$k$-means as a variational EM approximation of Gaussian mixture models
J\"org L\"ucke, Dennis Forster

TL;DR
This paper demonstrates that k-means clustering can be derived as a special case of a variational EM approximation for Gaussian Mixture Models, providing new theoretical insights and generalizations.
Contribution
It shows that k-means arises from truncated variational EM without requiring small Gaussian variances, and links k-means to a free energy framework for better understanding and extensions.
Findings
k-means increases a free energy associated with truncated distributions
Generalizations of k-means can be derived by considering multiple closest clusters
Embedding k-means into a free energy framework allows for theoretical interpretation of its variants
Abstract
We show that -means (Lloyd's algorithm) is obtained as a special case when truncated variational EM approximations are applied to Gaussian Mixture Models (GMM) with isotropic Gaussians. In contrast to the standard way to relate -means and GMMs, the provided derivation shows that it is not required to consider Gaussians with small variances or the limit case of zero variances. There are a number of consequences that directly follow from our approach: (A) -means can be shown to increase a free energy associated with truncated distributions and this free energy can directly be reformulated in terms of the -means objective; (B) -means generalizations can directly be derived by considering the 2nd closest, 3rd closest etc. cluster in addition to just the closest one; and (C) the embedding of -means into a free energy framework allows for theoretical interpretations of other…
Click any figure to enlarge with its caption.
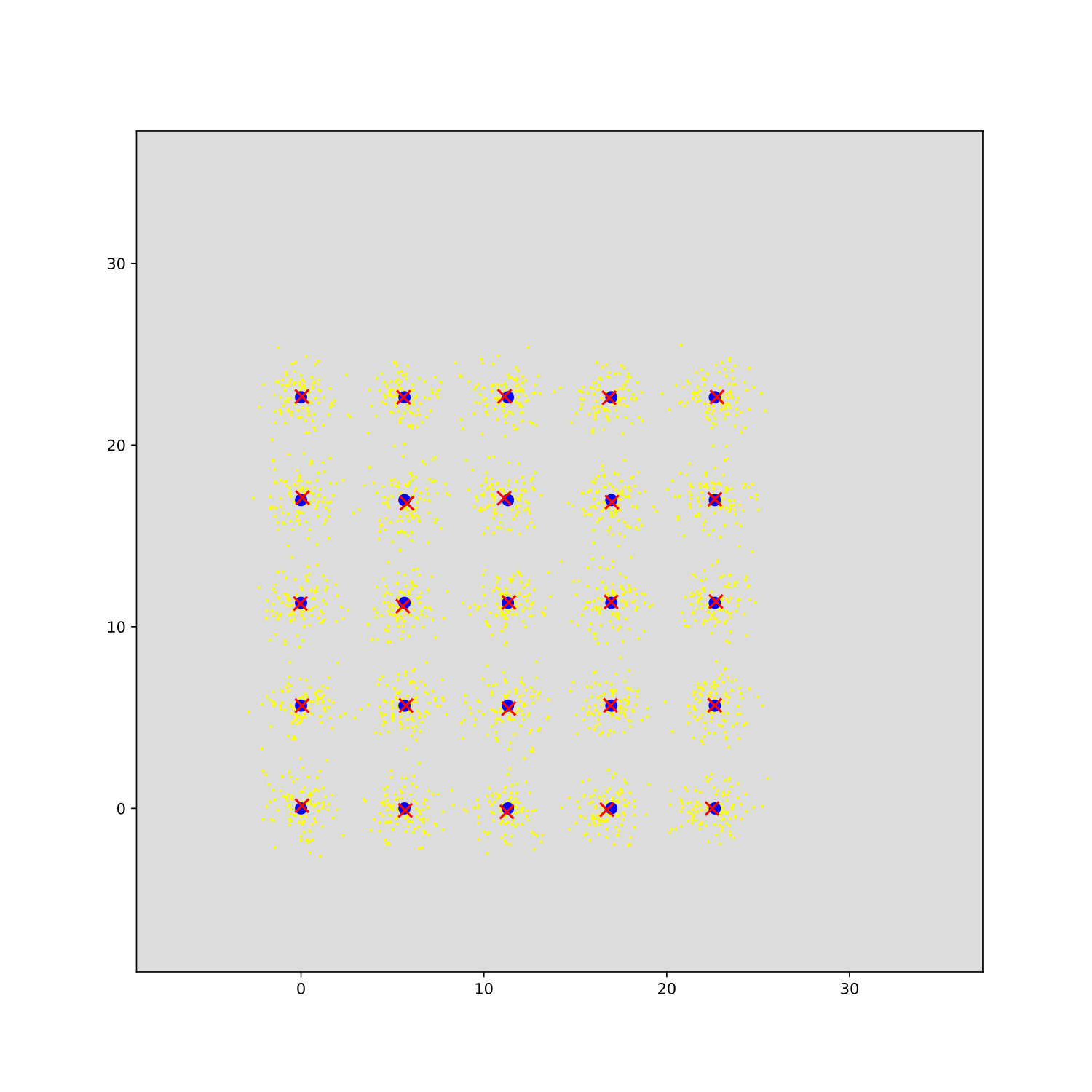 Figure 1
Figure 1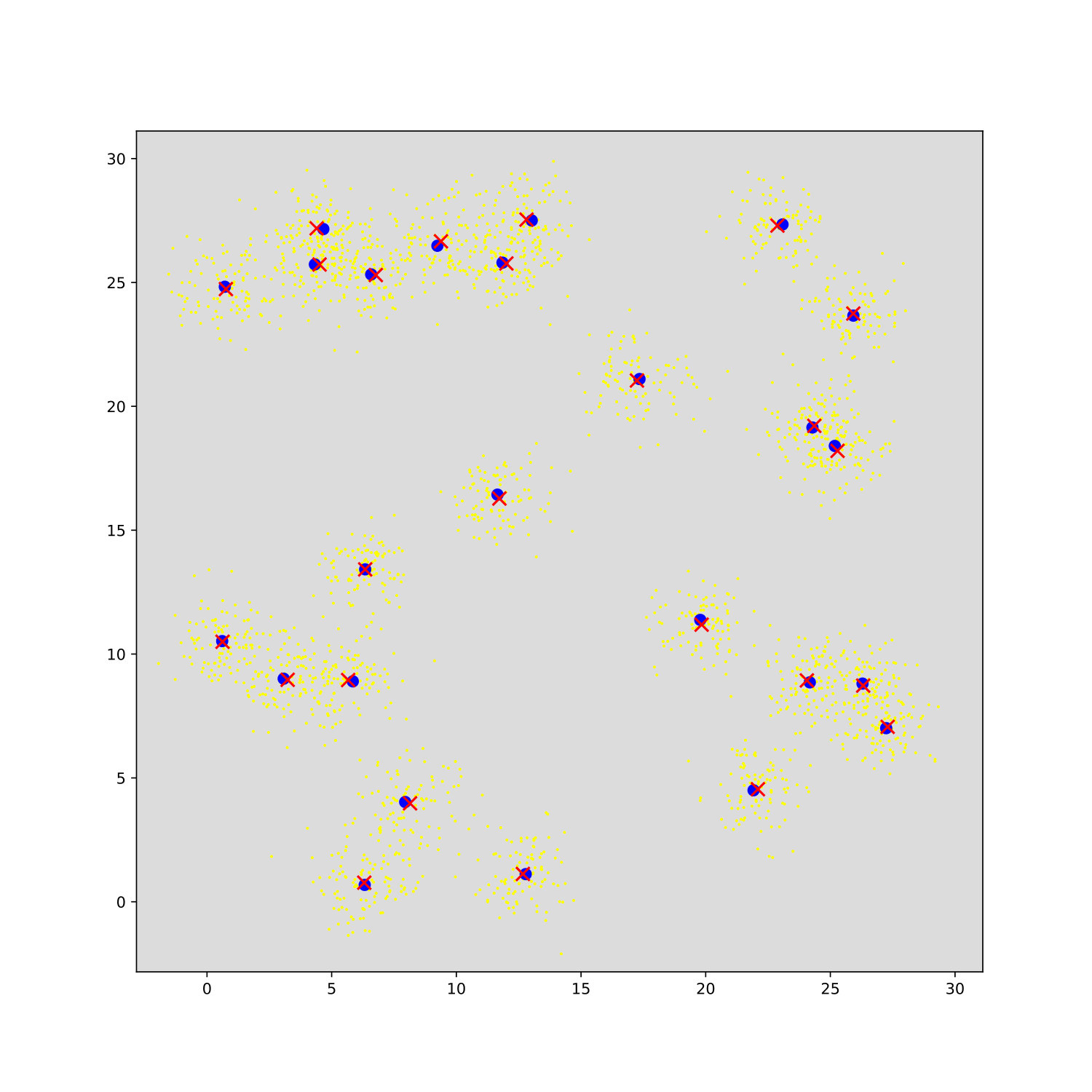 Figure 2
Figure 2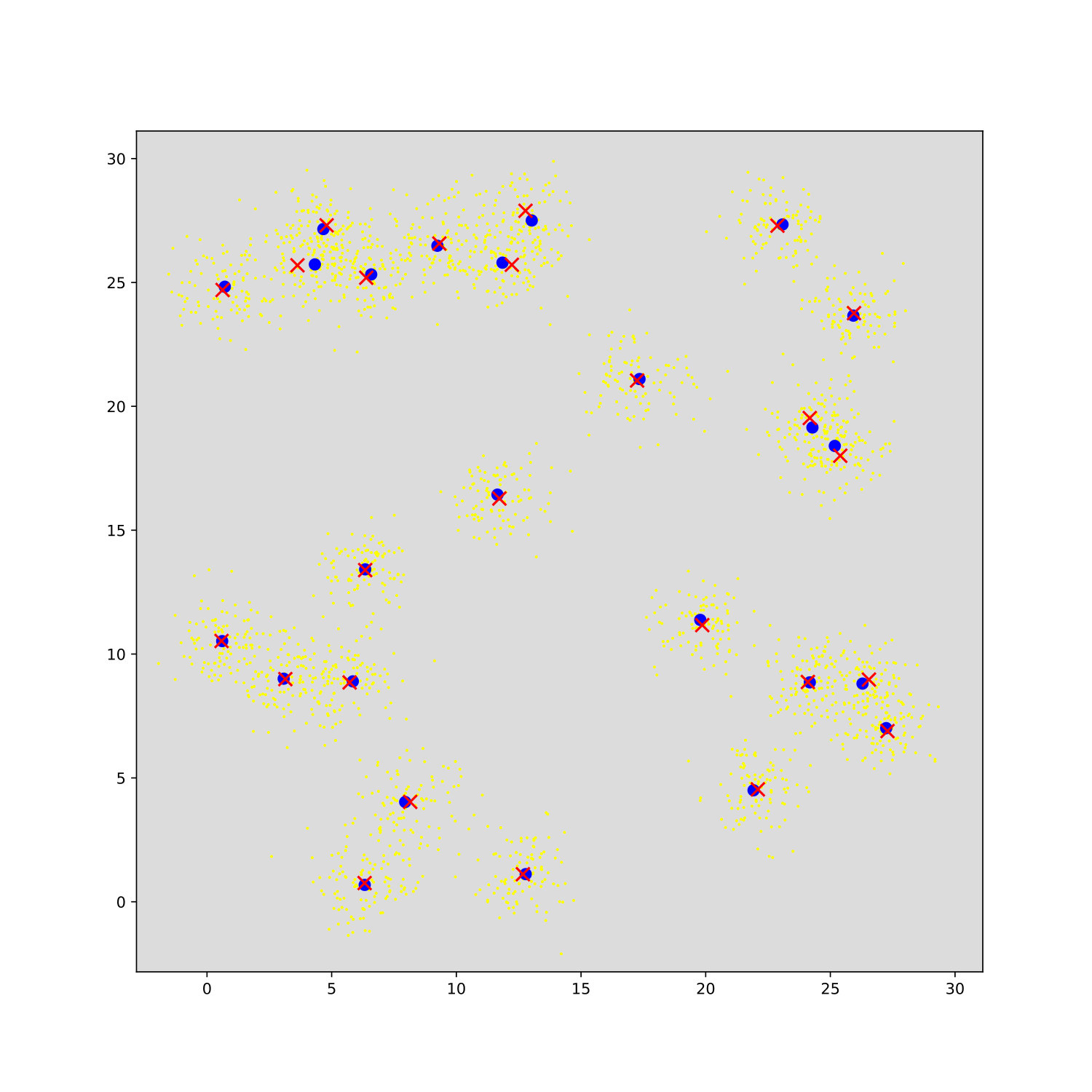 Figure 3
Figure 3| Algorithm | BIRCH (grid) | BIRCH ( random positions) | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mean | best | mean | best | mean | best* | mean | best* | mean | best | mean | best | mean | best* | mean | best* | |
| -means | -6.127 | -6.016 | 5,503 | 4,836 | 0.971 | 0.992 | 0.977 | 0.987 | -5.842 | -5.789 | 4,535 | 4,291 | 0.819 | 0.856 | 0.879 | 0.875 |
| -means-C’ | -6.117 | -6.016 | 5,476 | 4,837 | 0.973 | 0.992 | 0.978 | 0.986 | -5.828 | -5.771 | 4,637 | 4,331 | 0.811 | 0.864 | 0.880 | 0.880 |
| lazy--means | -6.117 | -6.016 | 5,452 | 4,837 | 0.974 | 0.992 | 0.978 | 0.987 | -5.850 | -5.803 | 4,592 | 4,351 | 0.809 | 0.846 | 0.876 | 0.880 |
| DBSCAN | – | – | – | – | 0.989 | 0.989 | 0.982 | 0.982 | – | – | – | – | 0.502 | 0.502 | 0.800 | 0.800 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
-means as a variational EM approximation of Gaussian mixture models
Jörg Lücke
Dennis Forster
Machine Learning Lab, University of Oldenburg, Ammerländer Heerstr. 114-118, 26129 Oldenburg, Germany
Abstract
We show that -means (Lloyd’s algorithm) is obtained as a special case when truncated variational EM approximations are applied to Gaussian Mixture Models (GMM) with isotropic Gaussians. In contrast to the standard way to relate -means and GMMs, the provided derivation shows that it is not required to consider Gaussians with small variances or the limit case of zero variances. There are a number of consequences that directly follow from our approach: (A) -means can be shown to increase a free energy associated with truncated distributions and this free energy can directly be reformulated in terms of the -means objective; (B) -means generalizations can directly be derived by considering the 2nd closest, 3rd closest etc. cluster in addition to just the closest one; and (C) the embedding of -means into a free energy framework allows for theoretical interpretations of other -means generalizations in the literature. In general, truncated variational EM provides a natural and rigorous quantitative link between -means-like clustering and GMM clustering algorithms which may be very relevant for future theoretical and empirical studies.
keywords:
MSC:
41A05, 41A10, 65D05, 65D17 \KWDKeyword1, Keyword2, Keyword3
††journal: Pattern Recognition Letters
1 Introduction
Clustering is the task of associating a set of data points with a set of clusters (typically with ), where such an association is defined by a high similarity of points within one cluster compared to the similarity of any two points of different clusters. Different criteria for data point similarity and different algorithmic properties have led to the development of a large variety of clustering algorithms in the course of more than half a century. Two of the presumably most influential classes of algorithms are -means-like algorithms (Lloyd, 1982; Jain, 2010, and many more) and Gaussian Mixture Models (GMMs).
-means. The -means algorithm and its many variants (e.g. Steinley, 2006) have been used since the 1950’s and are often considered as the most popular clustering algorithms (Berkhin, 2006). If we denote by the data points (with ) and by the cluster centers (with ), then the most common form of -means is given by Alg. 1, with as Euclidean metric. After initialization of , Alg. 1 increases the -means objective given by
[TABLE]
The updates of and in Alg. 1 are usually derived from (1). Because of its few elementary algorithmic steps, -means is easy to implement, and it has been observed to work very well in practice (e.g. Duda et al., 2001).
GMM. GMM-based clustering algorithms (e.g. McLachlan and Basford, 1988) are derived from a probabilistic data model . While general GMMs allow for different mixing proportions and multivariate Gaussian distributions, we will for the purposes of this study consider equal mixing proportions and equally sized, isotropic Gaussians:
[TABLE]
i.e., we will use a ‘flat’ prior and equal and isotropic variance of the clusters. The most standard form to update the GMM model parameters is derived using expectation maximization (EM; Dempster et al., 1977), which results for GMM (2) in Alg. 2 (Barber, 2012, & refs. therein).
After initialization of , the algorithm maximizes the data log-likelihood given by:
[TABLE]
with {\cal N}(\vec{y}^{\,(n)};\vec{\mu}_{c},\sigma^{2}\hbox{1\hskip-1.2pt\vrule depth=0.0pt,height=6.88889pt,width=0.7pt\vrule depth=0.0pt,height=0.3pt,width=1.19995pt}) as given in (2). Note that (3) is normalized by the number of data points for this study. As is customary for GMMs, we refer to the posteriors as responsibilities (abbreviate by ). Computing the in Alg. 2 is referred to as E-step, while updates of parameters and in Alg. 2 are referred to as M-step.
Related Work and Our Contribution. The popularity of -means and GMM algorithms has resulted in many theoretical as well as empirical studies of their functional and theoretical properties. Considerable progress using novel versions could be made, and much insight could be gained for -means (Har-Peled and Sadri, 2005; Arthur and Vassilvitskii, 2006; Arthur et al., 2009; Bachem et al., 2016) and GMMs (Chaudhuri et al., 2009; Kalai et al., 2010; Moitra and Valiant, 2010; Belkin and Sinha, 2010; Xu et al., 2016) relatively recently. Because of their similarity, -means and GMMs have long been formally related to each other. It is thus well-known (see, e.g. MacKay, 2003; Barber, 2012, & refs. therein) that -means (Alg. 1) can be obtained as a limit case of EM for GMM (2). This limit is given by considering increasingly small , i.e., . The responsibilities in Alg. 2 then become equal to one for the closest cluster and zero otherwise, and the -means algorithm (Alg. 1) is recovered. Furthermore, approaches using algorithms which modify EM algorithms by introducing additional ‘hard’ assignment steps of data points to clusters have been used to relate -means and GMM clustering. Given a generative model, such approaches are often referred to as ‘hard’ EM (e.g. Segal et al., 2002; Van den Oord and Schrauwen, 2014), as ‘classification EM’ (CEM; e.g. Celeux and Govaert, 1992) for GMMs, or as ‘Viterbi training’ for HMMs (e.g. Allahverdyan and Galstyan, 2011). For data distributions with negligible cluster overlap (a setting which is closely related to the limit ), ‘hard’ assignment algorithms can be shown to be equivalent to standard EM (e.g. Celeux and Govaert, 1992). ‘Hard’ assignments can also be informally interpreted as a variational approach but (to the knowledge of the authors) neither proofs nor quantitative results have been provided (compare Suppl. B). In contrast to ‘hard’ cluster assignments, the assignment is ‘soft’ in EM for GMMs. ‘Hard’ assignments have sometimes been considered disadvantageous as the relative importance of the clusters for the data points is not taken into account. Different -means generalizations have therefore been suggested, e.g., with aims to enhance -means convergence Har-Peled and Sadri (2005) or to relax its ‘hard’ cluster assignment (e.g. Bezdek, 1981; Celeux and Govaert, 1992; MacKay, 2003; Miyamoto et al., 2008). As for clustering in general, -means also remained of interest in the probabilistic Machine Learning community, and notably in the field of non-parametric approaches. Welling and Kurihara (2006) suggested ‘Bayesian -means’, for instance, and used variational Bayesian approximations in order to obtain -means-like run time behavior for model selection. Later on, Kulis and Jordan (2012) also used a Bayesian treatment, and combined it with the relation of -means to GMMs obtained in the limit . In this way they derived new ‘hard assignment’ algorithms based on a Gibbs sampler used within a non-parametric approach (also compare Broderick et al., 2013).
In this work, we derive the -means algorithm from a novel class of variational EM algorithms applied to GMMs. Most notably -means is obtained cleanly and rigorously without any assumptions on . Variational EM seeks to optimize a lower bound (the free energy; Neal and Hinton,1998) of the data log-likelihood by making use of variational distributions that approximate full posterior probabilities. The free energy is also frequently referred to as the evidence lower bound (ELBO; e.g. Hoffman et al., 2013). For our study, we apply truncated posteriors (Lücke and Eggert, 2010) as variational distributions in their fully variational formulation (Lücke, 2018). After having shown that -means is a variational approximation, -means and its generalizations can be quantitatively related to GMMs without taking the limit to zero cluster variances or without assuming to be small compared to cluster-to-cluster distances. Furthermore, the observation that -means is a variational optimization implies that it optimizes a lower bound of a GMM log-likelihood. Hence, we can derive lower free energy bounds for -means and its generalizations that quantify the link between the -means and the GMM objective. As such we provide a closer theoretical link between these two central classes of clustering methods than has previously been established.
Truncated approaches have been applied to mixture models before. Work by Dai and Lücke (2014) used truncated approximations for a position invariant mixture model, and Forster et al. (2018) for a hierarchical Poisson mixture. Work by Shelton et al. (2014) was the first to apply truncated EM to standard GMMs, followed by Hughes and Sudderth (2016) who additionally used a constraint likelihood optimization to find cluster centers for truncated posteriors. None of these contributions has derived -means as a variational EM algorithm for GMMs nor did any contribution provide quantitative free energy results or the links to generalizations of -means derived in this study.
2 Truncated variational EM and GMMs
The basic idea of truncated EM is the use of truncated approximations of exact posterior distributions (e.g. Lücke and Eggert, 2010; Sheikh et al., 2014). In the notation as used for GMMs above, the truncated approximation takes the form:
[TABLE]
where is a set of cluster indices (containing different clusters associated with data point ). Suppl. A and Fig. S1 provide an example. The set of all we denote by , i.e., . As is customary for truncated distributions (Lücke and Eggert, 2010; Dai and Lücke, 2014; Shelton et al., 2014; Hughes and Sudderth, 2016), we take the sizes of all to be equal, , with . The truncated approximation (4) is a good approximation if contains all those clusters with significant posterior mass (i.e., significant non-zero responsibilities ). Truncated approaches can represent very accurate approximations for many data sets, as typically most responsibilities are negligible.
In order to derive a learning algorithm for GMMs based on truncated distributions, we have to answer the question how the parameters and are to be updated. For our purposes we will here make use of a recent study which addressed this question for general models (with discrete latents) by embedding truncated distributions into a fully variational optimization framework (Lücke, 2018). More specifically, we use the result of Lücke (2018) that the free energy as a lower bound of the data likelihood is monotonically increased if: (A) the parameters are updated using standard M-steps, with exact posteriors replaced by truncated posteriors; and (B) that the sets can be found using a simplified expression for the free energy.
For GMMs, this means that we can use the standard M-steps of Alg. 2 and replace with the truncated approximations in (4). For the GMM (2), the truncated responsibilities and M-steps are thus:
[TABLE]
The parameters of the truncated distributions have to be found in the variational E-step. In order to do so, we use the simplified free energy derived in (Lücke, 2018, Prop. 3), which takes for our GMM (2) the following form:
[TABLE]
The truncated variational E-step (TV-E-step) first optimizes w.r.t. and the obtained truncated responsibilities are then used in the M-step (6) to optimize w.r.t. . The form of the free energy (7) and the result that it is monotonically increased by iterating TV-E-step and M-step are the crucial theoretical results by Lücke (2018) that are used in this study. Neither of these two results is straight-forward: (A) truncated distributions themselves depend on the model parameters , and (B) it requires a number of derivations exploiting specific properties of truncated distributions to obtain the concise form used for expression (7).
The TV-E-step now requires finding sets which increase . The free energy (7) is computationally tractable, so a new could in principle be found by directly comparing of a new with of the current . We can slightly reformulate the problem by considering a specific data point and cluster for which we ask when any other replacing cluster would increase the free energy . By virtue of the properties of GMM (2) and due to the specific structure of the free energy (summation and concavity of the logarithm in Eqn. 7), we can then show:
**Proposition 1
**Consider the GMM (2) and the free energy (7) for data points . Furthermore, consider for a fixed the replacement of a cluster by a cluster . Then the free energy increases if and only if
[TABLE]
**Proof
**First observe that the free energy is increased if because of the summation over in (7) and because of the concavity of the logarithm. Analogously, the free energy stays constant or decreases for . If we use the GMM (2), we obtain for the joint:
[TABLE]
The first two factors are independent of the data point and cluster. The criterion for an increase of the free energy can therefore be reformulated as follows:
[TABLE]
Prop. 1 means that we have to replace clusters in that are relatively distant from by those closer to in order to increases the free energy . Any such procedure gives with M-step (6) rise to a variational EM algorithm that monotonically increases the lower bound (7) of likelihood (3). For an arbitrary generative model, the degree how much is increased or how long one should seek new clusters in the E-step is a design choice of the algorithm. In the case of GMMs (and other mixture models) we can exhaustively enumerate all clusters such that can be fully maximized.
**Corollary 1
**Same prerequisites as for Prop. 1. The free energy is maximized w.r.t. (with fixed ) if and only if for all the set contains the clusters closest to data point .
**Proof
**We assume that there are no equal distances among all pairs of data points and cluster centers. If contains the closest clusters, it applies: . If we now consider an arbitrary and replace an arbitrary by an arbitrary it applies such that by virtue of Prop. 1 decreases. As any arbitrary such replacement (any change of ) results in a decrease of the free energy, is maximized if contains the closest clusters.
We can now formulate a truncated variational EM (TV-EM) algorithm for GMM (2), here referred to as -means- (Alg. 3).
3 -means and truncated variational EM for GMMs
TV-EM for GMMs (Alg. 3) increases the similarity between -means and standard EM for GMMs in two ways: (A) it relates Euclidean distances to a variational free energy and thus to the GMM likelihood; and (B) it introduces ‘hard’ zeros in the updates of model parameters (some or many are zero). Crucial remaining differences are, however, (A) the weighted updates of the cluster centers in Eqn. 6 compared to the -means update, and (B) the update of the cluster variance in Eqn. 6 along with the cluster centers for Alg. 3 which does not have a correspondence in -means. By considering the first difference, the obvious next step is to consider a boundary case of Alg. 3 by demanding that the sets shall contain just one element, i.e., we set . All derivations above apply for all , and while standard EM for the GMM (2) is recovered for , we find that for standard -means (Alg. 1) is recovered.
**Proposition 2
**Consider the TV-EM algorithm (Alg. 3) for the GMM (2) with . If we set , then the TV-EM updates of the cluster centers (6) become independent of the variance and are given by the standard -means algorithm in Alg. 1.
**Proof
**If we choose for all , then each computed in the TV-E-step of Alg. 3 contains according to Corollary 1 the index of the cluster center closest to as only element. If we denote these centers by , we get and obtain for the truncated responsibilities in (5):
[TABLE]
which is identical to in Alg. 1. By using for the M-step, we consequently obtain:
[TABLE]
Now observe that the computation of and the updates of the do not involve the parameter . The cluster centers can thus be optimized without requiring knowledge about the cluster variances , i.e., the optimization becomes independent of . As the TV-EM updates for and are identical to the updates of and in Alg. 1, the optimization procedure for the is given by the standard -means algorithm.
A direct consequence of Prop. 2 is that standard -means provably monotonically increases the truncated free energy (7) with . Notably, only for this choice of the updates of cluster means and variance decouple. We can, of course, add the variance updates to standard -means but this does not effect the updates. With or without updates the free energy monotonically increases. If our goal is the maximization of the free energy objective, the updates should be included, however. According to the independence of -optimization from , it would be sufficient to update once and only after -means has optimized the cluster centers.
Prop. 2 shows that -means is obtained from a variational free energy objective. This free energy is in turn closely related to the likelihood objective of GMMs (3). By analyzing the free energy for more closely, we can make this relation more explicit.
**Proposition 3
**Consider a set of data points and the -means algorithm (Alg. 1) where and denote, respectively, the cluster assignments and cluster centers computed in one iteration. Furthermore, let denote the variance computed with and as in Eqn. 6:
[TABLE]
It then follows that each -means iteration monotonically increases the free energy given by:
[TABLE]
where is Euler’s number. The free energy (15) is a lower bound of the GMM log-likelihood (3). The difference between log-likelihood (3) and free energy (15) is given by:
[TABLE]
If for all and where applies: , i.e., if clusters are well separable, then the bound becomes tight.
**Proof
**In the -means case () each only contains one cluster which is given by the cluster assignments as: . If we abbreviate this cluster for with , it follows for the free energy (7) after one -means iteration:
[TABLE]
where we inserted the Gaussian density and then used . and are the parameters obtained after a single -means iteration. Following (6) we can therefore insert the expression for , noting that the are the same as in (17). The last term of (17) then simplifies to . If we now rewrite this as and combine with the second summand, we obtain (15).
The difference (16) between log-likelihood and free energy can be derived from the KL-divergence D_{\mathrm{KL}}\big{(}q_{1:C}^{(1:N)},r_{1:C}^{(1:N)}\big{)}. Using results of (Lücke, 2018) the KL-divergence for a truncated distribution is given by: D_{\mathrm{KL}}\big{(}q_{1:C}^{(1:N)},r_{1:C}^{(1:N)}\big{)}=-\sum_{n}\log(\sum_{c\in{\cal K}^{(n)}}r_{c}^{(n)}). Inserting (Alg. 2) for the GMM (2), we obtain:
[TABLE]
using again expression (14) for . If for all , with , then the last term of (18) is dominated by those , with , such that D_{\mathrm{KL}}\big{(}q_{1:C}^{(1:N)},r_{1:C}^{(1:N)}\big{)}\!\rightarrow\!0.
Prop. 3 makes explicit the difference to the GMM likelihood objective if -means is used for parameter optimization (we elaborate in Suppl. B). Furthermore, by using Prop. 3, we can now directly link the GMM likelihood to the -means objective.
**Corollary 2
**If and are updated by -means (Alg. 1), then it applies for the GMM likelihood (3) after each iteration that
[TABLE]
where is the -means objective (1). The lower free energy bound (right-hand-side of Eqn. 19) is strictly monotonically increased.
**Proof
**If are the cluster assignments of the first for-loop in Alg. 1, and the centers of the second for-loop, then in Prop. 3 can directly be replaced by . The free energy is thus a function of the -means objective. As -means has been shown to strictly monotonically decrease the objective (compare, e.g., Anderberg, 1973; Inaba et al., 2000), the lower free energy bound (19) is strictly monotonically increased by -means.
4 Applications of Theoretical Results
The principled link between -means and variational GMMs can be used for a number of theoretical applications and interpretations of previous algorithms, including soft--means, lazy--means, fuzzy -means, and previous GMM variants with ‘hard’ posterior zeros. For such comparisons, let us first generalize Prop. 3 for -means- with .
**Proposition 4
**Same prerequisites as for Prop. 3. If and are updated using -means- (Alg. 3), then a lower free energy bound of the log-likelihood (3) is monotonically increased. The bound is after convergence given by:
[TABLE]
**Proof
**For GMM (2) the entropy of the noise distribution, {\cal H}(p(\vec{y}\,|\,c,\Theta))={\cal H}({\cal N}(\vec{y};\vec{\mu}_{c},\sigma^{2}\hbox{1\hskip-1.2pt\vrule depth=0.0pt,height=6.88889pt,width=0.7pt\vrule depth=0.0pt,height=0.3pt,width=1.19995pt})), does not change with . The GMM therefore has an entropy limit (Lücke and Henniges, 2012) given by:
[TABLE]
which is derived simply by inserting (2) into . If we (following Lücke and Henniges, 2012) reformulate the free energy (7) such that it is expressed in terms of this entropy limit, we obtain: \begin{array}[]{c}{\cal F}({\cal K},\Theta)=\overline{Q}(\Theta)+\frac{D}{2}\big{(}1\,-\frac{\sigma^{2}_{\mathrm{new}}}{\sigma^{2}}\big{)}+\frac{1}{N}\sum_{n}{\cal H}(q^{(n)}_{c}),\end{array} where is the variance after the M-step of -means-. At convergence, the ratio converges to one and we obtain (20).
Already by considering (7), we can conclude that for the same applies if . Prop. 4 now shows that the free energy difference is (after convergence) solely given by the entropy of the truncated distributions. For the entropy is zero, for the entropy is maximal and (20) can be used to estimate the likelihood during learning.
Alg. 3 (-means-), for which Prop. 4 applies, can be compared to soft--means (MacKay, 2003), which was suggested as a ‘non-hard’ -means generalization. Soft--means and -means- share an additional parameter for data variance. For -means- this is the variance itself, for soft--means this parameter is the ‘stiffness’ parameter , which also closely links to (essentially ) of GMM (2). However, -means- makes -means ‘softer’ by allowing for more than one non-zero value for the cluster assignments. This is different from soft--means, which maintains non-zero values for all cluster assignments. Related to this, problems with sensitivity to stiffness values and sensitivity to initial conditions compared to standard -means (Barbakh and Fyfe, 2008) may be related to Prop. 1 and Prop. 2 which imply that for any approach with , updates of should (in contrast to soft--means) not be neglected. -means- is itself closely related to the GMM algorithms of Shelton et al. (2014) and Hughes and Sudderth (2016). But while Shelton et al. (2014) and Hughes and Sudderth (2016) focus on EM acceleration, no proofs that their algorithms monotonically increase free energies are given (we elaborate in Suppl. C).
In general, other selection criteria than (8) could be derived for other mixture models. Visa versa also other versions of -means based on other criteria than (8) can be interpreted as variational EM. An example is lazy--means which is a relatively recent -means generalization used to study convergence properties (Har-Peled and Sadri, 2005). Lazy--means only reassigns a data point from a cluster to a new cluster if:
[TABLE]
where is small, and -means is recovered for .
By considering Prop. 1, any replacement of states in according to (21) would also increase the free energy (7). Based on our variational interpretation, lazy--means corresponds to a partial TV-E-step. In analogy to Prop. 1, we can show that (7) is monotonically increased, but it is not necessarily maximized, i.e., Corollary 1 does not apply. However, the essential observation of a decoupled and update only depends on being equal to one. Prop. 2 thus generalizes to the lazy--means case, and the same applies for Corollary 2 (see Suppl. D for the proofs). For lazy--means, polynomial running time bounds could be derived (Har-Peled and Sadri, 2005). By virtue of Corollary 2, this means that the corresponding log-likelihood bound can be optimized in polynomial time. More generally, Corollary 2 (as well as the other results) can serve for transferring many of the diverse run-time complexity results for -means and -means-like algorithms to results for GMM bounds. Likelihood bounds are, on the other hand, of interest for theoretical studies of GMM optimization (e.g. Kalai et al., 2010; Moitra and Valiant, 2010; Xu et al., 2016). The here established link can thus serve to transfer results from -means-like approaches (e.g. Arthur et al., 2009) to GMM clustering.
In this study, we have focused on -means and its relation to GMMs with isotropic Gaussians and equal mixing proportions (Eqn. 2). The analytical tools applied here could be used similarly for general GMM densities. Also in the general case it would be possible to define algorithms only considering the most relevant clusters for updates. However, the criterion to assign clusters to data points would diverge considerably from the closest cluster selection used by -means. As a consequence, even when choosing =, a general GMM density would not result in a decoupling of updates from the updates of the other model parameters. We elaborate in Suppl. C.
Finally, a very popular -means version is fuzzy -means (e.g., Bezdek, 1981, for references), which takes the form of a generalization of the -means objective (1) by using non-binary in the place of the -means assignments. Fuzzy -means algorithms then update weighted cluster assignments and cluster centers in order to minimize such objectives. Prop. 4 serves best to highlight the differences between standard fuzzy -means and -means-, because it shows that the average entropy of the cluster assignments emerges in the context of GMMs as a term in addition to a softened objective. Standard algorithms for fuzzy -means (e.g. Bezdek, 1981; Yang, 1993) are different as they usually generalize the -means objective without an additional entropy term. Notably, newer versions of fuzzy -means have been suggested to improve on earlier versions by introducing additional regularization terms. One of these regularizations takes the form of the entropy of cluster assignments (compare Miyamoto et al., 2008, Sec. 2). Considering Eqn. 20 of Prop. 4, we could now relate the regularization constant of entropy regularized fuzzy -means to the GMM log-likelihood optimization, or introduce novel versions of fuzzy -means with many weights set to ‘hard’ zeros. Other, e.g., quadratic regularizations (see Miyamoto et al., 2008) are, on the other hand, not as closely related to the GMM objective but may correspond to other data statistics.
5 Numerical Verification
Before we conclude, we briefly numerically verify the main theoretical results of this work. We use a BIRCH dataset with clusters on a grid with data points per cluster (same data set for all runs) as partly shown in Fig. 1I. Fig. 1A shows different runs of standard -means and the time course of the free energy and likelihood computed using (15) and (3), respectively. The shown exemplary runs converge to different optima. The run with highest final free energy recovers all cluster centers and results in a log-likelihood larger than the log-likelihood of the generating (ground-truth) parameters. We verified that this (small) overfitting effect decreases with increasing . The bound for the best run is relatively tight, which is consistent with (16) of Prop. 3 for small . The gap is larger for local optima, which have to have a larger according to (14) and consequently higher entropy for of including . The gap also increases for clusters with larger overlap in Fig. 1D/J, where we use the same setting as for Fig. 1A but with randomly (uniformly) distributed cluster centers (see Fig. 1J and 1K). Note that we use the seeding of -means++ (Arthur and Vassilvitskii, 2006) for Fig. 1. The initial values of are thus already relatively high (see ).
Fig. 1E shows different runs of -means- for the data as used for Fig. 1J. Using -means- with different numbers of winning clusters can prevent shifted cluster centers caused by unsymmetrical cluster overlaps (compare Fig. 1J and 1K). Final likelihoods of the best runs with can hence be higher than those for -means. Fig. 1E,J,K can also serve as numerical verification of the differences between free energies for different . Suppl. E elaborates on this. Figs. 1C/F give additional results on the purity. Here we also compare to the popular DBSCAN method (Ester et al., 1996). While for the well separated grid data set the purity is comparably high, for the random set with larger overlaps, the purity for DBSCAN is with around 0.5 no longer comparable. More detailed results are given in Tab. S1, where we also show results for lazy--means. Finally, Figs. 1G and H verify our results using real and large scale data. The KDD-Cup 2004 Protein Homology Task (KDD, Caruana et al., 2004) comprises 145 751 samples of 74-dimensional data points. We observe tighter bounds between log-likelihood (3) and free energy (7) for better solutions of increasing . Already for the -gap decreases significantly relative to -means and vanishes nearly completely for .
6 Conclusion
We have established a novel and, we believe, very natural link between -means and EM for GMMs by showing that -means is a special case of a truncated variational EM approximations for GMMs. The link can serve to transfer theoretical research between -means-like and GMM clustering approaches (Sec. 4 treated some examples). Of the many studies which consider -means and data samples of GMMs (e.g. Chaudhuri et al., 2009, & refs. therein), there is none that provides the close theoretical links and free energy results provided here (also see Suppl. B). Earlier work by Pollard (1982) is maybe one of the most relevant studies, as it proves a theorem which relates the convergence points of -means to an underlying distribution. In the sense of a central limit theorem, this distribution is given by a GMM with clusters of specific covariance. Cluster overlap in the samples influences the cluster shapes via non-zero off-diagonal elements. The question of Pollard (1982) is thus how to fit a GMM (in a central limit theorem sense) to correspond to -means convergence points. Prop. 3 may be related to the theorem of Pollard (1982) but a closer inspection would require a more extensive analysis.
Other than the above discussed theoretical link of -means to GMM clustering, our investigations may also be useful for the analysis and improvement of further aspects of -means-like and GMM clustering. GMMs are used to address a wide range of tasks. Two examples may be image denoising (e.g. Zoran and Weiss, 2011) and video tracking (e.g. Jepson et al., 2003; Lan et al., 2015, 2018). Training -means may, however, often be more efficient, which can be of importance, e.g., when a lot of data has to be processed in short times. By assigning a probabilistic interpretation to -means, it may offer itself as a faster alternative to GMMs in such settings. Similarly, -means- could be used as a compromise between GMMs and efficient -means versions. A further aspect our results can be related to is the estimation of cluster numbers. The standard -means algorithm (Alg. 1), standard EM for GMMs (Alg. 2) as well as -means- (Alg. 3) require the number of clusters as input. A large number of studies have addressed this disadvantage of the standard approaches. Model selection and fully Bayesian approaches (Fraley and Raftery, 1998; Rasmussen, 2000; Neal, 2000) are common methods to estimate the cluster numbers of GMMs from data. For -means, well known contributions are the -means algorithm (Pelleg et al., 2000), the -means algorithm (Hamerly and Elkan, 2004) as well as approaches based on clustering stability (see von Luxburg, 2010, & refs. therein). All the approaches for -means use standard -means iterations or full -means runs as part of the complete algorithm, e.g., as subroutines in split-and-merge approaches (Ueda et al., 2000, & refs. therein). There are different options how the results of this study can be combined with these previous studies. For -means-like approaches, our results (e.g., Eqn. 14) could be used to quantify how well the BIC selection criterion used by -means can be expected to work. If for a given data set -means is not well approximating GMM solutions (e.g., for larger cluster overlaps), -means- iterations would offer themselves as alternative iterations within an -means setting. Less directly, -means- algorithms could (A) be used in conjunction with statistical tests for Gaussianity of projected data as in -means, or (B) they could be used (like -means) to define stability scores for stability-based selections of cluster numbers. Also in these two cases, improvements can be expected especially when cluster overlaps are large. Finally, -means and -means- could be combined with general Bayesian model selection (Schwarz, 1978) as their free energies (Eqns. 19 and 20, respectively) provide likelihood approximations.
More generally, -means is usually not directly integrated into probabilistic frameworks as the limit to zero cluster variance remained the most well known relation between -means and GMMs. From the probabilistic point of view, this limit is unsatisfactory, however, as the likelihood of data points under a GMM with also approaches zero. Truncated approaches (which allow for a -means/GMM relation with finite variances ) are novel compared to standard variational approaches which assume a-posteriori independence (e.g. Saul et al., 1996; Jaakkola, 2000). Truncated EM approaches (Lücke and Eggert, 2010; Sheikh et al., 2014; Lücke, 2018) aim at scalable and accurate approximations without assuming a-posteriori independence; a goal they share with many later approaches (e.g. Mnih and Gregor, 2014; Rezende and Mohamed, 2015; Salimans et al., 2015; Kucukelbir et al., 2016). Truncated EM is a natural variational approximation for -means-like algorithms, and is here not only related but becomes, indeed, identical to standard -means.
Acknowledgements
We acknowledge funding by the DFG projects SFB 1330 (B2) and EXC 2177/1 (cluster of excellence H4a 2.0).
Supplementary A Illustration of truncated posterior approximations
Fig. S1 illustrates truncated distributions for an example with two-dimensional data points () with clusters. As can be observed, the truncated distributions with is capturing the posterior structure for data point well. For basically all data points (grey dots), truncated distributions with are sufficiently exact; and for most data points already represent a very good approximations. Also the case , which correspond to the -means case, will sufficiently well model the posterior because for most data points in this example the posterior is dominated by the value of the closest cluster. Also see Figs. S2 and S3 for numerical verifications.
Supplementary B -Means and hard cluster assignments for GMMs
Here we provide more details on how -means or the -means objective has previously been related to maximum likelihood optimization of GMMs.
Classification expectation maximization. The log-likelihood objective of GMMs (3) and the quantization error (1) optimized by -means are non-trivially related. This is also the case for the GMMs with isotropic and equal Gaussian variances and equal mixing proportions as considered here (Eq. 2). For the purposes of our study we emphasize this point as earlier contributions reported results for clustering criteria from which one may incorrectly infer a trivial relation between (1) and (3). One example of such previous work (see Celeux and Govaert, 1992, and references therein) does, for instance, consider a classification expectation maximization (CEM) algorithm for clustering. The paper defines a classification maximum likelihood (CML) objective which is (in the notation of this paper) given by:
[TABLE]
where the are the binary weights of Alg. 1. In the paper (Celeux and Govaert, 1992) it is then shown that the problem of maximizing the CML objective (22) is equivalent to the problem of minimizing the quantization error (1). Although (22) is also referred to as a maximum likelihood (ML) objective (see Celeux and Govaert, 1992, and references therein), note the difference between this classification maximum likelihood (CML) objective (22) and the standard ML objective for GMMs in (3). Essentially, the sum over clusters in (3) and the logarithm can not be trivially commuted to obtain (22). Eq. (16) can be regarded as quantification of the difference between (22) and (3) in terms of the ratio between data-to-cluster center distances and (compare initial discussion of Celeux and Govaert, 1992). Eq. (16) is ultimately a consequence of applying Jensen’s inequality to commute logarithm and the sum over clusters, which gives rise to a lower free energy bound. Only if cluster centers are far apart compared to , the sum over will for each data point be dominated by the terms of within cluster distances. This is the case of well separable clusters, i.e., if ‘hard’ data partitions are representing a good approximation of ‘soft’ a-posterior assignments. In that case the KL-divergence becomes zero. Also see Supplement E below for numerical experiments showing differences between the -means and log-likelihood objectives.
Hard cluster assignments and variational distributions. As discussed in the main text, the by far most common approach to relate -means and Gaussian mixture models is to take the limit to zero cluster variances . This relation is very commonly used in text books as well as in the research literature itself. Alternatively, and related to this study, -means is for didactic purposes also sometimes casually related to GMM optimization using variational EM. Such a relation is usually confined to derivations that make the relation of -means to GMM data models plausible. For instance, if the free energy w.r.t. a variational distribution is in its standard form given by
[TABLE]
then one can informally define to be equal to one if and only if corresponds to the maximal value of . For GMM (2) are then given by:
[TABLE]
As the entropy for such a distribution is equal to zero, the free energy reduces to
[TABLE]
where denotes the cluster closest to data point . -means is then often taken as optimizing this objective.
In order to make any mathematically rigorous statements, the argumentation above lacks, at closer inspection, a solid theoretical foundation in two important aspects: (A) Derivations of the free energy using variational distributions all assume to be strictly positive ( for all and ), which is violated for defined as in Eq. (26). (B) Relating -means to a free energy objective as (27) implicitly assumes the variational distributions to be independent of the model parameters (i.e., independent of and in our case). Considering Eq. (26) also this independence is not given (which is in contrast, e.g., to mean field distributions). The model parameters can also not simply be assumed to be constant as is the case for full posteriors in standard EM: The proof verifying that values for the model parameters can be held fixed is given for full posteriors only (see, e.g., Lemma 1 of Neal and Hinton, 1998) but it does not necessarily apply for general variational distributions defined using model parameters .
The here applied results (Lücke, 2018) do address both these aspects: variational distributions with ‘hard’ zeros are treated (Point A), and variational distributions that can depend on the model parameters are explicitly considered (Point B). Addressing any of these two points is non-trivial (see Propositions 1 and 2 in Lücke (2018), for Point A; and, e.g., Propositions 3-5 in Lücke (2018), for Point B). However, if treated rigorously, results for a large class of distributions (which includes distributions of Eq. 26) can be derived, and the derived results apply for any generative model with discrete latents. Notably, also truncated variational distributions with non-zero entropy are included as well as distributions (26) in which does not necessarily apply for the closest cluster (such distributions are important, e.g., in relation to lazy--means, see Proposition 4). In this paper we make use of results of Lücke (2018) by applying them to GMMs given by Eq. (2) (e.g., through Propositions 1 and 4 which in turn use the simplified free energy (7) of Lücke (2018)).
The difficulties to cleanly and rigorously treat distributions such as (26) may explain why (to the knowledge of the authors) any relation of -means and variational approaches is rather informally discussed (compare, e.g., Jordan et al. (1997), who, e.g., relate Viterbi training to variational EM). If the relation of -means to GMMs is made more explicit, the literature, including popular text books (e.g. MacKay, 2003; Barber, 2012), drops back to the zero variance limit to derive -means.
Supplementary C Generalization of criterion (8) for general GMMs
Consider a general standard GMM of the form:
[TABLE]
where are the mixing proportions, is a for each positive definite covariance matrix, and denotes the determinant. We denote by the set of all parameters. For GMM (28) to (30) a corresponding variational free energy is because of Eq. (7) (first line) increased if and only if:
[TABLE]
In comparison, Shelton et al. (2014) use an estimated E-step, which does consequently not guarantee a monotonic increase of a free energy. Hughes and Sudderth (2016) do use a constrained likelihood optimization to find the best clusters per data point (related to Corollary 1), but a complete proof for general GMMs would require Proposition 5 of Lücke (2018), which warrants that M-steps can be derived while the parameters of the variational distributions remain fixed.
Considering (31), note that the criterion to select clusters now depends on all model parameters (in contrast to the criterion of Eq. 8). If algorithms for parameter updates are defined based on (31), all current parameter values have to be considered in E-steps which compute generalizations of the responsibilities (compare Eq. 5). Notably, even if these responsibilities become binary for the choice , the selection of the non-zero values of would still require the other parameter values. There would consequently not be a -means-like decoupling from other parameter updates like for the GMM defined by Eq. (2).
Supplementary D Generalizations for lazy--means
If we change the cluster selection criterion (8) to the criterion for lazy--means (21), then it follows from Proposition 1 that each cluster assignment in lazy--means increases the free energy (7). As the M-steps (equal to the -means M-steps) then increase the free energy w.r.t. , it follows that lazy--means monotonically increases the same free energy objective. Corollary 1 does not apply but we can generalize Proposition 2.
Proposition (Generalization of Proposition 2 for lazy--means)
Consider the TV-EM algorithm (Alg. 3) but with criterion (21) instead of criterion (8). If we set , then the TV-EM updates of the cluster centers (6) become independent of the variance and are given by the lazy--means algorithm.
**Proof
**The proof is analogous to the one of Proposition 2 with the only difference that is now a cluster of for which applies: . The cluster assignments thus become those of lazy--means, while the parameter updates remain those of standard -means (i.e., the same as used for lazy--means).
As Propositions 1 and 2 can be generalized, the fact that lazy--means optimizes the same free energy as -means does also imply that Corollary 2 can be used to relate lazy--means to the GMM objective (3).
Supplementary E More details on the numerical experiments
Fig. S2 shows additional results of -means- on the BIRCH data sets, namely the log-likelihood, quantization error, purity and NMI (where likelihood and purity values are the same as those in Fig. 1, but shown here again for easier comparison). Tab. S1 gives a numerical comparison of these results to the DBSCAN and lazy--means algorithms. The results on the quantization error compared to the likelihoods in Fig. S2 and Tab. S1 highlight the fact that optimization of the -means criterion (i.e., the quantization error) does generally not directly coincide with optimization of free energies by -means- with (including optimization of likelihoods by EM for GMM for ). For the NMI and purity scores, we find that on the BIRCH set with random clusters (and therefore larger overlaps) -means is prone to trade off NMI with decreasing purity scores (which results in a lower than average NMI score for the shown run with the highest combined score of NMI and purity). The -means- algorithm, on the other hand, already results for in high NMI and purity scores near the ground truth.111For the formulars of purity and NMI, see Manning et al. 2008, chapter: Evaluation of clustering, https://nlp.stanford.edu/IR-book/html/htmledition/evaluation-of-clustering-1.html
Manning, C. D., Raghavan, P. and Schütze, H., 2008, Introduction to Information Retrieval, Cambridge University Press.
Fig. S3 shows enlarged versions of plots A, D, E, G of Fig. 1 with more details in the caption. In addition to these results we also verified that the free energies (7), (15) and the right-hand-side of (19) are numerically equal for -means. For -means- we verified that free energies (7) and (20) are equal at convergence.
Note that Fig. S3 can also be interpreted as numerically verifying that the free energies and the likelihood objective of the GMM (2) are not trivially related. This includes the free energy (15) which is optimized by -means and which corresponds to . Comparison of the means of Figs. S3(F) and (G) already shows the difference when comparing results between (-means) to . Finally, the numerical experiment of Fig. S4 is deliberately chosen to highlight the difference between the -means objective (1) and the GMM log-likelihood (3). By applying -means, the -means free energy increases (the quantization error gets smaller) but the log-likelihood gets worse. Results for the cluster centers recovered by -means and EM for GMM (2) are very different.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Allahverdyan and Galstyan (2011) Allahverdyan, A., Galstyan, A., 2011. Comparative analysis of Viterbi training and maximum likelihood estimation for HM Ms, in: NIPS, pp. 1674–1682.
- 2Anderberg (1973) Anderberg, M.R., 1973. Cluster Analysis for Applications. Academic Press.
- 3Arthur et al. (2009) Arthur, D., Manthey, B., Röglin, H., 2009. k-means has polynomial smoothed complexity, in: IEEE Symp. Foundations of Comp. Sci., pp. 405–414.
- 4Arthur and Vassilvitskii (2006) Arthur, D., Vassilvitskii, S., 2006. How slow is the k-means method?, in: Comp. Geo., pp. 144–153.
- 5Bachem et al. (2016) Bachem, O., Lucic, M., Hassani, H., Krause, A., 2016. Fast and provably good seedings for k-means, in: NIPS, pp. 55–63.
- 6Barbakh and Fyfe (2008) Barbakh, W., Fyfe, C., 2008. Online clustering algorithms. International Journal of Neural Systems 18, 185–194.
- 7Barber (2012) Barber, D., 2012. Bayesian reasoning and machine learning. Cam. Univ. Press.
- 8Belkin and Sinha (2010) Belkin, M., Sinha, K., 2010. Polynomial learning of distribution families, in: Symp. Comp. Sci., pp. 103–112.