TL;DR
This paper demonstrates that adding noise to discrete variables allows existing nonparametric estimators designed for continuous data to be effectively extended to mixed data, simplifying implementation and preserving asymptotic properties.
Contribution
It provides a theoretical justification for using noise addition to handle discrete variables in nonparametric estimation, enabling straightforward extension of continuous estimators to mixed data.
Findings
Adding noise from a specific class justifies continuous convolution estimators for mixed data.
Asymptotic properties of estimators transfer from continuous to mixed data settings.
The approach simplifies implementation of nonparametric methods with mixed data.
Abstract
In practice, data often contain discrete variables. But most of the popular nonparametric estimation methods have been developed in a purely continuous framework. A common trick among practitioners is to make discrete variables continuous by adding a small amount of noise. We show that this approach is justified if the noise distribution belongs to a certain class. In this case, any estimator developed in a purely continuous framework extends naturally to the mixed data setting. Estimators defined that way will be called continuous convolution estimators. They are extremely easy to implement and their asymptotic properties transfer directly from the continuous to the mixed data setting.
Click any figure to enlarge with its caption.
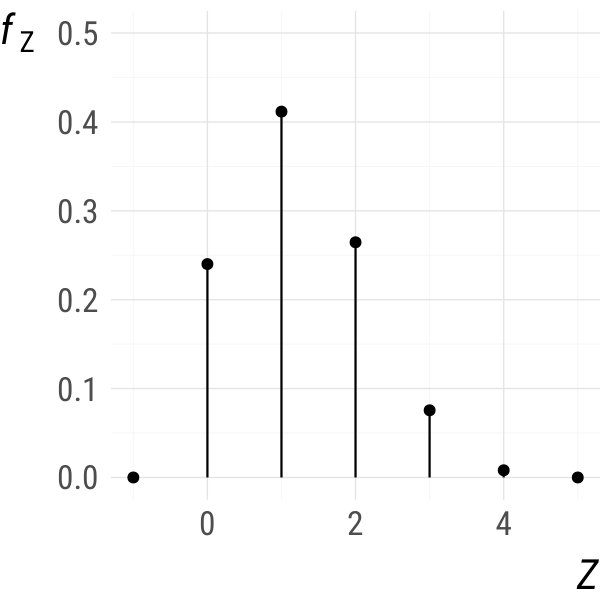 Figure 1
Figure 1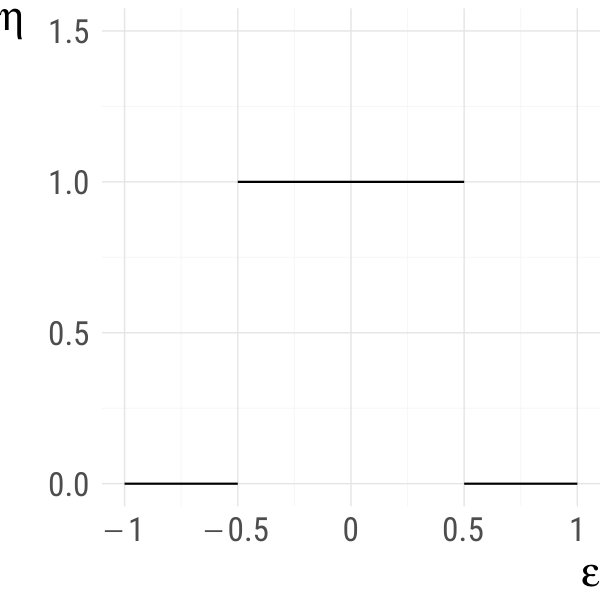 Figure 2
Figure 2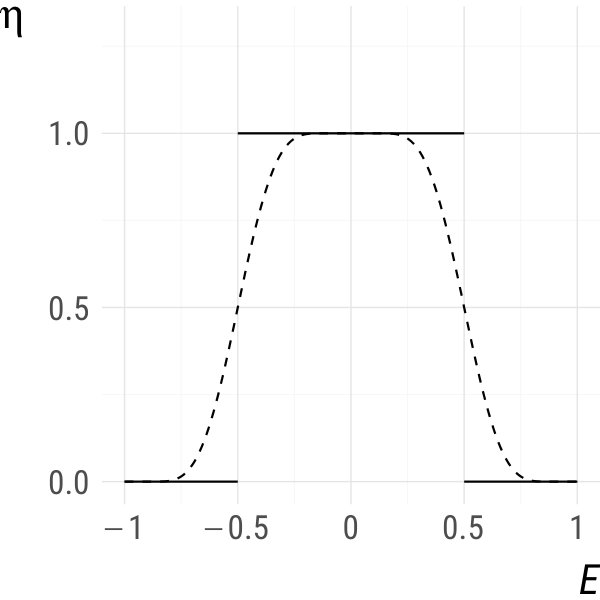 Figure 3
Figure 3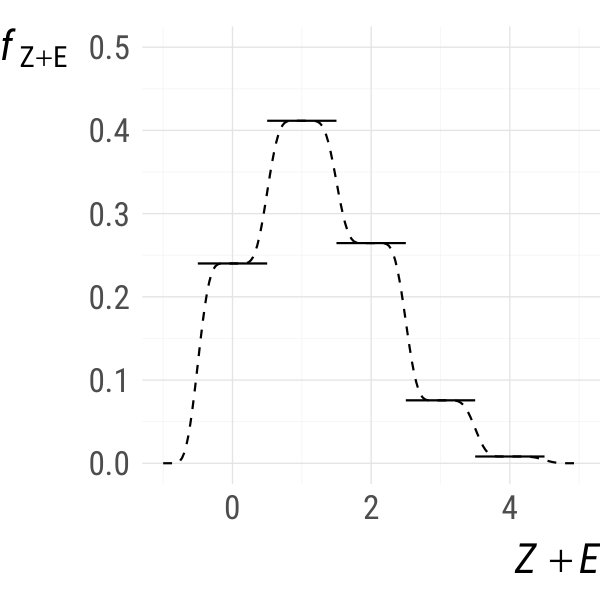 Figure 4
Figure 4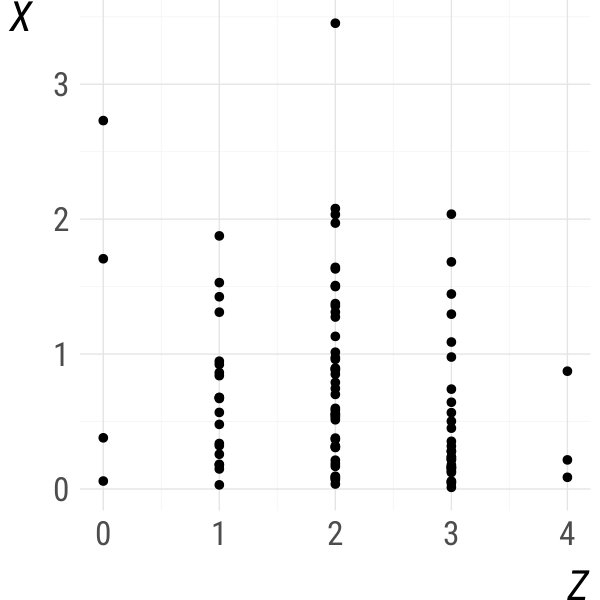 Figure 5
Figure 5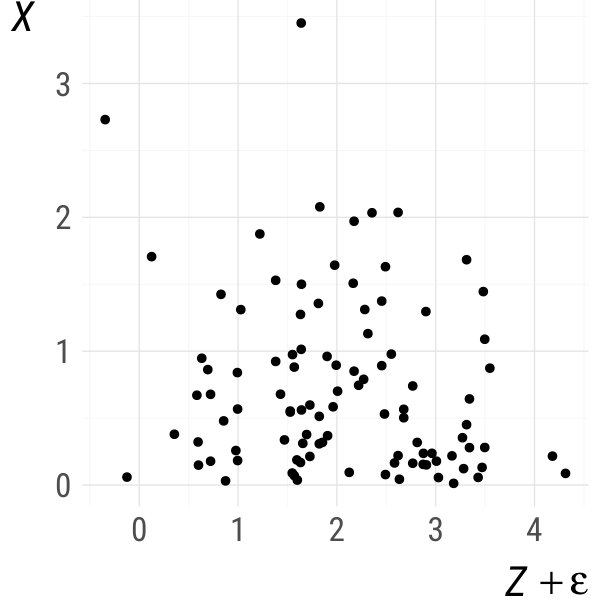 Figure 6
Figure 6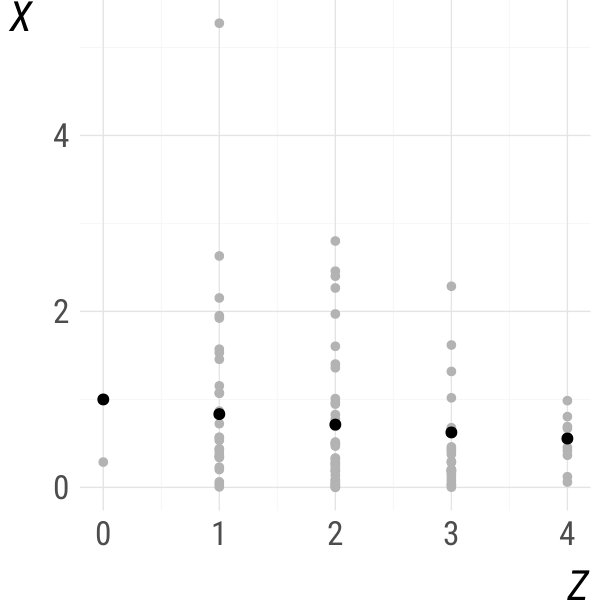 Figure 7
Figure 7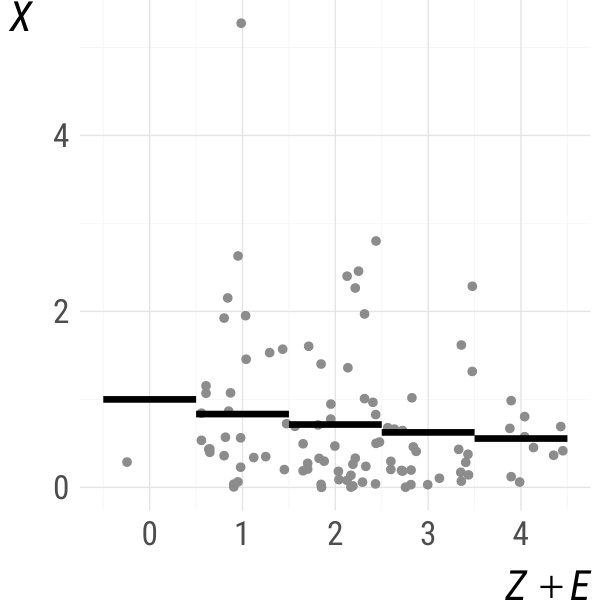 Figure 8
Figure 8Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
A generic approach to nonparametric function estimation with mixed data
Thomas Nagler
Department of Mathematics, Technical University of Munich, Boltzmanstraße 3, 85748 Garching, Germany [email protected]
Abstract
Most nonparametric function estimators can only handle continuous data. We show that making discrete variables continuous by adding noise is justified under suitable conditions on the noise distribution. This principle is widely applicable, including density and regression function estimation.
keywords:
Density , discrete , jitter , mixed data , nonparametric , regression
1 Introduction
In applications of statistics, data containing discrete variables are omnipresent. An online retailer records information on how many purchases a customer made in the past. Social scientists typically use discrete scales on which study participants rate their satisfaction, attitude, or feelings. Another common example is where data describe unordered categories, like gender or business sectors.
Suppose that is a random vector with discrete component and continuous component . This includes the cases , (all variables are discrete) and , (all variables are continuous). We consider problems where one aims at estimating a functional of the density/probability mass function based on observations , . This formulation is general enough to include many common problems in nonparametric function estimation, in particular: density estimation, regression, and classification.
Some nonparametric estimation techniques have been specifically designed to allow for mixed continuous and discrete data (Ahmad and Cerrito, 1994; Li and Racine, 2003; Hall et al., 1983; Efromovich, 2011), but the number is small and the more sophisticated methods are often developed in a purely continuous framework. Examples are local polynomial methods (Fan and Gijbels, 1996; Loader, 1999) or copula-based estimators (e.g., Otneim and Tjøstheim, 2016; Nagler and Czado, 2016; Kauermann and Schellhase, 2014). These methods are no longer consistent when applied to mixed data types.
There is a popular trick among practitioners to get an approximate answer nevertheless: just make the data continuous by adding noise to each discrete variable. This trick is sometimes called jittering or adding jitter. Examples where it has been successfully applied are: avoiding overplotting in data visualization (Few, 2008), adding intentional bias to complex machine learning models (Zur et al., 2004), deriving theoretical properties of concordance measures (Denuit and Lambert, 2005), or nonparametric copula estimation for mixed data (Genest et al., 2017). An example of its misuse was pointed out by Nikoloulopoulos (2013) in the context of parametric copula models. Generally, the trick lacks theoretical justification because it can introduce bias. But we shall see that this issue is resolved under a suitable choice of noise distribution.
This letter aims to formalize this somewhat “dirty” trick and to provide a starting point for a more nuanced investigation of its properties. Some open questions and partial answers will be given at the end.
2 Jittering mixed data
2.1 Preliminaries and notation
We assume throughout that all random variables live in a space with a natural concept of ordering. Unordered categorical variables can always be coded into a set of binary dummy variables (for which gives a natural ordering). We further assume without loss of generality that any discrete random variable, say , is supported on a set . For any continuous random vector , we write for its joint density. In case is a discrete random vector, denotes its density with respect to the counting measure, i.e., . A random vector with mixed types will be partitioned into . Then is the density with respect to the product of the counting and Lebesgue measures,
[TABLE]
2.2 The density of a jittered random vector
The jittered version of a random vector is defined by adding noise to all discrete variables.
Definition 1**.**
Let be a bounded density function that is continuous almost everywhere on . The jittered version of the random vector is defined as , where is independent of .
Provided that exists, the density of the jittered vector is simply the discrete-continuous convolution of and the noise density :
[TABLE]
We observe a close relationship between the densities and . If we know at all values , we can immediately compute at all values . The other direction is more interesting for our purposes: can we recover from known values of ? In general, this poses a rather challenging deconvolution problem. But we can make things easier by a suitable choice of noise density . In fact, there is a large class of noise densities densities for which no deconvolution is necessary and and coincide on .
Proposition 1**.**
It holds
[TABLE]
for any joint density and all , if and only if the following two conditions are satisfied:
, 2. 2.
there exists such that for all .
A simple, but powerful implication is that we can estimate the discrete-continuous density by estimating the purely continuous density .
2.3 A convenient class of noise distributions
In the following we give a particularly convenient class of noise densities.
Definition 2**.**
We say that for some , if for all , where is an absolutely continuous probability density function, for all , and for all .
The class satisfies (1), but adds two more restrictions to the conditions given in Proposition 1: (i) the random noise is componentwise independent, (ii) it is constant in a neighborhood of zero. The first restriction is made purely for convenience and will be discussed further in Section 4.2. The second ensures that the derivatives of with respect to vanish for all . This property is particularly useful in nonparametric density estimation, since an estimators’ bias is usually proportional to derivatives of the target density.
Proposition 2**.**
If , , and such that , then
[TABLE]
Example 1**.**
Let and . Set where and . The density of can be calculated as
[TABLE]
It is easy to check that and that is times continuously differentiable everywhere on . Hence, if is times continuously differentiable in for all , is times continuously differentiable everywhere on . Also, coincides with everywhere on . This is illustrated in Fig. 1 for (the uniform distribution on , solid), as well as and (dashed). ∎
3 Nonparametric function estimation via jittering
3.1 Jittering estimators
Suppose we want to estimate a functional of , where . Let , …, be a stationary sequence of random vectors having the same distribution as . Let further , , be independent and identically distributed vectors that have the same distribution as (as in Definition 1) and are independent of .
Definition 3**.**
An estimator of is called jittering estimator if it is a measurable function of the jittered data, i.e., .
Jittering estimators are extremely easy to implement: all one needs is a way to generate random noise and an estimator that works for continuous data. The following two examples introduce jittering analogues of popular estimators that, in their original version, are only applicable to continuous data.
Example 2** (Kernel density estimation).**
The jittering kernel density estimator of is
[TABLE]
where and is a symmetric, multivariate density function. The classical kernel density estimator of Parzen (1962) and Rosenblatt (1956) is recovered when for all .
Example 3** (Local linear regression).**
The jittering local linear regression estimator of is
[TABLE]
where and are as in Example 2. With for all , we recover the classical local linear regression estimator (e.g., Fan and Gijbels, 1996).
3.2 Applications: estimating a regression function
Now suppose that there is another functional such that . We shall call the jittering equivalent of . Now if is an estimator of , then it is also an estimator of . This means that we can use any estimator that works in a purely continuous setting to estimate the target functional , even though is the density of a mixed data model. An example for such a situation is density estimation where and (see Proposition 1). But the setup is much more general and covers most common regression problems, as the following examples show.
Example 4** (Mean regression, continuous response).**
The conditional mean can be expressed as
[TABLE]
The jittering equivalent is . The discrete response case is analogous.
Example 5** (Distribution regression, discrete response).**
The conditional distribution function can be expressed as
[TABLE]
The jittering equivalent is
[TABLE]
The continuous response case is similar, but does not require a correction term as in the previous display.
Example 6** (Quantile regression).**
For , the conditional quantile function corresponding to can be expressed as T_{q,d}(f_{\bm{Z},\bm{X}})=\inf\bigl{\{}\bar{z}_{1}\in\mathbb{R}\colon T_{p,d}(f_{\bm{Z},\bm{X}})\geq\alpha\bigr{\}}, where is as in Example 5. The jittering equivalent is T_{q,d}^{*}(f_{\bm{Z},\bm{X}})=\inf\bigl{\{}\bar{z}_{1}\in\mathbb{R}\colon T_{p,d}^{*}(f_{\bm{Z},\bm{X}})\geq\alpha\bigr{\}}. The continuous response case is analogous.
3.3 Asymptotic properties
A convenient fact about jittering estimators is that asymptotic properties for estimating directly translate into properties for estimating . The following result is trivial, but important enough to be stated formally.
Proposition 3**.**
Let and be two functionals such that . If for some sequence and random variable , almost surely, in probability, or in distribution, then also almost surely, in probability, or in distribution.
In particular, any (strongly) consistent estimator of is at the same time a (strongly) consistent estimator of . Even better: since we can choose the noise distribution we gain some control over the local behavior of the jittered density . If is sufficiently well-behaved, this allows us to control the local behavior of the estimation target , too. For example, the form of the regression functionals and Proposition 2 imply that all derivatives of w.r.t. vanish in a -neighborhood of . This allows to estimate regression functionals without bias for the discrete part and, thus, to improve the convergence rates of the estimator ; see Nagler (2017) for an in-depth analysis of the jittering kernel density estimator.
4 Discussion
4.1 Benefits
The most obvious benefit of jittering estimators is convenience. For their implementation, all one needs is an estimator that works in the continuous setting and a way to simulate random noise. This is easily achieved in modern statistical software. At second glance, the method opens many possibilities to extend existing estimators to the mixed data setting. This is increasingly useful with increasing complexity of the estimators. In many cases, there is otherwise no straightforward way to adapt an estimator to mixed data.
A less obvious benefit arises for studying general properties of a nonparametric function estimation problem. In the continuous setting, asymptotic arguments are often easier and well-established. For example, jittering arguments make it straightforward to derive minimax-optimal rates of convergence in nonparametric mixed data models; see Nagler (2017) in the case of density estimation.
4.2 Issues and open questions
Curse of dimensionality
A key issue for nonparametric estimators is the curse of dimensionality. In a continuous setting, the speed of convergence decreases exponentially in the dimension. For example, the classical convergence rate for estimating a -dimensional continuous density is . A discrete density on the other hand can always be estimated with rate, so there is no curse of dimensionality. It is not obvious, which regime jittering estimators fall into, since a discrete density is estimated by exchanging it with a continuous surrogate.
Unfortunately, this question has no general answer and depends on the estimators’ characteristics. The main criterion is how “local” the estimator operates; or more specifically, if the estimator is only affected by data in a compact neighborhood. For example, B-spline methods and kernel estimators with a compact kernel function will usually fall into the discrete regime, whereas Bernstein polynomials and kernel estimators with unbounded kernels fall into the continuous one. But we should stress that such considerations are only asymptotic and the behavior on finite samples will likely fall somewhere in between.
Efficiency
Typically, adding noise brings about some unnecessary variance. The magnitude of this effect depends on the characteristics of the estimator. Generally, this additional variance can be reduced by averaging estimates over multiple independent jitters (cf., Genest et al., 2017). In specific cases, a jittering estimator can be inherently efficient, with no need for averaging (see, Nagler, 2017, Section 4.1).
Choice of noise distribution
When using the jittering technique, an immediate question is which noise distribution to choose. The necessary conditions given in Proposition 1 are fairly broad and allow for a variety of noise distributions.
A referee asked whether it would be possible to preserve some dependence characteristics of the data. Unfortunately, dependence between discrete variables and its connection to the continuous counterpart is a highly subtle issue. One such subtlety is that there is no density when continuous variables are perfectly dependent, but the probability mass function for perfectly dependent variables exists. Genest and Neslehova (2007) address many other interesting issues. The article also provides some arguments for using independent noise, because it is the only way to preserve the equality between probabilistic and analytical definitions of some margin-free dependence measures like Kendall’s and Spearman’s (their equation 7) or tie-corrected versions (p. 495).
In any case, one should understand jittering as an estimation technique rather than a modeling technique. Interpreting the jittered model independently of the “true” one is unlikely to be beneficial. The letter’s only criterion for validity of jittering was consistency of estimators. But we should expect that a data-driven choice of noise distribution would improve estimators’ accuracy. A closer examination of the noise distribution’s effect will be a promising path for future research.
Restriction to nonparametric techniques
Finally, we should warn that this methodology is only valid for nonparametric estimators. Usually, the shape of functionals of the jittered density can not be captured by parametric models, leading to estimators that are inconsistent.
Acknowledgements
This work was partially supported by the German Research Foundation (DFG grant CZ 86/5-1). The author thanks two anonymous referees for raising many interesting points that greatly improved the comprehensiveness of this contribution.
References
- Ahmad and Cerrito (1994)
Ahmad, I. A., Cerrito, P. B., 1994. Nonparametric estimation of joint discrete-continuous probability densities with applications. Journal of Statistical Planning and Inference 41 (3), 349–364.
- Denuit and Lambert (2005)
Denuit, M., Lambert, P., 2005. Constraints on concordance measures in bivariate discrete data. Journal of Multivariate Analysis 93 (1), 40–57.
- Efromovich (2011)
Efromovich, S., 2011. Nonparametric estimation of the anisotropic probability density of mixed variables. Journal of Multivariate Analysis 102 (3), 468 – 481.
- Fan and Gijbels (1996)
Fan, J., Gijbels, I., 1996. Local polynomial modelling and its applications: monographs on statistics and applied probability 66. Vol. 66. CRC Press.
- Few (2008)
Few, S., 2008. Solutions to the problem of over-plotting in graphs. Visual Business Intelligence Newsletter.
- Genest and Neslehova (2007)
Genest, C., Neslehova, J., 2007. A primer on copulas for count data. Astin Bulletin 37 (02), 475–515.
- Genest et al. (2017)
Genest, C., Nešlehová, J. G., Rémillard, B., 2017. Asymptotic behavior of the empirical multilinear copula process under broad conditions. Journal of Multivariate Analysis.
- Hall et al. (1983)
Hall, P., et al., 1983. Orthogonal series methods for both qualitative and quantitative data. The Annals of Statistics 11 (3), 1004–1007.
- Kauermann and Schellhase (2014)
Kauermann, G., Schellhase, C., 2014. Flexible pair-copula estimation in d-vines with penalized splines. Statistics and Computing 24 (6), 1081–1100.
- Li and Racine (2003)
Li, Q., Racine, J., 2003. Nonparametric estimation of distributions with categorical and continuous data. Journal of Multivariate Analysis 86 (2), 266–292.
- Loader (1999)
Loader, C., 1999. Local regression and likelihood. Springer New York.
- Nagler (2017)
Nagler, T., 2017. Asymptotic analysis of the jittering kernel density estimator. arXiv:1705.05431.
- Nagler and Czado (2016)
Nagler, T., Czado, C., 2016. Evading the curse of dimensionality in nonparametric density estimation with simplified vine copulas. Journal of Multivariate Analysis 151, 69–89.
- Nikoloulopoulos (2013)
Nikoloulopoulos, A. K., 2013. On the estimation of normal copula discrete regression models using the continuous extension and simulated likelihood. Journal of Statistical Planning and Inference 143 (11), 1923–1937.
- Otneim and Tjøstheim (2016)
Otneim, H., Tjøstheim, D., 2016. The locally gaussian density estimator for multivariate data. Statistics and Computing, 1–22.
- Parzen (1962)
Parzen, E., 09 1962. On estimation of a probability density function and mode. The Annals of Mathematical Statistics 33 (3), 1065–1076.
URL http://dx.doi.org/10.1214/aoms/1177704472
- Rosenblatt (1956)
Rosenblatt, M., 09 1956. Remarks on some nonparametric estimates of a density function. The Annals of Mathematical Statistics 27 (3), 832–837.
URL http://dx.doi.org/10.1214/aoms/1177728190
- Zur et al. (2004)
Zur, R., Jiang, Y., Metz, C., 2004. Comparison of two methods of adding jitter to artificial neural network training. International Congress Series 1268, 886 – 889, {CARS} 2004 - Computer Assisted Radiology and Surgery. Proceedings of the 18th International Congress and Exhibition.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Ahmad and Cerrito (1994) Ahmad, I. A., Cerrito, P. B., 1994. Nonparametric estimation of joint discrete-continuous probability densities with applications. Journal of Statistical Planning and Inference 41 (3), 349–364.
- 2Denuit and Lambert (2005) Denuit, M., Lambert, P., 2005. Constraints on concordance measures in bivariate discrete data. Journal of Multivariate Analysis 93 (1), 40–57.
- 3Efromovich (2011) Efromovich, S., 2011. Nonparametric estimation of the anisotropic probability density of mixed variables. Journal of Multivariate Analysis 102 (3), 468 – 481.
- 4Fan and Gijbels (1996) Fan, J., Gijbels, I., 1996. Local polynomial modelling and its applications: monographs on statistics and applied probability 66. Vol. 66. CRC Press.
- 5Few (2008) Few, S., 2008. Solutions to the problem of over-plotting in graphs. Visual Business Intelligence Newsletter.
- 6Genest and Neslehova (2007) Genest, C., Neslehova, J., 2007. A primer on copulas for count data. Astin Bulletin 37 (02), 475–515.
- 7Genest et al. (2017) Genest, C., Nešlehová, J. G., Rémillard, B., 2017. Asymptotic behavior of the empirical multilinear copula process under broad conditions. Journal of Multivariate Analysis.
- 8Hall et al. (1983) Hall, P., et al., 1983. Orthogonal series methods for both qualitative and quantitative data. The Annals of Statistics 11 (3), 1004–1007.
