-sensitive. Hence, we are interested in , i.e., the language of spanning trees encoded by adjacency lists.
Theorem 5.1**.**
* has an error-sensitive proof-labeling scheme with certificates of size bits, and sensitivity .*
Proof 5.2**.**
We show that the classical proof-labeling scheme for is error-sensitive. Let us first remind precisely what this scheme is.
On instances of the language, i.e., on labeled graphs where encodes a spanning tree of , the prover does the following. It chooses an arbitrary root of , and then assigns to every node a certificate where , is the ID of the parent of in the tree (where we consider that the root is its own parent), and is the hop-distance in the tree from to . The verifier at every node first checks that:
- •
the adjacency lists are consistent, that is, if is in the list of , then is in the list of ;
- •
there exists a neighbor of with ID , we denote it ;
- •
the node has the same root-ID as all its neighbors in ;
- •
.
Then, the verifier checks that:
- •
if then , and for every other neighbor listed in , and ;
- •
if then , , and every neighbor of listed in satisfies and .
The scheme and later steps of the proof are illustrated in Figure 2.
By construction, if , then accepts at every node. Conversely, if , then, for every certificate function , at least one node rejects. To establish error-sensitivity for the above proof-labeling scheme, let us assume that rejects at nodes with some certificate function . Then, let be the labeled graph coinciding with except that all edges for which rejects at both endpoints are removed both from , and from the adjacency lists in of the endpoints of these edges. Note that modifying into only requires to edit labels of nodes that are rejecting. Note that the graph might be disconnected. Also note that the edges described in the labeling that are still present in form a forest. (This is because the verification of the counters ensures that any cycle is cut by our procedure).
Let be a connected component of . We claim that the edges of form a forest in . If there is a cycle in the edges of , then this cycle already existed in because no edges were added when transforming into . Let us consider such a cycle in (if it exists), and let us consider the certificates given by to the nodes of this cycle. Either an edge is not oriented, i.e., no nodes use this edge to point to its parent, or the cycle is consistently oriented but some distances are not consistent. In both cases, two adjacent nodes of the cycle would reject when running . It follows that this cycle cannot be present in , as at least one edge has been removed. As a consequence form a forest of . If a node is connected to no other nodes by an edge of , then we will consider such isolated node as a tree of a unique node. With this convention, is a spanning forest of .
We now bound the number of trees in by a function of . The number of trees in is equal to the sum of the number of trees in each component . Let us run on the graph , and let be the number of rejecting nodes. Observe that, for every two nodes and in a component , it holds that . Indeed, otherwise, there would exist two adjacent nodes and in with , resulting in rejecting at both nodes, which would yield the removal of from . Consequently, at most one tree of has a root whose ID corresponds to the ID given to the nodes in the certificate. Therefore, in every tree described in , except at most one, there exists at least one node that rejects (typically a vertex that is pointing to itself, but whose root-ID is different from its ID). As a consequence, the number of trees in is upper bounded by , and the total number of trees is bounded by . Now, by construction of the proof-labeling scheme, the nodes that accept when running on also accept in . Therefore .
For every connected component , let be the set of nodes of . We claim that there exists a node of that rejects when we run on . Suppose by contradiction that there exists a component where no node reject. Then no edges between and the rest of the graph would have been removed, and therefore there would be only one component in the graph. And then, as we know that at least one node rejects there would be a contradiction. Therefore . It follows that encodes a spanning forest with at most trees in total. Such a labeling can thus be modified to get a spanning tree by modifying the labels of at most nodes. That is, is error-sensitive with parameter .
Last, but not least, we show that the compact proof-labelling scheme in [29, 31] for minimum-weight spanning tree (MST), as specified in Eq. (6) of Section 4, is error-sensitive whenever the edge-weights are pairwise distinct.
Theorem 5.3**.**
* admits an error-sensitive proof-labeling scheme with certificates of size bits, and sensitivity .*
The proof of Theorem 5.3 is quite technical. So, before entering into the details of the proof, let us provide the reader with some intuitions. A classic proof-labeling scheme for mst (see, e.g., [28, 29, 31]) consists in encoding a run of Borůvka algorithm. Recall that Borůvka algorithm maintains a spanning forest whose trees are also called fragments. Starting with the forest in which every node forms a fragment, Borůvka algorithm proceeds in a sequence of steps where, at each step, the lightest edge outgoing from every fragment of the current forest is selected, and is added to the mst. The fragments linked by the selected edges are merged, and the algorithm goes to the next step. This algorithm eventually produces a single fragment, which is a mst of the whole graph, after at most a logarithmic number of steps.
At each node , the certificate of the classical proof-labeling scheme for mst consists of a table with a logarithmic number of fields, one for each step of Borůvka algorithm. The corresponding entry of the table provides a proof of correctness for the fragment including at this step, plus the certificate of a tree pointing to the lightest outgoing edge of the fragment. The verifier verifies the structures of the fragments, and the fact that no edges outgoing from each fragment have smaller weights than the one given in the certificate. It also checks that the different fields of the certificate are consistent. In particular, it checks that, if two adjacent nodes are in the same fragment at the same step, then they are also in the same fragment at the next step.
To prove that this classic scheme is actually error-sensitive, we perform the same decomposition as in the proof of Theorem 5.1, by removing the edges that have both endpoints rejecting. We then consider each connected component of the remaining graph, and the subgraph of that component induced by the edges of the given labeling. In general, is not a mst of the component , as it can even be disconnected. Nevertheless, we can still make use of a key property, which is that the subgraph is not far from a mst of . Indeed, the edges of form a forest, and these edges belong to a mst of the component. As a consequence, it is sufficient to add a few edges to for obtaining a mst. Thus, to show that is indeed not far from being a mst of , we define a relaxed version of Borůvka algorithm, and show that the labeling of the nodes corresponds to a proper run of this modified version of Borůvka algorithm. We then show how to slightly modify both the run of the modified Borůvka algorithm, and the labeling of the nodes, to get a mst of the component. Finally, we prove that the collection of msts of the components can be transformed into a single mst of the whole graph, by editing a few node labels only.
The rest of the section is dedicated to formalizing the above intuition.
**Proof of Theorem 5.3. ** We show that the proof-labeling scheme for MST described in [29, 31] is error-sensitive. Let be an edge-weighted graph. For simplicity we assume that all the edge-weights of are distinct, and thus the MST is unique. It is now folklore (see, e.g., [37]) that one can run a parallel version of Borůvka algorithm which proceeds in at most rounds, where each round consists in merging fragments in parallel. Note that a merging may involve more than just two fragments during a single round, so the number of fragments may actually decrease faster than by a factor 2 at each round.
The standard proof-labeling scheme for mst. Recall that, in the proof-labeling scheme of [29, 31], the prover essentially encodes at each node the run of the parallel version of Borůvka algorithm. More specifically, the certificate at each node is divided into fields, one for each round , plus an additional one. The field corresponding to round in the certificate of a node contains:
a pointer to a parent of in a rooted tree that is supposed to span the fragment including at round , rooted at an arbitrary node of the fragment, whose ID is the ID of the fragment, and the local proof used at to certify that is indeed a spanning tree of the fragment; 2. 2.
a pointer to a parent of in another rooted tree , also spanning the fragment, but rooted at the endpoint of the lightest edge outgoing the fragment, with the local proof at certifying ; 3. 3.
the ID of the other endpoint of the edge , and its weight.
The tree ensures the connectivity of the fragment, and is used in the merging procedure of Borůvka algorithm, while is used to make sure that the edge is indeed the edge of minimum weight incident to the fragment. The additional field is used to encode and certify locally the mst of the whole network.
The verifier checks that, for each round, the two spanning trees and of the fragment are correct. It also checks that the run is consistent, that is:
- •
two adjacent nodes with same fragment ID at some round have the same fragment ID and the same lightest outgoing edges for all further rounds;
- •
if an edge is used to merge two fragments at some round, then its endpoints belong to the same fragment for all remaining rounds;
- •
if a spanning tree is pointing to an edge, then this edge exists, and it is used to merge the fragment with another fragment;
- •
the final spanning tree has exactly the edges described by the given labeling, and it correctly spans the whole graph, i.e., all the nodes have the same root-ID for this tree.
It is proved in [29, 31] that is a proof-labeling scheme for mst. We show that it is error-sensitive.
Edge deletion. Let us fix some some certificate function , and let us assume that nodes reject with certificate . We perform the same decomposition as in the proof of Theorem 5.1, removing from and the edges whose two extremities are rejecting. We obtain a labeled graph . Let be a connected component of , and let us run the verifier on with the same certificate function. Let be the number of rejecting nodes in . As argued in the proof of Theorem 5.1, the number of rejecting nodes in the whole graph can only decrease from to . Therefore, .
Let us consider a node that is rejecting in . We claim that the only cases for which a node rejects are (1) it is not a root in one of the trees encoded in the certificates, but there are inconsistencies with its parent (i.e., no parent, or incorrect root-ID, or incorrect distance counter), or (2) it is the root in one of the trees encoded in the certificates, but it is not incident to the edge announced in the certificate. This is because, using the same line of arguments as the proof of Theorem 5.1, if another case of rejection would exist, then there would be an edge whose both endpoints reject, but such an edge cannot exist in , by construction (these edges have precisely be removed when doing the decomposition).
Lazy Borůvka. We will now consider a relaxed version of Borůvka algorithm that we call “lazy Borůvka”. As the classical version of Borůvka, the lazy variant grows a forest of fragments. Initially, there is one fragment per node. At each round, lazy Borůvka proceeds in three steps. First it picks an arbitrary name for each fragment. Second, for each fragment , it considers all edges connecting to a fragment with different name, and either chooses the incident edge with smallest weight, or do not choose any edge, in which case we say that is skipping its turn. Third, Lazy Borůvka merges the fragments that are linked by edges selected during the second step. The algorithm stops whenever all the fragments have the same name.
Note that in general lazy Borůvka does not produce an MST, and it may even not terminate. However, if the names assigned to adjacent fragments are distinct at each round, and if there is no round such that all fragments skip their turn at every round , then lazy Borůvka eventually produces an MST.
Given a fragment , we refer to all fragments including during the further rounds of lazy Borůvka as its successors. The fragments of the previous rounds contained in called predecessors. Also, a maximal set of adjacent fragments having the same name during a same round is called a cluster.
We restrict our attention to the runs of lazy Borůvka satisfying the following two properties:
P1
If some fragments form a cluster, then all their successors will also be part of a same cluster, but they will remain in different fragments.
P2
At every round of the run, at most one fragment per cluster chooses an edge, and all the other skip their turn.
We show that corresponds to the outcome of a run of lazy Borůvka satisfying the above two properties.
Claim 2**.**
The labeling is the outcome of a correct run of lazy Borůvka on , and this run satisfies the properties P1 and P2.
Proof of the claim. Let us consider an execution of lazy Borůvka where fragments are as described by the certificates, and the names of the fragments are the root-ID of the corresponding fragments. As we argued before, these fragments are well-defined, that is, they are trees with correct proof, and the same root-ID at every node. Moreover these fragments are consistent from any round to the next one, because they satisfy the consistency properties checked by the verifier. The fact that the root-ID may not be the ID of the root of the tree is not a problem, as it corresponds to a name. Finally, recall that if a node of rejects when checking round , this is because that node has no parent in a tree encoded in the certificate, and either it does not have the appropriate root ID, or it is not incident to the appropriate edge. In both cases, there are no outgoing edges corresponding to that fragment for round . We interpret this fact as the fact that this fragment skipped its turn at this round. It follows that the different steps are valid for lazy Borůvka, and they correspond to .
We now prove that the run has property P1 and P2.
For establishing P1, let us assume, for the purpose of contradiction, that, at some round in , two adjacent fragments and have the same name, but two successors and have different names. If this is the case, then, when verifying the certificates, both endpoints of an edge connecting to reject. Indeed, the certificates describe this run, and the verifier checks that the rounds are consistent. There are no such edge in by construction of , thus this situation does not occur. Also, if the two successors and are identical, then, at some round, the certificates tell that a fragment is taking an edge to a fragment that has the same root-ID, which is impossible (as such an edge would have been removed when creating ). These arguments generalize to clusters, by connectivity.
For establishing P2, let us assume that, at some round , two fragments of a cluster choose an edge. It means that in the certificates of this run, there were two fragments with correct spanning trees pointing to these edges. As the verifier checks that two adjacent nodes with the same root-ID have the same outgoing edge, this implies that either the outgoing edge was the same in the certificates of the two fragments, or this edge was different for the two fragments. In the former case, at least one of the two fragments will take no edge because it will detect that it does not have the edge . In the latter case, all the edges between these fragments would have both endpoints rejecting, and then they would not be adjacent as these edges would have been removed. Again, these arguments generalize to cluster, by connectivity.
Finally, the termination of the run is also correct with respect to the specification of lazy Borůvka. This is because of two facts. First, in the certificate, the last field describes a tree that has the same root-ID at every node, and the verifier checks this. Thus this holds after the decomposition step. The run stops at a round where all the fragments have the same name. Second, suppose there was a round before the last round described by the certificate at which all the fragments had the same name. Then thanks to P1, at round , the fragments were exactly the same as in the last round, and every node has skipped all the remaining rounds. Thus we can consider round if it was the last round. It still holds that the run corresponds to , and has property P1 and P2. This completes the proof of Claim 2.
Getting closer to an MST. In general, whenever it terminates, lazy Borůvka can produce a forest which is arbitrarily far from being an MST. Nevertheless, we show that, as the run satisfies the properties P1 and P2, the forest produced by this run is at distance at most from an MST of , where is the number of rejecting node in . To do so, we now modify the run , by applying iteratively an operation on the run, adding edges to . This addition of edges is repeated until one obtains a run where, at every round, not two adjacent fragments have the same name, that is, until one obtains a run that builds an MST.
We now describe the operation that we apply to a run, and the labeling associated with the resulting run. Consider the first round for which there is a cluster with more than one fragment. Let be such a cluster. There are only a few cases to consider.
- •
Case 1: none of the fragments in is choosing an edge, although there are fragments with names different from the one of that are adjacent to . In this case, for this round, we assign new distinct names to all of the fragments in , making sure that these names are not already used at that round by other fragments — that is, we use “fresh” names.
- •
Case 2: one of the fragments of is choosing an edge that has minimum weight among all edges that connect this fragment to the other fragments of , including the fragments of . In this case, we replace the names of the other fragments of by fresh names.
- •
Case 3: a fragment of the cluster is choosing an edge , although the lightest edge outgoing from is an edge that connects it to a fragment of . In this case, we add a round between round and round where all fragments of are given distinct names, and every fragment is skipping its turn, except , which is choosing the edge . Also we add this edge to the labeling.
- •
Case 4: round is the last round. In this case, we have only one cluster containing all the remaining fragments. We consider the lightest edge connecting two fragments in , and add a round between round and round where all fragments of are given distinct names, and every fragment is skipping its turn except , which is choosing the edge . Also we add this edge to the labeling.
Claim 3**.**
If a correct run of lazy Borůvka satisfies property P1 and P2, and corresponds to the current labeling, then the above operations preserve these properties.
Proof of the claim. Let us consider a correct run of lazy Borůvka satisfyng property P1 and P2, and that corresponds to the current labeling. We consider the four cases of the operation, and establish the claim for each of them.
- •
Case 1. The run is still correct after the renaming because the fragments of were skipping, from which it follows that the modification of the names does not affect their behavior. The behavior of the other fragments is still the same because we have chosen fresh names. In particular if, at round , a fragment chooses an edge to a fragment , then this action is still valid as and still have different names. P2 and the outcome of the run are still correct as we have not changed the fact that the nodes are skipping, and we have not modified the labeling. Finally, P1 holds because we have considered the first round with a cluster containing more than one fragment, so the predecessors of the fragments of had different names at the previous rounds.
- •
Case 2. The same line of reasoning as in Case 1 holds. That is, the behavior is unchanged, the change of name does not affect the correctness of the actions of neither the fragments of , nor the ones outside , and P1 holds because we consider the first round.
- •
Case 3. Let us consider first the round that we have added. The fragment chooses the lightest edge to a fragment that has a different name, because we have chosen different names for all the fragments. Therefore, this round is correct for lazy Borůvka algorithm. Now we have to check that the next rounds are also correct. Merging two fragments, we may cause several problems. First, the name of this fragment could be incorrectly defined, as the names of the successors of these fragments can be different. However, this cannot be the case because P1 holds in the run before the modification. Second, the merged fragment could take two edges at the same round, one taken by the successor of before the operation, and one taken by the successor of before the operation. In fact, this cannot happen, because of P2. Finally the behavior of the other fragments is unchanged as they only consider the names of their adjacent fragments, and these names have not beed modified. Therefore the run is still correct after the operation. Moreover, we have added a new edge in the labeling, thus the run still describes the labeling at hand. Property P1 and P2 still hold for the added round, and they also hold for the next rounds, as we have just merged two fragments of the same cluster, which implies that the names remain unchanged, and if two fragments of a cluster were now choosing an edge at the same round, then this also happened in the run before the operation, which a contradiction.
- •
Case 4. The same reasoning as for the previous case also holds in this case.
This case analysis completes the proof of Claim 3.
Thanks to Claim 2, the labeling is the outcome of a correct run of lazy Borůvka on , and this run satisfies the properties P1 and P2. Therefore we can apply the operation on it. We claim that we can iterate this operation, and eventually get a run in which there are no clusters with more than just one fragment, after a finite number of iterations.
To see why, let us first prove that, after an iteration for which we have used Case 3 or Case 4, the number of fragments in the final cluster has decreased by one. Let us consider the two fragments that we have merged during the operation. In the run before the operation, these two fragments had successors that were never merged, because of P1. It follows that these successors were distinct fragments at the end. Now that we have merged them, they form only one fragment at the end. As the behavior of the other fragments is not affected by the change, the number of fragment at the end has therefore indeed decreased by one.
Let us now prove that for Cases 1 and 2, the sum, over the rounds, of the number of clusters with more than one fragment has strictly decreased. This is because we have scattered such a cluster in both Case 1 and Case 2, without creating new ones. Also, the number of fragments in the final cluster remains unchanged. Therefore, at every step, either the number of fragment in the final cluster has decreased by one, or it remains unchanged but the sum, over the runs, of the number of clusters with more than one fragment has strictly decreased. The operation can be repeated for a finite amount of time. After all these operations, the run is such that, at every round, no two adjacent fragments have the same name. Therefore, the modified labeling is a spanning tree of .
Overall, we have added exactly one edge every time we have decreased by one the number of fragments in the final cluster. Thus, the number of edges added is equal to the number of fragments in the final cluster in the original run , minus one. This number is at most . Indeed, at most one fragment contains no rejecting nodes, since only one fragment can have the node whose ID was used as the root-ID in the certificates, and all the roots of the other fragments reject, with rejecting nodes in total. Therefore the distance (i.e., the number of modified edges) between the original labeling and the modified labeling , which is a correct spanning tree of , is at most . As the same reasoning holds for every connected component, by defining a “spanning” tree of a disconnected graph as the union of trees spanning each of its connected component, we get that the modified labeling is the spanning tree of , and it is at distance at most from the original labeling .
Comparison with the original spanning tree. We now compare the modified labeling with the spanning tree of the original graph . We claim that the set of edges described by can be transformed into a spanning tree of by adding or removing at most edges. Indeed, recall that, to go from to , we have removed only the edges that were between two rejecting nodes. Let us call this set of edges. Let us go backwards, and let us remove edges from to go to while keeping track of the spanning tree. Among the edges of , at most can be part of the MST of , as otherwise there would be a cycle since there are only rejecting nodes. Removing the other edges from does not change the MST. Let be without these edges, and let us also remove them from .
Now, let us consider one of the remaining edges in , denoted by . Let be the graph without this edge . If removing disconnects the graph, then the spanning tree of is the same as the one of , without . If removing does not disconnect the graph, then we define as the edge of smallest weight in the cut between the nodes that are closer to in the tree, and the ones that are closer to in the tree. The resulting spanning tree is minimum. To see why, let us check that, for every cycle in the graph, the heaviest edge is not part of the spanning tree. The only cycles that we have to consider are the ones that contain . Suppose that the edge is the heaviest of a cycle in . This cycle must cross the cut via another edge, and this edge must have a smaller weight, as otherwise would not be the heaviest. This contradicts the definition of , and thus, by adding , we obtain a spanning tree of . We can repeat this construction until there are no more edges in . At the end, the graph , and the spanning tree of is the modified . We have therefore added or removed at most edges.
To conclude, in the first step from to , we have edited only the labels of the rejecting nodes, thus labels at most. Then, we got from each labeling to the final labeling by adding at most edges. Thus, in the whole graph, we have modified at most labels in total. Finally, we have added or removed at most additional edges, and thus we have modified at most labels. Thus, overall, we have edited at most labels. It follows that the distance of to MST is at most linear in the number of rejecting nodes, from which it follows that the proof-labeling scheme is error-sensitive. The sensitivity is 1/7. This completes the proof of Theorem 5.3 ∎
6 Conclusion and perspectives
In this paper, we have considered on a variant of proof-labeling scheme, named error-sensitive proof-labeling scheme. We have provided a structural characterization of the distributed languages that can be verified using such a scheme. This characterization highlights the fact that some basic network properties do not have error-sensitive proof-labeling schemes, which is in contrast to the fact that every network property has a proof-labeling scheme. However, important network properties, like cycle-freeness, leader, spanning tree, MST, etc., do admit error-sensitive proof-labeling schemes. Moreover, these schemes can be designed with the same certificate size as the one for the classic proof-labeling schemes for these properties.
Our study of error-sensitive proof-labeling schemes raises intriguing questions. In this paper, we have considered two scenarios only for a given language: either the language does not admit error-sensitive proof-labeling schemes, or it admits an error-sensitive proof-labeling scheme with the same certificate size as the optimal proof-labeling schemes.
Open question 1**.**
Is it the case that, for every language, either the language is not error-sensitive, or it is error-sensitive at no cost (that is, the optimal certificate size is the same with and without the error-sensitivity requirement)?
Another interesting topic is the sensitivity parameter. In this paper, for a given language, we have been interested in the existence of -sensitive scheme for some constant , but we have not tried to optimize . It would be interesting to study whether we can optimize beyond the values derived in this paper.
Open question 2**.**
In Theorem 5.1 and 5.3, we derive error-sensitive schemes with optimal certificate size, with sensitivity parameters and , for spanning tree and minimum spanning tree, respectively. Are these sensitivity parameters optimal?
The two questions above are actually related. Indeed, a larger sensibility parameter implies more constraints on the certification. Therefore, in general, certificate size grows with the required sensitivity. Nevertheless, we do not know which way the certificate size grows.
Open question 3**.**
For a given language, is it the case that there is a threshold value for the sensitivity parameter (that could be 0), such that, below this threshold, one gets error-sensitivity at no cost in term of certificate size, while, above this threshold, error-sensitivity is impossible? Instead, is there a smooth trade-off between the sensitivity and the certificate size?
Another desirable property for a proof-labeling scheme is proximity-sensitivity, requiring that every error is detected by a node located closely to the location of the error. Proximity-sensitivity however appears to be a very demanding notion, stronger than error-sensitivity. Indeed, the former implies the latter whenever the errors are spread out in the network at sufficiently large mutual distances.
Open question 4**.**
Under which circumstances it is possible to design proximity-sensitive proof-labeling schemes? Is it possible to provide a simple characterization of the languages admitting proximity-sensitive proof-labeling schemes?
Finally, let us mention error-sensitivity for network properties. This paper has been motivated by self-stabilizing algorithms, for which mechanisms used to locally certify the correctness of global states of the system are required. More recently, there has been a new direction explored in local certification, which consists in designing proof-labeling schemes for properties of the network itself. For example, [18, 17, 12] design compact proof-labeling schemes for planar and bounded-genus graphs. In such setting, our notion of error-sensitivity is not relevant, as the distance is about the number of edits at the vertices, whereas for network properties, one should consider edits on the graph itself. A natural question is:
Open question 5**.**
Can we generalize error-sensitivity to network properties? If yes, is planarity an error-sensitive property?
Acknowledgments.
We thank the reviewers of the conference and journal versions of this paper, for their careful reading and useful suggestions.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Yehuda Afek and Shlomi Dolev. Local stabilizer. J. Parallel Distrib. Comput. , 62(5):745–765, 2002.
- 2[2] Yehuda Afek, Shay Kutten, and Moti Yung. The local detection paradigm and its application to self-stabilization. Theor. Comput. Sci. , 186(1-2):199–229, 1997.
- 3[3] Baruch Awerbuch, Shay Kutten, Yishay Mansour, Boaz Patt-Shamir, and George Varghese. Time optimal self-stabilizing synchronization. In 25th ACM Symposium on Theory of Computing (STOC) , pages 652–661, 1993.
- 4[4] Baruch Awerbuch, Boaz Patt-Shamir, and George Varghese. Self-stabilization by local checking and correction (extended abstract). In 32nd IEEE Symposium on Foundations of Computer Science (FOCS) , pages 268–277, 1991.
- 5[5] Joffroy Beauquier, Sylvie Delaët, Shlomi Dolev, and Sébastien Tixeuil. Transient fault detectors. Distributed Computing , 20(1):39–51, 2007.
- 6[6] Lélia Blin and Pierre Fraigniaud. Space-optimal time-efficient silent self-stabilizing constructions of constrained spanning trees. In 35th IEEE International Conference on Distributed Computing Systems (ICDCS) , pages 589–598, 2015.
- 7[7] Lélia Blin, Pierre Fraigniaud, and Boaz Patt-Shamir. On proof-labeling schemes versus silent self-stabilizing algorithms. In 16th International Symposium on Stabilization, Safety, and Security of Distributed Systems (SSS) , pages 18–32, 2014.
- 8[8] Christian Boulinier, Franck Petit, and Vincent Villain. When graph theory helps self-stabilization. In Proceedings of the Twenty-Third Annual ACM Symposium on Principles of Distributed Computing, PODC 2004 , pages 150–159, 2004.