A three-dimensional statistical model for imaged microstructures of porous polymer films
Sandra Barman, David Bolin

TL;DR
This paper introduces a 3D Gaussian random field model for porous polymer microstructures, enabling efficient simulation and fitting to microscopy images, and investigates how microstructure affects drug release.
Contribution
It develops a novel stochastic PDE-based model for 3D porous microstructures and provides an efficient MCMC fitting method to analyze microscopy data.
Findings
Model fits stationary microstructure regions well
Goodness-of-fit measures based on diffusion and geometry are effective
Model helps understand microstructure's impact on drug release
Abstract
A thresholded Gaussian random field model is developed for the microstructure of porous materials. Defining the random field as a solution to stochastic partial differential equation allows for flexible modelling of non-stationarities in the material and facilitates computationally efficient methods for simulation and model fitting. A Markov Chain Monte Carlo algorithm is developed and used to fit the model to three-dimensional confocal laser scanning microscopy images. The methods are applied to study a porous ethylcellulose/hydroxypropylcellulose polymer blend that is used as a coating to control drug release from pharmaceutical tablets. The aim is to investigate how mass transport through the material depends on the microstructure. We derive a number of goodness-of-fit measures based on numerically calculated diffusion through the material. These are used in combination with measures…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1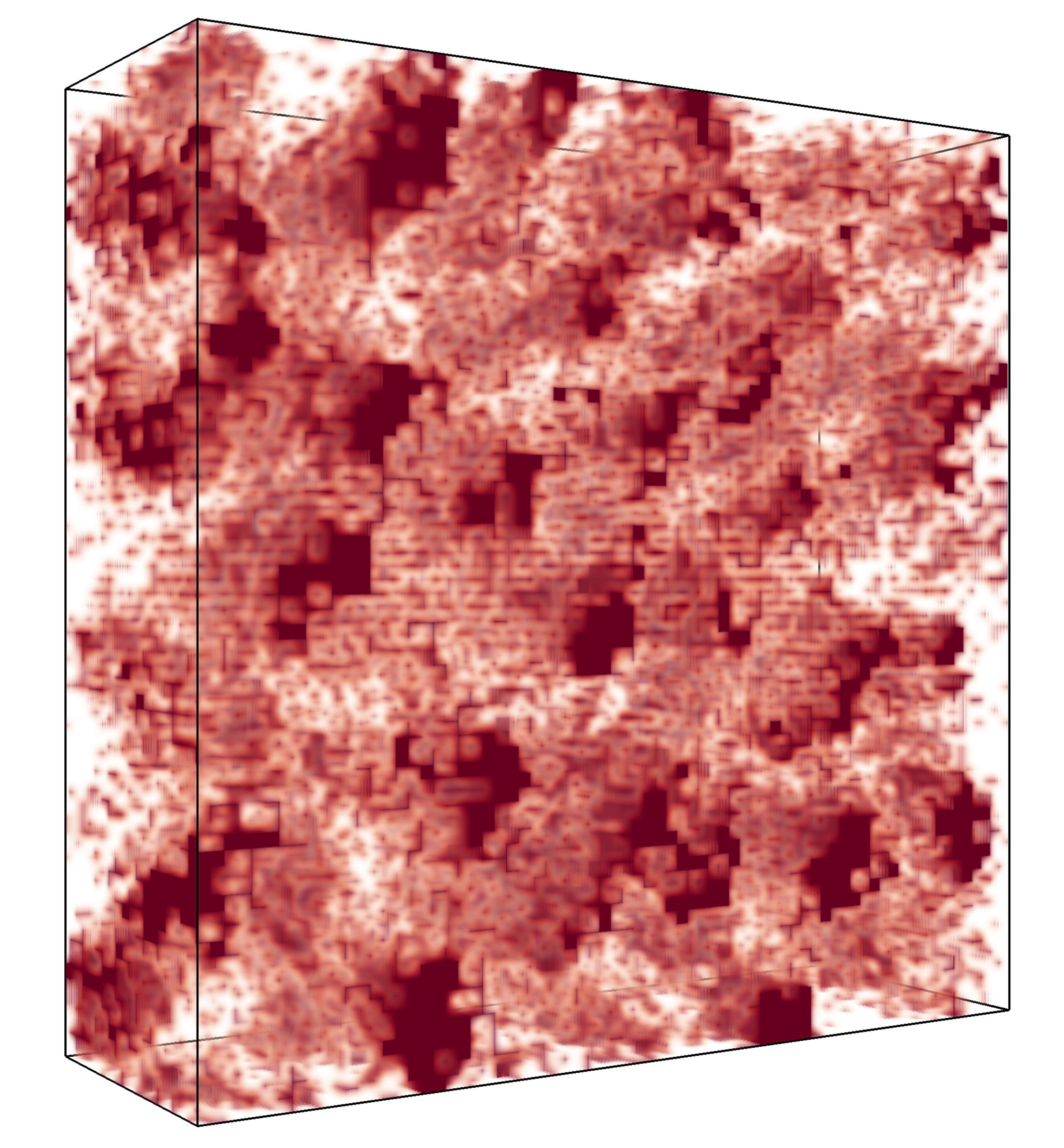 Figure 2
Figure 2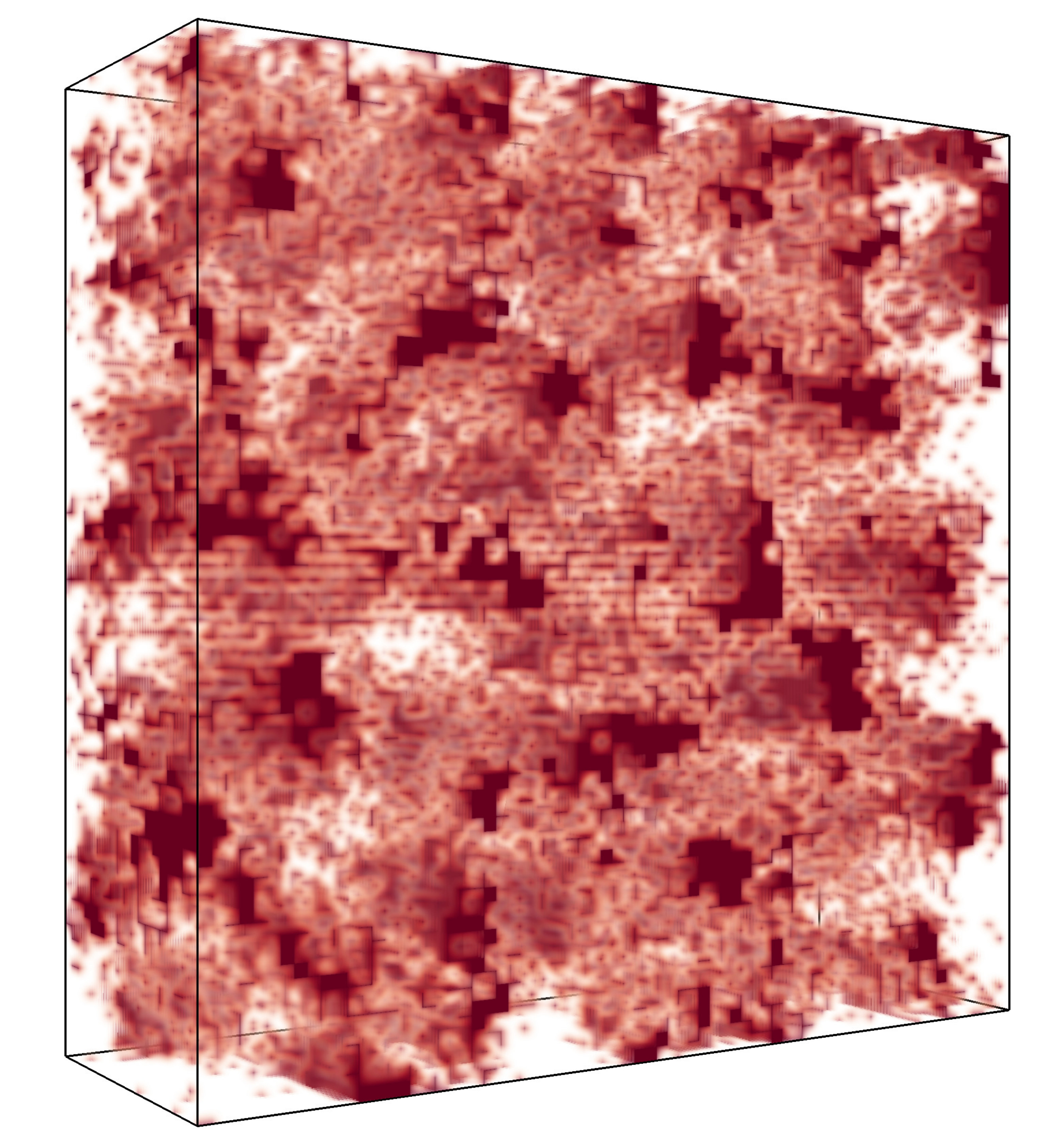 Figure 3
Figure 3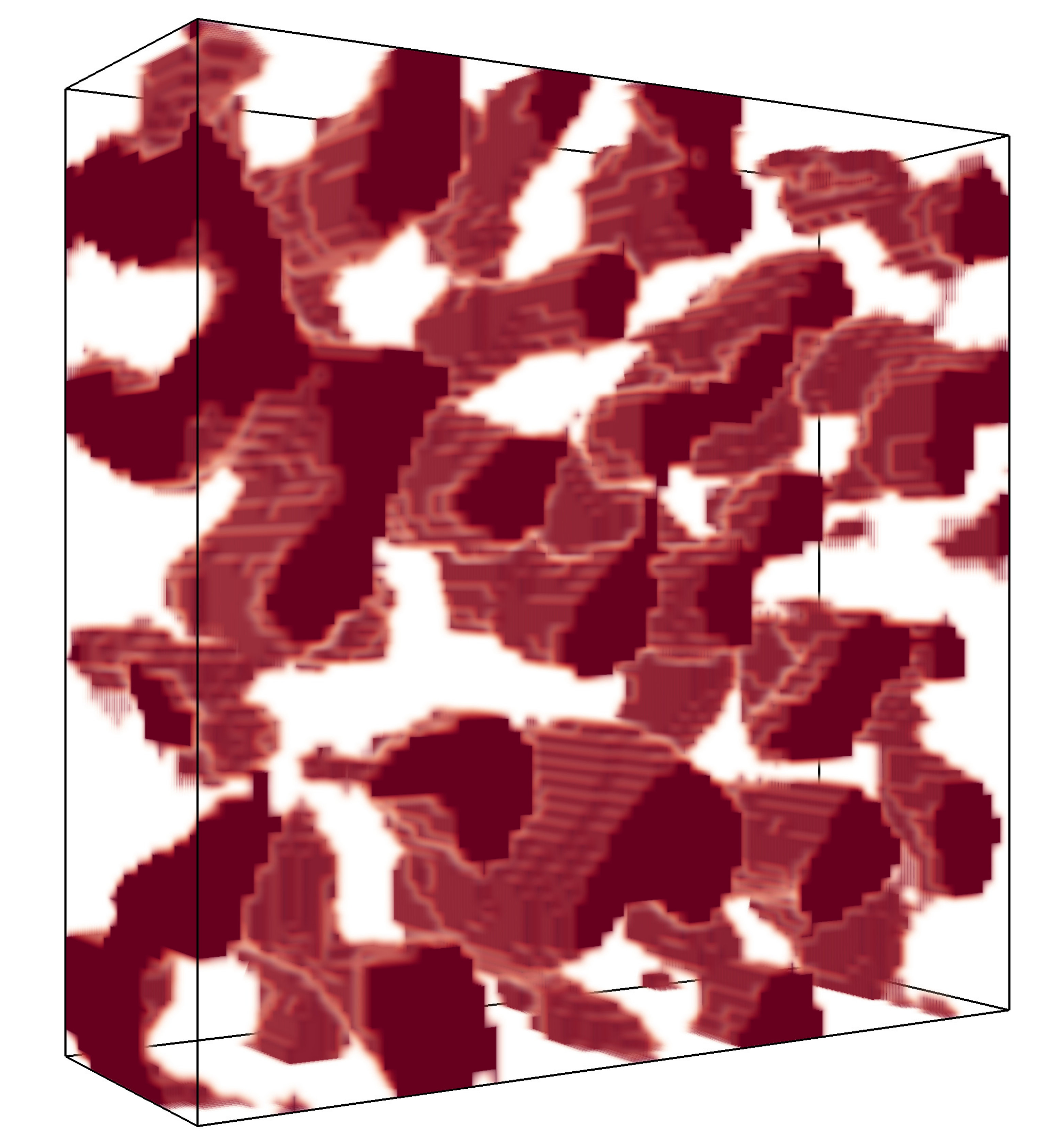 Figure 4
Figure 4 Figure 5
Figure 5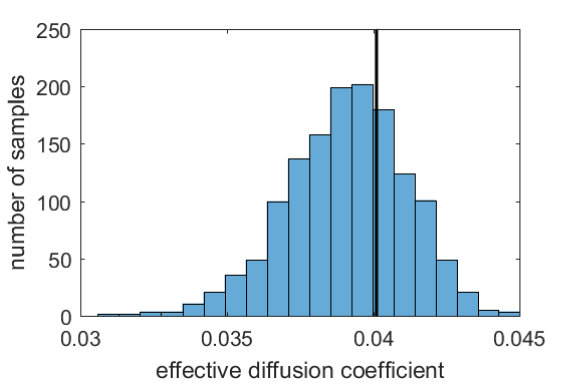 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8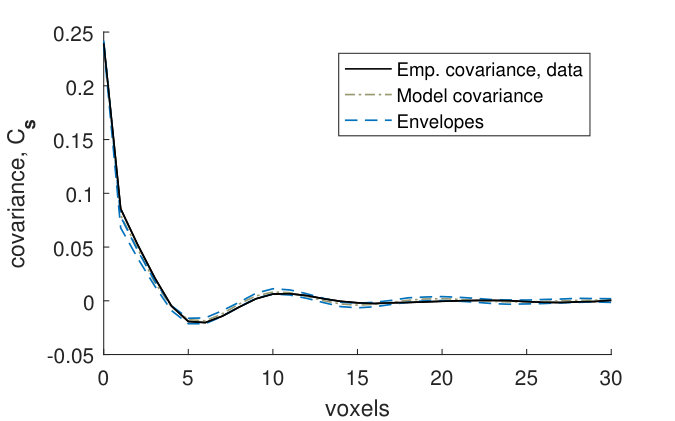 Figure 9
Figure 9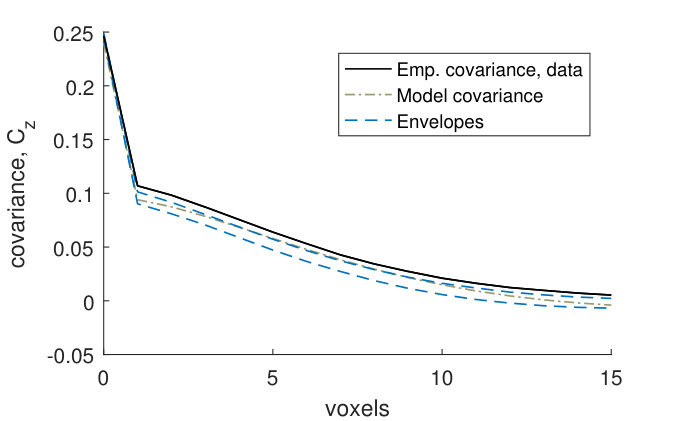 Figure 10
Figure 10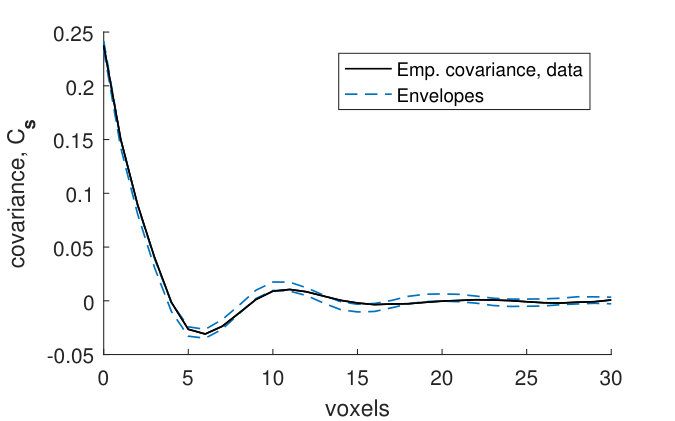 Figure 11
Figure 11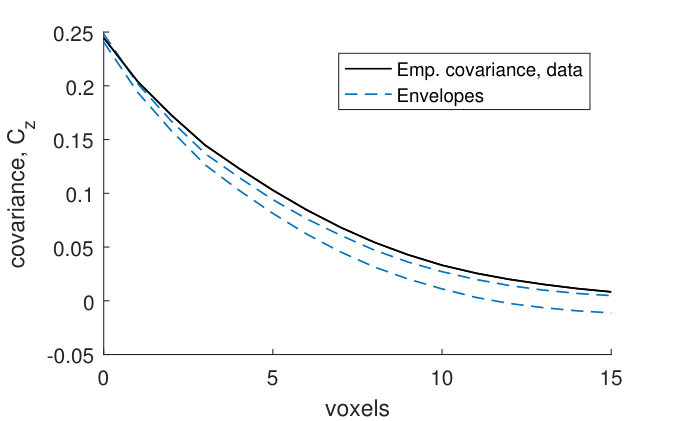 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16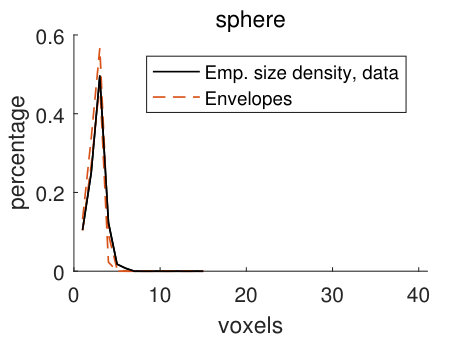 Figure 17
Figure 17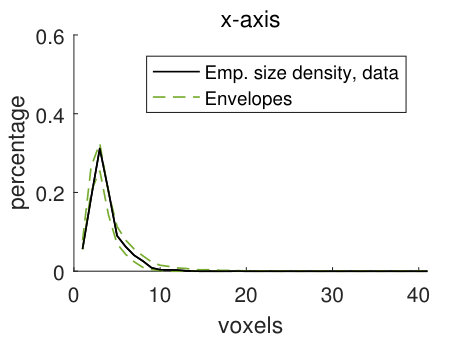 Figure 18
Figure 18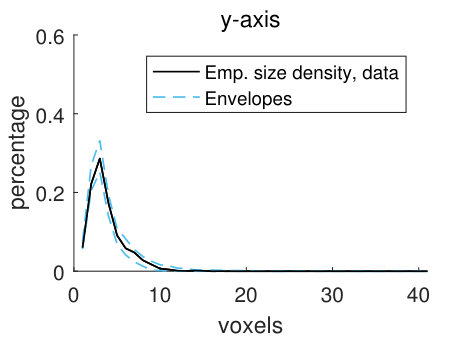 Figure 19
Figure 19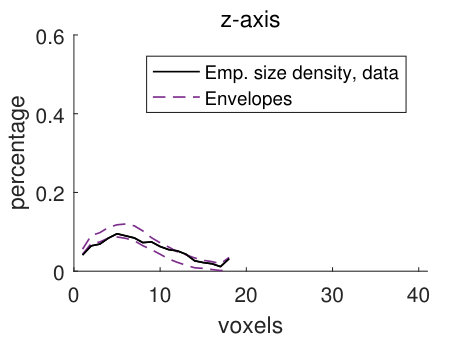 Figure 20
Figure 20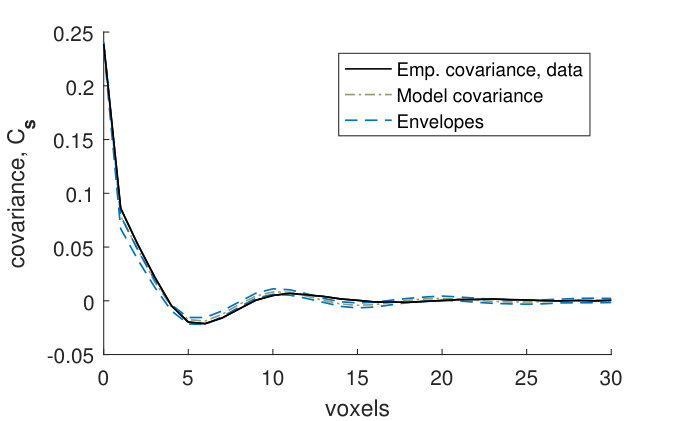 Figure 21
Figure 21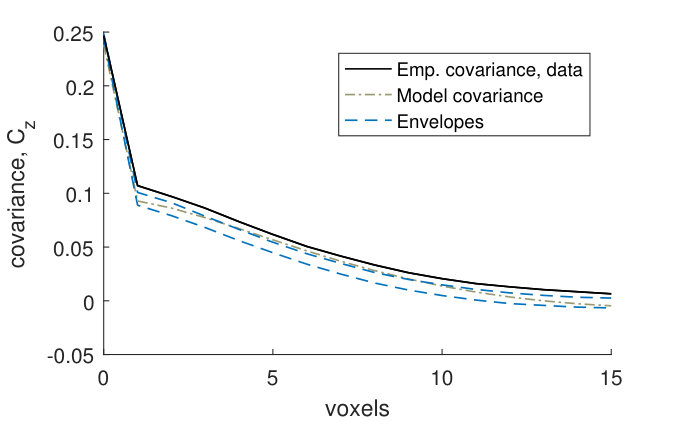 Figure 22
Figure 22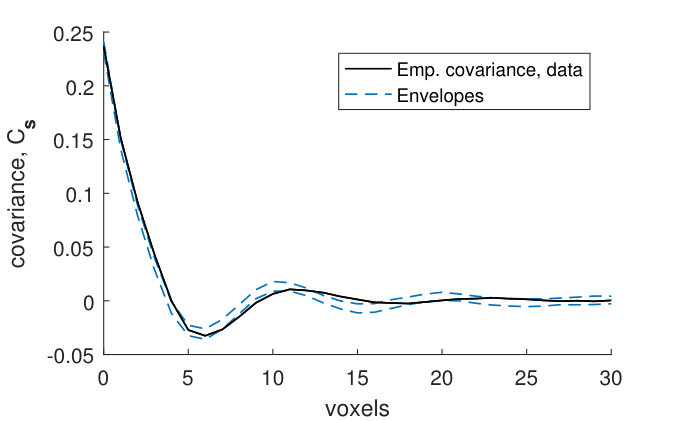 Figure 23
Figure 23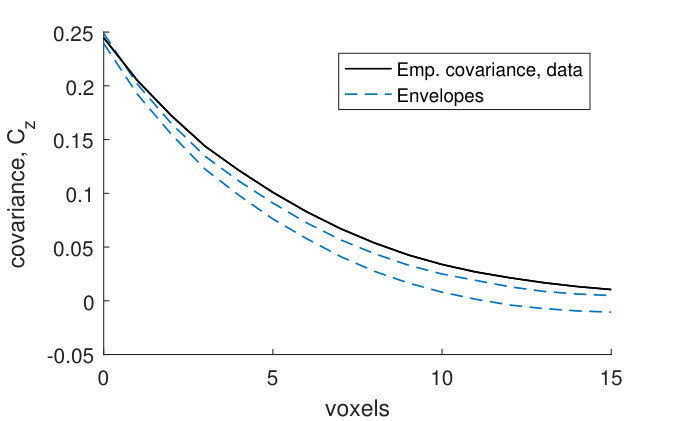 Figure 24
Figure 24 Figure 25
Figure 25 Figure 26
Figure 26 Figure 27
Figure 27 Figure 28
Figure 28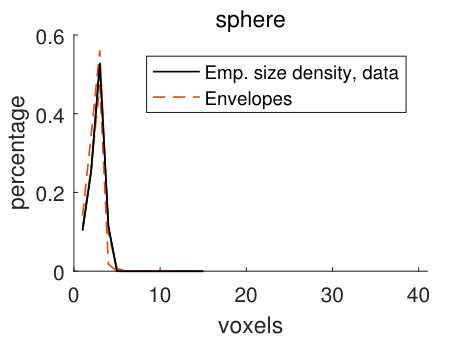 Figure 29
Figure 29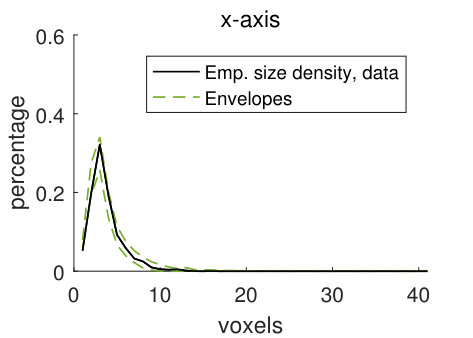 Figure 30
Figure 30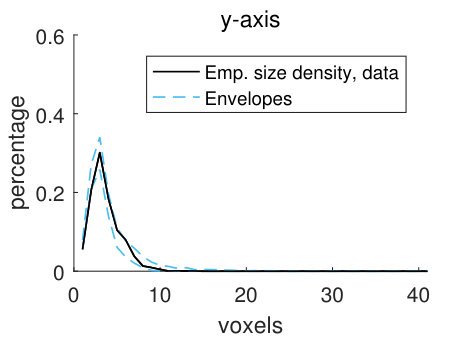 Figure 31
Figure 31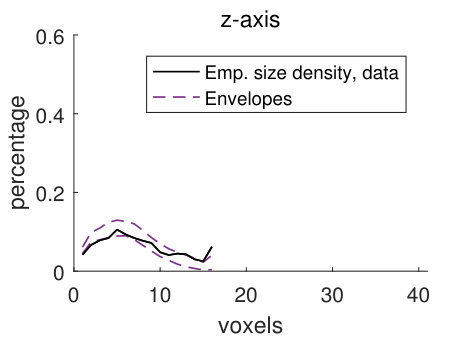 Figure 32
Figure 32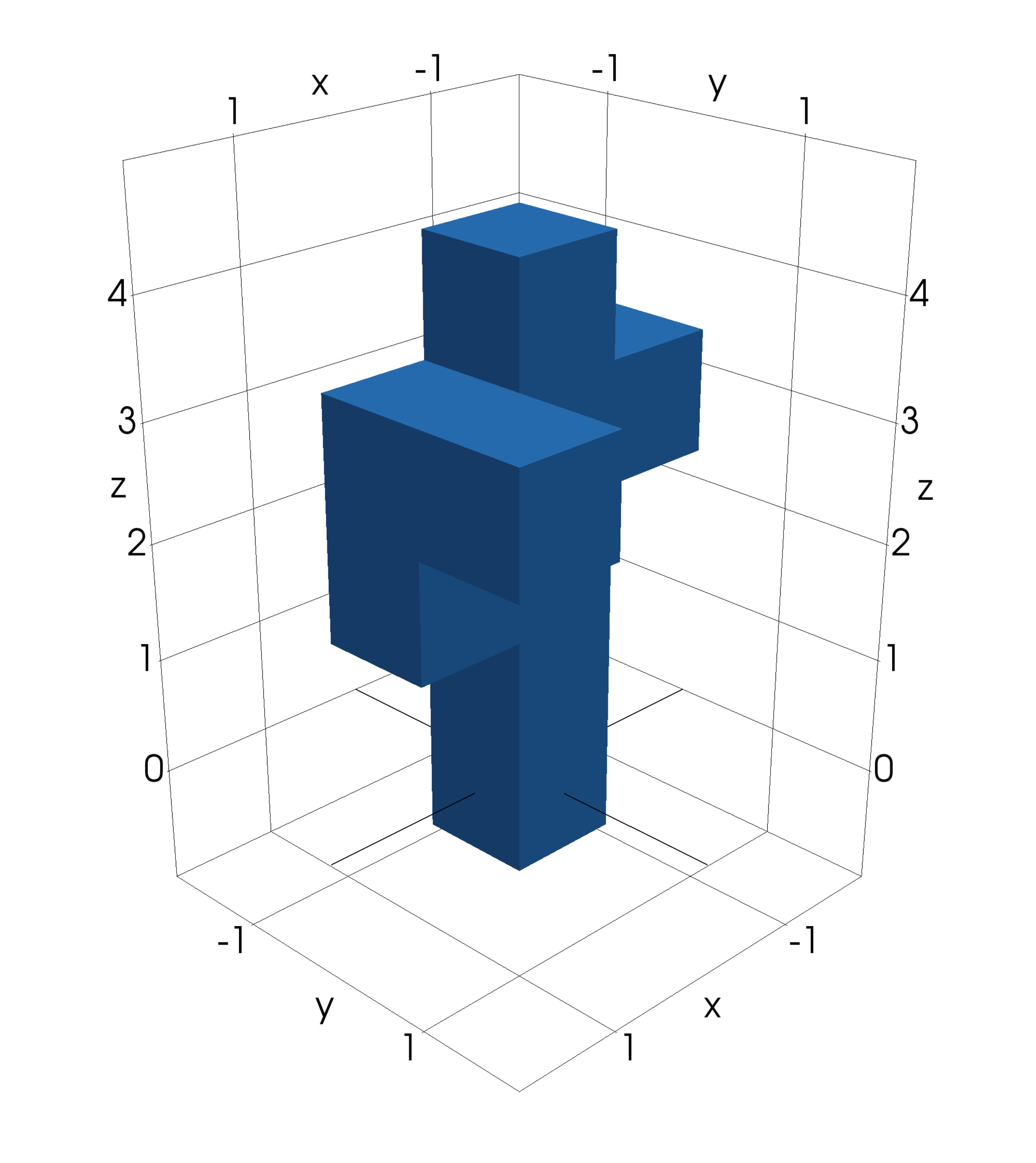 Figure 33
Figure 33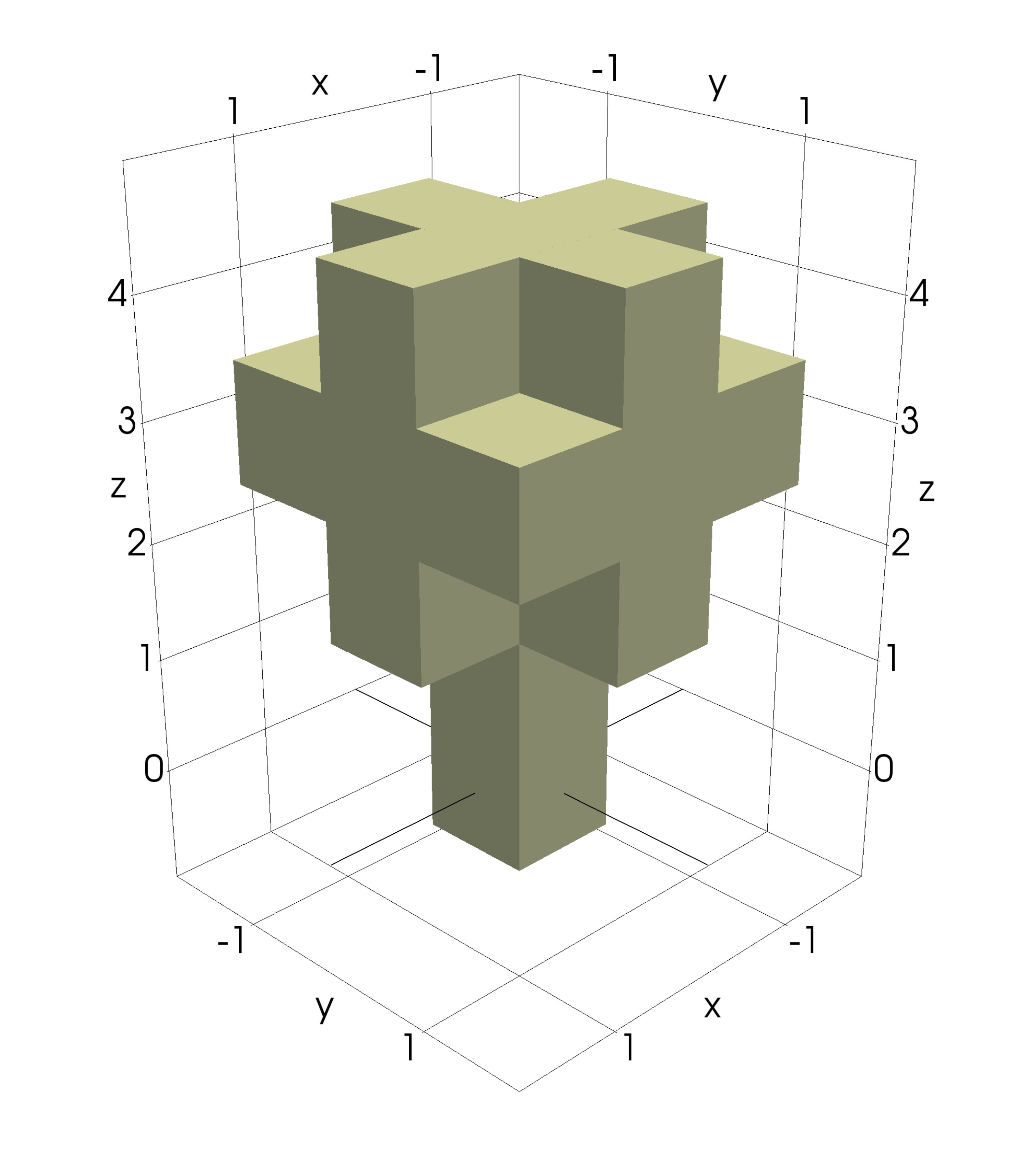 Figure 34
Figure 34 Figure 35
Figure 35 Figure 36
Figure 36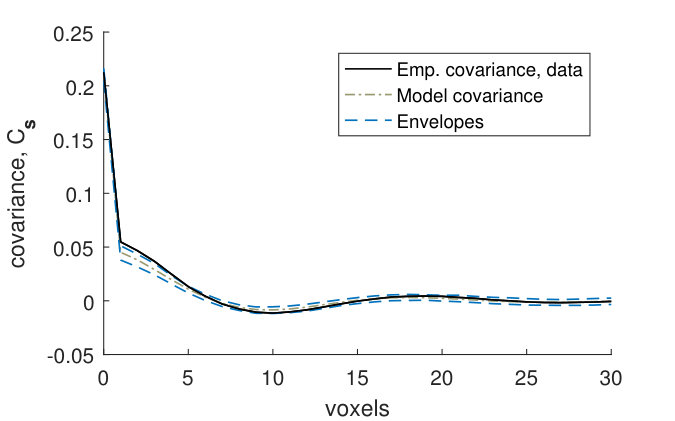 Figure 37
Figure 37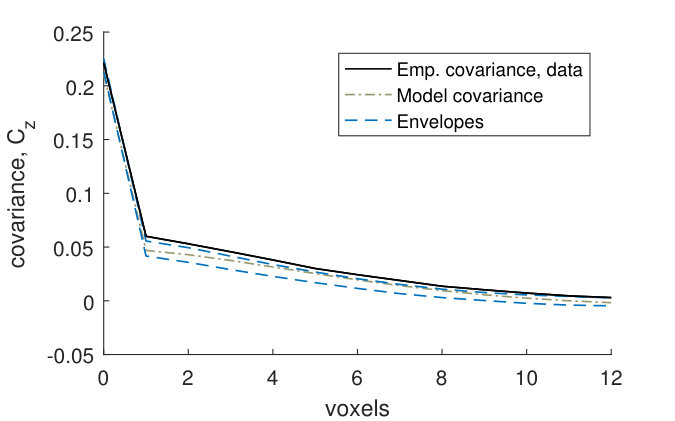 Figure 38
Figure 38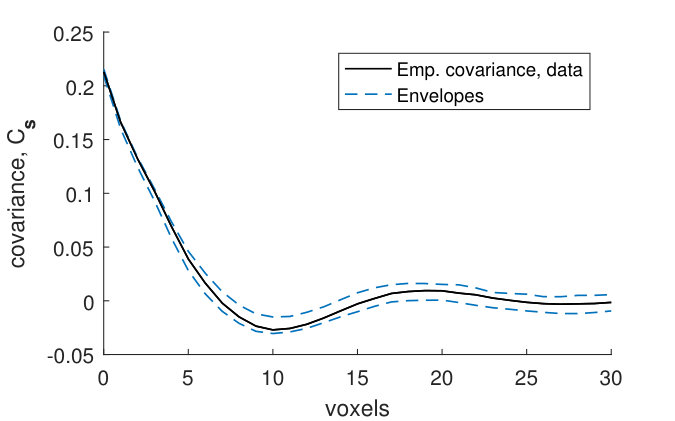 Figure 39
Figure 39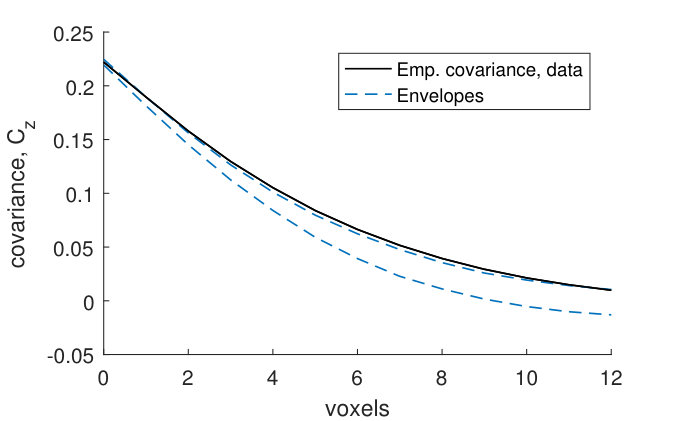 Figure 40
Figure 40| CPU-time | |||||
|---|---|---|---|---|---|
| Preconditioner | Full Cholesky factor evaluated | PCG | Total | PCG iterations | Proportion non-zero elements |
| (yes) no | (7.3) 0.9 | (8.4) 1.0 | (42) 42 | 0.003 | |
| (yes) no | (32.8) 2.9 | (35.4) 2.9 | (70) 70 | 0.004 | |
| - | 9.3 | 9.3 | 2555 | ||
| no preconditioner | - | 19.4 | 19.4 | 5967 | - |
| yes | 27.3 | 30.2 | 135 | 0.007 | |
| yes | 27.8 | 30.7 | 138 | 0.007 | |
| Sample | Voxel size (m3) | Number of voxels |
|---|---|---|
| Parameter estimates | Volume fraction | Surface area | ||||
|---|---|---|---|---|---|---|
| Sample | (, ) | (, ) | Sample | Fitted model | Sample | Fitted model |
| 0.697 | 0.698 (0.004) | 0.161 | 0.173 (0.004) | |||
| 0.694 | 0.694 (0.004) | 0.150 | 0.170 (0.004) | |||
| 0.691 | 0.692 (0.004) | 0.148 | 0.159 (0.003) | |||
| 0.684 | 0.685 (0.006) | 0.210 | 0.217 (0.004) | |||
| 0.610 | 0.609 (0.007) | 0.254 | 0.271 (0.003) | |||
| 0.615 | 0.621 (0.007) | 0.248 | 0.269 (0.003) | |||
| 0.618 | 0.616 (0.005) | 0.291 | 0.306 (0.003) | |||
| 0.619 | 0.606 (0.006) | 0.345 | 0.358 (0.003) | |||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSoil Geostatistics and Mapping · Groundwater flow and contamination studies · Statistical Methods and Inference
A three-dimensional statistical model for imaged microstructures of porous polymer films
Sandra Barman and David Bolin111Correspondence to: David Bolin, Department of Mathematical Sciences, University of Gothenburg, 41296 Gothenburg, Sweden. Tel: +46 31 772 53 75; email: [email protected]
Department of Mathematical Sciences
Chalmers University of Technology and the University of Gothenburg
Abstract: A thresholded Gaussian random field model is developed for the microstructure of porous materials. Defining the random field as a solution to stochastic partial differential equation allows for flexible modelling of non-stationarities in the material and facilitates computationally efficient methods for simulation and model fitting. A Markov Chain Monte Carlo algorithm is developed and used to fit the model to three-dimensional confocal laser scanning microscopy images. The methods are applied to study a porous ethylcellulose/hydroxypropylcellulose polymer blend that is used as a coating to control drug release from pharmaceutical tablets. The aim is to investigate how mass transport through the material depends on the microstructure. We derive a number of goodness-of-fit measures based on numerically calculated diffusion through the material. These are used in combination with measures that characterize the geometry of the pore structure to assess model fit. The model is found to fit stationary parts of the material well.
Keywords: Porous media, Gaussian field, Gaussian Markov random field, Markov Chain Monte Carlo, model validation.
Introduction
Studies of porous media have applications in many areas, ranging from geophysics, energy, electrical and chemical engineering, composite material design, and biomedical and pharmaceutical science (Vafai, 2015; Torquato, 2002), to the oil industry (Blunt, Bijeljic, Dong, Gharbi, Iglauer, Mostaghimi, and Paluszny, 2013), and modelling of transport in polymer-electrolyte fuel cells (Weber et al., 2014).
The macroscopic properties—e.g. electrical conductivity, heat or mass transfer—depend not only on the properties of the material, but also on the microscopic geometry of the pore structure. It is therefore important to characterize the microstructure, and determine how it influences the macroscopic properties. We study the microstructure of a porous ethylcellulose/hydroxypropylcellulose (EC/HPC) polymer blend, which is used as a coating to control the drug release from pharmaceutical tablets. To create coatings with desired transport properties it is important to understand how the properties of the microstructure depend on the different manufacturing parameters, and how those properties influence mass transport—in this case diffusion—of the drug through the coating.
Statistical properties of the microstructure of porous media can be obtained from microscopy data, which then can be related to the macroscopic properties. However, producing the porous material and doing the microscopy imaging can be time-consuming and costly. Formulating a stochastic model for the pore structure, which can be fitted to microscopy images of the material, is therefore useful. It is easier and cheaper to control and change different microscopic properties of the stochastic simulations from the model than it would be to produce samples of the material with these properties. By determining the macroscopic properties of each stochastic simulation, the simulations can be used to understand how the microscopic properties influence the macroscopic properties.
Thresholded Gaussian random fields were among the first stochastic models used to reconstruct heterogeneous materials (Torquato, 2002, p. 295), and such models have been used to characterize the microstructure and its relation to macroscopic properties of porous media in e.g. Adler, Jacquin, and Quiblier (1990); Roberts and Teubner (1995); Mukherjee and Wang (2007). Other examples of stochastic models and methods used to make inferences about macroscopic properties of porous media are random set models (Hermann and Elsner, 2014), network models (Blunt, Jackson, Piri, and Valvatne, 2002; Gaiselmann, Neumann, Schmidt, Pecho, Hocker, and Holzer, 2014), process-based models (Malek, Eikerling, Wang, Navessin, and Liu, 2014), and simulated annealing-based reconstructions (Yeong and Torquato, 1998; Kim and Pitsch, 2009). These models are usually validated by comparing the statistical properties of the model with those of the imaged pore structures. Also macroscopic properties computed for the stochastic simulations from the model are often compared with those computed for the pore structure obtained from microscopy images, as well as with experimental results. These macroscopic properties can be estimated in different ways: by computing analytical bounds or by solving the governing equations approximately on simplified network models or in the pore structure (see e.g. Torquato (2002, Chapter 21); Mukherjee, Kang, and Wang (2011); Weber et al. (2014)).
In this work, we develop a new class of thresholded Gaussian random field models for the microstructure of porous materials. Instead of specifying the Gaussian random field through its mean and covariance function, we specify the field as a solution to a specific stochastic partial differential equation (SPDE). The reason for this is twofold: Firstly, the model can easily be extended to handle non-stationarities in the material by allowing for spatially varying parameters in the SPDE. Secondly, a computationally efficient representation of the model can be constructed by discretising the SPDE using a finite element method. Using this representation, we develop a Markov Chain Monte Carlo (MCMC) algorithm that can be used to fit the model to large three-dimensional confocal laser scanning microscopy images.
We also construct a number of goodness-of-fit measures based on numerically calculated diffusion through the material. These can be combined with measures that characterize the geometry of the pore structure to test the goodness-of-fit when the model is used in practice. We use the methods to study the microstructure of EC/HPC polymer blends with two different weight ratios. The polymer blend is used as coating which controls drug release from pharmaceutical tablets and the aim is to investigate how mass transport properties of the material depend on the microstructure. The model is fitted to stationary but anisotropic parts of confocal laser scanning microscopy (CLSM) images of the EC/HPC films and is found to fit the data well.
The article is structured as follows. In the next section, the data, model, estimation procedure, and validation methods are presented. After this, the results for the EC/HPC data are presented, and the article concludes with a discussion of the results and future work. The supplementary material for the article contains three appendices that gives additional details and results.
Materials and methods
CLSM images of porous EC/HPC polymer films
EC/HPC polymer blends are used as coatings to control the release of drug from tablets. The HPC is water soluble while the EC is not, and so the HPC will be leached out when the tablet is immersed in water, creating a porous structure through which drug can be transported. The microstructure of the EC/HPC polymer blend is determined by the polymers’ weight ratios and molecular weights, and by processing parameters such as the temperature and spraying rate used in the manufacturing of the coating (Marucci, Hjärtstam, Ragnarsson, Iselau, and Axelsson, 2009, 2013; Andersson, Hjärtsam, Stadig, von Corswant, and Larsson, 2013). We analyse CLSM images of two EC/HPC free films—i.e. films that have been sprayed onto a rotating drum—one with and one with HPC weight ratio. More details about the preparation and imaging of these films can be found in Häbel, Rajala, Boissier, Marucci, Schladitz, Redenbach, and Särkkä (2017). The EC/HPC material has previously been studied experimentally in Marucci, Hjärtstam, Ragnarsson, Iselau, and Axelsson (2009, 2013); Andersson, Hjärtsam, Stadig, von Corswant, and Larsson (2013) and characterized statistically in Häbel, Andersson, Olsson, Olsson, Larsson, and Särkkä (2016, 2017). The mass transport properties of the material have been investigated using numerically calculated diffusion in Gebäck, Marucci, Boissier, Arnehed, and Heintz (2015).
In the manufacturing of the films, the EC and HPC phase separate into regions rich in EC and regions rich in HPC. The phase separation continues until the solution has dried. Layers are sprayed onto the film one after the other. The drying of the film is slightly different at the top of the film compared to at the bottom, causing the average size of the pores to be smaller at the top than at the bottom. This is expected to have an effect on the pore shapes, and we observed that the pore shapes are slightly elongated in the direction perpendicular to the layers (depth), i.e. the pore shapes are anisotropic.
To fit our model, we selected parts of the CLSM image stacks which have approximately homogeneous pore sizes: four image samples from the HPC film, and four image samples from the HPC film. The eight sets of CLSM images were chosen to be representative of the variation in pore size in the middle part of the two films.
The intensity of the signal decreases with depth. To account for this, we first thresholded (binarized) the CLSM images with a threshold that was a function of depth. See Figure 1 for a comparison of binarized and original CLSM images. The threshold was determined by fitting a quadratic function to the and intensity value quantiles for the and HPC samples respectively, calculated for each layer individually. The resulting threshold decreases slowly with depth.
The pore structure model
In this section, we define the model for the pore structure. To simplify indexing, we define so that a location in the CLSM image is written as , where corresponds to the depth of the film. The model for the noisy binarized CLSM image is obtained by taking a Gaussian field with additive noise and thresholding it, as
[TABLE]
Here is the number of voxels in the sample, is the threshold, and are independent standard Gaussian variables that capture measurement noise. The model for the pore structure is obtained by smoothing with a filter ,
[TABLE]
where means that there is a pore at voxel , and that there is no pore. The filter that is used is a simple mean value filter, which takes the unweighted average in a 3-by-3-by-3 or a 5-by-5-by-5 neighbourhood depending on the pore sizes of the sample, combined with a global re-thresholding to obtain the correct volume fraction. See Figure 2 for an example of a sample from and the corresponding model structures, obtained using the model for that is defined in the next section.
Separable oscillating Gaussian Matérn fields
To capture the different shapes of pores in the depth of the film (corresponding to the z-direction) compared to the within the layers (the -planes), the stochastic model should be anisotropic and allow for a different behaviour in the -direction. We do this by using a Gaussian random field with a separable covariance function given as , where is the variance of the process. The anisotropy in the -direction can then be controlled by letting the correlation function be different from the correlation function .
The imaged pore structures have regularly spaced pores, as can be seen from Figure 1. To obtain a Gaussian field that is regular we need to use an oscillating covariance function. Covariance functions with differing oscillating strengths should be allowed for, since covariance functions estimated from different binarized CLSM image samples are oscillating to various degrees. We use the family of oscillating Matérn correlation functions
[TABLE]
introduced by Lindgren et al. (2011). Here is the modified Bessel function of the second kind and order zero. The positive parameters scales the correlation functions, and so control the correlation ranges and the spacing between the correlation functions’ peaks. The spacing determines the typical distance between neighbouring peaks in the Gaussian field. The parameters control the amount of oscillation in the correlation functions. For , the functions are equal to the well-known regular Matérn correlation function, with smoothness parameter for and for . The oscillation of the correlation functions is more pronounced the closer is to one, and the corresponding Gaussian field will therefore be more regular for higher values of . Examples of the correlation functions and are shown in Figure 3. Figure 4 shows correlations for the Gaussian field , with parameters taken from the model fitted to the dataset , where the oscillation parameters were and . A stochastic simulation of this Gaussian field is shown in Figure 2(a). The correlation is symmetric in the -plane since is isotropic, and has a different behaviour along the -axis since the joint covariance is anisotropic.
Lindgren, Rue, and Lindström (2011) derived the oscillating Matérn covariance function as the covariance function of the solution to a certain SPDE. By similar arguments, one can show that in our case can be represented as the solution to the SPDE
[TABLE]
where is the Laplace operator, is a parameter that controls the variance, and and are independent Gaussian white noise fields. A stationary weak solution to this SPDE has the property that the component fields and are real, independent, and have the same distribution. These fields are stationary and isotropic and we call them separable oscillating Gaussian Matérn fields.
There are two important reasons for representing using the SPDE (3). First, it allows us to define non-stationary extensions of the separable oscillating Gaussian Matérn field by allowing the parameters to be spatially varying. This will be used in future work to analyse larger samples of EC/HPC films where the stationarity assumption is problematic. Secondly, the representation makes it possible to approximate the Gaussian field using a Gaussian Markov random field (GMRF). A GMRF is a multivariate Gaussian random vector with a sparse precision matrix (inverse covariance matrix). As we will see later, the sparsity greatly reduces the computational cost of fitting the model to data.
The Gaussian Markov random field approximation
A GMRF approximation of the separable oscillating Gaussian Matérn field is obtained by solving the SPDE (3) approximately using the finite element method, on a bounded domain with Neumann boundary conditions. The idea is to approximate by a basis expansion , where is a suitable basis and are stochastic weights. Here a good choice of basis is the Kronecker basis , where and are piecewise linear and continuous basis functions obtained by a triangulation of and respectively. The basis functions and take the value one in node and zero in all other nodes in their respective triangulations. The distribution of the stochastic weights is derived using the Galerkin method (Lindgren, Rue, and Lindström, 2011). Straightforward calculations give that , where and . The Kronecker structure of the precision matrix is a result of the separability of the covariance of , and of the choice of basis functions. The two matrices and are given by
[TABLE]
for , where is a diagonal matrix with diagonal elements and is a sparse matrix with elements . Since the matrices and are sparse, so is , and the weights is therefore a GMRF with the sparse precision matrix .
With this approach is a piecewise linear approximation of . We refer to the stochastic weights as the separable oscillating Matérn GMRF. The value of at the node of a basis function is the corresponding weight. When the triangulation used to construct the basis functions is refined, the approximating field converges weakly to (Lindgren, Rue, and Lindström, 2011) .
The domain is chosen to be slightly larger than the domain of the CLSM image to reduce the effect of the boundary conditions imposed on the SPDE. We use one basis function for each voxel in the sample, with the node of the basis function at the center of the voxel, as well as basis functions outside the domain of the sample. For further details, see Appendix A.
Markov Chain Monte Carlo model fitting
To fit the model to the noisy binarized CLSM image sample , the parameters and the threshold have to be estimated. Evaluating the likelihood of the model is too computationally demanding, so we estimate the model using Markov Chain Monte Carlo (MCMC) in a Bayesian context instead of doing maximum likelihood estimation.
Let be a matrix that maps the values of the GMRF to the values of the piecewise linear approximation at the voxels in the CLSM image, where as before is the number of voxels and is the number of stochastic weights. Specifically, element in is obtained by evaluating the th basis function in the location of the th voxel, so that is a vector that contains the values for at the voxels of the CLSM image.
Approximating with , we have from model (1) that if , and otherwise. This means that we can write the full model as
[TABLE]
Here denotes the Bernoulli distribution, denotes the distribution function of a standard normal random variable, and is a prior distribution for the parameters.
The MCMC algorithm we use to estimate the parameters is a blocked Metropolis-within-Gibbs sampler, see Appendix A for details. The algorithm is used to estimate the joint posterior density and the posterior expectation is taken as a point estimate of the parameters. When simulating from the fitted model, we draw parameters from the posterior distribution of the parameters.
Sampling from the posterior distribution of is the most computationally demanding part of the MCMC algorithm. A method for reducing the complexity of the sampling is presented in Appendix A. The method takes advantage of the Kronecker structure of the precision matrix and its Cholesky factor, and the sparsity of these matrices. The most important implication of the Kronecker structure, which we use to improve the computational efficiency of the method, is that matrix-vector operations can be computed efficiently as follows.
For a matrix , where and , we have that
[TABLE]
where denotes the vectorization operator which maps a matrix to a vector by stacking the columns of the matrix, and is an matrix containing the elements of with (Buis and Dyksen, 1996). Using the same trick for the inverse we get
[TABLE]
using that .
For full matrices and , computing without taking advantage of the Kronecker structure requires operations, whereas the computation only requires operations, which is a considerable reduction. In the method for posterior sampling, the matrix-vector operations (5) and (6) can be performed efficiently due to the sparsity of the Kronecker product matrices, further reducing the computational cost. Moreover, using (5) and (6), the MCMC algorithm can be implemented so that we never need to store full Kronecker products. These reductions in algorithmic complexity are crucial for making it possible to fit the model to images of realistic sizes. Further details are given in Appendix A.
Model validation
To assess the model fit we need to measure the similarities between the binarized CLSM image and the pore structure obtained by filtering the binarized CLSM image, and the stochastic simulations from the corresponding fitted models (4) and (2). We have chosen the following measures: the empirical covariance function, size distributions with respect to linear and spherical shapes, and measures related to numerically calculated diffusion. Other popular summarizing functions that could be applied as measures of goodness-of-fit are, e.g., the contact distribution functions, empty space functions and chord length distribution functions (see Chiu, Stoyan, Kendall, and Mecke, 2013, for a review). These are all related to the size distributions. Below we present the goodness-of-fit measures in more detail.
Covariance functions
As a first assessment of the model fit, we look at marginal covariance functions for both models (4) and (2). To obtain the theoretical covariance of model (4), we use the following result for a thresholded Gaussian vector: If is a zero-mean bivariate Gaussian vector with unit variances and correlation , then the covariance between the elements of the vector thresholded at levels and respectively is , where is the density of a bivariate Gaussian vector with unit variances and correlation (Cramér and Leadbetter, 1967, pp. 26–27). The covariances of the model are obtained using that is a zero-mean Gaussian vector with unit variances and correlations , , where . Since the marginal distribution of the field evaluated in an -plane is stationary and isotropic except for boundary effects, the variances will be approximately constant, and the correlations will depend only on the distance between the voxels and for voxels lying in the same -plane (as long as the voxels are far enough away from the boundary). Therefore we consider a single marginal covariance function for voxels lying in the same -plane. Similarly, we consider a single marginal covariance function for voxels lying on the same -line.
We compare the empirical marginal covariance functions and estimated from the binarized CLSM image , with envelopes estimated from stochastic simulations from the fitted noise model (4), as well as with the theoretical covariance functions and of this model. We also compare the empirical marginal covariance functions estimated from the filtered CLSM pore structure , with envelopes estimated from stochastic simulations from the fitted pore model (2). We use simultaneous -envelopes, defined as in Bolin and Lindgren (2016) so that percent of the covariance functions estimated from stochastic simulations lie completely within the envelopes.
Size distributions
The morphological size distributions, or granulometries, were introduced in Matheron (1967) as a way of characterizing porous media and random closed sets, and is a common tool in image analysis (Soille, 2004). Size distributions provide a measure of size for sets—such as porous structures—that do not have well-defined shapes. Local sizes are measured with respect to simpler sets, so called structuring elements, such as spheres and line segments, and the set of voxels in the three-dimensional pore space of a pore structure is seen as a realization of a random set , which consists of those voxels where there is a pore.
To define the size distribution of a random set with respect to a structuring element , first define the local size of a point with respect as the largest value for which the rescaled structuring element can be translated so that it fits within the set and covers the point . Figure 5 illustrates this local size concept, in this case for two-dimensional sets, showing local sizes with respect to three structuring elements . The local sizes with respect to the circle (Panel (a)) are smaller in the middle of the ellipse compared to the local sizes with respect to the lines (Panels (b) and (c)), since it is possible to fit longer lines within the ellipse covering these pixels than it is possible to fit circles with those lines as radii.
The size distribution gives the probability that a point has a local size with respect to which is greater than or equal to . We let ) denote the corresponding size density. The size distribution and density do not depend on the point if the random set is stationary.
For the discretely indexed random set , we let the distance between two neighbouring voxels be one. We estimate stationary size distributions , with lines aligned with the coordinate axes and the sphere as structuring elements. In addition, we also estimate these four size distributions for the random set , which consists of the voxels in the matrix (the solid part of the pore structure). The size distributions estimated from stochastic simulations from the pore model (2) are compared to the size distributions estimated from the filtered CLSM pore structure , using simultaneous envelopes. For details about the estimation, see Appendix B.
Numerically calculated diffusion
The final aim is to use the developed model to analyze how mass transport—mainly diffusion—of drug through the EC/HPC coating depends on the microstructure. Because of this, we in this work use numerical calculations of diffusion to test the model fit. We compare the diffusion calculated in the filtered CLSM pore structure with the diffusion calculated in stochastic simulations from the fitted pore model (2).
The diffusion calculations are done using the software Gesualdo (Gebäck and Heintz, 2014), which provides a diffusive flux vector for each voxel in the pore space (see Figure 6 for an illustration). The diffusive flux gives the amount of particles transported in steady state in the -direction, per unit square area and second, the amount transported in the -direction, and the amount transported in the -direction. Since the -direction is the direction of transport, the effective diffusion coefficient for the pore structure is defined as the average of , taken over the whole structure including the matrix where is set to zero.
We compare both the effective diffusion coefficient and the diffusive flux. The comparison of the diffusive flux is done using 3D histograms of the diffusive flux vectors. Since a stochastic simulation from the model is random, the corresponding flux histogram of the diffusive flux vectors is a random histogram. To test if the random histograms for the simulated pore structures are similar to that from the CLSM pore structure, we test if the set where the model histogram values are usually high is included in the set where the CLSM histogram values are high, and if there are no high values in the CLSM histogram where the model histogram values are usually low. To do this formally we use the excursion set methodology by Bolin and Lindgren (2015).
The set where the model histogram values are usually high is characterised by a positive excursion set. This is defined as a maximal set in which, with a given probability , all values of the model histogram are above a given value :
[TABLE]
Here is the random set of 3D bins where the model histogram exceeds the value . Similarly, we define the negative excursion set as a maximal set where for most model histograms all values are below the given value :
[TABLE]
where . Set , where is the diffusive flux histogram of the CLSM pore structure. Selecting a high probability , we can then test if , where and are estimated from model simulations. If this inequality is satisfied, it implies that flux field through the observed CLSM pore structure is similar to flux fields obtained from model simulated pore structures.
Computation
The MCMC algorithm was implemented in Matlab (MATLAB, 2015) and so was the estimation of the size distributions. The triangulation of the domain was done using the R package INLA (Rue, Martino, and Chopin, 2009) and the 2D-covariance estimation was done using the R package RandomFields (Schlater, Malinowski, Menck, Oesting, and Strokorb, 2015). The excursion sets and simultaneous envelopes were estimated using the R package excursions (Bolin and Lindgren, 2016). The diffusive flux was calculated using the software Gesualdo (Gebäck and Heintz, 2014).
Results
In this section, detailed results for the model fitted to the CLSM image are presented. The results for the other CLSM image samples are similar, see Appendix C. The MCMC algorithm was run for iterations, making sure that the chains reach stationarity. Each iteration took around – seconds. About – of each iteration was spent sampling the posterior distribution of the GMRF.
Regarding the prior densities for the parameters, we used uniform priors for the oscillation parameters, , an improper uniform prior on the entire for the threshold , and gamma priors for the range and variance parameters, . Figure 7 shows these densities as well as the estimated posterior densities. Because of the vast amount of data, the posterior distributions of the parameters are insensitive to the priors and have quite small variances. The posterior distribution for the oscillation parameter has a higher variance than the oscillation parameter , which is likely caused by the fact that there are fewer voxels and hence less information in the -direction.
Figure 8 shows stochastic simulations from the models (4) and (2) with parameters chosen as the posterior expectation . Comparing these to the binarized CLSM image and the filtered CLSM pore structure, which are also shown in the figure, it seems like the model simulations are similar to the data.
Figures 9(a) and 9(b) show that for the fitted noise model (4), the empirical covariances for the binarized CLSM image goes above the model envelopes at small distances. The model marginal covariance functions were computed using the posterior mean of the parameters. The variances in the model and in the empirical variance of the CLSM image are almost the same, and hence this is caused by the variance of the GMRF in the fitted model (4) being too small compared to the variance of the noise. In other words, the signal to noise-ratio is underestimated in the fitted model. However, Figures 9(c) and 9(d) show that the empirical covariances of the CLSM pore structure falls within the model envelopes (although with a small margin for the -line) for the fitted pore model (2). Hence the underestimation of the signal to noise-ratio does not have a big effect on the pore model.
The empirical size densities in the pore space and in the matrix, shown in Figure 10, tend to lie within the model envelopes, showing that the geometry of the CLSM pore structure and the stochastic simulations from model (2) are similar. Comparing the size densities with respect to the different structuring elements, there is room for longer lines along the -axis than along the other two axes, and the size densities with respect to the lines are naturally larger than those for the sphere. Comparing the size densities of the pore space and the matrix, it is clear that we can fit larger structuring elements in the matrix than in the pore space. This is not surprising since we have a smaller volume fraction of pores than of matrix. The high values of the size density for the largest voxel in Panels (d) and (h) are caused by boundary effects. Since the size of a sample (the CLSM pore structure or stochastic simulations) is , local sizes with respect to the line aligned with the -axis cannot be larger than . But if we think of the sample as being part of a larger pore structure, we cannot tell if the local sizes that are found to be in fact are larger. For further discussion of this, see Appendix B.
Figure 11 shows that the effective diffusion coefficient of the diffusion computed using Gesualdo in the CLSM pore structure lies well within the range of the effective diffusion coefficients computed in stochastic simulations from model (2). The figure also shows the estimated negative and positive excursion sets and , which were estimated from the model diffusive flux histograms corresponding to the same stochastic pore structures. In the figure one can see that the inclusions hold, which means that the set where the CLSM histogram takes values above includes the set where for most model histograms all values are above . Also, no bins with values above in the CLSM histogram are included in the set where for most model histograms all values are below . This indicates that the diffusive flux computed in the CLSM pore structure is similar to the diffusive flux computed in the stochastic pore structures. One can also note that the estimated excursion sets for the model are symmetric in and , which is explained by the fact that the model is isotropic in the -plane.
Discussion
We have formulated a parametric stochastic model for the pore structure of films of EC/HPC polymer blends, with the aim to analyze the mass transport through the films. The model is based on a separable oscillating Gaussian Matérn field, which is stationary and anisotropic. The field is obtained as the solution to an SPDE, which is solved using the finite element method giving an approximation of the Gaussian field by a GMRF. The model was fitted to CLSM images using an MCMC algorithm which takes advantage of the sparsity of the GMRF approximation and uses the Kronecker structure of its precision matrix in a, for this type of problem, new way to reduce the complexity of the algorithm. The computational efficiency of this model fitting algorithm allowed fitting the model to CLSM images of realistic sizes. We characterized the stochastic simulations from the model using the covariance and pore size distributions, and developed a measure using excursion sets to characterize the diffusive flux computed in the stochastic simulations. Using these measures we concluded that the model fits the CLSM images well.
A strength of the GMRF approximation is that it is not constrained to the triangulation that was used to estimate the parameters in the GMRF. Instead a finer triangulation can be used for the stochastic simulation from the model. As long as the same parameters are used, the model will be a linear approximation of the same continuously indexed Gaussian field. This is useful, since it is more computationally demanding to fit the model than to simulate from the model.
We use a simple filter to obtain the pore structure of model (2). A better alternative could be to use the posterior mean of the pore structure given the data, obtained from the MCMC algorithm, or to use a filter that e.g. takes the point spread function into account. However, the filter has no effect on the model fit since the model is fitted to model (4). Also, since the binarized CLSM data and stochastic simulations from model (4) are filtered in the same way, the filter should not have a large effect on the model validation either.
An important aspect to consider is what size of the observation window is sufficient to get good parameter estimates, i.e. how big the so called representative volume element is (Chiu, Stoyan, Kendall, and Mecke, 2013, pp. 236–237). In our case, the biggest concern is whether we have enough data in the -direction, since we use rather thin samples to ensure stationarity. The range of the correlation in the -direction is large compared to the size of the samples—as can be seen by comparing the correlation for the fitted model in the -direction, with the size of the CLSM image in the -direction, which is voxels. To see if the parameter estimates are sensitive to the size of the CLSM image sample in the -direction, we fitted the model to the combination of two in the -direction consecutive samples, both of size voxels in the -direction, where the two samples have different pore sizes. With this larger combined sample, the point-estimates of all the parameters—and particularly the range parameters and which control the size of the pores in the -plane and -direction respectively—turned out to lie between the point-estimates for the model fitted to the two samples individually. Thus the estimate of the size of the pores in the combined sample lies somewhere between the estimates of the individual samples, which indicates that the observation windows in the individual samples are large enough for us to obtain valid estimates of the range parameters.
Despite the different techniques that were used to decrease the computational effort, the model fitting method is still computationally demanding. Other less demanding methods, such as the minimum contrast method, where the parameters are chosen to minimize the distance between a summarizing function and the estimate of the function computed from the data, and the pairwise likelihood have previously been used for this type of problems, see Wilson and Nott (2001). An advantage with the likelihood-based MCMC algorithm is that it uses more of the information in the data than the less computationally demanding methods. It would be interesting to perform a comparison of the parameter estimates from the MCMC algorithm with estimates from other model fitting methods, similar to what was done in Sidén, Eklund, Bolin, and Villani (2017).
Following Lindgren, Rue, and Lindström (2011), the model can be made non-stationary by letting the parameters of (3) be slowly varying functions, which is useful for capturing non-stationarities in the EC/HPC films. The model can also be extended using nested SPDEs (Bolin and Lindgren, 2011) to capture other types of anisotropies in the data. These extensions are interesting for future work where the model will be used to investigate how the mass transport depends on the microstructure of the material.
Acknowledgements
This work is funded by the Swedish Foundation for Strategic Research (SSF grant AM13-0066), the Knut and Alice Wallenberg foundation (KAW grant 20012.0067), and the Swedish Research Council (grant 2016-04187). We are grateful to Holger Rootzén for modelling ideas and valuable suggestions. We would also like to thank Henrike Häbel, Mariagrazia Marucci and Christine Boissier for supplying the data, and Jonas Wallin for sharing code that was used in the estimation method. Finally, we thank Aila Särkkä, Christian von Corswant, and everyone involved in the SSF project for valuable discussions.
Appendix A Details of the model and the model fitting algorithm
The triangulation used in the GMRF approximation
The triangulations of the domains and have a node in each voxel of the CLSM image. The domains are larger than the domain of the CLSM voxels, to reduce the effect of the boundary conditions imposed on the SPDE (see Lindgren, Rue, and Lindström, 2011). For an example, see Figure 12. The interior nodes in the dense subset of the triangulation of are the microscopy data voxels. The exterior nodes are less densely spaced for computational efficiency. Because is an interval, the -triangulation is simply a division of the domain into subintervals. However, instead of using the model on the full domain , we consider the marginal distribution of only the interior nodes. This allows us to reduce the effect of the boundary conditions at a lower computational cost. In practice, this means that we use the precision matrix , instead of . Here,
[TABLE]
where denotes the indices that correspond to the interior nodes, and denotes the indices that correspond to the exterior nodes. Finding the marginal precision matrix can be done efficiently since is low-dimensional, but is too computationally demanding for .
The MCMC algorithm
The MCMC algorithm used to to estimate the model parameters is explained in more detail here.
To simplify the sampling of , we introduce the auxiliary variables . Then the distribution of is multivariate Gaussian, which is easy to simulate from. The MCMC algorithm uses a Metropolis-within-Gibbs sampler, from which we obtain a Markov chain which has the desired posterior density as stationary distribution. The variables and parameters are updated in three separate blocks, which makes simulation of the vectors and easier while maintaining a low autocorrelation of the Markov Chain. A similar Gibbs sampler for binary data can be found in Albert and Chib (1993).
We start by selecting starting values , and then repeat the following three steps for .
Sample for and . This step requires sampling a multivariate GMRF, which is the most computationally expensive step of the estimation procedure. How this is done is explained in the next section. 2. 2.
Sample using a Metropolis Hastings step. For this, a new threshold is proposed using a random walk proposal, and given the proposed threshold the proposal density for is
[TABLE]
which is a product of independent truncated Gaussians. Here if , and otherwise. Finally and are accepted or rejected jointly. 3. 3.
Sample using a Metropolis Hastings step where each parameter is proposed separately. Constrained random walk proposals are used for the parameters and , and log-normal proposals for the parameters and . With the proposed parameters , the gamma conditional density
[TABLE]
is then used as the proposal density for . The parameters are accepted or rejected jointly.
Reducing the computational complexity of the MCMC algorithm
The most computationally demanding part of the MCMC algorithm is to sample from . We use the method introduced in Papandreou and Yuille (2010), and used in Sidén, Eklund, Bolin, and Villani (2017) to sample large GMRFs without having to compute the full Cholesky factor of , with the following two steps:
Generate , where are independent, and and are the upper triangular Cholesky factors of and respectively. By the properties of the Kronecker product, is the Cholesky factor of . All three matrix-vector products can be computed without evaluating the full matrices. The first product is computed as in (4), and the other two are computed using that is a binary matrix with one non-zero element per row. 2. 2.
Compute by solving approximately using a preconditioned conjugate gradient (PCG) method (Demmel, 1997).
The PCG-method in the second step solves the system approximately where is a positive definite and symmetric preconditioner. A good preconditioner approximates in such a way that is well-conditioned and can be computed efficiently. Sidén, Eklund, Bolin, and Villani (2017) used the preconditioner with , where denotes an incomplete Cholesky factorization. We instead use the preconditioner with Cholesky factor , and use the structure of the preconditioner and of to compute using (4) and (5) without evaluating the full matrices. Table 1 compares these two choices with some other natural choices of preconditioners for sampling , and shows that using and is better than using and in this case, since it leads to a more sparse preconditioner. From the results in the table, it is also clear that it is better to avoid evaluating the full Cholesky factor of the preconditioner by using its Kronecker structure, if possible.
Using (4) and (5) reduces the amount of elements we need to store in the MCMC algorithm from to , where and —not taking the sparsity of and into account—since we never store full Kronecker products. As can be seen in Table 1, the gain from using (5) can be substantial for the PCG step, which is the most computationally demanding part of the algorithm. Another potentially demanding part is the computation of the Cholesky factor of , which is done to evaluate when sampling the parameters . The complexity of the Cholesky factorization of the sparse is , and the complexity of the factorization of the sparse with an optimal reordering is (Rue and Held, 2005, Ch. 2.4). Compare this with the cost of factorizing a dense matrix, which is . Performing the Cholesky factorization on the full matrix would therefore take operations if were dense, whereas the lower bound using the Kronecker structure of its Cholesky factor is operations, taking into account the sparsity.
Thus it is clear that the algorithmic complexity of the MCMC algorithm is greatly reduced by using the sparsity and Kronecker product structure of the precision matrix and its Cholesky factor. This allows us to fit the model to much larger data sets. Using (5) we can also generate samples from the GMRF efficiently.
Appendix B Estimation of the size distributions
The local size in a point in a (random) set with respect to a structuring element can be defined using the morphological operation opening, denoted . The opening of by consists of an erosion followed by a Minkowski addition with . The opened set can be written
[TABLE]
The local size is defined as , where . It follows that, if the supremum can be attained, the local size in a point is the largest value for which the rescaled structuring element can be translated so that it fits within the set and covers the point .
We define the size distribution for a random set with respect to a convex structuring element as
[TABLE]
i.e. the size distribution gives the probability that the local size with respect to in a point in is greater than or equal to . Since the structuring element is convex, is equivalent to , and so the size distribution can be written as (Matheron, 1975; Delfiner, 1972).
When estimating the size distribution of a stationary random set defined on , which is only observed in a bounded window , we have to consider the boundary effects to get an unbiased estimate. If we do not have any information about the set outside of , we can in general only observe the opened set in the smaller window (Ohser and Schladitz, 2009). This means that we cannot determine the local size in a point close to the boundary of the observation window , since we need information about the surrounding of the point. To account for this, we can use a minus-sampling estimator of the size distribution based on the unbiased estimate of , where denotes the volume of the set. Properties of minus-sampling estimators for size distributions for random closed sets can be found in Moore and Archambault (1991), and properties for discretely indexed random sets in Sivakumar and Goutsias (1997).
Because we select microscopy data samples that have homogeneous pore sizes, our observation windows are small in the -direction. Therefore, we do not use the unbiased minus-sampling estimator since that would reduce the observation window of the sample further. Instead we approximate with the opened set , which is equivalent to assuming that there are no pores outside of the observation window . This gives us a biased estimate of . However, the bias has the same effect for the filtered CLSM pore structure and the stochastic simulations from the model, since the observation windows are of the same size, and hence will not affect comparisons.
The size distribution for a structuring element is thus estimated as
[TABLE]
for , where the maximal local size is determined by the observation window in which the set is observed. The size density is estimated as .
Appendix C Results for all CLSM samples
Here we present results for the model fitted to all CLSM samples. More results for sample can be found in Section “Results”. For some samples, only every second or third voxel in the CLSM image was kept, depending on the average size of the pores. There is also a resolution difference between the and CLSM images. Thus, the distances between voxels are not the same in all samples (see Table 2). However, we chose the size of the domains so that the fitted parameters are comparable between the samples. The estimated oscillation parameters are fairly similar for all model fits (Table 3).
A larger range parameter for the model corresponds to a smaller covariance range and hence smaller pores. The samples for the two CLSM images were ordered so that the first two samples had smaller pore sizes than the last two samples for each image, which can be seen in the estimated range parameters. One can also note that the estimated range parameters are larger for the samples with HPC than for the samples with HPC.
The differences between the sample and fitted model volume fractions are no more than two percent, and the differences between the sample and fitted model surface areas are –, where the surface areas were calculated using the algorithm provided by Legland, Kiên, and Devaux (2011). The volume fractions of the samples differ from the theoretical HPC weight ratios. The depth dependent threshold was always determined using a larger part of the CLSM image than the sample itself, and there may e.g. be edge effects or dust particles outside of the sample contributing to the volume fraction discrepancies.
The covariance functions and size distributions (Figures 13–19) for the remaining samples show that the model provides a relatively good fit. It is clear that the signal to noise ratio of the covariance functions corresponding to the noise model (1) is underestimated (Panels (a)–(b)). However, as was the case for sample , this underestimation does not have a big effect on the pore model.
The marginal covariance functions in the -plane, , for both the noise and pore model, fit better at smaller distances (Panels (a) and (c)). For half of the samples, the ranges of the estimated covariances are slightly underestimated, although the shapes of are consistent with the model envelopes (Figures 13, 15–17, Panels (a) and (c)). A possible explanation comes from the fact that even though the samples were kept small in the -direction, the pore sizes decrease slightly along the -axis from the bottom to the top of each sample. The estimated range parameters could then have been chosen to better fit the part of the sample with smaller pore sizes. For samples with high estimated oscillation parameters , the smaller peaks and troughs of the covariances do not seem to be as pronounced as those of the model envelopes (Figures 15–18, Panels (a) and (c)). This might be because the peaks and troughs shift and therefore cancel out due to the decreasing pore size along the -axis. The size distributions lie within their envelopes to a higher extent than the covariance functions (Panels (e)–(l)). Thus the pore shapes of stochastic simulations from the fitted pore models correspond well to the pore shapes of the pore structures obtained from the CLSM samples.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Adler et al. (1990) P.M. Adler, C.G. Jacquin, and J.A. Quiblier. Flow in simulated porous media. International Journal of Multiphase Flow , 16(4):691–712, 1990.
- 2Albert and Chib (1993) J.H. Albert and S. Chib. Bayesian analysis of binary and polychotomous response data. Journal of the American statistical Association , 88(422):669–679, 1993.
- 3Amestoy et al. (1996) Patrick R Amestoy, Timothy A Davis, and Iain S Duff. An approximate minimum degree ordering algorithm. SIAM Journal on Matrix Analysis and Applications , 17(4):886–905, 1996.
- 4Andersson et al. (2013) H. Andersson, J. Hjärtsam, M. Stadig, C. von Corswant, and A. Larsson. Effects of molecular weight on permeability and microstructure of mixed ethyl-hydroxypropyl-cellulose films. European Journal of Pharmaceutical Sciences , 48(1):240–248, 2013.
- 5Blunt et al. (2002) M.J. Blunt, M.D. Jackson, M. Piri, and P.H. Valvatne. Detailed physics, predictive capabilities and macroscopic consequences for pore-network models of multiphase flow. Advances in Water Resources , 25(8):1069–1089, 2002.
- 6Blunt et al. (2013) M.J. Blunt, B. Bijeljic, H. Dong, O. Gharbi, S. Iglauer, P. Mostaghimi, and A. Paluszny. Pore-scale imaging and modelling. Advances in Water Resources , 51:197–216, 2013.
- 7Bolin and Lindgren (2011) D. Bolin and F. Lindgren. Spatial models generated by nested stochastic partial differential equations, with an application to global ozone mapping. The Annals of Applied Statistics , 5(1):523–550, 2011.
- 8Bolin and Lindgren (2015) D. Bolin and F. Lindgren. Excursion and contour uncertainty regions for latent Gaussian models. Journal of the Royal Statistical Society: Series B (Statistical Methodology) , 77(1):85–106, 2015.