Active Collaborative Ensemble Tracking
Kourosh Meshgi, Maryam Sadat Mirzaei, Shigeyuki Oba, Shin Ishii

TL;DR
This paper introduces an active collaborative ensemble tracking method that enhances classifier diversity and cooperation through an optimized information exchange mechanism, improving real-world online tracking performance.
Contribution
It proposes a novel active information exchange scheme for ensemble tracking that maintains classifier diversity and improves collective accuracy.
Findings
Demonstrates improved tracking accuracy on real-world datasets.
Maintains classifier diversity through optimized co-training.
Outperforms existing ensemble tracking methods.
Abstract
A discriminative ensemble tracker employs multiple classifiers, each of which casts a vote on all of the obtained samples. The votes are then aggregated in an attempt to localize the target object. Such method relies on collective competence and the diversity of the ensemble to approach the target/non-target classification task from different views. However, by updating all of the ensemble using a shared set of samples and their final labels, such diversity is lost or reduced to the diversity provided by the underlying features or internal classifiers' dynamics. Additionally, the classifiers do not exchange information with each other while striving to serve the collective goal, i.e., better classification. In this study, we propose an active collaborative information exchange scheme for ensemble tracking. This, not only orchestrates different classifier towards a common goal but also…
Click any figure to enlarge with its caption.
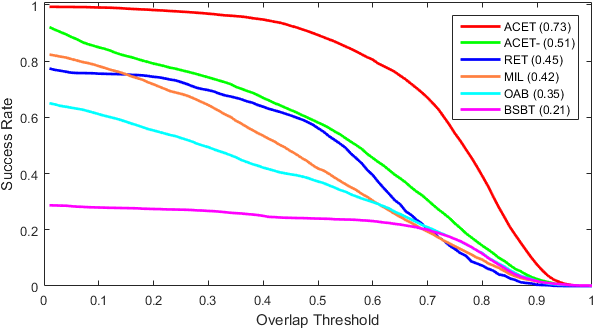 Figure 1
Figure 1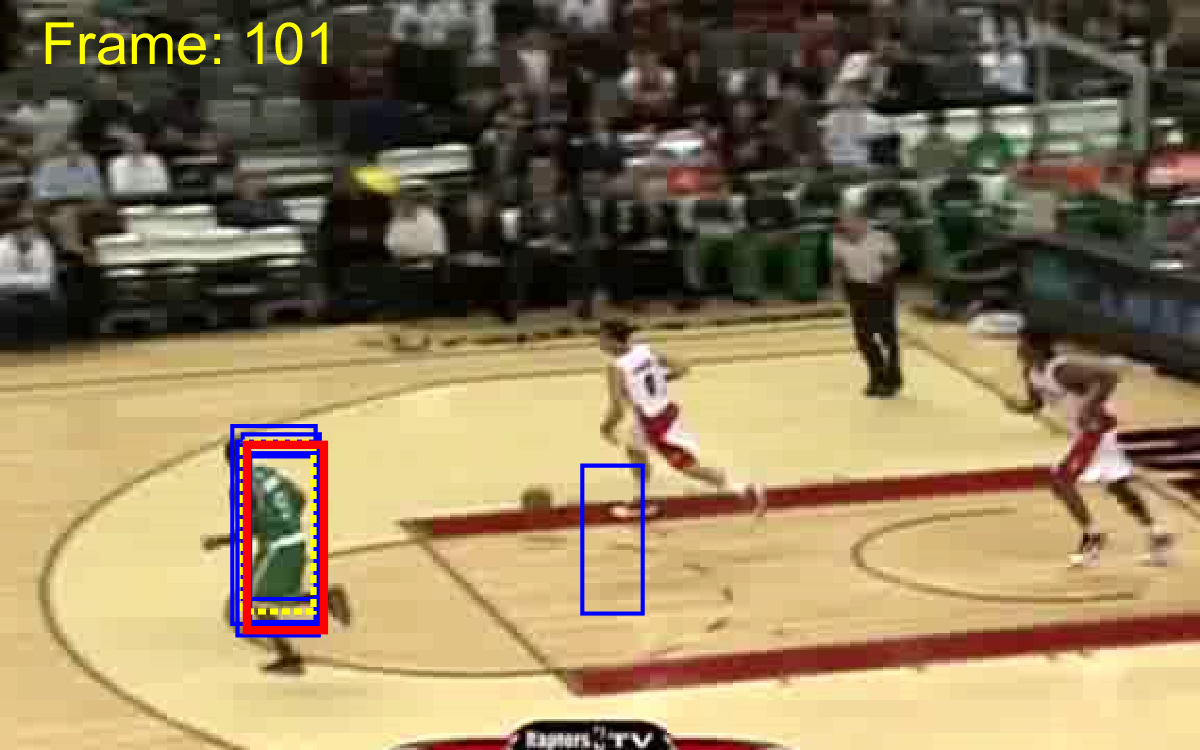 Figure 2
Figure 2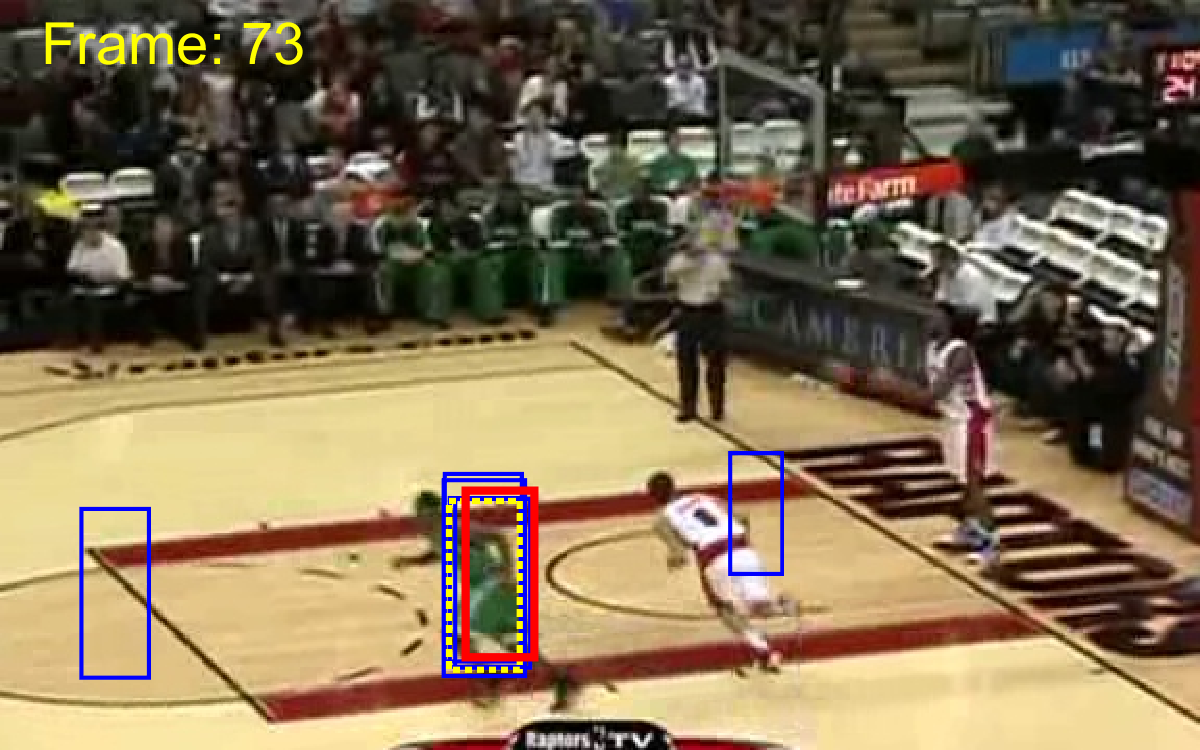 Figure 3
Figure 3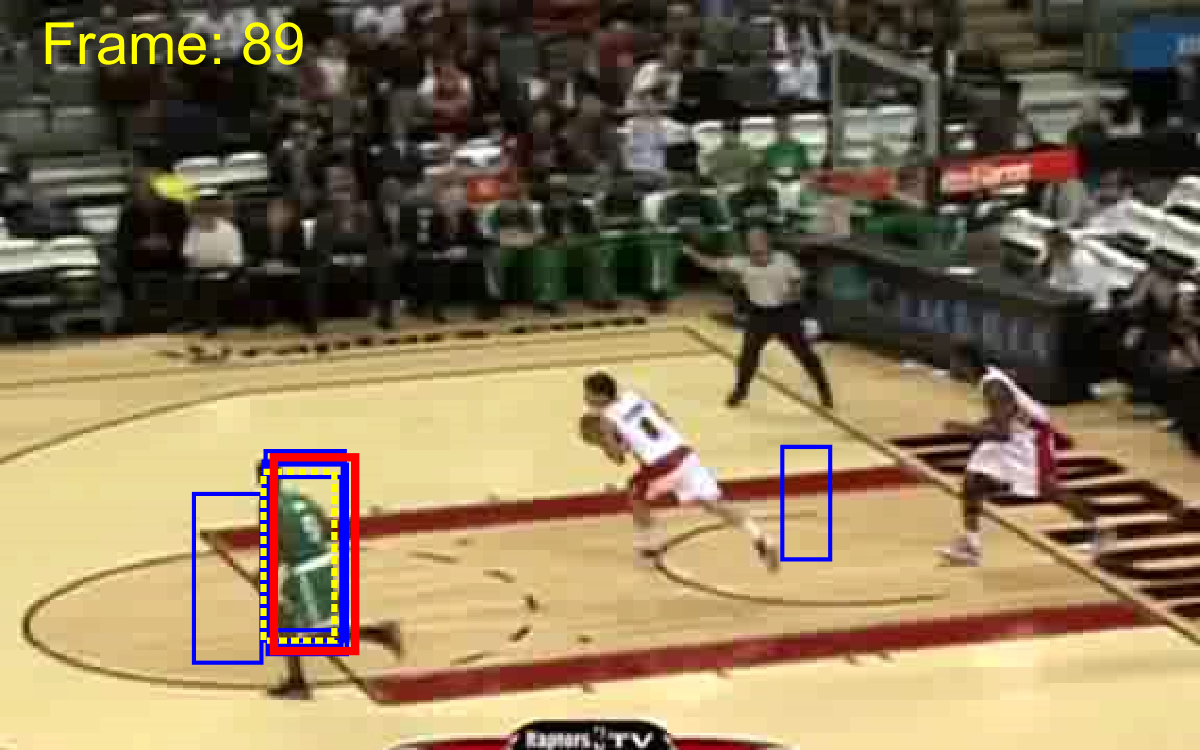 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8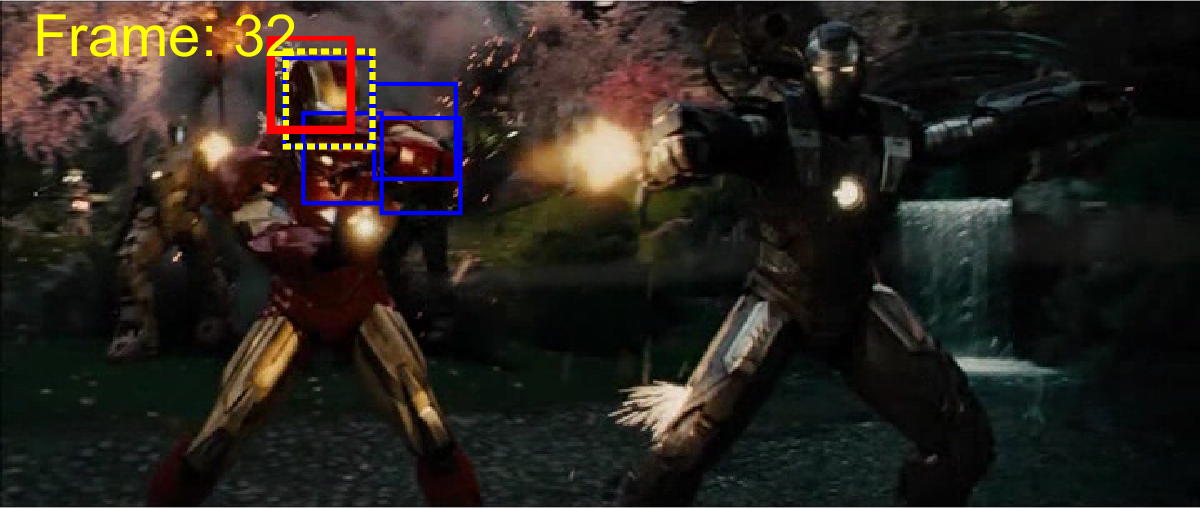 Figure 9
Figure 9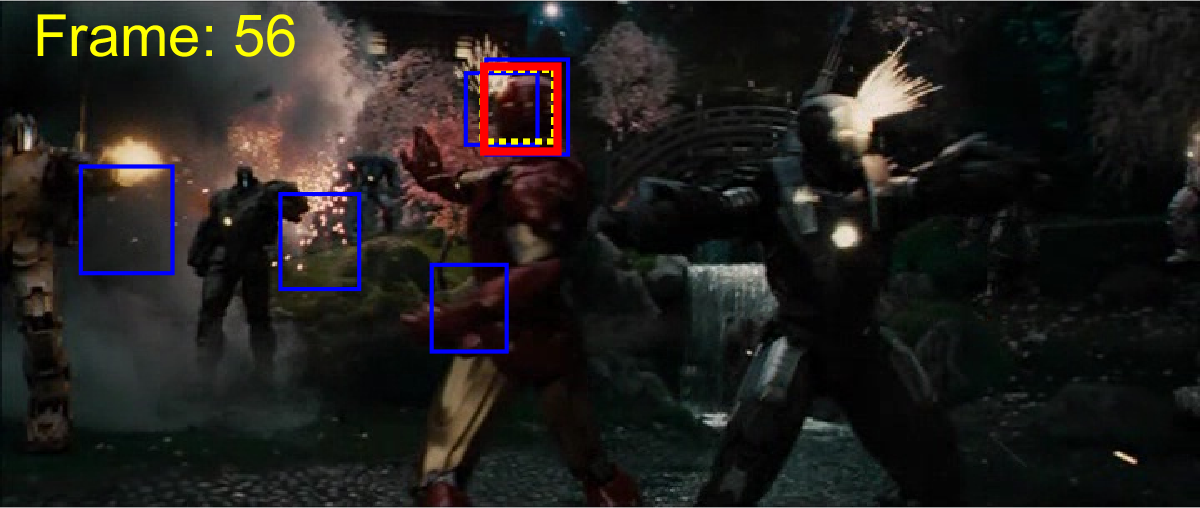 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14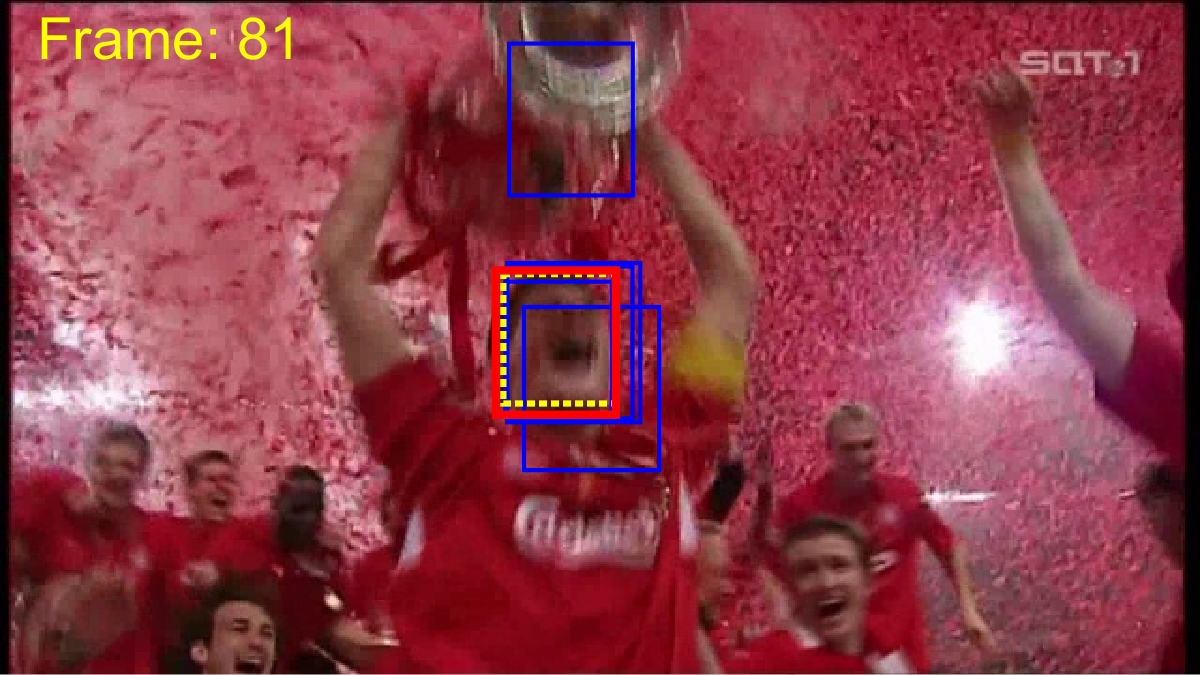 Figure 15
Figure 15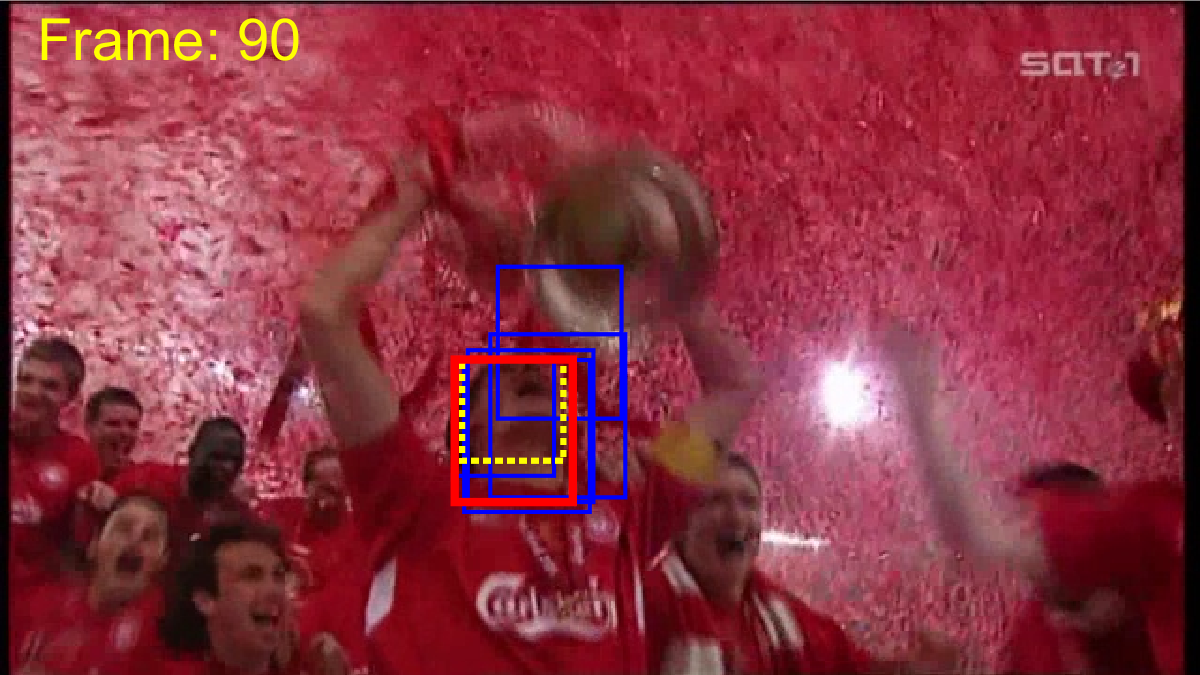 Figure 16
Figure 16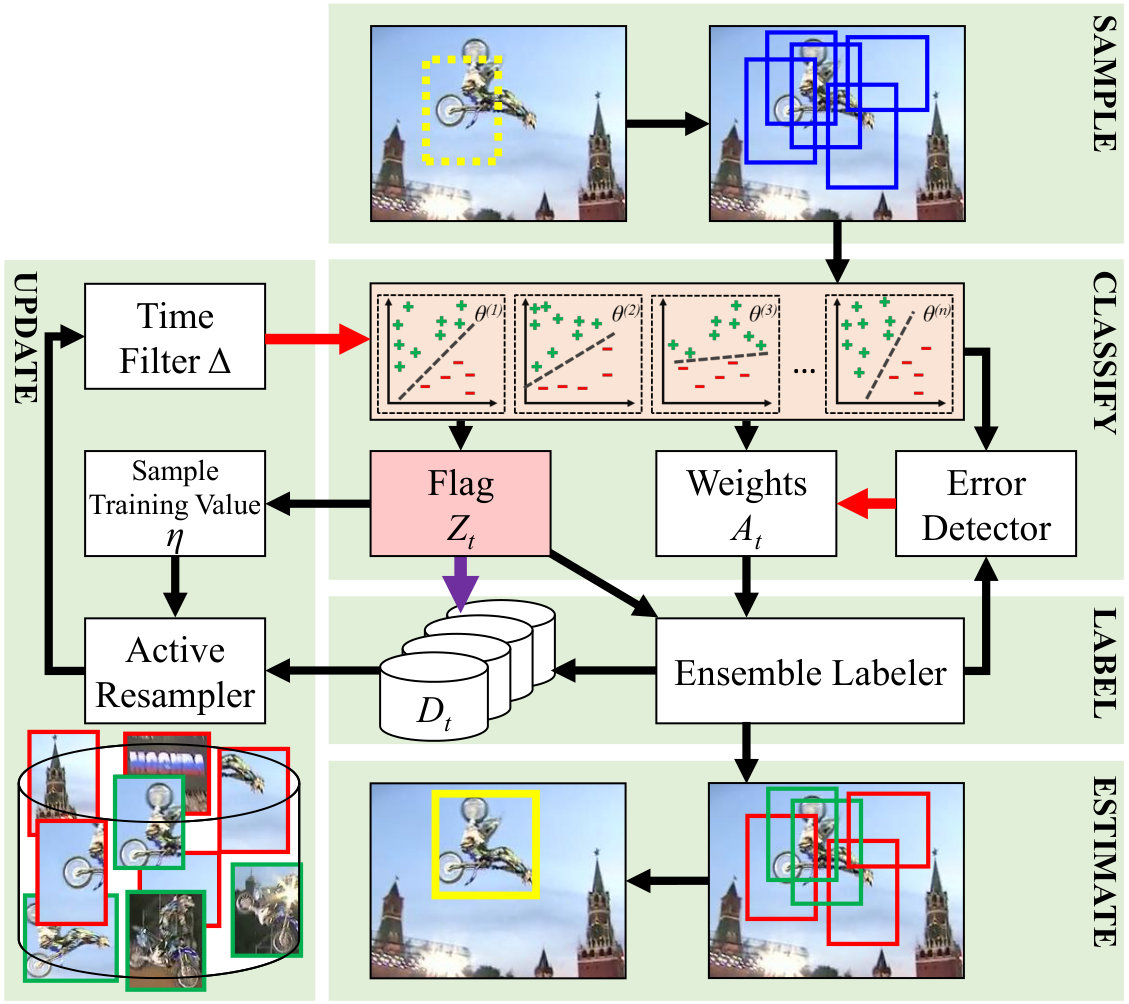 Figure 17
Figure 17| Attribute | TLD | STRK | MEEM | MUSTer | SRDCF | CCOT | Ours |
|---|---|---|---|---|---|---|---|
| IV | 0.48 | 0.53 | 0.62 | 0.73 | 0.70 | 0.75 | 0.78 |
| DEF | 0.38 | 0.51 | 0.62 | 0.69 | 0.67 | 0.69 | 0.69 |
| OCC | 0.46 | 0.50 | 0.61 | 0.71 | 0.70 | 0.76 | 0.77 |
| SV | 0.49 | 0.51 | 0.58 | 0.71 | 0.71 | 0.76 | 0.77 |
| IPR | 0.50 | 0.54 | 0.58 | 0.69 | 0.70 | 0.72 | 0.77 |
| OPR | 0.48 | 0.53 | 0.62 | 0.70 | 0.69 | 0.74 | 0.77 |
| OV | 0.54 | 0.52 | 0.68 | 0.73 | 0.66 | 0.79 | 0.84 |
| FM | 0.45 | 0.52 | 0.65 | 0.65 | 0.63 | 0.72 | 0.79 |
| MB | 0.41 | 0.47 | 0.63 | 0.65 | 0.69 | 0.72 | 0.77 |
| BC | 0.39 | 0.52 | 0.67 | 0.72 | 0.80 | 0.70 | 0.73 |
| LR | 0.36 | 0.33 | 0.43 | 0.50 | 0.58 | 0.70 | 0.44 |
| ALL | 0.49 | 0.55 | 0.62 | 0.72 | 0.70 | 0.75 | 0.76 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsVideo Surveillance and Tracking Methods · Advanced Chemical Sensor Technologies · Olfactory and Sensory Function Studies
Active Collaborative Ensemble Tracking
Kourosh Meshgi, Maryam Sadat Mirzaei, Shigeyuki Oba, Shin Ishii
Graduate School of Informatics, Kyoto University
Yoshida-Honmachi, Sakyo Ward, Kyoto 606–8501, Japan
Abstract
A discriminative ensemble tracker employs multiple classifiers, each of which casts a vote on all of the obtained samples. The votes are then aggregated in an attempt to localize the target object. Such method relies on collective competence and the diversity of the ensemble to approach the target/non-target classification task from different views. However, by updating all of the ensemble using a shared set of samples and their final labels, such diversity is lost or reduced to the diversity provided by the underlying features or internal classifiers’ dynamics. Additionally, the classifiers do not exchange information with each other while striving to serve the collective goal, i.e., better classification. In this study, we propose an active collaborative information exchange scheme for ensemble tracking. This, not only orchestrates different classifier towards a common goal but also provides an intelligent update mechanism to keep the diversity of classifiers and to mitigate the shortcomings of one with the others. The data exchange is optimized with regard to an ensemble uncertainty utility function, and the ensemble is updated via co-training. The evaluations demonstrate promising results realized by the proposed algorithm for the real-world online tracking.
1 Introduction
Visual tracking is one of the fundamental problems in computer vision, having a broad range of applications from human-computer interfaces, to automatic surveillance, video description/editing/indexing, and autonomous navigation systems. Generative trackers attempt to construct a robust object appearance model, or to learn it on-the-fly using advanced machine learning techniques such as subspace learning [37], hash learning [13], dictionary learning [43], and sparse learning [7]. On the other hand, discriminative models focus on target/background separation using correlation filters [24, 10, 11] or dedicated classifiers [33], which assist them to dominate the visual tracking benchmarks [46]. Tracking-by-detection methods primarily treat tracking as a detection problem to avoid having model object dynamics especially in the case of sudden motion changes, extreme deformations, and occlusions [44, 5].
However, these trackers are still vulnerable to illumination variation, in-plane and out-of-plane rotations, scale changes, and background clutter. Typical problems of tracking-by-detection schemes are (i) label noise, where inaccurate labels confuses the classifier and and degrade the classification accuracy [44], (ii) self-learning loop, in which the classifier are re-trained by their own output from earlier frames, thus accumulating error over time [5], (iii) model drift, that is a side-effect of imperfect model update [29] and mismatch between model update frequency and target evolution rate [17], (iv) equal weights for all samples in evaluating the target [20] and training the classifier [26], despite the uneven contextual information in different samples, and (v) assuming stationary distribution of target, which does not hold for most of the real-world scenarios with drastic target appearance changes [5].
Ensemble tracking [3, 16, 34, 38, 4, 39, 15, 27, 6, 48] and co-tracking [44] frameworks provide effective frameworks to tackle one or more of these challenges. In such frameworks, the self-learning loop is broken, and the labeling process is performed by eliciting the belief of a group of classifiers (ensemble) or another classifier that has a stronger belief about the sample’s label (collaborator). However, these frameworks typically do not address some of the fundamental demands of tracking-by-detection approaches like a proper model update to avoid model drift or non-stationary of the target sample distribution. Here, the non-stationarity means that the appearance of an object may change so significantly that a negative sample in the current frame looks more similar to a positive example in the previous frames. Besides, ensemble classifiers do not exchange information, and collaborative classifiers entirely trust the other classifier to label the challenging samples for them and are susceptible to label noise.
We propose an effective integration of ensemble tracking and co-tracking, which involves the merits of each while their complementary nature counteracts the demerits of each other. Here, an ensemble of trackers is employed to label a sample. Those classifiers that are uncertain about the label, are excluded from the final decision about the sample’s label, and the rest of the classifiers perform a weighted voting for labeling the sample. The contributing classifiers are then retrained with the newly labeled samples, based on the concept of co-training. If the classifiers disagree each other for most of the samples, it is likely that the target is mostly occluded. The use of an ensemble would undermine label noise problem, while co-training breaks the self-learning loop, provides an effective model update, and enforce the diversity into the ensemble. By providing different memory spans for different members of the ensemble, the model update rate of the ensemble is automatically adjusted to the evolution rate of the target, and limited memory horizon resolves the issues with non-stationarity of the observations. By limiting the classifiers’ retraining data to only the most informative ones (i.e., to assume different “training values” for samples), the non-stationarity is better addressed, the generalizability of the ensemble is improved, and speed of the tracker is boosted.
We evaluated our proposed framework (active collaborative ensemble tracking or ACET) with other ensemble trackers and also the state-of-the-art in visual tracking on object tracking dataset [46] to demonstrate the effectiveness of this method, and discussed its merits and demerits.
2 Related Work
Ensemble-based Tracking: Using a (linear) combination of several (weak) classifiers with different associated weights has been proposed in a seminal work by Avidan [3]. Align with this study, constructing an ensemble by boosting [16], online boosting [34, 27], multi-class boosting [38] and multi-instance boosting [4, 49] provides better and better performance for ensemble trackers. The boosting may or may not couple with the ensemble changes such as feature adjustment [15] or addition/deletion of the ensemble’s members [16, 39]. To date, boosting has been widely used in self-learning based tracking methods despite its low endurance against label noise [40]. An alternative way to tune the weights of the weights of an ensemble is via a Bayesian treatment [6]. Aside from using different features, the members of an ensemble may be constructed from randomized subsets of training data [32] or different time snapshots of a classifier evolving by time [48].
Training Value of Samples: Lapedriza et al. [26] discussed that different samples have different training value for a classifier, and using a wisely selected subset of samples for training/retraining the classifier outperforms the training with full dataset, for instance, due to mislabeled or inaccurately demarcated samples. Having a better training set for a tracking-by-detection classifier leads to enhanced generalization and faster convergence to the final performance which is suitable for converging to the piece-wise stationary target distribution (the distribution may change by every drastic change of target’s appearance). To address this, researchers came by different approaches to provide good samples for tracking using context [18, 23], saliency maps [25], confidence maps [44], and optical flow [22]. Adaptive weights for the samples based on their appearance similarity to the target [35], occlusion state [30], and spatial distance to previous target location [47] have also been considered, however, selecting an efficient subset for classifier re-training have been ignored, as most of the trackers retrain on all of the data, a randomized subset of it [32], or in special cases re-sample the training data based on their boosting value [28]. A “clean” subset of training samples to re-train the classifier can achieve much higher performance than the full set [51, 36], therefore, a principled ordering and selection of the samples reduces the cost of labeling and accelerate the performance with smaller re-training sample size [45]. Different studies have tried to provide this small clean subset by different approaches: pruning outliers [12] and hard-to-learn samples [1], learning easy-to-classify examples first (as known as the Curriculum learning)[8], treating samples as noisy observations [14], defining a training value for each sample by treating each sample as a separate classifier [26], and robust loss functions for special classifiers (e.g., SVMs). Arguably, the most common setting is active learning, which selects the training samples to be labeled/selected at each step for higher gains in performance. Some approaches focus on learning the hardest examples first (e.g., those closest to the decision boundary), whereas some others gauge the information contained in the sample and select the most informative ones first. For instance, in the case of an ensemble of classifiers, the samples for which the ensemble disagrees the more, contains more information about how to train the ensemble. This concept is known as query-by-committee [41] that tries to provide the best classifier with as few labeled instances as possible.
3 Proposed Method
A tracking-by-detection algorithm usually estimates the target state in time by obtaining several samples , scoring them , labeling them , and aggregating them, . To obtain a sample, a distribution or region-of-interest is sampled to obtain a transformation that defines the state of the sample compared to the previous target location, , and the sample appearance is defined as . This sample is then evaluated by the classifier with scoring function ,
[TABLE]
Based on the score, a label is assigned to the sample. For supervised-learning classifiers [2], the label is either positive (target) or negative (background), but semi-supervised classifiers (e.g., [17, 38]) or multi-instance learning (e.g., [4, 50]) allow the samples, which the classifier is uncertain about, to remain unlabeled by the classifier,
[TABLE]
in which and denotes the lower and upper thresholds respectively. The unlabeled data are either discarded, used for later stages of tracking, or labeled by other mechanisms embedded in the tracker [17, 42, 44]. The target state, as mentioned, is estimated using , and the classifier is updated by the all or a subset of the labeled data denoted by ,
[TABLE]
where is the model update function. The subset may involve all new data for online trackers (), a subset of the new data () or recent data (), and keyframe data () [31, 21].
3.1 Ensemble Discriminative Tracking
A popular approach to robustify the classification in tracking-by-detection framework is to construct an ensemble of different (weak) classifiers , and combine their opinion about a sample by voting,
[TABLE]
In most of the cases, the weak classifiers are linearly combined with different associated weights,
[TABLE]
where the weights are tuned using boosting [3, 16, 32] or Bayesian treatment [5]. A larger weight implies that the corresponding classifier of th eensemble is more discriminative, hence more useful. The labels are calculated from eq(2) with and as the lower and upper thresholds for the ensemble score.
Finally, each classifier’s model is updated independently,
[TABLE]
indicating that all of the ensemble members are trained with a similar set of samples .
3.2 Co-Training
Built on co-training principle [9], collaborative tracking (co-tracking) provides a framework in which the classifiers exchange their information to promote tracking results and break self-learning loop. In this two-classifier framework [44], the challenging samples for one classifier is labeled by the other one, i.e., if a classifier finds a sample difficult to label, it relies on the other classifier to label it for this frame and similar samples in the future.
[TABLE]
The collaborative label is obtained by applying eq(2) on this score. The weights of the classifiers are adjusted by comparing the labels of each classifier to the collaborative label. Eventually, the trackers which label a sample are getting updated by it.
3.3 Active Collaborative Ensemble Tracker
The proposed tracker, ACET, is an ensemble tracker in which the co-training rule provides the samples for retraining each classifier, and active learning selects the most informative ones to improve the generalization and efficiency of the model update. Furthermore, by forgetting older samples with different memory horizons, the ensemble is diversified and non-stationary target appearance distributions are better accommodated.
Here, the ensemble is constructed of similar classifiers but with different memory spans . Sample is obtained from a Gaussian field centered on last target state, . This sample is then scored by all members of the ensemble. Those members that are uncertain about labeling the sample are marked by flag ,
[TABLE]
which in turn helps to calculate the score of ensemble,
[TABLE]
and label it using eq(2) with and as thresholds.
Since the number of samples are limited, an approximation of the target location is obtained by calculating the expectation of target, i.e., by taking a weighted average of the target candidates (i.e., positive samples).
[TABLE]
Following the rule of co-training, only the classifiers that engaged in labeling a sample () should be updated with that sample. However, not all the samples are equally useful to train the ensemble. For instance, a sample for which half of the ensemble are uncertain about its label would be better for training compared to a sample for which only one of the classifiers is uncertain. To measure the “informativeness” of a sample, we count the number of the classifiers that elicit a strong belief about its label, . Then for training of each classifier of the ensemble, based on query-by-committee concept [41], those samples with are sorted based on and the first are used for retraining (stored in ).
[TABLE]
where contains the labels of the samples in . As a result, the diversity of the ensemble is increased by co-training, selective updating, and different memory horizons.
The weights of the classifier is calculated based on its agreement with the whole ensemble. The error of each classifier is determined by
[TABLE]
in which is the indicator function. Then the weight of each classifier is calculated as,
[TABLE]
in which is a small constant. If the error average of the ensemble is very high, , then the target is likely to be mostly occluded. Algorithm 1 and Figure 1 summarize the proposed tracker.
4 Experiments
The proposed framework is comprised of several parameters: (i) Sampling parameters such as number and sampling distribution covariance , (ii) Ensemble parameters such as classifier count , their memory spans and labeling thresholds , and (iii) Tracking parameters such as occlusion threshold and retraining subset size . On a P-IV PC at 3.5 GHz, ACET achieved 37.16 fps with a Mathlab/C++ implementation.
4.1 Evaluation Protocol
To evaluate the tracker, we employ success plot which measures the performance of a tracker which is a combination of its accuracy, reliability, and scale adaptation.
The experiments are conducted to object tracking benchmark videos [46], which become a de-facto standard in comparing the performance of the trackers, and includes several subcategories, exploiting the performance of the trackers against various visual tracking challenges: illumination and scale variations (IV, SV), in- and out-of-plane rotations (IPR, OPR), fast motion and motion blur (FM, MB), deformations and low-resolution (DEF, LR), occlusion and shear problem (OCC, OV), and background clutter (BC).
4.2 Comparison with other Ensemble Trackers
For this experiment, we compare the proposed tracker (ACET) with online boosting tracker (OAB [16]) that utilizes different features to construct weak classifiers as ensemble members, and randomized ensemble tracker (RET [5]) that make different strong classifiers out of a pool of weak classifiers, and construct the ensemble out of those strong classifiers. We also include MIL [4] and BSBT[42] to represent ensemble trackers based on semi-supervised and multi-instance learning. Here, we implement a version of our tracker (ACET-) that use the same feature set to construct different members of the ensemble and the active learning and memory horizon subsampling is disabled. For the sake of compatibility with published RET results, 13 overlapping sequences with OTB-50 have been used.
Figure 2 illustrate that the proposed framework works better than other ensemble methods regardless of the ensemble member construction. Yet, it is evident that using all features along with subsampling schemes for re-training classifier (by active learning and different memory spans) significantly improve the tracking performance.
4.3 Comparison with State-of-the-art
To provide a fair comparison, we compared ACET with state-of-the-art tracking-by-detection algorithms TLD [22], STRK [19], MEEM [48], correlation filter trackers SRDCF [10], CCOT [11] and multi-memory tracker MUSTer [21]. The comparison based on the area under curve of the success plot is presented in Table 1. It is evident that ACET outperforms the other trackers in most of the categories and in total performance over the 50 videos. Yet, it should be noted that since the tracker utilized two features that are both sensitive to low resolution target appearances, (as expected) it is not able to perform well in LR category. The good performance of the tracker in target appearance change categories (IV, DEF, OCC, OV) can be attributed to the robustness of ensemble due to co-learning, while the good results on transformation categories (SV, IPR, OPR) can be attributed to good generalization obtained by active learning sample selection for ensemble retraining. Different memory spans helped the tracker to dominate motion categories (FM, MB), and a robust diverse ensemble obtained by all of these approaches resolved background clutter (BC) effectively. The quality of results are showed in Figure 3.
5 Conclusions
In this study we proposed a novel framework for ensemble tracking, in which the classifiers exchange their data based on co-learning concept, and only the most informative samples are used for updating the classifiers to enhance generalization and accelerate convergence to non-stationary distributions of target appearance. Co-learning reduces the label noise, and break the self-learning loops that cause model drift, and together with different memory spans for the ensemble provides a robust model update scheme for ensemble tracking. The proposed tracker, ACET, outperformed other ensemble trackers and state-of-the-art on OTB-50[46] database.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] A. Angelova, Y. Abu-Mostafam, and P. Perona. Pruning training sets for learning of object categories. In CVPR’05 .
- 2[2] S. Avidan. Support vector tracking. PAMI , 2004.
- 3[3] S. Avidan. Ensemble tracking. PAMI , 29, 2007.
- 4[4] B. Babenko, M.-H. Yang, and S. Belongie. Visual tracking with online multiple instance learning. In CVPR’09 , 2009.
- 5[5] Q. Bai, Z. Wu, S. Sclaroff, M. Betke, and C. Monnier. Randomized ensemble tracking. In ICCV’13 , 2013.
- 6[6] Y. Bai and M. Tang. Robust tracking via weakly supervised ranking svm. In CVPR’12 , 2012.
- 7[7] C. Bao, Y. Wu, H. Ling, and H. Ji. Real time robust l 1 tracker using accelerated proximal gradient approach. In CVPR’12 .
- 8[8] Y. Bengio, J. Louradour, R. Collobert, and J. Weston. Curriculum learning. In ICML’09 , 2009.