Visual-Based Analysis of Classification Measures with Applications to Imbalanced Data
Dariusz Brzezinski, Jerzy Stefanowski, Robert Susmaga, Izabela, Szcz\k{e}ch

TL;DR
This paper introduces a visualization technique in barycentric coordinates to compare 22 classification measures, especially for imbalanced data, and provides analytical insights and an online tool for better measure selection.
Contribution
It presents a novel 3D visualization method for analyzing classification measures and adapts it for imbalanced data, offering new insights and tools for measure comparison.
Findings
Identified key differences among 22 measures
Derived parameter thresholds for measure properties
Provided an online tool for measure analysis
Abstract
With a plethora of available classification performance measures, choosing the right metric for the right task requires careful thought. To make this decision in an informed manner, one should study and compare general properties of candidate measures. However, analysing measures with respect to complete ranges of their domain values is a difficult and challenging task. In this study, we attempt to support such analyses with a specialized visualization technique, which operates in a barycentric coordinate system using a 3D tetrahedron. Additionally, we adapt this technique to the context of imbalanced data and put forward a set of properties which should be taken into account when selecting a classification performance measure. As a result, we compare 22 popular measures and show important differences in their behaviour. Moreover, for parametric measures such as the F and…
Click any figure to enlarge with its caption.
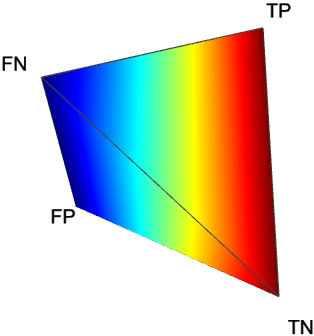 Figure 1
Figure 1 Figure 2
Figure 2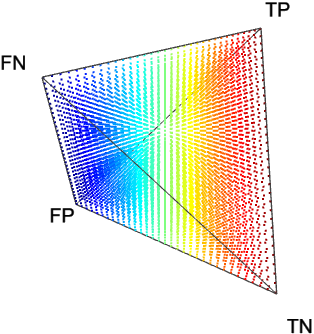 Figure 3
Figure 3 Figure 4
Figure 4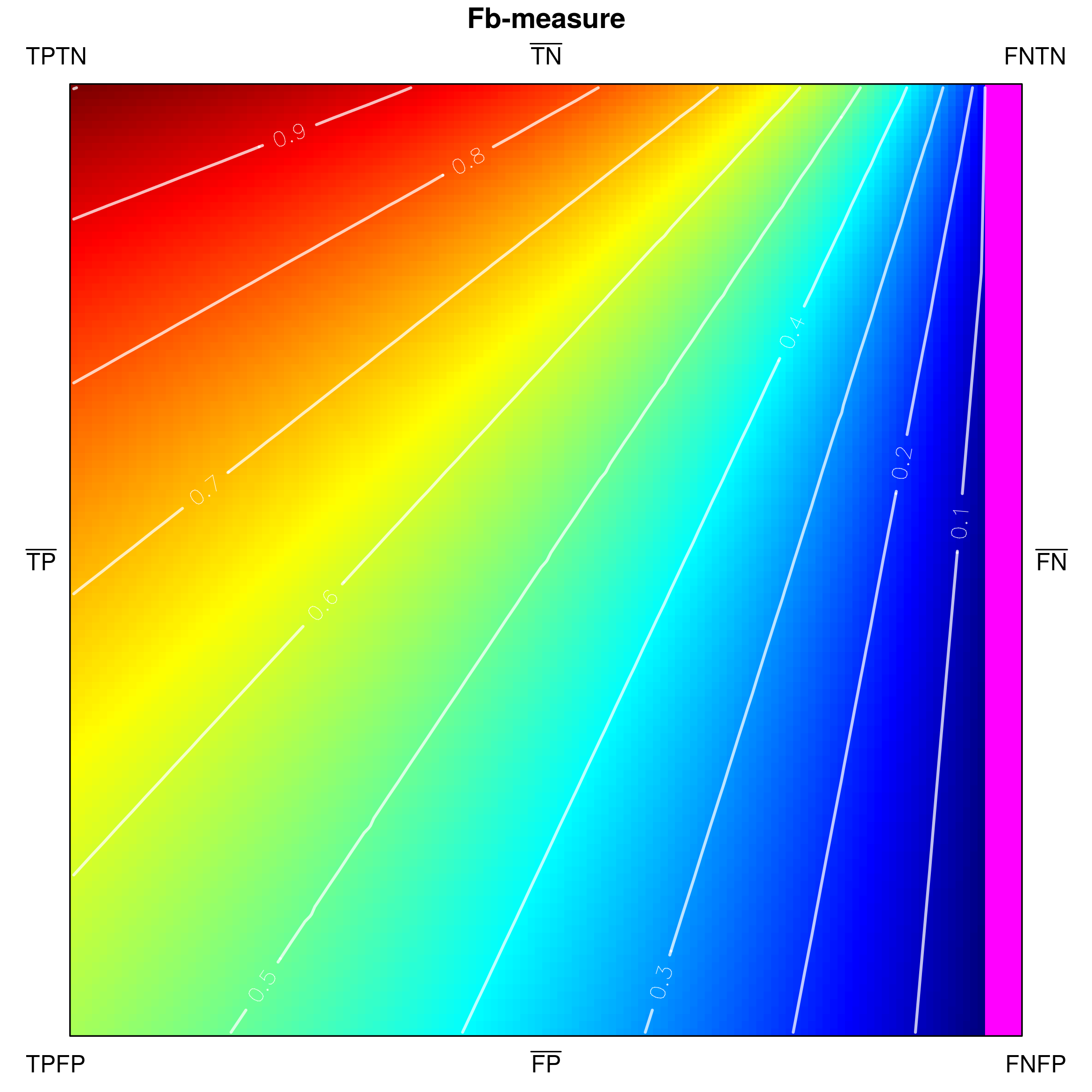 Figure 5
Figure 5 Figure 6
Figure 6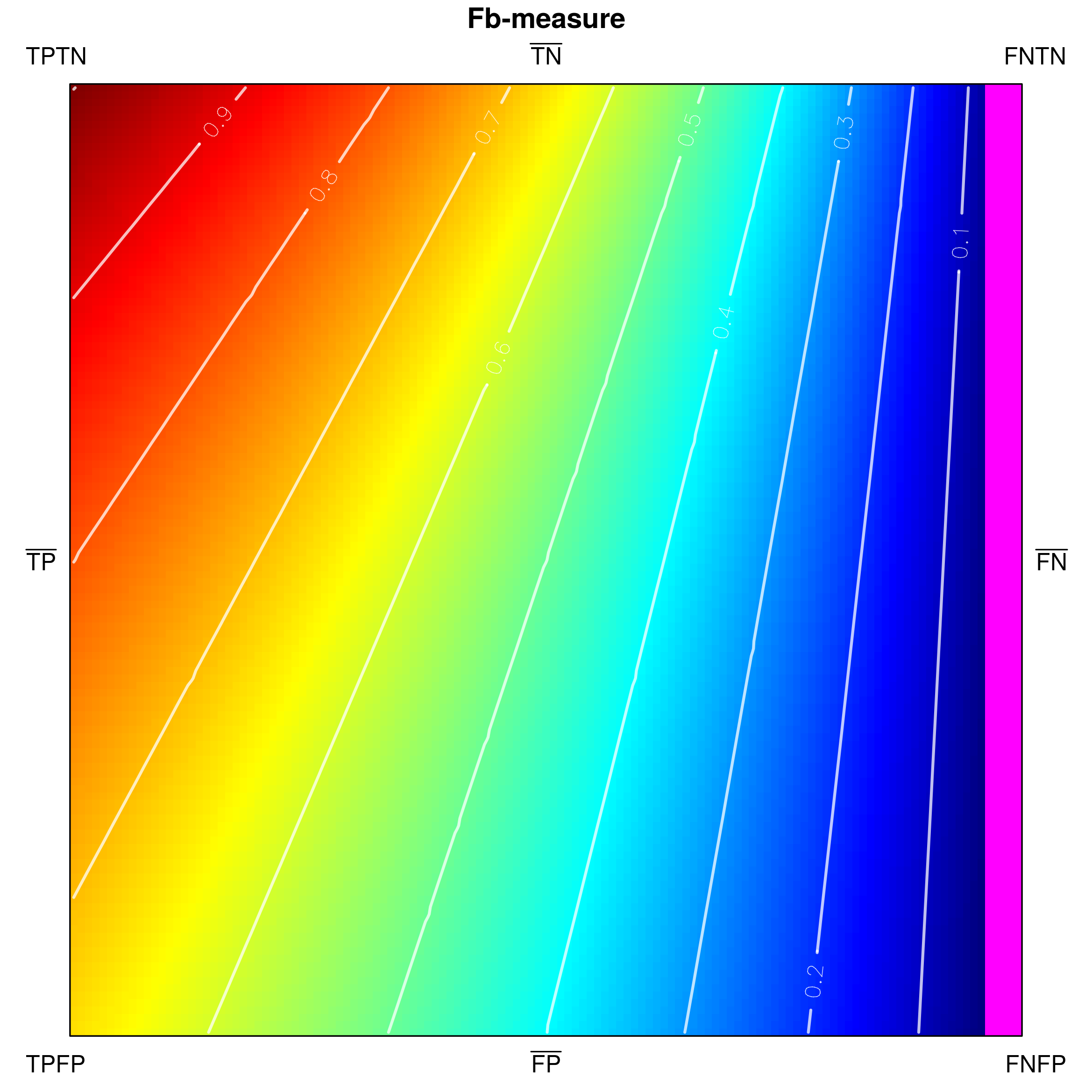 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10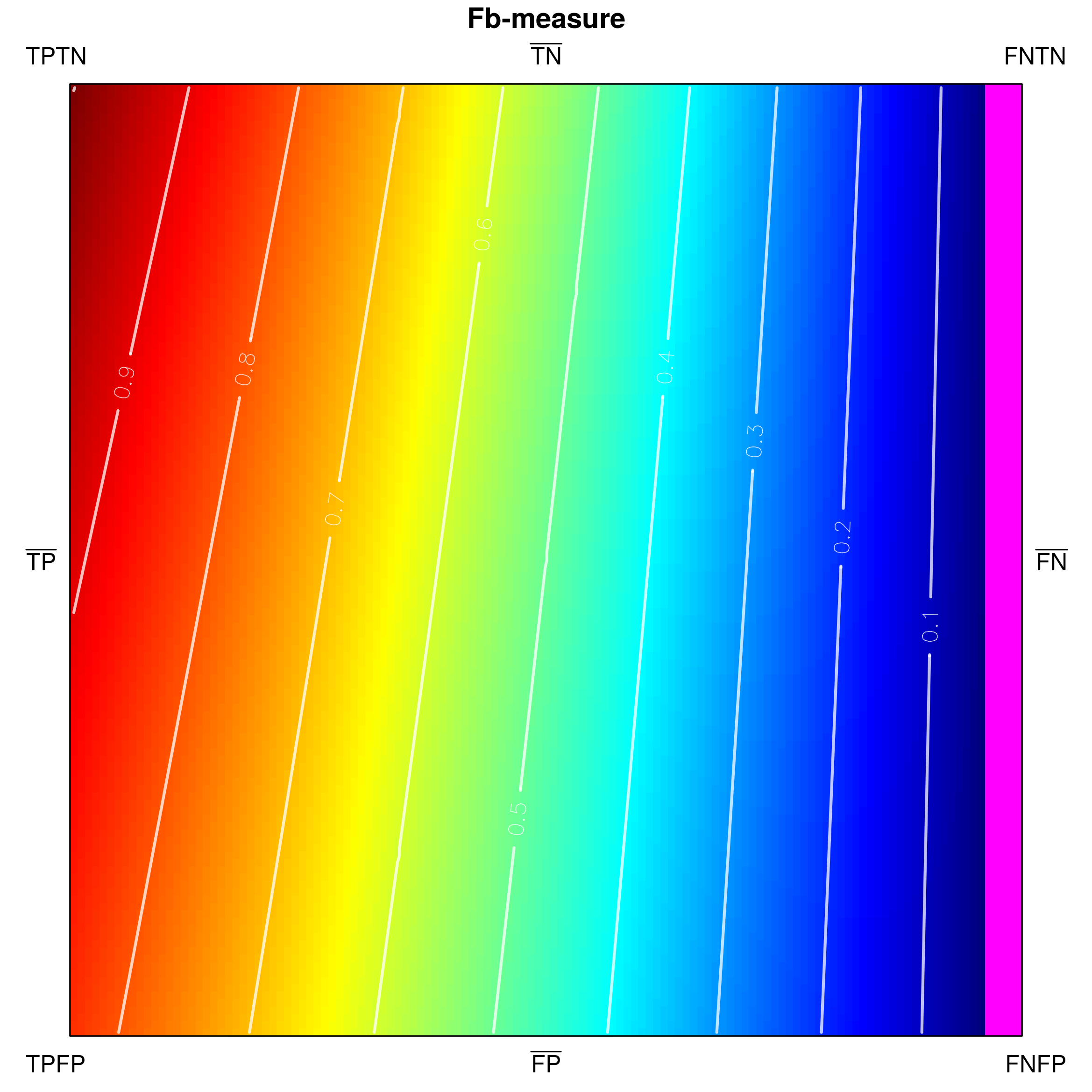 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15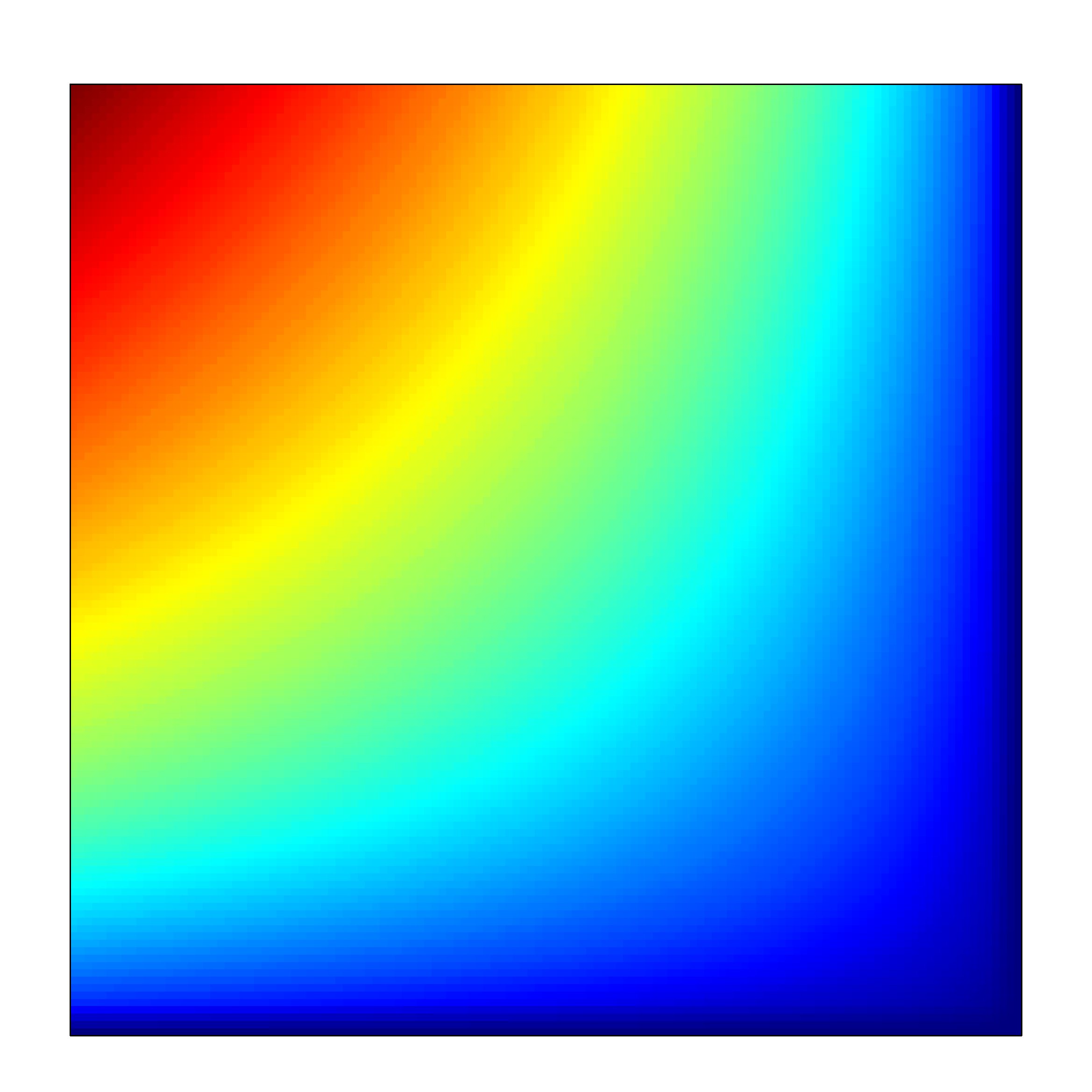 Figure 16
Figure 16 Figure 17
Figure 17 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22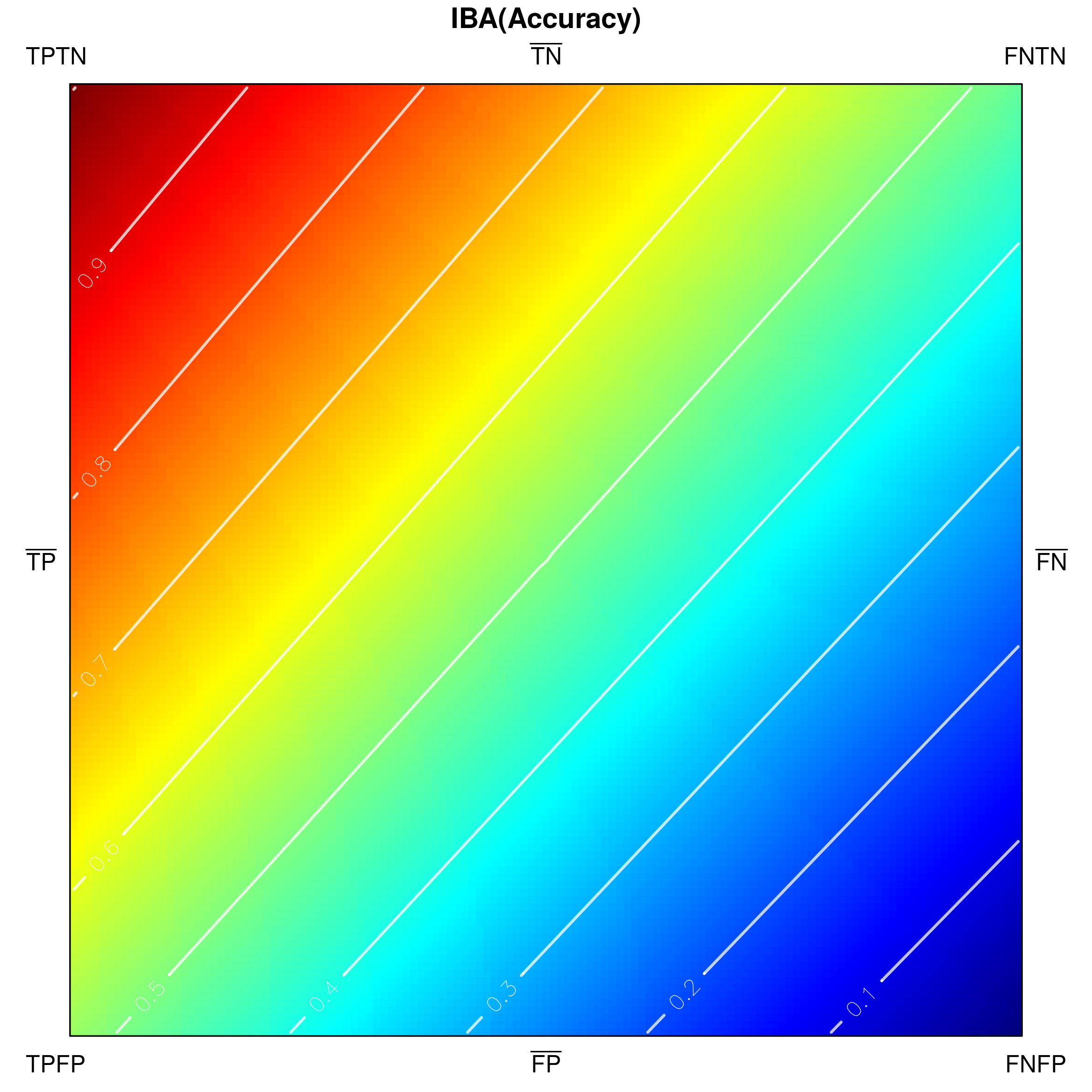 Figure 23
Figure 23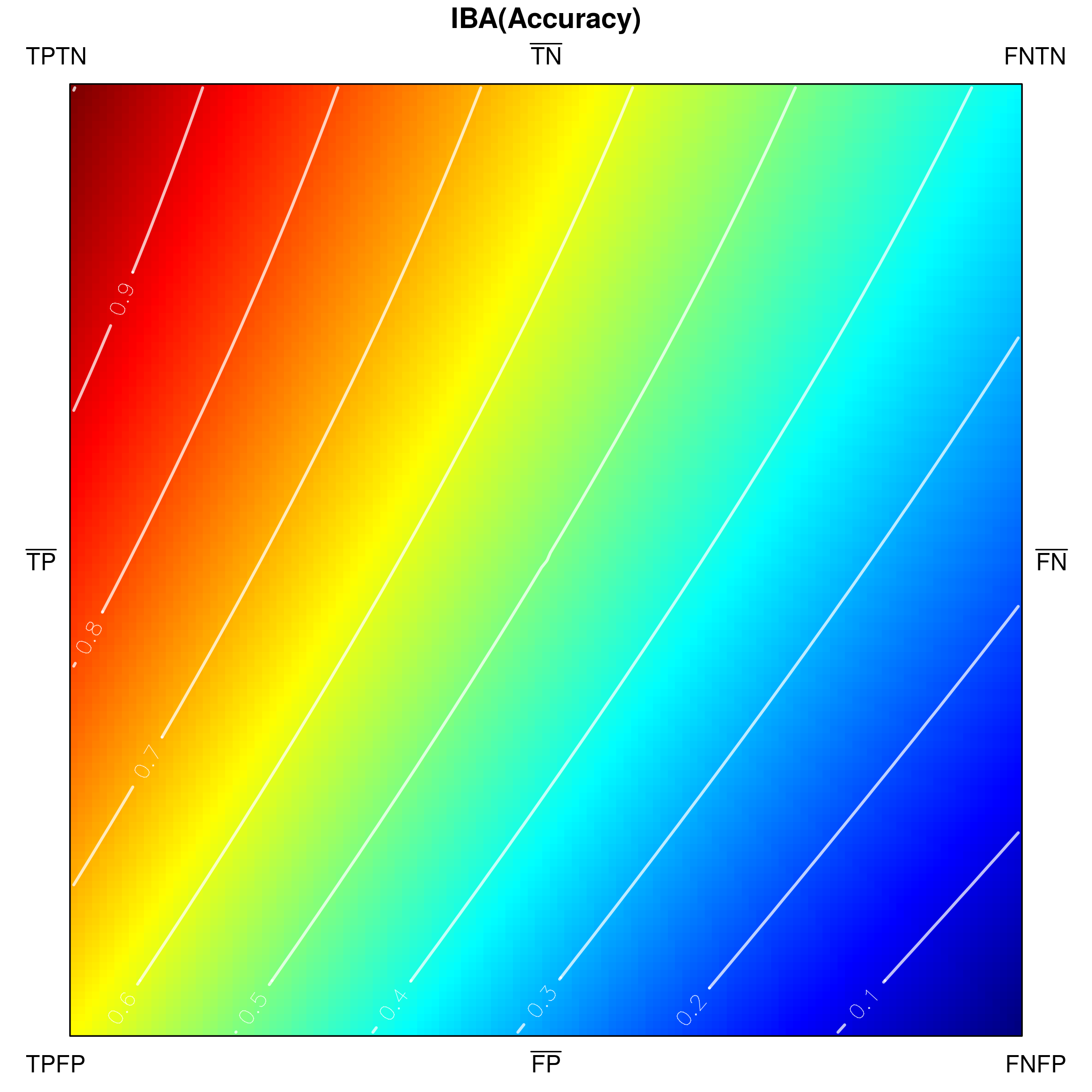 Figure 24
Figure 24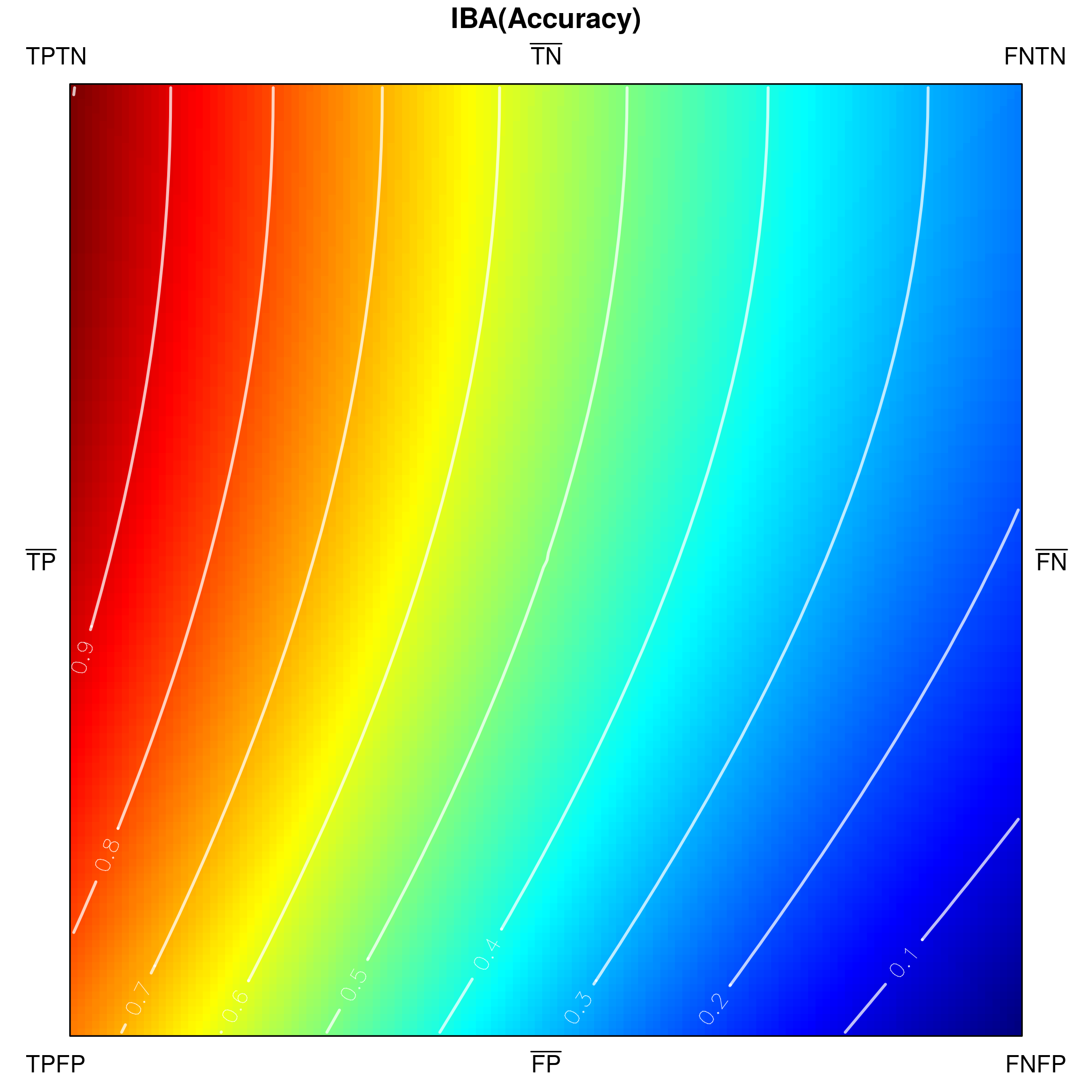 Figure 25
Figure 25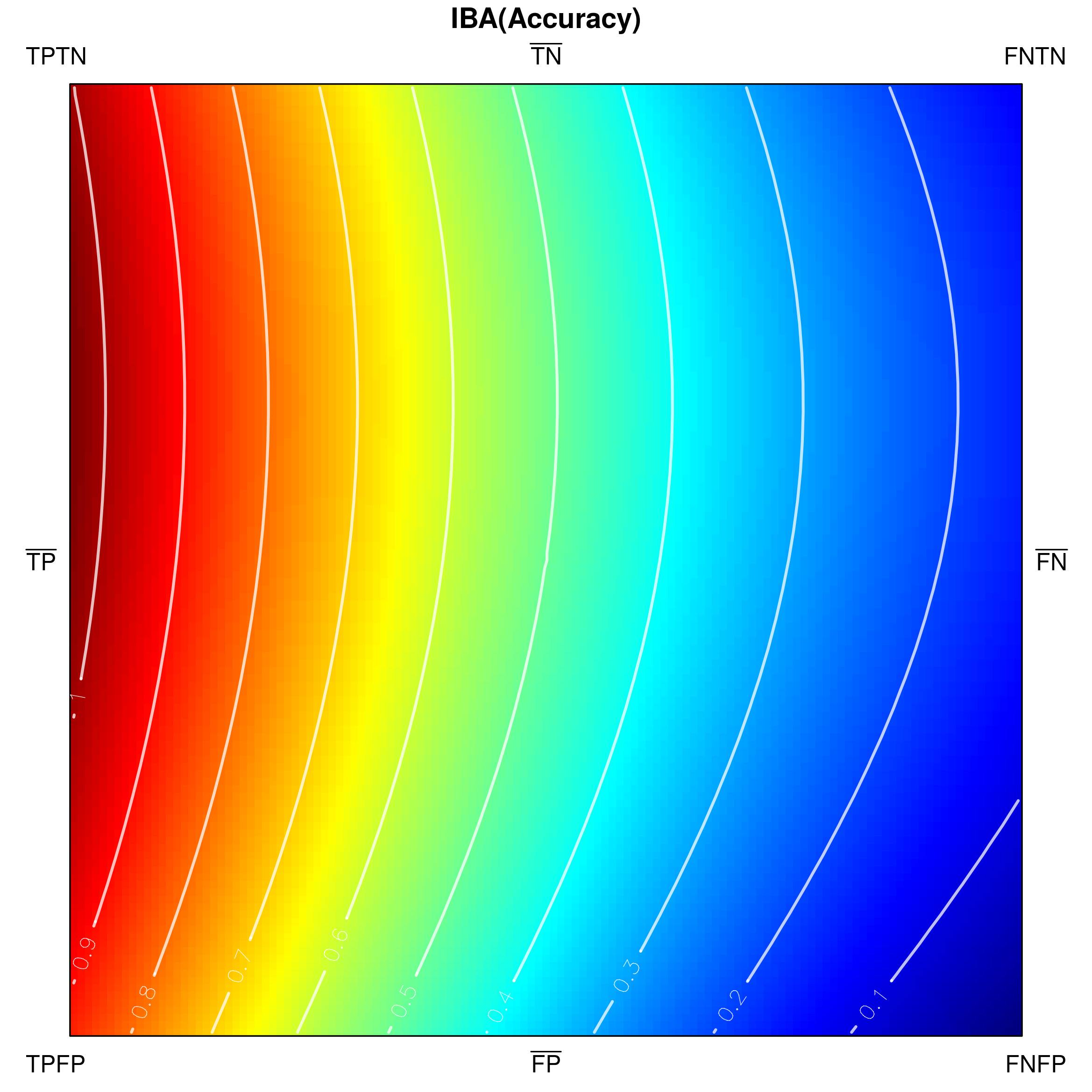 Figure 26
Figure 26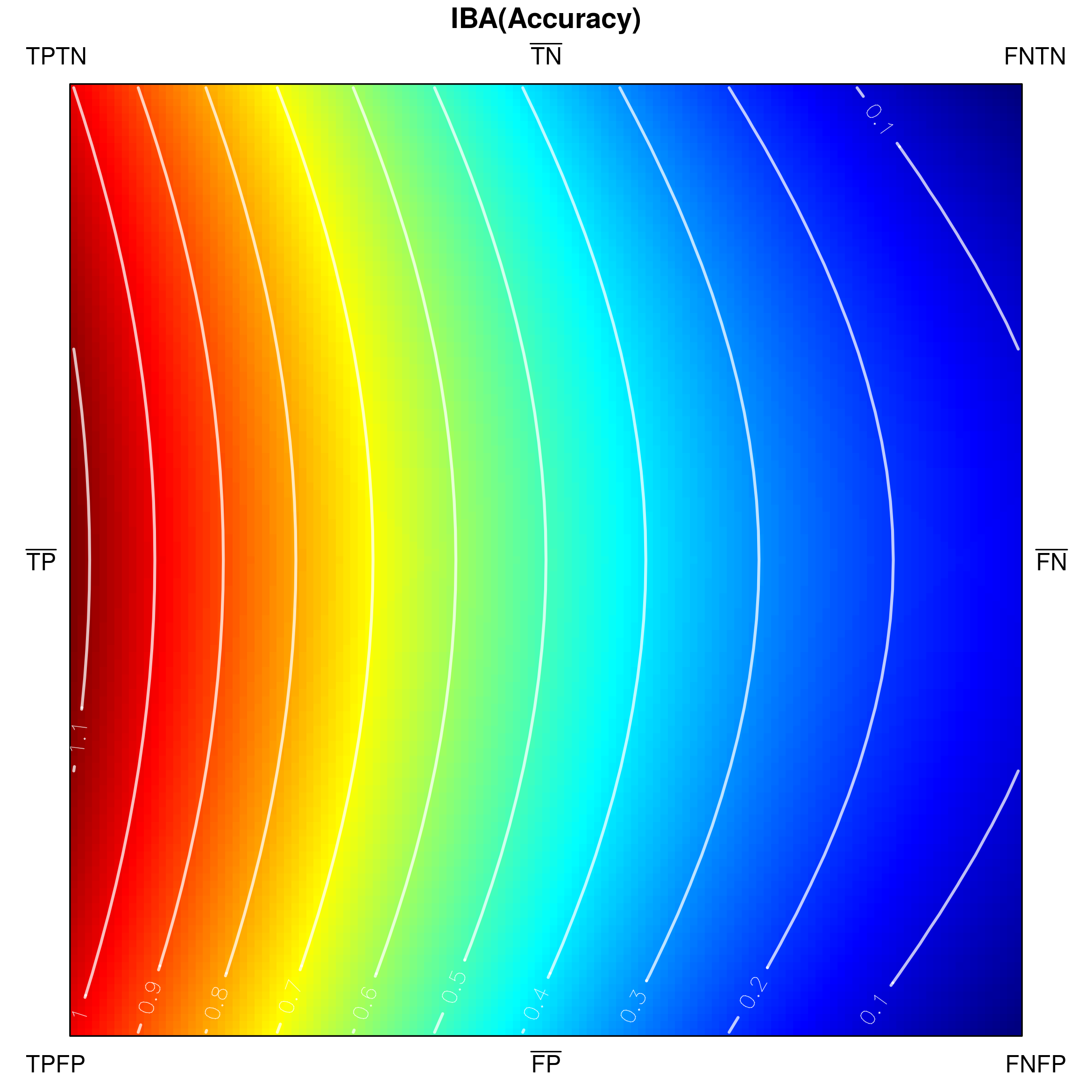 Figure 27
Figure 27 Figure 28
Figure 28 Figure 29
Figure 29 Figure 30
Figure 30 Figure 31
Figure 31 Figure 32
Figure 32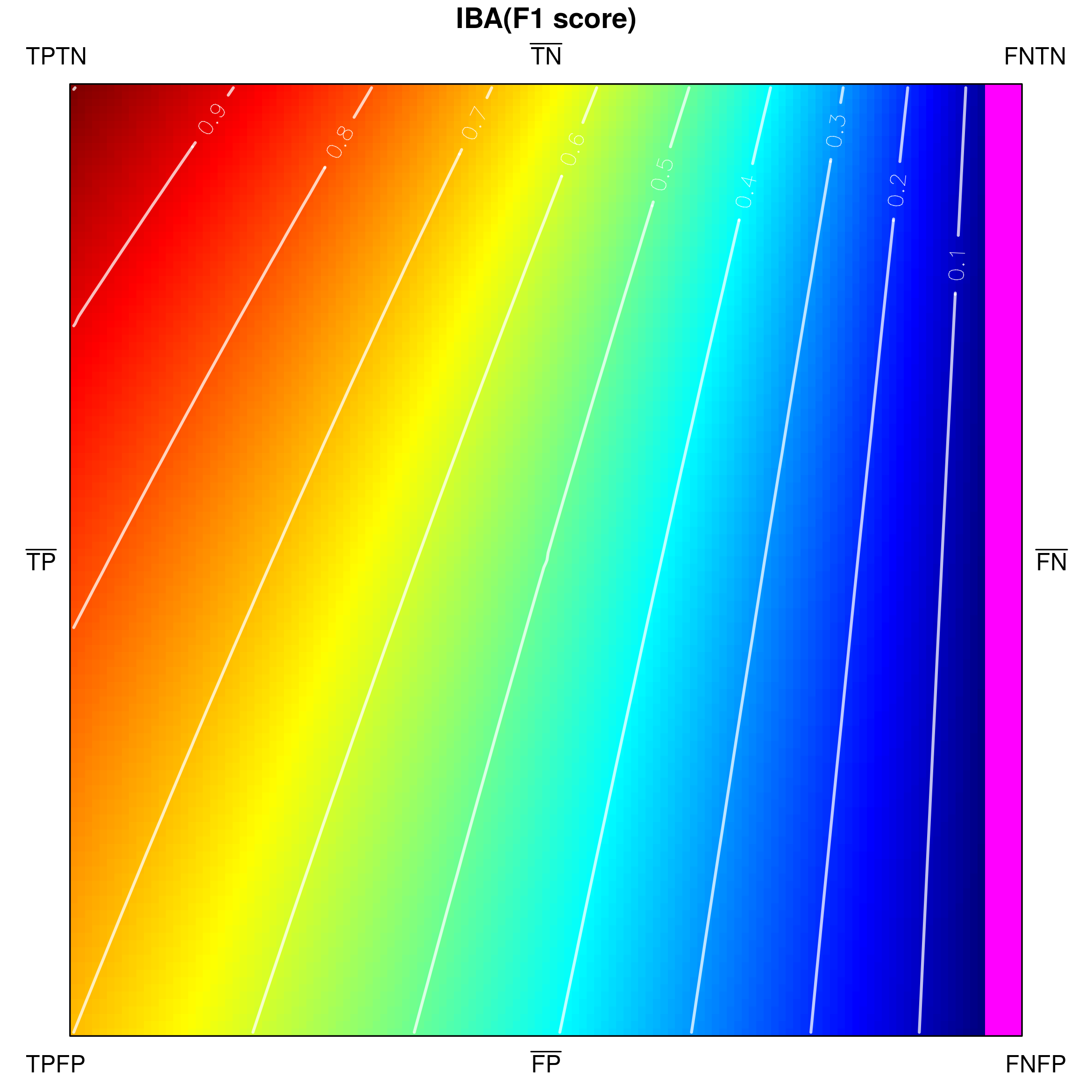 Figure 33
Figure 33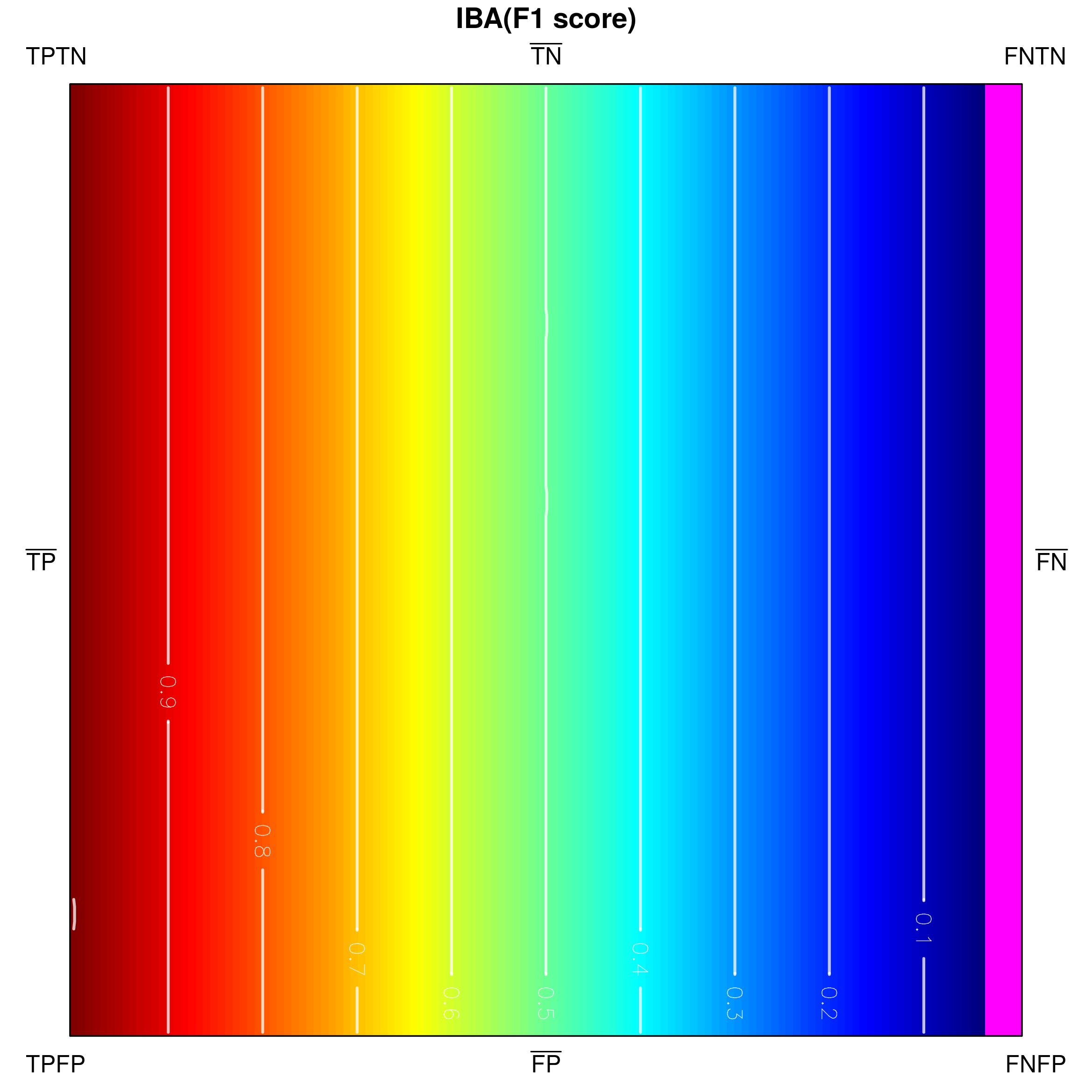 Figure 34
Figure 34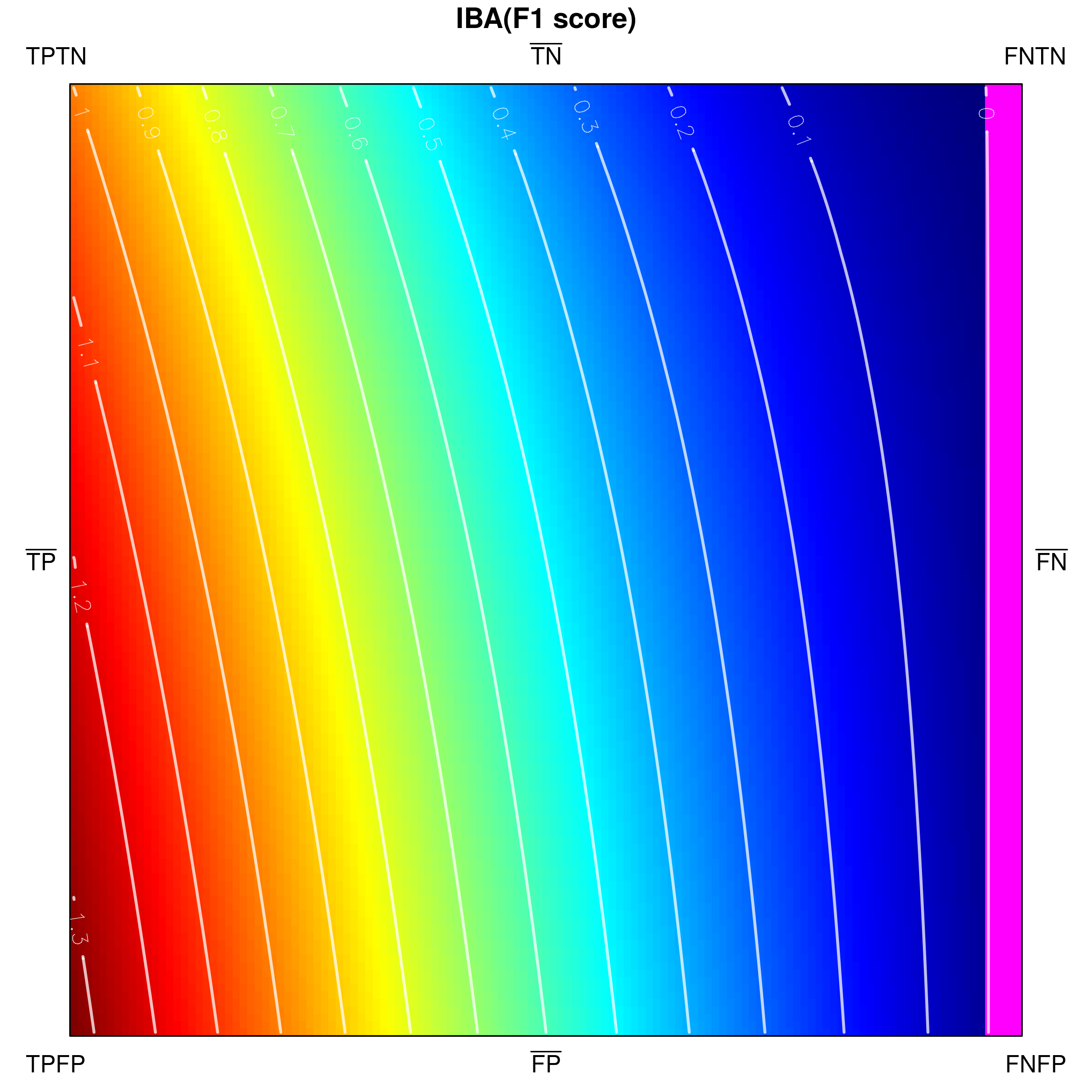 Figure 35
Figure 35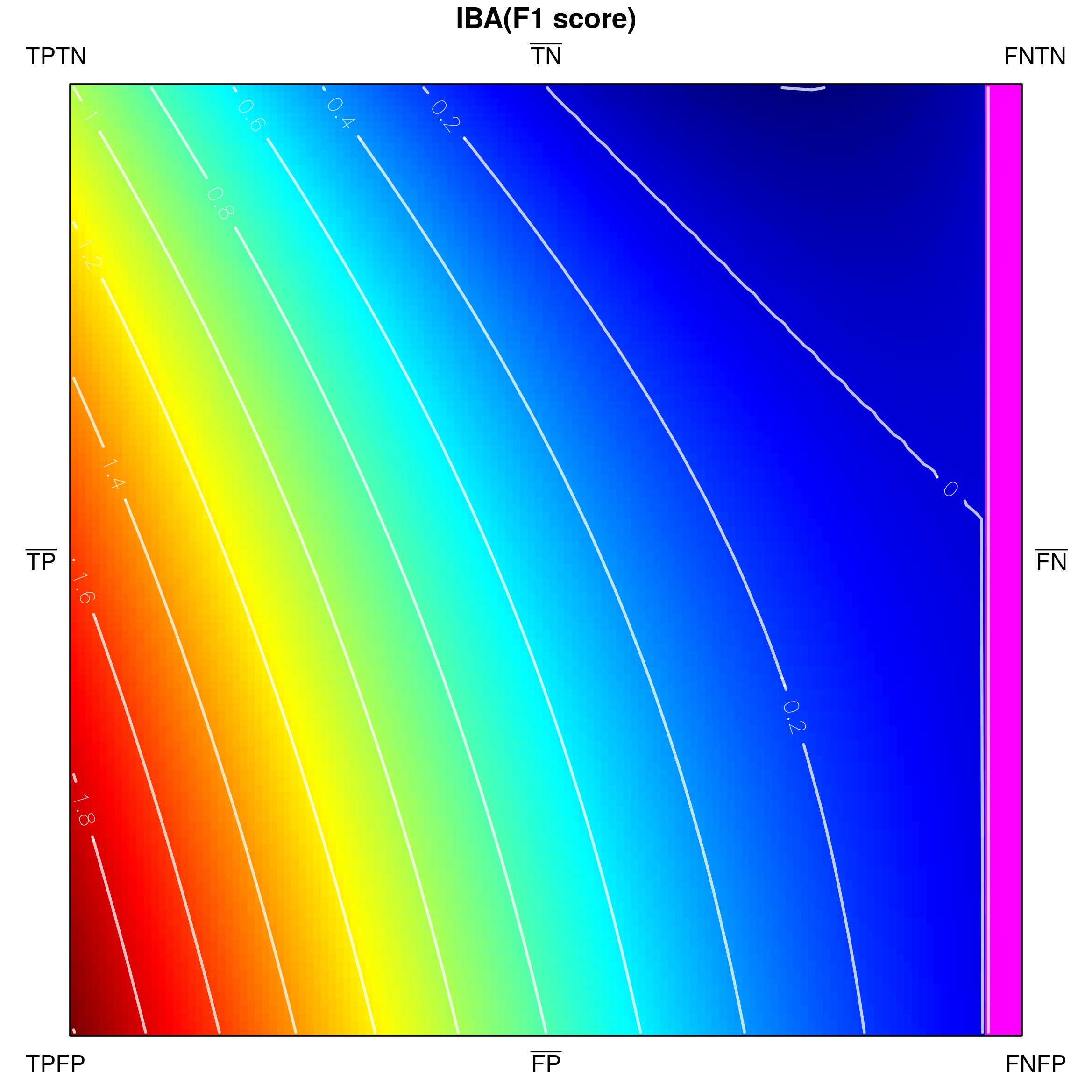 Figure 36
Figure 36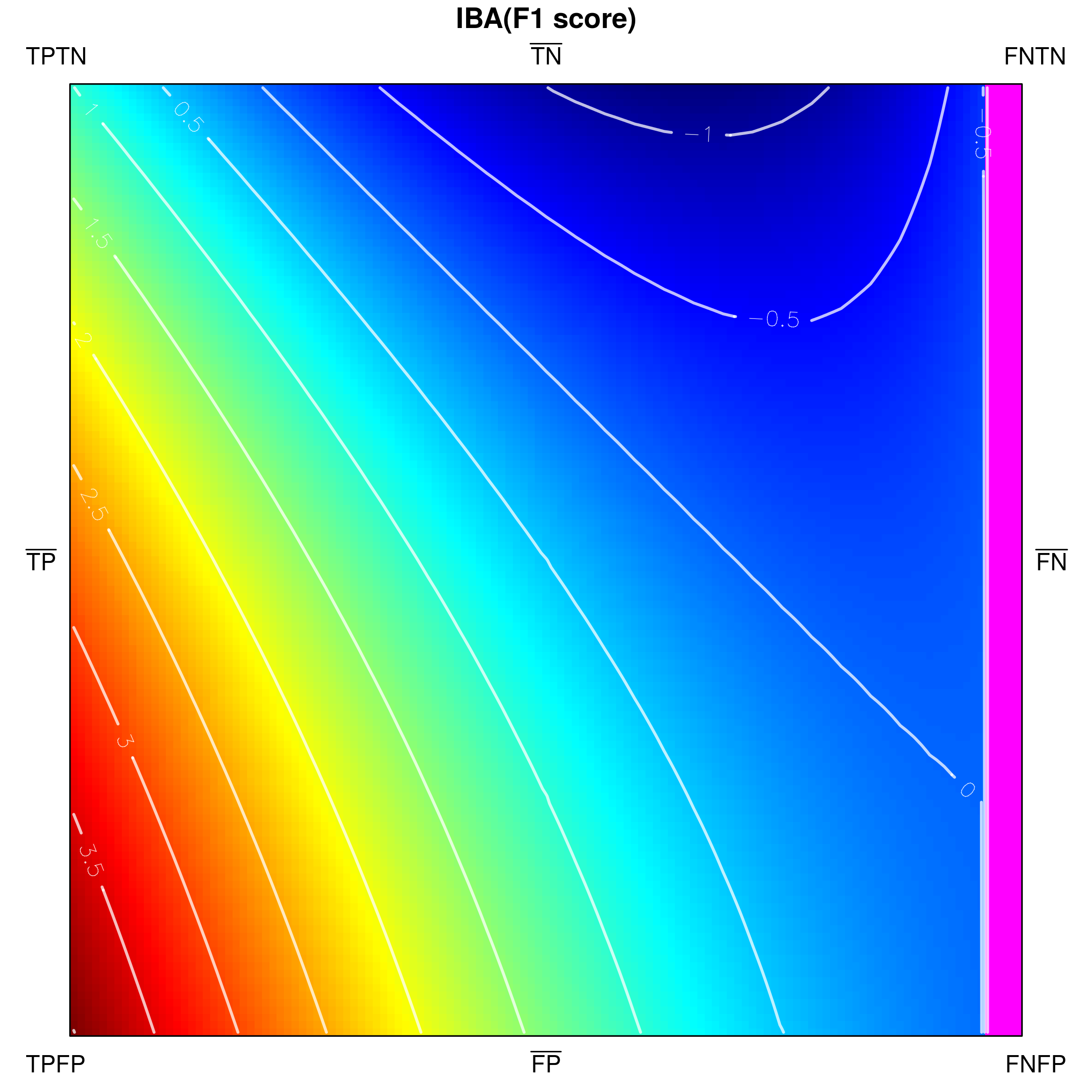 Figure 37
Figure 37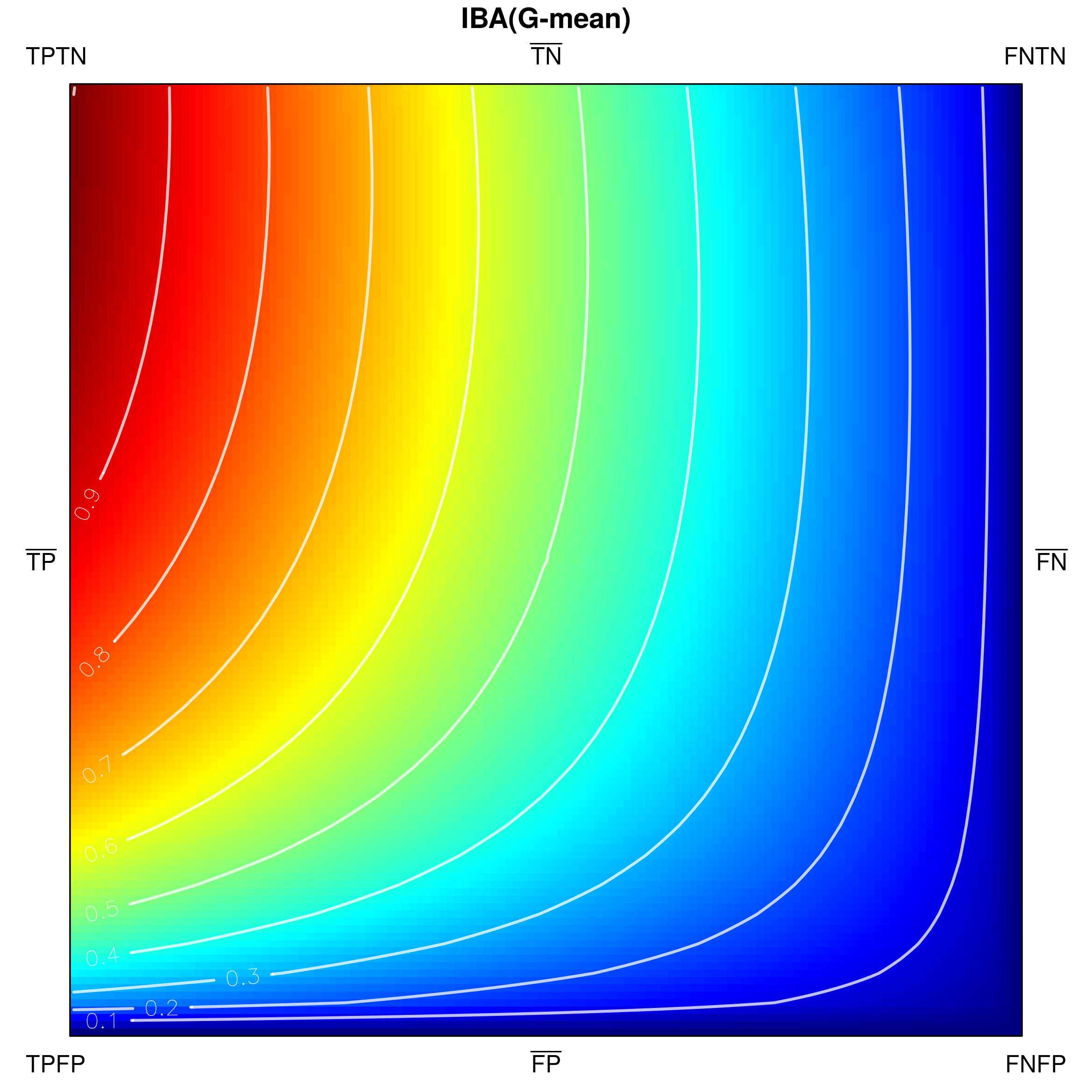 Figure 38
Figure 38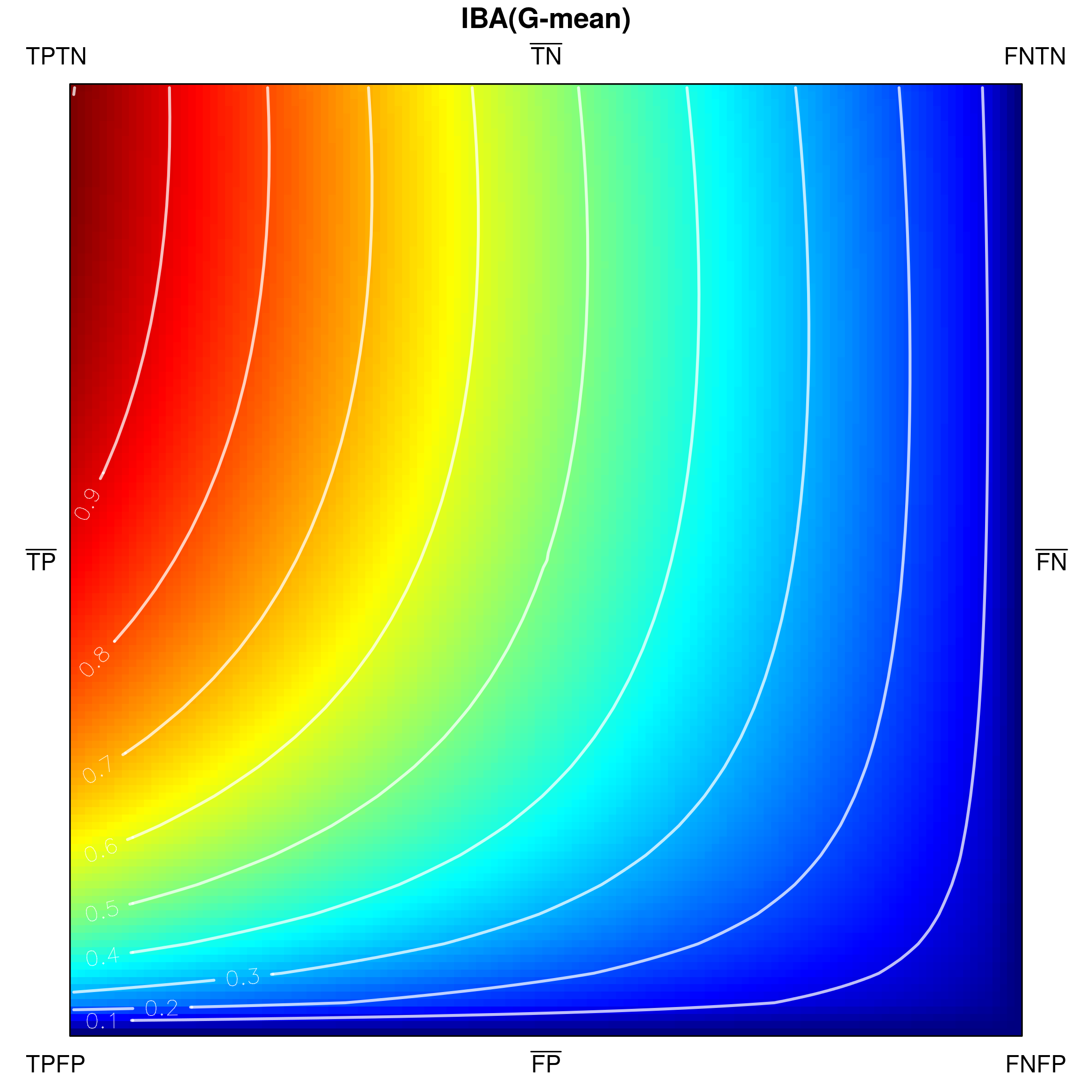 Figure 39
Figure 39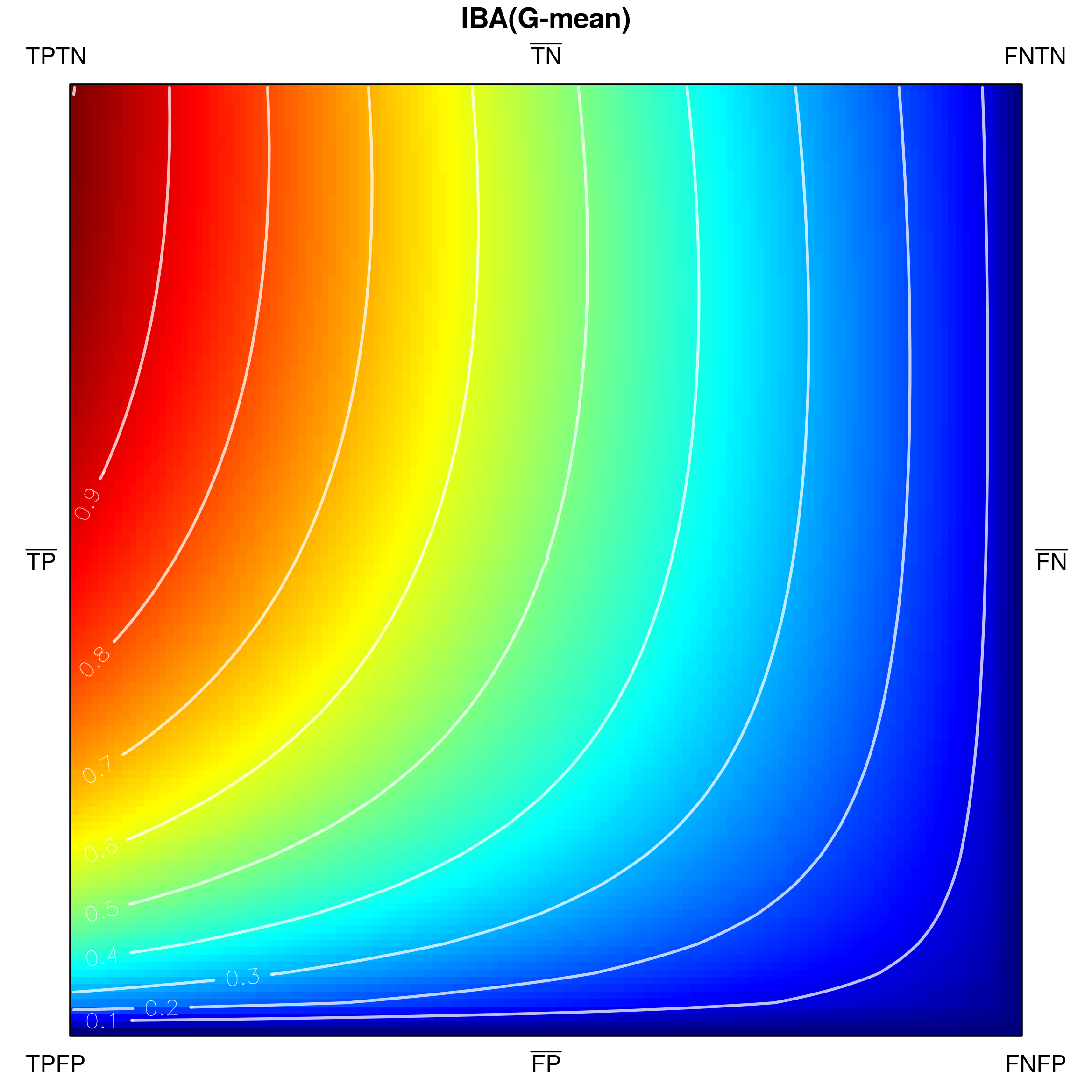 Figure 40
Figure 40| Positive | Negative | total | |
|---|---|---|---|
| Positive | |||
| Negative | |||
| total |
| Measure | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Accuracy | none | |||||||||
| Area Under Lift | –; – | |||||||||
| Balanced accuracy | –; – | |||||||||
| F1-score | –– | |||||||||
| False negative rate | – | |||||||||
| False positive rate | – | |||||||||
| Fβ, | –– | |||||||||
| G-mean | –; – | |||||||||
| IBAα(Accuracy), | –; – | |||||||||
| IBAα(F1-score), | ––; – | |||||||||
| IBAα(G-mean), | –; – | |||||||||
| IBAα(Fβ), | ––; – | |||||||||
| Jaccard coefficient | ||||||||||
| Kappa | ; | |||||||||
| Log odds-ratio | –; –; –; – | |||||||||
| MCC | –; –; –; – | |||||||||
| Neg. predictive value | – | |||||||||
| OP | –; –; – | |||||||||
| Pointwise AUC-ROC | –; – | |||||||||
| Precision | – | |||||||||
| Recall | – | |||||||||
| Specificity | – |
| Measure | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| IBA0(G-mean) = G-mean | –; – | |||||||||
| IBAα(G-mean), | –; – | |||||||||
| IBAα(G-mean), | –; – |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Visual-Based Analysis of Classification Measures with Applications to Imbalanced Data
Dariusz Brzezinski
Jerzy Stefanowski
Robert Susmaga
Izabela Szczęch
Institute of Computing Science, Poznan University of Technology,
ul. Piotrowo 2, 60–965 Poznan, Poland
Abstract
With a plethora of available classification performance measures, choosing the right metric for the right task requires careful thought. To make this decision in an informed manner, one should study and compare general properties of candidate measures. However, analysing measures with respect to complete ranges of their domain values is a difficult and challenging task. In this study, we attempt to support such analyses with a specialized visualization technique, which operates in a barycentric coordinate system using a 3D tetrahedron. Additionally, we adapt this technique to the context of imbalanced data and put forward a set of properties which should be taken into account when selecting a classification performance measure. As a result, we compare 22 popular measures and show important differences in their behaviour. Moreover, for parametric measures such as the Fβ and IBAα(G-mean), we analytically derive parameter thresholds that change measure properties. Finally, we provide an online visualization tool that can aid the analysis of complete domain ranges of performance measures.
keywords:
classification , performance measures , visualization , barycentric system , class imbalance
††journal: Information Sciences
\SetBgColor
black \SetBgScale1 \SetBgOpacity1 \SetBgAngle0 \SetBgContents NOTICE: This is a preliminary version of an article submitted to Information Sciences
1 Introduction
Classification is one of the most important machine learning tasks, commonly applied to many real-world problems. One of the crucial ingredients of this supervised learning task is the selection of a performance measure that allows the user to discern good classifiers from bad ones. An appropriate measure should support choosing the best classifier among several candidates and help tune its parameters. As a result, the selected performance measure is responsible for the optimization of the learning process [8].
Although researchers often consider performance measures that promote predicting correctly the highest number of instances, many applications require other ways of handling errors referring to particular subsets of examples. This is especially true for imbalanced data [18, 23], where classifiers are biased towards the majority classes yet the under-represented minority class is usually of more value to human experts.
Since typical performance measures, such as classification accuracy, are not appropriate for imbalanced data [10, 27], several more relevant measures have been considered. The most popular ones include precision, recall (sensitivity), specificity, and their aggregates, e.g. G-mean or F1-score. These and other measures for imbalanced data are typically defined on the basis of confusion matrices summarizing the predictions of a binary classifier. Looking into the related studies, one can notice that the number of such measures is relatively high and each represents different aspects of classification performance, often leading to quite different interpretations [20]. This shows that there is no one measure that would be the best choice in all situations. However, which measure is used in a given problem seems to be, to a large extent, dictated simply by the measure‘s popularity rather than a thorough discussion of its properties.
Although there are a few systematic studies on different properties of classifier performance measures [19, 16, 11, 30], we still postulate the need for thorough analysis of the measures‘ behaviour. In particular, methods for: interpreting and comparing measures with respect to whole domain ranges, analysing their nature for different class and prediction distributions, and detecting the presence of unusual values are much needed. Theoretical investigations of these aspects are often very laborious and time consuming, especially when multi-dimensional aspects, provided by the confusion matrices, need to be taken into account. Due to these difficulties, such an analysis could be alternatively carried out with visual techniques to aid the understanding and interpretability of various measure properties.
In this paper, we put forward a new visualization technique for analysing entire domains of classification performance measures, which depicts all possible configurations of predictions in a confusion matrix, regardless of the used classifier. For this purpose, we adapt an approach originally created for rule interestingness measures to the context of classification [31]. Contrary to existing performance measure visualizations, such as ROC space [11], the proposed approach presents measures in a space which is defined directly on elements of the confusion matrix, is easily interpretable in 3D, and remains defined for all elements of the domain. Moreover, based on the devised visualization, we propose ten properties which should be taken into account while selecting evaluation measures, particularly for class imbalanced data. Consequently, we compare 22 popular classifier performance measures (both non-parametric and parametric) and highlight important differences in their behaviour. Finally, we demonstrate that the proposed approach can lead to concrete results by deriving property thresholds for the parametrized Fβ and IBAα(G-mean) measures.
The main contributions of our paper are as follows:
- •
In Section 3, we adapt a technique for visualizing classification performance measures using the barycentric coordinate system and discuss its characteristics. Additionally, we present an online tool that implements the proposed technique and allows for the analysis of several predefined and custom user-defined 4D measures.
- •
In Section 4, we put forward ten properties, providing knowledge on the behaviour of the classifier performance measures for class biased problems. The introduced properties involve analysing maxima, minima, elements of symmetry, monotonicity, and undefined values.
- •
In Section 5.1, using the proposed visualization technique we analyse and compare 22 classification measures with respect to the proposed properties.
- •
In Section 5.2, we analyse how the proposed properties change for parametric measures. More precisely, we study the effect of internal parametrization on the Fβ measure and external parametrization for IBAα(G-mean). Apart from visual inspection, we analytically derive threshold parameter values for the selected measures.
- •
In Section 6, we discuss the most important issues in analysing classification performance measures and draw lines of further investigations.
2 Related Works
2.1 Classifier performance measures
Classifiers can be assessed in many aspects, such as their predictive ability, training time, memory usage, model complexity, interpretability, or other criteria [20]. In this paper, we consider predictive performance only and focus on measures that evaluate crisp binary classifier predictions; measures specific to only rankers or probabilistic classifiers are out of the scope of this study. Furthermore, we concentrate mainly on measures which take into account the binary class imbalance problem.
As discussed in [18], when dealing with imbalanced data measures should focus on the more interesting minority class. Such measures are defined as functions of the confusion matrix for two-class problems, with the minority class typically referred to as positive (), while the remaining majority class as negative () [20, 17] (multiple non-positive classes, if present, are usually aggregated into one).
Table 1 illustrates a two-class confusion matrix, which may be regarded as a special case of a contingency table that can be multi-dimensional in general. The (True Positive) and (True Negative) entries denote the number of examples classified correctly by the classifier as positive and negative, while the (False Negative) and (False Positive) indicate the number of misclassified positive and negative examples, respectively. Based on these values, the most common performance measures are defined as:
[TABLE]
Many other classification performance measures were proposed based on values from the confusion matrix; for their reviews see [18, 20, 19, 16, 2]. In this study, we analyse the properties of 22 measures, listed and defined in the supplementary material.111https://dabrze.shinyapps.io/Tetrahedron/ Below, we highlight four measures, chosen for diversity of their characteristics, which we will analyse and compare in more detail:
[TABLE]
The Fβ combines precision and recall as a weighted harmonic mean, with the parameter as their relative weight. Commonly and then the measure is referred to as F1-score. G-mean [21] is the geometric mean of sensitivity and specificity, which takes into account the relative balance of recognition of both positive and negative classes. The Matthews Correlation Coefficient (MCC) expresses a correlation between the actual and predicted classification and returns a value between (total disagreement) and (perfect classification). We highlight MCC in our study as it was considered by some authors as one of the recommended measures for imbalanced data [2, 3]. Optimized precision (OP) combines sensitivity and specificity in a more complex way, also producing values in the range [28].
Apart from these ’’closed-formula‘‘ measures, we shall also analyze in more detail a representative of what may be thought of as ’’open-formula‘‘ measures, in this case \textit{IBA{}_{\alpha}}(M). This particular measure-wrapper is aimed at applying more weight to minority class predictions in a given measure , according to a user-defined parameter [13, 14].
These and other measures were compared in such surveys as e.g. [18, 16, 17, 2], however usually with respect to discussing the main differences in their definitions. Additionally, the F1-score was thoroughly analysed by Powers [26] who claimed that some of its properties, such as focusing only on the minority class and assuming that actual and predicted distributions are identical, may be critical flaws. Another theoretical study showed that aggregating sensitivity and specificity presented more suitable behaviour than measures aggregating precision and recall [19]. Nevertheless, theoretical analyses of measures with respect to complete ranges of domain values are very laborious and have been done only for a few classifier performance measures.
2.2 Visualization of measures
In this paper, we focus on visualizing measures defined on a binary confusion matrix. We note that this should not be confused with visualizations of classifier performance, e.g. using ROC graphs [9], precision-recall curves [7], lift charts [25], or other attempts to graphically present experimental comparisons of classifiers [33, 1, 5]. Our intention is to study general properties of measures rather than visualize the predictive performance of a classifier on a given dataset.
The 3D visualizations of sum-constrained matrices, applicable in particular to confusion matrices, have already been considered in different papers. Below, we recapitulate shortly three approaches, which bear some relation to the (regular) tetrahedron visualization used throughout this paper [22, 6, 11].
Le Bras et al. [22] introduce a system of 3D spaces (referred to as the Formal Framework), in which the contents of sum-constrained matrices can be represented. Because of the three actual degrees of freedom of a sum-constrained matrix, domains consisting of three variables are required and sufficient to express the matrix entries. However, the choice of a particular domain, with three particular variables, may vary depending on the application at hand.
While the representations with three variables might be used to produce 3D visualizations of measures, the paper of Le Bras et al. [22] does not exploit this fact in too much a detail, as its focus lies elsewhere. The authors introduce three very particular, application-driven, 3D domains referred to as: confidence, examples and counterexamples. In its central part, the paper recalls 38 measures related to association rules and defines them consistently in terms of the matrix entries, as well as in terms of the three proposed domains. This allows for conducting dedicated analyses of the measures (e.g. expressing the Piatetsky-Shapiro recommendations [24] in the examples domain), with the main objective of identifying measures most relevant to association rule pruning. The introduced and in detail scrutinized properties include: all-monotonicity, generalized universal existential upward closure, and opti-monotonicity [22].
As far as the tetrahedron-based visualization is concerned, the examples and counterexamples 3D spaces introduced in [22] assume the shapes of tetrahedra. However, contrary to the approach presented in our paper, the domains are designed for analysing rule interestingness measures. Moreover, the tetrahedra of the examples and counterexamples domains are irregular, since these domains are assumed to have two orthogonal variables each, implying shapes with two orthogonal edges incident with one vertex, a feature unattainable in the regular tetrahedron.
Celotto [6] has introduced 2D visualization spaces that are very natural to the considered measures, i.e., Bayesian confirmation measures. The primary space, suitably referred to as the confirmation space, consists of: (-axis) and (-axis). As noted within the paper, the 2D representation of sum-constrained matrices is incomplete, and thus aptly called a fingerprint of the measure. The incompleteness results from the fact that the fingerprint changes as some third parameter which defines the third dimension, in this case chosen to be , is varied.
The confirmation space is initially set side by side with its analogue, denoted as dual confirmation space, and another 2D space, i.e. the ROC space, which consists of false positive rate (-axis) and true positive rate (-axis). However, because confirmation measures remain the main focus of the study of Celotto [6], presented analyses are basically confined to the confirmation space and its dual, which are used to analyse 19 measures. The measure analyses, principally concerned with identifying measures most relevant to classification rule pruning, include visualizations of some ordinal equivalence aspects and a multitude of symmetry aspects. The latter also include visually-assisted design and synthesis of measures possessing desired symmetries.
The 2D confirmation spaces introduced by Celotto correspond to rectangular cross-sections of the 3D tetrahedron presented in this paper. However, contrary to the presented approach, in [6] these originally non-independent variables are presented as orthogonal and of unified ranges, which thus requires some amount of orthonormalization.
Flach [11] mentions several possible definitions of variables suitable for 3D visualizations of confusion matrices, but focuses primarily on 3D ROC space, a generalization of traditional 2D ROC space [20]. The 3D ROC space consists of the false positive rate (-axis) and true positive rate (-axis), which basically constitute traditional ROC space, together with the frequency of positives (-axis). This choice had been dictated by the general topic of the paper, which was the analysis of classifier performance measures and their behaviour in ROC spaces. Notice that the three variables are selected so that the resulting -plane hosts the ROC space, while the third co-ordinate varies with the actual class distribution. In result, the 3D ROC space is thus a collection of stacked-up ROC spaces, with the -coordinate corresponding to the proportion of the positive class. Owing to the variable mutual orthogonality and similar ranges ( for and and for ) the total domain shape is thus a pseudo-cube, i.e. a cube with both the lowermost layer, corresponding to , and the uppermost layer, corresponding to , removed.
In the cited study [11], Flach combines the proportion of classes with misclassification costs, generally referred to as skew, and focuses on analysing 8 selected measures in terms of sensitivity to skew. The considered key notions involve: skew-equivalence and weak/strong skew-insensitivity of the measures. We also note that a similar techniques have been used to analyse rule quality measures. The most well known are coverage spaces, introduced by Fürnkrantz and Flach [12], which plot the number of positive training examples and negative ones covered by the rule in the given data. Coverage spaces can be considered similar to ROC spaces in analysing isometrics of evaluation measures.
The stacked 2D spaces considered by Flach [11] basically correspond to the rectangle-shaped cross-sections of the tetrahedron presented in this paper. However, ROC spaces are presented in square form, which requires some amount of orthogonal rescaling compared to the approach presented in this paper. Furthermore, contrary to the visualization technique introduced in this paper, 3D ROC space remains undefined for confusion matrices with or .
3 The barycentric visualization technique
As presented in Table 1, a confusion matrix for binary classification consists of four entries: , , , . However, for a dataset of examples these four entries are constrained, as . Therefore, for a given constant , any three values in the confusion matrix uniquely define the fourth value. This property allows to visualize any classification performance measure based on the two-class confusion matrix using a 4D barycentric coordinate system [35].
In the barycentric coordinate system point locations are specified relatively to vertices of a simplex (a triangle, tetrahedron, etc.). A 4D barycentric coordinate system is a tetrahedron, where each dimension is represented as one of the four vertices. Choosing vectors that represent , , , as vertices of a regular tetrahedron in a 3D space, one arrives at a barycentric coordinate system as in Fig. 1.
In this system, every confusion matrix is represented as a point of the tetrahedron. Let us illustrate this fact with a few examples. Figure 1 shows a skeleton of a tetrahedron with 4 exemplary points:
- •
one located in vertex , which represents ,
- •
one located in the middle of edge –, which represents ,
- •
one located in the middle of face ––, which represents ,
- •
one located in the middle of the tetrahedron, which represents .
One way of understanding this representation is to imagine a point in the tetrahedron as the centre of mass of the examples in a confusion matrix. If all examples are true positives, then the entire mass of the predictions is at and the point coincides with vertex . If all examples are false negatives, the point lies on vertex , etc. Generally, whenever () then the point is closer to the vertex corresponding to rather than .
Using the barycentric coordinate system makes it possible to depict the originally 4D data (two-class confusion matrices) as points in 3D. Moreover, as in [31, 32], an additional variable based on the depicted four values may be rendered as colour. Although any colour map can be used, in the following paragraphs we utilize the map shown in Fig. 2: dark blue — minimum values, to dark brown — maximum values. Areas of the same colour signify then the same values of the variable. The shape of such areas is determined by the nature of the visualized variable and usually occurs as lines in 2D (isoliness) and surfaces in 3D (isosurfaces) Undefined values of the measures will be rendered in magenta, i.e., a colour not occurring in the map.
Here, we adapt this procedure to colour-code the values of classification performance measures, which remain the principal focus of this paper. In this respect, the presented approach is different from [31] and [32], in which Bayesian confirmation measures were mainly addressed. In particular, this paper introduces and discusses those aspects of the tetrahedron-based visualization that are especially useful for the analysis of classification performance measures.
The described visualization technique has been implemented as an interactive web application, available at: https://dabrze.shinyapps.io/Tetrahedron/. The application can visualize 86 predefined 4D measures, including the 22 classification performance measures described further. The user can also visualize custom measures by providing their formulae. For the remainder of the paper, the reader is encouraged to use this tool to interactively analyse the described properties of various classification measures.
Since classification accuracy is one of the simplest and most often used performance measures, let us use it for an exemplary visualization in Fig. 3. Its values range from [math] to , and there are no undefined ones. One can notice that confusion matrices with a high number of and result in low accuracy, whereas high and yield high accuracy. The visualization in Fig. 3a is only partially comprehensive, as it only shows the externals of the tetrahedron which correspond to very specific confusion matrices. However, both external as well as internal areas can be shown, e.g. by padding tetrahedron points (Fig. 3b), using ’’under the skin‘‘ views (Fig. 3c) or performing cross-sections (Fig. 4).
The indicated cross-sections are of particular interest in the context of analysing measures for class imbalance problems. Notice that traversing the tetrahedron alongside the vertical axis (up-down in Fig. 4a) corresponds to changing the proportions between sums and , which specify the cardinalities of the actual classes. If , then a situation of balanced classes is reproduced; otherwise the classes are imbalanced.
How a measure behaves for a particular class proportion may be visualized by producing a cross-section of the tetrahedron with a horizontal plane that cuts its vertical height. Figures 4b and 4c show the two cross-sections visible in Fig. 4a), one at (positive class as the minority class) and one at (class balance), as seen from above the tetrahedron. Cutting the shape with a horizontal plane at produces the lower, rectangular cross-section (4b), while at — the upper, square one (4c). In their corresponding figures, the cross-sections are oriented so that their sides incident with face –– of the tetrahedron are positioned at the bottom, while those incident with face –– — at the top. It is additionally worth noting that at every section the proportion of the rectangle‘s side lengths follows that of (the horizontal side) and (the vertical side), i.e. the class cardinalities.
Accordingly to the notation of the vertices of the tetrahedron, the sides and vertices of a cross-section rectangle are labelled as follows:
- •
sides: (left), (upper), (right), (lower),
- •
vertices: (upper-left), (upper-right), (lower-right), (lower-left).
The two axes, and , of the 2D space in which all cross-sections are represented (including those for and ), correspond to the false negative rate, recall, and the true negative rate, specificity. The orientation of the axes results from the fact that traversing the rectangle left-to-right corresponds to increasing from [math] to , whereas traversing the rectangle down-up corresponds to increasing from [math] to . The resulting 2D space of the presented cross-section is thus an analogue of 2D ROC space, where, somewhat reversely, the false positive rate, specificity, and the true positive rate, recall, are used as and axes, respectively.
The presented rectangular cross-sections and 2D ROC space constitute the same, though seen from different angles, cross-sections of the tetrahedron. However, contrary to 3D ROC space [11], the presented technique does not involve any non-linear transformations of the elements of the confusion matrix and remains defined for all elements of the domain. Furthermore, because the proposed barycentric coordinates directly correspond to elements of the confusion matrix, the visualization is easily interpretable also in 3D, which helps analysing the whole range of possible domain values.
In the following sections, we demonstrate the usage of the visualization technique in some analyses of the considered classifier performance measures for imbalanced data. The technique, including the cross-sections, was particularly used to visualize several postulated properties of the measures.
4 Properties of Measures for Imbalanced Data
With a visualization technique at hand, it is much easier to define and interpret potentially desirable measure properties. In this section we put forward and discuss ten properties designed to highlight characteristic features of classifier performance measures designed for imbalanced data. The proposed properties can aid researchers in the selection of measures suitable for a given context and raise much needed discussion on the applicability of measures in certain domains.
Recall that the interpretation of the rectangular cross-section discussed in Section 3 is as follows.
- •
side / : full/null recognition of the positive class (Fig. 5),
- •
side / : full/null recognition of the negative class (Fig. 6).
In this context, we postulate to analyse classifier performance measures with respect to ten properties:
:
vertex maximal value,
:
side minimal value,
:
side minimal value,
:
horizontal lines weakly monotonic value growth (from to ),
:
vertical lines weakly monotonic value growth (from to ),
:
side less than maximal value except for vertex ,
:
side less than maximal value except for vertex ,
:
for any two corresponding points on sides and (e.g. middle points) the value on side is greater or equal to that on ,
:
values invariant under exchange of with and with ,
:
the existence (and the location) of undefined values.
If present, undefined measure values are excluded from the above considerations, except for the last property, which is directly concerned with those values. Similarly, all but the last two properties are analysed only for ’non-degenerated‘ rectangular cross-sections, i.e. cross-sections corresponding to and . On the other hand, the ’degenerated‘ cross-section, i.e. cross-sections that result in rectangles of either zero breadth or zero width, are taken into account only in the and properties. The presented properties may be regarded as a basic ’check-list‘, providing knowledge on the behaviour of classifier performance measures for imbalanced data.
Notice that when all feasible rectangular cross-sections of the considered type are taken into account, the properties naturally extend from 2D in the rectangles to 3D in the tetrahedron. For example, points of all rectangles form edge – of the tetrahedron, sides of all rectangles form face –– of the tetrahedron, etc. This multidimensional nature of the measures renders the analytical process of their property verification harder, emphasizing the usefulness of the introduced visual-based 3D analyses.
Recall that the analysed measures are functions of , , and , , which constitute the elements of the confusion matrix (see Table 1). In this context, denotes the value of any of the considered classification performance measures.
Property ensures that perfect predictions of both classes always render the best measure value (see Fig. 7). Notice that vertex , being the common part of both side and side , is actually the only point of full recognition of both the positive and the negative class. Because corresponds to , this implies .
Properties and state that not recognizing one of the classes should correspond to the worst possible measure value (see Fig. 8). Recall that side and side correspond to null recognition of the positive and the negative class, respectively. In binary classification, a null recognition of any of the two classes (which concerns the minority class in most cases) is certainly insufficient. Thus, it is naturally required that measures should obtain minimal values on sides and . This boils down to and .
Properties and require that growing and values should coincide with a weakly monotonic growth of the measure‘s value (see Fig. 9). As far as is concerned, observe that the greater is in the confusion matrix, the closer we move from side to side in the rectangular cross-section, which translates directly to increased recognition of the positive class. Naturally, it would be counter-intuitive if such increased recognition resulted in decreasing values of the measure. Thus, its weakly monotonic growth is expected. As opposed to requirements and , which concern merely the borders of the cross-section, concerns the entirety of the cross-section. In particular, also side , where the value is required to be minimal (according to property ), satisfies the weak monotonicity. Property boils down to the following condition: if , then . Analogously property , which boils down to the condition: if , then .
Properties and tackle the problem of maximal values of the measure. Observe that in a two-class problem, the full recognition of just one class (only positive or only negative), which can be achieved trivially, should not render the highest value of the measure. Only the full recognition of both classes should be rewarded with the maximum, as stated by . Thus, properties and require that the measure‘s values on sides and should be less than maximal, except for the very vertex . If a classification measure fulfils this property, a simple majority or minority stub will never be mistaken with the best possible classifier. This boils down to: if , then .
Property reveals the class bias resulting from asymmetric class evaluation, typical for class imbalance problems. It is introduced to guarantee that full recognition of only the negative class is never rewarded with a higher value than the full recognition of only the positive one (assuming the respective other class is recognized to the same degree). In particular, since the recognition of the positive class is of high importance, the middle point of side (i.e. when the whole positive and half of the negative class is recognized) should not be assessed with a lower value than the middle point of side (i.e. when the whole negative and half of the positive class is recognized). Similarly for all other pairs of corresponding points on sides and (three of which are depicted in Fig. 10). In terms of the entries of the confusion matrix, property boils down to: , where (in Fig. 10 takes on values , and ). Notice that the weak nature of the property is implied by the fact that it does not specify by how much the full recognition of the positive class should be favoured over the full recognition of the negative class. On the other hand the unsatisfied reveals instantly, however, that the measure favours (in the above sense) the negative over the positive.
Much the same, property deals with the issue of asymmetric class handling. It tests if the classes can be exchanged without influencing the measure‘s behaviour. This could be especially relevant in highly dynamic situations, e.g. in data streams plagued by concept drift [4], in which the percentage of the positive class may increase to make it actually (albeit temporarily) the majority class [34]. Expressed with the confusion matrix, boils down to: .
Finally, property pinpoints the existence and the location of undefined values ( whenever a positive value is divided by [math], whenever a negative value is divided by [math], and whenever [math] is divided by [math]). As such, it highlights potential numerical pitfalls that can arise when calculating the measure values. While occurring fairly seldom with real life data, such undefined values are needed to fully characterize and thoroughly compare the considered measures.
In the following section, we use the proposed ten properties to compare various classification measures.
5 Visual-based Analysis of Selected Measures
Having presented the visualization technique in Section 3 and having defined the properties to be researched in Section 4, now we use the proposed tools to analyse 22 classification measures. The selected set of measures includes the most popular ones defined using elements from a two-class confusion matrix, and comprises non-parametric as well as parametric indices. Table 2 presents the analysis results for the selected measures, whereas their definitions are available in the supplementary data222https://dabrze.shinyapps.io/Tetrahedron/.
Looking at the entries of Table 2, one can notice that the proposed properties clearly differentiate the analysed measures. Having realized the differences in the measures‘ behaviour, one can more accurately choose the measures for the application at hand.
Let us start with having a closer look at one exemplary property listed in Table 2, i.e. the existence and location of undefined values (). The undefined measure values, usually resulting from division by zero, and commonly neglected, may well occur with imbalanced data, e.g. during unstratified cross-validation procedures when one of the two classes happens to be unrepresented in the learning or the testing set. The problem becomes aggravated for multi-class problems when the measure is macro-averaged for all classes, since the resulting average becomes undefined if at least one of the averaged values is undefined.
An interesting observation is that, except for accuracy, all of the considered measures contain undefined values. In particular, the Kappa statistic is undefined when there exist only positive or only negative examples in the dataset and none of them is misclassified, which translates to two different locations in the tetrahedron, namely vertex and vertex . Even worse, balanced accuracy is undefined when there are only positive or only negative examples in the dataset, which translates directly to whole edges – and – in the tetrahedron. Worst of all, F1-score (as well as its generalizations) exhibits undefined values in the whole face ––, which occurs when all positive examples are misclassified (even when both classes are represented).
5.1 Non-parametric Measures
Let us now conduct a more detailed visual analysis of the four highlighted measures from Section 2: F1-score, G-mean, Mathews Correlation Coefficient (MCC), and Optimized precision (OP), putting particular emphasis on their behaviour with respect to imbalanced data. Due to the page limit, in this paper we present only cross-sections produced for and . However, other cross-sections of the tetrahedron, including cross-sections produced for higher levels of class imbalance, can be viewed in the online visualization tool.
The analysis of F1-score, visualized in Fig. 11a, show that the growth (although monotonic) of the measure along side is very slow and does not fulfil the property when the data are imbalanced. To illustrate this, consider Fig. 11a (left), which corresponds to class imbalance, and a point located in the middle of . The value there is much lower than the corresponding point on side . Taking into account the fact that the middle point of corresponds to full recognition of the positive class and 50% recognition of the negative class, this shows that with class imbalance high values corresponding to full recognition of the positive class are harder to obtain. Expressed in terms of values in the confusion matrix: , where . Notice that while F1-score fulfils for (11a (right)), it does not for the above mentioned (11a (left)), which means that the property is not satisfied in general (i.e. throughout the tetrahedron). Evidently, the property cannot be verified using only one selected cross-section. As may be observed using the online tool (in particular, by animating from down to [math]), this flawed feature of the measure aggravates for increasing class imbalance (i.e. when drops). This may be quite surprising as the F1-score is often brought out in the literature as especially suited for the positive class. Generalizations of F1-score will be discussed in subsection 5.2 devoted to parametric measures.
The visual-based analysis of G-mean (Fig. 11b) reveals that the measure satisfies the devised properties. In particular, it satisfies some important properties not fulfilled by F1-score, MCC and OP. First, as opposed to the other three measures, G-mean features minimal values on whole sides and . Additionally, it enjoys the property, which makes the measure especially useful in the contexts of imbalanced data: for any two corresponding points on sides and , the value on side happens to be equal (and thus not smaller) to that on . This means that for any : .
As to the behaviour of MCC (Fig. 11c), one can observe that its values on sides and are not minimal, which violates properties and . Even worse, comparing cross-sections for and , one can observe that small values are harder to obtain with the increase of class imbalance. Furthermore, similarly to the F1-score, MCC does not satisfy property . Even though for balanced classes (Fig. 11c(right)) the corresponding points in and feature equal values, this deteriorates with growing disproportion between classes (Fig. 11c(left)). In other words, for imbalanced data it is easier to obtain undue high values by recognizing the negative class.
Finally, let us consider measure OP (Fig. 11d). The visual-based analysis reveals that OP is the only of the selected measures that does not satisfy properties and . Observe that traversing the cross-sections horizontally right-to-left or vertically bottom-up (thus increasing the recognition of one of the classes while keeping the recognition of the second one constant) the values of the measure first increase and then decrease. In fact, the visual analysis discloses that the measure is designed to increase its values monotonically only when the recognition of both classes increases. Undeniably, the increase of the recognition of both classes at the same time is highly desirable and should imply increasing measure values, however, the observed behaviour of OP in (acceptable) cases when the classifier increases the recognition of one class, while keeping the recognition of the other constant is rather surprising and counter-intuitive.
5.2 Parametric Measures
Recalling that the classifier performance measures are functions of the four entries of the confusion matrix, it may be observed that as far as their analytical forms are concerned, the various measures may be divided into unparametrized (e.g. G-mean measure) and parametrized (e.g. Fβ measure). This parametrization process has been designed to lend the measures some amount of universality, as is the case with Fβ, where the parameter is supposed to control the class bias. As such control is much desired, external parametrization procedures have also been developed to modify the measures‘ behaviour, e.g. by adapting them to problems with imbalanced data. One such procedure, called Index of Balanced Accuracy (IBAα) [13, 14, 15], produces a parametrized measure, in which the controls the amount by which the original measure is actually modified.
The above approaches allow us to focus on two following parametrization types:
- •
internal parametrization, (e.g. Fβ),
- •
external parametrization, (e.g. IBAα(G-mean)),
though also a kind of a simultaneous parametrization, e.g. IBAα(Fβ), is feasible.
Observe that measure parametrization actually increases the number of available degrees of freedom, making the inherently complex analyses of such measures even more challenging. The principal question is: how are the particular parameter values to be established? And further, what are their applicability ranges?
Procedures adapted to answer these questions vary from simple trial-and-error approaches to more intricate ones, in which parameter values are possibly gleaned from accessible data. In all cases visualization seems indispensable, providing valuable insights as to the measures‘ behaviour throughout their multidimensional, parametrized domains.
Let us now conduct a more detailed visual analysis of measures, representing both types of parametrization: Fβ (internal) and IBAα(G-mean) (external), which illustrates the impact of the parametrization upon the measures‘ behaviour with respect to imbalanced data. Consistently, we present only cross-sections produced for and , while other cross-sections as well as the entire tetrahedrons can be viewed in our online visualization tool.
5.2.1 Internal parametrization: Fβ
While F1-score is a regular harmonic mean of precision and recall, Fβ originated as a weighed version of this mean. In Fβ and act as non-negative () weights of precision and recall, respectively. This means that may be chosen to produce any convex combination of and to be actually used in the mean. Let denote precision and denote recall, the weighted harmonic mean of and is: (from now on: ).
After setting333Some authors set instead, resulting in , which allows for some further interpretation of such [29]; not to be pursued in this paper. , one gets , which finally produces: Fβ = . Notice that in this scheme:
- •
corresponds to (emphasis on precision),
- •
corresponds to (equal emphasis),
- •
corresponds to (emphasis on recall).
Of course, for , measure Fβ becomes = F1-score, which is thus the regular (unweighed) harmonic mean of precision and recall.
The harmonic mean, used in this context happens to be the most conservative of the three popular Pythagorean means: arithmetic (), geometric () and harmonic (), as they satisfy , but it is also easy to visualize the two others in this role. To what extent and in which regions of the domain these three different means of precision and recall actually diverge from one another may be observed e.g. in Figs 12 and 13, where both precision and recall as well as their three means (arithmetic: , geometric: and harmonic: ) are shown. This visualization illustrates well the concave isolines of and , which means that they obtain excessively high values for increasingly divergent recognition of classes, making the best choice out of three in this respect.
Deciding on the mean, however, is not enough, as the remaining problem regards changes in the measure‘s behaviour across the differing . Unfortunately, for the harmonic mean as well as for the other two means, the measure‘s values gradually shift away from the positive class as decreases, making all the three (regular) means of precision and recall (and thus the F1-score in particular) less and less suited for imbalanced data. This is where the weighed means, in particular Fβ (the weighed harmonic mean of precision and recall) may actually turn out to be more useful.
The arising question regards the appropriate value of . Clearly, the desired bias towards the positive class requires , which corresponds to applying more weight to recall. The visual solution to this problem is provided in Fig. 14, which shows cross-section visualizations of Fβ for three values of . The range of these values has been inspired by the accessible data, in this case the class ratios considered in previous sections: and . These values may be assumed to directly express the -based weights of precision and recall, i.e. and , which translate to and , respectively.
Despite the fact that all ten of the earlier discussed properties of F1-score and Fβ (for ) are identical, as exemplified in Table 2, the increasing difference between F1-score and Fβ resulting from the changing values of is clearly visible in Fig. 14, revealing the truly multidimensional complexity of the measures‘ domains.
A slightly closer explanation may only be due for property, as Fβ‘s particular visualization for in Fig. 14 suggests that the measure satisfies the requirements of (its values on the side are not lower than their counterparts on the side for both and ), whereas Table 2 states that is not met by Fβ. This is because the ten proposed properties are of general character, i.e. they concern the whole tetrahedron, which means that they must be satisfied in cross-sections corresponding to all feasible class proportions. In case of Fβ=5, for some class ratios that are lower than those considered in the presented visualizations, e.g. for (easily reproducible in the online visualization tool), the conditions are actually not satisfied, thus justifying the contents of Table 2.
Nevertheless, for cases when the class ratio is known or predictable, the visualizations are of utmost practical value. In the discussed situation, the visual-based analysis may suggest non-trivial values of for which Fβ certainly satisfies selected properties, in this case the conditions of for a particular . A thorough analysis of cross-sections clearly suggested the existence of a particular dependency between and the class proportion, which influences the property. This observation inspired us to derive analytically the borderline value of that ensures that is met by Fβ.
Proposition 1**.**
Fβ satisfies property for (for proof see the Appendix).
Practically this means that the user must bear in mind the class proportions and may use it to make Fβ satisfy property, if needed.
5.2.2 External parametrization: IBAα(G-mean)
Applying any external parametrization, e.g. the IBAα scheme [13, 14, 15], to different measures evokes the usual problems, first of all related to establishing the values of required parameters. Visualization provides a very practical solution to these issues, as shall be demonstrated in this section.
Given a classifier performance measure , a parameter and a tentative measure , the formula:
[TABLE]
defines the parametrization of , in which this measure is multiplicatively combined with . Of course, \textit{IBA{}{\alpha}}(M)=M for . Simultaneously, when and then , which, together with , implies \textit{IBA{}{\alpha}}(M)\geq 0.
The scheme has been conceived to increase the measure orientation towards the positive class, which makes it a good choice in the imbalanced contexts. Notice, however, that neither is a classic classifier performance measure (as its domain includes negative values), nor is \textit{IBA{}{\alpha}}(M) a simple convex combination of and . This renders strictly analytical (without any visualization tool) analysis of \textit{IBA{}{\alpha}}(M) very hard, especially for larger values of . In result, while the general goal of reorienting the measure towards the positive class is certainly achieved by IBAα, it is not instantly clear how this reorientation is practically manifested. In particular, one might be interested in identifying whether measure subjected to \textit{IBA{}_{\alpha}}(M) satisfies any of the postulated properties, or not (and, if it does, which ones and for what ranges of ).
Below, we visualize and analyse G-mean externally parametrized according to IBAα for . The combination IBAα(G-mean) was particularly recommended and analytically studied for the aforementioned values by García et al. [13]. Tracing the influence of on G-mean within the IBAα approach may well be started with the visualization of the components of the parametrization procedure, see Fig. 15, as only having realized the behaviour of G-mean and , can one infer how the changing impacts the parametrized measure. Clearly, for , IBAα(G-mean) G-mean, so only exerts any influence on the result. Notice that features a rather unexpected growth towards vertex , implying the specific behaviour of IBAα(G-mean), see Fig. 16. Because the combination is multiplicative, the values of G-mean are being ’amplified‘ by the corresponding values of , in particular: increased for , and decreased for .
As stated in Table 2 G-mean satisfies all of the proposed properties. The important question is how the application of external parametrization to the measure influences its properties, e.g. the property (thoroughly discussed for internal parametrization). Unsurprisingly, IBAα(G-mean) may be proven to satisfy the property for all assumed values of . Notably, this comes with a cost, as this parametrization of G-mean is not equally stable with respect to all other properties.
Proposition 2**.**
IBAα(G-mean) satisfies property for (for proof see the Appendix).
Practically, this means that the IBAα(G-mean) does not depart from the original G-mean in terms of . However, a thorough visual-based analysis of the impact of the parameter on satisfying by IBAα(G-mean) suggested a border-line value of . Inspired thereby, we derived the exact value analytically.
Proposition 3**.**
IBAα(G-mean) satisfies property for (for proof see the Appendix).
Table 3 gathers the results concerning the ten devised properties for particular intervals of the parameter implied by its border-line value.
In particular, the entries for G-mean and for IBAα∈(0,1/3](G-mean) state that such external parametrization eliminates the symmetry of handling both classes. It is the result of incorporating the class-asymmetric component in the IBAα parametrization procedure. The parametrized G-mean becomes slightly (as does not exceed ) more oriented towards the positive class (see also Fig. 16), and thus does not satisfy the property any more. Nevertheless, other properties remain satisfied as long as . The behaviour of IBAα(G-mean) changes drastically, however, when exceeds (see Table 3 and Fig. 16). On one hand, for one gets the much desired focus on the positive class, reflected by the property (for any two corresponding points on sides and , the value on side is strictly greater than that on ), however, for this comes with the inevitable cost of losing not only the above-mentioned property, but also the property (manifested by non-monotonic growth of the measure from to ). Additionally, for the maximal value of IBAα(G-mean) drifts away from vertex (i.e. the full recognition of both classes is no longer rewarded with the maximal measure value) violating the and properties. In this context, the usability of IBAα(G-mean) for becomes questionable.
6 Conclusions
In this paper, we proposed a new visualization technique for analysing classification performance measures and contributed an interactive tool implementing it in the form of a web application. The technique uses a barycentric coordinate system by projecting values from the confusion matrix into a three-dimensional figure — a tetrahedron. Unlike simpler visualizations this technique:
- •
provides general interpretations in terms of the four values of the two-class confusion matrix,
- •
involves exclusively linear, and thus easily interpretable, 4D 3D transformations,
- •
allows for analysing full ranges of measure values with respect to all possible combinations of confusion matrix entries,
- •
naturally illustrates the constraint, manifested in the shape of the space (i.e. tetrahedron),
- •
remains defined for all possible combinations of the matrix entries,
- •
admits multiple cross-sections with natural interpretations in terms of simple measures, e.g. horizontal cross-sections, which correspond to the proportion of actual classes (i.e. the positive () and the negative () class) and are thus especially well suited for analysis of imbalanced data.
Using this visualization technique, we analysed 22 classifier performance measures in terms of ten purposefully defined properties, which can help assess the measures in the context of class imbalanced data. The analysis included non-parametric as well as parametric measures, which led to discovering property changes upon certain parametrizations for the latter. In particular, we have derived threshold values for selected properties of Fβ and IBAα(G-mean). The detection of these non-trivial thresholds would be difficult without the proposed visualization technique.
The analysis of the selected measures illustrates how the proposed visualization can depict individual characteristics and potential caveats of each measure. It is worth stressing that it was not our intention to promote any single measure as the best, since the measure choice always finally depends on the user and the application at hand. Nevertheless, our visualization tool and the results gathered in Table 2 should support making this choice.
As future work, we plan to consider also other properties, such as gradients of measure as functions of the four arguments. Moreover, it would be interesting to analyse the effects of applying cost matrices to the visualized measures. Similarly, the effects of micro- and macro-averaging of binary measures in multi-class scenarios are worth studying. Finally, we hope that the visualization technique may be helpful in defining new classifier performance measures.
Acknowledgement
This research was partly supported by the FNP START scholarship (first author) and Institute of Computing Science Statutory Funds.
Appendix: Proofs of Propositions
Proof of Proposition 1
For (the positive class) and (the negative class), the (positive) class ratio is expressed as . Given that, satisfies the property if for every , provided both sides of the inequality are defined.
Because Fβ, a function of precision (everywhere below in this subsection: ) and recall (everywhere below in this subsection: , is defined as F with , and
- •
on the left-hand side:
- –
,
- –
, so under the assumed , ,
- •
on the right-hand side:
- –
, so under the assumed , for ,
- –
, so under the assumed , ,
the inequality is expressed as:
The assumed , , , ensure , so:
The assumed and ensure , so assuming additionally ensures , so:
The assumed ensures , so:
The assumed , , ensure , so:
The assumed allows for:
Assuming additionally allows for:
Intermediate conclusion: given (the positive class) and (the negative class) the inequality: is fully defined and holds for if is taken to satisfy .
The two remaining border cases (resulting from additionally assuming and ) are:
- •
:
which cannot be established, as , and thus Fβ, is undefined on the right-hand side.
- •
:
which holds trivially, as the argument on both sides is the same
(so, on both sides, either Fβ is undefined or it is defined and equal).
Final conclusion: given (the positive class) and (the negative class) the inequality:
[TABLE]
is fully defined and holds for every if is taken to satisfy .
This result may be further simplified, because changes linearly with and for : (which means that is required to satisfy condition ), while for : (which means that is required to satisfy condition ). Notice that the assumed and ensure , which subsumes the assumed . Setting to satisfy ensures satisfying both conditions.
Summarizing all the considered cases, ensures for every for which both sides of the inequality are defined, which proves that F satisfies .
Proof of Proposition 2
Let (the positive class) and (the negative class). IBAα(G-mean) satisfies the property if IBAα(G-mean) IBAα(G-mean) for every , provided both sides of the inequality are defined.
IBAα(G-mean) is a function of recall (everywhere below in this subsection: ) and specificity (everywhere below in this subsection: ), and
- •
on the left-hand side:
- –
, so under the assumed , ,
- –
, so under the assumed , ,
- •
on the right-hand side:
- –
, so under the assumed , ,
- –
, so under the assumed , .
Given , and , IBAα(G-mean) is defined in terms of and as: IBAα(G-mean) = .
In result, IBAα(G-mean) satisfies the property if IBAα(G-mean) IBAα(G-mean), which is also expressed as:
Assuming additionally , which implies , and dividing by
Assuming additionally , which implies , and dividing by
Intermediate conclusion: given (the positive class) and (the negative class) the inequality: IBAα(G-mean) IBAα(G-mean) is fully defined and holds for every if is taken to satisfy .
The two remaining border cases (resulting from additionally assuming and ) are:
- •
:
IBAα(G-mean) IBAα(G-mean)
IBAα(G-mean) IBAα(G-mean)
which holds trivially for every ,
- •
:
IBAα(G-mean) IBAα(G-mean)
which holds trivially, as the argument on both sides is the same
(so, on both sides, either IBAα(G-mean) is undefined or it is defined and equal).
Final conclusion: given (the positive class) and (the negative class) the inequality: IBAα(G-mean) IBAα(G-mean) is fully defined and holds for every if is taken to satisfy .
Summarizing all the considered cases, ensures
[TABLE]
for every for which both sides of the inequality are defined, which proves that IBAα≥0(G-mean) satisfies .
Proof of Proposition 3
Let , where is a function of recall (everywhere below in this subsection: ), specificity (everywhere below in this subsection: ) and , denote IBAα(G-mean).
Given , and :
[TABLE]
.
satisfies the property if it features a weakly monotonic value growth along vertical lines in its cross-sections for , which is equivalent to it being a weakly increasing function of .
Calculating allows for:
Assuming additionally , which implies , and dividing by
Assuming additionally , which implies , and multiplying by
Let . is defined and continuous for , and , and treats and independently (as indicated by and , which are independent of and ). Thus,
Consider :
- •
case produces (holds trivially),
- •
case produces , with ,
- •
case produces , with , further resolved into:
- –
for and : , in which sub-case
- –
for and : , in which sub-case
- –
for and : , in which sub-case
The resulting conditions on are: with , , and , while the assumed condition is (with some of them subsuming some others). Setting to satisfy ensures satisfying all those conditions.
Intermediate conclusion: given : is non-negative function of and is non-negative function of and is a weakly increasing function of if is taken to satisfy .
The two remaining border cases (resulting from additionally assuming and ) are:
- •
: for and , so is a weakly increasing function of (thus also for ),
- •
: for and (including the above considered ), while simultaneously for and (including the above considered ) and 444Proving is analogous to proving , so is a weakly increasing function of (thus also for ).
Final conclusion: given , is a weakly increasing function of if is taken to satisfy .
Summarizing all the considered cases, ensures the weakly increasing character of = IBAα(G-mean) as a function of for any , being equivalent to featuring a weakly monotonic value growth along vertical lines in its cross-sections for , which proves that IBAα(G-mean) satisfies .
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Alaíz-Rodríguez et al. [2008] R. Alaíz-Rodríguez, N. Japkowicz, P. E. Tischer, A Visualization-Based Exploratory Technique for Classifier Comparison with Respect to Multiple Metrics and Multiple Domains, in: Proc. 19th European Conf. Mach. Learn., Part II, 660–665, 2008.
- 2Baldi et al. [2000] P. Baldi, S. Brunak, Y. Chauvin, C. Andersen, H. Nielsen, Assessing the Accuracy of Prediction Algorithms for Classification: An Overview, Bioinformatics 16 (2000) 412–424.
- 3Bekkar et al. [2013] M. Bekkar, H. Djemaa, A. Taklit, Evaluation Measures for Models Assessment Over Imbalanced Data Sets, Journal of Inform. Eng. and Appl. 3 (10) (2013) 27–38.
- 4Brzezinski and Stefanowski [2017] D. Brzezinski, J. Stefanowski, Prequential AUC: Properties of the Area Under the ROC Curve for Data Streams with Concept Drift, Knowledge and Information Systems 52 (2) (2017) 531–562.
- 5Caruana and Niculescu-Mizil [2004] R. Caruana, A. Niculescu-Mizil, Data Mining in Metric Space: An Empirical Analysis of Supervised Learning Performance Criteria, in: Proc. 10th ACM SIGKDD Int. Conf. Knowl. Discovery Data Mining, 69–78, 2004.
- 6Celotto [2017] E. Celotto, Visualizing the behavior and some symmetry properties of Bayesian confirmation measures, Data Min. Knowl. Discov. 31 (3) (2017) 739–773.
- 7Davis and Goadrich [2006] J. Davis, M. Goadrich, The relationship between Precision-Recall and ROC curves, in: Proc. 23rd Int. Conf. Mach. Learn., 233–240, 2006.
- 8Domingos [2012] P. M. Domingos, A few useful things to know about machine learning, Commun. ACM 55 (10) (2012) 78–87.