Efficient design of experiments for sensitivity analysis based on polynomial chaos expansions
E. Burnaev, I. Panin, B. Sudret

TL;DR
This paper introduces an adaptive experimental design method based on polynomial chaos expansions and D-optimality for efficient estimation of Sobol' sensitivity indices in global sensitivity analysis.
Contribution
It proposes a novel adaptive design approach for selecting experimental points to accurately estimate Sobol' indices using polynomial chaos expansions.
Findings
The method improves efficiency in sensitivity analysis.
Applications demonstrate the effectiveness of the proposed approach.
The approach reduces computational costs for Sobol' indices estimation.
Abstract
Global sensitivity analysis aims at quantifying respective effects of input random variables (or combinations thereof) onto variance of a physical or mathematical model response. Among the abundant literature on sensitivity measures, Sobol' indices have received much attention since they provide accurate information for most of models. We consider a problem of experimental design points selection for Sobol' indices estimation. Based on the concept of -optimality, we propose a method for constructing an adaptive design of experiments, effective for calculation of Sobol' indices based on Polynomial Chaos Expansions. We provide a set of applications that demonstrate the efficiency of the proposed approach.
Click any figure to enlarge with its caption.
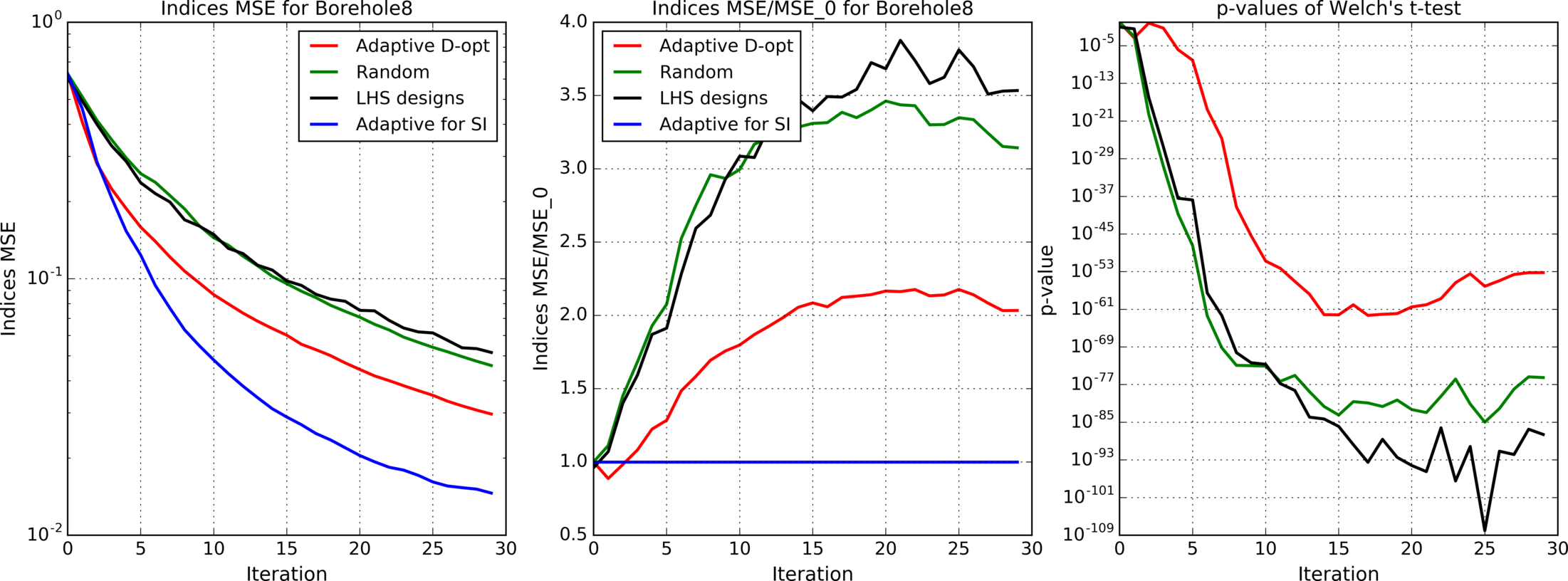 Figure 1
Figure 1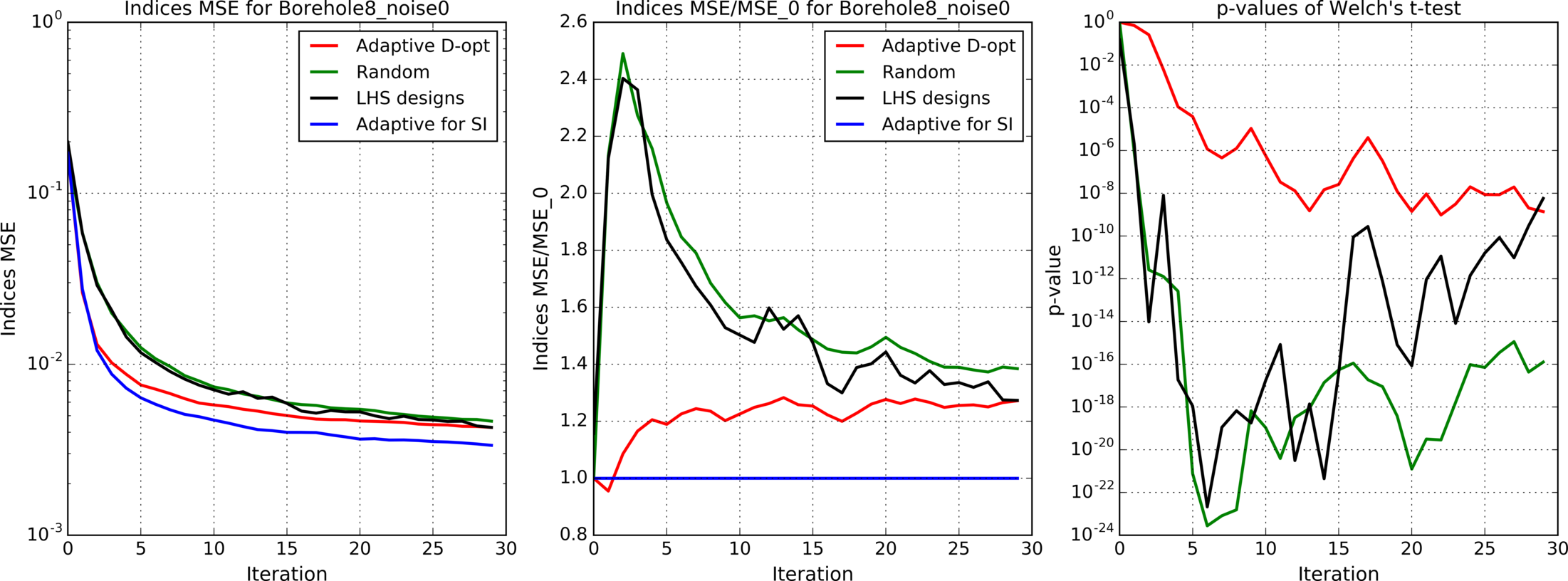 Figure 2
Figure 2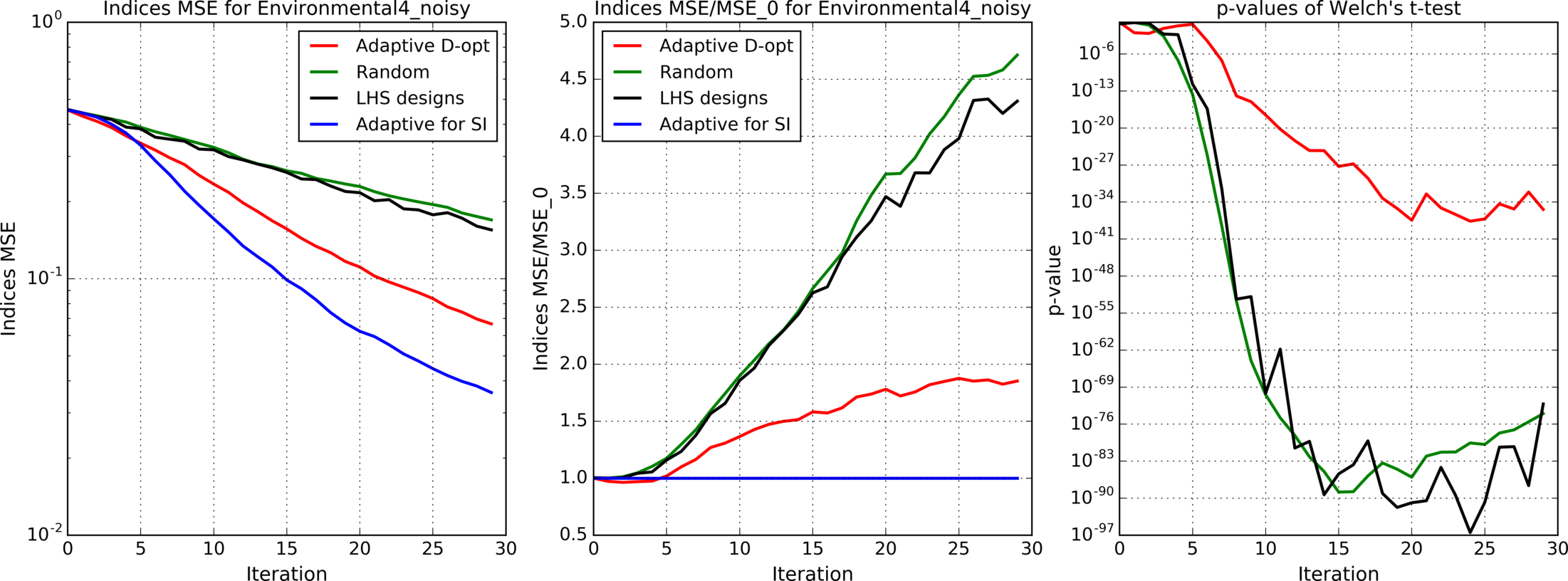 Figure 3
Figure 3 Figure 4
Figure 4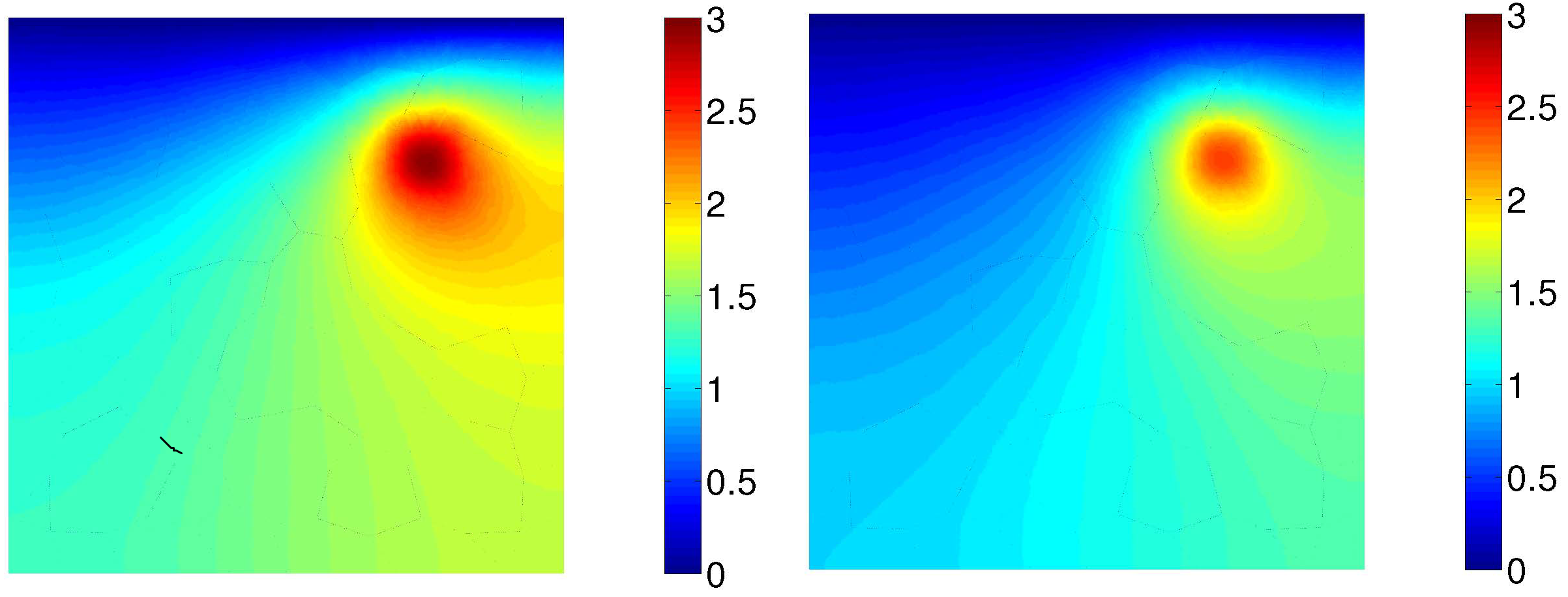 Figure 5
Figure 5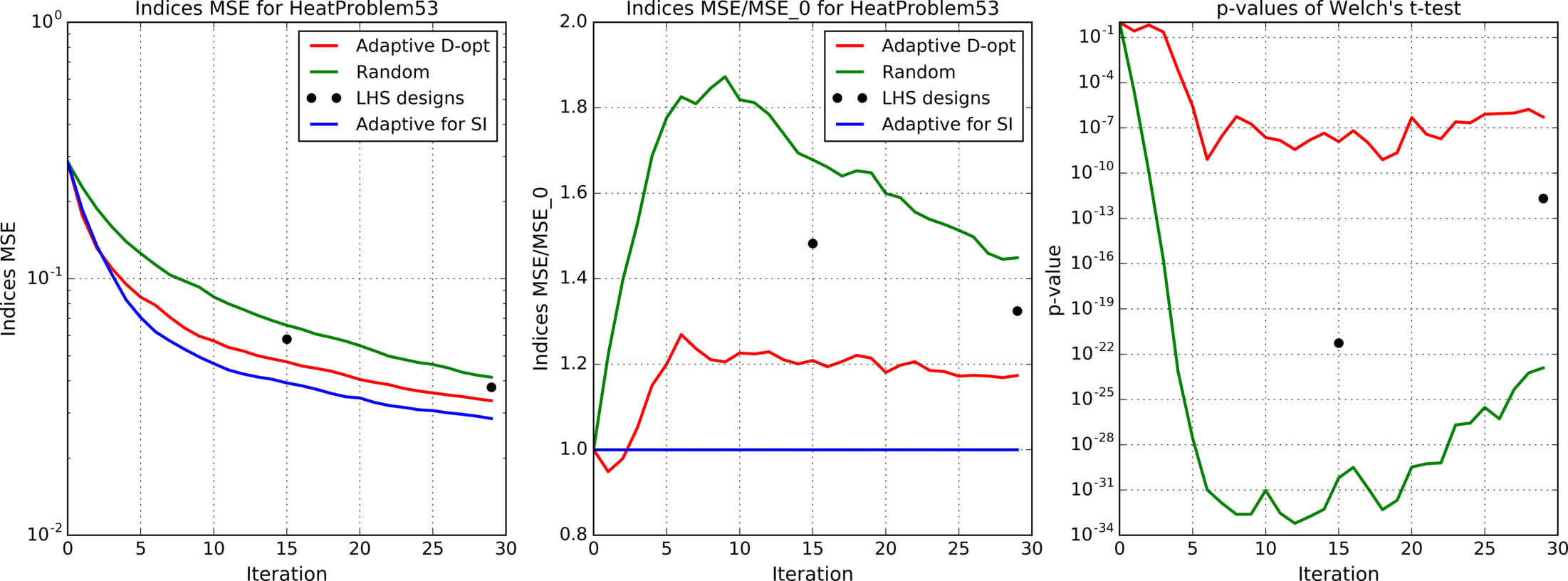 Figure 6
Figure 6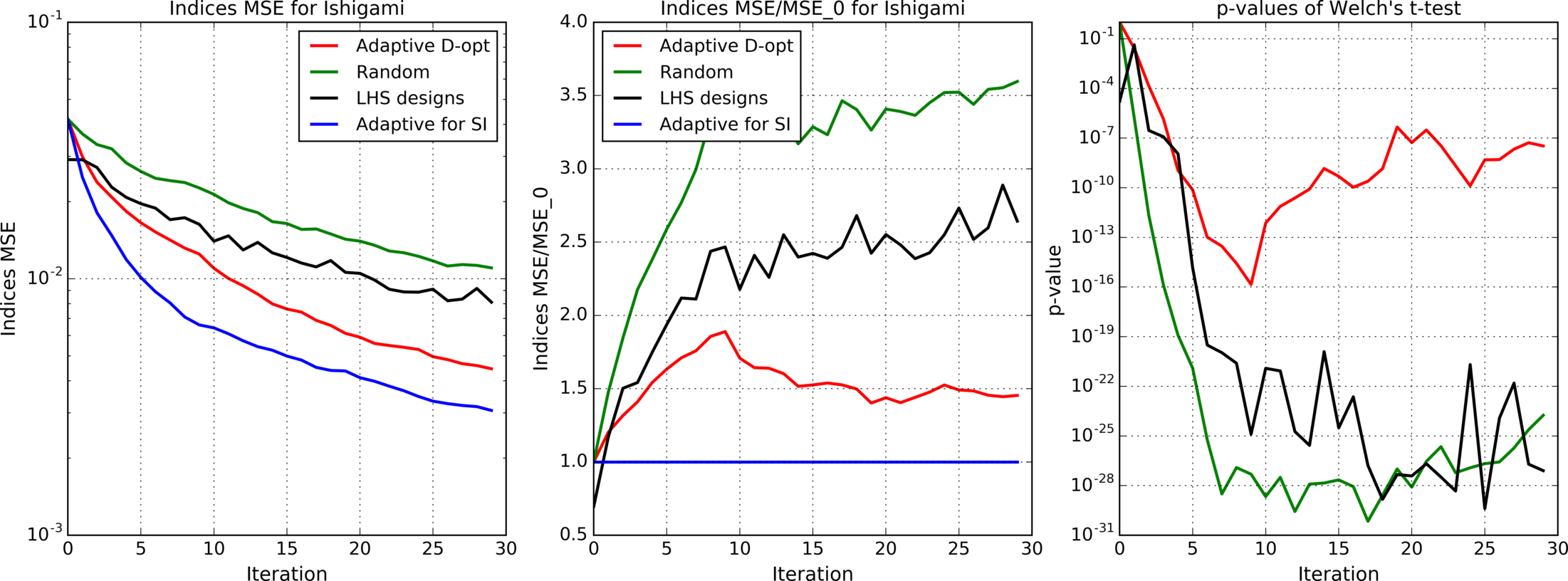 Figure 7
Figure 7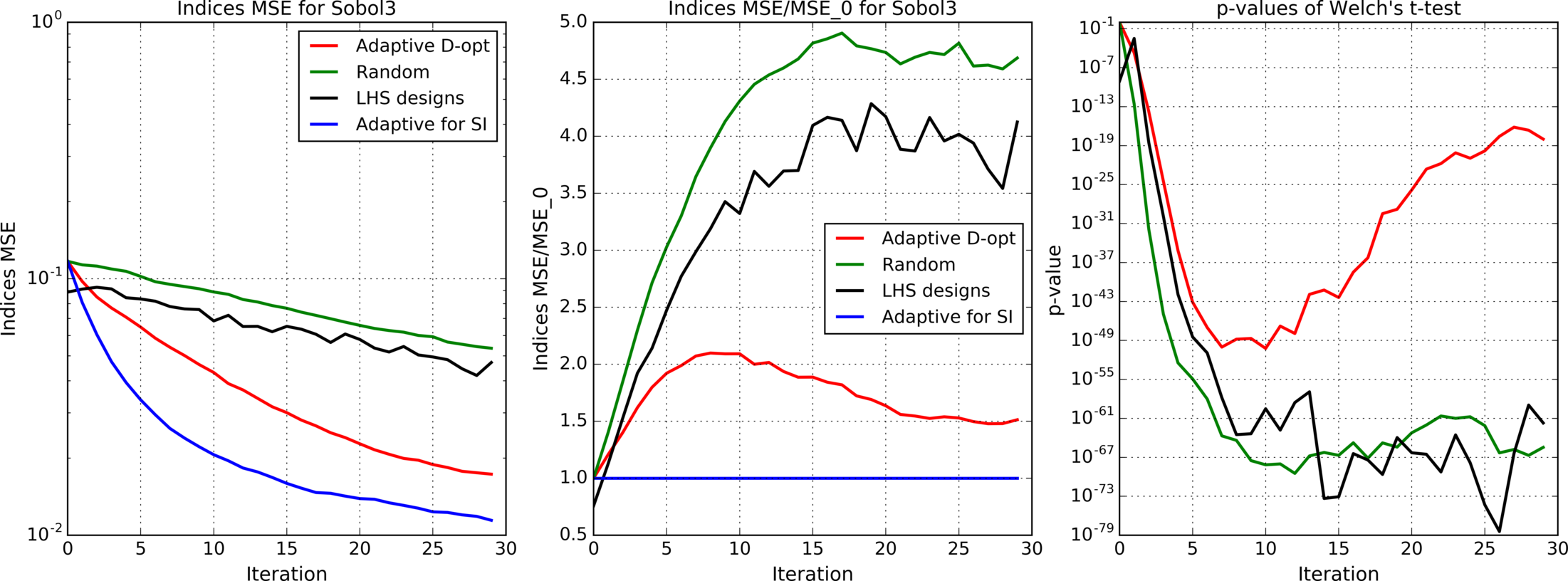 Figure 8
Figure 8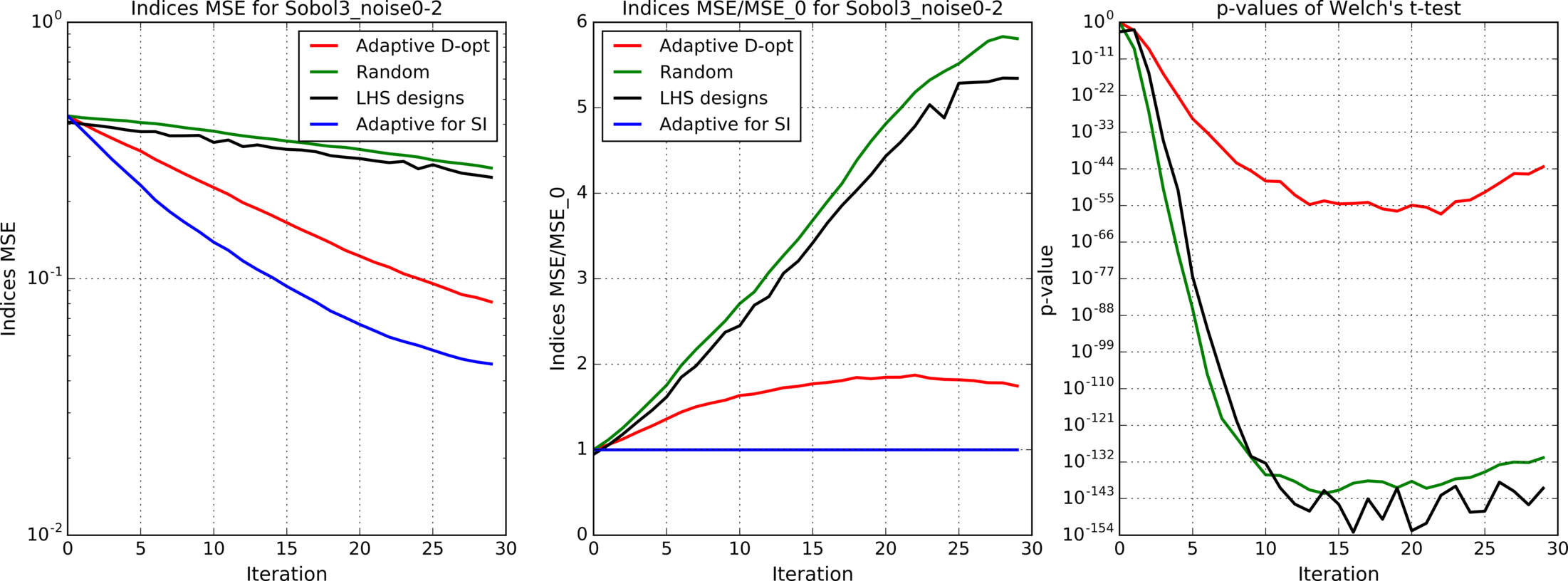 Figure 9
Figure 9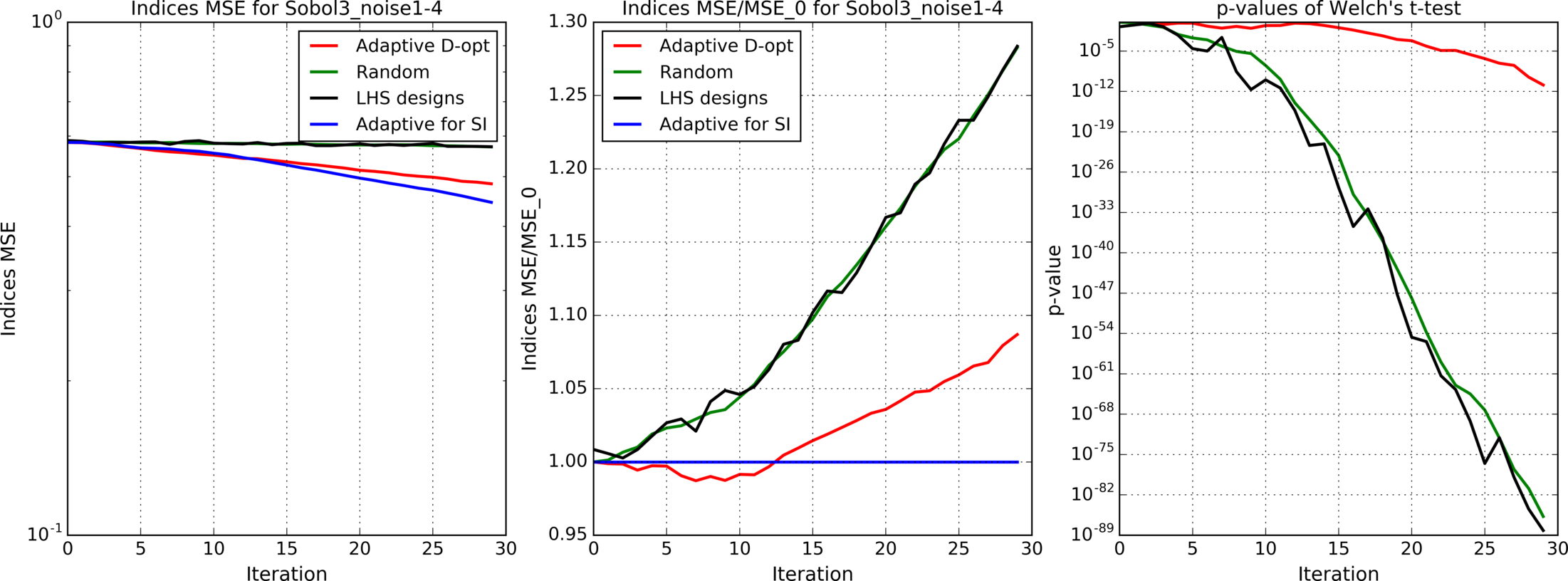 Figure 10
Figure 10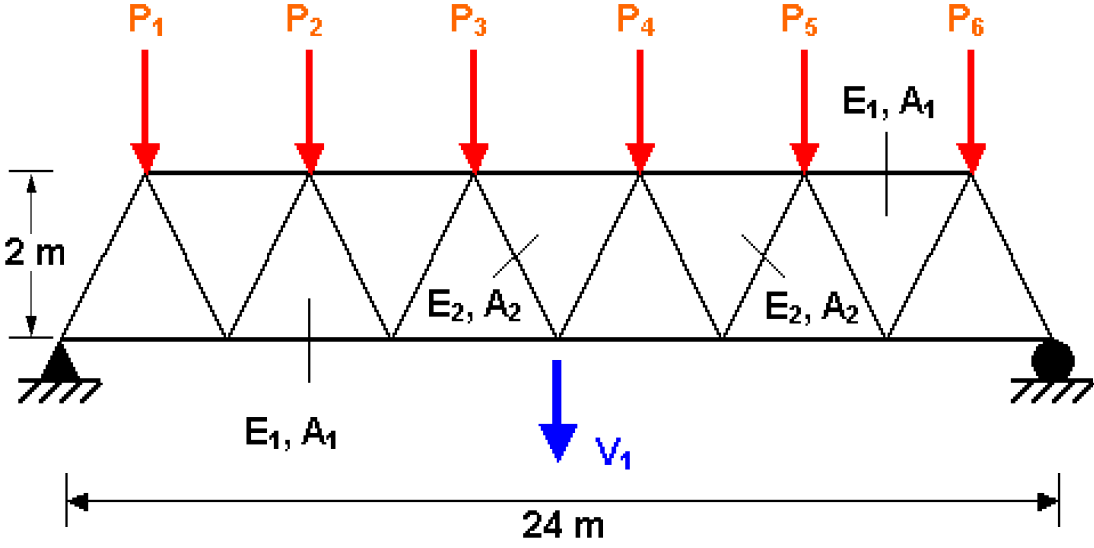 Figure 11
Figure 11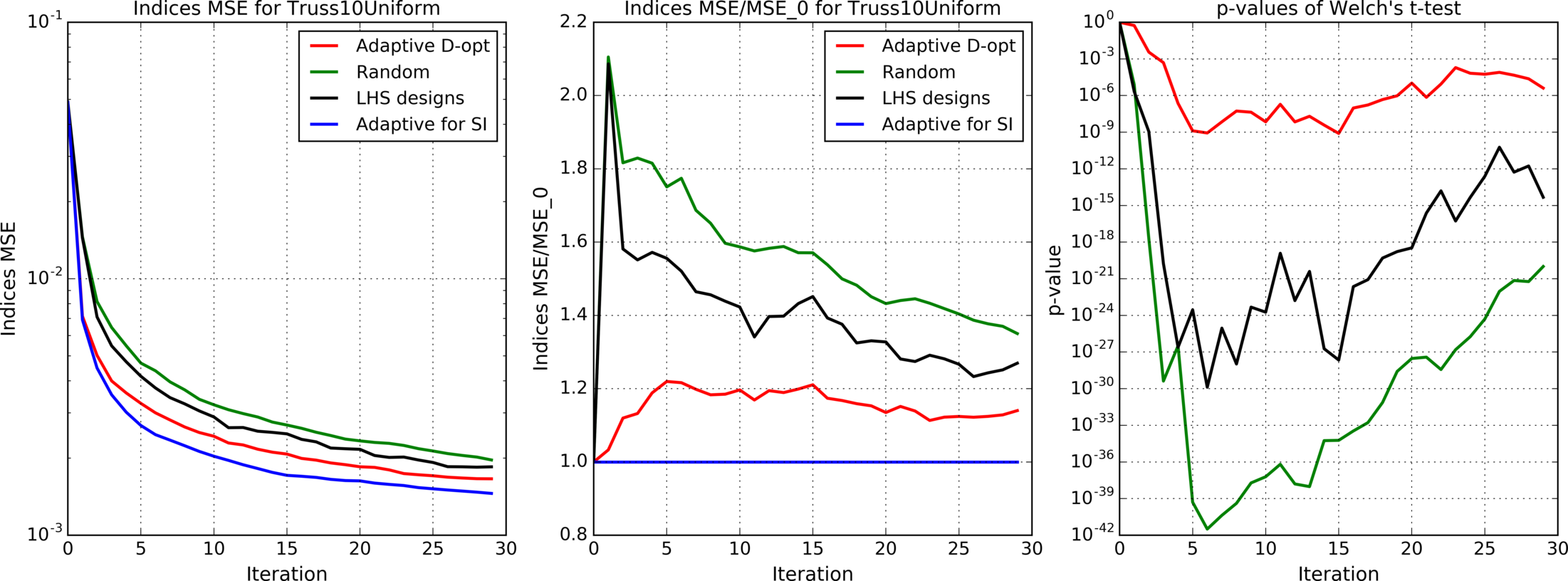 Figure 12
Figure 12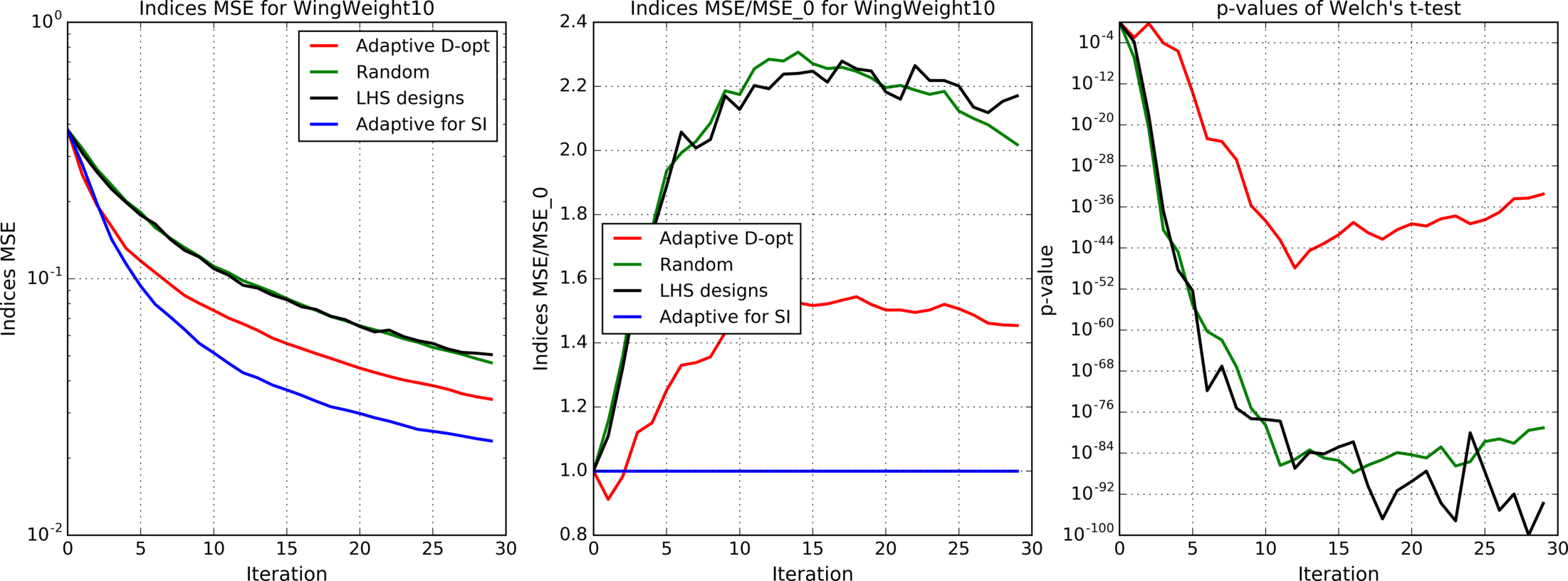 Figure 13
Figure 13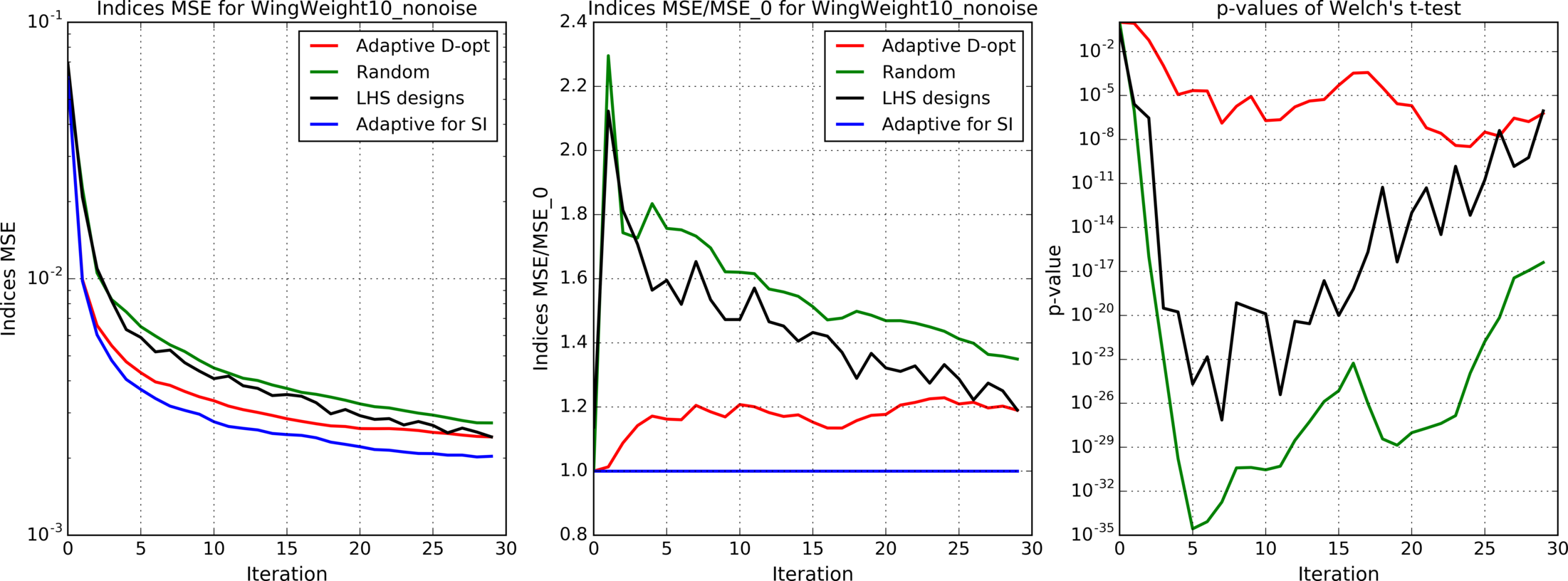 Figure 14
Figure 14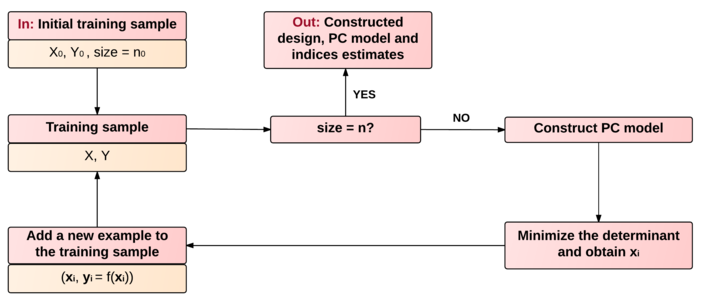 Figure 15
Figure 15| Characteristic | Sobol | Ishigami | Environmental | Borehole | WingWeight |
|---|---|---|---|---|---|
| Input dimension | |||||
| Input distributions | Unif | Unif | Unif | Unif | Unif |
| PCE degree | |||||
| -norm | |||||
| Regressors number | |||||
| Initial design size | |||||
| Added noise std | (0, 0.2, 1.4) | — | (, ) | (, ) |
| Characteristic | Truss | Heat transfer |
|---|---|---|
| Input dimension | ||
| Input distributions | Unif | Norm |
| PCE degree | ||
| -norm | ||
| Regressors number | ||
| Initial design size | ||
| Added noise std | — | — |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsProbabilistic and Robust Engineering Design · Structural Response to Dynamic Loads · Rice Cultivation and Yield Improvement
Efficient design of experiments for sensitivity analysis based on polynomial chaos expansions
E. Burnaev
Skolkovo Institute of Science and Technology, Building 3, Nobel st., Moscow 143026, Russia
Kharkevich Institute for Information Transmission Problems, Bolshoy Karetny per. 19, Moscow 127994, Russia
National Research University Higher School of Economics
Myasnitskaya st. 20, Moscow 109028, Russia
I. Panin
Kharkevich Institute for Information Transmission Problems, Bolshoy Karetny per. 19, Moscow 127994, Russia
B. Sudret
Chair of Risk, Safety and Uncertainty Quantification, ETH Zurich, Stefano-Franscini-Platz 5, 8093 Zurich, Switzerland
Abstract
Global sensitivity analysis aims at quantifying respective effects of input random variables (or combinations thereof) onto variance of a physical or mathematical model response. Among the abundant literature on sensitivity measures, Sobol indices have received much attention since they provide accurate information for most of models. We consider a problem of experimental design points selection for Sobol’ indices estimation. Based on the concept of -optimality, we propose a method for constructing an adaptive design of experiments, effective for calculation of Sobol’ indices based on Polynomial Chaos Expansions. We provide a set of applications that demonstrate the efficiency of the proposed approach.
Keywords: Design of Experiment – Sensitivity Analysis – Sobol Indices – Polynomial Chaos Expansions – Active Learning
1 Introduction
Computational models play important role in different areas of human activity (see [1, 2, 3]). Over the past decades, computational models have become more complex, and there is an increasing need for special methods for their analysis. Sensitivity analysis is an important tool for investigation of computational models.
Sensitivity analysis tries to find how different model input parameters influence the model output, what are the most influential parameters and how to evaluate such effects quantitatively (see [4]). Sensitivity analysis allows to better understand behavior of computational models. Particularly, it allows us to separate all input parameters into important (significant), relatively important and unimportant (nonsignificant) ones. Important parameters, i.e. parameters whose variability has a strong effect on the model output, need to be controlled more accurately. Complex computational models often suffer from over-parameterization. By excluding unimportant parameters, we can potentially improve model quality, reduce parametrization (which is of great interest in the field of meta-modeling) and computational costs [29].
Sensitivity analysis includes a wide range of metrics and techniques: e.g. the Morris method [5], linear regression-based methods [6], variance-based methods [7]. Among others, Sobol’ (sensitivity) indices are a common metric to evaluate the influence of model parameters [11]. Sobol’ indices quantify which portions of the output variance are explained by different input parameters and combinations thereof. This method is especially useful for the case of nonlinear computational models [12].
There are two main approaches to evaluate Sobol’ indices. Monte Carlo approach (Monte Carlo simulations, FAST [13], SPF scheme [14] and others) is relatively robust (see [8]), but requires large number of model runs, typically in the order of for an accurate estimation of each index. Thus, it is impractical for a number of industrial applications, where each model evaluation is computationally costly.
Metamodeling approaches for Sobol’ indices estimation allow one to reduce the required number of model runs [6, 10]. Following this approach, we replace the original computational model by an approximating metamodel (also known as surrogate model or response surface) which is computationally efficient and has some clear internal structure [9]. The approach consists of the following general steps: selection of the design of experiments (DoE) and generation of the training sample, construction of the metamodel based on the training sample, including its accuracy assessment and evaluation of Sobol’ indices (or any other measure) using the constructed metamodel. Note that the evaluation of indices may be either based on a known internal structure of the metamodel or via Monte Carlo simulations based on the metamodel itself.
In general, the metamodeling approach is more computationally efficient than an original Monte Carlo approach, since the cost (in terms of the number of runs of the costly computational model) reduces to that of the training set (usually containing results from a few dozens to a few hundreds model runs). However, this approach can be nonrobust and its accuracy is more difficult to analyze. Indeed, although procedures like cross-validation [29, 15] allow to estimate quality of metamodels, the accuracy of complex statistics (e.g. Sobol’ indices), derived from metamodels, has a complicated dependency on the metamodels structure and quality (see e.g. confidence intervals for Sobol’ indices estimates [16] in case of Gaussian Process metamodel [17, 18, 19, 20, 21] and bootstrap-based confidence intervals in case of polynomial chaos expansions [22]).
In this paper, we consider a problem of a DoE construction in case of a particular metamodeling approach: how to select the experimental design for building a polynomial chaos expansion for further evaluation of Sobol’ indices, that is effective in terms of the number of computational model runs?
Space-filling designs are commonly used for sensitivity analysis. Methods like Monte Carlo sampling, Latin Hypercube Sampling (LHS) [23] or sampling in FAST method [13] try to fill “uniformly” the input parameters space with design points (points are some realizations of parameters values). These sampling methods are model free, as they make no assumptions on the computational model.
In order to speed up the convergence of indices estimates, we assume that the computational model is close to its approximating metamodel and exploit knowledge of the metamodel structure. In this paper, we consider Polynomial Chaos Expansions (PCE) that is commonly used in engineering and other applications [24]. PCE approximation is based on a series of polynomials (Hermite, Legendre, Laguerre etc.) that are orthogonal w.r.t. the probability distributions of corresponding input parameters of the computational model. It allows to calculate Sobol’ indices analytically from the expansion coefficients [25, 26].
In this paper, we address the problem of design of experiments construction for evaluating Sobol’ indices from a PCE metamodel. Based on asymptotic considerations, we propose an adaptive algorithm for design construction and test it on a set of applied problems. Note that in [36], we investigated the adaptive design algorithm for the case of a quadratic metamodel (see also [37]). In this paper, we extend these results for the case of a generalized PCE metamodel and provide more examples, including real industrial applications.
The paper is organized as follows: in Section 2, we review the definition of sensitivity indices and describe their estimation based on a PCE metamodel. In Section 3, asymptotic analysis of indices estimates is provided. In Section 4, we introduce an optimality criterion and propose a procedure for constructing the experimental design. In Section 5, we provide experimental results, applications and benchmark with other methods of design construction.
2 Sensitivity Indices and PCE Metamodel
2.1 Sensitivity Indices
Consider a computational model , where is a vector of input variables (aka parameters or features), is an output variable and is a design space. The model describes behavior of some physical system of interest.
We consider the model as a black-box: no additional knowledge on its inner structure is assumed. For some design of experiments we can obtain a set of model responses and form a training sample
[TABLE]
which allows us to investigate properties of the computational model.
Let us assume that there is a prescribed probability distribution with independent marginal distributions on the design space (). This distribution represents the uncertainty and/or variability of the input variables, modelled as a random vector with independent components. In these settings, the model output becomes a stochastic variable.
Assuming that the function is square-integrable with respect to the distribution (i.e. ), we have the following unique Sobol’ decomposition of (see [11]) given by
[TABLE]
which satisfies
[TABLE]
where and are index sets: .
Due to orthogonality of the summands, we can decompose variance of the model output:
[TABLE]
In this expansion is the contribution of the summand to the output variance, also known as the partial variance.
Definition 1**.**
The sensitivity index (Sobol’ index) of the subset of model input variables is defined as
[TABLE]
The sensitivity index describes the amount of the total variance explained by uncertainties in the subset of model input variables.
Remark 1**.**
In this paper, we consider only sensitivity indices of type , called first-order or main effect sensitivity indices.
2.2 Polynomial Chaos Expansions
Consider a set of multivariate polynomials that consists of polynomials having the form of tensor product
[TABLE]
where is a univariate polynomial of degree belonging to the -th family (e.g. Legendre polynomials, Jacobi polynomials, etc.), is the set of nonnegative integers, is some fixed set of multi-indices .
Suppose that univariate polynomials are orthogonal w.r.t. -th marginal of the probability distribution , i.e. if for . Particularly, Legendre polynomials are orthogonal w.r.t. standard uniform distribution; Hermite polynomials are orthogonal w.r.t. Gaussian distribution. Due to independence of components of , we obtain that multivariate polynomials are orthogonal w.r.t. the probability distribution , i.e.
[TABLE]
Provided , the spectral polynomial chaos expansion of takes the form
[TABLE]
where are expansion coefficients.
In the sequel we consider a PCE approximation of the model obtained by truncating the infinite series to a finite number of terms:
[TABLE]
By enumerating the elements of we also use an alternative form of (4):
[TABLE]
where is a column vector of coefficients and is a mapping from the design space to the extended design space defined as a column vector function . Note that index corresponds to multi-index , i.e.
[TABLE]
The set of multi-indices is determined by some truncation scheme. In this work, we use hyperbolic truncation scheme [27], which corresponds to
[TABLE]
where is a fixed parameter and is a fixed maximal total degree of polynomials. Note that in case of , we have polynomials in and a smaller leads to a smaller number of polynomials.
There is a number of strategies for estimating the expansion coefficients in (4). In this paper, the least-square (LS) minimization method is used [28]. Unlike (3), the key idea consists in considering the original model as the sum of a truncated PC expansion and a residual , i.e.
[TABLE]
where thanks to orthogonality property (2) the residual process can be considered as an i.i.d. noise process with and , such that and are orthogonal w.r.t. the distribution .
The coefficients are obtained by minimizing the mean square residual:
[TABLE]
which is approximated by using the training sample :
[TABLE]
2.3 PCE post-processing for sensitivity analysis
Consider some PCE model . According to [25], we have an explicit form of Sobol’ indices (main effects) for model :
[TABLE]
where and is the set of multi-indices such that only index on the -th position is nonzero: , , .
Suppose for simplicity that the multivariate polynomials are not only orthogonal but also normalized w.r.t. the distribution :
[TABLE]
where is the Kronecker symbol, i.e if , otherwise . Then (7) takes the form
[TABLE]
Thus, (8) provides a simple expression for calculation of Sobol’ indices in case of the PCE metamodel. If the original model of interest is close to its PCE approximation , then we can use expression (8) for indices with estimated coefficients (6) to approximate Sobol’ indices of the original model:
[TABLE]
where .
3 Asymptotic Properties
In this section, we consider asymptotic properties of indices estimates in Eq. (9) if the coefficients are estimated by LS approach (6). Let be LS estimate (6) of the true coefficients vector based on the training sample . In this section and further, if some variable has index , then this variable depends on training sample (1) of size .
Define the information matrix as
[TABLE]
Then, we can obtain asymptotic properties of the indices estimates (9) based on model (5) while new data points are added to the training sample sequentially. In order to prove these asymptotic properties we require only that and are orthogonal w.r.t. the distribution , and we do not need to require that multivariate polynomials are orthonormal.
Theorem 1**.**
Let the following assumptions hold true:
We assume that there is an infinite sequence of points in the design space , generated by the corresponding sequence of i.i.d. random vectors, such that a.s.
[TABLE]
where , where is a symmetric and non-degenerate matrix (* and ), and new design points are added successively from this sequence to the design of experiments .* 2. 2.
Let the vector-function be defined by its components according to (8):
[TABLE]
and , where is defined by (6). 3. 3.
Assume that for the true coefficients of model (5):
[TABLE]
where is the matrix of partial derivatives defined as
[TABLE]
and with ,
then
[TABLE]
Proof.
Let us denote by the column vector, generated by the i.i.d. residual process values (see (5)), and by the design matrix. We can easily get that
[TABLE]
We can represent as , where is a sequence, generated by i.i.d. random vectors , , such that thanks to the fact that and are orthogonal for , and .
Thus from (11) and the central limit theorem we get that
[TABLE]
Applying -method (see [30]) to the vector-function at the point , we obtain required asymptotics (14). ∎
Remark 2**.**
Note that the elements of have the following form
[TABLE]
where and multi-index . The elements of can be also represented as
[TABLE]
Remark 3**.**
We can see that conditions of the theorem do not depend on the type of orthonormal polynomials.
Remark 4**.**
In case are multivariate polynomials, orthonormal w.r.t. the distribution , we get that is the identity matrix.
Remark 5**.**
In the proof of theorem 1 we are trying to make as less assumptions as possible in order to depart from original polynomial chaos model (3) as little as possible. That is why the only important assumption is that and are orthogonal w.r.t. the distribution . However, we can also consider model (5) as a regression one, and so the error term is modelled by a white noise, independent from , see the discussion of the polynomial chaos approach from a statistician’s perspective in [31]. Nevertheless, even in the case of such interpretation of model (5) we still get the same asymptotic behavior (14).
Remark 6**.**
In case and are not only orthogonal for , but also are independent, we get that . Then asymptotics (14) takes the form
[TABLE]
In applications it seems reasonable to assume that and are approximately independent for . Then for practical purposes we can use asymptotics (17), for which it is easier to calculate the asymptotic covariance matrix. Therefore in the sequel for applications we are going to use this simplified expression.
4 Design of Experiments Construction
4.1 Preliminary Considerations
Taking into account the results of Theorem 1, the limiting covariance matrix of the indices estimates depends on
Noise variance , 2. 2.
True values of PC coefficients , defining , 3. 3.
Experimental design , defining .
If we have a sufficiently accurate approximation of the original model, then in the above assumptions, asymptotic covariance in (17) provides a theoretically motivated functional to characterize the quality of the experimental design. Indeed, generally speaking the smaller the norm of the covariance matrix , the better the estimation of the sensitivity indices apparently should be. Theoretically, we could use this formula for constructing an experimental design that is effective for calculating Sobol’ indices: we could select designs that minimize the norm of the covariance matrix. However, there are some problems when proceeding this way:
- •
The first one relates to selecting some specific functional for minimization. Informally speaking, we need to choose “the norm” associated with the limiting covariance matrix;
- •
The second one refers to the fact that we do not know true values of the PC model coefficients, defining ; therefore, we will not be able to accurately evaluate the quality of the design.
The first problem can be solved in different ways. A number of statistical criteria for design optimality (-, -optimality and others, see [32]) are known. Similar to the work [36], we use the -optimality criterion, as it a provides computationally efficient procedure for design construction. -optimal experimental design minimizes the determinant of the limiting covariance matrix. If the vector of the estimated parameters is normally distributed then -optimal design allows to minimize the volume of the confidence region for this vector.
The second problem is more complex. The optimal design for estimating sensitivity indices that minimizes the norm of limiting covariance matrix depends on true values of the indices, so it can be constructed only if these true values are known. However, in this case design construction makes no sense.
The dependency of the optimal design for indices evaluation on the true model parameters is a consequence of the indices estimates nonlinearity w.r.t. the PC model coefficients. In order to underline this dependency, the term “locally -optimal design” is commonly used [33]. In this setting there are several approaches, which are usually associated with either some assumptions about the unknown parameters, or adaptive design construction (see [33]). We use the latter approach.
In the case of adaptive designs, new design points are generated sequentially based on current estimates of the unknown parameters. This allows to avoid prior assumptions on these parameters. However, this approach has a problem with a confidence of the solution found: if at some step of the design construction process parameters estimates are significantly different from their true values, then the design, which is constructed based on these estimates, may lead to new parameters estimates, which are even more different from the true values.
In practice, during the construction of adaptive design, the quality of the approximation model and assumptions on non-degeneracy of results can be checked at each iteration and one can control and adjust the adaptive strategy.
4.2 Adaptive DoE Algorithm
In this section, we introduce the adaptive algorithm for constructing a design of experiments that is effective to estimate sensitivity indices based on the asymptotic -optimality criterion (see description of Algorithm 1 and its scheme in Figure 1). As it was discussed, the main idea of the algorithm is to minimize the confidence region for indices estimates. At each iteration, we replace the limiting covariance matrix by its approximation based on the current PC coefficients estimates.
As for initialization, we assume that there is some initial design, and we require that this initial design is non-degenerate, i.e. such that the initial information matrix is nonsingular (). In addition, at each iteration the non-degeneracy of the matrix , related to the criterion to be minimized, is checked.
4.3 Details of the Optimization procedure
The idea behind the proposed optimization procedure is analogous to the idea of the Fedorov’s algorithm for constructing optimal designs [34]. In order to simplify optimization problem (18), we use two well-known identities:
- •
Let be some nonsingular square matrix, and be vectors such that , then
[TABLE]
- •
Let be some nonsingular square matrix, and be vectors of appropriate dimensions, then
[TABLE]
Let us define , then applying (19), we obtain
[TABLE]
[TABLE]
where , , . Assuming that matrix is nonsingular and applying (20), we obtain
[TABLE]
The resulting optimization problem is
[TABLE]
or explicitly (18) is reduced to
[TABLE]
5 Benchmark
In this section, we validate the proposed algorithm on a set of computational models with different input dimensions. Several analytic problems and two industrial problems based on finite element models are considered. Input parameters (variables) of the considered models have independent uniform and independent normal distributions. For some models, additionally independent gaussian noise is added to their outputs.
At first, we form non-degenerate random initial design, and then we use various techniques to add new design points iteratively. We compare our method for design construction (denoted as Adaptive for SI) with the following methods:
- •
Random method iteratively adds new design points randomly from the set of candidate design points ;
- •
Adaptive D-opt iteratively adds new design points that maximize the determinant of information matrix (10): ([34]). The resulting design is optimal, in some sense, for estimation of the PCE model coefficients. We compare our method with this approach to prove that it gives some advantage over usual -optimality. Strictly speaking, -optimal design is not iterative but if we have an initial training sample then the sequential approach seems a natural generalization of a common -optimal designs.
- •
LHS. Unlike other considered designs, this method is not iterative as a completely new design is generated at each step. This method uses Latin Hypercube Sampling, and it is common to compute PCE coefficients.
The metric of design quality is the mean error defined as the distance between estimated and true indices averaged over runs with different random initial designs (- runs). We consider not only the mean error but also its variance. Particularly, we use Welch’s t-test (see [35]) to ensure that the difference of mean distances is statistically significant for the considered methods. Note that lower p-values correspond to bigger confidence.
In all cases, we assume that the truncation set (retained PCE terms) is selected before an experiment.
5.1 Analytic Functions
The Sobol’ function
is commonly used for benchmarking methods in global sensitivity analysis
[TABLE]
where . In our case parameters , are used. Independent gaussian noise is added to the output of the function. The standard deviation of noise is [math] (without noise), and that corresponds to , and of the function standard deviation, caused by the inputs uncertainty. Analytical expressions for the corresponding sensitivity indices are available in [11].
Ishigami function
is also commonly used for benchmarking of global sensitivity analysis:
[TABLE]
where . Theoretical values for its sensitivity indices are available in [16].
Environmental function
models a pollutant spill caused by a chemical accident [44]
[TABLE]
[TABLE]
where is the indicator function; input variables and their distributions are defined as: , mass of pollutant spilled at each location; , diffusion rate in the channel; , location of the second spill; , time of the second spill. is the concentration of the pollutant at the space-time vector , where and .
We consider a cross-section corresponding to , and suppose that independent gaussian noise is added to the output of the function.
The Borehole function
models water flow through a borehole. It is commonly used for testing different methods in numerical experiments [42, 43]
[TABLE]
where input variables and their distributions are defined as: , radius of borehole (m); , transmissivity of upper aquifer (/yr); , radius of influence (m); , potentiometric head of upper aquifer (m); , transmissivity of lower aquifer (/yr); , potentiometric head of lower aquifer (m); , length of borehole (m); , hydraulic conductivity of borehole (m/yr).
Besides the deterministic case, we also consider stochastic one when independent gaussian noise is added to the output of the function.
The Wing Weight function
models weight of an aircraft wing [38]
[TABLE]
[TABLE]
where input variables and their distributions are defined as: , wing area (); , weight of fuel in the wing (lb); , aspect ratio; , quarter-chord sweep (degrees); , dynamic pressure at cruise (lb/); , taper ratio; , aerofoil thickness to chord ratio; , ultimate load factor; , flight design gross weight (lb); , paint weight (lb/).
Besides the deterministic case, we also consider stochastic one when independent gaussian noise is added to the output of the function.
Experimental setup:
In the experiments, we assume that the set of candidate design points is a uniform grid in the -dimensional hypercube. Note that affects optimization quality. Experimental settings for analytical functions are summarized in Table 1.
5.2 Finite Element Models
Case 1: Truss model.
The deterministic computational model, originating from [39], resembles the displacement of a truss structure with members as shown in Figure 2.
Ten random variables are considered:
- •
, (Pa) ;
- •
() ;
- •
() ;
- •
- (N) .
It is assumed that all the horizontal elements have perfectly correlated Young’s modulus and cros-sectional areas with each other and so is the case with the diagonal members.
Case 2: Heat transfer model.
We consider the two-dimensional stationary heat diffusion problem described in [40]. The problem is defined on the square domain shown in Figure 3(a), where the temperature field is described by the partial differential equation:
[TABLE]
with boundary conditions on the top boundary and on the left, right and bottom boundaries, where denotes the vector normal to the boundary; is a square domain within and is the indicator function of . The diffusion coefficient, , is a lognormal random field defined by
[TABLE]
where is a standard Gaussian random field and the parameters and are such that the mean and standard deviation of are and , respectively. The random field is characterized by an autocorrelation function . The quantity of interest, , is the average temperature in the square domain within (see Figure 3(a)).
To facilitate solution of the problem, the random field is represented using the Expansion Optimal Linear Estimation (EOLE) method (see [41]). By truncating the EOLE series after the first terms, is approximated by
[TABLE]
In the above equation, are independent standard normal variables; is a vector with elements , where are the points of an appropriately defined mesh in ; and are the eigenvalues and eigenvectors of the correlation matrix with elements , where . We select in order to satisfy inequality
[TABLE]
The underlying deterministic problem is solved with an in-house finite-element analysis code. The employed finite-element discretization with triangular elements is shown in Figure 3(a). Figure 3(b) shows the temperature fields corresponding to two example realizations of the diffusion coefficient.
Experimental Setup.
For these finite element models, we assume that the set of candidate design points is
- •
a uniform grid in the -dimensional hypercube for the Truss model;
- •
LHS design with normally distributed variables in -dimensional space for the Heat transfer model.
Experimental settings for all models are summarized in Table 2.
5.3 Results
Figures 4(a), 4(b), 4(c), 5, 6, 7(a), 7(b), 8(a), 8(b) show results for analytic functions. Figures 9 and 10 present results for finite element models. We provide here mean errors, relative mean errors w.r.t the proposed method and -values to ensure that the difference of mean errors is statistically significant.
In the presented experiments, the proposed method performs better than other considered methods in terms of the mean error of estimated indices. Particularly note its superiority over standard LHS approach that is commonly used in practice. The difference in mean errors is statistically significant according to Welch’s t-test.
Comparison of figures 4(a), 4(b), 4(c) with different levels of additive noise shows that the proposed method is effective when the analyzed function is deterministic or when the noise level is small.
Because of robust problem statement and limited accuracy of the optimization, the algorithm may produce duplicate design points. Actually, it’s a common situation for locally -optimal designs [33]. If the computational model is deterministic, one may modify the algorithm, e.g. exclude repeated design points.
Although high dimensional optimization problems may be computationally prohibitive, the proposed approach is still useful in high dimensional settings. We propose to generate a uniform candidate set (e.g. LHS design of large size) and then choose its subset for the effective calculation of Sobol’ indices using our adaptive method, see results for Heat transfer model in Figure 10 (note that due to computational complexity we provide for this model results only for iterations of the LHS method).
It should be noted that in all presented cases the specification of sufficiently accurate PCE model (reasonable values for degree and -norm defining the truncation set) is assumed to be known a priori and the size of the initial training sample is sufficiently large. If we use an inadequate specification of the PCE model (e.g. quadratic PCE in case of cubic analyzed function), the method will perform worse in comparison with methods which do not depend on PCE model structure. In any case, usage of inadequate PCE models may lead to inaccurate results. That is why it is very important to control PCE model error during the design construction. For example, one may use cross-validation for this purpose [29]. Thus, if the PCE model error increases during design construction this may indicate that the model specification is inadequate and should be changed.
6 Conclusions
We proposed the design of experiments algorithm for evaluation of Sobol’ indices from PCE metamodel. The method does not depend on a particular form of orthonormal polynomials in PCE. It can be used for the case of different distributions of input parameters, defining the analyzed computational models.
The main idea of the method comes from metamodeling approach. We assume that the computational model is close to its approximating PCE metamodel and exploit knowledge of a metamodel structure. This allows us to improve the evaluation accuracy. All comes with a price: if additional assumptions on the computational model to provide good performance are not satisfied, one may expect accuracy degradation. Fortunately, in practice, we can control approximation quality during design construction and detect that we have selected inappropriate model. Note that from a theoretical point of view, our asymptotic considerations (w.r.t. the training sample size) simplify the problem of accuracy evaluation for the estimated indices.
Our experiments demonstrate: if PCE specification defined by the truncation scheme is appropriate for the given computational model and the size of the training sample is sufficiently large, then the proposed method performs better in comparison with standard approaches for design construction.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] K.J.Beven. Rainfall-Runoff Modelling. The Primer, Wiley, 360 pp, Chichester, 2000.
- 2[2] P. Dayan and L. F. Abbott (2001). Theoretical Neuroscience: Computational and Mathematical Modeling of Neural Systems (MIT Press, Cambridge, MA).
- 3[3] S. Grihon, E.V. Burnaev, M.G. Belyaev, and P.V. Prikhodko. Surrogate Modeling of Stability Constraints for Optimization of Composite Structures. Surrogate-Based Modeling and Optimization. Engineering applications. Eds. by S. Koziel, L. Leifsson. Springer, 2013. P. 359—391.
- 4[4] A. Saltelli, K. Chan, M. Scott. Sensitivity analysis. Probability and statistics series. West Sussex: Wiley, (2000)
- 5[5] M.D. Morris. Factorial sampling plans for preliminary computational experiments. Technometrics, 33:161—174, 1991.
- 6[6] B. Iooss, P. Lemaitre. (2015) A review on global sensitivity analysis methods. In: Meloni C, Dellino G (eds) Uncertainty management in Simulation-Optimization of Complex Systems: Algorithms and Applications, Springer
- 7[7] A. Saltelli, M. Ratto, T. Andres, F. Campolongo, J. Cariboni, D. Gatelli, et al. Global Sensitivity Analysis - The Primer. Wiley (2008)
- 8[8] J. Yang. (2011). Convergence and uncertainty analyses in Monte-Carlo based sensitivity analysis. Environ. Modell. Softw. 26, 444—457.