Unsupervised Clustering and Active Learning of Hyperspectral Images with Nonlinear Diffusion
James M. Murphy, Mauro Maggioni

TL;DR
This paper introduces an unsupervised spectral-spatial diffusion learning method for hyperspectral image segmentation that effectively handles high dimensionality and noise, with an active learning variation that improves clustering accuracy with minimal labeled data.
Contribution
The paper proposes a novel nonlinear diffusion-based clustering and segmentation method for hyperspectral images, incorporating spectral and spatial information, and introduces an active learning variant for enhanced performance.
Findings
Outperforms state-of-the-art hyperspectral segmentation techniques
Robust to parameter choices and noise
Low computational complexity
Abstract
The problem of unsupervised learning and segmentation of hyperspectral images is a significant challenge in remote sensing. The high dimensionality of hyperspectral data, presence of substantial noise, and overlap of classes all contribute to the difficulty of automatically clustering and segmenting hyperspectral images. We propose an unsupervised learning technique called spectral-spatial diffusion learning (DLSS) that combines a geometric estimation of class modes with a diffusion-inspired labeling that incorporates both spectral and spatial information. The mode estimation incorporates the geometry of the hyperspectral data by using diffusion distance to promote learning a unique mode from each class. These class modes are then used to label all points by a joint spectral-spatial nonlinear diffusion process. A related variation of DLSS is also discussed, which enables active learning…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23 Figure 24
Figure 24 Figure 25
Figure 25 Figure 26
Figure 26 Figure 27
Figure 27 Figure 28
Figure 28 Figure 29
Figure 29 Figure 30
Figure 30 Figure 31
Figure 31 Figure 32
Figure 32 Figure 33
Figure 33 Figure 34
Figure 34 Figure 35
Figure 35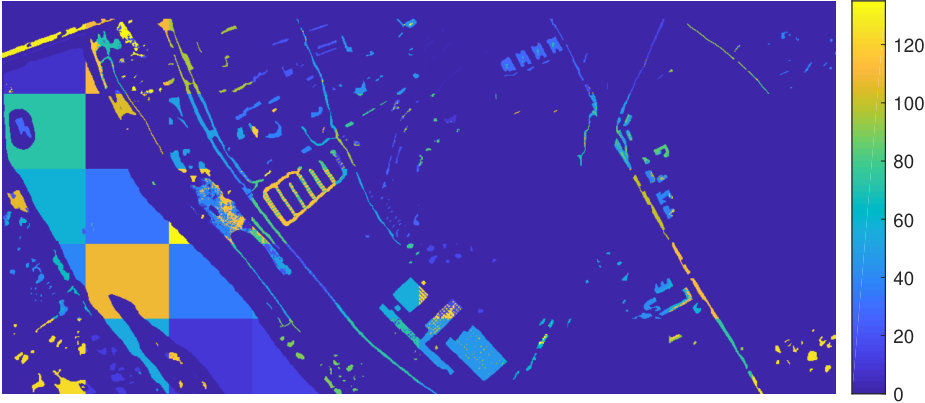 Figure 36
Figure 36 Figure 37
Figure 37 Figure 38
Figure 38 Figure 39
Figure 39 Figure 40
Figure 40| Dataset | IP | Pavia | Salinas A | KSC |
|---|---|---|---|---|
| Estimated Number of Classes | 4 | 6 | 6 | 4 |
| Number of Labeled GT Classes | 3 | 6 | 6 | 4 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Unsupervised Clustering and Active Learning of Hyperspectral Images with Nonlinear Diffusion
James M. Murphy
Mauro Maggioni
J.M. Murphy is with the Department of Mathematics at Tufts University; email: [email protected]
M. Maggioni is with the Department of Mathematics, Department of Applied Mathematics and Statistics, Institute of Data Intensive Engineering and Science, and the Mathematical Institute of Data Sciences at Johns Hopkins University; email: [email protected]
Abstract
The problem of unsupervised learning and segmentation of hyperspectral images is a significant challenge in remote sensing. The high dimensionality of hyperspectral data, presence of substantial noise, and overlap of classes all contribute to the difficulty of automatically clustering and segmenting hyperspectral images. We propose an unsupervised learning technique called spectral-spatial diffusion learning (DLSS) that combines a geometric estimation of class modes with a diffusion-inspired labeling that incorporates both spectral and spatial information. The mode estimation incorporates the geometry of the hyperspectral data by using diffusion distance to promote learning a unique mode from each class. These class modes are then used to label all points by a joint spectral-spatial nonlinear diffusion process. A related variation of DLSS is also discussed, which enables active learning by requesting labels for a very small number of well-chosen pixels, dramatically boosting overall clustering results. Extensive experimental analysis demonstrates the efficacy of the proposed methods against benchmark and state-of-the-art hyperspectral analysis techniques on a variety of real datasets, their robustness to choices of parameters, and their low computational complexity.
I Introduction
I-A Machine Learning for Hyperspectral Data
Hyperspectral imagery (HSI) has emerged as a significant data source in a variety of scientific fields, including medical imaging [1], chemical analysis [2], and remote sensing [3]. Hyperspectral sensors capture reflectance at a sequence of localized electromagnetic ranges, allowing for precise differentiation of materials according to their spectral signatures. Indeed, the power of hyperspectral imagery for material discrimination has led to its proliferation, making manual analysis of hyperspectral data infeasible in many cases. The large data size of HSI, combined with their high dimensionality, demands innovative methods for storage and analysis. In particular, efficient machine learning algorithms are needed to automatically process and glean insight from the deluge of hyperspectral data now available.
The problem of HSI classification, or supervised segmentation, is to label each pixel in a given HSI as belonging to a particular class, given a training set of labeled samples (pixels) from each class. A variety of statistical and machine learning techniques have been used for HSI classification, including nearest-neighbor and nearest subspace methods [4, 5], support vector machines [6, 7], neural networks [8, 9, 10] and regression methods [11, 12]. These methods are design to perform well especially when the number of labeled training pixels is large.
The process of labeling pixels typically requires an expert and it is costly. This motivates the design of machine learning techniques that require little or no labeled training data. So on the other end of the spectrum from classification, we have the problem of HSI clustering, or unsupervised segmentation, which has the same goal as HSI classification, but no labeled training data is available. This is considerably more challenging, and is an ill-posed problem unless further assumptions are made, for example about the distribution of the data and how it relates to the unknown labels. Recent techniques for hyperspectral clustering include those based on particle swarm optimization [13], Gaussian mixture models (GMM) [14], nearest neighbor clustering [15], total variation methods [16], density analysis [17], sparse manifold models [18, 19], hierarchical nonnegative matrix factorization (HNMF) [20], graph-based segmentation [21], and fast search and find of density peaks clustering (FSFDPC) [17, 22, 23].
Another interesting modality is active learning for HSI classification. This is a supervised technique where a small, automatically but carefully chosen set of pixels is labeled, as opposed to the standard supervised learning setting, in which the labels are usually randomly selected. Active learning can lead to high quality classification results with significantly fewer labeled samples than in the case of randomly selected training data. Since far fewer training points are available in the active learning setting, the structure of the data may be analyzed with unsupervised learning, in order to decide which data points to query for labels. Thus, active learning may be understood as a form of semisupervised learning that exploits both global structure of the data—learned without supervision—and a small number of supervised training data points. A variety of active learning methods have been successfully deployed in remote sensing [24], including those based on relevance feedback [25], region-based heuristics [26], exploration-based heuristics [27], belief propagation [28], support vector machines [29], and regression [30].
Machine learning for HSI suffers from several major challenges. First, the dimensionality of the data to be analyzed is high: it is not uncommon for the number of spectral bands in an HSI to exceed . The corresponding sampling complexity for such a high number of dimensions renders classical statistical methods inapplicable. Second, clusters in HSI are typically nonlinear in the spectral domain, rendering methods that rely on having linear clusters ineffective. Third, there is often significant noise and between-cluster overlap among HSI classes, due to the materials being imaged and poor sensing conditions. Finally, HSI images may be quite large, requiring machine learning methods with computational complexity essentially linear in the number of pixels.
This article addresses the problems of HSI clustering and, relatedly, active learning, which overcome these significant challenges. The methods we propose combine density-based methods with geometric learning through diffusion geometry [31, 32] in order to identify class modes. This information is then used to propagate labels on training data to all data points through a nonlinear process that incorporates both spectral and spatial information. The use of data-dependent diffusion maps for mode detection significantly improves over current state-of-the-art methods experimentally, and also enjoys robust theoretical performance guarantees [33]. The use of diffusion distances exploits low-dimensional structures in the data, which allows the proposed method to handle data that is high-dimensional but intrinsically low-dimensional, even when nonlinear and noisy. Moreover, the spectral-spatial labeling scheme takes advantage of the geometric properties of the data, and greatly improves the empirical performance of clustering when compared to labeling based on spectral information alone. In addition, the proposed unsupervised method assigns to each data point a measure of confidence for the unsupervised label assignment. This leads naturally to an active learning algorithm in which points with low confidence scores are queried for training labels, which then propagate through the remaining data. The proposed algorithms enjoy nearly linear computational complexity in the number of pixels in the HSI and in the number of spectral dimensions, thus allowing for its application to large scenes. Extensive empirical results, including comparisons with many state-of-the-art techniques, for our method applied to HSI clustering and active learning are in Sections III-E and III-F, respectively.
I-B Overview of Proposed Method
The proposed unsupervised clustering method is provided with data (for HSI, = number of pixels and = number of spectral bands) and the number of classes, and outputs labels { each , by proceeding in two steps:
Mode Identification: This step consists first in performing density estimation and analyzing the geometry of the data to find modes , one for each class.
- 2.
Labeling Points: Once the modes are learned, they are assigned a unique label. Remaining points are labeled in a manner that preserves spectral and spatial proximity.
By a mode, we mean a point of high density within a class, that is representative of the entire class. We assume is known, but otherwise we have no access to labeled data; in Section V we discuss a method for estimating .
One of the key contributions of this article is to measure similarities in the spectral domain not with the widely used Euclidean distance or distances based on angles (correlations) between points, but with diffusion distance [31, 32], which is a data-dependent notion of distance that accounts for the geometry—linear or nonlinear—of the distribution of the data. The motivation for this approach is to attain robustness with respect to the shape of the distributions corresponding to the different classes, as well as to high-dimensional noise. The modes, suitably defined via density estimation, are robust to noise, and the process we use to pick only one mode per class is based on diffusion distances. The labeling of the points from the modes respects the geometry of the data, by incorporating proximity in both spectral and spatial domains.
We model as samples from a distribution where each corresponds to the probability distribution of the spectra in class , and the nonnegative weights correspond to how often each class is sampled, and satisfy . More precisely, sampling means first sampling , then sampling from conditioned on the event .
I-B1 Mode Identification
The computation of the modes is a significant aspect of the proposed method, which we now summarize for a general dataset , consisting of classes. The mode identification algorithm outputs a point (“mode”) for each . We make the assumption that modes of the constituent classes can be characterized as a set of points such that
the empirical density of each is relatively high; 2. 2.
the diffusion distance between pairs , for , is relatively large.
The first assumption is motivated by the fact that points of high density ought to have nearest neighbors corresponding to a single class; the modes should thus produce neighborhoods of points that with high confidence belong to a single class. However, there is no guarantee that the densest points will correspond to the unique classes: some classes may have a multimodal distribution, meaning that the class has several modes, each with potentially higher density than the densest point in another class. The second assumption addresses this issue, requiring that modes belonging to different distributions are far away in diffusion distance.
Enforcing that these modes are far apart in diffusion distance has several advantages over enforcing they are far apart in Euclidean distance. Importantly, it leads, empirically, to a unique mode from each class. This is true even when certain classes are multimodal. Moreover, diffusion distances are robust with respect to the shape of the support of the distribution, and are thus suitable for identifying nonlinear clusters. An instance of these advantages of diffusion distance is illustrated in the toy example Figure 1, with the results of the proposed mode detection algorithm in Figure 3. We postpone the mathematical and algorithmic details to Section II-B.
I-B2 Labeling Points
At this stage we assume that we found exactly one mode for each class, to which a unique and arbitrary class label is assigned. The remaining points are now labeled in a two-stage scheme, which takes into account both spectral and spatial information. It is known that the incorporation of spatial information with spectral information has the potential to improve machine learning of hyperspectral images, compared to using spectral information alone [7, 28, 23, 34, 35, 36, 37, 38, 39, 40]. Spatial information is computed for each pixel by constructing a neighborhood of some fixed radius in the spatial domain, and considering the labels within this neighborhood. For a given point, let spectral neighbor refer to a near neighbor with distances measured in the spectral domain, and let spatial neighbor refer to a near neighbor with distances measured in the spatial domain.
In the first stage, a point is given the same label as its nearest spectral neighbor of higher density, unless that label is sufficiently different from the labels of the point’s nearest spatial neighbors, in which case the point is left unlabeled. This produces an incomplete labeling in which we expect the labeled points to be far from the spectral and spatial boundaries of the classes, since these are points that are unlikely to have conflicting spectral and spatial labels. The first stage thus labels points using only spectral information, though spatial information may prevent a label from being assigned.
In the second stage we label each of the points left unlabeled in the first stage, by assigning the consensus label of its nearest spatial neighbors (see Section II-C), if it exists, or otherwise the label of its nearest spectral neighbor of higher density. In this way the yet unlabeled points, typically near the spatial and spectral boundaries of the classes, benefit from the spatial information in the already labeled points, which are closer to the centers of the classes. The second stage thus labels points using both spectral and spatial information. Figure 2 shows an instance of this two-stage labeling process.
This method of clustering combines the diffusion-based learning of modes with the joint spectral-spatial labeling of pixels and is called spectral-spatial diffusion learning (DLSS), detailed in Section II-C. We contrast it with another novel method we propose, called diffusion learning (DL), in which modes are learned as in DLSS, but the labeling proceeds simply by enforcing that each point has the same spectral label as its nearest spectral neighbor of higher density. DL therefore disregards spatial information, while DLSS makes significant use of it, particularly in the second stage of the labeling. Our experiments show that while both DL and DLSS perform very well, DLSS is generally superior.
I-C Major Contributions
We propose a clustering algorithm for HSI with several significant innovations. First, diffusion distance is proposed to measure distance between high-density regions in hyperspectral data, in order to determine class modes. Our experiments show that this distance efficiently differentiates between points belonging to the same cluster and points in different clusters. This correct identification of modes from each cluster is essential to any clustering algorithm incorporating an analysis of modes. Compared to state-of-the-art fast mode detection algorithms, the proposed method enjoys excellent empirical performance; theoretical performance guarantees are beyond the scope of the present article and will be discussed in a forthcoming article [33].
A second major contribution of the proposed HSI clustering algorithm is the incorporation of spatial information through the labeling process. Labels for points are determined by diffusing in the spectral domain from the labeled modes, unless spatial proximity is violated. By not labeling points that would violate spatial regularity, the proposed algorithm first labels points that, with high confidence, are close to the spectral modes of the distributions. Only after labeling all of these points are the remaining points, further from the modes, labeled. This enforces a spatial regularity which is natural for HSI, because under mild assumptions, a pixel in an HSI is likely to have the same label as the most common label among its nearest spatial neighbors [7, 28, 23, 34, 35, 36, 37, 38, 39, 40]. In both stages, DLSS takes advantage of the geometry of the dataset by using data-adaptive diffusion processes, greatly improving empirical performance. The proposed methods are in the number of points () and ambient dimension of the data () when the intrinsic dimension of the data is small, and thus have near optimal complexity, suitable for the big data setting.
A third major contribution is the introduction of an active learning scheme based on distances of points to the computed modes. In the context of active learning, the user is allowed to label only a very small number of points, to be chosen parsimoniously. We propose an unsupervised method for determining which points to label in the active learning setting. We note that pixels that are equally far in diffusion distance from their nearest two modes are likely to be near class boundaries, and hence to be the most challenging pixels to label by the proposed unsupervised method. Our active learning method requires the labels of only the pixels whose distances to their nearest two modes are closest. The proposed active learning method builds naturally on the fully unsupervised method, since the computation of distances to nearest mode are already computed by the DL and DLSS algorithms, and hence the computational complexity of the proposed active learning method does not differ significantly from the fully unsupervised method. Our experiments show that this method can dramatically improve labeling accuracy with a number of labels of the total pixels. This work is detailed in Section III-F.
II Unsupervised Learning Algorithm and Active Learning Variation
II-A Motivating Example and Approach
A key aspect of our algorithm is the method for identifying the modes of the classes in the HSI data. This is challenging because of the high ambient dimension of the data, potential overlaps between distributions at their tails, along with differing densities, sampling rates, and distribution shapes.
Consider the simplified example in Figure 3, showing the same data set as that in Figure 1. The points of high density lie close to the center of , and close to the two ends of the support of . After computing an empirical density estimate, the distance between high density points is computed. If Euclidean distance is used to remove spurious modes, i.e. modes corresponding to the same distribution, then the learned modes both correspond to ; see subfigure (a) of Figure 3. When diffusion distance is used rather than Euclidean distance, the learned modes correspond to two different classes; see subfigure (b) of Figure 3. This is because the modes on the opposite ends of the support of are far in Euclidean distance but relatively close in diffusion distance. Furthermore, the substantial region of low density between the two distributions forces the diffusion distance between them to be relatively large. This suggests that diffusion distance is more useful than Euclidean distance for comparing high density points for the determination of modes, under the assumption that multimodal regions have modes that are connected by regions of not-too-low density. The results of the proposed clustering algorithm, as well a low-dimensional representation of diffusion distances, appears in Figure 4. In the low-dimensional embedding corresponding to diffusion distance coordinates, the parabolic segment is linear and compressed, enabling the correct learning of modes. Labels are then assigned according to these modes in the diffusion coordinates, which can be projected back onto the original data to yield a clustering of the original data.
II-B Diffusion Distance
We now present an overview of diffusion distances. Additional analysis and comments on implementation appear in [31, 32]. Diffusion processes on graphs lead to a data-dependent notion of distance, known as diffusion distance. This notion of distance has been applied to a variety of application problems, including analysis of stochastic and dynamical systems [31, 41, 42, 43], semisupervised learning [44, 45], data fusion [46, 47], latent variable separation [48, 49], and molecular dynamics [50, 51]. Diffusion maps provide a way of computing and visualizing diffusion distances, and may be understood as a type of nonlinear dimension reduction, in which data in a high number of dimensions may be embedded in a low-dimensional space by a nonlinear coordinate transformation. In this regard, diffusion maps are related to nonlinear dimension reduction techniques such as isomap [52], Laplacian eigenmaps [44], and local linear embedding [53], among several others.
Consider a discrete set . The diffusion distance [31, 32] between , denoted , is a notion of distance that incorporates and is uniquely determined by the underlying geometry of . The distance depends on a time parameter , which enjoys an interpretation in terms of diffusion on the data. The computation of involves constructing a weighted, undirected graph with vertices corresponding to the points in , and weighted edges given by the weight matrix
[TABLE]
for some suitable choice of and with the set of -nearest neighbors of in with respect to Euclidean distance. A fast nearest neighbors algorithm yields in quasilinear time in for small (see Section IV-A for details). The degree of is
A Markov diffusion, representing a random walk on (or ) has transition matrix P(x,y)={W(x,y)}\big{/}{\deg(x)}\,. For an initial distribution on , the vector is the probability over states at time . As increases, this diffusion process on evolves according to the connections between the points encoded by . This Markov chain has a stationary distribution s.t. , given by . The diffusion distance at time is
[TABLE]
The computation of involves summing over all paths of length connecting to , so is small if are strongly connected in the graph according to , and large if are weakly connected in the graph.
The eigendecomposition of allows to derive fast algorithms to compute : the matrix admits a spectral decomposition (under mild conditions, see [32]) with eigenvectors and eigenvalues , where . The diffusion distance (2) can then be written as
[TABLE]
The weighted eigenvectors are new data-dependent coordinates of , which are in fact close to being geometrically intrinsic [31]. Euclidean distance in these new coordinates is diffusion distance on .
Diffusion distances are parametrized by , which measures how long the diffusion process on has run when the distances are computed. Small values of allow a small amount of diffusion, which may prevent the interesting geometry of from being discovered, but provide detailed, fine scale information. Large values of allow the diffusion process to run for so long that the fine geometry may be washed out. In this work an intermediate regime is typically when the diffusion geometry of the data is most useful; in all our experiments we set . The choices of in the construction of are in general important, see Section III-G.
Note that under the mild condition that the underlying graph is connected, for . Hence, for large and , so that the sum (3) may approximated by its truncation at some suitable . In our experiments, was set to be the value at which the decay of the eigenvalues begins to decrease; this is a standard heuristic for diffusion maps. The subset used in the computation of is a dimension-reduced set of diffusion coordinates. The truncation also enables us to compute only a few eigenvectors, reducing computational complexity, see Section IV-A. In this sense, the mapping
[TABLE]
is a dimension reduction mapping of the ambient space to .
II-C Unsupervised HSI Clustering Algorithm Description
We now discuss the proposed HSI clustering algorithm in detail; see Figure 5 for a flowchart representation.
Let be the HSI, and let be the number of clusters. As described in Section I-B, our algorithm proceeds in two major steps: mode identification and labeling of points.
The algorithm for learning the modes of the classes is summarized in Algorithm 1. It first computes an empirical density for each point with a kernel density estimator
[TABLE]
where . Here is the Euclidean distance in , and is the set of -nearest neighbors to , in Euclidean distance. The use of the Gaussian kernel density estimator is standard, enjoying strong theoretical guarantees [54, 55] but certainly other estimators may be used. In our experiments we set , though our method is robust to choosing larger . The parameter in the exponential kernel is set to be one twentieth the mean distance between all points (one could use the median instead in the presence of outliers). Once the empirical density is computed, the modes of the HSI classes are computed in a manner similar in spirit to [22], but employing diffusion distances. We compute the time-dependent quantity that assigns, to each pixel, the minimum diffusion distance between the pixel and a point of higher empirical density:
[TABLE]
where is the diffusion distance between , at time . In the following we will use the normalized quantity , which has maximum value . The modes of the HSI are computed as the points yielding the largest values of the quantity
[TABLE]
Such points should be both high density and far in diffusion distance from any other higher density points, and can therefore be expected to be modes of different cluster distributions. This method provably detects modes correctly under certain distributional assumptions on the data [33].
Once the modes are detected, each is given a unique label. All other points are labeled using these mode labels in the following two-stage process, summarized in Algorithm 2. In the first stage, running in order of decreasing empirical density, the spatial consensus label of each point is computed by finding all labeled points within distance in the spatial domain of the pixel in question; call this set . If one label among occurs with relative frequency , that label is the spatial consensus label. Otherwise, no spatial consensus label is given. In detail, let denote the labels of the spatial neighbors within radius . Then the spatial consensus label of is
[TABLE]
After a point’s spatial consensus label is computed, its spectral label is computed as its nearest neighbor in the spectral domain, measured in diffusion distance, of higher density. The point is then given the overall label of the spectral label unless the spatial consensus label exists (i.e. is in (7)) and differs from the spatial consensus label. In this case, the point in question remains unlabeled in the first stage. Note that points that are unlabeled are considered to have label 0 for the purposes of computing the spatial consensus label, so in the case that most pixels in the spatial neighborhood are unlabeled, the spatial consensus label will be 0. Hence, only pixels with many labeled pixels in their spatial neighborhood can have a consensus spatial label. In this first stage, a label is only assigned based on spectral information, though the spatial information may prevent a label from being assigned.
Upon completion of the first stage, the dataset will be partially labeled; see Figure 2. In the second stage, an unlabeled point is given the label of its spatial consensus label, if it exists, or otherwise the label of its nearest spectral neighbor of higher density. Thus, in the second stage, a label is assigned based on joint spectral-spatial information.
Points of high density are likely to be labeled according to their spectral properties. The reasons for this are twofold. First, these points are likely to be near the centers of distributions, and hence are likely to be in spatially homogeneous regions. Second, points of high density are labeled before points of low density, so it is unlikely for high density points to have many labeled points in their spatial neighborhoods. This means that the spatial consensus label is unlikely to exist for these points. Conversely, points of low density may be at the boundaries of the classes, and are hence more likely to be labeled by their spatial properties. The incorporation of spatial information into machine learning for HSI is justified by the fact that HSI images typically show some amount of spatial regularity, in that if a pixel’s nearest spatial neighbors all have the same class label, it is likely that the pixel has this same label, compared to the case in which the pixel’s nearest spatial neighbors have random labels [7, 28, 23, 34, 35, 36, 37, 38, 39, 40]. The spatial information regularizes and improves performance, but it cannot take the place of the spectral information, as shall be seen in Section III-G2: the spectral information is more discriminative than the spatial information, and is the more important of the two.
The proposed method, combining Algorithms 1, 2 is called spectral-spatial diffusion learning (DLSS). In our experimental analysis, the significance of the spectral-spatial labeling scheme is validated by comparing DLSS against a simpler method, called diffusion learning (DL). This method learns class modes as in Algorithm 1, but labels all pixels simply by requiring each point have the same label as its nearest spectral neighbor of higher density. The expectation is that DLSS will generally outperform DL, due to the former’s incorporation of spatial data; this is confirmed by our experiments.
II-D Active Learning DLSS Variation
Both the DL and DLSS methods are unsupervised. We now present a variation of the DLSS method for active learning of hyperspectral images, where a few well-chosen pixels are automatically selected for labeling. The DLSS method labels points beginning with the learned class modes, and mistakes tend to be made on points that are near the class boundaries; in the active learning scheme the algorithm will ask for the labels of the points whose distances from their nearest two modes are closest. That is, points whose nearest mode is ambiguous will be labeled using training data, and all other points will be labeled as in the DLSS algorithm.
More precisely, we fix a time , and for each pixel , let be the two modes closest to in diffusion distance . We compute the quantity
[TABLE]
If is close to 0, then there is substantial ambiguity as to the nearest mode to . Suppose the user is afforded the labels of exactly points. Then the labels requested in our active learning regime are the minimizers of . The proposed active learning scheme is summarized in Algorithm 3. To evaluate performance, we consider a range of values in our experiments. The active learning setting is most interesting when is very small, where is the total number of pixels in the image.
Note that the active learning algorithm can be iterated, by labeling points then recomputing the quantity (8) to determine the most challenging points after some labels have been introduced [56].
III Experiments
III-A Algorithm Evaluation Methods and Experimental Data
We consider several HSI datasets to evaluate the proposed unsupervised (Algorithms 1, 2) and active learning (Algorithm 3) algorithms. For evaluation in the presence of ground truth (GT), we consider three quantitative measures, besides visual performance, namely:
Overall Accuracy (OA): Total number of correctly labeled pixels divided by the total number of pixels. This method values large classes more than small classes. 2. 2.
Average Accuracy (AA): The average, over classes, of the OA of each class. This method values small classes and large classes equally. 3. 3.
*Cohen’s *-statistic (): A measurement of agreement between two labelings, corrected for random agreement [57]. Letting be the observed agreement between the labeling and the ground truth and the expected agreement between a uniformly random labeling and the ground truth, . corresponds to perfect overall accuracy, corresponds to labels no better than what is expected from random guessing.
In order to perform quantitative analysis with these metrics and make consistent visual comparisons, the learned clusters are aligned with ground truth, when available. More precisely, let be the set of permutations of . Let be the clusters learned from one of the clustering methods, and let be the ground truth clusters. Cluster is assigned label , with . We remark that while this alignment method maximizes the overall accuracy of the labeling and is most useful for visualization, better alignments for maximizing and may exist.
We consider real HSI datasets to shed light on strengths and weaknesses of the proposed algorithm. These datasets are standard, have ground truth, and are publicly available111http://www.ehu.eus/ccwintco/index.php?title=Hyperspectral_Remote_Sensing_Scenes. Experiments with active learning are performed for these same real HSI datasets with Algorithm 3. Additional experiments on synthetic and real HSI data are available, for conciseness, only in an appendix in the online preprint version.
Note that some images are restricted to subsets in the spatial domain, which is noted in their respective subsections. This is because unsupervised methods for HSI struggle with data containing a large number of classes, due to variation within classes and similarity between certain end-members of different classes [16]. Hence, the Indian Pines, Pavia, and Kennedy Space Center datasets are restricted to reduce the number of classes and achieve meaningful clusters. The Salinas A dataset is considered in its entirety. The ground truth, when available, is often incomplete, i.e. not all pixels are labeled. For these datasets, labels are computed for all data, then the pixels with ground truth labels are used for quantitative and visual analysis. The number of class labels in the ground truth images were used as parameter for all clustering algorithms, though the proposed method automatically estimates the number of clusters; see Section V. Grayscale images of the projection of the data onto its first principal component and images of ground truth (GT), colored by class, for the Indian Pines, Pavia, Salinas A, and Kennedy Space Center datasets are in Figures 6, 8, 9, and 11, respectively. The projection onto the first principal component of the data is presented as a simple visual summary of the data, though it washes out the subtle information presented in individual bands.
Since the proposed and comparison methods are unsupervised, experiments are performed on the entire dataset, including points without ground truth labels. The labels for pixels without ground truth are not accounted for in the quantitative evaluation of the algorithms tested. Note that additional experiments, not shown, were performed, using only the data with ground truth labels. These experiments consisted in restricting the HSI to the pixels with labels, which makes the clustering problem significantly easier. Quantitative results were uniformly better for all datasets and methods in these cases; the relative performances of the algorithms on a given dataset remained the same.
III-B Comparison Methods
We consider a variety of benchmark and state-of-the-art methods of HSI clustering for comparison. First, we consider the classic -means algorithm [55] applied directly to . This method is not expected to perform well on HSI data, due to the non-spherical shape of clusters, high dimensionality, and noise, all well-known problems for -means. Several dimension reduction methods to reduce the dimensionality of the data, while preserving important discriminatory properties of the classes, as well as increasing the signal-to-noise ratio in the projected space, are also used as benchmarks for comparison with the proposed method. These methods first reduce the dimension of the data from to , where is the number of classes, then run -means on the reduced data. We consider linear dimension reduction via principal component analysis (PCA); independent component analysis (ICA) [58, 59], using the fast implementation [60]222https://www.cs.helsinki.fi/u/ahyvarin/papers/fastica.shtml; and random projections via Gaussian random matrices, shown to be efficient in highly simplified data models [61, 62].
We also consider more computationally intensive methods for benchmarking. DBSCAN [63] is a popular density-based clustering method, that although highly parameter-dependent, has proved useful for a variety of unsupervised tasks. Spectral clustering (SC) [64, 65] has been applied with success in classification and clustering HSI [36]. The spectral embedding consists of the top row-normalized eigenvectors of the normalized graph Laplacian ; in this features space -means is then run (see Section III-G). We also cluster with Gaussian mixture models (GMM) [14, 66, 67], with parameters determined by expectation maximization (EM).
Finally we consider several recent, state-of-the-art clustering methods: sparse manifold clustering and embedding (SMCE) [18, 19]333http://vision.jhu.edu/code/, which fits the data to low-dimensional, sparse structures, and then applies spectral clustering; hierarchical clustering with non-negative matrix factorization (HNMF) [20]444https://sites.google.com/site/nicolasgillis/code, which has shown excellent performance for HSI clustering when the clusters are generated from a single endmember; a graph-based method based on the Mumford-Shah segmentation [68][21], related to spectral clustering, and called fast Mumford-Shah (FMS) in this article (we use a highly parallelized version555http://www.ipol.im/pub/art/2017/204/?utm_source=doi); fast search and find of density peaks clustering (FSFDPC) algorithm [22], which has been shown effective in clustering a variety of data sets.
III-C Relationship Between Proposed Method and Comparison Methods
The FSFDPC method has similarities with the mode estimation aspect of our work, in that both algorithms attempt to learn the modes of the classes via a density-based analysis, as described in, for example, [17, 22]. Our method is quite different, however: the proposed measure of distance between high density points is not Euclidean distance, but diffusion distance [31, 32], which is more adept at removing spurious modes, due to its incorporation of the geometry of the data. This phenomenon is illustrated in Figures 1,3. The assignment of labels from the modes is also quite different, as diffusion distances are used to determine spectral nearest neighbors, and spatial information is accounted for in our DLSS algorithm. FSFDPC, in contrast, assigns to each of the modes its own class label, and to the remaining points a label by requiring that each point has the same label as its Euclidean nearest neighbor of higher density. This means that FSFDPC only incorporates spectral information measured in Euclidean distance, disregarding spatial information. The benefits of both using diffusion distances to learn modes, and incorporating spatial proximities into the clustering process are very significant, as the experiments demonstrate.
Both FSFDPC and the proposed algorithm have some similarities to DBSCAN which, however, performs poorly for data with clusters of differing densities, and is highly sensitive to its parameters. Note that FSFDPC was in fact proposed to improve on these drawbacks of DBSCAN [22].
The proposed DLSS and DL algorithms also share commonalities with spectral clustering, SMCE, and FMS in that these comparison methods compute eigenvectors of a graph Laplacian in order to develop a nonlinear notion of distance. This is related to computing the eigenvectors of the Markov transition matrix in the computation of diffusion maps. The proposed method, however, directly incorporates density into the detection of modes, which allows for more robust clustering compared to these methods, which work by simply applying -means to the eigenvectors of the graph Laplacian. Moreover, our technique does not rely on any assumption about sparsity (unlike SMCE), and is completely invariant under distance-preserving transformations (it shares this property with SMCE), which could be useful if different imaging modalities (e.g. compressed modalities) were used.
Additionally, our approach is connected to semisupervised learning techniques on graphs, where initial given labels are propagated by a diffusion process to other vertices (points); see [45] and references therein. Here of course we have proceeded in an unsupervised fashion, replacing initial given labels by estimated modes of the clusters.
III-D Summary of Proposed and Comparison Methods
The experimental methods are summarized in Table I. The two novel methods we proposed are the full spectral-spatial diffusion learning method (DLSS), as well as a simplified diffusion learning method (DL). We note that several algorithms were not implemented by the authors of this article: publicly available libraries were used when available. Links to these libraries are noted where appropriate.
All experiments and subsequent analyses, except those involving FMS, were performed in MATLAB running on a 3.1 GHz Intel 4-Core i7 processor with 16 GB of RAM; code to reproduce all results is available on the authors’ website666http://www.math.jhu.edu/~jmurphy/.
III-E Unsupervised HSI Clustering Experiments
III-E1 Indian Pine Dataset
The Indian Pines dataset used for experiments is a subset of the full Indian Pines datasets, consisting of three classes that are difficult to distinguish visually; see Figure 6. This dataset is expected to be challenging due to the lack of clear separation between the classes. Results for Indian Pines appear in Figure 7 and Table 12.
The proposed methods, DL and DLSS, perform the best, with DLSS strongly outperforming the rest. For the average accuracy statistic, DBSCAN performs as well as DL, indicating that the clusters for this data are likely of comparable empirical density. The use of diffusion distances for mode detection and determination of spectral neighbors is evidently useful, as DL significantly outperforms FSFDPC, which has among the best quantitative performance of the comparison methods. Moreover, the use of the proposed spectral-spatial labeling scheme DLSS clearly improves over spectral-only labeling DL: as seen in Figure 7, DLSS correctly labels many small interior regions that DL labels incorrectly.
III-E2 Pavia Dataset
The Pavia dataset used for experiments consists of a subset of the original dataset, and contains six classes, with one of them spread out across the image. As can be seen in Figure 8, the yellow class is small and diffuse, which is expected to add challenge to this example. Results appear in Table 12. Visual results appear in the online preprint version of this article.
The proposed methods give the best results, which also provide evidence of the value of both the diffusion learning stage and the spectral-spatial labeling scheme. The proposed DLSS algorithm makes essentially only two errors: the yellow-green class is slightly mislabeled, and the blue-green class in the bottom right is labeled completely incorrectly. However, both of these errors are made by all algorithms, often to a greater degree. Among the comparison methods, SMCE performs best; classical spectral clustering also performs well.
III-E3 Salinas A Dataset
The Salinas A dataset (see Figure 9) consists of 6 classes arrayed diagonally. Some pixels in the original images have the same values, so some small Gaussian noise (variance was added as a preprocessing step to distinguish these pixels.
For this dataset, the proposed DLSS method performs best, with the only error made in splitting the bottom right cluster into two pieces, an error made by all algorithms. The simpler DL method also performs well, as does the benchmark spectral clustering algorithm. Comparing the labeling for DL and DLSS, the small regions of mislabeled pixels in DL are correctly labeled in DLSS, because these pixels are likely of low empirical density, and hence benefit from being labeled based on both spectral and spatial similarity, not spectral similarity alone. However, some pixels correctly classified by DL were labeled incorrectly by DLSS, indicating that the spatial proximity condition enforced in DLSS may not lead to improved results for every pixel. Details on this, and how to tune the size of the neighborhood with which spatial consensus labels are computed, are given in Section III-G2.
III-E4 Kennedy Space Center Data Set
The Kennedy Space Center dataset used for experiments consists of a subset of the original dataset, and contains four classes. Figure 11 illustrates the first principal component of the data, as well as the labeled ground truth, which consists of the examples of four vegetation types which dominate the scene. Results appear in Table 12.
The proposed methods yield the best results, noting that the FMS method also performs well. Most linear methods, such as -means with linear dimension reduction or NMF, perform poorly, suggesting that nonlinear methods are needed for this data. Spectral clustering performs much better than the linear methods. We note that spatial information for this dataset is less helpful than for the Indian Pines and Pavia datasets.
III-E5 Overall Comments on Clustering
Quantitative results for the clustering experiments appear in Table 12. We see that the DLSS method performs best among all metrics for all datasets. The DL method generally performs second best, though DBSCAN, spectral clustering, and SMCE occasionally perform comparably to DL. It is notable that DL outperforms FSFDPC, which uses a similar labeling scheme, but computes modes with Euclidean distances, rather than diffusion distances. This provides empirical evidence for the need to use nonlinear methods of measuring distances for HSI.
III-F Active Learning
To evaluate our proposed active learning method, Algorithm 3, the same labeled HSI datasets were clustered with increasing the percentage of labeled points, chosen as in Algorithm 3. Note that corresponds the the unsupervised DLSS algorithm. The empirical results for this active learning scheme appear in Figure 13. We also consider selecting the labeled points uniformly at random; we hypothesize our principled approach will be superior to random sampling.
The plots indicate that the proposed active learning can produce dramatic improvements in labeling with very few training labels. Indeed, an improvement in overall accuracy from to for Indian Pines can be achieved with only 3 labels. Even more dramatic is the Salinas A dataset, in which 3 labeled points improves the overall accuracy from to . The Pavia dataset enjoys some improved performance, though the random labels do about as well as the principled labels, and Kennedy Space Center dataset labelings are not affected by the small collection of labeled points. In the case of Pavia, however, the overall accuracy was already very large, so active learning seems not needed for this data set. Note that our principled scheme is generally superior to using randomly selected labeled points, which leads to a more gradual improvement in accuracy, compared to the huge gains that can be seen with the proposed principled method.
It is interesting to compare our active learning results to a state-of-the-art supervised method. We consider the supervised HSI classification with edge preserving filtering method (EPF) [69] algorithm, which combines a support vector machine with an analysis of spectral-spatial probability maps to label points. Using a publicly available implementation 777http://xudongkang.weebly.com/, we ran this algorithm using and of points as training data, generated as a uniformly random sample over all labeled points. 10 experiments were ran on each of the four datasets considered, with results averaged. Quantitative results are shown in Table 14. The supervised results are generally superior to the results achieved by the unsupervised DL and DLSS method. The proposed active learning, however, is able to achieve the same performance on the Salinas A dataset using two orders of magnitude fewer points. This is because the proposed active learning method only uses training points for pixels that are considered especially important, whereas the EPF algorithm trains on a random subset of points. Moreover, when only of training points are used, our active learning DLSS method with of training points used outperforms the EPF method on the Indian Pines, Salinas A, and Kennedy Space Center datasets. This indicates the promise of the proposed active learning method, as it is able to outperform a state-of-the-art supervised method in the regime in which a low proportion of training points is available.
III-G Parameter Analysis
We now discuss the parameters used in all methods, starting with those used for all comparison methods, and then discussing the two key parameters for the proposed method: diffusion time and radius size for the computation of the spatial consensus label in Algorithm 2. For experimental parameters except these, a range of parameters were considered, and those with best empirical results were used.
All instances of the -means algorithm are run with iterations, with random initializations each time, and number of clusters equal to the known number of classes in the ground truth. Each of the linear dimension reduction techniques, PCA, ICA, and random projection, embeds the data into , where is the number of clusters. DBSCAN is highly dependent on several parameters, and a grid search was used on each dataset to select optimal parameters. Note that this means DBSCAN was optimized specifically for each dataset, while other methods used a fixed set of parameters across all experiments. Spectral clustering is run by computing a weight matrix as in , with and . The top eigenvectors are then normalized to have Euclidean norm , then used as features with -means.
Among the state-of-the-art methods, HNMF uses the recommended settings listed in the available online toolbox888https://sites.google.com/site/nicolasgillis/code. For FSFDPC, the empirical density estimate is computed as described in Section II-C, with a Gaussian kernel and 20 nearest neighbors. For SMCE, the sparsity parameter was set to be 10, as suggested in the online toolbox999http://www.vision.jhu.edu/code/. The FMS algorithm depends on several key parameters; grid search was implemented, and empirically optimal parameters with respect to a given dataset were used. Note that this means FMS was, like DBSCAN, optimized specifically for each dataset, while other methods used a fixed set of parameters across all experiments.
For the proposed algorithm, the same parameters for the density estimator as described above are used, in order to make a fair comparison with FSFDPC. Moreover, in the construction of the graph used to compute diffusion distances, we use the same construction as in spectral clustering and SMCE, again to make fair comparisons. The remaining parameters, diffusion time and spatial radius, were set to and , respectively, for all experiments. We justify these choices and analyze their robustness in the following subsections.
III-G1 Diffusion Time
The most important parameter when using diffusion distances is the time parameter , see eqn. . The larger is, the smaller the contribution of the smaller eigenvalues in the spectral computation of . Allowing to vary, connections in the dataset are explored by allowing the diffusion process to evolve. For small values of , all points appear far apart because the diffusion process has not reached far, while for large values of , all points appear close together because the diffusion process has run for so long that it has dissipated over the entire state space. In general, the interesting choice of is moderate, which allows for the data geometry to be discovered, but not washed out in long-term.
In Figure 15, all the accuracy measures for in are displayed.
The behavior is robust with respect to time. For Indian Pines, performance is largely constant, except for a dip from time to . For the Pavia, Salinas A, and Kennedy Space Center examples, the performance is invariant with respect to the diffusion time. We conclude that a large range of or would have led to the same empirical results as our choice .
III-G2 Spatial Diffusion Radius
The spatial consensus radius can also impact the performance of the proposed DLSS algorithm. Recall that this is the distance in the spatial domain used to compute the spatial consensus label (see Section II-C and definition (7)). If is too small, insufficient spatial information is incorporated; if is too large, the spectral information becomes drowned out. All measures of accuracy for each dataset for in appear in Figure 16.
We see a trade-off between spectral and spatial information, suggesting that should take a moderate value sufficiently greater than 0 but less than 10. This trade-off can be interpreted in the following way: empirically optimal results are achieved when both spectral and spatial information contribute harmoniously, and results deteriorate when one or the other dominates. We choose for all experiments, though other choices would give comparable (or sometimes better) quantitative results for the datasets considered.
We note that the role of the spatial radius is analogous to the role of a regularization parameter for a general statistical learning problem. Taken too small, the problem is insufficiently regularized, leading to poor results. Taken too large, the regularization term dominates the fidelity term, leading also to poor results. In particular, the geometric regularity of the clusters in the spatial domain determine how large may be taken while still preserving the spectral information. If the clusters are convex and not too elongated, then taking large is reasonable. On the other hand, if the classes are very irregular spatially, for example highly non-convex or elongated, choosing too large will wash out the spectral information which is generally more discriminative than the spatial information, resulting in inaccurate clustering.
III-H Large Scale Experiments
The results of Section III-E analyzed subsets of larger images, in order to reduce the number of classes to allow for effective unsupervised learning [16]. In order to evaluate the robustness of these results, we performed experiments in which the full HSI scenes were subdivided into small patches with fewer classes, then each patch—with a smaller number of classes than the total scene—were clustered. The results on individual patches may be used as the basis for a statistical evaluation of the performance of each clustering method. For the Indian Pines, Pavia, and Kennedy Space Center datasets, experiments for the entire dataset, suitably partitioned into smaller patches, were performed, with DLSS again performing best among all studied methods. Note that Salinas A had only 6 classes, and was considered in its entirety. The Indian Pines data set was partitioned into 24 rectangular patches of equal size; Pavia into 50 rectangular patches of equal size, and Kennedy Space Center into 25 patches of equal size. On each piece that contained some non-trivial ground truth, all clustering algorithms were ran. A series of statistical tests on the differences in performance were then executed as follows. For a pair of methods—denoted method and — let be the overall accuracy of methods and on patch , and let . The sample mean difference in error between methods and across the different patches is , where is the total number of patches with ground truth. It is of interest to investigate whether can be inferred to be different from 0. In order to perform a statistical test, the sample standard deviation of difference between methods is computed as . Then, the null hypothesis that may be tested against the alternative hypothesis that by performing a two-sided -test [70] with degrees of freedom. The normalized -scores for the corresponding to the DLSS method and running through all other methods are reported in Table 20. The test confirms that for all methods , the hypothesis that DLSS does not significantly differ from method () is rejected in favor of the alternative hypothesis that DLSS significantly differs from method ) at the level. This provides evidence that DLSS performs competetively with benchmark and state-of-the-art HSI clustering algorithms across HSI with a variety of land cover types and complexity. Note that the values are are not independent for different , due to correlations across images. However, the -test still provides a powerful method for inferring statistical significance in this case, despite this theoretical assumption not being satisfied.
In addition to providing the basis for a statistical evaluation of the proposed algorithm, splitting large, complicated HSI into patches for clustering allows to over-segment the image. Examples of the oversegmented maps, where we do not attempt to synchronize the labels across patches, appear in Figures 17, 18, 19. It is a topic of future research to combine these patches using the DLSS framework.
IV Overall Comments on the Experiments and Conclusion
We proposed a novel unsupervised method for clustering HSI, using data-dependent diffusion distances to learn modes of clusters, followed by a spectral-spatial labeling scheme based on diffusion in both the spectral and spatial domains. We demonstrated on various data sets that the proposed DLSS algorithm performs well compared to state-of-the-art techniques, and that the DLSS algorithm outperforms DL thanks to the incorporation of spatial information. We remark that the methods which employ linear dimension reduction, including PCA, ICA, and random projections, generally outperform methods that use no dimension reduction, but do not perform as well as those which used nonlinear dimension reduction, including spectral clustering, SMCE, DL, and DLSS. This indicates that while HSI data does exhibit intrinsically low-dimensional structure, the data lies close not to subspaces, but manifolds, i.e. nonlinear sets of low dimensionality.
The proposed DL method, consisting of the geometric learning of modes but only spectral assignment of labels, largely outperforms all comparison methods (see Table 12). In particular, it outperforms in all examples considered the very popular and recent FSFDPC algorithm. This indicates that Euclidean distance is insufficient for learning the modes of complex HSI data. Moreover, the joint spectral-spatial labeling scheme DLSS improves over DL in all instances. In fact, DLSS gives the overall best performance for all datasets and all performance metrics.
The incorporation of active learning in the DLSS algorithm dramatically improves the accuracy of labeling of the Indian Pines, Pavia, and Salinas A datasets with very few label queries. This parsimonious use of training labels has the potential to greatly improve the efficiency of machine learning tasks for HSI, in which the number of labels necessary to label a significant proportion of the image is very high. The proposed active learning method can perform competitively with the state-of-the-art supervised EPF spectral-spatial classification algorithm, using a fraction of the number of labeled pixels.
IV-A Computational Complexity and Runtime
Let the data be . For the Indian Pines dataset, ; for the Pavia dataset, ; for the Salinas A dataset, ; for the Kennedy Space Center dataset, . The most expensive step in DLSS is the construction of the nearest neighbor graph: we achieve near-linear scaling in , , using the cover trees algorithm [71] with a constant that depends exponentially on the intrinsic dimension of the data, which is quite small in all the data sets considered. Once the nearest neighbors are found, the kernel density estimator, the random walk, and its eigenvectors can all be quickly constructed in time , assuming that the number of nearest neighbors used in the density estimator is and that the number of eigenvectors needed is . Computing the nearest spectral neighbor of higher empirical density, computing the spatial consensus labels, and active learning respectively have negligible computational complexity. We show empirical runtimes in Table II, which demonstrates that the proposed methods have superior runtimes to spectral clustering and DBSCAN, and are substantially faster than SMCE.
V Future Research Directions
A drawback of many clustering algorithms, including the ones presented in this paper, is the assumption that the number of clusters, , is known a priori. While unsupervised clustering experiments typically assume is known, it is of interest to develop methods that allow efficient and accurate estimation of , in order to make a truly unsupervised clustering method. Initial investigations suggest that looking for the “kink” in the sorted plot of could be used to detect automatically. More precisely, we check if there is a prominent peak in the value , where where the points are the data, sorted in decreasing order of their values. This is a discrete version of the gradient, so we are looking for a sharp drop-off in the sorted curve. If there is a prominent such maxima in , precisely defined as a local maximum that is greater in magnitude than double the previous value, and also at least half the magnitude of the global maximum, we estimate as this peak. If there is no such prominent peak, then we proceed to examine the second order information . This is a discrete approximation to the second derivative of , to find when begins to flatten. Initial analysis on the Indian Pines, Pavia, Salinas A and Kennedy Space Center datasets used in this article confirm the promise of analyzing the decay of ; results showing plots of values appear in Figure 21, while the corresponding statistics and are shown in Figure 22. The estimated number of clusters appear in Table III.
It is of interest to prove under what assumptions on the distributions and mixture model the plot correctly determines . Moreover, in the case that one cluster is noticeably smaller or harder to detect than others, as in the case of the Indian Pines dataset, it may be advantageous to use a different statistic on the finite difference curve, rather than the proposed derivative conditions on . Initial mathematical results and more subtle conjectures are proposed in an upcoming article [33].
Moreover, all unsupervised algorithms considered in this paper struggle with very large HSI scenes consisting of many classes. This is due to the large variation within clusters compared to the differences between clusters, which leads to genuine classes being split incorrectly; this is a well-known challenge for unsupervised clustering of HSI [16]. In Section III-H it is shown that DLSS is very effective at clustering on different patches of a large HSI. It remains an open question how to combine the results on these patches into a global clustering, which amounts to determining when to merge clusters learned in distinct patches. Automatically implementing such mergers with the DLSS framework is a direction of future research.
The present work is essentially empirical: it is not known mathematically under what constraints on the mixture model the method proposed for learning modes succeeds with high probability. Besides being of mathematical interest, this would be useful for understanding the limitations of the proposed method for HSI. To understand this phenomenon rigorously, a careful analysis of diffusion distances for data drawn from a non-parametric mixture model is required, which is related to investigating performance guarantees for spectral clustering and mode detection [72, 73].
It is also of interest to explicitly incorporate spectral-spatial features into the diffusion construction. It is known that use of spectral-spatial features is beneficial for supervised learning of HSI [69, 74, 75], and their use in unsupervised learning is an exciting research direction. Indeed, incorporating the spatial properties of the scene into the graph from which diffusion distances are generated may render the explicit spatial regularization step of the proposed algorithm redundant, thus improving runtime.
Acknowledgments
The authors would like to thank Ed Bosch for his helpful comments on a preliminary version of this paper. This research was partially supported by NSF-ATD-1222567, NSF-ATD-1737984, AFOSR FA9550-14-1-0033, AFOSR FA9550-17-1-0280, NSF-IIS-1546392, and ARO subcontract to W911NF-17-P-0039. We would also like to thank the anonymous reviewers of this article, whose valuable comments significantly improved the presentation and content of this article.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] G. Lu and B. Fei. Medical hyperspectral imaging: a review. Journal of Biomedical Optics , 19(1):010901–010901, 2014.
- 2[2] Y. Wang, G. Chen, and M. Maggioni. High-dimensional data modeling techniques for detection of chemical plumes and anomalies in hyperspectral images and movies. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , 9(9):4316–4324, 2016.
- 3[3] M.T. Eismann. Hyperspectral remote sensing . SPIE, 2012.
- 4[4] L. Ma, M.M. Crawford, and J. Tian. Local manifold learning-based k 𝑘 k -nearest-neighbor for hyperspectral image classification. IEEE Transactions on Geoscience and Remote Sensing , 48(11):4099–4109, 2010.
- 5[5] W. Li, E.W. Tramel, S. Prasad, and J.E. Fowler. Nearest regularized subspace for hyperspectral classification. IEEE Transactions on Geoscience and Remote Sensing , 52(1):477–489, 2014.
- 6[6] F. Melgani and L. Bruzzone. Classification of hyperspectral remote sensing images with support vector machines. IEEE Transactions on Geoscience and Remote Sensing , 42(8):1778–1790, 2004.
- 7[7] M. Fauvel, J.A. Benediktsson, J. Chanussot, and J.R. Sveinsson. Spectral and spatial classification of hyperspectral data using SV Ms and morphological profiles. IEEE Transactions on Geoscience and Remote Sensing , 46(11):3804–3814, 2008.
- 8[8] F. Ratle, G. Camps-Valls, and J. Weston. Semisupervised neural networks for efficient hyperspectral image classification. IEEE Transactions on Geoscience and Remote Sensing , 48(5):2271–2282, 2010.