Complexity-theoretic limitations on blind delegated quantum computation
Scott Aaronson, Alexandru Cojocaru, Alexandru Gheorghiu, Elham Kashefi

TL;DR
This paper investigates the fundamental complexity-theoretic limitations of blind delegated quantum computation protocols, showing that certain secure protocols are unlikely to exist under standard conjectures and exploring their implications.
Contribution
It provides complexity-theoretic constraints on the existence of information-theoretically secure blind quantum delegation protocols, highlighting their limitations and implications for quantum computational complexity.
Findings
Classical communication protocols imply unlikely complexity class containments.
Protocols for quantum sampling problems relate to non-uniform circuit sizes.
One-round quantum-classical protocols constrain the functions that can be delegated.
Abstract
Blind delegation protocols allow a client to delegate a computation to a server so that the server learns nothing about the input to the computation apart from its size. For the specific case of quantum computation we know that blind delegation protocols can achieve information-theoretic security. In this paper we prove, provided certain complexity-theoretic conjectures are true, that the power of information-theoretically secure blind delegation protocols for quantum computation (ITS-BQC protocols) is in a number of ways constrained. In the first part of our paper we provide some indication that ITS-BQC protocols for delegating computations in which the client and the server interact only classically are unlikely to exist. We first show that having such a protocol with bits of classical communication implies that . We…
Click any figure to enlarge with its caption.
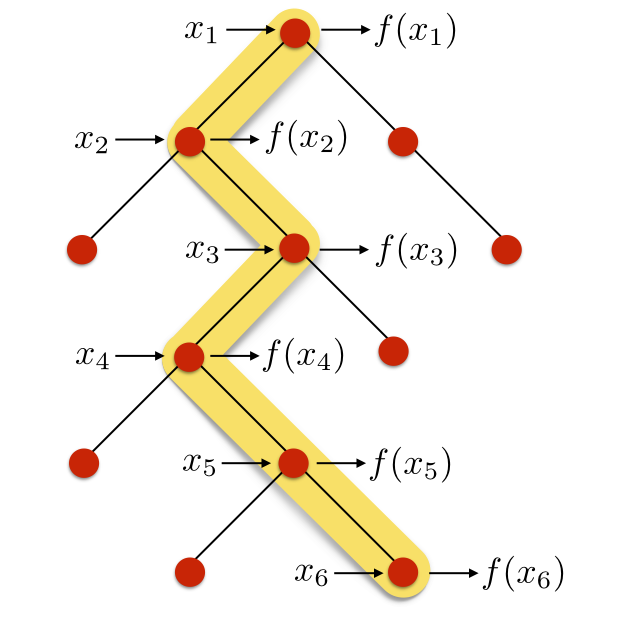 Figure 1
Figure 1 Figure 2
Figure 2Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
11affiliationtext: Department of Computer Science, University of Texas at Austin22affiliationtext: School of Informatics, University of Edinburgh33affiliationtext: Department of Computing and Mathematical Sciences, California Institute of Technology44affiliationtext: CNRS LIP6, Université Pierre et Marie Curie, Paris
Complexity-theoretic limitations on blind
delegated quantum computation
Scott Aaronson111Email: [email protected]
Alexandru Cojocaru222Email: [email protected]
Alexandru Gheorghiu333Email: [email protected]
Elham Kashefi444Email: [email protected]
Abstract
Blind delegation protocols allow a client to delegate a computation to a server so that the server learns nothing about the input to the computation apart from its size. For the specific case of quantum computation we know, from work over the past decade, that blind delegation protocols can achieve information-theoretic security (provided the client and the server exchange some amount of quantum information). In this paper we prove, provided certain complexity-theoretic conjectures are true, that the power of information-theoretically secure blind delegation protocols for quantum computation (ITS-BQC protocols) is in a number of ways constrained.
In the first part of our paper we provide some indication that ITS-BQC protocols for delegating polynomial-time quantum computations in which the client and the server interact only classically are unlikely to exist. We first show that having such a protocol in which the client and the server exchange bits of communication, implies that . We conjecture that this containment is unlikely by proving that there exists an oracle relative to which . We then show that if an ITS-BQC protocol exists in which the client and the server interact only classically and which allows the client to delegate quantum sampling problems to the server (such as BosonSampling) then there exist non-uniform circuits of size , making polynomially-sized queries to an oracle, for computing the permanent of an matrix.
The second part of our paper concerns ITS-BQC protocols in which the client and the server engage in one round of quantum communication and then exchange polynomially many classical messages. First, we provide a complexity-theoretic upper bound on the types of functions that could be delegated in such a protocol by showing that they must be contained in . Then, we show that having such a protocol for delegating -hard functions implies .
1 Introduction
An important area of research in modern cryptography is that of performing computations on encrypted data. The general idea is that a client wants to compute some function on some input , but lacks the computational power to do this in a reasonable amount of time. Luckily, the client has access to a computationally powerful server (cloud, cluster etc) which can compute quickly. However, because the computation might involve sensitive or classified information, or the server could be compromised remotely, we would like the input to be hidden from the server at all times. The client can simply encrypt , but this raises the question: how can the server compute if it doesn’t know ? The general problem of computing on encrypted data was first considered by Rivest, Adleman and Dertouzos [1]. Since then, instances of this problem have appeared in many areas of modern research including those of electronic voting, machine learning on encrypted data, program obfuscation and others [2, 3, 4, 5, 6, 7].
It was shown in 2009, when Gentry produced the first fully homomorphic encryption scheme, that performing classical computations on encrypted data is possible [8]. In homomorphic encryption the client has a pair of efficient algorithms , which respectively perform encryption and decryption, and which satisfy the property , for any function from some set . In other words, the server evaluates on the encrypted input using and returns this to the client which can then decrypt it to . Of course, the server should not be able to infer information about from , a condition which is typically expressed through the criterion of semantic security [9]. If the set contains all polynomial-sized circuits then the scheme becomes a fully homomorphic encryption scheme, commonly abbreviated FHE. All known FHE schemes are secure under cryptographic assumptions.
Computing on encrypted data becomes particularly interesting when the server is a quantum computer. This is because efficient quantum algorithms have been found for various problems which are believed to be intractable for classical computers. In fact, it has been shown that if a classical computer and a quantum computer are both given black-box or oracle access to certain functions, then the quantum computer exponentially outperforms the classical computer [10, 11, 12, 13]. Classical clients would therefore be highly motivated to delegate problems to quantum computers. However, ensuring the privacy of their inputs is challenging. In particular, we’d have to solve the following problems:
- •
Devise an encryption scheme which is secure against quantum computers and does not leak information to the server about the client’s input.
- •
Ensure that the encryption scheme allows the client to recover the output of the computation from the result provided by the quantum server.
- •
Ensure that the protocol is efficient for the client. Ideally, the number of rounds of interaction between the client and the server as well as the client’s local computations, should scale at most polynomially with the size of the input.
In spite of these stringent requirements, protocols that achieve these properties already exist and are known collectively as delegated blind quantum computing schemes [14]. In such protocols, a probabilistic polynomial-time client is able to delegate polynomial-time quantum computations to a server in such a way that the client’s input (apart from an upper bound on its size) is kept hidden from the server in an information-theoretic sense. All of the above schemes require the client and the server to share at least one round of quantum communication. Universal Blind Quantum Computation (UBQC), shown schematically in Figure 1, is an example of such a protocol [15].
The first blind delegation protocol was devised by Childs in [16], and since then these protocols have been improved and extended in various works [17, 18, 19, 20, 21, 22, 23, 24]. UBQC and related protocols require the client and the server to exchange only one quantum message, while the rest of the communication is classical [15, 25, 26]. This quantum message (which is sent by the client to the server) consists of a tensor product of single-qubit states. As such, the only quantum capability the client needs is the ability to prepare single-qubit states.
In this paper, we explore two questions pertaining to blind delegation protocols:
- (1)
Is there a scheme for blind quantum computing that is information-theoretically secure, and that requires only classical communication between client and server?
- (2)
For schemes in which the client and the server are allowed one round of quantum communication, which functions can the client delegate to the server while maintaining information-theoretic security? In particular, could the client delegate the evaluation of -hard functions?
We provide some indication, based on complexity-theoretic conjectures, that the answer to the first question is no. In other words, provided these complexity-theoretic conjectures hold, a classical client running in polynomial time and communicating only classically with a server cannot delegate arbitrary polynomial-time quantum computations to that server while keeping its input hidden in an information-theoretic sense. Importantly, our result does not contradict recent results on quantum fully homomorphic encryption with a classical client [27, 28], since those schemes are based on cryptographic assumptions: we are interested only in information-theoretic security.
In answer to the second question, we provide a complexity-theoretic upper bound on the types of functions that can be evaluated by UBQC-type protocols (i.e. protocols in which the client can send one quantum message to the server555In fact our result concerns protocols in which the client and the server start with one round of quantum communication, followed by polynomially-many rounds of classical communication. In other words, not only is there one quantum message from the client to the server, but the server is also allowed to respond with a quantum message.). We show that, under plausible complexity-theoretic assumptions, this upper bound prevents the client from delegating -hard functions to the server. Thus, allowing for quantum communication between the client and the server expands the set of functions that the client can delegate to the server to include , but not enough so as to include as well.
1.1 Main results
We phrase our results formally using the concept of a generalised encryption scheme (GES) introduced by Abadi, Feigenbaum and Killian [29], which is defined in Section 2.3. Roughly speaking, a GES is a protocol between a probabilistic polynomial-time classical client and a computationally unbounded server for computing on encrypted data. The client sends the server a description of some function666Unless otherwise specified, we restrict our attention to decision problems. This is why the function has the codomain . . Using some polynomial-time algorithm denoted , the client encrypts its input , and sends to the server. The server and the client then interact for a number of rounds which is polynomial in the length of . Finally, using a polynomial-time decryption algorithm denoted , the client decrypts the server’s responses and obtains with probability . Importantly throughout the protocol, the server learns no more than the length of . Because the server is computationally unbounded, the scheme requires information-theoretic security. Abadi et al. gave a complexity theoretic upper bound on the types of functions that admit such a scheme. They showed that any function that the client could delegate in a GES must be contained in the class . We give a simplified proof of this result in Section 2.3.
The GES framework allows us to restate the questions we address in this paper as follows:
- (1)
Can we design a GES for delegating functions? Note that, by the Abadi et al. result, this is the same as asking whether . We will consider two variants on the GES framework: one which allows the client to delegate sampling problems to the server, and one in which the total communication between client and server is bounded by , for some constant . For the former, we show that having such a scheme for quantum sampling problems, like BosonSampling, implies that circuits exist which can compute the permanent of a matrix more efficiently than we believe is possible. For the latter, having a GES with bounded communication for polynomial-time quantum computation implies that , and we argue that this containment is unlikely by providing an oracle separation between these classes.
- (2)
If we change the GES framework to allow one round of quantum communication between the client and the server, what functions can the client delegate to the server? We answer this question by “quantising” the Abadi et al. result and showing that such functions would be contained in (a quantum analogue of ). We also show that is unlikely to contain -hard functions.
1.1.1 Generalised encryption scheme for BQP decision problems
As we have mentioned, for the case of decision problems, Abadi et al. showed that the class of problems that a client can delegate to a server using the GES framework is contained in . They also observed that if -hard functions could be delegated by the client using a GES, then , and, in particular, . Yap showed that having such a containment leads to a collapse of the polynomial hierarchy at the third level [30]. In other words, it seems unlikely that -hard problems would admit a GES.
What about -hard functions? The Abadi et al. result implies that having a GES for -hard functions leads to . While we would like to argue, similarly, that such a containment leads to a collapse of the polynomial hierarchy, even isn’t known to lead to such a collapse. We instead consider a modified GES in which the total communication between the client and the server is upper bounded by a polynomial of fixed degree, , in the size of the input777Note that we impose no such restriction on the running time of the client.. In that case, it can be shown that (see the proof of Theorem 7). We argue that this containment is unlikely based on the following result, which we prove in Section 3:
Theorem 1**.**
For each , there exists an oracle such that is not contained in .
Essentially, the theorem shows that relative to an oracle , there are problems that can be solved by a polynomial-time quantum algorithm, but which a classical client cannot delegate to a server in a GES with bounded communication. Since the oracle is parameterised by , we are in fact defining a family of oracles. The specific problem on which the oracle is based is a version of Simon’s problem [11]. Simon’s problem is the following: for an input of size , and given oracle access to a function that is guaranteed to be either an injective function, or a -to- and periodic function888In other words, there exists a period , , such that for all , , it is the case that iff. ., the task is to decide which is the case. Simon provided a polynomial-time quantum algorithm for solving this problem, thus showing that it belongs to (relative to the function oracle). For the case in which one should accept when the function is -to-, the problem can be shown to be outside of (relative to the function oracle). As such, Simon’s problem provides an oracle separation between and .
In Simon’s original construction, the oracle function is the same for all inputs of size . Note that, this version of the problem can be solved with one bit of advice: for all inputs of size , the advice bit simply specifies whether the function is -to- or -to- and periodic. Therefore such a setup would not be useful in our case. For this reason, in our proof of Theorem 1, the function that the oracle provides access to is input-dependent. The problem we define, relative to this oracle, is again to decide whether the function is -to- or the function is -to- and periodic. However, we can show that, by considering a sufficiently large domain for these functions — in other words, by letting for some — the problem is not contained in , but is nevertheless contained in . The proof uses a diagonalisation argument and can be found in Section 3.
Unfortunately, the same oracle cannot be used to separate from . This is because is a function of ; to prove a separation with respect to , where the length of the advice string can be any polynomial, we would have to find an oracle that works for all possible values of . It would be interesting to see whether the oracle that Raz and Tal [31] recently used to prove a separation between and could also be used in order to separate from , or even from . We leave this as an open problem.
One can argue that oracle results do not constitute compelling evidence on the relationships between complexity classes. For example, it has been known for a while that there exist oracles such that but , and that, while , there is an oracle such that . Nonetheless, oracles allow us to study the query complexity of problems in different models of computation. In fact, there are situations in practice where computer programs are restricted to making black-box calls to functions in order to determine their properties [32]. Apart from this, oracle results have also inspired a number of important developments in algorithms and complexity theory999A notable example is the fact that Simon’s oracle separation between and led to Shor’s algorithm for factoring and computing the discrete logarithm [33]. For more arguments concerning the usefulness of oracle results, see Section 1.3 of [34].
1.1.2 Generalised encryption scheme for BQP sampling problems
We consider what would happen if we have a generalised encryption scheme which allowed a client to delegate a sampling problem, such as BosonSampling, to the server. BosonSampling, defined by Aaronson and Arkhipov in [35], is essentially the problem of simulating the statistics of photons (bosons) passing through a linear optics network. One starts with a configuration of identical photons in known locations (referred to as modes). The photons then pass through the linear optics network, which consists of optical elements (beamsplitters and phase shifters). Finally, one performs a measurement to determine the new locations of the photons in the output modes of the system. The reason this is referred to as a sampling problem is because we have a probability distribution over the different configurations of photons in the output modes. In exact BosonSampling, which is the problem we consider, the task is to produce a sample from that probability distribution. Aaronson and Arkhipov showed that the probability of observing a particular configuration of photons is proportional to the squared permanent of a matrix that can be obtained efficiently from the description of the optical network. They also showed that no polynomial-time probabilistic algorithm can sample from this distribution, unless the polynomial hierarchy collapses at the third level [35]. As such, while a quantum computer could simulate the optical network and sample from the target distribution in polynomial time, it seems unlikely that classical computers could do the same.
In a GES for exact BosonSampling, the client’s input would be a description of a linear optics network101010In principle, one could also specify the configuration of the photons in the input modes as part of the client’s input. Equivalently, however, one can always initialise the input modes to some fixed initial state, and produce whichever starting state is in fact desired by altering the linear optics network.. The client would like to delegate to the server the task of sampling from the BosonSampling distribution associated with this network, while keeping the description of the network hidden from the server. In other words, upon interacting with the server and decrypting its responses, the client should obtain a sample from the BosonSampling distribution. At the same time, the server learns at most an upper bound on the size of the network. We show the following:
Theorem 2**.**
If exact BosonSampling admits a GES, then for any matrix , there exist circuits of size , making polynomially-sized queries to an oracle, for computing the permanent of .
Computing the permanent of a matrix is a problem known to be -hard. By Toda’s theorem, this means that if computing the permanent were possible at any level of the polynomial hierarchy, the hierarchy would collapse at that level [36]. Moreover, the best known algorithm for computing the permanent, by Björklund, has a run-time of [37]. Prior to that, the leading algorithm for computing the permanent was Ryser’s algorithm, developed over years ago, which requires arithmetic operations [38]. We conjecture that the circuits of Theorem 2 do not exist and, thus, that there can be no GES for BosonSampling. The proof of this result can be found in Section 4.
1.1.3 Quantum generalised encryption scheme
While having a GES for delegating computations seems unlikely, we know that giving the client some minimal quantum capabilities removes this limitation: schemes such as UBQC exist which allow for the information-theoretically secure blind delegation of quantum computations. In the spirit of the Abadi et al. result, it is natural to consider quantum generalised encryption schemes (or QGES), in which the client is no longer classical, and investigate the complexity-theoretic upper bounds on functions that admit such a protocol. For the QGES, we are still assuming information-theoretic security and that the encryption scheme leaks at most the size of the input. However, unlike the GES, the client is now assumed to be a quantum computer performing polynomial-time computations111111It should be noted that our upper bound on the power of QGES schemes also holds if the client is restricted to computations (as is the case in UBQC), since .. Additionally, the client and the server perform one round of quantum communication at the beginning of the protocol. The rest of the communication is classical.
We impose one other restriction on the QGES, known as offline-ness. Roughly speaking, an offline protocol is one in which the client does not need to commit to any particular input (of a given size), after having sent the quantum message to the server. The quantum message only depends on the size of the input. We note that offline-ness is a property which UBQC and all other currently known blind quantum computing protocols share. From a practical perspective, this presents the client with the option of sending the first quantum message to the server and deciding at a later time on which input the server should perform the computation. One could imagine, for instance, that the client and the server have access to a quantum channel for a limited amount of time. In practice, such a situation can occur if the communication between the parties is mediated by a satellite, as is the case with satellite-based quantum-key distribution [39]. In this case, the satellite is in the line of sight of the two parties for only a few minutes at a time. Our result is the following:
Theorem 3**.**
The class of functions that a client can delegate to a server in an offline QGES is contained in .
Note that the class can be seen as a quantum analogue of the class which we encounter in the GES case. We therefore view Theorem 3 as a “quantisation” of the Abadi et al. bound on the power of generalised encryption schemes.
Again, in the spirit of the Abadi et al. result, one can ask whether -complete functions are contained in . In other words: does giving quantum capabilities to the client increase the class of functions that it can securely delegate so that this class contains ? We give an indication that the answer is no:
Theorem 4**.**
* implies .*
Note that if in the above expression were replaced with , this would imply a collapse of the polynomial hierarchy at the third level. Our result is as close to a collapse of the polynomial hierarchy as one can reasonably hope to get, given a quantum hypothesis. Hence, while a QGES does allow the client to delegate computations, it seems to be no more useful than the regular GES for delegating -hard functions.
One could ask why we would even be interested in delegating -hard problems to a quantum computer, given that we do not expect quantum computers to be able to solve such problems in polynomial time [40]. First of all, from a theoretical perspective, note that in the QGES formalism we are not limiting the server to polynomial-time quantum computations, but instead assuming that it has unbounded computational power. Therefore, the way to view this result is not as “how can a client blindly delegate the evaluation of -hard functions to a quantum computer?” but as “can quantum communication help in blindly delegating the evaluation of -hard functions to an unbounded server?”.
From a practical perspective, while we do not believe that quantum computers can solve -complete problems in polynomial time, they could, in principle, solve such problems quadratically faster than classical computers, thanks to Grover’s algorithm [41]. Even though the speedup of Grover’s algorithm is only quadratic, from (say) to , our result is only concerned with the length of the computation performed on the client side, and therefore applies to Grover’s algorithm just as it would to a quantum algorithm achieving exponential speedup. In fact, as is mentioned in [42], there are -complete problems for which quantum computers provide a superpolynomial speedup, at least with respect to the best known classical algorithms. Our no-go theorem indicates that clients cannot exploit such speedups by delegating the computation to the server, even when allowing some quantum communication, if we also want to keep their inputs hidden in an information-theoretic sense.
Proofs of these results can be found in Section 5.
1.2 Related work
As mentioned, the problem of computing on encrypted data was first considered by Rivest, Adleman and Dertouzos [1], which then led to the development of homomorphic encryption and eventually to fully homomorphic encryption with Gentry’s scheme [8]. Since then there have been many other FHE protocols relying on more standard cryptographic assumptions and having more practical requirements [43, 44, 45].
While FHE is similar to the GES in many respects, there are also significant differences. For starters, FHE protocols have only one round of interaction between the client and the server, whereas a GES allows for polynomially many rounds. Additionally, the GES assumes the server is computationally unbounded and hence requires information-theoretic security. In contrast, FHE relies on computational security. More precisely FHE schemes have semantic security against polynomial-time (quantum) algorithms [8].
The problem of quantum computing on encrypted data was introduced by Childs [16] and Arrighi and Salvail [46]. Further development eventually led to UBQC [15, 25] and a scheme of Broadbent [26]. The latter was followed by the construction of the first schemes for quantum fully homomorphic encryption (QFHE) [47, 48]. For a review of blind quantum computing and related protocols see [14].
In the QFHE schemes of [47, 48], the server is a polynomial-time quantum computer and the client has some quantum capabilities of its own, although it is not able to perform universal quantum computations. Both the size of the exchanged messages and the number of operations of the client are polynomial in the size of the input. More recently, QFHE schemes have been proposed in which the client is completely classical [27, 28]. Similar to FHE, these protocols rely on computational assumptions for security [49] and involve one round of back and forth interaction between the client and the server. QFHE with information-theoretic security (and a computationally unbounded server) has been considered by Yu et al. in [50], where it is shown that it is impossible to have such a scheme for arbitrary unitary operations (or even arbitrary reversible classical computations). This result was later reproved by Newmann and Shi using quantum random-access codes [51]. In relation to our work, QFHE with information-theoretic security can be viewed as a one-round QGES in which the server responds with a quantum message. The complexity-theoretic upper bound we prove for QGES computable functions would then apply to QFHE as well (provided that in QFHE we only leak the size of the input to the server), since our proof allows a quantum message from the server just as well as a classical message.
The possibility of a classical client delegating a blind computation to a quantum server was considered by Morimae and Koshiba [52]. They showed that such a protocol in which the client leaks no information about its input to the server and there is only one round of interaction leads to , considered an unlikely containment. We consider the more general setting of a GES for functions, where the number of rounds can be polynomial in the size of the input and we allow the encryption to leak the size of the input. In fact, the question of whether a GES, as defined in Abadi et al. [29], can exist for quantum computations was raised before by Dunjko and Kashefi [53].
1.3 Future work
As we remarked in Section 1.1, in the case of decision problems, the existence of a GES with bounded communication, for polynomial-time quantum computations, leads to the inclusion . We argue that this containment is unlikely based on the existence of an oracle separating the two complexity classes. A natural extension of this result would be to prove an oracle separation between and . This would provide more compelling evidence that a GES for quantum computations cannot exist.
In the case of sampling problems, we showed that a GES for BosonSampling implies the existence of circuits of size , making polynomially-sized queries to an oracle, for computing matrix permanents. Can this result be strengthened so as to provide circuits for computing matrix permanents that would be ruled out by the strong exponential-time hypothesis? Alternatively, could one use other quantum sampling problems (such as random circuit sampling or problems [54]) to show that having a GES for such a problem leads to a collapse of the polynomial hierarchy?
We also defined the QGES, which extends the GES by allowing the client to send one quantum message to the server, and gave an upper bound for the set of functions that can be delegated using an offline version of such a scheme. The immediate question one could ask is: what upper bound can we give for an online QGES? A related question is: what upper bound can we give for a QGES that allows all of the communication between the client and the server to be quantum? The difficulty in answering both of these questions is that the offline property of the QGES is what allowed us to relate the set of functions that can be delegated to advice classes. Without this property, it seems that a different approach would be needed to provide a complexity-theoretic upper bound.
Another direction that can be explored has to do with the size of the quantum communication between the client and the server. In a QGES in which the client’s quantum message is logarithmic or poly-logarithmic in the size of the input (while the classical communication is still polynomial), is it still possible to delegate functions to the server? Of course, this question only makes sense if we assume that the client is not able to perform computations itself.
2 Preliminaries
2.1 Quantum information and computation basics
In this subsection we provide a few basic notions regarding quantum information and quantum computation and refer the reader to the appropriate references for a more in depth presentation [55, 56].
A quantum state (or a quantum register) is a unit vector in a complex Hilbert space, . We denote quantum states, using standard Dirac notation, as , called a ‘ket’ state. The dual of this state is denoted , called a ‘bra’, and is a member of the dual space . We will only be concerned with finite-dimensional Hilbert spaces. Qubits are states in two-dimensional Hilbert spaces. Traditionally, one fixes an orthonormal basis for such a space, called computational basis, and denotes the basis vectors as and . Gluing together systems to express the states of multiple qubits is achieved through tensor product, denoted . The notation denotes a state comprising of copies of . If a state cannot be expressed as , for any and any , we say that the state is entangled.
Quantum mechanics dictates that there are two ways to change a quantum state: unitary evolution and measurement. Unitary evolution involves acting with some unitary operation (so , where the operation denotes the hermitian adjoint, obtained through transposing and complex conjugating) on , thus producing the mapping .
Measurement, in its most basic form, involves expressing a state in a particular orthonormal basis, , and then choosing one of the basis vectors as the state of the system post-measurement. The index of that vector is the classical outcome of the measurement. The post-measurement vector is chosen at random and the probability of obtaining a vector is given by . There are more general types of measurement, however this is the only type that is relevant to our paper.
States denoted by kets are also referred to as pure states as they are states of maximal information for a quantum system. In other words, having a pure state for a particular quantum system means knowing all there is to know about the state of that system. When maximal information is not available, states are referred to as mixed and can be represented using density matrices. These are positive semidefinite, trace one, hermitian operators. The density matrix of a pure state is .
An essential operation concerning density matrices is the partial trace. This provides a way of obtaining the density matrix of a subsystem that is part of a larger system. Partial trace is linear, and is defined as follows. Given two density matrices and with Hilbert spaces and , we have that:
[TABLE]
In the first case one is ‘tracing out’ system , whereas in the second case we trace out system . This property together with linearity completely defines the partial trace. For if we take any general density matrix, , on , expressed as:
[TABLE]
where () and () are orthonormal bases for and , if we would like to trace out subsystem , for example, we would then have:
[TABLE]
An important result, concerning the relationship between mixed states and pure states which we use in our paper, is the fact that any mixed state can be purified. In other words, for any mixed state over some Hilbert space one can always find a pure state such that 121212One could allow for purifications in larger systems, but in our paper we restrict attention to same dimensions. and:
[TABLE]
Moreover, the purification is not unique and so another important result is the fact that if is another purification of then there exists a unitary , acting only on (the additional system that was added to purify ) such that:
[TABLE]
We will refer to this as the purification principle.
Quantum computation is most easily expressed in the quantum gates model. In this framework, gates are unitary operations which act on groups of qubits. As with classical computation, universal quantum computation is achieved by considering a fixed set of quantum gates which can approximate any unitary operation up to a chosen precision. The most common universal set of gates is given by:
[TABLE]
In order, the operations are known as Pauli and Pauli , Hadamard, the -gate and controlled-NOT. Note that general controlled- operations are operations performing the mapping , . The matrices express the action of each operator on the computational basis. A classical outcome for a particular quantum computation can be obtained by measuring the quantum state resulting from the application of a sequence of quantum gates.
The final notion which needs mentioning is the quantum SWAP test. This is a simple procedure for determining whether two quantum states are close to each other or far apart. We express closeness in terms of the absolute value of their inner product . The test involves preparing a qubit in the state and performing a controlled-SWAP operation between that qubit and the state . SWAP is defined by the mapping , so we obtain the state:
[TABLE]
If one then applies a Hadamard operation to the first qubit and measures it in the computational basis it can be shown that the probability of obtaining outcome is .
2.2 Complexity theory
2.2.1 Decision problems
We use standard complexity theory notation and refer the reader to the Complexity Zoo [57] for the definitions of standard complexity classes. Briefly, is the class of decision problems131313A decision problem is a problem in which for every input , the output is either “yes” or ”no”. A decision problem can be represented as either a function , or as a subset of representing the “yes” instances to the problem. Such a set is known as a language. that can be solved by a deterministic polynomial-time classical algorithm (or Turing machine). If the algorithm is allowed to use randomness (and we require that it outputs the correct answer with probability greater than ) the corresponding class is . The class of decision problems for which “yes” instances admit a polynomial-sized proof string (or witness) that can be verified by the polynomial-time algorithm is known as 141414There is an equivalent definition of as the set of all decision problems that can be solved by a non-deterministic polynomial-time algorithm (or Turing machine). The non-deterministic part simply means that the algorithm can guess a witness.. The analogous class for “no” instances is , referred to as the complement of . Once again, if the polynomial-time algorithm also uses randomness the corresponding classes are and , respectively. The class of decision problems that can be decided in polynomial-time by a quantum algorithm is denoted . There are two quantum analogues of . One is which is the class of decision problems in which “yes” instances admit a quantum witness, of polynomially-many qubits, that can be verified by a polynomial-time quantum algorithm. The other is , which is the same as except the witness is a classical bit-string, rather than a quantum state. Complements of these classes are denoted and , respectively. For all classes mentioned here, we say that a problem is hard for the class if for all problems there exists a deterministic polynomial-time algorithm mapping each “yes” instance of to a “yes” instance of and each “no” instance of to a “no” instance of , respectively. We also say that is complete for if is hard for and .
As a slight abuse of terminology, we will sometimes say “ machine/algorithm” or “ machine/algorithm” to mean either a probabilistic polynomial-time algorithm, or a polynomial-time quantum algorithm, respectively. Analogous terminology may be used for the other classes as well151515For instance, a “ machine” refers to a polynomial-time quantum algorithm that also receives a classical witness string..
An important category of complexity classes that we encounter throughout the paper is that of advice classes. Let us provide a definition of this concept:
Definition 1**.**
Let be a complexity class and a family of functions . The complexity class , known as with advice, is the set of all languages , for which there exists an and a function such that for all , iff. .
As an example, consider the class . This consists of all languages that can be decided by a deterministic polynomial-time algorithm, that receives polynomially-many bits of advice for all inputs of the same length. In other words, for all inputs , the algorithm also receives some string , aiding it in deciding whether to accept or not. Analogously consists of languages that can be decided by a polynomial-time verifier receiving a witness for “yes” instances and a trusted advice string that only depends on the size of the input. We also encounter the class in which the size of the advice string is , for some fixed constant .
Some of the advice classes used in the paper are not covered by Definition 1. For instance, the class denotes the set of languages that can be decided by a machine that receives randomised polynomial-size advice. In other words, for all inputs , the probabilistic algorithm also receives some string , that is drawn from a distribution . We can see that this does not satisfy Definition 1 since the advice string is not the result of some deterministic function, but is a sample from a probability distribution. It should therefore be understood that corresponds to polynomial-size advice drawn from a probability distribution that only depends on the size of the input. An important result we use, concerning randomised advice, is the following:
Theorem 5** (Aaronson [58]).**
**
It should be noted that the equalities are only known to hold for classes of decision problems.
We can similarly have quantum advice. As an example, the class denotes the set of languages that can be decided by a machine that receives as advice a quantum state of polynomially-many qubits. In other words, for all inputs , the quantum algorithm also receives a quantum state , such that . Hence, the suffix will indicate polynomially-sized quantum advice and represents a quantum state of polynomially-many qubits that only depends on the size of the input.
The concept of oracles is also used throughout the paper. Briefly, an oracle is a black box function that can be invoked by an algorithm (either classical or quantum) in order to obtain the solution to some problem in one time step. For example, the class of problems which can be solved by a deterministic polynomial-time algorithm with access to some oracle function is denoted . If is an oracle for some -complete problem, then the corresponding class is denoted . Oracles can be used to define the polynomial hierarchy. The zeroth level of the polynomial hierarchy is given by the classes , . The ’th level of the hierarchy is then defined as , . Finally, the polynomial hierarchy is defined as . We say that the polynomial hierarchy collapses at level iff. . While not a decision class, we also mention which is the class of all functions that take as input a description of a polynomial-time algorithm and output the number of inputs that the algorithm accepts (i.e. the number of “yes” instances). An important result in complexity theory is Toda’s theorem [36], which states that .
For quantum classes, oracles are viewed as unitary operations that perform mappings of the form , where is the oracle function. Additionally, whenever a result involving complexity classes remains true when those classes are given access to an oracle, , we say that the result relativises.
2.2.2 Sampling problems and BosonSampling
This section discusses sampling problems. These are problems for which the input specifies a probability distribution and the goal is to sample either exactly or approximately from that distribution. In this paper, we will only be interested in exact sampling and specifically in the BosonSampling problem, defined by Aaronson and Arkhipov [35]. As mentioned in the introduction, in BosonSampling, identical photons (bosons) are sent through a linear optics network and non-adaptive measurements are performed to count the number of photons in each mode. In more detail, for a quantum system with modes and photons, the basis states of the system are of the form , where denotes the number of photons in mode (so ). A general state, is then a state of the form:
[TABLE]
Note that the number of basis states is . The action of the linear optics network can be expressed as a matrix , where is the set of all column-orthonormal matrices. Let be the matrix obtained by taking copies of the ’th row of , for all . If the initial state of the system consists of one photon in each of the first modes (it is assumed that ), a state denoted as , then it can be shown (see [35]) that the probability of observing the state , upon passing the photons through the network described by and measuring the number of photons in each mode, will be:
[TABLE]
where denotes the permanent of a matrix , and is defined as:
[TABLE]
with the symmetric group of all permutations of the elements up to .
Exact BosonSampling is then the problem of sampling from the distribution defined by Equation 7. This problem is believed to be hard for classical computers and to explain why we first need to state a result known as Stockmeyer’s approximate counting method:
Theorem 6** (Stockmeyer [59]).**
Let be a function that can be computed by a deterministic polynomial-time algorithm and let:
[TABLE]
Then for all there exists a algorithm that computes to within a multiplicative factor of 161616In other words, the algorithm computes such that ..
Now, suppose there existed a algorithm that, given (the description of the linear optics network) as input, could sample from the distribution of Equation 7. This algorithm can be viewed as a deterministic polynomial-time computable function that, given and a string , drawn from the uniform distribution, for some polynomial , produces a vector (of the form described above). The fact that this algorithm can sample from the BosonSampling distribution can be expressed mathematically as:
[TABLE]
where denotes the fact that was drawn uniformly at random from the set .
Consider now the state (or any state in which all are either [math] or ). What is the probability of observing in the output modes? Using Equation 7 we see that it is . We will define a function as follows:
[TABLE]
Note that is computable in polynomial time (since it simply involves evaluating and testing whether the output is ). The probability that the algorithm produces the output can then be expressed as:
[TABLE]
But this sum can be estimated, up to multiplicative error, in using Stockmeyer’s method. In other words, there is a algorithm for estimating . It is shown in [35] that one can consider any matrix and embed it in (with only an added polynomial overhead) so that the probability of sampling the state is proportional to . By the above argument, this means that computing a multiplicative estimate for the squared permanent of a matrix over is in . However, computing such an estimate is -hard [35]. It is also known that is contained in the third level of the polynomial hierarchy [60], which leads us to conclude, using Toda’s theorem, that the polynomial hierarchy collapses at the third level. Such a collapse is regarded as unlikely and therefore the existence of an efficient classical algorithm for BosonSampling is also considered unlikely.
2.3 Generalised Encryption Scheme (GES)
The basis of most of the results in our paper is the generalised encryption scheme. We state its definition from [29]:
Definition 2** ([29] Generalised Encryption Scheme (GES)).**
A generalised encryption scheme (GES) is a two party protocol between a classical client , and an unbounded server , characterised by:
- •
A function .
- •
A cleartext input , for which the client wants to compute .
- •
An expected polynomial-time key generation algorithm which works as follows: for any , with probability greater than we have , where . If the algorithm does not return then we have , where .
- •
A polynomial-time deterministic algorithm which works as follows: for any , and we have that , where .
- •
A polynomial-time deterministic decryption algorithm , which works as follows: for any , and we have that , where .
And satisfying the following properties:
There are rounds of communication, such that . Denote the client’s message in round as and the server’s message as . 2. 2.
On cleartext input , runs the key generation algorithm until success to compute a key . This happens before the communication between and is initiated, and the key is used throughout the protocol. 3. 3.
In round of the protocol, computes , where denotes the server’s responses up to and including round , i.e. . We assume that is the empty string. then sends to . 4. 4.
In round of the protocol, responds with , such that . Additionally, the server’s responses are drawn probabilistically from a distribution which is consistent with property . 5. 5.
At the end of the protocol, computes and with probability , we have that .
Let us provide some intuition for this definition. The purpose of a GES is to allow a client to compute some which it cannot compute with its own resources. It does this by interacting with a computationally powerful server for a number of rounds which is polynomial in the size of the input. Importantly, the GES allows the client to hide some information about from the server. We make this statement more precise through the following definition:
Definition 3**.**
Let be a random variable denoting the input to a GES and a random variable denoting the transcript of the protocol for input (in other words is a collection of all the messages exchanged between the client and the server, in a run of the GES, on input ). We say that a GES leaks at most iff. and are independent given .
Finally, we state and give a simplified proof of the main theorem from [29], which we will use throughout the paper:
Theorem 7** ([29] GES leaking size of input).**
If a function admits a GES which leaks at most the size of the input (i.e. ), then .
Proof.
Suppose that admits a GES which leaks at most the size of the input. We start by first considering the simplified case of a GES with only one round of interaction between the client and the server. The protocol works as follows:
The client runs until success to produce an encryption key . 2. 2.
The client computes the encrypted string (where the last entry is the empty string) and sends it to the server. 3. 3.
The server sends a response . 4. 4.
The client decrypts his response obtaining . With probability greater than we have that .
Assuming the existence of the one-round GES, let us construct an algorithm for computing . In other words we are going to construct a probabilistic polynomial-time algorithm that receives a checkable witness and randomised polynomial-sized advice (the distribution from which we sample the advice will be the same for inputs of the same size). The algorithm takes as input and works as follows:
- •
Denoting , the algorithm receives as advice a string as well as , where is the server’s response, in the one-round GES, when being sent from the client. Here is simply some key which can be used to encrypt . The only reason we include as part of the advice is so that we can whether . If this is the case then the algorithm simply decrypts obtaining with high probability. The next steps assume that .
- •
From the assumption that the GES leaks at most the size of the input, there must be some key , such that . If there did not exist such a key and the server received he would know that the input could not be and thus learn more than the size of the input, which is not allowed. More formally, it would mean that the input and the transcript of the protocol are not independent, given the length of the input, since certain transcripts (certain ’s) can only occur for certain inputs. The key, , will be the witness that the algorithm receives. The algorithm can check whether .
- •
The algorithm now simply computes , which by the definition of the GES, will be with probability greater than .
We have therefore given an algorithm for computing . To recap, the part comes from the fact that the algorithm is probabilistic, runs in polynomial time and receives the key as a witness. The advice is because the server’s response is drawn from some probability distribution (which depends only on the length of the input). From Theorem 5, we know that hence . Since the GES frameworks requires that the key must exist irrespective of the value of , this means that in our algorithm both the case and the have a verifiable witness. Therefore it is also the case that and so .
We now need to generalise this to the case where the client and the server interact for a polynomial number of rounds. Because the protocol is leaking at most the size of the input, denoted , any transcript of the protocol will only depend on . Therefore we can make the algorithm’s advice to be a complete transcript of the protocol drawn from the distribution of all possible transcripts for inputs of length . The witness would then be a key that makes the input compatible with this transcript. From the definition of the GES this again guarantees that we obtain the correct outcome with probability .
Note that if the total communication between the client and the server (i.e. the size of the transcript) were bounded by , for some constant , the above argument shows that the functions computable in this setting are contained in 171717Strictly speaking, the above argument shows that such functions would be contained in with randomised advice of size . However, the proof that can be adapted to show that with -size randomised advice is the same as , with . Essentially, we can “derandomise” the advice using deterministic advice of a larger size. The same argument cannot be used, however, to derandomise the part of the algorithm and obtain . This is because the size of the randomness used in is an arbitrary polynomial.. This is because, as we have seen, the transcript is given as advice and so it will also be bounded in length by . ∎
We have seen that the functions that can be delegated in a GES are contained in . A question we might have regarding this result is: what can we say about ? In other words, if a machine uses the GES as an oracle, does that allow it to solve more problems? Intuitively, we would expect the answer to be no and indeed using a result of Brassard [61] which shows that , together with Adleman’s theorem (that ) [62] we prove the following:
Lemma 1**.**
.
Proof.
It is clear that , so only we need to show that . To do this, we first use Adleman’s theorem [62], that , which we know is relativising and have that . Next, it is easy to show that . This is because the advice received by the machine can just as easily be obtained from the oracle. In other words, for any given input and advice for the machine, the machine can simply query the oracle with in order to obtain the same advice 181818The fact that the oracle responds with a single bit (acceptance or rejection) is not a problem, since the machine can query the oracle for each bit of .. It then simulates the machine.
We have therefore reduced our problem to showing that . This can be done by adapting Brassard’s proof [61] that . The essential part of that proof is to show that , while the containment in follows by complementation. The idea is that for any algorithm, , deciding some language, we can devise an algorithm, NA, which also decides that language.
The NA algorithm will simulate until it makes a query to the oracle. At this point NA can non-deterministically guess the response to this query. To do so, note that if some language then it is the case that and , where is the complement of . In other words, there exist non-deterministic algorithms and for deciding and , respectively. Assuming ’s query is for the language , NA will simulate , and for each non-deterministic branch of this simulation it will then also simulate . Since and are complementary, it cannot happen that both the and the parts of the branches are accepting. We will therefore have branches in which both and were rejecting and branches in which either was accepting or was accepting. These latter branches determine the answer to the query for the oracle. The NA algorithm will continue simulating on these branches and reject on all others.
We can see that the above reasoning would also work if the oracle was and the algorithm NA were an algorithm receiving some advice string whose length is polynomial in the size of the input. Our modified NA can continue to simulate the oracle queries if we assume that the advice it receives is the concatenation of advices received by the oracle for all queries. Since the number of queries is polynomial, the concatenation will also be polynomially bounded and hence constitutes a valid advice string for an algorithm. Therefore and through complementation .
Because , our result follows immediately. ∎
We end this section with an explanation of what it means to have a GES for sampling problems. The client’s input, , will be a description of a probability distribution, . Upon interacting with the server and applying the decryption procedure the client obtains such that:
[TABLE]
In other words, the output of is distributed according to . Just as with the GES for decision problems, throughout the interaction, the server should only be able to learn . For the specific case of BosonSampling, with modes and photons, the input will be an column-orthonormal matrix . The associated distribution will be the one described in Section 2.2.2, namely:
[TABLE]
where is a particular configuration of the photons in the modes.
The proof of Theorem 7 applies to the sampling case as it did to the decision case. We therefore have that if the client can delegate exact sampling from to the server, using the GES, there exists an algorithm for exactly sampling from . Importantly, however, the result of Theorem 5 no longer applies and we cannot equate this algorithm with a sampling algorithm. That result applies to decision classes. In fact, in the sampling case, it will be simpler to consider the sampling algorithm as a algorithm (since ). In other words, the existence of a GES for sampling from implies the existence of a probabilistic polynomial-time algorithm, with an oracle, and which receives randomised polynomial-sized advice, for sampling from .
3 Oracle separation between BQP and MA/O(nd)
In order to prove Theorem 1 we will construct an oracle using a version of the complement of Simon’s problem [11]. Recall that Simon’s problem is the following: given a function (for some ) which is promised to be either -to- or have Simon’s property ( is -to- and there exists some , , such that for , iff ), decide which is the case. In particular, for Simon’s problem, the deciding algorithm should accept if the function has Simon’s property and reject if it is a -to- function. The complement of this problem simply flips these two conditions. If one is not given an explicit description of but restricts access to this function through an oracle then Simon’s problem can be used to separate from . To be precise, the oracle is some function such that for , if we consider restricted to the domain , denoted , is either a -to- function or a function satisfying Simon’s property. A language which is then contained in but not in is as shown in [11]. In fact, as we’ve mentioned before, the complement of this language191919Note that Simon’s problem is a promise problem, so when speaking about the complement of we are in fact referring to . can be used to separate and [34]. Lemma 2, which we prove below, is essentially a proof of this fact for a slightly different version of the oracle.
Before proving Lemma 2, let us first address a technical point. As we remarked in the introduction, an unconstrained GES for would imply . Therefore, we would ideally like to construct an oracle to separate and . The intuition in constructing this hypothetical oracle would be following: instead of considering a function for each input length , we consider a function , for each input string . In other words, for a fixed input length, , there will be functions which need to be decided. But the machine receives only a polynomial amount of advice, which is the same for all of these functions. Therefore this advice should be insufficient to help the machine in deciding all of these inputs. Formalising this intuition for any polynomial is problematic, as will become clear later (see the last paragraph of the proof of Lemma 4). For this reason, we will fix the degree of the polynomial and prove that . To do this, let us first prove the separation between and , for our specific oracle.
Lemma 2**.**
There exists an oracle , based on the complement of Simon’s problem, such that .
Proof.
The separation of and with respect to an oracle has been shown a number of times before, [10, 63, 64], including with the complement of Simon’s problem. However, we prove this lemma for our particular version of Simon’s problem where instead of assigning a function to each input length, we assign different functions to different inputs.
We proceed by defining an oracle and a language which we refer to as the complement of Simon’s problem or , such that and . We start with the latter as it also clarifies what the oracle should do:
[TABLE]
Strictly speaking, the problem we are defining is a promise problem, so the set defined above is the set of instances to the problem, whereas the set of instances is not the complement but the set:
[TABLE]
Here, by “Simon function” we mean a function having Simon’s property.
It is clear from this definition that the oracle is the one providing the functions for which we want test whether they are -to- or have Simon’s property. Of course, the whole point is to restrict access to the descriptions of those functions and force the algorithm solving the problem to perform queries to the oracle. It is also clear that for any such , will be contained in since we can just run Simon’s algorithm on the given input and flip acceptance and rejection. As is standard in quantum query complexity, we assume that the behaviour of the quantum oracle is to perform the unitary operation .
The oracle can be viewed as some function taking as input the tuple and outputting , where is a function which is either bijective or has Simon’s property. Essentially , which is given in unary, specifies the domain size of our functions, is an index for a particular function and is the value on which we evaluate . These last two elements of the tuple are specified in binary and the oracle should be defined for all and all . We will denote the set of functions used by the oracle for domain size as , in other words:
[TABLE]
Next, we construct a so-called adversarial oracle . This just means defining the family of sets , in such a way that every non-deterministic Turing machine using the oracle fails to decide correctly . The proof will use a diagonalisation argument.
Since the set of non-deterministic Turing machines is countable we consider the ’th machine, , and check its behaviour when , for some which we define later on. Suppose we take some index , and tentatively make the ’th function in a -to- function. By simulating the behaviour of on this input we can check to see whether it accepts or rejects. If it rejects, then we are done, since will incorrectly decide this input. Conversely, if accepts, then by definition there exists a polynomial-sized path, in the non-deterministic computation tree of the machine, which leads to acceptance. We denote this path as , and denote the length of as . can make at most queries to on this path which we can represent as a list of tuples: , where are the queried variables. An example of such a path is shown in Figure 2.
We now simply consider a Simon function that matched on the queried values, i.e. . How do we know such a function exists? The number of possible bit masks such that is (since is excluded). By having match on the queried values it must be that produces different outputs for each of these values. Therefore for any , it must be that . This means that there are values of which are restricted. But and since can take on possible values, if is sufficiently large so that , then we can simply choose an which is not restricted. We therefore pick to be large enough so that and then take to be some mask from the available . We thus have a Simon function which produces the same responses to the queries on path as the -to- function . If we now just take to be , then will still be an accepting path and therefore will decide incorrectly on the input .
Through this construction, all non-deterministic Turing machines will have some input on which they decide incorrectly, thus concluding the proof. ∎
Lemma 3**.**
There exists an oracle , based on the complement of Simon’s problem, such that .
Proof.
The arguments from Lemma 2 can be used to show that even if the deciding machine receives a polynomial amount of randomness, it still cannot correctly input (with high probability). This corresponds to showing that the complement of Simon’s problem also lies outside of , relative to the oracle.
The idea for this case will be to pick the oracle at random and then reduce the problem to the case without randomness. Suppose the oracle is a -to- function or a Simon function with equal probability (in either case, the specific function that is picked is chosen uniformly at random). An algorithm is essentially a probability distribution over algorithms. If the complement of Simon’s problem, with respect to the random oracle, is in , then there must be an machine that decides the problem correctly with probability at least , over the random choice of the oracle.
We have therefore reduced the task of showing that the problem is not in to that of showing that it is not in . Consider a non-deterministic Turing machine that accepts a particular input (of the form described in Equation 15) of length . If the machine accepts this input that means that there exists an accepting non-deterministic path, making queries, where . Assuming the function is a Simon function, from the proof of Lemma 2, it’s clear that the probability of finding a collision after queries , (and thus distinguishing the function from a -to- function), assuming one has not been found after queries, is:
[TABLE]
But since , this probability is exponentially small in . Since, for any given input, there is an equal chance of it being a -to- function or a Simon function, it follows that the probability that the algorithm accepts correctly is at most , which will be smaller than , for sufficiently large . ∎
Next, we prove:
Lemma 4**.**
For each , there exists an oracle , such that .
Proof.
To begin with, the class is the class of problems solved by a deterministic polynomial-time Turing machine , which receives an advice of length , when the input is of size (in our case the input size is since we defined as being the length of inputs to the -to- and Simon functions).
In contrast to the previous case, instead of having the ability to non-deterministically choose one of exponentially many paths, a polynomial-time Turing machine receives some non-uniform information to help it in deciding . Each advice determines a new behaviour for which can even involve a different sequence of queries to the oracle. What we want to show is that irrespective of what advice might receive, it still cannot always correctly decide . To do this, we consider functions over a larger domain than just -bit strings. In other words, for each we choose such that the set contains functions of the form . The oracle, which we now denote as , still receives queries of the form , where , but now .
First we need to argue that the problem can still be decided in . This is indeed the case, since expanding the domains of the functions simply changes the running time of the quantum algorithm from to . But since is just a fixed constant, the algorithm still runs in polynomial time, hence .
The harder part is showing . As before, we will prove this by diagonalisation by considering the set of all (deterministic) Turing machines and showing that no matter which advice the ’th machine receives it cannot correctly decide . Care must be taken, as each advice induces a different behaviour and one must consider the oracle so that all possible advice strings lead to failure. This is in contrast with the previous case where we were only interested in the behaviour of one accepting path of the non-deterministic computation tree.
Suppose we take the ’th deterministic polynomial-time Turing machine, , and examine what happens for an input of length , where will be chosen later (as before). Since the advice is a binary string of length there are possible advice strings. Whichever one uses it will be the same for all inputs of length .
Let us now consider the first index of length , namely and assign a -to- function to this index. We can inspect the behaviour of for and for each possible advice string. If for more than half of the advice strings rejects, then we keep at index . This means that half of all advice strings have been eliminated (there is at least one input on which those strings lead to deciding incorrectly). If, however more than half of all advice strings make accept , we will attempt to turn into a Simon function while keeping acceptance for those advice strings. This will again lead to the elimination of (at least) half of all advice strings.
For each advice , where , will make a sequence of polynomially many queries to . Denote that sequence of queries together with the responses as:
[TABLE]
where . We now consider a Simon function such that for all in which with advice and queries accepts and for all , we have that . In other words will give identical responses to the queries which make accept. Since ranges from to and ranges from to , the maximum number of variables which are queried is of order . But unlike in the previous lemma, this number is exponential in the size of the input, so how can we be sure that such a Simon function even exists? The trick is that we can choose the domain size through and make it large enough to accommodate for a Simon function with this property.
As before, because is bijective, no two queried variables will produce the same answer. Therefore, there cannot be a bit mask () relating any pair of the queries. These will be the restricted values of . The total number of such values is also of order , however the total number of possible values is . Thus, if we simply choose such that then we can find a Simon function which matches the responses of on the queries.
Hence, for this case if we use as the function for index we will eliminate half of the possible advice strings. Thus, no matter how behaves we are able to eliminate half of all possible advice strings with our first input of length . Clearly this process can be repeated for the next index and so on until the last index. We are effectively halving the number of potentially useful advice strings with each index. Since we are doing this times, to eliminate all possible advice strings we just need to ensure that or . To achieve this, simply choose (recall that ) large enough so that the inequality holds.
We therefore have that for all , and for all possible advice strings, there will always be an input to which is decided incorrectly, hence .
Note that the same proof would not work for . A crucial element in our proof was the fact that we can make (which determines the size of the domain of each function) to be much larger than (which determines the length of the advice). But this is only possible because is fixed from the very beginning. If the advice length could be any arbitrary polynomial then no matter what constant value of we decided upon for our oracle, there would always be some and hence some polynomial length of the advice string for which the proof does not work. A possible “fix” would be to make part of the input in some form, so that it too can increase. So if, say, was included in the input as a unary string, where is some monotonically increasing function, then for sufficiently large , . But we immediately notice the problem with this approach. While it is true that in this case the problem cannot be decided in it would also no longer be decidable in either. This is because the query complexity of the quantum algorithm becomes which is no longer polynomial unless is the constant function. Hence, proving separation from seems to require some non-trivial modification of this proof or a totally different technique. ∎
Finally, we can prove Theorem 1 by combining the previous results.
Proof of Theorem 1.
Let us first show that, relative to an oracle, the complement of Simon’s problem is not contained in . The oracle will be defined in the exact same way as for the case. The same reasoning as before applies here. Take the ’th non-deterministic Turing machine and examine its behaviour for some input , where and is chosen as before. For each index, we tentatively pick a -to- function and examine what the machine does for each advice of length . If more than half of the advice strings lead to rejection then we keep the bijective function and proceed to the next index. Otherwise we replace it with a Simon function. In this case, for each advice in which the machine accepts, there will be some polynomial-sized path leading to acceptance. We will pick one accepting path for each advice on which the machine accepts and ensure that the Simon function produces the same responses to the queries on those paths. This reduces the problem to the previous case. We know that for sufficiently large such a function exists and therefore each index will render half of the possible advice strings useless. By also choosing large enough we can make sure that all advice strings are eliminated and thus that the problem is incorrectly decided by all non-deterministic Turing machines irrespective of the advice (of length ).
For the case, one can use the same proof as in Lemma 3 to reduce to the case. It follows that . ∎
4 GES for exact BosonSampling and circuits for the permanent
To prove Theorem 2, we first need to show a number of results concerning permanents of matrices. The purpose of these results is to eventually show that having an oracle for estimating the squared permanent of a matrix taking values in , yields a polynomial-time algorithm, with random access to bits of advice, for exactly computing the permanent. This result together with the assumption that a GES allows the client to sample exactly from the BosonSampling distribution and a result of Björklund, from [37], will allow us to prove Theorem 2.
Let us first introduce some helpful notation: for a matrix, , we will denote as the matrix obtained by deleting row and column from .
Lemma 5**.**
Let . There exists a matrix such that:
- •
**
- •
**
- •
**
Proof.
Let be the following matrix:
[TABLE]
We can see that . It is also not difficult to see that , through a Laplace expansion. We now perform a Laplace expansion along the last row of , to compute its permanent:
[TABLE]
But and hence . ∎
Lemma 6**.**
Let , , , such that and defined as follows:
[TABLE]
Then, it is the case that:
[TABLE]
Proof.
We will prove this by induction over . For the case we have:
[TABLE]
By doing a Laplace expansion along the first row of , we get:
[TABLE]
Now note that:
[TABLE]
So and , therefore:
[TABLE]
We now assume the relation is true for and prove it for . To do this, we will first Laplace expand the permanent of along the first row:
[TABLE]
The reason for separating the terms this way, is because , with , is of the same form as and we can therefore apply the induction hypothesis. Doing so yields:
[TABLE]
Where is obtained from by deleting rows and and columns and . Taking common factors we get:
[TABLE]
But notice that:
[TABLE]
since it is a Laplace expansion along the first row of . This leads to:
[TABLE]
The matrix is of the same form as :
[TABLE]
We can see this by taking:
[TABLE]
Together with the induction hypothesis this gives us:
[TABLE]
Now note that and , hence:
[TABLE]
But the term in parenthesis is so:
[TABLE]
By substituting this into Equation 27, we get:
[TABLE]
After grouping terms:
[TABLE]
But:
[TABLE]
Thus:
[TABLE]
This concludes the proof. ∎
Using the above lemmas, we can now show the following:
Theorem 8**.**
Let be an oracle that, given a matrix , outputs a number such that:
[TABLE]
where . Then, for any there exists a polynomial time algorithm for computing , which has random access to bits of advice and making queries to .
Proof.
The theorem shows that having an oracle for computing a multiplicative approximation for the squared permanent of a matrix, implies the existence of a polynomial time algorithm, with bits of advice, that can compute the permanent exactly.
The proof of this theorem is inspired from a similar result of Aaronson and Arkhipov (see Theorem 4.3 from [35]). In that case, the oracle was outputting a multiplicative approximation of the squared permanent of an arbitrary real matrix. In our case, however, the matrices are restricted to entries from , which means that we cannot directly use that result.
We prove the theorem by induction. For the case of the algorithm simply outputs . Suppose now that we have an algorithm for computing the permanents of matrices with entries from . We will use this algorithm to compute the permanent of . Firstly, if , then and we are done. Additionally, we are going to use the oracle to check if any of the minors of are non-zero. If all of them are zero, then again and we are done. So let’s assume that and 202020The permanent is invariant under permutations of rows and columns. Thus, if has a non-zero minor, we can simply permute the columns of , so that is that minor..
We know from Lemma 6, that if we take a matrix , , such that and then construct:
[TABLE]
we have that:
[TABLE]
If and , then:
[TABLE]
From Lemma 5, we know that for any matrix , there exists an matrix , such that , and . If one used such a in the construction of , then it is immediate that and that . The algorithm will search for such a , construct the corresponding and use the oracle to test if . If the permanent of is zero, then one can compute the permanent of using Equation 37.
But how do we search for and, furthermore, how do we compute ? This is where we make use of advice. Note that since , we have that:
[TABLE]
hence, there are at most possible values for the permanents of matrices. Similarly, there are at most possible values for the permanents of the minors of matrices.
The advice, to our algorithm, will consist of tuples , comprising of a matrix together with the permanent of its top left minor and the ratio between that matrix’s permanent and the permanent of its top left minor, with , for some constant . Here , with the bottom right entry being [math] and . The matrices in the tuples are such that all possible values for the fraction are covered. From the above discussion, it’s clear that there will be at most such tuples. Furthermore, the tuples are sorted in ascending order with respect to those fractions.
For a given matrix , our algorithm should search through this advice in order to find a matrix such that , where is constructed from and as in Lemma 6. When such a matrix is found, we have that:
[TABLE]
But is given in the advice tuple and is computed recursively by our algorithm, hence we have computed the permanent of .
To find the matrix we will perform a binary search over the advice. Suppose that ranges from to . Additionally, let , so that:
[TABLE]
This means that computing gives us a multiplicative approximation for . Because the values are sorted in ascending order, this means that the function:
[TABLE]
is monotonically increasing as a function of and furthermore that there is a unique value such that . In our case, however, we have a multiplicative approximation for , which we denote as . This function will be monotonically decreasing between and and increasing between and . We look for using binary search as follows: compute and for the middle two points, and of the interval . If either of them is [math], then we are done. Otherwise, if , then search the interval , otherwise the interval . Repeat this recursively until the minimum is found.
Given that the advice is of length , the algorithm will query it (and consequently as well) at most times. Additionally, the construction of each takes time and since this is done at most times, the complexity of this step is . Finally, the algorithm performs recursive calls to itself (in order to compute ) and if we add up the running times of each step we find that the total runtime will be . ∎
Theorem 9**.**
If a algorithm can sample exactly from the BosonSampling distribution then for any matrix , there exist circuits of size , making polynomially-sized queries to an oracle, for computing .
Proof.
The starting point for our proof is a result by Björklund [37]. He showed that, for , the permanent of an matrix, , can be expressed as a linear combination of permanents of matrices. It should be noted that these matrices are not necessarily minors of the original matrix. Nevertheless, each matrix can be computed efficiently given the input matrix, .
Our task will be to compute all of these permanents and then perform the linear combination so as to arrive at the permanent of . We will use the result of Theorem 8 together with the fact that there exists a algorithm for exact BosonSampling, to show that the permanent of a matrix can be computed in polynomial time, using random access to bits of advice and polynomially-sized queries to an oracle. Crucially, the -sized advice will be the same for all matrices. This means that all permanents can be computed in time with access to bits of advice. The explicit value of , as a function of , will be chosen later.
Consider a matrix, , and a value , to be chosen later. We embed , a scaled version of , as a submatrix of a BosonSampling matrix . In other words, , with (see [35] for more details). We then have that the probability of detecting one photon in each output mode, a state which we denote as , is:
[TABLE]
Since , to ensure that , it suffices to set .
If a machine can simulate the output distribution of a BosonSampling instance, , that means that:
[TABLE]
where is a algorithm and is the advice string, of size polynomial in , drawn from the distribution . Note that only depends on . If we can estimate up to multiplicative error in polynomial time (potentially with the help of an oracle and bits of advice) then we will effectively be simulating the oracle from Theorem 8.
To do this, first note that if , the smallest possible value of is . We will therefore consider our advice string to consist of samples from , along with their associated probabilities212121The fact that the advice has size will ensure that, if is non-zero, then a such that is overwhelmingly likely to be sampled when we generate the advice.. Denote the set of these samples as . This allows us to define:
[TABLE]
as a multiplicative estimate for . But is a algorithm, which means that we can view it as a polynomial-time function, which receives as input (apart from and ) a random string , for some polynomial . The function will output either , corresponding to the cases where outputs , or [math], corresponding to the cases where produces some other output. We therefore have that:
[TABLE]
and this leads to our estimate of being:
[TABLE]
Computing exactly would require summing exponentially many terms. However notice that is a sum of exponentially many positive numbers, each of which can be evaluated in polynomial time (given access to the advice). For this reason, we can use Stockmeyer’s approximate counting method to compute a multiplicative estimate of [59]. This will, of course, also yield a multiplicative estimate for itself.
We have thus given an algorithm for computing a multiplicative estimate of a matrix that works in time polynomial in , performs queries to an oracle and has random access to bits of advice. This algorithm can now be viewed as an implementation of the oracle from Theorem 8. Using that theorem, leads to a polynomial-time algorithm, with access to an oracle and -size advice, for computing exactly. However, since the advice is the same for all matrices, by repeating this procedure for all matrices and combining the results we obtain an algorithm for computing that runs in time , uses bits of advice and makes polynomially-sized queries to an oracle.
The last step is to convert this algorithm into a circuit. Since the algorithm has a running time of , by choosing , for some suitable constant , we will have circuits of size at most . These circuits, must also operate on the bits of advice. Note that . To reproduce the random access to these bits, we will assume that the gates have unbounded fan-in. The advice bits are therefore hardcoded into the circuit and “fed” into each part of the algorithm that makes use of them. Since only polynomially-many bits of the advice are used at any given point, this can only increase the size of our circuit by a polynomial factor. This concludes the proof. ∎
With the above result, the proof of Theorem 2 is immediate:
Proof of Theorem 2.
Recall from the end of Section 2.3 that the existence of a GES for sampling from a distribution, , implies the existence of a probabilistic polynomial-time algorithm, with an oracle, and which receives randomised polynomial-sized advice, for sampling from . In other words, having a GES for BosonSampling means having a algorithm that can sample from the exact BosonSampling distribution. We now notice that the result of Theorem 9 relativises. In particular, this means that if a algorithm can sample from the exact BosonSampling distribution, then for any matrix , there exist circuits of size , making polynomially-sized queries to an oracle, for computing . ∎
5 Quantum GES
5.1 An upper bound for QGES functions
This section is, in a certain sense, dedicated to ‘quantising’ the Abadi et al. result. First of all, we need to define the quantum generalised encryption scheme. Since we’re defining this in analogy to UBQC and other blind quantum computing protocols, our QGES considers a single quantum message from the client to the server, rather than allowing the entire interaction between client and server to be quantum. More formally, we have the following:
Definition 4** (Quantum Generalised Encryption Scheme (QGES)).**
A quantum generalised encryption scheme (QGES) is a two party protocol between a quantum polynomial-time client , and an unbounded server , characterised by:
- •
A function .
- •
A cleartext input , for which the client wants to compute .
- •
An expected polynomial-time key generation algorithm which works as follows: for any , with probability greater than we have , where . If the algorithm does not return then we have , where .
- •
A quantum polynomial-time algorithm , that takes as input classical bit strings and produces as output a quantum state, which works as follows: for any , we have that , where and .
- •
A polynomial-time deterministic algorithm which works as follows: for any , and we have that , where .
- •
A polynomial-time deterministic decryption algorithm , which works as follows: for any , and we have that , where .
And satisfying the following properties:
There are rounds of communication, such that . Denote the client’s message in round as and the server’s message as . 2. 2.
On cleartext input , runs the key generation algorithm until success to compute a key . This happens before the communication between and is initiated, and the key is used throughout the protocol. then runs to obtain a quantum encryption of the input, and sends it to 222222It should be noted that it makes no difference for our definition if the client sends the whole state to the server or part of it. The state received by the server will be mixed and the only important property we require is that the client has a purification of this state.. 3. 3.
In round of the protocol, computes , where denotes the server’s responses up to and including round , i.e. . We assume that is the empty string. then sends to . 4. 4.
In round of the protocol, responds with , such that . 5. 5.
At the end of the protocol, computes and with probability , it must be that .
As mentioned in the introduction, we add an additional requirement to our QGES known as offline-ness. What this means is that the client can send a quantum state to the server, representing an encryption of the input, and decide afterwards which input it intends to use. Essentially the client is free to change its mind about the input and not commit to a particular input when the protocol commences. More formally, we define the offline condition as follows:
Definition 5** (Offline QGES).**
In a QGES, let:
[TABLE]
be the state of the client’s system on input in a superposition over possible keys and encryptions. Here, is the set of encryption keys which are compatible with (i.e. could have resulted from the key generation algorithm acting on , ) and is the quantum encryption of using the key . The subscripts and indicate the key register and the encrypted input register, respectively.
For , let be two different inputs for such that . We say that the QGES is offline if there exists a polynomial-sized quantum circuit, , acting only on the key register, , such that .
The definition essentially says that there exists an efficient procedure that the client can apply on her local system in order to map from one input of size , to a different input of the same size. One might ask whether this property is not immediately satisfied by a QGES leaking only the size of the input. Indeed, leaking only the size of the input is equivalent to saying that the density matrix corresponding to the quantum encryption, which the server receives, is the same for all inputs of the same size. In other words, it is the case that:
[TABLE]
for any . Since the density matrix is the same, that means that there exists a unitary (acting on the client’s system) which can map one purification of this state, corresponding to one input, to another, corresponding to a different input. This unitary must be verifiable in the sense that the client can check (using a quantum SWAP test) whether the unitary maps to the correct purification. However, this unitary need not have a polynomial-sized quantum circuit representation. The offline condition simply imposes that such a circuit always exists. As we’ve mentioned before, UBQC and all other existing delegated blind quantum computation protocols satisfy this property.
We are now ready to prove Theorem 3, showing that functions that can be delegated by the client to the server in an offline QGES are contained in :
Proof of Theorem 3.
For an input for which the client wants to compute , consider the state:
[TABLE]
where the notation is the same as in Definition 5. If we trace out the key register, , the resulting density matrix is the mixed state of possible encrypted states which the server will receive:
[TABLE]
The assumption that the protocol only leaks the size of the input to the server implies that for any two inputs , it is the case that . In fact, something stronger is true. The server’s ‘view’ of the protocol should be the same in both cases. By this we mean that the server’s system as well as the distribution of his classical messages must be independent of , given the size of . Therefore, we should consider a state comprising of his system and his response after receiving the quantum encryption, for a particular input, :
[TABLE]
Here, is the unitary performed by the server in order to produce his response, which will be stored in the response register, initially set to , where . This unitary will of course involve the encrypted state provided by the client and the server’s private ancilla, denoted as (but will not involve the key register). Note that the server’s response is a classical bit string. Hence, the state in the response register, obtained through the application of the unitary , will be a probabilistic mixture over computational basis states. This, however, makes no difference in our proof and we can just as well assume that his response is a general quantum state.
If we again trace out the register we obtain some state . This state encodes the distribution of possible messages exchanged by the client and the server in one round of interaction, as well as the server’s private system. Since , it is also the case that . By the purification principle, this means that if we consider the states:
[TABLE]
[TABLE]
there exists a local unitary, , acting only on the key register which can map to , for any two inputs and . In fact, let us examine the states of the system for inputs and before is applied:
[TABLE]
[TABLE]
These states are also related by . This can be inferred from the following relations. First, we know that:
[TABLE]
And also that:
[TABLE]
Therefore:
[TABLE]
But and commute because they act on different systems and therefore and will cancel out, leaving:
[TABLE]
This is also illustrated in the following diagram:
\textstyle{\ket{\chi_{x_{1}}}\ignorespaces\ignorespaces\ignorespaces\ignorespaces\ignorespaces\ignorespaces\ignorespaces\ignorespaces}$$\scriptstyle{V_{K}\otimes I_{ERS}}$$\scriptstyle{I_{K}\otimes U_{ERS}}$$\textstyle{\ket{\chi_{x_{2}}}}$$\textstyle{\ket{\phi_{x_{1}}}\ignorespaces\ignorespaces\ignorespaces\ignorespaces}$$\scriptstyle{V_{K}\otimes I_{ERS}}$$\textstyle{\ket{\phi_{x_{2}}}\ignorespaces\ignorespaces\ignorespaces\ignorespaces}$$\scriptstyle{I_{K}\otimes U^{\dagger}_{ERS}}
Since the protocol is offline, we know that must be a polynomial-sized quantum circuit. Note that even if we trace out the server’s ancilla from the states and , the resulting states are still related by on the key register. This allows us to define a algorithm computing any function which admits a QGES. To do so we first introduce some notation. We will consider the following states:
[TABLE]
[TABLE]
which are simply superpositions over the valid keys for two different inputs and . Next we consider:
[TABLE]
[TABLE]
which include the encrypted states and the server’s response. Lastly, we trace out the server’s ancilla from both these states resulting in:
[TABLE]
[TABLE]
From the above argument the two states and and the two states and are related through the same polynomial-sized quantum circuit acting only on the key register.
We can now present the algorithm. Let us first consider the one round case. The algorithm would work as follows:
The input to the algorithm is some string for which we want to compute . 2. 2.
The algorithm receives as advice the string which is simply some string of the same length as . Additionally, it receives the state . It is clear that both of these only depend on and have a length which is polynomial in hence constituting a valid advice. 3. 3.
From the definition of the key generating function, the algorithm can efficiently produce the states and . 4. 4.
The classical witness is a description of the quantum circuit . 5. 5.
The algorithm tests that maps to . This can be done through a quantum SWAP test. 6. 6.
Use to map to . 7. 7.
By measuring the response register of , the algorithm obtains the response that the server would have produced in an interaction with the client in the QGES protocol. Applying the decryption algorithm to this response will yield the correct result with high probability.
The probability of success of the algorithm can be boosted by providing polynomially many copies of as advice and performing multiple SWAP tests. Additionally this algorithm can be made to compute the complement of as well which would gives us a containment.
Let us now consider the case of polynomially many rounds of interaction, of which the first round involves quantum interaction. We’ve shown that for that first round, we can design a polynomial-time quantum algorithm, receiving quantum advice and a classical witness, to emulate the client in the QGES. For the rounds after the quantum interaction, we essentially have a classical GES. Our algorithm would then operate as in the proof of Theorem 7. In other words, apart from the quantum advice and the witness providing the circuit , the algorithm will also receive classical (randomised) advice corresponding to a transcript of the classical interaction in the protocol, and a key to decrypt this transcript. It follows that will be contained in . ∎
A question we might ask is: why can’t we adapt this proof to the case of full quantum communication between the client and the server? For this case, we would need a stronger version of the offline-ness condition that imposes the existence of a polynomial-size quantum circuit for mapping the entire transcript of the protocol, corresponding to some input to that of some input (where ). Another question is whether the class of interest should in fact be since a client could use the QGES as an oracle. Just as we showed that we can show that:
Lemma 7**.**
**
Proof.
This proof is similar to the one showing that . Just like in that case, the inclusion is immediate and we need only show that . The containment in follows by complementation.
Consider a quantum algorithm QA for deciding problems in . We will show that this algorithm can be simulated by a algorithm, denoted NQA. Since , and have bounded error in deciding problems, we can assume, from standard amplification techniques, that this error is of order , where is the size of the input. We will also assume that for all quantum algorithms measurements are postponed until the end of the circuit.
We will treat the case without advice first, and then explain how to deal with the quantum advice at the end. To start with, NQA will simulate QA until it makes a query to the oracle. In the standard definition of oracles the oracle is just a classical function that solves a decision problem. However, when dealing with quantum algorithms such as QA it is also possible to speak of quantum oracles, where the oracle can be viewed as some unitary operation (technically a sequence of unitary operations for each possible input length, see [65] for more details) which QA can query even in superposition. Our result will cover this more general case of quantum oracles. We would therefore like the NQA algorithm to be able to simulate this quantum oracle.
Firstly, just like in the classical case we have that if some language then and , where is the complement of . This means that there exist polynomial-sized quantum circuits and which take some input along with classical witnesses and , respectively, and decide correctly, when the output is measured, with probability at least, . In other words, receives as input and receives as input , respectively, where . If we were to run both and on , because and are complementary, the output qubits, when measured, will also be complementary with high probability.
Assume that and are circuits which act on qubits. We define a new quantum circuit called which operates on qubits. applies to the first qubits and to the next qubits. It then applies a Pauli to the output qubit of and a CCNOT operation from the output qubits of and onto the the ’th qubit. It then applies again to the output qubit of and then and on the first qubits. An illustration of this circuit (acting on the input) is given in Figure LABEL:fig:simquery.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Ronald L Rivest, Len Adleman, and Michael L. Dertouzos. On data banks and privacy homomorphisms. 1978. Foundations of secure computation , 4(11):169–180.
- 2[2] Ivan Damgård, Jens Groth, and Gorm Salomonsen. The Theory and Implementation of an Electronic Voting System , pages 77–99. Springer US, Boston, MA, 2003.
- 3[3] Thore Graepel, Kristin Lauter, and Michael Naehrig. ML Confidential: Machine Learning on Encrypted Data. In Proceedings of the 15th International Conference on Information Security and Cryptology , ICISC’12, pages 1–21, Berlin, Heidelberg, 2013. Springer-Verlag.
- 4[4] Joël Alwen, Manuel Barbosa, Pooya Farshim, Rosario Gennaro, S. Dov Gordon, Stefano Tessaro, and David A. Wilson. On the Relationship between Functional Encryption, Obfuscation, and Fully Homomorphic Encryption , pages 65–84. Springer Berlin Heidelberg, Berlin, Heidelberg, 2013.
- 5[5] Sanjam Garg, Craig Gentry, Shai Halevi, Mariana Raykova, Amit Sahai, and Brent Waters. Candidate indistinguishability obfuscation and functional encryption for all circuits. In Proceedings of the 2013 IEEE 54th Annual Symposium on Foundations of Computer Science , FOCS ’13, pages 40–49, Washington, DC, USA, 2013. IEEE Computer Society.
- 6[6] Arjan Jeckmans, Andreas Peter, and Pieter Hartel. Efficient Privacy-Enhanced Familiarity-Based Recommender System , pages 400–417. Springer Berlin Heidelberg, Berlin, Heidelberg, 2013.
- 7[7] Kristin E. Lauter. Practical applications of homomorphic encryption. In Proceedings of the 2012 ACM Workshop on Cloud Computing Security Workshop , CCSW ’12, pages 57–58, New York, NY, USA, 2012. ACM.
- 8[8] Craig Gentry. Fully homomorphic encryption using ideal lattices. In Proceedings of the Forty-first Annual ACM Symposium on Theory of Computing , STOC ’09, pages 169–178, New York, NY, USA, 2009. ACM.