Pre-earthquake State Identification by Micro-earthquake Spike Trains Dissimilarity Analysis
Arash Andalib, Raheleh Baharloo, Jose C. Principe

TL;DR
This study investigates whether analyzing micro-earthquake spike train dissimilarities can identify pre-earthquake states, potentially serving as precursors for larger seismic events by examining statistical independence and physical model compatibility.
Contribution
It introduces a novel statistical approach using spike train dissimilarity measures to detect pre-earthquake states and assesses its relation to physical earthquake models.
Findings
Increased spike train dissimilarity correlates with upcoming earthquakes.
The method shows compatibility with the Burridge-Knopoff physical model.
Pre-earthquake states can be statistically identified through this approach.
Abstract
The exact mechanisms leading to an earthquake are not fully understood and the space-time structural features are non-trivial. Previous studies suggest the seismicity of very low intensity earthquakes, known as micro-earthquakes, may contain information about the source process before major earthquakes, as they can quantify modifications to stress or strain across time that finally lead to a major earthquake. This work uses the history of seismic activity of micro-earthquakes to analyze the spatio-temporal statistical independence among the monitoring stations of a seismic network. Using point process distance measures applied to the micro-earthquakes' spike trains recorded in these stations, a pre-earthquake state is defined statistically with the aim of finding a relation between the level of dissimilarity among stations' readings and the future occurrence of larger earthquakes in the…
Click any figure to enlarge with its caption.
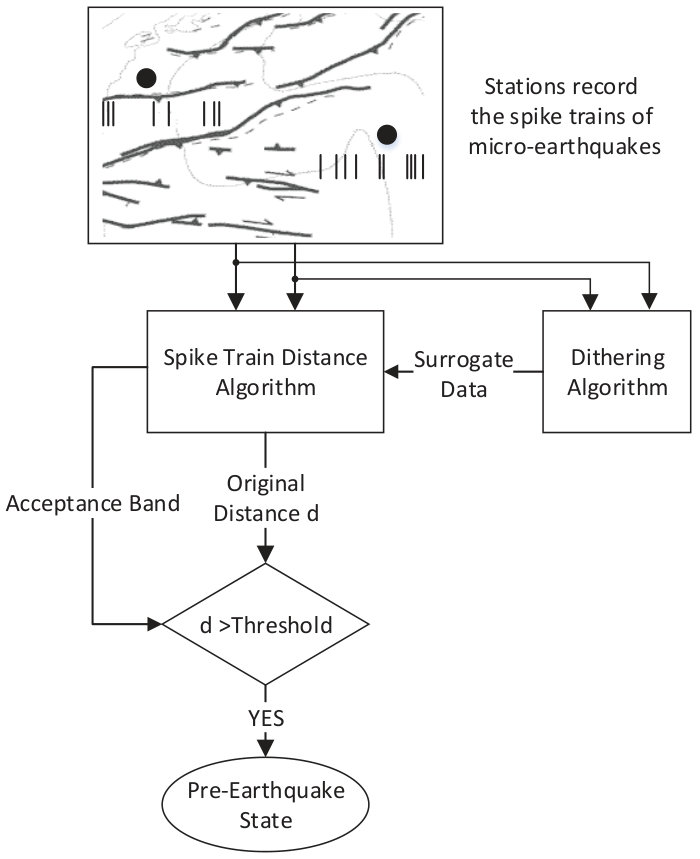 Figure 1
Figure 1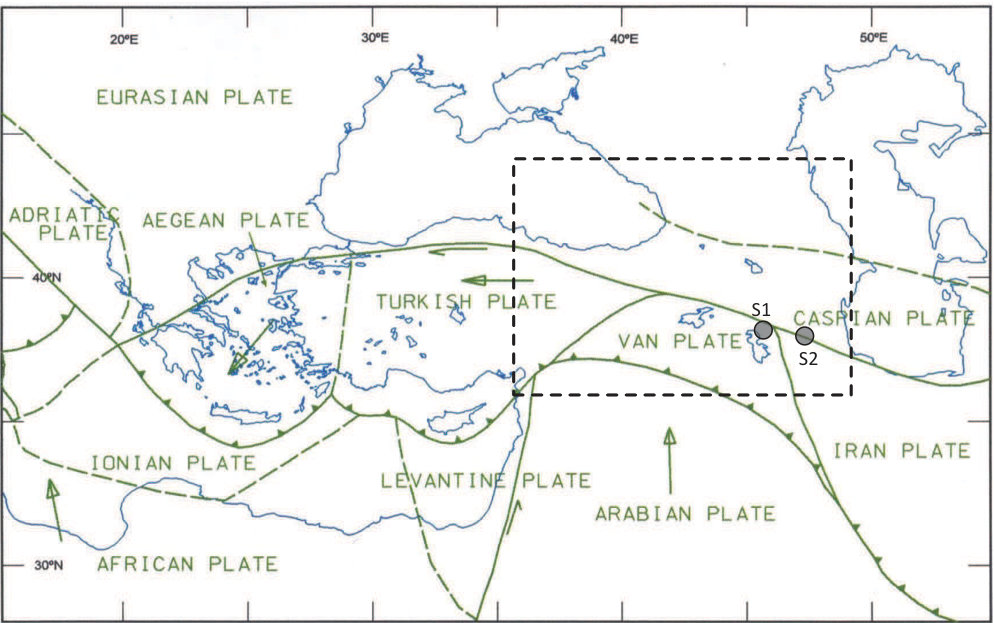 Figure 2
Figure 2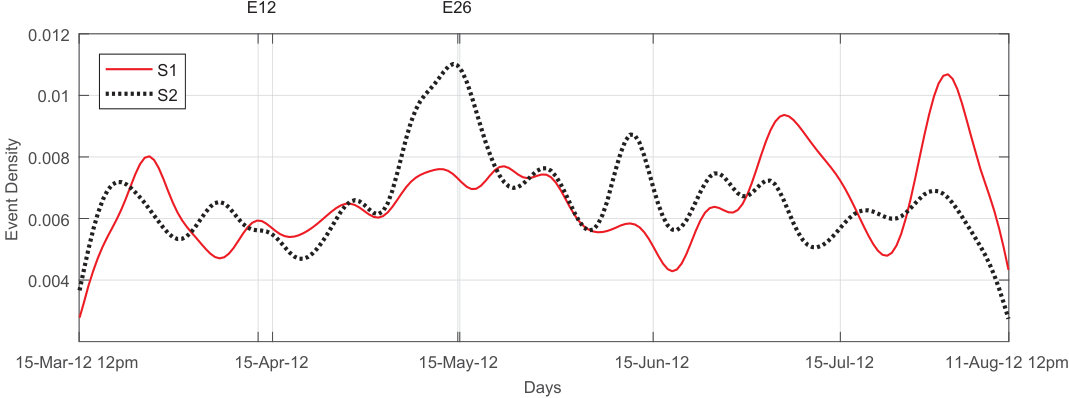 Figure 3
Figure 3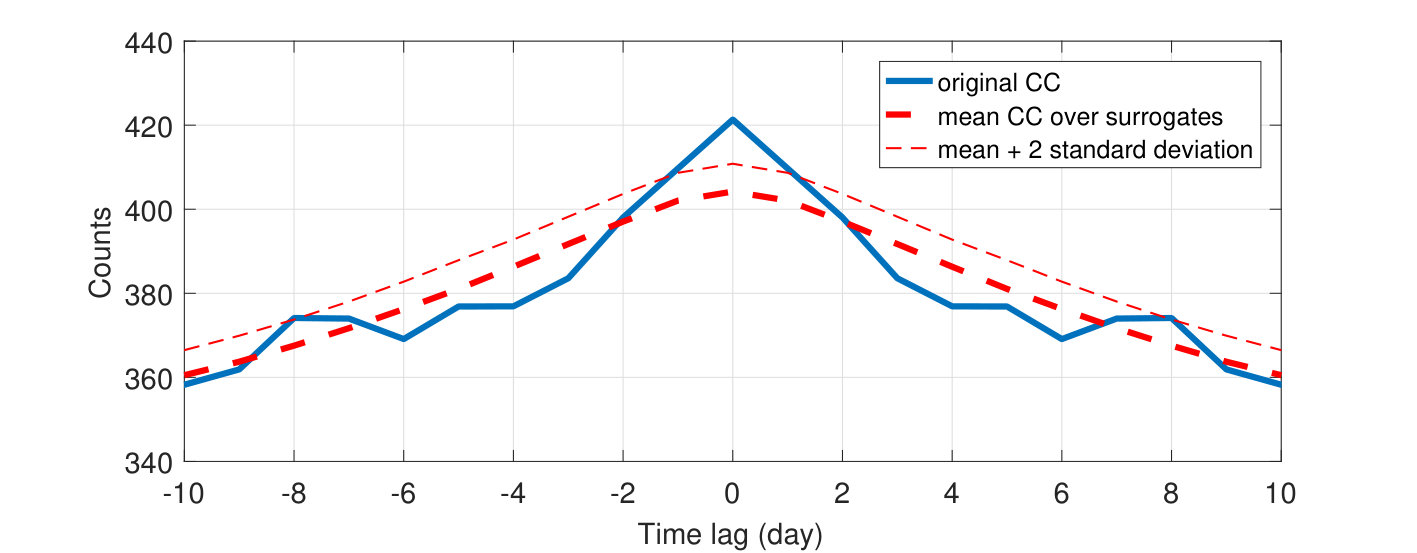 Figure 4
Figure 4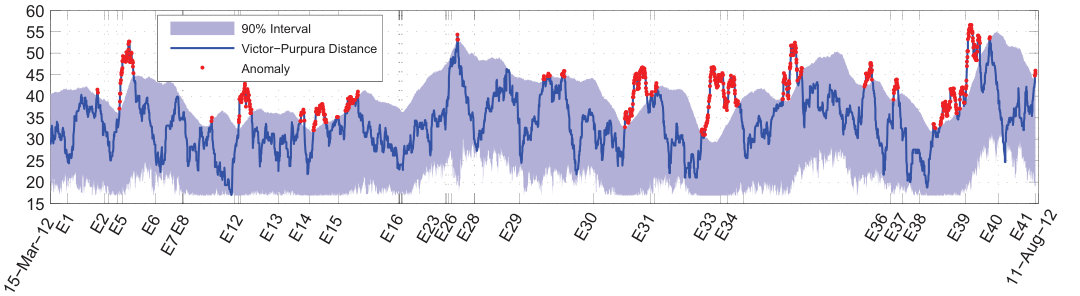 Figure 5
Figure 5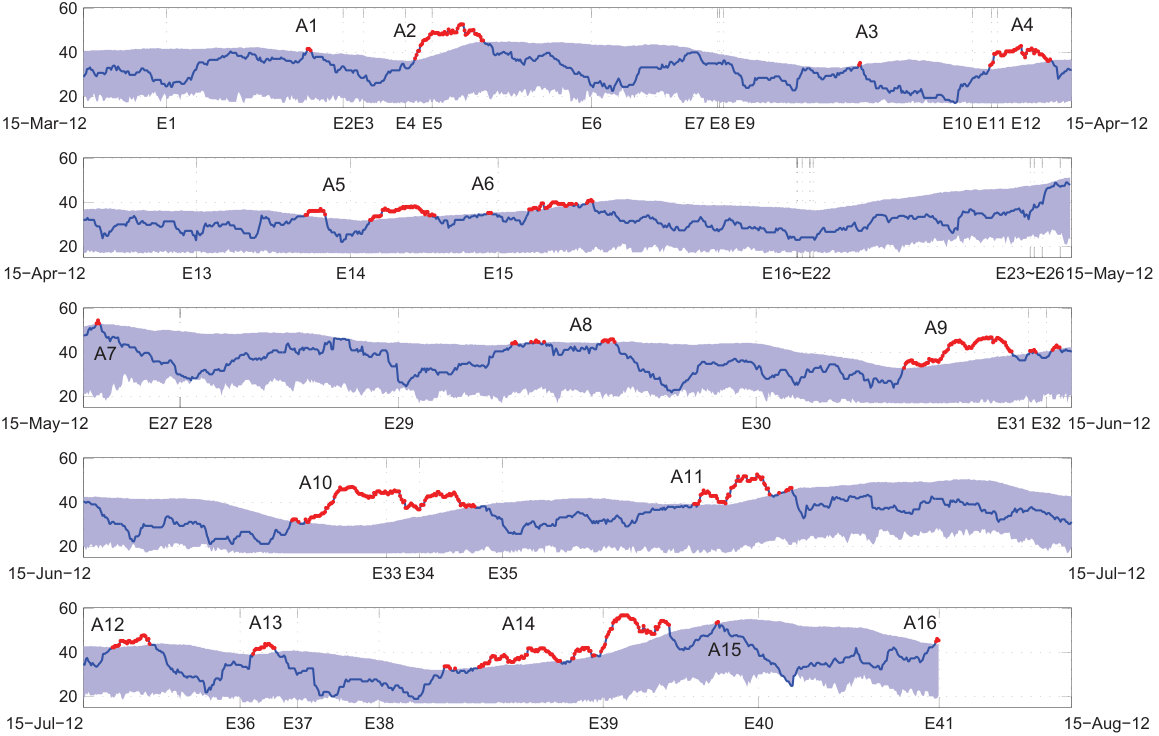 Figure 6
Figure 6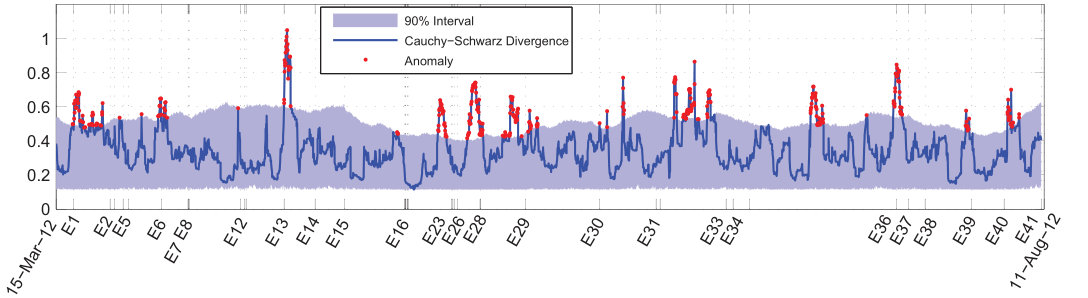 Figure 7
Figure 7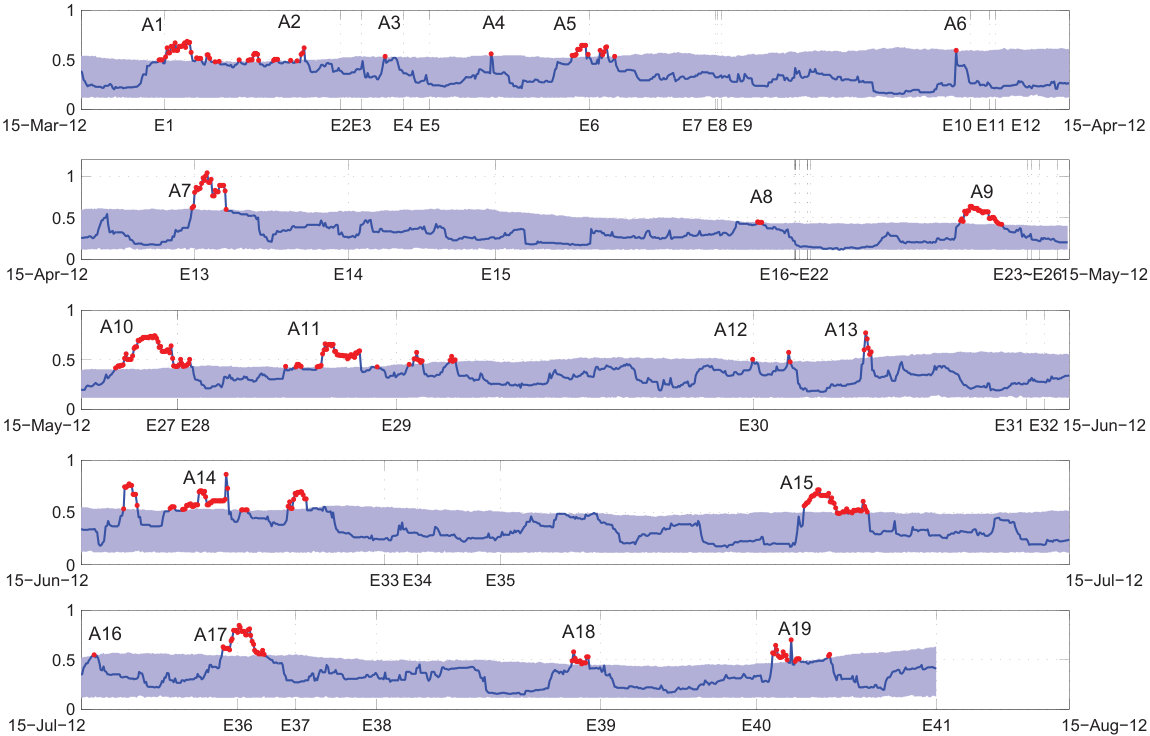 Figure 8
Figure 8| DATE | TIME | MAG. | LOCATION | LAT. | LON. | DEP.b | |
|---|---|---|---|---|---|---|---|
| E1 | 2012-03-18 | 02:38:16 | 4.4 | northern Iran | 36.82 | 49.20 | 14 |
| E2 | 2012-03-23 | 15:43:37 | 4.2 | eastern Turkey | 38.94 | 43.62 | 5 |
| E3 | 2012-03-24 | 06:57:47 | 4.2 | eastern Turkey | 38.92 | 43.53 | 5 |
| E4 | 2012-03-25 | 14:50:29 | 4 | eastern Turkey | 39.94 | 42.94 | 3.4 |
| E5 | 2012-03-26 | 10:35:32 | 5 | eastern Turkey | 39.17 | 42.33 | 5 |
| E6 | 2012-03-31 | 10:38:18 | 4.2 | eastern Turkey | 39.079 | 43.78 | 5 |
| E7 | 2012-04-04 | 09:41:40 | 4.4 | eastern Turkey | 38.88 | 43.57 | 2.6 |
| E8 | 2012-04-04 | 11:05:16 | 4 | Turkey-Syria border | 36.93 | 37.05 | 8.4 |
| E9 | 2012-04-04 | 14:18:38 | 4.4 | eastern Turkey | 39.23 | 41.03 | 10 |
| E10 | 2012-04-12 | 09:32:42 | 4.1 | eastern Turkey | 38.69 | 43.05 | 2.2 |
| E11 | 2012-04-13 | 00:04:50 | 4.2 | Turkey-Iran border | 39.03 | 44.04 | 5 |
| E12 | 2012-04-13 | 04:22:08 | 4.3 | eastern Turkey | 38.67 | 43.18 | 5 |
| E13 | 2012-04-18 | 23:30:58 | 4.5 | eastern Turkey | 38.84 | 43.58 | 5 |
| E14 | 2012-04-23 | 15:50:20 | 4.1 | Georgia | 42.32 | 45.25 | 10 |
| E15 | 2012-04-28 | 03:17:04 | 4.7 | eastern Turkey | 38.49 | 40.74 | 5 |
| E16 | 2012-05-07 | 04:40:27 | 5.6 | Azerbaijan | 41.55 | 46.79 | 11 |
| E17 | 2012-05-07 | 05:38:03 | 4.6 | Azerbaijan | 41.47 | 46.75 | 11.9 |
| E18 | 2012-05-07 | 05:40:31 | 4.6 | Azerbaijan | 41.423 | 46.76 | 16.6 |
| E19 | 2012-05-07 | 08:36:24 | 4.2 | Azerbaijan | 41.51 | 46.77 | 16.8 |
| E20 | 2012-05-07 | 14:15:14 | 5.3 | Azerbaijan | 41.55 | 46.72 | 11.9 |
| E21 | 2012-05-07 | 14:36:20 | 4 | Azerbaijan | 41.51 | 46.73 | 11.7 |
| E22 | 2012-05-07 | 16:58:56 | 4.4 | Azerbaijan | 41.56 | 46.79 | 14 |
| E23 | 2012-05-14 | 06:46:23 | 4.3 | Azerbaijan | 38.70 | 48.76 | 21.4 |
| E24 | 2012-05-14 | 09:58:20 | 4.1 | Azerbaijan | 41.25 | 47.23 | 7.4 |
| E25 | 2012-05-14 | 15:51:02 | 4 | Azerbaijan | 41.19 | 47.23 | 10.5 |
| E26 | 2012-05-15 | 04:54:38 | 4.2 | Azerbaijan | 41.54 | 46.73 | 17 |
| E27 | 2012-05-18 | 14:46:35 | 4.9 | Azerbaijan | 41.58 | 46.76 | 14.8 |
| E28 | 2012-05-18 | 14:47:22 | 5.1 | Azerbaijan | 41.44 | 46.79 | 18.1 |
| E29 | 2012-05-25 | 11:22:38 | 4.4 | eastern Turkey | 38.12 | 38.60 | 5 |
| E30 | 2012-06-05 | 16:29:48 | 4.2 | Azerbaijan | 41.49 | 46.79 | 38.3 |
| E31 | 2012-06-14 | 05:52:53 | 5.3 | Turkey-Syria-Iraq | 37.29 | 42.33 | 5.4 |
| E32 | 2012-06-14 | 19:17:43 | 4.2 | eastern Turkey | 38.06 | 42.55 | 2.5 |
| E33 | 2012-06-24 | 20:07:20 | 4.9 | eastern Turkey | 38.71 | 43.65 | 5 |
| E34 | 2012-06-25 | 20:05:59 | 4.3 | Azerbaijan | 41.26 | 47.11 | 10 |
| E35 | 2012-06-28 | 08:39:16 | 4.2 | eastern Turkey | 38.72 | 43.35 | 5.3 |
| E36 | 2012-07-20 | 13:51:12 | 4.3 | Georgia | 42.53 | 44.14 | 10 |
| E37 | 2012-07-22 | 09:26:02 | 5 | central Turkey | 37.55 | 36.38 | 7.6 |
| E38 | 2012-07-24 | 22:53:39 | 4.5 | eastern Turkey | 38.69 | 43.43 | 5 |
| E39 | 2012-07-31 | 23:12:11 | 4.1 | eastern Turkey | 38.68 | 43.05 | 5 |
| E40 | 2012-08-05 | 20:37:23 | 5 | Turkey-Syria-Iraq | 37.42 | 42.97 | 17.5 |
| E41 | 2012-08-11 | 12:23:18 | 6.4 | northwestern Iran | 38.33 | 46.83 | 11 |
| True | False | |
|---|---|---|
| Positive | 13 (E2,E12,E14,E15,E28,E31,E33, | 2 (A8,A11) |
| E34,E36,E37,E39,E40,E41) | ||
| Negative | n/a | 12 (E1,E5,E6,E7,E8,E13,E16, |
| E23,E26,E29,E30,E38) |
| Precursory | |||
| Eearthquake | Anomaly | Time | Duration |
| E1 | Not Detected | No Precursory | - |
| E2, E3 | A1 | 27 hours | 3 hours |
| E4,E5 | Not Detected | No Precursory | - |
| E6 | Not Detected | No Precursory | - |
| E7, E9 | Not Detected | No Precursory | - |
| E8 | Not Detected | No Precursory | - |
| E10, E11, E12 | A3 | 86 hours | 3 hour |
| E13 | Not Detected | No Precursory | - |
| E14 | A5 | 35 hours | 16 hours |
| E15 | A6 | 9 hours | 3 hours |
| E16 to E22 | Not Detected | No Precursory | - |
| E23 | Not Detected | No Precursory | - |
| E24, E25, E26 | Not Detected | No Precursory | - |
| E27, E28 | A7 | 65 hours | 4 hours |
| E29 | Not Detected | No Precursory | - |
| E30 | Not Detected | No Precursory | - |
| E31, E32 | A9 | 95 hours | 84 hours |
| E33, E35 | A10 | 71 hours | Up to the event time |
| E34 | A10 | 94 hours | Up to the event time |
| E36 | A12 | 99 hours | 31 hours |
| E37 | A13 | 37 hours | 20 hours |
| E38 | Not Detected | No Precursory | - |
| E39 | A14 | 122 hours | 97 |
| E40 | A15 | 34 | 3 |
| E41 | A16 | 3 hours | Up to the event time |
| True | False | |
|---|---|---|
| Positive | 19 (E1,E2,E5,E6,E12,E13,E16,E23,E26,E28 | 3 (A4,A15,A16) |
| E29,E30,E31,E33,E34,E36,E37,E39,E41) | ||
| Negative | n/a | 6 (E7,E8,E14,E15,E38,E40) |
| Precursory | |||
| Eearthquake | Anomaly | Time | Duration |
| E1 | A1 | 4 hours | Up to the event time |
| E2, E3 | A2 | 48 hours | 8 hours |
| E4,E5 | A3 | 13 hours | 1 hour |
| E6 | A5 | 13 hours | Up to the event time |
| E7, E9 | Not Detected | No Precursory | - |
| E8 | Not Detected | No Precursory | - |
| E10, E11, E12 | A6 | 11 hours | 1 hour |
| E13 | A7 | 2 hours | Up to the event time |
| E14 | Not Detected | No Precursory | - |
| E15 | Not Detected | No Precursory | - |
| E16 to E22 | A8 | 26 hours | 4 hours |
| E23 | A9 | 49 hours | 32 hours |
| E24, E25, E26 | A9 | 53 hours | 32 hours |
| E27, E28 | A10 | 48 hours | Up to the event time |
| E29 | A11 | 84 hours | 41 hours |
| E30 | A12 | 1 hour | 1 hour |
| E31, E32 | A13 | 121 hours | 6 hours |
| E33, E35 | A14 | 71 hours | 14 hours |
| E34 | A14 | 94 hours | 14 hours |
| E36 | A17 | 11 hours | Up to the event time |
| E37 | A17 | 54 hours | 32 hours |
| E38 | Not Detected | No Precursory | - |
| E39 | A18 | 21 hours | 13 |
| E40 | Not Detected | No Precursory | - |
| E41 | A19 | 122 hours | 21 hours |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsGeochemistry and Geologic Mapping · earthquake and tectonic studies · Geological and Geochemical Analysis
∎
11institutetext: The authors are with the Electrical and Computer Engineering Department, University of Florida, Gainesville, FL 32611, USA
Tel.: +1-352-392-2682
Fax: +1-352-392-0044
E-mails: {andalib, principe}@cnel.ufl.edu, [email protected]
Pre-earthquake State Identification by Micro-earthquake Spike Trains Dissimilarity Analysis
Arash Andalib
Raheleh Baharloo
José C. Príncipe
Abstract
The exact mechanisms leading to an earthquake are not fully understood and the space-time structural features are non-trivial. Previous studies suggest the seismicity of very low intensity earthquakes, known as micro-earthquakes, may contain information about the source process before major earthquakes, as they can quantify modifications to stress or strain across time that finally lead to a major earthquake. This work uses the history of seismic activity of micro-earthquakes to analyze the spatio-temporal statistical independence among the monitoring stations of a seismic network. Using point process distance measures applied to the micro-earthquakes' spike trains recorded in these stations, a pre-earthquake state is defined statistically with the aim of finding a relation between the level of dissimilarity among stations' readings and the future occurrence of larger earthquakes in the region. This paper also addresses the compatibility of this statistical approach with the Burridge-Knopoff spring-block physical model for earthquakes. Based on the results, there is evidence for an earthquake precursory state associated with an increase in spike train dissimilarity as evaluated by a statistical surrogate test.
Keywords:
Earthquake precursory pre-earthquake stateevent related dissimilarityspike train distance measurePoint process divergence
1 Introduction
Relative movements of tectonic plates lead to a slow accumulation of stress over time and along the faults near the boundaries of the plates that sometimes are exhibited by abundant micro-earthquakes. The accumulated energy is then suddenly released during an earthquake once the stress loading reaches a trigger threshold. This activity may in turn stimulate neighboring faults, developing a sequence of occurrences in space and time, to bring the dynamic medium to a new state of equilibrium bib:26 , bib:28 . Therefore, while the major energy release may seem isolated to a particular time and fault location, in general, an earthquake cannot be analyzed locally in time or space bib:1 , bib:2 and it is reasonable to look for spatial and temporal statistical dependences (aka correlation) in previous recordings, to find important information about impending earthquakes. Given the unpredictability of seismic events, the most common approach is to use a statistical approach based on point processes bib:3 , bib:27 . One difficulty is that the major earthquakes are rare and the physical processes time varying, so there is insufficient data to create accurate statistical models. One alternative is to attempt to relate micro-earthquakes with larger earthquakes, taking advantage of the larger density of micro-earthquakes and their spatial information between stations to infer statistical relationships across scales. The seismicity of micro-earthquakes in a long-term period of one decade, prior to a major earthquake, has been used to explain how the seismic or tectonic processes change ahead of large earthquakes bib:22 , but there has been no attempt in defining significant statistical criteria based on micro-earthquake activity that can be used as a precursor of large earthquakes. This work proposes to apply signal processing methods to detect abnormal seismic activities on a set of faults. In order to capitalize on the spatio-temporal structure of the micro-earthquake data a pre-earthquake state is statistically defined, also called earthquake precursory activity. The proposed method quantifies the interaction between the faults' activities obtained by seismic recordings in a distributed network across space by means of the micro-earthquakes that are produced, and uses distance measures on spike trains to evaluate their dissimilarity structure over time.
A typical seismic network includes several monitoring stations, which may be located tens to hundreds of kilometers apart from each other. These stations record local seismic activities over time. For a micro-earthquake network, the sensors are even able to detect micro-earthquakes (i.e., events with magnitudes Richter), which cannot be felt beyond several kilometers from their epicenters. While the magnitudes of these low-intensity events carry information, this work just considers the timings of micro-earthquakes so they are reduced to time-series of spike trains also called a point process. Previously, statisticians have modeled the event distribution of strong earthquakes over time bib:3 . Recent studies have tried to find the distribution of the number of earthquakes with magnitude larger than two on a single location to find an indicator for the temporal correlation in a single spike train bib:4 . Another approach bib:5 characterized the behavior of earthquake aftershocks using prototype point patterns by clustering the sequence of aftershocks of given main shocks .
This paper analyzes the dissimilarity of the spike trains from micro-earthquakes readings at the stations of a broad-band seismic network, with the aim of extracting precursors for all earthquakes in the region, which preserves the spatial information because these small events are only detected by the closest station. Larger events, however, are recorded in almost every local station, making it unreasonable to evaluate dissimilarity between the spike trains of larger earthquakes. Here, dissimilarity is selected because it can be efficiently estimated by divergence between spike trains, while the converse (similarity) is much harder to quantify because it requires measures of statistical dependence. The Victor-Purpura (VP) distance measure bib:6 , bib:7 is selected, which is sensitive to rate and coincidence of events. Furthermore, another measure from information theoretic learning, the Cauchy-Schwarz (CS) divergence bib:8 is used, which quantifies the distance between the probability laws of two point processes in probability space. This latter metric is generally more robust than distance measures; fewer assumptions are also made when using it. The results of this study suggest that extreme dissimilarities are followed by light to significant earthquakes.
This paper is organized as follows. Sect. 2 defines the pre-earthquake state and outlines how the significance of this definition is tested by surrogate method. Sect. 3 describes the distance measures that are employed to analyze the spike trains. Sect. 4 covers the characteristics of the seismic recordings used in this study. Sect. 5 presents the results of applying dissimilarity measures to the spike trains along with how the similarities change over time. Lastly, Sect. 6, states the conclusions and offers some suggestions for the possible extensions.
2 Methodology
Here, a statistical approach is pursued to identify abnormal behaviors ahead of large earthquakes. This approach starts with the micro-earthquakes' event times recorded in at least two stations of a sensitive broadband seismic network and applies point process distance measures to evaluate dissimilarity of the spatial seismic activity over time. Abnormal values are then identified using a statistical threshold and are labeled as the pre-earthquake state. Fig. 1 illustrates the block diagram of this method, which indicates how the signal processing approaches are applied to the station measurements of the faults. This is what is discussed in detail in the rest of this paper.
2.1 Definition of the Pre-Earthquake State
The pre-earthquake state in this paper is defined as an occasional or durable increase in dissimilarity of spatial seismic activity, only if the amount of dissimilarity passes a statistical threshold value. The extreme (maximal) dissimilarity in the collected data quantifies a critical change in connectivity of the regional faults, which can result in a large earthquake that settles the whole system in a new state. The pre-earthquake state is based on a statistical evaluation of pairwise dissimilarity instead of physical principles. It is, however, compatible with the spring-block physical model for earthquakes and other seismic activities bib:23 . Indeed the Burridge-Knopoff spring-block model shows that the slip of one fault redefines the forces on local faults, so further slips occur and subsequently cause multiple reactionary events. When the system stress loading reaches a threshold value, a large earthquake is triggered, after which the process of relaxation begins. Based on the idea of self-organized criticality for earthquakes bib:24 , both the trigger point and relaxation point can be characterized by spatio-temporal correlation among the faults. This is exactly what the definition of pre-earthquake state is based on.
2.2 Statistical Test Design
To examine the hypothesis that “major earthquakes are preceded by an increase in dissimilarity of micro-earthquakes,” the null hypothesis is defined as “increases in dissimilarity are merely the results of local fluctuations and they are not related to an earthquake”. The goal is to find whether the null hypothesis can be rejected at a certain level. One option to implement the null hypothesis is to generate a Poisson point processes as a surrogate for the micro-earthquake spike trains. However, this is not easy because the rate of micro-earthquakes is continuously changing as demonstrated in Fig. 3, and this will confound the test. One widely used alternative is to synthetically create a set of spike trains by modifying the original spikes. This modification should destroy the feature of interest, which is the correlation between spike trains of earthquakes, while keeping the other statistical properties such as density intact. The surrogate data is then used to estimate the acceptance interval for normal fluctuations in dissimilarity. A dissimilarity beyond the acceptance interval is considered as an anomaly.
The dissimilarity metrics that are used in this paper do not distinguish between coincidence and changes in firing rate. Therefore, it seems quite reasonable to use surrogates that experience destruction in both coincidence and firing rates. However, if the method completely destroys the firing rate profile and reduces the inhomogeneous point process to a homogeneous one, a little change in the rate profile will lead to a false positive. The method employed to generate the surrogate data is uniform spike time dithering bib:20 , which randomly displaces spikes in a dithering window. To enforce causality in prediction, the method is slightly modified here such that dithering window always follows the original position of each spike.
Using spike time dithering to generate surrogate data, there is a hyper parameter, which is the size of the dithering window. The dithering window needs to be long enough to destroy any coincidences in the original signal. The process of dithering also somewhat smooths the local rate profile, an effect that increases with an increase in window length. As a rule of thumb, a window length two to four times that of the window to compute the distance is recommended bib:20 for enough correlation destruction. Here, a statistical approach is used to find the optimal length of dithering window, which indeed is the minimum length that guarantees surrogates with destructed correlation. This length is equal to the lag where the original spike trains are uncorrelated. This lag corresponds to the first local minimum of cross-correlation histogram bib:30 of original spike trains. In Sect. 5, binned cross-correlation bib:29 between micro-earthquake spike trains is computed for this purpose.
Using the dithering method explained above, two sets of surrogates are obtained from micro-earthquake data of the two stations. To produce the acceptance band, distances are computed between one-to-one pairs of surrogates from the two stations, and then are made to have identical statistical distribution via quantile normalization.
Other free parameters of each method are selected and fixed for the whole time period using 5-fold cross-validation, where each fold roughly equals one month. The positive predictive value, that is, the proportion of true positives in the positive calls, is used as the measure of fit.
3 Spike Trains Distance Measures
The concept of distance is conversely and strongly related to statistical dependence, which extends the concept of correlation between time series. However, unlike conventional amplitude based signals, spike train spaces are devoid of an obvious algebra. To tackle this difficulty, time binning may be used to map a spike train to Euclidean space, which allows the use of the Euclidean inner product. This process, however, has disadvantages. While binning with a coarse bin size sacrifices time precision, smaller bin sizes may keep temporal structure but are sensitive to temporal fluctuations and also suffer from dimensionality problem.
Binless measures of spike train dissimilarity have been proposed to overcome these difficulties. Most of these measures consider the spike trains to be points in an abstract metric space, proposed by Victor and Purpura bib:6 , bib:7 . The widely used time dependent approaches include the Victor-Purpura's distance bib:7 , the van Rossum distance bib:9 , and the similarity measure proposed by Schreiber et al. bib:10 (see bib:11 , bib:12 for a comparison). All of these measures are dependent upon a smoothing parameter that controls the method's sensitivity to dissimilarities in spike rate or spike coincidences. Hence, they still include a free parameter, which indicates the time precision for distance analysis, almost similar to bin size, but without time quantization.
The Victor-Purpura's distance is one of the measures that is used in this work. In addition, the Cauchy-Schwarz dissimilarity measure is used, which corresponds to the correlation measure used by Schreiber et al.
3.1 Victor-Purpura's Distance
The VP distance defines the dissimilarity between two spike trains in terms of the minimum cost of transforming one spike train into the other by just three elementary operations: spike insertion, spike deletion (each with a cost of one), and shifting one spike in time to synchronize with the other. The cost of a time shift for a spike at to is , where defines the time-scale with inverse time unit. The VP distance between spike trains and is defined as
[TABLE]
where is the set of all possible sequences of elementary operations that transform to , or vice-versa, and . That is, denotes the index of the spike time of manipulated in the -th step of a sequence. is the cost associated with the step of mapping the -th spike of at to , corresponding to -th spike of , or vice-versa.
Given two spike trains, each with a single spike, the distance is
[TABLE]
This means that the VP algorithm shifts a spike at most, far from the other. Otherwise, it is cheaper to delete one of the spikes and insert another for a cost of 2. The distance may be considered as a scaled and inverted triangular kernel applied to the spike trains bib:11 . This interpretation encourages the use of alternate dissimilarity measures based on different kernels.
3.2 Cauchy-Schwarz Dissimilarity
An alternative dissimilarity measure based on the Cauchy-Schwarz (CS) divergence bib:8 uses the Laplacian kernel. The kernel size tunes the time scale of the measure, and plays the reciprocal role of the free parameter of the VP distance bib:11 . Here, by choosing a large the measure is more sensitive to dissimilarity in the firing rates of the spike trains, similar to the VP distance with a small value. It also can be defined from the inner product of intensity functions (firing rates) of the spike trains in .
For a spike train with spikes on the time interval and the spike times , can be represented as a sum of time-shifted impulses
[TABLE]
The firing rate can be estimated using a kernel smoothing representation of the spike train as
[TABLE]
with as the smoothing kernel. This kernel needs to be non-negative valued with a unit area constraint. The memoryless cross intensity (mCI) kernel bib:13 is defined on spike trains as
[TABLE]
Using exponential decay for kernel smoothing, the mCI kernel can be evaluated efficiently as
[TABLE]
where is the Laplacian kernel bib:14 . The Cauchy-Schwarz dissimilarity is then defined as
[TABLE]
Mercer’s theorem bib:15 implies that for the symmetric non-negative definite function that is square integrable, the kernel has an eigen-decomposition as
[TABLE]
where is the nonlinear mapping from the input space to the reproducing kernel Hilbert space induced by the kernel function. Thus, Eq. (7) is equivalent to
[TABLE]
The RKHS bib:21 interpretation of the CS divergence is interesting, because it does not require explicit PDF estimation. Instead, this representation provides enough space to extend the algorithm for earthquake precursory using the properties of the functional space, as will be discussed later in this paper.
4 Experimental Data
The original data is continuously recorded by surface broadband stations of the Iranian Seismological Center (IRSC). The recordings are then digitized and sent to a remote network center over satellite communication channels. At network center, the data is analyzed by a virtual seismic analyst to identify the events in real-time. The outcomes are also reviewed by an experienced seismic analyst. In this study, micro-earthquake data identified in two stations of IRSC network, Tabriz sub-network, from March 15, 2012 to August 11, 2012, are used for experiments. This is a five-month period prior to the earthquake M6.4 in northwest Iran. To define the target area, which may have precursors (warning) based on the analysis of this data set, the existing studies which explain the regional tectonic settings bib:17 , bib:25 are useful. Fig. 2 illustrates the tectonic map of the Alpine system and the position of the two stations S1 and S2 (the bullets). These stations are very close to the boundaries of Iranian, Turkish, Van, and Arabian tectonic plates. The target area of this study is located at the intersection of these plates and is shown within the dashed-line rectangle (latitude: to degrees, longitude: to degrees). Unfortunately, not every seismic station that cover the whole area is accessible. However, this figure explains why a far earthquake in the rectangle may have a precursor provided by the two stations of this study.
The rectangular search of the U.S. Geological Survey (USGS) catalog over the five-month time period includes 41 earthquakes , whose characteristics are presented in Table 1. The main shocks, that is, those events that are not immediately followed by a larger earthquake, are highlighted. Among these events, there are 25 main shocks, six foreshocks and 10 aftershocks. The aftershocks are ignored, but the prediction of foreshocks is still important.
Before computing the dissimilarity of spike trains, it is noteworthy to consider the instantaneous rate of micro-earthquakes recorded in each individual station. Here, the rate profiles are created using the Gaussian kernel smoothing method with optimal bandwidth for the kernels bib:18 . Fig. 3 shows the smoothed signals. The bandwidth values are optimally set to 2.97843 and 2.97739 for the two stations S1 and S2, respectively. It is very important to bear in mind that the output of the smoothing filter depends on future events. Hence, it is not a causal estimator. The rate profiles may be used to understand the characteristics of the input data, however cannot provide predictability. As shown in Fig. 3, both the recorded event densities and their difference at each time instance are highly variable and demonstrate different behavior prior to major events. There are minimum and maximum differences in micro-earthquake event densities just before the major events E12 (M4.3, April 13, 2102) and E26 (M4.2, May 15, 2012), respectively. This suggests a method based on rate profile thresholding may not be enough to provide consistent information about upcoming earthquakes.
5 Results and Discussions
The results for applying the VP distance and CS divergence to micro-earthquakes recorded in stations S1 and S2 of Tabriz sub-network are presented. Each measure is applied to spike time vectors obtained over a sliding window. These vectors span the entire time period of interest. Hence, the output is a time resolved profile of dissimilarity of seismic activities between the two stations. Together with the distances, the one-tailed (positive) acceptance intervals from the surrogate data test at 90% confidence will be depicted to clearly show moments when the dissimilarities between spike trains exceed the limit of normal fluctuations on spike train structure dictated by the statistical test. The acceptance band is produced using two set of surrogates from original spike trains of stations S1 and S2, each set including 1,000 surrogates. Spike time dithering method explained in Sect. 2 is used for surrogates. Following the statistical test design explained earlier, the cross-correlation (CC) of 2-day binned spike trains of micro-earthquakes is computed to find the optimal dithering window. Fig. 4 depicts the original cross-correlation (the thick solid line). As expected, the cross-correlation decreases as lag increases, and has the first local minimum at 6 days. Therefore, the optimal length of dithering window is selected as 6 days. Fig. 4 also depicts the mean CC over the surrogates (the thick dashed-line) and mean CC plus twice the standard deviation (the fine dashed-line). Obviously, the surrogate CC follows the shape of original CC.
5.1 Results for Victor-Purpura's distance
The VP distance for the original spike trains is illustrated in Fig. 5. Here, q is set to 100 , meaning that the VP algorithm only shifts a spike which is at most 2/100 (28.8 minutes) far from the other. The length of sliding window is set to 2 days and it slides one hour at each step. To define the one-tailed 90% acceptance interval, the VP distances at each step are sorted , where denotes the sliding window position, and is the number of surrogates. The lower and upper limits are then and , respectively.
The monthly plot of Fig. 6 has better visualization and the anomalies are also labeled. Comparing the anomalies with times of occurrence of major earthquakes reveals that there are extreme dissimilarities prior to 13 earthquakes, namely E2, E12, E14, E15, E28, E31, E33, E34, E36, E37, E39, E40, and E41. These anomalies may be considered as true warnings for corresponding earthquakes including E41, which is the deadly Varzaghan-Ahar earthquake M6.4 in northwest Iran. However, there are also two false positive warnings, and 12 earthquakes happen without any anomaly. The performance of the algorithm in providing efficient warnings prior to the major earthquakes is summarized in Table 2. When producing the confusion matrix in this table, the aftershocks are ignored again. Furthermore, a main shock that has a foreshock is reported as true positive, provided that the algorithm successfully predict the first earthquake, that is, the foreshock. This is the case for E12 and E28. On the other hand, while there is an anomaly before the main shock E5 it is reported false negative because the anomaly appears only after the corresponding foreshock E4.
Table 3 presents the precursory behavior for each earthquake. Each row of the table includes one main shock in bold, preceded (succeeded) with corresponding foreshocks (aftershocks), if any. The true positive anomalies are also reported for each group of earthquakes. Precursory time, with a mean value of 59.77 hours , is the earliest warning before the event. Duration, with a mean value of 33.15 hours , indicates how long the warning have been in effect in average, that is, how long the dissimilarity have been above the acceptance interval just prior to the event.
5.2 Results for Cauchy-Schwarz divergence
The same experiment is repeated, using the Cauchy-Schwarz divergence instead of VP distance. The results are illustrated in Fig. 7. The kernel width is set to Hour using the cross-validation method explained earlier. Other parameters are the same as those of the VP distance.
Compared with the VP distance, the CS divergence tends to be more sensitive with respect to the surrogate. The confusion matrix is presented in Table 4. The CS divergence is doing slightly better compared with the VP distance. The monthly plot of Fig. 8 indicates that there are precursors prior to 19 out of 25 main shocks and there are three false alarms (A4, A15, and A16), given an 86% positive predictive value, which is comparable to the surrogate confidence. However, six main shocks have not any precursor.
Table 5 discusses the precursory behavior when using the CS divergence. Here, the mean value for precursory time is 44.53 hours and the mean precursory duration is 15.71 hours .
Based on these results, it seems that the null hypothesis can be rejected using the CS measure and conclude that this method has been able to identify the pre-earthquake state based on temporal increases in dissimilarity. Although the goal in this paper is not to compare dissimilarity measures, further work is needed to explain the superior performance of the CS dissimilarity measure upon the VP distance for the surrogate test presented here. From a theoretic perspective, divergence is a stricter and a stronger statistic bib:19 , in the sense that it compares the entire probability laws. It can therefore go beyond comparing just simple statistics such as mean firing rate or spike count. It is also shown that CS dissimilarity is less sensitive to missing spikes bib:13 . Some earthquakes may not be registered by one or more monitoring stations in a seismic network, so it is important for the measure to be resistant to missing spikes and avoid deviation.
6 Conclusion
This paper provided a statistical representation for the pre-earthquake state by using spike train distances applied to micro-earthquakes, and tested its performance as an earthquake precursor. The spike train dissimilarity measures of Victor-Purpura distance and Cauchy-Schwarz divergence were applied to spike trains of micro-earthquakes to examine the idea that increases in dissimilarity in at least two stations may be considered as a warning for future occurrence of major earthquakes. While evidences of precursory behavior were observed using the VP distance, the CS divergence had higher performance in validating the hypothesis.
The relationship between the magnitudes of the earthquakes and the precursory behavior was not addressed in this paper. The magnitude of micro-earthquakes was ignored, and earthquakes were not incorporated in the input data set. A possible improvement is to utilize the theory of reproducing kernel Hilbert spaces (RKHS), where tensor products of multiple kernels can be defined to insert magnitude information and exploit the theory of “marked Point processes” to define distances, which takes advantage of the full information available in the earthquake catalog. Another possible extension is to insert the exact location information of the input events and relax the obligation of just labeling the input events with the stations. This may be helpful to predict the location of target earthquakes, a topic that is not addressed in this paper.
Acknowledgements.
The authors of this paper are grateful to the Iranian Seismological Center for providing the data used in this study. The authors would also like to thank Dr. John F. Dewey for his helpful insight on the tectonic settings of the region of this study, and Isaac Sledge for proofreading the manuscript.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1(1) P. Tosi, V. D. Rubeis, V. Loreto, and L. Pietronero, “Space–time correlation of earthquakes,” Geophysical Journal International , vol. 173, no. 3, pp. 932–941, 2008.
- 2(2) A. V. M. Herz and J. J. Hopfield, “Earthquake cycles and neural reverberations: Collective oscillations in systems with pulse-coupled threshold elements,” Phys. Rev. Lett. , vol. 75, pp. 1222–1225, Aug 1995. [Online]. Available: http://link.aps.org/doi/10.1103/Phys Rev Lett.75.1222
- 3(3) V. P. Plagianakos and E. Tzanaki, “Chaotic analysis of seismic time series and short term forecasting using neural networks,” in Proc. IEEE International Joint Conference on Neural Networks , vol. 3, 2001, pp. 1598–1602.
- 4(4) R. J. Geller, D. D. Jackson, Y. Y. Kagan, and F. Mulargia, “Earthquakes cannot be predicted,” Science , vol. 275, pp. 1616–1617, 1997.
- 5(5) Y. Ogata, “Statistical models for earthquake occurrence and residual analysis for point processes,” Journal of American Statististical Association , vol. 83, pp. 9–27, 1988.
- 6(6) Y. Kagan and D. Vere-Jones, “Problems in the modelling and statistical analysis of earthquakes,” in Athens Conference on Applied Probability and Time Series Analysis . Springer, 1996, pp. 398–425.
- 7(7) R. Stefansson, Advances in earthquake prediction . New York: Springer, 2011, pp. 92–93.
- 8(8) M. Karsai, K. Kaski, A. L. Barabási, and J. Kertész, “Universal features of correlated bursty behavior,” Scientific Reports 2 , 2012.