An Experimental Comparison of Uncertainty Sets for Robust Shortest Path Problems
Trivikram Dokka, Marc Goerigk

TL;DR
This paper compares various uncertainty set assumptions for robust shortest path problems using real-world traffic data, evaluating their reasonableness and guiding future algorithmic development.
Contribution
It empirically tests different uncertainty set models on real traffic data, linking theoretical assumptions to practical applicability.
Findings
Certain uncertainty models better fit real traffic data.
Some models lead to more conservative but reliable solutions.
The study guides future research towards more realistic uncertainty modeling.
Abstract
Through the development of efficient algorithms, data structures and preprocessing techniques, real-world shortest path problems in street networks are now very fast to solve. But in reality, the exact travel times along each arc in the network may not be known. This lead to the development of robust shortest path problems, where all possible arc travel times are contained in a so-called uncertainty set of possible outcomes. Research in robust shortest path problems typically assumes this set to be given, and provides complexity results as well as algorithms depending on its shape. However, what can actually be observed in real-world problems are only discrete raw data points. The shape of the uncertainty is already a modelling assumption. In this paper we test several of the most widely used assumptions on the uncertainty set using real-world traffic measurements provided by the City…
Click any figure to enlarge with its caption.
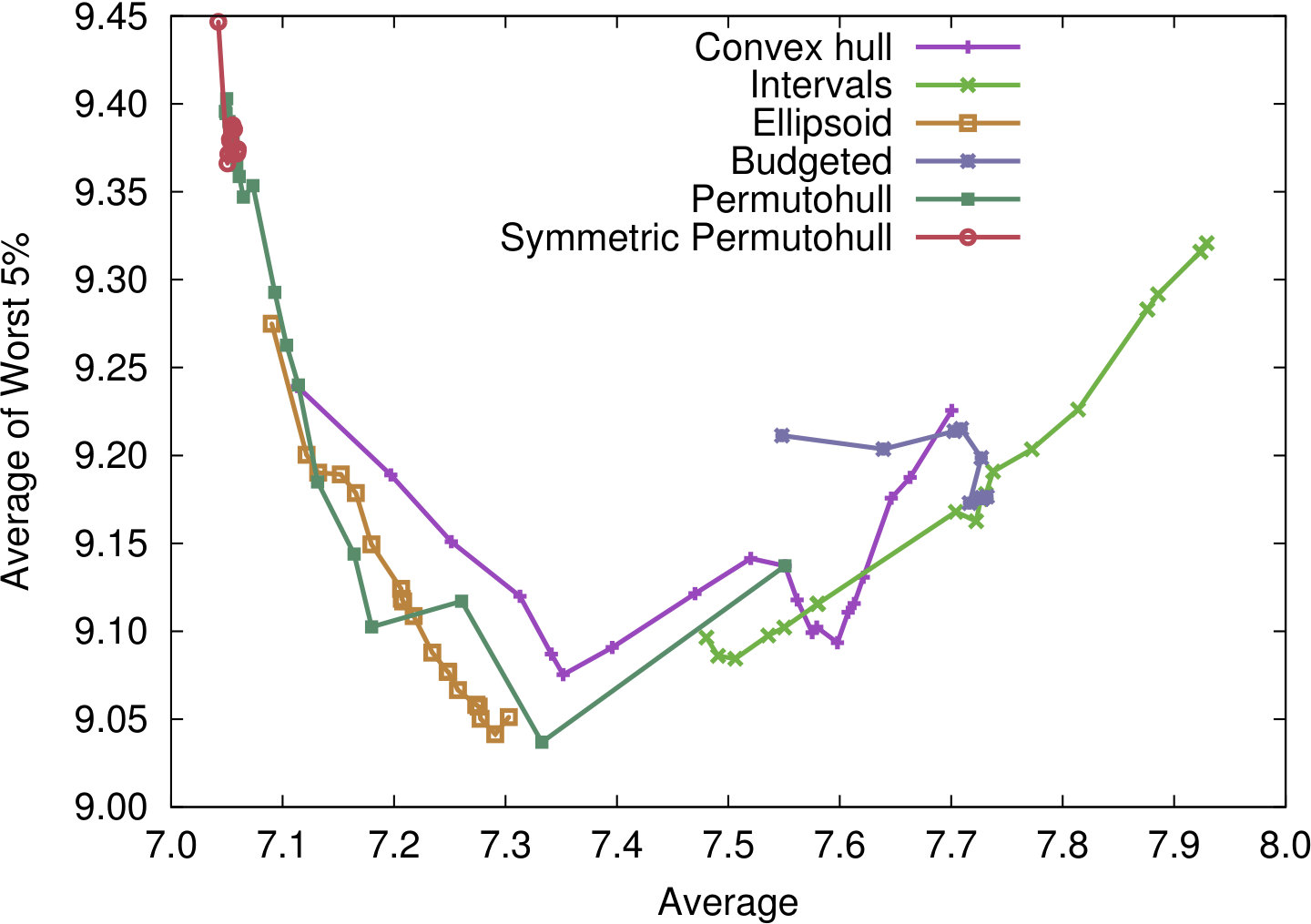 Figure 1
Figure 1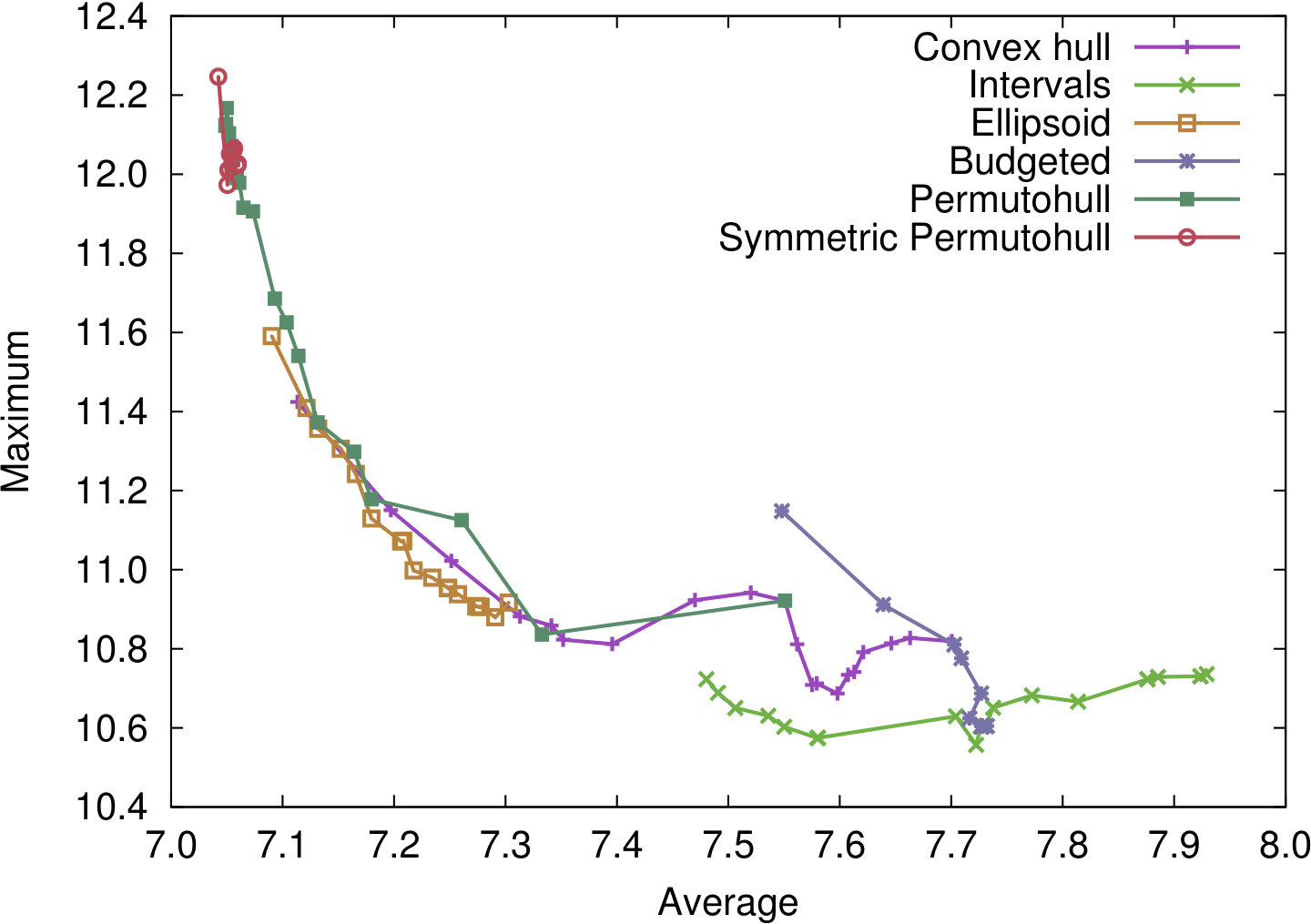 Figure 2
Figure 2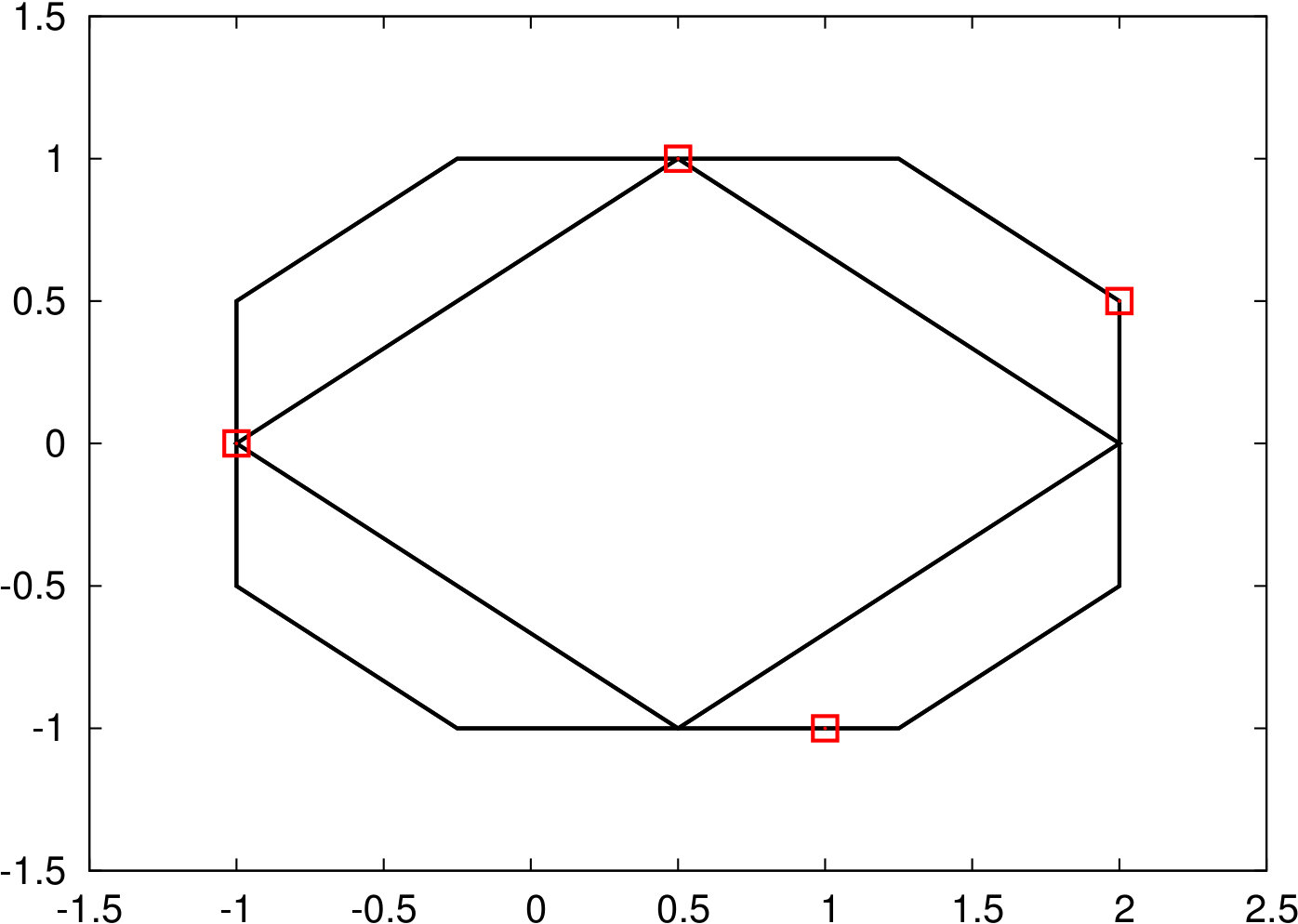 Figure 3
Figure 3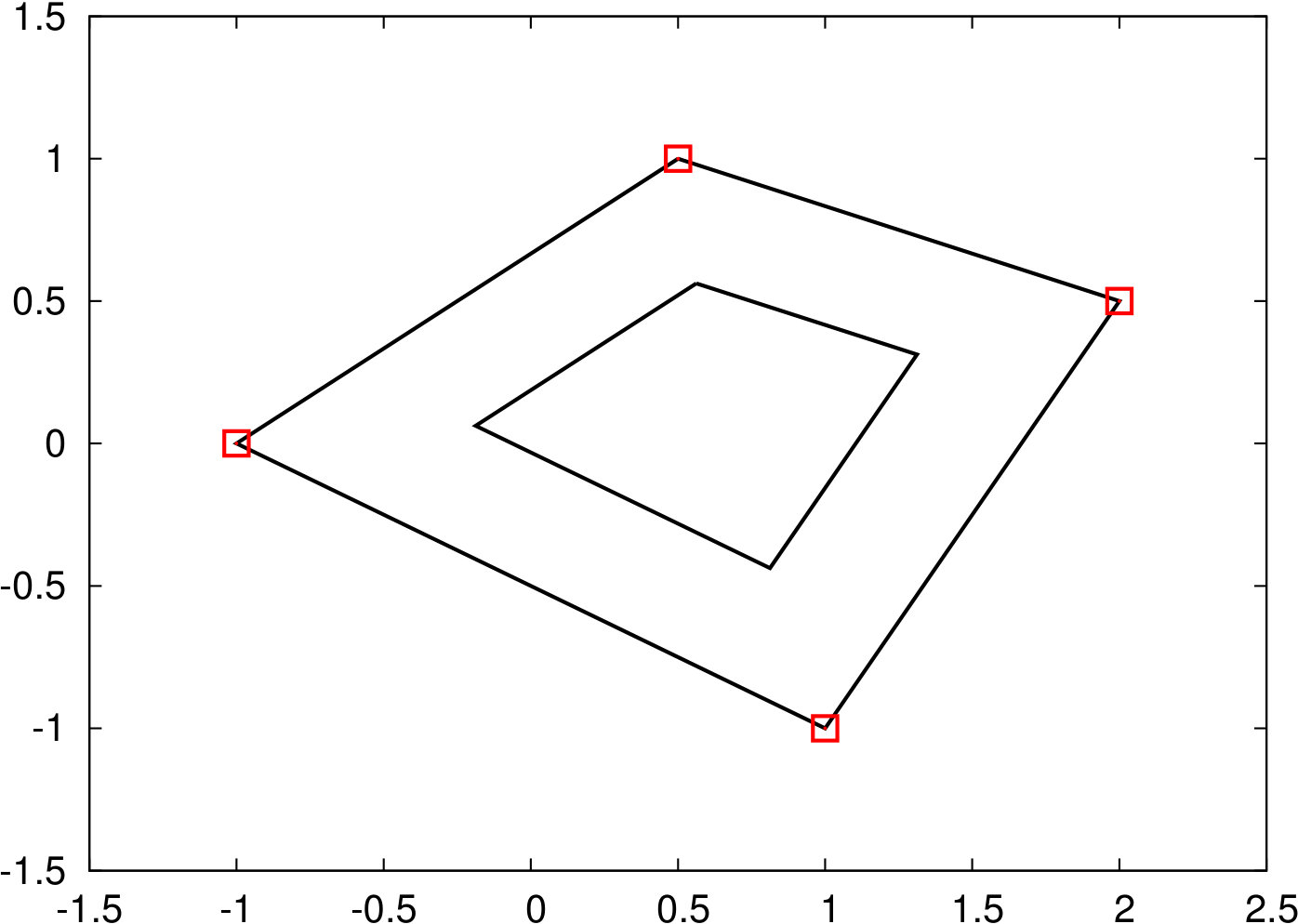 Figure 4
Figure 4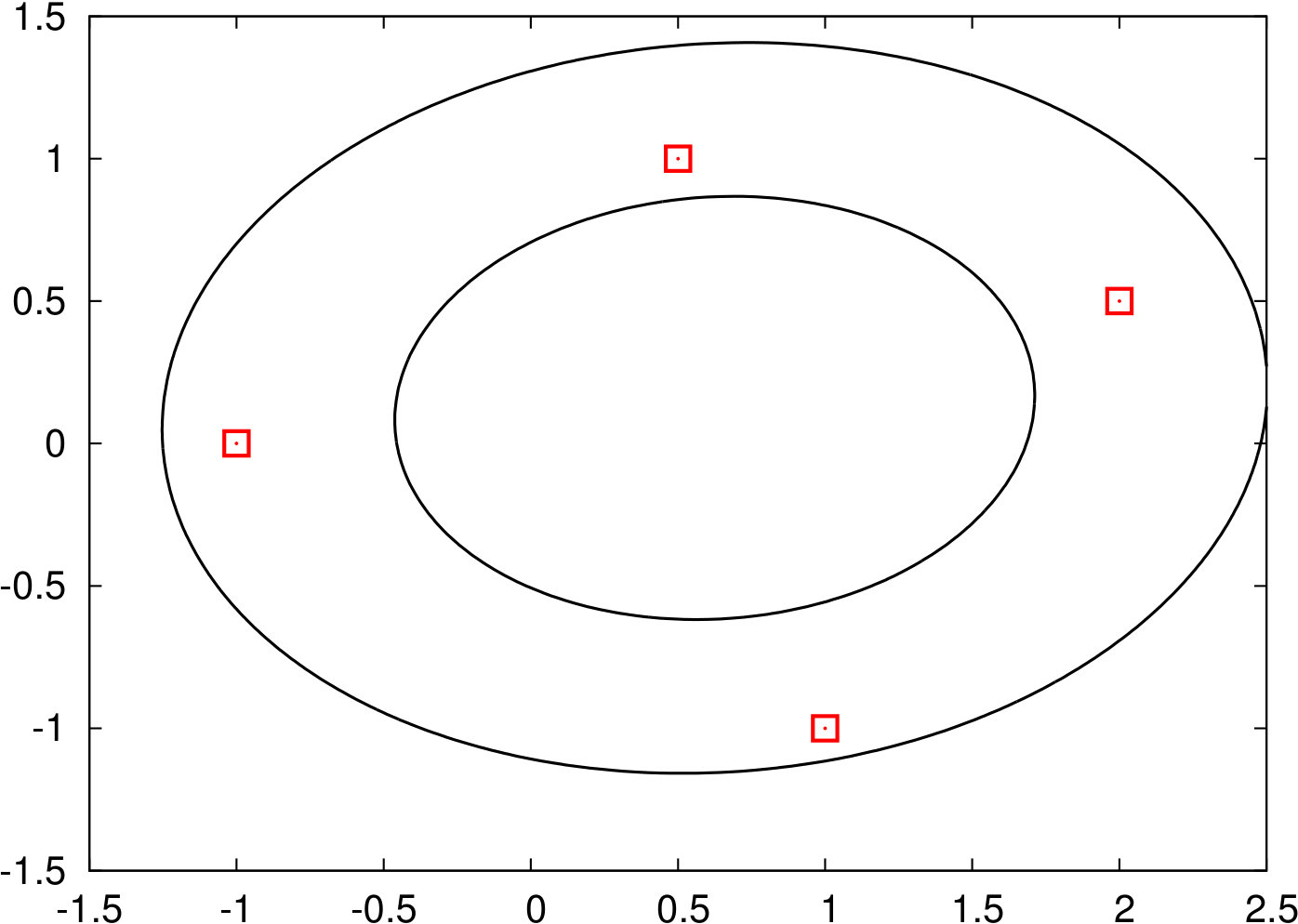 Figure 5
Figure 5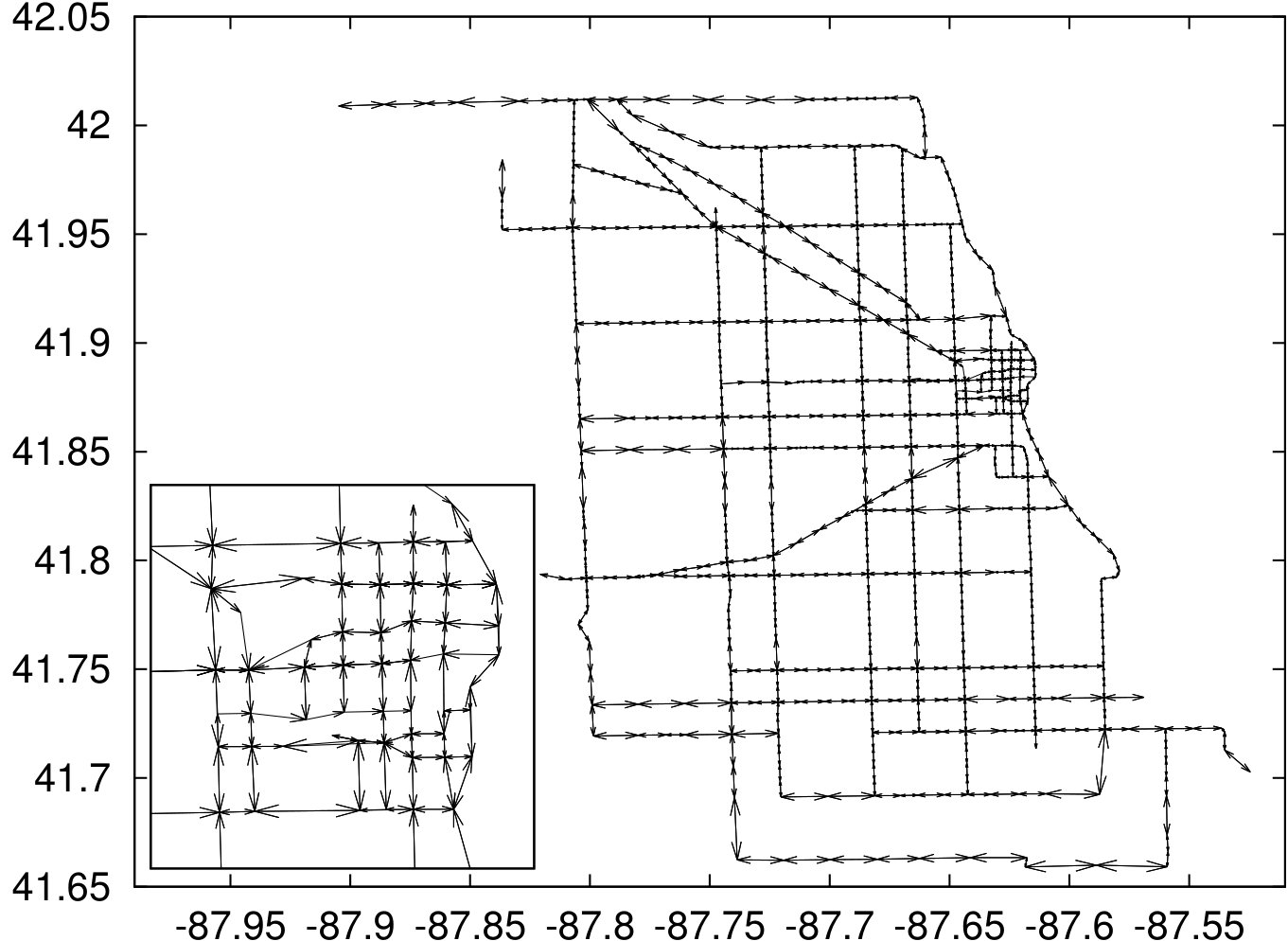 Figure 6
Figure 6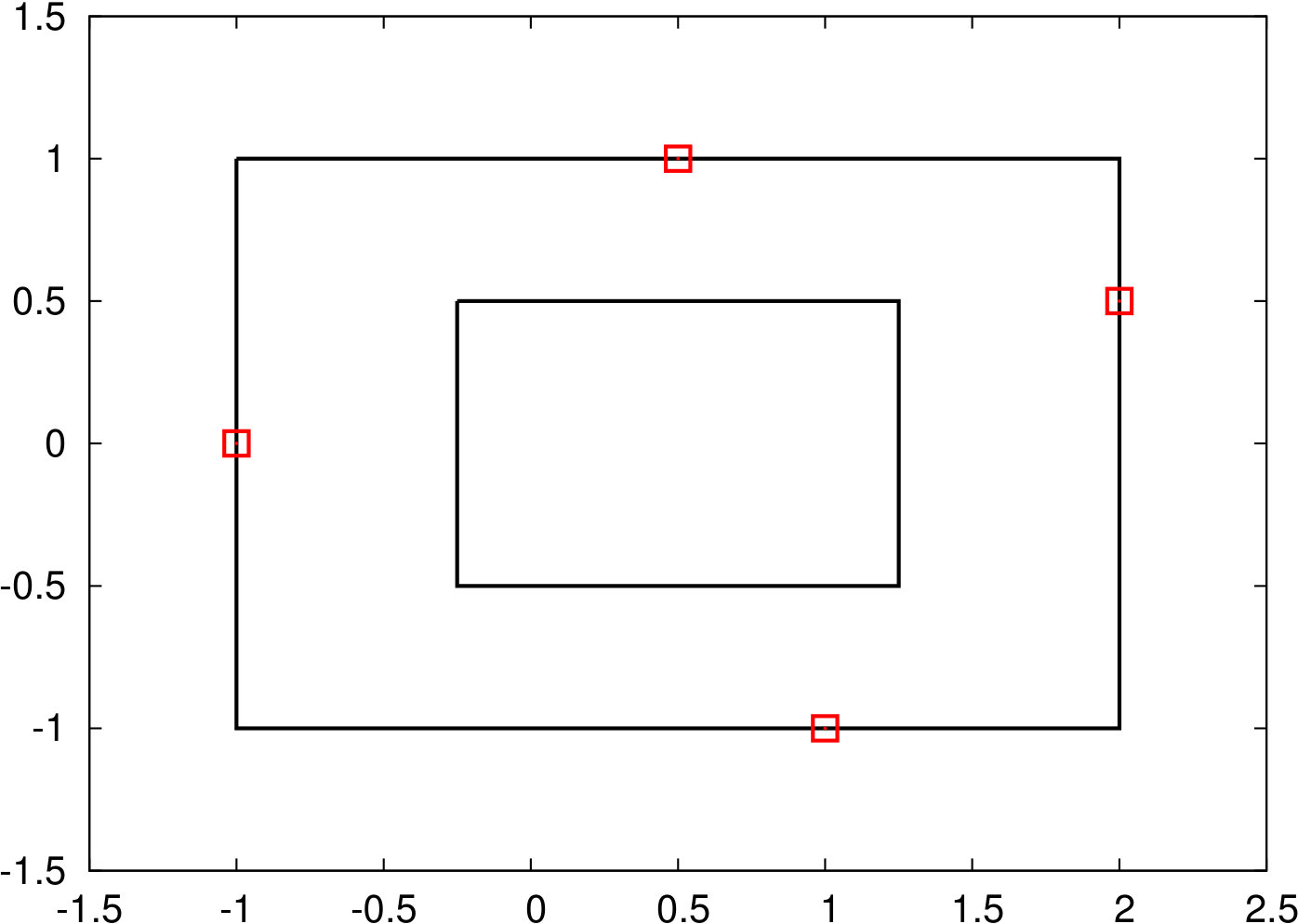 Figure 7
Figure 7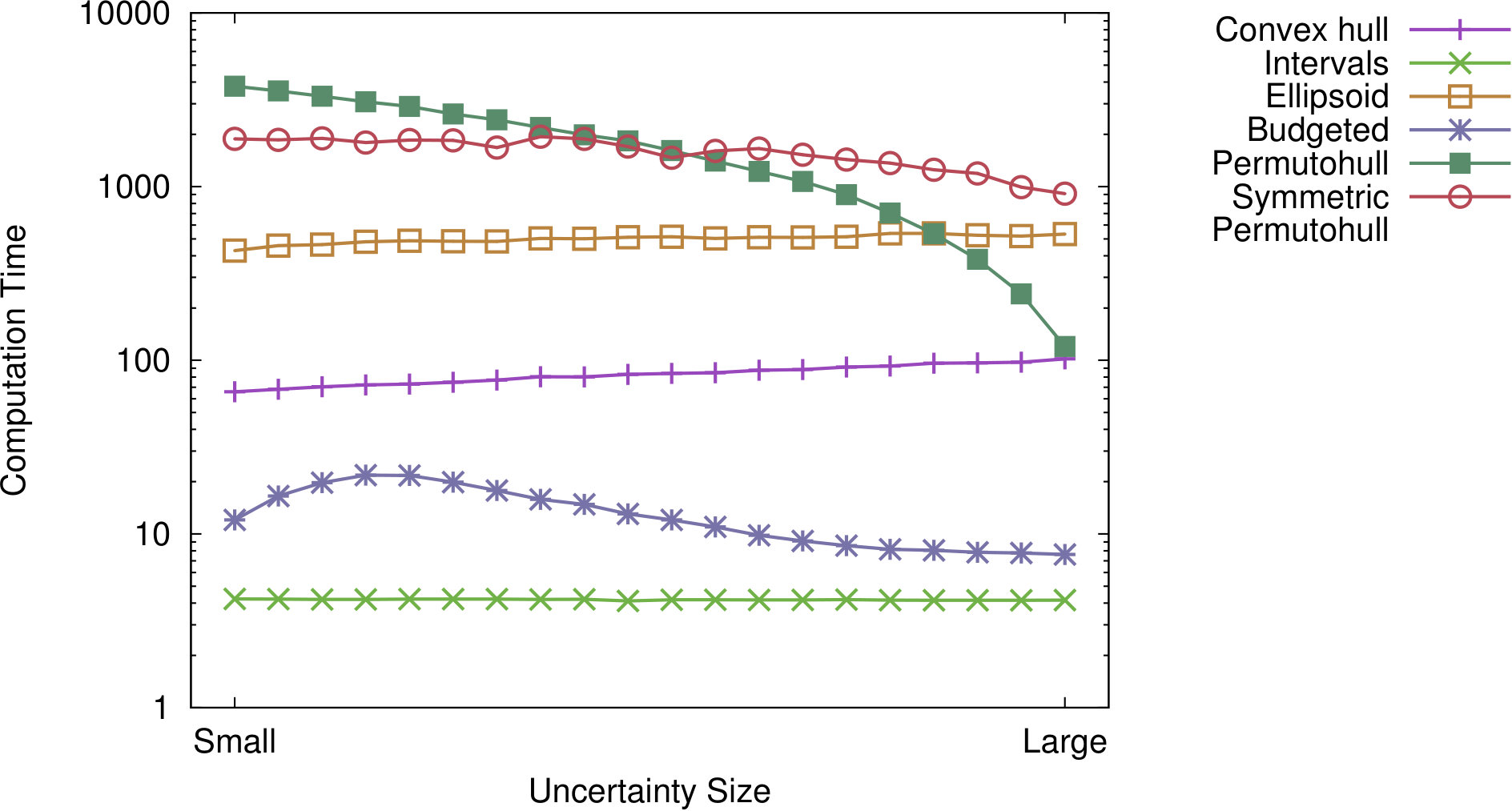 Figure 8
Figure 8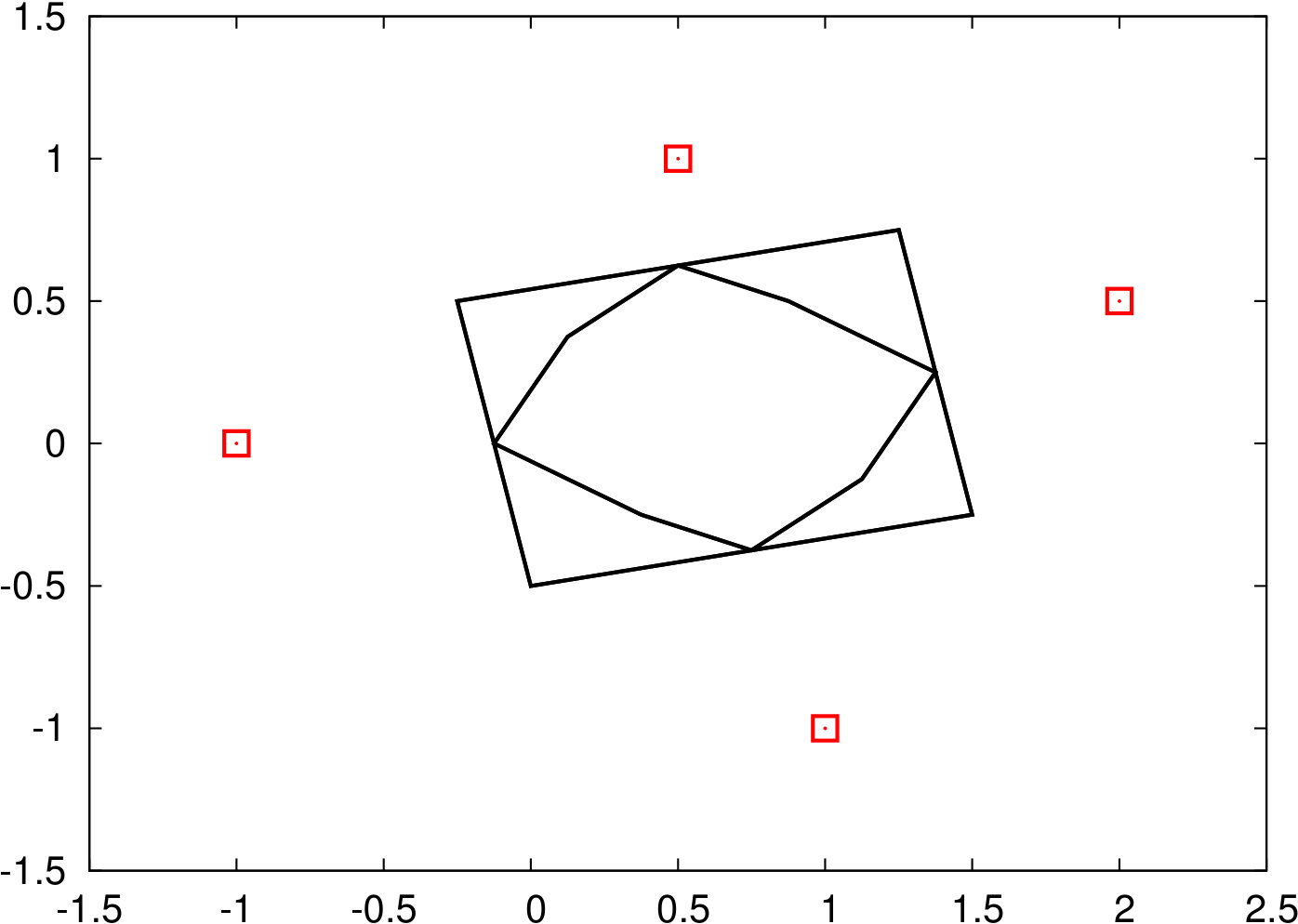 Figure 9
Figure 9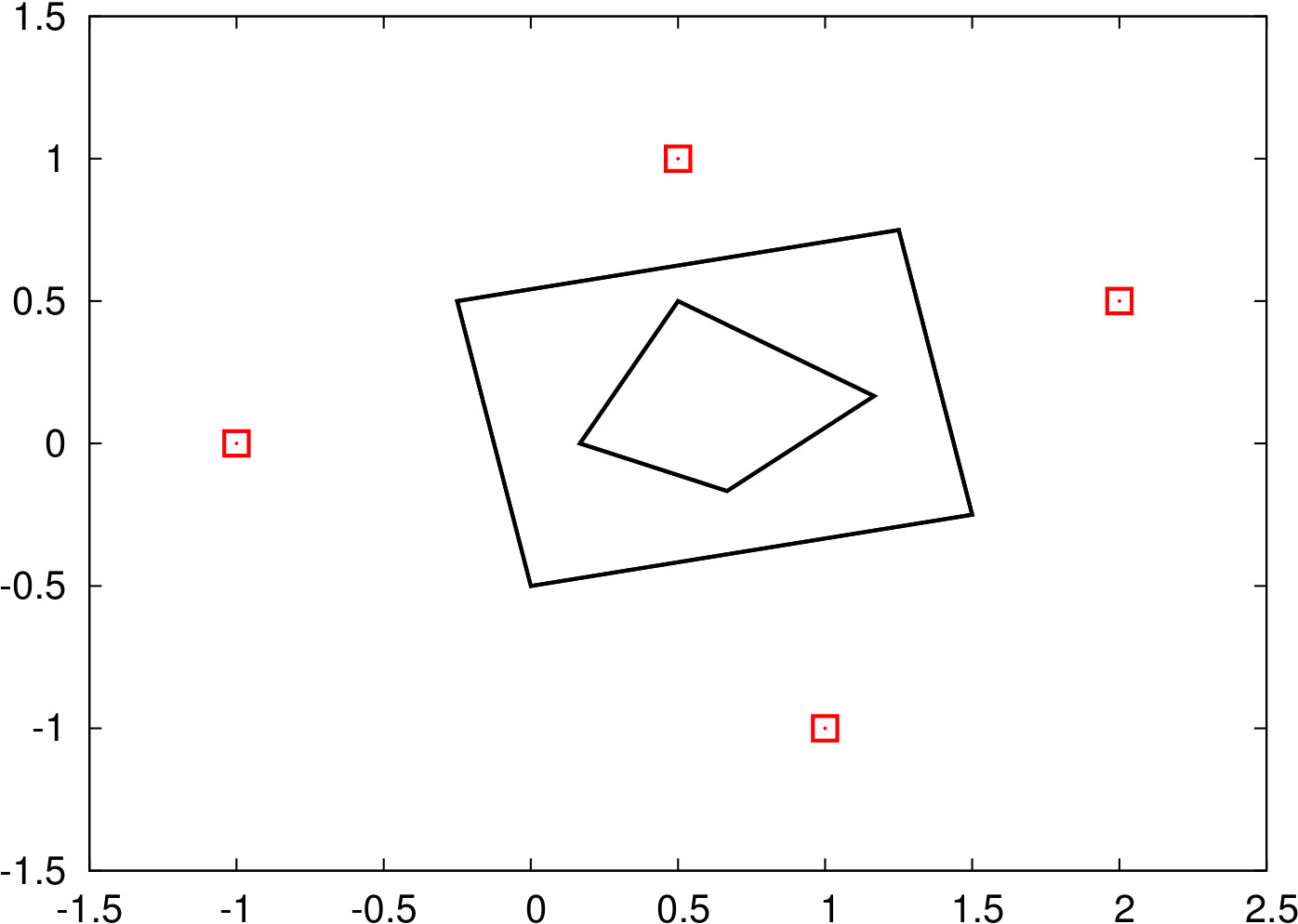 Figure 10
Figure 10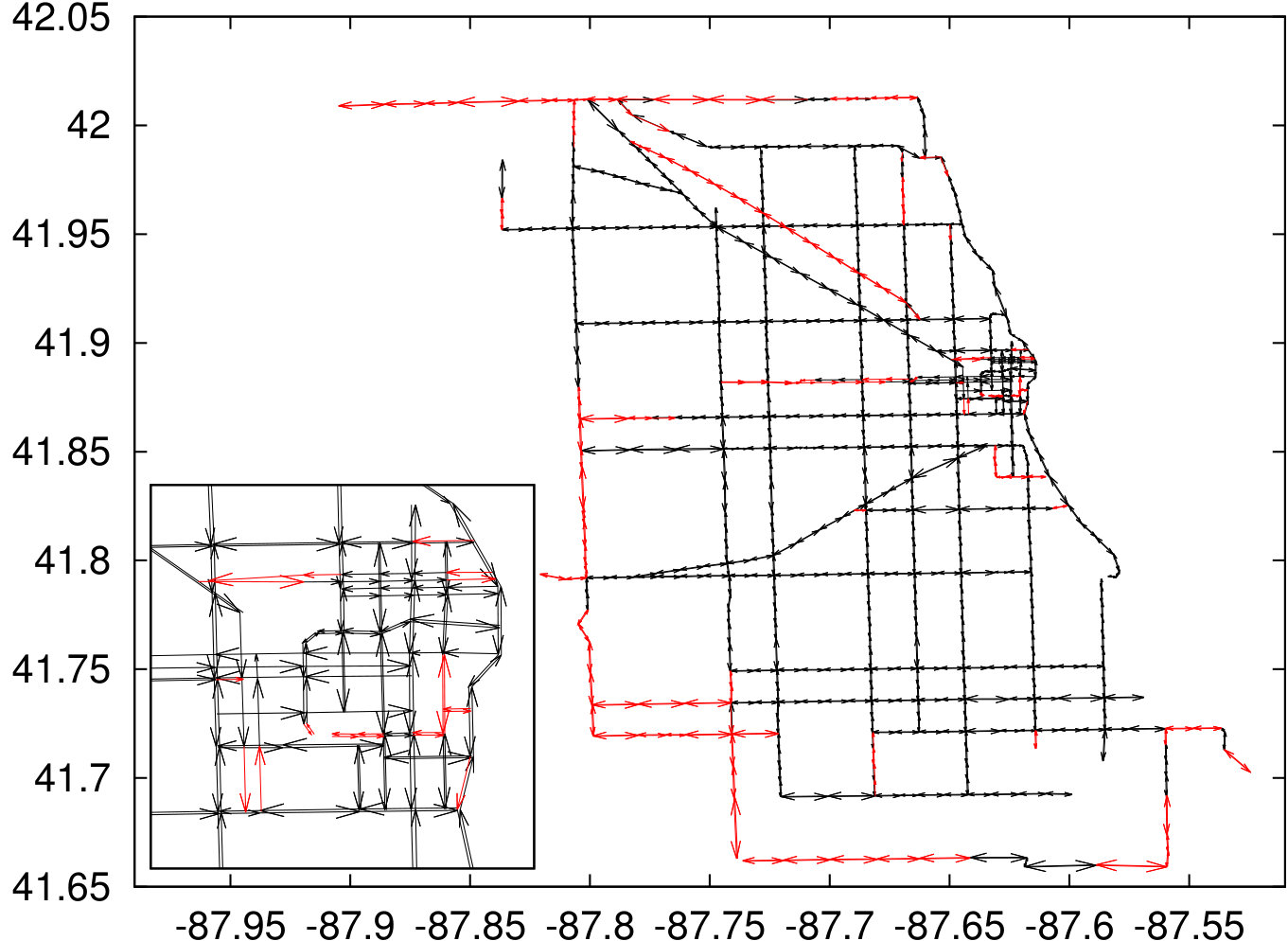 Figure 11
Figure 11| Complexity | NPH | P | NPH | P | NPH | NPH |
|---|---|---|---|---|---|---|
| Model | IP | LP | ISOCP | MIP | MIP | MIP |
| Add. Const. | 0 | 1 | ||||
| Add. Var. | 1 | 0 | 1 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
An Experimental Comparison of Uncertainty Sets for Robust Shortest Path Problems
Trivikram Dokka
Department of Management Science, Lancaster University, Lancaster, United Kingdom
Marc Goerigk
Department of Management Science, Lancaster University, Lancaster, United Kingdom
Abstract
Through the development of efficient algorithms, data structures and preprocessing techniques, real-world shortest path problems in street networks are now very fast to solve. But in reality, the exact travel times along each arc in the network may not be known. This lead to the development of robust shortest path problems, where all possible arc travel times are contained in a so-called uncertainty set of possible outcomes.
Research in robust shortest path problems typically assumes this set to be given, and provides complexity results as well as algorithms depending on its shape. However, what can actually be observed in real-world problems are only discrete raw data points. The shape of the uncertainty is already a modelling assumption. In this paper we test several of the most widely used assumptions on the uncertainty set using real-world traffic measurements provided by the City of Chicago. We calculate the resulting different robust solutions, and evaluate which uncertainty approach is actually reasonable for our data. This anchors theoretical research in a real-world application and allows us to point out which robust models should be the future focus of algorithmic development.
**Keywords: ** robust shortest paths, uncertainty sets, real-world data, experimental study
1 Introduction
The problem of finding shortest paths in real-world networks has seen considerable algorithmic improvements over the last decade [BDG*+*16]. In the typical problem setup, one assumes that all data is given exactly. But also robust shortest path problems have been considered, where travel times are assumed to be given by a set of possible scenarios. In [YY98], it was shown that the problem of finding a path that minimizes the worst-case length over two scenarios is already weakly NP-hard. For general surveys on results in robust discrete optimization, we refer to [ABV09, KZ16].
There are many possibilities how to model the scenario set that is used for the robust optimization process (see, e.g., [MG04, Büs12]), and it is not obvious which is ”the right” one. Part of the current research ignores the problem by simply assuming that the uncertainty was ”given” in some specific form, while this does not happen in reality.
In fact, the starting point for all uncertainty sets is raw data, given as a set of observations of travel times. This data is then processed to fit different assumptions on the shape and size of the uncertainty set, and preferences of the decision maker. So far, the discussion of these uncertainty sets has been led by theoretical properties, such as the computational tractability of the resulting robust model. We believe that this leads to a gap in the literature, where models are not sufficiently underpinned by actual real-world data to verify results. The purpose of this paper is to close this gap. We use real-world traffic observations by the City of Chicago to create a selection of the best-known and most-used uncertainty sets from the research literature. Using these uncertainty sets, we calculate different robust solutions and compare their performance. This allows us to determine which uncertainty sets are actually valuable for real-world robust shortest path problems. Our results give strong impulses for future research in the field by pointing out which problems are most worthy to solve more efficiently.
In Section 2 we briefly introduce all six uncertainty sets used in this study, and discuss the complexity of the resulting robust problems. The experimental setup and results are then presented in Section 3, before concluding this paper in Section 4.
2 Uncertainty Sets for the Shortest Path Problem
Let a directed graph with nodes and arcs be given. In the classic shortest path problem, each arc has some specific travel time . Given a start node and a target node , the aim is to find a path minimizing the total travel time, i.e., to solve
[TABLE]
where denotes the set of --paths, and . For our setting we assume instead that a set of travel time observations is given, with . This is the available raw data. In the well-known robust shortest path problem we assume that an uncertainty set is produced based on this raw data, and solve the robustified problem
[TABLE]
that is, we search for a path that minimizes the worst-case costs over all scenarios. In the following sections we detail different possibilities from the current literature to generate based on . Each set is equipped with a scaling parameter to control its size.
2.1 Convex Hull
In this approach, also known as discrete uncertainty (see [YY98, KZ16]), we set . The resulting robust problem can then be written as
[TABLE]
Note that this problem is equivalent to using . The problem is known to be NP-hard already for two scenarios.
Scaling: Let be the average of , i.e., . For a given , we substitute each point with , and take the convex hull of the scaled data points.
2.2 Intervals
We set as the smallest hypercube containing all data, i.e., . For ease of notation, we write and . The resulting robust problem is then
[TABLE]
which is a classic shortest path problem. Robust shortest path problems with interval uncertainty are therefore easy to solve, but frequently used, especially in the so-called min-max regret setting (see [CG15b]).
Scaling: We use for some .
2.3 Ellipsoid
Ellipsoidal uncertainty sets were first proposed in [BTN98, BTN99] and stem from the observation that the iso-density locus of a multivariate normal distribution is an ellipse. We use an ellipsoid of the form with size parameter that is centered on . We create it using a normal distribution found as a maximum-likelihood fit. Recall that the best fit of a multivariate normal distribution with respect to data points is given by
[TABLE]
and
[TABLE]
The resulting problem can then be formulated as
[TABLE]
which is an integer second-order cone program (ISOCP), see [BTN98] for details. Due to the convexity of the constraints, the problem can still be solved with little computational effort by standard solvers.
2.4 Budgeted Uncertainty
This approach was introduced in [BS03], and is based on interval uncertainty . To reduce the conservatism of this approach one assumes that only at most many values can be simultaneously higher than the midpoint . Formally,
[TABLE]
Using the dual of the inner worst-case problem, the following compact mixed-integer program can be found:
[TABLE]
This approach has the advantage that probability bounds can be found that compare favorably with those for ellipsoidal uncertainty [BS04], while this problem also remains polynomially solvable by enumerating possible values for the variable. This means that many problems of the original type need to be solved. For these reasons, the budgeted uncertainty approach has been very popular in the literature.
2.5 Permutohull
The final two uncertainty sets we consider were proposed in [BB09]. The original inspiration comes from risk measures; the authors show that any so-called distortion risk measure leads to a polyhedral uncertainty set. A risk measure is a distortion risk measure if and only if there exists , where denotes the -dimensional simplex such that
[TABLE]
where the sorting is chosen such that .
The conditional value at risk with is a well-known distortion risk measure. Intuitively, it is the expected value amongst the worst outcomes. Using the matrix
[TABLE]
the th column of induces the risk measure . The corresponding polyhedra are called the -permutohull and defined as
[TABLE]
To find the resulting robust problem, we first consider the worst-case problem for fixed .
[TABLE]
Dualising this problem then gives the robust counterpart
[TABLE]
which is a mixed-integer program (note that this approach is actually the same as the ordered weighted averaging method, see [CG15a]). The problem is NP-hard, as it contains the convex hull of as a special case. Through the choice of , there are possible sizes of this uncertainty.
2.6 Symmetric Permutohull
In the same setting as before, the symmetric permutohull was also introduced in [BB09]. By using the columns of the matrix
[TABLE]
it was shown that the resulting polyhedra are symmetric with respect to . Note that these problems are also NP-hard, as contains the min-max approach for as a special case.
2.7 Summary of Uncertainty Sets
In total we described six methods to generate uncertainty set based on the raw data . Figure 1 illustrates these sets using a raw dataset with four observations (shown as red points). The complexity to solve the resulting robust models, as well as the type of program with the numbers of additional variables and constraints compared to the classic shortest path problem are shown in Table 1.
While the robust model with budgeted uncertainty sets can be solved in polynomial time using combinatorial algorithms, we still used the MIP formulation for our experiments, as it was sufficiently fast.
3 Real-World Experiments
3.1 Data Collection and Cleaning
We used data provided by the City of Chicago111https://data.cityofchicago.org, which provides a live traffic data interface. We recorded traffic updates in a 15-minute interval over a time horizon of 24 hours spanning Monday March 27th 2017 morning to Tuesday March 28th 2017 morning. A total of 98 data observations were thus used.
Every observation contains the traffic speed for a subset of a total of 1,257 segments. For each segment the geographical position is available, see the resulting plot in Figure 2(a) with a zoom-in for the city center. The complete travel speed data set contains a total of 54,295 observations. There were 1,027 segments where the data was recorded at least once of the 96 time points. Nearly for 88% of the segments, speeds were recorded for at least 50 records with only 1% (10 segments) where only one observation was recorded. We used linear interpolation to fill the missing records keeping in mind that data was collected over time. The data after removing missing records and filling missing values can be found at www.lancaster.ac.uk/~goerigk/robust-sp-data.zip.
As segments are purely geographical objects without structure, we needed to create a graph for our experiments. To this end, segments were split when they crossed or nearly crossed, and start- and end-points that were sufficiently close to each other were identified as the same node. The resulting graph is shown in Figure 2(b); note that this process slightly simplified the network, but kept its structure intact. The final graph contains 538 nodes and 1308 arcs.
3.2 Setup
Each uncertainty set is equipped with a size parameter. For each parameter we generated 20 possible values:
- •
For and , .
- •
For , .
- •
For , .
- •
For , we used columns .
- •
For , we used columns .
Each uncertainty set is generated using only every second scenario (i.e., 48 out of 96), but all 96 scenarios are then used to evaluate the solutions. Furthermore, we generated 200 random pairs uniformly, and used each of the methods on the same 200 pairs. Each of our 120 methods hence generates objective values.
It is highly non-trivial to assess the quality of these solutions, see [CG16b]. If one just uses the average objective value, as an example, then one could as well calculate the solution optimizing the average scenario case to find the best performance with respect to this measure. To find a balanced evaluation of all methods, we used four performance criteria:
- •
the average objective value,
- •
the average of the worst-case objective value for each pair, and
- •
the average value of the worst 5% of objective values for each pair (as in the CVaR measure)
We also considered the average rank. To this end, we rank all 120 methods for each specific combination of pair and scenario. The best performing methods are ranked at 1, the second-best at 2 etc. We then take the average rank over all observations. However, this measure was strongly correlated with the average objective value and is therefore not presented.
For all experiments we used a computer with a 16-core Intel Xeon E5-2670 processor, running at 2.60 GHz with 20MB cache, and Ubuntu 12.04. Processes were pinned to one core. We used CPLEX v.12.6 to solve all problem formulations.
3.3 Results
We present our findings in the two plots of Figure 3. In each plot, the 20 parameter settings that belong to the same uncertainty set are connected by a line. They are complemented with Figure 4 showing the total computation times for the methods over all 200 shortest path calculations.
The first plot in Figure 3(a) shows the trade-off between the average and the maximum objective value; the second plot in Figure 3(b) shows the trade-off between the average and the average of the 5% worst objective values. Note that for all performance measures, smaller values indicate a better performance – hence, good trade-off solutions should move from the top left to the bottom right of the plots. In general, the points corresponding to the parameter settings that give weight to the average performance can be on the left sides of the curves, while the more robust parameter settings are on the right sides, as would be expected.
We first discus Figure 3(a). In general, we find that most concepts to indeed present a trade-off between average performance and robustness through their scaling parameter. The symmetric permutohull solutions have the best average performance, while interval solutions are the most robust. Interestingly, that even holds for interval solutions where the scaling parameter is very small. The budgeted uncertainty does not give a good trade-off between worst-case and average-case performance, which confirms previous results on artificial data [CG16a]. Scaling interval uncertainty sets achieves better results than using budgeted uncertainty. Solutions generated with ellipsoidal uncertainty sets slightly outperform (dominate in the Pareto sense) solutions generated with permutohull uncertainty. We also note that methods that are computationally more expensive tend to achieve better average performance at the cost of decreases robustness. The simplest and cheapest method, interval uncertainty, gives the most robust solutions. Solutions using the convex hull of raw data tend to be outperformed by the approaches that process data.
We now consider the results presented in Figure 3(b). Here the average is plotted against the average performance of the 5% worst performing scenarios, averaged over all pairs. We note that for interval uncertainty, these two criteria are connected, with the best solutions for small parameter size dominating all solutions for larger parameter size. For the permutohull and the ellipsoidal uncertainty solutions, the order slightly changed with the former often dominating the latter. Permutohull solutions are designed to be efficient for the CVaR criterion, and the best-performing solution with respect to this aspect is indeed generated by this approach. However, also solutions with ellipsoidal, interval and convex hull uncertainty perform well.
Regarding computation times (see Figure 4), note that the two polynomially solvable approaches are also the fastest when using Cplex; these computation times can be further improved using specialized algorithms. Using the convex hull is faster than using ellipsoids, which are in turn faster than using the symmetric permutohull. For the standard permutohull, the computation times are sensitive to the uncertainty size; if the vector that is used in the model has only few entries, then computation times are smaller. This is in line with the intuition that the problem becomes easier if less scenarios need to be considered.
To summarize our findings in our experiment on the robust shortest path problem with real-world data:
- •
Convex hull solutions are amongst the more robust solutions, but tend to be outperformed by the other approaches.
- •
Interval solutions perform bad on average, but are the most robust. Especially when the scaling is small they can give a decent trade-off, and are easy and fast to compute.
- •
Ellipsoidal uncertainty solutions have very good overall performance and represent a large part of the non-dominated points in our results.
- •
We do not encourage the use of budgeted uncertainty for robust shortest path problems. Scaling interval uncertainty sets gives better results and is easier to use and to solve.
- •
Permutohull solutions offer good trade-off solutions, whereas symmetric permutohull solutions tend to be less robust, but provide an excellent average performance. These methods are also require most computational effort to find.
In the light of these findings, the interval and discrete (=convex hull) uncertainty sets that are widely used in robust combinatorial optimization do warrant research attention, as they may not produce the best solutions, but are relatively fast to solve. However, permutohull and ellipsoidal uncertainty tend to produce solutions with a better trade-off, while being computationally more challenging. The algorithmic research for robust shortest path problems with such structure should therefore become a future focus.
4 Conclusion
In this paper wo constructed uncertainty sets for the robust shortest path problem using real-world traffic observations for the City of Chicago. We evaluated the model suitability of these sets by finding the resulting robust paths, and comparing their performance using different performance indicators.
Naturally, conclusions can only be drawn within the reach of the available data. In our setting we considered solutions that are robust with respect to all possible travel times within a day. A use-case would be that a path needs to be computed for a specific day, but the precise hour is not known. Using different sets of observations will result in solutions that are different in another sense, e.g., one could use observations over different days during the morning rush hours, or observations that span work days and a weekend. It is possible that these sets will provide different structure.
Finally, we have observed that using ellipsoidal uncertainty sets provides high-quality solutions with less computational effort than for the permutohull. If one uses only the diagonal entries of the matrix , then one ignores the data correlation in the network. For the resulting problem specialized algorithms exist, see, e.g. [Nik09]. In additional experiments we found that even by using Cplex, computation times were considerably reduced when only using the diagonal entries of , but the solution quality remained roughly the same.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[ABV 09] Hassene Aissi, Cristina Bazgan, and Daniel Vanderpooten. Min–max and min–max regret versions of combinatorial optimization problems: A survey. European journal of operational research , 197(2):427–438, 2009.
- 2[BB 09] Dimitris Bertsimas and David B Brown. Constructing uncertainty sets for robust linear optimization. Operations research , 57(6):1483–1495, 2009.
- 3[BDG + 16] Hannah Bast, Daniel Delling, Andrew Goldberg, Matthias Müller-Hannemann, Thomas Pajor, Peter Sanders, Dorothea Wagner, and Renato F Werneck. Route planning in transportation networks. In Algorithm Engineering , pages 19–80. Springer, 2016.
- 4[BS 03] Dimitris Bertsimas and Melvyn Sim. Robust discrete optimization and network flows. Mathematical programming , 98(1):49–71, 2003.
- 5[BS 04] Dimitris Bertsimas and Melvyn Sim. The price of robustness. Operations research , 52(1):35–53, 2004.
- 6[BTN 98] Aharon Ben-Tal and Arkadi Nemirovski. Robust convex optimization. Mathematics of operations research , 23(4):769–805, 1998.
- 7[BTN 99] Aharon Ben-Tal and Arkadi Nemirovski. Robust solutions of uncertain linear programs. Operations research letters , 25(1):1–13, 1999.
- 8[Büs 12] Christina Büsing. Recoverable robust shortest path problems. Networks , 59(1):181–189, 2012.