Nonsymmetric Reduction-based Algebraic Multigrid
Thomas A. Manteuffel, Steffen Munzenmaier, John Ruge, and Ben S., Southworth

TL;DR
This paper introduces a new nonsymmetric reduction-based algebraic multigrid method, nAIR, which effectively solves hyperbolic PDE discretizations with high connectivity and unstructured meshes, outperforming existing AMG techniques.
Contribution
It develops a convergence framework for nonsymmetric AMG and proposes nAIR, a fast, scalable reduction-based solver tailored for hyperbolic PDE discretizations with triangular structure.
Findings
nAIR achieves significant speedups in setup times for high connectivity problems.
nAIR effectively solves steady state transport problems on unstructured meshes.
nAIR outperforms existing AMG methods on several classes of nearly triangular matrices.
Abstract
Algebraic multigrid (AMG) is often an effective solver for symmetric positive definite (SPD) linear systems resulting from the discretization of general elliptic PDEs, or the spatial discretization of parabolic PDEs. However, convergence theory and most variations of AMG rely on being SPD. Hyperbolic PDEs, which arise often in large-scale scientific simulations, remain a challenge for AMG, as well as other fast linear solvers, in part because the resulting linear systems are often highly nonsymmetric. Here, a novel convergence framework is developed for nonsymmetric, reduction-based AMG, and sufficient conditions derived for -convergence of error and residual. In particular, classical multigrid approximation properties are connected with reduction-based measures to develop a robust framework for nonsymmetric, reduction-based AMG. Matrices with block-triangular structure…
Click any figure to enlarge with its caption.
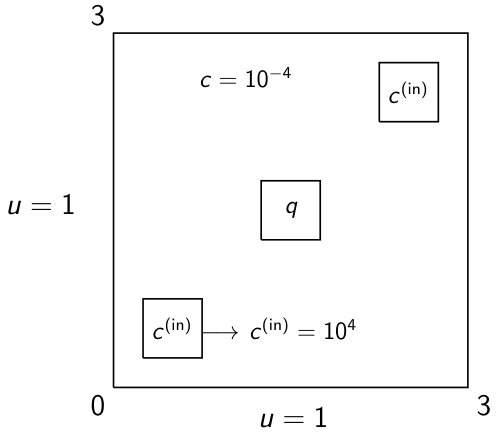 Figure 1
Figure 1 Figure 2
Figure 2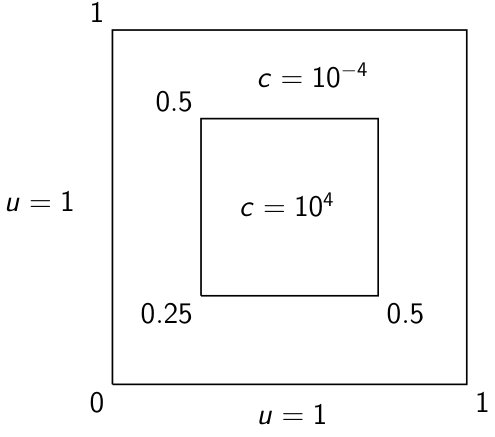 Figure 3
Figure 3 Figure 4
Figure 4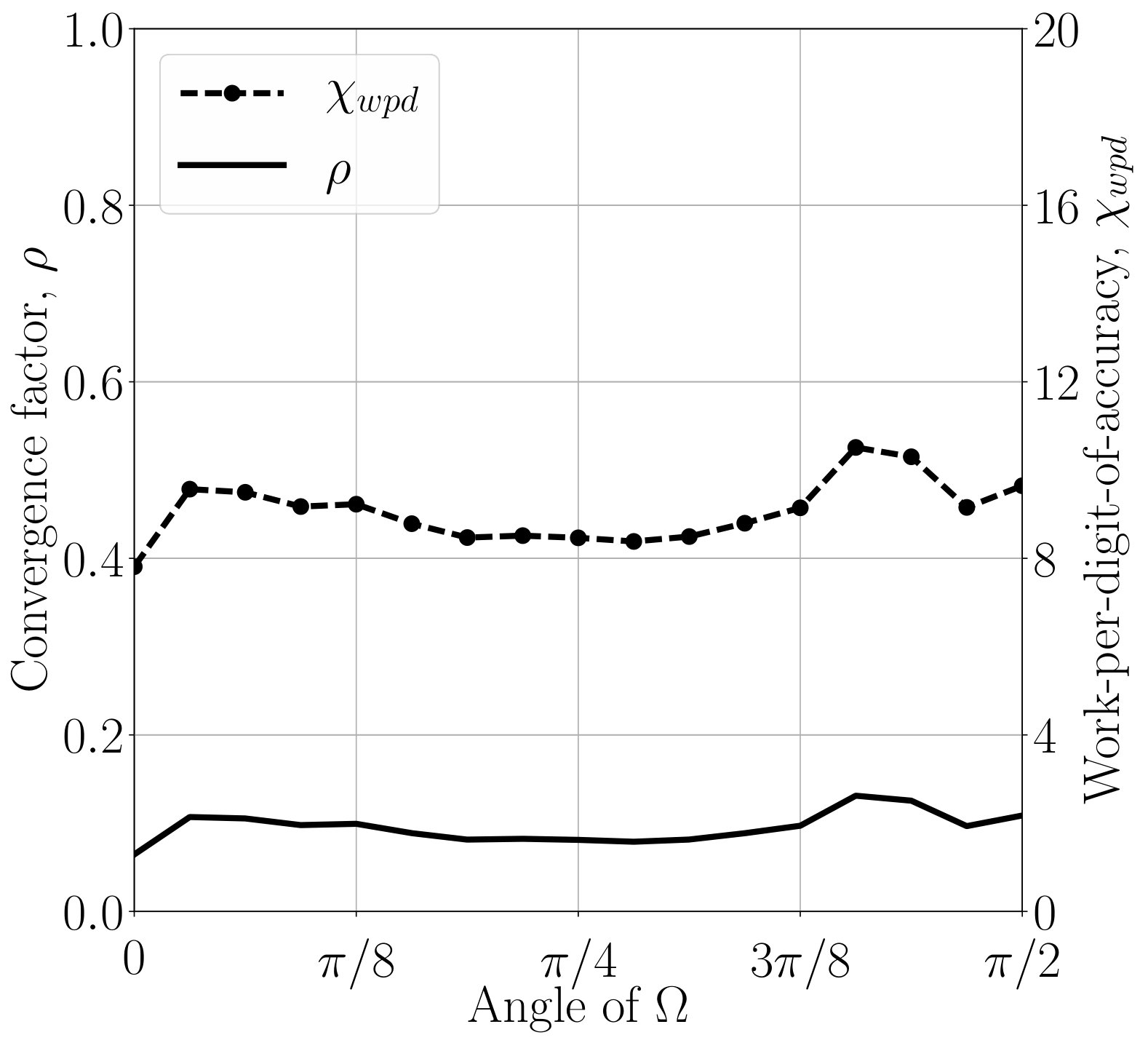 Figure 5
Figure 5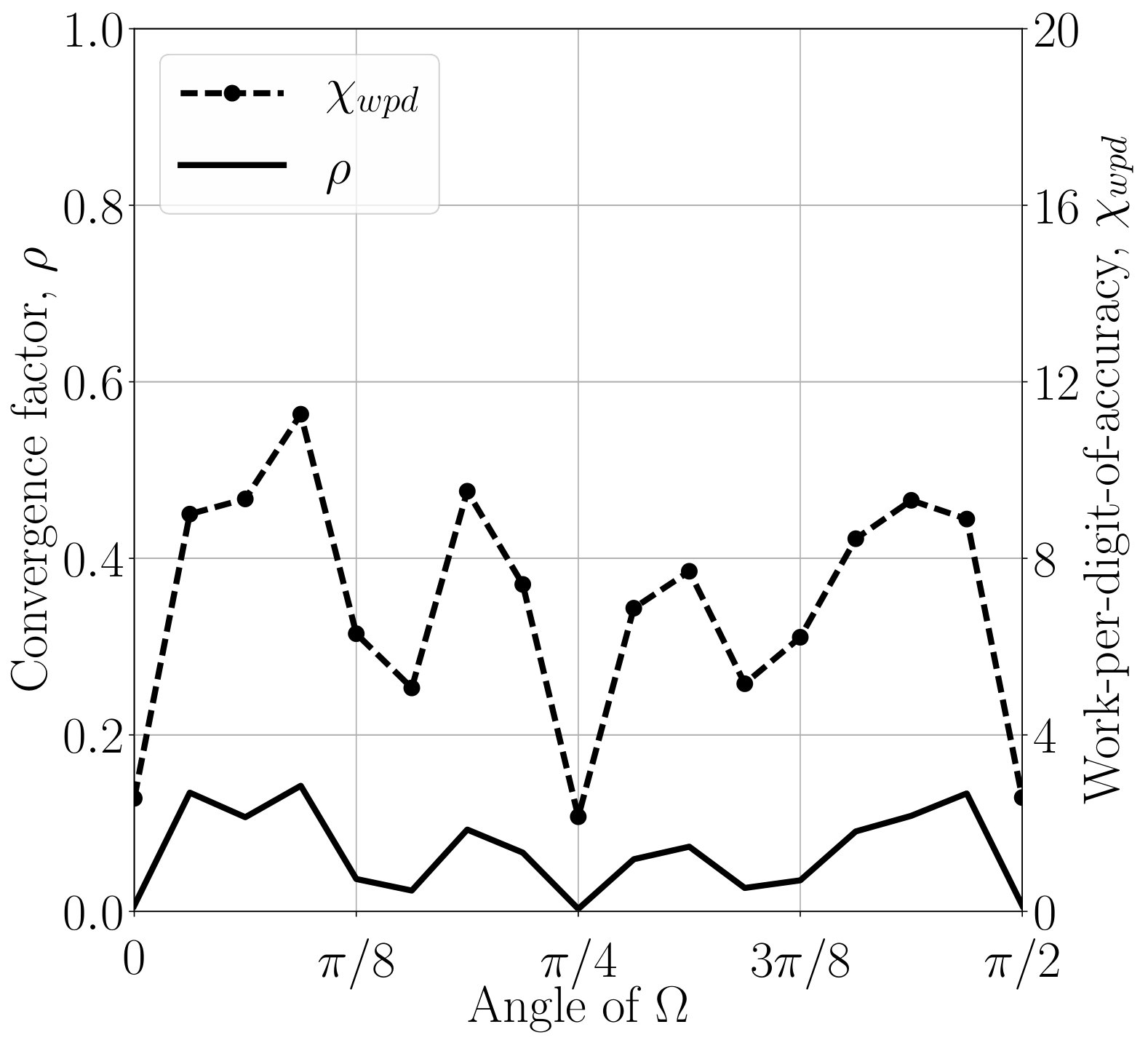 Figure 6
Figure 6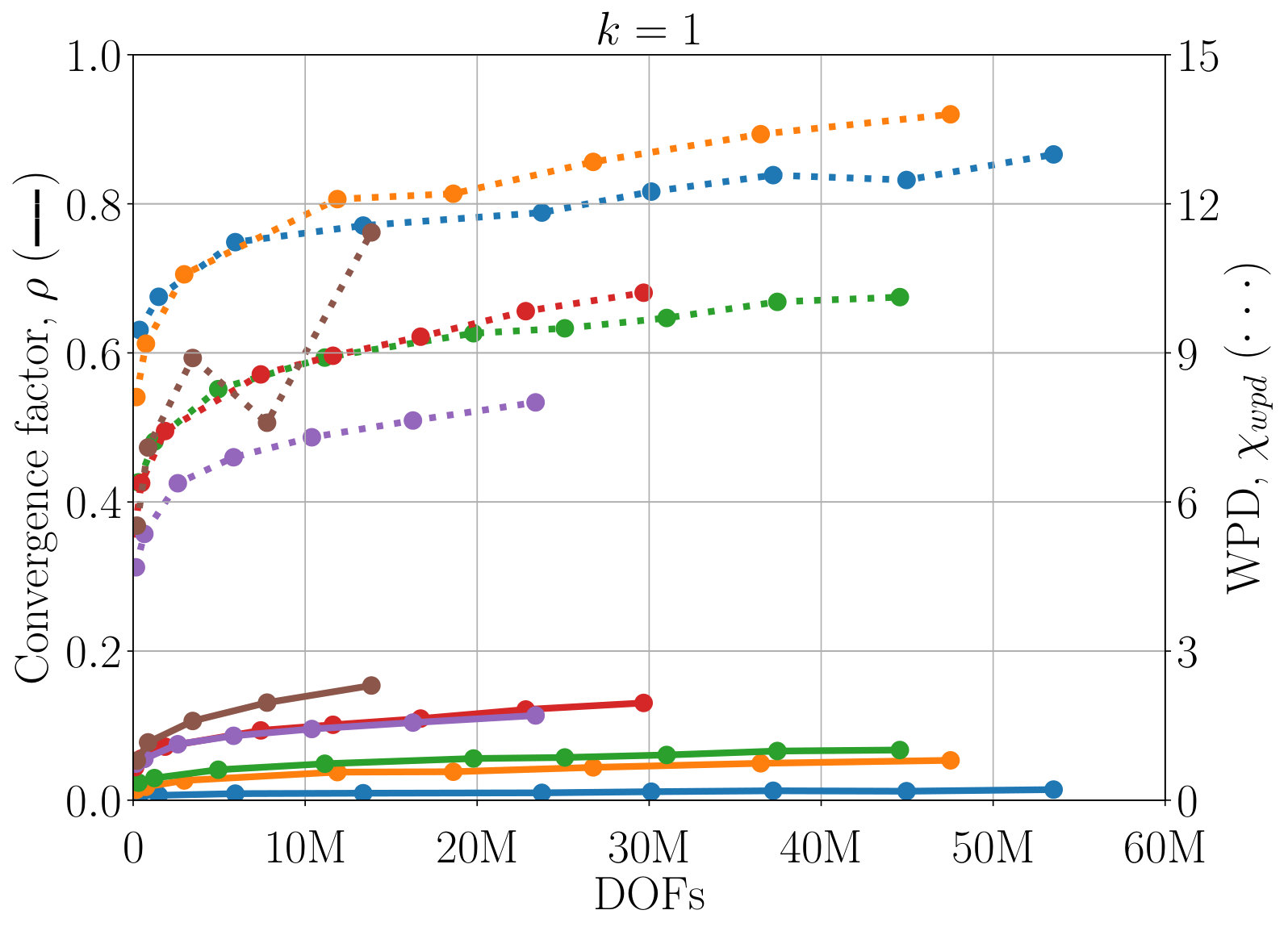 Figure 7
Figure 7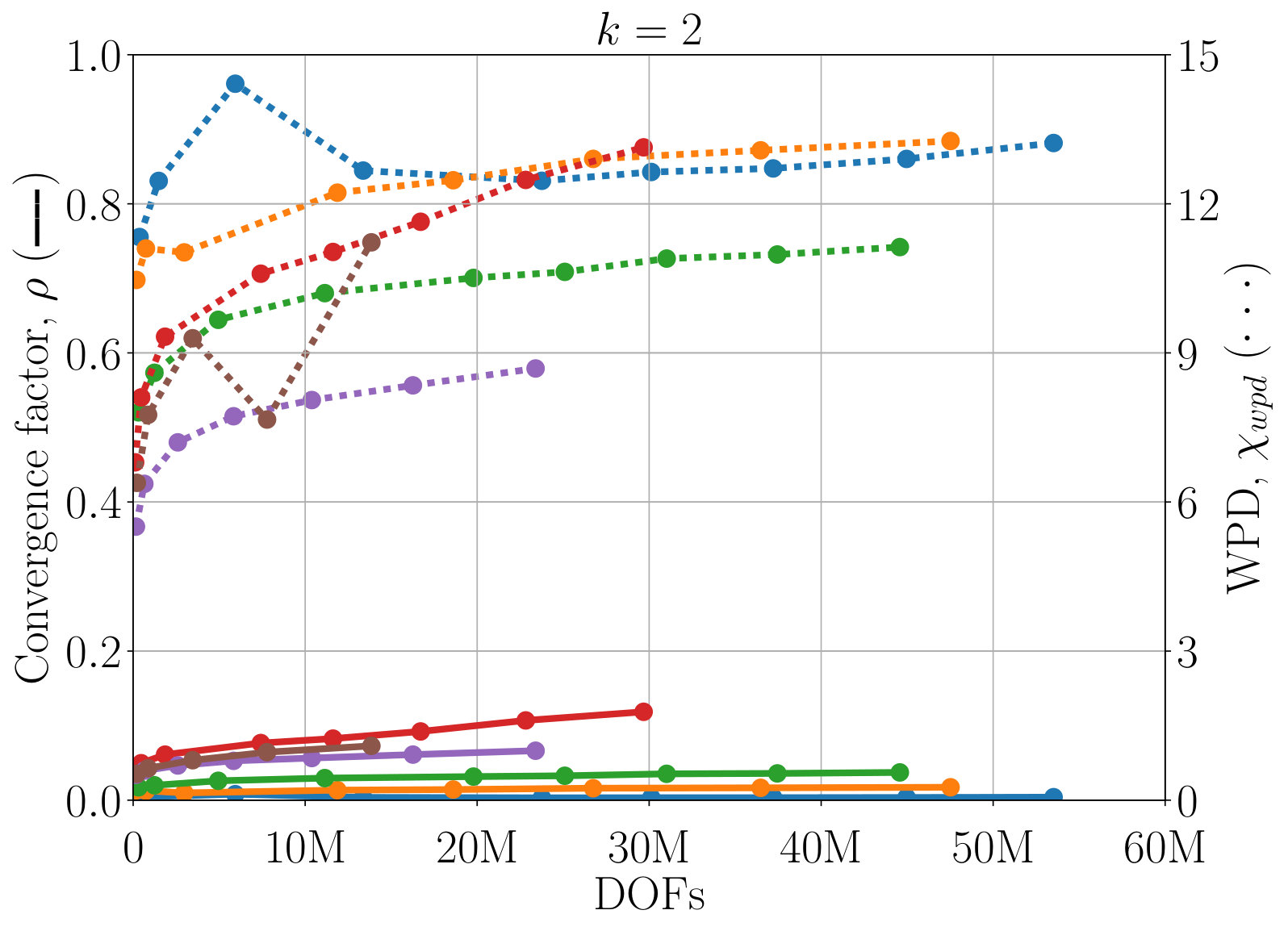 Figure 8
Figure 8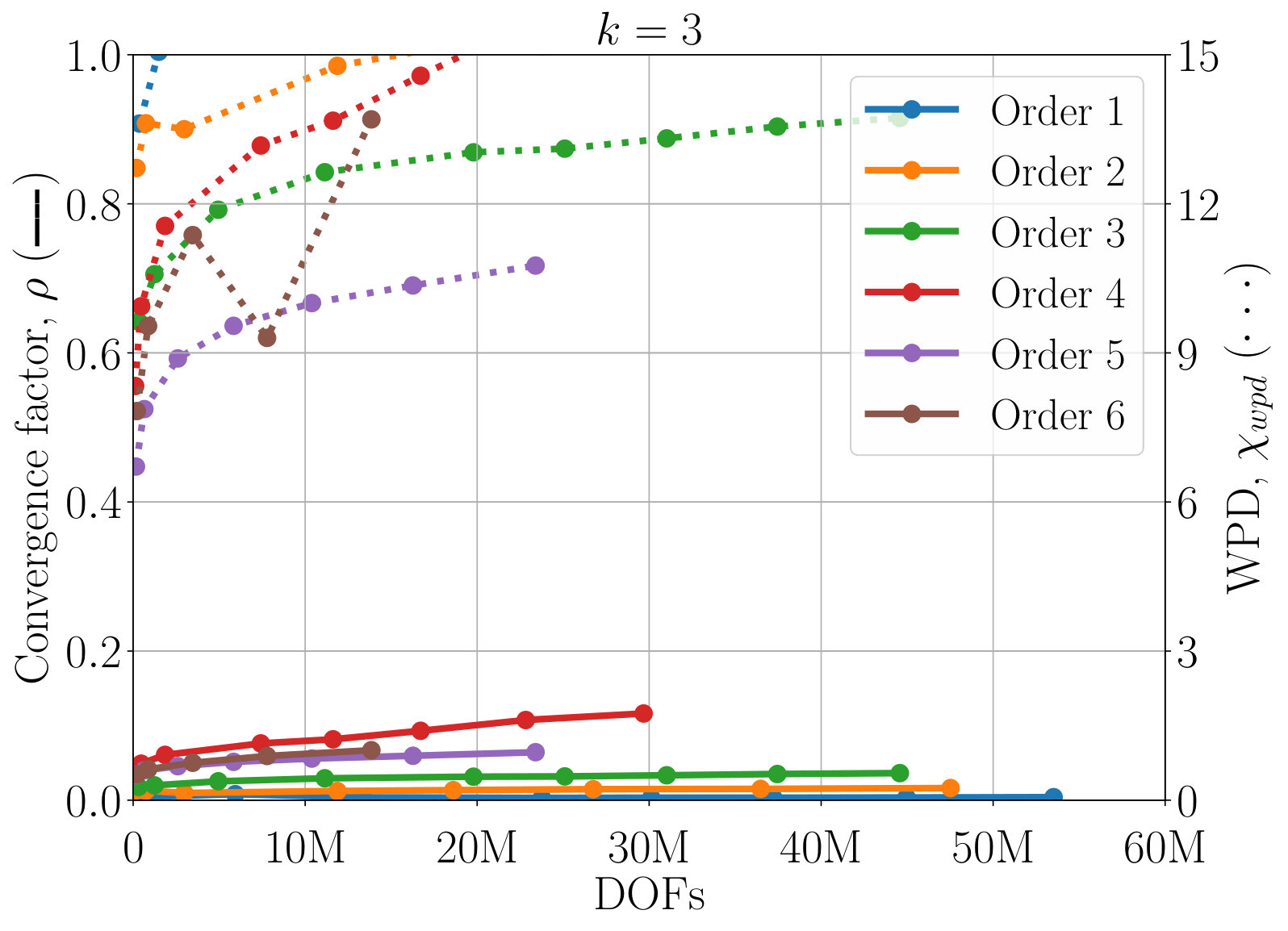 Figure 9
Figure 9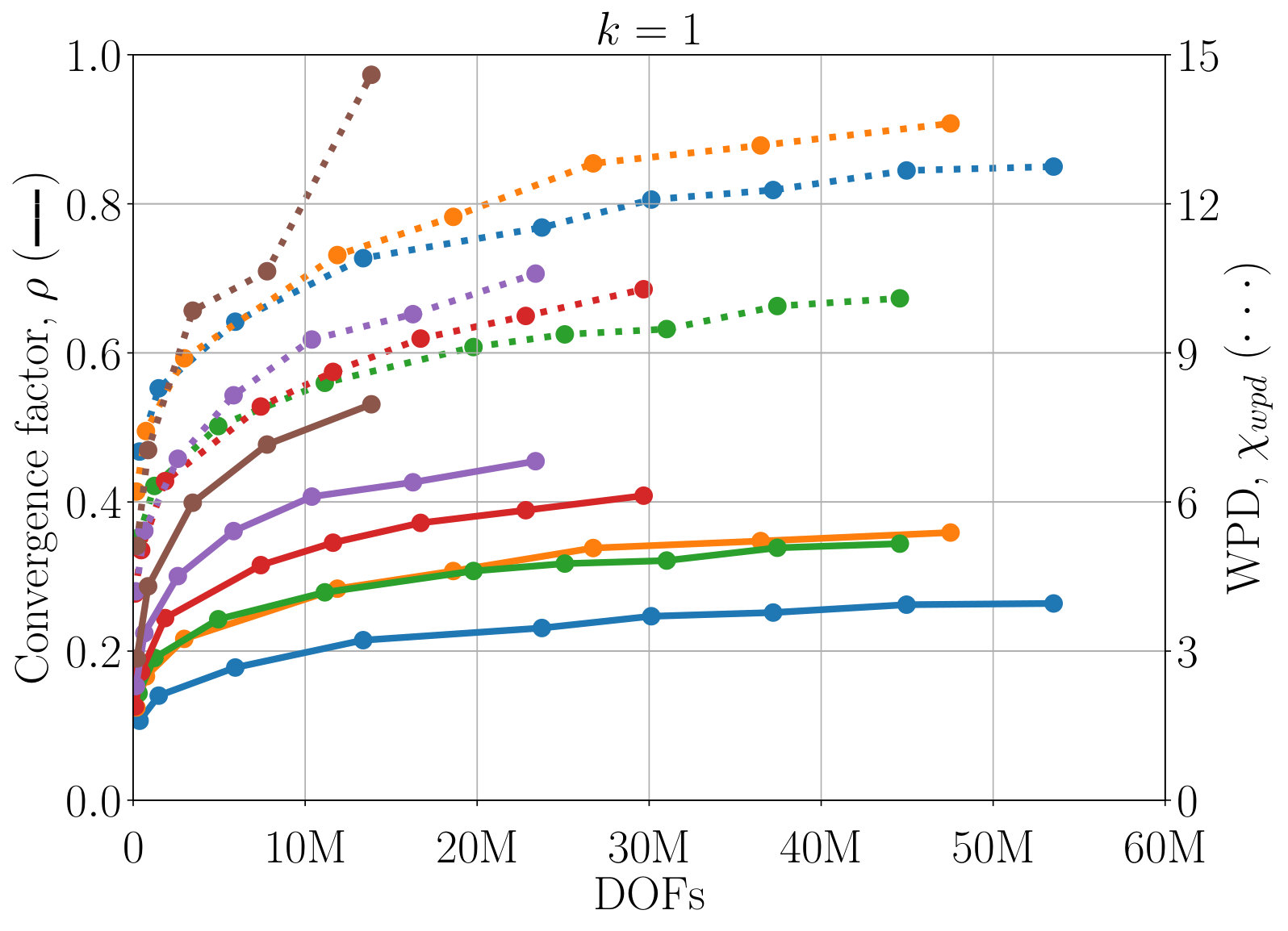 Figure 10
Figure 10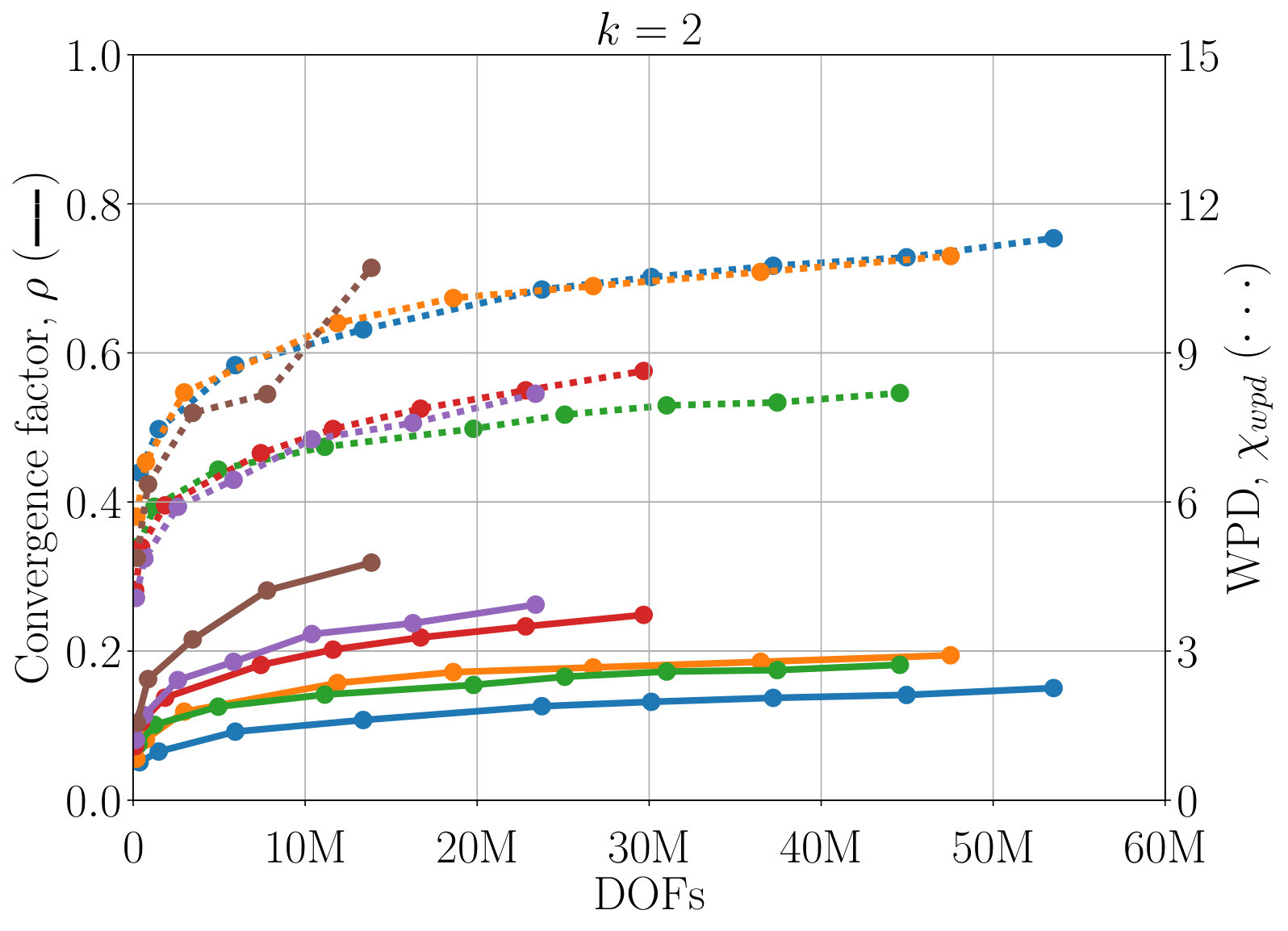 Figure 11
Figure 11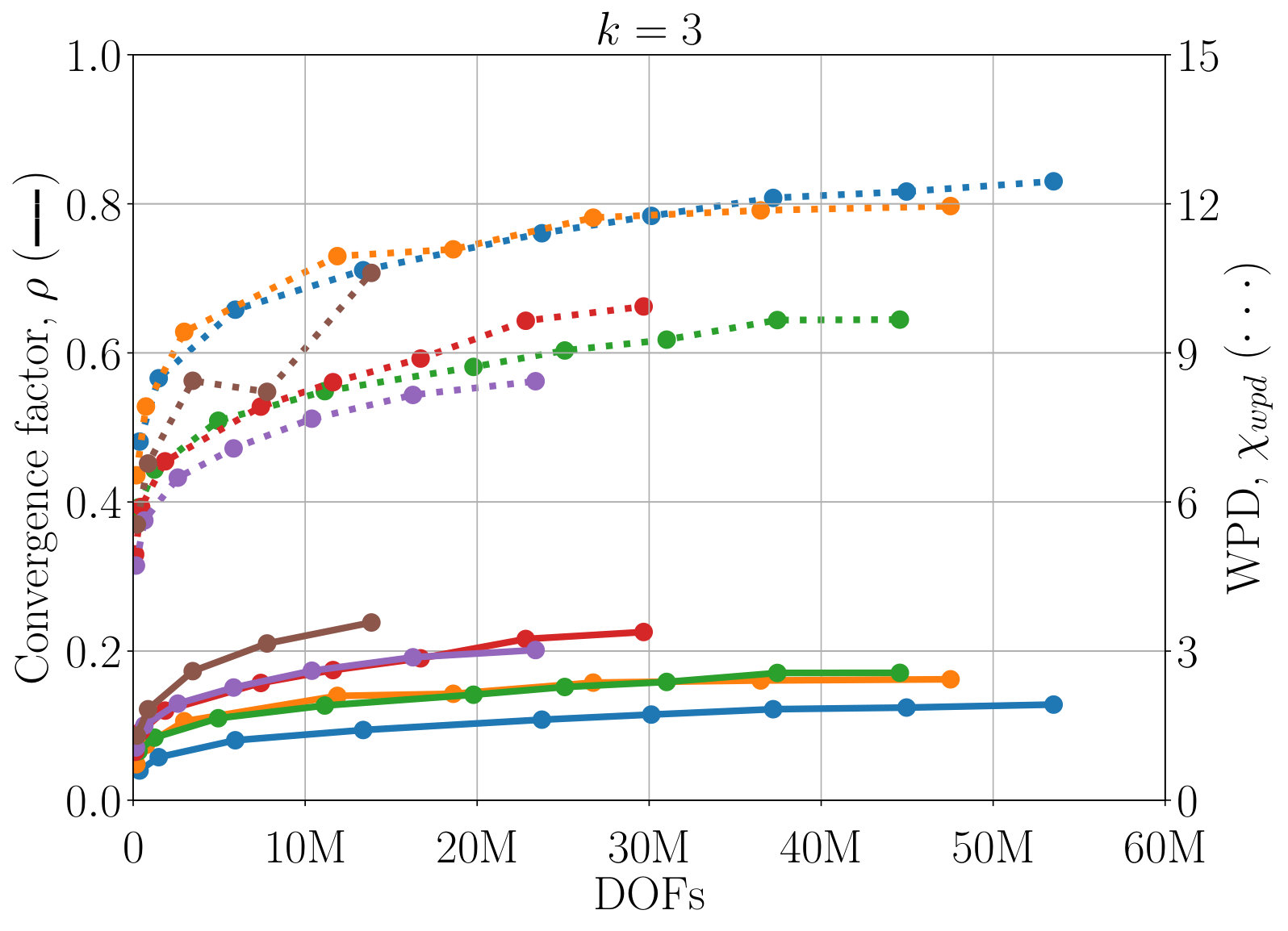 Figure 12
Figure 12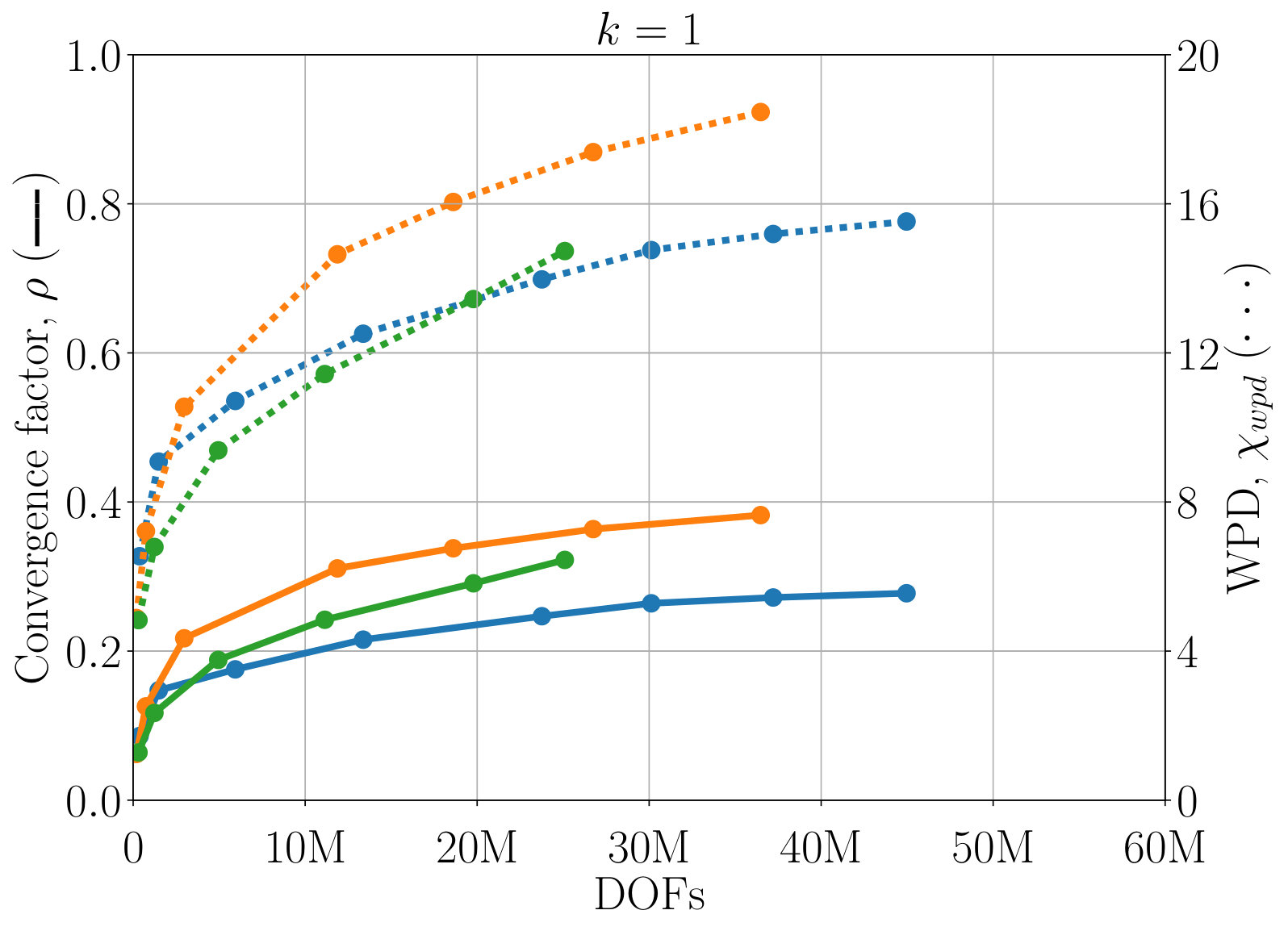 Figure 13
Figure 13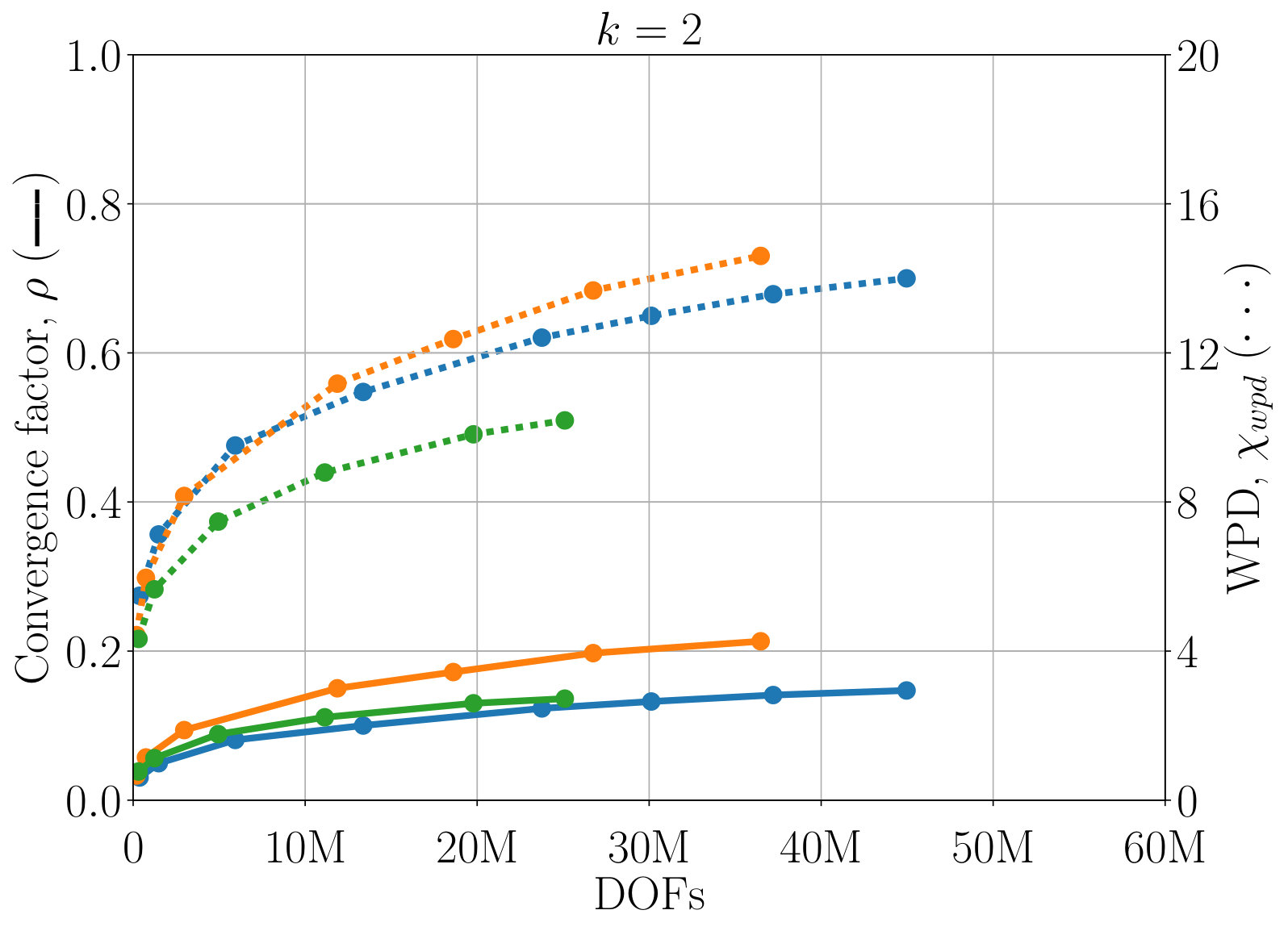 Figure 14
Figure 14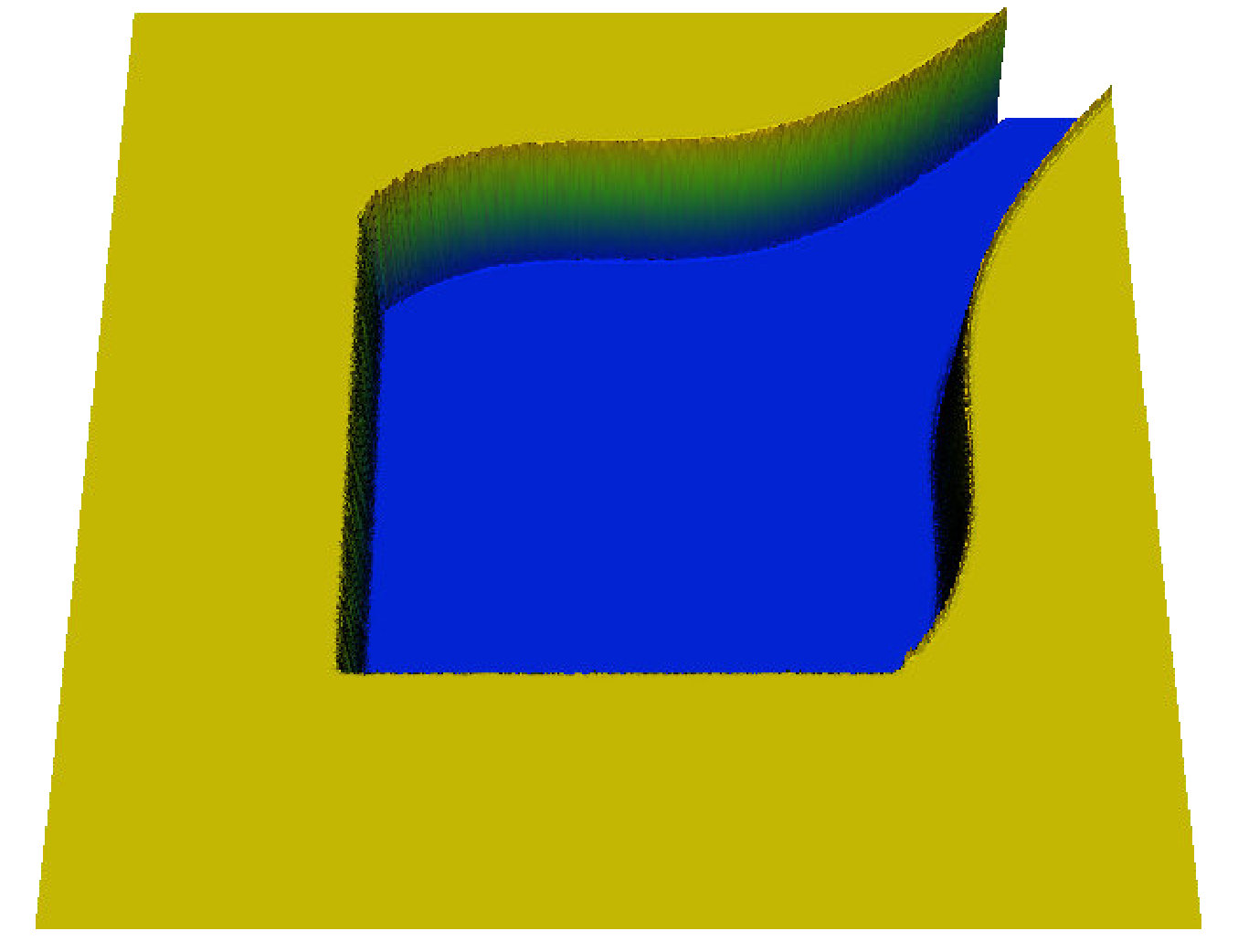 Figure 15
Figure 15 Figure 16
Figure 16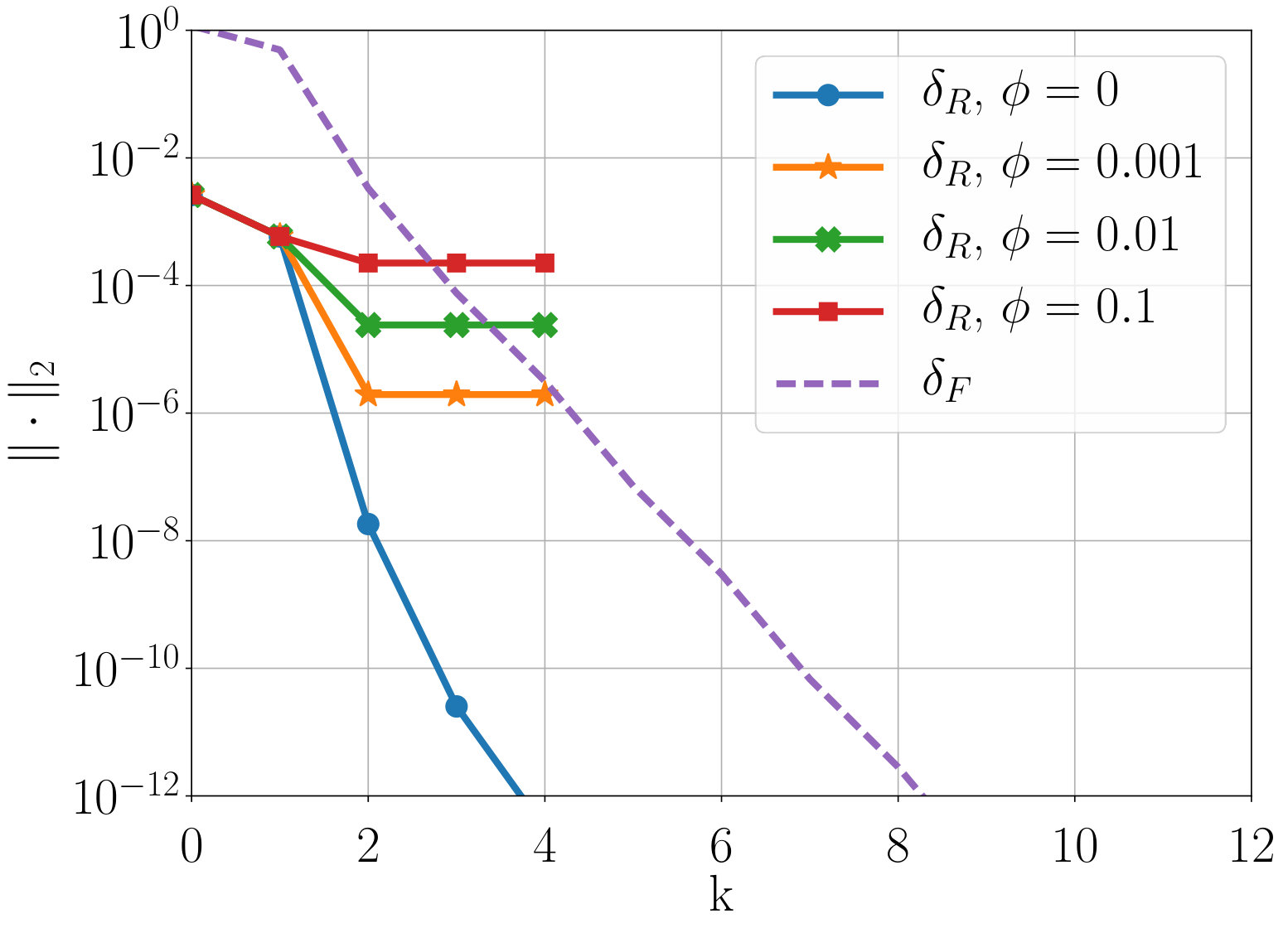 Figure 17
Figure 17 Figure 18
Figure 18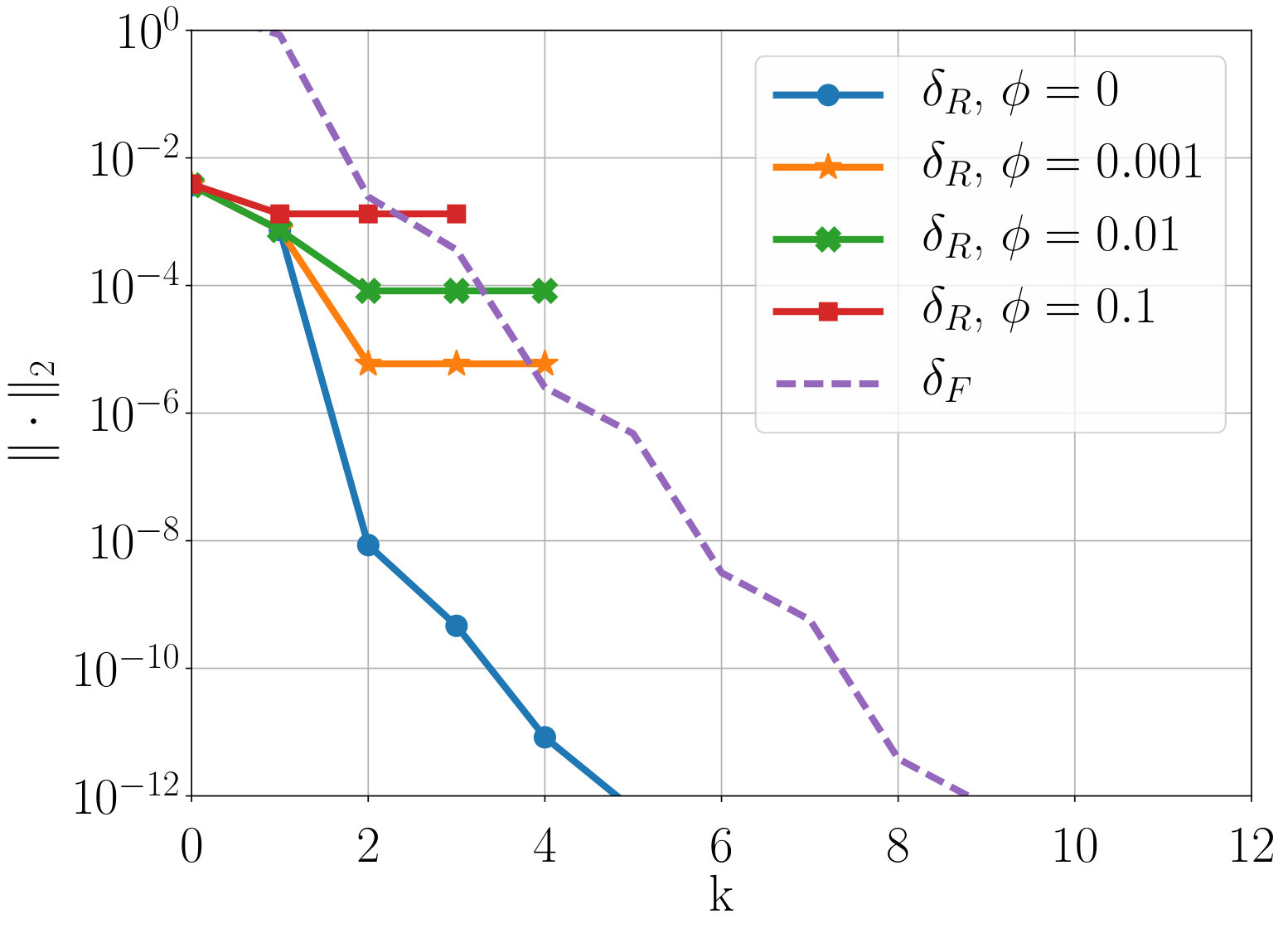 Figure 19
Figure 19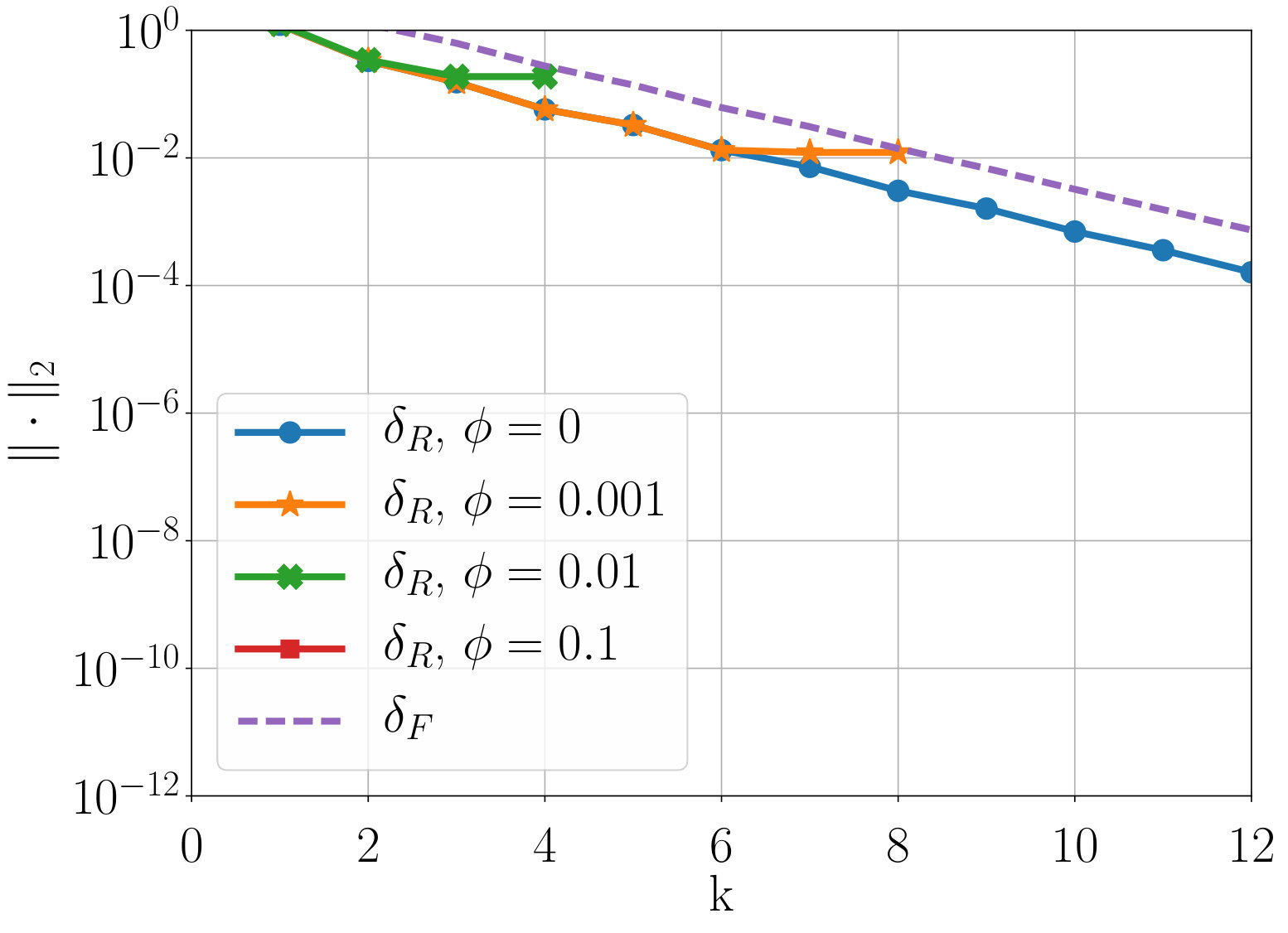 Figure 20
Figure 20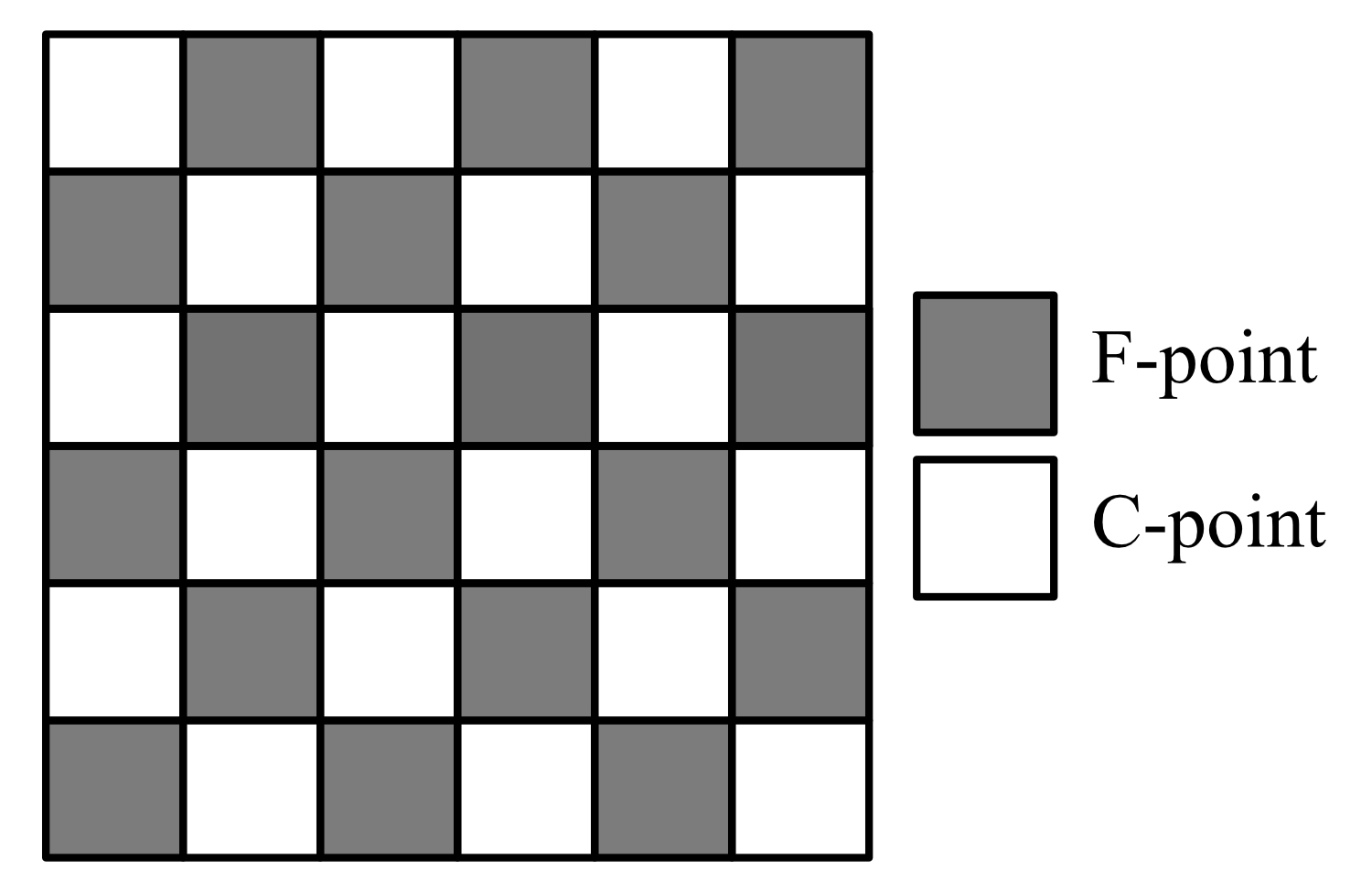 Figure 21
Figure 21 Figure 22
Figure 22| / | 1 | 5 | 10 | 25 | 50 | 100 | 250 | 500 |
|---|---|---|---|---|---|---|---|---|
| 0.0001 | 0.0002 | 0.0002 | 0.0004 | 0.0006 | 0.001 | 0.002 | 0.005 | |
| 0.0002 | 0.0006 | 0.0011 | 0.0026 | 0.0051 | 0.010 | 0.026 | 0.053 | |
| 0.0011 | 0.0051 | 0.0102 | 0.0257 | 0.0527 | 0.111 | 0.334 | – | |
| 0.01 | 0.0102 | 0.0527 | 0.1112 | 0.3335 | – | – | – | – |
| 0.1 | 0.1112 | – | – | – | – | – | – | – |
| degree FEM | nnz | CC | Speedup | ||||
|---|---|---|---|---|---|---|---|
| 1 | 2.5M | 24M | 0.09 | 42.4 | 41.7 | 0 | – |
| 1 | 2.5M | 24M | 0.10 | 10.9 | 11.0 | 1e-3 | 3.9 |
| 2 | 1.9M | 41M | 0.12 | 38.4 | 42.8 | 0 | – |
| 2 | 1.9M | 41M | 0.13 | 8.5 | 9.9 | 1e-3 | 4.3 |
| 3 | 2.2M | 85M | 0.14 | 32.6 | 38.2 | 0 | – |
| 3 | 2.2M | 85M | 0.17 | 6.8 | 8.9 | 1e-3 | 4.3 |
| Problem | CC | ||||
|---|---|---|---|---|---|
| P1 | 1553001 | 1 | 0.57 | 8.56 | 35.74 |
| P2 | 88800 | 1 | 0.22 | 4.52 | 6.85 |
| P2 | 88800 | 2 | 0.14 | 5.63 | 6.71 |
| P3 | 88800 | 1 | 0.46 | 4.54 | 13.59 |
| P3 | 88800 | 2 | 0.35 | 5.72 | 12.62 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
\newsiamthm
claimClaim \newsiamremarkremarkRemark \newsiamremarkexplExample \newsiamremarkconjectureConjecture
\headersNonsymmetric Reduction-based AMGManteuffel, Münzenmaier, Ruge, and Southworth
Nonsymmetric Reduction-based
Algebraic Multigrid††thanks: This research was conducted with Government support under and awarded by DoD, Air Force Office of Scientific Research, National Defense Science and Engineering Graduate (NDSEG) Fellowship, 32 CFR 168a. This work was performed under the auspices of the U.S. Department of Energy under grant numbers (SC) DE-FC02-03ER25574 and (NNSA) DE-NA0002376, and Lawrence Livermore National Laboratory under contract B614452.
Thomas A. Manteuffel Department of Applied Mathematics, University of Colorado at Boulder.
Steffen Münzenmaier Fakultät für Mathematik, Universität Duisburg-Essen.
John Ruge 22footnotemark: 2
Ben S. Southworth Department of Applied Mathematics, University of Colorado at Boulder (). [email protected]
Abstract
Algebraic multigrid (AMG) is often an effective solver for symmetric positive definite (SPD) linear systems resulting from the discretization of general elliptic PDEs, or the spatial discretization of parabolic PDEs. However, convergence theory and most variations of AMG rely on being SPD. Hyperbolic PDEs, which arise often in large-scale scientific simulations, remain a challenge for AMG, as well as other fast linear solvers, in part because the resulting linear systems are often highly nonsymmetric. Here, a novel convergence framework is developed for nonsymmetric, reduction-based AMG, and sufficient conditions derived for -convergence of error and residual. In particular, classical multigrid approximation properties are connected with reduction-based measures to develop a robust framework for nonsymmetric, reduction-based AMG.
Matrices with block-triangular structure are then recognized as being amenable to reduction-type algorithms, and a reduction-based AMG method is developed for upwind discretizations of hyperbolic PDEs, based on the concept of a Neumann approximation to ideal restriction (AIR). AIR can be seen as a variation of local AIR (AIR) introduced in previous work, specifically targeting matrices with triangular structure. Although less versatile than AIR, setup times for AIR can be substantially faster for problems with high connectivity. AIR is shown to be an effective and scalable solver of steady state transport for discontinuous, upwind discretizations, with unstructured meshes, and up to 6th-order finite elements, offering a significant improvement over existing AMG methods. AIR is also shown to be effective on several classes of “nearly triangular” matrices, resulting from curvilinear finite elements and artificial diffusion.
1 Introduction
Solving large, sparse linear systems is fundamental to the numerical solution of partial differential equations (PDEs). For high-dimensional PDEs, even a moderate resolution of the discrete problem can lead to enormous problem sizes, which require highly efficient, parallel solvers. Ultimately, it is important that a solver is both algorithmically scalable (fast), with a cost in floating point operations linear or near-linear with the number of unknowns, and scalable in parallel (scalable), where these operations can be efficiently distributed across many processors. For symmetric positive definite (SPD) matrices, such as those that arise in the discretization of elliptic PDEs or the spatial discretization of a parabolic PDE in time, a number of fast, scalable, iterative or direct methods have been developed. However, there remains a lack of fast, scalable solvers for the highly nonsymmetric matrices that arise in the discretization of hyperbolic PDEs and full space-time discretizations of general PDEs. A subset of such highly nonsymmetric matrices are block-triangular matrices, with blocks that are small enough to invert directly, which is one focus of this work.
For PDEs of elliptic type, algebraic multigrid (AMG) is among the fastest class of linear solvers. When applicable, AMG converges in linear complexity with the number of degrees-of-freedom (DOFs), and scales in parallel like , up to hundreds of thousands of processors, [6]. Originally, AMG was designed for essentially SPD linear systems, and convergence of AMG is relatively well understood in the SPD setting [10, 26, 60, 63, 11]. Nonsymmetric matrices pose unique difficulties for AMG in theory and in practice. In particular, coarse-grid correction, a fundamental part of AMG’s fast convergence, is generally not a contraction in the nonsymmetric setting, meaning that coarse-grid correction can increase error. There have been efforts to develop AMG theory and methods in the nonsymmetric setting [13, 39, 46, 57, 61, 46, 36, 42, 47, 48]. However, the theoretical understanding of nonsymmetric AMG remains limited, with very few convergence bounds proved in norm, and there has yet to be a robust and scalable AMG solver for highly nonsymmetric problems.
For the most part, previous work on nonsymmetric AMG has appealed to traditional AMG thought, where coarse-grid correction captures (right) singular vectors associated with small singular values and relaxation attenuates error associated with large singular values. Here, we take a different, reduction-based approach, appealing to the premise that certain “ideal” restriction and interpolation operators can lead to a reduction-based (nonsymmetric) AMG method. Although a reduction-based solver is not a new concept, here we recognize (i) an important class of linear systems for which reduction can be highly effective, and (ii) develop a theoretical framework explaining the convergence of nonsymmetric reduction-based AMG in norm.
Background on sparse triangular systems, reduction, and reduction-based AMG is given in Section 2. A novel convergence framework is then developed for nonsymmetric, reduction-based AMG in Section 3, including sufficient conditions for -convergence of error and residual, and a formal connection of reduction-based AMG to classical multigrid approximation properties. Section 4 then recognizes block-triangular and near-triangular matrices to be well-suited for reduction-based AMG, and discusses such operators in the context of discontinuous discretizations of advection. In particular, for hyperbolic-type PDEs, a Neumann approximation to the ideal restriction operator (AIR) provides an accurate, sparse approximation, and an AMG algorithm referred to as AIR is developed based on this principle. This is a similar approach to that developed in [40] (AIR), but AIR can offer setup-times that are orders of magnitude faster than AIR in some cases. Steady state transport is used as a model problem, which arises in large-scale simulation of neutron and radiation transport [1, 5, 18, 31, 51]. Results in Section 6 show that AIR outperforms current state-of-the art methods, and is able to attain an order-of-magnitude reduction in residual in only 1–2 iterations, even for high-order discretizations on unstructured grids.
2 Reduction-based algebraic multigrid
2.1 Triangular matrices and parallelism
Sparse matrices with triangular structure arise in a number of interesting settings. In contrast to elliptic and parabolic PDEs, the solution of hyperbolic PDEs lies on characteristic curves, and the solution at any point depends only on the solution upwind along its given characteristic. This allows for very steep gradients or “fronts” to propagate through the domain. Due to such behavior, discontinuous, upwind discretizations are a natural approach to discretizing many hyperbolic PDEs [14, 44, 45, 52]. For a fully upwinded discretization, the resulting matrix has a block-triangular structure in some (although potentially unknown) ordering. Implicit time-stepping schemes or steady state solutions then require the solution of such linear systems. There has also been growing interest in parallel-in-time solvers. Although most work on these has been geometric in nature, one can also consider algebraically solving the sparse matrix equations associated with a full space-time discretization. Such discretizations using an explicit time-stepping scheme (for any PDE) result in triangular matrices, and an implicit time-stepping scheme coupled with an upwind discretization of a hyperbolic PDE also leads to a block triangular matrix.
Solving linear systems with block-triangular structure is easy in serial using a forward or backward solve. However, there are cases where a block-triangular solve arises in the parallel setting. In particular, any time an upwind advective discretization is either (i) part of a larger PDE discretization that cannot be stored on a small number of processors, or (ii) coupled to other variables that are not inverted easily and require parallel preconditioners, a triangular-type solve is necessary in parallel. Scheduling algorithms have been developed for sparse matrices that can add some level of parallelism to this process, but such algorithms are primarily relevant for shared memory environments [2, 4, 34, 35], and, from the perspective of simulation of PDEs, efficiency in a distributed-memory environment is fundamental. In the simplest case of a perfectly structured processor grid of squares/cubes over some -dimensional domain, and a fixed, constant direction of flow, a forward solve in parallel scales like for processors [5]. However, for non-constant flow or non-uniform processor grids with respect to the flow and domain, this convergence can suffer. In fact, for any processor configuration over a given domain, it is straightforward to construct a velocity field for advection such that a distributed forward solve takes communication steps to complete. Even if each step of this process is fast, linear or even square-root scaling in is poor parallel performance.
Iterative-type methods offer an alternative (potentially) more amenable to parallelism. However, Krylov and most other traditional iterative-type methods are generally either divergent or too slow (with respect to convergence) to be considered a tractable approach, and solving large, sparse, block-triangular linear systems in (distributed-memory) parallel environments remains a difficult task. Geometric multigrid has been applied to hyperbolic PDEs and upwind discretizations using the well-known line-smoother approach [50, 3, 64], but such an approach requires a fixed/known direction over which to relax and has limits in terms of parallel scalability. When considering time-dependent hyperbolic PDEs, explicit time-stepping schemes can be used to avoid solving linear systems. But, explicit schemes suffer from stability constraints, such as the Courant-Friedrichs-Lewy (CFL) condition, which often require extremely small time steps, a process that is sequential and can limit performance in the parallel setting. AMG is known to scale like in parallel, and an AMG solver that is effective on block triangular and near-triangular matrices would overcome many of the aforementioned difficulties.
2.2 Reduction-based AMG
Reduction consists of solving of a problem by equivalently solving multiple smaller problems. In thinking about triangular systems, a direct forward or backward solve is a reduction algorithm: starting with a system of size , eliminate one DOF, and reduce the problem to size . Although this is a sequential algorithm, it suggests that reduction is an effective and tractable approach for triangular systems, which we demonstrate in this paper.
Given an matrix , suppose the DOFs are partitioned into C-points and F-points. For explanation, assume that the unknowns have been ordered with the F-points followed by the C-points. In this context, a well-known example of reduction is a block LDU decomposition:
[TABLE]
Here, solving is reduced to solving two systems, and the Schur complement, . LDU decompositions assume that the action of is available to compute the action of the first and third matrix blocks in (1), while in practice it is typically not. However, approximating such a decomposition is the goal behind numerous preconditioners. In fact, a two-level reduction-based AMG method can be posed as a variant of a block LDU decomposition, which is what we develop here by algebraically approximating the operators that lead to reduction in (1): and .
Algebraic multigrid applied to the linear system , , consists of two processes: relaxation and coarse-grid correction, designed to be complementary in the sense that they effectively reduce error associated with different parts of the spectrum of . Relaxation often takes the form
[TABLE]
where is some approximation to such that the action of can be easily computed. Coarse-grid correction typically takes the form
[TABLE]
where and are interpolation and restriction operators, respectively, between and the next coarser grid in the AMG hierarchy, , and back. Denote the projection . A two-level -cycle is then given by combining coarse-grid correction in (3) with pre- and post-relaxation steps as in (2), resulting in a two-grid error propagation operator of the form
[TABLE]
A classical AMG approach is used here, where a CF-splitting of DOFs defines the coarse grid [10, 55]. Operators , and can then be written in block form:
[TABLE]
where interpolates to F-points via linear combinations of coarse-grid DOFs, and restricts F-point residuals. Note that (4) implicitly assumes the same CF-splitting for and , although the sparsity patterns for nonzero elements of and may be different. For notation, denote the coarse-grid operator:111 is used to denote the coarse-grid operator instead of the traditional notation, to avoid confusion with subscripts denoting C-points.
[TABLE]
Define the “ideal restriction” and “ideal interpolation” operators as
[TABLE]
These operators define the LDU reduction in (1). Note that with or , independent of the other. Ideal interpolation has been explored in the context of reduction-based geometric multigrid methods [28, 54, 23, 22], and is well-motivated under classical AMG theory for SPD matrices, where it is optimal in a certain sense with respect to two-grid convergence [26, 63]. Ideal restriction was also discussed in the context of reduction in [26] and, in [40, Section 2.3], shown to be the unique restriction operator that gives an exact coarse-grid correction at C-points, independent of interpolation. This result, along with a corollary on ideal interpolation [40, Section 2.2], are summarized in the following results.
Lemma 2.1** (Ideal restriction).**
For a given CF-splitting, assume that is nonsingular and let , and take the block form as given in (4). Then, an exact coarse-grid correction at C-points is attained for all if and only if . Furthermore, the error in coarse-grid correction is given by
[TABLE]
*A coarse-grid correction using followed by an exact solve on F-points, results in an exact two-grid solver, independent of . *
Corollary 2.2** (Ideal interpolation).**
*For a given CF-splitting, assume that is nonsingular and let , and take the block form as given in (4). Then, an exact solve on F-points, followed by a coarse-grid correction using , yields an exact two-level solver, independent of . *
Thus, in the nonsymmetric setting, ideal transfer operators are “ideal” in a reduction sense: when coupled with an exact solve on F-points, and each lead to an exact two-level method, independent of the accompanying interpolation and restriction operators, respectively. Note that the ordering of solving the coarse- and fine-grid problems is important: in order to be an exact reduction, the F-point solve must follow coarse-grid correction with , while the F-point solve must precede coarse-grid correction with .
2.3 Relation to existing methods
Schur-complement preconditioning and reduction-based solvers are not new to the literature. Numerous algorithms have been based on a block LDU decomposition (1) and approximate Schur complement (for example, [17, 38, 42, 43, 46, 56, 8]). Reduction has also been studied in the multigrid and AMG context, originally in the geometric setting [28, 54], more recently algebraically [12, 37], and also as the basis for the multigrid reduction-in-time (MGRIT) parallel-in-time method [23, 21, 22]. MGRIT is designed for nonsymmetric problems, but is geometric in nature and relies on the very specific matrix structure that arises in time integration, more or less a block 1D advection problem. The AMG developments in [12, 37] are fully algebraic and reduction-based, but assume a Galerkin coarse grid, meaning restriction is defined as . For the highly nonsymmetric systems considered here, this is typically not a good choice [41, 40], motivating a Petrov-Galerkin method, where . Unfortunately, choosing also introduces new difficulties, because if and are not “compatible” in some sense, the norm of coarse-grid correction can be [41, 40], leading to a divergent method.
Approximating the ideal restriction or interpolation operators has also been considered in other (non-reduction-based) AMG methods, including [39, 49, 61]. Also motivated in a block-LDU sense, ideal restriction and interpolation are approximated in [61] by performing a constrained minimization over a fixed sparsity pattern for and . A similar constrained minimization approach for nonsymmetric systems was used in [39, 49], where ideal operators of and for and , respectively, are approximated using a constrained minimization. In these cases, the solvers appeal to more classical convergence theory by enforcing constraints to interpolate certain (known) vectors associated with small singular values exactly.
The AIR algorithm, developed here and in [40], takes a somewhat converse approach. Building on the discussion in Section 2.2, AIR relies on an accurate approximation to , and couples this with an accurate F-relaxation scheme to achieve a reduction-based algorithm. In particular, the focus is on reduction through the ideal restriction operator. In [40, Lemma 1], it is shown that for , care must also be taken when building to ensure a stable coarse-grid correction. Theory developed here indicates that when approximates , building interpolation to accurately capture right singular vectors associated with small singular values is sufficient for a stable coarse-grid correction, as well as two-grid convergence in the - and -norms. How accurately the derived conditions require to interpolate modes depends on how accurately .
This paper can be seen as a companion paper to the AIR method developed in [40]. The theory developed here is more general than that in [40], and provides rigorous explanation as to why better interpolation methods are needed when considering advection-diffusion-reaction [40] compared with pure advection-reaction (here and [40]). Conversely, the method developed here is less general than AIR, effective primarily on the purely advective or nearly advective case, but as a result, also has a significantly cheaper setup cost. The basic idea is that AIR approximates ideal restriction by solving many small, dense, linear systems, which can be moderately expensive as the problem size grows. AIR recognizes that, for advective-type discretizations, a similar approximation can be obtained by a few sparse matrix products. A detailed algorithmic comparison of AIR and AIR can be found in [40].
Finally, theory on convergence of nonsymmetric AMG in the -norm was developed simultaneously with this work in [41]. There, approximation properties are assumed on and . Here, we replace one approximation property assumption on either or with a measure of distance of or from ideal restriction or interpolation, respectively, and consider convergence in the - and -norms. If this distance cannot be made small, then one should revert back to a framework as in [41], focusing on more traditional approximation properties for and .
3 Convergence of reduction-based AMG
3.1 Framework
Let , , and take the form introduced in (4). Error propagation of coarse-grid correction is given by , where is a (generally non-orthogonal in any known inner product) projection onto the range of (Section 2). The motivation for AIR as an AMG algorithm is straightforward. Recall that ideal restriction gives an exact approximation at C-points, independent of interpolation. Following this with a direct solve on F-points gives an exact two-level method (Lemma 2.1). Although we do not expect ideal restriction in practice, here we assume that an accurate approximation to leads to an accurate solution at C-points, which we follow with F-relaxation to distribute this accuracy to F-points.
Let be an approximation to . First, measures of the accuracy of F-relaxation as well as the difference between ideal interpolation and restriction and the interpolation and restriction used in practice are defined, respectively, as
[TABLE]
Here, and are measured relative to . Throughout the paper it will be assumed that has been scaled so that . However, is explicitly carried through the derivation of bounds and proofs of convergence for completeness.
The error-propagation matrix associated with F-point relaxation is given by
[TABLE]
The product of these two error matrices, , can be put into a very convenient form [40],
[TABLE]
where
[TABLE]
If , then becomes ideal interpolation. The better approximates , the closer is to ideal interpolation. Here, is referred to as the “effective interpolation” of this method [40].
Next, note that has the form
[TABLE]
where
[TABLE]
A little extra work using (5) yields
[TABLE]
Using (18),
[TABLE]
Similarly, can be expanded as
[TABLE]
As mentioned in (8), the error-propagation matrix is given by . The residual-propagation matrix is similar, given by . Each of these can now be assembled to a convenient outer-product form.
For error propagation, combining (25) with (35) gives
[TABLE]
Likewise, using (7), (25), and (35), the residual-propagation matrix is given by
[TABLE]
The outer-product formulation provides a natural representation of powers of and , where
[TABLE]
In particular, it is easily verified from (7), (47) and (51) that
[TABLE]
is identical for and .
This is a fundamental observation for proving convergence-in-norm of reduction-based AMG. In particular, it is often the case that and/or are greater than one. However, (55) and (59) show that raising error- and residual-propagation to powers is equivalent to considering powers of a different matrix, (63). Thus, bounding can lead to a convergent method, which is summarized in the following lemma.
Lemma 3.1**.**
Let , , and be chosen such that
[TABLE]
Then, the iteration will converge with bounds
[TABLE]
Proof 3.2**.**
*The proof follows from (55), (59), (62), and the discussion above. *
Note that the bound on is independent of , but the separate terms are not. This can easily be adjusted by scaling the second and third terms by and , respectively.
In Section 4.1, we show that it is often possible in practice to construct such that is quite small relative to . Recall that, for hyperbolic problems, . On a relatively coarse grid, it is possible that and, consequently, , regardless of . In fact, is a reasonable choice in that context because that choice reduces the complexity of , making the algorithm more efficient. However, in general, a better may be necessary for convergence. The following section develops conditions for which .
Remark 3.3** (Pre-F-relaxation).**
*Because ideal restriction gives an exact coarse-grid correction at C-points, thus far we have considered post-F-relaxation to distribute this accuracy to F-points. If instead, is chosen to approximate , a pre-F-relaxation scheme may be more appropriate (see Corollary 2.2). It is easy to show that pre-F-relaxation enjoys the same asymptotic behavior as post-F-relaxation. *
3.2 Two-grid convergence
In this section, conditions are derived to bound . The focus of this work is on problems for which , and or , can be made small relative to . However, for a given family of discretizations, and are typically fixed, independent of ; that is, the accuracy of approximation to ideal operators does not improve as . To bound as , additional measures must be taken to account for the term in (63), because . To do so, we consider a classical multigrid “weak approximation property” for and .
Definition 3.4** (WAP on with respect to SPD ).**
An interpolation operator, , satisfies the weak approximation property (WAP) with respect to SPD matrix , with constant if, for any on the fine grid, there exists a on the coarse grid such that
[TABLE]
Recall that the Schur complement of is . Comparing the coarse-grid operator (5) with the Schur complement yields
[TABLE]
Now, assume that satisfies the WAP with respect to , with constant . Then, for every ,
[TABLE]
Let satisfy the infimum above. Then,
[TABLE]
Noting from (69) that , we can form a constrained maximization problem and bound
[TABLE]
where . In particular, let . Then,
[TABLE]
Following from (64) and (70), observe that
[TABLE]
Note that, given with WAP constant , we may choose so that . Later, will be chosen slightly smaller. Combining, we arrive at
[TABLE]
This result is generalized in the following Lemma.
Lemma 3.5**.**
Suppose satisfies the WAP with respect to , with constant . Then, if is chosen such that ,
[TABLE]
*where .
Similarly, suppose satisfies the WAP with respect to , with constant . Define and assume that . Then,*
[TABLE]
Proof 3.6**.**
*The results follow from the above discussion and noting that . Results for follow a similar derivation as that for . *
The above discussion is summarized in the following results.
Theorem 3.7**.**
Let , , and be defined as above. If is chosen so that satisfies the WAP with respect to , with constant , then can be chosen to approximate and can be chosen to approximate so that
[TABLE]
*where . *
Proof 3.8**.**
The proof follows from Lemma 3.5 and the bound using (62),
[TABLE]
Theorem 3.9**.**
Let , , and be defined as above. If is chosen so that satisfies the WAP with respect to and constant , then can be chosen to approximate and can be chosen to approximate such that
[TABLE]
*where . *
Proof 3.10**.**
*The proof follows from the discussion above and the proof of Theorem 3.7. *
Theorems 3.7 and 3.9 give insight into the roles of restriction, interpolation, and F-relaxation. F-relaxation can help convergence bounds, but only to a certain extent. For an exact solve on F-points, . Then, for example, in Theorem 3.7, to ensure that , we must have . This can be accomplished both through a more accurate interpolation with respect to the WAP or a more accurate approximation to ideal restriction. As increases, that is, F-relaxation becomes less effective, interpolation and restriction must improve through reduced and/or .
The -convergence of error and residual also follows from Theorems 3.7 and 3.9 and Lemma 3.1. Although it is possible that , if the hypothesis are satisfied, there exists and such that . Iterations before these values of are reached may appear to be diverging, but they will eventually converge with asymptotic factor . How long it takes to reach asymptotic convergence depends on the other matrix blocks in . This has been observed in practice.
Consider and with respect to the size of the mesh. From (47), it is clear that choosing yields . In the case that is a discrete approximation of a PDE, may grow with , the size of the system, whereas, may be fixed. Although is independent of , without additional approximation properties on , the norm of may not be bounded independent of . This would lead to a method for which it takes more iterations to reach a given accuracy as the problem size increases. Building on Lemma 3.5, conditions for residual and error propagation bounded independent of are given in the following corollary.
Corollary 3.11** (Bounded Residual and Error).**
Assume that satisfies the WAP with respect to , with constant , Theorem 3.7 holds, and the condition numbers of and are independent of problem size. Then, for , is bounded, independent of problem size, and converges with asymptotic rate .
*If, in addition, satisfies a WAP with respect to , then for , is bounded, independent of problem size and converges with asymptotic rate . *
Proof 3.12**.**
*Consider the terms in (59). Under the assumption that satisfies a WAP with respect to , it was shown in Lemma 3.5 that is bounded independent of . All other terms in the equation are bounded independent of . Likewise, consider the terms in (55). From Lemma 3.5, if satisfies a WAP with respect to , then is bounded independent of . *
Remark 3.13** (C-point relaxation).**
In a two-level setting, adding relaxation over C-points as part of the pre- or post-relaxation scheme offers little to no improvement of convergence. Suppose , where , that is, the same approximation is used for F-relaxation as for approximating . Now, consider following the F-point relaxation with a C-point relaxation. Similar to F-point relaxation, the error-propagation operator associated with C-point relaxation is given by
[TABLE]
where is an approximation to . Noting that the C-point rows of are zero when (see (21)), multiplying by yields
[TABLE]
*This demonstrates that, in the context of a two-grid method, with reasonable choice of , C-point relaxation does not improve the solution. In the multilevel setting, C-point relaxation can offer some improvement in convergence, but remains much less important than F-relaxation. *
4 The triangular case
Building on the previous section, this section develops an accurate approximation to for matrices with block-triangular or near-triangular structure. Numerical examples demonstrate the accuracy of nAIR in the context of convergence constants derived in Section 3. Although reduction can be achieved with ideal restriction or interpolation, focusing on ideal restriction allows for coupling the AIR method with established interpolation methods. One result here is that error and residual propagation of AIR are nilpotent in the case of block-triangular matrices, which compensates for inaccurate interpolation near boundaries.
As motivation, consider a block-discontinuous discretization of a steady state advection or advection-reaction equation in two dimensions,
[TABLE]
for arbitrary velocity field (without cycles, or else the problem is not well posed), forcing function , reaction field , and some inflow and outflow boundary conditions (for example, see Section 6). Suppose a uniform square mesh is used in two dimensions. Then, for many discretizations, such as discontinuous Galerkin, among others, DOFs in each element of the mesh depend on exactly two other elements in the mesh, specifically the two elements upwind with respect to the direction of flow, and each element in the mesh corresponds to a non-overlapping block in the matrix. In the multigrid context, consider a block red-black coarsening scheme, where C-points and F-points represent entire finite elements, as shown in Figure 1.
For linear finite elements, the DOFs corresponding to a block discretization are often located at the vertices of the mesh, with one DOF contained in each element touching a given vertex. For higher-order discretizations, there are more DOFs, but the underlying principle remains the same: all DOFs in a given finite element only depend on DOFs within that element, or DOFs in either of the two upwind elements. Looking at Figure 1, note that for any velocity field , all F-point blocks depend only on C-point blocks, and C-point blocks depend only on F-point blocks. If is scaled to have unit diagonal, then it follows that the submatrix , and thus, ideal restriction and exact F-relaxation are trivial to compute in practice.
Of course, this example holds for a block diffusion discretization as well (that is, there as well). However, for advection, the coarse-grid operator maintains a similar structure to the fine grid. Note that for any C-point, the corresponding row of is nonzero in C-point blocks that can be reached through a C-F-C path in the graph. Generally for an advection problem, (i) each C-point has about three coarse-grid connections, (ii) all connections are upwind (and, thus, strictly lower triangular in the matrix), and (iii) at least one of these connections is essentially cross-stream, making it a weak connection. In this case, coarsening similar to Figure 1 based on strong connections leads to an , but for which is well conditioned and easily approximated with a sparse matrix. In contrast, each coarse-grid point in a diffusion discretization is connected to eight other points, making and difficult to approximate effectively in a sparse manner, and multilevel reduction much more difficult.
On unstructured meshes, non-quadrilateral elements, higher dimensions, or coarser grids in an AMG hierarchy, it is typically not the case that . Nevertheless, similar principles suggest that can be approximated efficiently, which is confirmed directly in Section 4.2 and implicitly in numerical results of Section 6.
4.1 Neumann approximate ideal restriction
For general matrices, a naive and often ineffective approach to approximate is to use a truncated Neumann expansion. However, in the case of block-triangular matrices, particularly those resulting from the discretization of differential operators, a truncated Neumann inverse expansion can provide a remarkably accurate approximation. For ease of notation, assume that has been scaled to have unit diagonal, and suppose we have determined a CF-splitting (or block CF-splitting if is block lower triangular). Then, let , where is the strictly lower triangular part of . Because is nilpotent, can be written as a finite Neumann expansion:222Because there are no cycles in the graph of , the degree of nilpotency is given by the maximum graph distance between any two F-points, say . In the case of an acyclic graph, this is equivalent to the longest path problem. For discretizations of differential operators that result in an acyclic graph, it is generally the case that .
[TABLE]
To approximate , we consider an order- approximation given by truncating (71): , for some . Define a restriction operator based on a Neumann approximate ideal restriction (AIR):
[TABLE]
Error in as an approximate inverse can be measured as , which gives a measure of how accurately we approximate .
Note that the error relation does not require to be lower triangular. However, triangular structure is fundamental to being small as increases, particularly when considering the discretization of differential operators. Consider as the adjacency matrix of a directed acyclic graph. Then gives the sum of weighted walks of length from vertex to vertex (weight given by product of the walk’s edges). Thus, we are interested in the number of F-F connections and size of the weights. For the discretization of differential operators, off-diagonal elements are typically small relative to the diagonal, and an AMG CF-splitting is chosen to eliminate strong F-F connections. In the case of triangular matrices, such as an upwind discretization of advection, regardless of the problem dimension, there only exist walks from node to nodes downstream of , in the direction along the characteristic. This means that the sparsity pattern of only reaches out to neighbors in effectively one direction. Thus, as increases, the number of neighbors within distance should not increase significantly, while the product of edges should decay rapidly.
Remark 4.1** (Nilpotent Error Propagation).**
It is straight forward to show that if is lower triangular in some ordering and , , and are truncated Neumann approximations to , then two-grid error propagation based on Jacobi F-relaxation is strictly lower triangular. Moreover, multilevel error propagation, with coarse-grid correction based on AIR and Jacobi F-relaxation, is also strictly lower triangular and, thus, nilpotent.
Although, the degree of nilpotency is not sufficiently small to be considered practical, nilpotency of error propagation is directly impactful near the boundaries of the domain, where DOFs actually fall off the nilpotent cliff in iterations. AMG often struggles with interpolation near domain boundaries, and the nilpotent behavior of AIR eliminates this problem. This benefit has been observed in practice.
4.2 Evaluating constants
This section considers nAIR applied to discontinuous Galerkin discretizations of the steady state transport equation and an advection-diffusion-reaction equation, with diffusion coefficient . Both discretizations are on unstructured meshes with a moving (non-constant) velocity field and material discontinuities of between different subdomains. Further details on the transport discretization can be found in Section 6. The advection-diffusion-reaction equation follows an analogous derivation, and is discussed in [40]. Recall, when approximating ideal restriction (as opposed to ideal interpolation), the theoretical constants of interest are
[TABLE]
as well as the constant for which satisfies a WAP (see Theorem 3.7). The purpose of this section is to demonstrate that, on an interesting and difficult model problem, AIR leads to , where has been scaled so that .) Following from Theorem 3.7, we then show that strong two-grid convergence is provable under minimal assumptions on for the transport equation. Results also show why the reduction approach is successful for advection discretizations, but less effective for diffusive problems.
Figure 2 plots and as a function of number of iterations and degree of Neumann expansion, respectively. In practice, it is usually not a good idea to form transfer operators using neighbors further than distance two, unless coarsening aggressively, due to the rapid increase in the number of nonzeros in coarse-grid operators. Similarly, transfer operators are typically only formed based on strong connections in the matrix, again to limit coarse-grid fill in, particularly in the multilevel setting. Here, strong connections for each row are defined as entries larger than times the largest row element (positive or negative).
Looking at the left column of Figure 2, we see that for both 1st- and 4th-order discretizations of the steady state transport problem, AIR based on distance-one or -two strong neighbors is able to achieve between . Furthermore, three iterations of F-relaxation leads to , and four iterations improves this to . In the diffusion-dominated case, (right column), results are not as good. For linear elements, distance-two AIR achieves at best and four iterations of F-relaxation only yields , while the 4th-order discretization is worse.
Table 1 plots two-grid convergence bounds from Theorem 3.7 as a function of constants and , for a fixed . Note that due to small and , only mild assumptions must be made on interpolation for rapid two-grid convergence. Although constants are likely to increase somewhat in the multilevel setting, the initial discussion in Section 4 suggests that good approximations to and can still be obtained on coarser levels in the hierarchy.
The constant , where , is evaluated in [41] for a hyperbolic steady state transport equation, discretized with SUPG and DG finite element discretizations (for details, see Section 6 here or [41]). There, modified classical AMG interpolation [19] is shown to have constant of 157 and 204 for SUPG and DG, respectively. Typically . Say . Then and . Applying the same tests to the one-point interpolation used here yields constants on the order of and , and and 42. In practice, we find that the sparser structure of one-point interpolation is advantageous in the multilevel setting, and we see equivalent convergence with the two methods, despite the larger constant using one-point interpolation.
Interestingly, in [41] an analogous algorithm to AIR for interpolation is numerically shown to have constants and and 10. Furthermore, tests suggest the constants may be independent of problem size, a property which may not be the case for one-point and classical interpolation. Note that those tests did not use an efficient algorithm to build the interpolation, and extending AIR-like ideas to interpolation for hyperbolic-type problems is ongoing work. However, such numbers indicate that better interpolation operators (than existing methods) can be constructed for hyperbolic-type problems, and, with such interpolation, two-grid convergence could be obtained with fairly weak approximations of .
5 Algorithm
The main components of AIR follow that of a standard Petrov-Galerkin multigrid scheme with no pre-relaxation. Section 5.1 introduces details on the AMG components of AIR, including parameters and routines for strength-of-connection, CF-splitting, interpolation, restriction, and relaxation. Other details, including support of block structure in matrices and a filtering procedure to reduce complexity, are discussed in Section 5.2.
5.1 AMG components
Effective F-relaxation and an accurate approximation to ideal restriction both require to be relatively well conditioned. This is consistent with motivation for a classical AMG strength-of-connection and CF-splitting [10, 55], which are used here. Jacobi F-relaxation is used with one more iteration than the degree of the Neumann approximation of . Restriction is built using a degree-one Neumann expansion (71) applied to strong connections in , with connection drop-tolerance . These parameters are motivated through the comparison of AIR with in Section 4.1.
From Theorem 3.7, if we approximate , then should be built targeting approximation properties, in a classical AMG sense. It turns out, classical AMG interpolation formulae [10, 55] do not satisfy approximation properties on hyperbolic transport discretizations [41]. Fortunately, is a very accurate approximation to for problems tested here, making interpolation less important. We propose a “one-point interpolation” scheme, where each F-point is interpolated by value from its strongest C-connection. One-point interpolation resembles a degree-zero Neumann expansion, but is sparser, having exactly one nonzero per row, and each nonzero is set to one as opposed to the value of .333One-point interpolation also resembles an unsmoothed aggregation interpolation operator, but here some “aggregates” may have many points and others only one. In aggregation-based AMG, aggregates are typically chosen to be comparable in size, and there are never aggregates of size one that have strong connections in the matrix. This ensures that the constant is in the range of interpolation, with minimal nonzero requirements of . In practice, one-point interpolation performs best compared to many different interpolation methods tested in terms of total work and time to solution. In fact, AIR was shown to have good approximation properties for scalar hyperbolic problems in [41], and using these ideas to develop improved interpolation methods for hyperbolic problems is ongoing work.
5.2 Blocks, filtering, and parallelization
Some PDE discretizations lead to matrix equations with a natural block structure. The two most common examples are: (i) systems of PDEs, where a block in the matrix corresponds to multiple variables discretized on a single spatial node, or (ii) block discontinuous discretizations, such as discontinuous Galerkin (DG), where each finite element forms a block in the matrix. In either case, a block lower triangular matrix can be transformed to lower triangular by scaling the system by the block-diagonal inverse, or AIR can be performed in the block setting, coarsening and forming transfer operators by block. For most results, we scale by the block-diagonal inverse because the two approaches have shown comparable convergence factors, and forming AIR in the setup phase is cheaper and simpler in the scalar (non block) matrix case. However, Section 6.3 shows results for block AIR as well, where coarsening, restriction, interpolation, and relaxation are all done in a block fashion.
One way to further reduce complexity in an AMG solver is truncating or lumping operators. The idea is simple: remove entries from a matrix in the hierarchy, , that are smaller than some threshold, typically with respect to the diagonal element of the given row. Such methods have been used in AMG for symmetric problems with diffusive components [9, 25, 59]). Heuristically, eliminating small entries is even more appropriate in the hyperbolic setting, because the solution at any given point only depends on the solution at other points upwind along the characteristic. In the discrete setting, small entries that arise in matrix operations are often not aligned with the characteristic and are more of a numerical effect, suggesting that some can be eliminated without degrading convergence. Numerical results confirm this; in particular, removing entries in the case of SPD matrices is a delicate process [9, 25, 59], but Section 6 shows that entries can be removed from discretizations of steady state transport aggressively, without a degradation in convergence. For some drop-tolerance , elements \{a_{ij}\text{ | }j\neq i,|a_{ij}|\leq\varphi|a_{ii}|\} are eliminated (that is, set to zero) for each row of matrix . A drop tolerance of has proved to be effective for many problems tested, and is used for all results presented here.
Finally, AIR applied to triangular systems is intended for highly parallel environments, where traditional triangular solves are not easily parallelized. This work focuses on algorithmic details and theory, and does not develop parallel performance models or present parallel scaling results. However, it is well known that AMG scales in parallel to hundreds of thousands of cores [6], with a communication cost of , for processors [24, 32]. The algorithm developed here takes on the form of a traditional AMG method, with the additional cost of building and storing a restriction operator, which can be performed efficiently in parallel.
6 Numerical results
In this section, we apply AIR to discontinuous discretizations of the steady state transport equation. For problems in which the steady state is well posed (no cycles in flow), the steady state case is equivalent to the time dependent problem with an infinite time step. In this context, successful results on steady state flow also indicate that AIR is applicable in the time-dependent regime with implicit time-stepping schemes of arbitrary step size.
The computational cost or complexity of an AMG algorithm is typically measured in work units (WU), where one WU is the cost to perform one sparse matrix-vector multiplication with the initial matrix. Operator complexity (OC) gives the cost in WUs to perform one sparse matrix-vector multiplication on each level in an AMG hierarchy, and cycle complexity (CC) gives the cost in WUs to perform one AMG iteration, including pre- and post-relaxation, computing and restricting the residual, and coarse-grid correction. For convergence factor , the work-unit-per-digit-of-accuracy (WPD), , is an objective measure of AMG performance, giving the total WUs necessary to achieve an order-of-magnitude reduction in the residual:444Although WPD is a good measure of serial performance, it does not reflect parallel efficiency of the algorithm.
[TABLE]
where is the effective convergence factor.
6.1 Test problems and discretizations
The model problem used here is the steady state transport equation:
[TABLE]
for domain and inflow boundary . Multiple cases are studied that encompass spatially dependent source terms, , discontinuities in the material coefficient, , and constant and non-constant flow direction, , over structured and unstructured meshes. When is constant, we denote , for some angle . Two model domains are considered, the inset domain and block-source domain, shown with solutions in Figure 4. In each domain, inflow boundaries consist of the south and west boundaries with inflow , and the material coefficient is piecewise constant in both cases, with changes of eight orders of magnitude, as shown in Figure 4. The inset domain has no source (), while the block-source domain has an interior source in the interior block. These terms ( and ) are fixed for all experiments, except the non-triangular case (Section 6.4). Multiple velocity fields are considered. Solutions with constant flow are shown in Figure 4, and several variations of the inset domain with non-constant flow are shown in Figure 6 in Section 6.2. All numerical experiments use and as specified in Figure 4, but multiple velocity fields are considered.
To accompany the different domains considered, multiple upwind discretizations are implemented. A first-order lumped corner balance (LCB) finite element discretization [44, 45] is applied on structured and unstructured meshes. Standard fully upwinded discontinuous Galerkin (DG) discretizations [33, 53] are also tested, with finite element orders . A comprehensive introduction can be found in [20]. Standard upwinded DG methods arise as special cases in [14] and for almost-scattering-free problems in [52]. The structured meshes used are triangular crossed-square meshes, conforming to the material discontinuities in , while random triangulations, again conforming to material discontinuities, are used as unstructured meshes. Additional discretizations based on highly elongated meshes with curvilinear elements, as well as continuous (linear) elements with artificial diffusion, are briefly explored in Section 6.4.
As motivation for AIR, we first highlight the difficulties that existing varieties of AMG face solving these discretizations. Tests were run using the PyAMG library [7], hypre [27], and ML [29]. Classical AMG methods are not well developed for the nonsymmetric setting; methods such as BoomerAMG in hypre [32] use a Galerkin, coarse grid, and are able to solve discontinuous transport discretizations based on linear finite elements, with convergence factors on the order of 0.8–0.9. However, convergence is not scalable and does not extend beyond linear elements. Aggregation- and energy-minimization-based AMG methods are better developed for nonsymmetric problems. The most successful existing solver appears to be the nonsymmetric smoothed aggregation (NSSA) solver in the ML library [29, 57, 61]. With GMRES acceleration, NSSA is able to converge on most problems tested here. In all cases, however, NSSA takes several times more iterations than AIR and often requires significant relaxation, such as a -cycle, for good convergence. For difficult problems, AIR offers a speedup of or more over the current state-of-the-art.
6.2 Angular variation, non-constant flow, and 3d
Problems in higher dimensions, anisotropies on unstructured meshes, and non-grid-aligned anisotropies can prove difficult for AMG solvers [39, 58]. Here, we show AIR to be robust in all of these cases. Figure 5 shows performance of AIR for LCB discretizations of the inset problem on structured and unstructured meshes, with fixed angle , and angles . Because unstructured meshes are often used in practice and typically more difficult from a solver perspective, further results use an unstructured mesh and the angle is (arbitrarily) fixed to . 555For some angles, AIR converges faster on an unstructured mesh than a structured mesh. However, the wall-clock time of the setup and solve phase is at least faster in all cases for a structured mesh over an unstructured mesh. It is possible that a structured mesh makes for a more structured matrix amenable to matrix-vector operations, but a detailed analysis is outside the scope of this work.
In addition to being robust with respect to angular variations, AIR is insensitive to flow direction and problem dimensionality. Figure 6 shows the solution to three different non-constant flows defined on the inset domain, and the corresponding performance of AIR, along with results for a fixed direction on the inset and block-source domain.
Table 2 shows results of AIR applied to steady state transport in three dimensions for different finite element orders. The three-dimensional domain is a unit cube, with inside of a centered interior cube of size , and outside of that subdomain, similar to the 2d inset domain (Figure 4). A random tetrahedral mesh is used, conforming to discontinuities in , and a constant velocity field, . As in 2d, choice of and does not affect results on an unstructured mesh (see Figure 5); here we use . In all cases, AIR is able to achieve fast convergence at a moderate cost. Due to the increased matrix connectivity in three dimensions, filtering is particularly useful here, reducing WPD by a factor of four or more in all cases, and total time-to-solution (not shown) by factors of 3–4.
This is also a good example to demonstrate the speedup that AIR can provide over AIR in setup time. For 3rd-order elements in 3D, with about 2M DOFs, distance-1 AIR takes 2995 seconds to build the solver and 43 seconds to solve to residual tolerance. Distance-one AIR (approximately corresponding to distance-two AIR) takes only 38 second to setup and 52 seconds to solve. Despite convergence factors that are slightly larger with AIR compared to AIR, the overall time to solution is significantly smaller. Furthermore, it is simple and moderately cheap to go from distance-one to distance-two AIR; for example, the setup time here increases modestly to about 60 seconds with distance-two AIR, while distance-three AIR (approximately corresponding to distance-two AIR) is completely intractable.
6.3 Scaling in and element order
Next, we study the scaling of AIR with respect to DOFs. One exciting feature of AIR is its ability to solve high-order finite-element discretizations, something that AMG methods often struggle with. Here, V-cycles and F-cycles are considered, with degree of AIR and . Although F-cycles originate in full multigrid, which focuses on achieving discretization-level accuracy in a single F-cycle [15], accuracy with respect to discretization is not considered in this work. Instead, the F-cycle is used as it can provide more robust convergence and scaling than a V-cycle, at a much lower cost than alternatives such as W-cycles and K-cycles. Figure 7 shows scaling of WPD and convergence factor of AIR applied to upwind DG discretizations of the inset problem, as a function of number of DOFs. Although there remains a slow growth in WPD, likely due to an increase in iterations before asymptotic convergence rates are achieved, convergence factors have effectively asymptoted for lower-order finite elements, and are leveling off even for 6th-order finite elements.
One benefit of the reduction approach is that convergence of AIR can be improved by increasing the accuracy of the Neumann approximation. Figure 7 demonstrates that convergence is improved a notable amount by increasing to , and again for to . This allows us to attain V-cycle convergence factors on the order of for 6th-order finite elements. Similar improvements in convergence can be obtained by decreasing the strength tolerance, , leading to a more accurate approximation of . Because increasing also increase the density of coarse-grid operators, in practice, one must find the balance between complexity and convergence factors. Here, we see that the V-cycle with appears to be the most effective choice, because the WPD is less than that of , or F-cycles for all finite element orders. The best choice in terms of total time (including setup) likely depends on how many linear systems are being solved, and it is possible is faster for a single or small number of systems. Note that having the option to make this choice is a benefit of AIR, because, in general, classical AMG methods do not have a natural and robust way to improve convergence the way that increasing can.
So far all results have employed scaling the matrix by the block-diagonal inverse. However, AIR is also amenable to a block implementation, where coarsening, restriction, and interpolation are all done by block. This is particularly relevant for systems of PDEs with coupled variables, where scaling out the block diagonal is unlikely to capture the necessary couplings. Figure 8 demonstrates block AIR applied to the same problem as in Figure 7, this time directly using the DG block structure, for orders 1, 2, and 3 finite elements. Convergence factors are similar to those achieved by scaling by the block diagonal inverse. The WPD is higher because we do not filter in the block setting, and because, when using a block sparse matrix, even zero entries in otherwise nonzero blocks must be stored. This results in a larger OC and, thus, larger WPD.
6.4 Non-triangular matrices
Finally, it is well-known that a Neumann approximation for ideal operators is, in general, not effective for non-triangular matrices, such as a symmetric discretization of diffusion. However, for “nearly triangular” matrices, AIR remains an effective solver. Here, we demonstrate the performance of AIR on three such problems in Table 3.
P1 corresponds to a streamline upwind Petrov-Galerkin (SUPG) discretization of (72) on the inset problem, using linear finite elements. SUPG discretizations use an upwinded scheme for advection, with a small diffusive component added for stability [16]. This results in a small, global, symmetric component added to a triangular matrix. P2 and P3 correspond to 4th-order, upwind DG discretizations of (72) in 2d, on high-order curvilinear finite elements [62]. Here, , , and is the right-hand side corresponding to the exact solution . Curvilinear finite elements can be non-convex and produce cycles in the mesh, wherein the resulting matrix for a fixed direction of flow is mostly block triangular, with some number of strongly connected components (SCCs) that are non-triangular and large in magnitude [30]. P2 has 97 SCCs of size two and 15 SCCs of 3–6 DOFs. P3 has 40 SCCs of size two, 11 small SCCs with 3–6 DOFs, and one large SCC consisting of 1951 DOFs, implying there is a substantial non-triangular block in the matrix.
It should be noted that even in serial, solving such a problem algebraically is nontrivial, particularly when there is a global symmetric component. One approach is to use a lower-triangular preconditioner that inverts the advective components exactly, equivalent to an ordered Gauss-Seidel iteration. This would likely converge well; however, without geometric knowledge of the velocity field and corresponding ordering of DOFs in the matrix, the right relaxation ordering cannot be easily determined. In [30], a cycle-breaking strategy was proposed to approximate an optimal relaxation ordering in the context of larger transport simulations on meshes with curvilinear elements. This proved successful on linear systems with SCCs, but convergence of the larger transport “source iteration” was slower than using an exact solve, and this approach does not overcome the inherent limitation of Gauss-Seidel in parallel.
Each of these problems is nearly triangular in a different regard. Here, we apply one AIR V-cycle as a preconditioner for GMRES, and results in Table 3 show AIR to be an effective preconditioner in all cases.
Classical AMG with GMRES acceleration does not converge on either problem. NSSA using GMRES acceleration and Jacobi relaxation converges for both problems. For the harder problem, P3, NSSA converges with factors on the order of for a -cycle and for a -cycle, with cycle complexities likely on the order of 8-9 and 11, respectively, and corresponding WPDs of 66 and 79.666ML does not detail complexity in the same manner as PyAMG, so these estimates are for comparison purposes between NSSA and nAIR. However, this convergence is sensitive to parameters. For example, reasonable convergence is attained for an aggregation threshold of , but NSSA does not converge for , and iterations are halted due to a singular GMRES Hessenberg matrix for .
7 Conclusions
This work studies reduction-based AMG for highly nonsymmetric matrices. Theory is developed indicating that, along with accurate approximations of the ideal operators, a scalable method also requires that interpolation or restriction satisfy a classical multigrid approximation property. A reduction-based AMG method is then developed, denoted AIR, which is shown to be an effective solver for upwind discretizations. Strong convergence factors are shown when AIR is applied to the steady state transport equation, on multiple domains, with high-order upwind discretizations, and unstructured meshes or meshes with curvilinear elements. Although AIR as presented here proves robust for several “nearly triangular” problems, when significant non-triangular components are introduced, the performance of AIR will quickly degrade, and the more general variation, AIR [40], is more appropriate.
A serial implementation of AIR is available in the PyAMG library [7], available at https://github.com/ben-s-southworth/pyamg/tree/air, and a parallel implementation is now available in the hypre library [27] (https://github.com/hypre-space/hypre).
Acknowledgment
The authors thank Steve McCormick for helpful discussions in the development of AIR.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] M. P. Adams, M. L. Adams, and W. D. Hawkins , Provably optimal parallel transport sweeps on regular grids , in International Conference on Mathematics and Computational Methods Applied to Nuclear Science & Engineering, Idaho, 2013, Texas A and M University, College Station, United States, pp. 2535–2553.
- 2[2] F. L. Alvarado and R. Schreiber , Optimal parallel solution of sparse triangular systems , SIAM Journal on Scientific Computing, 14 (1993), pp. 446–460.
- 3[3] S. Amarala and J. W. L. Wan , Multigrid Methods for Systems of Hyperbolic Conservation Laws , Multiscale Modeling & Simulation, 11 (2013), pp. 586–614.
- 4[4] E. Anderson and Y. Saad , Solving sparse triangular linear systems on parallel computers , International Journal of High Speed Computing, 1 (1989), pp. 73–95.
- 5[5] T. S. Bailey and R. D. Falgout , Analysis of massively parallel discrete-ordinates transport sweep algorithms with collisions , in International Conference on Mathematics, Computational Methods, and Reactor Physics, Saratoga Springs, NY, 2009, Lawrence Livermore National Laboratory, Livermore, United States, pp. 1751–1765.
- 6[6] A. H. Baker, R. D. Falgout, T. V. Kolev, and U. M. Yang , Scaling Hypre’s Multigrid Solvers to 100,000 Cores , in High-Performance Scientific Computing, Springer London, London, 2012, pp. 261–279.
- 7[7] W. N. Bell, L. N. Olson, and J. B. Schroder , Py AMG: Algebraic multigrid solvers in Python v 3.0 , 2015, https://github.com/pyamg/ . Release 3.0.
- 8[8] M. Benzi, G. H. Golub, and J. Liesen , Numerical solution of saddle point problems , Acta numerica, 14 (2005), pp. 1–137.