Social Media Advertisement Outreach: Learning the Role of Aesthetics
Avikalp Srivastava, Madhav Datt, Jaikrishna Chaparala, Shubham Mangla,, Priyadarshi Patnaik

TL;DR
This paper introduces a novel approach to evaluate and enhance social media advertisement outreach by analyzing aesthetic attributes, addressing biases, and providing a normalization method to improve user engagement on platforms like Twitter.
Contribution
It proposes a new method to assess and optimize aesthetic features of promotional images, accounting for biases, to improve outreach effectiveness on social media.
Findings
Normalization of biases improves outreach scoring accuracy
Certain aesthetic features significantly influence user engagement
Optimizing aesthetic attributes can enhance promotional image performance
Abstract
Corporations spend millions of dollars on developing creative image-based promotional content to advertise to their user-base on platforms like Twitter. Our paper is an initial study, where we propose a novel method to evaluate and improve outreach of promotional images from corporations on Twitter, based purely on their describable aesthetic attributes. Existing works in aesthetic based image analysis exclusively focus on the attributes of digital photographs, and are not applicable to advertisements due to the influences of inherent content and context based biases on outreach. Our paper identifies broad categories of biases affecting such images, describes a method for normalization to eliminate effects of those biases and score images based on their outreach, and examines the effects of certain handcrafted describable aesthetic features on image outreach. Optimizing on the…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2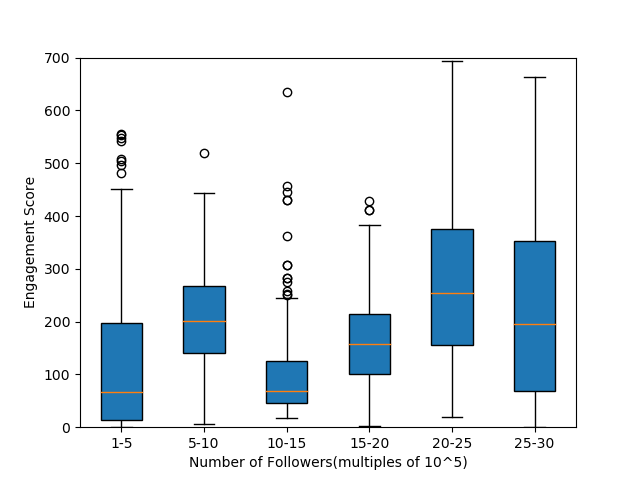 Figure 3
Figure 3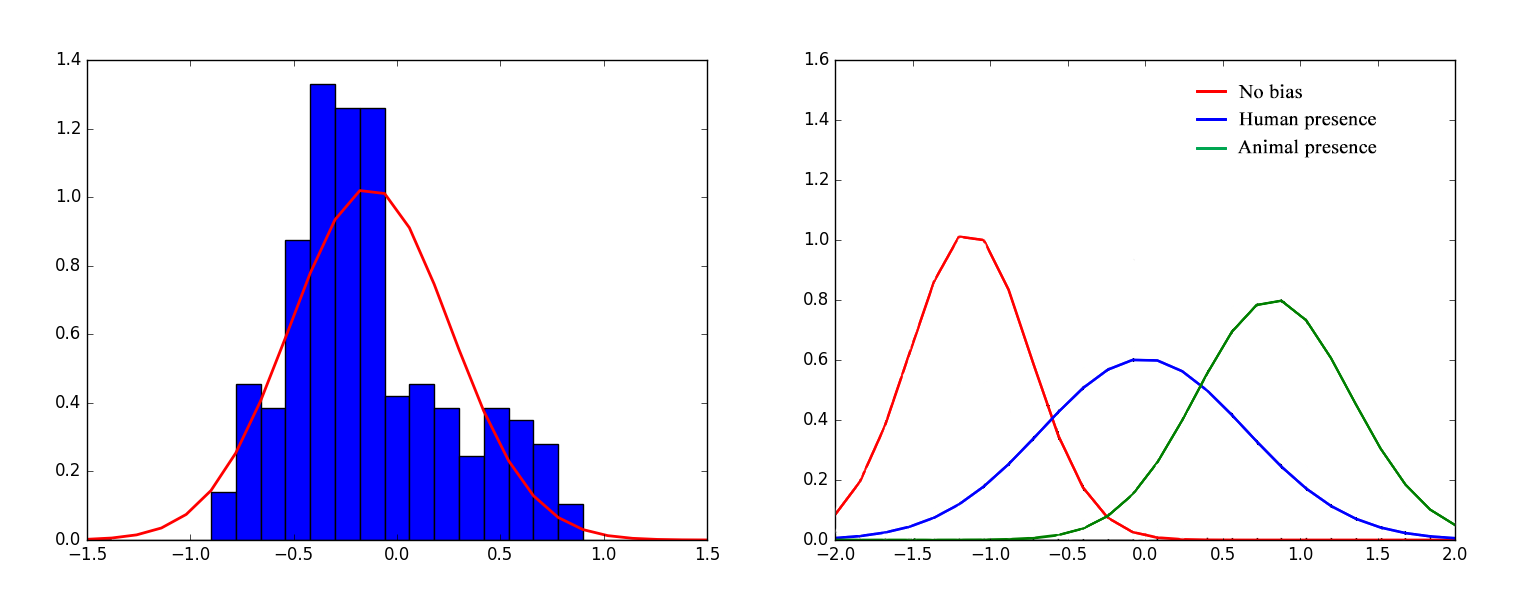 Figure 4
Figure 4 Figure 5
Figure 5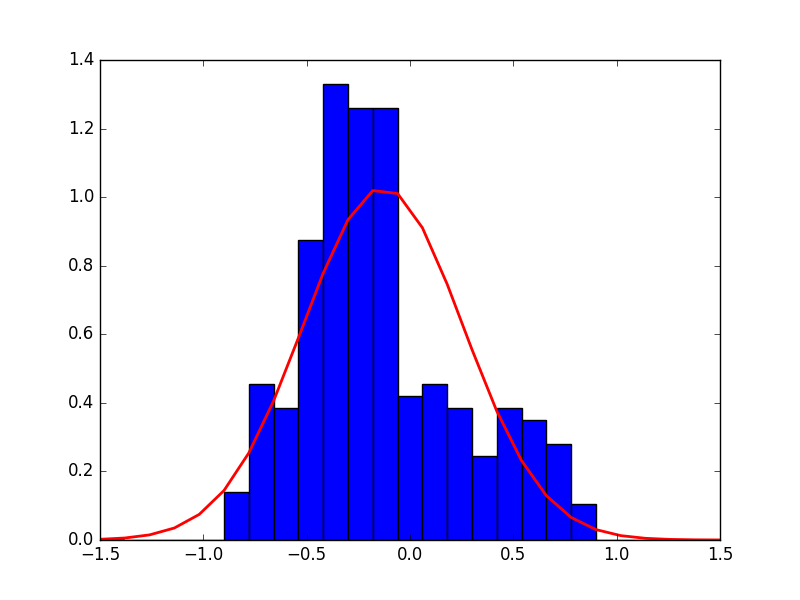 Figure 6
Figure 6| Discounts/Give-aways | Human Presence |
|---|---|
| Hashtags/Celebrity Mentions | Animal Presence |
| Special Days/Holiday Season | Product Launches |
| Social/Motivational Message | Brand Popularity |
| Photo.Net | Twitter Ads | ||
|---|---|---|---|
| Familiarity measure | Low DoF hue component | ||
| Brightness measure |
|
||
|
Low DoF saturation | ||
| 3rd largest patch size | RAG segment count |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAesthetic Perception and Analysis · Visual Attention and Saliency Detection · Consumer Behavior in Brand Consumption and Identification
Social Media Advertisement Outreach: Learning the Role of Aesthetics
Avikalp Srivastava
IIT Kharagpur
,
Madhav Datt
Harvard University
,
Jaikrishna Chaparala
IIT Kharagpur
,
Shubham Mangla
IIT Kharagpur
and
Priyadarshi Patnaik
IIT Kharagpur
(2017)
Abstract.
Corporations spend millions of dollars on developing creative image-based promotional content to advertise to their user-base on platforms like Twitter. Our paper is an initial study, where we propose a novel method to evaluate and improve outreach of promotional images from corporations on Twitter, based purely on their describable aesthetic attributes. Existing works in aesthetic based image analysis exclusively focus on the attributes of digital photographs, and are not applicable to advertisements due to the influences of inherent content and context based biases on outreach.
Our paper identifies broad categories of biases affecting such images, describes a method for normalizing outreach scores to eliminate effects of those biases, which enables us to subsequently examine the effects of certain handcrafted describable aesthetic features on image outreach. Optimizing on the features resulting from this research is a simple method for corporations to complement their existing marketing strategy to gain significant improvement in user engagement on social media for promotional images.
††copyright: acmcopyright††journalyear: 2017††copyright: acmcopyright††conference: SIGIR ’17; August 07-11, 2017; Shinjuku, Tokyo, Japan††price: 15.00††doi: http://dx.doi.org/10.1145/3077136.3080759††isbn: 978-1-4503-5022-8/17/08
1. Introduction
In an effort to reach out to their user base, corporations spend millions of dollars developing creative image-based promotional content for social media platforms such as Twitter. The ability of corporations to engage a large portion of their target audience has very direct monetary consequences for them. Because of their focus on sales and brand promotion, these images come with certain inherent content and context based biases beyond just aesthetic attributes that influence overall outreach.
Most aesthetic focused advertisement outreach research and development is based on data from advertisement quality surveys. Conducting such surveys is an extremely resource intensive task. There has also been significant work in aesthetic image analysis (Datta et al., 2006, 2008; Marchesotti et al., 2011; Murray et al., 2012) for predicting user ratings of digital photographs. However, these studies cannot be applied to promotional images on social media, because, social media user engagement of an image, unlike user ratings, are influenced by multiple factors beyond just image aesthetics.
In our paper, we develop an engagement score for images on Twitter, identify such broad ”biases” or factors, propose an automated method to identify their presence in images and learn a transformation on scores to eliminate the effects of such biases. We select a set of hand-crafted describable image aesthetic features and train our system to learn the relative significance and influence of each of these features on engagement. To ensure that the results of our research are actionable by graphic designers, we restrict our work to human understandable/describable features and do not use generic or learned deep features such as the ones used in (Marchesotti et al., 2011).
We also go on to show that low level features that work for digital photography (not accounting for biases) do not work for social media ad success. We use the model described in (Datta et al., 2006) for aesthetics of digital photographs as a baseline. Our method performs significantly better (71.8% vs 57.5%) than the baseline on classifying our dataset of 8000 promotional images on Twitter into successful and unsuccessful images.
In the end, we describe the basic function and design of an automated interactive system based on the results obtained from our model. The system takes promotional images from corporations as input and provides human understandable/describable aesthetic attributes of the image that may be tuned (for example, increasing spatial smoothness of hue property by 14%) by designers to obtain the most significant increase in engagement on Twitter.
Through this paper, our key contribution is developing a method to deal with the bias related challenges associated with analyzing effects of aesthetic features on outreach of social media advertisement images. This elimination of bias to give comparable image scores based only on aesthetic attributes, across different images and pages on social media, opens possibilities for research in computational aesthetics around the social media advertising industry.
2. Data Collection
We build a data set of 8,000 image based promotional tweets by scraping Twitter profiles of 80 different corporations. These corporations are particularly active on Twitter and have between 36,000 () to 13 million () followers, and 3,000 () to 753,000 () tweets. We select these corporations from across 20 broad categories such as retail, fast food, automobiles etc. to account for the diversity in promotional image representation. We scrape such image based promotional tweets along with their likes count, retweets count, date and time, page followers, page tweets and tweet text from the Twitter API for each corporation page, in proportion to their total number of tweets.
For each such image page , we define our engagement evaluation score , as the sum of image likes and image retweets. Due to inherent industry differences, and the variances across pages in total followers, we normalize our scores to ensure comparability between scores from different pages. We get a Pearson Correlation Coefficient of 0.46 and Spearman Rank Correlation of 0.63, suggesting no linear or monotonic correlation between number of followers and average engagement scores of a page. This is also supported by the sampled distribution in Figure 2.
Therefore, in order to account for the difference in image based tweet engagement between pages of different sizes, industries etc. we use the mean and variance of engagement scores of images from the page for normalization. Thus, we define normalized engagement : For image ,
[TABLE]
where and are mean and standard deviation of image scores from page .
3. Bias driven engagement
Datasets used by previous aesthetic image researches (Photo.Net (Datta et al., 2006), DPChallenge (Datta et al., 2008), AVA (Murray et al., 2012)) only involve digital photographs rated by users purely based on their aesthetic appeal. Image based promotions on Twitter contain certain content and context based biases that significantly influence engagement scores , for example, advertisements involving a cute cat will, on average, have much greater success and outreach, and consequently higher scores compared to aesthetically better images free from any significant biases. This makes analyzing the effects of aesthetic features on engagement an extremely challenging task. To ensure that our scores represent effects of, and are strongly correlated with visual appeal and aesthetic factors, we detect biases affecting each image and remove their influences on the score.
For each Twitter page within our 8000 image dataset, we detect outliers in terms of engagement scores using normalized local outlier factor scores and manually identify 8 broad categories of the most significant biases (listed in Table 1). In this paper, we account for and eliminate the effects of 4 biases - Animal Presence (cats, dogs etc.), Human Presence (babies, celebrities etc.), Special Days (Black Friday, Christmas etc.), and Discounts. Handling the remaining biases is beyond the scope of this paper and can give direction to future research in this area.
3.1. Bias Identification
We use the Viola-Jones face detector to give a binary classification detecting the presence of faces (as a proxy for human presence) in promotional images. To detect presence of animals, we train a spatial pyramid matching based SVM classifier described by Lazebnik et al. (Lazebnik et al., 2006) on 5000 images of cats and dogs (most frequently occurring animals) scraped from the web. We manually identify all the 4 above mentioned biases from a sample of 1000 images from our 8000 image dataset, to assess quality of our automated bias identification, and obtained 75.5% accuracy for human presence detection and 69.6% accuracy for animal presence detection.
To extract text from the image, we use the Tesseract OCR Engine. In this paper, we define tweet text as the OCR extracted text along with the text associated with each image from its tweet. To account for the surge in Twitter engagement in periods leading up to major holidays such as Christmas, Black Friday, Halloween etc. we define date ranges around each such holiday (for example 7 days before and after Christmas). We manually build a list of words commonly associated with holidays (such as Thanksgiving, Hanukkah etc.) We augment this list of words by finding the most linguistically and semantically similar words using GloVe (Pennington et al., 2014), which are then manually validated and filtered, and classify all tweets which occur within a holiday date range containing any of these words as Holiday biased.
To identify tweets affected by biases caused by discounts/offers, we repeat the same process as described above using a different set of common initial words such as free, discount, sale, offer etc. with GloVe. We also identify tweets that urge users to retweet to get offers or win as part of some promotion. On our manually labeled 1000 image test set, we obtain 88.3% accuracy on holiday-themed image identification and 84.4% accuracy in identification of discounts and offers. While some images contain multiple biases, we restrict our paper to images with at most one bias which constitute a majority of our dataset (923 of our sampled 1000 images).
3.2. Bias Removal
We define set of unbiased images and mutually exclusive sets of identified biased images , where Images with human presence, Images with animal presence, Holiday-themed images, Images with discounts.
We define the discrete probability distribution of scores of images as , and that of image scores , for , as . To eliminate the effects of the bias, we apply the transformation , such that the distribution can be used as an approximation of , while maintaining relative ranking order of image scores of biased images as in their original distribution . Since, we transform to eliminate the effects of bias, should be distributed similar to , and transformed image scores for are used as if the original images had not been affected by the bias. To this effect, we use the Kullback-Leibler divergence as our objective function for minimization, to capture the loss incurred while using to approximate .
Let be the set of scores for images in , thus the set of transformed scores is obtained as follows:
[TABLE]
where the probability distribution of the set is defined as . Thus, we learn the transformation , where is the space of all transformation functions, such that
[TABLE]
[TABLE]
In this paper, we explore the space of polynomial functions , where the parameter defines the degree of polynomial for the input features . Therefore for the space , as parameterized by on the input is defined as follows:
[TABLE]
We add another constraint that , so that during transformation, the relative ranking order of biased images is maintained and arbitrary transformations that disregard original distribution’s ranking information and overfit are disallowed. For the bias associated with in consideration, the input to the system is the matrix given by:
[TABLE]
where . At each step, the intermediate output transformation is given by
[TABLE]
where , where represent the intermediate approximate values of the transformed score . We minimize the above described divergence or loss function, to learn the values for the matrix . With the learned , we apply the transformation to image scores in to eliminate effects of bias described in . We repeat this process for each set of biased images in .
4. Aesthetic Feature Learning
Computational assessment of aesthetic image quality is a well tackled problem. Having removed the content and context based biases associated with the scores received by the images in our dataset, we obtain image features strongly related with aesthetic appeal and visual attractiveness of the image to get the feature vector for each image i. We now formulate our feature learning problem with training data set , where , i.e. represents the transformed score of image after bias elimination. A function is learned for providing feedback and suggestions for improving user engagement through image feature tuning.
4.1. Feature Selection And Extraction
We select describable/human-understandable image attributes based on handcrafted features used in previous works, augmenting the list with an additional set of features deemed important to capture the multi-object majority nature identified in advertisement images vis-a-vis photographic images. We implement the features defined by Datta et al. (Datta et al., 2006) in addition to non-overlapping features from Ke et al.(Ke et al., 2006), compositional attributes from Dhar et al.(Dhar et al., 2011), along with added features based on Region Adjacency Graphs (RAG) such as threshold and recursive normalized cut information. Thus, we obtain a total of describable aesthetic features for each image.
4.2. Experimental Evaluation
We use a standard support vector regressor with RBF kernel to learn the function where denotes the feature based vector set and denotes the set of normalized and bias-removed engagement scores. This provides a quantitative evaluation of the relation between the feature vector values to the predicted engagement score, necessary for providing feedback on feature tuning for the query image to maximize the outreach through increased aesthetic and visual appeal, given that all other components for that image remain same.
We also show that aesthetic features that work for digital photographs do not necessarily work for promotions/advertisement based images. From our dataset , we sample 20% points to form our test set T. To model our data for the classification task, we specify thresholds to partition images with scores in the lowest and highest quartile as ”unsuccessful” and ”successful” respectively. We first run a SVM classifier model to learn weights for the features used in (Datta et al., 2006) on the Photo.net dataset and use this trained model to classify on our test set T. While the accuracy of trained model on test set from Photo.net dataset is 69.12% (close to value reported in (Datta et al., 2006)), on T this model’s accuracy reduces to 57.5%. Our 74 feature model trained on Twitter advertisement training dataset performs with 71.8% accuracy on T, and on inspection we find that a good proportion of misclassified images contained biases we didn’t handle in this study, and thus also good motivation for future work. The reduced accuracy achieved when using aesthetic features learned from non-advertisement dataset strongly suggests that it is necessary to capture image features linked with success of advertisement related images differently from those of purely aesthetically motivated digital photographs.
4.3. Applications and Feedback System
Our paper describes the basic functioning and design of a system, based on our trained SVM regressor, to identify the aesthetic feature tunings that can be applied to image based promotions, in conjugation with other marketing strategies, to maximize user engagement.
Given an input promotional advertisement image i, we apply our system for feature extraction to obtain the feature vector . Our system ideally seeks to find the nearest-neighbor feature vectors for that lead to maximum increase in predicted engagement. That is, the system outputs a set of features and percentage changes for each, from our initially chosen human-understandable feature space, to maximize predicted engagement scores for the image. However, from a practical perspective, a graphics designer would be more interested in a tuning that provides changes to small number of features, rather than suggesting small changes to a large number of features, which can be inconvenient. A user may restrict the number of features where changes are suggested to at most k, where each feature is not changed by more than a value s. For finding the optimal tuning combination among these k features, a distance of s on either side of the original feature value is traversed in steps of size t. The tuning combination that achieves the highest predicted engagement score from the trained support vector regressor is chosen as the suggestion output, as demonstrated in Figure 5.
5. Conclusion and Future Work
Our paper proposes a novel method to evaluate and improve outreach of promotional images from corporations on Twitter by identifying inherent biases and transforming scores to eliminate their effect on engagement in order to discover attributes that contribute most to advertisement outreach. Our model gives an aesthetic-feature based representation with corresponding outreach scores, enabling vector space model based retrieval strategies. It also opens new possibilities for research and applications of computational aesthetic analysis of images in the social media advertisement industry. Exploring and tackling the biases excluded by this study, using generic or deep learned features, computational improvements on the feedback system etc. promise exciting scope for future work.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1(1)
- 2Datta et al . (2006) Ritendra Datta, Dhiraj Joshi, Jia Li, and James Z Wang. 2006. Studying aesthetics in photographic images using a computational approach. In European Conference on Computer Vision . Springer, 288–301.
- 3Datta et al . (2008) Ritendra Datta, Jia Li, and James Z Wang. 2008. Algorithmic inferencing of aesthetics and emotion in natural images: An exposition. In Image Processing, 2008. ICIP 2008. 15th IEEE International Conference on . IEEE, 105–108.
- 4Dhar et al . (2011) Sagnik Dhar, Vicente Ordonez, and Tamara L Berg. 2011. High level describable attributes for predicting aesthetics and interestingness. In Computer Vision and Pattern Recognition (CVPR), 2011 IEEE Conference on . IEEE, 1657–1664.
- 5Ke et al . (2006) Yan Ke, Xiaoou Tang, and Feng Jing. 2006. The design of high-level features for photo quality assessment. In Computer Vision and Pattern Recognition, 2006 IEEE Computer Society Conference on , Vol. 1. IEEE, 419–426.
- 6Lazebnik et al . (2006) Svetlana Lazebnik, Cordelia Schmid, and Jean Ponce. 2006. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In Computer vision and pattern recognition, 2006 IEEE computer society conference on , Vol. 2. IEEE, 2169–2178.
- 7Marchesotti et al . (2011) Luca Marchesotti, Florent Perronnin, Diane Larlus, and Gabriela Csurka. 2011. Assessing the aesthetic quality of photographs using generic image descriptors. In Computer Vision (ICCV), 2011 IEEE International Conference on . IEEE, 1784–1791.
- 8Murray et al . (2012) Naila Murray, Luca Marchesotti, and Florent Perronnin. 2012. AVA: A large-scale database for aesthetic visual analysis. In Computer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on . IEEE, 2408–2415.