TL;DR
Watset introduces a graph-based method for automatically inducing synsets from synonymy graphs and word embeddings, effectively handling ambiguity and outperforming existing methods on multiple datasets.
Contribution
The paper proposes a novel meta-clustering approach that combines synonym graphs and word sense induction to automatically generate high-quality synsets.
Findings
Outperforms five state-of-the-art methods in F-score
Effective on datasets for English and Russian
Handles ambiguous words through sense induction
Abstract
This paper presents a new graph-based approach that induces synsets using synonymy dictionaries and word embeddings. First, we build a weighted graph of synonyms extracted from commonly available resources, such as Wiktionary. Second, we apply word sense induction to deal with ambiguous words. Finally, we cluster the disambiguated version of the ambiguous input graph into synsets. Our meta-clustering approach lets us use an efficient hard clustering algorithm to perform a fuzzy clustering of the graph. Despite its simplicity, our approach shows excellent results, outperforming five competitive state-of-the-art methods in terms of F-score on three gold standard datasets for English and Russian derived from large-scale manually constructed lexical resources.
Click any figure to enlarge with its caption.
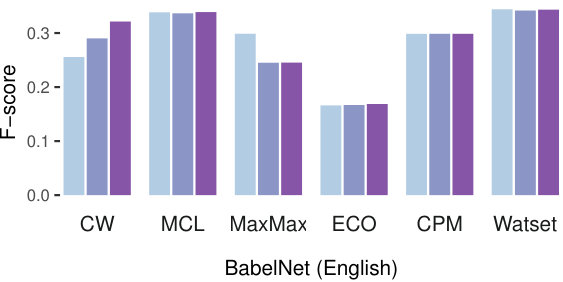 Figure 1
Figure 1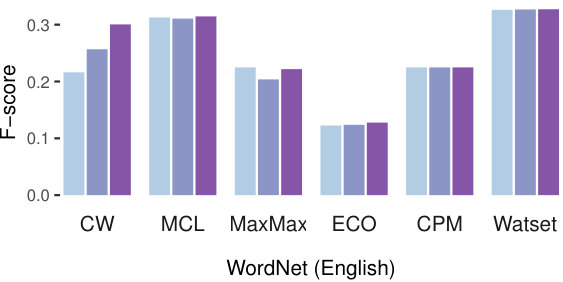 Figure 2
Figure 2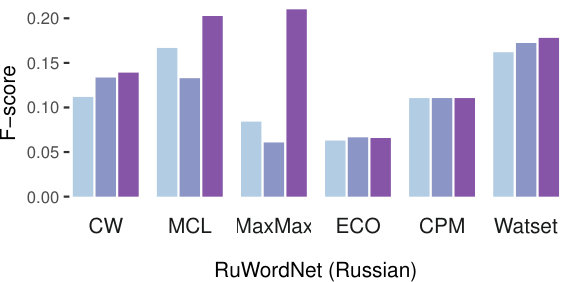 Figure 3
Figure 3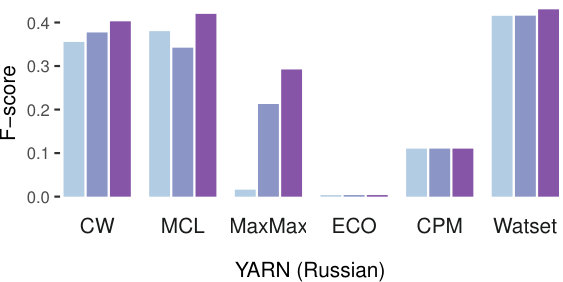 Figure 4
Figure 4 Figure 5
Figure 5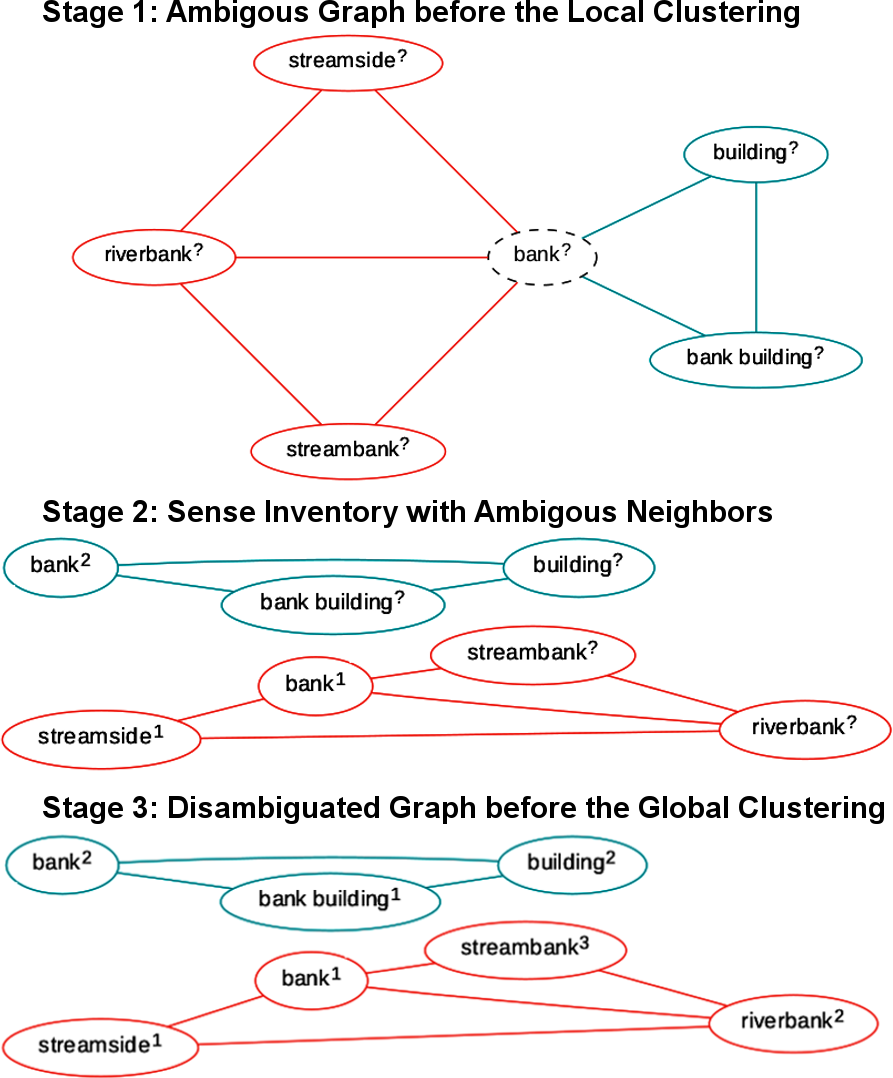 Figure 6
Figure 6| Resource | # words | # synsets | # synonyms | |
|---|---|---|---|---|
| WordNet | En | |||
| BabelNet | En | |||
| RuWordNet | Ru | |||
| YARN | Ru |
| Language | # words | # synonyms |
|---|---|---|
| English | ||
| Russian |
| WordNet | BabelNet | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Method | # words | # synsets | # synonyms | P | R | F1 | P | R | F1 |
| Watset[MCL, MCL] | |||||||||
| MCL | |||||||||
| Watset[MCL, CWlog] | |||||||||
| CWtop | |||||||||
| Watset[CWlog, MCL] | |||||||||
| Watset[CWlog, CWlog] | |||||||||
| CPM | |||||||||
| MaxMax | |||||||||
| ECO | |||||||||
| RuWordNet | YARN | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Method | # words | # synsets | # synonyms | P | R | F1 | P | R | F1 |
| Watset[CWnolog, MCL] | |||||||||
| Watset[MCL, MCL] | |||||||||
| Watset[CWtop, CWlog] | |||||||||
| MCL | |||||||||
| Watset[MCL, CWtop] | |||||||||
| CWnolog | |||||||||
| MaxMax | |||||||||
| CPM | |||||||||
| ECO | |||||||||
| Resource | P | R | F1 | |
|---|---|---|---|---|
| BabelNet on WordNet | En | |||
| WordNet on BabelNet | En | |||
| YARN on RuWordNet | Ru | |||
| BabelNet on RuWordNet | Ru | |||
| RuWordNet on YARN | Ru | |||
| BabelNet on YARN | Ru |
| Size | Synset |
|---|---|
| 2 | {decimal point, dot} |
| 3 | {gullet, throat, food pipe} |
| 4 | {microwave meal, ready meal, TV dinner, frozen dinner} |
| 5 | {objective case, accusative case, oblique case, object case, accusative} |
| 6 | {radio theater, dramatized audiobook, audio theater, radio play, radio drama, audio play} |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Watset: Automatic Induction of Synsets from a Graph of Synonyms
Dmitry Ustalov
Alexander Panchenko
Chris Biemann
Abstract
This paper presents a new graph-based approach that induces synsets using synonymy dictionaries and word embeddings. First, we build a weighted graph of synonyms extracted from commonly available resources, such as Wiktionary. Second, we apply word sense induction to deal with ambiguous words. Finally, we cluster the disambiguated version of the ambiguous input graph into synsets. Our meta-clustering approach lets us use an efficient hard clustering algorithm to perform a fuzzy clustering of the graph. Despite its simplicity, our approach shows excellent results, outperforming five competitive state-of-the-art methods in terms of F-score on three gold standard datasets for English and Russian derived from large-scale manually constructed lexical resources.
1 Introduction
A synset is a set of mutual synonyms, which can be represented as a clique graph where nodes are words and edges are synonymy relations. Synsets represent word senses and are building blocks of WordNet Miller (1995) and similar resources such as thesauri and lexical ontologies. These resources are crucial for many natural language processing applications that require common sense reasoning, such as information retrieval Gong et al. (2005) and question answering Kwok et al. (2001); Zhou et al. (2013). However, for most languages, no manually-constructed resource is available that is comparable to the English WordNet in terms of coverage and quality. For instance, Kiselev et al. (2015) present a comparative analysis of lexical resources available for the Russian language concluding that there is no resource compared to WordNet in terms of coverage and quality for Russian. This lack of linguistic resources for many languages urges the development of new methods for automatic construction of WordNet-like resources. The automatic methods foster construction and use of the new lexical resources.
Wikipedia111http://www.wikipedia.org, Wiktionary222http://www.wiktionary.org, OmegaWiki333http://www.omegawiki.org and other collaboratively-created resources contain a large amount of lexical semantic information---yet designed to be human-readable and not formally structured. While semantic relations can be automatically extracted using tools such as DKPro JWKTL444https://dkpro.github.io/dkpro-jwktl and Wikokit555https://github.com/componavt/wikokit, words in these relations are not disambiguated. For instance, the synonymy pairs (bank, streambank) and (bank, banking company) will be connected via the word ‘‘bank’’, while they refer to the different senses. This problem stems from the fact that articles in Wiktionary and similar resources list undisambiguated synonyms. They are easy to disambiguate for humans while reading a dictionary article, but can be a source of errors for language processing systems.
The contribution of this paper is a novel approach that resolves ambiguities in the input graph to perform fuzzy clustering. The method takes as an input synonymy relations between potentially ambiguous terms available in human-readable dictionaries and transforms them into a machine readable representation in the form of disambiguated synsets. Our method, called Watset, is based on a new local-global meta-algorithm for fuzzy graph clustering. The underlying principle is to discover the word senses based on a local graph clustering, and then to induce synsets using global sense clustering. We show that our method outperforms other methods for synset induction. The induced resource eliminates the need in manual synset construction and can be used to build WordNet-like semantic networks for under-resourced languages. An implementation of our method along with induced lexical resources is available online.666https://github.com/dustalov/watset
2 Related Work
Methods based on resource linking surveyed by Gurevych et al. (2016) gather various existing lexical resources and perform their linking to obtain a machine-readable repository of lexical semantic knowledge. For instance, BabelNet Navigli and Ponzetto (2012) relies in its core on a linking of WordNet and Wikipedia. UBY Gurevych et al. (2012) is a general-purpose specification for the representation of lexical-semantic resources and links between them. The main advantage of our approach compared to the lexical resources is that no manual synset encoding is required.
Methods based on word sense induction try to induce sense representations without the need for any initial lexical resource by extracting semantic relations from text. In particular, word sense induction (WSI) based on word ego networks clusters graphs of semantically related words Lin (1998); Pantel and Lin (2002); Dorow and Widdows (2003); Véronis (2004); Hope and Keller (2013); Pelevina et al. (2016); Panchenko et al. (2017a), where each cluster corresponds to a word sense. An ego network consists of a single node (ego) together with the nodes they are connected to (alters) and all the edges among those alters Everett and Borgatti (2005). In the case of WSI, such a network is a local neighborhood of one word. Nodes of the ego network are the words which are semantically similar to the target word.
Such approaches are able to discover homonymous senses of words, e.g., ‘‘bank’’ as slope versus ‘‘bank’’ as organisation Di Marco and Navigli (2012). However, as the graphs are usually composed of semantically related words obtained using distributional methods Baroni and Lenci (2010); Biemann and Riedl (2013), the resulting clusters by no means can be considered synsets. Namely, (1) they contain words related not only via synonymy relation, but via a mixture of relations such as synonymy, hypernymy, co-hyponymy, antonymy, etc. Heylen et al. (2008); Panchenko (2011); (2) clusters are not unique, i.e., one word can occur in clusters of different ego networks referring to the same sense, while in WordNet a word sense occurs only in a single synset.
In our synset induction method, we use word ego network clustering similarly as in word sense induction approaches, but apply them to a graph of semantically clean synonyms.
Methods based on clustering of synonyms, such as our approach, induce the resource from an ambiguous graph of synonyms where edges a extracted from manually-created resources. According to the best of our knowledge, most experiments either employed graph-based word sense induction applied to text-derived graphs or relied on a linking-based method that already assumes availability of a WordNet-like resource. A notable exception is the ECO approach by Gonçalo Oliveira and Gomes (2014), which was applied to induce a WordNet of the Portuguese language called Onto.PT.777http://ontopt.dei.uc.pt We compare to this approach and to five other state-of-the-art graph clustering algorithms as the baselines.
ECO Gonçalo Oliveira and Gomes (2014) is a fuzzy clustering algorithm that was used to induce synsets for a Portuguese WordNet from several available synonymy dictionaries. The algorithm starts by adding random noise to edge weights. Then, the approach applies Markov Clustering (see below) of this graph several times to estimate the probability of each word pair being in the same synset. Finally, candidate pairs over a certain threshold are added to output synsets.
MaxMax Hope and Keller (2013) is a fuzzy clustering algorithm particularly designed for the word sense induction task. In a nutshell, pairs of nodes are grouped if they have a maximal mutual affinity. The algorithm starts by converting the undirected input graph into a directed graph by keeping the maximal affinity nodes of each node. Next, all nodes are marked as root nodes. Finally, for each root node, the following procedure is repeated: all transitive children of this root form a cluster and the root are marked as non-root nodes; a root node together with all its transitive children form a fuzzy cluster.
Markov Clustering (MCL) van Dongen (2000) is a hard clustering algorithm for graphs based on simulation of stochastic flow in graphs. MCL simulates random walks within a graph by alternation of two operators called expansion and inflation, which recompute the class labels. Notably, it has been successfully used for the word sense induction task Dorow and Widdows (2003).
Chinese Whispers (CW) Biemann (2006) is a hard clustering algorithm for weighted graphs that can be considered as a special case of MCL with a simplified class update step. At each iteration, the labels of all the nodes are updated according to the majority labels among the neighboring nodes. The algorithm has a meta-parameter that controls graph weights that can be set to three values: (1) top sums over the neighborhood’s classes; (2) nolog downgrades the influence of a neighboring node by its degree or by (3) log of its degree.
Clique Percolation Method (CPM) Palla et al. (2005) is a fuzzy clustering algorithm for unweighted graphs that builds up clusters from -cliques corresponding to fully connected sub-graphs of nodes. While this method is only commonly used in social network analysis, we decided to add it to the comparison as synsets are essentially cliques of synonyms, which makes it natural to apply an algorithm based on clique detection.
3 The Watset Method
The goal of our method is to induce a set of unambiguous synsets by grouping individual ambiguous synonyms. An outline of the proposed approach is depicted in Figure 1. The method takes a dictionary of ambiguous synonymy relations and a text corpus as an input and outputs synsets. Note that the method can be used without a background corpus, yet as our experiments will show, corpus-based information improves the results when utilizing it for weighting the word graph’s edges.
A synonymy dictionary can be perceived as a graph, where the nodes correspond to lexical entries (words) and the edges connect pairs of the nodes when the synonymy relation between them holds. The cliques in such a graph naturally form densely connected sets of synonyms corresponding to concepts Gfeller et al. (2005). Given the fact that solving the clique problem exactly in a graph is NP-complete Bomze et al. (1999) and that these graphs typically contain tens of thousands of nodes, it is reasonable to use efficient hard graph clustering algorithms, like MCL and CW, for finding a global segmentation of the graph. However, the hard clustering property of these algorithm does not handle polysemy: while one word could have several senses, it will be assigned to only one cluster. To deal with this limitation, a word sense induction procedure is used to induce senses for all words, one at the time, to produce a disambiguated version of the graph where a word is now represented with one or many word senses. The concept of a disambiguated graph is described in Biemann (2012). Finally, the disambiguated word sense graph is clustered globally to induce synsets, which are hard clusters of word senses.
More specifically, the method consists of five steps presented in Figure 1: (1) learning word embeddings; (2) constructing the ambiguous weighted graph of synonyms ; (3) inducing the word senses; (4) constructing the disambiguated weighted graph by disambiguating of neighbors with respect to the induced word senses; (5) global clustering of the graph .
3.1 Learning Word Embeddings
Since different graph clustering algorithms are sensitive to edge weighting, we consider distributional semantic similarity based on word embeddings as a possible edge weighting approach for our synonymy graph. As we show further, this approach improves over unweighted versions and yields the best overall results.
3.2 Construction of a Synonymy Graph
We construct the synonymy graph as follows. The set of nodes includes every lexeme appearing in the input synonymy dictionaries. The set of undirected edges is composed of all edges retrieved from one of the input synonymy dictionaries. We consider three edge weight representations:
- •
ones that assigns every edge the constant weight of 1;
- •
count that weights the edge as the number of times the synonymy pair appeared in the input dictionaries;
- •
sim that assigns every edge a weight equal to the cosine similarity of skip-gram word vectors Mikolov et al. (2013).
As the graph is likely to have polysemous words, the goal is to separate individual word senses using graph-based word sense induction.
3.3 Local Clustering: Word Sense Induction
In order to facilitate global fuzzy clustering of the graph, we perform disambiguation of its ambiguous nodes as illustrated in Figure 2. First, we use a graph-based word sense induction method that is similar to the curvature-based approach of Dorow and Widdows (2003). In particular, removal of the nodes participating in many triangles tends to separate the original graph into several connected components. Thus, given a word , we extract a network of its nearest neighbors from the synonymy graph . Then, we remove the original word from this network and run a hard graph clustering algorithm that assigns one node to one and only one cluster. In our experiments, we test Chinese Whispers and Markov Clustering. The expected result of this is that each cluster represents a different sense of the word , e.g.:
[TABLE]
We denote, e.g., bank1, bank2 and other items as word senses referred to as . We denote as a cluster corresponding to the word sense . Note that the context words have no sense labels. They are recovered by the disambiguation approach described next.
3.4 Disambiguation of Neighbors
Next, we disambiguate the neighbors of each induced sense. The previous step results in splitting word nodes into (one or more) sense nodes. However, nearest neighbors of each sense node are still ambiguous, e.g., (bank3, building?). To recover these sense labels of the neighboring words, we employ the following sense disambiguation approach proposed by Faralli et al. (2016). For each word in the context of the sense , we find the most similar sense of that word to the context. We use the cosine similarity measure between the context of the sense and the context of each candidate sense of the word :
[TABLE]
A context is represented by a sparse vector in a vector space of all ambiguous words of all contexts. The result is a disambiguated context in a space of disambiguated words derived from its ambiguous version :
[TABLE]
3.5 Global Clustering: Synset Induction
Finally, we construct the word sense graph using the disambiguated senses instead of the original words and establishing the edges between these disambiguated senses:
[TABLE]
Running a hard clustering algorithm on produces the desired set of synsets as our final result. Figure 2 illustrates the process of disambiguation of an input ambiguous graph on the example of the word ‘‘bank’’. As one may observe, disambiguation of the nearest neighbors is a necessity to be able to construct a global version of the sense-aware graph. Note that current approaches to WSI, e.g., Véronis (2004); Biemann (2006); Hope and Keller (2013), do not perform this step, but perform only local clustering of the graph since they do not aim at a global representation of synsets.
3.6 Local-Global Fuzzy Graph Clustering
While we use our approach to synset induction in this work, the core of our method is the ‘‘local-global’’ fuzzy graph clustering algorithm, which can be applied to arbitrary graphs (see Figure 1). This method, summarized in Algorithm 1, takes an undirected graph as the input and outputs a set of fuzzy clusters of its nodes . This is a meta-algorithm as it operates on top of two hard clustering algorithms denoted as and , such as CW or MCL. At the first phase of the algorithm, for each node its senses are induced via ego network clustering (lines 1--7). Next, the disambiguation of each ego network is performed (lines 8--15). Finally, the fuzzy clusters are obtained by applying the hard clustering algorithm to the disambiguated graph (line 16). As a post-processing step, the sense labels can be removed to make the cluster elements subsets of .
4 Evaluation
We conduct our experiments on resources from two different languages. We evaluate our approach on two datasets for English to demonstrate its performance on a resource-rich language. Additionally, we evaluate it on two Russian datasets since Russian is a good example of an under-resourced language with a clear need for synset induction.
4.1 Gold Standard Datasets
For each language, we used two differently constructed lexical semantic resources listed in Table 1 to obtain gold standard synsets.
English.
We use WordNet888https://wordnet.princeton.edu, a popular English lexical database constructed by expert lexicographers. WordNet contains general vocabulary and appears to be de facto gold standard in similar tasks Hope and Keller (2013). We used WordNet 3.1 to derive the synonymy pairs from synsets. Additionally, we use BabelNet999http://www.babelnet.org, a large-scale multilingual semantic network constructed automatically using WordNet, Wikipedia and other resources. We retrieved all the synonymy pairs from the BabelNet 3.7 synsets marked as English.
Russian.
As a lexical ontology for Russian, we use RuWordNet101010http://ruwordnet.ru/en Loukachevitch et al. (2016), containing both general vocabulary and domain-specific synsets related to sport, finance, economics, etc. Up to a half of the words in this resource are multi-word expressions Kiselev et al. (2015), which is due to the coverage of domain-specific vocabulary. RuWordNet is a WordNet-like version of the RuThes thesaurus that is constructed in the traditional way, namely by a small group of expert lexicographers Loukachevitch (2011). In addition, we use Yet Another RussNet111111https://russianword.net/en (YARN) by Braslavski et al. (2016) as another gold standard for Russian. The resource is constructed using crowdsourcing and mostly covers general vocabulary. Particularly, non-expert users are allowed to edit synsets in a collaborative way loosely supervised by a team of project curators. Due to the ongoing development of the resource, we selected as the gold standard only those synsets that were edited at least eight times in order to filter out noisy incomplete synsets.
4.2 Evaluation Metrics
To evaluate the quality of the induced synsets, we transformed them into binary synonymy relations and computed precision, recall, and F-score on the basis of the overlap of these binary relations with the binary relations from the gold standard datasets. Given a synset containing words, we generate a set of pairs of synonyms. The F-score calculated this way is known as Paired F-score Manandhar et al. (2010); Hope and Keller (2013). The advantage of this measure compared to other cluster evaluation measures, such as Fuzzy B-Cubed Jurgens and Klapaftis (2013), is its straightforward interpretability.
4.3 Word Embeddings
English.
We use the standard -dimensional word embeddings trained on the billion tokens Google News corpus Mikolov et al. (2013).121212https://code.google.com/p/word2vec
Russian.
We use the -dimensional word embeddings trained using the skip-gram model with negative sampling Mikolov et al. (2013) using a context window size of with the minimal word frequency of on a billion tokens corpus of books. These embeddings were shown to produce state-of-the-art results in the RUSSE shared task131313http://www.dialog-21.ru/en/evaluation/2015/semantic_similarity and are part of the Russian Distributional Thesaurus (RDT) Panchenko et al. (2017b).141414http://russe.nlpub.ru/downloads
4.4 Input Dictionary of Synonyms
For each language, we constructed a synonymy graph using openly available language resources. The statistics of the graphs used as the input in the further experiments are shown in Table 2.
English.
Synonyms were extracted from the English Wiktionary151515We used the Wiktionary dumps of February 1, 2017., which is the largest Wiktionary at the present moment in terms of the lexical coverage, using the DKPro JWKTL tool by Zesch et al. (2008). English words have been extracted from the dump.
Russian.
Synonyms from three sources were combined to improve lexical coverage of the input dictionary and to enforce confidence in jointly observed synonyms: (1) synonyms listed in the Russian Wiktionary extracted using the Wikokit tool by Krizhanovsky and Smirnov (2013); (2) the dictionary of Abramov (1999); and (3) the Universal Dictionary of Concepts Dikonov (2013). While the two latter resources are specific to Russian, Wiktionary is available for most languages. Note that the same input synonymy dictionaries were used by authors of YARN to construct synsets using crowdsourcing. The results on the YARN dataset show how close an automatic synset induction method can approximate manually created synsets provided the same starting material.161616We used the YARN dumps of February 7, 2017.
5 Results
We compare Watset with five state-of-the art graph clustering methods presented in Section 2: Chinese Whispers (CW), Markov Clustering (MCL), MaxMax, ECO clustering, and the clique percolation method (CPM). The first two algorithms perform hard clustering, while the last three are fuzzy clustering methods just like our method. While the hard clustering algorithms are able to discover clusters which correspond to synsets composed of unambigous words, they can produce wrong results in the presence of lexical ambiguity (one node belongs to several synsets). In our experiments, we rely on our own implementation of MaxMax and ECO as reference implementations are not available. For CW171717https://www.github.com/uhh-lt/chinese-whispers, MCL181818http://java-ml.sourceforge.net and CPM191919https://networkx.github.io, available implementations have been used. During the evaluation, we delete clusters equal or larger than the threshold of 150 words as they hardly can represent any meaningful synset. The notation Watset[MCL, CWtop] means using MCL for local clustering and Chinese Whispers in the top mode for global clustering.
5.1 Impact of Graph Weighting Schema
Figure 3 presents an overview of the evaluation results on both datasets. The first step, common for all of the tested synset induction methods, is graph construction. Thus, we started with an analysis of three ways to weight edges of the graph introduced in Section 3.2: binary scores (ones), frequencies (count), and semantic similarity scores (sim) based on word vector similarity. Results across various configurations and methods indicate that using the weights based on the similarity scores provided by word embeddings is the best strategy for all methods except MaxMax on the English datasets. However, its performance using the ones weighting does not exceed the other methods using the sim weighting. Therefore, we report all further results on the basis of the sim weights. The edge weighting scheme impacts Russian more for most algorithms. The CW algorithm however remains sensitive to the weighting also for the English dataset due to its randomized nature.
5.2 Comparative Analysis
Table 3 and 4 present evaluation results for both languages. For each method, we show the best configurations in terms of F-score. One may note that the granularity of the resulting synsets, especially for Russian, is very different, ranging from 4 000 synsets for the CPM method to 67 645 induced by the ECO method. Both tables report the number of words, synsets and synonyms after pruning huge clusters larger than 150 words. Without this pruning, the MaxMax and CPM methods tend to discover giant components obtaining almost zero precision as we generate all possible pairs of nodes in such clusters. The other methods did not show such behavior.
Watset robustly outperforms all other methods according to F-score on both English datasets (Table 3) and on the YARN dataset for Russian (Table 4). Also, it outperforms all other methods according to recall on both Russian datasets. The disambiguation of the input graph performed by the Watset method splits nodes belonging to several local communities to several nodes, significantly facilitating the clustering task otherwise complicated by the presence of the hubs that wrongly link semantically unrelated nodes.
Interestingly, in all the cases, the toughest competitor was a hard clustering algorithm---MCL van Dongen (2000). We observed that the ‘‘plain’’ MCL successfully groups monosemous words, but isolates the neighborhood of polysemous words, which results in the recall drop in comparison to Watset. CW operates faster due to a simplified update step. On the same graph, CW tends to produce larger clusters than MCL. This leads to a higher recall of ‘‘plain’’ CW as compared to the ‘‘plain’’ MCL, at the cost of lower precision.
Using MCL instead of CW for sense induction in Watset expectedly produces more fine-grained senses. However, at the global clustering step, these senses erroneously tend to form coarse-grained synsets connecting unrelated senses of the ambiguous words. This explains the generally higher recall of Watset[MCL, ]. Despite the randomized nature of CW, variance across runs do not affect the overall ranking: The rank of different versions of CW (log, nolog, top) can change, while the rank of the best CW configuration compared to other methods remains the same.
The MaxMax algorithm shows mixed results. On the one hand, it outputs large clusters uniting more than hundred nodes. This inevitably leads to a high recall, as it is clearly seen in the results for Russian because such synsets still pass under our cluster size threshold of 150 words. Its synsets on English datasets are even larger and get pruned, which results in low recall. On the other hand, smaller synsets having at most 10--15 words were identified correctly. MaxMax appears to be extremely sensible to edge weighting, which also complicates its practical use.
The CPM algorithm showed unsatisfactory results, emitting giant components encompassing thousands of words. Such clusters were automatically pruned, but the remaining clusters are relatively correctly built synsets, which is confirmed by the high values of precision. When increasing the minimal number of elements in the clique , recall improves, but at the cost of a dramatic precision drop. We suppose that the network structure assumptions exploited by CPM do not accurately model the structure of our synonymy graphs.
Finally, the ECO method yielded the worst results because the most cluster candidates failed to pass through the constant threshold used for estimating whether a pair of words should be included in the same cluster. Most synsets produced by this method were trivial, i.e., containing only a single word. The remaining synsets for both languages have at most three words that have been connected by a chance due to the edge noising procedure used in this method resulting in low recall.
6 Discussion
On the absolute scores.
The results obtained on all gold standards (Figure 3) show similar trends in terms of relative ranking of the methods. Yet absolute scores of YARN and RuWordNet are substantially different due to the inherent difference of these datasets. RuWordNet is more domain-specific in terms of vocabulary, so our input set of generic synonymy dictionaries has a limited coverage on this dataset. On the other hand, recall calculated on YARN is substantially higher as this resource was manually built on the basis of synonymy dictionaries used in our experiments.
The reason for low absolute numbers in evaluations is due to an inherent vocabulary mismatch between the input dictionaries of synonyms and the gold datasets. To validate this hypothesis, we performed a cross-resource evaluation presented in Table 5. The low performance of the cross-evaluation of the two resources supports the hypothesis: no single resource for Russian can obtain high recall scores on another one. Surprisingly, even BabelNet, which integrates most of available lexical resources, still does not reach a recall substantially larger than 0.5.202020We used BabelNet 3.7 extracting all 3 497 327 synsets that were marked as Russian. Note that the results of this cross-dataset evaluation are not directly comparable to results in Table 4 since in our experiments we use much smaller input dictionaries than those used by BabelNet.
On sparseness of the input dictionary.
Table 6 presents some examples of the obtained synsets of various sizes for the top Watset configuration on both languages. As one might observe, the quality of the results is highly plausible. However, one limitation of all approaches considered in this paper is the dependence on the completeness of the input dictionary of synonyms. In some parts of the input synonymy graph, important bridges between words can be missing, leading to smaller-than-desired synsets. A promising extension of the present methodology is using distributional models to enhance connectivity of the graph by cautiously adding extra relations.
7 Conclusion
We presented a new robust approach to fuzzy graph clustering that relies on hard graph clustering. Using ego network clustering, the nodes belonging to several local communities are split into several nodes each belonging to one community. The transformed ‘‘disambiguated’’ graph is then clustered using an efficient hard graph clustering algorithm, obtaining a fuzzy clustering as the result. The disambiguated graph facilitates clustering as it contains fewer hubs connecting unrelated nodes from different communities. We apply this meta clustering algorithm to the task of synset induction on two languages, obtaining the best results on three datasets and competitive results on one dataset in terms of F-score as compared to five state-of-the-art graph clustering methods.
Acknowledgments
We acknowledge the support of the Deutsche Forschungsgemeinschaft (DFG) foundation under the ‘‘JOIN-T’’ project, the DAAD, the RFBR under the project no. 16-37-00354 mol_a, and the RFH under the project no. 16-04-12019. We also thank three anonymous reviewers for their helpful comments, Andrew Krizhanovsky for providing a parsed Wiktionary, Natalia Loukachevitch for the provided RuWordNet dataset, and Denis Shirgin who suggested the Watset name.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Abramov (1999) Nikolay Abramov. 1999. The dictionary of Russian synonyms and semantically related expressions [Slovar’ russkikh sinonimov i skhodnykh po smyslu vyrazhenii] . Russian Dictionaries [Russkie slovari], Moscow, Russia, 7th edition. In Russian.
- 2Baroni and Lenci (2010) Marco Baroni and Alessandro Lenci. 2010. Distributional Memory: A General Framework for Corpus-based Semantics . Computational Linguistics 36(4):673--721. https://doi.org/10.1162/coli_a_00016 . · doi ↗
- 3Biemann (2006) Chris Biemann. 2006. Chinese Whispers: An Efficient Graph Clustering Algorithm and Its Application to Natural Language Processing Problems . In Proceedings of the First Workshop on Graph Based Methods for Natural Language Processing . Association for Computational Linguistics, New York City, NY, USA, Text Graphs-1, pages 73--80. http://dl.acm.org/citation.cfm?id=1654774 .
- 4Biemann (2012) Chris Biemann. 2012. Structure Discovery in Natural Language . Theory and Applications of Natural Language Processing. Springer Berlin Heidelberg. https://doi.org/10.1007/978-3-642-25923-4 . · doi ↗
- 5Biemann and Riedl (2013) Chris Biemann and Martin Riedl. 2013. Text: now in 2D! A framework for lexical expansion with contextual similarity . Journal of Language Modelling 1(1):55--95. https://doi.org/10.15398/jlm.v 1i 1.60 . · doi ↗
- 6Bomze et al. (1999) Immanuel M. Bomze, Marco Budinich, Panos M. Pardalos, and Marcello Pelillo. 1999. The maximum clique problem . In Handbook of Combinatorial Optimization , Springer US, pages 1--74. https://doi.org/10.1007/978-1-4757-3023-4_1 . · doi ↗
- 7Braslavski et al. (2016) Pavel Braslavski, Dmitry Ustalov, Mukhin Mukhin, and Yuri Kiselev. 2016. YARN: Spinning-in-Progress . In Proceedings of the 8th Global Word Net Conference . Global Word Net Association, Bucharest, Romania, GWC 2016, pages 58--65. http://gwc 2016.racai.ro/procedings.pdf .
- 8Di Marco and Navigli (2012) Antonio Di Marco and Roberto Navigli. 2012. Clustering and Diversifying Web Search Results with Graph-Based Word Sense Induction . Computational Linguistics 39(3):709--754. https://doi.org/10.1162/COLI_a_00148 . · doi ↗
