Multivariate Multiscale Dispersion Entropy of Biomedical Times Series
Hamed Azami, Alberto Fernandez, and Javier Escudero

TL;DR
This paper introduces multivariate multiscale dispersion entropy (mvMDE), a new method for analyzing complex biomedical multichannel signals that overcomes limitations of existing entropy measures, providing more stability, speed, and accuracy in detecting physiological states.
Contribution
The paper presents mvMDE, an extension of MDE, which improves stability, speed, and applicability for short and large-channel multivariate signals compared to mvMSE and mvMFE.
Findings
mvMDE better discriminates physiological states.
mvMDE is more stable for short signals.
mvMDE is faster and requires less storage.
Abstract
Objective: Due to the non-linearity of numerous biomedical signals, non-linear analysis of multi-channel time series, notably multivariate multiscale entropy (mvMSE), has been extensively used in biomedical signal processing. However, mvMSE has three drawbacks: 1) mvMSE values are either undefined or unreliable for short signals; 2) mvMSE is not fast enough for real-time applications; and 3) the computation of mvMSE for signals with a large number of channels requires the storage of a huge number of elements. Methods: To deal with these problems and improve the stability of mvMSE, we introduce multivariate multiscale dispersion entropy (MDE - mvMDE) as an extension of our recently developed MDE, to quantify the complexity of multivariate time series. Results: We assess mvMDE, in comparison with mvMSE and multivariate multiscale fuzzy entropy (mvMFE), on correlated and uncorrelated…
Click any figure to enlarge with its caption.
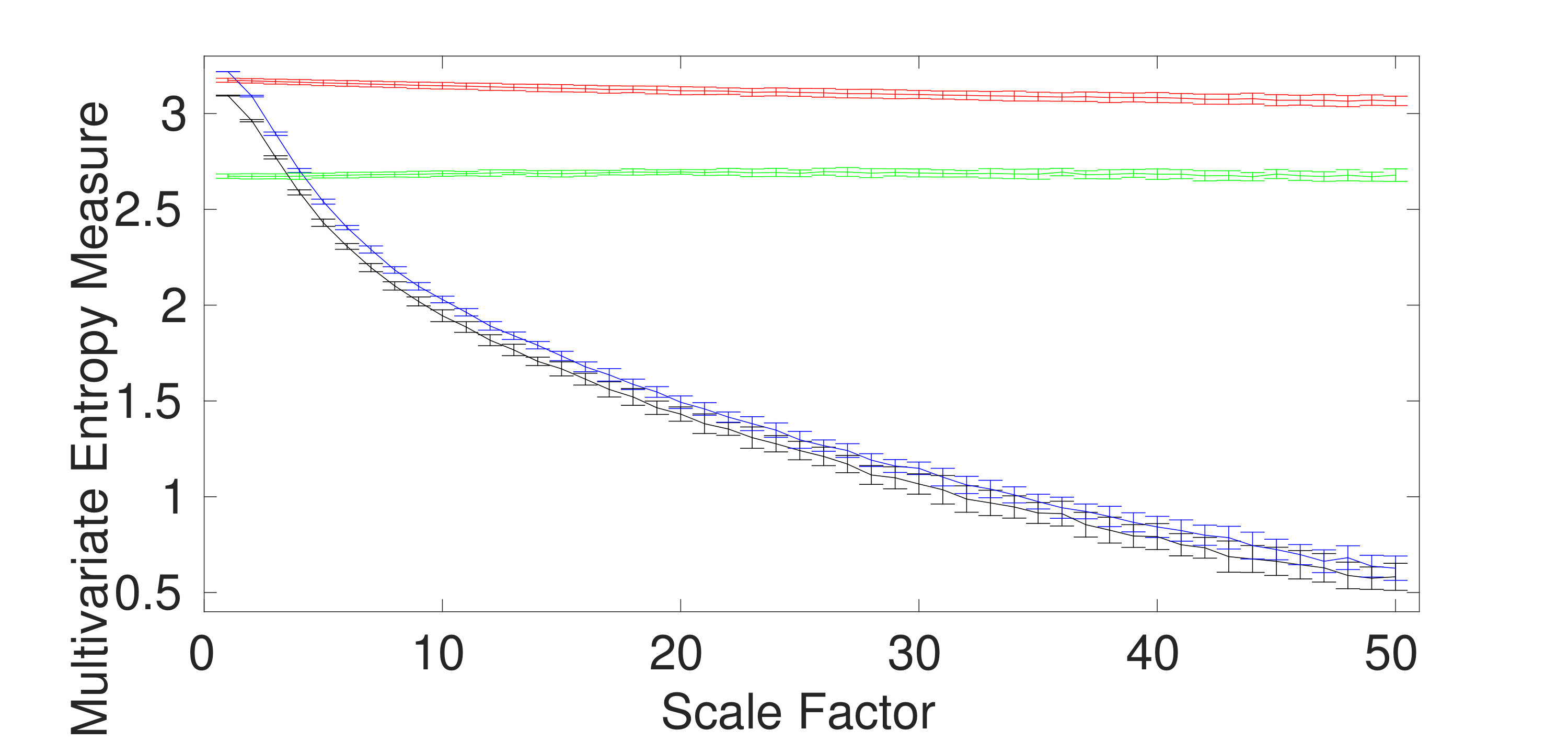 Figure 1
Figure 1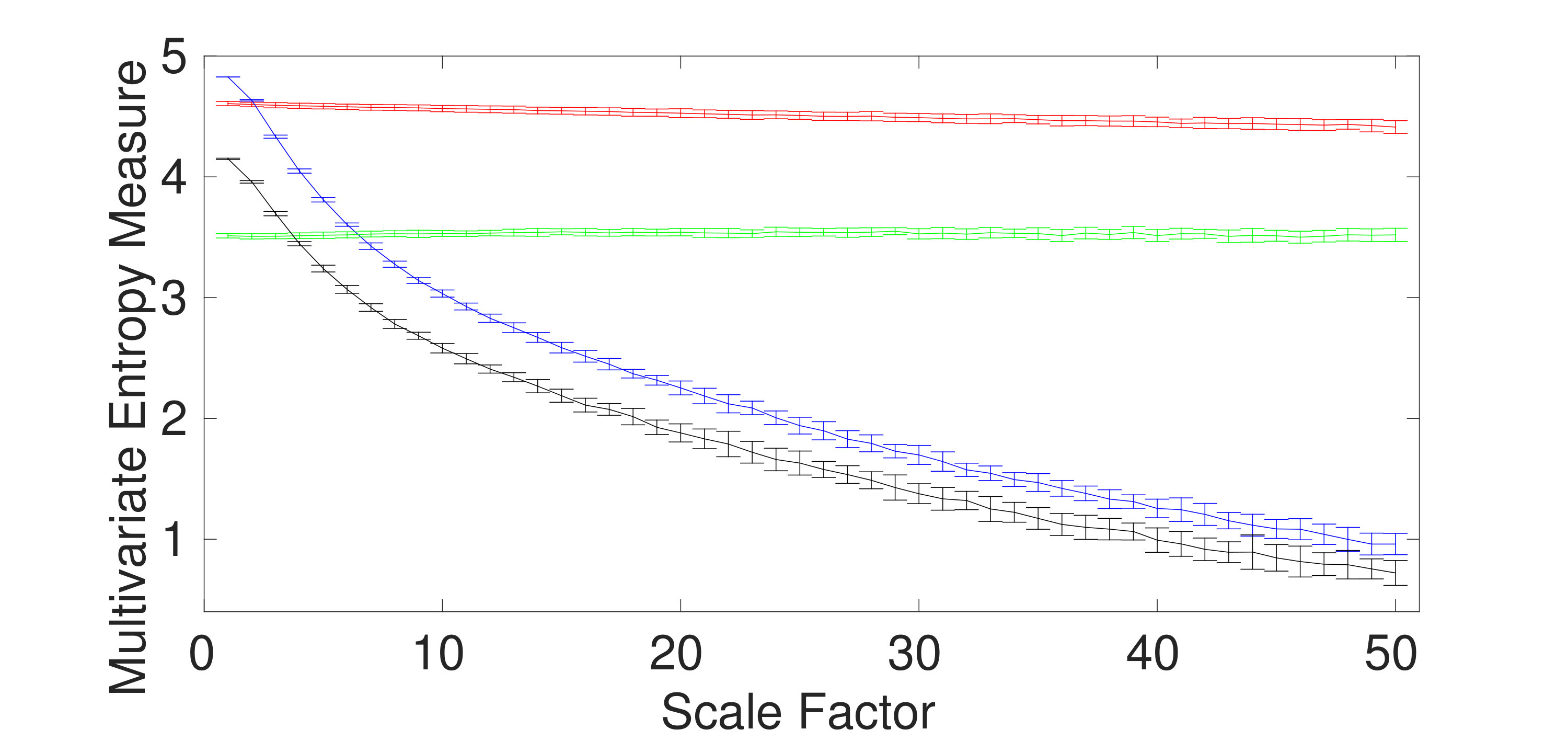 Figure 2
Figure 2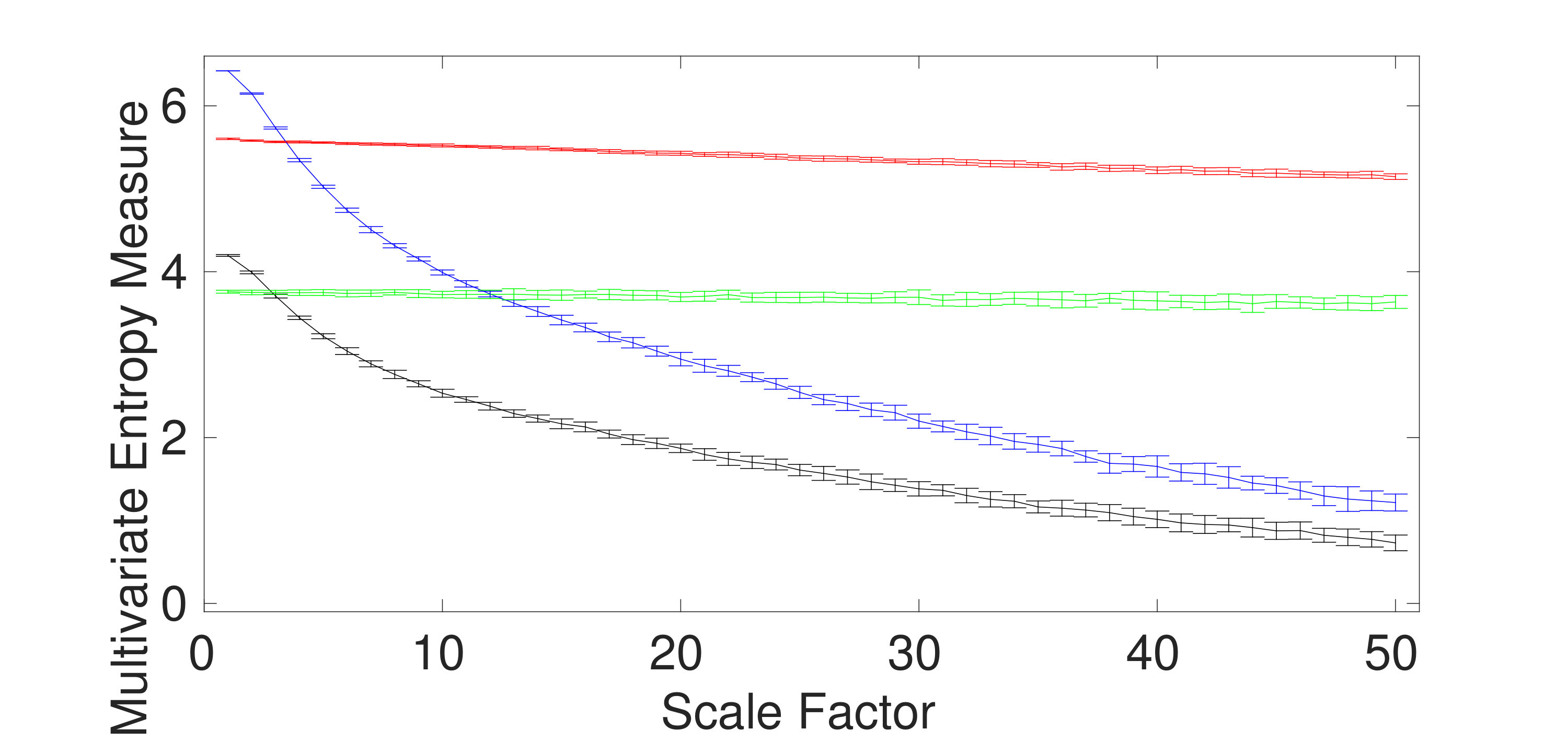 Figure 3
Figure 3 Figure 4
Figure 4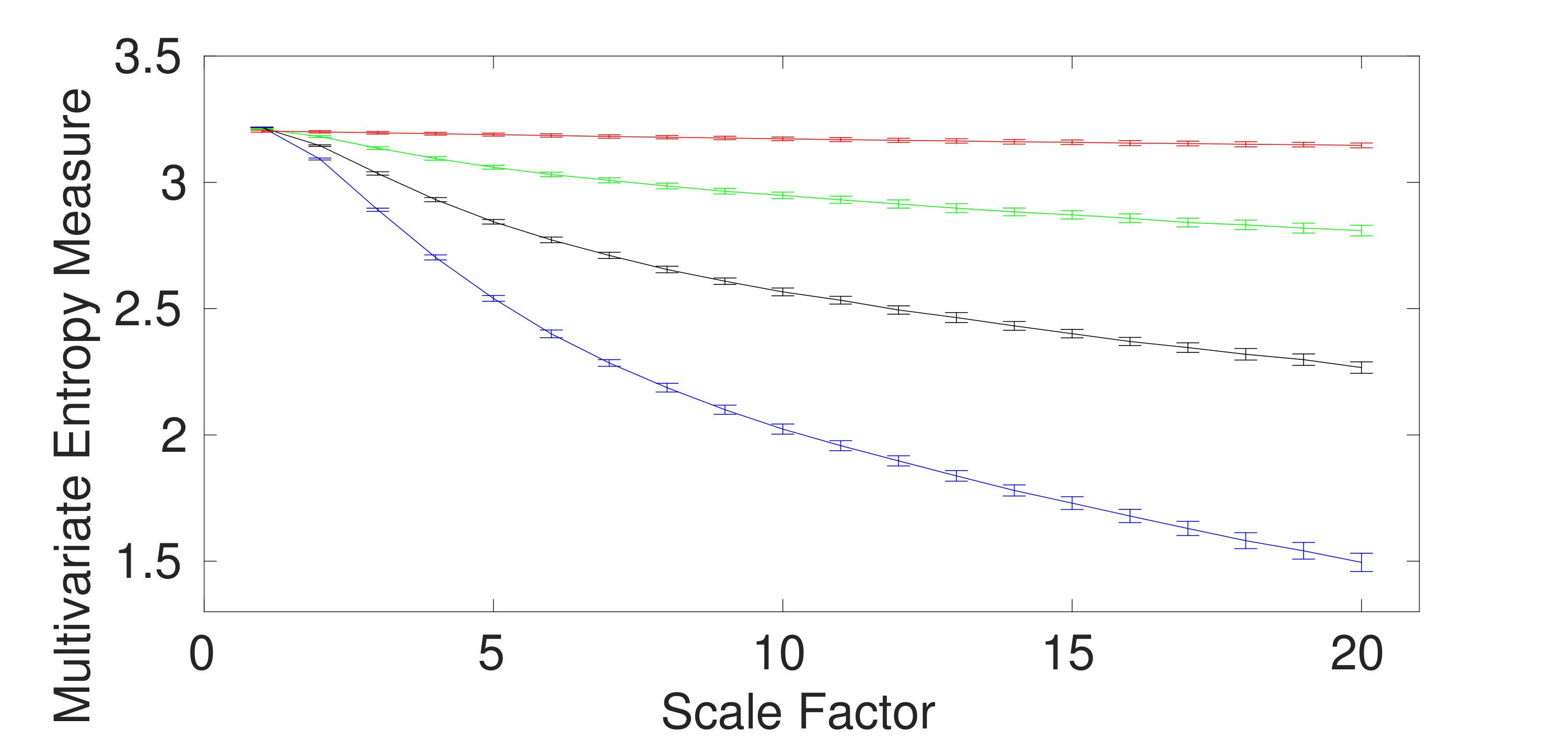 Figure 5
Figure 5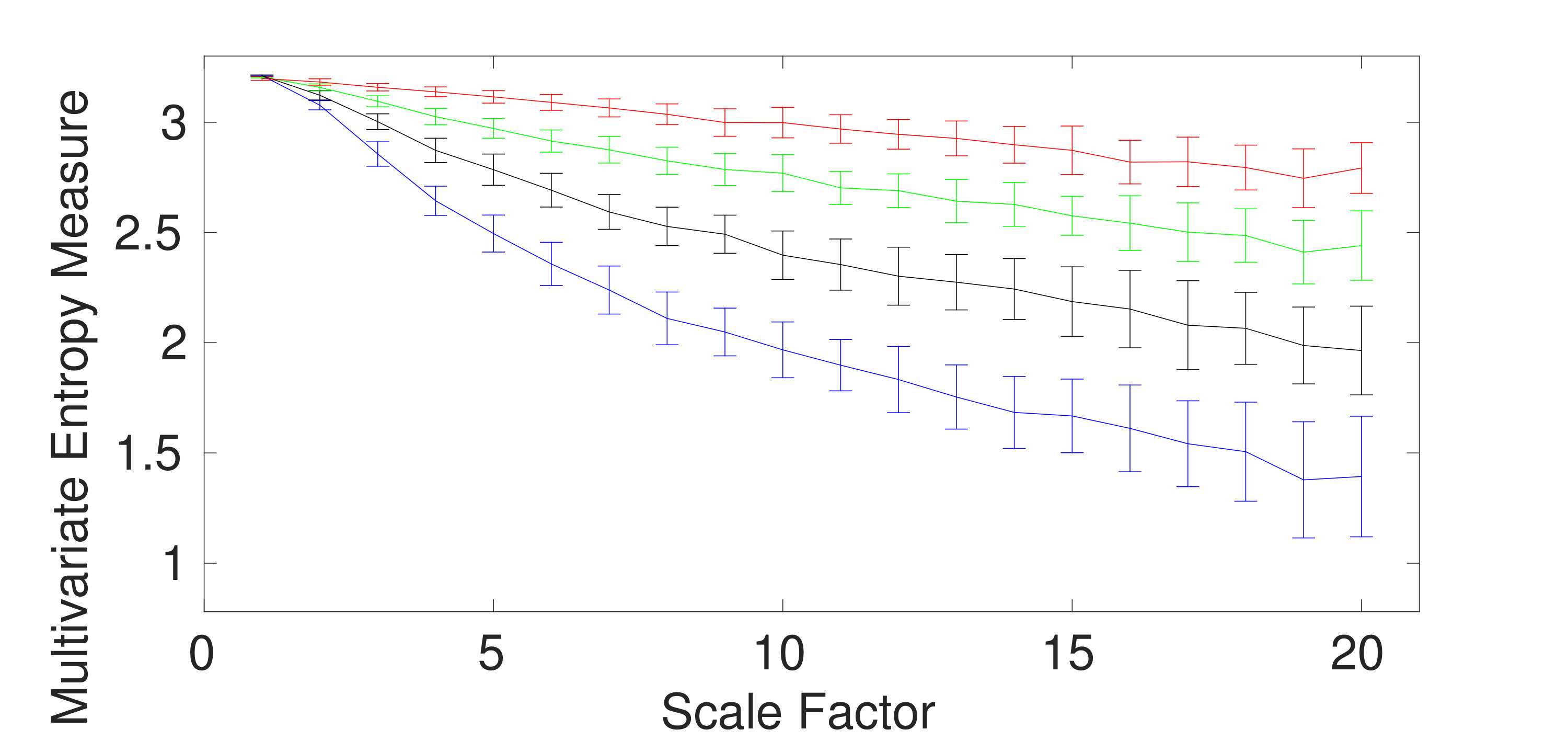 Figure 6
Figure 6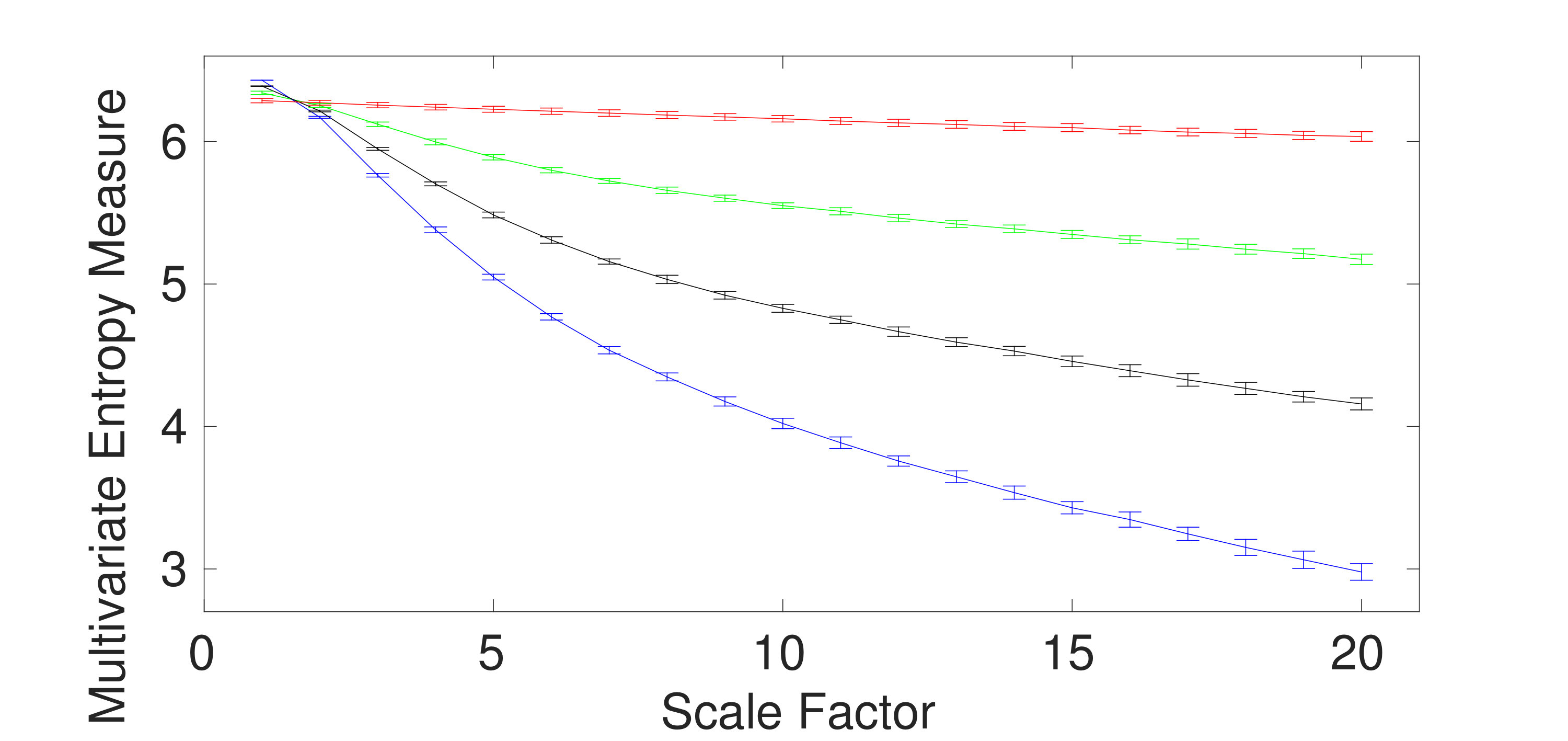 Figure 7
Figure 7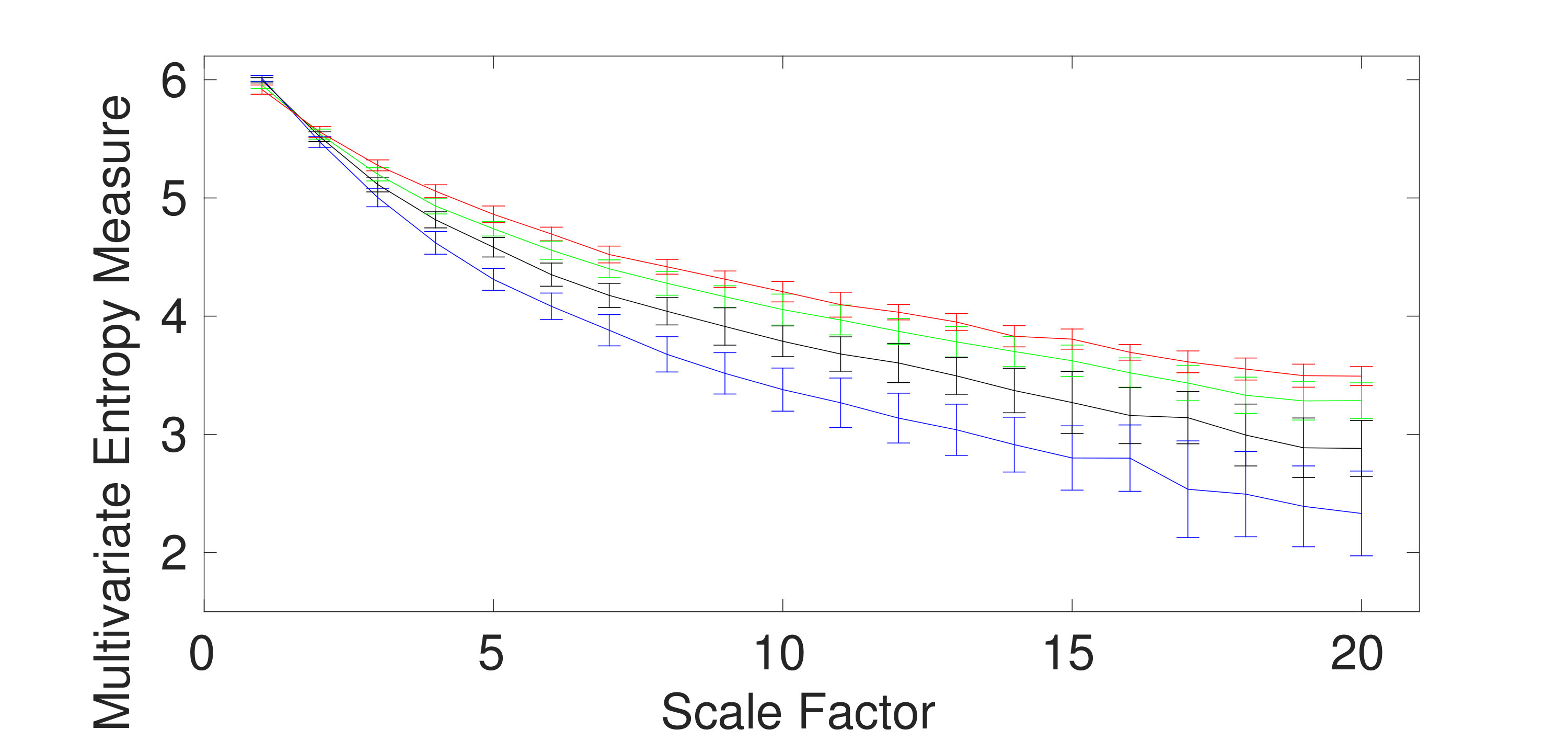 Figure 8
Figure 8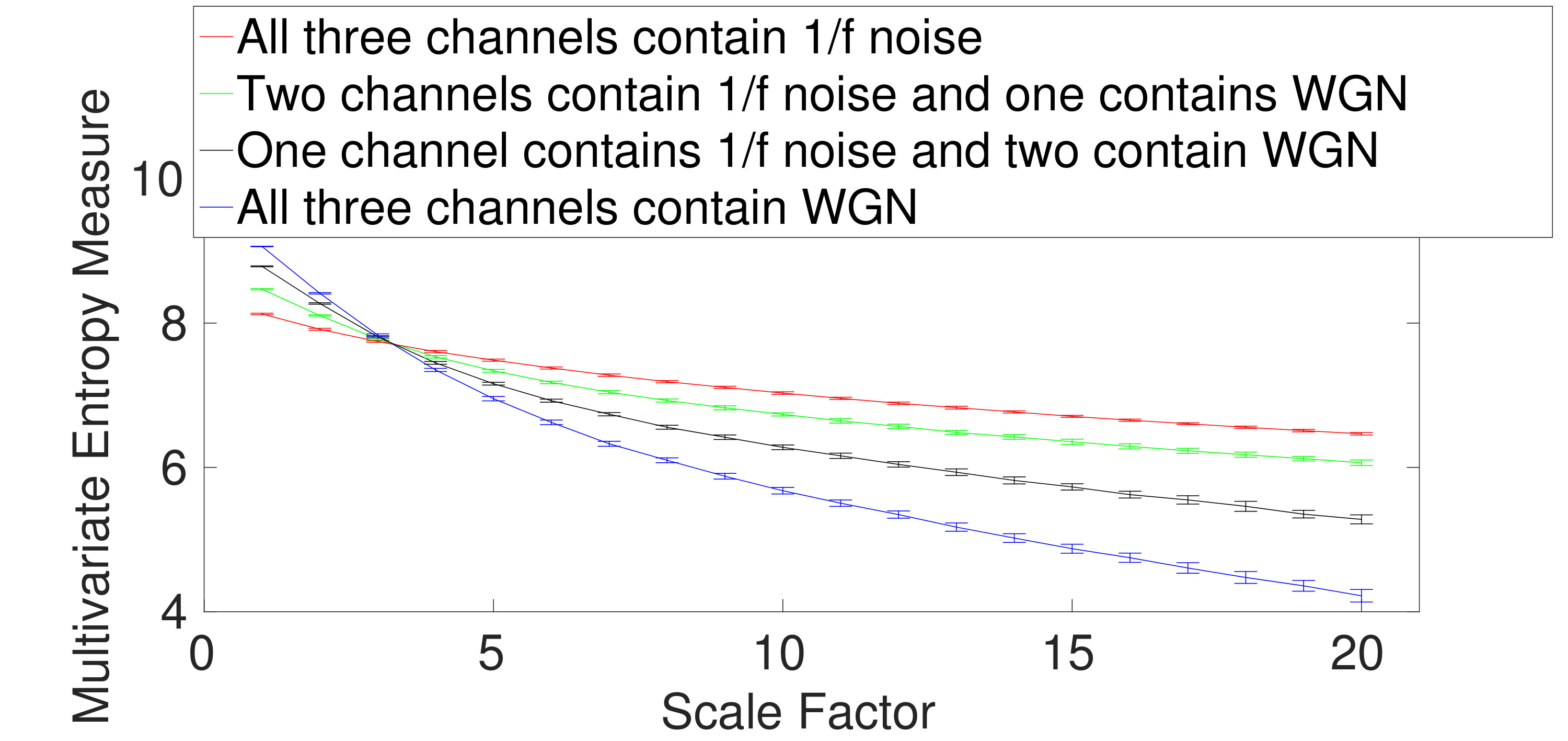 Figure 9
Figure 9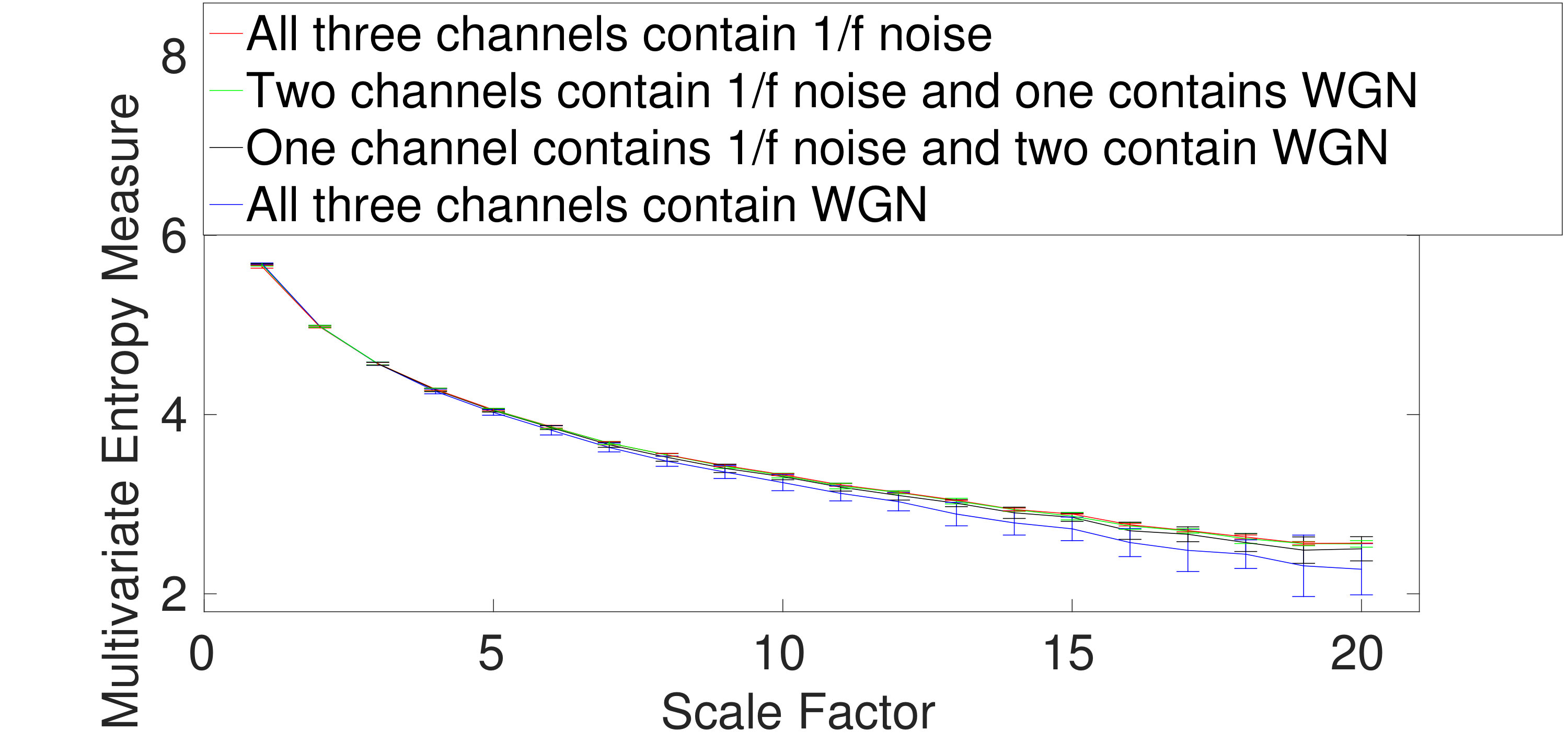 Figure 10
Figure 10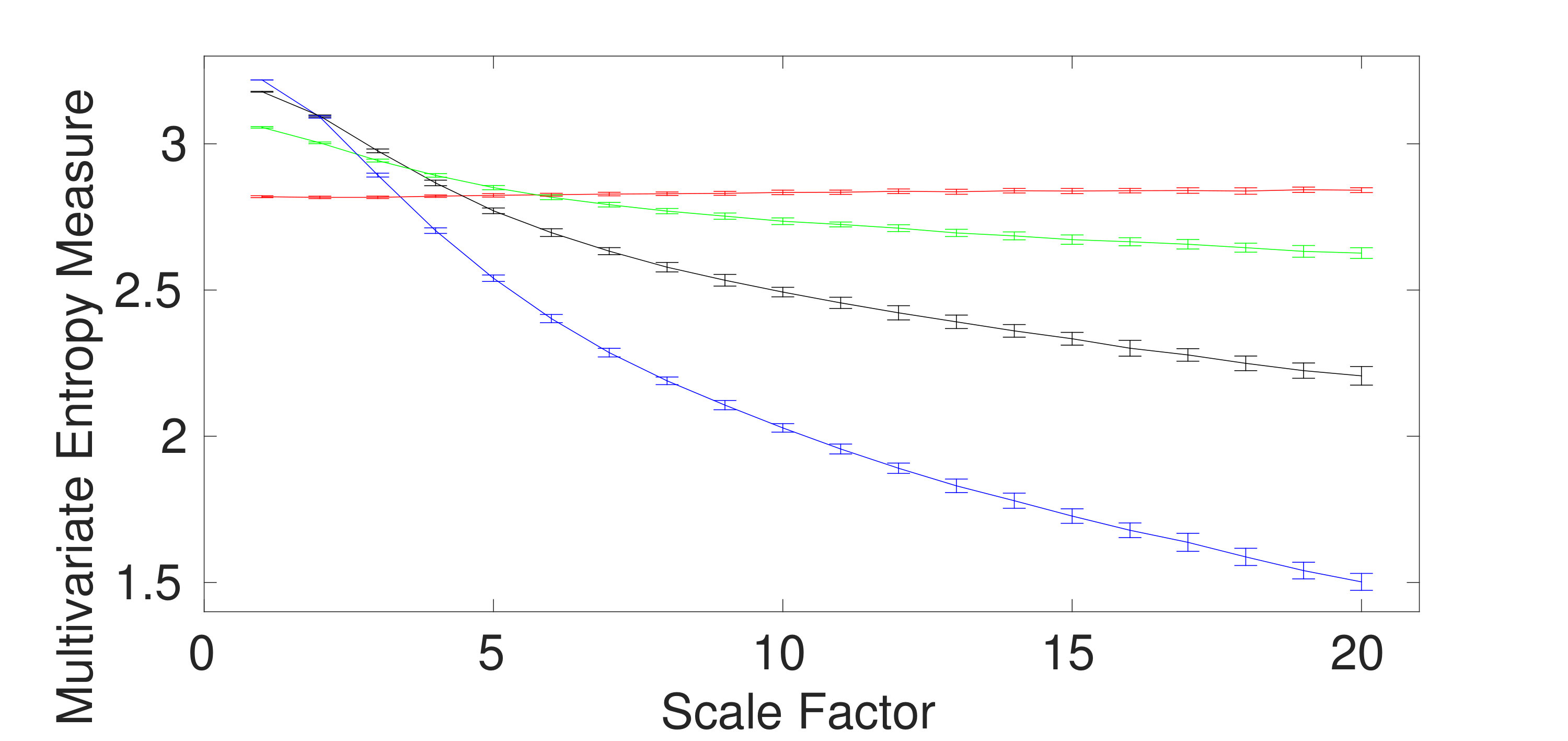 Figure 11
Figure 11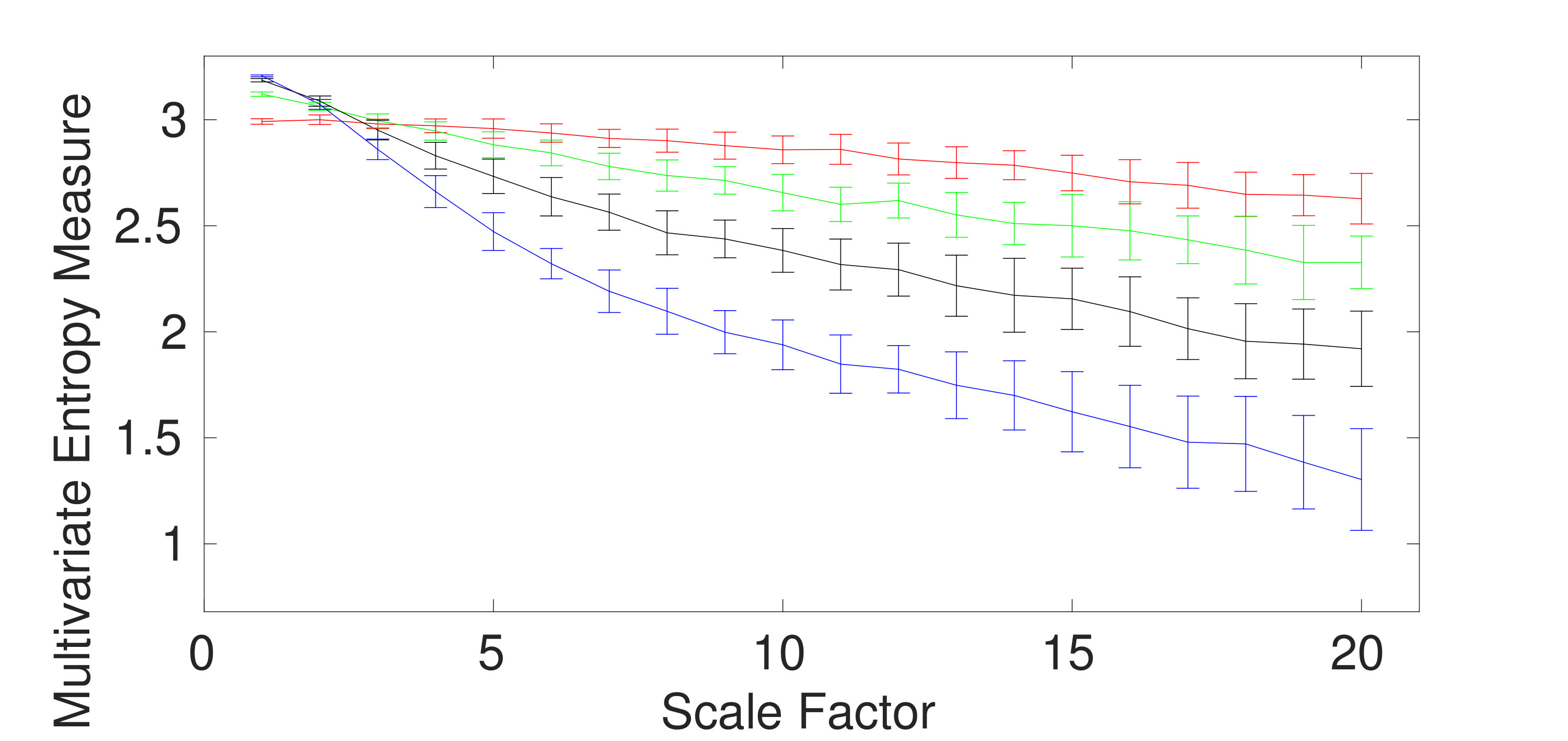 Figure 12
Figure 12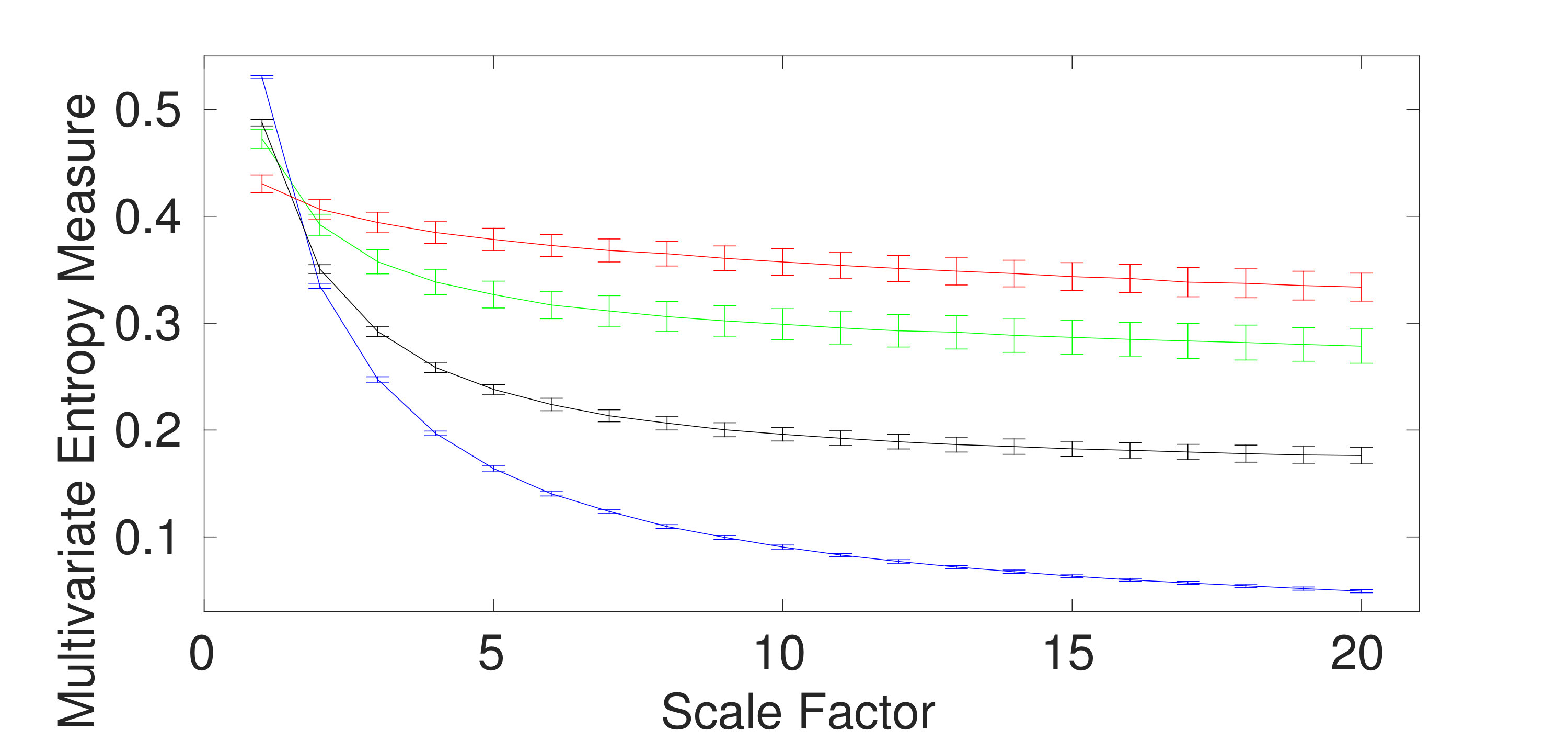 Figure 13
Figure 13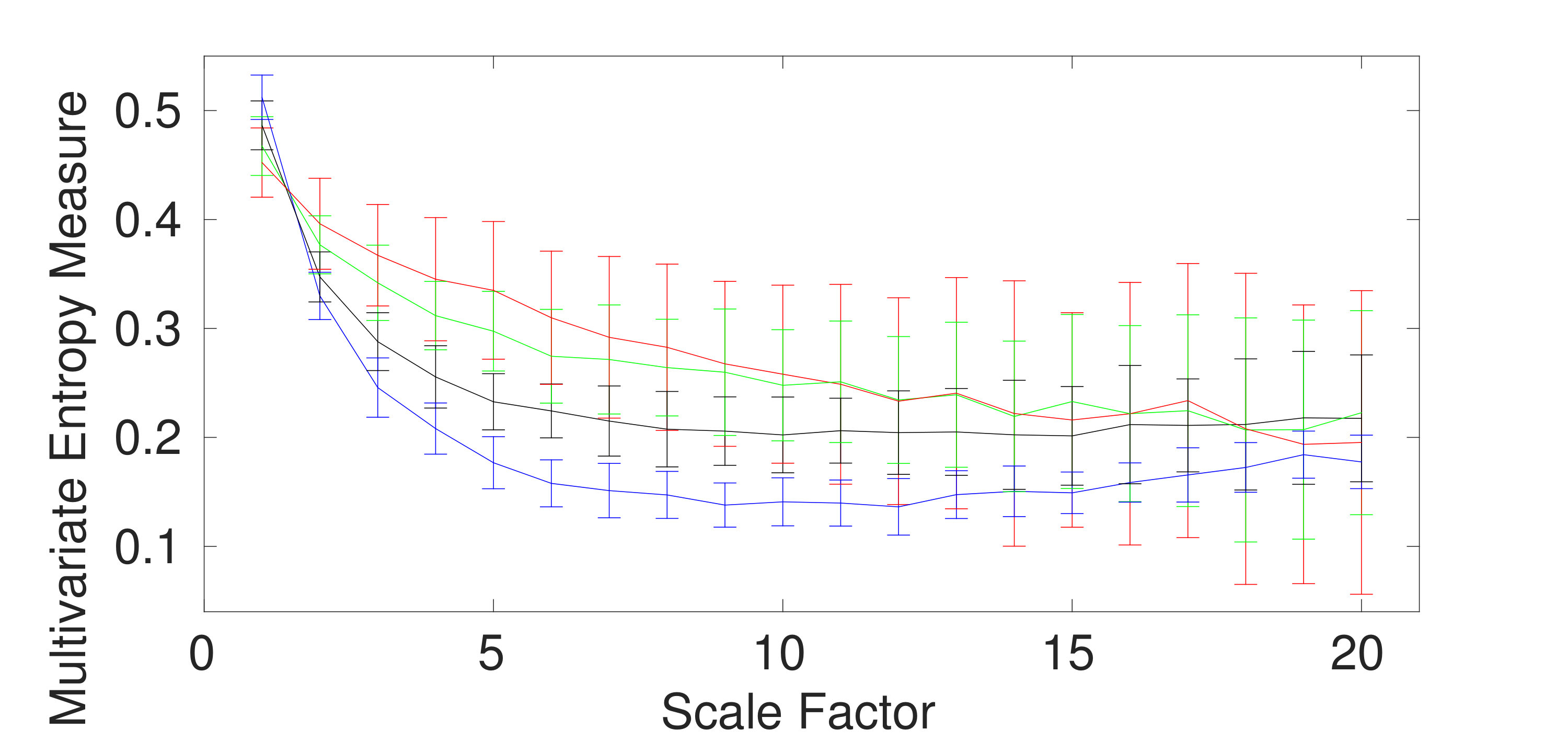 Figure 14
Figure 14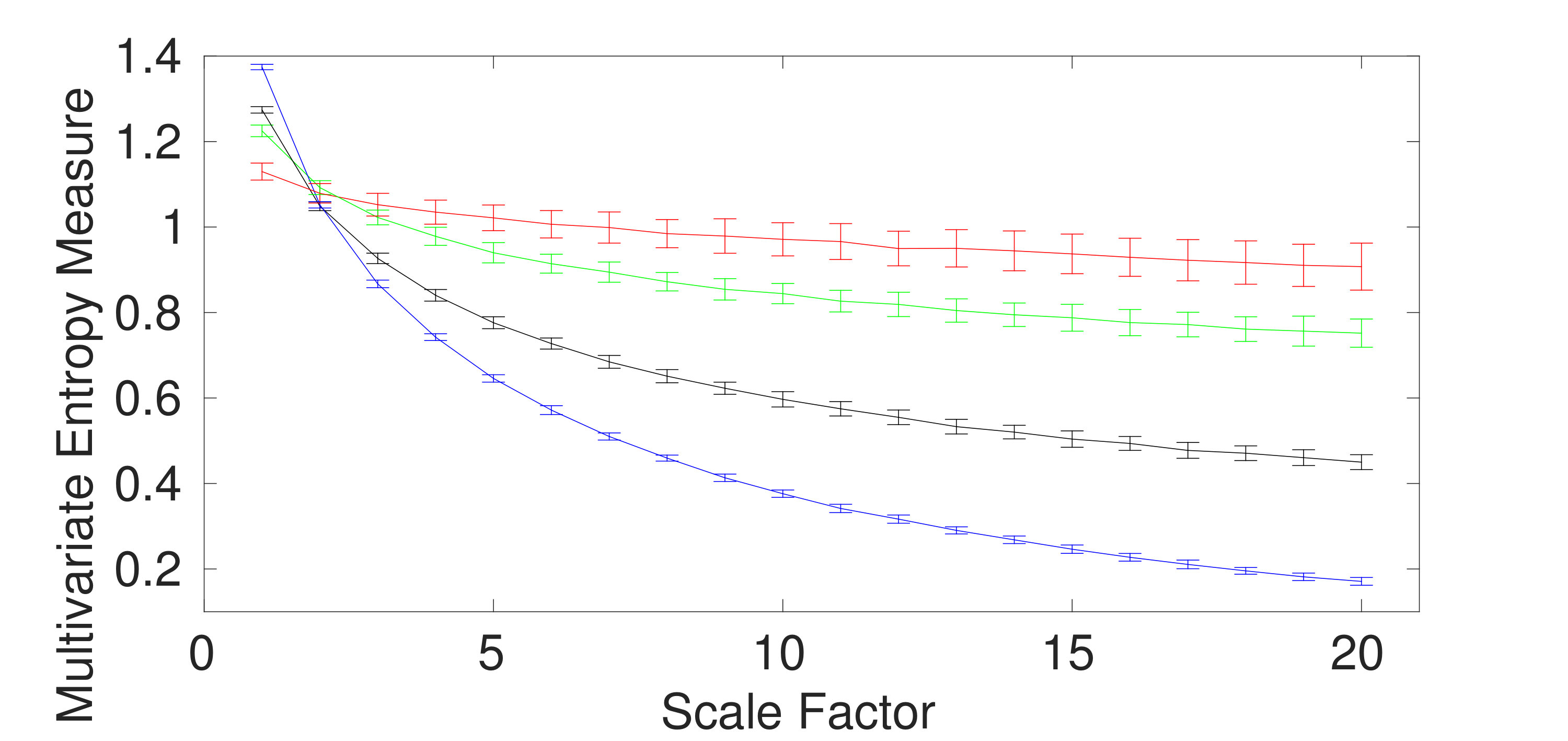 Figure 15
Figure 15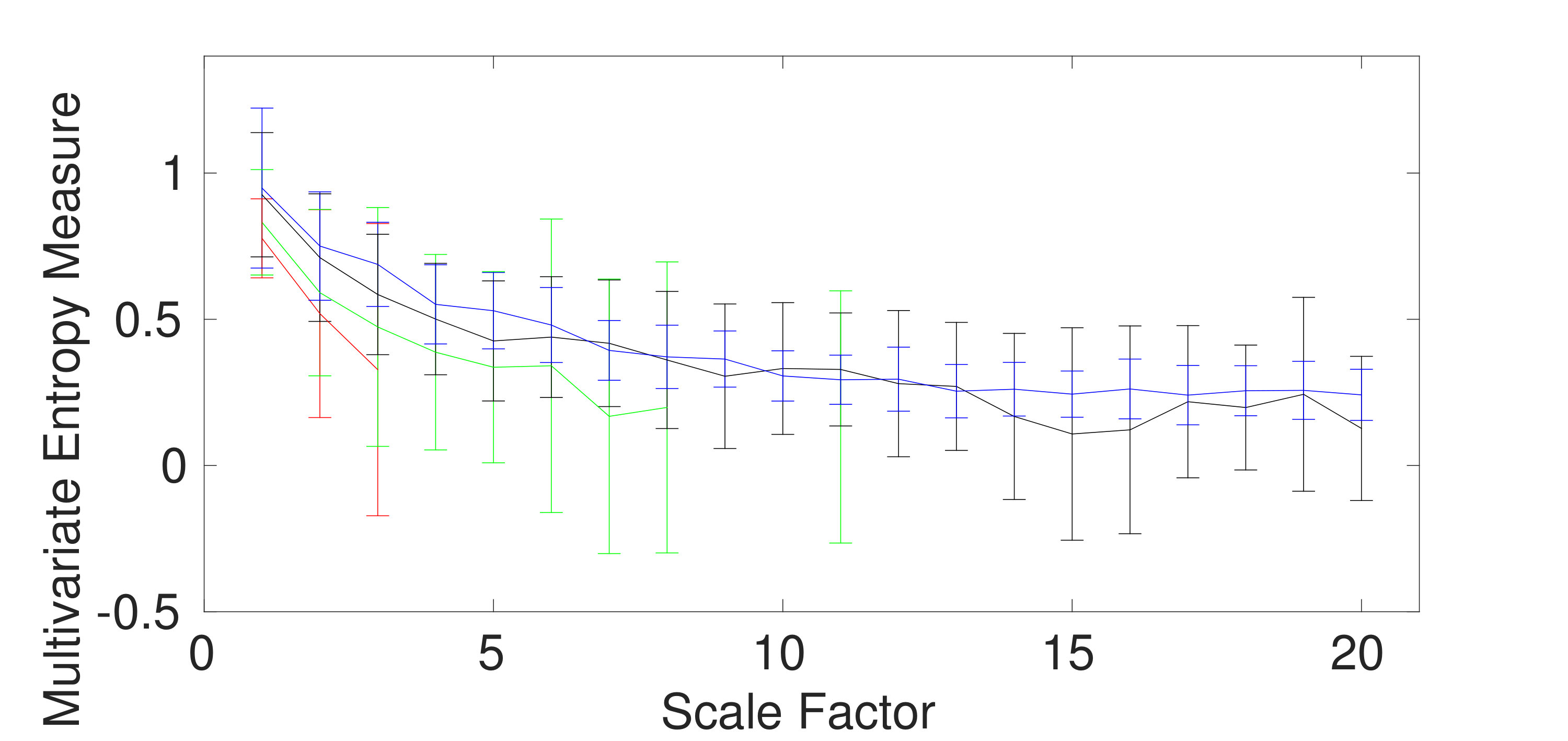 Figure 16
Figure 16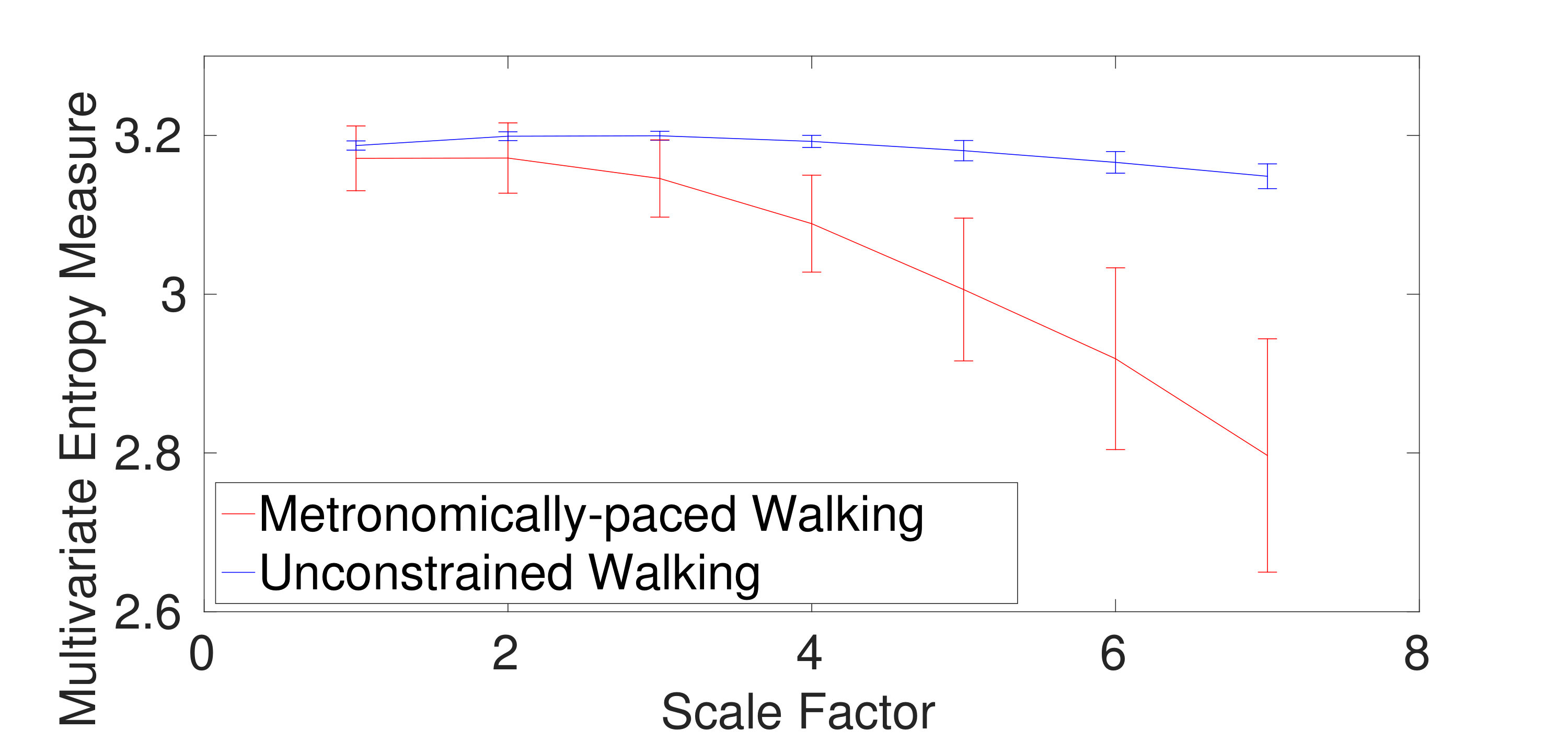 Figure 17
Figure 17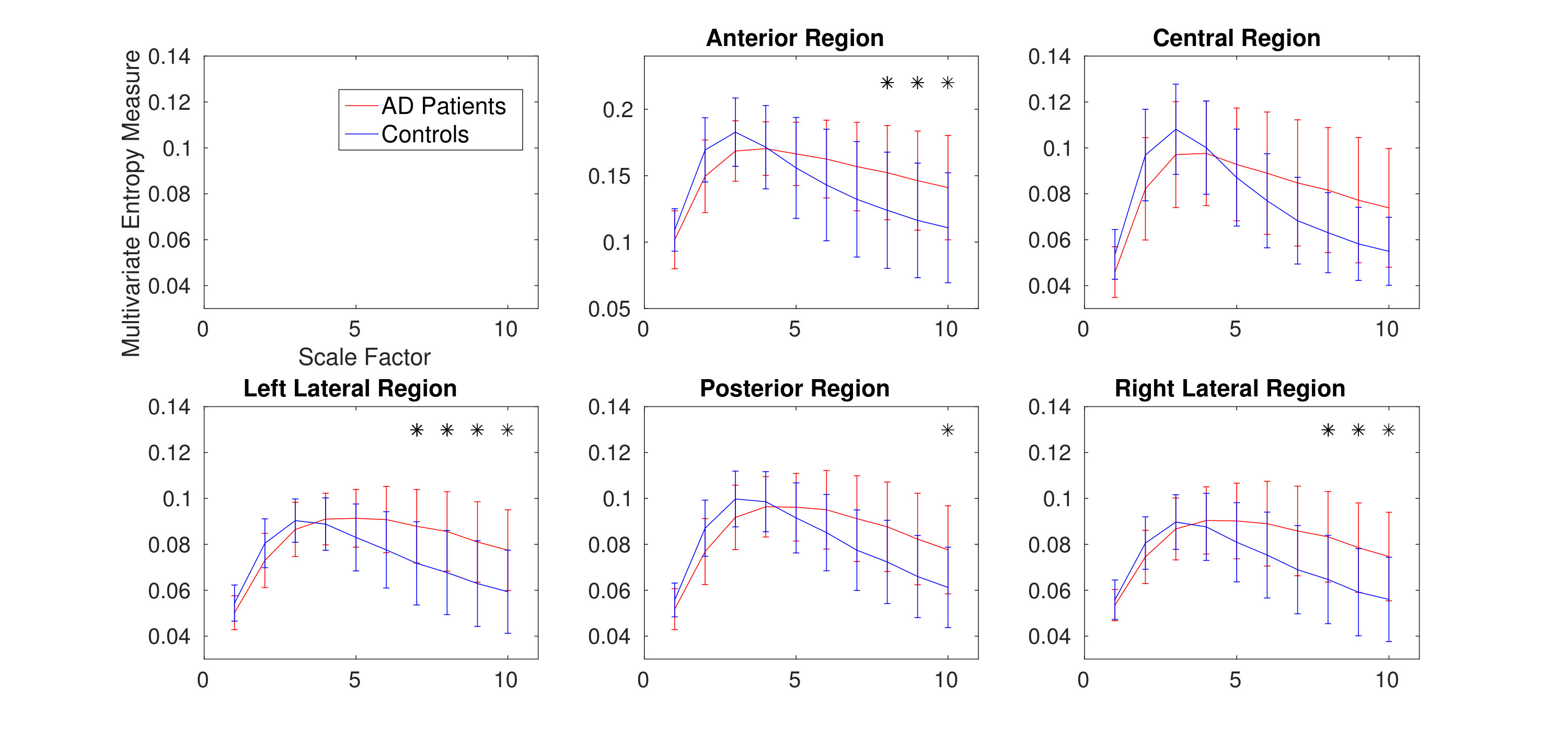 Figure 18
Figure 18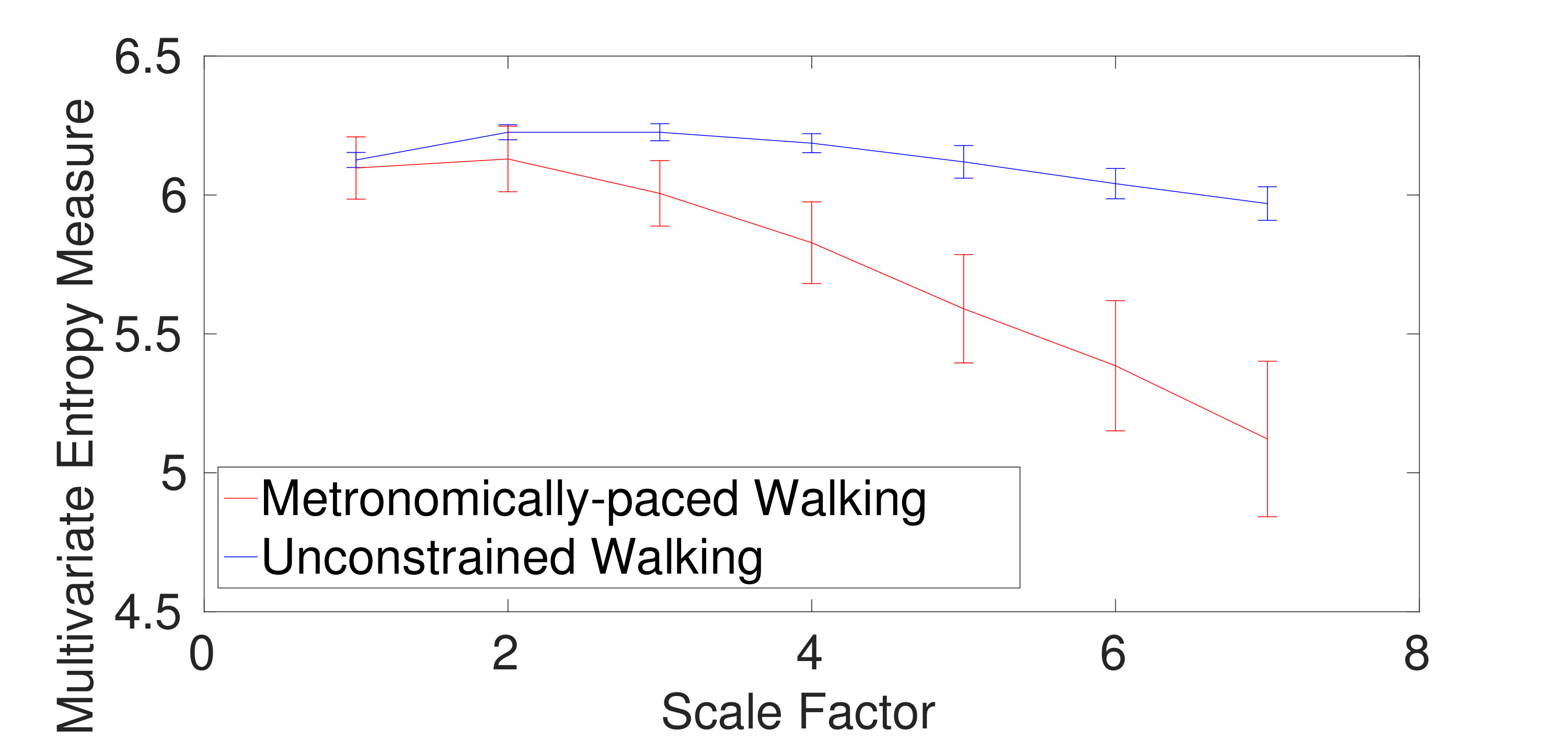 Figure 19
Figure 19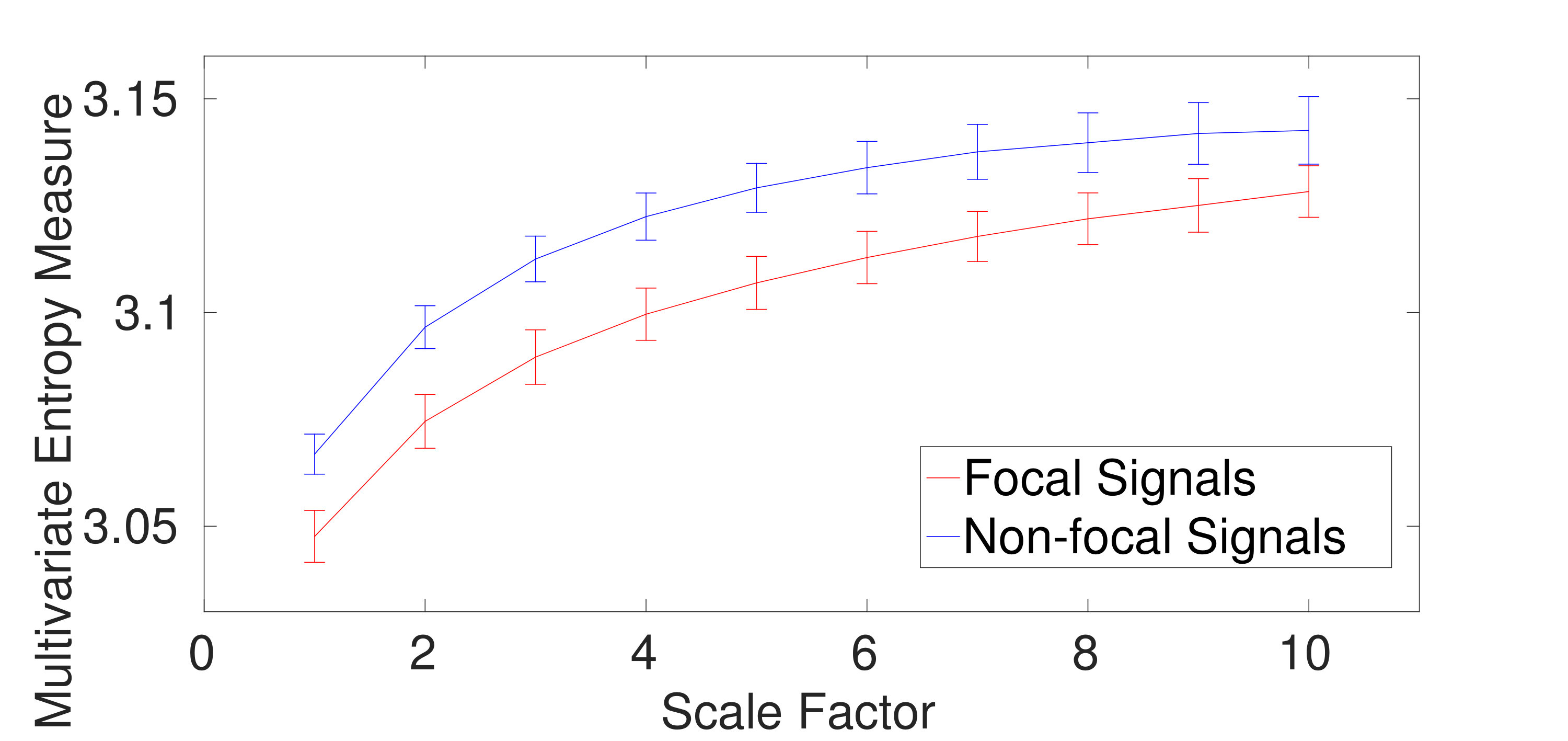 Figure 20
Figure 20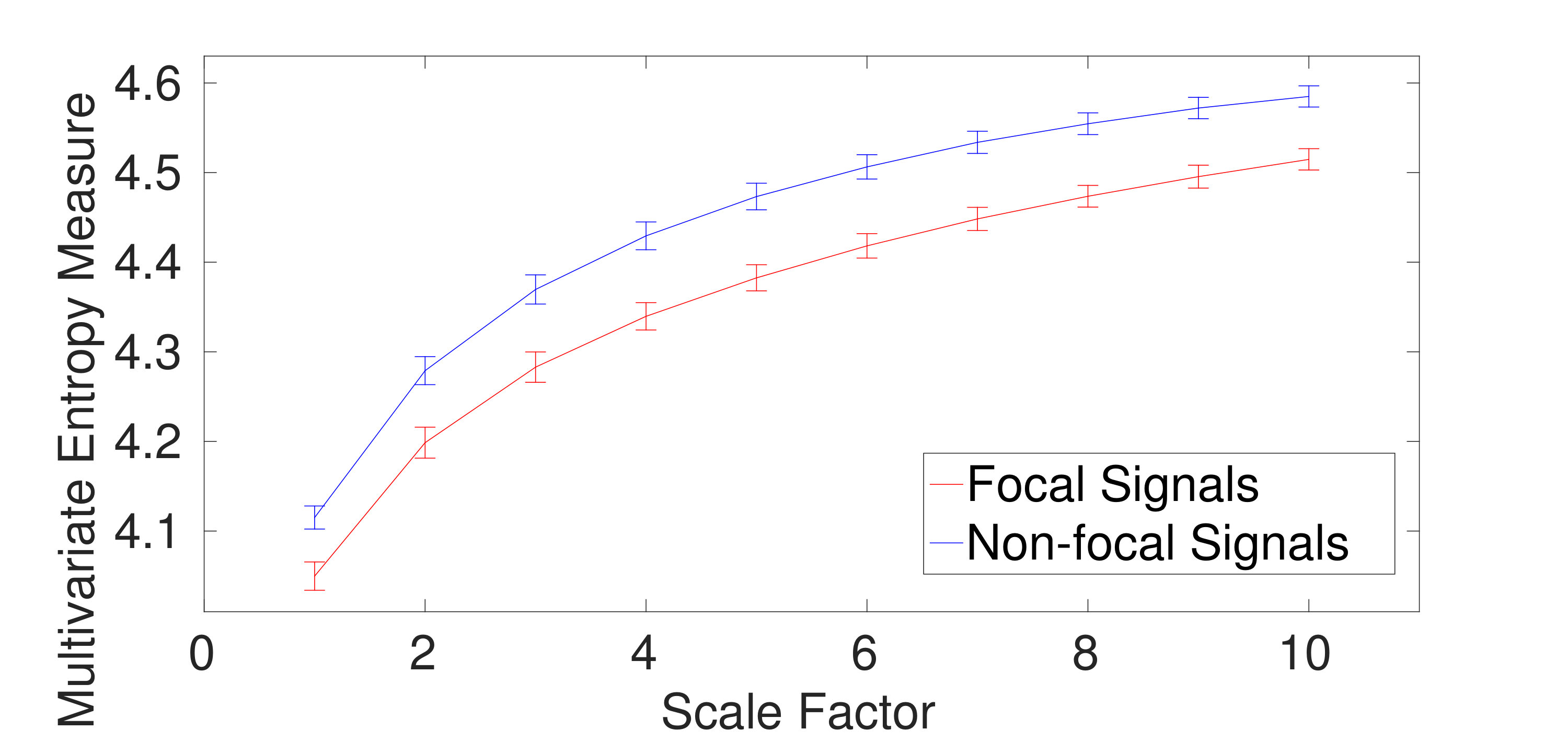 Figure 21
Figure 21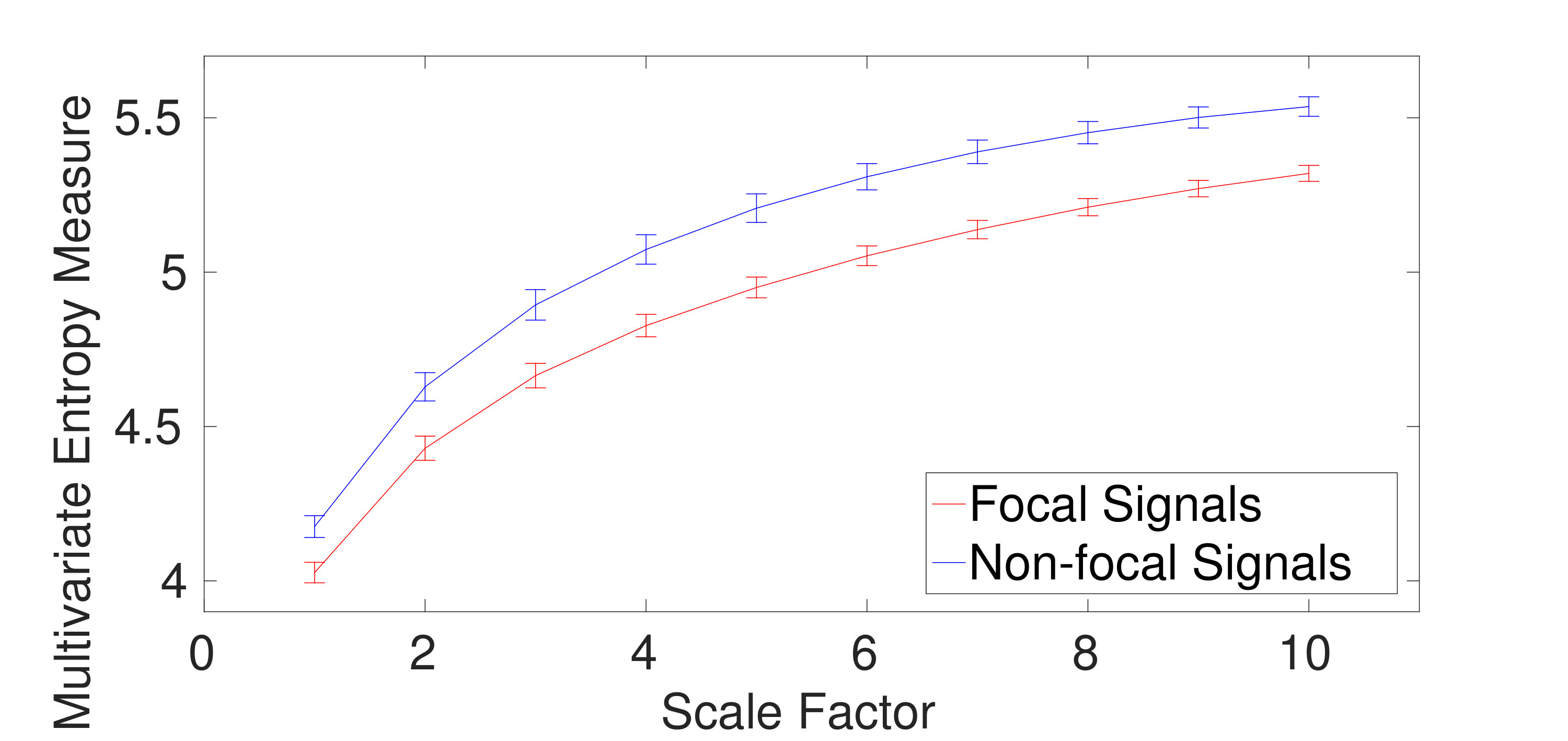 Figure 22
Figure 22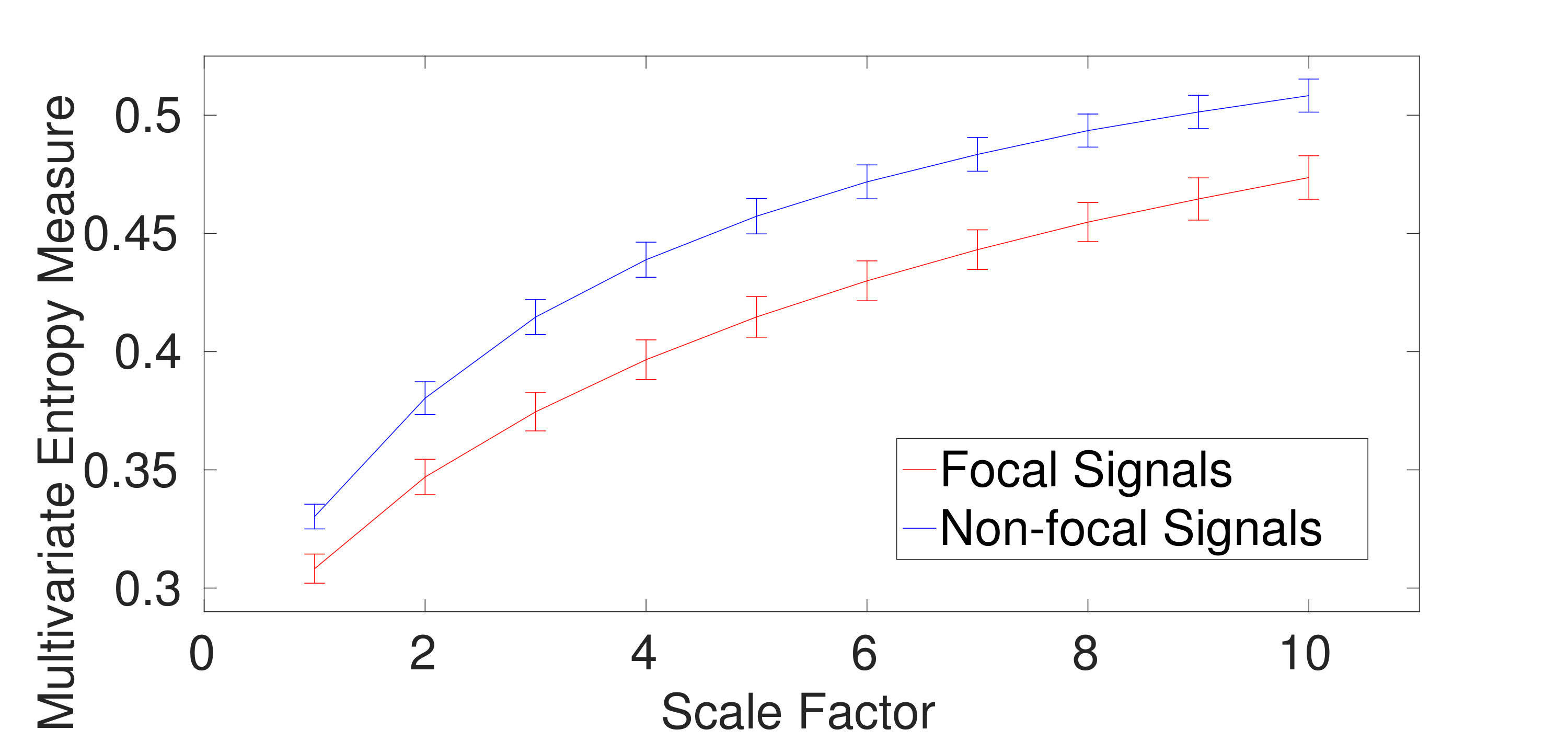 Figure 23
Figure 23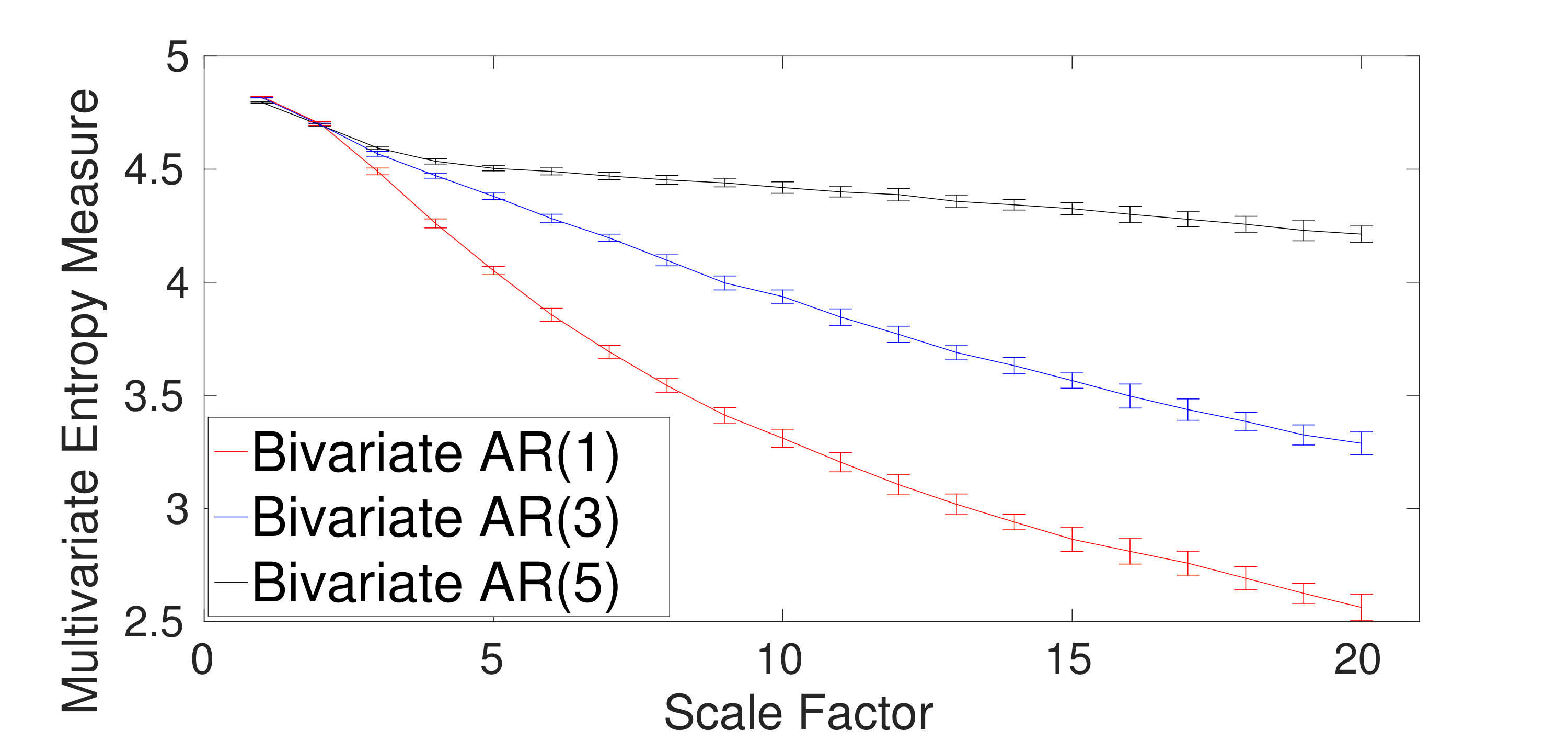 Figure 24
Figure 24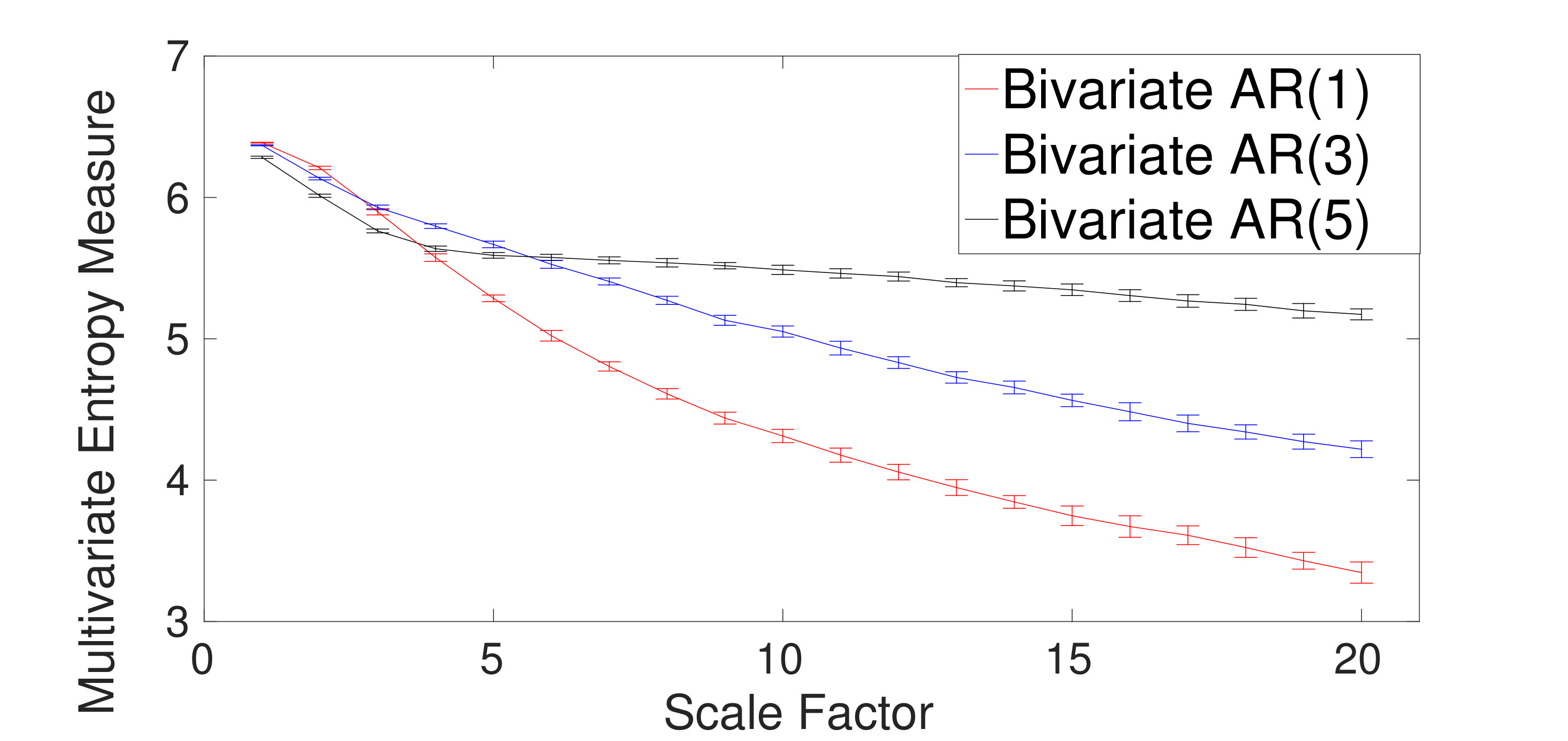 Figure 25
Figure 25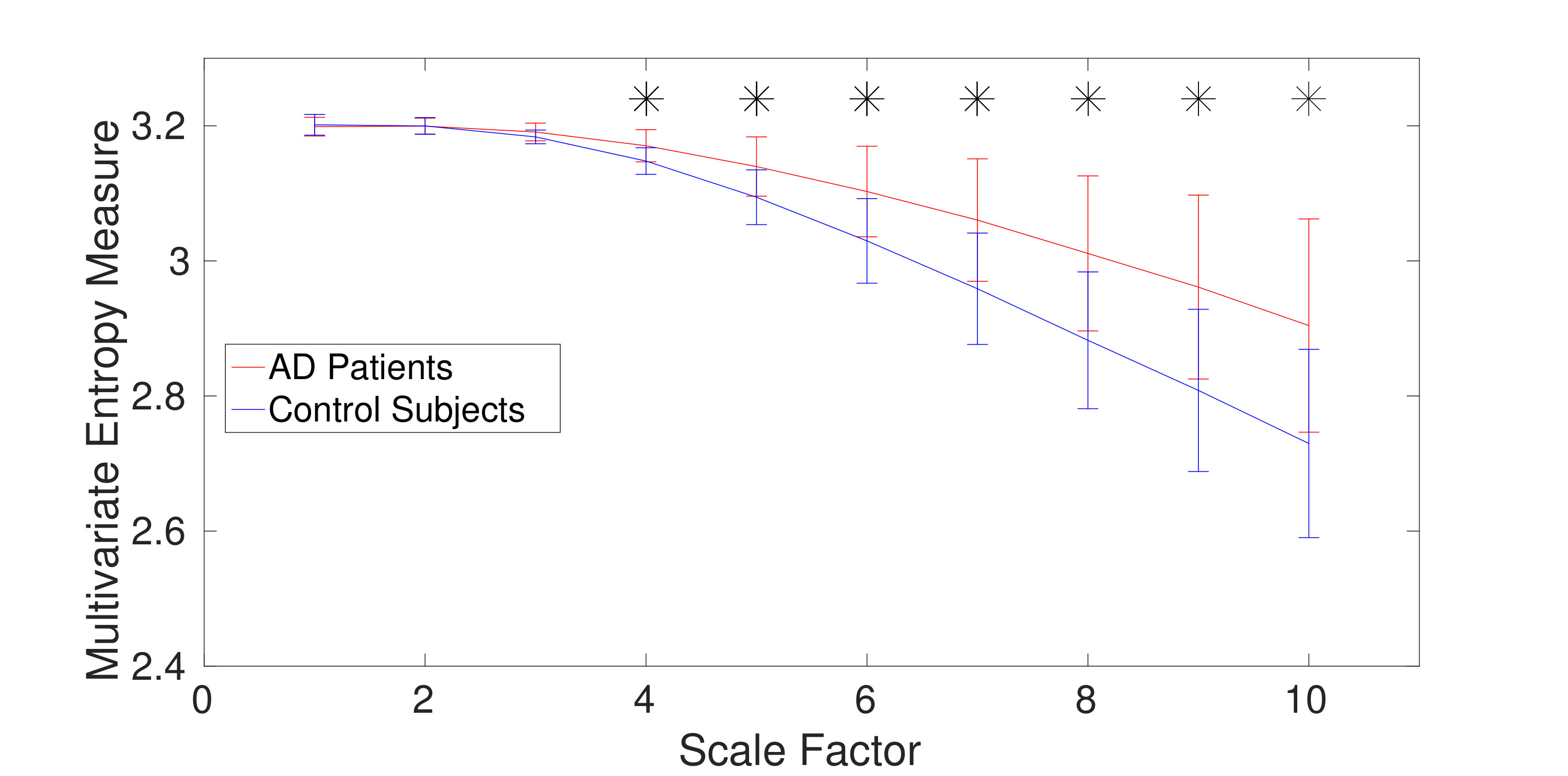 Figure 26
Figure 26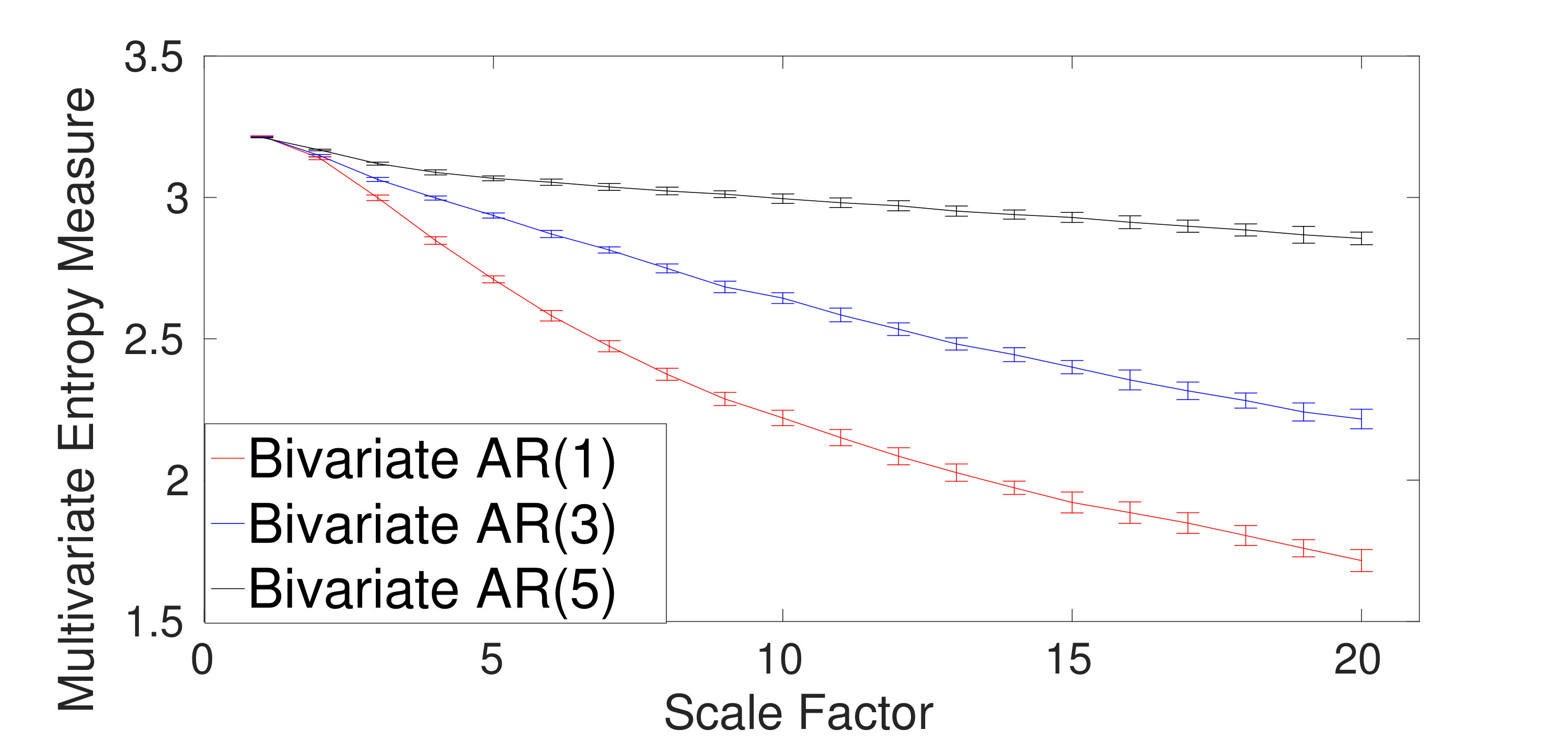 Figure 27
Figure 27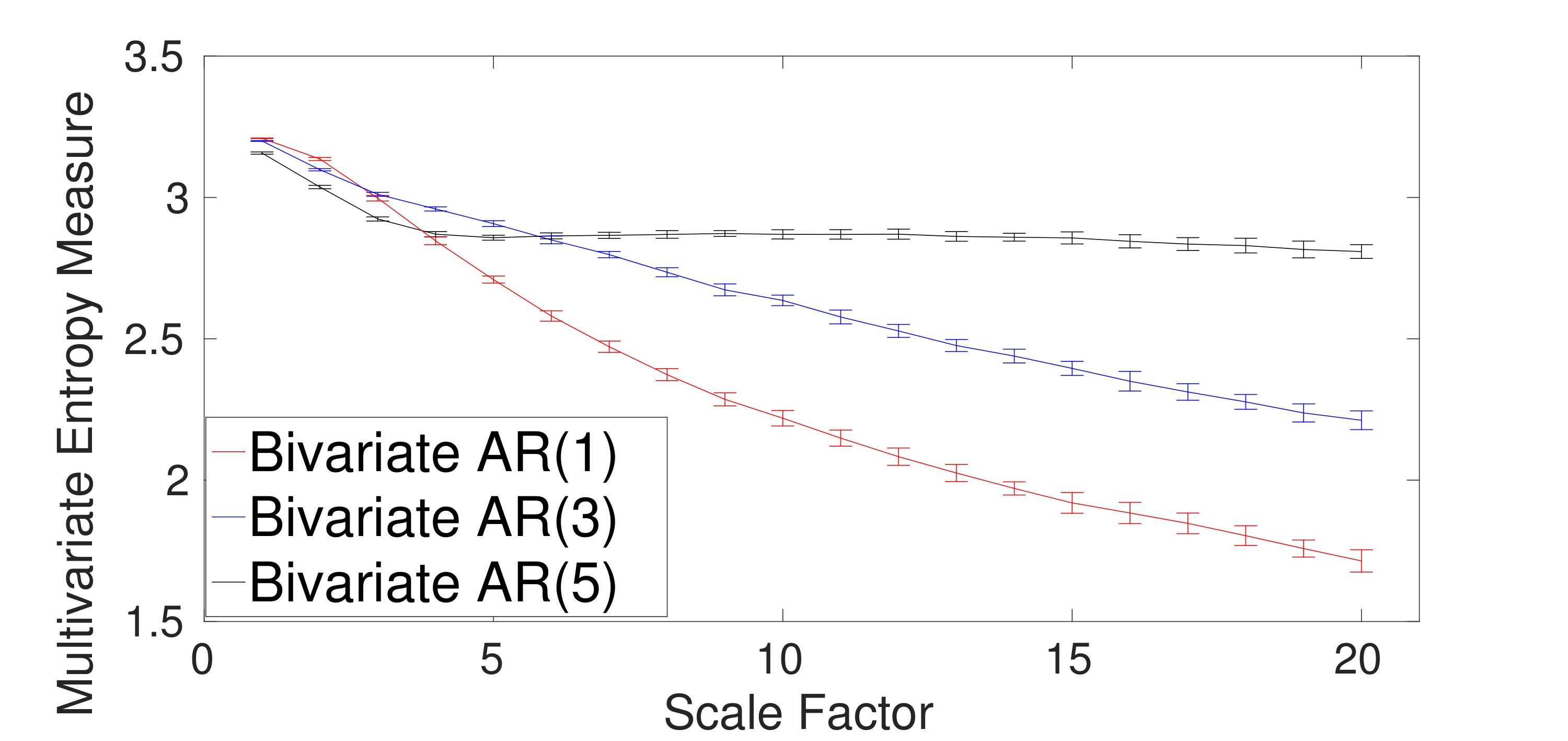 Figure 28
Figure 28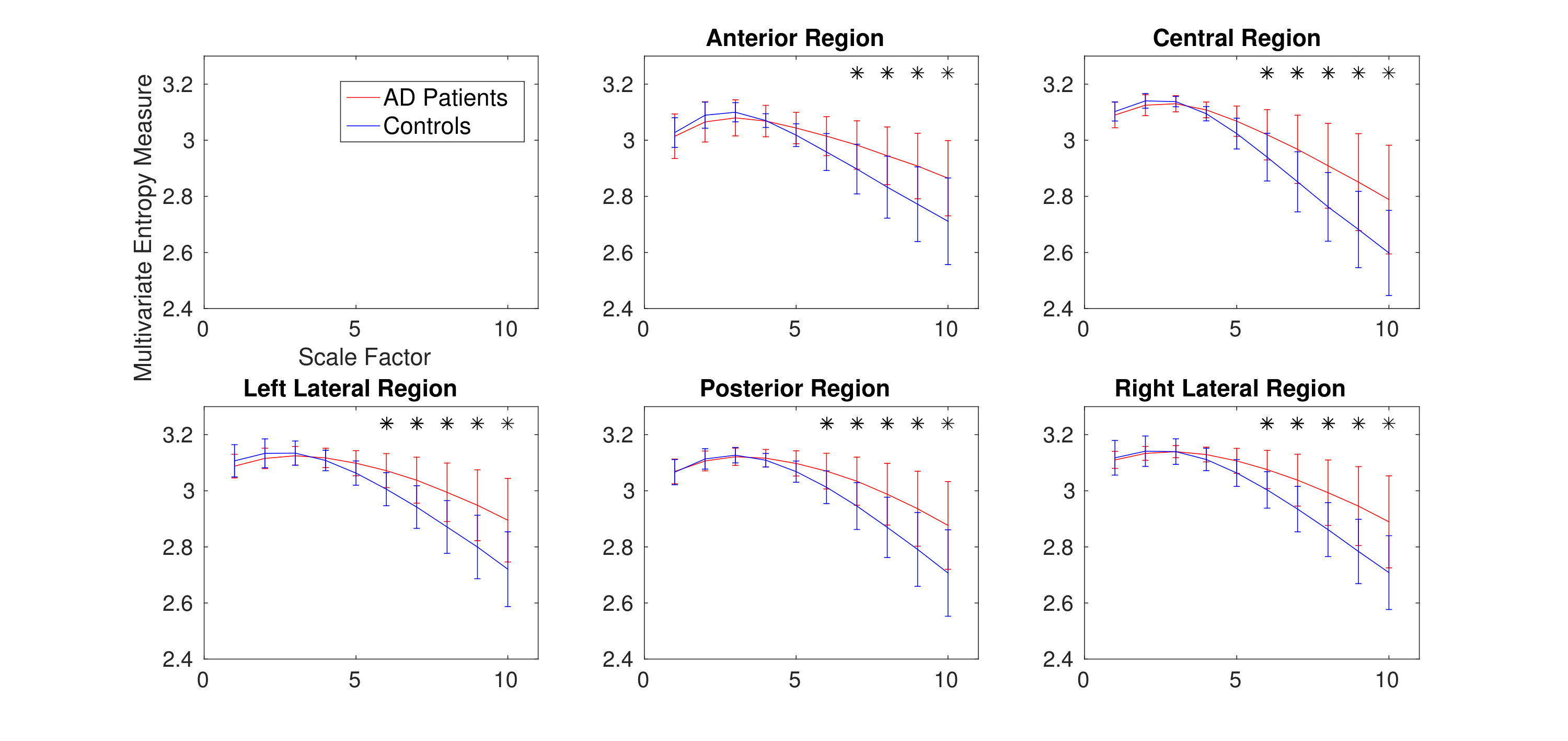 Figure 29
Figure 29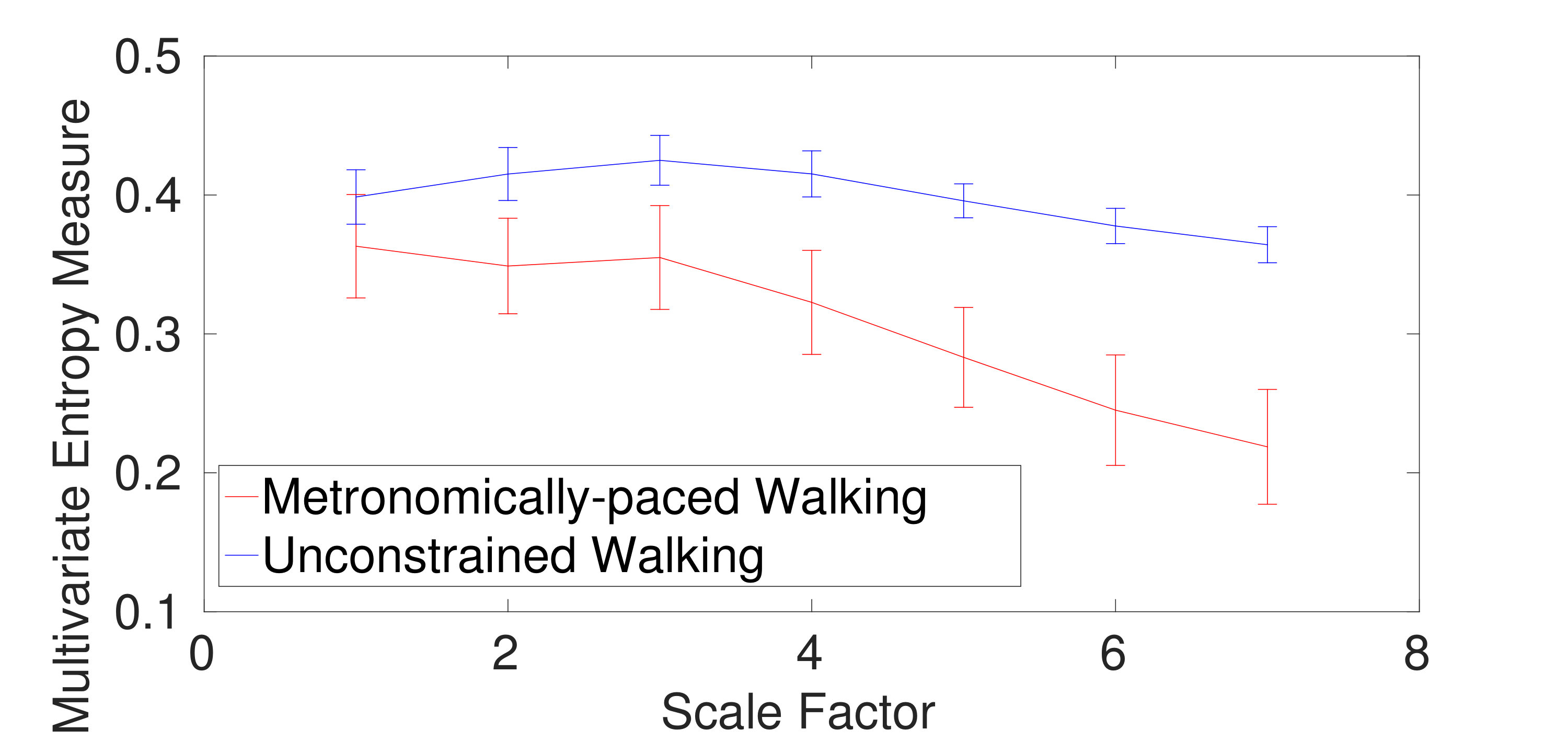 Figure 30
Figure 30| Time series | mvMDE-I | mvMDE-II | mvMDE-III | mvMDE | mvMSE | mvMFE |
|---|---|---|---|---|---|---|
| All three channels contain noise | 0.0028 | 0.0025 | 0.0037 | 0.0022 | 0.0405 | 0.0355 |
| Two channels contain noise and one contains WGN | 0.0042 | 0.0032 | 0.0036 | 0.0044 | 0.0283 | 0.0274 |
| One channel contains noise and two contain WGN | 0.0066 | 0.0052 | 0.0058 | 0.0061 | 0.0305 | 0.0292 |
| All three channels contain WGN | 0.0072 | 0.0080 | 0.0092 | 0.0101 | 0.0232 | 0.0211 |
| Number of channels and samples | mvMSE | mvMFE | mvMDE-I | mvMDE-II | mvMDE-III | mvMDE |
|---|---|---|---|---|---|---|
| 2 channels and 1,000 samples | 0.141 s | 0.153 s | 0.083 s | 0.116 s | 0.100 s | 0.089 s |
| 2 channels and 3,000 samples | 0.598 s | 0.723 s | 0.240 s | 0.3126 s | 0.280 s | 0.265 s |
| 2 channels and 10,000 samples | 4.234 s | 5.334 s | 0.736 s | 1.010 s | 0.919 s | 0.868 s |
| 5 channels and 1,000 samples | 0.544 s | 0.636 s | 0.191 s | 91.240 s | 0.903 s | 0.229 s |
| 5 channels and 3,000 samples | 3.174 s | 3.586 s | 0.568 s | 169.275 s | 2.209 s | 0.670 s |
| 5 channels and 10,000 samples | 28.229 s | 31.242 s | 1.850 s | 454.199 s | 7.271 s | 2.312 s |
| 8 channels and 1,000 samples | 1.479 s | 1.573 s | 0.298 s | out of memory error | 103.096 s | 0.354 s |
| 8 channels and 3,000 samples | 9.421 s | 9.972 s | 0.820 s | out of memory error | 245.034 s | 1.028 s |
| 8 channels and 10,000 samples | out of memory error | out of memory error | 2.687 s | out of memory error | 745.633 s | 3.509 s |
| mvMFE | mvMFE | mvMDE-III | mvMDE-III | mvMDE | mvMDE |
| for SPW | for MPW | for SPW | for MPW | for SPW | for MPW |
| 0.040 | 0.116 | 0.005 | 0.025 | 0.002 | 0.019 |
| mvMFE | mvMFE | mvMDE-II | mvMDE-II |
|---|---|---|---|
| of focal signals | of non-focal signals | of focal signals | of non-focal signals |
| 0.019 | 0.015 | 0.006 | 0.008 |
| mvMDE-III | mvMDE-III | mvMDE | mvMDE |
| of focal signals | of non-focal signals | of focal signals | of non-focal signals |
| 0.003 | 0.003 | 0.002 | 0.002 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Multivariate Multiscale Dispersion Entropy of Biomedical Times Series
Hamed Azami1,∗, Student Member, IEEE, Alberto Fernández2, and Javier Escudero1, Member, IEEE 1 H. Azami and J. Escudero are with the Institute for Digital Communications, School of Engineering, The University of Edinburgh, Edinburgh, King’s Buildings, EH9 3FB, United Kingdom. (Phone: +44 131 650 5599, emails: [email protected], [email protected]). *Corresponding author.2 A. Fernández is with the Departamento de Psiquiatría y Psicología Médica, Universidad Complutense de Madrid, Madrid, Spain. He is also with Laboratorio de Neurociencia Cognitiva y Computacional, Centro de Tecnología Biomédica, Universidad Politecnica de Madrid and Universidad Complutense de Madrid, Madrid, Spain and with the Insitituto de Investigación Sanitaria San Carlos (IdSSC).
Abstract
Objective: Due to the non-linearity of numerous biomedical signals, non-linear analysis of multi-channel time series, notably multivariate multiscale entropy (mvMSE), has been extensively used in biomedical signal processing. However, mvMSE has three drawbacks: 1) mvMSE values are either undefined or unreliable for short signals; 2) mvMSE is not fast enough for real-time applications; and 3) the computation of mvMSE for signals with a large number of channels requires the storage of a huge number of elements. Methods: To deal with these problems and improve the stability of mvMSE, we introduce multivariate multiscale dispersion entropy (MDE - mvMDE), as an extension of our recently developed MDE, to quantify the complexity of multivariate time series. Results: We assess mvMDE, in comparison with mvMSE and multivariate multiscale fuzzy entropy (mvMFE), on correlated and uncorrelated multi-channel noise signals, bivariate autoregressive processes, and three biomedical datasets. The results show that mvMDE takes into account dependencies in patterns across both the time and spatial domains. The mvMDE, mvMSE, and mvMFE methods are consistent in that they lead to similar conclusions about the underlying physiological conditions. However, the proposed mvMDE discriminates various physiological states of the biomedical recordings better than mvMSE and mvMFE. In addition, for both the short and long time series, the mvMDE-based results are noticeably more stable than the mvMSE- and mvMFE-based ones. Conclusion: For short multivariate time series, mvMDE, unlike mvMSE, does not result in undefined values. Furthermore, mvMDE is noticeably faster than mvMFE and mvMSE and also needs to store a considerably smaller number of elements. Significance: Due to its ability to detect different kinds of dynamics of multivariate signals, mvMDE has great potential to analyse various physiological signals.
Index Terms:
Complexity, multivariate multiscale dispersion entropy, biomedical multivariate time series, electroencephalogram, magnetoencephalogram.
I Introduction
Multivariate techniques are needed to analyse data consisting of more than one time series [1]. The majority of physiological and pathophysiological activities include interactions between different kinds of single processes. Thus, we expect that parameters or measures with different origins are considered in a multivariate way [1, 2]. Furthermore, recent developments in sensor technology enabling routine recordings of multi-channel signals have led to an increasing popularity of this kind of analysis on biomedical data [3, 1].
Advances on information theory and non-linear dynamical approaches have recently allowed the study of different kinds of multivariate time series [4]. Due to the intrinsic non-linearity of diverse physiological processes, non-linear analysis of multivariate time series has been broadly used in biomedical engineering with the aim of studying the relationship between simultaneously recorded signals [4].
Multivariate multiscale entropy (mvMSE) as a powerful non-linear measure is based on a combination of multivariate sample entropy (SampEn - mvSE) and the coarse-graining process [5]. mvMSE, by taking into account both the spatial and time domains, shows the complexity of multi-channel signals [5]. Complexity reflects the degree of structural richness of time series [6, 5] and is different with that of irregularity or uncertainty defined from classical entropy methods such as SampEn [7], permutation entropy (PerEn) [8], and dispersion entropy (DisEn) [9]. That is to say, neither completely regular or certain nor completely irregular (uncorrelated random) time series are truly complex, since none of them is structurally rich at a global level [10, 6, 11, 5].
The multivariate multiscale entropy-based analysis is interpreted based on: 1) the multivariate time series X is more complex than the multivariate time series Y, if for the most temporal scales, the mvSE measures for X are larger than those for Y; 2) a monotonic fall in the multivariate entropy values along the temporal scale factors shows that the signal only includes useful information at the smallest scale factors; and 3) a multivariate signal illustrating long-range correlations and complex creating dynamics is characterized by either a constant mvSE or this demonstrates a monotonic rise in mvSE with the temporal scale factor [5].
Although the mvMSE is a powerful and widely-used method, when applied to short signals, the results may be undefined or unreliable [12]. To alleviate this shortcoming, multivariate multiscale fuzzy entropy (mvMFE) based on multivariate fuzzy entropy (mvFE) and the coarse-graining process was suggested [13]. To decrease the running time of the mvMFE proposed in [13], we have recently proposed an mvMFE with a new fuzzy membership function [12]. Nevertheless, the mvMFE is still slow for real-time applications and may lead to unreliable results for short signals, as shown later.
To overcome the problem of unreliable values for mvMFE and mvMSE, multivariate multiscale PerEn (mvMPE) was proposed [14]. To have more information regarding the amplitude of multi-channel signals, multivariate weighted multiscale PerEn (mvWMPE) has recently been developed [15]. However, both the mvMPE and mvWMPE do not take into account the cross-statistical properties between multiple input channels and do not follow the concept of complexity for some signals such as white Gaussian noise (WGN) and noise [12, 10, 5].
mvMSE and mvMFE have growing appeal and broad use. They have been successfully used in a number of biomedical signal processing applications, such as, to characterise electroencephalogram (EEG) signals in Alzheimer’s disease (AD) [16, 17], to analyze the multivariate cardiovascular time series [18], to characterize focal and non-focal EEG time series [12], to analyze the complexity of interbeat interval and interbreath signals [5], and to analyze the postural fluctuations in fallers and non-fallers older adults [19].
However, mvMSE and mvMFE have the following shortcomings: 1) mvMSE and mvMFE values may be unreliable and unstable for short signals; 2) they are not quick enough for real-time applications; and 3) computation of mvMSE and mvMFE of a signal with a large number of channels needs to have large memory space, as shown later. To address these drawbacks, we propose four algorithms to extend our recently developed MDE to its multivariate versions, termed multivariate MDE (mvMDE). To evaluate the mvMDE methods, we use both synthetic and real multivariate datasets. Our results indicate that mvMDE is noticeably faster than the existing methods, leads to more stable results, better discriminates different kinds of biomedical time series, does not lead to undefined values for short multivariate time series, and needs to store a considerably smaller number of elements in comparison with mvMSE and mvMFE.
II Multivariate Multiscale Dispersion Entropy (mvMDE)
In this study, we propose and explore three different alternative implementations of mvMDE until we arrive at a fourth and preferred one. All the mvMDE implementations include two main steps: 1) coarse-graining process for multivariate time series; and 2) multivariate dispersion entropy (mvDE), as an extension of our recently developed DisEn [9]. It is worth noting that for all the mvMDE algorithms, the mapping based on the normal cumulative distribution function (NCDF) used in the calculation of mvDE for the first temporal scale factor is maintained fixed across all scales. In fact, in the mvMDE, and of the NCDF are respectively set at the average and standard deviation (SD) of the original time series and they remain constant for all temporal scale factors. This fact is similar to in the mvMSE and mvMFE, setting at a certain percentage (usually 15%) of the SD of the original signal and remaining constant for all scales [5, 12].
II-A Coarse-Graining Process for Multivariate Signals
Assume we have a p-channel time series of length . In the mvMDE algorithms, for each channel, the original signal is first divided into non-overlapping segments of length , named scale factor. Next, for each channel, the average of each segment is calculated to derive the coarse-grained signals as follows [5, 12]:
[TABLE]
where denotes the length of the coarse-grained signal. The second step of mvMDE is calculating the mvDE of each coarse-grained signal.
II-B Background Information for the mvDE
We build four diverse alternative implementations of mvDE (mvDE-I to III and mvDE) until we arrive at a preferred (or optimal) one, i.e., mvDE. However, we here present all the simpler alternatives (mvDE-I to III), since they can still be useful in some settings and allow for clearer comparisons with other current approaches.
II-B1 mvDE-I
The mvDE-I of the multi-channel coarse-grained time series , which is based on the mvMPE algorithm [14], is calculated as follows:
a) First, are mapped to c classes with integer indices from 1 to c. Since the amplitude values of each of series () may be dominated by the components of vectors coming from the time series with the largest amplitudes, we scale all of the data channels to the same amplitude range. To this end and to overcome the problem of assigning the majority of to only few classes when maximum or minimum values are noticeable larger or smaller than the mean/median value of the signal, the NCDF of each of is first calculated. In fact, the NCDF maps X into from 0 to 1 as follows:
[TABLE]
where and are the SD and mean of time series , respectively. Then, we use a linear algorithm to assign each to an integer from 1 to . To do so, for each member of the mapped signal, we use , where denotes the member of the classified signal in the channel and rounding involves either increasing or decreasing a number to the next digit. Note that, although this part is linear, the whole mapping approach is non-linear because of the use of NCDF.
b) Time series are made with embedding dimension and time delay according to , [9][7][8]. Each time series is mapped to a dispersion pattern , where , ,…, . The number of possible dispersion patterns that can be assigned to each time series is equal to , since the signal has members and each member can be one of the integers from 1 to [9].
c) For each channel and for each of potential dispersion patterns , relative frequency is obtained as follows:
[TABLE]
where means cardinality. In fact, shows the number of dispersion patterns of that is assigned to , divided by the total number of embedded signals with embedding dimension multiplied by the number of channels.
d) Finally, based on the Shannon’s definition of entropy, the mvDE-I is calculated as follows:
[TABLE]
In case all possible dispersion patterns have equal probability value, the highest value of mvDE-I is obtained, which has a value of . In contrast, if there is only one different from zero, which demonstrates a completely regular/certain signal, the smallest value of mvDE-I is obtained. In the algorithm of mvDE-I, we compare dispersion patterns of a p-channel signal with potential patterns. Thus, at least elements are stored.
To work with reliable statistics to calculate MDE, it was recommended [20]. For mvMDE-I, since the mvDE-I counts the dispersion patterns for every channel of a multivariate time series, it is suggested . mvMDE-I works appropriately when the components of a multivariate signal are statistically independent. However, the mvMDE-I algorithm, like mvMPE [14], does not consider the spatial domain of time series. To overcome this problem, we propose mvMDE-II based on the Taken’s theorem [21, 12].
II-B2 mvDE-II
The algorithm of mvDE-II is as follows:
a) First, like mvDE-I, are mapped to based on the NCDF.
b) To take into account both the spatial and time domains, multi-channel embedded vectors are generated according to the multivariate embedding theory [21]. The multivariate embedded reconstruction of Z is defined as:
[TABLE]
where and denote the embedding dimension and the time lag vectors, respectively. Note that the length of is . For simplicity, we assume and , that is, all the embedding dimension values and all the delay values are equal.
c) Each series is mapped to a dispersion pattern , where , ,…, . The number of possible dispersion patterns that can be assigned to each time series is equal to , since the signal has members and each member can be one of the integers from 1 to .
d) For each of potential dispersion patterns , relative frequency is obtained based on the DisEn algorithm [9] as follows:
[TABLE]
e) Finally, based on the Shannon’s definition of entropy, the mvDE-II is calculated as follows:
[TABLE]
In the algorithm of mvDE-II, at least elements are stored. Thus, when p is large, the algorithm needs huge space of memory to store elements. To work with reliable statistics to calculate mvMDE-II, it is recommended . Thus, although mvDE-II deals with both the spatial and time domains, the length of a signal and its number of channels should be very large and small, respectively, to reliably calculate mvDE-II values. To alleviate the problem, we propose mvDE-III.
II-B3 mvDE-III
The algorithm of mvDE-III is as follows:
a) First, like the mvDE-I and mvDE-II approaches, are mapped to .
b) Multivariate embedded vectors are generated according to the Taken’s embedding theorem [21] with p embedding dimension vectors () with length , where denotes the element of m. For simplicity, we assume and .
c) Each series is mapped to a dispersion pattern . The number of possible dispersion patterns that can be assigned to each time series is equal to , since the signal has members and each member can be one of the integers from 1 to [9]. Since we count the number of patterns for each of p different , we have a times increase in the number of dispersion patterns in comparison with mvDE-II, leading to more reliable results for a signal with a small number of sample points, as shown later.
d) For each channel and for each of potential dispersion patterns , relative frequency is obtained as follows:
[TABLE]
e) Finally, based on the Shannon’s definition of entropy, the mvDE-II is calculated as follows:
[TABLE]
In the algorithm of mvDE-III, at least elements are stored. Although this number is noticeably smaller than that for mvDE-II, the algorithm still needs to have large memory space for a signal with a large number of channels. To work with reliable statistics to calculate mvMDE-III, it is recommended . Therefore, albeit mvMDE-III takes into account both the spatial and time domains and needs to smaller number of sample points in comparison with mvMDE-II, there is a need to have a large enough number of samples and small number of channels. To alleviate these deficiencies, we propose mvDE.
II-C Multivariate Dispersion Entropy (mvDE)
The mvDE algorithm is as follows:
a) First, like mvDE-I to III, the multivariate signal is mapped to c classes with integer indices from 1 to c.
b) Like mvDE-II, to consider both the spatial and time domains, multivariate embedded vectors are created based on the Taken’s embedding theorem [21]. For simplicity, we assume and .
c) For every , all combinations of the elements in taken m at a time, termed (), are created. The number of the combinations is equal to . Therefore, for all channels, we have dispersion patterns.
d) For each and for each of potential dispersion patterns , relative frequency is obtained as follows:
[TABLE]
e) Finally, based on the Shannon’s definition of entropy, the mvDE is calculated as follows:
[TABLE]
In the mvDE algorithm, at least elements are stored. This number is noticeably smaller than those for mvDE-I to III, leading to more stable results for signals with a short length and a large number of samples. As the number of patterns obtained by the mvMDE method is , it is suggested to work with reliable statistics.
II-D Parameters of the mvMDE, mvMSE, and mvMFE Methods
In addition to the maximum scale factor described before, there are three other parameters for the mvMDE methods, including the embedding dimension vector m, the number of classes c, and the time delay vector d. In practice, it is recommended , because some information with regard to the frequency may be ignored for . We need to keep away the trivial case of having only one dispersion pattern. For simplicity, we use and for all signals used in this study, although the range leads to similar results. For more information about c, , and , please refer to [9].
In this study, , , and for the mvMSE and mvMFE were respectively set as 1, 2, and 0.15 of the SD of the original time series following recommendations in [5, 12]. The maximum scale factor for mvMSE and mvMFE also follows [12, 5]. In the algorithm of mvSE and mvFE, at least elements are stored. Matlab codes of mvMFE and mvMSE are available at http://dx.doi.org/10.7488/ds/1432. Overall, the characteristics and limitations of the mvSE, mvFE, and mvDE algorithms for a p-channel signal with length N are summarized in Table I.
III Evaluation Signals
In this section, the descriptions of correlated and uncorrelated noise signals and real time series used in this study are given.
III-A Synthetic Signals
The irregularity of multivariate noise is lower than multivariate WGN, whereas the complexity of the former is higher than the latter [10, 12, 5]. Thus, noise and WGN signals have been commonly used to assess the multivariate multiscale entropy techniques [22, 12, 5]. For more information, please refer to [6, 10, 12, 5].
To understand the behaviour of the mvMDE methods on uncorrelated WGN and noise, we first generated a trivariate time series, where originally all three data channels were realization of mutually independent noise. Then, we gradually decreased the number of data channels representing noise (from 3 to 0) and at the same time, increased the number of variates representing independent WGN (from 0 to 3) [22]. The number of channels was always three.
To create correlated bivariate noise time series, we first generated a bivariate uncorrelated random time series H. Afterwards, H was multiplied with the standard deviation (hereafter, sigma) and then, the value of the mean (hereafter, mu) was added. Next, H was multiplied by the upper triangular matrix L obtained from the Cholesky decomposition of a defined correlation matrix R (which is positive and symmetric) to set the correlation. Here, we set according to [5, 12]. An in-depth study on the effect of correlated and uncorrelated noise and WGN on multiscale entropy approaches can be found in [6, 5].
Based on the fact that the larger the order of an AR process, the more complex the AR process [5], we evaluate the mvMDE, mvMSE, and mvMFE methods on a bivariate AR process describing the evolution of a set of two variables as a linear function of their past values according to:
[TABLE]
where y is the vector of variables, is the maximum lag in the bivariate AR model, denotes the matrix of parameters corresponding to lag order , and is the vector of error terms assumed to be WGN[23]. For simplicity, we set .
III-B Real Biomedical Datasets
1) Dataset of Stride Internal Fluctuations: To investigate the ability of the proposed mvMDE methods to reveal the long-range correlations and dynamics of multivariate signals, the stride interval recordings are used [24, 25]. The time series were recorded from ten young, healthy men. Mean age was 21.7 years, changing from 18 to 29 years. Height and weight were 1.77 0.08 meters (mean SD) and 71.8 10.7 kg (mean SD), respectively. All ten participants provided informed written consent walking for 1 hour at slow, normal, and fast paces and also walking a metronome set to each subject’s mean stride interval. Three walking paces were considered as different variables from the same system. In this way, we expect to be able to discriminate between the metronomically-paced and self-spaced walking. For further information, please refer to [25].
2) Dataset of Focal and Non-focal Brain Activity: The ability of the mvMDE methods, in comparison with mvMFE and mvMSE, to differentiate focal from non-focal recordings is evaluated using a publicly-available EEG dataset [26]. The dataset includes 5 patients and, for each patient, there are 750 focal and 750 non-focal bivariate signals. The length of each recording was 20 s with sampling frequency of 512 Hz (10240 sample points). Further information can be found in [26]. Before computing the aforementioned methods, all recordings were digitally filtered employing an FIR band-pass filter with cut-off frequencies at 0.5 Hz and 40 Hz.
3) Surface MEG Recordings in Alzheimer’s Disease: We analysed resting state MEG time series recorded with a 148-channel whole-head magnetometer. All 62 participants agreed for the research, which was approved by the local ethics committee. To screen the cognitive status, a mini-mental state examination (MMSE) was done. There were 36 AD patients (age = years, all data given as mean SD, and MMSE score = ) and 26 controls (age = years, and MMSE score = ). The difference in age between two groups was not significant (-value = 0.1911, Student’s -test) [27]. The distribution of MEG sensors is shown in Fig. 2 in [27]. For each participant, five minutes of MEG resting state activity were recorded at a sampling frequency of 169.5 Hz. The signals were divided into 10 s segments (1695 samples) and visually inspected using an automated thresholding procedure to discard epochs noticeably contaminated with artifacts. All recordings were digitally band-pass filtered with a Hamming window FIR filter of order 200 and cut-off frequencies at 1.5 Hz and 40 Hz. For more information, please see [27].
IV Results and Discussions
IV-A Synthetic Signals
We first apply the proposed and existing methods to 40 independent realizations of uncorrelated trivariate WGN and noise, described in Section III. The number of sample points for each of the noise and WGN signals were 15000. The average and SD of the results for mvMDE-I, mvMDE-II, mvMDE-III, mvMDE, mvMSE, and mvMFE are depicted in Fig. 1(a) to 1(f), respectively. Using all the existing and proposed methods, the entropy values of trivariate WGN signals are higher than those of the other trivariate time series at low scale factors. However, the entropy values for the coarse-grained trivariate noise signals stay almost constant or decrease slowly along the temporal scale factor, while the entropy values for the coarse-grained WGN signal monotonically decreases with the increase of scale factors. When the length of WGN signals, obtained by the coarse-graining process, decreases (i.e., the scale factor increases), the mean value of inside each signal converges to a constant value and the SD becomes smaller. Therefore, no new structures are revealed at higher temporal scales. This demonstrates a multivariate WGN time series has information only in small temporal scale factors. In contrast, for trivariate noise signals, the mean value of the fluctuations inside each signal does not converge to a constant value.
For all the methods, the higher the number of variates representing noise, the higher complexity the trivariate signal, in agreement with the fact that multivariate noise is structurally more complex than multivariate WGN [5, 12, 10]. Here, for multivariate noise and WGN, was 20 for mvMDE, according to Section II.
To compare the results obtained by the mvMDE, mvMSE, and mvMFE methods, we used the coefficient of variation (CV) defined as the SD divided by the mean. In fact, CV permits comparison of variability estimates regardless of the magnitude values. We investigate the results obtained by uncorrelated noise signals at scale factor 10, as a trade-off between short and long scale factors. As can be seen in Table II, the smallest CV values for uncorrelated trivariate noise, an uncorrelated combination of bivariate noise and univariate WGN, an uncorrelated combination of bivariate WGN and univariate noise, and trivariate WGN are achieved by mvMDE, mvMDE-II, mvMDE-II, and mvMDE-I, respectively. Overall, the smallest CV values for trivariate noise and WGN profiles are reached by the mvMDE methods, showing the superiority of the mvMDE methods over mvMSE and mvMFE in terms of stability of results.
To assess the ability of the mvMDE methods to characterize short signals in comparison with mvMFE and mvMSE, we use trivariate and WGN noise with length of 300 sample points. The results for the mvMDE, mvMSE, and mvMFE approaches at temporal scales 1 to 20 are depicted in Fig. 2(a) to 2(f), respectively. As can be seen in Fig. 2(a) and 2(d), the mvMDE-I and mvMDE methods better discriminate different dynamics of the noise signals. However, the mvMSE values are undefined at higher scale factors. Although the mvMFE- and mvMDE-II-based values are defined at all scale factors, they cannot distinguish the dynamics of different noise signals. The profiles obtained by mvMDE-III are more distinguishable than mvMDE-II, as mentioned that mvMDE-III needs a smaller number of sample points. Nevertheless, the profiles obtained by mvMDE-III have overlaps at several scale factors. Overall, the results show the superiority of mvMDE-I and mvMDE over mvMDE-II, mvMDE-III, mvMSE, and mvMFE for short uncorrelated signals.
To evaluate the computational time of mvMSE, mvMFE, mvMDE-I to III, and mvMDE, we use uncorrelated multivariate WGN time series with different lengths, changing from 100 to 10,000 sample points, and different number of channels, changing from 2 to 8. The results are depicted in Table III. The simulations have been carried out using a PC with Intel (R) Xeon (R) CPU, E5420, 2.5 GHz and 8-GB RAM by MATLAB R2015a. The results show that the computation times for mvMSE and mvMFE are close. The slowest algorithm is mvMDE-II, while the fastest ones are mvMDE-I and mvMDE, in that order. For an 8-channel signal with 10,000 samples, using mvMSE, mvMFE, and mvMDE-II, the array exceeded the memory available. Overall, in terms of computation time and memory space, mvMDE outperforms all the existing and proposed methods taking into account both the time and spatial domains.
Univariate multiscale entropy approaches only consider every data channel separately and fail to take into account the cross-channel information of multivariate time series [5]. Uncorrelated multi-channel WGN has less structural complexity and more irregularity compared with multi-channel noise. To assess the ability of the existing and proposed multivariate entropy methods to reveal the dynamics across the channels, we created 40 independent realizations of different combinations of bivariate noise and WGN time series with length 20,000 (according to [5, 12]), making the channels correlated. Fig. 3(a) to 3(d) respectively show the results obtained using the mvMDE-I, mvMDE-II, mvMDE-III, and mvMDE to model both the within- and cross-channel properties in multivariate signals.
mvMDE-I cannot discriminate the correlated from uncorrelated WGN or noise. This fact is revealed in Fig. 3 (a). Therefore, mvMDE-I should only be used when the components of a multi-channel time series are statistically independent. Multivariate multiscale entropy-based methods at scale factor 1 show the irregularity of multi-channel signals [5]. The mvMDE-II, mvMDE-III, and mvMDE values at scale 1 show that the uncorrelated WGN is the most irregular and unpredictable time series in agreement with [6], while the most irregular signals using mvMFE and mvMSE are the correlated WGN [12, 5], in contrast with the fact that correlated multi-channel WGN signals are more predictable and regular than uncorrelated WGN ones [6, 20].
The correlated bivariate noise is the most complex signal using the mvMDE-II, mvMDE-III, and mvMDE. The second most complex signal is the uncorrelated bivariate noise, as can be seen in Fig. 3. The decreases of the uncorrelated bivariate WGN noise profiles using mvMDE-II, mvMDE-III, and mvMDE are the largest, evidencing the fact that the uncorrelated WGN is the least complex time series. These facts are also in agreement with the previous studies [5, 12, 10]. Therefore, as desired, the mvMDE-II, mvMDE-III, and mvMDE deal with both the cross- and within-channel correlations.
The ability of the mvMDE methods to characterize multivariate AR processes is further evaluated using bivariate AR(1), AR(3), and AR(5). The results obtained by the mvMDE-I, mvMDE-II, mvMDE-III, and mvMDE are shown in Fig. 4(a) to 4(d). As expected, when the lag order increases, the complexity of the corresponding time series using the mvMDE approaches increases, in agreement with the fact that a larger lag order denotes a more complex time series [5].
IV-B Real Biomedical Datasets
Discrimination of aged and diseased individuals’ from control or healthy subjects’ time series is a long-lasting challenge in the physiological complexity literature [6, 12, 5, 28]. To this end, we use the mvMDE methods, in comparison with mvMFE as an improved version of mvMSE [12], to detect different types of dynamical variability of multivariate recordings of three physiological datasets. Of note is that we do not use the mvMDE-I for biomedical signals, because it does not take into account both the spatial and time domains at the same time.
1) Dataset of Stride Internal Fluctuations: For the self-paced versus metronomically-paced stride interval fluctuations, the results obtained by the mvMDE-III, mvMDE, and mvMFE, respectively depicted in Fig. 5(a), (b), and (c), show that the self-paced unconstrained walk’s fluctuations have more complexity and greater long-range correlations than the metronomically-paced walk’s series, in agreement with those obtained by mvMSE, and multivariate empirical mode decomposition-enhanced by mvSE [24]. We did not use mvMDE-II, as the signals do not follow the minimum number of samples required for mvMDE-II. To compare the results, the CV values for both the metronomically- and self-paced walk (MPW and SPW) at scale factor 4, as a trade-off between the long and short scales, are shown in Table IV. The CV values for the mvMDE-III- and mvMDE-based profiles are smaller than those for mvMFE, showing the superiority of the proposed methods over mvMFE in terms of the stability of results. The smallest CV values are achieved by the mvMDE.
2) Dataset of Focal and Non-focal Brain Activity: For the focal and non-focal EEG recordings, the results obtained by mvMDE-II, mvMDE-III, mvMDE, and mvMFE, respectively depicted in Fig. 5 (a), (b), (c), and (d), show that the focal time series are less complex than the non-focal ones, in agreement with previous studies [26][29]. The CV values for the focal- and non-focal-based results at scale 6 are shown in Table V. All the mvMDE-based CV values are smaller than those using mvMFE, showing more stability of the results obtained by the proposed methods. Moreover, the CV values for mvMDE are smaller than those for mvMDE-III, and the latter ones are smaller than those for mvMDE-II, suggesting that the mvMDE leads to more stable profiles.
3) Surface MEG Recordings in Alzheimer’s Disease: To assess the ability of mvMDE, in comparison with mvMFE, we applied the methods to the 148-channel MEG signals to discriminate AD patients from controls. Because mvMFE needs to store a huge number of elements for a signal with a large number of channels, mvMFE was not able to simultaneously analyse all 148 time series. However, the results using mvMDE are depicted in Fig. 6. It represents an advantage of mvMDE over mvMFE for signals with a large number of channels. To compare the mvMFE and mvMDE, we applied the methods to five main scalp regions, namely, anterior (17 channels), right (34 channels) and left lateral (34 channels), central (29 channels), and posterior (34 channels) areas, leading to the smaller number of channels to noticeably decrease the number of elements stored by the use of the mvMFE algorithm.
The average and SD of mvMDE and mvMFE values for five regions are respectively shown in Fig. 7(a) and 7(b). As can be seen in Fig. 6 and Fig. 7, the average mvMDE and mvMFE values for AD patients are smaller than those for controls at lower scale factors (short-time scale factors), while at higher scales, the AD subjects’ recordings have larger entropy values (long-time scale factors) for both the mvMFE and mvMDE, in agreement with [30, 31, 16]. Because the larger the number of channels, the smaller the mvMSE and similarly mvMFE values [16], the entropy values for anterior region are larger than those for the other four regions. It is worth noting that we only use mvMDE, as the signals do not follow the minimum number of samples required for mvMDE-II and III.
The Mann–Whitney U-test was used to assess the differences between the mvMDE and mvMFE profiles at each temporal scale for AD patients versus controls, because the mvMDE and mvMFE values at each scale factor did not follow a normal distribution. The temporal scales with p-values smaller than 0.001 are shown with * in Fig. 6 and Fig. 7. The p-values show that the mvMDE, compared with the mvMFE, significantly discriminated the controls from subjects with AD at a larger number of scale factors. Moreover, the smallest p-value was achieved by the mvMDE, evidencing the superiority of mvMDE over mvMFE.
On the whole, the profiles for the real datasets evidence the advantage of mvMDE-II, mvMDE-III, and mvMDE over mvMFE to discriminate different types of dynamics of multi-channel signals as well as the superiority of mvMDE over mvMFE in terms of ability to discriminate various dynamics of time series, computational time, and memory cost. As mentioned before, mvMPE does not consider the spatial domain. We have also refined the mvMPE [14] on the basis of mvMDE-II, mvMDE-III, and mvMDE. These approaches have the following advantages over the first version of mvMPE [14]: 1) they take into account both the spatial and time domains; 2) their results were more stable than the mvMPE-based ones; and 3) better distinguished different dynamics of multivariate signals. However, since the mvMDE methods are considerably faster, result in more stable profiles, and lead to larger differences between physiological conditions of recordings, for simplicity, we did not report the mvMPE-based results. Our future study will aim at proposing the refined composite mvMDE (RCmvMDE) approaches according to [12]. Moreover, we will explore the mvMDE and RCmvMDE on other physiological and non-physiological time series.
V Conclusions
To quantify the complexity of biomedical multivariate time series, we built four diverse alternative implementations of mvMDE as further developments of our recently introduced MDE [20]. These insights help towards a comprehensive understanding of four strategies to extend a univariate-based entropy method to its multivariate versions and therefore, provide invaluable information for future studies on multivariate time series. Although mvMDE was the best algorithm in terms of ability to discriminate dynamics of multivariate signals, computational time, and memory cost, the simpler alternatives (mvDE-I to III) may still be useful in some settings.
We assessed their performance on the correlated and uncorrelated multivariate noise signals, the bivariate AR time series, and three physiological datasets. The results showed the similar behavior of mvMSE-, mvMFE-, and mvMDE-based profiles. However, mvMDE had the following advantages over the existing methods: 1) it was noticeably faster than the existing methods; 2) mvMDE, in comparison with mvMSE and mvMFE, resulted in more stable profiles; 3) mvMDE better discriminated different kinds of biomedical signals; 4) for short multivariate time series, mvMDE, unlike mvMSE, did not result in undefined values; and 5) mvMDE, compared with mvMSE and mvMFE, needed to store a considerably smaller number of elements.
Overall, we expect the mvMDE approach to play a key role in the assessment of complexity in multivariate time series.
Acknowledgement
The MATLAB codes of the mvMDE techniques and the refined versions of mvMPE will be made publicly-available upon publication.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] S. Cerutti, D. Hoyer, and A. Voss, “Multiscale, multiorgan and multivariate complexity analyses of cardiovascular regulation,” Philosophical Transactions of the Royal Society of London A: Mathematical, Physical and Engineering Sciences , vol. 367, no. 1892, pp. 1337–1358, 2009.
- 2[2] S. Cerutti, “Multivariate and multiscale analysis of biomedical signals: Towards a comprehensive approach to medical diagnosis,” in Computer-Based Medical Systems (CBMS), 2012 25th International Symposium on , pp. 1–5, IEEE, 2012.
- 3[3] M. U. Ahmed and D. P. Mandic, “Multivariate multiscale entropy analysis,” IEEE Signal Processing Letters , vol. 19, no. 2, pp. 91–94, 2012.
- 4[4] E. Pereda, R. Q. Quiroga, and J. Bhattacharya, “Nonlinear multivariate analysis of neurophysiological signals,” Progress in neurobiology , vol. 77, no. 1, pp. 1–37, 2005.
- 5[5] M. U. Ahmed and D. P. Mandic, “Multivariate multiscale entropy: A tool for complexity analysis of multichannel data,” Physical Review E , vol. 84, no. 6, p. 061918, 2011.
- 6[6] M. Costa, A. L. Goldberger, and C.-K. Peng, “Multiscale entropy analysis of biological signals,” Physical review E , vol. 71, no. 2, p. 021906, 2005.
- 7[7] J. S. Richman and J. R. Moorman, “Physiological time-series analysis using approximate entropy and sample entropy,” American Journal of Physiology-Heart and Circulatory Physiology , vol. 278, no. 6, pp. H 2039–H 2049, 2000.
- 8[8] C. Bandt and B. Pompe, “Permutation entropy: a natural complexity measure for time series,” Physical review letters , vol. 88, no. 17, p. 174102, 2002.