Past, Present, Future: A Computational Investigation of the Typology of Tense in 1000 Languages
Ehsaneddin Asgari, Hinrich Sch\"utze

TL;DR
This paper introduces SuperPivot, a novel method for analyzing tense across over 1000 languages using a superparallel corpus, significantly advancing crosslingual typological research in low-resource languages.
Contribution
It extends existing methodologies by enabling typological analysis with minimal overt marking, allowing large-scale crosslingual study of tense in low-resource languages.
Findings
SuperPivot performs well in crosslingual tense analysis.
Analyzed over 1000 languages, the largest such study to date.
Method overcomes previous limitations by requiring minimal overt features.
Abstract
We present SuperPivot, an analysis method for low-resource languages that occur in a superparallel corpus, i.e., in a corpus that contains an order of magnitude more languages than parallel corpora currently in use. We show that SuperPivot performs well for the crosslingual analysis of the linguistic phenomenon of tense. We produce analysis results for more than 1000 languages, conducting - to the best of our knowledge - the largest crosslingual computational study performed to date. We extend existing methodology for leveraging parallel corpora for typological analysis by overcoming a limiting assumption of earlier work: We only require that a linguistic feature is overtly marked in a few of thousands of languages as opposed to requiring that it be marked in all languages under investigation.
Click any figure to enlarge with its caption.
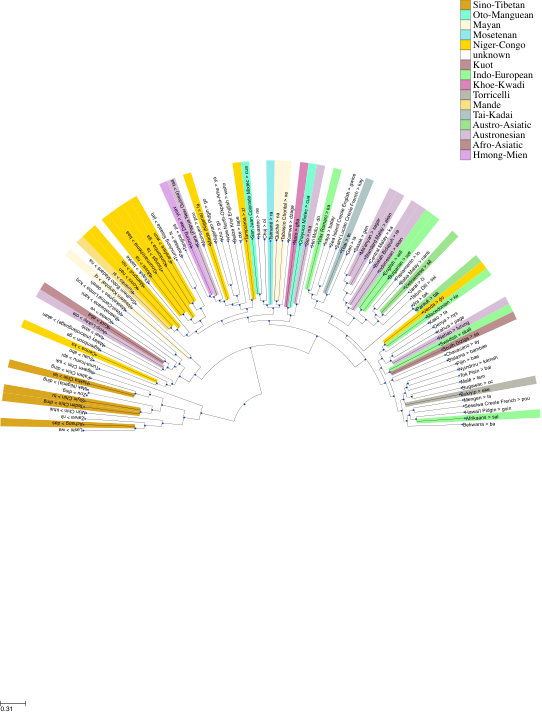 Figure 1
Figure 1 Figure 2
Figure 2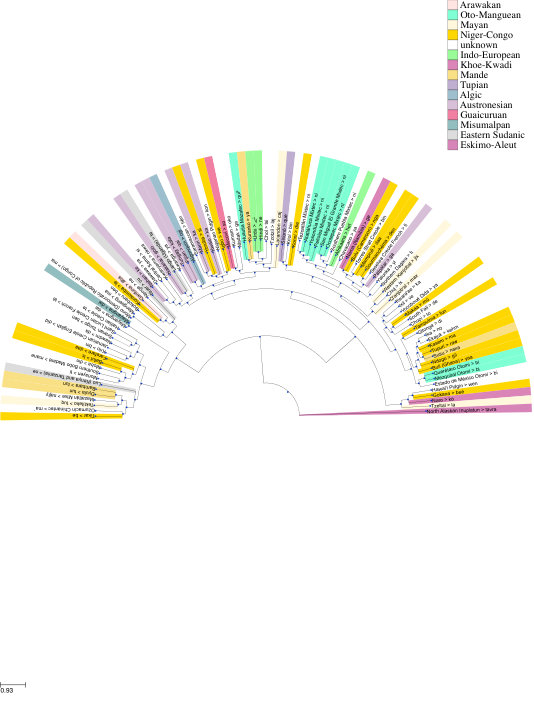 Figure 3
Figure 3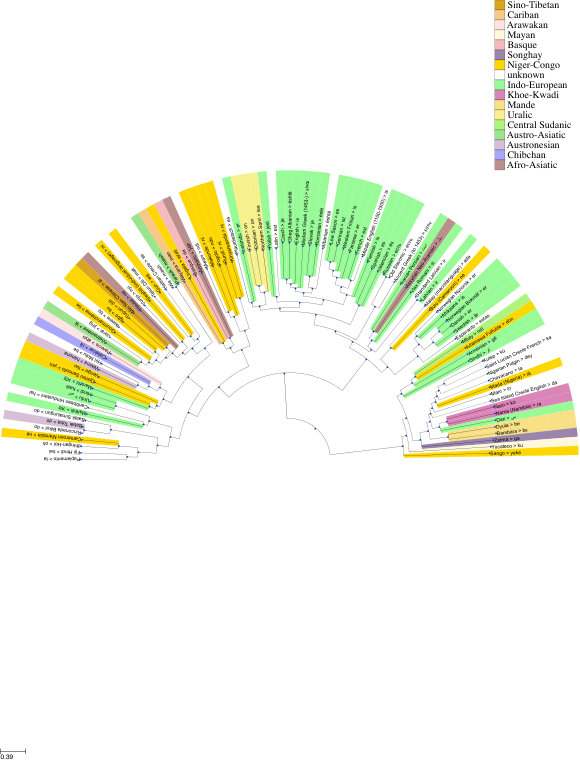 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6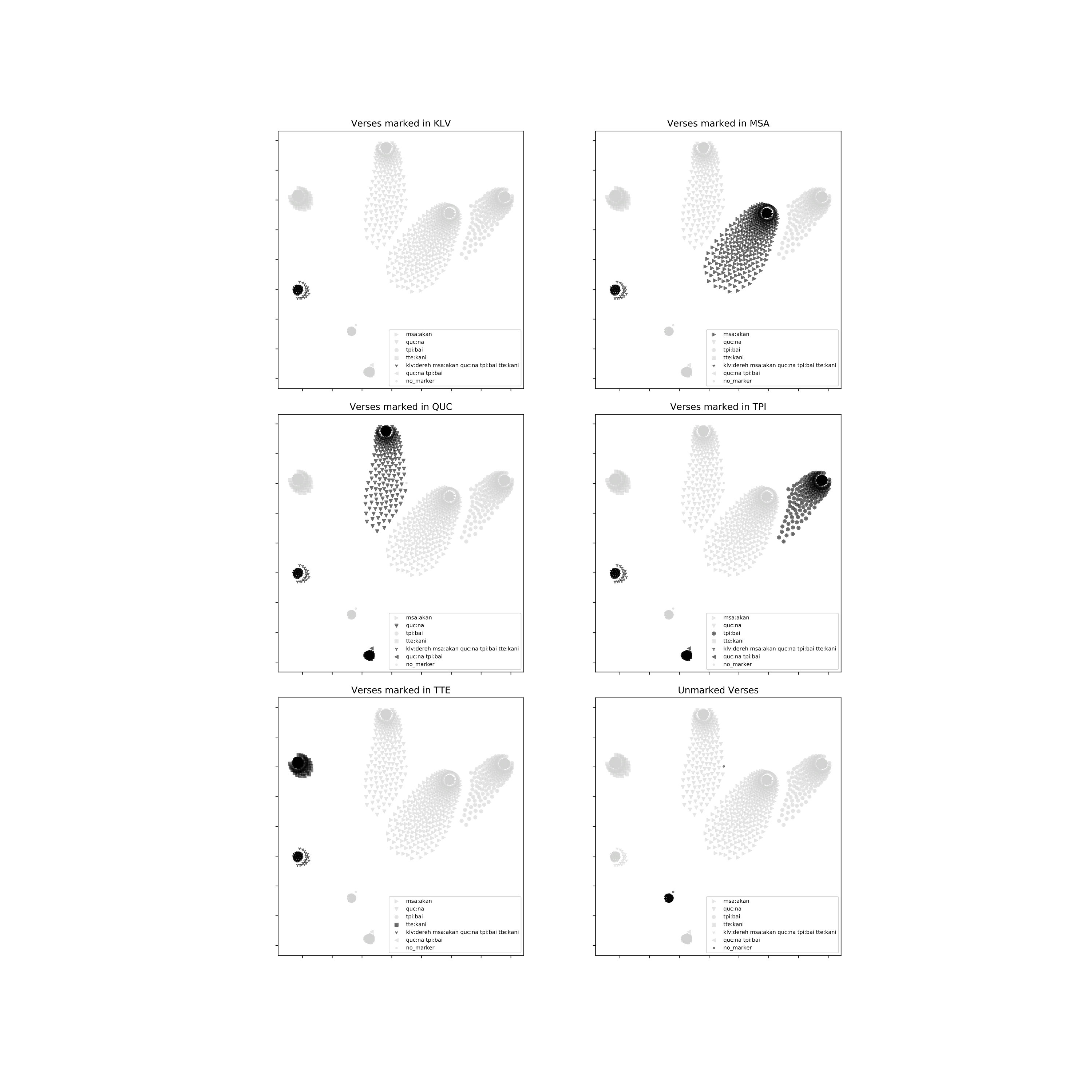 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.