Super-Resolution of Wavelet-Encoded Images
Vildan Atalay Aydin, Hassan Foroosh

TL;DR
This paper introduces a novel multiview super-resolution method that explicitly relates high-frequency spectra of the HR image to LR images, enabling more accurate reconstruction by focusing on spectral extrapolation rather than iterative optimization.
Contribution
It derives explicit closed-form spectral relationships for multiview super-resolution, reducing reliance on iterative regularization and improving reconstruction accuracy.
Findings
Outperforms state-of-the-art methods in super-resolution quality
Reduces computational complexity by avoiding iterative optimization
Effectively reconstructs high-frequency details from multiple views
Abstract
Multiview super-resolution image reconstruction (SRIR) is often cast as a resampling problem by merging non-redundant data from multiple low-resolution (LR) images on a finer high-resolution (HR) grid, while inverting the effect of the camera point spread function (PSF). One main problem with multiview methods is that resampling from nonuniform samples (provided by LR images) and the inversion of the PSF are highly nonlinear and ill-posed problems. Non-linearity and ill-posedness are typically overcome by linearization and regularization, often through an iterative optimization process, which essentially trade off the very same information (i.e. high frequency) that we want to recover. We propose a novel point of view for multiview SRIR: Unlike existing multiview methods that reconstruct the entire spectrum of the HR image from the multiple given LR images, we derive explicit…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1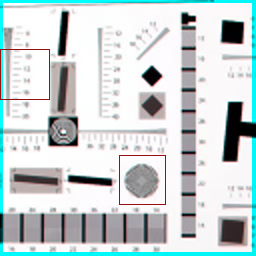 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4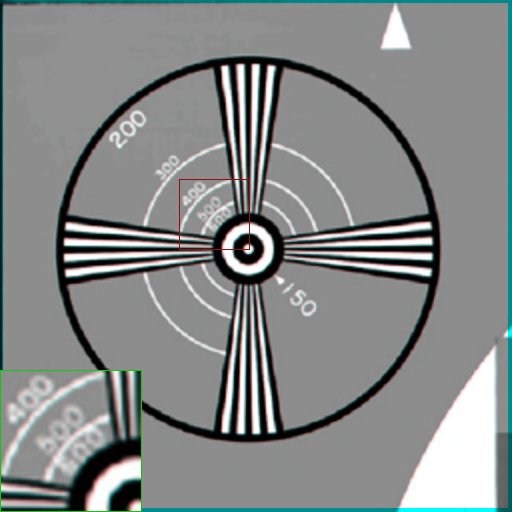 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10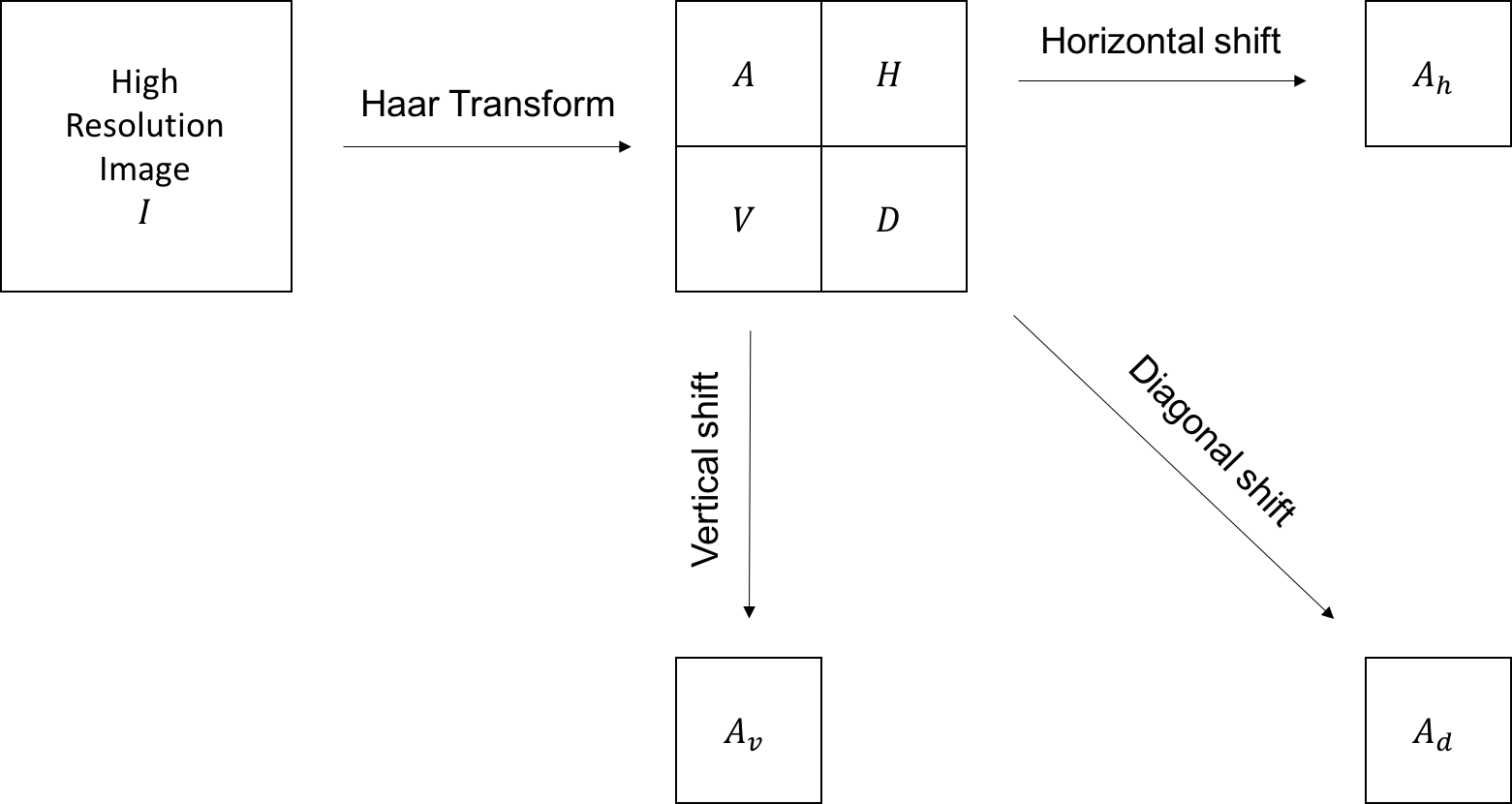 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23 Figure 24
Figure 24 Figure 25
Figure 25 Figure 26
Figure 26 Figure 27
Figure 27 Figure 28
Figure 28 Figure 29
Figure 29 Figure 30
Figure 30 Figure 31
Figure 31 Figure 32
Figure 32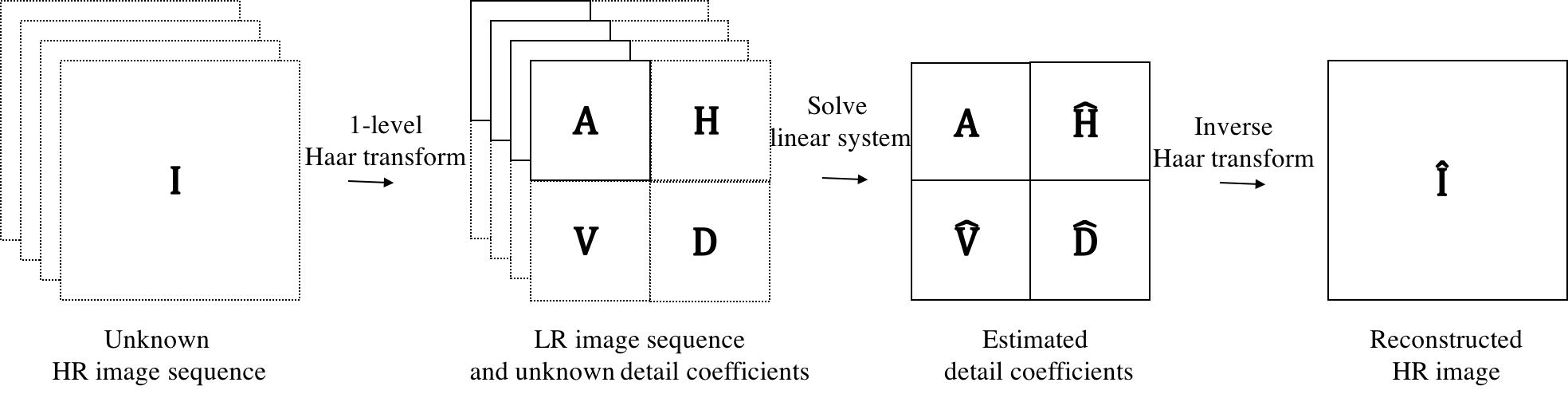 Figure 33
Figure 33 Figure 34
Figure 34 Figure 35
Figure 35 Figure 36
Figure 36 Figure 37
Figure 37 Figure 38
Figure 38 Figure 39
Figure 39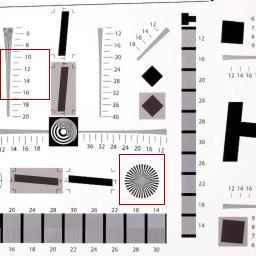 Figure 40
Figure 40| Reference HR image | |
| level Haar wavelet transform approximation, horizontal, vertical, and diagonal detail coefficients of , respectively | |
| Matrices to be multiplied by approximation and detail coefficients (i.e. ) of the reference HR image, that are used to define in-band shift of the reference LR image (i.e. ) | |
| Number of hypothetically added levels in case of non-integer shifts | |
| Integer shift amount after the hypothetically added levels () |
| Image | Bicubic | [110] | [10] | [40] | [35] | Proposed | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR | RMSE | SSIM | PSNR | RMSE | SSIM | PSNR | RMSE | SSIM | PSNR | RMSE | SSIM | PSNR | RMSE | SSIM | PSNR | RMSE | SSIM | |
| Lena | 26.57 | 11.97 | 0.81 | 22.69 | 18.70 | 0.68 | 22.51 | 19.1 | 0.77 | 26.82 | 11.62 | 0.83 | 28.37 | 9.73 | 0.88 | 32.65 | 5.94 | 0.96 |
| Car tag | 26.86 | 11.58 | 0.87 | 18.57 | 30.06 | 0.54 | 22.92 | 18.21 | 0.78 | 23.83 | 17.38 | 0.84 | 29.86 | 8.19 | 0.93 | 33.15 | 5.61 | 0.97 |
| Chart | 24.28 | 15.57 | 0.84 | 19.80 | 26.10 | 0.72 | 22.00 | 20.26 | 0.79 | 23.00 | 18.05 | 0.85 | 26.07 | 12.68 | 0.89 | 29.85 | 8.20 | 0.96 |
| Mandrill | 22.13 | 19.94 | 0.61 | 20.76 | 23.37 | 0.50 | 15.15 | 44.59 | 0.42 | 22.98 | 18.09 | 0.63 | 22.25 | 19.69 | 0.63 | 24.09 | 15.93 | 0.90 |
| Circles | 14.15 | 50.02 | 0.66 | 22.55 | 19.02 | 0.96 | 25.23 | 13.97 | 0.97 | 27.42 | 10.85 | 0.98 | 37.33 | 3.47 | 0.99 | 33.57 | 5.34 | 0.99 |
| Car | 24.01 | 16.07 | 0.80 | 21.43 | 21.64 | 0.71 | 21.47 | 21.54 | 0.74 | 23.23 | 17.59 | 0.82 | 25.02 | 14.30 | 0.86 | 31.14 | 7.07 | 0.97 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Image Processing Techniques · Advanced Vision and Imaging · Image and Signal Denoising Methods
Super-Resolution of Wavelet-Encoded Images
Vildan Atalay Aydin and Hassan Foroosh Vildan Atalay Aydin and Hassan Foroosh are with the Department of Computer Science, University of Central Florida, Orlando, FL, 32816 USA (e-mails: [email protected] and [email protected]).
Abstract
Multiview super-resolution image reconstruction (SRIR) is often cast as a resampling problem by merging non-redundant data from multiple low-resolution (LR) images on a finer high-resolution (HR) grid, while inverting the effect of the camera point spread function (PSF). One main problem with multiview methods is that resampling from nonuniform samples (provided by LR images) and the inversion of the PSF are highly nonlinear and ill-posed problems. Non-linearity and ill-posedness are typically overcome by linearization and regularization, often through an iterative optimization process, which essentially trade off the very same information (i.e. high frequency) that we want to recover. We propose a novel point of view for multiview SRIR: Unlike existing multiview methods that reconstruct the entire spectrum of the HR image from the multiple given LR images, we derive explicit expressions that show how the high-frequency spectra of the unknown HR image are related to the spectra of the LR images. Therefore, by taking any of the LR images as the reference to represent the low-frequency spectra of the HR image, one can reconstruct the super-resolution image by focusing only on the reconstruction of the high-frequency spectra. This is very much like single-image methods, which extrapolate the spectrum of one image, except that we rely on information provided by all other views, rather than by prior constraints as in single-image methods (which may not be an accurate source of information). This is made possible by deriving explicit closed-form expressions that define how the local high frequency information that we aim to recover for the reference high resolution image is related to the local low frequency information in the sequence of views. The locality of these expressions due to modeling using wavelets reduces the problem to an exact and linear set of equations that are well-posed and solved algebraically without requiring regularization or interpolation. Results and comparisons with recently published state-of-the-art methods show the superiority of the proposed solution.
Index Terms:
Discrete Wavelet Transforms Image Reconstruction Image Resolution Image Restoration Wavelet Coefficients
I Introduction
Super-resolution [78, 75, 76, 62, 72, 19, 73, 49, 74] has a wide-range of applications in various areas of imaging and computer vision, such as self-localization [54, 58, 26], image annotation [92, 93, 94, 90, 89, 91], surveillance [52, 53, 57], action recognition [87, 8, 6, 83, 82, 86, 9, 81, 7, 21, 88, 4], target tracking [85, 79, 64, 65], shape description and object recognition [106, 23, 22, 1, 1], image-based rendering [2, 14, 12, 84], and camera motion estimation [55, 26, 25, 24, 56, 28, 27, 5], to name a few. The goal of multiview super-resolution image reconstruction is to obtain a high resolution (HR) image by fusing a sequence of degraded or aliased low resolution (LR) images of the same scene where degradation can be a consequence of motion, camera optics, atmosphere, insufficient sampling, etc.
Approaches to solve the SRIR problem can be classified into frequency domain, interpolation, regularization, and learning-based methods ([67, 96]).
Fourier-based methods make use of the aliasing property of LR images in order to reconstruct an HR image. Even though these methods are intuitive and have low computational complexity, due to their global nature, they only allow linear space invariant blur (PSF). Moreover, it is difficult to identify a global frequency-domain a priori knowledge to overcome ill-posedness. Some examples of Fourier domain techniques include the following works: [98] exploit the relationship between Continuous Fourier Transform (CFT) of the unknown HR scene and Discrete Fourier Transform (DFT) of the shifted and sampled LR images; [69] utilize double random phase encoding in the imaging process in order to achieve SRIR with a single image. [70] apply combined Fourier-wavelet de-convolution and de-noising algorithm; and [100] perform registration and reconstruction in the Fourier domain using multiple unregistered images.
Spatial-domain interpolation-based methods ([48, 109, 110]), on the other hand, tackle Fourier-domain obstacles by fusing the information from all LR images using a general interpolation technique, such as the nearest neighbor, bilinear, bicubic, etc. However, these methods result in overly smoothed images. As an example of interpolation based methods, [48] update the HR estimate by iteratively back-projecting the difference between the approximation and exact image. Moreover, [109] utilize multi-surface fitting; whereas, [33] interpolate along the edge direction. [shekarforoush1999data] generalize Papoulis’ sampling theorem to merge nonuniform samples of multiple channels.
In order to stabilize the ill-posed problem of SRIR, regularization-based methods optimize a cost function with a regularization term by incorporating prior knowledge. Some of these methods employ probabilistic estimators such as the maximum likelihood ([60, 37]), maximum a posteriori ([80, 18]), and Bayesian ([10, 20, 68]). The problems with these methods are determination of the prior model, high computational cost, and over-smoothing caused by regularization. More examples of regularization-based methods include the following works: [63] employ Bregman iteration for Total Variation Regularization; [47] carry out canonical correlation analysis for human face SRIR task; [40] minimize norm and utilize regularization based on a bilateral prior; [39] minimize a multi-term cost function; and [105] constrain the SRIR process by using a spatially weighted TV model for different image regions. [62] investigate the contradiction between multichannel super resolution and regularization within the adaptive regularization framework.
Finally, machine learning is also used for SRIR ([36, 43, 104]), where an HR image is obtained from LR images by utilizing training sets of LR/HR images or patch pairs. The problems with these methods again include their high computational cost, and correspondence ambiguities between HR and LR images. [103] utilize kernel partial least squares to implement regression along with a compensation of the primitive HR image with a residual HR image. Clustering and supervised neighbor embedding is employed by [107]. [45] combine multi-image SRIR and example-based approaches based on the assumption that patches in natural images recur many times inside the image; [59] propose a video super resolution method with a convolutional neural network (CNN) that is trained on both spatial and temporal dimensions of videos; and [31] extend video bilevel dictionary learning to multiframe super resolution using motion estimation.
In order to overcome the drawbacks of aforementioned methods, recent research in SRIR explores wavelet-based techniques ([50, 70, 34, 35, 97]). The intuition behind these approaches is that the LR images can be used to model the low-pass subbands of the unknown HR images, in order to reconstruct the high frequency information lost during image acquisition. The use of wavelets is also motivated by the fact that they are widely used in wavelet-encoded imaging ([3, 32, 71, 61]). Therefore, our motivation to study the proposed wavelet-based SRIR is due to the drawbacks of aforementioned methods, growing trend of wavelet-encoded imaging, and the properties of wavelets which include orthogonality, signal localization, and low computing requirements.
Our approach is very much like single-image super-resolution methods that attempt to extend the spectrum of a single image to higher frequencies, but using information from other images, rather than prior knowledge. In that sense, our method is half-way between single-image and multi-image methods, taking advantage of the best of both worlds. In the scope of this paper, we assume that displacements between the reference and other LR images are known a priori or estimated. We also assume that the displacements are pure translational, or corrected to be so. Our contributions are as follows: 1. We establish explicit closed-form expressions that define how the local high frequency information that we aim to recover for the reference HR image is related to the local low frequency information in the given sequence of LR views. 2. We assume that the LR images correspond to the polyphase approximation coefficients of the first level wavelet transform of unknown HR images, which allows us to reduce the inverse problem to a collection of well-posed linear problems (local linearity). Our approach is closed-form, and provides results that are superior to the state-of-the-art. We provide the derived formulae utilizing the Haar wavelet transform as an example due to their locality and low computational requirements; however, a general formulation for wavelets can be derived as well. Our exceptional results are attributed to the accuracy, well-posedness, and the linearity of the equations derived in Section III, and the inherent nature of wavelets, making them very effective in signal localization.
The remainder of this paper is organized as follows. In Section II, a brief summary of wavelet-based methods for SRIR is provided. The notations used throughout the paper along with the derived closed-form linear relationships are defined in Section III. Section IV presents the general SRIR observation model, as well as the proposed approach. The stability analysis of the proposed SRIR method is examined in Section V. Finally, Section VI presents the experimental results and comparisons with both single and multi-image state-of-the-art techniques.
II Related Work
Wavelet-based SRIR approaches can be summarized as follows. In order to reduce noise in SRIR methods, [70] apply a combined Fourier-wavelet deconvolution and denoising algorithm to multiframe SRIR. Authors first produce a sharp and noisy image by fast Fourier based image restoration, then reduce noise by space invariant nonlinear wavelet thresholding. The need to invert large matrices in their method results in solving the problem in the Fourier domain, which has its drawbacks mentioned in Section LABEL:intro. On the other hand, to reduce degradation artifacts such as blurring and the ringing effect, [95] utilize zero padding in the wavelet domain followed by cycle spinning. Their method adopts a simplified edge profile and linear regression for edge degradations. Furthermore, to preserve edges, [34] utilize stationary and discrete wavelet transforms together in an interpolation-based framework. However, even though better than conventional interpolation techniques, the latter two methods still lack sharp edges.
[108] solve a constrained optimization problem utilizing wavelet domain Hidden Markov Tree (HMT) model for the prior knowledge problem, since HMT characterizes the statistics of real world images accurately. In order to suppress the artifacts left after employing their method, cycle spinning is used which leads to blurring as in other interpolation based methods.
[66], contrary to the conventional interpolation based methods, use the regularity and structure in the interlaced sampling of LR images. Even though, for 2D images, they utilize reshaping property of the Kronecker product, which only doubles the complexity for 1D, their method is based on conjugate gradient which is still time consuming. For deblurring, [29] derive iterative algorithms, which decompose HR image obtained from an iteration into different frequency components and add them to the next iteration. Their method utilizes wavelet thresholding for denoising, where high-frequency components are penalized, making their method dependent on accurate noise estimation. Moreover, [50] handle image registration and reconstruction together, by first estimating the homographies between multiple images, then reconstructing the HR image in a wavelet-based iterative back-projection scheme.
Learning-based methods in wavelet-domain include the following works: [51] handle the problem of representing the relationship between LR-HR frames with training their dataset with HR images by learning from wavelet coefficients at finer scales, followed by regularization in a least squares manner; and [44] follow Jiji’s method and employ discrete wavelet transform for training, where a cost function based on maximum a posteriori estimation is optimized with gradient descent method, employing an Inhomogeneous Gaussian Markov random field prior. [35], to solve the problem of varying contents in different images or image patches, learn various sets of bases from a precollected dataset of example image patches, and select one set of bases adaptively to characterize the local sparse wavelet domain. However, these methods are all based on optimization which requires high computational cost.
The above stated methods are performed either iteratively which requires high computational time or based on interpolation which results in overly smooth images. Our goal is to derive a direct relationship between LR images for a closed-form SRIR solution, which prevents sacrificing high quality. Our paper can be viewed as a generalization of the work by [97] to some extent. [97] utilize Taylor series expansion to approximate the high frequency information that we want to recover. Their method is constrained to use LR images which have specific translations (namely 1 pixel in horizontal and 1 pixel in vertical directions). Our method, on the other hand, generalizes the translations for any shift; while determining the exact relationship between LR images and the subbands, instead of providing an approximation.
III Subpixel Shifts of a Low Resolution Image
In-band (i.e. wavelet domain) subpixel shift method along with the related notation are provided in this section.
III-A Notation
Here, we provide the notations used throughout the paper in Table I.
Bold uppercase letters in the following sections demonstrate matrices whereas bold lowercase ones indicate vectors. The subscripts demonstrate horizontal, vertical, and diagonal translations, respectively. Finally, the subscript indicates the th LR or HR image.
III-B Subpixel Shifts
Our goal for the proposed SRIR method is to reconstruct the lost high frequency information of an unknown HR image, given a sequence of subpixel shifted LR images. For this purpose, we first derive the relationship that relates these LR images to the high frequency information of the unknown HR image. This relationship can be described by in-band shift (i.e. in the wavelet domain) of a reference LR image.
In order to find the aforementioned relationship, we first assume that the reference HR image is known. The reference LR image is the approximation coefficients obtained by decomposing the HR image for 1-level Haar Transform. Then, we define shifted LR images based on the resultant Haar coefficients of the HR image. The shifting process is illustrated in Fig. 1, where shifted LR images (i.e. ) are described based on the first level approximation and detail coefficients of the reference HR image (i.e. ).
Below, we derive the mathematical expressions which demonstrate this relationship. The derived equations relate the high-frequency part (i.e. detail wavelet coefficients) of a reference HR image to the low-frequency information provided by the LR image sequence.
Let A, H, V, and D be the first level approximation (i.e. reference LR image), horizontal, vertical, and diagonal detail coefficients, respectively, of a reference HR image, , of size , where and are positive integers. Since 1-level wavelet transform reduces the size of HR image by half in each direction for approximation and detail coefficients, we require the size of HR image to be divisible by 2. Now, a translated LR image in an arbitrary direction can be expressed in matrix form using the level Haar transform of as in the following equation in (1).
[TABLE]
As already mentioned in Section III-A, F and K stand for matrices to be multiplied by the first level lowpass and highpass subbands of the reference HR image, where subscripts and indicate horizontal and vertical shifts. stands for a shifted image in any direction. The low/high-pass subbands together with are of size , and are , whereas and are .
By examining the translational shifts between two LR images in the Haar domain, we realize that horizontal translation reduces to zero and to the identity matrix. This could be comprehended by examining the coefficient matrices defined later in this section (namely, Eq. (3)), by making related vertical components zero (specifically, and ). This observation lets us define a horizontally shifted image by using only approximation and horizontal detail coefficients. Likewise, vertical translation solely necessitates approximation and vertical detail coefficients, in which case is reduced to zero and is equal to the identity matrix. As a result, the equation shown above in Eq. (1), can be expressed for each translation direction as in Eq. (LABEL:linear):
[TABLE]
Here, our focus is on subpixel translations. Contrary to the general concept of approximating a subpixel shift by upsampling an image followed by an integer shift, our method models subpixel shift directly on the original coefficients of the reference HR image, without upsampling. We observe that:
(1) Viewing the wavelet transform of the image as in Fig. 2, upsampling an image is equivalent to adding levels to the bottom of the transform, and setting the detail coefficients to zero while the approximation coefficients remain the same.
(2) Shifting the upsampled image by an amount of is a counterpart of shifting the original image by an amount of , where is the number of added levels.
Fig. 2 demonstrates an example of the upsampling process described above where , which implies that only 1 level of zero detail coefficients are added. Assuming that the HR image is given, Haar Transform of this HR image can be found readily. For upsampling, these Haar Transform coefficients are utilized as approximation coefficients with more levels of detail coefficients which are set to be zero. Here, gray boxes demonstrate added zeros.
These observations allow us to shift a reference LR image in-band (when the corresponding HR image is given) for a subpixel amount without actually upsampling it, which saves memory and reduces the computational cost. In order to shift the reference LR image, the original approximation and detail coefficients of the reference HR image are utilized with a hypothetically added level () and an integer shift value () at the added level.
Now, the aforementioned matrices, , , , and can be defined, in bidiagonal Toeplitz matrix form as follows.
[TABLE]
[TABLE]
[TABLE]
[TABLE]
where and demonstrate the integer shift amounts at the hypothetically added level and the number of added levels for and directions, respectively.
As mentioned earlier, and are , while and are . Sizes of these matrices also indicate that in-band shift of a reference LR image is performed using only the original level Haar coefficients (which are of size ) without upsampling. These matrices show that a 2-pixel neighborhood in the approximation and detail coefficients of a reference HR image is utilized to shift a reference LR image in-band. When the shift amount is negative, diagonals of the matrices interchange. We leave these matrices as square for them to be nonsingular in the SRIR process, otherwise these matrices could be adapted for periodic boundary condition by making them rectangular.
When the shift amount is not divisible by , in order to reach an integer value at the th level, the shift value at the original level is rounded to the closest decimal point which is divisible by .
Here, derived matrices to calculate the first level lowpass subband of a shifted image (i.e. ) are demonstrated. The counterparts for the first level detail coefficients (e.g. ) of the shifted HR images can be found in a similar manner, in order to shift the entire HR reference image directly in the Haar domain. Since for our SRIR method, we will only employ the relationship for approximation coefficients (i.e. LR images), we only provide the related equations.
IV Super Resolution Image Reconstruction
In this section, we first present the SRIR observation model, followed by our proposed method.
IV-A Observation Model
Let denote the desired HR image, and be the th observed LR image. The super resolution observation model is given by:
[TABLE]
where , , , and denote motion, blurring effect, downsampling operator, and noise term for the th LR image, respectively, and is the number of observed LR images. and i are the th LR image and unknown HR images, respectively, represented in lexicographical order.
Given a sequence of observed LR images, , the goal of SRIR is to reconstruct an unknown HR image, i.
IV-B Proposed Method
As in the underlying idea of wavelet-based SRIR algorithms, we assume that the given LR image sequence is the lowpass subbands (i.e. approximation coefficients of 1-level Wavelet Transform) of unknown HR images. The goal is to reconstruct the unknown highpass subbands (i.e. detail coefficients of 1-level Wavelet Transform) of one of these HR images which is chosen as the reference one. The SRIR method described below is the inverse process of the method described in Section III, where HR images are unknown, and high frequency information for one of these underlying HR images is estimated by solving a related linear system.
The relationship between two subpixel shifted LR images depends on the highpass subbands of the underlying reference HR image, as demonstrated in the previous section. This fact is used to construct a linear system of equations based on known LR images (i.e. in Section III) and unknown highpass subbands of the reference HR image (i.e. in Section III) using related formulae from Eq. (LABEL:linear) depending on the translation direction. Since there are three unknowns (i.e. horizontal, vertical, and diagonal detail coefficients of the unknown HR image), three shifted LR images together with the reference LR image are required to solve the linear system. Once this system is solved for the unknowns, inverse Haar transform utilizing the reference LR image and the estimated highpass subbands of the underlying unknown reference HR image gives the reconstructed HR image.
Fig. 3 shows a pictorial explanation of the proposed method, where solid boxes indicate known or estimated coefficients and dotted boxes show unknown ones. Images with the hat symbol (i.e. ) stands for estimated coefficients. As the figure demonstrates, assuming the LR sequence is first level approximation coefficients of the wavelet transform, we estimate the unknown high frequency information of the reference HR image in order to reconstruct the estimated HR image.
In the scope of this paper, we assume that the registration between images are known a priori or has been estimated. Translational shifts can be estimated using one of the methods by [42, 77, 41, 15, 16, 13, 17, 38, 101]. Even though the equations derived in Section III are for subpixel shifts, we apply the proposed SRIR method to the intersection area of any given shift, which may include an integer part, as well.
The proposed algorithm can also be explained step by step in Algorithm - Super Resolution Image Reconstruction as follows.
V Stability Analysis
In this section, we will investigate the stability of our method.
As mentioned in Section IV, our method constructs a linear system of equations based on given LR images and related shifts. Since the LR images (i.e. A, , , and ) and the displacements between them are known, , and D are the only unknowns of the constructed system. This linear system may appear in four forms which include:
1 horizontally, 1 vertically, 1 diagonally shifted image
1 horizontally, 2 diagonally shifted images
1 vertically, 2 diagonally shifted images
3 diagonally shifted images
along with the reference LR image, A, where second and third cases demonstrate the same properties. Thus, we will consider the first, second, and last cases in our analysis.
Case 1 (1 horizontal, 1 vertical, 1 diagonal) : This case constructs a linear system of equations exactly as shown in Eq. (LABEL:linear). This linear system is solved first for H using the equation for , then for V using the equation for , and finally for D using the equation for and substituting the information found for H and V. Since the coefficient matrices are invertible, this system is stable.
Case 2 and 3 (1 horizontal/vertical, 2 diagonal) : Here, we will explore Case 2 with 1 horizontally and 2 diagonally shifted images. Case 3 will demonstrate similar features as mentioned above.
This case includes one and two from Eq. (LABEL:linear) for one horizontal and two diagonally shifted images, where the linear system takes the form:
[TABLE]
Again, as in Case 1, the first equation is stable, therefore H can be found easily. Solving equations for and for V results in:
[TABLE]
where
[TABLE]
In order to tackle the instability problem caused by inverting multiplication and summation of matrices in Eq. (6), we right multiply this equation with . Since and differ only by the shift value for the two diagonally shifted images, results in the identity matrix multiplied by a scalar which depends only on the shifts. Thus, the equation for V becomes:
[TABLE]
where
[TABLE]
where is defined as a constant.
Truncated Singular Value Decomposition (TSVD) is used with the resulting equation in (7) to find V. Rank of TSVD method is decided based on minimizing the following cost function:
[TABLE]
where U shows the identity (i.e. unit) matrix, subscript is Frobenius norm, and stands for rank-r approximation of a matrix X.
In order to successfully truncate X at , we follow a theorem by [46] (Theorem 3.2), which implies that there must be a well-determined gap between the two consecutive singular values at (i.e. ) and (i.e. ).
As one can see in Eq. (7), the stability of our method is partially dependent on the closeness of shift amounts.
Case 4 (3 diagonal) : The final case includes three diagonally shifted images together with the reference image. Therefore, the linear system is constructed as:
[TABLE]
By solving the system above in Eq. (V) for H, we find a generalized Sylvester equation as in:
[TABLE]
where
[TABLE]
By examining for , in the generalized Sylvester equation, could be changed by multiplication by a scalar (as in in Eq. (7)), which leaves as an upper bidiagonal matrix, since is also upper bidiagonal. Moreover, since is an upper bidiagonal matrix, inverse of is an upper triangular matrix ([99]). Therefore, by multiplication of two upper triangular matrices, we obtain upper triangular matrices for . By following similar analysis, we observe that are lower triangular matrices.
Here, we refer to a theorem by [30] for a generalized Sylvester equation to have a unique solution. Interested reader can find the proof for this theorem in the referred paper; we include the theorem here to make this paper self-contained.
Theorem: The matrix equation in (10) has a unique solution if and only if
and are regular matrix pencils,
and 2. 2.
where shows the generalized eigenvalues of the matrix pencils, defines the spectra of the generalized eigenvalues, and demonstrates a matrix pencil.
The matrix pencils constructed as , and , using the given and in Eq. (10), are not guaranteed either to be regular, or to have empty intersection of generalized eigenvalue spectra. For instance, when any of the two LR images have negative horizontal shift amount, the related has zero diagonals, and a zero element on the diagonal makes the matrix pencil singular when a matrix pencil is upper/lower triangular ([11]). Since we know that , and , for , are upper and lower triangular matrices, respectively, forming upper/lower triangular matrix pencils, two images with negative horizontal shifts satisfy requirements for singular matrix pencils.
Based on these facts, solution methods utilized for generalized Sylvester equation cannot be employed here. Therefore, in order to find a solution to the system in Eq. (V), we first vectorize the equations using Kronecker tensor product, before solving for the unknowns:
[TABLE]
for . Here, lowercase bold letters indicate column-vise vectorized versions of , and D, and these vectors have size . The Kronecker tensor products in parenthesis result in matrices of size , where and are the size of LR images.
By solving Eq. (V) for h, we find the following equation which appears similar to the equation for V in Eq. (6):
[TABLE]
where
[TABLE]
for , and
[TABLE]
Here, in order to solve for h, we follow a similar approach to the one used to reach Eq. (7) from Eq. (6), where Eq. (12) is left multiplied by in order to reduce the instability. Again, TSVD is utilized to solve the equation with the same cost function used in Eq. (8).
As in Cases 2 and 3, the stability of our solution depends partly on the closeness of shift values which affects the matrix inversions.
VI Experimental Results
In this section, we first present the implementation details, followed by results for the proposed method along with comparisons to the recent state-of-the-art and conventional techniques. Comparisons are made based on qualitative and quantitative evaluations on both commonly adapted test examples and real world images to demonstrate the influence of compression artifacts and sensor noise on the proposed method. LR image sequences are synthetically generated. Computational time efficiency of the proposed method against other methods are also presented. Moreover, HR and LR reference images for all test cases and zoomed parts in detailed areas for each image are provided.
VI-A Implementation Details
LR image sequences are synthesized by the method explained in Section IV (Imaging Process in Algorithm). LR images are divided into overlapping blocks of size , in order to reduce memory usage and decrease computational time.
To simulate the motion estimation error for the proposed method, HR reference image is shifted randomly for a shift amount which is not necessarily divisible by and shifts are rounded to the closest decimal divisible by for the calculations, as described before in Section III.
For the cases when the shift amounts are not subpixel (which might be integer or include an integer part), we find the intersection area of the images which can be described as subpixel shift. We apply the same method to the intersected area, where boundaries are lost for the maximum integer amount among all shifts.
In order to reduce the boundary problem caused by square coefficient matrices and which does not include the information in the boundaries, the last rows and columns of calculated , and D are extrapolated.
Color images are handled by the conventional approach ([35, 104]), in YIQ color space, where only the illuminance channel of images are dealt with the proposed method, since human visual system is more sensitive to changes in illuminance channel. The chrominance channels are upsampled using bicubic interpolation.
VI-B Qualitative Comparison
We compared our method with both multiframe and single image SRIR techniques including interpolation-based ones which are Bicubic interpolation and Robust Super Resolution ([110]), a regularization-based methods by [10] and [40], and finally a wavelet-domain learning-based method by [35]. Compared methods were given the same input images and knowledge of registration (if required).
Figs. 4, 5, and 7 to 10 show results obtained with our method, the state-of-the-art, and conventional ones. As can be seen from these figures, in zoomed areas particularly, the proposed method generates sharper edges with less artifacts compared to other methods.
While bicubic interpolation ((c) parts in all related figures) tend to introduce blur to the images, Robust SR technique leaves jaggy artifacts on the edges which are easily seen in (d) parts of Figs. 4, 5, and 7 of Lena, Car tag, and Resolution chart images. Babacan’s method alleviates the jaggy artifacts in most cases, yet the final results remain overly smoothed; whereas, Farsiu’s method does not reconstrut details that can be observed especially in part (f) of Figs. 7 and 8 of Resolution chart and Mandrill images. Dong’s method, even though better at removing artifacts and achieving natural looking results compared to the other methods, also is prone to leave blurry images as can be recognized without difficulty in (g) parts of Resolution chart, Mandrill and Car images in Figs. 7, 8, and 10. In addition, compared methods fail to recover fine details which is mostly recognized in car tags and numbers in Figs. 5, 7, 9, and 10.
On the other hand, the proposed method, seen in (h) parts of Figs. 4, 5, and 7 to 10, is able to recover sharp edges without visual artifacts, or blurring the images which leads to generating the closest results to the ground truth. Particularly, Resolution chart, Mandrill and Car images in Figs. 7, 8, and 10 demonstrate the high quality achieved with the proposed method. Recovered texture details with our method can be observed in all test cases upon a closer look, specifically in the feather texture of Lena’s hat in Fig. 4 and hair texture in cheeks of Mandrill image in Fig. 8. Overall, the proposed method removes artifacts and blur while preserving sharp edges without sacrificing a natural look.
VI-C Quantitative Comparison
To further investigate the effectiveness of our method, we also conduct a comparison based on objective measurements PSNR, RMSE and SSIM ([102]), summarized in Table II. Comparisons are based on the illuminance channel of images reconstructed with all methods. The best of all cases are in bold text. While Robust SR performs the worst based on most measurements for all images except Circles in Fig. 9, Dong’s method has much better results compared to the other methods since in order to alleviate the correspondence ambiguity, their method uses different patches in a single image to learn various sets of bases. However, as can be seen also from Table II, in most cases, quantitative comparisons confirm visual ones which shows that our method outperforms the state-of-the-art. Even though for Circles image in Fig. 9, the quantitative measurements are better for Dong’s method, with a closer look in the green bordered square, it can be seen that details are recovered better in our method, e.g. ”600” circle.
VI-D Computational Efficiency
The computational complexity of the proposed method depends on matrix multiplications () along with the TSVD method ( where is the approximation rank). Since all blocks have the same size and use the same shift information, matrix inversions are handled only once, and the proposed super resolution method is applied to all blocks in parallel. Our method can also be applied as a sparse method in order to reduce time complexity, considering the fact that coefficient matrices are either bidiagonal or at most triangular matrices.
Time complexity of the proposed method and state-of-the-art is compared in Table III, where average time taken for different size LR images is shown in seconds. Block size of all compared cases are set to . As can be seen from the table, the proposed method outperforms regularization based method ([10]) (where outliers of [10] are removed for a fair comparison) and learning based method ([35]) especially when the image sizes are relatively large. Since [104] learns a compact representation for image patch pairs in LR and HR images to capture the cooccurrence prior, their method has a lower computational time complexity for smaller size images; however, as the size increases, the proposed method outperforms [104] as well.
A comparison of block sizes with time in seconds and PSNR for the proposed method is shown in Fig. 6. The results are calculated for 100 different images for 100 random shift amounts, and the average time and PSNR are shown in the graphs (after removing the outliers). As one can see from the graph, as block sizes increase, PSNR improves; however, time complexity increases at the same time. Therefore, the block sizes can be decided based on the application depending on the importance of time or accuracy. Although the graph demonstrates the results for square sized blocks, the block sizes are decided based on the image sizes, which can as well be rectangular.
VII Summary and Conclusions
As a final remark, a direct wavelet-based super resolution technique is proposed in this paper by first deriving exact in-band relationships between two subpixel shifted images, then utilizing these relationships in a linear system form to reconstruct high frequency information of a low resolution reference image. Our results outperform the conventional as well as advanced recently published methods. We attribute this to the accuracy, well-posedness and the linearity of the equations derived in Section III and the inherent local nature of wavelets, making them very effective in signal localization. In summary, we present herein a method for super-resolution by effectively estimating the high frequency information in the Haar domain, which in a sense is a hybrid approach between single image and multi-image methods, taking advantage of the best of both worlds.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Muhammad Ali and Hassan Foroosh. Character recognition in natural scene images using rank-1 tensor decomposition. In Image Processing (ICIP), 2016 IEEE International Conference on , pages 2891–2895. IEEE, 2016.
- 2[2] Mais Alnasser and Hassan Foroosh. Image-based rendering of synthetic diffuse objects in natural scenes. In Pattern Recognition, 2006. ICPR 2006. 18th International Conference on , volume 4, pages 787–790. IEEE.
- 3[3] Marc Antonini, Michel Barlaud, Pierre Mathieu, and Ingrid Daubechies. Image coding using wavelet transform. IEEE Transactions on image processing , 1(2):205–220, 1992.
- 4[4] Nazim Ashraf and Hassan Foroosh. Human action recognition in video data using invariant characteristic vectors. In Image Processing (ICIP), 2012 19th IEEE International Conference on , pages 1385–1388. IEEE, 2012.
- 5[5] Nazim Ashraf, Imran Junejo, and Hassan Foroosh. Near-optimal mosaic selection for rotating and zooming video cameras. Computer Vision–ACCV 2007 , pages 63–72, 2007.
- 6[6] Nazim Ashraf, Yuping Shen, Xiaochun Cao, and Hassan Foroosh. View-invariant action recognition using weighted fundamental ratios. Journal of Computer Vision and Image Understanding (CVIU) , 117:587–602, 2013.
- 7[7] Nazim Ashraf, Yuping Shen, and Hassan Foroosh. View-invariant action recognition using rank constraint. In Pattern Recognition (ICPR), 2010 20th International Conference on , pages 3611–3614. IEEE, 2010.
- 8[8] Nazim Ashraf, Chuan Sun, and Hassan Foroosh. View-invariant action recognition using projective depth. Journal of Computer Vision and Image Understanding (CVIU) , 123:41–52, 2014.