Targeted matrix completion
Natali Ruchansky, Mark Crovella, Evimaria Terzi

TL;DR
This paper introduces Targeted, a framework for completing matrices containing low-rank submatrices, achieving lower reconstruction errors by separately processing these submatrices with state-of-the-art methods.
Contribution
The paper presents a novel framework that identifies low-rank submatrices within larger matrices and applies targeted completion, improving accuracy over classical methods.
Findings
Targeted reduces reconstruction errors significantly.
It effectively identifies low-rank submatrices from partial observations.
Achieves better performance than classical matrix completion methods.
Abstract
Matrix completion is a problem that arises in many data-analysis settings where the input consists of a partially-observed matrix (e.g., recommender systems, traffic matrix analysis etc.). Classical approaches to matrix completion assume that the input partially-observed matrix is low rank. The success of these methods depends on the number of observed entries and the rank of the matrix; the larger the rank, the more entries need to be observed in order to accurately complete the matrix. In this paper, we deal with matrices that are not necessarily low rank themselves, but rather they contain low-rank submatrices. We propose Targeted, which is a general framework for completing such matrices. In this framework, we first extract the low-rank submatrices and then apply a matrix-completion algorithm to these low-rank submatrices as well as the remainder matrix separately. Although for the…
Click any figure to enlarge with its caption.
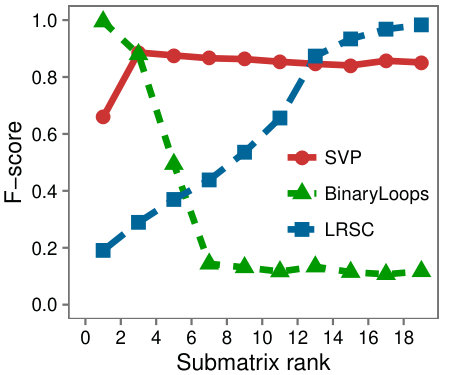 Figure 1
Figure 1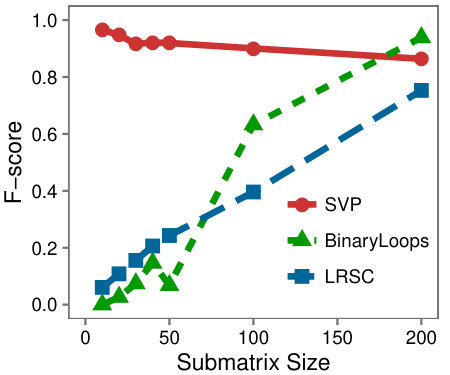 Figure 2
Figure 2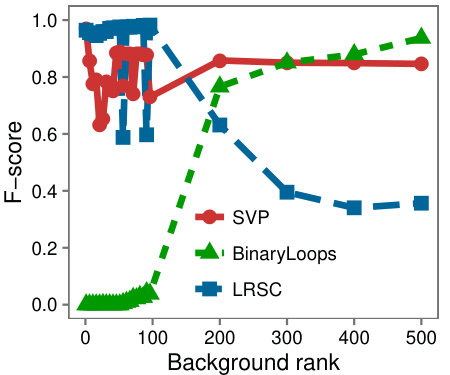 Figure 3
Figure 3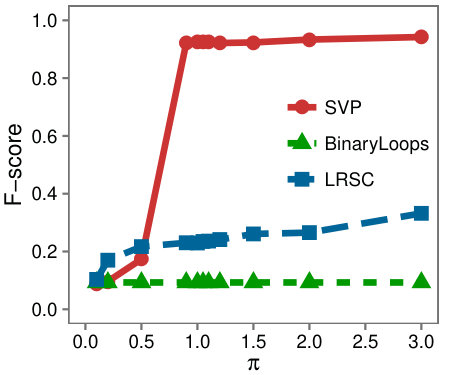 Figure 4
Figure 4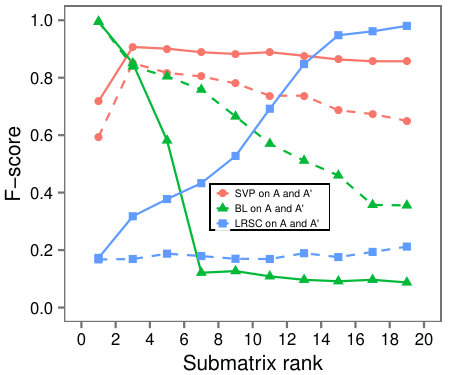 Figure 5
Figure 5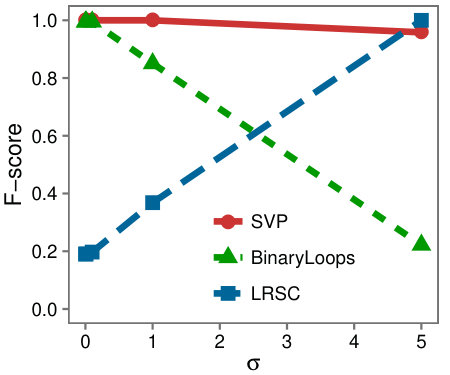 Figure 6
Figure 6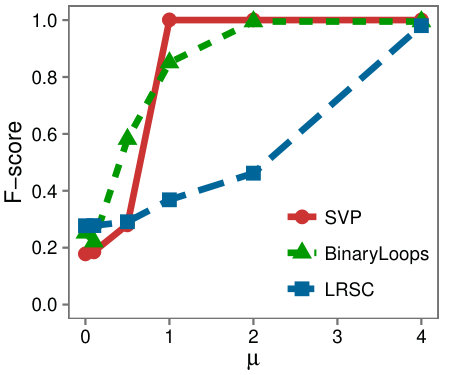 Figure 7
Figure 7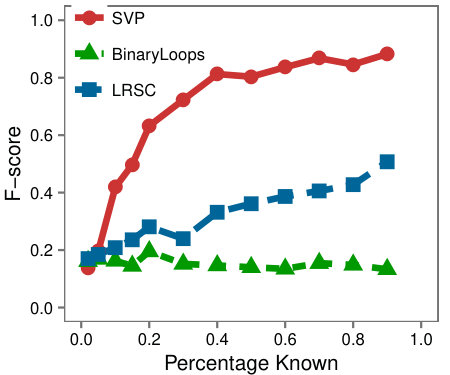 Figure 8
Figure 8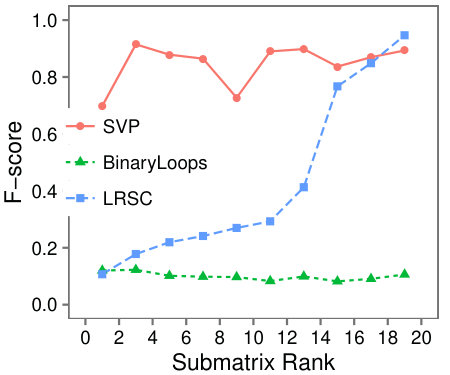 Figure 9
Figure 9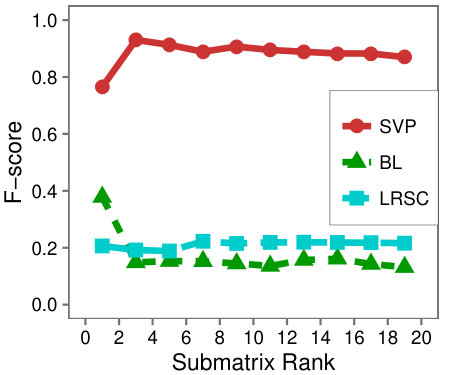 Figure 10
Figure 10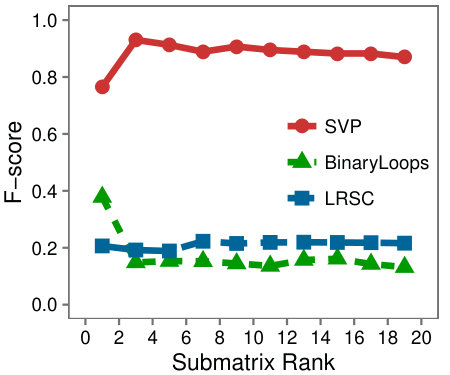 Figure 11
Figure 11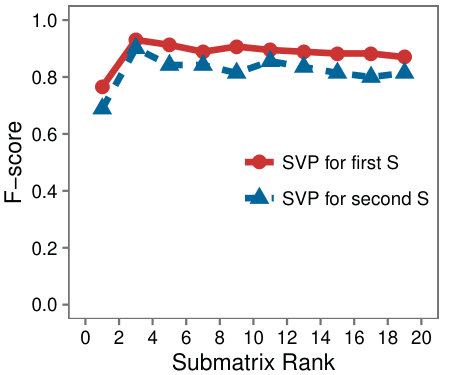 Figure 12
Figure 12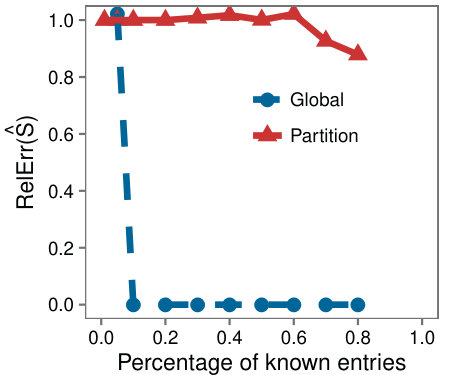 Figure 13
Figure 13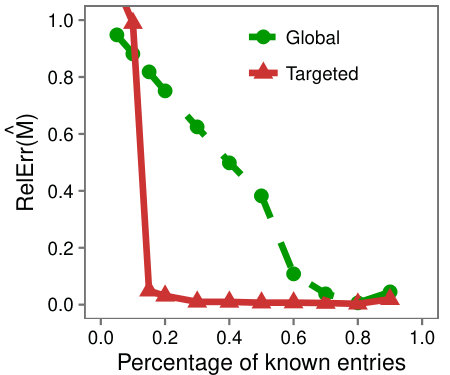 Figure 14
Figure 14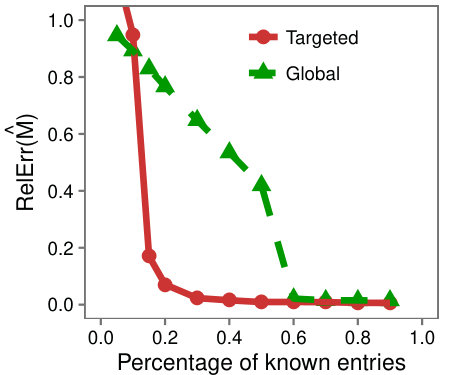 Figure 15
Figure 15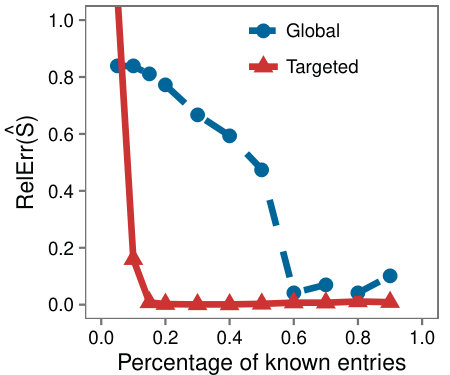 Figure 16
Figure 16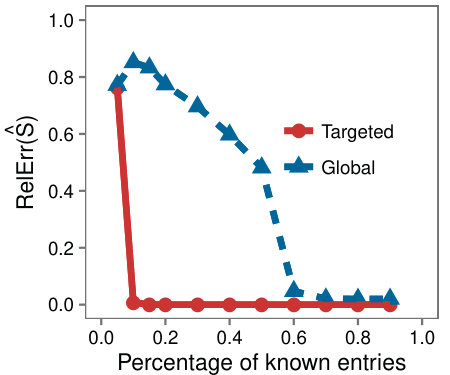 Figure 17
Figure 17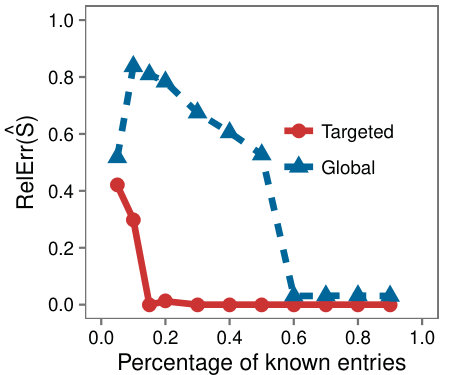 Figure 18
Figure 18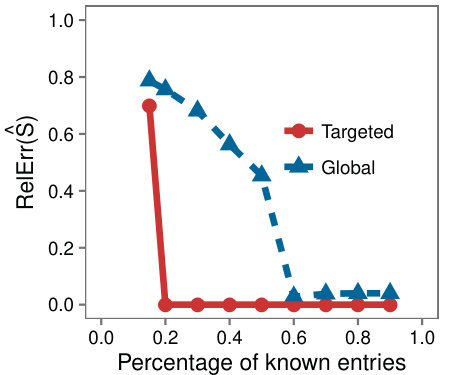 Figure 19
Figure 19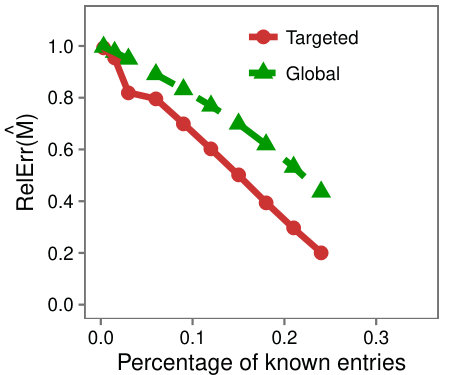 Figure 20
Figure 20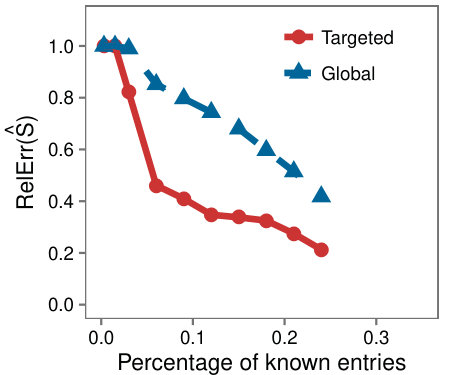 Figure 21
Figure 21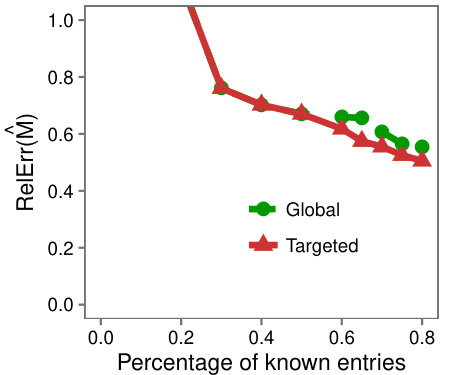 Figure 22
Figure 22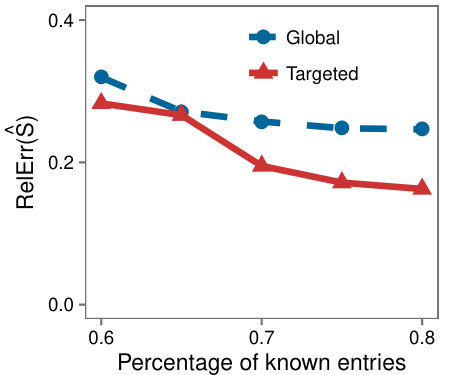 Figure 23
Figure 23| LMaFit | |||||
|---|---|---|---|---|---|
| Targeted |
| SVP | |||||
|---|---|---|---|---|---|
| BinaryLoops | |||||
| LRSC |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Targeted matrix completion††thanks: This research was supported in part by NSF grants CNS-1618207, IIS-1320542, IIS-1421759 and CAREER-1253393, as well as a gift from Microsoft.
Natali Ruchansky University of Southern California, [email protected]
Mark Crovella Boston Unversity, {crovella, evimaria}@cs.bu.edu
Evimaria Terzi††footnotemark:
Abstract
Matrix completion is a problem that arises in many data-analysis settings where the input consists of a partially-observed matrix (e.g., recommender systems, traffic matrix analysis etc.). Classical approaches to matrix completion assume that the input partially-observed matrix is low rank. The success of these methods depends on the number of observed entries and the rank of the matrix; the larger the rank, the more entries need to be observed in order to accurately complete the matrix. In this paper, we deal with matrices that are not necessarily low rank themselves, but rather they contain low-rank submatrices. We propose Targeted, which is a general framework for completing such matrices. In this framework, we first extract the low-rank submatrices and then apply a matrix-completion algorithm to these low-rank submatrices as well as the remainder matrix separately. Although for the completion itself we use state-of-the-art completion methods, our results demonstrate that Targeted achieves significantly smaller reconstruction errors than other classical matrix-completion methods. One of the key technical contributions of the paper lies in the identification of the low-rank submatrices from the input partially-observed matrices.
1 Introduction
The problem of matrix completion continues to draw attention and innovation for its utility in data analysis. Many datasets encountered today can be represented in matrix form; from user-item ratings in recommender systems, to protein interaction levels in biology, to source-destination traffic volumes in the city or Internet. This type of measurement data is often highly incomplete, bringing about the need to estimate the missing entries which is precisely the goal of matrix completion.
Matrix data collected from many of these applications has also been observed to be low rank [7, 13, 20]. The assumption that the underlying matrix is low-rank is key to many matrix completion methods used today [4, 6, 10, 15, 17, 21, 24]. In fact, there is a direct relationship between the number of observed entries and the rank of the underlying matrix; the larger the rank, the more entries are required for an accurate reconstruction to be produced.
In this paper, we deviate from the strict low-rank assumption of the overall matrix and we assume that the matrix has many lower-rank submatrices. For example, in user-preference data, such submatrices may correspond to subsets of users that behave similarly with respect to only subsets of products. Not only is our assumption observed in practical settings, but is also the standard assumption in many recommender- system principles; for example, in collaborative filtering, recommendations are made to a user based on the preferences of other similar users [1, 14, 22]. Further, the assumption is a common in the analysis of traffic networks, datasets in the natural sciences (e.g., gene expression data), and more. Despite the fact that the assumption of the existence of low-rank submatrices is prevalent to many data-analysis settings, there is very little work in the matrix-completion literature that exploits this structure; existing matrix-completion methods need to be enhanced to work well for matrices that contain low-rank submatrices.
The central contribution of our paper is that we propose a new matrix completion paradigm that allows for the completion of partially-observed matrices that contain low-rank submatrices. This framework, which we call Targeted, works as follows: first, in a completely unsupervised manner, it identifies partially-observed submatrices that we expect to be low rank. Then, using standard matrix-completion s it completes each submatrix as well as the remainder of the matrix separately (once the submatrices are removed).
Since most real-world datasets do not come with auxiliary information on the location of low-rank submatrices, we also study the problem of finding low-rank submatrices within a partially-observed matrix. Therefore, a second technical contribution of our paper is the design of SVP (Singular Vector Projection), which identifies low-rank submatrices in an unsupervised manner. Inspired by the Singular Value Decomposition, SVP is simple and efficient – requiring only the computation of the first left and right singular vectors of the input.
From the practical point of view, our experiments with generated data using different models demonstrate that SVP is extremely accurate in identifying low-rank submatrices in partially-observed data. With SVP as an important tool at hand, we demonstrate in the experiments that Targeted is able to significantly improve the accuracy of matrix completion both in real and synthetic datasets.
2 Related work
In this section, we highlight the existing work related to matrix completion, as well as the problem of finding a low-rank submatrix, which we call LRDiscovery.
Matrix completion: Existing approaches to low-rank matrix completion span a wide range of techniques, from norm minimization [5], to singular value thresholding [4], to alternating minimization [24], to name a few. What these approaches have in common is that they assume the whole matrix has low rank, and pose an optimization to fit a single rank- model to the entire matrix. These algorithmss are different from ours since they do not take advantage of the presence of low-rank submatrices.
To the best of our knowledge, the only matrix-completion algorithm that tries to exploit the existence of multiple low-rank submatrices is an algorithm called LLORMA, which was proposed by Lee et al. [16]. Although Lee et al. pose their task as a matrix factorization problem, at a high-level, they also argue that using several smaller factorizations as opposed to a single (global) factorization is more accurate and efficient. The LLORMA algorithm samples a fixed number of submatrices using information about the distances between the input rows and columns. The output is a linear combination of the factorizations of the selected submatrices. The main difference between our framework and LLORMA is that Targeted does not require knowledge of the distances between the rows and the columns of the matrix. Hence, Targeted is more efficient and practical. Another difference is that the LLORMA algorithm relies on a good sampling of represen- tative submatrices and an adequate number of them, whereas the Targeted algorithm does not rely on such sampling. Further, these submatrices selected by LLORMA are not necessarily low rank, since this is not the goal of the algorithm nor of the specific problem it addresses.
Low-rank submatrix discovery: Although there exists work on discovering structure in data, there is little work on the specific problem of discovering low-rank submatrices embedded in larger matrices. We review two lines of research that are most related to the LRDiscovery problem.
To the best of our knowledge, Rangan [19] was the first to explicitly ask the question of finding a low-rank submatrix from a larger matrix. The work focuses on a particular instance where the entries of the matrix and the submatrix adhere to a standard Gaussian distribution with mean zero and variance one, and the submatrix has rank less than five. The algorithm, which we call BinaryLoops, searches for a low-rank submatrix by comparing the -sign patterns of the entries in rows and columns. The output is a nested collection of rows and a nested collection of columns, hence requiring an additional search on the collections to select the right set of rows and columns. The underlying assumptions restrict the success of BinaryLoops to instances where the submatrix is large and has rank less than five. Since our analysis does not make the same assumptions and uses the data values themselves, the SVP algorithm succeeds on a larger range of submatrix sizes and ranks. Furthermore, SVP directly outputs a subset of rows and columns indexing the discovered submatrix and does not require setting a tuning parameter.
The second line of related work, is subspace clustering (SC) as studied in [9, 23], though it does not address exactly the same problem. SC assumes that the rows of the matrix are drawn from a union of independent subspaces, ands seeks to find a clustering of the rows into separate subspaces. SC is related to LRDiscovery in the special case where the low-rank submatrix is only a subset of the rows of the matrix, spanning all columns, and where the submatrix is also an independent subspace. In our experiments, we observe that these algorithms (appropriately modified for our problem) cannot accurately separate the submatrix when the values in the submatrix are not significantly larger than the rest. Further, the algorithms are sensitive to the presence of large values elsewhere in the data. In contrast, our analysis does not assume that the submatrix is an independent subspace and SVP proves to be much more resilient.
Planted Clique: Interestingly, the SVP algorithm we propose for finding a low-rank submatrix bears resemblances to the algorithm for the Planted Clique problem presented by Alon et al. in [2]; both algorithms use some of the singular vectors of a matrix to discover a submatrix with a particular property. Although a clique corresponds a rank-one submatrix of the adjacency matrix, a low-rank submatrix is not necessarily a clique. Further, the success of the algorithm developed in [2] relies on assumptions on the node degrees that allow bounds to be placed on the gap between the second and third eigenvalues. Not only is it unclear that such assumptions would hold in our setting, but it is also not clear whether they are meaningful in the context of low-rank submatrices.
3 Preliminaries
Throughout we use to refer to an fully-known matrix of rank , with to denoting the -th row of and the entry . If is not completely known we use to denote the subset of entries that are observed. The partially observed matrix is denoted as , and when a matrix completion algorithm is applied to we use to denote the output estimate. To measure the error of we use the relative Frobenius error:
[TABLE]
For a low-rank submatrix of , we use and to denote the rows and columns of the original matrix that fully define . That is, . For a set of rows we use the term complement to refer to the set of rows . We also use to denote the complement of , that is if and , then .
The notation is reserved for the first singular vector of , and for any other (sub)matrix we use the corresponding lowercase to denote the -th right singular vector of .
Finally, we use the following conventions: as shorthand for the norm of a vector or matrix. Recall, that the norm of a matrix is its first singular value. For vectors and , we also use to denote the inner product of and .
4 The Targeted matrix-completion framework
The Targeted framework for matrix completion takes as input a partially-observed matrix and proceeds in three main steps: first, identify low-rank submatrices, then separate them from the rest of the data, and finally, complete the extracted low-rank submatrices as well as the whole matrix using an existing matrix completion algorithm. The steps of Targeted are described in more detail below as well as in upcoming sections.
Step 1) Identification of low-rank submatrices: In this step, Targeted deploys our own low-rank submatrix identification technique, which we call SVP and we describe in full detail in Section 5.
Step 2) Separation of the low-rank submatrices: In this step, Targeted separates the low-rank submatrices from the rest of the data. To do this we extract each submatrix , and then replace the entries of with zeros, i.e. for each .
Step 3) Matrix completion: For the completion phase we deploy a state-of-the-art matrix completion algorithm in order to complete all the extracted low-rank submatrices, found in Step 1, as well as the remaining matrix, constructed in Step 2. For our experiments, we use the LMaFit [24] matrix completion algorithm because it is extremely accurate and efficient in practice.
To the best of our knowledge, Step 1 has not been fully addressed in the literature to date. In fact, the problem of finding a low-rank submatrix in a fully known, let alone partially known, matrix is an open and interesting problem. Hence before investigating the benefit of a Targeted framework for matrix completion, we describe our algorithm for Step 1 in the next section.
5 Low-rank submatrix discovery
In this section, we study the first step of Targeted: the problem of finding a low-rank submatrix which we call LRDiscovery. We first focus on developing an algorithm for the setting where the matrix is fully known, and provide an analysis of when it is likely to succeed. Next, we extend to the partially-observed setting.
5.1 Exposing low-rank submatrices.
First, we lay out our main analytical contribution in which we characterize when the singular vectors of can be used to expose evidence that there exists a low-rank submatrix in . We focus the discussion on finding the rows of this submatrix (i.e., we fix ), but the analysis is symmetric for the columns. The following two parameters are key to our characterization:
[TABLE]
The first parameter measures the magnitude of the -norm of with respect to . The second parameter, , measures the geometric orientation of with respect to . Intuitively, when is small, and are well-separated. When and are clear from the context we use to denote and to denote .
The two parameters allow us to characterize the behavior of with respect to the magnitude and geometry of in . In particular, we show that when is large and is adequately small with respect to , the normalized projection of a row on will be larger than that of on . The gap between the projections suggests an approach to LRDiscovery that uses to expose evidence of . To simplify the discussion and capture the intuition above we define:
[TABLE]
Here is an operator that normalizes each row of matrix . Hence, the above is designed to capture the differences in the average projection of rows of and on the first singular vector of .
The crux of our analysis lies in the following proposition:
Proposition 5.1
If and , then , i.e. is -close to .
Intuitively, Proposition 5.1 indicates that if has large -norm and is geometrically well-separated from , then the normalized projection of on will be larger for than for – larger by approximately . This separation suggests that the projections can be used as a feature for separating from .
Proof sketch of Proposition 5.1. Due to space limitations, we sketch the proof of Proposition 5.1 through the case in which consists of two rank-one submatrices: and its complement . Recall that the first singular vector of is and the first singular vector of is .
A key first step is to show that can always be expressed as a (linear) combination of just and , i.e. . We derive expressions for and , showing that
[TABLE]
[TABLE]
in which , , is the -th entry of , and is a constant. Next we show that can be expressed in terms of , , and :
[TABLE]
Putting together the above, it is possible to obtain expressions for and in terms of and . Finally, can be expressed in terms of these inner products and simplifying we obtain Proposition 5.1.
Toy case of rank-1: To explore the implications of Proposition 5.1, we continue to examine the case in which consists of two rank-one components. In this case, . We claim that the set of are either identical for all , or take one of two values:
[TABLE]
Since and are rank one, and . Thus, the gap between the projections of and the projections of is . Using Proposition 5.1, we can say that if the specified conditions on and hold, then is -close to . Hence, as long as and are not parallel, the gap between and with respect to is nonzero, and can be used to find the indices of .
The case with larger ranks: In the case where and its complement have arbitrary ranks, the situation is not so simple. The complication comes from the fact even if the corresponding projection on may not be exactly , and in particular it may be small. The generalization of Proposition 5.1 to larger ranks can be made using the claim that there is still a subset that will have a large projection on .
Proposition 5.2
If the rank- submatrix is nondegenerate, , and , then with such that is -close to .
An rank matrix is nondegenerate if there is no singular submatrix smaller than .
The intuition of the proof of Proposition 5.2 follows that of the rank-1 case. The first step is to derive an expression for in terms of the singular vectors and , and expressions for the subsequent inner products with . Next, we consider , and using nondegeneracy we claim that there is a subset of the rows of that will have high inner product with . We can then show that for each , is -close to . Finally, putting everything together we can show that is -close to ().
In the above discussion we focused on subsets of rows (i.e. the case where ). The results generalize to the case where is a subset of both rows and columns (), by applying the above analysis recursively on and . Hence, we have expressed conditions under which low-rank submatrices can be discovered by the first singular vectors of a matrix, namely: and . As we will demonstrate experimentally in Section 6, these conditions are natural in real world data. An intuitive example is a group of users whose rating patterns for a subset of movies are highly similar, yet differ from other users and on other movies. The conditions lead to an intuitive algorithm that succeeds on a broader set of problem instances than any existing related approach.
5.2 Extracting low-rank submatrices.
In this section, we provide a simple and effective algorithm for finding a low-rank submatrix . Our algorithm builds upon the results of the previous section, which imply the following: the projections of on for will have larger values than the corresponding projections of for . Hence, a straightforward way to find is to project onto and partition the projections into high and low values. This is exactly the idea behind our algorithm for finding .
The pseudo code of this algorithm, which we call SVP standing for Singular Vector Projection, is below:
=
Compute the first right singular vector of . 2. 2.
Project.
Construct the vector of projections on the singular vector . 3. 3.
Partition the rows of into two groups based on the corresponding values in . Identify the set of rows to be the group that has the largest average of the corresponding values. 4. 4.
Repeat steps (1) and (2) on to find .
The SVP algorithm consists of two main steps (applied independently to the rows and the columns of ). After computing , the rows (resp. columns) of are normalized and projected on . These -dimensional points are then clustered into two clusters – in our implementation we use -means. The cluster of rows (resp. columns) with the largest mean is assigned to . Hence, following Proposition 5.1, we can intuitively say that if is large and is small then the low-rank submatrix in is discoverable by SVP.
A reasonable extension is to create multi-dimensional ’s by projecting onto more than one of the singular vectors of . Our experiments indicated that on average, using three singular vectors improves the accuracy with a minimal effect on the efficiency; using more than three singular vectors did give any significant improvement, and we conjecture that this is tied to our use of k-means.
To find multiple low-rank submatrices, SVP can be run on the matrix formed by removing the rows and columns of , i.e. . If the number of low-rank submatrices in is known a priori, SVP can be repeated exactly this many times. Otherwise, the difference in the average projection between the output partitions, , can be used as a stopping criterion where is the output of SVP. For example, allow the algorithm to keep iterating while is greater than a threshold, and stop when it falls below; in our experiments, we found to work well. Another possibility is to replace the submatrix with random noise that is small relative to the values in the rest of the data and rerun on the modified matrix; such an approach would allow for the discovery of submatrices that overlap in rows or columns.
5.3 Dealing with incomplete matrices.
The main tool that SVP relies on is finding the first singular vectors of a matrix. Since the Singular Value Decomposition of an incomplete matrix is not defined, extending SVP to handle incomplete data translates to developing an approach to estimating the singular vectors of a matrix with missing entries. To do this we follow the Incremental-SVD approach first described by Simon Funk in the context of the Netflix challenge [11], and later expanded and implemented in the IncPack toolbox [3]. Hence Step 1 in the SVP described in Section 5.2 is replaced with: =Incremental-SVD.
We experimented with other approaches such as treating the missing entries as zeros and applying the regular SVD algorithm. Further, since this approach may result in over-fitting we modified an implementation of a QR-based power method to stop at an early iteration when the value of stabilizes. All three of these methods gave similar results, without a clear and consistent winner. Finally, we considered an aggregate of the three approaches using clustering aggregation techniques (such as by Gionis et al. in [12]) which slightly improved accuracy at the cost of efficiency.
We note that in principle we require accurate estimation of the direction of the singular vector, as opposed to accurate estimation of the matrix entries; however, we are not aware of any approach for this goal.
6 Experiments
In this section we answer the question posed in Section 1, namely: Can the knowledge of the existence of a low-rank submatrix improve the accuracy of completion? We do this by evaluating the performance of Targeted on datasets with missing entries, and demonstrate the large improvement in accuracy over the state-of-the-art matrix completion algorithms.
For our comparison, we use LMaFit [24] as a representative matrix-completion algorithm that operates on the whole matrix, assuming it is low-rank. Again, the reason we picked LMaFit is because it is extremely accurate and efficient in practice. In our experiments, we consider both synthetic and real world data. After this main set of experiments, we study the behavior of SVP (step 1 in the Targeted framework) over a wide range of matrix instances, and show that SVP succeeds in more cases than the comparison algorithms.
Setup: Throughout the experiments we generate a random matrix of rank with entries following a standard Gaussian distribution with mean equal to zero and variance equal to one, we call this the background matrix. We then plant a submatrix of rank with entries adhering to a centered Gaussian distribution. We maintain constant at ; as this value is only slightly larger than 1, the instances we generate are hard for SVP.
6.1 Evaluation of targeted matrix-completion
To quantify the improvement in matrix completion when using Targeted, we compare the accuracy of the completions produced by each approach. We setup the experiments as described above and set the rank of the matrix to a low rank and the rank of the submatrix to a lower rank . To form the partially observed we vary the percentage of observed entries from to , and measure the relative error (RelError) of each completion according to Equation 3.1 in Section 3.
Figure 1 shows the relative error over (left) and over (right). Immediately we observe the large increase in accuracy when using the Targeted framework. Whereas LMaFit requires approximately of the entries to be known to achieve a relative error lower than , Targeted completion only needs about of the entries for the same accuracy.
To test the accuracy when the matrix contains multiple low-rank submatrices, we follow the same setup but plant three low-rank submatrices of equal size and rank. In Figure 2, we see that the results are consistent for each submatrix; we observe that the Targeted framework achieves a large improvement over LMaFit for each submatrix, and for the whole matrix.
One insight into the success of Targeted is that a single model is not enough for standard matrix completion to capture a matrix with low-rank submatrices. Hence, a Targeted framework that isolates the low-rank submatrices and completes them separately is much more accurate. An observation we made in practice was that the success of Targeted was also due to the reliance of matrix completion on accurate rank-estimation. Techniques for estimating the rank of a partially-observed matrix often err when the input contains low-rank submatrices. However, when applied separately to each component, both the rank estimate and consequently the completion are more accurate.
Sanity check: We wish to check whether the benefit of Targeted can be attributed to the fact that the completion algorithm is applied to submatrices. We do this by asking: given a matrix that does not have low-rank submatrices, will the accuracy of completion increase if the algorithm is run on submatrices?
We follow the same setup as Figure 1, but on a matrix without low-rank submatrices. We selected a random submatrix of , and completed it separately to mimic Targeted; call this approach Partion. Figure 3 shows the RelError over as a function of the percentage of known entries. We see that completing submatrices separately does not help the completion algorithm, implying that the accuracy of Targeted is not due solely to its application on smaller parts of the matrix.
Running time evaluation: To evaluate the change in running time when adopting Targeted, we vary the size of with three low-rank submatrices and fix the density at . In Table 1, we see that Targeted decreases the runtime. This improvement comes from the fact that the completion algorithm becomes more efficient when run on smaller matrices with smaller rank, but also because the rank estimation procedures execute faster.
Case study with gene-expression data: To further validate the usefulness of our approach we use a real-world yeast dataset of size formed by micro-array expression data 111The data is described in is described in [18] and can be downloaded at http://mulan.sourceforge.net/datasets-mlc.html. Each row in the data represents a gene and each column is an experiment; thus, entry is the expression level of gene in experiment . For each gene, the dataset also provides a phylogenetic profile over 14 groups in the form of a binary vector.
To evaluate Targeted on this dataset, we hide a percentage of the known entries just as in the synthetic experiments. Using a threshold of (discussed in Section 5.2) we evaluate the error over the discovered low-rank submatrix in the estimates produced by the LMaFit and Targeted. Figure 4 shows the RelError as a function of the percentage of known entries.
Since this matrix data comes with auxiliary attribute information, we go one step further and analyze the submatrix discovered by SVP. The identified submatrix was with . By comparing the phylogenetic profiles, we found that the genes in were similar. Specifically, when we compared the profiles of the genes in with the genes not in , we found that the average Hamming distance between the profiles of was with a median of and a standard deviation of , while the average Hamming distance among the rest of the genes was and a median of and a standard deviation of . Thus we conclude that the SVP helped isolate a subset of genes with similar profile patterns; according to [18], genes with close profile patterns have similar behavior in biology.
Case study with traffic data: As another real world example we consider a partially observed Internet traffic matrix. Each row corresponds to a source Autonomous System (AS), each column corresponds to a destination prefix, and each entry holds the volume of traffic that flowed from an AS to a prefix. The dataset is only partially observed with of the entries missing. To mimic the setup of the synthetic experiments, we hid a portion of the known entries and evaluated the accuracy at each step.
In Figure 5 we see the same behavior as on synthetic data, with Targeted achieving higher accuracy on the low-rank submatrix. The effect is less pronounced on the whole matrix which we observed to be because the complement of the submatrices had high rank, and LMaFit is less accurate in this setting.
6.2 Evaluation of SVP
In the previous experiments we have demonstrated the improvement the Targeted framework brings to matrix completion. We now isolate and analyze the algorithmic approach to Step 1 – the task of finding a low-rank submatrix on fully known matrices. Our results demonstrate that SVP is effective, efficient, and outperforms other heuristics for the same problem for a large variety of instances.
For experiments we set to rank of the matrix to and the rank of the planted submatrix to . Since the objective of our problem is to find the indices and , we evaluate the accuracy of our framework using the combination of precision and recall to the standard F-Score. The F-score takes values in and the higher its value the better.
We compare SVP against the algorithm by Rangan in [19] (which we call BinaryLoops) and algorithms for Subspace Clustering; the approaches are discussed in detail in Section 2. For Subspace Clustering we show results for LRSC by Vidal and Favaro in [23] since it offers the best balance of accuracy and efficiency; we used the authors’ original implementation. The baseline algorithms required minor modifications since none of them explicitly output the indices of a submatrix. For BinaryLoops we set , according to the author’s recommendation. For LRSC we set when clustering and select the output with the highest accuracy (a user without ground truth would pick the one with lowest empirical rank). All algorithms were coded in Matlab.
Varying size and rank: First we examine a variety of problem instances by comparing the F-Scores of the different algorithms as we vary (a) the rank of , (b) the size of , (c) the rank of the background matrix, and (d) .
Figure 6 shows that SVP accurately locates the low-rank submatrix for the majority of instances, whether is large or small. In Figure 6(d), we see that in line with our analysis, SVP succeeds precisely as the value of grows larger than one.
In contrast to the resilience of SVP observed in the problem instances, LRSC and BinaryLoops are more sensitive to changes. LRSC performs best when the rank and size of are large, and the background rank is small. On the other hand, BinaryLoops has an opposite behavior, performing best on instances where the rank of is less than five, and the background rank is large. These behaviors are in agreement with the analysis and the design of these algorithms in the original papers in which they were introduced.
Data with missing entries: To compare SVP to BinaryLoops, and LRSC on incomplete data, we setup the experiment as described in the setup in Section 6. Figure 7(a) shows the F-score of each algorithm as a function of the percentage of known entries. The results indicate that when the number of known entries is 20% or above the performance of SVP is significantly better than that of BinaryLoops and LRSC.
Multiple submatrices: Finally we test whether the different algorithms are affected by the presence of multiple low-rank submatrices. We setup the experiment as described in the start of Section 6 and plant a second submatrix of the same size and rank as , with .
Figure 7(b) shows the F-Score of each algorithm for the task of finding one submatrix (either or ) as a function of the ranks . We observe that SVP significantly outperforms LRSC and BinaryLoops, and is unaffected by the presence of the second submatrix. Further, after removal of the first submatrix discovered, SVP retains the high level of accuracy for subsequent submatrices.
Running time: We compare the running times of SVP, BinaryLoops and LRSC as the size of the input matrix increases. The running times of the different algorithms are shown in Table 2 in seconds, recall all are in Matlab.
We observe that the difference in the running times is more pronounced for large matrices. For those matrices SVP is the most efficient one, followed by BinaryLoops. The running time of LRSC is times larger than the running time of BinaryLoops and times larger than that of SVP. Note that the running time of SVP is dominated by computing the first singular vectors of and our implementation of SVP uses the off-the-shelf SVD decomposition of MatLab. In principle, we could improve this running time by using other SVD speedups and approximations, such as the one proposed in [8].
7 Conclusions
The problem of matrix completion is consistently attracting attention and advancement due to its relevance to real-world problems. Classical approaches to the problem assume that the data comes from a low-rank distribution and fit a single, rank- model to the whole matrix. However, many applications implicitly assume that the matrix contains submatrices that are even lower rank. Despite the popularity of this assumption, there exist very little work in the matrix completion literature which takes low-rank submatrices into account.
In this work, we propose a Targeted framework that explicitly takes into account the presence of low-rank submatrices. In this framework, the first step is to find low-rank submatrices, and then to apply matrix completion on each component separately. One of the technical contributions is the development of the SVP algorithm for find low-rank submatrices in fully and partially known matrices.
Our experiments with real and synthetic data show that Targeted increases the accuracy of the completion of matrices containing low-rank submatrices. Further, the experiments demonstrate that SVP is an efficient and effective algorithm for extracting low-rank submatrices.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] C. C. Aggarwal. Recommender Systems . Springer, 2016.
- 2[2] N. Alon, M. Krivelevich, and B. Sudakov. Finding a large hidden clique in a random graph. Random Structures and Algorithms , 13(3-4):457–466, 1998.
- 3[3] C. Baker. Incremental svd package. http://www.math.fsu.edu/~cbaker/Inc PACK/ , 2012.
- 4[4] J.-F. Cai, E. J. Candès, and Z. Shen. A singular value thresholding algorithm for matrix completion. SIAM Journal on Optimization , 20(4):1956–1982, 2010.
- 5[5] E. J. Candès and B. Recht. Exact matrix completion via convex optimization. Commun. ACM , 2012.
- 6[6] Y. Chen, S. Bhojanapalli, S. Sanghavi, and R. Ward. Coherent matrix completion. In International Conference on Machine Learning (ICML) , 2014.
- 7[7] M. Davenport and J. Romberg. An overview of low-rank matrix recovery from incomplete observations.
- 8[8] P. Drineas, R. Kannan, and M. W. Mahoney. Fast monte carlo algorithms for matrices ii: Computing a low-rank approximation to a matrix. SIAM Journal on Computing , 36(1):158–183, 2006.