An efficient data structure for counting all linear extensions of a poset, calculating its jump number, and the likes
Marcel Wild

TL;DR
This paper introduces an efficient data structure that leverages compressed ideal lattice representations to count linear extensions, compute jump numbers, and facilitate distributed computation in posets.
Contribution
It presents a novel data structure and approach for efficiently processing poset ideals, enabling scalable distributed computations for related combinatorial problems.
Findings
Efficient counting of linear extensions achieved.
Compressed ideal lattice representation reduces computational complexity.
Supports distributed computation for large posets.
Abstract
Achieving the goals in the title (and others) relies on a cardinality-wise scanning of the ideals of the poset. Specifically, the relevant numbers attached to the k+1 element ideals are inferred from the corresponding numbers of the k-element (order) ideals. Crucial in all of this is a compressed representation (using wildcards) of the ideal lattice. The whole scheme invites distributed computation.
Click any figure to enlarge with its caption.
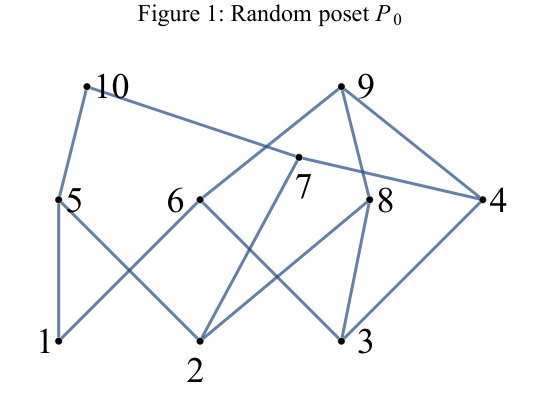 Figure 1
Figure 1Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsCommutative Algebra and Its Applications · Topological and Geometric Data Analysis · Advanced Database Systems and Queries
An efficient data structure for counting all linear extensions of a poset, calculating its jump number, and the likes
Marcel Wild
ABSTRACT: Achieving the goals in the title (and others) relies on a cardinality-wise scanning of the ideals of the poset. Specifically, the relevant numbers attached to the elment ideals are inferred from the corresponding numbers of the -element (order) ideals. Crucial in all of this is a compressed representation (using wildcards) of the ideal lattice. The whole scheme invites distributed computation.
1 Introduction
The uses of (exactly) counting all linear extensions of a poset are well documented, see e.g. [1] and [9, Part II]. Hence we won’t dwell on this, nor on the many applications of the other tasks tackled in this article. Since all of them are either NP-hard or #P-hard [1], we may be forgiven for not stating a formal Theorem; the numerical evidence of efficiency must do (Section 8).
It is well known [5, Prop. 3.5.2] that a linear extension corresponds to a path from the bottom to the top of the ideal lattice of . Attempts to exploit for calculating the number of linear extensions of were independently made in [6], [8], [9]. In the author’s opinion they suffer from a one-by-one generation of and (consequently) an inability or unawareness to retrieve all -element ideals fast.
Section 2 offers as a cure the compressed representation of introduced111We mention that apart from other set systems can be compressed in similar ways. See [12] for a survey. in [11]. It is based on wildcards and “multivalued” rows, as opposed to -rows bitstrings. This key data structure is not affected by the sheer size of but rather by the number of arising multivalued rows. As case in point, if is a 100-element antichain then but can be represented by the single multivalued row .
Sections 3 to 6 are dedicated to calculating, respectively, the number of all linear extensions, the average ranks, the rank probabilities (touching upon the conjecture), and the weighted jump number . Section 7 glimpses at further potential uses and generalizations of the key data structure.
2 The key data structure
Consider the poset in Figure 1. As mentioned, the crucial ingredient of our method is a compressed representation of ; this is provided in Table 1.
[TABLE]
Table 1: Compression of with wildcards
Each subset of will be identified with a length bitstring in the usual way; for instance “” . Each multivalued row represents a certain set of ideals (i.e. their matching bitstrings). Namely, is the set of all bitstrings subject to two types of conditions; either local or spread-out. As to local, if the -th entry of is [math] or then must be [math] or accordingly. If the -th entry is then there is no222Our symbol “2” corresponds to the common don’t-care symbol “” but better provides the idea that has two options. restriction on . As to spread-out, suppose contains the wildcard (in any order). That signifies that when the bit of , that occupies the position of , happens to be 1 then also the bits of occupying the positions of the ’s must be 1. A multivalued row can contain several such wildcards, in which case they are independent from each other (and distinguished by subscripts in Table 1). Thus but since the -wildcard is violated. It is straightforward to calculate the cardinality from Table 1:
(1)
What is more, the numbers of -element ideals are readily obtained as coefficients of fairly obvious polynomials. For instance the polynomial for is , and so contains (e.g) two -element, one -element and no 4-element ideal. See [11] for details. Instead of “key data structure” we henceforth use the catchier term ideal-coal-mine. It evokes the picture of an “ideal-tree” [2,7] having undergone intense compression.
3 Counting all linear extensions
In order to calculate the number of linear extensions of in Figure 1 we proceed cardinality-wise, but now (as opposed to calculating the numbers ) need to access all -ideals individually. Nevertheless the ideal-coal-mine in Table 1 continues to be useful.
First, for each (or any other ) and any it can be decided fast whether or not remains an ideal (and hence a lower cover of in the lattice ). Namely, if is the set of all upper covers of in then clearly
(2) is an ideal iff .
For instance but because . On the other hand since .
Say that by induction for we obtained the lexicographically ordered list (3) of all pairs where ranges over all -element ideals of , and denotes the number of linear extensions of the induced subposet .
(3) , ,
Here “lexicographic” refers to the first components of the pairs: The sets when translated to length ten dyadic numbers in the obvious way satisfy . The corresponding list for is obtained by scanning in each row of Table 1 the ideals of cardinality . Specifically, suppose that by processing to the list has grown (lexicographically) so far:
(4)
We turn to and notice that it doesn’t contain cardinality ideals. But has two of them, i.e. and . Evidently
(5)
where are the lower covers of in . The lower covers of are among the sets . Applying criterion (2) one checks (see Figure 1) that only and qualify. To find out the values and needed in (5) we look for the paris and in list (3). Generally speaking, using binary search to locate an element in an ordered list of length takes time . We obtain that . Similarly has the lower covers
[TABLE]
and after consulting (3) one obtains . The pairs and are now inserted in list (4) at the right place. After processing rows and in Table 1 the same way as one obtains the analogon of list (3) for . List (3) can now be discarded. In the end the list for contains just one pair, i.e. .
3.1 As to distributed computation ( parallelization), suppose the sorted list of pairs , where ranges over the -element ideals, has been compiled at the control unit of a distributed network. The control unit then sends to all satellites and (according333The amount of work for each satellite can be predicted accurately since as seen in Section 2 the number of -element ideals in any multivalued row is easily calculated. to their capacities) distributes the rows of the ideal-coal-mine among them. Each satellite sieves the -element ideals from its rows and, by using and (5), creates a sorted list of pairs . The lists are sent back to the control unit where they are merged to a sorted list . This completes the cycle. In the same way all tasks to be discussed in this article are susceptible to distributed computation.
4 Calculating the average ranks
Given an ideal of and a linear extension of the induced poset , we define the rank of any (w.r.to and ) as the position that occupies in . The average rank of in is defined as
(6) (see e.g. [1])
where denotes the set of all linear extensions of . Thus . In order to calculate recursively we let be the maximal elements of and make a case distinction.
Case 1: . Putting as well as for , we claim that
(7)
Proof of (7). The set gets partitioned into parts according to which element appears last in . Since is not maximal we have for all . Hence if is of type and if by definition results by dropping from , then and . Conversely each is of type . Consequently
[TABLE]
The claim follows upon division with throughout.
Case 2: , say without loss of generality . We claim that
(8)
Proof of (8). We consider the same partitioning of as in the proof of (7). Yet now there are that end in . As for any their number is but evidently for each such . Consequently
from which the claim follows upon dividing by .
5 Rank probabilities and the conjecture
Let be the number of linear extensions of in which occupies the -th position. The parameters can be calculated recursively akin to Section 4. Hence is the (absolute) rank probability that occupies the -th rank in a random linear extension. Basic probability theory yields
(9) .
Equation (9) thus yields the average ranks as a side product of the rank probabilities. The extra information provided by these probabilities may however not justify the effort computing them when gets large.
5.1 In the remainder of Section 5 we calculate the relative rank probability that precedes in a random linear extension . Since when in , and when in , we henceforth focus on incomparable . Obviously where generally for any ideal we define as the number of linear extensions of where precedes . In order to calculate recursively we let be the maximal elements of and put for all .
Case 1: Neither nor are maximal in . Then for all , and obviously
(10)
Case 2: is maximal (say ) but not . Then in none of the many linear extensions of that end in , we have preceeding , and so
(11)
Case 3: is maximal (say but not . Then in all many linear extensions of that end in , we have preceeding , and so
(12)
Case 4: Both and are maximal. If say and then
(13)
5.2 The famous conjecture states that for every poset which is not linearly ordered, there are elements such that (and whence also ). If this conjecture is false (it fails for infinite posets) then our fast algorithm for calculating all probabilities might be helpful in finding a counterexample.
6 Calculating the weighted jump number
Recall that in any linear extension of a -element poset the pair is called a jump if is not an upper cover of . Suppose that associated with each ordered pair of incomparable elements of is a penalty . Define as the sum of all numbers where ranges over the jumps of . Further call the weighted jump number of . If all are set to 1 then is the “ordinary” jump number of , i.e. the minimum number of jumps occuring in any linear extension of .
6.1 Let us see how our framework for calculating caters for as well. Consider some -element ideal of and some linear extension of . Then is a maximal element of and is a linear extension of the ideal . If is a lower cover of then . Otherwise .
For each ideal and each maximal element let be the minimum of all numbers where ranges over all linear extensions of of type . If we manage to calculate all recursively then will be obtained as the minimum of all numbers where ranges over the maximal elements of .
As to calculating , putting we see that can be obtained from as follows. Let be the maximal elements of which happen to be lower covers of (possibly there are none), and let be the remaining maximal elements of (possibly there are none). Then
(14)
The formally best algorithm [10] for calculating has complexity and apparently has not yet been implemented. In fact the only implemented and published algorithm prior to the present article seems to be [4]. It uses so-called greedy chains of to calculate the ordinary jump number. A generalization of [4] to the weighted case is not straightforward.
6.2 Apart from calculating the number , how can we get an optimal linear extension , i.e. satisfying ? As for general dynamic programming tasks, proceed as follows. After each type (14) update store the element that achieves , respectively . Ties are broken arbitrarily. After the so enhanced algorithm of 6.1 has finished, do the following. Starting with , and always picking the lower cover of determined by the pinpointed element, yields .
7 Further applications and generalizations
We glimpse at two further applications of the ideal-coal-mine: Scheduling with time-window constraints (7.1), and the risk polynomial of a poset (7.2). We also speculate on generalizing all tasks discussed in this article from posets to antimatroids (7.3).
7.1 Instead of penalities suppose that coupled to each is a positive number which can be interpreted as the duration to complete job . For each put . Suppose that each job needs to be completed within a time-window . For each ideal let be the number of all linear extensions of that satisfy for all . Evidently can again be obtained recursively as the sum of all numbers where is such that happens to be in .
In a similar vein, but more involved, one can calculate the (weighted) jump number restricted to the subset of all linear extensions that satisfy the time-window constraints. See also [2].
7.2 In the nice math-biology mix [7], where e.g. spaces of genotypes are modelled as distributive lattices, a crucial rôle is placed by the so called risk polynomial of . (Admittedly the following remarks may be too vague for readers unfamiliar with [7] but they may provide a flavour of things.) The many444However, for some applications plenty variables are equated. variables of are indexed by the nontrivial ideals of . Furthermore, by [7, Thm.15] equals the sum of certain products where runs over . The precise definition of in [7, eq.(12)], corrobarated by [6, Example 16], seems to indicate that scanning can be avoided by processing the much fewer filters of . Namely (dual to what we did with ideals), considering as a poset and letting be its minimal elements, the risk polynomial (whose variables are thus indexed by ideals of ) accordingly decomposes as a sum of polynomials
[TABLE]
If is the smaller filter (similarly for is defined), say with minimal elements , then arises from the polynomials in natural ways.
7.3 The ideal lattice of a poset is an example of a set system which is union-closed and graded in the sense that all maximal chains from to have the same length . Such set systems are precisely the set systems of all feasible sets of an antimatroid. Antimatroids are important structures in combinatorial optimization. The so called basic words are to antimatroids what linear extensions are to posets. Chances are good that the ideal-coal-mine carries over from the poset level to the antimatroid level.
8 Numerics
The author coded both the ideal-coal-mine (Section 2) and the count of linear extensions (Section 3) as Mathematica 11.0 notebooks555Using an Intel i5-3470 CPU processor with 3.2 GHz.. For instance, let us look at a randomly generated “thin” 180-element poset , i.e. consisting of 45 levels, each of cardinality 4, such that each element in level (except for ) has exactly two lower covers in level . It took 9 seconds to display the ideals in multivalued rows. Processing the ideals one-by-one took seconds and yielded
(15)
We chose a thin poset in order to have many small ’s, as opposed to few large ones. In particular the highest was . The effect is that the type (3) and (4) lists don’t get too long666As mentioned in 3.1, the type (4) lists can be made as short as pleased by parallelizing. Not so the type (3) lists, but they are only subject to binary search (as opposed to binary search and insertion).. That the magnitude of the ’s is important becomes apparent in the next example where is obtained by cutting top and bottom of the -element Boolean lattice. We calculated , i.e. the sixth Dedekind number, in 16 seconds (using 24871 multivalued rows).
The largest level of Id is the middle one with and level to level all have cardinality . Although is (roughly) only 2.3 times it took 3.2 times longer than for to calculate
(16)
This number confirms the number reported in [9, p.129], whose computation on a computer server took 16 hours, thus about our time. We mention that Neil Sloane’s “Integer Sequences” website features , as well as plenty other numbers of lesser interest. Let us only best one of them. Taking as the first five levels of the Fibonacci 1-differential poset Kavvadias computed . We confirmed this number in 0.5 seconds and went on to calculate in 55 seconds where consists of the bottom six levels of . Also (where the -element poset consists of the bottom seven levels) is within reach because (calculated in 1.5 sec) is not outrageously high. Trouble is, as discussed above, that is too high to be handled without parallelizing.
For an updated version of the present article the author sollicites interesting proposals of jump number computations (or the other parameters discussed).
References
- [1]
G. Brightwell, P. Winkler, Counting linear extensions, Order 8 (1991) 225-242. 2. [2]
A. Mingozzi, Bianco, S. Ricciardelli, Dynamic programming strategies for the Traveling Salesman Problem with time window and precedence constraints, Oper. Res. 45 (1997) 365-377. 3. [3]
M. Habib, L. Nourine, Tree structure for distributive lattices and its applications. Theoretical Computer Science 165 (1996) 391-405. 4. [4]
L. Bianco, P. Dell’Olmo, S. Giordani, An optimal algorithm to find the jump number of partially ordered sets, Computational Optimization and Applications 8 (1997) 197-210. 5. [5]
R.P. Stanley, Enumerative Combinatorics, Volume 1, Cambridge Studies in Advanced Mathematics 49 (1997). 6. [6]
M. Peczarski, New results in minimum-comparison sorting, Algorithmica 40 (2004) 133-145. 7. [7]
N. Beerenwinkel, N. Eriksson, B. Sturmfels, Evolution on distributive lattices, Journal of Theoretical Biology 242 (2006) 409-420. 8. [8]
K. De Loof, B. De Baets, H. De Meyer, Exploiting the lattice of ideals representation of a poset, Fundamenta Informaticae 71 (2006) 309-321. 9. [9]
O. Wienand, Algorithms for symbolic computation and their applications, PHD, University of Kaiserslauten 2011. 10. [10]
D. Kratsch, S. Kratsch, The jump number problem: Exact and parametrized, Lecture Notes in Computer Science 8246 (2013) 230-242. 11. [11]
M. Wild, Output-polynomial enumeration of all fixed-cardinality ideals of a poset, respectively all fixed-cardinality subtrees of a tree, Order 31 (2014) 121-135. 12. [12]
M. Wild, ALLSAT compressed with wildcards, Part 1: Converting CNF’s to orthogonal DNF’s, preliminary version, available on ResearchGate.