A Framework for Rate Efficient Control of Distributed Discrete Systems
Jie Ren, Solmaz Torabi, and John MacLaren Walsh

TL;DR
This paper develops a framework to minimize communication in distributed control systems modeled as Markov decision processes, balancing information exchange costs with control performance.
Contribution
It introduces an information-theoretic approach to determine minimal control information exchange and proposes an optimization method for efficient control and messaging schemes.
Findings
Derived minimum control information exchange for various models
Enabled tradeoff analysis between communication cost and control performance
Validated approach with wireless resource allocation examples
Abstract
A key issue in the control of distributed discrete systems modeled as Markov decisions processes, is that often the state of the system is not directly observable at any single location in the system. The participants in the control scheme must share information with one another regarding the state of the system in order to collectively make informed control decisions, but this information sharing can be costly. Harnessing recent results from information theory regarding distributed function computation, in this paper we derive, for several information sharing model structures, the minimum amount of control information that must be exchanged to enable local participants to derive the same control decisions as an imaginary omniscient controller having full knowledge of the global state. Incorporating consideration for this amount of information that must be exchanged into the reward…
Click any figure to enlarge with its caption.
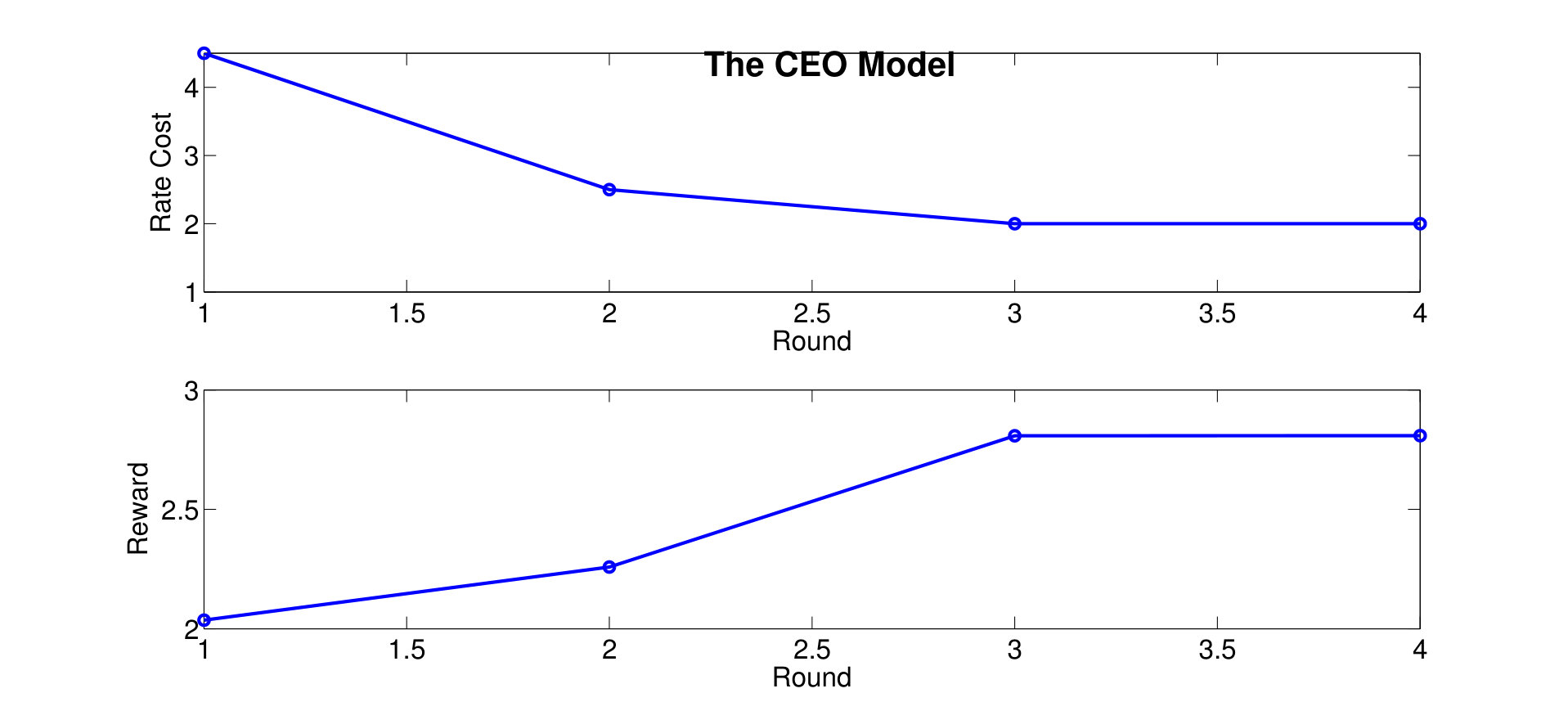 Figure 1
Figure 1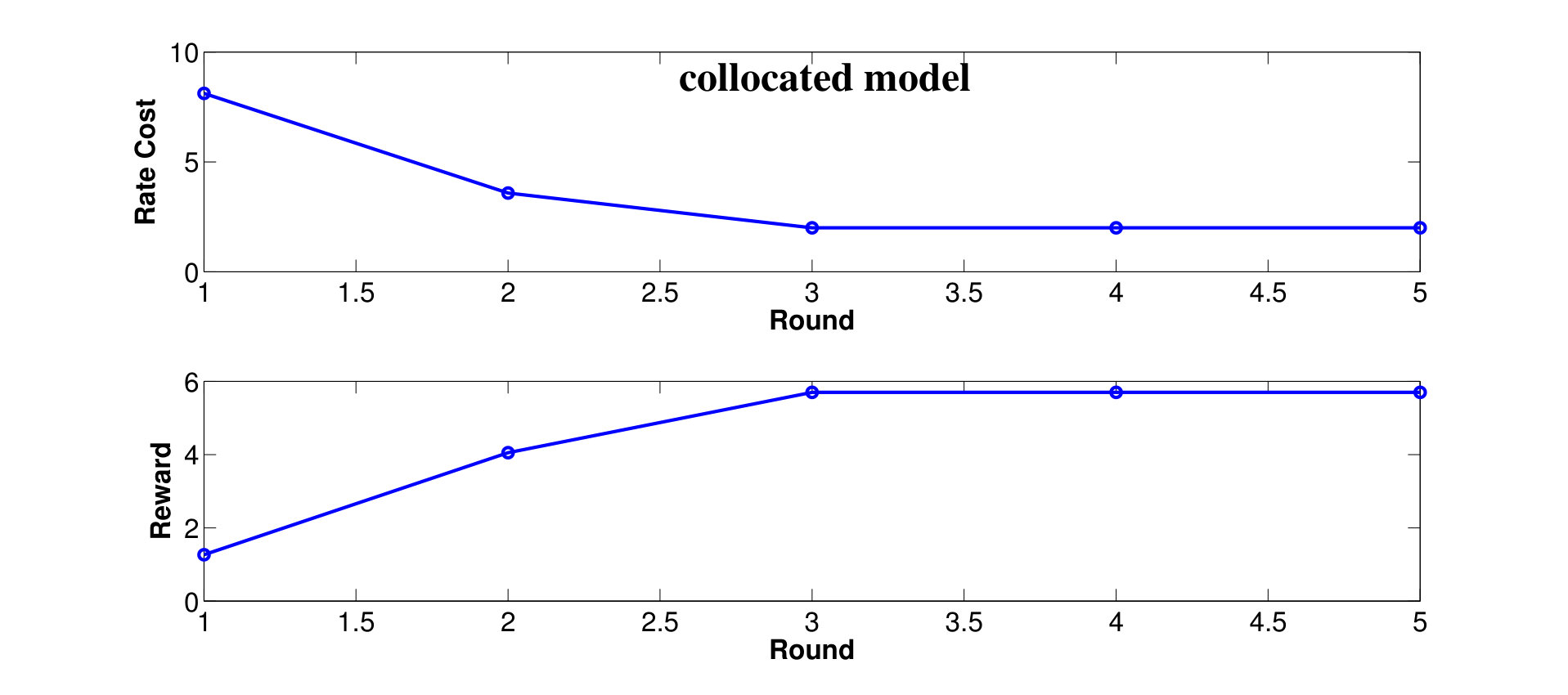 Figure 2
Figure 2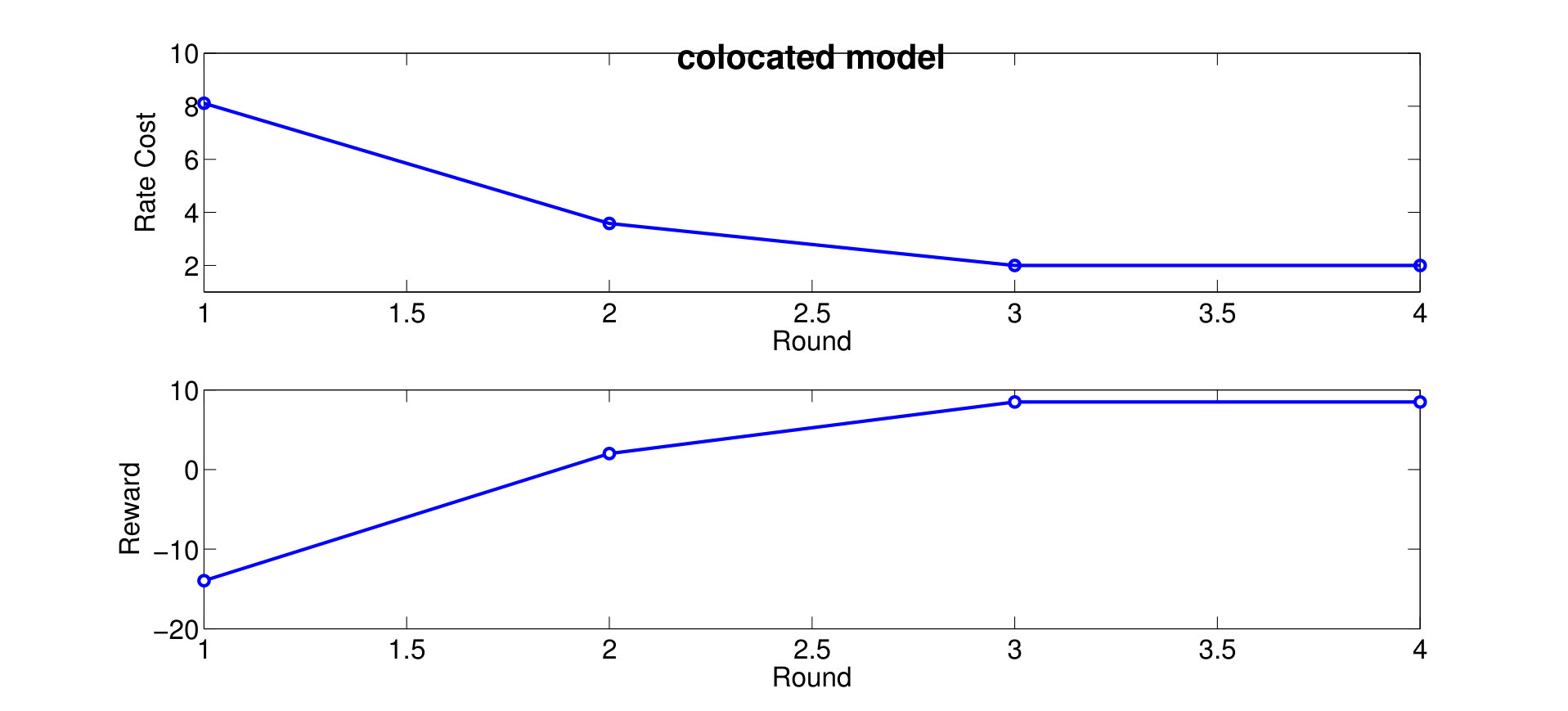 Figure 3
Figure 3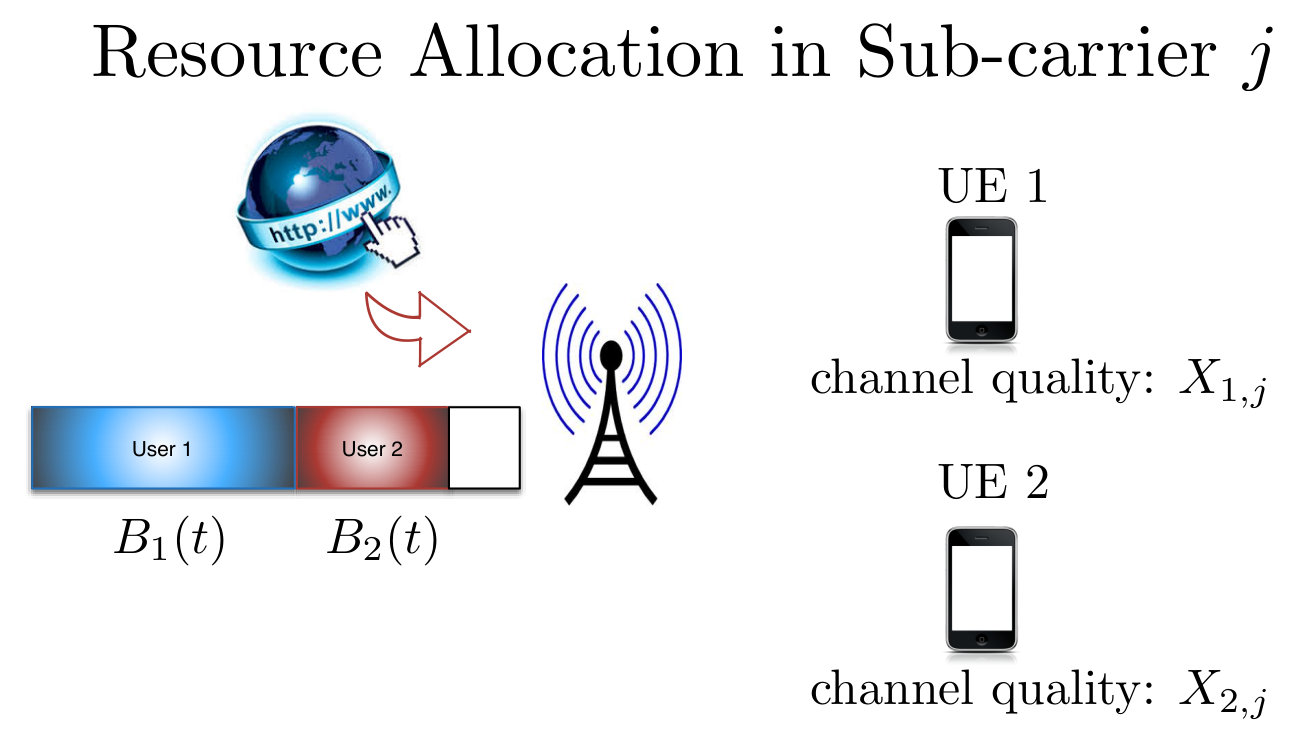 Figure 4
Figure 4 Figure 5
Figure 5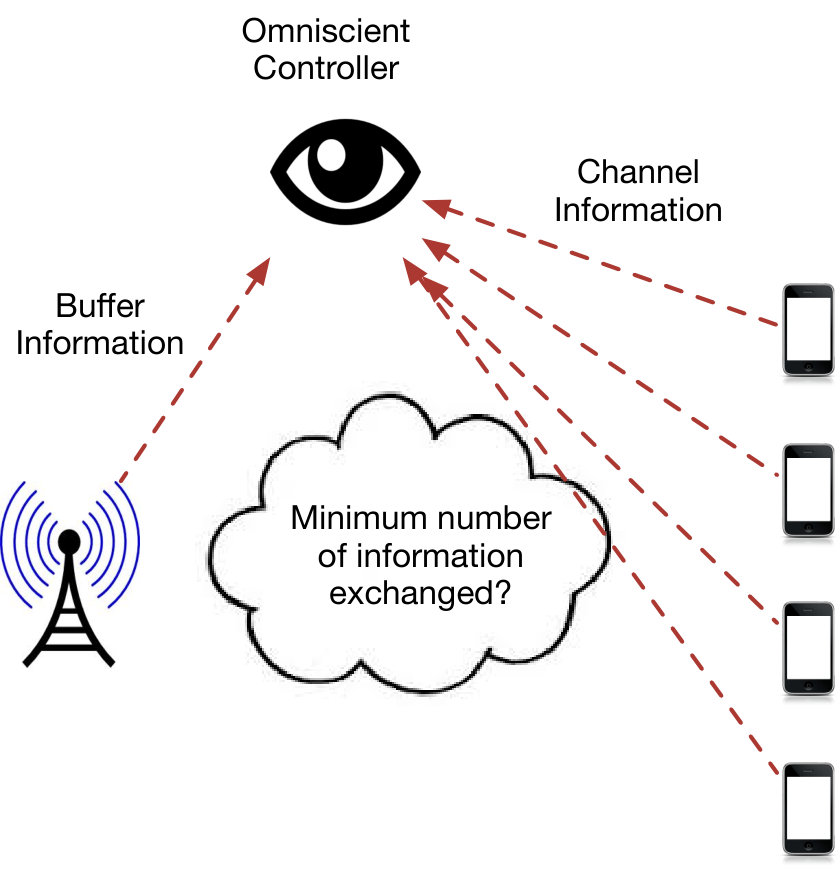 Figure 6
Figure 6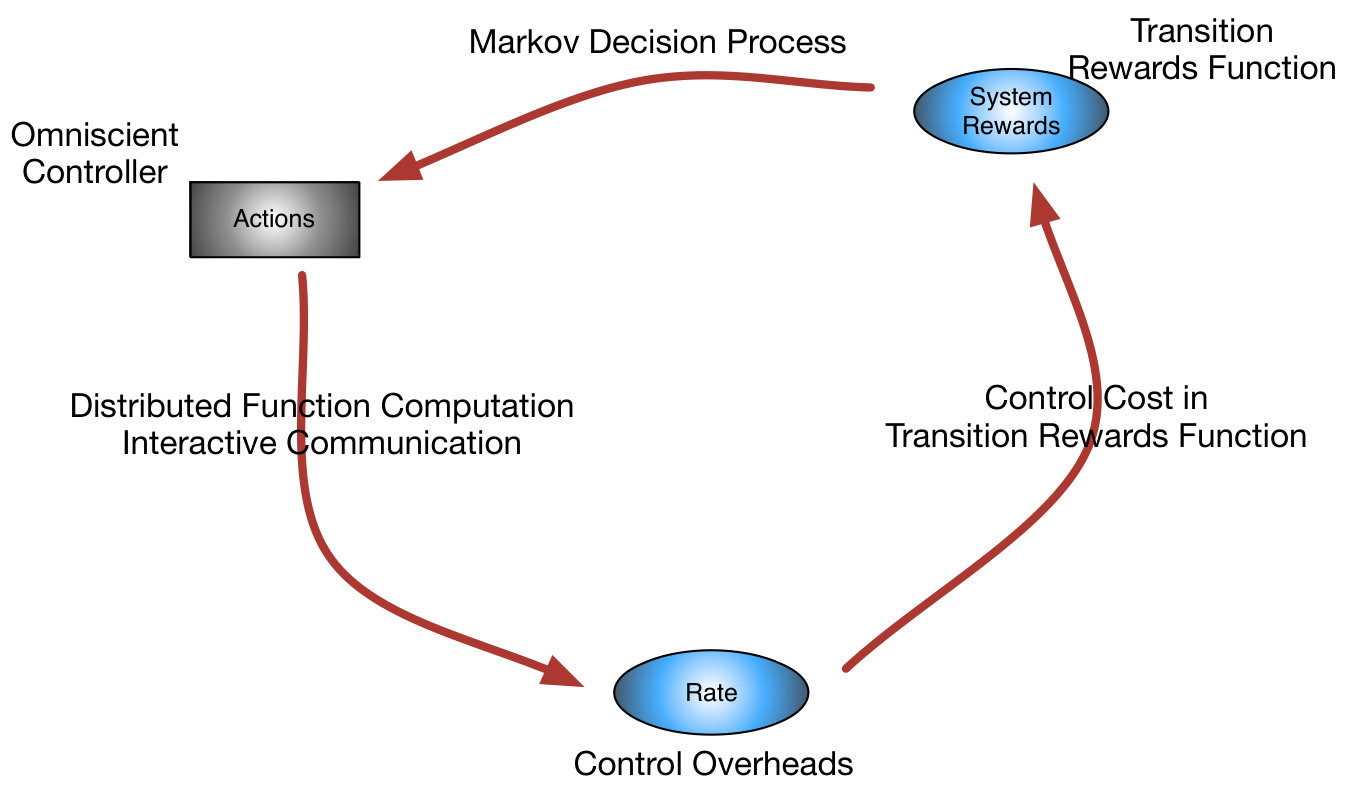 Figure 7
Figure 7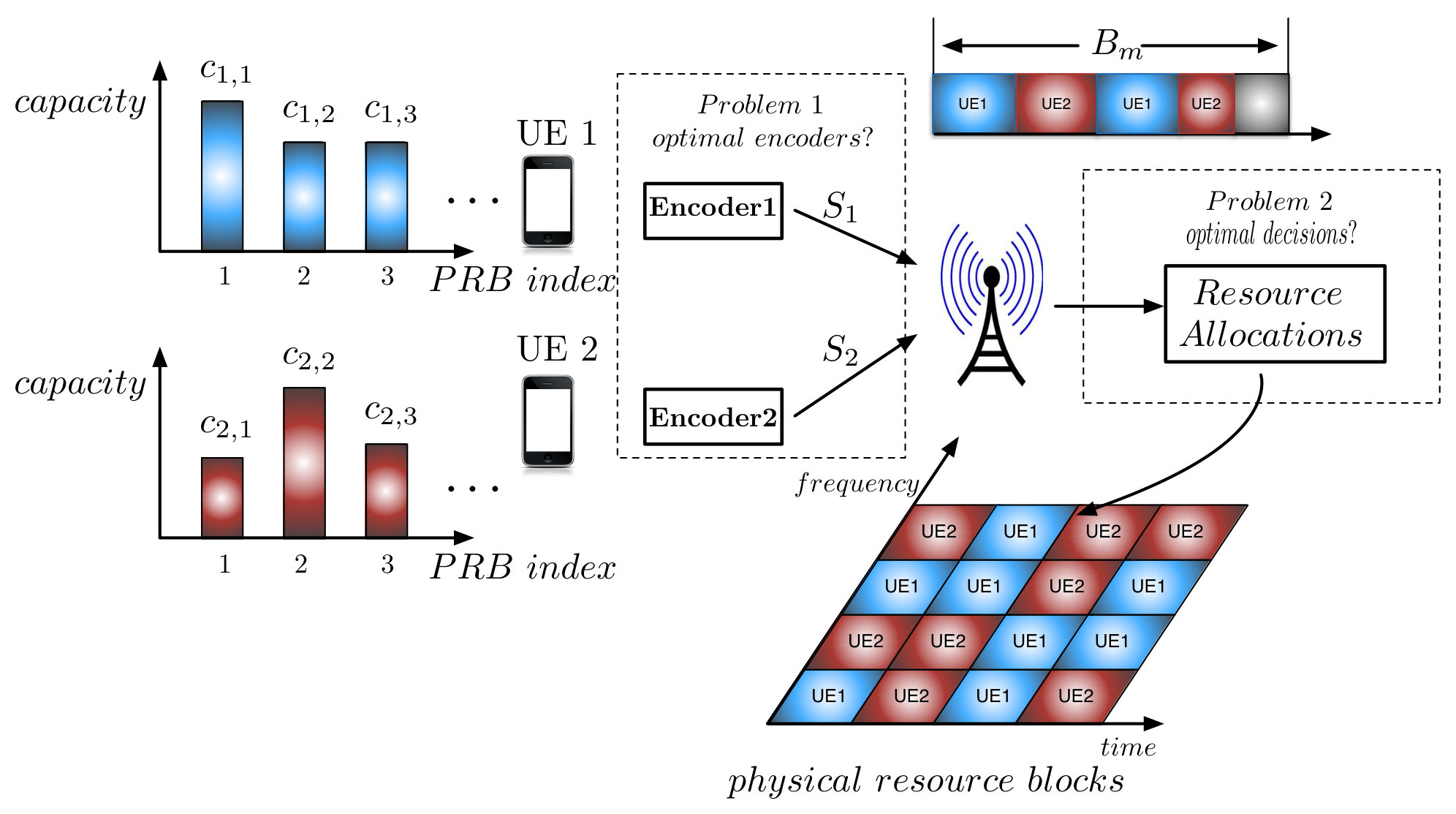 Figure 8
Figure 8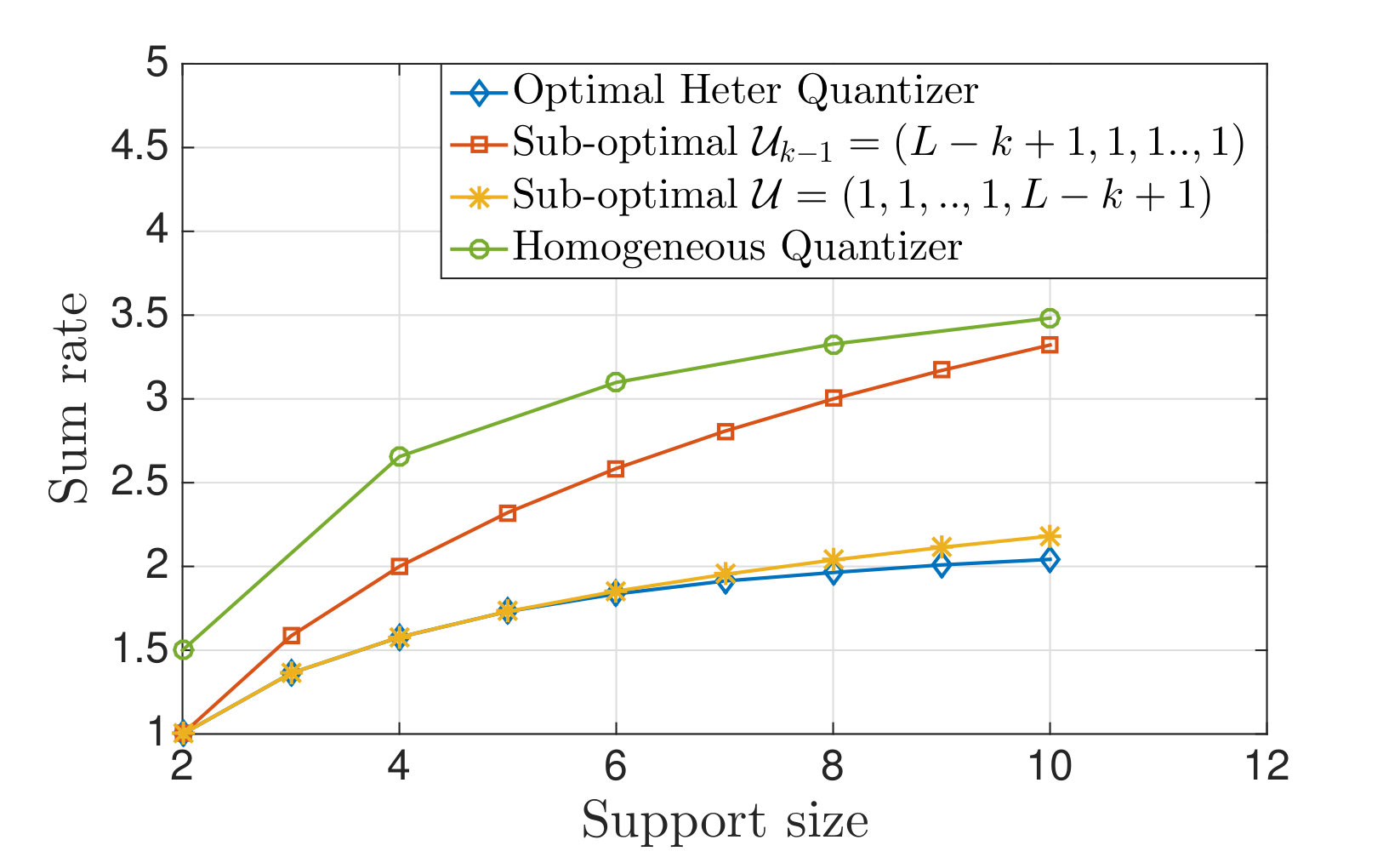 Figure 9
Figure 9 Figure 10
Figure 10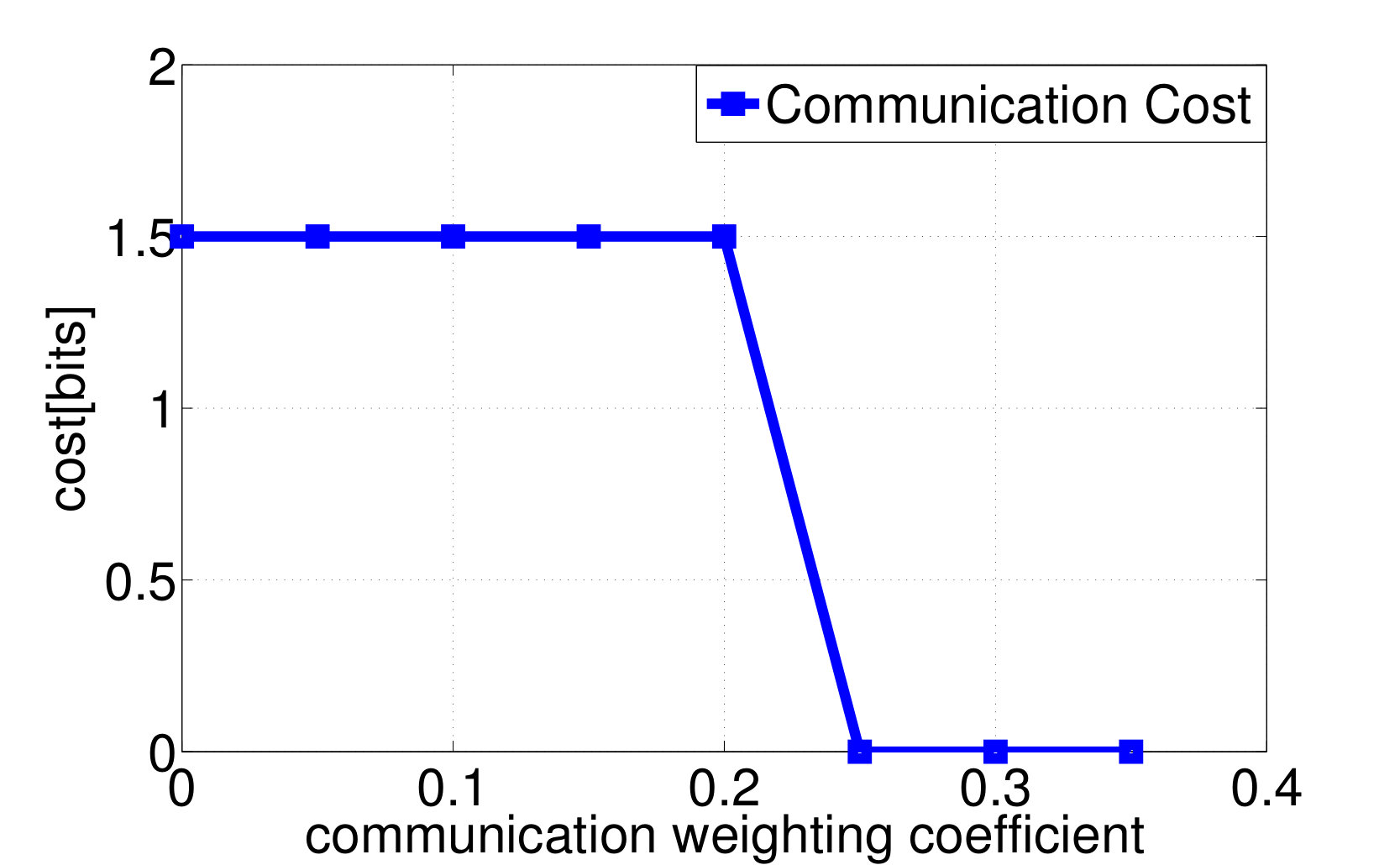 Figure 11
Figure 11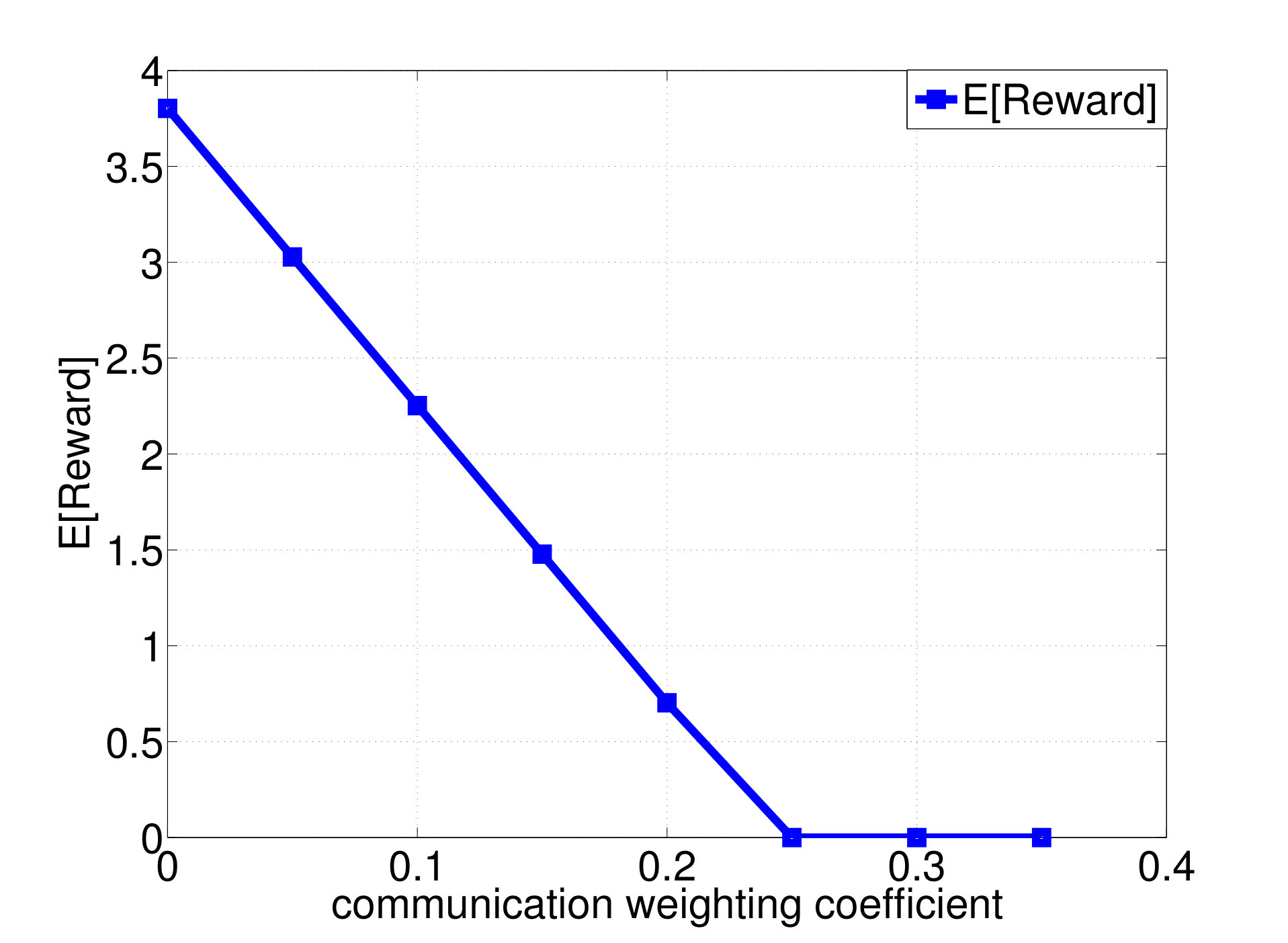 Figure 12
Figure 12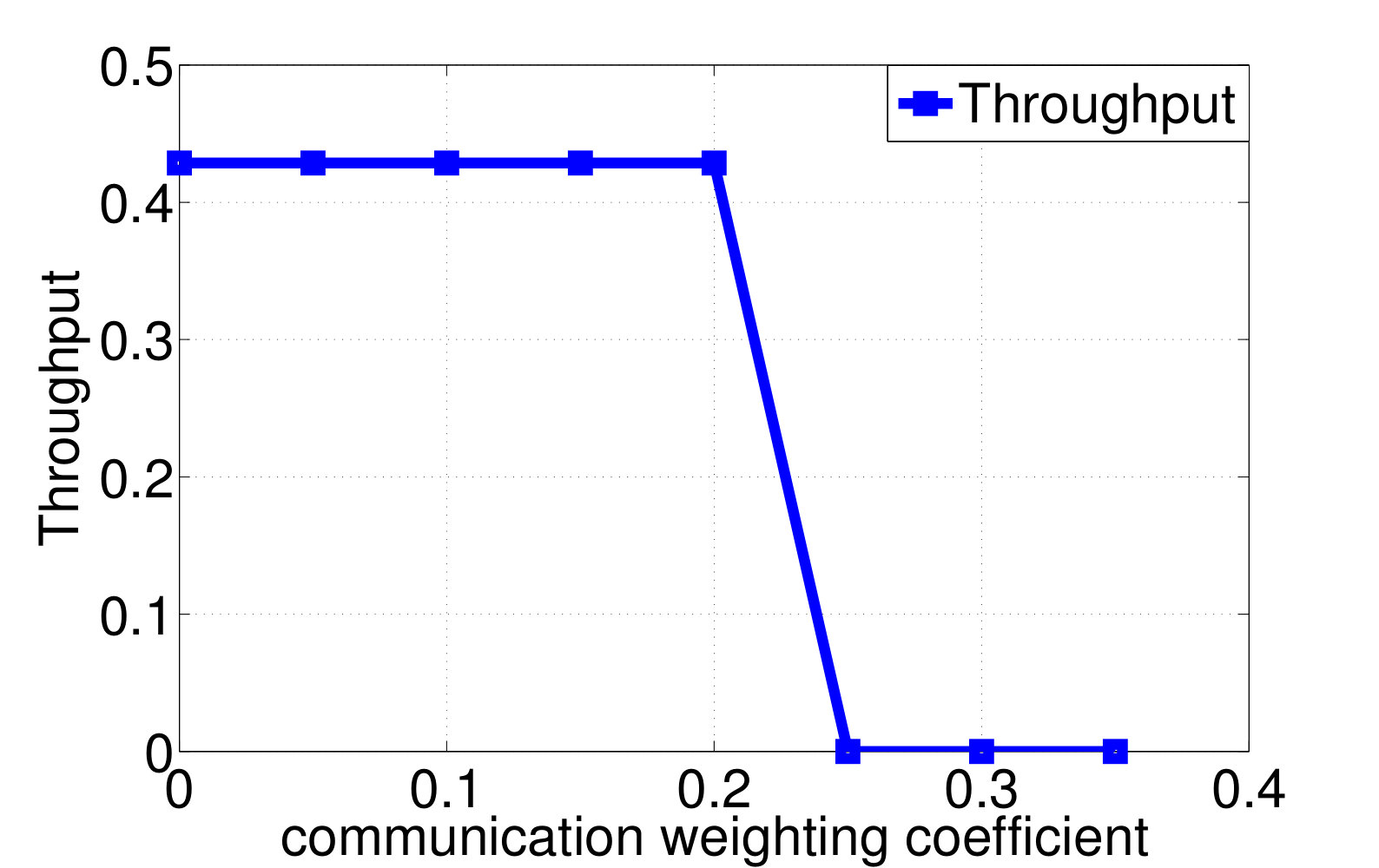 Figure 13
Figure 13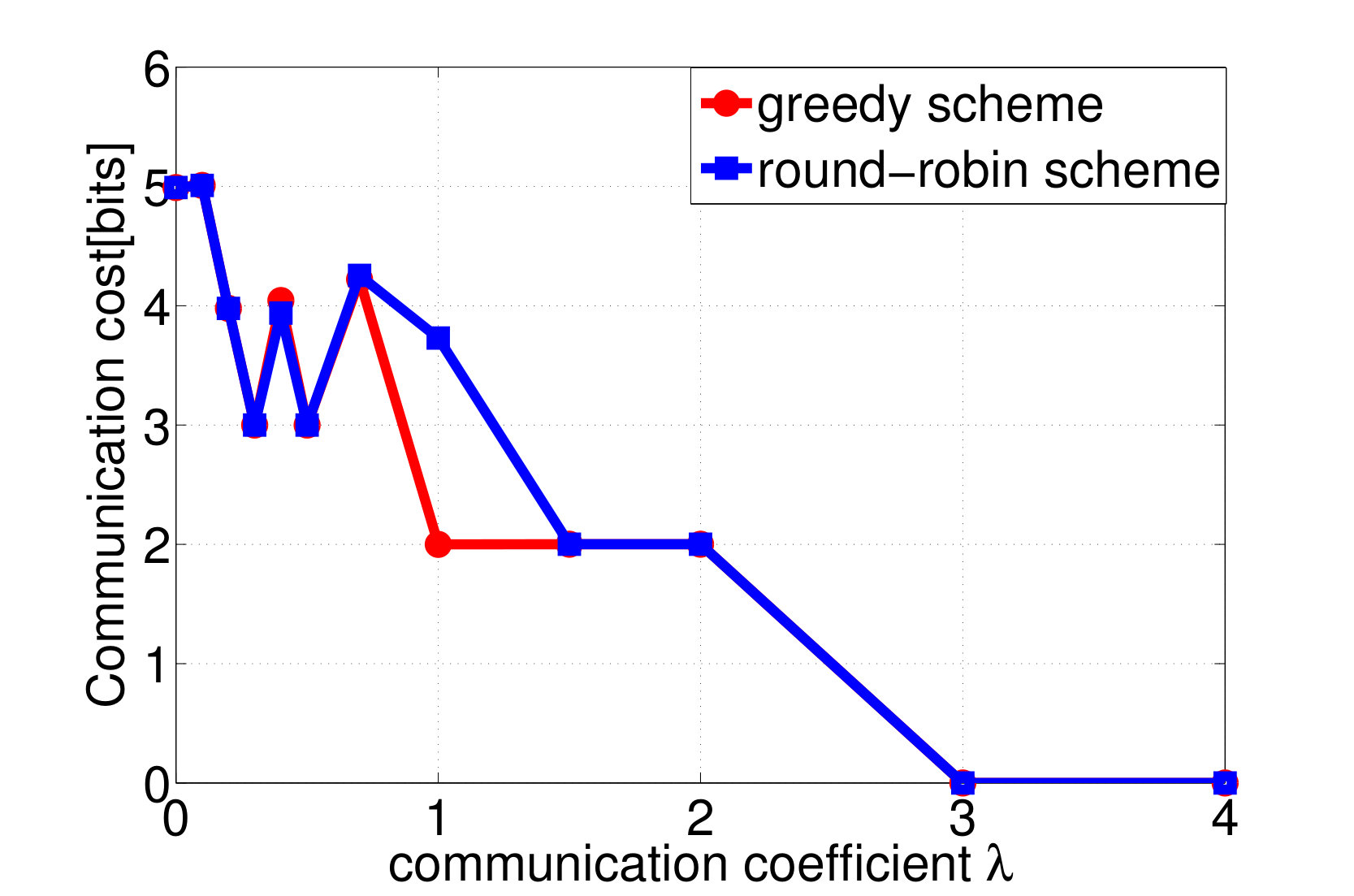 Figure 14
Figure 14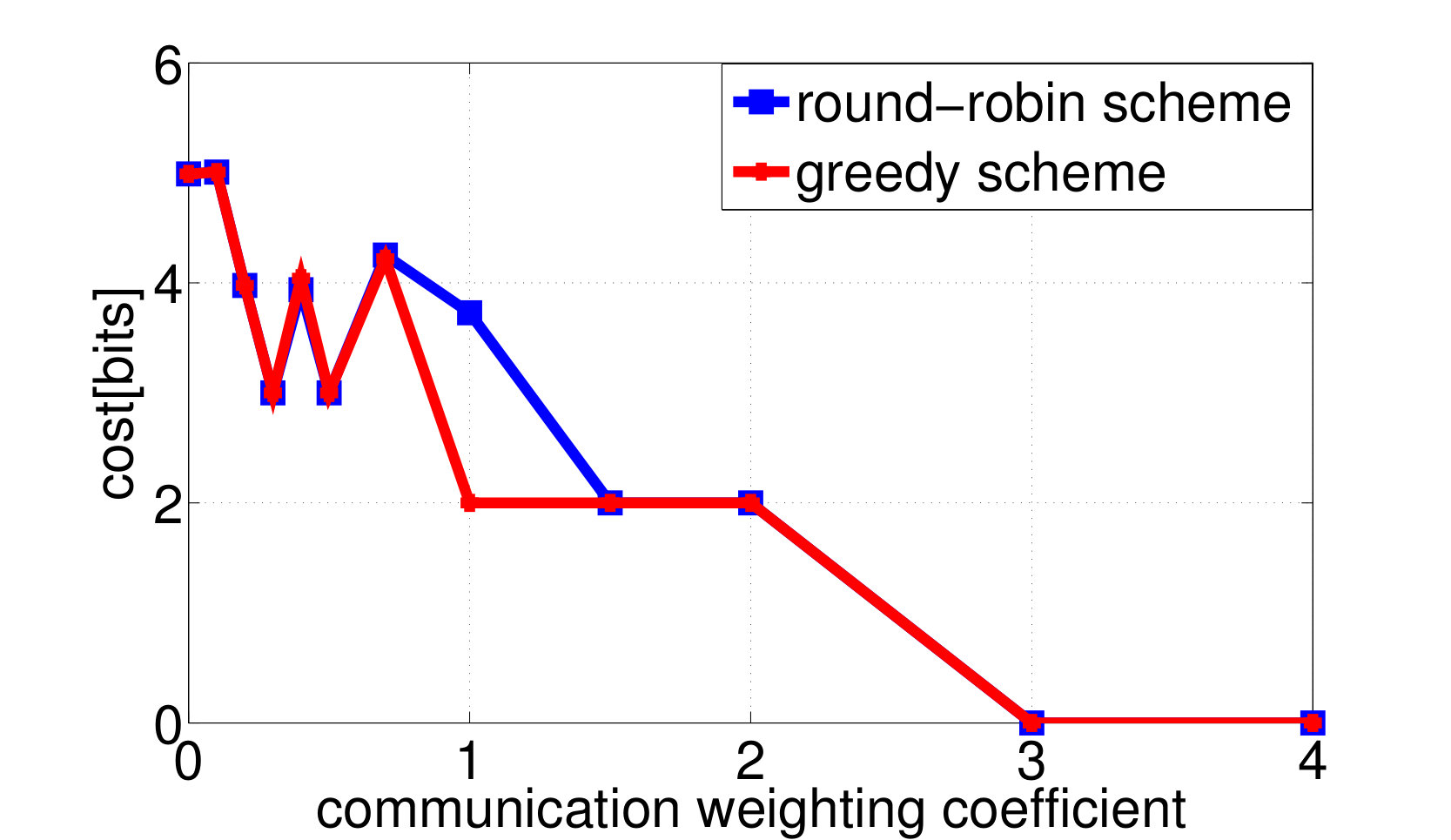 Figure 15
Figure 15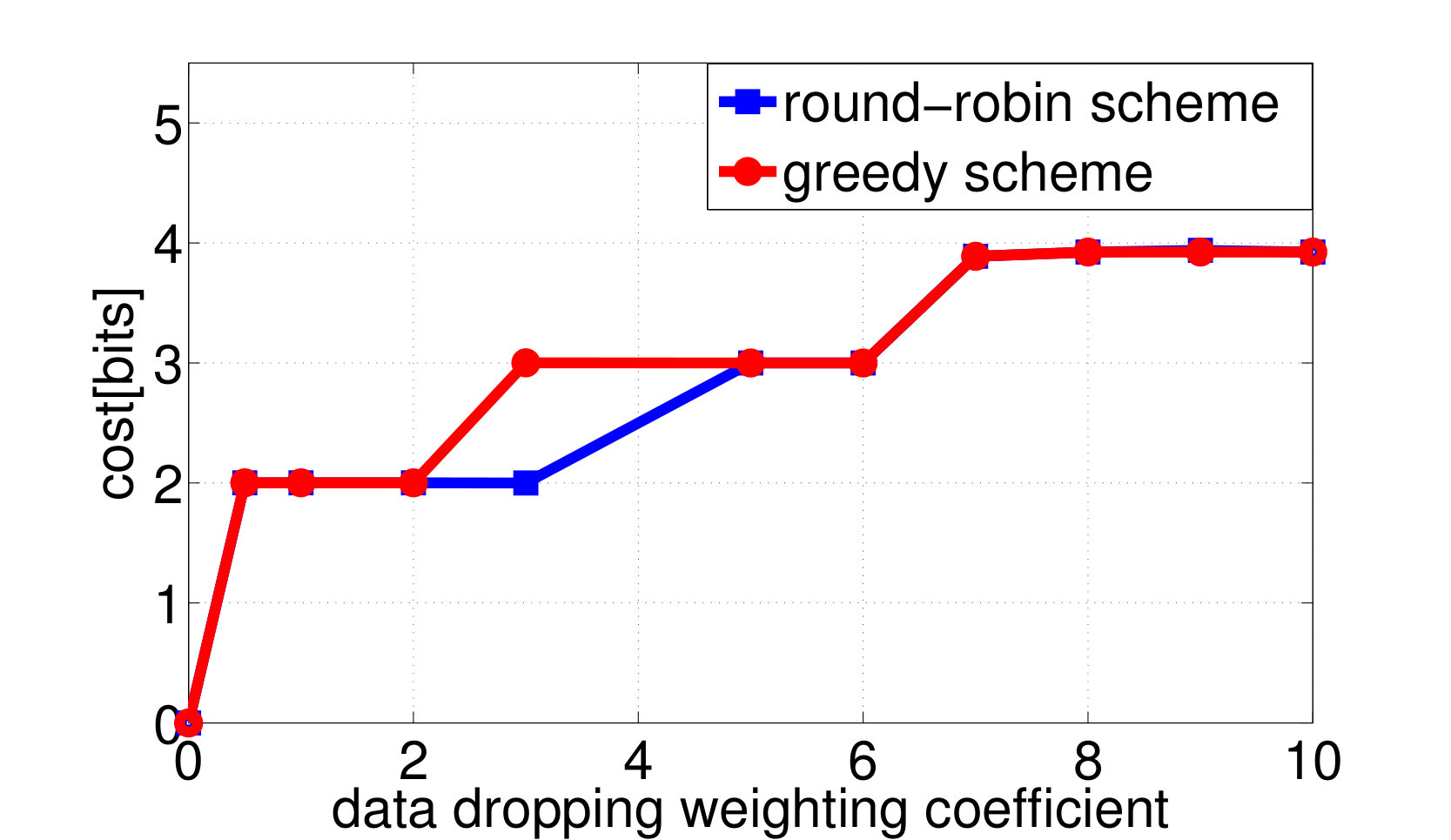 Figure 16
Figure 16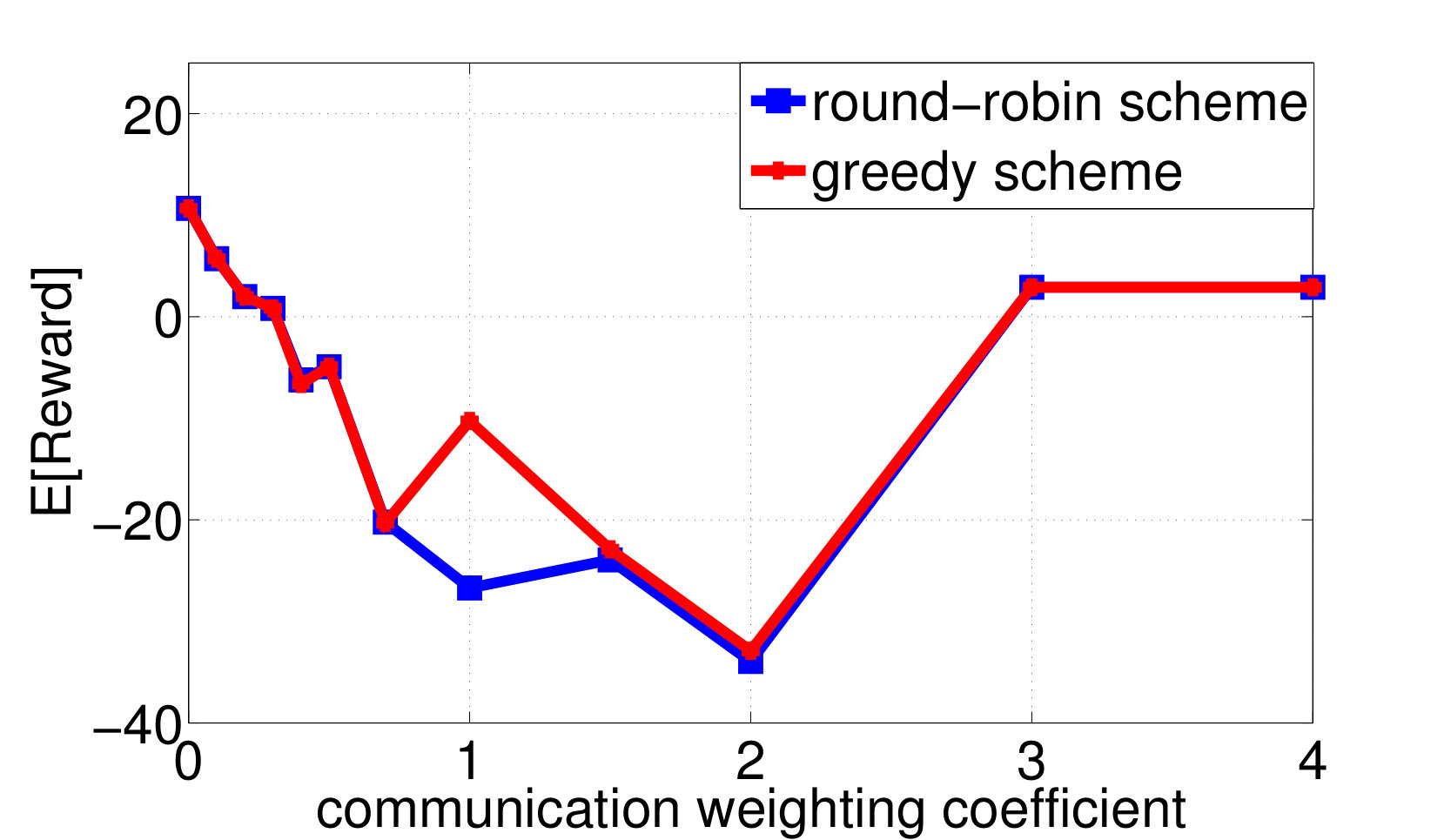 Figure 17
Figure 17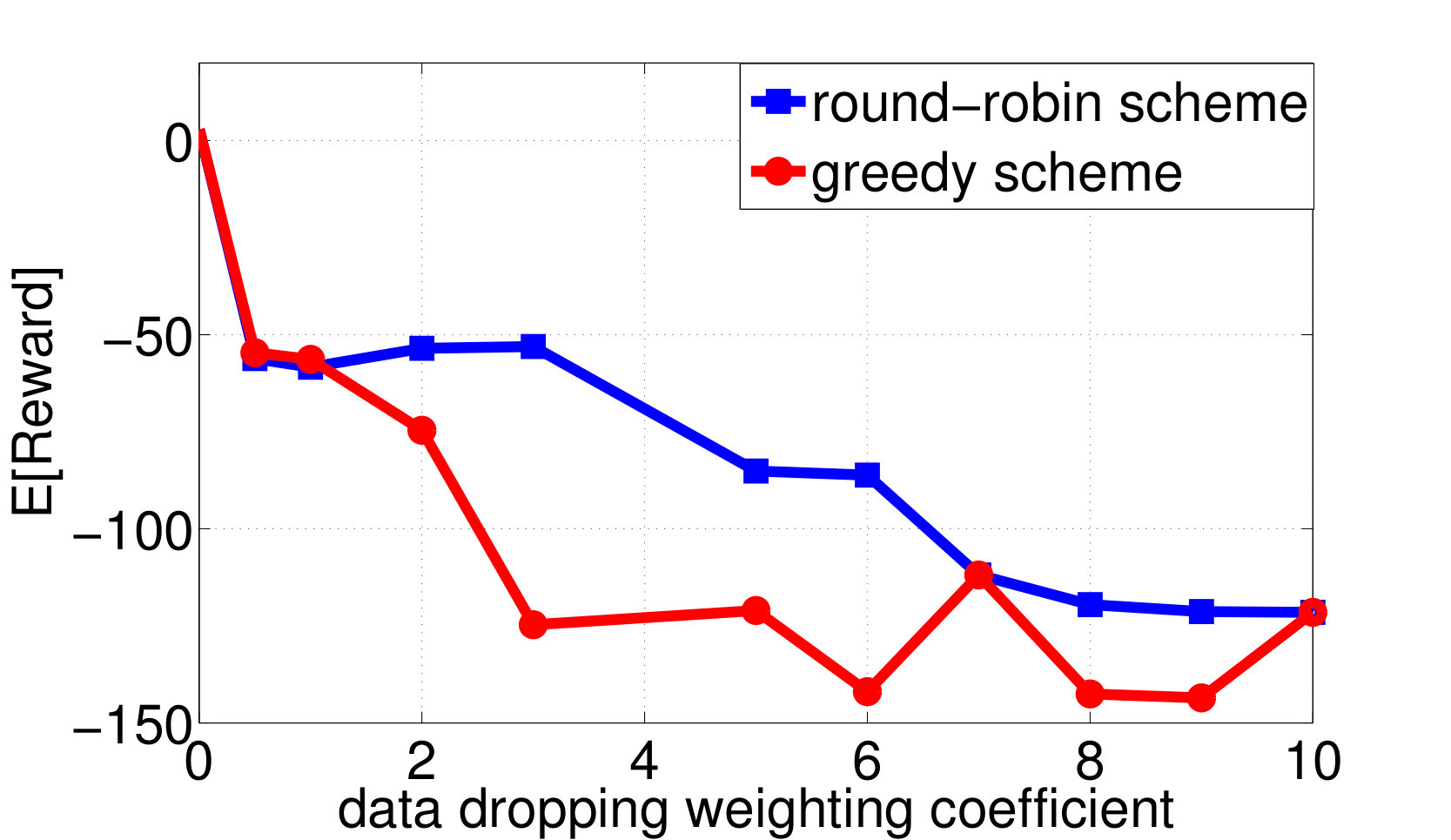 Figure 18
Figure 18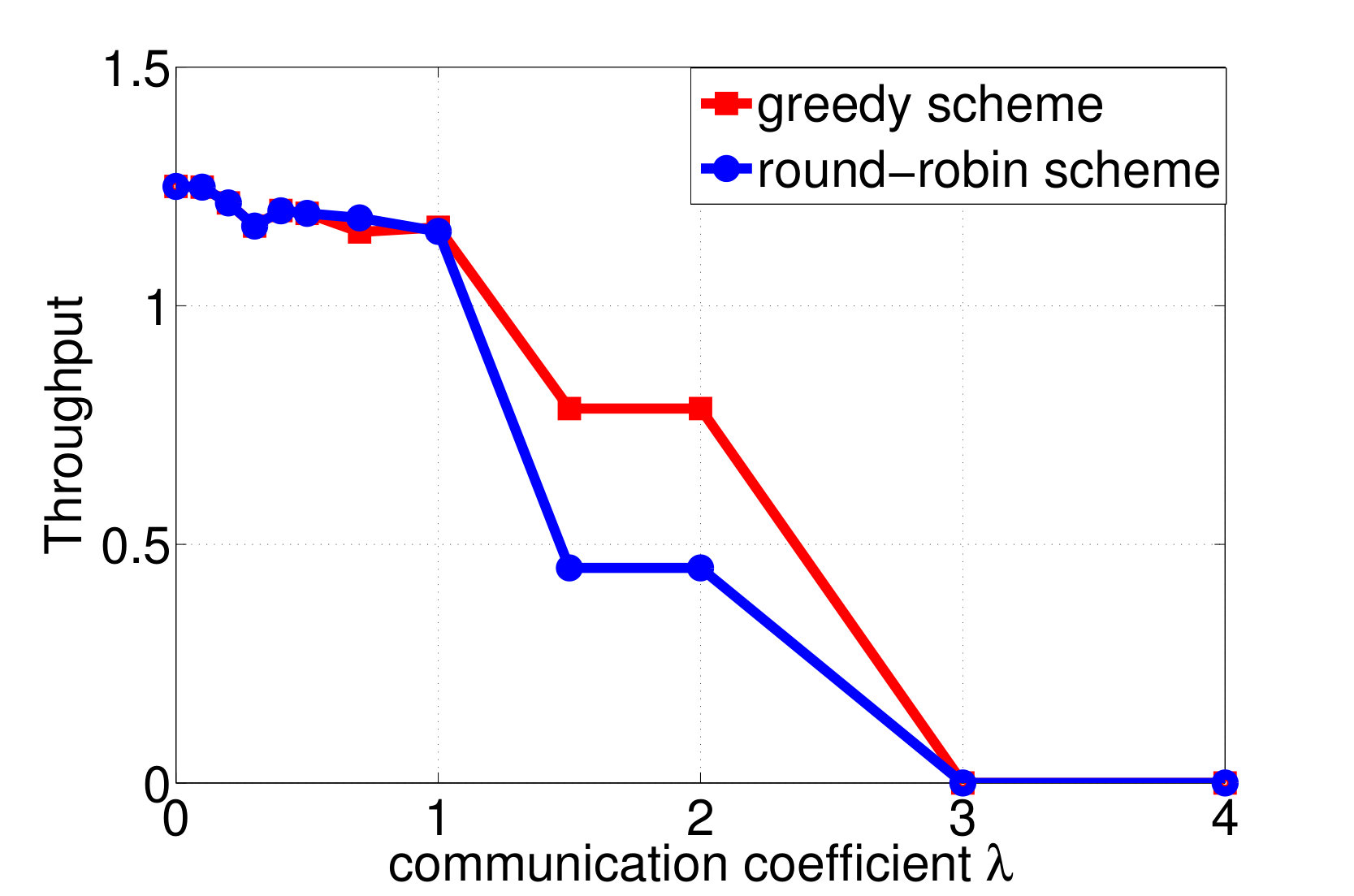 Figure 19
Figure 19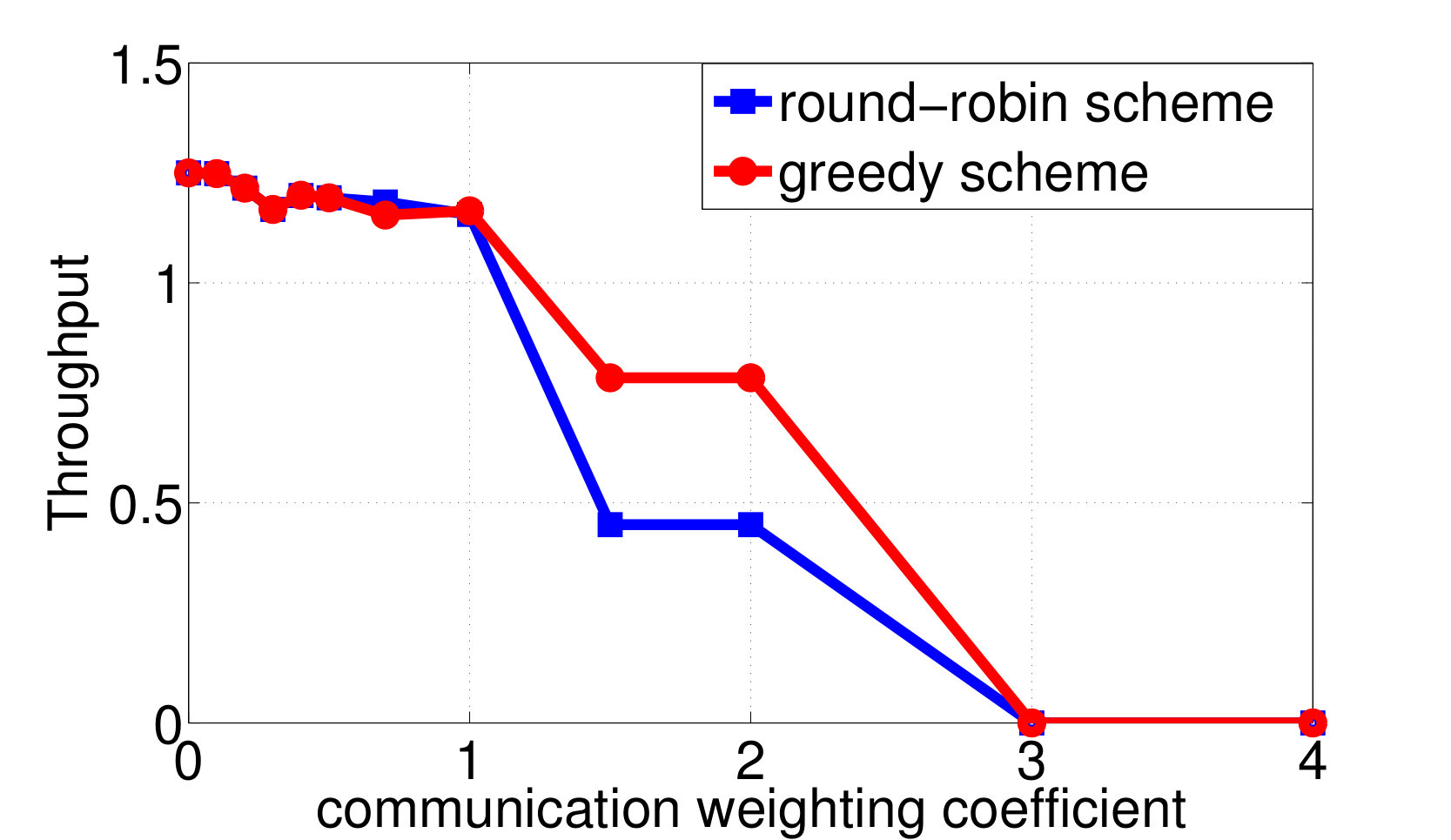 Figure 20
Figure 20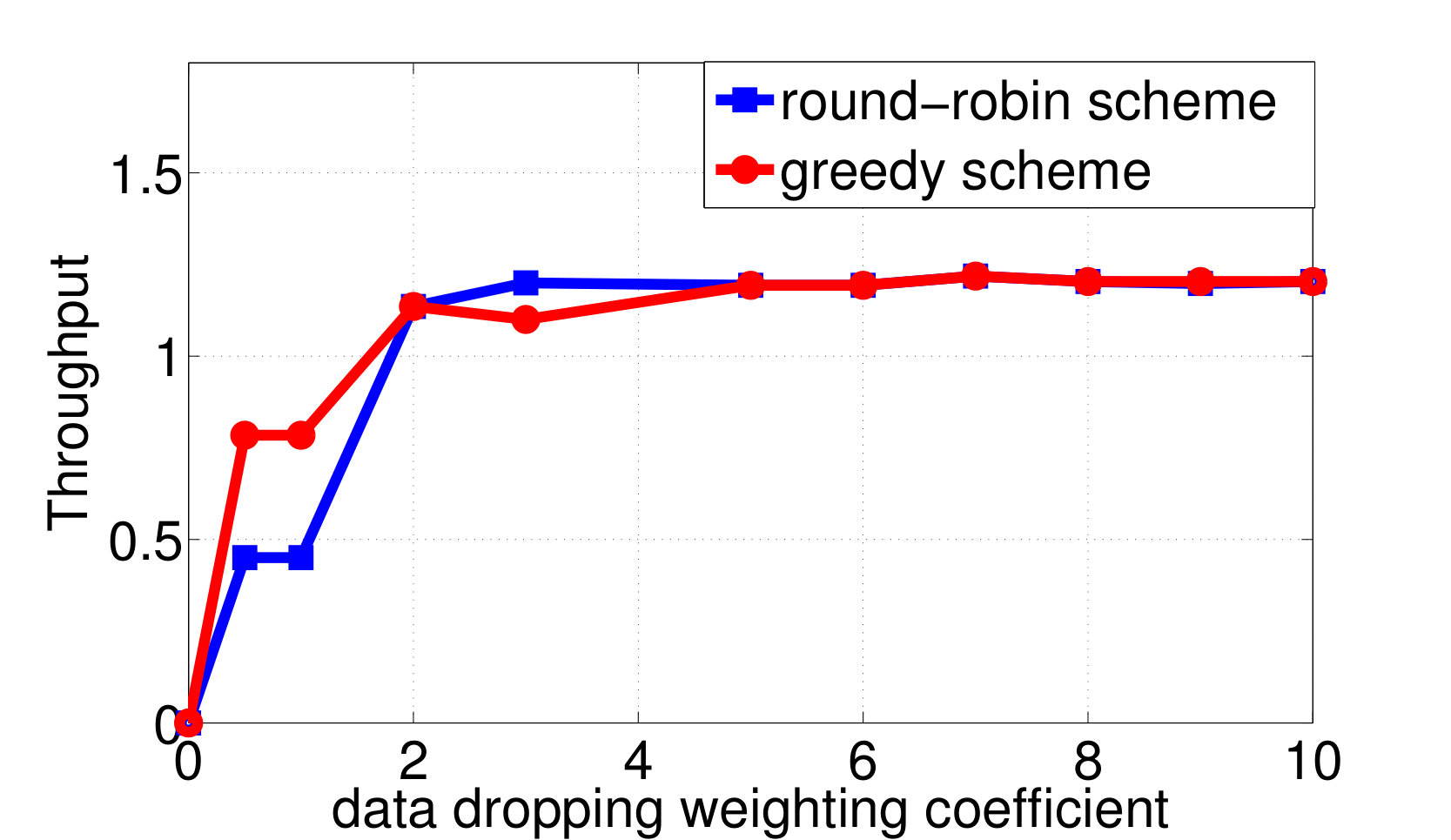 Figure 21
Figure 21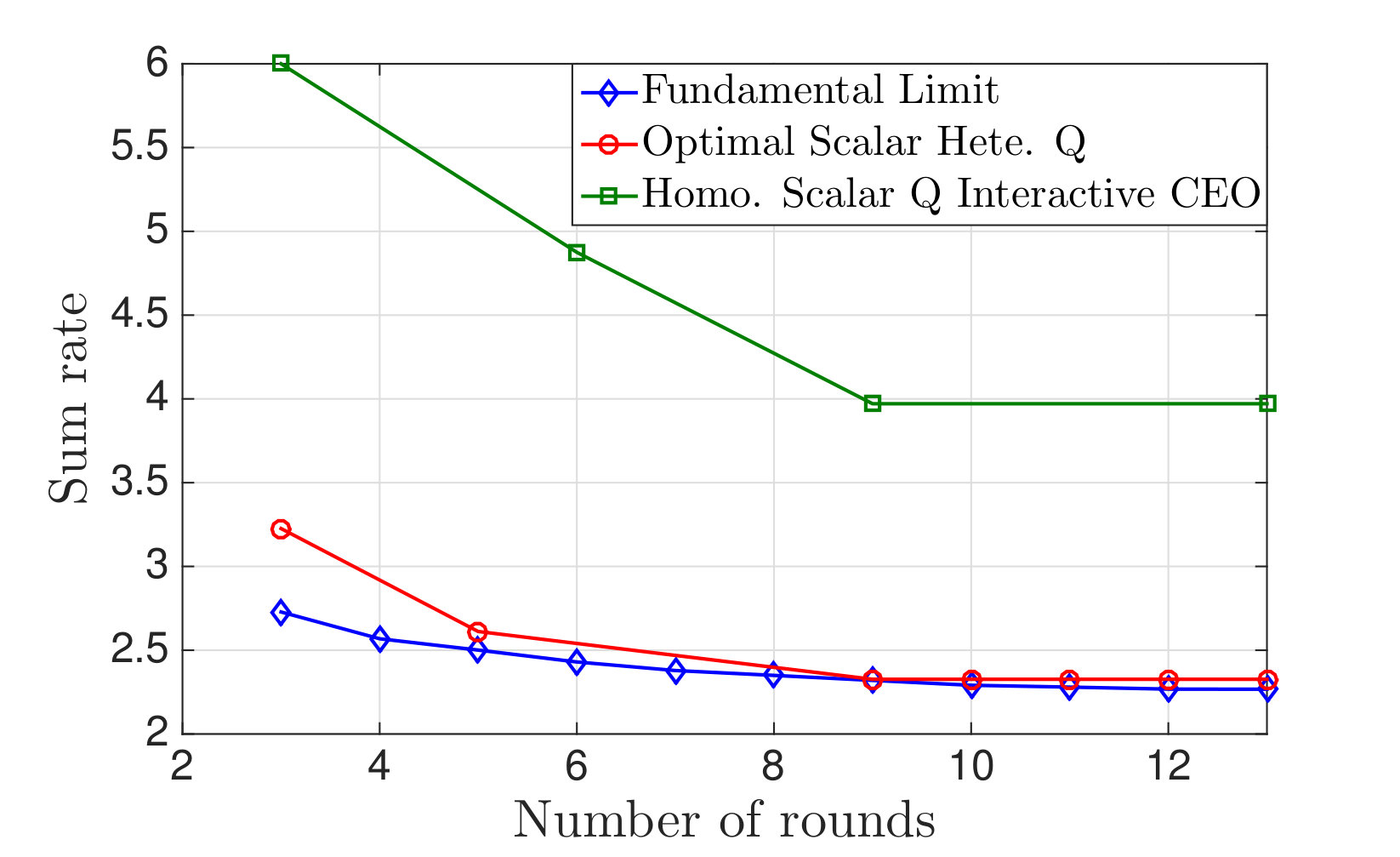 Figure 22
Figure 22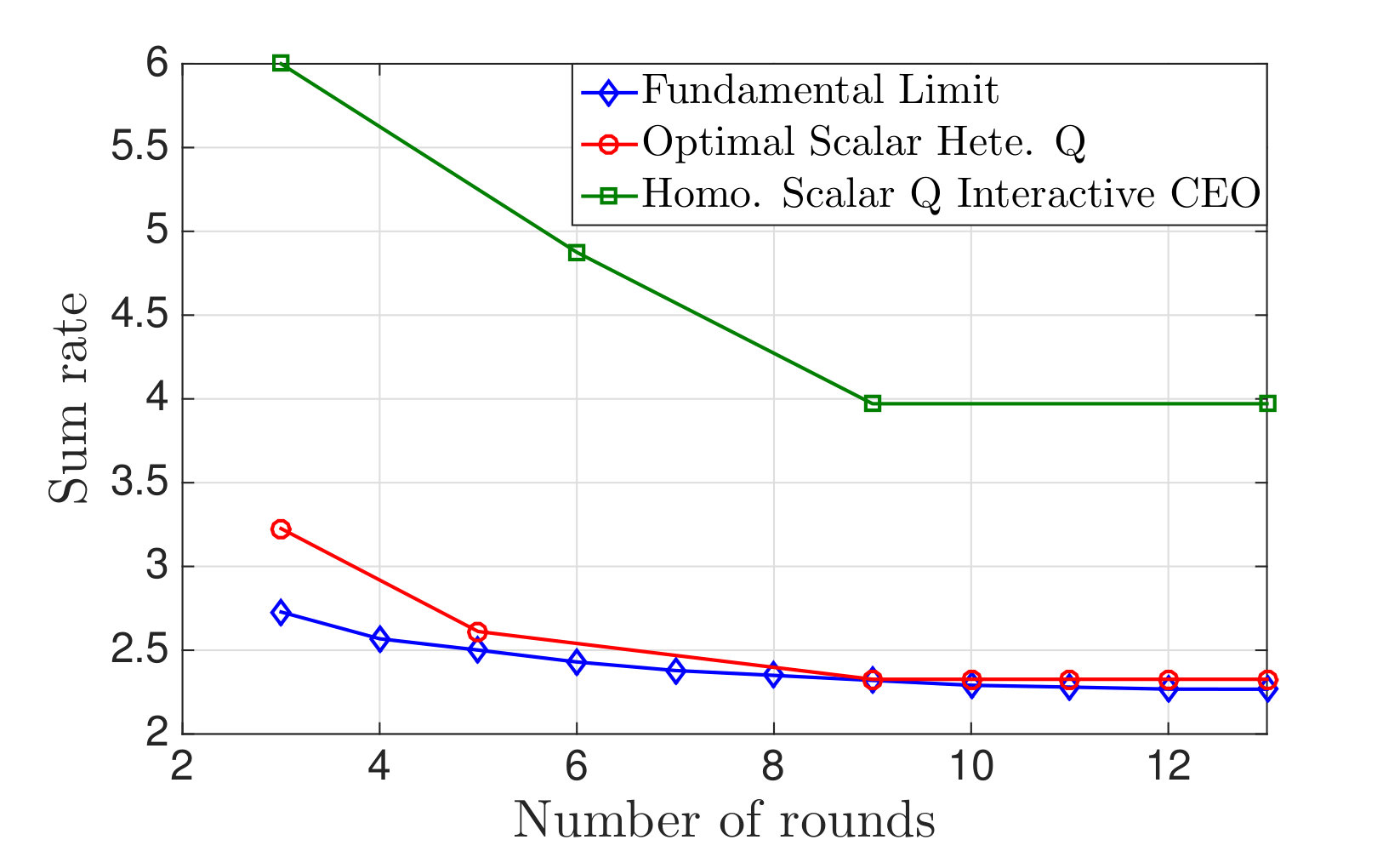 Figure 23
Figure 23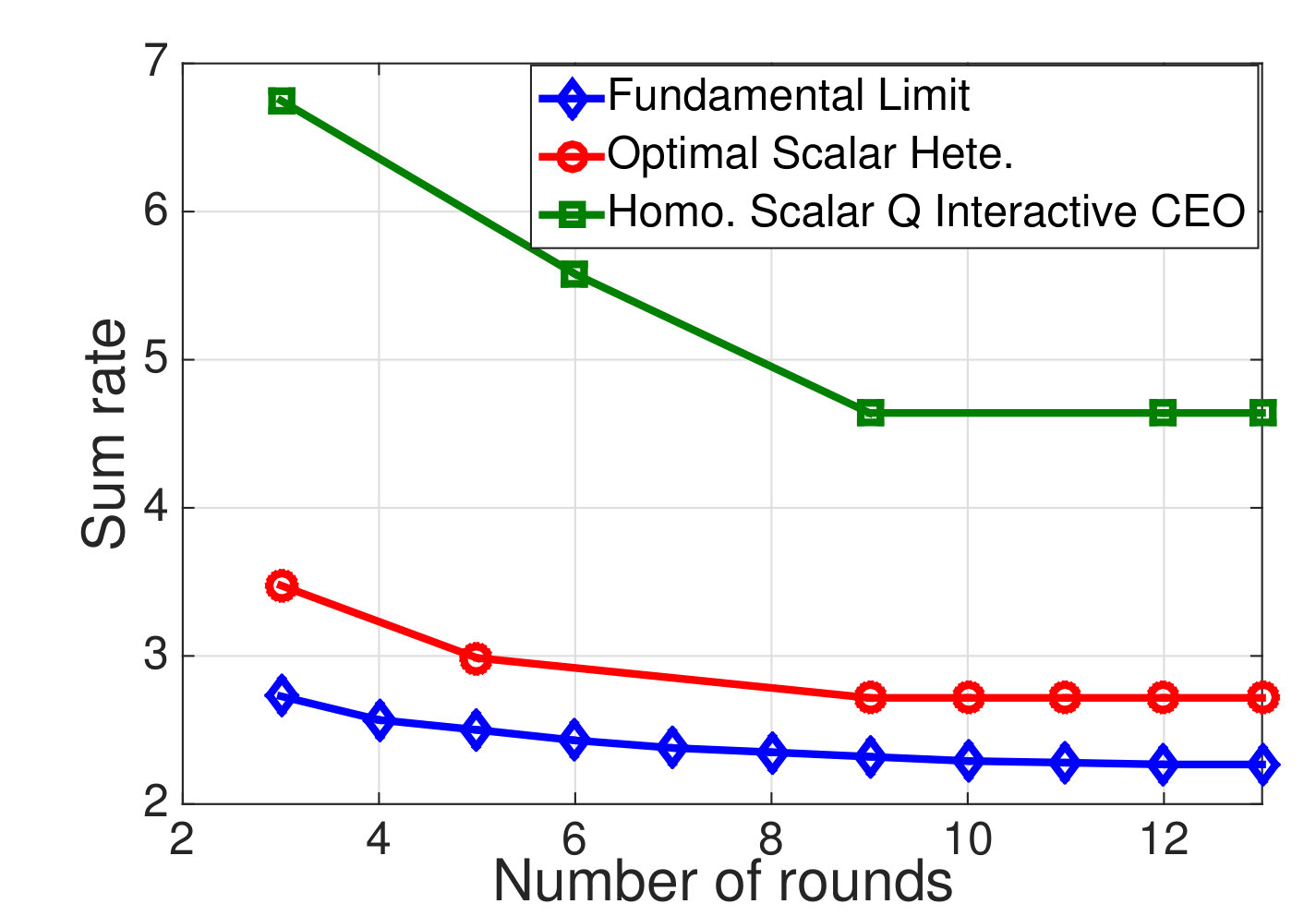 Figure 24
Figure 24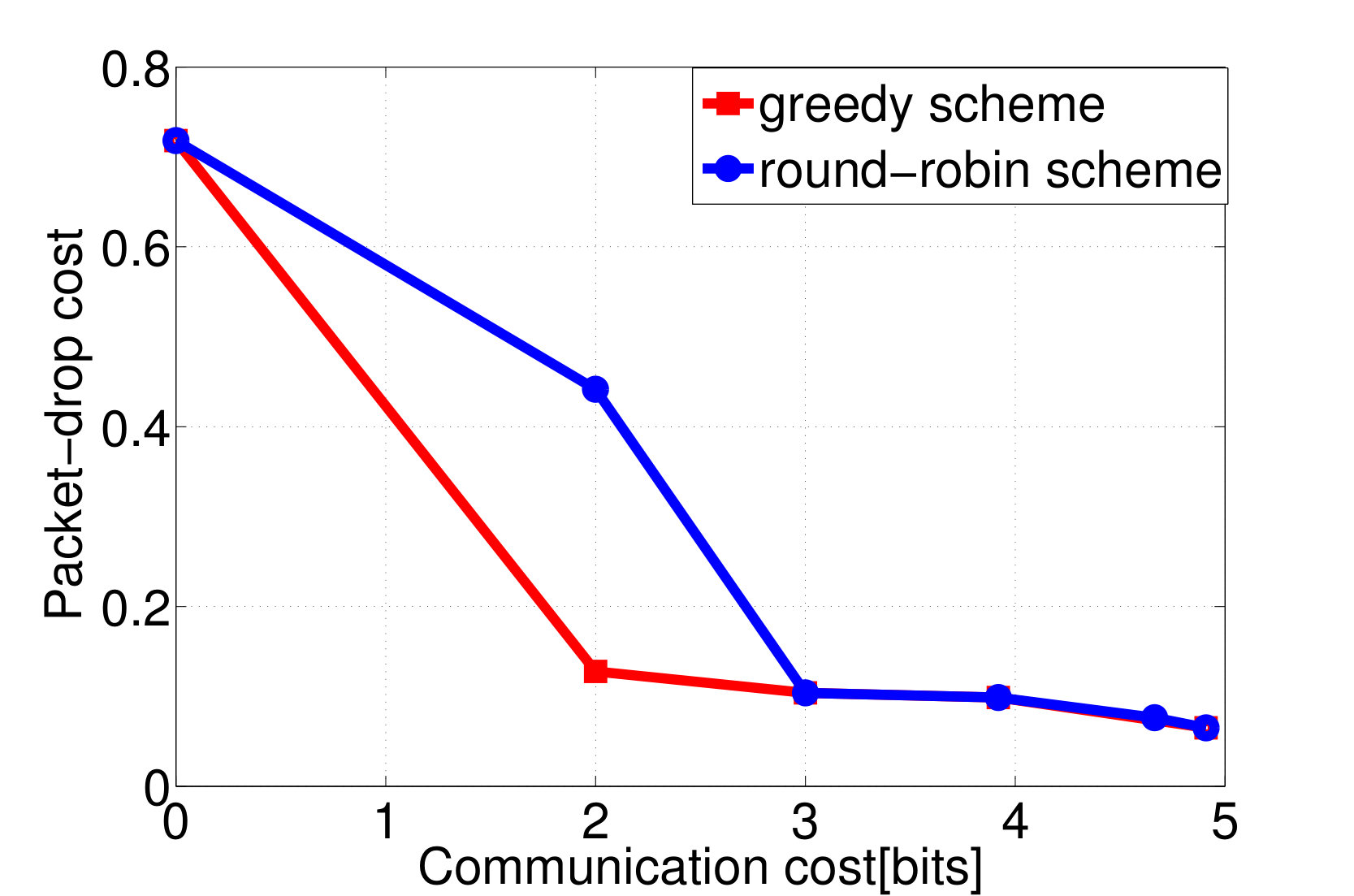 Figure 25
Figure 25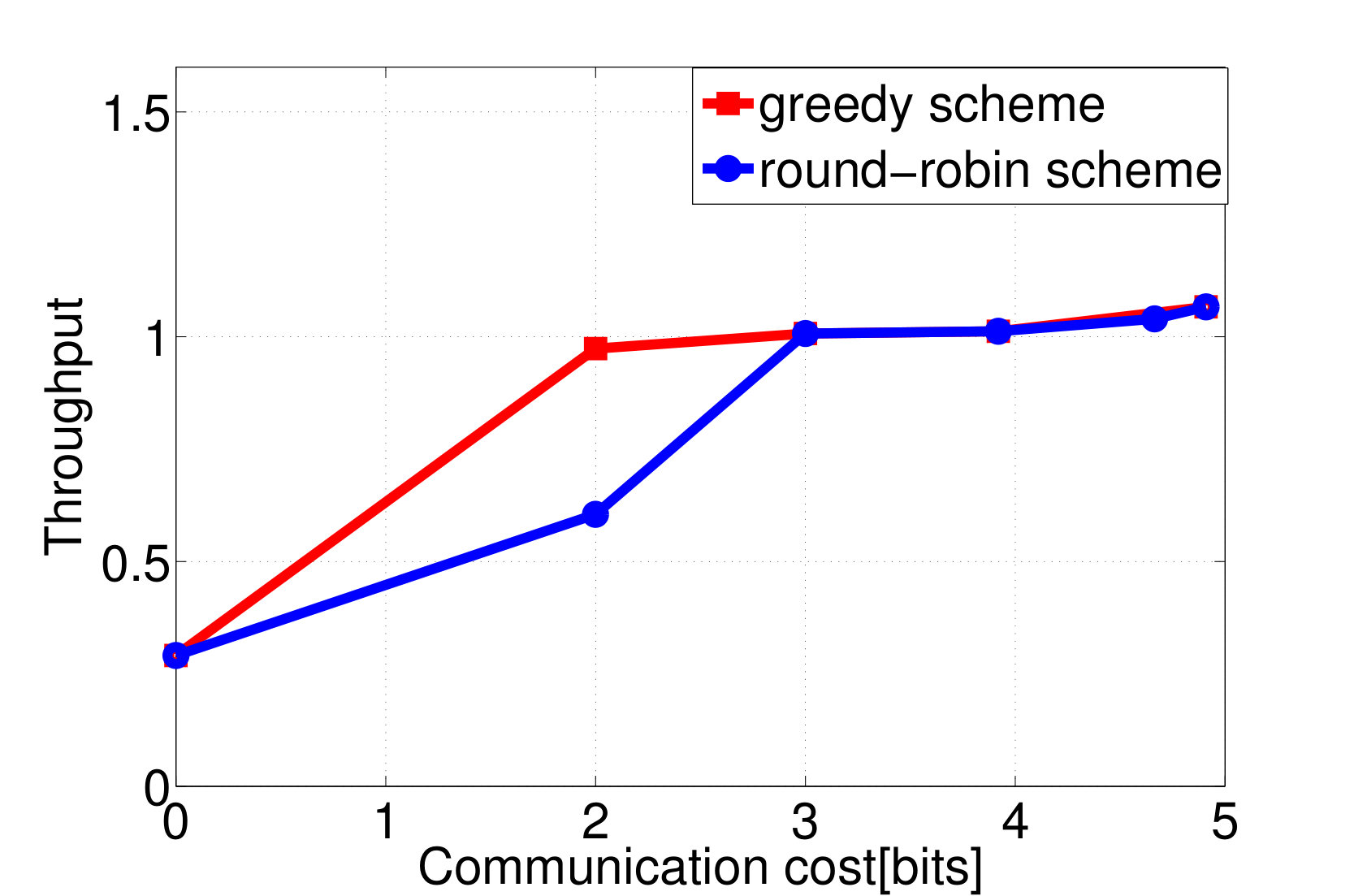 Figure 26
Figure 26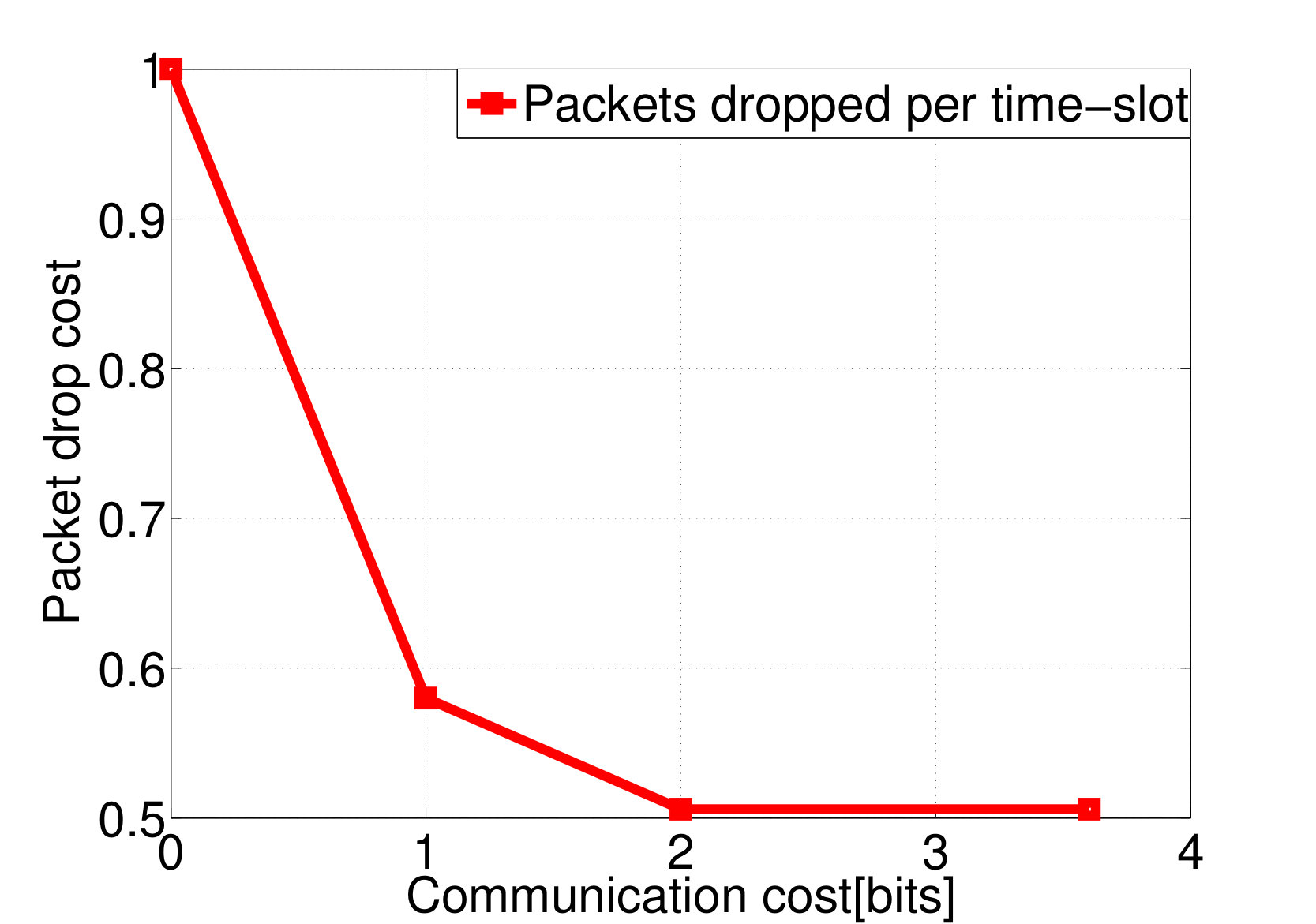 Figure 27
Figure 27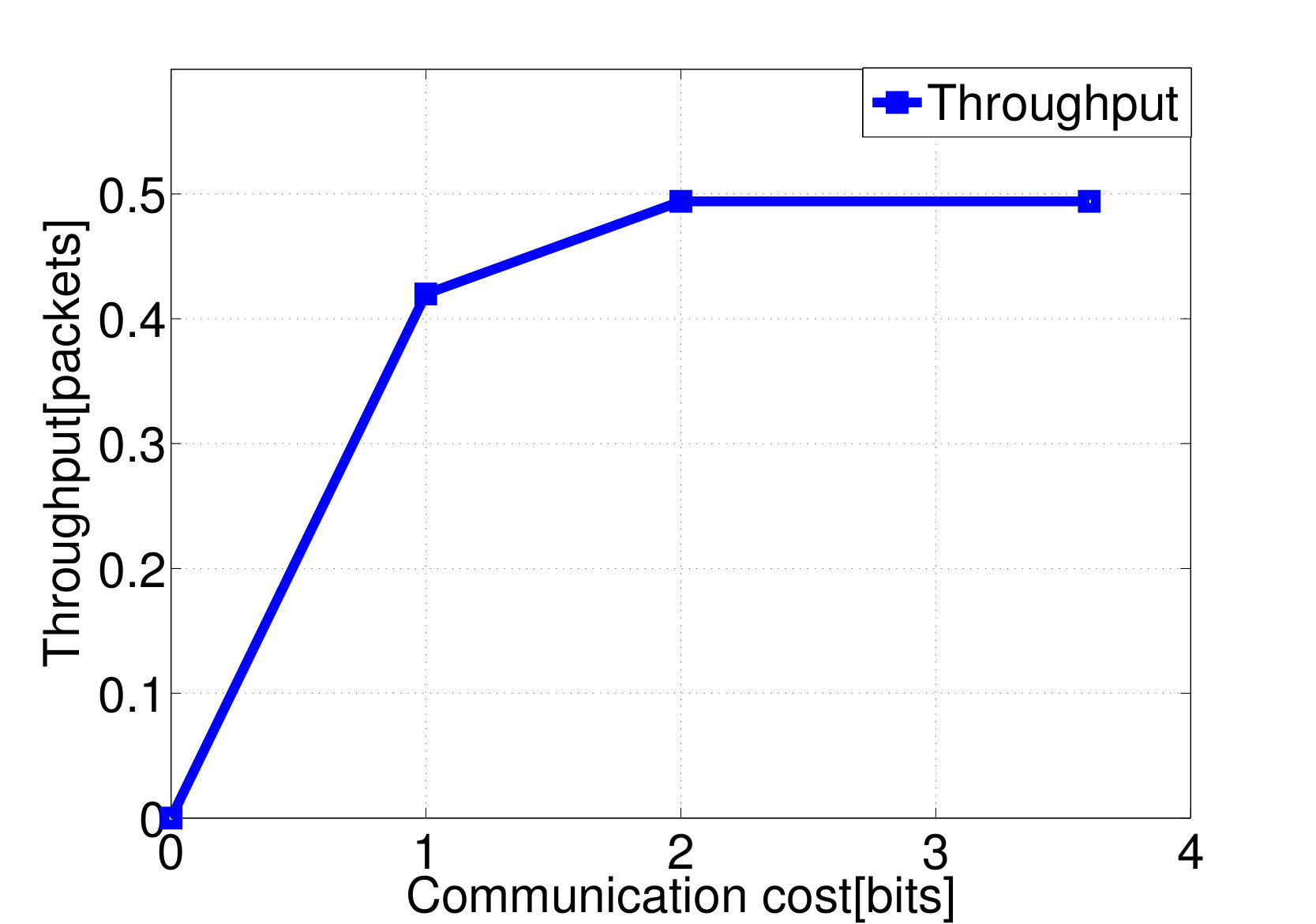 Figure 28
Figure 28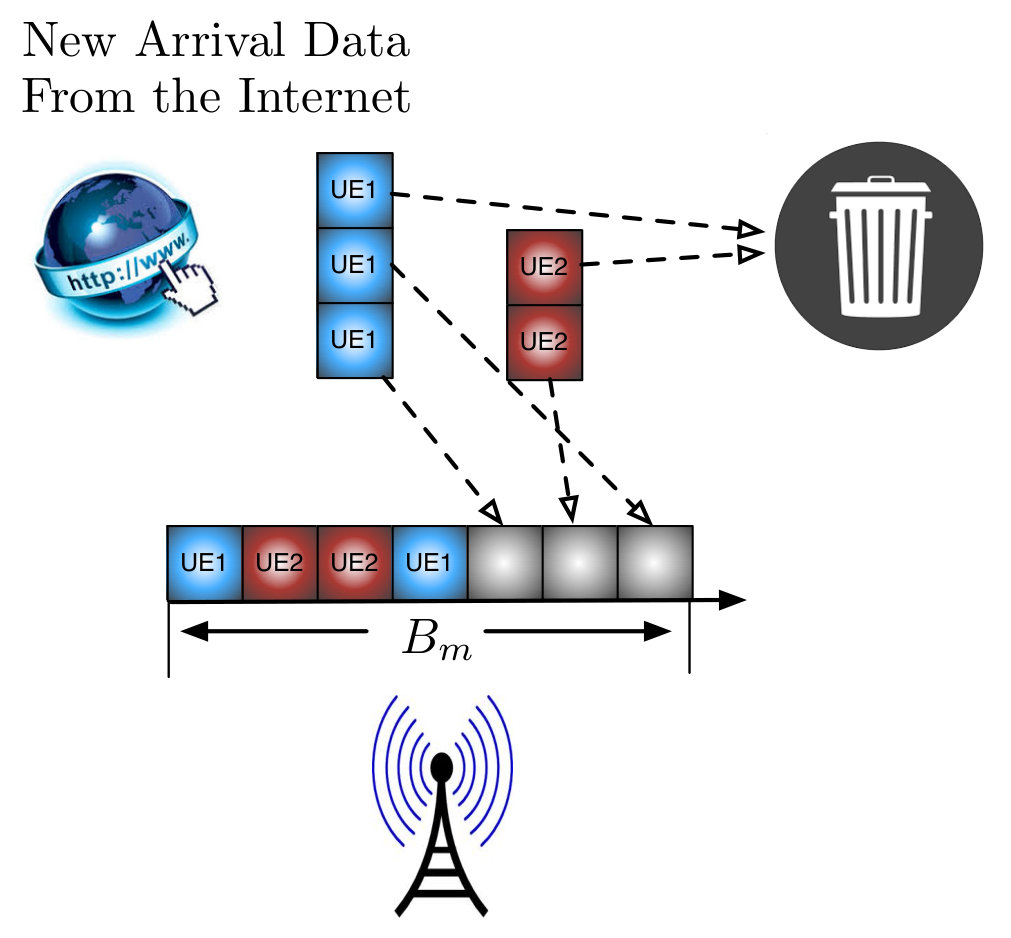 Figure 29
Figure 29 Figure 30
Figure 30Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAge of Information Optimization · Distributed systems and fault tolerance · Distributed Control Multi-Agent Systems
A Framework for Rate Efficient Control of Distributed Discrete Systems
Jie Ren, Solmaz Torabi, John MacLaren Walsh
(June 1, 2016)
Abstract
A key issue in the control of distributed discrete systems modeled as Markov decisions processes, is that often the state of the system is not directly observable at any single location in the system. The participants in the control scheme must share information with one another regarding the state of the system in order to collectively make informed control decisions, but this information sharing can be costly. Harnessing recent results from information theory regarding distributed function computation, in this paper we derive, for several information sharing model structures, the minimum amount of control information that must be exchanged to enable local participants to derive the same control decisions as an imaginary omniscient controller having full knowledge of the global state. Incorporating consideration for this amount of information that must be exchanged into the reward enables one to trade the competing objectives of minimizing this control information exchange and maximizing the performance of the controller. An alternating optimization framework is then provided to help find the efficient controllers and messaging schemes. A series of running examples from wireless resource allocation illustrate the ideas and design tradeoffs.
I Introduction
The framework of Markov decision processes (MDP) [1, 2] provides a principled method for the optimal design of controllers for discrete systems. By solving a Bellman’s equation, for example through either a value or policy iteration, one derives a control mapping assigning to each possible state of the system a control action to take, in a manner that maximizes a long run discounted expected reward. Of increasing interest, however, are those discrete systems which are decentralized or distributed, in the sense that no single participant in the system has full access to the global system state, but rather this global state is the concatenation of a series of local states, each of which are directly observed at different locations.
For instance, a series of agents may each observe their own local state, and have a set of local actions to choose from [3, 4, 5], and the desire may be to design individual local controllers. The fact that the global system state is not available at any location either requires sufficient information to be exchanged, either through ordinary communications or through the system’s state [6, 7], to remedy the situation, or a modification of the control framework. One way to address in part this distributed knowledge of network state is to use the framework of partially observable Markov decision processes (POMDP) to synthesize controllers. In general optimal control of a POMDP requires the controller to maintain probabilistic belief-states about the current system state based on all previous control actions and all previous observations, then assigning a control action based on these belief states. Thus a key issue in the selection/design of POMDPs are problem structures which enable simple forms for this control action [8]. As they are even more complex, solving general decentralized multiagent (PO)MDPs are NEXP-complete [9], and a rich literature, e.g. [10, 11, 12, 13, 14, 15] and many others, have addressed finding approximate solutions.
A key issue in the literature about decentralized and/or distributed MDPs is the role and amount of communication and coordination. Relationships between communication and control have been established in several contexts in the literature. Information theoretic limits have been incorporated into the classical case of a single observer remotely controlling a linear system through a noisy channel [16, 17], with a focus on determining the minimum rate required to achieve control objectives [17] [18], [19]. In this vein, [20] proposes the notion of anytime capacity and gives a necessary and sufficient condition on communication reliability needed over a noisy channel to stabilize an unstable scalar linear process when the observer has access to noiseless feedback of the channel output. Building on these ideas, [21, 22, 23] provide explicit construction of anytime reliable codes with efficient encoding and decoding over noisy channels. Shifting to a decentralized control context, deep connections between communications between controllers through the system state and network coding have recently been investigated [24, 6, 7].
Despite this long standing interest between relationships between communication and control, the role of information theoretic limits when state observations from a MDP are distributed has been less well developed in the literature. Here, the literature studying communication and coordination has not made use of related ideas from multiterminal information theory to compute communication cost. [25], for instance, considers a multi-agent coordination with agent decisions made in a self-interested environment, while [26] discusses the computational complexity of finding optimal decisions in a communicative multi-agent team decision problem (COM-MTDP) along the dimension of communication cost. Similarly [27, 28, 29], recognize that communication incurs a cost in the global reward function, and show that whether or not to communicate is also a decision to make. However, none of these models in [25, 26, 27, 28, 29] make use of relevant information theoretic limits when computing a communication cost. Part of the reason that information theoretic limits have not been fully brought to bear in the distributed MDP is that the limits for the relevant models, for instance for distributed [30, 31] and/or interactive function computation [32, 33], have been only somewhat recently derived. Bearing this in mind, this paper aims to harness information theoretic limits and coding designs that approach them, to help synthesis efficient control schemes for a distributed MDP.
In particular, in Section II we consider a MDP model in which the state can be considered a vector of local states, each of which are directly observed at a different location. If the goal is to have this distributed MDP operate in the same manner as an omniscient MDP having full access to this global state, then a natural way to achieve this is through the exchange of state information between the participants. This information exchange, however, can be costly, and furthermore, in order to achieve the same performance, i.e. simulate, an omniscient controller, all that is truly necessary is that the system make the same decisions. As such, it can be desirable to determine the minimal amount of information that must be exchanged in order to enable the distributed system to learn the decisions the centralized omniscient controller would take. Lower bounds on this minimal amount of control information necessary are provided in Section III using recent results from information theory regarding quantization, both interactive and non-interactive, for decentralized function computation. Alternatively as described in Section IV, one may wish to incorporate the cost of the communication into the reward, enabling the control designer to trade the cost of the communication for the performance of the controller. In this case, the messaging scheme and controller must be designed simultaneously, and in order to provide candidate solutions to the associated optimization, we present in Section IV-A an alternating optimization based method guaranteed to yield a sequence of rewards which converges. When the the messaging scheme and control map selected by this scheme converges, we prove that it must lie at a Nash equilibrium of the total reward, which combines the reward of the controller with the cost of the communication. Several examples drawn from the design of downlink resource controllers for wireless networks throughout the manuscript demonstrate the ideas.
II Omniscient Control of a Distributed Markov Decision Process
Consider a distributed discrete stochastic control system modeled a Markov Decision Process (MDP) for whom the global system state at time , {\color[rgb]{1.00,0.00,0.00}\boldsymbol{\mathrm{S}}}_{\mathtt{t}}\in\boldsymbol{\mathscr{S}}, is itself a vector composed of a series of local states {\color[rgb]{1.00,0.00,0.00}S}_{\mathtt{n},\mathtt{t}}\in\mathscr{S}_{\mathtt{n}} each observed at one network node , so that
[TABLE]
The global network state {\color[rgb]{1.00,0.00,0.00}\boldsymbol{\mathrm{S}}}_{\mathtt{t}} evolves according to a Markov Chain whose transition matrix at time is selected by the control action {\color[rgb]{1.00,0.00,0.00}A}_{\mathtt{t}}
[TABLE]
Additionally, there is a reward function indicating the payment obtained when the global system state transitions from to after action is taken.
An omniscient controller having access to the series of global states {\color[rgb]{1.00,0.00,0.00}\boldsymbol{\mathrm{S}}}_{\mathtt{t}},\mathtt{t}\in\mathbb{N} would select the actions {\color[rgb]{1.00,0.00,0.00}A}_{\mathtt{t}} maximizing the total discounted expected reward
[TABLE]
The argument to the solution to this optimization is a mapping assigning to each state the optimum action to take, so that the optimal {\color[rgb]{1.00,0.00,0.00}A}_{\mathtt{t}}^{*}=\mathsf{c}({\color[rgb]{1.00,0.00,0.00}\boldsymbol{\mathrm{S}}}_{\mathtt{t}}). Bellman’s equation states that the solution to this optimization must solve the following system of equations
[TABLE]
[TABLE]
The solution to this simultaneous system of equations, and the associated optimal control mapping, can be found by first determining the limit of the following value iteration
[TABLE]
then solving for the control policy via
[TABLE]
Alternatively, one can utilize a policy iteration, which performs a recursion in which first
[TABLE]
is solved, followed by a solution of the linear system
[TABLE]
for . until the control mapping can be selected to remain the same under the update, at which point the iteration ceases, see, e.g. [34][8].
Note that in many problems, for a given , there is more than one choice for achieving the maximum in (5). In this instance, one can derive a set of candidate (omniscient) control functions which are those obeying the constraints
[TABLE]
each of which achieves the maximum long run expected reward.
Ex. 1** (Downlink Wireless Resource Allocation):**
An example of a practical problem having the structure outlined by (4) and (5) is that of distributing resources on a wireless downlink. Time is slotted. There is a basestation which has a shared buffer containing individual information that must be sent to a series of users, with the amount waiting for a user during time slot being denoted by . Collectively, these buffer sizes form the local state at the basestation {\color[rgb]{1.00,0.00,0.00}S}_{\mathtt{N}+1,\mathtt{t}}=(B_{1,\mathtt{t}},\ldots,B_{\mathtt{N},\mathtt{t}}). Each user has a channel state {\color[rgb]{1.00,0.00,0.00}S}_{\mathtt{n},\mathtt{t}}, indicating how much information can be reliably transmitted to this user during the present timeslot, which evolves independently of other users channel states according to a Markov chain with transition distribution p(i_{\mathtt{n}},j_{\mathtt{n}})=\mathbb{P}[{\color[rgb]{1.00,0.00,0.00}S}_{\mathtt{n},\mathtt{t}+1}=j_{\mathtt{n}}|{\color[rgb]{1.00,0.00,0.00}S}_{\mathtt{n},\mathtt{t}}=i_{\mathtt{n}}]. During each time slot , a random amount of additional traffic arrives destined for each user at the basestation’s buffer, independently of other time slots and previous arrivals. If the basestation’s buffer can not accommodate this traffic, it is dropped.
During each time slot, it must be decided which of the users to give the resource to, and thus this forms the action in the MDP, . Additionally, both the users and the basestation must know the outcome of this decision. After the user to transmit to is selected, an amount of their traffic that is the minimum between their capacity during the slot and the amount of traffic waiting for them in the buffer will be successfully transmitted to them and removed from the buffer, yielding the Markov chain dynamics
[TABLE]
where is the amount of new traffic arriving during the time slot for each user, and the vector \boldsymbol{T}({\color[rgb]{1.00,0.00,0.00}A}_{\mathtt{t}},{\color[rgb]{1.00,0.00,0.00}\boldsymbol{\mathrm{S}}}_{\mathtt{t}-1}) has th element
[TABLE]
while the function performs the package dropping process when the arriving traffic can not be accommodated in the buffer. Note that this assumption, that for this amount of information to be successfully transmitted and received, all the users and basestation need to know is who to schedule, is consistent with assumption that the physical layer below the scheduler uses a rateless code with feedback, which can be closely approximated with hybrid ARQ [35, 36, 37].
When making the decision of who to schedule, several important metrics can be considered, and thereby combined, into the reward. A very natural metric is the throughput, which measures how much information is transmitted, summed over all the users. This gives the reward function
[TABLE]
Other metrics such as the average or maximum delay a users traffic experiences are also reasonable metrics which can be incorporated into the reward function, for instance by adding them together with rates that can trade them for one another.
With the selected metrics included in the reward function, the MDP framework gives a formal way of deciding who to allocate the resources to during each time slot. A series of examples throughout the rest of the paper will find this optimal controller and investigate properties, such as how much information must be exchanged in order to perform it.
II-A Simulating the Omniscient MDP via Information Exchange
However, as the system is distributed, no single node is given access to the global network state, and control must be performed by the nodes learning which action to take through some sort of communication enabled strategy. Additionally, we will introduce the constraint that an observer not given access to any of the local states, but rather accessing only all of the control messages the nodes share with one another, must be able to infer which action was taken. In order to enable the system to be easily monitored, we further require this user observing no state to be able to learn an optimal action {\color[rgb]{1.00,0.00,0.00}A}_{\mathtt{t}} selected exclusively from the information shared during the time slot during which the omniscient control action {\color[rgb]{1.00,0.00,0.00}A}_{\mathtt{t}} must be taken.
For such a strategy, a key question is how much information must be shared in order to enable the optimal control action {\color[rgb]{1.00,0.00,0.00}A}_{\mathtt{t}}^{*}=\mathsf{c}({\color[rgb]{1.00,0.00,0.00}\boldsymbol{\mathrm{S}}}_{\mathtt{t}}) the omniscient controller would have taken to be selected based on the shared information. In other words, how much information must be shared in order to enable the system to simulate the omniscient controller in the sense that every node, including the one having access to no local state observations and only observing the shared control messages during time slot , can learn the action the controller will take, thereby enabling the distributed system to obtain the same expected (discounted) long run reward as the omniscient system.
The answer to this question depends, of course, on the model for the way the information is exchanged, the control map , and particular characteristics of the transition kernels . Clearly the problem of designing this communication has been transformed into one of distributed function computation, as each node observing a local state {\color[rgb]{1.00,0.00,0.00}S}_{\mathtt{n},\mathtt{t}} must convey a message {\color[rgb]{1.00,0.00,0.00}M}_{\mathtt{n},\mathtt{t}} during the time slot such that {\color[rgb]{1.00,0.00,0.00}A}_{\mathtt{t}}^{*}=\mathsf{c}({\color[rgb]{1.00,0.00,0.00}\boldsymbol{\mathrm{S}}}_{\mathtt{t}}) can be learned from the messages {\color[rgb]{1.00,0.00,0.00}M}_{\mathtt{n},\mathtt{t}},\ \mathtt{n}\in\mathscr{N}. Additionally, the capability to select any and still achieve the maximum reward enables this amount of information exchanged to be further minimized over .
Ex. 2** (Downlink Wireless Resource Allocation, Continued):**
The assumptions made above, and the associated problem of minimizing overhead, have special practical significance for the downlink wireless resource allocation setup of example 1. Only the basestation has direct access to the buffer and observes the amount of information that has arrived destined for the various users, and only the users observe their downlink channel qualities, yet sufficient information must be exchanged for the system to make an informed decision regarding who to schedule on the downlink and how much information to send to them. The omniscient controller having access to all of this state distributed throughout the network could make a series of decisions by solving the associated MDP. At present, for instance in the LTE and WiMax standards, these decisions are made by the basestation, which requests and receives channel quality statistics from the users, then schedules the users and how much information to send to them, transmitting its decisions on the downlink [38]. Additionally, it is desirable to minimize this amount of control information through an efficient design, as this type of control measurement and decision information, together with reference signals, has reached roughly a quarter to a third of the time frequency footprint in LTE and LTE advanced [38]. Furthermore, it is essential that the messages exchanged during time slot are all that must be overhead in order to learn the control decision action, as nodes come and go from the network, and it is essential that nodes that have just arrived in the current slot be able to determine what the control decisions were. Finally, we note that it is evident from the problem description for example 1, that the various local states, which are the channel state at each user and the buffer state at the basestation, evolve according to independent Markov chains given the control actions.
III Minimal Coordination Communication Required for Distributed Simulation of the MDP
For general models with arbitrary dependence between observations, multiterminal information theory has yet to determine the minimum sum rate required for distributed function computation, however, these limits are known for a handful of special cases, including those where the local observations are independent. In this independent case, the transition kernel and initial state distribution admit a factorization
[TABLE]
This factorization, in turn, implies that the local states evolve independently of one another, once an action has been specified, and as such, the quantities available to be encoded into messages at the nodes are independent of one another, so that \mathbb{P}[{\color[rgb]{1.00,0.00,0.00}\boldsymbol{\mathrm{S}}}_{\mathtt{t}}=\boldsymbol{\mathrm{i}}]=\prod_{\mathtt{n}\in\mathscr{N}}\mathbb{P}[{\color[rgb]{1.00,0.00,0.00}S}_{\mathtt{n},\mathtt{t}}=i_{\mathtt{n}}]\ \forall\boldsymbol{\mathrm{i}}\in\boldsymbol{\mathscr{S}}. The fundamental limits for this special case can be further subdivided based upon whether the messages {\color[rgb]{1.00,0.00,0.00}M}_{\mathtt{n},\mathtt{t}} must all be sent in parallel and in a non-interactive manner, or if interaction between users over multiple rounds of communication during one time slot is allowed.
III-A One Shot, Non-Interactive Distributed Simulation of the Omniscient MDP
In the non-interactive case, under the assumptions made regarding the monitoring node, the minimum sum-rate required for distributed function computation of a given control map with independent sources (in this case, the independent states) is given by the sum of the graph entropies of the characteristic graphs for each user [31][30].
The characteristic graph for user has as its set of nodes the possible local states of user . An edge exists in the characteristic graph if there are values such that \mathbb{P}[{\color[rgb]{1.00,0.00,0.00}\boldsymbol{\mathrm{S}}}_{\mathtt{t}}=(i_{1},\ldots,i_{\mathtt{n}-1},i_{\mathtt{n}},i_{\mathtt{n}+1},\ldots,i_{\mathtt{N}})]>0 and \mathbb{P}[{\color[rgb]{1.00,0.00,0.00}\boldsymbol{\mathrm{S}}}_{\mathtt{t}}=(i_{1},\ldots,i_{\mathtt{n}-1},j_{\mathtt{n}},i_{\mathtt{n}+1},\ldots,i_{\mathtt{N}})]>0 and .
Since the local states are independent, the probability distribution will be positive on a product support , and there is no edge, i.e. , if for all possible values of other local states , \mathsf{c}(i_{1},\ldots,i_{\mathtt{n}-1},i_{\mathtt{n}},i_{\mathtt{n}+1},\ldots,{\color[rgb]{1.00,0.00,0.00}S}_{\mathtt{N}})=\mathsf{c}(i_{1},\ldots,i_{\mathtt{n}-1},j_{\mathtt{n}},i_{\mathtt{n}+1},\ldots,{\color[rgb]{1.00,0.00,0.00}S}_{\mathtt{N}}). As such, there is a transitive property in the complement of the characteristic graph: namely if there is no edge and no edge in the characteristic graph, then there is also no edge , therefore the maximal independent sets of the characteristic graph do not overlap, and form a partition of the set of vertices of the graph. Owing to this transitivity property in the complement of the characteristic graphs [31][39], each of these graph entropies is in fact the chromatic entropy
[TABLE]
where represent all colorings of the characteristic graph . This minimum expected rate can be achieved within one bit by Huffman coding the coloring of the characteristic graph achieving the minimum entropy, which then can be achieved by assigning different colors to its different maximal independent sets. Selecting an omniscient control map requiring the minimum rate, then gives the minimum non-interactive rate of
[TABLE]
Note further than when searching minimum entropy colorings of the graph to calculate the chromatic entropy, it suffices to consider exclusively the greedy-colorings [40] obtained by iteratively removing maximal independent sets.
The following two examples describe the control rate required under this form of one-shot, non-interactive sharing of quantized local states, for two particular distributed MDPs.
Ex. 3** (Minimum control information for , Non-Interactive):**
Let’s assume in example 2 that the buffer size is infinite, and each user has infinitely many backlogged packets destined for it in the buffer. Then the control decision is made regarding only the users’ channel qualities, and the objective is to let the basestation learn the control decision of which user should occupy the resource block after observing all the messages sent from the users.
Let the local states {\color[rgb]{1.00,0.00,0.00}S}_{1},\ldots,{\color[rgb]{1.00,0.00,0.00}S}_{N} be independent and identically distributed downlink channel qualities from a known distribution on a discrete support set , if the basestation wishes to maximize the system throughput, the control decision becomes finding one of the users with the best channel quality, i.e.
[TABLE]
For this problem, it is shown in [39] that the characteristic graphs obey the properties that if then , and that if then . It is also shown in [39] that the minimum information required to determine the control action can be computed as in (16), and at most bits can be saved relative to the scheme in which the users simply send their un-coded channel qualities to the basestation.
Ex. 4** (Rate Required for Simulating an Omniscient Wireless Resource Controller with No Interaction):**
Return to the case of a finite buffer size without any backlogged packets in example 2, and assume that the channel qualities where {\color[rgb]{1.00,0.00,0.00}S}_{\mathtt{n},\mathtt{t}} are independently uniformly distributed on the support . In addition, let the amount of additional traffic that arrives destined for each user be independent across users and time, and be distributed on the support with probabilities . Additionally, let the packet dropping function operate according to Algorithm 1, in a manner consistent with a total buffer size of . Let the controller aim to maximize the throughput reward (13). If , which means there are users and basestation in the system, the optimal control decisions by solving the MDP problem of (4) and (10) with discounting factor will give a maximal total discounted reward of if the system starts from the all [math] initial state {\color[rgb]{1.00,0.00,0.00}\boldsymbol{\mathrm{S}}}_{0}=({\color[rgb]{1.00,0.00,0.00}S}_{1,0},{\color[rgb]{1.00,0.00,0.00}S}_{2,0},{\color[rgb]{1.00,0.00,0.00}S}_{3,0})=(0,0,(0,0)). Meanwhile, the expected amount of system throughput per time-slot will be and the expected amount of data dropped per time-slot will be . Calculating the characteristic graphs and determining the Huffmann codes associated with the minimum entropy colorings, we find that the associated optimal control decision can be learned via a quantization of local states (the channel states at each of the two users and the buffer size at the basestation), with a minimum non-interactive rate of bits. The encoder mappings with respect to the minimum rate are given as:
[TABLE]
[TABLE]
for the users, and
[TABLE]
for the basestation. A control mapping can be decided deterministically with the given optimal control and the encoders , i.e. \mathsf{c}^{\prime}(\mathsf{q}_{1}({\color[rgb]{1.00,0.00,0.00}S}_{1})=1,\mathsf{q}_{2}({\color[rgb]{1.00,0.00,0.00}S}_{2})=2,\mathsf{q}_{3}({\color[rgb]{1.00,0.00,0.00}S}_{3})=3)=2 and \mathsf{c}^{\prime}(\mathsf{q}_{1}({\color[rgb]{1.00,0.00,0.00}S}_{1})=1,\mathsf{q}_{2}({\color[rgb]{1.00,0.00,0.00}S}_{2})=1,\mathsf{q}_{3}({\color[rgb]{1.00,0.00,0.00}S}_{3})=3)=1.
III-B Interactive, Collocated Network, Simulation of the Omniscient MDP
In the interactive communication case, a natural lower bound on the rate can be obtained via a collocated network messaging model. In this model, communication happens over multiple rounds, in which users consecutively take turns sending a message which is overheard by all of the other users. In particular, in round , the node with index sends a message {\color[rgb]{1.00,0.00,0.00}M}_{\mathtt{t}}^{(\mathtt{r})} based on its observation {\color[rgb]{1.00,0.00,0.00}S}_{\mathtt{w}(\mathtt{r}),\mathtt{t}} and all of the messages {\color[rgb]{1.00,0.00,0.00}M}_{\mathtt{t}}^{(1)},\ldots,{\color[rgb]{1.00,0.00,0.00}M}_{\mathtt{t}}^{(\mathtt{r}-1)} sent in the previous rounds up until this time. After rounds the communication finishes and the optimum omniscient control action {\color[rgb]{1.00,0.00,0.00}A}_{\mathtt{t}}^{*}=\mathsf{c}({\color[rgb]{1.00,0.00,0.00}\boldsymbol{\mathrm{S}}}_{\mathtt{t}}) must be completely determined from {\color[rgb]{1.00,0.00,0.00}M}_{\mathtt{t}}^{(1)},\ldots,{\color[rgb]{1.00,0.00,0.00}M}_{\mathtt{t}}^{(\mathtt{R})}. Ma and Ishwar [33] have shown that the minimum sum-rate, over all block codes, that can be obtained by such a strategy is lower bounded by the solution to following repeated convex geometric calculation. The solution is written with respect to the rate reduction functional, which maps the coordinates for the marginal probability distributions for each of the local observations to a conditional entropy,
[TABLE]
The rate required if the function is to be computed after rounds of communication is then expressed as
[TABLE]
i.e. by evaluating the rate reduction functional at the marginal probability distribution \boldsymbol{p}_{{\color[rgb]{1.00,0.00,0.00}\boldsymbol{\mathrm{S}}}_{\mathtt{r}}}. The rate reduction functional, in turn, is found via the following iterative convex program
[TABLE]
[TABLE]
Here for each fixed context , the operator concavify is computing the upper concave envelope of the function , i.e. viewing this restriction as a function from .
Note that for the problem at hand, this lower bound may not be achievable, as scalar quantization and coding strategies are required by the assumptions we have made in our distributed MDP setup, while this lower bound may in general only be achieved with a limit of vector quantization schemes. In particular, only scalar quantization is available in the problem under consideration because no repeated observations are available for use in a larger block-length as we have added the constraint that the user overhearing exclusively all of the messages during time slot must be able to learn {\color[rgb]{1.00,0.00,0.00}A}_{\mathtt{t}}^{*}=\mathsf{c}({\color[rgb]{1.00,0.00,0.00}\boldsymbol{\mathrm{S}}}_{\mathtt{t}}). Nonetheless, as we demonstrate in the following example, often the best scalar quantization based interaction schemes still yield a rate which is very close to this fundamental limit.
Ex. 5** (Minimum control information for , Interactive):**
Consider the infinite packet buffer backlog and throughput maximization variant of the wireless resource allocation as described in Example 3, with the added ability that the users and basestation can all interact with one another while sending their messages. In particular, the users can each take turns sending messages, one at a time, over rounds, such that all the other participants, including the basestation which sends no messages, overhear each message. The goal is to enable anyone who overhears all of these messages to learn the index of at least one user whose channel quality is the same as the maximum channel quality over all of the users. The curve labelled Fundamental limit in Fig. 1 calculates the fundamental limit (24) lower bounding the total number of bits must be exchanged in order to perform this calculation for the case of and for channel qualities uniformly distributed over the set . As explained above, this fundamental limit is in general only achievable with vector quantization schemes, while the problem setup at hand demands that scalar quantization schemes must be used. Additionally, a second curve in Fig. 1, labelled “optimal scalar Hete. Q” gives the rate required by the best possible scalar quantization scheme, followed by Huffman coding, for this problem, and this is seen to be quite close to the vector quantization limit. This curve was found via exhaustive search over all scalar quantization schemes. In addition to presenting this problem in detail and describing these curves,[41] also considers reduced complexity restricted to smaller quantizer search spaces. Finally, the curve “Homo. scalar Q interactive” indicates the rate required if all of the users must send their messages in parallel, then, after all of these messages are received, can send another series in parallel and so on, which is the interactivity model considered in [42]. While this does count as a form of interaction, requiring the users to send their messages in parallel substantially increases the rate required.
IV Incorporating Communication Cost into the Reward Function
The previous discussion has assumed that the reward function is completely given, but in many problems, the cost of communicating over the network may subtract from the reward of the decisions. In this manner, it may be desirable to design the MDP to consider this cost explicitly by incorporating it as a weighted term into the reward function. In particular, suppose that the total number of bits communicated by the partial state sharing scheme in the messages {\color[rgb]{1.00,0.00,0.00}M}_{\mathtt{n},\mathtt{t}},\mathtt{n}\in\mathscr{N} when the state vector is {\color[rgb]{1.00,0.00,0.00}\boldsymbol{\mathrm{S}}}_{\mathtt{t}}=\boldsymbol{\mathrm{i}} is denoted by , then we can form an augmented reward function
[TABLE]
including the communication cost reflecting the number of bits transmitted in order to enable the system learn the action. The goal then shifts to solving the optimization problem
[TABLE]
where the constraint set is defined as
[TABLE]
or equivalently, the set of such that can be rewritten as a function of exclusively ,
[TABLE]
Observe that while the observation of the encodings form effectively an observation for a partial observed Markov decision process (POMDP) [8][44], the requirement we have made that we are able to determine the controller’s (i.e. running the full state knowledge MDP) action decisions from exclusively the observation during the same time step implies a different problem structure from a POMDP as the memory of past observations or action decisions for determining the state distribution must be neglected.
Select some map and, for any given controller , define the transition matrix whose th element is
[TABLE]
The objective function in the optimization can then be rewritten as
[TABLE]
The presence of the constraint that makes the joint optimization problem (26) a substantially more difficult combinatorial optimization problem than an ordinary MDP. For small problems, the set of control maps can be enumerated, and for each such control map, the component
[TABLE]
of the expected reward associated with the minimum control information overhead can be calculated using the results in section III-A for a non-interactive messaging scheme, while if interactive communications are enabled, then the results in section III-B can be used. In both cases, the probability distribution for {\color[rgb]{1.00,0.00,0.00}\boldsymbol{\mathrm{S}}} is selected as being multiplicatively proportional to to ensure that the reward will be maximized by the encoding. After determining in this manner the expected discounted reward \max_{\boldsymbol{\mathsf{q}}|(\mathsf{c},\boldsymbol{\mathsf{q}})\in\mathscr{F}}\sum_{\mathtt{t}\in\mathbb{N}}\gamma^{\mathtt{t}}\left(\mathbb{E}\left[\mathsf{R}_{\mathsf{c}({\color[rgb]{1.00,0.00,0.00}\boldsymbol{\mathrm{S}}}_{\mathtt{t}})}({\color[rgb]{1.00,0.00,0.00}\boldsymbol{\mathrm{S}}}_{\mathtt{t}},{\color[rgb]{1.00,0.00,0.00}\boldsymbol{\mathrm{S}}}_{\mathtt{t}+1})-\lambda|\boldsymbol{\mathsf{q}}({\color[rgb]{1.00,0.00,0.00}\boldsymbol{\mathrm{S}}}_{\mathtt{t}})|\right]\right), maximized over all encoding schemes, for each control map , the control map yielding the expected maximum reward for the particular can be selected. Furthermore, a tradeoff between the control overhead and the expected reward can be traced by varying in this optimization.
Ex. 6** (Overhead Performance Tradeoff for Wireless Resource Allocation, Tiny Model):**
Consider again the setup of distributed wireless resource allocation described in example 1, with mobile users each observing their local channel quality {\color[rgb]{1.00,0.00,0.00}S}_{\mathtt{n},\mathtt{t}} at each time instant , where {\color[rgb]{1.00,0.00,0.00}S}_{\mathtt{n},\mathtt{t}} is uniformly distributed on the support . Additionally, let the amount of additional traffic that arrives destined for each user be uniformly distributed on the support , and let the buffer size limit at the basestation be , with the packet dropping process described as in Example 4. The system is started in the all [math] initial state, in which the buffer is empty and the channel qualities are all [math]. Let (25) be the transition reward function where the term represents the system throughput by choosing action at state as in (13), and consider the one-shot, non-interactive, control information sharing model in which each node (i.e. each user and the base station) sends a quantized representation of their state to everyone else, enabling them all to learn the control action directly from these messages. Finding the optimum solution to (26) via exhaustive search over all control mappings for different enables the control overhead versus throughput tradeoff and the control overhead versus the packet dropping cost tradeoff plotted in Fig. 2a and 2b to be traced out. We observe from Fig. 2 that, at least bits of control overheads are required to guarantee the expected system throughput achieves the limit.
IV-A Finding Candidate Quantizations through Alternating Optimization
However, in many problems, the sort of exhaustive search approach to solving the combinatorial optimization (26) just described is nowhere near computationally feasible, as the number of possible control maps to search over are . In this case, an alternating optimization approach yields a lower complexity search method that can be well suited to finding candidate solutions to this optimization problem.
A reasonable goal for such an alternating optimization method is to alternate between optimizing the control map, then optimizing the quantizer. Let the iteration index in this algorithm be , and the control map and local state encoders at iteration be denoted by and respectively. At a given iteration in the algorithm, the control map minimizing the augmented value function among all control maps that can be determined from the present encoding could be selected by solving
[TABLE]
Next, the local encodings which achieve the minimum expected sum rate while enabling distributed computation of the new control map are selected
[TABLE]
As this admits a form of an alternating maximization, the sequence of expected values will be monotone increasing. As this sequence is bounded above via the global optimum, this sequence must converge to a limit. In general this limit may or may not be the global optimum, as all that can be guaranteed is that this limit is associated with a Nash equilibrium. In particular, the limit of this iteration has the property that in no unilateral change individually in the control map or the quantizer can yield a higher expected reward, although it may be possible to modify them both together and achieve a higher reward.
To solve (33), if the non-interactive communications structure is used, the results in section III-A and equation (16) can be used as a fairly tight and close bound with associated close achievability scheme (within one bit), while if interactive communications are enabled, then the results in section III-B and equations (22,24) can be used as a bound.
Solving (32) however, can be quite complicated, as the direct search solution to the combinatorial optimization has complexity . To simplify matters, the control map update (32) can itself be attacked with an alternating optimization which has an overall iteration update complexity proportional to . In its simplest form, this alternating minimization cycles through the different possible quantizations , updating the associated in an order determined by a selected bijection according to
[TABLE]
[TABLE]
[TABLE]
wherein
[TABLE]
Alternatively, a more greedy form of the alternating optimization can be selected, which replaces (34) with
[TABLE]
Putting these pieces together, the overall low complexity alternating optimization algorithm to find candidate solutions to (26) consists of (34) or (38) and (35),(36),and (33). As this algorithm is an alternating optimization, with the individual dimensions in the optimization being , and each of the , the sequence of expected rewards achieved by each update is monotone increasing. As this sequence of expected rewards is bounded above by the global maximum (26), it must converge to a limit, and depending on the initialization , this limit may or may not be the global maximum. When the sequence of control maps and quantizations also converges it must at least be to a Nash equilibrium as summarized in the following theorem.
Thm. 1**:**
The iterative method for solving the constrained MDP (26) that is described by (34) or (38) and (35),(36),and (33) yields a monotone increasing sequence of expected rewards which converges. Additionally, when the sequence of control maps and quantizations converges, , the convergent pair are a Nash equilibrium [45], in the sense that no unilaterial deviation in any of the axes or for each , can yield an increase in the expected reward.
Ex. 7** (Overhead Performance Tradeoff for Wireless Resource Allocation, Larger Model):**
We apply the aforementioned alternating optimization algorithm to solve the following example. Consider again the wireless resource allocation setup of examples 1 and 6, but in which () mobile users observe their local channel quality {\color[rgb]{1.00,0.00,0.00}S}_{\mathtt{n},\mathtt{t}} at time-slot , distributed on the support with probabilities . Additionally, the amount of additional traffic arrivals destined for each user, be distributed on the support with probabilities . The basestation observes the buffer state {\color[rgb]{1.00,0.00,0.00}S}_{3} which has a buffer limit , and let the packet dropping process be the same as the one described in Example 4.
We refer to the algorithm consisting of (34),(35), (36), and (33) as the round-robin alternating optimization algorithm, and the algorithm consisting of (38), (35), (36), and (33) as the greedy alternating optimization algorithm. For the quantizers and information sharing strategies to learn the action, we assume that a one-shot, non-interactive scheme must be used. Furthermore, both algorithms are initialized with the trivial quantizers which simply relay the full local state.
Note that, as observed by Thm. 1, while these alternating optimization methods will always yield a sequence of rewards which is monotone non-decreasing and converges, when the associated control map and quantizer converge, they will in general only be to a Nash equilibrium, and possibly not a global optimum. This local convergence was indeed observed in the experiments, as some multipliers s lead quantization and control mappings with negative expected discounted rewards, while when not sending any control information, the expected reward will be lower bounded by [math]. Hence, while the quantization and control schemes presented in the remainder of this example are guaranteed to be Nash equilibria, there is a chance that they are not globally optimal. Nonetheless, they are highly optimized, and, thus, the tradeoffs they yield, by varying between the expected throughput and the control overhead are quite interesting.
By applying both the round-robin and the greedy algorithm, we find local optimal quantizations and control mappings for different choice of . The expected throughput, and the communication cost are computed as shown in Fig. 3a and 3b. Based on the local optimal solutions we found, we also plot the throughput versus control overheads tradeoff and the packet dropping cost versus control overheads tradeoff in Fig. 3c and 3d.
We observe from Fig. 3a that the expected system throughput is maximized when . In such a case, the communication cost is not involved in the transition reward function, the optimal control mapping becomes to pick the user that maximize the instant throughput, and the optimal encoders are designed to minimize the control overheads while guarantee that the optimal control mapping can be learned by any node with only observing all of the control messages. We also observe from Fig. 3b that the control overheads become [math] when , this is because, as grows larger, the system realizes that the cost it pays to encode the local states weights more than the reward it could earn by sending data traffics to the destined user, hence the optimal decision is to not encode any local state and blindly schedule a user to occupy the resource block. Finally, we observe from Fig. 3a that the expected system throughput per time-slot goes to [math] when the system decision is to blindly pick a user. This is because, although the basestation may pick users and send data traffics in the first few time-slots, however, in a long run, the global state must be absorbed to one of the recurrent classes in which, the instant throughput will always remain [math], as the buffer fills with traffic destined for the other users and stays full. In fact, given a blind control mapping with no local observation as
[TABLE]
those global states with the same buffer local state {\color[rgb]{1.00,0.00,0.00}S}_{\mathtt{N}+1}=(b_{1},\ldots,b_{\mathtt{N}}) satisfying
[TABLE]
and
[TABLE]
will form a recurrent class. The result that the expected system throughput becomes [math] when the system decision is to blindly pick a user indicates that a system with randomly picking users at all time-slots will perform better than the deterministic control mapping system, which matches the conclusion in [46][44]. It is important to note, however, that this would be precluded by the present model, which would require which user would be transmitted to be known deterministically to a participant just arriving in the network who in this case would not have observed anything since there is no control information being sent. Additional control rate savings and increased rewards enabled by randomization, which will require the assumption of synchronized common randomness at all participants in the scheme, are an important direction for future work.
V Conclusion
This paper analyzed a Markov decision process in which the state was composed of a series of local states, each observed at a different location in a network. Using recent results from multiterminal information theory regarding distributed and interactive function computation, the minimum amount of control information that would be necessary to exchange in order for the system to simulate a centralized controller having access to the global state was determined. Next, the information theoretic cost of communication was incorporated into the reward function in the MDP, and the problem of simultaneously designing the controller and the messaging scheme to maximize the associated combined reward was formulated, creating a tradeoff between communication and performance. To provide candidate solutions for the associated optimization problem, an alternating optimization method was presented that produces a sequence of rewards that always converges, and when the associated messaging scheme and controller map converges, it converges to a Nash equilibrium for the problem. A series of running examples from downlink wireless resource allocation illustrated the ideas throughout. Important directions for future investigation involve allowing time varying messaging and control schemes, the use of historical observations of messages in a POMDP like framework, and the use of rate distortion theory to aid with the derivation of tradeoffs between communication and control reward in the present decentralized MDP context.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] R. Bellman, “A markovian decision process,” DTIC Document, Tech. Rep., 1957.
- 2[2] M. L. Putterman, Markov Decision Processes: Discrete Stochastic Dynamic Programming . New York: John Wiley & Sons, Mar. 2005.
- 3[3] K. Hsu and S. I. Marcus, “Decentralized control of finite state markov processes,” IEEE Transactions on Automatic Control , vol. 27, no. 2, pp. 426–1431, April 1982.
- 4[4] Y. C. Ho and K. C. Chu, “Team decision theory and information structures in optimal control problems - part i,” IEEE Transactions on Automatic Control , vol. 17, no. 1, pp. 15–22, February 1972.
- 5[5] N. R. Sandell, P. Varaiya, M. Athans, and M. Safonov, “Survey of decentralized control methods for large scale systems,” IEEE Transactions on Automatic Control , vol. 23, no. 2, pp. 108–128, April 1978.
- 6[6] S. Y. Park and A. Sahai, “Network coding meets decentralized control: Capacity-stabilizabililty equivalence,” in Decision and Control and European Control Conference (CDC-ECC), 2011 50th IEEE Conference on . IEEE, 2011, pp. 4817–4822.
- 7[7] ——, “Network coding meets decentralized control: Network linearization and capacity-stabilizablilty equivalence,” ar Xiv preprint ar Xiv:1308.5045 , 2013. [Online]. Available: http://arxiv.org/pdf/1308.5045 v 1.pdf
- 8[8] V. Krishnamurthy, Partially Observed Markov Decision Processes From Filtering to Controlled Sensing . Cambridge University Press, 2016.