Tensor Graphical Lasso (TeraLasso)
Kristjan Greenewald, Shuheng Zhou, Alfred Hero III

TL;DR
TeraLasso is a scalable tensor generalization of the Bigraphical Lasso that accurately estimates high-dimensional precision matrices with limited data, revealing conditional dependencies in multiway data such as space and time.
Contribution
This paper introduces TeraLasso, a novel tensor graphical model with a scalable estimation algorithm, extending the Bigraphical Lasso to multiway data with theoretical guarantees.
Findings
Accurately estimates precision matrices from limited high-dimensional data.
Recovers meaningful conditional dependency graphs in complex datasets.
Proven statistical consistency and convergence rates for the estimators.
Abstract
This paper introduces a multi-way tensor generalization of the Bigraphical Lasso (BiGLasso), which uses a two-way sparse Kronecker-sum multivariate-normal model for the precision matrix to parsimoniously model conditional dependence relationships of matrix-variate data based on the Cartesian product of graphs. We call this generalization the {\bf Te}nsor g{\bf ra}phical Lasso (TeraLasso). We demonstrate using theory and examples that the TeraLasso model can be accurately and scalably estimated from very limited data samples of high dimensional variables with multiway coordinates such as space, time and replicates. Statistical consistency and statistical rates of convergence are established for both the BiGLasso and TeraLasso estimators of the precision matrix and estimators of its support (non-sparsity) set, respectively. We propose a scalable composite gradient descent algorithm and…
Click any figure to enlarge with its caption.
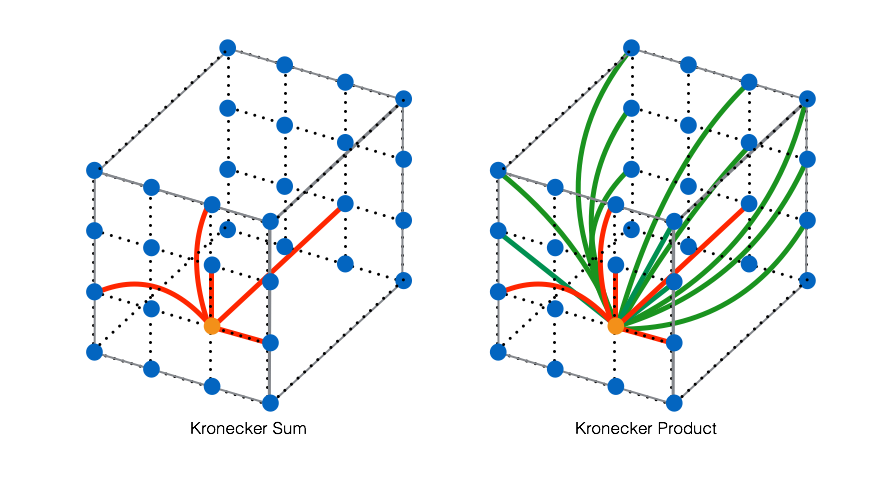 Figure 1
Figure 1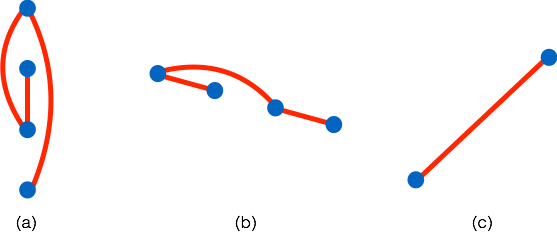 Figure 2
Figure 2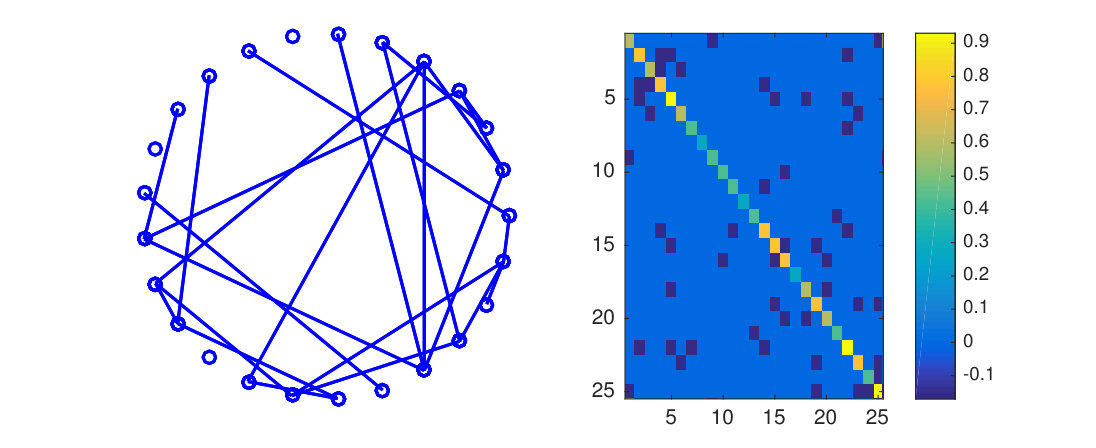 Figure 3
Figure 3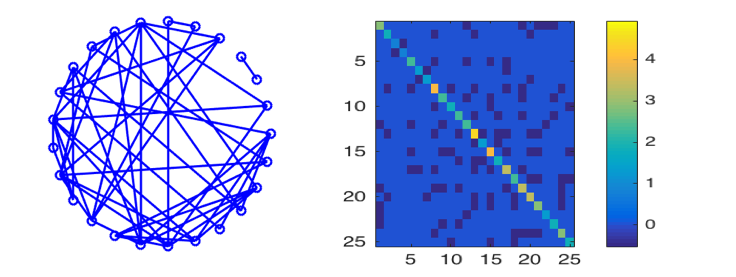 Figure 4
Figure 4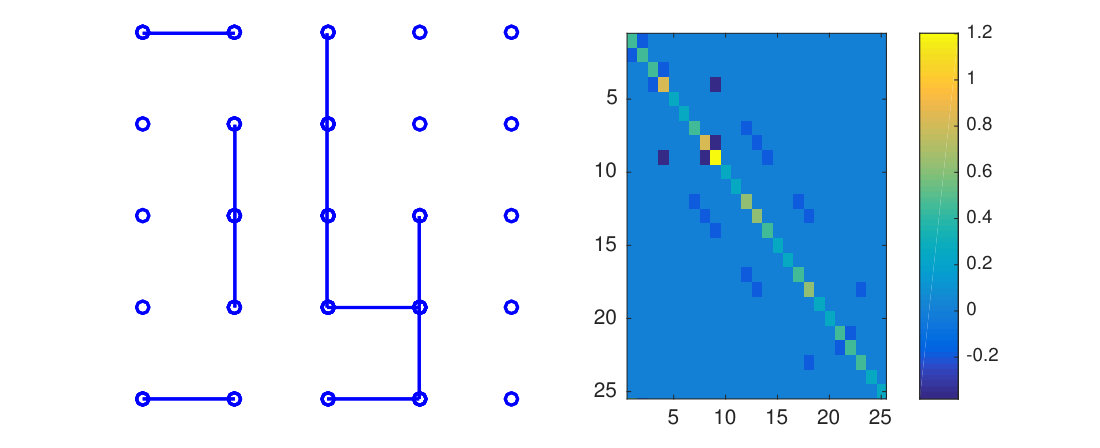 Figure 5
Figure 5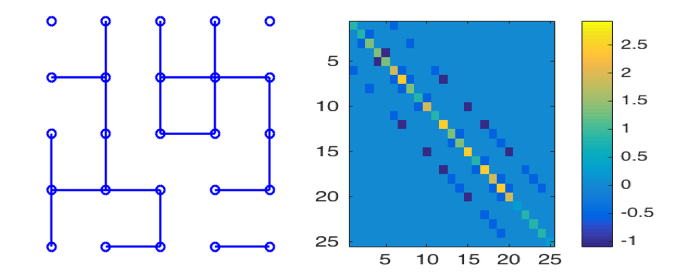 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10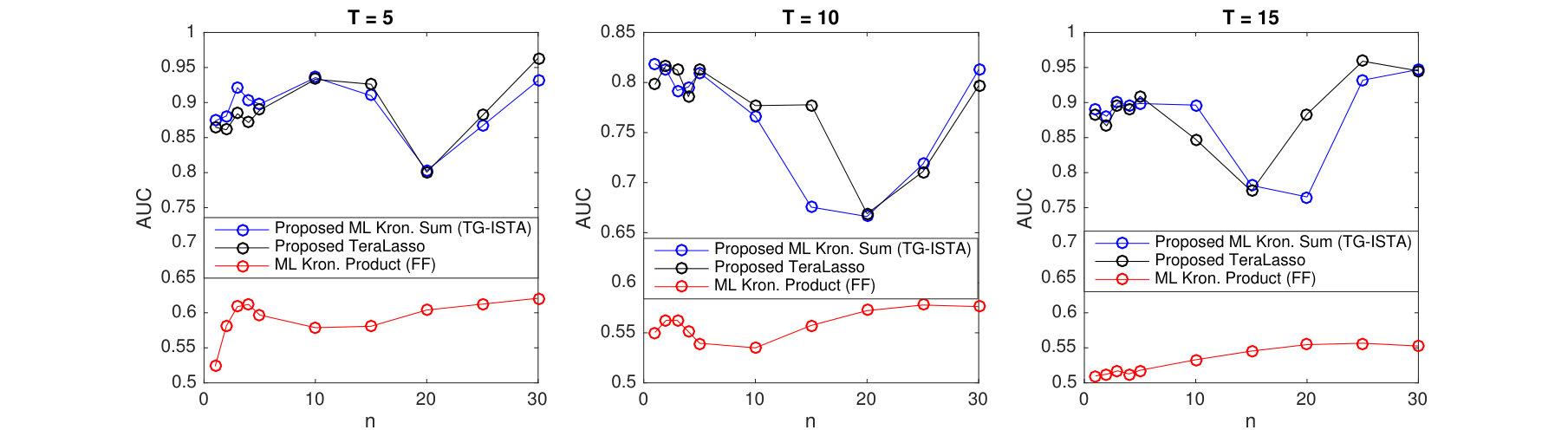 Figure 11
Figure 11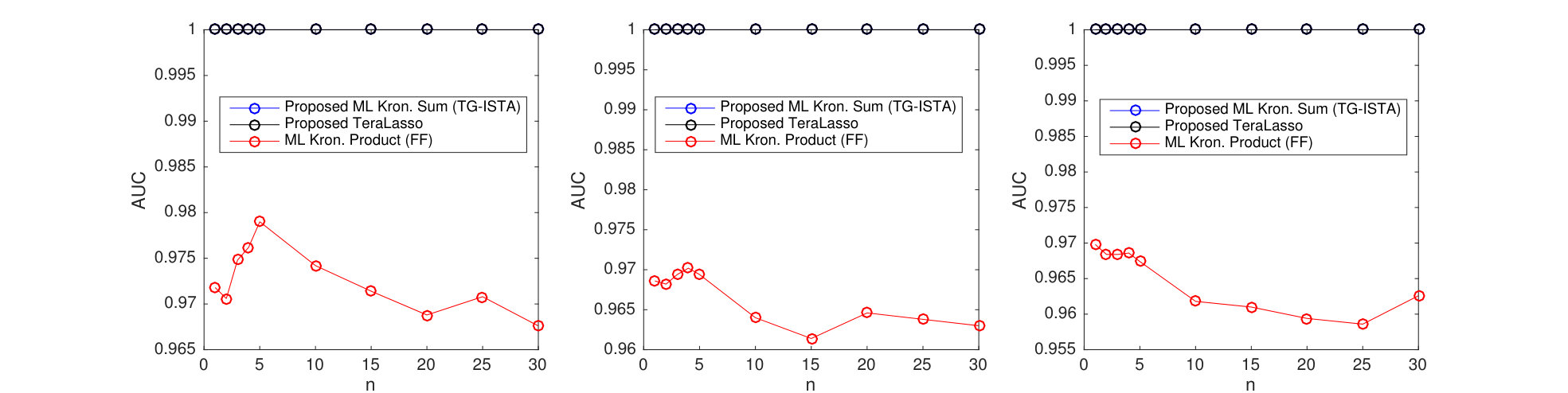 Figure 12
Figure 12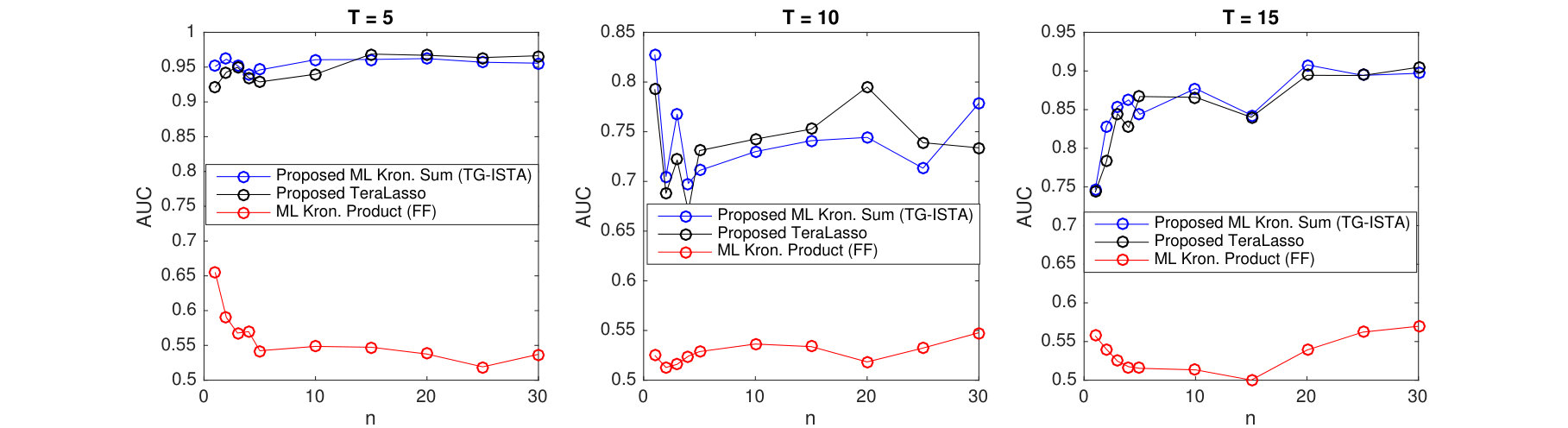 Figure 13
Figure 13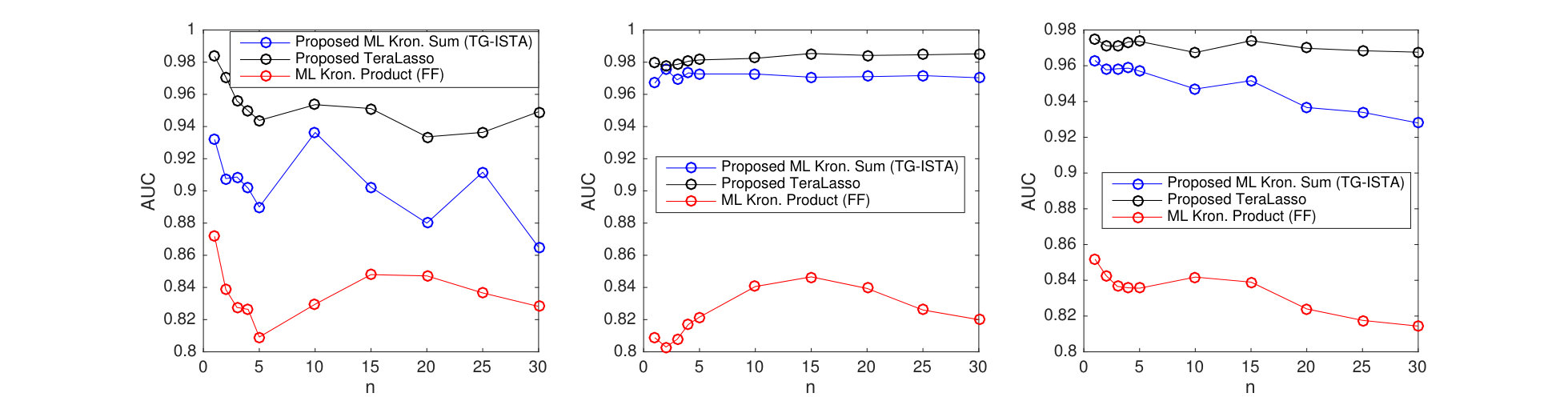 Figure 14
Figure 14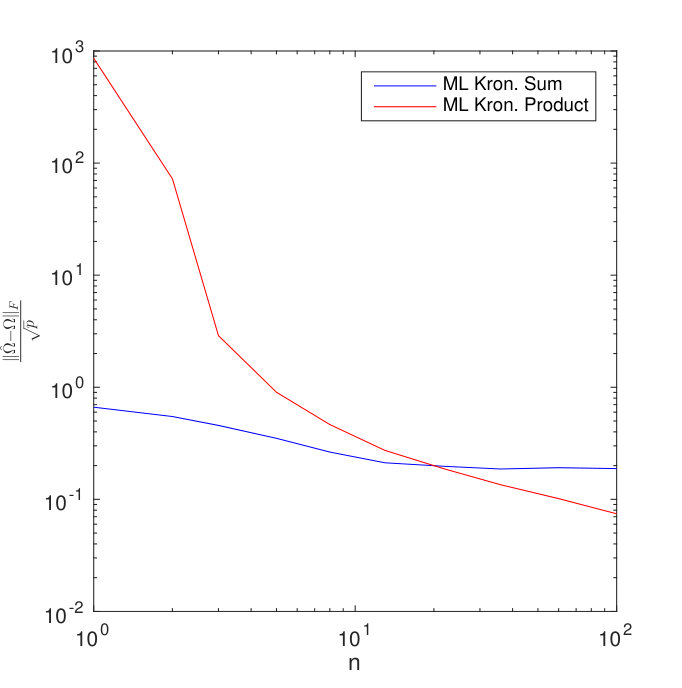 Figure 15
Figure 15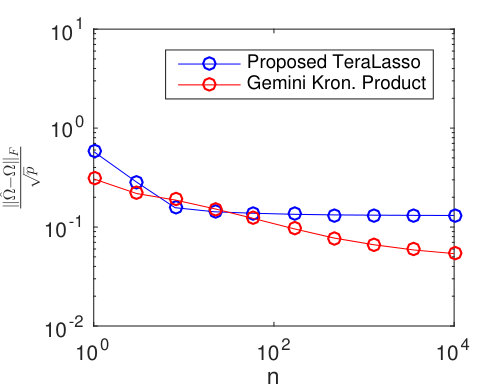 Figure 16
Figure 16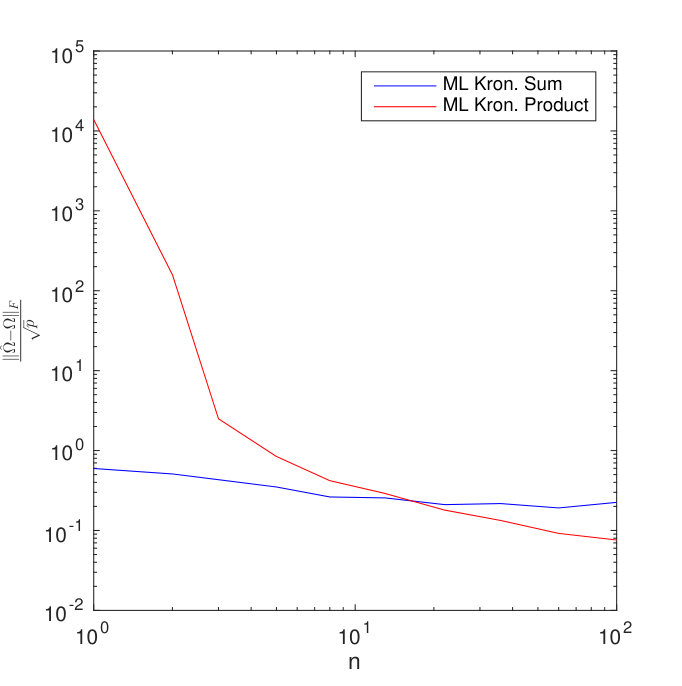 Figure 17
Figure 17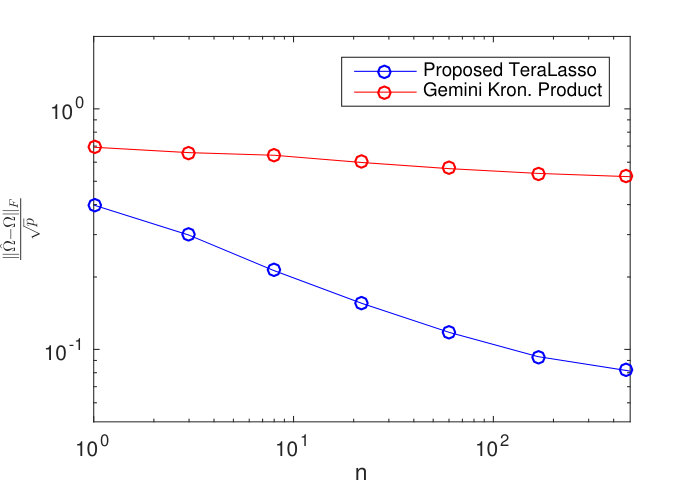 Figure 18
Figure 18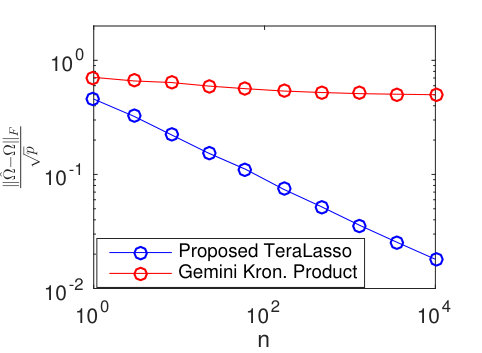 Figure 19
Figure 19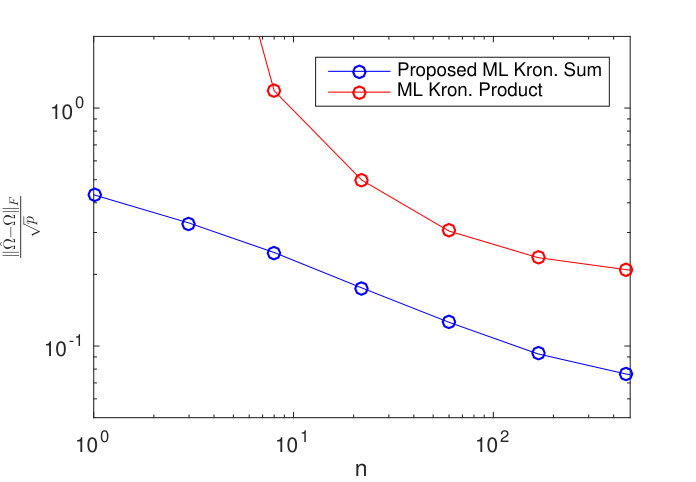 Figure 20
Figure 20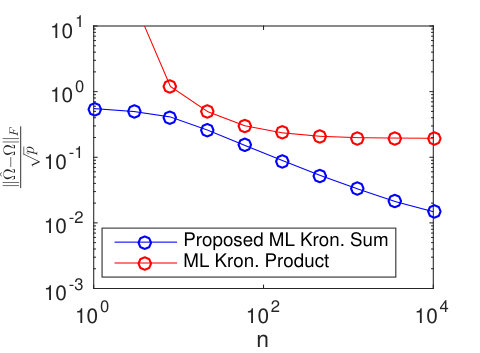 Figure 21
Figure 21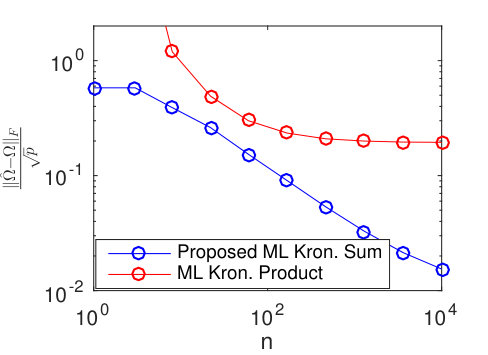 Figure 22
Figure 22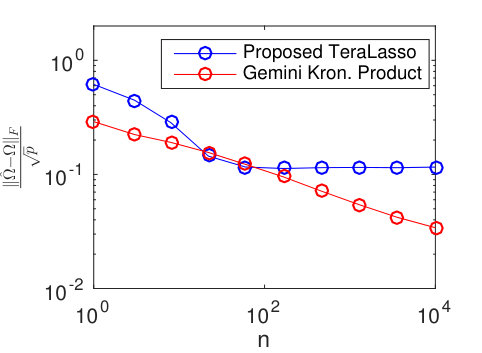 Figure 23
Figure 23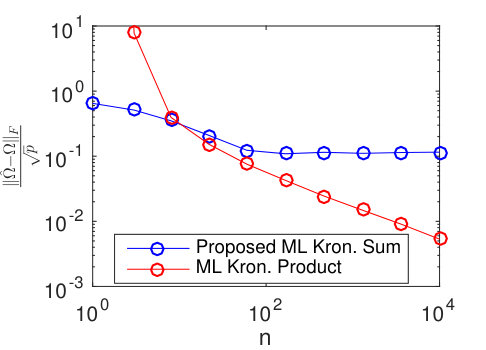 Figure 24
Figure 24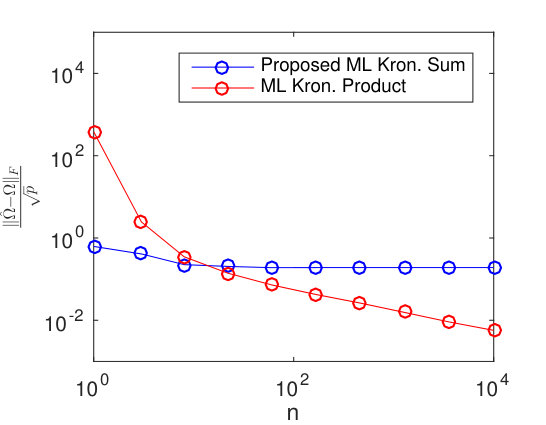 Figure 25
Figure 25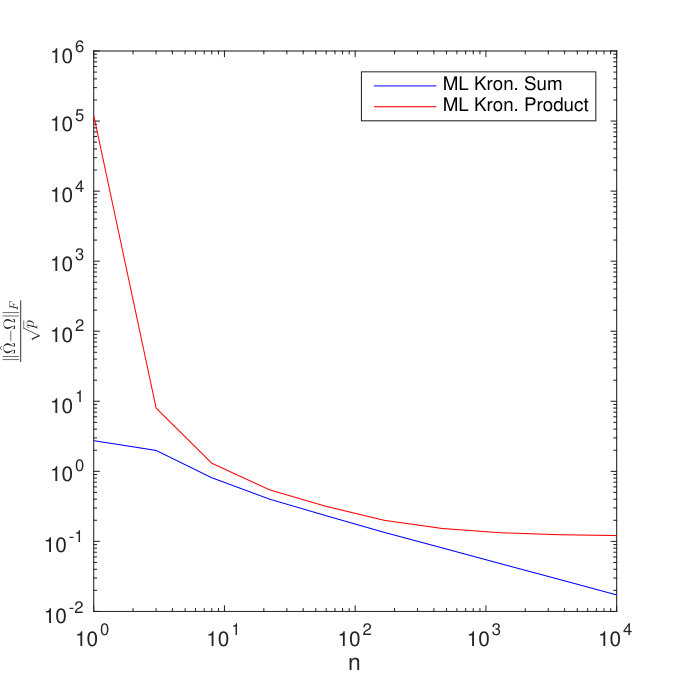 Figure 26
Figure 26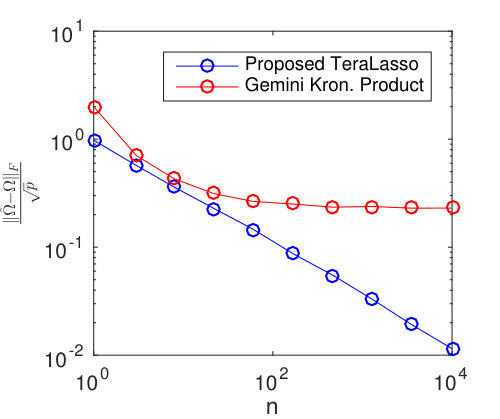 Figure 27
Figure 27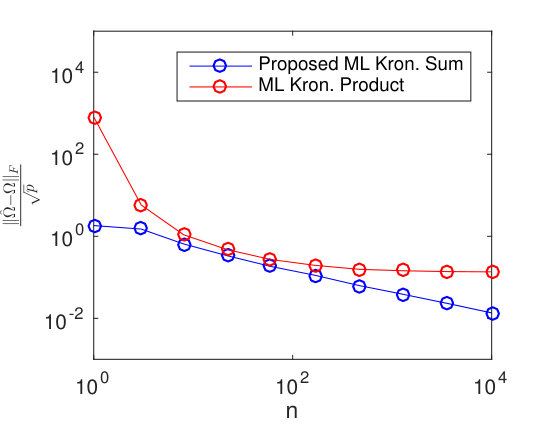 Figure 28
Figure 28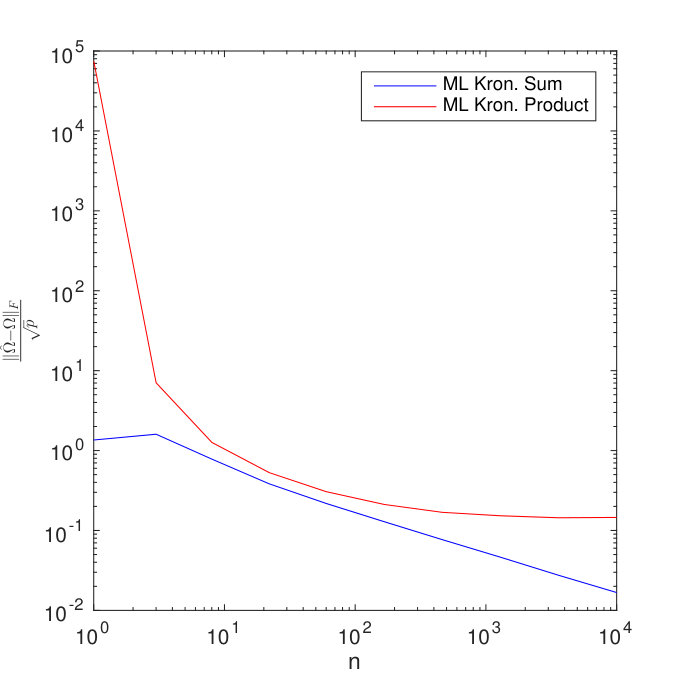 Figure 29
Figure 29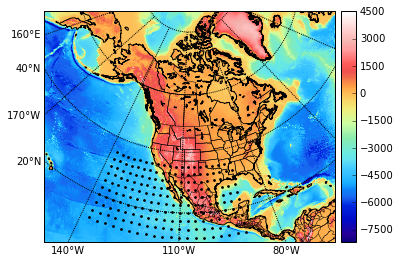 Figure 30
Figure 30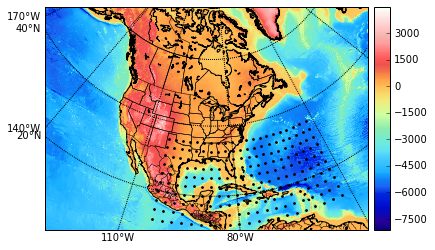 Figure 31
Figure 31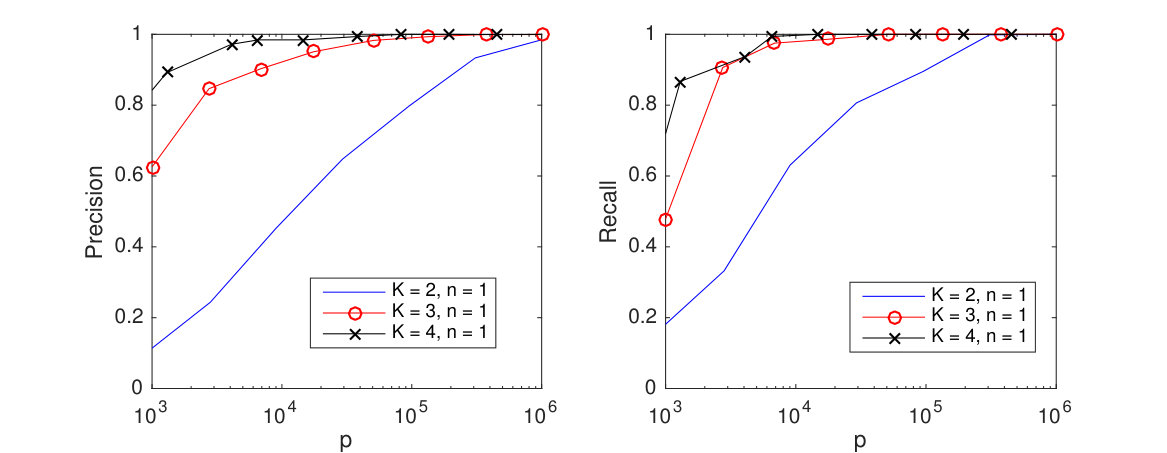 Figure 32
Figure 32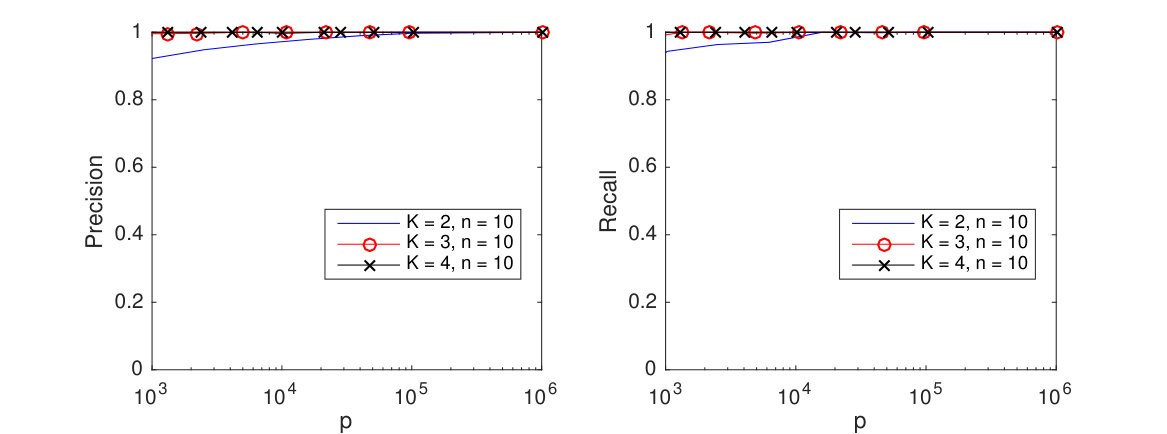 Figure 33
Figure 33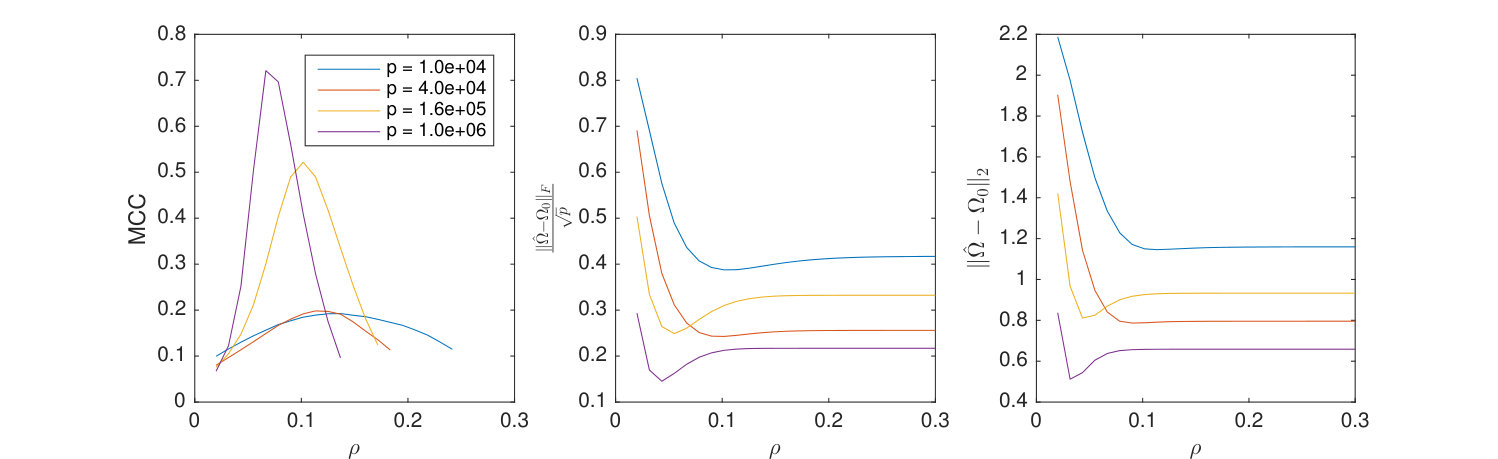 Figure 34
Figure 34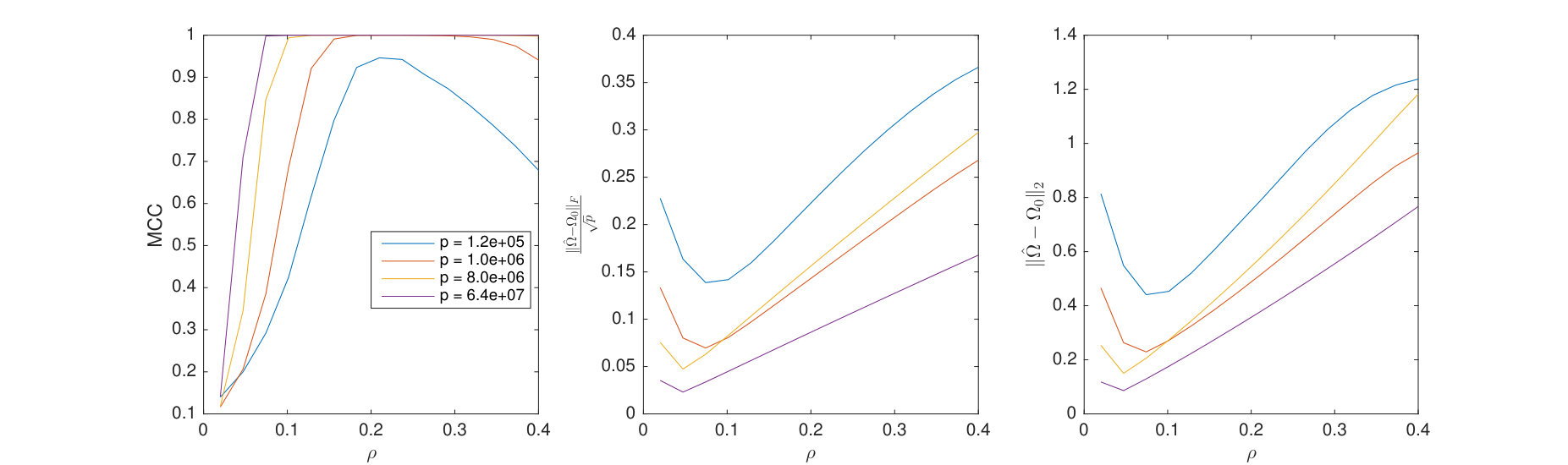 Figure 35
Figure 35 Figure 36
Figure 36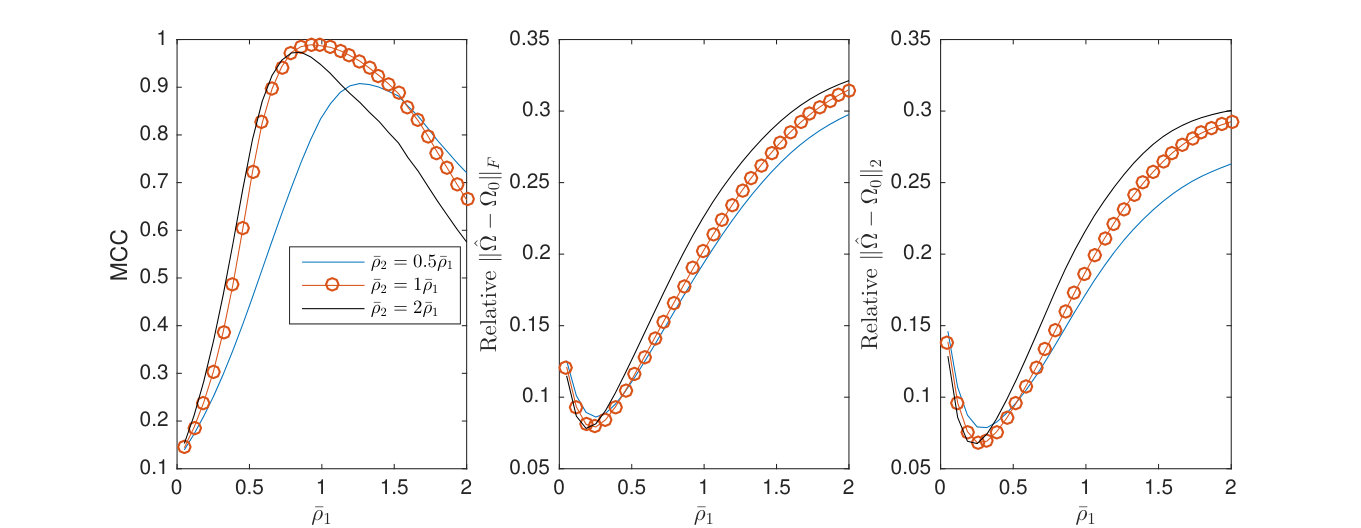 Figure 37
Figure 37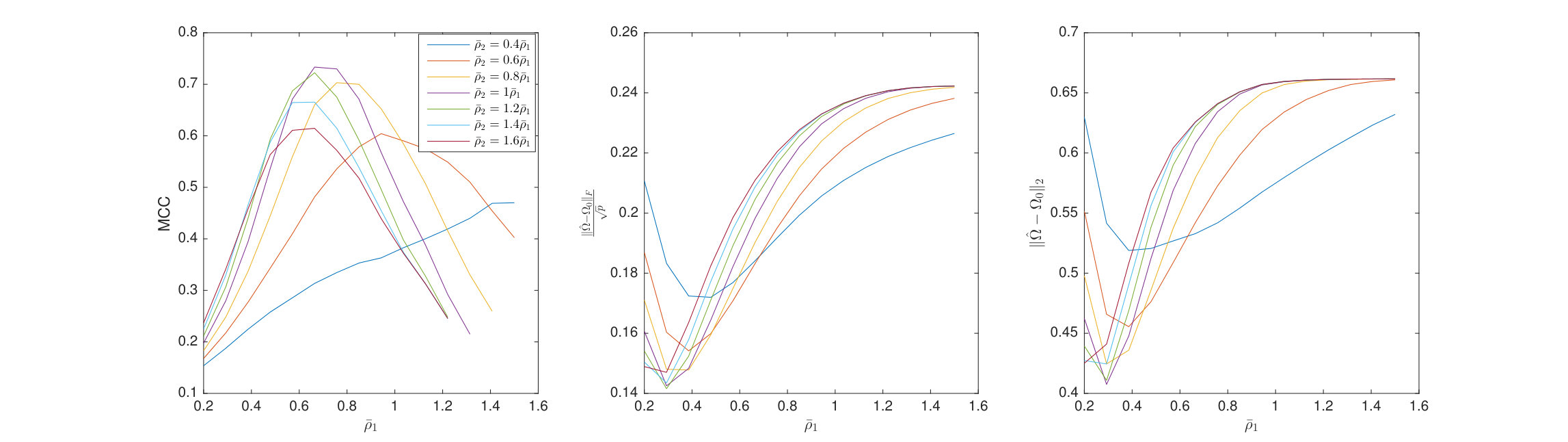 Figure 38
Figure 38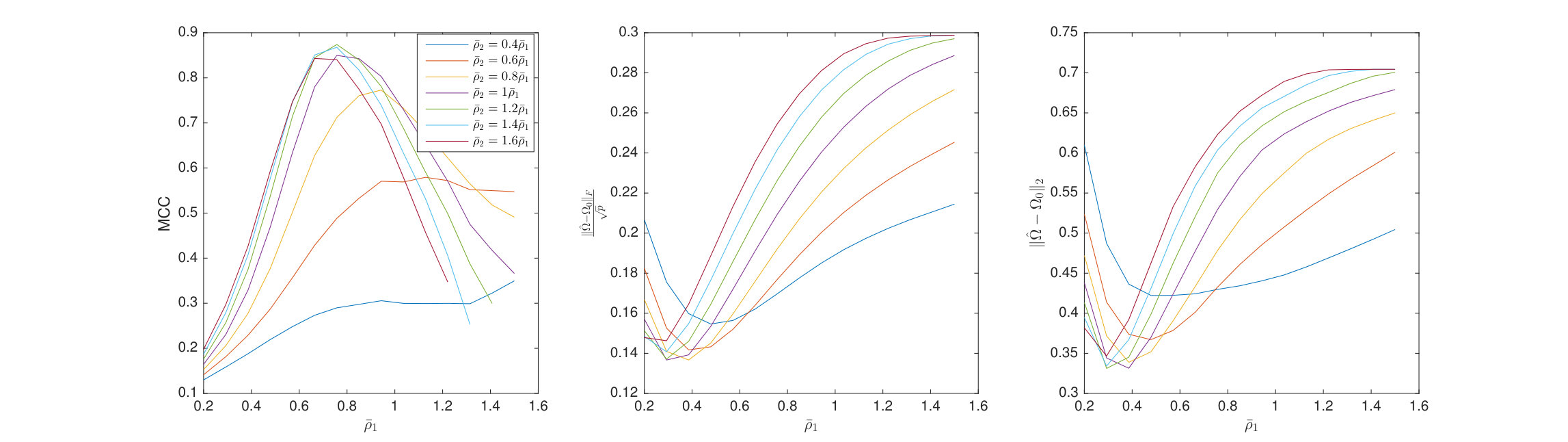 Figure 39
Figure 39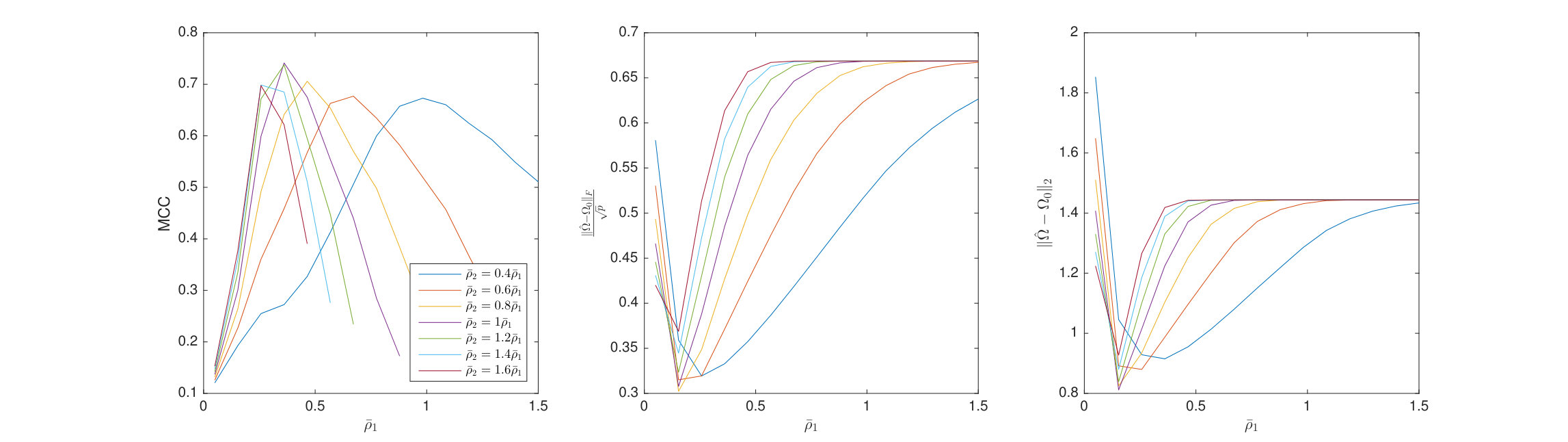 Figure 40
Figure 40Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Tensor Graphical Lasso (TeraLasso)
Kristjan Greenewald
IBM Research, Cambridge, USA.
Shuheng Zhou
University of California, Riverside, USA.
Alfred Hero III
University of Michigan, Ann Arbor, USA.
Abstract
This paper introduces a multi-way tensor generalization of the Bigraphical Lasso (BiGLasso), which uses a two-way sparse Kronecker-sum multivariate-normal model for the precision matrix to parsimoniously model conditional dependence relationships of matrix-variate data based on the Cartesian product of graphs. We call this generalization the Tensor graphical Lasso (TeraLasso). We demonstrate using theory and examples that the TeraLasso model can be accurately and scalably estimated from very limited data samples of high dimensional variables with multiway coordinates such as space, time and replicates. Statistical consistency and statistical rates of convergence are established for both the BiGLasso and TeraLasso estimators of the precision matrix and estimators of its support (non-sparsity) set, respectively. We propose a scalable composite gradient descent algorithm and analyze the computational convergence rate, showing that the composite gradient descent algorithm is guaranteed to converge at a geometric rate to the global minimizer of the TeraLasso objective function. Finally, we illustrate the TeraLasso using both simulation and experimental data from a meteorological dataset, showing that we can accurately estimate precision matrices and recover meaningful conditional dependency graphs from high dimensional complex datasets.
1 Introduction
The increasing availability of matrix and tensor-valued data with complex dependencies has fed the fields of statistics and machine learning. Examples of tensor-valued data include medical and radar imaging modalities, spatial and meteorological data collected from sensor networks and weather stations over time, and biological, neuroscience and spatial gene expression data aggregated over trials and time points. Learning useful structures from these large scale, complex and high-dimensional data in the low sample regime is an important task in statistical machine learning, biology and signal processing.
As the precision matrix (inverse covariance matrix) encodes interactions and, for tensor-valued Gaussian distributions, conditional independence relationships between and among variables, multivariate statistical models, such as the matrix normal model (Dawid (1981)), have been proposed for estimation of these matrices. However, the number of parameters of the precision matrix of a -way data tensor grows as . Therefore in high dimensions unstructured precision matrix estimation is impractical, requiring very large sample sizes. Undirected graphs are often used to describe high dimensional distributions. Under sparsity conditions, the graph can be estimated using 1-penalization methods, such as the graphical Lasso (GLasso) (Friedman et al., 2008) and multiple (nodewise) regressions (Meinshausen et al., 2006). Under suitable conditions, such approaches yield consistent (and sparse) estimation in terms of graphical structure and fast convergence rates with respect to the operator and Frobenius norm for the covariance matrix and its inverse. However, many of the statistical models that have been considered still tended to be overly simplistic and not fully reflective of reality. For example, in neuroscience one must take into account temporal correlations as well as spatial correlations, which reflect the connectivity formed by the neural pathways. Yet, this line of high dimensional statistical literature mentioned above has primarily focused on estimating linear or graphical models with i.i.d. samples. In the case of graphical models, the data matrix is usually assumed to have independent rows or columns that follow the same distribution. The independence assumptions substantially simplify mathematical derivations but they tend to be very restrictive. For instance, the cortical circuits can change over time due to activities such as motor learning, attention or visual stimulation. This data typically has a complex structure that is organized by the experiment’ s design, with one or more experimental factors varying according to a predefined pattern.
On the theoretical and methodological front, recent work demonstrated another regime where further reductions in the sample size are possible under additional structural assumptions on the conditional dependency graphs which arise naturally in the above mentioned contexts when handling data with complex dependencies. For example, the matrix-normal model as studied in Tsiligkaridis et al. (2013) and Zhou (2014) restricts the topology of the graph to tensor product graphs where the precision matrix corresponds a Kronecker product representation. Moreover, (Zhou, 2014) showed that one can estimate the covariance and inverse covariance matrices well using only one instance from the matrix-variate normal distribution. Along the same lines, the Bigraphical Lasso framework was proposed to parsimoniously model conditional dependence relationships of matrix-variate data based on the Cartesian product of graphs (Kalaitzis et al., 2013) as opposed to the direct product graphs of the matrix-normal models above. These models naturally generalize to multilinear settings with more than two axes of structure as demonstrated in the present work. The present work addresses the problem of sparse modeling of a structured precision matrix for tensor-valued data; more precisely, we aim to estimate the structure and parameters for a class of Gaussian graphical models by restricting the topology to the class of Cartesian product graphs, with precision matrices represented by a Kronecker sum for data with complex dependencies.
Toward these goals, we will introduce the tensor graphical Lasso (TeraLasso) procedure for estimating sparse -way decomposable precision matrices. We will show that our concentration of measure analysis enables a significant reduction in the sample size requirement in order to estimate parameters and the associated conditional dependence graphs along different coordinates such as space, time and experimental conditions. We establish consistency for both the Bigraphical Lasso and Tensor graphical Lasso estimators and obtain optimal rates of convergence in the operator and Frobenius norm for estimating the associated precision matrix, and for structure recovery. Finally, we demonstrate using simulations and real data that the Kronecker sum precision model has excellent potential for improving computational scalability, structural interpretation, and its applications to classification, prediction, and visualization for complex data analysis.
A philosophical motivation of TeraLasso’s Kronecker sum (Cartesian graph) model is that it achieves the maximum entropy among all models for which the tensor component projections of the covariance matrix are fixed, see Section 3. A compelling justification for the proposed Kronecker sum model for the precision matrix is that similar models have been successfully used in other fields, including regularization of multivariate splines, design of physical networks, and decomposition of solutions of partial differential equations governing many physical processes. Additional discussion of these practical motivations for the model is in Section 1.3 below.
1.1 The multi-way Kronecker sum precision matrix model
We follow the notation and terminology of Kolda and Bader (2009) for modeling tensor-valued data arrays. Define the vector of component dimensions and let denote the product of these dimensions
[TABLE]
To simplify the multiway Kronecker notation, we define
[TABLE]
where denotes the Kronecker (direct) product and . Using this notation, the -way Kronecker sum of matrix components can be written as
[TABLE]
In the special case of this Kronecker sum representation reduces to the more familiar . The vectorization of a -way tensor is denoted as and is defined as in Kolda and Bader (2009). Likewise, we define the transpose of a -way tensor analogously to the matrix transpose, i.e. .
When the precision matrix has a decomposition of the form (1) the Kronecker sum components are sparse, and the -way data has a multivariate Gaussian distribution, the sparsity pattern of corresponds to a conditional independence graph across the -th dimension of the data.
Figure 1 illustrates the Kronecker sum model proposed in (1) for and . Specifically, are identical tridiagonal precision matrices corresponding to a one dimensional autoregressive-1 (AR-1) process. In the Figure the precision matrix is shown on the left and covariance on the right.
The entries of each are replicated times across for each . This regular structure permits the aggregation of corresponding entries in the sample covariance matrix, resulting in variance reduction in estimating . This Kronecker sum gives a nonseparable and interlocking repeating block structure in the covariance matrix.
We propose the following sparse Kronecker sum estimator of the precision matrix in (1), which we call the Tensor Graphical Lasso (TeraLasso). The TeraLasso minimizes the negative -penalized Gaussian log-likelihood function over the domain of precision matrices having Kronecker sum form:
[TABLE]
is a sparsity-inducing regularization function parameterized by a regularization parameter , and
[TABLE]
is the set of positive semidefinite matrices that are decomposable into a Kronecker sum of fixed factor dimensions . In this paper we consider -amenable regularizers (Loh et al., 2017). The norm constraint is required for the solution to be well defined when is not a convex penalty. These penalties includes nonconvex regularizers such as SCAD and MCP, as well as the traditional regularizer .
Observe that sparsity in the off diagonal elements of directly creates sparsity in . As in the graphical Lasso, incorporating an -penalty over entries of with the tensor-valued Gaussian or matrix-normal (pseudo)-loglikelihood promotes a sparse graphical structure in ; see for example (Banerjee et al., 2008; Yuan and Lin, 2007; Zhou, 2014; Zhou et al., 2011). In this work, we allow for the more general case of nonconvex regularization functions as considered in Loh et al. (2017). While sometimes difficult to tune in practice, nonconvex regularization provides strong nonasymptotic guarantees on the elementwise estimation error of , implying strong, single sample support recovery guarantees when the smallest nonzero element of is bounded from below.
The contributions of this paper are as follows. The sparse multivariate-normal Bigraphical Lasso (BiGLasso) model is extended to the sparse tensor-variate () TeraLasso model, allowing the modeling of data with arbitrary tensor degree . A new subgaussian concentration inequality (Corollary F.29 in the supplement) is presented that gives rates of statistical convergence (Theorems 1-3) of the TeraLasso estimator as well as the BiGLasso estimator, when the sample size is low (even equal to one). TeraLasso’s generalization of BiGlasso from 2-way to -way decompositions is important as it expands the domain of application, allowing a data scientist to group variables into their natural domains along multiple tensor axes. For example, with a health data set that is collected over space, time, people and replicates, TeraLasso’s 3-way tensor decomposition (timespacepeople) can account for possible dependency structure between people, while a 2-way BiGLasso or KLasso approach decomposing over (timespace) would unnecessarily enforce an assumption of independence between people. Alternately, BiGLasso or KLasso could group two axes together (e.g. (timespace)people), however, this would create a large, unstructured factor whose estimation would require many more replicates than the 3-way decomposition that TeraLasso uses to give each axis its own factor.
A highly scalable, first-order ISTA-based algorithm is proposed to minimize the TeraLasso objective function. We prove (Theorem H.42 in the supplement) that it converges to the global optimum with a geometric convergence rate, and demonstrate its practical advantages on high dimensional problems. As compared to the alternating block coordinate descent algorithm proposed by Kalaitzis et al. (2013) for the BiGLasso, the proposed ISTA algorithm enjoys a per-iteration computational speedup over BiGLasso of order . Our numerical results show that the BiGLasso algorithm often requires many more iterations to converge than our ISTA method. Numerical comparisons are presented demonstrating that TeraLasso significantly improves performance in small sample regimes. To demonstrate the application of TeraLasso to real world data we use it to estimate the precision matrix of spatio-temporal meteorological data collected by the National Center for Environmental Prediction (NCEP). Our results show that the TeraLasso precision matrix estimator degrades much more slowly than other estimators as one reduces the number of samples available to fit the model. The intuitive graphical structure, the robust eigenstructure and a maximum-entropy interpretation make the TeraLasso model a compelling choice for modeling tensor data, much as the Bigraphical Lasso provides a meaningful alternative to the matrix-normal model.
1.2 Relevant prior work
The use of tensor product models for multiway data has a long history. In the statistical context, directly fitting a Kronecker product to multiway data yields a first order approximation corresponding to fitting the mean (Kolda and Bader, 2009) when the fitting criteria is the Frobenius norm of the residuals. Many such methods involve low-rank factor decompositions including: PARAFAC and CANDECOMP as in Harshman and Lundy (1994); Faber et al. (2003); Tucker decomposition-based methods such as Tucker (1966) and Hoff (2016); and hybrid methods such as Johndrow et al. (2017). In contrast, second order methods have been used to approximate multiway structure of the covariance (Werner et al., 2008; Pouryazdian et al., 2016). Series decomposition methods have been proposed for fitting the covariance matrix in Frobenius norm using sums of Kronecker products (Tsiligkaridis and Hero, 2013; Greenewald and Hero, 2015; Rudelson and Zhou, 2017; Greenewald et al., 2017).
Kronecker product approximations to the inverse covariance have fitted matrix normal models (Allen and Tibshirani, 2010) and sparse matrix normal models (Leng and Tang, 2012; Zhou, 2014; Tsiligkaridis et al., 2013). In contrast to the Kronecker sum model (1) for the precision matrix , the -way Kronecker product model is . The Kronecker product decomposition implies a separable property of the precision matrix across the data dimensions, which one might expect to become an increasingly restrictive condition as increases. In this paper we show that the proposed Kronecker sum model (1) can be a worthwhile alternative representation.
A two factor () sparse Kronecker sum model for the precision matrix was introduced and studied in Kalaitzis et al. (2013). The model was fitted to the sample covariance matrix using an iterative procedure called BiGlasso, which required the diagonal entries of to be known. Conditions guaranteeing convergence were not provided. Here we extend the BiGlasso model to arbitrary and unknown diagonal entries of , provide a faster converging optimization algorithm, and obtain strong convergence guarantees and bounds on the convergence rate for all , including . For completeness, we also obtain (Appendix J of the supplement) bounds on the convergence rate for the known-diagonal setting of Kalaitzis et al. (2013).
The qualitative differences between the Kronecker product and Kronecker sum models for the precision matrix can be better appreciated by considering the product graphs that are induced by them. For given sparse Kronecker factors , the Kronecker product model corresponds to the direct (tensor) product of the component graphs while the Kronecker sum model corresponds to the Cartesian product111The Cartesian product of two graphs and is a graph with vertices being the Cartesian product of and , and with edges such that node is adjacent to if and only if either and is adjacent to in , or and is adjacent to in . of these components (Hammack et al., 2011). The direct product graph and Cartesian product graph differ greatly; the former has a number of edges equal to , while the latter has a number of edges equal to , where denote the node and edge sets of the -th component graph222The notation denotes the row dimension of and denotes the number of non-zero upper triangular entries of . To illustrate, if the number of non-zero entries of is for some , the number of edges induced in the direct product graph by inserting a single new edge into the first component graph is equal to , where we recall that is the number of covariates (rows of ). On the other hand, for the Cartesian product graph it is only regardless of . Hence, as and increase, using the Kronecker product model a single edge in can create a proliferation of edges while the number of new edges in the Kronecker sum model is fixed, independent of . A concrete example of these differences is illustrated in Figure 2. The qualitative differences between the Kronecker product and Kronecker sum models for the precision matrix are summarized in Table 1.
1.3 Rationale for the proposed multiway Kronecker sum model
This paper develops a scalable, fast and accurate estimation procedure, the TeraLasso, for multiway precision matrices using higher order Kronecker sum models. To justify the practical utility of the TeraLasso we illustrate it on a spatio-temporal meteorological dataset. We have also applied it to other applications not presented here. While comprehensive validation of the model on a larger corpus of real data is beyond the scope of this paper, there is ample evidence that the model will have many statistical applications. We base this assessment on the wide use of Kronecker sum models, equivalently Cartesian product graph models, in biology, physics, social sciences, and network engineering, among other fields (Imrich et al., 2008; Van Loan, 2000). In particular the Kronecker sum arises in solving the celebrated Sylvester equation for a matrix which, for , takes the form . The Sylvester equation can be solved by expressing the equation in vectorized form as (for arbitrary this becomes the tensor Sylvester equation ), but this is often impractical in high dimension. Such equations result from the discretization of separable -dimensional PDEs with tensorized finite elements (Grasedyck, 2004; Kressner and Tobler, 2010; Beckermann et al., 2013; Shi et al., 2013; Ellner et al., 1986). As a result Kronecker sums come in many areas of applied math, including, beam propagation physics (Andrianov (1997)); control theory (Luenberger, 1966; Chapman et al., 2014); fluid dynamics (Dorr, 1970); and spatio-temporal neural processes (Schmitt et al., 2001).
Closer to home, the Kronecker sum model arises in multivariate spline data analysis, e.g. as applied to harmonic analysis on graphs (Kotzagiannidis and Dragotti (2017)). More recently, Fey et al. (2018) has proposed tensor B-splines defined over a Cartesian product basis for geometric Convolutional Neural Networks (CNN). Kronecker sums have been proposed as precision matrices for weighting the quadratic regularizer in smoothed multivariate spline regression. In particular, Wood (2006) observed that, as compared to the Kronecker product, the Kronecker sum reduces the coupling between the axes when used as a spline smoothing penalty for generalized additive mixed model regression. This observation motivated Wood (2006) and Eilers and Marx (2003) to use the inverse of a Kronecker sum matrix as a penalty, or prior, for smoothing -dimensional regressions (see also work by Lee and Durbán (2011) and Wood et al. (2016)). This approach has been applied to spatio-temporal forest health modeling (for which ) (Augustin et al., 2009), brain development modeling (Holland et al., 2014), and analysis of the impact of climate and weather on spatio-temporal patterns of beetle populations (Preisler et al., 2012), among other applications. In these spline regression problems the Kronecker sum appears as a precision matrix parameterizing a Gaussian prior on the spline coefficient vector , where the prior is of the form . Here, are regularization coefficients and are coordinate-wise smoothing matrices, .
Instead of using the Kronecker sum to model the a priori precision matrix of a set of spline parameters, this paper proposes the Kronecker sum as a model for the precision matrix of the multiway data in the likelihood function, where the data matrix takes the place of the spline coefficient vector . The stated advantages of the Kronecker sum model for the spline regression setting (Wood, 2006) can be expected to carry over to the precision matrix estimation setting of TeraLasso. In particular, like the spline regression prior, the TeraLasso smooths each axis separately, while summing over the others, thereby reducing coupling between the tensor axes as compared to the Kronecker product. For data that has structure similar to that imposed by (Wood, 2006) on the spline regression coefficients this should result in a more accurate fit. Indeed, if a population of regression spline problems was available, in principle one could apply the TeraLasso to estimating the best precision matrix of the spline coefficients that would minimize the population-averaged fitting error.
Outline. The remainder of the paper is organized as follows. We introduce notation and some preliminary results in Section 2, and our proposed TeraLasso model in Section 3. High dimensional consistency results are presented in Section 4, first with convex regularizers and then with non-convex sparsity regularizers. The first order ISTA optimization algorithm is described in Section 5, and conditions are specified for which the algorithm converges geometrically to the global optimum. Finally, Sections 6 and 7 illustrate the proposed TeraLasso estimator on simulated and real data, with Section 8 concluding the paper. We place all technical proofs in the supplementary material, along with additional experiments and further exploration of the properties and implications of the Kronecker sum subspace and the associated identifiable parameterization.
2 Notation and Preliminaries
We use upper case letters, e.g. for matrices and tensors, bold lower case for vectors, and denote the element of a matrix as and the element of a tensor as . Fibers are the higher-order analogue of matrix rows and columns. A fiber of a tensor is obtained by fixing every index but one, the mode- fiber of tensor is denoted as the column vector . Following definition by Kolda and Bader (2009), tensor unfolding or matricization of along the th-mode is denoted as , formed by arranging the mode- fibers as columns of the resulting matrix of dimension . The column ordering is not important so long as it is consistent.
For a vector in , denote by the Euclidean norm of . The operator and Frobenius norms of a matrix are denoted as and respectively; the notation denotes the vectorization of the matrix ; denotes the matrix infinity norm and denotes the max norm. The determinant is denoted as . We use the inner product throughout. Define the set of matrices with Kronecker sum structure of fixed dimensions :
[TABLE]
where the set of matrices defined in (4) is obtained by restricting to the positive cone, i.e.,
[TABLE]
Note that the set (5) is linearly spanned by the components, since there are no nonlinear interactions between any of the parameters. Thus is a linear subspace of , and we can define a unique projection operator onto :
[TABLE]
A closed-form expression for is given in Section I.3 of the supplementary material. Note that the dimensionality of the subspace is , which is often significantly smaller than the ambient dimension .
Parameterization of by . Note that does not uniquely determine , i.e., without further constraints the Kronecker sum parameterization is not fully identifiable. It is easy to verify, however, that both are identifiable, where we define the notation . We can then write the identifiable decomposition
[TABLE]
and correspondingly . Note that while the offdiagonal factors can take on any values, is not completely free (for a fully orthogonal parameterization see Section D of the supplement).
Interpretation of correlation coefficients. The quantities do not by themselves correspond to correlation coefficients. Due to the repeating structure of the Kronecker sum each element will appear in distinct symmetric subblocks of , and in each (th) subblock it will have a correlation coefficient uniquely defined for that subblock:
[TABLE]
where . The overall correlation structure is preserved across the blocks, simply the strength of the correlations are modulated by the contributions of the other additive factors in the block.333Recall that the need not be positive definite and need not be .
3 Models and Methods
Let be independent realizations of the -way tensor . Define for all . Define as the sample covariance. The mode- Gram matrix and factor-wise covariance are given by
[TABLE]
noting that the elements of these matrices are effectively inner products between order tensors. is the sample covariance of the data unfolded across the th tensor axis, while denotes the population covariance matrix along the same axis. These Gram matrices can be represented as elementwise aggregations over entries in the full sample covariance (3), with locations indexed by as:
[TABLE]
In tensor covariance modeling when the dimension is much larger than the number of samples , the Gram matrices are often used to model the rows and columns separately, notably in the matrix-variate estimation methods of Zhou (2014) and Kalaitzis et al. (2013). Observe that the TeraLasso estimator (2) of the precision matrix can be expressed as
[TABLE]
where is the set of positive semidefinite Kronecker sum matrices (4).
Ignoring regularization, the objective function in curly brackets can be written as where and , with a normalizing constant. The non-negativity of the Kullback-Liebler divergence implies that the Kronecker sum model is a maximum entropy model, as previously pointed out for the case of by Kalaitzis et al. (2013). Alternatively, Kronecker sum models can be characterized as regularizing the precision matrix estimation problem with a minimally informative prior over the set .
The class of Kronecker sum matrices is a highly structured, lower-dimensional subspace of . By definition of the Kronecker sum (1), each entry of appears in entries of . By imposing that the precision matrix have both Kronecker sum structure and sparse structure through the penalty , TeraLasso is able to effectively regularize the precision estimation problem.
We assume the penalty is -amenable in the sense of Loh et al. (2017).
Definition 1** ( amenable regularizer)**
A regularizer is -amenable when and if
* is symmetric around zero and .* 2. 2.
* and are both nondecreasing on .* 3. 3.
* is differentiable for all .* 4. 4.
The function is convex. 5. 5.
. 6. 6.
* for all .*
Note that the regularizer is -amenable. Example nonconvex penalties in this class include the SCAD penalty (Fan and Li, 2001) and the MCP penalty (Zhang et al., 2010), both defined in Appendix K of the supplement.
Observe that for nonzero (i.e. nonconvex ) the constraint on the spectral norm of () in the TeraLasso objective function (8) is necessary since without it a global minimum may not exist (Loh et al., 2017). For spectral norm constraint parameter set to , we show (Lemma G.34 in the supplement) that (8) with -amenable is convex and has a unique global minimizer. For the penalty, the objective is always convex and can be set to infinity.
4 High Dimensional Consistency of the TeraLasso
Let be an isotropic -subgaussian random vector with independent entries satisfying , . The condition on a scalar random variable is equivalent to subgaussian decay of the tails of , implying . The extension to random vectors is straightforward. Specifically, is a subgaussian random vector with positive definite covariance when
[TABLE]
where denotes a positive definite square root factor of . We then call to be an order- subgaussian random tensor with covariance when is a subgaussian random vector in defined as in (9).
We assume the data are independent and identically distributed subgaussian random tensors whose inverse covariance follows the Kronecker sum model (1), namely, that , where is a subgaussian random vector in as defined in (9). A special case of the subgaussian model is the Gaussian model, for which the zeros in the precision matrix define the conditional independencies among the variables . This conditional independence relation does not hold for the general subgaussian case, but nonetheless strong convergence of the TeraLasso precision matrix estimator is preserved.
In addition to the subgaussian generative model given above, we make the following technical assumptions on the true model, guaranteeing sparsity in and its eigenvalues being bounded away from zero and infinity.
(A1)
Define the support set of the th Kronecker sum component of the precision matrix by for . We assume is sparse, i.e. .
(A2)
The minimal eigenvalue satisfies , and the maximum eigenvalue satisfies .
Defining the support set of as , (A1) implies .
4.1 Regularization with penalty
With , the constraint on is unnecessary, and (8) becomes
[TABLE]
where is the off diagonal norm. The objective (10) is jointly convex, and its minimization over has a unique solution (see Section B.6 of the supplement). We require an additional assumption
(A3)
The sample size and the component dimensions satisfy the following condition:
[TABLE]
where and is the condition number of .
Note this assumption holds for and sufficiently large , which can hold for any . We obtain the following bounds on the Frobenius and operator norm error of the TeraLasso estimator (10). The constants () are given in the proof (see the supplement), and do not depend on , , , or .
Theorem 1** (Frobenius error bound)**
Suppose the assumptions (A1)-(A3) hold, and that is the minimizer of (10) with . Then with probability at least
[TABLE]
Theorem 2** (Factorwise and L2 error bounds)**
Suppose the conditions of Theorem 1 hold. Then with probability at least ,
[TABLE]
and as a result
[TABLE]
Theorems 1 and 2 are proved in Section E of the supplement. Observe that the theorem predicts (2) that, for fixed and , the estimation error of the parameters of converges to zero as the dimensions go to infinity (recall that ). This implies that for increasing dimensions the TeraLasso will converge even for a single sample . Due to the repeating structure and increasing dimension of , the parameter estimates can converge without the overall Frobenius error converging.
Comparison to GLasso. The Frobenius norm bound in Theorem 1 improves on the subgaussian GLasso rate of Rothman et al. (2008); Zhou et al. (2011) by a factor of . If the dimensions are equal ( and are constant over ) and is fixed, Theorem 2 implies , indicating that TeraLasso with replicates estimates the identifiable representation of with an error rate equivalent to that of GLasso with and available replicates.
Independence along an axis. Suppose that the data tensor is i.i.d. along the first axis, i.e. . Then instead of a -way TeraLasso, a model with replicates would suffice, yielding a factorwise error bound (Theorem (2)) of , as compared to the factorwise error bound of associated with the full -way model (since ). Hence having a priori knowledge of independence (allowing the use of the model) does not meaningfully improve the rate over the the original -way model so long as . A similar satisfying result holds for the Frobenius error bound in Theorem 1.
4.2 Nonconvex Regularizers and Single Sample Support Recovery
Nonconvex regularization will provide nonasymptotic guarantees on the elementwise estimation error, implying strong, single sample support recovery guarantees when the smallest nonzero element of is bounded from below. On the other hand, these stronger results require more restrictive assumptions on sparsity of the precision matrix and its smallest nonzero element. Specifically, we will require the following:
(A4)
The degree (maximum number of nonzero edges connected to a node) of the sparsity graph of each factor is bounded by a constant .
(A5)
The sample size satisfies: for some large enough.
(A6)
There exist constants such that and
[TABLE]
In (A6) the notation denotes the submatrix of formed by extracting the rows and columns corresponding to the index set . Under these assumptions we have the following result.
Theorem 3** (Nonconvex Regularizers)**
Suppose the regularizer in (8) is -amenable, and . Then with probability at least as in Theorem 1, (8) has a unique stationary point (given by the oracle estimator defined in the supplement), with (for all )
[TABLE]
[TABLE]
[TABLE]
[TABLE]
The proof is given in Section G in the supplement, and uses arguments analogous to those of Loh et al. (2017) along with concentration inequalities arising from the structure of the TeraLasso model.
Theorem 3 implies that the elements (of both and the offdiagonals of ), and thus the support (of both and the ) can be estimated using a single sample () provided is large enough. The Frobenius norm convergence rates (both factorwise and overall) for the convex and nonconvex regularizers remain effectively the same (comparing Theorem 3 to Theorems 1 and 2), hence the primary benefit of the nonconvex bound is the ability to guarantee support recovery in exchange for additional assumptions.
5 TG-ISTA Algorithm
In this section, we introduce an iterative soft thresholding (ISTA) method, restricted to the convex set of possible positive semidefinite Kronecker sum precision matrices, to implement the TeraLasso optimization (8). We call this implementation Tensor Graphical Iterative Soft Thresholding (TG-ISTA).
5.1 Composite gradient descent and proximal first order methods
Our goal is to solve the objective (8). This objective function can be decomposed into the sum of a differentiable function and a lower semi-continuous but nonsmooth function : for :
[TABLE]
For objectives of this form, Nesterov (2007) proposed a first order method called composite gradient descent. Composite gradient descent has been specialized to the case of and is widely known as Iterative Soft Thresholding (ISTA) (see for example Tseng (2010); Combettes and Wajs (2005); Beck and Teboulle (2009); Nesterov (1983, 2004)). An extension to nonconvex regularizers is given in Loh and Wainwright (2013).
The linearity of the constraint set suggests the use of gradient descent where the gradients are projected onto the associated dimensional linear subspace. The positive definite restriction can then be handled in a similar way as Guillot et al. (2012) did for the vanilla GLasso. We therefore derive composite gradient descent in the linear subspace of , creating a positive definite sequence of iterates given by the recursion
[TABLE]
where the initial matrix can be chosen as the identity. We enforce the positive semidefinite constraint at each step by performing backtracking line search to find a suitable stepsize (see Algorithm 1) (Guillot et al., 2012). We decompose and solve the problem (14) for the case of the TeraLasso objective in Section 5.2 below.
5.2 TG-ISTA implementation of TeraLasso
To apply this form of composite gradient descent to the TeraLasso objective, the projected gradient of is required for (5.1). For simplicity, consider the regularized case. The general nonconvex case is described in the next section and the supplement. Since the gradient of with respect to is (Lemma I.55 in the supplementary material)
[TABLE]
While many different conventions for parameterizing the projection using the are possible, the projection remains unique. Alternate parameterizations will not affect the convergence or output of the algorithm. Since the gradient of with respect to is (Boyd and Vandenberghe, 2009), the projected gradient takes the form
[TABLE]
The matrices are computed via the expressions given in Lemma I.55 in the supplement. Combining (5.2) and (16), the projected gradient of the objective is
[TABLE]
Lemma 4** (Decomposition of objective)**
For of the form
[TABLE]
the unique solution to (14) with is given by where
[TABLE]
The proof is in supplement Section B.5. The right hand side of (18) is the proximal operator of the penalty on the off diagonal entries. The solution has closed form, as given in Beck and Teboulle (2009),
[TABLE]
where we define the off diagonal shrinkage operator as
[TABLE]
The composite gradient descent algorithm is given in Algorithm 1. In Section H of the supplement, a scalable geometric rate of convergence of TG-ISTA to the global minimum is derived (Theorem H.42). In Section C.2 of the supplement we show that each iteration can be computed in floating point operations.
5.3 TG-ISTA for a nonconvex regularizer
The estimation algorithm is largely the same as Algorithm 1, except with an additional term added to the gradient. Specifically, the updates are of the form
[TABLE]
where is the step size and
[TABLE]
The update (23) can be decomposed into the factorwise updates
[TABLE]
where for and . These updates can be inserted into the framework of Algorithm 1, with an added step of enforcing the constraint, e.g. via step size line search. The algorithm is summarized in Algorithm 2 in Supplement B.1.
Theorem 5** (Convergence of Algorithm 2)**
Algorithm 2 will converge to the global optimum when the norm constraint parameter is chosen to be less than or equal to .
Proof 5.6**.**
Follows since for the objective (8) is convex on the convex constraint set (Lemma G.34, supplement).
6 Validation on synthetic data
Random graphs were created for each factor using both an Erdos-Renyi (ER) topology and a random grid graph topology444Code for experiments is included in the supplementary material and can be found at https://github.com/kgreenewald/teralasso.. These ER type graphs were generated according to the method of Zhou et al. (2010). Initially we set , where , and randomly select edges and update as follows: for each new edge , a weight is chosen uniformly at random from ; we subtract from and , and increase by . This keeps positive definite. We repeat this process until all edges are added. Finally, we form . An example 25-node, ER graph and precision matrix are shown in Figure 3.
The random grid graph is produced in a similar way, with the exception that edges are only allowed between adjacent nodes, where the nodes are arranged on a square grid (Figure 3(b)). Algorithm 1 in Section B.3 of the supplement describes how the random vector is generated under the Kronecker sum model.
6.1 Validation of theoretical algorithmic convergence rates
To verify the geometric convergence of the TG-ISTA implementation (Theorem H.42 in the supplement), we generated Kronecker sum inverse covariance graphs and plotted the Frobenius norm between the inverse covariance iterates and the optimal point . We set the to be random ER graphs with edges where , and determined the value for using cross validation. Figure 4 shows the results as a function of iteration, for a variety of and configurations and the 1 convex regularization. Figure 12 in Supplement B.1 repeats these experiments with the nonconvex SCAD and MCP penalties, using the same random seed. For comparison, the statistical error of the optimal point is also shown, as optimizing beyond this level provides reduced benefit. As predicted, linear or better convergence to the global optimum is observed. The small number of iterations combined with the low computational cost per iteration confirm the algorithmic efficiency of the TG-ISTA implementation of TeraLasso. Additional numerical experiments demonstrating fast convergence on larger scale problems are given in Section C.2 of the supplement.
6.2 Regularization with penalty
In the TeraLasso objective (10), the sparsity of the estimate is controlled by distinct tuning parameters for . The convergence condition on in Theorem 1 suggests that the can be set as with being a single scalar tuning parameter, depending on absolute constants and . Below, we experimentally validate the reliability of this tuning strategy.
The performance is empirically evaluated using several metrics including: the Frobenius norm () and spectral norm () error of the precision matrix estimate and the Matthews correlation coefficient to quantify the edge misclassification error. Let the number of true positive edge detections be TP, true negatives TN, false positives FP, and false negatives FN. The Matthews correlation coefficient is defined as (Matthews, 1975)
[TABLE]
where each nonzero off diagonal element of is considered as a single edge. Larger values of MCC imply better edge estimation performance, with implying complete failure and perfect edge set estimation.
Shown in Figure 5 are the MCC, normalized Frobenius error, and spectral norm error as functions of and where the constants giving Note achieves near optimal results.
Having verified the single tuning parameter approach, hereafter we will cross-validate only . In supplement Section C.3, we provide experimental verification in a wide variety of experimental settings (including varying the relative size of the tensor dimensions ) that our bounds on the rate of convergence for the 1 regularized model are tight. Figure 6 illustrates how increasing dimension and improves single sample performance. Shown are the average TeraLasso edge detection precision and recall values for different values of in the single and 5-sample regimes, all increasing to (perfect structure estimation) as , , and increase.
6.3 Nonconvex Regularization
Here the penalized TeraLasso is compared to TeraLasso with nonconvex regularization (8). Shown in Figure 7 are the MCC, normalized Frobenius error, and spectral norm error for estimating and Erdos-Renyi graphs as functions of regularization parameter for each of 1, SCAD (103), and MCP (104) regularizers in a variety of configurations. Figure 8 shows similar results for a variant of the spiked identity model of Loh et al. (2017). Observe that nonconvex regularization improves performance slightly, not only for structure estimation (MCC) but for the Frobenius norm error (due to the reduction in bias) as well. This improvement is increased in the spiked identity case.
7 NCEP Windspeed Data
The TeraLasso model is illustrated on a meteorological dataset. The US National Center for Environmental Prediction (NCEP) maintains records of average daily wind velocities in the lower troposphere, with daily readings beginning in 1948. The data is available online at ftp://ftp.cdc.noaa.gov/Datasets/ ncep.reanalysis.dailyavgs/surface. Velocities are recorded globally, in a latitude-longitude grid with spacings of 2.5 degrees in each coordinate. Over bounded areas, the spacing is approximately a rectangular grid, suggesting a model (latitude vs. longitude) for the spatial covariance, and a model (latitude vs. longitude vs. time) for the full spatio-temporal covariance.
Consider the time series of daily-average wind speeds. Following Tsiligkaridis and Hero (2013), we regress out the mean for each day in the year via a 14-th order polynomial regression on the entire history from 1948-2015. We extract two spatial grids, one from eastern North America, and one from western North America (Figure 9). Figure 10 shows the TeraLasso estimates for latitude and longitude factors using time samples from January in years following 1948, for both the eastern and western grids. Observe the approximate AR structure, and the break in correlation (Figure 10 (b), longitude factor) in the Western Longitude factor. The location of this break corresponds to the high elevation line of the Rocky Mountains. In the supplement, we compare the TeraLasso estimator to the unstructured shrinkage estimator, the non-sparse Kronecker sum estimator (TeraLasso estimator with sparsity parameter ), and the Gemini sparse Kronecker product estimator of Zhou (2014). It is shown that the TeraLasso provides a significantly better fit to the data.
To illustrate the utility of the estimated precision matrices, we use them to construct a season classifier. NCEP windspeed records are taken from the 51-year span from 1948-2009. We estimate spatial precision matrices on consecutive days in January and June of a training year respectively, and running anomaly detection on -day sequences of observations in the remaining 50 testing years. We report average classifier performance by averaging over all 51 possible partitions of the 51-year data into 1 training and 50 testing years. The sequences are labeled as summer (June), and winter (January), and we compute the classification error rate for the winter vs. summer classifier obtained by choosing the season associated with the larger of the likelihood functions
[TABLE]
We consider the spatial-temporal precision matrix for a spatial-temporal array of size , with the first () factor corresponding to the latitude axis of the spatial array, the second a factor corresponding to the longitude axis, and the third factor a factor corresponding to a temporal axis of length . The spatial-temporal array is created by concatenating temporally consecutive spatial samples. We use regularization.
Results for different sized temporal covariance extents () are shown in Figure 11 for TeraLasso, with unregularized TeraLasso (ML Kronecker Sum) and maximum likelihood Kronecker product estimator (Werner et al., 2008; Tsiligkaridis et al., 2013) results shown for comparison. In this experiment, we use the ML Kronecker product estimator instead of the Gemini, as for this maximum-likelihood classification task the maximum-likelihood based approach performs significantly better than the factorwise objective approach of the Gemini estimators, which is not surprising as the Kronecker product is not a good fit for this data (Section C.4 of the supplement). Note the superior performance and increased single sample robustness of the proposed ML Kronecker Sum and TeraLasso estimates as compared to the Kronecker product estimate, confirming the better fit of TeraLasso. In each case, the nonmonotonic behavior of the Kronecker product curves is due partly to randomness associated with the small test sample size, and partly due to the fact that the Kronecker product in has overly strong coupling across tensor directions, giving large bias.
8 Conclusion
A factorized model, called the TeraLasso, is proposed for the precision matrix of tensor-valued data that uses Kronecker sum structure and sparsity to regularize the precision matrix estimate. An ISTA-like optimization algorithm is presented that scales to high dimensions. Statistical and algorithmic convergence are established for the TeraLasso that quantify performance gains relative to other structured and unstructured approaches. Numerical results demonstrate single-sample convergence as well as tightness of the bounds. Finally, an application to real tensor-valued () meteorological data is considered, where the TeraLasso model is shown to fit the data well and enable improved single-sample performance for estimation and anomaly detection. Future work includes combining first moment tensor representation methods for mean estimation such as PARAFAC (Harshman and Lundy, 1994) with the second order TeraLasso method introduced in this paper for estimating the covariance.
9 Acknowledgement
The research reported in this paper was partially supported by US Army Research Office grant W911NF-15-1-0479, US Department of Energy grant DE-NA0002534, NSF grant DMS-1316731, and the Elizabeth Caroline Crosby Research Award from the Advance Program at the University of Michigan.
Appendix A Appendix outline
This supplement is organized as follows. Sections B-C focus on the implementation and numerical convergence of the TeraLasso algorithm and Sections D-H focus on theory and proofs of convergence. Section B presents the algorithm for TeraLasso with nonconvex regularization and describes additional properties of the TeraLasso algorithm, including a discussion of the choice of step size, decomposition of the gradient update, and proof of joint convexity of the objective. Section C presents additional numerical experiments, including convergence of the nonconvex algorithm, larger scale TG-ISTA convergence experiments, additional discussion comparing the fit of the TeraLasso model to the wind speed data, and a discussion of the geometric differences between the Gemini and TeraLasso objectives.
We then proceed to the convergence analysis. Section D describes properties of the Kronecker sum and the Kronecker sum subspace that are needed for the remainder of the discussion. Proof of the main Frobenius norm theorem and of the spectral norm theorem are in Section E, with the concentration bounds proven in Section F. Section G proves the result on nonconvex regularization, and Section H presents and proves theorems on the geometrical convergence of the TG-ISTA algorithm. Relevant properties and identities relating to the space spanned by Kronecker sum matrices are contained in Appendix I, and a discussion of the case where the diagonal elements of are known is given in Appendix J.
Appendix B TeraLasso algorithm step size and numerical convergence proofs
B.1 Convergence of nonconvex regularization algorithm
The TG-ISTA implementation of the TeraLasso algorithm for nonconvex regularizers is shown in Algorithm 2. The primary differences from the 1 regularized case are (a) the addition of the norm constraint, and (b) the use of the nonconvex regularizer in the gradient computation.
B.2 Choice of step size
Here we propose a method (24) for selecting the stepsize parameter at each step that ensures convergence of the algorithm. We follow the approach of Beck and Teboulle (2009) and Guillot et al. (2012). Since and the the positive definite cone is an open set, there will always exist a small enough such that . We prove geometric convergence when is chosen such that and
[TABLE]
where is a quadratic approximation to given by
[TABLE]
At each iteration , we thus perform a line search to select an appropriate . We first select an initial stepsize and compute the update (19). If the resulting is not positive definite or does not decrease the objective sufficiently according to (24), we decrease the stepsize to for and re-evaluate if the resulting satisfies the conditions. This backtracking process is repeated (setting stepsize equal to where is incremented) until the resulting satisfies the conditions. Since by construction is positive definite, and the positive definite cone is an open set, there will be a step size small enough such that the conditions are satisfied. In practice, if after a set number of backtracking steps the conditions are still not satisfied, we can always take the safe step
[TABLE]
As the safe stepsize often leads to slower convergence, we use the more aggressive Barzilai-Borwein step to set a starting at each time. The Barzilai-Borwein stepsize presented in Barzilai and Borwein (1988) creates an approximation to the Hessian, in our case given by
[TABLE]
We derive the gradient in the next section. The norms and inner products in (26) and (25) can be efficiently computed factorwise (using the and only) using the formulas in Appendix I.1.
B.3 Generation of Kronecker Sum Random Tensors
Generating random tensors given a Kronecker sum precision matrix can be made efficient by exploiting the Kronecker sum eigenstructure. Algorithm 3 allows efficient generation of data following the TeraLasso model.
B.4 Detailed TeraLasso Algorithm
Algorithm 4 shows additional details of the implementation of Algorithm 1 in the main text.
B.5 Decomposition of Objective: Proof of Lemma 4
For simplicity of notation define to be the projection of onto the cone of positive definite Kronecker sum matrices:
[TABLE]
Using this notation and substituting in (17) from the main text, the objective (14) becomes
[TABLE]
Expanding out the Kronecker sums, for
[TABLE]
the Frobenius norm term in the objective (27) can be decomposed into a sum of a diagonal portion and a factor-wise sum of the off diagonal portions. This holds by Property 2 in Appendix A which states the off diagonal factors have disjoint support in . Thus,
[TABLE]
Substituting into the objective (27), we obtain
[TABLE]
This objective is decomposable into a sum of terms each involving either the diagonal or one of the off diagonal factors . Thus, we can solve for each portion of independently, giving
[TABLE]
Since the diagonal is not regularized in (28), we have
[TABLE]
i.e.
[TABLE]
This means we can equivalently obtain the solution of the problem (28) by solving
[TABLE]
completing the proof.
∎
B.6 Proof of Joint Convexity
Our objective function is
[TABLE]
We have the following theorem. This theorem proves the joint convexity of the objective function (30) and the uniqueness of the minimizer .
Theorem B.7**.**
The objective function (30) is jointly convex in . Furthermore, define the set where the global minimum . There exists a unique , defined in (4), that achieves the minimum of such that
[TABLE]
Proof B.8**.**
By definition,
[TABLE]
is an affine function of . Thus, since is a concave function on the space of positive definite matrices (Boyd and Vandenberghe, 2009), all the terms of are convex since convex functions of affine functions are convex and the elementwise norm is convex. Hence is jointly convex in on . Hence, every local minima is also global. Furthermore, for positive at least one global minimum must exist since has a global minimum at zero.
We show that a nonempty set of such that is minimized maps to a unique . If only one point exists that achieves the global minimum, then the statement is proved. Otherwise, suppose that two distinct points and achieve the global minimum . Then, for all define
[TABLE]
By convexity, for all , i.e. is constant along the specified affine line segment. This can only be true if (up to an additive constant) the first two terms of are equal to the negative of the second two terms along the specified segment. Since
[TABLE]
is strictly convex and smooth on the positive definite cone (i.e. the second derivative along any line never vanishes) (Boyd and Vandenberghe, 2009) and the sum of the two elementwise 1 norms along any affine combination of variables is at most piecewise linear when smooth, this cannot hold when varies with . Hence, must be a constant with respect to . Thus, the minimizing is unique and Theorem B.7 is established.
∎
Appendix C Additional experiments
C.1 Convergence of nonconvex regularization algorithm
Figure 12 illustrates the convergence of the nonconvex Algorithm 2 (experiment described more thoroughly in the main text).
C.2 Computational Complexity of TG-ISTA
In Section H, we show that TG-ISTA reaches the statistical error floor in
[TABLE]
iterations.
Each TG-ISTA iteration is also computationally efficient. Due to the representation (10), the TG-ISTA implementation of TeraLasso never needs to form the full covariance. The memory footprint of the proposed implementation is as opposed to the storage required by BiGLasso and GLasso. Since the training data itself requires storage, the storage footprint of the TG-ISTA implementation of TeraLasso is scalable to large values of when the decrease in , e.g. . The computational cost per iteration is dominated by the computation of the gradient, which is performed by doing eigendecompositions of size respectively and then computing the projection of the inverse of the Kronecker sum of the resulting eigenvalues. The former step costs , and the second step costs , giving a cost per iteration of . For and , this gives a dramatic improvement on the cost per iteration of unstructured Graphical Lasso algorithms (Guillot et al., 2012; Hsieh et al., 2014). In addition, for the cost per iteration is comparable to the cost per iteration of the most efficient () Kronecker product GLasso methods such as Zhou (2014).
Figure 13 shows convergence speeds on various random ER graph estimation scenarios, with the BiGLasso of Kalaitzis et al. (2013) shown for comparison. Note that the BiGLasso algorithm only applies when the diagonal elements of are known, so it cannot be considered to solve the general BiGLasso or TeraLasso objectives. Observe that TeraLasso’s ability to efficiently exploit the Kronecker sum structure to obtain computational and memory savings allows it to quickly converge to the optimal solution, while the alternating-minimization based BiGLasso algorithm is impractically slow. All computation was timed on a 4-core, 64 bit, 2.5GHz CPU system using Matlab 2016b.
C.3 Convergence rate verification
In this section, we verify that our bounds on the rate of convergence are tight in the case of 1 regularization. We will hold and constant. We set as in Theorem 1. By Lemma D.9 in the supplement, this implies an “effective sample size” proportional to the inverse of the bound on :
[TABLE]
For each experiment below, we varied and over 6 scenarios. To ensure that the constants in the bound were minimally affected, we held constant over all scenarios, and let and when . We let vary by powers of 2, i.e. where is a constant, allowing us to create a fixed matrix and set to ensure the eigenvalues of and thus remain unaffected as () changes.
Results averaged over random training data realizations are shown in Figure 14 for ER ( edges per factor), random grid ( edges per factor), and AR-1 graphs (AR parameter for both factors). Observe that in each case, the curves for all scenarios are very close despite the wide variation in dimensionality, indicating that our bound on the rate of convergence in Frobenius norm is tight.
C.4 Additional details for wind speed data experiments
For the wind speed data example in the main text, we first regressed out the mean for each day in the year via a 14-th order polynomial regression on the entire history from 1948-2015. As in the main text, we extracted two spatial grids, one from eastern North America, and one from Western North America, with the latter including an expansive high-elevation area and both Atlantic and Pacific oceans (Figure 9). We compare the TeraLasso estimator to the unstructured shrinkage estimator, the non-sparse Kronecker sum estimator (TeraLasso estimator with sparsity parameter ), and the Gemini sparse Kronecker product estimator of Zhou (2014). Figure 15 shows the estimated precision matrices trained on the eastern grid, using time samples from January in years following 1948. Note the graphical structure reflects approximate auto-regressive (AR) spatial and temporal structure in each dimension. The TeraLasso estimation is much more stable than the Kronecker product estimation for small sample size .
To quantify the fit of the estimated precision matrices to the observed wind data, we compare to an unstructured estimator in a higher sample regime. After training each estimated precision matrix (TeraLasso, Gemini, and ML Kronecker Product) on a 30-day summer interval from 1 year, as in the main experiment, we create a sample covariance from the same 30-day summer intervals in the remaining 50 years. We evaluate the precision matrices estimated by TeraLasso, Gemini, and ML Kronecker product using a normalized Frobenius error metric:
[TABLE]
If this metric is small, the structured is close to the unstructured , indicating a good fit to the data. The small ridge is included to ensure that the unstructured inverse estimator is well-conditioned, with the minimum taken over to present the most optimistic view of Gemini and the ML Kronecker product. The results for each precision matrix are TeraLasso: 0.0728, Gemini: 0.903, and ML Kronecker Product: 0.76, confirming the superior performance of the TeraLasso estimator.
C.5 Comparison between TeraLasso and Gemini (Kronecker product) log determinant geometry
In this section, we present further analysis of the relation of the performance of TeraLasso in this wind data setting to its inherently more robust eigenstructure.
Recall the TeraLasso objective
[TABLE]
where . The Gemini Kronecker product algorithm Zhou (2014) uses a similar objective function to estimate the Kronecker product covariance, which can be shown to be equivalent to
[TABLE]
Observe that, for , the Gemini objective function (37) is the same as in TeraLasso objective function (36) except for the log determinant term. Figure 16 (a) compares the Kronecker product Gemini estimator to TeraLasso on data generated using precision matrix , and again on data generated using the Kronecker sum precision matrix , where are each random ER graphs (generated as in the main text) with 5 nonzero edges. In all cases, we used the theoretically dictated optimal penalty for TeraLasso from Theorem 1 in the main text and for Gemini from Theorem 3.1 in Zhou (2014). Note that both methods perform well in the single sample regime, even under model misspecification. This apparent symmetricity is very different from the relation of the ML Kronecker sum (TeraLasso with zero penalty) and the ML Kronecker product (not directly related to Gemini), whose results on the same data are also shown in Figure 16 (b). In this case, the ML Kronecker product performs poorly in the single sample regime, whereas the ML Kronecker sum performs well in all regimes, surpassing the ML Kronecker product method in the low sample regime even when the data is generated under the Kronecker product model.
This seems to indicate that the Gemini estimator leverages some of the inherent stability of the ML Kronecker sum objective (TeraLasso) to solve the more unstable Kronecker product covariance estimation problem.
To further illuminate the connection between TeraLasso and Gemini, we now examine the relationship of the geometry of the differing log determinant terms. Let the eigenvalues of be denoted as , and suppose that so we can assume all the . Using the properties of determinants and the additivity of the eigenvalues in a Kronecker sum we can write
[TABLE]
Observe that the partial derivative of the log determinant with respect to any one eigenvalue is .
Correspondingly, the log determinant of a Kronecker product is
[TABLE]
Observe that the partial derivative of the log determinant with respect to any one eigenvalue is .
Thus, the geometry of the Kronecker sum log determinant term is significantly flatter than the Kronecker product log determinant, especially for larger , indicating that the Kronecker sum estimator (TeraLasso) will enjoy more flexibility when matching the sample covariances than a Kronecker product method will.
A parallel interpretation can be obtained by recalling that the Kronecker sum of two sparse graphs is significantly sparser than the Kronecker product of the same two graphs, as discussed in the introduction of the main text.
Appendix D Identifiable Parameterization of
Observe that for any scalar
[TABLE]
and thus the trace of each factor is non-identifiable, and we can write
[TABLE]
where are any scalars such that .
The following lemma addresses this trace ambiguity, and creates an orthogonal, identifiable decomposition of into factors.
Based on the original parameterization
[TABLE]
we know that the number of degrees of freedom in is much smaller than the number of elements . We thus seek a lower-dimensional parameterization of . The Kronecker sum parameterization is not identifiable on the diagonals, so we seek a representation of that is identifiable. In the main text, we noted that is identifiable (where ), but cannot be a parameter of the model since not all diagonal vectors can be expressed as a Kronecker sum. Hence while this diagonal-based decomposition is useful for stating identifiable factorwise error bounds, it is does not truly serve as a parameterization. We show in Lemma D.9 that the space is linearly, identifiably, and orthogonally parameterized by the quantities . Specifically,
Lemma D.9**.**
Let and . Then can be identifiably written as
[TABLE]
where and the identifiable parameters can be computed as
[TABLE]
By orthogonality, the Frobenius norm can be decomposed as
[TABLE]
noting that
[TABLE]
Proof D.10**.**
Part I: Identifiable Parameterization. Let . By definition, there exists such that
[TABLE]
where . Observe that by construction, so we can set , creating
[TABLE]
Note that in this representation, , so letting ,
[TABLE]
and (39) in the Lemma results. It is easy to verify any expressible in the form (39) is in .
Thus, parameterizes . It remains to show that this parameterization is identifiable.
Part II: Orthogonal Parameterization. We will show that under the linear parameterization of by , each of the components are linearly independent of the others.
To see this, we compute the inner products between the components:
[TABLE]
for all . We have recalled that by definition, for all . Since all the inner products are identically zero, the components are orthogonal, thus they are linearly independent. Hence, by the definition of linear independence, this linear parameterization is uniquely determined by (i.e. it is identifiable).
Part III: Decomposition of Frobenius norm. Using the identifiability and orthogonality of this parameterization, we can find a direct factorwise decomposition of the Frobenius norm on .
By orthogonality (cross term inner products equal to zero)
[TABLE]
This completes the first decomposition, representing the squared Frobenius norm as weighted sum of the squared Frobenius norms on each component.
For convenience, we also observe that given any with identifiable parameterization
[TABLE]
we can absorb the scaled identity into the Kronecker sum and still bound the Frobenius norm decomposition. Specifically, observe that
[TABLE]
Substituting this into (41),
[TABLE]
where the last term follows because implies that .
Observe that
[TABLE]
hence Lemma D.9 is proved.
∎
The identifiable parameterization of in Lemma D.9 will provide a way to bound the spectral norm relative to the Frobenius norm. This is used to form the spectral norm bound in Theorem 2.
The following lemma is also used in the proof of Theorem 1 (cf. Proposition E.26).
Lemma D.11** (Spectral Norm Bound).**
For all ,
[TABLE]
Proof D.12**.**
Using the identifiable parameterization of
[TABLE]
and the triangle inequality, we have
[TABLE]
∎
D.1 Inner Product in
Lemma D.13** (Kronecker sum inner Products).**
Suppose . Then for any , ,
[TABLE]
Proof D.14**.**
[TABLE]
where we have used the definition of the submatrix notation and the matrices . See Appendix I for the notation being used here. ∎
Appendix E Proof of Theorems 1 and 2 ( regularized case)
Let be the true value of the precision matrix . Since and is convex, and we can decompose into diagonal and Kronecker sum off diagonal components:
[TABLE]
where and . Recall that the and terms are all identifiable given . Similarly, we can write
[TABLE]
Let be the indicator function. For an index set and a matrix , define the operator that projects onto the set . Let be the projection of onto the true sparsity pattern of . Let be the complement of , and . Furthermore, let
[TABLE]
be the projection of onto the sparsity set and its complement. Recall neither nor includes the diagonal.
We now provide a deterministic bound on the difference in the penalty terms.
Lemma E.15**.**
Denote by
[TABLE]
Then
[TABLE]
Proof of Lemma E.15. By the decomposability of the norm and the reverse triangle inequality , we have
[TABLE]
since is assumed to follow sparsity pattern by (A1). ∎
Let be the event that for some constant ,
[TABLE]
and for each , denote by the event such that
[TABLE]
holds for some absolute constant which is chosen such that probability statement in Lemma E.16 holds:
Lemma E.16**.**
Lemma E.16 is proved in Section F. Using the definition of event , in Section E.2 we prove the following lemma.
Lemma E.17**.**
Denote by . Then on event the following holds: for all as in (42)
[TABLE]
where are some absolute constants.
We then have the following lemma, which we prove in Section E.3.
Lemma E.18**.**
On event , we have for ,
[TABLE]
where is an absolute constant.
E.1 Proof of Theorem 1
Let
[TABLE]
be the difference between the objective function (10) at and at . Clearly minimizes , which is a convex function with a unique minimizer on (cf. Theorem B.7). Define
[TABLE]
where for some large enough absolute constant to be specified,
[TABLE]
In particular, we set for as in Lemma E.18.
Proposition E.19 follows from Zhou et al. (2010).
Proposition E.19**.**
If for all as defined in (49). then for all in
[TABLE]
for (E.1). Hence if for all , then for all .
Proof E.20**.**
By contradiction, suppose for some . Let . Then , where by definition of . Hence since by the convexity of the positive definite cone because and . By the convexity of , we have that , contradicting our assumption that for . ∎
Proposition E.21**.**
Suppose for all . We then have that
[TABLE]
Proof E.22**.**
By definition, , so . Thus if on , then by Proposition E.19 (section D.1), where is defined therein. The proposition results. ∎
Lemma E.23**.**
Under (A1) - (A3), for all for which ,
[TABLE]
The proof is in Section E.4.
By Proposition E.21, it remains to show that on under event . We show this indeed holds.
Lemma E.24**.**
On event , we have for all .
Proof E.25**.**
Throughout this proof, we assume that event holds. By Lemma E.23, if , we can write (48) using the objective (10),
[TABLE]
We next bound the inner product term under event . Substituting the bound of Lemma E.17 and (43) into (E.25), under event , we have by choice of where for all ,
[TABLE]
For the diagonal part, we have by Lemma E.18
[TABLE]
we have for all , and , and for ,
[TABLE]
which holds for all , where we use the following bounds: for all .
[TABLE]
and
[TABLE]
where , which holds so long as is chosen to be large enough in
[TABLE]
For example, we set .
Theorem 1 follows from Proposition E.21 immediately. ∎
E.2 Proof of Lemma E.17
Assume that the event of Lemma E.16 holds. Using the definition of (42), the projection operator , and letting , we have
[TABLE]
where we have used the fact that is zero along the diagonal and thus has zero inner product with . Substituting Lemma E.18 and the definitions of subevents under , we have by (E.2) and Lemma D.13,
[TABLE]
∎
E.3 Proof of Lemma E.18: Bound on Inner Product for Diagonal
Let . Recall the identifiable parameterization of (Lemma D.9)
[TABLE]
where and are given in the lemma. We then have and
[TABLE]
by othogonality of the decomposition. By Lemma D.13, we can write
[TABLE]
Moreover, under , we have
[TABLE]
Summing these terms together, we have
[TABLE]
where in (E.3), we have used the following inequality in view of (54):
[TABLE]
∎
E.4 Proof of Lemma E.23
We first state Proposition E.26
Proposition E.26**.**
*Under (A1)-(A3), for all , *
[TABLE]
so that , where is an open interval containing .
Proof E.27**.**
We first show that (56) holds for . Indeed, by Corollary D.11, we have for all
[TABLE]
so long as
[TABLE]
where is the condition number of .
Next, it is sufficient to show that and for some . Indeed, for ,
[TABLE]
given that by definition of and (56).
Thus we have that is infinitely differentiable on the open interval of . This allows us to use the Taylor’s formula with integral remainder to prove Lemma E.23, drawn from Rothman et al. (2008).
Let us use as a shorthand for
[TABLE]
where is vectorized. Now, the Taylor expansion gives
[TABLE]
The last inequality holds because and .
We now bound , following arguments from (Zhou et al., 2011; Rothman et al., 2008).
[TABLE]
Now, suppose that
[TABLE]
where (56), we have for all ,
[TABLE]
so long as the condition in (A3) holds, namely,
[TABLE]
Hence,
[TABLE]
Thus, substituting into (57), the lemma is proved. ∎
E.5 Proof of Theorem 2: Factorwise and Spectral Norm Bounds
Proof E.28**.**
Part I: Factor-wise bound. From the proof of Theorem 1, we know that under event ,
[TABLE]
Furthermore, since the identifiable parameterizations of are of the form (40) by construction in Lemma D.9)
[TABLE]
we have that the identifiable parameterization of is
[TABLE]
where , . Observe that .
*By Lemma D.9 then, *
[TABLE]
Thus, the estimation error on the underlying parameters is bounded by (58)
[TABLE]
or, dividing both sides by
[TABLE]
Recall that , so . Substituting into (60)
[TABLE]
From this, it can be seen that the bound converges as the increase with constant . To put the bound in the form stated in the theorem, note that since
[TABLE]
Part II: Spectral norm bound. The factor-wise bound immediately implies the bound on the spectral norm of the error under event . We recall the identifiable representation (59)
[TABLE]
By Property 3a in Appendix I and the fact that the spectral norm is upper bounded by the Frobenius norm,
[TABLE]
where in the second line, we have used the fact that for elements of the norm relation implies . ∎
Appendix F Proof of Lemma E.16: Subgaussian Concentration
We first state the following concentration result, proved in Section F.1. Recall that .
Lemma F.29** (Subgaussian Concentration).**
Suppose that for all . Then, with probability at least ,
[TABLE]
for all , where is a constant depending on given in the proof.
We can now prove Lemma E.16.
Proof F.30**.**
By Lemma F.29 we have that event (46), i.e. the event that
[TABLE]
holds with probability at least .
Note that . Viewing as a covariance factor since , we can invoke the proof of Lemma F.29 and show that with probability at least the event (45) will hold. Recall that . By the union bound, we have .∎
F.1 Proof of Lemma F.29
Define a -way generalization of the invertible Pitsianis-Van Loan type (Van Loan and Pitsianis, 1993) rearrangement operator , which maps matrices to matrices. For a matrix we set
[TABLE]
where we use the subblock notation (see Section 2 in the main text). Using this notation, we have the following concentration result.
Lemma F.31**.**
Let and . Assume that where has independent entries such that , , and . Let . Then for all :
[TABLE]
where is an absolute constant and is the subgaussian norm.
Proof F.32**.**
We prove the lemma for . The proof for the remaining follow similarly.
By the definition (63) of the permutation operator and letting ,
[TABLE]
Hence,
[TABLE]
where , .
Thus, by the Hanson-Wright inequality (Rudelson et al., 2013),
[TABLE]
since and . Substituting
[TABLE]
for all , i.e. since by definition.
∎
We can now prove Lemma F.29.
Proof F.33**.**
Consider the inner product , where is an arbitrary matrix. Let
[TABLE]
By the definition of the factor covariances and the rearrangement operator , it can be seen that
[TABLE]
and that similarly by the definition of the factor covariances
[TABLE]
Hence,
[TABLE]
by the linearity of the rearrangement operator, the definition of the inner product, and the definition of the unit vector as the -th column of the identity matrix.
We can apply Lemma F.31 and take a union bound over . By Lemma F.31,
[TABLE]
for . Taking the union bound over all , we obtain
[TABLE]
Setting for large enough and recalling that , with probability at least we have
[TABLE]
where we assume and let . Hence, by (72)
[TABLE]
with probability at least . The first inequality follows from the triangle inequality and the last inequality from the definition of and . ∎
Appendix G Nonconvex Regularizers: Proof of Theorem 3
Recall that the support sets are the set of nonzero elements of and , respectively. Define to be the set of matrices in with support contained in , that is
[TABLE]
The set is the set of Kronecker sum matrices following the true sparsity pattern of the Kronecker sum .
Note that is a linear subspace of since is a linear subspace and the intersection of two linear subspaces is a linear subspace. Hence the (L2 norm) projection onto is given by
[TABLE]
where is the linear projection operator projecting onto matrices in with sparsity pattern , and is the previously defined projection onto defined in Section 2 of the main text. Note that since the sparsity pattern is the sparsity pattern of a Kronecker sum matrix in , projection onto does not change the Kronecker structure.
By reshaping we obtain the representation
[TABLE]
where is the projection matrix associated with the linear subspace . Recall that is the vectorization operator, and the projection matrix in linear algebra is where is an orthonormal basis for the subspace.
We first summarize the proof of Theorem 3.
Proof plan: The proof concept is to apply the primal-dual witness technique of Loh et al. (2017) to our sparse Kronecker sum precision matrix estimator. Since the nonconvex graphical lasso proof in Loh et al. (2017) relied on the set of sparse matrices being a linear subspace of , we can simply replace the sparse subspace in their proof with our sparse Kronecker sum subspace and proceed in a similar fashion. The primal-dual witness technique can be briefly summarized as
- (i)
Prove the regularized objective function (8) is strictly convex over the constraint set, so that any zero subgradient point is the unique global minimizer. 2. (ii)
Construct a zero subgradient point of the oracle estimator objective function using Brouwer’s theorem. 3. (iii)
Prove this zero subgradient point converges to the true . 4. (iv)
Prove that the zero subgradient point of the oracle objective is also a zero subgradient point of the full objective function (8), hence it is the unique global minimizer and converges to .
Proceeding with the full proof, we first have the following lemma.
Lemma G.34**.**
Suppose is -amenable. Then for , the objective function (8) is strictly convex over the constraint set.
Proof G.35**.**
Recall that
[TABLE]
which is a deterministic quantity not depending on the data. Hence, for , the minimum eigenvalue satisfies
[TABLE]
This implies that is convex for . Furthermore, by -amenability, is convex for . Therefore, since is a linear subspace, the complete objective (8) is convex for and . Since it is convex over , it is convex over as well, since is the intersection of and the convex positive definite cone. ∎
Since the objective is convex, a point in the subspace with zero subgradient will be the unique global minimum. Our first step will be to construct such a zero subgradient point.
We will first construct the (unique) oracle estimate where the oracle gives the support set of . We will then show that this oracle estimate is also a zero-subgradient point of the objective (8) and therefore its unique global minimizer.
Using the notation, we can write the oracle estimate as
[TABLE]
Our goal will be to construct a map such that (a) is a fixed point of if and only if is a fixed point of the oracle estimate (75), (b) maps the intersection of and the radius- -ball centered at the origin to itself for some , and (c) this is such that , for all . Then by Brouwer’s fixed point theorem we can show that must have a fixed point in that ball. By construction (a) above, this fixed point will correspond to a fixed point in the oracle estimator objective, hence the oracle estimate will have -ball error less than .
For , we will choose a Newton method step (gradient step preconditioned by inverse Hessian). Denote the pseudoinverse of a matrix as . We now write the map given by
[TABLE]
where , and we let be the Hessian of the objective function within :555With as above (where columns of form an orthonormal basis for the subspace ), and hence since is positive definite.
[TABLE]
The quantity is included as it is the Hessian of the objective function (74). The pseudoinverse is needed since is low rank, making the Hessian within low rank.
Clearly if , and vice versa, hence is a fixed point of if and only if is a fixed point of the oracle objective (75). Now
[TABLE]
since has at most nonzero entries per row. Hence the matrix is invertible and positive definite whenever , making a continuous map on and satisfying condition (c).
Define the constants and , in other words, we are assuming that the Hessian is well-conditioned in the -norm sense, which is possible since has eigenvalues bounded from above and below. We now show the following lemma by verifying the remaining condition (b) on and applying Brouwer’s fixed point theorem. Several relevant quantities are summarized in Table 2 for convenience.
Lemma G.36**.**
Let where is a constant depending only on the subgaussian parameter of the data and
[TABLE]
Assume the sample size satisfies . Then under event as in Theorem 1 there exists such that
[TABLE]
Proof G.37**.**
First, note that for any , since is the projection of the positive definite matrix onto the low rank subspace .
Suppose . Then
[TABLE]
hence
[TABLE]
by the definition of and the triangle inequality.
The first term of (76) can be bounded via the concentration inequalities used for the case. Specifically, note that
[TABLE]
where we have used . Now recall that under event , defined in (46) above,
[TABLE]
and under event , defined above in (45),
[TABLE]
Hence under event ,
[TABLE]
Finally, recall that by Lemma E.16 event holds with probability .
Moving on to the second term of (76), we apply the matrix expansion
[TABLE]
and note that (since implies )
[TABLE]
where we have used the fact that for symmetric matrices , .
We then obtain
[TABLE]
We have used to denote the inverse of the vectorization operator.
Via the triangle inequality and the linearity of the vectorization and projection operators,
[TABLE]
Now we can apply Holder’s inequality to obtain
[TABLE]
Then, using the fact that and substituting back into (80), we have
[TABLE]
Since our assumption implies that , we therefore have that
[TABLE]
*under event . Since , by Brouwer’s fixed point theorem (Ortega and Rheinboldt, 1970), must have a fixed point . Recalling that , we choose . Hence by construction and since both matrices have degree bounded by .
The last equality follows since is the fixed point of , i.e. , which can only occur if*
[TABLE]
∎
Using this lemma it remains to show that satisfies the constraints and is a zero-subgradient point of the complete objective (8), and hence is the unique global optimum.
Define to be the objective function (8) less the regularization terms, i.e.
[TABLE]
Lemma G.38**.**
The oracle estimate will be a zero-subgradient point of the global objective (8) if the inequalities
[TABLE]
and
[TABLE]
hold, where
[TABLE]
We have denoted and to be the gradient and Hessian respectively of projected onto the subspace ( is the projection matrix onto ).
Proof G.39**.**
In this proof, for simplicity we write to indicate applied elementwise to the offdiagonal elements of :
[TABLE]
Observe that by construction for any .
For the objective (8), the zero subgradient condition is given by
[TABLE]
where is an element of the subgradient of the off-diagonal 1 norm at . Adding and subtracting gives
[TABLE]
By the fundamental theorem of calculus we have (for ) that , hence
[TABLE]
*Rewriting in block form gives *
[TABLE]
where is the block of corresponding to the elements in along both axes, is the block of corresponding to the elements in the complement of , etc. After some algebra we obtain a solution
[TABLE]
since by definition. Now from Lemma G.36, under event
[TABLE]
and observe that since we have assumed that for some large enough. By our assumption that for all , we then have (again under event )
[TABLE]
Therefore, using condition (f) of the definition of a regularizer, and
[TABLE]
where we have applied the assumed inequalities. Since , it is a feasible subgradient and therefore is a zero subgradient point of the global objective function (8).
∎
We now show the inequalities (81), (82) assumed by Lemma G.38 hold under event . Note that
[TABLE]
and thus by (78), under event equation (81) holds with
It remains to show (82) holds with . We will first bound
[TABLE]
and then show that the expression on the left hand side of (82) is close to this quantity.
First, by the definition of the infinity norm and it can be shown that
[TABLE]
where we have used the expression (99) for the elements of the projected matrix and the fact that an average of a set of elements of cannot have magnitude larger than . Noting that ,
[TABLE]
since , and (81) holds under event with .
We now relate the bound in (84) to that required to show (82). Note that
[TABLE]
where we have defined
[TABLE]
Now, again invoking (81),
[TABLE]
The infinity norm of can be bounded as
[TABLE]
where we have set
[TABLE]
First note that by (83)
[TABLE]
and by the definition of .
Substituting into (87) gives
[TABLE]
We bound and in the following lemma, proved in Section G.1.
Lemma G.40**.**
Under the conditions of Lemma G.36,
[TABLE]
Applying Lemma G.40 to (88), we obtain
[TABLE]
and substituting into (86)
[TABLE]
since by our assumption that for some large enough.
Therefore, substituting into (85) we obtain
[TABLE]
proving the desired condition (82) holds. Hence the conditions of Lemma G.38 hold under event , and is the unique global minimizer of the complete objective (8).
The Frobenius and spectral norm bounds follow from the identities
[TABLE]
and
[TABLE]
where the latter identity follows by symmetry of .
G.1 Proof of Lemma G.40: Bound on
Proof G.41**.**
Consider that
[TABLE]
Hence, since by (83),
[TABLE]
By Lemma G.36, for ,
[TABLE]
We make use of the following matrix inequalities (Loh et al., 2017). For any invertible and matrix norm ,
[TABLE]
if . For any and matrices of equal dimension we have
[TABLE]
Applying (89) we get
[TABLE]
since is bounded by . Applying (90) to this yields
[TABLE]
which gives
[TABLE]
and
[TABLE]
Finally, recall that the projection matrix onto can be written as with so
[TABLE]
By the matrix expansion (79) we then have
[TABLE]
We can then use the bound (91) to obtain
[TABLE]
since .
∎
Appendix H Numerical Convergence of TG-ISTA
The following theorem shows that the iterates of the TG-ISTA implementation of TeraLasso converge geometrically to the global minimum:
Theorem H.42**.**
Let for all and let be the initialization of the TG-ISTA implementation of TeraLasso (Algorithm 4). Let
[TABLE]
and assume for all . Suppose further that is the global optimum. Then
[TABLE]
Furthermore, the step size which yields an optimal worst-case contraction bound is . The corresponding optimal worst-case contraction bound is
[TABLE]
Our proof uses results on the structure of the Kronecker sum subspace to extend to our subspace restricted setting the methodology that Guillot et al. (2012) used to derive the unstructured GLasso convergence rates.
We decompose the claims of Theorem H.42 into the following two theorems which we prove separately.
Theorem H.43**.**
Assume that the iterates of Algorithm 4 satisfy , for all , for some fixed constants . Suppose further that is the global optimum. If for all , then
[TABLE]
Furthermore, the step size which yields an optimal worst-case contraction bound is . The corresponding optimal worst-case contraction bound is
[TABLE]
Theorem H.44**.**
Let for all and let be the initialization of the TG-ISTA implementation of TeraLasso (Algorithm 4). Let
[TABLE]
and assume for all . Then the iterates of Algorithm 4 satisfy for all .
Observe that by Theorem H.44, the worst case contraction factor (93)
[TABLE]
scales at most as for of fixed order, since with high probability.
Let be the number of iterations required for to hold, i.e. for the optimization error to be smaller than the statistical error. By Theorem 1, we require
[TABLE]
Using worst case contraction factor , (94) will hold for such that (with high probability)
[TABLE]
Taking the logarithm of both sides and using , we have that the optimization error is guaranteed to equal the statistical error after iterations, where
[TABLE]
H.1 Proof of Theorem H.43
For convenience, define the Kronecker sum shrinkage operator as
[TABLE]
for and with all . Note that . Since is a convex function on , and since is a linear subspace, is a proximal operator by definition.
Recall that we can write the TG-ISTA update (27) using this Kronecker sum shrinkage operator as
[TABLE]
where is the sample covariance (3) and is its projection onto (5.2).
By convexity in and Theorem B.7, the optimal point is a fixed point of the ISTA iteration (Combettes and Wajs (2005), Prop 3.1). Thus,
[TABLE]
Since proximal operators are not expansive (Combettes and Wajs, 2005), we have
[TABLE]
For define by
[TABLE]
Since ,
[TABLE]
where is the projection matrix that projects onto the vectorized subspace . Thus, we have the Jacobian (valid for all )
[TABLE]
Recall that if is a differentiable mapping, then if and is convex, then if is the Jacobian of ,
[TABLE]
Thus, letting , for we have
[TABLE]
By Weyl’s inequality, and
[TABLE]
Furthermore, note that for any and projection matrix
[TABLE]
We then have
[TABLE]
where the latter inequality comes from (Guillot et al., 2012). Thus,
[TABLE]
as desired. Algorithm 4 will then converge if for all . The minimum of occurs at , completing the proof of Theorem H.43. ∎
H.2 Proof of Theorem H.44
We first prove the following properties of the Kronecker sum projection operator.
Lemma H.45**.**
For any and orthogonal matrices , let . Then
[TABLE]
Furthermore, if the eigendecomposition of is of the form with , we have
[TABLE]
and
[TABLE]
Proof H.46**.**
Recall
[TABLE]
since and the Frobenius norm is unitarily invariant. Now, note that for any matrix ,
[TABLE]
since . Since , the constraint can be moved to , giving
[TABLE]
If , then , completing the first part of the proof. As shown in Lemma I.55, is a diagonal matrix whose entries are weighted averages of the diagonal elements . Hence
[TABLE]
Since gives the eigenvalues of by the orthogonality of , this completes the proof. ∎
Lemma H.47**.**
Let be given positive constants and let . Assume . Then for
[TABLE]
we have
[TABLE]
Proof H.48**.**
*Let be the eigendecomposition of , where . Then all . Since , by the eigendecomposition property in Appendix I we have and , letting us apply Lemma H.45: *
[TABLE]
*where we set and recall the linearity of the projection operator (Lemma I.55). By Weyl’s inequality, *
[TABLE]
By Lemma H.45,
[TABLE]
Note that the only extremum of the function over is a global minimum at . Hence
[TABLE]
By our assumption, . Thus
[TABLE]
as desired, completing the proof. ∎
We then have the following lemma.
Lemma H.49**.**
For and with :
[TABLE]
Proof H.50**.**
Since by definition (95)
[TABLE]
we can use the fact that the eigenvalues of a Kronecker sum are the sums of the eigenvalues to show
[TABLE]
We have used the fact that is positive definite since it is in .
Via Weyl’s inequality and the proof of Lemma 6 in (Guillot et al., 2012),
[TABLE]
Hence,
[TABLE]
∎
H.2.1 Proof of Theorem H.44
To prove the lower inequality in Theorem H.44, we show the following.
Lemma H.51**.**
Let with all . Define
[TABLE]
and let . Assume . Then for every .
Proof H.52**.**
Since , , and . Lemma H.47 then implies that
[TABLE]
By Lemma H.49,
[TABLE]
Hence, since , whenever
[TABLE]
∎
The upper bound in Theorem H.44 results from the following lemma.
Lemma H.53**.**
Let be as in Lemma H.51 and let . Let for all . We then have for all when .
Proof H.54**.**
By Lemma H.51, for every . Since , by strong convexity . Hence . For and ,
[TABLE]
Hence, by Theorem H.42 . Thus
[TABLE]
so
[TABLE]
∎
This completes the proof of Theorem H.44. ∎
Appendix I Useful Properties of the Kronecker Sum and
I.1 Basic Properties
As the properties of Kronecker sums are not always widely known, we have compiled a list of some fundamental algebraic relations we use.
Sum or difference of Kronecker sums (Laub, 2005):
[TABLE] 2. 2.
Factor-wise disjoint off diagonal support (Laub, 2005). By construction, if for any and
[TABLE]
then for all
[TABLE]
Thus,
[TABLE] 3. 3.
Eigendecomposition: If are the eigendecompositions of the factors, then (Laub, 2005)
[TABLE]
is the eigendecomposition of . Some resulting identities useful for doing numerical calculations are as follows:
- (a)
L2 norm:
[TABLE] 2. (b)
Determinant:
[TABLE] 3. (c)
Matrix powers (e.g. inverse, inverse square root):
[TABLE]
Since the are diagonal, this calculation is memory and computation efficient.
I.2 Eigenstructure of
Kronecker sum matrices have Kronecker product eigenvectors with linearly related eigenvalues, as contrasted to the multiplicatively related eigenvalues in the Kronecker product. For simplicity, we illustrate in the case, but the result generalizes to the full tensor case. Suppose that and are the eigendecompositions of and . Then by Laub (2005), if , the eigendecomposition of is
[TABLE]
Thus, the eigenvectors of the Kronecker sum are the Kronecker products of the eigenvectors of each factor. This “block” structure is evident in the inverse Kronecker sum example in Section 1 of the main text. The structure of is discussed further in Canuto et al. (2014).
This eigenstructure representation parallels the eigenvector structure of the Kronecker product - specifically when
[TABLE]
Hence, use of the Kronecker sum model can be viewed as replacing the nonconvex, multiplicative eigenvalue structure of the Kronecker product with the convex linear eigenvalue structure of the Kronecker sum. This additive structure results in relatively more stable estimation of the precision matrix. As the tensor dimension increases, this structural stability of the Kronecker sum as compared to the Kronecker product becomes more dominant ( term sums instead of -order products).
I.3 Projection onto
We first introduce a submatrix notation. Fix a , and choose . Let and be such that with all other elements zero. Observe that . For any matrix , let be the submatrix of defined via
[TABLE]
The submatrix is defined for all and . When is a covariance matrix associated with a tensor , this subblock corresponds to the covariance matrix between the th and th slices of along the th dimension.
We can now express the projection operator in closed form:
Lemma I.55** (Projection onto ).**
*For any , *
[TABLE]
where
[TABLE]
Since the submatrix operator is clearly linear, is a linear operator.
Proof I.56**.**
Since is a linear subspace, projection can be found via inner products. Specifically, recall that if a subspace is spanned by an orthonormal basis , then
[TABLE]
Since is the space of Kronecker sums, the off diagonal elements are independent and do not overlap across factors. The diagonal portion is more difficult as each factor overlaps on the same entries, creating an overdetermined system. We can create an alternate parameterization of :
[TABLE]
where we constrain . Each of the terms in this sum is now orthogonal to all other terms since by construction
[TABLE]
for and all possible , . Thus, we can form bases for the and independently. To find the it suffices to project onto a basis for . We can divide this projection into two steps. In the first step, we ignore the constraint on and create the orthonormal basis
[TABLE]
for all . Recall that in a projection of , the coefficient of a basis component is given by . We can thus apply this elementwise to the projection of . Hence projecting onto these basis components yields a matrix where
[TABLE]
To enforce the constraint, we project away from the one-dimensional subspace spanned by . This projection is given by
[TABLE]
where by construction
[TABLE]
Equation (98) completes the projection onto a basis for , so we can expand the projection back into the original space. This yields a of the form
[TABLE]
Finally, for we can compute
[TABLE]
Combining all these together and substituting into (97) allows us to define the projection in terms of matrices , where we split the term evenly across the other factors. Specifically
[TABLE]
where
[TABLE]
An equivalent representation using factorwise averages is
[TABLE]
where
[TABLE]
Moving the trace corrections to a last term and putting the result in terms of the yields the lemma.
In Algorithm 4 we use an efficient method of computing this projected inverse in our setting by exploiting the eigendecomposition identities in Section I.2. ∎
Appendix J Known diagonal elements (correlation matrix form)
In the case where the diagonal of the precision matrix is known a priori, the estimation problem becomes easier. For simplicity, we consider the case that is in the form of a correlation matrix, i.e. , noting this was the setting originally the focus of Kalaitzis et al. (2013).
Note that since the diagonal elements are known, we do not need to estimate them and indeed can set all the . Revisiting the proof of Theorem 1, it is easy to show the following corollary, which shows strong convergence in the case of regularization. This replacement of the term in rate of Theorem 1 with a guarantees single sample convergence in the sparse setting when .
Corollary J.57**.**
Suppose the conditions of Theorem 1, and that is known. Then under event ,
[TABLE]
Furthermore, event holds with probability at least .
Proof J.58**.**
Dropping the diagonal term from the proof of Lemma E.24, we have that the dependence vanishes, and on event , we have for all where
[TABLE]
and
[TABLE]
The rest of the proof follows by substituting this new value of into the proof of Theorem 1.
Appendix K SCAD and MCP regularizers
The SCAD penalty (Fan and Li, 2001) with parameter (giving ) is given by
[TABLE]
which is linear (as the 1 norm) for small , constant for large , and has a transition between the two regimes for moderate .
The MCP penalty (Zhang et al., 2010) with parameter (giving ) is given by
[TABLE]
giving a more smooth transition between the approximately linear region and the constant region ().
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Allen and Tibshirani (2010) Allen, G. I. and Tibshirani, R. (2010) Transposable regularized covariance models with an application to missing data imputation. The Annals of Applied Statistics , 4 , 764–790.
- 2Andrianov (1997) Andrianov, S. N. (1997) A matrix representation of lie algebraic methods for design of nonlinear beam lines. In AIP Conference Proceedings , vol. 391, 355–360. AIP.
- 3Augustin et al. (2009) Augustin, N. H., Musio, M., von Wilpert, K., Kublin, E., Wood, S. N. and Schumacher, M. (2009) Modeling spatiotemporal forest health monitoring data. Journal of the American Statistical Association , 104 , 899–911.
- 4Banerjee et al. (2008) Banerjee, O., El Ghaoui, L. and d’Aspremont, A. (2008) Model selection through sparse maximum likelihood estimation for multivariate gaussian or binary data. The Journal of Machine Learning Research , 9 , 485–516.
- 5Barzilai and Borwein (1988) Barzilai, J. and Borwein, J. M. (1988) Two-point step size gradient methods. IMA Journal of Numerical Analysis , 8 , 141–148.
- 6Beck and Teboulle (2009) Beck, A. and Teboulle, M. (2009) A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM Journal on Imaging Sciences , 2 , 183–202.
- 7Beckermann et al. (2013) Beckermann, B., Kressner, D. and Tobler, C. (2013) An error analysis of galerkin projection methods for linear systems with tensor product structure. SIAM Journal on Numerical Analysis , 51 , 3307–3326.
- 8Boyd and Vandenberghe (2009) Boyd, S. and Vandenberghe, L. (2009) Convex optimization . Cambridge university press.