TL;DR
This paper presents a unified convex optimization framework for multi-period trading strategies, extending single-period models like Markowitz to plan sequences of trades with only the first executed, without focusing on prediction methods.
Contribution
It introduces a simple, comprehensive framework for single- and multi-period trading optimization, including approximations and implementation details, along with an open-source software library.
Findings
Framework effectively models trade-offs between return, risk, and costs.
Multi-period approach plans sequences of trades using future estimates.
Open-source library facilitates practical implementation.
Abstract
We consider a basic model of multi-period trading, which can be used to evaluate the performance of a trading strategy. We describe a framework for single-period optimization, where the trades in each period are found by solving a convex optimization problem that trades off expected return, risk, transaction cost and holding cost such as the borrowing cost for shorting assets. We then describe a multi-period version of the trading method, where optimization is used to plan a sequence of trades, with only the first one executed, using estimates of future quantities that are unknown when the trades are chosen. The single-period method traces back to Markowitz; the multi-period methods trace back to model predictive control. Our contribution is to describe the single-period and multi-period methods in one simple framework, giving a clear description of the development and the…
Click any figure to enlarge with its caption.
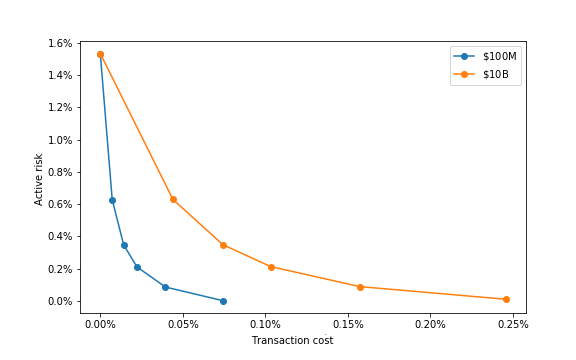 Figure 3
Figure 3 Figure 4
Figure 4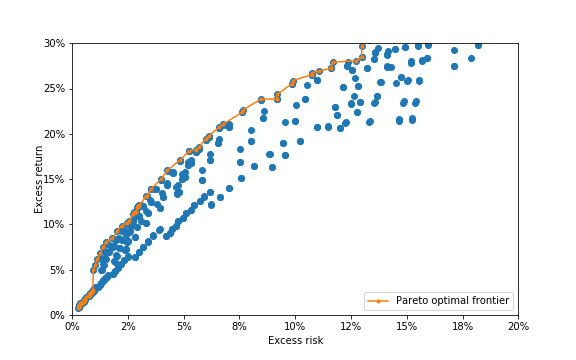 Figure 5
Figure 5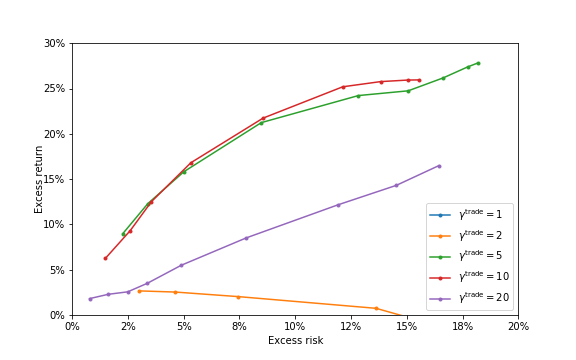 Figure 6
Figure 6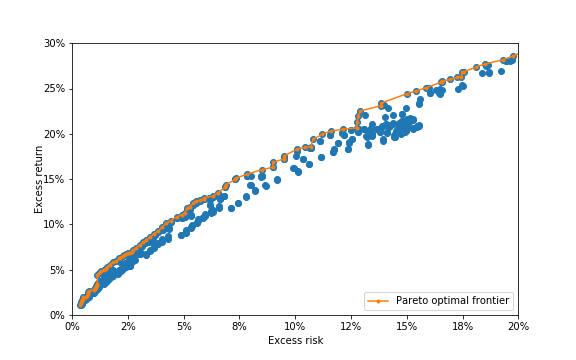 Figure 7
Figure 7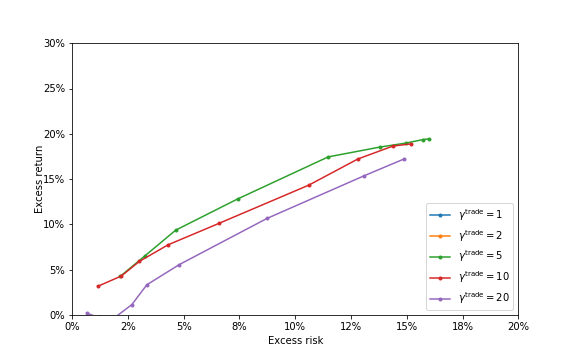 Figure 8
Figure 8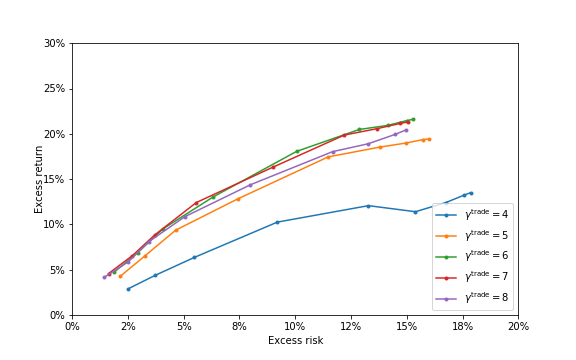 Figure 9
Figure 9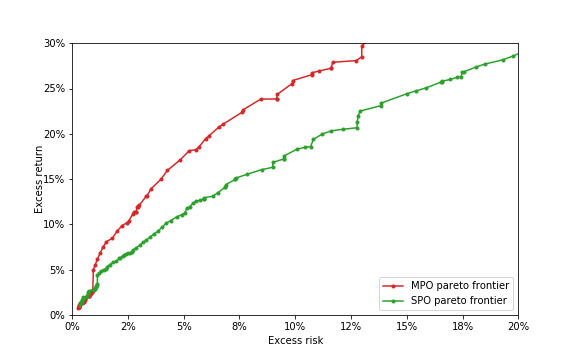 Figure 10
Figure 10| Initial | Rebalancing | Active | Active | Trans. | Turnover |
|---|---|---|---|---|---|
| total val. | frequency | return | risk | cost | |
| $100M | Daily | -0.07% | 0.00% | 0.07% | 220.53% |
| Weekly | -0.07% | 0.09% | 0.04% | 105.67% | |
| Monthly | -0.12% | 0.21% | 0.02% | 52.71% | |
| Quarterly | -0.11% | 0.35% | 0.01% | 29.98% | |
| Annually | -0.10% | 0.63% | 0.01% | 12.54% | |
| Hold | -0.36% | 1.53% | 0.00% | 0.00% | |
| $10B | Daily | -0.25% | 0.01% | 0.25% | 220.53% |
| Weekly | -0.19% | 0.09% | 0.16% | 105.67% | |
| Monthly | -0.20% | 0.21% | 0.10% | 52.71% | |
| Quarterly | -0.17% | 0.35% | 0.07% | 29.99% | |
| Annually | -0.13% | 0.63% | 0.04% | 12.54% | |
| Hold | -0.36% | 1.53% | 0.00% | 0.00% |
| Excess | Excess | |||
|---|---|---|---|---|
| return | risk | |||
| 1000.00 | 8.0 | 100 | 1.33% | 0.39% |
| 562.00 | 6.0 | 100 | 2.49% | 0.74% |
| 316.00 | 7.0 | 100 | 2.98% | 1.02% |
| 1000.00 | 7.5 | 10 | 4.64% | 1.22% |
| 562.00 | 8.0 | 10 | 5.31% | 1.56% |
| 316.00 | 7.5 | 10 | 6.53% | 2.27% |
| 316.00 | 6.5 | 10 | 6.88% | 2.61% |
| 178.00 | 6.5 | 10 | 8.04% | 3.20% |
| 100.00 | 8.0 | 10 | 8.26% | 3.32% |
| 32.00 | 7.0 | 10 | 12.35% | 5.43% |
| 18.00 | 6.5 | 0.1 | 14.96% | 7.32% |
| 6.00 | 7.5 | 10 | 18.51% | 10.44% |
| 2.00 | 6.5 | 10 | 23.40% | 13.87% |
| 0.32 | 6.5 | 10 | 26.79% | 17.50% |
| 0.18 | 7.0 | 10 | 28.16% | 19.30% |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Multi-Period Trading via Convex Optimization
Stephen Boyd
Stanford University
Enzo Busseti
Stanford University
Steven Diamond
Stanford University
Ronald N. Kahn
Blackrock
Kwangmoo Koh
Blackrock
Peter Nystrup
Technical University of Denmark
Jan Speth
Blackrock
Abstract
We consider a basic model of multi-period trading, which can be used to evaluate the performance of a trading strategy. We describe a framework for single-period optimization, where the trades in each period are found by solving a convex optimization problem that trades off expected return, risk, transaction cost and holding cost such as the borrowing cost for shorting assets. We then describe a multi-period version of the trading method, where optimization is used to plan a sequence of trades, with only the first one executed, using estimates of future quantities that are unknown when the trades are chosen. The single-period method traces back to Markowitz; the multi-period methods trace back to model predictive control.
Our contribution is to describe the single-period and multi-period methods in one simple framework, giving a clear description of the development and the approximations made. In this paper we do not address a critical component in a trading algorithm, the predictions or forecasts of future quantities. The methods we describe in this paper can be thought of as good ways to exploit predictions, no matter how they are made. We have also developed a companion open-source software library that implements many of the ideas and methods described in the paper.
Contents
Chapter 1 Introduction
Single and multi-period portfolio selection.
Markowitz [43] was the first to formulate the choice of an investment portfolio as an optimization problem trading off risk and return. Traditionally, this was done independently of the cost associated with trading, which can be significant when trades are made over multiple periods [39]. Goldsmith [29] was among the first to consider the effect of transaction cost on portfolio selection in a single-period setting. It is possible to include many other costs and constraints in a single-period optimization formulation for portfolio selection [42, 52].
In multi-period portfolio selection, the portfolio selection problem is to choose a sequence of trades to carry out over a set of periods. There has been much research on this topic since the work of Samuelson [57] and Merton [47, 48]. Constantinides [16] extended Samuelson’s discrete-time formulation to problems with proportional transaction costs. Davis and Norman [18] and Dumas and Lucian [24] derived similar results for the continuous-time formulation. Transaction costs, constraints, and time-varying forecasts are more naturally dealt with in a multi-period setting. Following Samuelson and Merton, the literature on multi-period portfolio selection is predominantly based on dynamic programming, which properly takes into account the idea of recourse and updated information available as the sequence of trades are chosen (see [28] and references therein). Unfortunately, actually carrying out dynamic programming for trade selection is impractical, except for some very special or small cases, due to the ‘curse of dimensionality’ [4, 9]. As a consequence, most studies include only a very limited number of assets and simple objectives and constraints. A large literature studies multi-period portfolio selection in the absence of transaction cost (see, e.g., [12] and references therein); in this special case, dynamic programming is tractable.
For practical implementation, various approximations of the dynamic programming approach are often used, such as approximate dynamic programming, or even simpler formulations that generalize the single-period formulations to multi-period optimization problems [9]. We will focus on these simple multi-period methods in this paper. While these simplified approaches can be criticized for only approximating the full dynamic programming trading policy, the performance loss is likely very small in practical problems, for several reasons. In [9], the authors developed a numerical bounding method that quantifies the loss of optimality when using a simplified approach, and found it to be very small in numerical examples. But in fact, the dynamic programming formulation is itself an approximation, based on assumptions (like independent or identically distributed returns) that need not hold well in practice, so the idea of an ‘optimal strategy’ itself should be regarded with some suspicion.
Why now?
What is different now, compared to 10, 20, or 30 years ago, is vastly more powerful computer power, better algorithms, specification languages for optimization, and access to much more data. These developments have changed how we can use optimization in multi-period investing. In particular, we can now quickly run full-blown optimizations, run multi-period optimizations, and search over hyper-parameter spaces in back-tests. We can run end-to-end analyses, indeed many at a time in parallel. Earlier generations of investment researchers, relying on computers much less powerful than today, relied much more on separate models and analyses to estimate parameter values, and tested signals using simplified (usually unconstrained) optimizations.
Goal.
In this tutorial paper we consider multi-period investment and trading. Our goal is to describe a simple model that takes into account the main practical issues that arise, and several simple and practical frameworks based on solving convex optimization problems [7] that determine the trades to make. We describe the approximations made, and briefly discuss how the methods can be used in practice. Our methods do not give a complete trading system, since we leave a critical part unspecified: Forecasting future returns, volumes, volatilities, and other important quantities (see, e.g., [32]). This paper describes good practical methods that can be used to trade, given forecasts.
The optimization-based trading methods we describe are practical and reliable when the problems to be solved are convex. Real-world single-period convex problems with thousands of assets can be solved using generic algorithms in well under a second, which is critical for evaluating a proposed algorithm with historical or simulated data, for many values of the parameters in the method.
Outline.
We start in chapter 2 by describing a simple model of multi-period trading, taking into account returns, trading costs, holding costs, and (some) corporate actions. This model allows us to carry out simulation, used for what-if analyses, to see what would have happened under different conditions, or with a different trading strategy. The data in simulation can be realized past data (in a back-test) or simulated data that did not occur, but could have occurred (in a what-if simulation), or data chosen to be particularly challenging (in a stress-test). In chapter 3 we review several common metrics used to evaluate (realized or simulated) trading performance, such as active return and risk with respect to a benchmark.
We then turn to optimization-based trading strategies. In chapter 4 we describe single-period optimization (SPO), a simple but effective framework for trading based on optimizing the portfolio performance over a single period. In chapter 5 we consider multi-period optimization (MPO), where the trades are chosen by solving an optimization problem that covers multiple periods in the future.
Contribution.
Most of the material that appears in this paper has appeared before, in other papers, books, or EE364A, the Stanford course on convex optimization. Our contribution is to collect in one place the basic definitions, a careful description of the model, and discussion of how convex optimization can be used in multi-period trading, all in a common notation and framework. Our goal is not to survey all the work done in this and related areas, but rather to give a unified, self-contained treatment. Our focus is not on theoretical issues, but on practical ones that arise in multi-period trading. To further this goal, we have developed an accompanying open-source software library implemented in Python, and available at
https://github.com/cvxgrp/cvxportfolio.
Target audience.
We assume that the reader has a background in the basic ideas of quantitative portfolio selection, trading, and finance, as described for example in the books by Grinold & Kahn [32], Meucci [49], or Narang [53]. We also assume that the reader has seen some basic mathematical optimization, specifically convex optimization [7]. The reader certainly does not need to know more than the very basic ideas of convex optimization, for example the overview material covered in chapter 1 of this book ([7]). In a nutshell, our target reader is a quantitative trader, or someone who works with or for, or employs, one.
Chapter 2 The Model
In this section we set the notation and give some detail of our simplified model of multi-period trading. We develop our basic dynamic model of trading, which tells us how a portfolio and associated cash account change over time, due to trading, investment gains, and various costs associated with trading and holding portfolios. The model developed in this section is independent of any method for choosing or evaluating the trades or portfolio strategy, and independent of any method used to evaluate the performance of the trading.
2.1 Portfolio asset and cash holdings
Portfolio.
We consider a portfolio of holdings in assets, plus a cash account, over a finite time horizon, which is divided into discrete time periods labeled . These time periods need not be uniformly spaced in real time or be of equal length; for example when they represent trading days, the periods are one (calendar) day during the week and three (calendar) days over a weekend. We use the label to refer to both a point in time, the beginning of time period , as well as the time interval from time to . The time period in our model is arbitrary, and could be daily, weekly, or one hour intervals, for example. We will occasionally give examples where the time indexes trading days, but the same notation and model apply to any other time period.
Our investments will be in a universe of assets, along with an associated cash account. We let denote the portfolio (or vector of positions or holdings) at the beginning of time period , where is the dollar value of asset at the beginning of time period , with meaning a short position in asset , for . The portfolio is long-only when the asset holdings are all nonnegative, i.e., for .
The value of is the cash balance, with meaning that money is owed (or borrowed). The dollar value for the assets is determined using the reference prices , defined as the average of the bid and ask prices at the beginning of time period . When , the portfolio is fully invested, meaning that we hold (or owe) zero cash, and all our holdings (long and short) are in assets.
Total value, exposure, and leverage.
The total value (or net asset value, NAV) of the portfolio, in dollars, at time is , where is the vector with all entries one. (This is not quite the amount of cash the portfolio would yield on liquidation, due to transaction costs, discussed below.) Throughout this paper we will assume that , i.e., the total portfolio value is positive.
The vector
[TABLE]
gives the asset holdings. The gross exposure can be expressed as
[TABLE]
the sum of the absolute values of the asset positions. The leverage of the portfolio is the gross exposure divided by the value, . (Several other definitions of leverage are also used, such as half the quantity above.) The leverage of a fully invested long-only portfolio is one.
Weights.
We will also describe the portfolio using weights or fractions of total value. The weights (or weight vector) associated with the portfolio are defined as . (Recall our assumption that .) By definition the weights sum to one, , and are unitless. The weight is the fraction of the total portfolio value held in cash. The weights are all nonnegative when the asset positions are long and the cash balance is nonnegative. The dollar value holdings vector can be expressed in terms of the weights as . The leverage of the portfolio can be expressed in terms of the weights as , the -norm of the asset weights.
2.2 Trades
Trade vector.
In our simplified model we assume that all trading, i.e., buying and selling of assets, occurs at the beginning of each time period. (In reality the trades would likely be spread over at least some part of the period.) We let denote the dollar values of the trades, at the current price: means we buy asset and means we sell asset , at the beginning of time period , for . The number is the amount we put into the cash account (or take out, if it is negative). The vector gives the trades normalized by the total value. Like the weight vector , it is unitless.
Post-trade portfolio.
The post-trade portfolio is denoted
[TABLE]
This is the portfolio in time period immediately after trading. The post-trade portfolio value is . The change in total portfolio value from the trades is given by
[TABLE]
The vector is the set of (non-cash) asset trades. Half its -norm is the turnover (in dollars) in period . This is often expressed as a percentage of total value, as .
We can express the post-trade portfolio, normalized by the portfolio value, in terms of the weights and normalized trades as
[TABLE]
Note that this normalized quantity does not necessarily add up to one.
2.3 Transaction cost
The trading incurs a trading or transaction cost (in dollars), which we denote as , where is the (dollar) transaction cost function. We will assume that does not depend on , i.e., there is no transaction cost associated with the cash account. To emphasize this we will sometimes write the transaction cost as . We assume that , i.e., there is no transaction cost when we do not trade. While is typically nonnegative, it can be negative in some cases, discussed below. We assume that the transaction cost function is separable, which means it has the form
[TABLE]
i.e., the transaction cost breaks into a sum of transaction costs associated with the individual assets. We refer to , which is a function from R into R, as the transaction cost function for asset , period . We note that some authors have used models of transaction cost which are not separable, for example Grinold’s quadratic dynamic model [31].
A generic transaction cost model.
A reasonable model for the scalar transaction cost functions is
[TABLE]
where , , , , and are real numbers described below, and is a dollar trade amount [32]. The number is one half the bid-ask spread for the asset at the beginning of the time period, expressed as a fraction of the asset price (and so is unitless). We can also include in this term broker commissions or fees which are a linear function of the number of shares (or dollar value) bought or sold. The number is a positive constant with unit inverse dollars. The number is the total market volume traded for the asset in the time period, expressed in dollar value, so has units of dollars. The number the corresponding price volatility (standard deviation) over recent time periods, in dollars. According to a standard rule of thumb, trading one day’s volume moves the price by about one day’s volatility, which suggests that the value of the number is around one. (In practice, however, the value of is determined by fitting the model above to data on realized transaction costs.) The number is used to create asymmetry in the transaction cost function. When , the transaction cost is the same for buying and selling; it is a function of . When , it is cheaper to sell than to buy the asset, which generally occurs in a market where the buyers are providing more liquidity than the sellers (e.g., if the book is not balanced in a limit order exchange). The asymmetry in transaction cost can also be used to model price movement during trade execution. Negative transaction cost can occur when . The constants in the transaction cost model (2.2) vary with asset, and with trading period, i.e., they are indexed by and .
Normalized transaction cost.
The transaction cost model (2.2) is in dollars. We can normalize it by , the total portfolio value, and express it in terms of , the normalized trade of asset , resulting in the function (with suppressed for simplicity)
[TABLE]
The only difference with (2.2) is that we use the normalized asset volume instead of the dollar volume . This shows that the same transaction cost formula can be used to express the dollar transaction cost as a function of the dollar trade, with the volume denoted in dollars, or the normalized transaction cost as a function of the normalized trade, with the volume normalized by the portfolio value.
With some abuse of notation, we will write the normalized transaction cost in period as . When the argument to the transaction cost function is normalized, we use the version where asset volume is also normalized. The normalized transaction cost depends on the portfolio value , as well as the current values of the other parameters, but we suppress this dependence to lighten the notation.
Other transaction cost models.
Other transaction cost models can be used. Common variants include a piecewise linear model, or adding a term that is quadratic in the trade value [2, 31, 28]. Almost all of these are convex functions. (We discuss this later.) An example of a transaction cost term that is not convex is a fixed fee for any nonzero trading in an asset. For simulation, however, the transaction cost function can be arbitrary.
2.4 Holding cost
We will hold the post-trade portfolio over the th period. This will incur a holding-based cost (in dollars) , where is the holding cost function. Like transaction cost, it is typically nonnegative, but it can also be negative in certain cases, discussed below. The holding cost can include a factor related to the length of the period; for example if our periods are trading days, but holding costs are assessed on all days (including weekend and holidays), the friday holding cost might be multiplied by three. For simplicity, we will assume that the holding cost function does not depend on the post-trade cash balance .
A basic holding cost model includes a charge for borrowing assets when going short, which has the form
[TABLE]
where is the borrowing fee, in period , for shorting asset , and denotes the negative part of a number . This is the fee for shorting the post-trade assets, over the investment period, and here we are paying this fee in advance, at the beginning of the period. Our assumption that the holding cost does not depend on the cash account requires . But we can include a cash borrow cost if needed, in which case . This is the premium for borrowing, and not the interest rate, which is included in another part of our model, discussed below.
The holding cost (2.4), normalized by portfolio value, can be expressed in terms of weights and normalized trades as
[TABLE]
As with the transaction cost, with some abuse of notation we use the same function symbol to denote the normalized holding cost, writing the quantity above as . (For the particular form of holding cost described above, there is no abuse of notation since is the same when expressed in dollars or normalized form.)
More complex holding cost functions arise, for example when the assets include ETFs (exchange traded funds). A long position incurs a fee proportional to ; when we hold a short position, we earn the same fee. This is readily modeled as a linear term in the holding cost. (We can in addition have a standard fee for shorting.) This leads to a holding cost of the form
[TABLE]
where is a vector with representing the per-period management fee for asset , when asset is an ETF.
Even more complex holding cost models can be used. One example is a piecewise linear model for the borrowing cost, which increases the marginal borrow charge rate when the short position exceeds some threshold. These more general holding cost functions are almost always convex. For simulation, however, the holding cost function can be arbitrary.
2.5 Self-financing condition
We assume that no external cash is put into or taken out of the portfolio, and that the trading and holding costs are paid from the cash account at the beginning of the period. This self-financing condition can be expressed as
[TABLE]
Here is the total cash out of the portfolio from the trades; (2.6) says that this cash out must balance the cash cost incurred, i.e., the transaction cost plus the holding cost. The self-financing condition implies , i.e., the post-trade value is the pre-trade value minus the transaction and holding costs.
The self-financing condition (2.6) connects the cash trade amount to the asset trades, , by
[TABLE]
Here we use the assumption that the transaction and holding costs do not depend on the (cash) component by explicitly writing the argument as the first components, i.e., those associated with the (non-cash) assets. The formula (2.7) shows that if we are given the trade values for the non-cash assets, i.e., , we can find the cash trade value that satisfies the self-financing condition (2.6).
We mention here a subtlety that will come up later. A trading algorithm chooses the asset trades before the transaction cost function and (possibly) the holding cost function are known. The trading algorithm must use estimates of these functions to make its choice of trades. The formula (2.7) gives the cash trade amount that is realized.
Normalized self-financing.
By dividing the dollar self-financing condition (2.6) by the portfolio value , we can express the self-financing condition in terms of weights and normalized trades as
[TABLE]
where we use and , and the cost functions above are the dollar value versions. Expressing the costs in terms of normalized values we get
[TABLE]
where here the costs are the normalized versions.
As in the dollar version, and assuming that the costs do not depend on the cash values, we can express the cash trade value in terms of the non-cash asset trade values as
[TABLE]
2.6 Investment
The post-trade portfolio and cash are invested for one period, until the beginning of the next time period. The portfolio at the next time period is given by
[TABLE]
where is the vector of asset and cash returns from period to period and denotes Hadamard (elementwise) multiplication of vectors. The return of asset over period is defined as
[TABLE]
the fractional increase in the asset price over the investment period. We assume here that the prices and returns are adjusted to include the effects of stock splits and dividends. We will assume that the prices are nonnegative, so (where the inequality means elementwise). We mention an alternative to our definition above, the log-return,
[TABLE]
For returns that are small compared to one, the log-return is very close to the return defined above.
The number is the return to cash, i.e., the risk-free interest rate. In the simple model, the cash interest rate is the same for cash deposits and loans. We can also include a premium for borrowing cash (say) in the holding cost function, by taking in (2.4). When the asset trades are chosen, the asset returns are not known. It is reasonable to assume that the cash interest rate is known.
Next period portfolio value.
For future reference we work out some useful formulas for the next period portfolio value. We have
[TABLE]
Portfolio return.
The portfolio realized return in period is defined as
[TABLE]
the fractional increase in portfolio value over the period. It can be expressed as
[TABLE]
This is easily interpreted. The portfolio return over period consists of four parts:
- •
is the portfolio return without trades or holding cost,
- •
is the return on the trades,
- •
is the transaction cost, and
- •
is the holding cost.
Next period weights.
We can derive a formula for the next period weights in terms of the current weights and the normalized trades , and the return , using the equations above. Simple algebra gives
[TABLE]
By definition, we have . This complicated formula reduces to when . We note for future use that when the per-period returns are small compared to one, we have .
2.7 Aspects not modeled
We list here some aspects of real trading that our model ignores, and discuss some approaches to handle them if needed.
External cash.
Our self-financing condition (2.6) assumes that no external cash enters or leaves the portfolio. We can easily include external deposits and withdrawals of cash by replacing the right-hand side of (2.6) with the external cash put into the account (which is positive for cash deposited into the account and negative for cash withdrawn).
Dividends.
Dividends are usually included in the asset return, which implicitly means they are re-invested. Alternatively we can include cash dividends from assets in the holding cost, by adding the term , where is the vector of dividend rates (in dollars per dollar of the asset held) in period . In other words, we can treat cash dividends as negative holding costs.
Non-instant trading.
Our model assumes all trades are carried out instantly at the beginning of each investment period, but the trades are really executed over some fraction of the period. This can be modeled using the linear term in the transaction cost, which can account for the movement of the price during the execution. We can also change the dynamics equation
[TABLE]
to
[TABLE]
where is the fraction of the period over which the trades occur. In this modification, we do not get the full period return on the trades when , since we are moving into the position as the price moves.
The simplest method to handle non-instant trading is to use a shorter period. For example if we are interested in daily trading, but the trades are carried out over the whole trading day and we wish to model this effect, we can move to an hourly model.
Imperfect execution.
Here we distinguish between , the requested trade, and , the actual realized trade. In a back-test simulation we might assume that some (very small) fraction of the requested trades are only partially completed.
Multi-period price impact.
This is the effect of a large order in one period affecting the asset price in future periods. In our model the transaction cost is only a function of the current period trade vector, not previous ones.
Trade settlement.
In trade settlement we keep track of cash from trades one day and two days ago (in daily simulation), as well as the usual (unencumbered) cash account which includes all cash from trades that occurred three or more days ago, which have already settled. Shorting expenses come from the unencumbered cash, and trade-related cash moves immediately into the one day ago category (for daily trading).
Merger/acquisition.
In a certain period one company buys another, converting the shares of the acquired company into shares of the acquiring company at some rate. This modifies the asset holdings update. In a cash buyout, positions in the acquired company are converted to cash.
Bankruptcy or dissolution.
The holdings in an asset are reduced to zero, possibly with a cash payout.
Trading freeze.
A similar action is a trading freeze, where in some time periods an asset cannot be bought, or sold, or both.
2.8 Simulation
Our model can be used to simulate the evolution of a portfolio over the periods . This requires the following data, when the standard model described above is used. (If more general transaction or holding cost functions are used, any data required for them is also needed.)
- •
Starting portfolio and cash account values, .
- •
Asset trade vectors . The cash trade value is determined from the self-financing condition by (2.7).
- •
Transaction cost model parameters , , , , and .
- •
Shorting rates .
- •
Returns .
- •
Cash dividend rates , if they are not included in the returns.
Back-test.
In a back-test the values would be past realized values, with the trades proposed by the trading algorithm being tested. Such a test estimates what the evolution of the portfolio would have been with different trades or a different trading algorithm. The simulation determines the portfolio and cash account values over the simulation period, from which other metrics, described in chapter 3 below, can be computed. As a simple example, we can compare the performance of re-balancing to a given target portfolio daily, weekly, or quarterly.
A simple but informative back-test is to simulate the portfolio evolution using the actual trades that were executed in a portfolio. We can then compare the actual and simulated or predicted portfolio holdings and total value over some time period. The true and simulated portfolio values will not be identical, since our model relies on estimates of transaction and holding costs, assumes instantaneous trade execution, and so on.
What-if simulations.
In a what-if simulation, we change the data used to carry out the simulation, i.e., returns, volumes, and so on. The values used are ones that (presumably) could have occurred. This can be used to stress-test a trading algorithm, by using data that did not occur, but would have been very challenging.
Adding uncertainty in simulations.
Any simulation of portfolio evolution relies on models of transaction and holding costs, which in turn depend on parameters. These parameters are not known exactly, and in any case, the models are not exactly correct. So the question arises, to what extent should we trust our simulations? One simple way to check this is to carry out multiple simulations, where we randomly perturb the model parameters by reasonable amounts. For example, we might vary the daily volumes from their true (realized) values by 10% each day. If simulation with parameters that are perturbed by reasonable amounts yields divergent results, we know that (unfortunately) we cannot trust the simulations.
Chapter 3 Metrics
Several generic performance metrics can be used to evaluate the portfolio performance.
3.1 Absolute metrics
We first consider metrics that measure the growth of portfolio value in absolute terms, not in comparison to a benchmark portfolio or the risk-free rate.
Return and growth rate.
The average realized return over periods is
[TABLE]
An alternative measure of return is the growth rate (or log-return) of the portfolio in period , defined as
[TABLE]
The average growth rate of the portfolio is the average value of over the periods . For per-period returns that are small compared to one (which is almost always the case in practice) is very close to .
The return and growth rates given above are per-period. For interpretability they are typically annualized [3]: Return and growth rates are multiplied by , where is the number of periods in one year. (For periods that are trading days, we have .)
Volatility and risk.
The realized volatility is the standard deviation of the portfolio return time series,
[TABLE]
(This is the maximum-likelihood estimate; for an unbiased estimate we replace with ). The square of the volatility is the quadratic risk. When are small (in comparison to ), a good approximation of the quadratic risk is the second moment of the return,
[TABLE]
The volatility and quadratic risk given above are per-period. For interpretability they are typically annualized. To get the annualized values we multiply volatility by , and quadratic risk by . (This scaling is based on the idea that the returns in different periods are independent random variables.)
3.2 Metrics relative to a benchmark
Benchmark weights.
It is common to measure the portfolio performance against a benchmark, given as a set of weights , which are fractions of the assets (including cash), and satisfy . We will assume the benchmark weights are nonnegative, i.e., the entries in are nonnegative. The benchmark weight (the unit vector with value 0 for all entries except the last, which has value 1) represents the cash, or risk-free, benchmark. More commonly the benchmark consists of a particular set of assets with weights proportional to their capitalization. The benchmark return in period is . (When the benchmark is cash, this is the risk-free interest rate .)
Active and excess return.
The active return (of the portfolio, with respect to a benchmark) is given by
[TABLE]
In the special case when the benchmark consists of cash (so that the benchmark return is the risk-free rate) this is known as excess return, denoted
[TABLE]
We define the average active return , relative to the benchmark, as the average of . We have
[TABLE]
Note that if and , i.e., we hold the benchmark weights and do not trade, the active return is zero. (This relies on the assumption that the benchmark weights are nonnegative, so .)
Active risk.
The standard deviation of , denoted , is the risk relative to the benchmark, or active risk. When the benchmark is cash, this is the excess risk . When the risk-free interest rate is constant, this is the same as the risk .
Information and Sharpe ratio.
The (realized) information ratio (IR) of the portfolio relative to a benchmark is the average of the active returns over the standard deviation of the active returns [32],
[TABLE]
In the special case of a cash benchmark this is known as Sharpe ratio (SR) [58, 59]
[TABLE]
Both and are typically given using the annualized values of the return and risk [3].
Chapter 4 Single-Period Optimization
In this section we consider optimization-based trading strategies where at the beginning of period , using all the data available, we determine the asset portion of the current trade vector (or the normalized asset trades ). The cash component of the trade vector is then determined by the self-financing equation (2.9), once we know the realized costs. We formulate this as a convex optimization problem, which takes into account the portfolio performance over one period, the constraints on the portfolio, and investment risk (described below). The idea goes back to Markowitz [43], who was the first to formulate the choice of a portfolio as an optimization problem. (We will consider multi-period optimization in the next section.)
When we choose , we do not know and the other market parameters (and therefore the transaction cost function ), so instead we must rely on estimates of these quantities and functions. We will denote an estimate of the quantity or function , made at the beginning of period (i.e., when we choose ), as . For example is our estimate of the current period transaction cost function (which depends on the market volume and other parameters, which are predicted or estimated). The most important quantity that we estimate is the return over the current period , which we denote as . (Return forecasts are sometimes called signals.) If we adopt a stochastic model of returns and other quantities, could be the conditional expectation of , given all data that is available at the beginning of period , when the asset trades are chosen.
Before proceeding we note that most of the effort in developing a good trading algorithm goes into forming the estimates or forecasts, especially of the return [13, 32]. In this paper, however, we consider the estimates as given. Thus we focus on the question, given a set of estimates, what is a good way to trade based on them? Even though we do not focus on how the estimates should be constructed, the ideas in this paper are useful in the development of estimates, since the value of a set of estimates can depend considerably on how they are exploited, i.e., how the estimates are turned into trades. To properly assess the value of a proposed set of estimates or forecasts, we must evaluate them using a realistic simulation with a good trading algorithm.
We write our estimated portfolio return as
[TABLE]
which is (2.10), with the unknown return replaced with the estimate . The estimated active return is
[TABLE]
Each of these consists of a term that does not depend on the trades, plus
[TABLE]
the return on the trades minus the transaction and holding costs.
4.1 Risk-return optimization
In a basic optimization-based trading strategy, we determine the normalized asset trades by solving the optimization problem
[TABLE]
with variable . Here is a risk function, described below, and is the risk aversion parameter. The objective in (4.2) is called the risk-adjusted estimated return. The sets and are the trading and holdings constraint sets, respectively, also described in more detail below. The current portfolio weight is known, i.e., a parameter, in the problem (4.2). The risk function, constraint sets, and estimated transaction and holding costs can all depend on the portfolio value , but we suppress this dependence to keep the notation light.
To optimize performance against the risk-free interest rate or a benchmark portfolio, we replace in (4.2) with or . By (4.1), these all have the form of a constant that does not depend on , plus
[TABLE]
So in all three cases we get the same trades by solving the problem
[TABLE]
with variable . (We will see later that the risk functions are not the same for absolute, excess, and active return.) The objective has four terms: The first is the estimated return for the trades, the second is the estimated transaction cost, the third term is the holding cost of the post-trade portfolio, and the last is the risk of the post-trade portfolio. Note that the first two depend on the trades and the last two depend on the post-trade portfolio . (Similarly, the first constraint depends on the trades, and the second on the post-trade portfolio.)
Estimated versus realized transaction and holding costs.
The asset trades we choose are given by , where is optimal for (4.3). In dollar terms, the asset trades are .
The true normalized cash trade value is found by the self-financing condition (2.9) from the non-cash asset trades and the realized costs. This is not (in general) the same as , the normalized cash trade value found by solving the optimization problem (4.3). The quantity is the normalized cash trade value with the realized costs, while is the normalized cash trade value with the estimated costs.
The (small) discrepancy between the realized cash trade value and the planned or estimated cash trade value has an implication for the post-trade holding constraint . When we solve (4.3) we require that the post-trade portfolio with the estimated cash balance satisfies the constraints, which is not quite the same as requiring that the post-trade portfolio with the realized cash balance satisfies the constraints. The discrepancy is typically very small, since our estimation errors for the transaction cost are typically small compared to the true transactions costs, which in turn are small compared to the total portfolio value. But it should be remembered that the realized post-trade portfolio can (slightly) violate the constraints since we only constrain the estimated post-trade portfolio to satisfy the constraints. (Assuming perfect trade execution, constraints relating to the asset portion of the post-trade portfolio will hold exactly.)
Simplifying the self-financing constraint.
We can simplify problem (4.3) by replacing the self-financing constraint
[TABLE]
with the constraint . In all practical cases, the cost terms are small compared to the total portfolio value, so the approximation is good. At first glance it appears that by using the simplified constraint in the optimization problem, we are essentially ignoring the transaction and holding costs, which would not produce good results. But we still take the transaction and holding costs into account in the objective.
With this approximation we obtain the simplified problem
[TABLE]
The solution to the simplified problem slightly over-estimates the realized cash trade , and therefore the post-trade cash balance . The cost functions used in optimization are only estimates of what the realized values will be; in most practical cases this estimation error is much larger than the approximation introduced with the simplification . One small advantage (that will be useful in the multi-period trading case) is that in the optimization problem (4.4), is a bona fide set of weights, i.e., ; whereas in (4.3), is (typically) slightly less than one.
We can re-write the problem (4.4) in terms of the variable , which we interpret as the post-trade portfolio weights:
[TABLE]
with variable .
4.2 Risk measures
The risk measure in (4.3) or (4.4) is traditionally an estimate of the variance of the return, using a stochastic model of the returns [43, 39]. But it can be any function that measures our perceived risk of holding a portfolio. We first describe the traditional risk measures.
Absolute risk.
Under the assumption that the returns are stochastic, with covariance matrix , the variance of is given by
[TABLE]
This gives the traditional quadratic risk measure for period ,
[TABLE]
It must be emphasized that is an estimate of the return covariance under the assumption that the returns are stochastic. It is usually assumed that the cash return (risk-free interest rate) is known, in which case the last row and column of are zero.
Active risk.
With the assumption that is stochastic with covariance , the variance of the active return is
[TABLE]
This gives the traditional quadratic active risk measure
[TABLE]
When the benchmark is cash, this reduces to , the absolute risk, since the last row and column of are zero. In the sequel we will work with the active risk, which reduces to the absolute or excess risk when the benchmark is cash.
Risk aversion parameter.
The risk aversion parameter in (4.3) or (4.4) is used to scale the relative importance of the estimated return and the estimated risk. Here we describe how the particular value arises in an approximation of maximizing expected growth rate, neglecting costs. Assuming that the returns are independent samples from a distribution, and is fixed, the portfolio return is a (scalar) random variable. The weight vector that maximizes the expected portfolio growth rate (subject to , ) is called the Kelly optimal portfolio or log-optimal portfolio [38, 10]. Using the quadratic approximation of the logarithm we obtain
[TABLE]
where and are the mean and covariance of the return . Assuming that the term is small compared to (which is the case for realistic daily returns and covariance), the expected growth rate can be well approximated as . So the choice of risk aversion parameter in the single-period optimization problems (4.3) or (4.4) corresponds to approximately maximizing growth rate, i.e., Kelly optimal trading. In practice it is found that Kelly optimal portfolios tend to have too much risk [10], so we expect that useful values of the risk aversion parameter are bigger than .
Factor model.
When the number of assets is large, the covariance estimate is typically specified as a low rank (‘factor’) component, plus a diagonal matrix,
[TABLE]
which is called a factor model (for quadratic risk). Here is the factor loading matrix, is an estimate of the covariance of (the vector of factor returns), and is a nonnegative diagonal matrix.
The number of factors is much less than (typically, tens versus thousands). Each entry is the loading (or exposure) of asset to factor . Factors can represent economic concepts such as industrial sectors, exposure to specific countries, accounting measures, and so on. For example, a technology factor would have loadings of 1 for technology assets and 0 for assets in other industries. But the factor loading matrices can be found using many other methods, for example by a purely data-driven analysis. The matrix accounts for the additional variance in individual asset returns beyond that predicted by the factor model, known as the idiosyncratic risk.
When a factor model is used in the problems (4.3) or (4.4), it can offer a very substantial increase in the speed of solution [55, 7]. Provided the problem is formulated in such a way that the solver can exploit the factor model, the computational complexity drops from to flops, for a savings of . The speedup can be substantial when (as is typical) is on the order of thousands and on the order of tens. (Computational issues are discussed in more detail in section 4.7.)
We now mention some less traditional risk functions that can be very useful in practice.
Transformed risk.
We can apply a nonlinear transformation to the usual quadratic risk,
[TABLE]
where is a nondecreasing function. (It should also be convex, to keep the optimization problem tractable, as we will discuss below.) This allows us to shape our aversion to different levels of quadratic risk. For example, we can take . In this case the transformed risk assesses no cost for quadratic risk levels up to . This can be useful to hit a target risk level, or to be maximally aggressive in seeking returns, up to the risk threshold . Another option is , where is a parameter. This assesses a strong cost to risks substantially larger than , and is closely related to risk aversion used in stochastic optimization.
The solution of the optimization problem (4.3) with transformed risk is the same as the solution with the traditional risk function, but with a different value of the risk aversion parameter. So we can think of transformed risk aversion as a method to automatically tune the risk aversion parameter, increasing it as the risk increases.
Worst-case quadratic risk.
We now move beyond the traditional quadratic risk to create a risk function that is more robust to unpredicted changes in market conditions. We define the worst-case risk for portfolio as
[TABLE]
Here , , are given covariance matrices; we refer to as the scenario. We can motivate the worst-case risk by imagining that the returns are generated from one of distributions, with covariances depending on which scenario occurs. In each period, we do not know, and do not attempt to predict, which scenario will occur. The worst-case risk is the largest risk under the scenarios.
If we estimate the probabilities of occurrence of the scenarios, and weight the scenario covariance matrices by these probabilities, we end up back with a single quadratic risk measure, the weighted sum of the scenario covariances. It is critical that we combine them using the maximum, and not a weighted sum. (Although other nonlinear combining functions would also work.) We should think of the scenarios as describing situations that could arise, but that we cannot or do not attempt to predict.
The scenario covariances can be found by many reasonable methods. They can be empirical covariances estimated from realized (past) returns conditioned on the scenario, for example, high or low market volatility, high or low interest rates, high or low oil prices, and so on [50]. They could be an analyst’s best guess for what the asset covariance would be in a situation that could occur.
4.3 Forecast error risk
The risk measures considered above attempt to model the period to period variation in asset returns, and the associated period to period variation in the portfolio return they induce. In this section we consider terms that take into account errors in our prediction of return and covariance. (The same ideas can be applied to other parameters that we estimate, like volume.) Estimation errors can significantly impact the resulting portfolio weights, resulting in poor out-of-sample performance [36, 51, 15, 37, 20, 25, 39].
Return forecast error risk.
We assume our forecasts of the return vector are uncertain: Any forecast with and is possible and consistent with what we know. In other words, is a vector of uncertainties on our return prediction . If we are confident in our (nominal) forecast of the return of asset , we take small; conversely large means that we are not very confident in our forecast. The uncertainty in return forecast is readily interpreted when annualized; for example, our uncertain return forecast for an asset might be described as , meaning any forecast return between and is possible.
The post-trade estimated return is then ; we define the minimum of this over as the worst-case return forecast. It is easy to see what the worst-case value of is: If we hold a long position, the return (for that asset) should take its minimum value ; if we hold a short position, it should take its maximum allowed value . The worst-case return forecast has the value
[TABLE]
The first term here is our original estimate (including the constant terms we neglect in (4.3) and (4.4)); the second term (which is always nonpositive) is the worst possible value of our estimated active return over the allowed values of . It is a risk associated with forecast uncertainty. This gives
[TABLE]
(This would typically be added to a traditional quadratic risk measure.) This term is a weighted -norm of the deviation from the weights, and encourages weights that deviate sparsely from the benchmark, i.e., weights with some or many entries equal to those of the benchmark [26, 34, 41].
Covariance forecast error risk.
In a similar way we can add a term that corresponds to risk of errors in forecasting the covariance matrix in a traditional quadratic risk model. As an example, suppose that we are given a nominal covariance matrix , and consider the perturbed covariance matrix
[TABLE]
where is a symmetric perturbation matrix with
[TABLE]
where is a parameter. This perturbation model means that the diagonal entries of covariance can change by the fraction ; ignoring the change in the diagonal entries, the asset correlations can change by up to (roughly) . The value of depends on our confidence in the covariance matrix; reasonable values are , , or more.
With , the maximum (worst-case) value of the quadratic risk over this set of perturbations is given by
[TABLE]
This shows that the worst-case covariance, over all perturbed covariance matrices consistent with our risk forecast error assumption (4.7), is given by
[TABLE]
where is the vector of asset volatilities. The first term is the usual quadratic risk with the nominal covariance matrix; the second term can be interpreted as risk associated with covariance forecasting error [34, 41]. It is the square of a weighted -norm of the deviation of the weights from the benchmark. (With cash benchmark, this directly penalizes large leverage.)
4.4 Holding constraints
Holding constraints restrict our choice of normalized post-trade portfolio . Holding constraints may be surrogates for constraints on , which we cannot constrain directly since it depends on the unknown returns. Usually returns are small and is close to , so constraints on are good approximations for constraints on . Some types of constraints always hold exactly for when they hold for .
Holding constraints may be mandatory, imposed by law or the investor, or discretionary, included to avoid certain undesirable portfolios. We discuss common holding constraints below. Depending on the specific situation, each of these constraints could be imposed on the active holdings instead of the absolute holdings , which we use here for notational simplicity.
Long only.
This constraint requires that only long asset positions are held,
[TABLE]
If only the assets must be long, this becomes . When a long only constraint is imposed on the post-trade weight , it automatically holds on the next period value , since .
Leverage constraint.
The leverage can be limited with the constraint
[TABLE]
which requires the post-trade portfolio leverage to not exceed . (Note that the leverage of the next period portfolio can be slightly larger than , due to the returns over the period.)
Limits relative to asset capitalization.
Holdings are commonly limited so that the investor does not own too large a portion of the company total value. Let denote the vector of asset capitalization, in dollars. The constraint
[TABLE]
where is a vector of fraction limits, and is interpreted elementwise, limits the long post-trade position in asset to be no more than the fraction of the capitalization. We can impose a similar limit on short positions, relative to asset capitalization, total outstanding short value, or some combination.
Limits relative to portfolio.
We can limit our holdings in each asset to lie between a minimum and a maximum fraction of the portfolio value,
[TABLE]
where and are nonnegative vectors of the maximum short and long allowed fractions, respectively. For example with , we are not allowed to hold more than 5% of the portfolio value in any one asset, long or short.
Minimum cash balance.
Often the cash balance must stay above a minimum dollar threshold (which can be negative). We express a minimum cash balance as the constraint
[TABLE]
This constraint can be slightly violated by the realized values, due to our error in estimation of the costs.
No-hold constraints.
A no-hold constraint on asset forbids holding a position in asset , i.e.,
[TABLE]
-neutrality.
A -neutral portfolio is one whose return is uncorrelated with the benchmark return , according to our estimate of . The constraint that be neutral takes the form
[TABLE]
Factor neutrality.
In the factor covariance model, the estimated portfolio risk due to factor is given by
[TABLE]
The constraint that the portfolio be neutral to factor means that , which occurs when
[TABLE]
Stress constraints.
Stress constraints protect the portfolio against unexpected changes in market conditions. Consider scenarios , each representing a market shock event such as a sudden change in oil prices, a general reversal in momentum, or a collapse in real estate prices. Each scenario has an associated (estimated) return . The could be based on past occurrences of scenario or predicted by analysts if scenario has never occurred before.
Stress constraints take the form
[TABLE]
i.e., the portfolio return in scenario is above . (Typically is negative; here we are limiting the decrease in portfolio value should scenario actually occur.) Stress constraints are related to chance constraints such as value at risk in the sense that they restrict the probability of large losses due to shocks.
Liquidation loss constraint.
We can bound the loss of value incurred by liquidating the portfolio over periods. A constraint on liquidation loss will deter the optimizer from investing in illiquid assets. We model liquidation as the transaction cost to trade over periods. If we use the transaction cost estimate for all periods, the optimal schedule is to trade each period. The constraint that the liquidation loss is no more than the fraction of the portfolio value is given by
[TABLE]
(For optimization against a benchmark, we replace this with the cost to trade the portfolio to the benchmark over periods.)
Concentration limit.
As an example of a non-traditional constraint, we consider a concentration limit, which requires that no more than a given fraction of the portfolio value can be held in some given fraction (or just a specific number ) of assets. This can be written as
[TABLE]
where the notation refers to the th largest element of the vector . The left-hand side is the sum of the largest post-trade positions. For example with and , this constraint prohibits holding more than of the total value in any assets. (It is not well known that this constraint is convex, and indeed, easily handled; see [7, section 3.2.3]. It is easily extended to the case where is not an integer.)
4.5 Trading constraints
Trading constraints restrict the choice of normalized trades . Constraints on the non-cash trades are exact (since we assume that our trades are executed in full), while constraints on the cash trade are approximate, due to our estimation of the costs. As with holding constraints, trading constraints may be mandatory or discretionary.
Turnover limit.
The turnover of a portfolio in period is given by . It is common to limit the turnover to a fraction (of portfolio value), i.e.,
[TABLE]
Limits relative to trading volume.
Trades in non-cash assets may be restricted to a certain fraction of the current period market volume (estimate),
[TABLE]
where the division on the right-hand side means elementwise.
No-buy, sell, or trade restriction.
A no-buy restriction on asset imposes the constraint
[TABLE]
while a no-sell restriction imposes the constraint
[TABLE]
A no-trade restriction imposes both a no-buy and no-sell restriction.
4.6 Soft constraints
Any of the constraints on holdings or transactions can be made soft, which means that are not strictly enforced. We explain this in a general setting. For a vector equality constraint on the variable or expression , we replace it with a term subtracted the objective of the form , where is the priority of the constraint. (We can generalize this to , with a vector, to give different priorities to the different components of .) In a similar way we can replace an inequality constraint with a term, subtracted from the objective, of the form , where is a vector of priorities. Replacing the hard constraints with these penalty terms results in soft constraints. For large enough values of the priorities, the constraints hold exactly; for smaller values, the constraints are (roughly speaking) violated only when they need to be.
As an example, we can convert a set of factor neutrality constraints to soft constraints, by subtracting a term from the objective, where is the priority. For larger values of factor neutrality will hold (exactly, when possible); for smaller values some factor exposures can become nonzero, depending on other objective terms and constraints.
4.7 Convexity
The portfolio optimization problem (4.3) can be solved quickly and reliably using readily available software so long as the problem is convex. This requires that the risk and estimated transaction and holding cost functions are convex, and the trade and holding constraint sets are convex. All the functions and constraints discussed above are convex, except for the self-financing constraint
[TABLE]
which must be relaxed to the inequality
[TABLE]
The inequality will be tight at the optimum of (4.3). Alternatively, the self-financing constraint can be replaced with the simplified version as in problem (4.4).
Solution times.
The SPO problems described above, except for the multi-covariance risk model, can be solved using standard interior-point methods with a complexity flops, where is the number of assets and is the number of factors. (Without the factor model, we replace with .) The coefficient in front is on the order of , which includes the interior-point iteration count and other computation. This should be the case even for complex leverage constraints, the power transaction costs, limits on trading and holding, and so on.
This means that a typical current single core (or thread) of a processor can solve an SPO problem with 1500 assets and 50 factors in under one half second (based conservatively on a computation speed of 1G flop/sec). This is more than fast enough to use the methods to carry out trading with periods on the order of a second. But the speed is still very important even when the trading is daily, in order to carry out back-testing. For daily trading, one year of back-testing, around 250 trading days, can be carried out in a few minutes or less. A generic 32 core computer, running 64 threads, can carry out a back-test on five years of data, with 64 different choices of parameters (see below), in under 10 minutes. This involves solving 80000 convex optimization problems. All of these times scale linearly with the number of assets, and quadratically with the number of factors. For a problem with, say, 4500 assets and 100 factors, the computation times would be around longer. Our estimates are conservatively based on a computation speed of 1G flop/sec; for these or larger problems multi-threaded optimized linear algebra routines can achieve 100G flop/sec, making the back-testing faster.
We mention one special case that can be solved much faster. If the objective is quadratic, which means that the risk and costs are quadratic functions, and the only constraints are linear equality constraints (e.g., factor neutrality), the problem can be solved with the same complexity, but the coefficient in front is closer to , around 50 times faster than using an interior-point method.
Custom solvers, or solvers targeted to specific platforms like GPUs, can solve SPO problems much faster. For example the first order operator-splitting method implemented in POGS [27] running on a GPU, can solve extremely large SPO problems. POGS can solve a problem with 100000 assets and 1000 factors (which is much larger than any practical problem) in a few seconds or less. At the other extreme, code generation systems like CVXGEN [44] can solve smaller SPO problems with stunning speed; for example a problem with 30 assets in well under one millisecond.
Problem specification.
New frameworks for convex optimization such as CVX [27], CVXPY [21], and Convex.jl [60], based on the idea of disciplined convex programming (DCP) [30], make it very easy to specify and modify the SPO problem in just a handful of lines of easy to understand code. These frameworks make it easy to experiment with non-standard trading and holding constraints, or risk and cost functions.
Nonconvexity.
The presence of nonconvex constraints or terms in the optimization problem greatly complicates its solution, making its solution time much longer, and sometimes very much longer. This may not be a problem in the production trading engine that determines one trade per day, or per hour. But nonconvexity makes back-testing much slower at the least, and in many cases simply impractical. This greatly reduces the effectiveness of the whole optimization-based approach. For this reason, nonconvex constraints or terms should be strenuously avoided.
Nonconvex constraints generally arise only when someone who does not understand this adds a reasonable sounding constraint, unaware of the trouble he or she is making. As an example, consider imposing a minimum trade condition, which states that if is nonzero, it must satisfy , where . This constraint seems reasonable enough, but makes the problem nonconvex. If the intention was to achieve sparse trading, or to avoid many very small trades, this can be accomplished (in a far better way) using convex constraints or cost terms.
Other examples of nonconvex constraints (that should be avoided) include limits on the number of assets held, minimum values of nonzero holdings, or restricting trades to be integer numbers of share lots, or restricting the total number of assets we can trade. The requirement that we must trade integer numbers of shares is also nonconvex, but irrelevant for any practical portfolio. The error induced by rounding our trade lists (which contain real numbers) to an integer number of shares is negligible for reasonably sized portfolios.
While nonconvex constraints and objective terms should be avoided, and are generally not needed, it is possible to handle many of them using simple powerful heuristics, such as solving a relaxation, fixing the nonconvex terms, and then solving the convex problem again [22]. As a simple example of this approach, consider the minimum nonzero trade requirement for . We first solve the SPO problem without this constraint, finding a solution . We use this tentative trade vector to determine which entries of will be zero, negative, or positive (i.e., which assets we hold, sell, or buy). We now impose these sign constraints on the trade vector: We require if , if , and if . We solve the SPO again, with these sign constraints, and the minimum trade constraints as well, which are now linear, and therefore convex. This simple method will work very well in practice.
As another example, suppose that we are limited to make at most nonzero trades in any given period. A very simple scheme, based on convex optimization, will work extremely well. First we solve the problem ignoring the limit, and possibly with an additional transaction cost added in, to discourage trading. We take this trade list and find the largest trades (buy or sell). We then add the constraint to our problem that we will only trade these assets, and we solve the portfolio optimization problem again, using only these trades. As in the example described above, this approach will yield extremely good, if not optimal, trades. This approximation will have no effect on the real metrics of interest, i.e., the portfolio performance.
There is generally no need to solve the nonconvex problem globally, since this greatly increases the solve time and delivers no practical benefit in terms of trading performance. The best method for handling nonconvex problems in portfolio optimization is to avoid them.
4.8 Using single-period optimization
The idea.
In this section we briefly explain, at a high level, how the SPO trading algorithm is used in practice. We do not discuss what is perhaps the most critical part, the return (and other parameter) estimates and forecasts. Instead, we assume the forecasts are given, and focus on how to use SPO to exploit them.
In SPO, the parameters that appear in the transaction and holding costs can be inspired or motivated by our estimates of what their true values will be, but it is better to think of them as ‘knobs’ that we turn to achieve trading behavior that we like (see, e.g., [17, chapter 8], [35, 19, 41]), as verified by back-testing, what-if simulation, and stress-testing.
As a crude but important example, we can scale the entire transaction cost function by a trading aversion factor . (The name emphasizes the analogy with the risk aversion parameter, which scales the risk term in the objective.) Increasing the trading aversion parameter will deter trading or reduce turnover; decreasing it will increase trading and turnover. We can even think of as the number of periods over which we will amortize the transaction cost we incur [31]. As a more sophisticated example, the transaction cost parameters , meant to model bid-ask spread, can be scaled up or down. If we increase them, the trades become more sparse, i.e., there are many periods in which we do not trade each asset. If we scale the -power term, we encourage or discourage large trades. Indeed, we could add a quadratic transaction term to the SPO problem, not because we think it is a good model of transaction costs, but to discourage large trades even more than the -power term does. Any SPO variation, such as scaling certain terms, or adding new ones, is assessed by back-testing and stress-testing.
The same ideas apply to the holding cost. We can scale the holding cost rates by a positive holdings aversion parameter to encourage, or discourage, holding positions that incur holding costs, such as short positions. If the holding cost reflects the cost of holding short positions, the parameter scales our aversion to holding short positions. We can modify the holding cost by adding a quadratic term of the short positions , (with the square interpreted elementwise and ), not because our actual borrow cost rates increase with large short positions, but to send the message to the SPO algorithm that we wish to avoid holding large short positions.
As another example, we can add a liquidation loss term to the holding cost, with a scale factor to control its effect. We add this term not because we intend to liquidate the portfolio, but to avoid building up large positions in illiquid assets. By increasing the scale factor for the liquidation loss term, we discourage the SPO algorithm from holding illiquid positions.
Trade, hold, and risk aversion parameters.
The discussion above suggests that we modify the objective in (4.4) with scaling parameters for transaction and holding costs, in addition to the traditional risk aversion parameter, which yields the SPO problem
[TABLE]
where , , and are positive parameters used to scale the respective costs. These parameters are sometimes called hyper-parameters, which emphasizes the analogy to the hyper-parameters used when fitting statistical models to data. The hyper-parameters are ‘knobs’ that we ‘turn’ (i.e., choose or change) to obtain good performance, which we evaluate by back-testing. We can have even more than three hyper-parameters, which scale individual terms in the holding and transaction costs. The choice of hyper-parameters can greatly affect the performance of the SPO method. They should be chosen using back-testing, what-if testing, and stress-testing.
This style for using SPO is similar to how optimization is used in many other applied areas, for example control systems or machine learning. In machine learning, for example, the goal is to find a model that makes good predictions on new data. Most methods for constructing a model use optimization to minimize a so-called loss function, which penalizes not fitting the observed data, plus a regularizer, which penalizes model sensitivity or complexity. Each of these functions is inspired by a (simplistic) theoretical model of how the data were generated. But the final choice of these functions, and the (hyper-parameter) scale factor between them, is done by out-of-sample validation or cross validation, i.e., testing the model on data it has not seen. For general discussion of how convex optimization is used in this spirit, in applications such as control or estimation, see [7].
Judging value of forecasts.
In this paper we do not consider forecasts, which of course are critically important in trading. The most basic test of a new proposed return estimate or forecast is that it do well predicting returns. This is typically judged using a simple model that evaluates Sharpe ratio or information ratio, implicitly ignoring all portfolio constraints and costs. If a forecast fails these simple SR or IR tests, it is unlikely to be useful in a trading algorithm.
But the true value of a proposed estimate or forecast in the context of multi-period trading can be very different from what is suggested by the simple SR or IR prediction tests, due to costs, portfolio constraints, and other issues. A new proposed forecast should be judged in the context of the portfolio constraints, other forecasts (say, of volume), transaction costs, holding costs, trading constraints, and choice of parameters such as risk aversion. This can be done using simulation, carrying out back-tests, what-if simulations, and stress-tests, in each case varying the parameters to achieve the best performance. The result of this testing is that the forecast might be less valuable (the usual case) or more valuable (the less usual case) than it appeared from the simple SR and IR tests. One consequence of this is that the true value of a forecast can depend considerably on the type and size of the portfolio being traded; for example, a forecast could be very valuable for a small long-short portfolio with modest leverage, and much less valuable for a large long-only portfolio.
Chapter 5 Multi-Period Optimization
5.1 Motivation
In this section we discuss optimization-based strategies that consider information about multiple periods when choosing trades for the current period. Before delving into the details, we should consider what we hope to gain over the single-period approach. Predicting the returns for the current period is difficult enough. Why attempt to forecast returns in future periods?
One reason is to better account for transaction costs. In the absence of transaction cost (and other limitations on trading), a greedy strategy that only considers one period at a time is optimal, since performance for the current period does not depend on previous holdings. However in any realistic model current holdings strongly affect whether a return prediction can be profitably acted on. We should therefore consider whether the trades we make in the current period put us in a good or bad position to trade in future periods. While this idea can be incorporated into single-period optimization, it is more naturally handled in multi-period optimization.
For example, suppose our single period optimization-based strategy tells us to go very long in a rarely traded asset. We may not want to make the trade because we know that unwinding the position will incur large transaction costs. The single-period problem models the cost of moving into the position, but not the cost of moving out of it. To model the fact that we will over time revert positions towards the benchmark, and thus must eventually sell the positions we buy, we need to model time beyond the current period. (One standard trick in single-period optimization is to double the transaction cost, which is then called the round-trip cost.)
Another advantage of multi-period optimization is that it naturally handles multiple, possibly conflicting return estimates on different time scales (see, e.g., [28, 54]). As an example, suppose we predict that a return will be positive over a short period, but over a longer period it will be negative. The first prediction might be relevant for only a day, while the second for a month or longer. In a single-period optimization framework, it is not clear how to account for the different time scales when blending the return predictions. Combining the two predictions would likely cancel them, or have us move according to whichever prediction is larger. But the resulting behavior could be quite non-optimal. If the trading cost is high, taking no action is likely the right choice, since we will have to reverse any trade based on the fast prediction as we follow the slow prediction in future periods. If the trading cost is low, however, the right choice is to follow the fast prediction, since unwinding the position is cheap. This behavior falls naturally out of a multi-period optimization, but is difficult to capture in a single-period problem.
There are many other situations where predictions over multiple periods, as opposed to just the current period, can be taken advantage of in multi-period optimization. We describe a few of them here.
- •
Signal decay and time-varying returns predictions. Generalizing the discussion above on fast versus slow signals, we may assign an exponential decay-rate to every return prediction signal. (This can be estimated historically, for example, by fitting an auto-regressive model to the signal values.) Then it is easy to compute return estimates at any time scale. The decay in prediction accuracy is also called mean-reversion or alpha decay (see, e.g., [13, 31, 28]).
- •
Known future changes in volatility or risk. If we know that a future event will increase the risk, we may want to exit some of the risky positions in advance. In MPO, trading towards a lower risk position starts well before increase in risk, trading it off with the transaction costs. In SPO, (larger) trading to a lower risk position occurs only once the risk has increased, leading to larger transaction costs. Conversely, known periods of low risk can be exploited as well.
- •
Changing constraints over multiple periods. As an example, assume we want to de-leverage the portfolio over multiple periods, i.e., reduce the leverage constraint over some number of periods to a lower value. If we use a multi-period optimization framework we will likely incur lower trading cost than by some ad-hoc approach, while still exploiting our returns predictions.
- •
Known future changes in liquidity or volume. Future volume or volatility predictions can be exploited for transaction cost optimization, for example by delaying some trades until they will be cheaper. Market volumes have much better predictability than market returns.
- •
Setting up, shutting down, or transferring a portfolio. These transitions can all be handled naturally by MPO, with a combination of constraints and objective terms changing over time.
5.2 Multi-period optimization
In multi-period optimization, we choose the current trade vector by solving an optimization problem over a planning horizon that extends periods into the future,
[TABLE]
(Single-period optimization corresponds to the case .)
Many quantities at times are unknown at time , when the optimization problem is solved and the asset trades are chosen, so as in the single-period case, we will estimate them. For any quantity or function , we let denote our estimate of given all information available to us at the beginning of period . (Presumably ; otherwise we can take , the realized value of at time .) For example is the estimate made at time of the return at time (which we denoted in the section on single-period optimization); is the estimate made at time of the return at time .
We can develop a multi-period optimization problem starting from (4.3). Let
[TABLE]
denote our sequence of planned trades over the horizon. A natural objective is the total risk-adjusted return over the horizon,
[TABLE]
(This expression drops a constant that does not depend on the trades, and handles absolute or active return.) In this expression, is known, but are not, since they depend on the trades (which we will choose) and the unknown returns, via the dynamics equation (2.11),
[TABLE]
which propagates the current weight vector to the next one, given the trading and return vectors. (This true dynamics equation ensures that if , we have .)
In adding the risk terms in this objective, we are implicitly relying on the idea that the returns are independent random variables, so the variance of the sum is the sum of the variances. We can also interpret as cost terms that discourage us from holding certain portfolios.
Simplifying the dynamics.
We now make a simplifying approximation: For the purpose of propagating and to in our planning exercise, we will assume and (i.e., that the one period returns are small compared to one). This results in the much simpler dynamics equation . With this approximation, we must add the constraints to ensure that the weights in our planning exercise add to one, i.e., , . So we will impose the constraints
[TABLE]
The current portfolio weights are given, and satisfy ; we get that for due to the constraints. (Implications of the dynamics simplification are discussed below.)
Multi-period optimization problem.
With the dynamics simplification we arrive at the MPO problem
[TABLE]
with variables and . Note that is not a variable, but the (known) current portfolio weights. When , the multi-period problem reduces to the simplified single-period problem (4.4). (We can ignore the constant , which does not depend on the variables, that appears in (5.1) but not (4.4).)
Using we can eliminate the trading variables to obtain the equivalent problem
[TABLE]
with variables , the planned weights over the next periods. This is the multi-period analog of (4.5).
Both MPO formulations (5.1) and (5.2) are convex optimization problems, provided the transaction cost, holding cost, risk functions, and trading and holding constraints are all convex.
Interpretation of MPO.
The MPO problems (5.1) or (5.2) can be interpreted as follows. The variables constitute a trading plan, i.e., a set of trades to be executed over the next periods. Solving (5.1) or (5.2) is forming a trading plan, based on forecasts of critical quantities over the planning horizon, and some simplifying assumptions. We do not intend to execute this sequence of trades, except for the first one . It is reasonable to ask then why we optimize over the future trades , since we do not intend to execute them. The answer is simple: We optimize over them as part of a planning exercise, just to be sure we don’t carry out any trades now (i.e., ) that will put us in a bad position in the future. The idea of carrying out a planning exercise, but only executing the current action, occurs and is used in many fields, such as automatic control (where it is called model predictive control, MPC, or receding horizon control) [40, 45], supply chain optimization [14], and others. Applications of MPC in finance include [33, 9, 6, 54].
About the dynamics simplification.
Before proceeding let us discuss the simplification of the dynamics equation, where we replace the exact weight update
[TABLE]
with the simplified version , by assuming that . At first glance it appears to be a gross simplification, but this assumption is only made for the purpose of propagating the portfolio forward in our planning process; we do take the returns into account in the first term of our objective. We are thus neglecting second-order terms, and we cannot be too far off if the per period returns are small compared to one.
In a similar way, adding the constraints for suggests that we are ignoring the transaction and holding costs, since if were a realized trade we would have . As above, this assumption is only made for the purpose of propagating our portfolio forward in our planning exercise; we do take the costs into account in the objective.
Terminal constraints.
In MPO, with a reasonably long horizon, we can add a terminal (equality) constraint, which requires the final planned weight to take some specific value, . A reasonable choice for the terminal portfolio weight is (our estimate of) the benchmark weight at period .
For optimization of absolute or excess return, the terminal weight would be cash, i.e., . This means that our planning exercise should finish with the portfolio all cash. This does not mean we intend to liquidate the portfolio in periods; rather, it means we should carry out our planning as if this were the case. This will keep us from making the mistake of moving into what appears, in terms of our returns predictions, to be an attractive position that it is, however, expensive to unwind. For optimization relative to a benchmark, the natural terminal constraint is to be in the (predicted) benchmark.
Note that adding a terminal constraint reduces the number of variables. We solve the problem (5.1), but with a given constant, not a variable. The initial weight is also a given constant; the intermediate weights are variables.
5.3 Computation
The MPO problem (5.2) has variables. In general the complexity of a convex optimization increases as the cube of the number of variables, but in this case the special structure of the problem can be exploited so that the computational effort grows linearly in , the horizon. Thus, solving the MPO problem (5.2) should be a factor slower than solving the SPO problem (4.5). For modest (say, a few tens), this is not a problem. But for (say) solving the MPO problem can be very challenging. Distributed methods based on ADMM [8, 9] can be used to solve the MPO problem using multiple processors. In most cases we can solve the MPO problem in production. The issue is back-testing, since we must solve the problem many times, and with many variations of the parameters.
5.4 How MPO is used
All of the general ideas about how SPO is used apply to MPO as well; for example, we consider the parameters in the MPO problem as knobs that we adjust to achieve good performance under back-test and stress-test. In MPO, we must provide forecasts of each quantity for each period over the next periods. This can be done using sophisticated forecasts, with possibly different forecasts for each period, or in a very simple way, with predictions that are constant.
5.5 Multi-scale optimization
MPO trading requires estimates of all relevant quantities, like returns, transaction costs, and risks, over trading periods into the future. In this section we describe a simplification of MPO that requires fewer predictions, as well as less computation to carry out the optimization required in each period. We still create a plan for trades and weights over the next periods, but we assume that trades take place only a few times over the horizon; in other time periods the planned portfolio is maintained with no trading. This preserves the idea that we have recourse; but it greatly simplifies the problem (5.1). We describe the idea for three trades, taken in the short term, medium term, and long term, and an additional trade at the end to satisfy a terminal constraint .
Specifically we add the constraint that in (5.1), trading (i.e., ) only occurs at specific periods in the future, for
[TABLE]
where
[TABLE]
We interpret as our short term trade, as our medium term trade, and as our long term trade, in our trading plan. The final nonzero trade is determined by the terminal constraint.
For example we might take and , with . If the periods represent days, we plan to trade now (short term), in a week (medium term) and in month (longer term); in 99 days, we trade to the benchmark. The only variables we have are the short, medium, and long term trades, and the associated weights, given by
[TABLE]
To determine the trades to make, we solve (5.1) with all other set to zero, and using the weights given above. This results in an optimization problem with the same form as (5.1), but with only three variables each for trading and weights, and three terms in the objective, plus an additional term that represents the transaction cost associated with the final trade to the benchmark at time .
Chapter 6 Implementation
We have developed an open-source Python package CVXPortfolio [11] that implements the portfolio simulation and optimization concepts discussed in the paper. The package relies on Pandas [46] for managing data. Pandas implements structured data types as in-memory databases (similar to R dataframes) and provides a rich API for accessing and manipulating them. Through Pandas, it is easy to couple our package with database backends. The package uses the convex optimization modeling framework CVXPY [21] to construct and solve portfolio optimization problems.
The package provides an object-oriented framework with classes representing return, risk measures, transaction costs, holding constraints, trading constraints, etc. Single-period and multi-period optimization models are constructed from instances of these classes. Each instance generates CVXPY expressions and constraints for any given period , making it easy to combine the instances into a single convex model. In chapter 7 we give some simple numerical examples that use CVXPortfolio.
6.1 Components
We briefly review the major classes in the software package. Implementing additional classes, such as novel policies or risk measures, is straightforward.
Return estimates.
Instances of the AlphaSource class generate a return estimate for period using only information available at that period. The simplest AlphaSource instance wraps a Pandas dataframe with return estimates for each period:
alpha_source = AlphaSource(return_estimates_dataframe)
Multiple AlphaSource instances can be blended into a linear combination.
Risk measure.
Instances of the RiskMeasure class generate a convex cost representing a risk measure at a given period . For example, the FullSigma subclass generates the cost where is an explicit matrix, whereas the FactorModel subclass generates the cost with a factor model of . Any risk measure can be switched to absolute or active risk and weighted with a risk aversion parameter. The package provides all the risk measures discussed in section 4.2.
Costs.
Instances of the TcostModel and HcostModel classes generate transaction and holding cost estimates, respectively. The same classes work both for modeling costs in a portfolio optimization problem and calculating realized costs in a trading simulation. Cost objects can also be used to express other objective terms like soft constraints.
Constraints.
The package provides classes representing each of the constraints discussed in section 4.4 and section 4.5. For example, instances of the LeverageLimit class generate a leverage limit constraint that can vary by period. Constraint objects can be converted into soft constraints, which are cost objects.
Policies.
Instances of the Policy class take holdings and value and output trades using information available in period . Single-period optimization policies are constructed using the SinglePeriodOpt subclass. The constructor takes an AlphaSource, a list of costs, including risk models (multiplied by their coefficients), and constraints. For example, the following code snippet constructs a SPO policy:
spo_policy = SinglePeriodOpt(alpha_source, [gamma_riskfactor_risk, gamma_tradetcost_model, gamma_hold*hcost_model], [leverage_limit])
Multi-period optimization policies are constructed similarly. The package also provides subclasses for simple policies such as periodic re-balancing.
Simulator.
The MarketSimulator class is used to run trading simulations, or back-tests. Instances are constructed with historical returns and other market data, as well as transaction and holding cost models. Given a MarketSimulator instance market_sim, a back-test is run by calling the run_backtest method with an initial portfolio, policy, and start and end periods:
backtest_results = market_sim.run_backtest(init_portfolio, policy, start_t, end_t)
Multiple back-tests can be run in parallel with different conditions. The back-test results include all the metrics discussed in chapter 3.
Chapter 7 Examples
In this section we present simple numerical examples illustrating the ideas developed above, all carried out using CVXPortfolio and open-source market data (and some approximations where no open source data is available). The code for these is available at
https://github.com/cvxgrp/cvxportfolio/examples.
Given our approximations, and other short-comings of our simulations that we will mention below, the particular numerical results we show should not be taken too seriously. But the simulations are good enough for us to illustrate real phenomena, such as the critical role transaction costs can play, or how important hyper-parameter search can be.
7.1 Data for simulation
We work with a period of 5 years, from January 2012 through December 2016, on the components of the S&P 500 index as of December 2016. We select the ones continuously traded in the period. (By doing this we introduce survivorship bias, not a concern since these examples have only a didactic purpose.) We collect open-source market data from Quandl [56]. The data consists of realized daily market returns (computed using closing prices) and volumes . We use the federal reserve overnight rate for the cash return. Following [1] we approximate the daily volatility with a simple estimator, , where and are the open and close prices for asset in period . We could not find open-source data for the bid-ask spread, so we used the value (5 basis points) for all assets and periods. As holding costs we use (1 basis point) for all assets and periods. We chose standard values for the other parameters of the transaction and holding cost models: , , for all assets and periods.
7.2 Portfolio simulation
To illustrate back-test portfolio simulation, we consider a portfolio that is meant to track the uniform portfolio benchmark, which has weight , i.e., equal fraction of value in all non-cash assets. This is not a particularly interesting or good benchmark portfolio; we use it only as a simple example to illustrate the effects of transaction costs. The portfolio starts with , and due to asset returns drifts from this weight vector. We periodically re-balance, which means using trade vector . For other values of (i.e., the periods in which we do not re-balance) we have .
We carry out six back-test simulations for each of two initial portfolio values, 10B. The six simulations vary in re-balancing frequency: Daily, weekly, monthly, quarterly, annually, or never (also called ‘hold’ or ‘buy-and-hold’). For each simulation we give the portfolio active return and active risk (defined in section 3.2), the annualized average transaction cost and the annualized average turnover
Table 7.1 shows the results. (The active return is included for completeness, but has no special meaning; it is the negative of the transaction cost plus a small random component.) We observe that transaction cost depends on the total value of the portfolio, as expected, and that the choice of re-balancing frequency trades off transaction cost and active risk. (The active risk is not exactly zero when re-balancing daily because of the variability of the transaction cost, which is included in the portfolio return.) Figure 7.1 shows, separately for the two portfolio sizes, the active risk versus the transaction cost.
7.3 Single-period optimization
In this section we show a simple example of the single-period optimization model developed in chapter 4. The portfolio starts with total value w_{1}=(\mathbf{1}/n,0)L^{\mathrm{max}}=3$. This simulation uses the market data defined in section 7.1. The forecasts and risk model used in the SPO are described below.
Risk model.
Proprietary risk models, e.g., from MSCI (formerly Barra), are widely used. Here we use a simple factor risk model estimated from past realized returns, using a similar procedure to [1]. We estimate it on the first day of each month, and use it for the rest of the month. Let be an estimation time period, and the time period two years before. Consider the second moment of the window of realized returns , and its eigenvalue decomposition , where the eigenvalues are in descending order. Our factor risk model is
[TABLE]
with . (The diagonal matrix is chosen so the factor model and the empirical second moment have the same diagonal elements.)
Return forecasts.
The risk-free interest rates are known exactly, for all . Return forecasts for the non-cash assets are always proprietary. They are generated using many methods, ranging from analyst predictions to sophisticated machine learning techniques, based on a variety of data feeds and sources. For these examples we generate simulated return forecasts by adding zero-mean noise to the realized returns and then rescaling, to obtain return estimates that would (approximately) minimize mean squared error. Of course this is not a real return forecast, since it uses the actual realized return; but our purpose here is only to illustrate the ideas and methods.
For all the return estimates for non-cash assets are
[TABLE]
where are independent. We use noise variance , so the noise components have standard deviation around 14%, around a factor of 10 larger than the standard deviaton of the realized returns. The scale factor is chosen to minimize the mean squared error , if we think of as a random variable with variance , i.e., . We use the typical value , i.e., a realized return standard deviation of around 2%, so . Our typical return forecast is on the order of . This corresponds to an information ratio , which is on the high end of what might be expected in practice [32].
With this level of noise and scaling, our return forecasts have an accuracy on the order of what we might expect from a proprietary forecast. For example, across all the assets and all days, the sign of predicted return agrees with the sign of the real return around 54% of the times.
Volume and volatility forecasts.
We use simple estimates of total market volumes and daily volatilities (used in the transaction cost model), as moving averages of the realized values with a window of length 10. For example, the volume forecast at time period and asset is .
SPO back-tests.
We carry out multiple back-test simulations over the whole period, varying the risk aversion parameter , the trading aversion parameter , and the holding cost multiplier (all defined and discussed in section 4.8). We first perform a coarse grid search in the hyper-parameter space, testing all combinations of
[TABLE]
a total of 45 back-test simulations. (Logarithmic spacing is common in hyper-parameter searches.)
Figure 7.2 shows mean excess portfolio return versus excess volatility (defined in section 3.2), for these combinations of parameters. For each value of , we connect with a line the points corresponding to the different values of , obtaining a risk-return trade-off curve for that choice of and . These show the expected trade-off between mean return and risk. We see that the choice of trading aversion parameter is critical: For some values of the results are so poor that the resulting curve does not even fit in the plotting area. Values of around 5 seem to give the best results.
We then perform a fine hyper-parameter search, focusing on trade aversion parameters values around ,
[TABLE]
and the same values of and . Figure 7.3 shows the resulting curves of excess return versus excess risk. A value around seems to be best.
For our last set of simulations we use a finer range of risk aversion parameters, focus on an even narrower range of the trading aversion parameter, and also vary the hold aversion parameter. We test all combinations of
[TABLE]
a total of 410 back-test simulations. The results are plotted in figure 7.4 as points in the risk-return plane. The Pareto optimal points, i.e., those with the lowest risk for a given level of return, are connected by a line. Table 7.2 lists a selection of the Pareto optimal points, giving the associated hyper-parameter values.
From this curve and table we can make some interesting observations. The first is that we do substantially better with large values of the holding cost multiplier parameter compared to , even though the actual hold costs (used by the simulator to update the portfolio each day) are very small, one basis point. This is a good example of regularization in SPO; our large holding cost multiplier parameter tells the SPO algorithm to avoid short positions, and the result is that the overall portfolio performance is better.
It is hardly surprising that the risk aversion parameter varies over this selection of Pareto optimal points; after all, this is the parameter most directly related to the risk-return trade-off. One surprise is that the value of the hold aversion hyper-parameter varies considerably as well.
In practice, we would back-test many more combinations of these three hyper-parameters. Indeed we would also carry out back-tests varying combinations of other parameters in the SPO algorithm, for example the leverage, or the individual terms in transaction cost functions. In addition, we would carry out stress-tests and other what-if simulations, to get an idea of how our SPO algorithm might perform in other, or more stressful, market conditions. (This would be especially appropriate given our choice of back-test date range, which was entirely a bull market.) Since these back-tests can be carried out in parallel, there is no reason to not carry out a large number of them.
7.4 Multi-period optimization
In this section we show the simplest possible example of the multi-period optimization model developed in chapter 5, using planning horizon . This means that in each time period the MPO algorithm plans both current day and next day trades, and then executes only the current day trades. As a practical matter, we would not expect a great performance improvement over SPO using a planning horizon of days compared to SPO, which uses day. Our point here is to demonstrate that it is different.
The simulations are carried out using the market data described in section 7.1. The portfolio starts with total value w_{1}=(\mathbf{1}/n,0)L^{\mathrm{max}}=3$. The risk model is the same one used in the SPO example. The volume and volatility estimates (for both the current and next period) are also the same as those used in the SPO example.
Return forecasts.
We use the same return forecast we generated for the previous example, but at every time period we provide both the forecast for the current time period and the one for the next:
[TABLE]
where and are the same ones used in the SPO example, given in (7.1). The MPO trading algorithm thus sees each return forecast twice, , i.e., today’s forecast of tomorrow’s return is the same as tomorrow’s forecast of tomorrow’s return.
As in the SPO case, this is clearly not a practical forecast, since it uses the realized return. In addition, in a real setting the return forecast would be updated at every time period, so that . Our goal in choosing these simulated return forecasts is to have ones that are similar to the ones used in the SPO example, in order to compare the results of the two optimization procedures.
Back-tests.
We carry out multiple back-test simulations varying the parameters , , and . We first perform a coarse grid search in the hyper-parameter space, with the same parameters as in the SPO example. We test all combinations of
[TABLE]
a total of 45 back-test simulations.
The results are shown in figure 7.5, where we plot mean excess portfolio return versus excess risk . For some trading aversion parameter values the results were so bad that they did not fit in the plotting area.
We then perform a more accurate hyper-parameter search using a finer range for , focusing on the values around , and also varying the hold aversion parameter. We test all combinations of
[TABLE]
for a total of 390 back-test simulations. The results are plotted in figure 7.6 as points in the risk-return plane. The Pareto optimal points are connected by a line.
Finally we compare the results obtained with the SPO and MPO examples. Figure 7.7 shows the Pareto optimal frontiers for both cases. We see that the MPO method has a substantial advantage over the SPO method, mostly explained by the advantage of a forecast for tomorrow’s, as well as today’s, return.
7.5 Simulation time
Here we give some rough idea of the computation time required to carry out the simulation examples shown above, focussing on the SPO case. The back-test simulation is single-threaded, so multiple back-tests can be carried out on separate threads.
Figure 7.8 gives the breakdown of execution time for a back-test, showing the time taken for each step of simulation, broken down into the simulator, the numerical solver, and the rest of the policy (data management and CVXPY manipulations). We can see that simulating one day takes around 0.25 seconds, so a back test over 5 years takes around 5 minutes. The bulk of this (around 0.15 seconds) is the optimization carried out each day. The simulator time is, as expected, negligible.
We carried out the multiple back-tests using a 32 core machine that can execute 64 threads simultaneously. To carry out 410 back-tests, which entails solving around a half million convex optimization problems, thus takes around thirty minutes. (In fact, it takes a bit longer, due to system overhead.)
We close by making a few comments about these optimization times. First, they can be considerably reduced by avoiding the -power transaction cost terms, which slow the optimizer. By replacing these terms with square transaction cost terms, we can obtain a speedup of more than a factor of two. Replacing the default generic solver ECOS [23] used in CVXPY with a custom solver, such as one based on operator-splitting methods [8], would result in an even more substantial speedup.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Almgren [2009] R. Almgren. High frequency volatility. Available at http://cims.nyu.edu/~almgren/timeseries/notes 7.pdf , 2009.
- 2Almgren and Chriss [2001] R. Almgren and N. Chriss. Optimal execution of portfolio transactions. Journal of Risk , 3(2):5–39, 2001.
- 3Bacon [2008] C. Bacon. Practical portfolio performance measurement and attribution . Wiley, 2nd edition, 2008.
- 4Bellman [1956] R. Bellman. Dynamic programming and Lagrange multipliers. Proceedings of the National Academy of Sciences , 42(10):767–769, 1956.
- 5Bemporad [2006] A. Bemporad. Model predictive control design: New trends and tools. In Proceedings of the 45th IEEE Conference on Decision and Control , pages 6678–6683. IEEE, 2006.
- 6Bemporad et al. [2014] A. Bemporad, L. Bellucci, and T. Gabbriellini. Dynamic option hedging via stochastic model predictive control based on scenario simulation. Quantitative Finance , 14(10):1739–1751, 2014.
- 7Boyd and Vandenberghe [2004] S. Boyd and L. Vandenberghe. Convex Optimization . Cambridge University Press, 2004.
- 8Boyd et al. [2011] S. Boyd, N. Parikh, E. Chu, B. Peleato, and J. Eckstein. Distributed optimization and statistical learning via the alternating direction method of multipliers. Foundations and Trends in Machine Learning , 3(1):1–122, 2011.
