Target Oriented High Resolution SAR Image Formation via Semantic Information Guided Regularizations
Biao Hou, Zaidao Wen, Licheng Jiao, Qian Wu

TL;DR
This paper introduces a semantic information guided regularization framework for SAR image formation, improving target focus and clutter suppression by leveraging semantic priors and high-level regularizers.
Contribution
It proposes a novel semantic regularizer and high-level prior-driven regularizer for target-oriented SAR imaging, enabling unsupervised semantic label inference and enhanced image quality.
Findings
Enhanced target scattering in SAR images
Superior clutter suppression compared to existing methods
Effective in unsupervised semantic label inference
Abstract
Sparsity-regularized synthetic aperture radar (SAR) imaging framework has shown its remarkable performance to generate a feature enhanced high resolution image, in which a sparsity-inducing regularizer is involved by exploiting the sparsity priors of some visual features in the underlying image. However, since the simple prior of low level features are insufficient to describe different semantic contents in the image, this type of regularizer will be incapable of distinguishing between the target of interest and unconcerned background clutters. As a consequence, the features belonging to the target and clutters are simultaneously affected in the generated image without concerning their underlying semantic labels. To address this problem, we propose a novel semantic information guided framework for target oriented SAR image formation, which aims at enhancing the interested target…
Click any figure to enlarge with its caption.
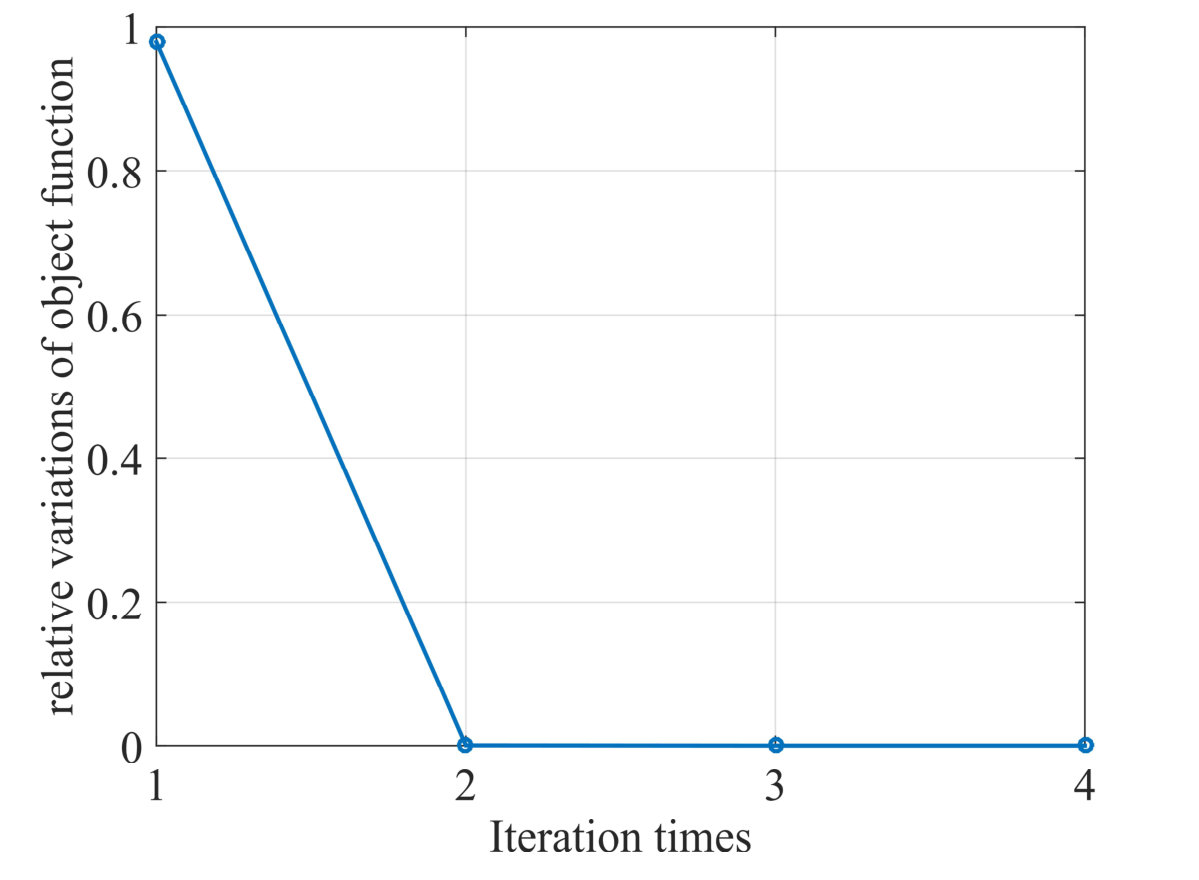 Figure 1
Figure 1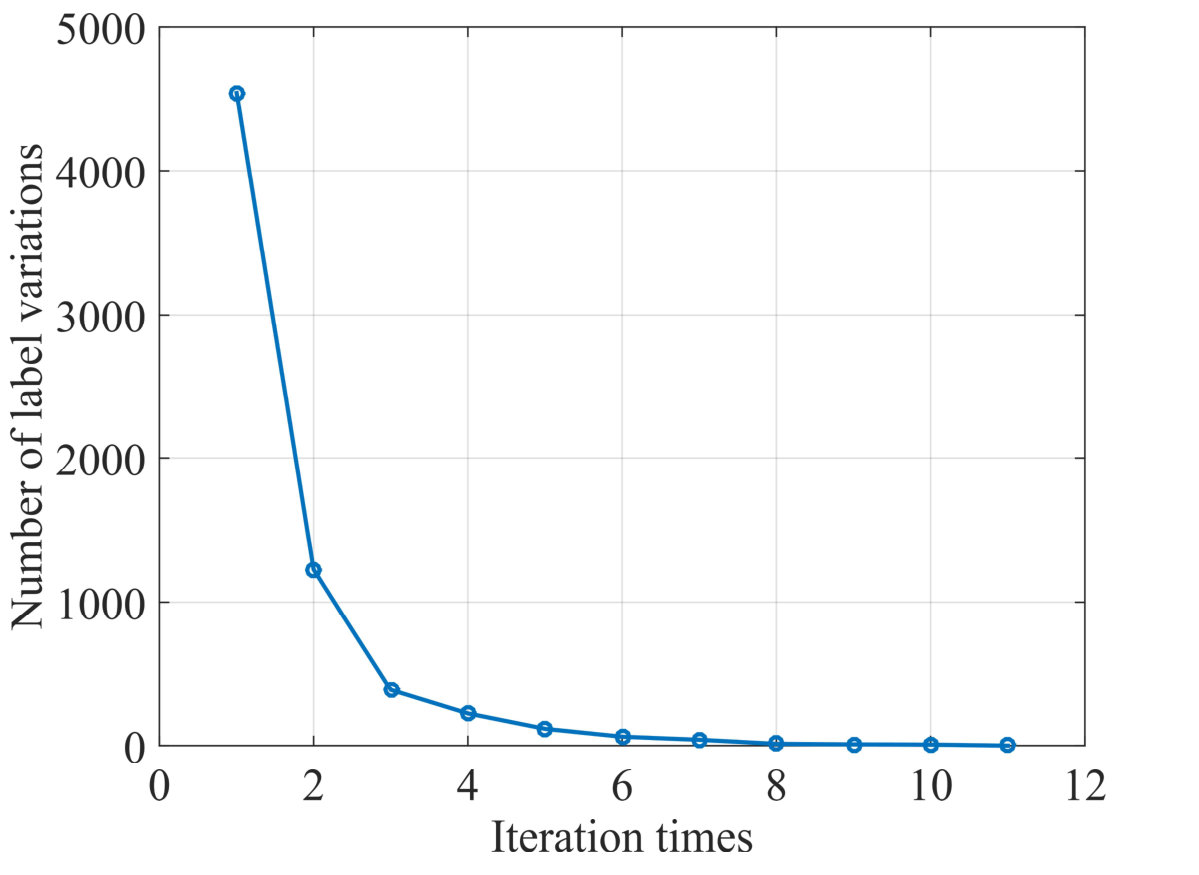 Figure 2
Figure 2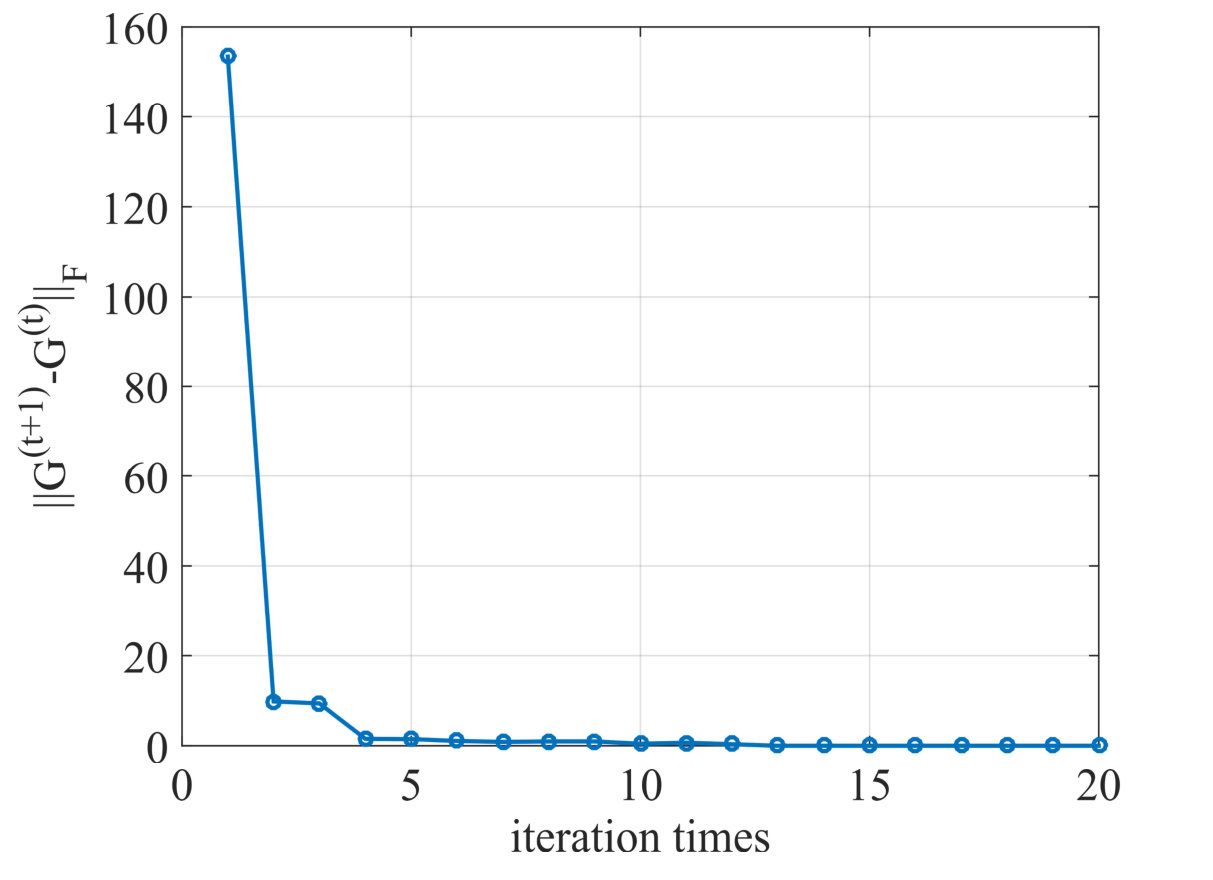 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7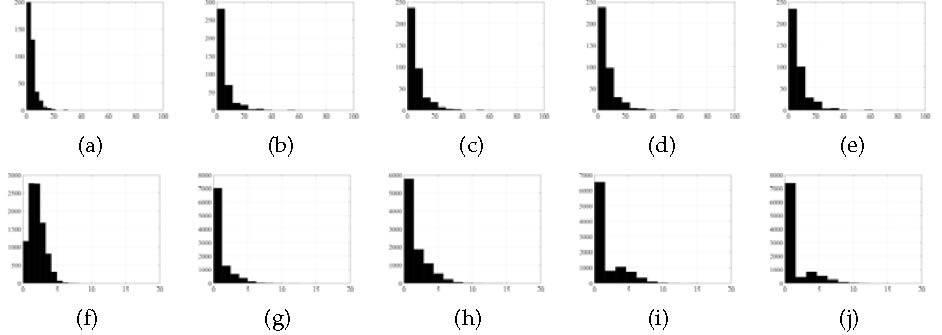 Figure 8
Figure 8 Figure 9
Figure 9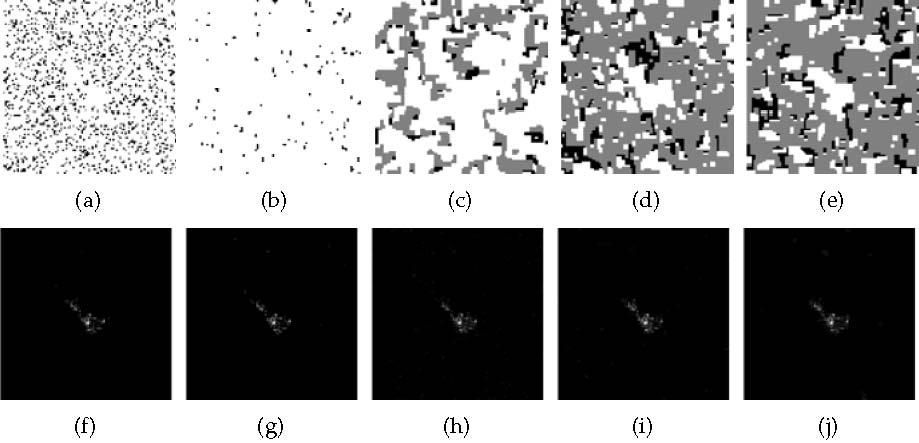 Figure 10
Figure 10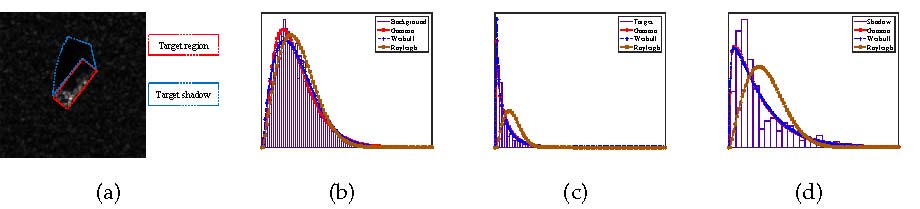 Figure 11
Figure 11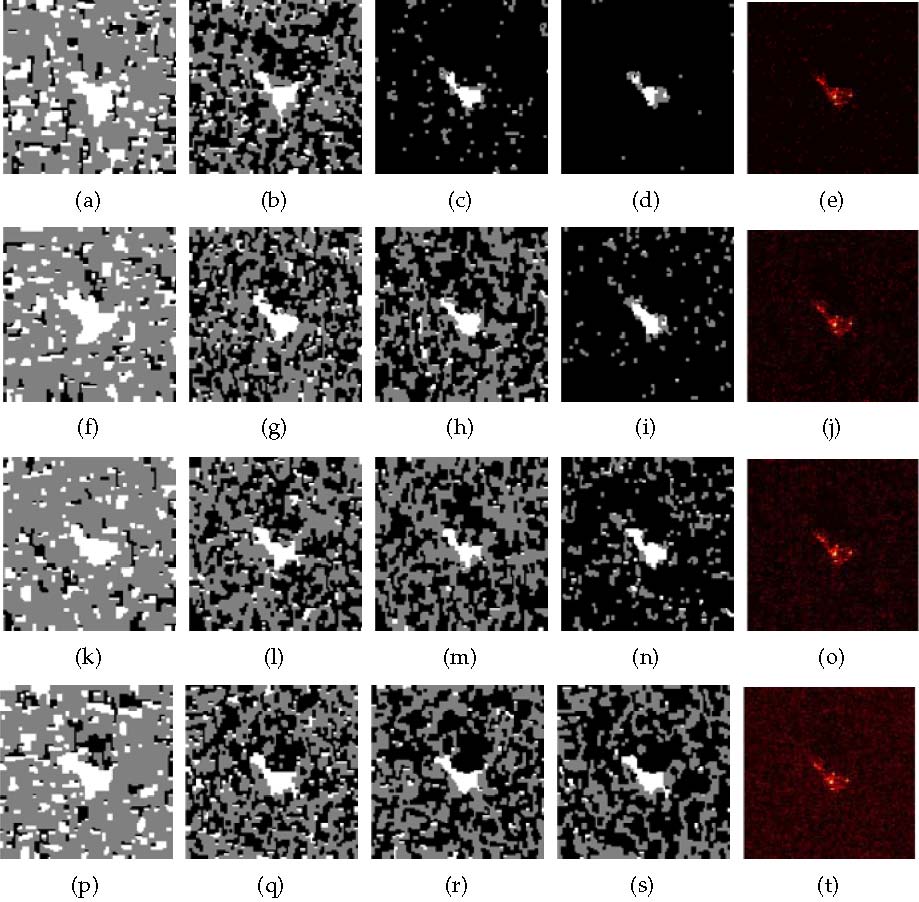 Figure 12
Figure 12 Figure 13
Figure 13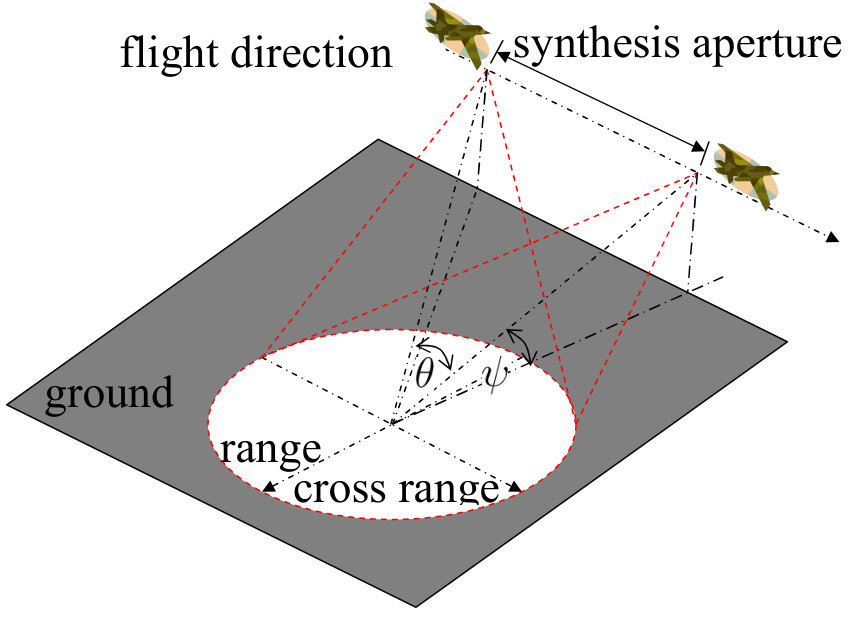 Figure 14
Figure 14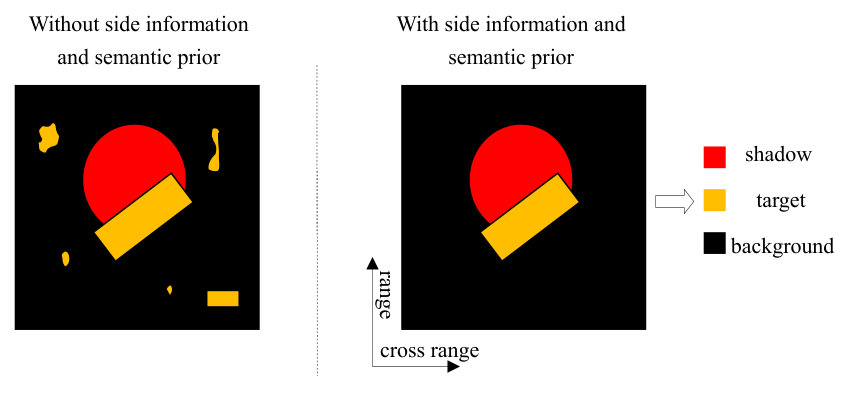 Figure 15
Figure 15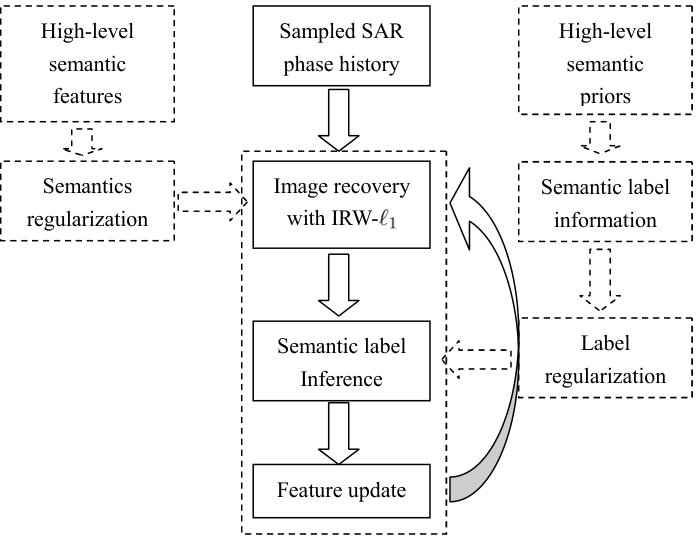 Figure 16
Figure 16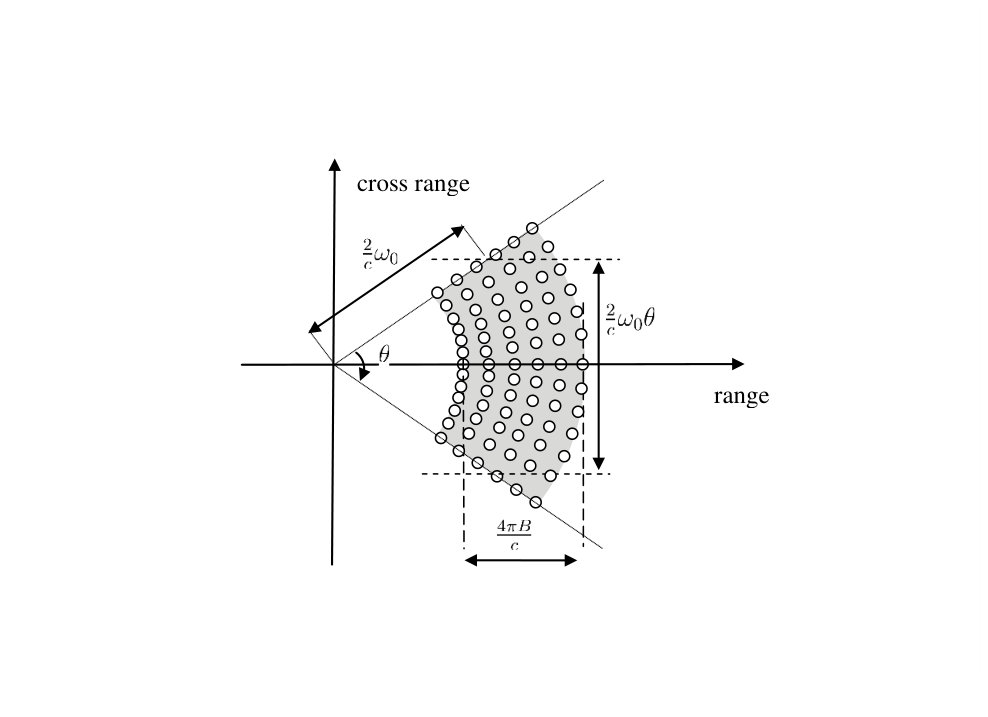 Figure 17
Figure 17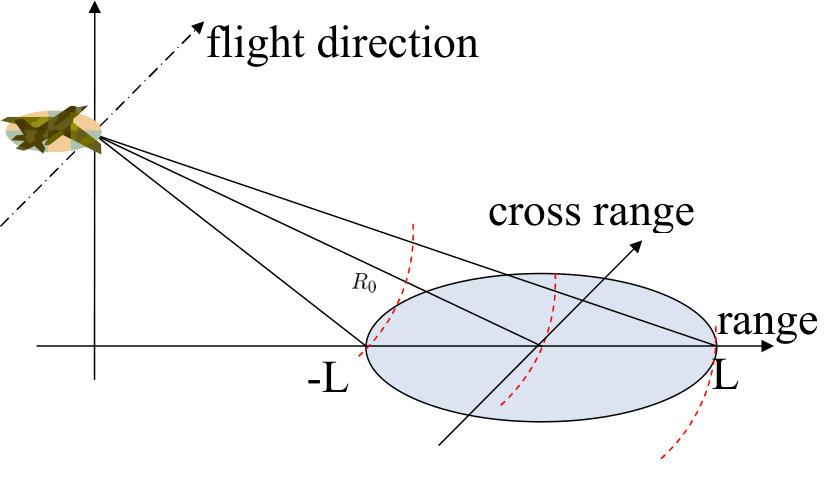 Figure 18
Figure 18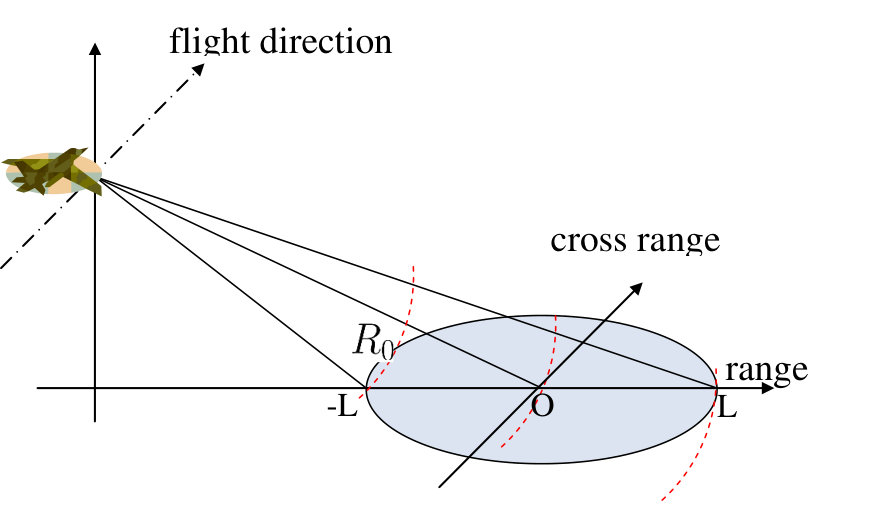 Figure 19
Figure 19| 0 | 1 | 1 | |
| 1 | 0 | 1 | |
| 1 | 1 | 0 |
| 0 | 1 | 1 | |
| 1 | 0 | 1 | |
| 1 | 1 | 0 |
| 0 | 2 | 1 | |
| 1 | 0 | 2 | |
| 2 | 1 | 0 |
| 0 | 1 | 2 | |
| 2 | 0 | 1 | |
| 1 | 2 | 0 |
| Target Type | Sequence | Target Size (m) | Resolution (m) |
|---|---|---|---|
| BMP2 | sn-9566 | ||
| BTR70 | sn-c71 | ||
| T72 | sn-132 |
| BTR | ||||||
| Algorithm | PTCR | PTCR | PTCR | |||
| PF-Imaging | 17.0008 | 7.7981 | 18.0431 | 12.7282 | 22.4897 | 66.1276 |
| Poi-Imaging | 41.0656 | 91.4789 | 39.5539 | 126.0911 | 32.2728 | 98.9543 |
| Reg-Imaging | 14.6138 | 1.1394 | 15.8597 | 2.1761 | 23.6771 | 47.6311 |
| IRW- | 36.6725 | 122.8220 | 35.6254 | 156.3631 | 31.4178 | 190.5878 |
| Tar-Imaging | 43.9012 | 178.5304 | 52.9407 | 203.5214 | 67.7273 | 212.9420 |
| T72 | ||||||
| Algorithm | PTCR | PTCR | PTCR | |||
| PF-Imaging | 13.0623 | 7.5820 | 13.5501 | 11.6905 | 15.6163 | 54.9055 |
| Poi-Imaging | 27.4130 | 81.6110 | 26.0462 | 95.1180 | 18.6934 | 57.4675 |
| Reg-Imaging | 11.7601 | 1.2717 | 12.5823 | 1.9718 | 16.4631 | 19.0626 |
| IRW- | 25.6452 | 106.5971 | 24.2680 | 121.0326 | 20.2626 | 142.5146 |
| Tar-Imaging | 30.0898 | 140.9991 | 31.3511 | 157.0146 | 35.6465 | 164.0307 |
| BMP2 | ||||||
| Algorithm | PTCR | PTCR | PTCR | |||
| PF-Imaging | 18.3315 | 12.5190 | 19.4606 | 20.8500 | 23.9939 | 109.2194 |
| Poi-Imaging | 42.9390 | 187.5272 | 41.4655 | 220.1853 | 32.1583 | 133.4031 |
| Reg-Imaging | 15.7512 | 1.7024 | 17.3495 | 3.3094 | 26.6544 | 83.3213 |
| IRW- | 38.3855 | 220.9719 | 37.4246 | 256.4996 | 32.8173 | 327.6412 |
| Tar-Imaging | 48.2299 | 324.4334 | 57.7635 | 337.1599 | 71.2109 | 343.3820 |
| BTR | |||||||
| Algorithm | PTCR | PTCR | PTCR | ||||
| PF-Imaging | 19.4720 | 18.9968 | 20.1229 | 26.9835 | 22.9048 | 71.6389 | |
| Poi-Imaging | 36.5063 | 49.3023 | 36.0164 | 66.4116 | 33.2154 | 126.6901 | |
| Reg-Imaging | 17.2455 | 3.1432 | 18.4907 | 5.0212 | 23.7910 | 17.9493 | |
| IRW- | 31.7427 | 61.6018 | 31.5526 | 76.8384 | 29.9430 | 132.1517 | |
| Tar-Imaging | 37.8679 | 61.0847 | 51.0485 | 89.9441 | 67.4151 | 147.0478 | |
| PTCR | PTCR | PTCR | PTCR | ||||
| 18.5537 | 14.4999 | 17.2832 | 8.8997 | 19.4325 | 21.5211 | 21.1940 | 38.7339 |
| 39.4840 | 126.2416 | 40.8699 | 89.2191 | 37.7610 | 96.6847 | 35.2627 | 93.3363 |
| 16.3993 | 2.4573 | 15.0495 | 1.2889 | 17.7144 | 4.0257 | 20.4397 | 8.4980 |
| 35.5973 | 153.8319 | 36.3232 | 112.3754 | 34.0552 | 128.0656 | 32.3910 | 131.9222 |
| 54.7527 | 200.9848 | 43.0305 | 148.0628 | 58.5966 | 142.3139 | 60.6819 | 150.5373 |
| T72 | |||||||
| Algorithm | PTCR | PTCR | PTCR | ||||
| PF-Imaging | 16.5688 | 16.4630 | 17.0673 | 22.6121 | 17.4500 | 60.1577 | |
| Poi-Imaging | 26.5466 | 41.3372 | 26.1173 | 58.6055 | 22.3225 | 109.4114 | |
| Reg-Imaging | 14.9497 | 2.9080 | 16.3057 | 3.5198 | 17.8552 | 14.4514 | |
| IRW- | 23.3785 | 50.1609 | 23.1091 | 62.3615 | 20.5810 | 111.6243 | |
| Tar-Imaging | 32.2291 | 58.1908 | 34.0190 | 80.3175 | 38.3358 | 133.1198 | |
| PTCR | PTCR | PTCR | PTCR | ||||
| 13.8400 | 13.1822 | 13.7775 | 8.1656 | 15.0942 | 18.0869 | 15.8337 | 33.4461 |
| 25.8153 | 98.4922 | 27.5579 | 71.3681 | 25.1231 | 88.0165 | 23.0272 | 83.8022 |
| 12.7821 | 2.2843 | 12.3372 | 1.2096 | 14.2741 | 3.0457 | 15.5342 | 6.6240 |
| 24.1176 | 124.4063 | 25.7013 | 94.5736 | 23.4015 | 109.1500 | 21.7270 | 111.0157 |
| 31.3624 | 153.8931 | 31.3459 | 119.8822 | 34.2360 | 126.7842 | 35.4924 | 128.7525 |
| BMP2 | |||||||
| Algorithm | PTCR | PTCR | PTCR | ||||
| PF-Imaging | 21.4360 | 41.7758 | 22.3384 | 48.9530 | 24.8024 | 132.4351 | |
| Poi-Imaging | 38.3302 | 88.9851 | 38.2651 | 112.0608 | 34.9934 | 215.0542 | |
| Reg-Imaging | 19.5468 | 5.8026 | 21.4904 | 8.1553 | 27.0500 | 34.9255 | |
| IRW- | 33.0347 | 99.4547 | 33.2900 | 117.2942 | 31.5695 | 213.9724 | |
| Tar-Imaging | 45.5195 | 105.2211 | 58.1724 | 141.9737 | 68.2833 | 236.0894 | |
| PTCR | PTCR | PTCR | PTCR | ||||
| 20.0459 | 22.7768 | 18.5443 | 14.6007 | 20.6941 | 36.1805 | 22.8670 | 74.8243 |
| 41.0814 | 154.5493 | 42.6230 | 137.0401 | 39.0203 | 134.0967 | 36.9405 | 148.7263 |
| 18.0004 | 2.9916 | 15.8433 | 1.6735 | 19.2744 | 6.3297 | 23.3238 | 17.0751 |
| 37.3317 | 218.1727 | 38.0015 | 169.9341 | 35.4457 | 190.5513 | 34.1575 | 214.8892 |
| 59.2517 | 290.5725 | 49.0573 | 245.5196 | 59.7272 | 213.8323 | 62.7116 | 229.5607 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Target Oriented High Resolution SAR Image Formation via Semantic Information Guided Regularizations
Biao Hou, Zaidao Wen, Licheng Jiao, and Qian Wu
Abstract
Sparsity-regularized synthetic aperture radar (SAR) imaging framework has shown its remarkable performance to generate a feature enhanced high resolution image, in which a sparsity-inducing regularizer is involved by exploiting the sparsity priors of some visual features in the underlying image. However, since the simple prior of low level features are insufficient to describe different semantic contents in the image, this type of regularizer will be incapable of distinguishing between the target of interest and unconcerned background clutters. As a consequence, the features belonging to the target and clutters are simultaneously affected in the generated image without concerning their underlying semantic labels. To address this problem, we propose a novel semantic information guided framework for target oriented SAR image formation, which aims at enhancing the interested target scatters while suppressing the background clutters. Firstly, we develop a new semantics-specific regularizer for image formation by exploiting the statistical properties of different semantic categories in a target scene SAR image. In order to infer the semantic label for each pixel in an unsupervised way, we moreover induce a novel high-level prior-driven regularizer and some semantic causal rules from the prior knowledge. Finally, our regularized framework for image formation is further derived as a simple iteratively reweighted minimization problem which can be conveniently solved by many off-the-shelf solvers. Experimental results demonstrate the effectiveness and superiority of our framework for SAR image formation in terms of target enhancement and clutters suppression, compared with the state of the arts. Additionally, the proposed framework opens a new direction of devoting some machine learning strategies to image formation, which can benefit the subsequent decision making tasks.
Index Terms:
High resolution SAR image, target oriented image formation, semantic information, regularization.
I Introduction
Automatic target recognition (ATR) is one of the most important decision making tasks for synthetic aperture radar (SAR), in which a high quality SAR image is required to provide some informative target features for recognition [1]. Therefore, the SAR platform operating in the spotlight mode is widely leveraged for ATR [1] since it can generate a target image with higher resolution by continuously illuminating the target scene from a series of viewing angles [2]. Conventionally, forming a SAR image, namely SAR imaging, relies on inverse Fourier transformation for the spotlight mode SAR, e.g., polar formatting algorithm and convolution back-projection algorithm [2, 3]. These approaches have been extensively leveraged for SAR image formation due to their simplicity and efficiency, but they still suffer from the following deficiencies in terms of the ATR task. 1). They rely on a perfectly received and sampled data to form a high quality image, which makes them sensitive to various non ideal or noisy environments such as limitations in the sampled data as well as viewing angles. In these scenarios, the quality and resolution of the obtained image will be generally degraded. 2). The contents of the underlying scene image and the features of the target are not concerned in these imaging algorithms so that the generated image will not provide a positive contribution to improve the performance of ATR or other decision-making tasks, e.g. segmentation etc.
These deficiencies consequently raise an issue whether we could develop a SAR imaging framework that is driven by the following decision-making tasks [4]. More specifically, for example, most ATR algorithms will generally exploit some features of the target extracted from a high resolution SAR image, such as the scattering points configuration, target contour and shape [1, 5]. If the imaging algorithm can take these features into consideration and simultaneously provide a feature enhanced target image, the subsequent ATR will be easier. For this purpose, etin and Karl [6] propose a promising feature enhanced SAR imaging framework which recasts the imaging procedure as solving a regularized linear inverse problem. This framework enables us to enhance some task-specific features via involving a variety of regularization functions [7]. In their framework, they adopt the norm and the total variation (TV) regularizer [8] to respectively enhance the magnitude of those dominated scattering points and the boundaries or edges in the image by exploiting their sparsity priors in the underlying image. Accordingly, their framework will suppress the sidelobes and produce a point enhanced or a piecewise smooth region enhanced image. It has been further evaluated that such enhancement can improve target recognition performance as expectation [9, 10]. Additionally, they give an empirically conclusion that their regularization framework is also robust to the partially sampled data as well as observation noise [9, 7]. This conclusion can be also confirmed and coincident with the latter emerging theory called compressive sampling or compressed sensing [11, 12, 13, 14], which theoretically demonstrates the overwhelming possibility of exactly recovering a sparse vector or a low rank matrix from its partially and randomly sampled entries111More precisely, recovering a low rank matrix with its partially known entries is referred to as matrix completion problem.. Over past decade, this novel theory brings a new road to SAR or inverse SAR (ISAR) imaging by exploiting the priors of sparsity in an image for the sake of relieving the sampling burden and achieving an apparent improvement on image quality and resolution [15, 16, 17, 18, 19, 20, 21, 22]. More details about these sparsity-driven SAR imaging algorithms can refer to the surveys and references therein [23, 4].
I-A Motivation
The above mentioned SAR imaging algorithms however only exploit the simple sparsity priors of several low level visual features in the image [24], which are insufficient and inaccurate to describe the complicated image contents and the target. Therefore, many researchers gradually concentrate on other priors and features. Wang et al. [25] propose a target enhanced ISAR imaging algorithm based on Bayesian compressed sensing framework [26] by exploiting the prior of continuity for the scatterers in the target scene. Additionally, Wang et al. further leverage the Markov prior to encourage the continuity features [27]. However, all above mentioned imaging algorithms are still unable to distinguish different semantic concepts in the image due to the gap between bottom level features and top level information in perception tasks [28]. Such gap is caused since the bottom level features such as points and edges are normally shared in different types of semantic objects. These shared low level features will firstly construct more complex structures as the mid-level features and finally form different semantic objects in the top level with different hierarchical approaches [29]. As a consequence, due to the loss of the high level semantic information, these sparsity-driven imaging algorithms will enhance/suppress all strong/weak scattering points and edges of both the targets of interest and the unconcerned background clutters without considering their diverse semantic labels. On one hand, from the ATR perspective, we generally pay more attention to those scattering points belonging to the interested target. In this regard, we only hope to enhance the points with the target tag while suppressing others to obtain a tangible target enhanced image with a prominent target to clutter ratio. On the other hand, from the data acquisition perspective, the amount of target pixels is much smaller than that of the complete image. Only reconstructing these target pixels will be consequently able to reduce the required observations, which will further relieve the burden in data acquisition and sampling. These two perspectives straightforward raise a suggestion for the ATR task that whether we could directly reconstruct an only target image instead of throwing the unconcerned background clutters away after fully reconstruction as the conventional way does. To this end, we exploit another two target priors to estimate the position of the target region [30] and reconstruct a specified number of scattering points within this region. But this algorithm heavily relies on a man-made target template in order to obtain an initial position estimation, which is not robust in practical environment and the issue of the semantic gap is not concerned as well.
I-B Main Contributions
Motivated by the above analysis and explicitly addressing the semantic gap during SAR imaging procedure, we propose a novel semantic information guided iterative regularization framework for target oriented high resolution SAR image formation, which aims at enhancing the target while suppressing the background clutters. The main contributions of our framework are summarized as following.
- •
We develop a semantics-specific regularizer for image formation by leveraging the statistical features of different semantic contents in a target scene image.
- •
In order to determine the semantic label for each pixel in the image, we induce a prior-driven regularizer and some semantic causal rules from the high level semantic prior knowledge.
- •
Our regularized framework for image formation is further derived as a simple iteratively reweighted minimization problem, which makes the optimization easier to be implemented.
The extensive experimental results on the public MSTAR database222https://www.sdms.afrl.af.mil/index.php?collection=mstar demonstrate the effectiveness and superiorities of our proposed framework in terms of target enhancement and clutters suppression, compared with the other state of the art imaging algorithms.
The remainder of this paper is organized as follows. Sec. II firstly reviews the basic imaging model for the spotlight mode SAR, and then we propose our target oriented SAR image formation framework in Sec. III. A detailed optimization scheme for the proposed framework is derived in Sec. IV followed by an analysis of its convergence and computational complexity. Experiments are conducted in Sec. V and we conclude this paper in Sec. VI.
II Spotlight Mode SAR Imaging Model
In this section, we will review the basic observation model of the spotlight SAR to introduce the regularized imaging formulation [2][6]. Suppose the spotlight mode SAR stares a detected target scene by transmitting a series of linear frequency modulated pulse signal
[TABLE]
where denotes the carrier radian frequency, is the so-called chirp rate, is the fast time and denotes the pulse width. Each transmitted pulse impinges the ground region and is subsequently reflected and received by the SAR platform. The geometry of this procedure is depicted in Figs. 1, where denotes the distance between the SAR platform and the center of region, is the depression angle measuring the angle between the scene and the line of sight, is the total viewing angle extent and is the radius of the scene patch.
After being demodulated, the observed echo signal from the -th viewing angle can be formulated as [17]
[TABLE]
where represents the radial spatial frequency, stands for the two dimensional microwave reflectivity density function of the illuminated target scene, namely the unknown SAR image and is the speed of light. It is worth noting that is actually a finite slice of the two-dimensional (2D) Fourier transform of . During the flight, SAR platform keeps on staring the target region and receives a collection of from different viewing angles . Then we can reformulate Eq. (2) into a more compact form as
[TABLE]
where is a two dimensional Fourier transformation type operator. For each continuous signal , if it is sampled by a measurement operator with the requirement of Nyquist sampling raw [31], we will obtain an -dimensional complex phase history vector . For all viewing angles, a cascade discrete phase history vector will be stacked as
[TABLE]
Then, combining Eq. (3) and (4), the discrete version of SAR observation model can be formulated as:
[TABLE]
where is the discrete complex SAR image of the underlying target scene and is its vector form. is a linear discrete approximation of as well as the sampling operator and is the additive measurement noise. With the formulation (5), SAR image reconstruction can be regarded as estimating from , which conventionally relies on the inverse or adjoint operator of in the case of a small noise and the perfectly sampled data. In many practical situations, the received data will however be undersampled due to the limitation of bandwidth so that only partial entries of are observed by , where is the down sampling matrix. In this situation, those conventional inverse operator based imaging algorithms will not perform well as Eq. (5) becomes ill-posed. Alternatively, the principle way to deal with this problem is to incorporate some constraint on the solution by regularization. Then a desired solution will be obtained from the following regularized linear inverse problem [7].
[TABLE]
where is a regularization function imposing some required properties on , is the regularization parameter and the second term is called the data fidelity. From the Bayesian inference aspect, the imaging problem can be also interpreted as an estimation of a latent variable given the observed variable and it can be formulated as the following maximum a posterior (MAP) estimator [25][26].
[TABLE]
where is the likelihood function of given the outcome and is the priori distribution of latent . When the multivariate Gaussian measurement noise with zero mean vector is considered in the previous algorithms, will be equivalent to the data fidelity in (6) and can control the noise precision. The remaining term will be described by the regularization function in (6), namely . In the next section, this term will be specially designed to meet our requirement.
III Semantic Information Guided Target Oriented High Resolution SAR Image Formation
In this section, we will explicitly address the problem of semantic gap in the imaging process and develop a target oriented SAR image formation framework, which aims at enhancing the target while suppressing the background clutters in the generated image. To implement this task, two core issues should be taken into consideration, i.e., 1) how to determine the semantic labels for every pixel in an unknown SAR image without available supervised training data and 2) which regularizer can be exploited to simultaneously enhance and suppress pixels according to their semantic labels. In the following subsections, we will address these two issues explicitly.
III-A Semantics-Specific Regularizer with Statistical Features
According to the above discussion, sparsity-driven imaging algorithms exploit the sparse priors of the pixel magnitude and edge or contour feature in an underlying SAR image. In this case, in (6) is chosen as the norm and TV regularizer to regularize each pixel and edge independently without concerning its semantic label. In order to involve the semantic information, it is supposed that the magnitude of each pixel will be conditioned on its semantic label and several semantic features in . When the label set is finite and it contains categories, all pixels in will be correspondingly clustered into disjoint groups based on their semantic labels. By assuming the conditional independence of each pixel on its label as well as within each group, we have
[TABLE]
where means that the semantic label of is , computes the total number of pixels in class and is the semantic feature set of this class. In this paper, three semantic labels in the target scene are concerned, including “background”, “target” as well as “shadow”, namely . Nevertheless, “shadow” actually is only an auxiliary label for target inference, which will be discussed in Sec. III-B.
Up to now, the important issue to design our semantics-specific regularizer becomes to determine . Intuitively, we could choose different distribution functions for the pixels with different labels, but for the sake of simplicity we assume all pixels are drawn from independent identical distributions (i.i.d) with distinct statistical features. Accordingly, various distributions can be investigated [32], such as generalized Gamma distribution [33], Weibull distribution [34], distribution [35] etc, in which the distribution parameters will be served as the statistical features. In our framework, we will exploit the Gamma distribution to model the pixel magnitude as follows.
[TABLE]
where is the gamma function, and are shape and scale statistical features for class , respectively and is the magnitude of pixel . To validate the compatibility of Gamma distribution compared with Rayleigh and Weibull, we choose a sample target SAR image from MSTAR database and fit the histograms of different semantic regions shown in Fig. LABEL:fig_illustratetargetshadow, where pixels belonging to the complete target and shadow are manually bounded by the red and blue dash boxes, respectively and the rest pixels belong to the background. It can be empirically observed from Figs. LABEL:fig_background, LABEL:fig_target and LABEL:fig_shadow that the histograms for different semantic regions are indeed the most coincident with the Gamma distribution.
Combining Eq. (9) with (8) and taking its negative logarithmic form, we have:
[TABLE]
where is a small constant which is introduced to avoid infeasible in the case of . With this formulation, if we leave out the irrelevant terms with respect to , our semantics-specific regularizer will be designed as
[TABLE]
We can see that this regularizer is explicitly determined by the semantic labels and features . By choosing different features, the gamma distributions with distinct shapes and scales will be required to capture different semantic classes, which we are able to simultaneously enhance the target pixels and suppress others and this issue will be discussed in Sec. III-C. Compared with the traditional regularization, our derived from the semantic related statistical distributions, comprises a weighted term and a sum of the logarithms term , in which the semantic labels and features , are specifically involved to control the distributions of different semantic classes. On the contrary, traditional norm or TV regularizer only derived from the simple bottom level priors treats every class equally without any distinction. To our best knowledge, this semantics-specific regularizer is initially developed in image reconstruction field. In particular, when and are identical for all classes, becomes the normal regularization.
III-B Prior-Driven Regularizer with High level Semantic Information
Assigning each pixel in the image with a proper candidate semantic label is generally referred to as the image semantic segmentation or pixel annotation which is another fundamental perception task in SAR image processing [36, 37]. However, most of the algorithms addressing this problem are based on some classification strategies, where a large number of labeled pixels are required to train a classifier in a supervised way. Otherwise, only pixels clustering or image segmentation can be implemented [38]. In our imaging scenario, the pixels in the underlying SAR image are unknown so that no pixel can be labeled as the training data. To address this problem, we have to incorporate some high level semantic priors and side information to infer the semantic labels in an unsupervised way and these semantic prior knowledge and side information can be readily obtained and induced from human’s perceptive and cognitive experiences or some common senses.
To establish the role of high level semantic priors and side information for label inference, we will firstly consider the following example. Suppose we have obtained a segmentation result of a SAR image with some unsupervised clustering algorithms shown in Fig. 3 (left). For a computer without providing it any other information of the target, shadow as well as background, it is not possible to assign the correct semantic label to each coloured segment. On the contrary, an expert who has known the side information of range and cross range direction as well as radar flight state is able to make an inference as following. Firstly, according to the principle of the spotlight mode SAR imaging, the shadow will locate in the downrange of the target when the radar is operated in side-looking mode [2]. According to the semantic prior knowledge, “target” and “shadow” always belong to a co-occurrence semantic pair in range direction so that the expert can state that target will locate beneath its shadow if range direction is established in Fig. 3 (right). Next, the man-made target will be continuous [25] and has an approximately regular geometry shape while other unconcerned natural objects or clutters are irregular in general. For example, a man-made tank or a building can be modeled with a regular rectangle in a high resolution SAR image [39, 1]. Through this shape prior, many unconcerned objects with irregular shapes can be excluded from the target of interest. Finally, side information about the volume of the target and the image resolution can be known in advance which can be served as the size semantic prior during target inference. Depending on this prior, the size of a target region in the SAR image can be approximately computed so that those oversized or undersized segments can be excluded. Accordingly, we will induce several causal rules with respect to the target from these high level semantic priors, namely 1) target pixel should appear beneath its shadow one, 2) target region should be continuous with an appropriate size and regular geometry shape333Actually, this paper does not consider the geometry shape for simplicity but this prior has already widely exploited in other applications.. These two rules can straightforwardly bridge the gap between each semantic concept and the segment, yielding the modified segmentation result associated with the estimated labels in Fig. 3 (right).
This example explicitly illustrates the superior effect of these high level semantic priors in label inference, where “shadow” served as an auxiliary semantic tag will help us to locate the target. Following the above inference process, we will infer the semantic label by means of the random field model. Let be the hidden image magnitude random field which is defined on a graph with the first order four neighbouring system and any a recovered magnitude SAR image is viewed as a configuration. Correspondingly, another hidden semantic label field is constructed for with a label configuration . Firstly, considering the continuity prior, it suggests that pixels with the same semantic labels will generally cover a continuous region with a high probability [27, 30, 25]. This prior property can be described by modeling as a Markov random field (MRF) [40]. According to the equivalence between Gibbs and MRF established by Hammersley-Clifford theorem, can be formulated with the following form
[TABLE]
where is the partition function for normalization with a parameter and is referred to as the energy function computing a sum of clique potential over all cliques set . In this paper, we only consider the pairwise potential function to encourage the label consistency between the node s and its neighbours . In the previous researches, many models have been investigated to construct this function such as homogenous Potts or more generally Ising model equipped with a simpler Hamiltonian function [41]. Nevertheless, these functions do not take the other semantic priors into account. Therefore, we specially design a semantic related pairwise function by further incorporating the co-occurrence prior. More concretely, in addition to encouraging the adjacent pairwise labels to be consistent, our function will impose different penalties according to the previous induced semantic causal rules, i.e., a larger penalty on those pairs violating the co-occurrence rule, and vice versa. Our final designed pairwise potential function is established in Table I, where the notation and stand for the spatial position between node “s” and “t” [34] in the image. We can observe from this function that a larger penalty is imposed on those pairs that “target” is above the “shadow” and “background” is above the “target”. Then the prior-driven regularizer for semantic labels can be derived from by leaving out the irrelevant constant term with respect to . The remaining causal rules will be considered during label inference process, which will be discussed in Sec. IV.
III-C Target-Enhanced Image Formation via Iteratively Reweighted Minimization
In the previous subsections, we have developed the regularizer by exploiting the statistical distribution features for different semantic class and the label prior function by incorporating several high level semantic priors. The rest issue concentrates on developing a computational framework of enhancing the target while suppressing others.
Let us review our imaging framework from Bayesian perspective, which we aim at simultaneous estimating a SAR image , its latent label configuration and a set of class-specific features from the partially observed phase history . Therefore, deriving from Eq. (7) and considering the Eqs. (12), (10), the final target oriented SAR image formation will be accordingly formulated as the following MAP
[TABLE]
This optimization problem can be alternatively solved by optimizing , and with the following iterative scheme:
[TABLE]
which respectively corresponds to SAR image formation, semantic label inference and feature parameters update. Compared with previous sparsity-regularized imaging frameworks, our regularizer seems to be more sophisticated in form than traditional norm or TV regularizer. However, we next attempt to simplify the optimization by some choices of feature parameters.
Considering our semantics-specific regularizer for SAR magnitude image
[TABLE]
when the shape feature , this regularizer will become the weighted regularizer, in which the weight will be assigned to those pixels of class to control the magnitude scale of pixels within this group. When , this regularizer will be a difference of convex (DC) function [42] or the convex-concave function [43]. A common strategy to deal with this problem is utilizing the majorization-minimization (MM) algorithm. Let be the concave function in (15). MM is an iterative algorithm which employs a series of surrogate functions at each iterative point such that and the equality holds when . Then the next point will be obtained as , yielding the following decrease in
[TABLE]
With the iteration proceeding, the function will be gradually minimized. In our case, the surrogate function of concave at can be set with its tangent function at current point as
[TABLE]
where stands for the inner product operator. With this type of surrogate function, the sub-problem in (14) of image recovery can be reformulated as a series of iterative optimizations.
[TABLE]
where is the current weight for -th entry in with value
[TABLE]
With above derivations, the first optimization problem in (14), namely image recovery can be reformulated as a simple iteratively reweighted minimization (IRW-) problem in the case of which can be readily solved by various existing solvers such as FISTA [44] and NESTA [45]. We can also observe from (19), this weight setting also includes the case , . Accordingly, if the weights of the target pixels are always smaller than those from other classes as , pixels excluding the target will be imposed on a larger penalty so as to generate a target enhanced image.
III-D Framework Interpretation and Analysis
According to above presentations, we have implemented the novel target oriented SAR image formation framework and we will illustrate this framework in Fig. 4. In this part, we will present an interpretation and analysis of the proposed framework to further highlight its superiorities.
Compared with the sparsity-driven imaging algorithms, we develop two new regularization functions, namely target-inducing and semantic priors-inducing instead of the conventional sparsity-inducing norm and piecewise smoothing-inducing TV regularizer. Our first function is used to regularize the pixels to be recovered to have different desired statistical features according to their semantic labels. The second one imposes the regularization on the latent semantic labels, which not only provides a local continuity property but also obeys the high level co-occurrence rule among these labels. These two semantic information guided regularization functions enable us to recover a target enhanced SAR image as well as the label configuration without exploiting any training data. Considering the complexity of the proposed functions during optimization, we further reformulate the subproblem of SAR image formation as a simpler IRW- problem under some constraints, which is much easier to be addressed with a broad of existing solvers.
According to the discussion in the previous section, the performance of regularizer is controlled by the latent semantic group structure as well as the desired features. A straightforward question naturally raises how to ensure a reliable label inference from the undersampled data especially when the undersampling rate is low. In our work, we alteratively reconstruct the image and update the labels, through which some false labels are expected to be adjusted in the subsequent iterations. Nevertheless, once the target pixels were labeled as the background or shadow, they would be always suppressed in the following iterations without refinement. To relieve such risk, we prefer a progressive suppression scheme by introducing a gradually increasing parameter in (14), where is the iteration, is a constant controlling the increasing rate and is the original required regularization parameter. More generally speaking, we impose a conditional prior distribution on to control its increasing rate. With this setting, a slight suppression will be realized on pixels in the first few iterations so that some falsely estimated labels are capable of being gradually refined in the subsequent iterations 444The requirement of exactly accurate estimation is always unrealistic so that the proposed strategy is only a feasible trick for relieve this problem. . This strategy will be empirically validated in Sec. V-A in detail and it works well in our experiments. After the first few iterations, larger weights will be imposed on those background and shadow pixels to yield a stronger suppression and then their magnitudes will mostly tend to zeros. In this situation, the pixels with “background” or “shadow” labels will be gradually clustered into one group containing zero values, yielding the following two unexpected consequences. In the first case, these zero pixels will be assigned with “background” label so that the “shadow” set will be gradually empty, leading to a broken down in FCM. In the other case, they will be regarded as the “shadow” pixels so that some target pixels with relatively small magnitude will be reassigned as the “background” leading to an incomplete target region. To get rid of these problems, a possible trick is to cluster the pixels into two groups instead of three after several iterations, namely target and others.
IV Optimization and Analysis
The proposed iterative framework consists of three phases, namely image formation with IRW-, semantic label inference and feature parameters update. In this section, we will present the detailed optimization schemes for each phase, respectively.
IV-A Iteratively Reweighted Minimization for Image Recovery
We have derived a IRW- framework for SAR image recovery, in which we solve a series of weighted minimization problem to estimate a current solution and then update the weight matrix iteratively. Therefore, the basic optimization in this subproblem will be a weighted minimization given as follows.
[TABLE]
This problem can be solved by many existing solvers and it will be addressed with FISTA in this paper [44]. FISTA is a fast version of traditional iterative shrinkage thresholding algorithm (ISTA) by involving a Nesterov acceleration strategy [46], which can provide a significantly better global convergence rate and preserve the computational simplicity. This algorithm is proceeding with the following iterative scheme:
[TABLE]
where , is its adjoint operator, is element-wise shrinkage operator which is given by (22), and .
[TABLE]
where is the element-wise product (Hadamard product). FISTA converges when it reaches a stationary point and we can then update the corresponding weight matrix with Eq. (19).
IV-B Semantic Label Inference
The subproblem for semantic label inference can be summarized as
[TABLE]
Considering the effectiveness and efficiency, we will adopt a fast greedy approach, termed as Iterated Conditional Modes (ICM) [47], whose central idea is to iteratively optimize a current active label with others fixed to obtain a local optimal solution. Due to the non-convexity of Opt. (23), the initial labels and the update order will generally have an impact on the solution. For semantic label initialization, we adopt the typical fuzzy c-means (FCM) clustering algorithm on the current magnitude image and obtain an initial unsupervised segmentation [48]. To assign semantic labels to the obtained clusters, we conclude from the semantic prior that the man-made target usually contains the strong scattering points due to its regular geometry structure such as dihedral. Therefore, among all semantic labels, the mean magnitude and variance of the target clusters will be the largest while those of shadow pixels will be the smallest. According to this prior knowledge, the semantic labels can be initially assigned to each segment. During the optimization, we will choose a stochastic order for convenience and the optimization problem with respect to the -th label will be
[TABLE]
where and if . The above (24) is a simple univariate and unidimensional optimization whose solution can be computed by checking the each value of that minimizes (24). It is worth pointing out that it will be much faster and efficient to synchronously optimize those nodes that are not adjacent. The algorithm stops when the number of variational labels between two iterations is lower than a predefined amount or the iteration reaches its maximum. After the algorithm stops, we empirically observe from the result that there always exists some isolated “target” points or regions. To refine the result, the prior of the target size can be used to further make a decision, where only the region with an appropriate size are preserved while others are simply set as the “background” label.
IV-C Semantic Feature Parameters Update
The optimization problem with respect to two semantic features is formulated as:
[TABLE]
After analyzing this optimization carefully, we find that admits a closed form solution given by
[TABLE]
where is the mean magnitude of pixels from class . Substituting (26) into (25), we can obtain a simpler problem only with respect to as:
[TABLE]
According to the previous presentation in Sec. III, these features directly determine the weight for pixels so that we have developed two types of constraints for the desired weights to yield a target enhanced SAR image. Considering the first type, we require that all weights of background pixels are no more than those of shadow while no less than those of target. It holds if and only if and , where and . In this case, , , and result in the following constraints on , and , respectively.
[TABLE]
All above constraint sets for , and should not be empty, we moreover have
[TABLE]
The final feasible sets for each will be correspondingly the intersection set of (28) and (29)555An implicitly constraint always holds according to the semantic prior discussed in the previous section.. If we ignore the coupled variables in the feasible set to obtain the approximate solutions for the sake of simplicity and efficiency, we can optimize each variable with the following iterative scheme, where all shape features can be empirically initialized as 1.
[TABLE]
is a simple univariate differentiable function. The solution to any a problem in (30) will exist either on the boundary of the feasible set or the root of the derivative function as is a monotone function. However, no closed form solution of the root can be derived so that we will instead use the following approximation666http://research.microsoft.com/en-us/um/people/minka/papers/minka-gamma.pdf. The iteration stops when the variation of objective function (27) is below a threshold.
[TABLE]
The global optimization stops when the iteration number reaches the maximum or the variation of between two iterations is below a predefined threshold and it is summarized in following Algorithm 1.
IV-D Convergence and Complexity Analysis
Since the exactly theoretical convergence proof for the global Algorithm 1 is relatively difficult, we only present the analysis and experimental validation on each algorithm in different phases, namely MM scheme for IRW- minimization, FISTA for weighted minimization and label inference with ICM and we choose the corresponding results from the first global iteration for illustration. It has been discussed in Sec. III-C that the MM algorithm aims to solve a concave-convex optimization (18) by exploiting and minimizing a surrogate function. This algorithm can iteratively decrease the objective function by (16) and generally converge to a local minimum [49]. We plot the variances vs. MM iteration times in Fig. 5 and we can see that the algorithm converges rapidly within 5 iterations to a stationary point. FISTA is a widely exploited solver for weighted minimization that is benefit from its simplicity for large scaled problem and fast convergence rate of [44], where stands for the iteration in this algorithm. Since this subproblem is a convex one, it can converge to a global solution ignoring the initial point. We plot the variations of objective function vs. iteration times in Fig. 5 and the algorithm stops only within 4 iterations. Finally, the greedy ICM algorithm is adopted for label inference, whose solution converges to a local minimal [47]. The number of variational labels vs. ICM iteration times is plotted in Fig. 5, where the algorithm also appears a rapid convergence.
Considering the computational complexity, the main computations focus on solving weighted minimization with FISTA since label inference and features update are the both simple univariate and unidimensional optimizations. Firstly, FISTA essentially involves three main operations, namely , and . in fact consists of three consecutive operations. and can be realised by performing 2D-DFT and 2D-iDFT with very cheap computational complexity. sets those unsampled entries to be 0 via simply binary masking. involves two consecutive operations, in which is firstly interpolated with zero padding and following a 2D-iDFT operation. For , the element-wise shrinkage operator only needs operations.
V Experiments and Discussion
In this section, we will validate the performance of our target oriented SAR image formation framework with a series of experiments on the public MSTAR target database [1]. This database collected by the Sandia National Laboratories Twin Otter spotlight mode SAR platform provides the complex SAR images of various military vehicles and we exploit three types of the target taken at depression angle for testing, namely BMP2 tanks (BMP2-SN9566), T72 tanks (T72-SN132) and BTR70 armored personnel carriers (BTR70-SNC71). Some sized magnitude images are exhibited in Figs. 6 and some detailed information of these targets are summarised in Table II.
Following previous works [6][9], the sampled phase history data can be simulated from the complex MSTAR image as following. Firstly, each complex SAR image is transformed into the spatial-frequency domain by performing the 2D-DFT operation, then we remove the surrounding 28 pixels-width zero padding data to obtain a 2D array. From the file headers, a 35dB Taylor window has been added on the phase history so that the fully sampled raw phase history will be obtained by dividing this array with the 2D Taylor window with . The undersampled phase history vector will be subsequently simulated as .
In order to demonstrate the effectiveness and superiority of our high level semantic-specific regularization function for target oriented SAR image formation, two typical sparsity-driven functions for low level feature enhancement [16][6] will be primarily compared, including regularization for point feature enhancement (Poi-Imaging) and TV regularizer for region smoothness enhancement (Reg-Imaging). Additionally, to show the performance of our weights (semantic features) in IRW-, we also compare the standard IRW- framework for SAR imaging [50][49], in which weights are determined by the magnitude of each pixel without considering their semantic information. Moreover, the image reconstructed from the conventional polar formatting algorithm (PF-Imaging) is also shown compared, which is actually the initial solution used in above imaging algorithms. In addition to visual evaluation, some quantitative criterions will be computed to evaluate the performance of target enhancement as well as background suppression, including 1) peak target-to-clutter ratio (PTCR): . and 2) average target intensity: . To compute these criterions, the manually segmentation result of each target image will be served as the ground truth.
V-A Parameter Analysis
In the proposed framework, two free parameters needs to be tuned in advance, including and . We will conduct two groups of experiments to validate their performances, where only phase history data are exploited in random for imaging.
Firstly, controls the increasing rate of the regularization parameter , which is introduced to progressively suppress the background pixels and avoid target missing. Nevertheless, larger value of will generally not only result in a slower increase of but will also decelerate the algorithm convergence. Therefore, an appropriate value of is required to achieve a balance between the accuracy of semantic label inference and convergence. To this end, we vary from 10 to 70 with 20 interval and display some of the intermediate results of the inferred label maps in the first four iterations and the reconstructed images in the fifth iteration in hot color map in Figs. 7, where the white, black and grey color stand for the target, shadow and background class, respectively.
Observing the estimated label maps Figs. 7(a)-(d), we essentially only concern the completeness of the target region rather than background and shadow777This is different from the semantic segmentation task which requires an exactly accuracy for every class.. In these maps, as our analysis in Sec. III-D, some target points are obvious misclassified with the proceeding of iteration, leading to a target missing label map in Fig. 7(d). Such problem is effectively relieved by an increase of and the corresponding label maps in Fig 7(n) and 7(s) will cover almost all target points and preserve the target shape perfectly. On the contrary, inspecting the last column of Figs. 7, the most background pixels have already been suppressed with rather low energy in the 5th iteration shown in Fig. 7(e) while the clutters in Fig. 7(t) are obvious with much larger energies. This phenomenon indicates a deceleration in the algorithm convergence. Therefore, we will select in the following experiments to reach a tradeoff.
Secondly, is the parameter of label prior distribution, which provides a tradeoff between likelihood and prior-inducing function in Eq. (23). Two types of priors are actually involved in the function, i.e., local label consistency and co-occurrence rules. On one hand, if is selected as a larger value, the inferred label map will intuitively be more consistent within each cluster group, and vice versa. On the other hand, a smaller value of may lead to an inaccurate or false inference due to the semantic gap. To verify these viewpoints, we test with values of and show the corresponding inferred label map (without semantic refinement) in the first iteration in Figs. 8.
In Fig. 8(a), the label map appears many isolated points in the case of . When the value of increases, such isolated points gradually disappear and more continuous regions emerge in Figs. 8(b) and (c). But the inferred labels are still incorrect for the most background and shadow points. When , the shape of the target can be outlined and some shadow points of the target emerge. It is also worth noting that although heavily influence the initial label inference, our proposed framework can also make a refinement in the subsequent iteration as discussed in Figs. 7. Therefore, we can always obtain a desired target enhanced image with different choices of , which are also correspondingly illustrated in the second row in Figs. 8. Following consideration of the simplicity, we will set in the following experiments.
V-B Framework Validation
In previous experiments, we have empirically established two important parameters in the framework and show that the label inference can be gradually refined with the iterative proceeding. In this part, the core issue of the proposed framework will be further validated, i.e., whether the framework can produce a target enhanced image in progress. To demonstrate this issue, the histograms in different iterations of target pixels and background clutters including the shadow points are illustrated in Figs. 9, respectively. According to the target histograms, the peak value is obviously enhanced from almost 30 to 60. After a careful inspection of the second row of histograms of the background clutters, more and more background pixels gradually tend to zero along with the iteration. Comparing Fig. 9(f) with Fig. 9(j), the number of background pixels approximating 0 is from less than 3000 to over 7000 while the target histograms almost keep unchanged. Therefore, the average magnitude of the background pixels is greatly decreased so as to yield an increase of PTCR. The experimental results clearly demonstrate the effectiveness of proposed iterative framework for target enhancement.
Next we will investigate the robustness of the proposed target oriented framework to different types of targets. Following the same parameters setting without further fine tuning, different types of the targets are tested for reconstruction and some of the results are shown in Figs. 10, where the corresponding primary images are also presented for comparison. It is obviously observed from the results that our framework is robust to different types of target as it can always generate an apparent target enhanced SAR image.
V-C Framework Comparison with Different Sampling Schemes
In the final experiments, we are to compare the proposed target oriented framework with other SAR imaging algorithms in various undersampling situations, where the so called undersampling rate is defined as the ratio between the number of entries in and that of . In our experiments, three types of undersampling schemes are simulated by the binary masks shown in Figs 11. From the figures, a pure global 2D random sampling from a Cartesian grid is instantiated by Mask-1 in Fig. 11(c). Nevertheless, this type of sampling scheme is ineffective in practical imaging situation because the complete phase history data from all viewing angles are still required. To relieve the burden on the requirement of a large amount of viewing angles for a high cross range resolution, a more suitable scheme is simulated as Mask-2 in Fig. 11(d) by which we can only randomly sample the received data from a few observation angles. In this case, the undersampling rate is simply computed by the ratio between the number of the sampled viewing angles and that of the complete viewing angles denoted by . Moreover, the sampling burden of a SAR platform mostly comes from the range direction to produce a high range resolution image, which conventionally requires a Nyquist sampling speed. To relieve this burden, undersampling in range direction is also taken into consideration as Mask-3 in Fig. 11(e), where we not only randomly select a few viewing angles but also randomly pick samples of the corresponding phase history. If the undersampling rate in range direction for all viewing angles is the same as , the total undersampling rate will be . Therefore, Mask-2 can be viewed as a special type of Mask-3 with . In the theory of compressive sampling, one of the sufficient conditions for exactly recovery is K-order restricted isometry property (RIP) [13], which provides a theoretical guarantee for the uniqueness recovery from an underdetermined problem with sparse regularization. In our case, we formulate our target oriented imaging as a MAP and thus it is essentially not an exactly recovery problem so that it is unnecessary to require such a condition on the measurement matrix. Nevertheless, the equivalent measurement matrix in our framework is the partial Fourier matrix whose RIP has been validated in many previous works [16][45].
V-C1 Sampling with Mask-1
Firstly, we exploit Mask-1 for SAR imaging with different algorithms in which the undersampling rate is chosen as , and . The resulted sample images are illustrated in following Figs 12 and the average quantitative evaluations computed from all tested images are listed in Table. III.
Observing Figs. 12 row by row at the first sight, the visual qualities of all the reconstructed images are progressively improved with the increase of . We also conduct the experiment in the case of , but the resulted target images of all algorithms will be hardly recognized so that we will not display those the failing reconstruction results for the sake of space limitation. Among all Figs. 12, the target images of Reg-Imaging are the worst from the visual perspective as it is already difficult to manually distinguish the target from these results, let alone automatic target recognition by a computer. This is mainly due to the fact that TV regularizer will concentrate on preserving the edges in the image. When the variance of the background clutters is large, many clutters will be falsely regarded as the edges so as to degrade the image. Looking up the Table III, the quantitative evaluations in terms of average PTCR and are also the worst for all types of the targets and . We can see that and PTCR are less than 5 and 20dB in the case of a small amount of . Until is increased to , its PTCR can achieve the slightly higher values than that of PF-Imaging, while are still the worst. Concerning the results of PF-Imaging in Figs. 12(a),(f) and (k), the target in Fig. 13(a) becomes rather blurry and merges in the background clutters, respectively. By checking the quantitative evaluations from Table III, the values are only better than Reg-Imaging algorithm. The rest three algorithms including Poi-Imaging, IRW- and Tar-Imaging all outperform PF-Imaging and Reg-Imaging in both visual and quantitative evaluations as following discussion. Firstly, the target images obtained from Poi-Imaging, IRW- and Tar-Imaging are more clear than that of PF-Imaging and Reg-Imaging, especially the resolution of target scatter points is greatly improved, which is actually benefit from the norm for point feature enhancement. Moreover, these three algorithms gain a remarkable better quantitative indexes. Comparing these three algorithms, our Tar-Imaging and IRW- can obtain a better visual image than Poi-Imaging when the sampling rate is only . We can see from Figs. 12(b),(d) and (e), the target in the latter two images is more complete in shape and profile. This result verifies the superiority of the iterative reweighted framework for reducing the required measurements. Nevertheless, it can be also observed from Fig. 12(d) that many background clutters are also enhanced while those in our 12(e) are suppressed due to the consideration of their semantic labels. We can further validate this issue from the quantitative performances in Table III, in which our algorithm achieves a significant improvement on both PTCR and . Specifically, our PTCR in different cases are almost more than twice of others, which clearly show the superiority of target enhancement and background clutter suppression.
V-C2 Sampling with Mask-2 and Mask-3
Next, we will compare all SAR imaging algorithms with Mask-2 and Mask-3 together since Mask-2 is a special type of Mask-3 with . In the experiments, seven pairs of sampling schemes are exploited, including , and for Mask-2 and , , and for Mask-3. The imaging results of the sample image are illustrated in following Figs. 13 and 14, respectively and the average quantitative evaluations computed from all tested images are listed in Table IV.
Intuitively speaking, compared with the Mask-1, the above conclusions also hold that our Tar-Imaging outperforms the other algorithms in the both visual and quantitative results. It is more specially in the results that there will be some fake target points appearing in the cross range in Figs. 13(a),(f) and (k) for PF-Imaging because of the reduced observation angels. However, these fake scattering points are all suppressed in Figs. 13(o) with our framework. If we compare Fig. 14(t) with Fig. 13(o) and Fig. 14(o), we will observe that when and , our framework can produce the similar target enhanced images from visual sight. On the contrary, it can be obviously noticed that the background clutters will get stronger as the range sampling rate reducing for other algorithms. We can also obtain this conclusion from Table IV. Taking BTR as an example, the PTCR for Tar-Imaging is 67.4151(dB) when and 58.5966(dB) when with almost 12(dB) decrease on average. PTCR for IRW- instead increases from 29.9430(dB) to 34.0552(dB) when is reduced from to . This phenomenon is also easy to understand because an increase of sampling rate will simultaneously enhance all target and background scatters without considering their semantic information. Therefore, the total magnitude of background clutters will become larger, leading to a decreased PTCR in the compared algorithms. This phenomenon further establishes the superiority of our framework by considering the semantic label for each pixel.
VI Concluding Remarks
In this paper, we develop a novel semantic information guided iterative framework for target oriented SAR image formation, which can effectively enhance the target scatters and suppress the background clutters simultaneously. In this framework, two types of semantic information guided regularization functions are developed for the underlying image and its semantic labels, respectively. Compared with the sparsity-regularized imaging algorithms, a plenty of experimental results demonstrate the superiorities of our framework in both visual and quantitative evaluations. The proposed framework sheds a new light on bridging the prior distribution to a simple reweighted norm. Based on this idea, much more types of regularizers could be further derived from different distributions for the possible future research. The main insufficiency of our framework is that it can only deal with the simple target scene with a few types of semantic contents. When the scene becomes intricate containing various types of objects, the accuracy of semantic label inference will be degraded so as to weaken the target quality in the generated image.
Some possible directions will be considered as our future researches. Firstly, we will evaluate the ATR performance with our imaging results. In addition to ATR, imaging frameworks driven by other high level perception tasks can be also developed in the future, such as imaging for segmentation. Next, some more informative high level semantic priors can be exploited and involved in the imaging procedure so that the framework will be robust to the intricate environment such as multiple targets. Finally, more representative features can be exploited or directly learned during the imaging process, which will correspondingly improve the imaging quality.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] R. Hummel, “Model-based atr using synthetic aperture radar,” in IEEE Int. Conf. Radar . IEEE, 2000, pp. 856–861.
- 2[2] W. G. Carrara, R. S. Goodman, and R. M. Majewski, Spotlight synthetic aperture radar- Signal processing algorithms(Book) , 1995.
- 3[3] M. D. Desai and W. K. Jenkins, “Convolution backprojection image reconstruction for spotlight mode synthetic aperture radar,” IEEE Trans. Image Process. , vol. 1, no. 4, pp. 505–517, Apr. 1992.
- 4[4] M. Ç Ç \c{C} etin, I. Stojanovi c ´ ´ 𝑐 \acute{c} , N. O ¨ ¨ 𝑂 \ddot{O} nhon, K. Varshney, S. Samadi, W. Karl, and A. Willsky, “Sparsity-driven synthetic aperture radar imaging: Reconstruction, autofocusing, moving targets, and compressed sensing,” IEEE Signal Process. Mag. , vol. 31, no. 4, pp. 27–40, Jul. 2014.
- 5[5] Y. Zhang, C. He, X. Xu, and M. Liao, “Attributed scattering center feature extraction of high resolution sar image and classification algorithm,” in IEEE Int. Geosci. Remote Sens. Symp. (IGARSS) , 2014, pp. 474–477.
- 6[6] M. Çetin and W. C. Karl, “Feature-enhanced synthetic aperture radar image formation based on nonquadratic regularization,” IEEE Trans. Image Process. , vol. 10, no. 4, pp. 623–631, Apr. 2001.
- 7[7] J. N. Franklin, “On tikhonov’s method for ill-posed problems,” Math. Comput. , vol. 28, no. 128, pp. 889–907, 1974.
- 8[8] S. Osher, M. Burger, D. Goldfarb, J. Xu, and W. Yin, “An iterative regularization method for total variation-based image restoration,” Multiscale Modeling and Simulation , vol. 4, no. 2, pp. 460–489, 2005.