RLE Plots: Visualising Unwanted Variation in High Dimensional Data
Luke C. Gandolfo, Terence P. Speed

TL;DR
RLE plots are a valuable visualization tool for detecting and assessing unwanted variation in high-dimensional data, especially in gene expression studies, and can evaluate the effectiveness of normalization procedures.
Contribution
This paper provides a detailed analysis and explanation of RLE plots, demonstrating their utility across various high-dimensional data types beyond microarrays.
Findings
RLE plots effectively reveal unwanted variation.
They help assess normalization success.
Applicable to diverse high-dimensional datasets.
Abstract
Unwanted variation can be highly problematic and so its detection is often crucial. Relative log expression (RLE) plots are a powerful tool for visualising such variation in high dimensional data. We provide a detailed examination of these plots, with the aid of examples and simulation, explaining what they are and what they can reveal. RLE plots are particularly useful for assessing whether a procedure aimed at removing unwanted variation, i.e. a normalisation procedure, has been successful. These plots, while originally devised for gene expression data from microarrays, can also be used to reveal unwanted variation in many other kinds of high dimensional data, where such variation can be problematic.
Click any figure to enlarge with its caption.
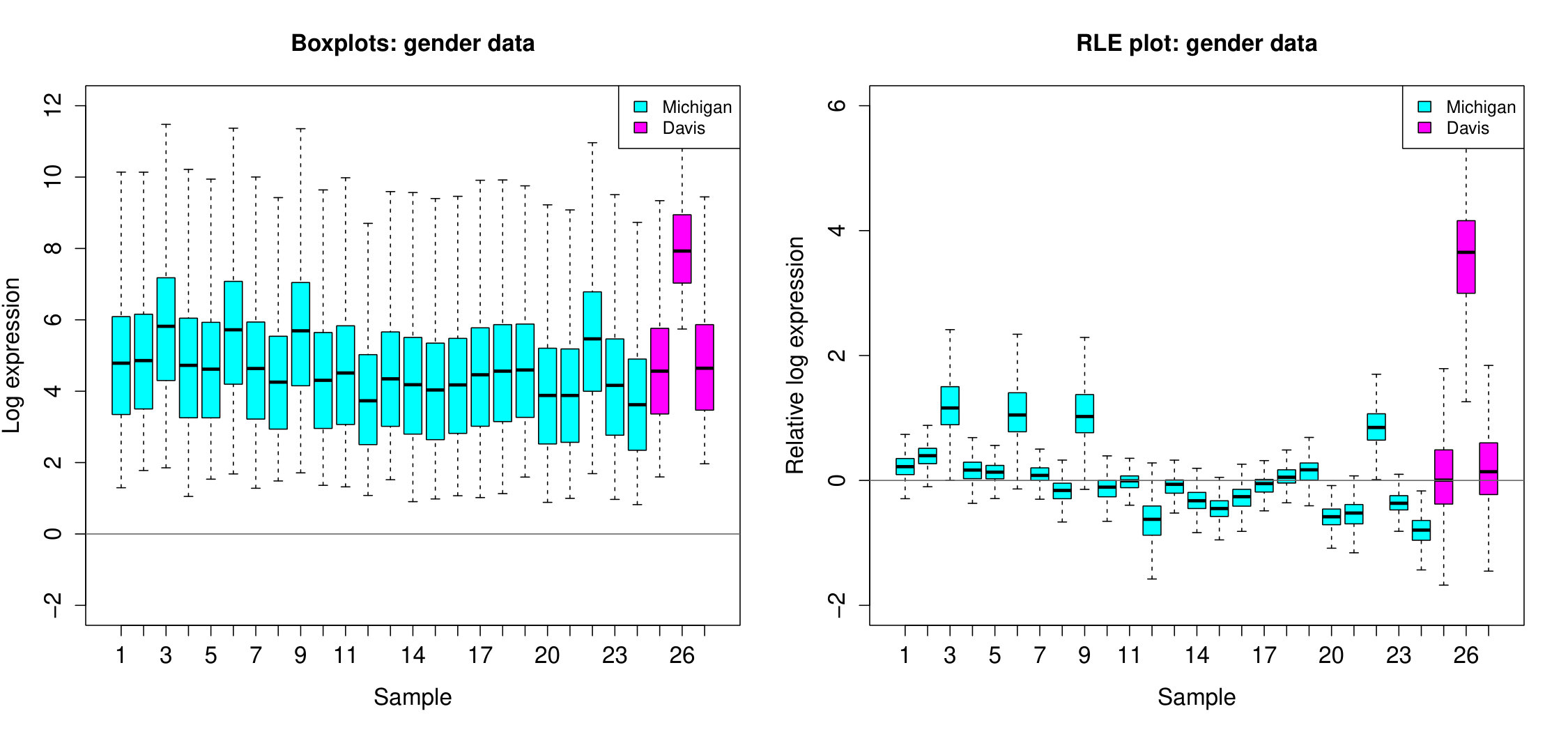 Figure 1
Figure 1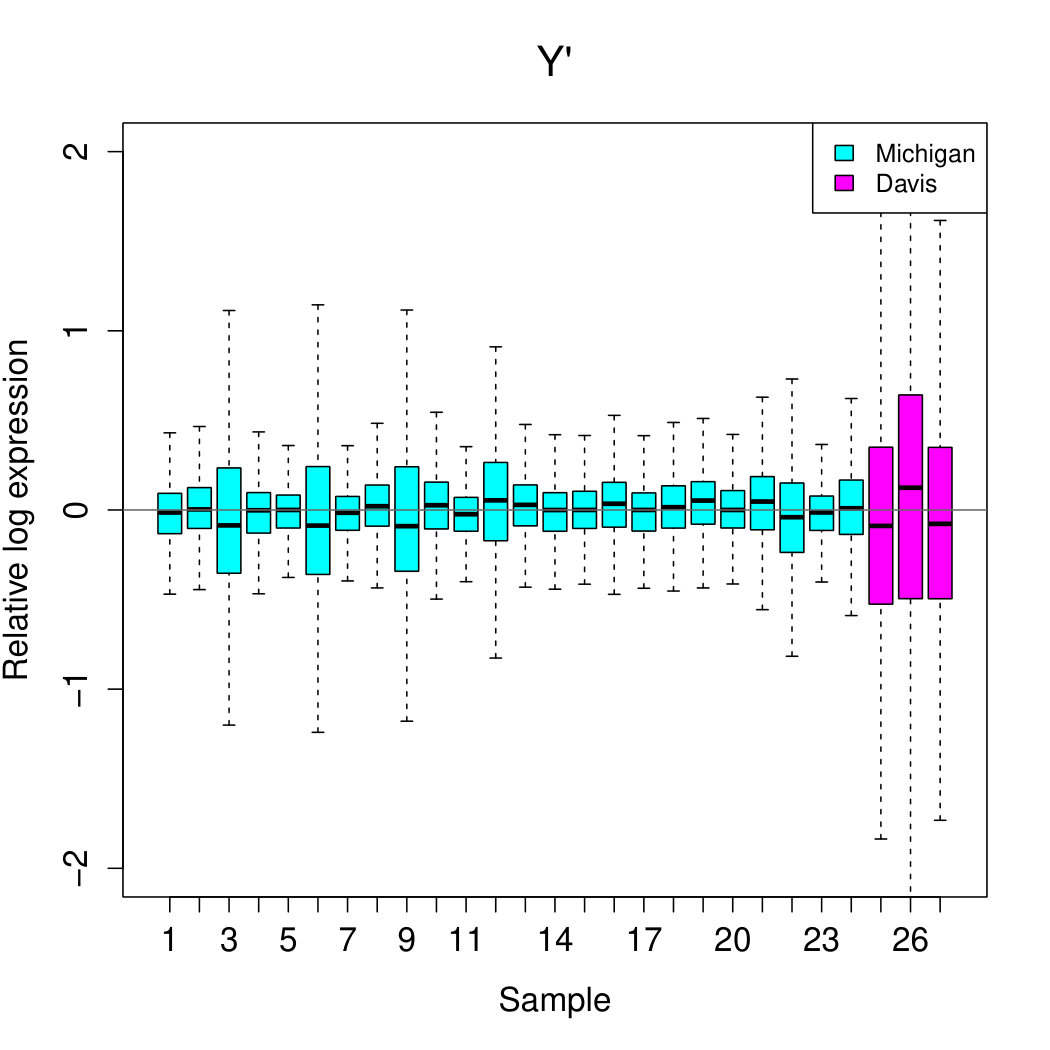 Figure 2
Figure 2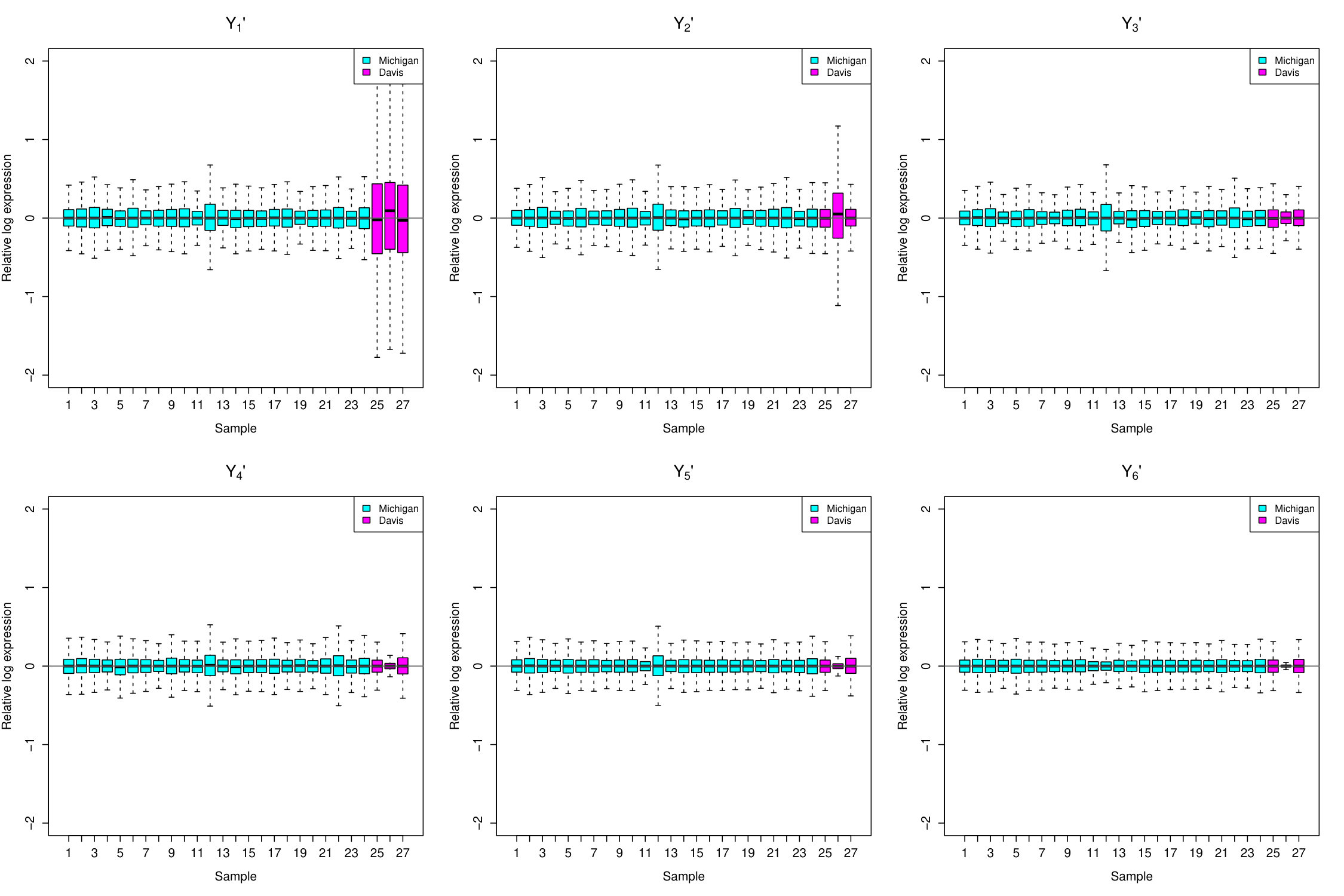 Figure 3
Figure 3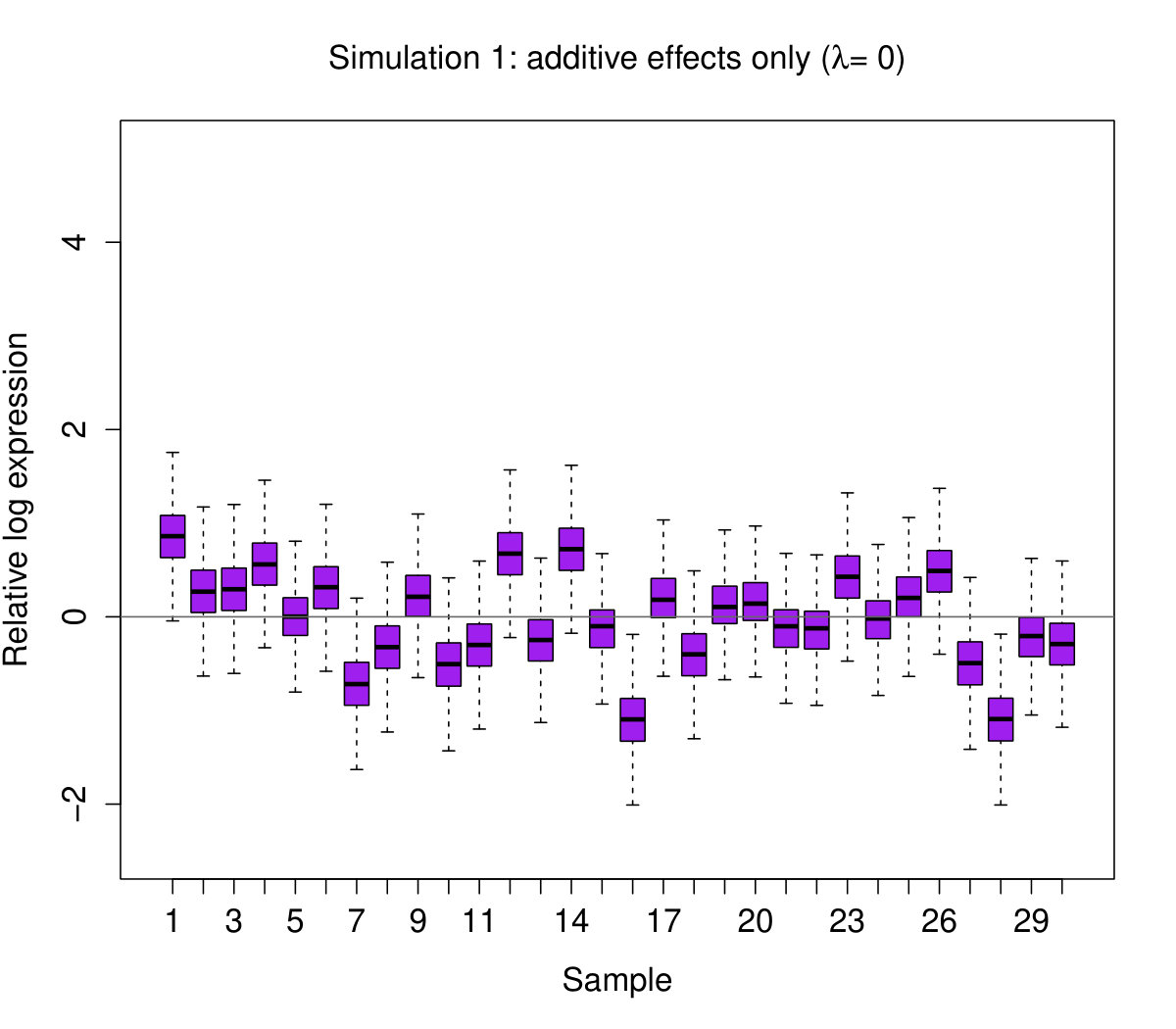 Figure 4
Figure 4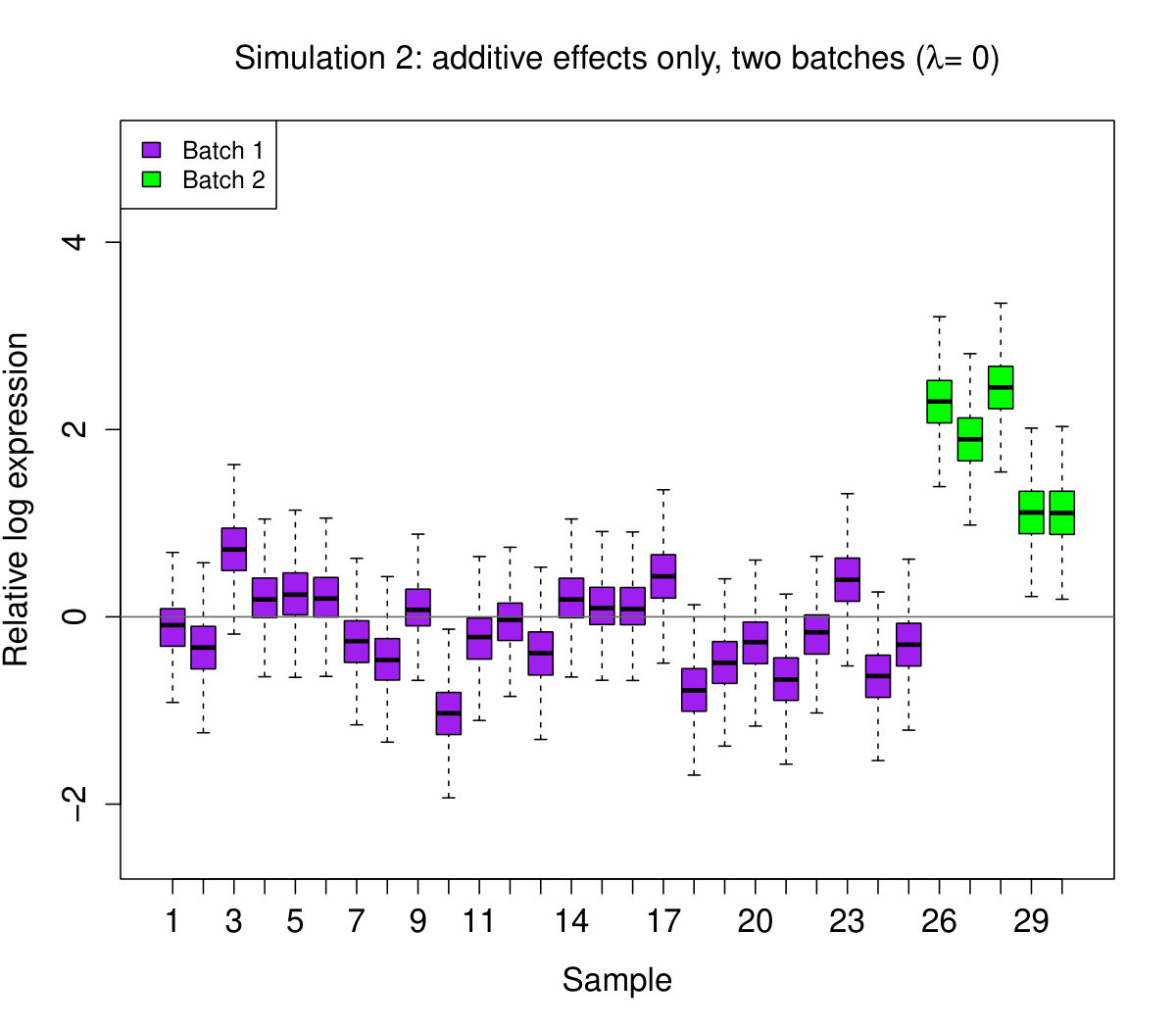 Figure 5
Figure 5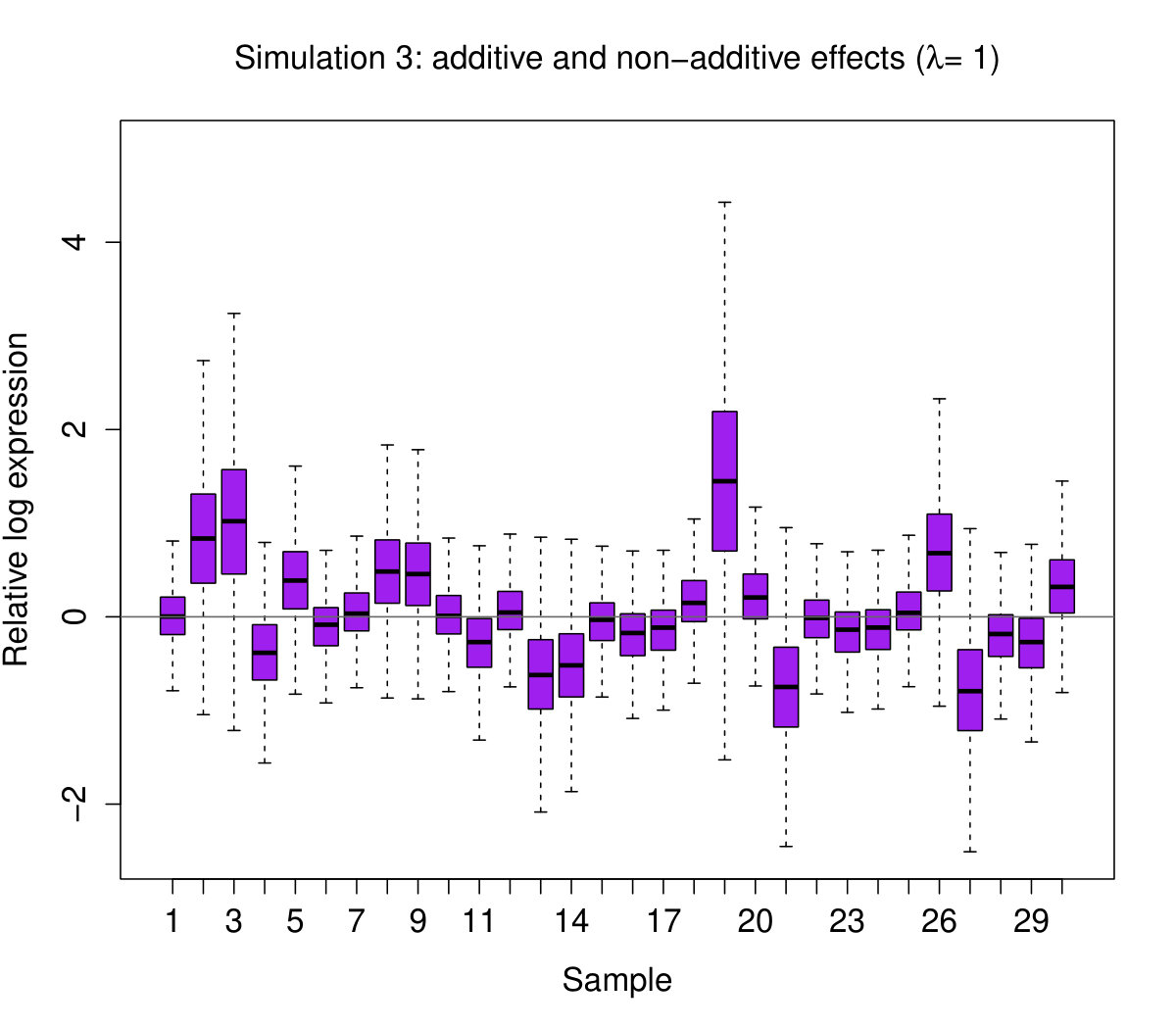 Figure 6
Figure 6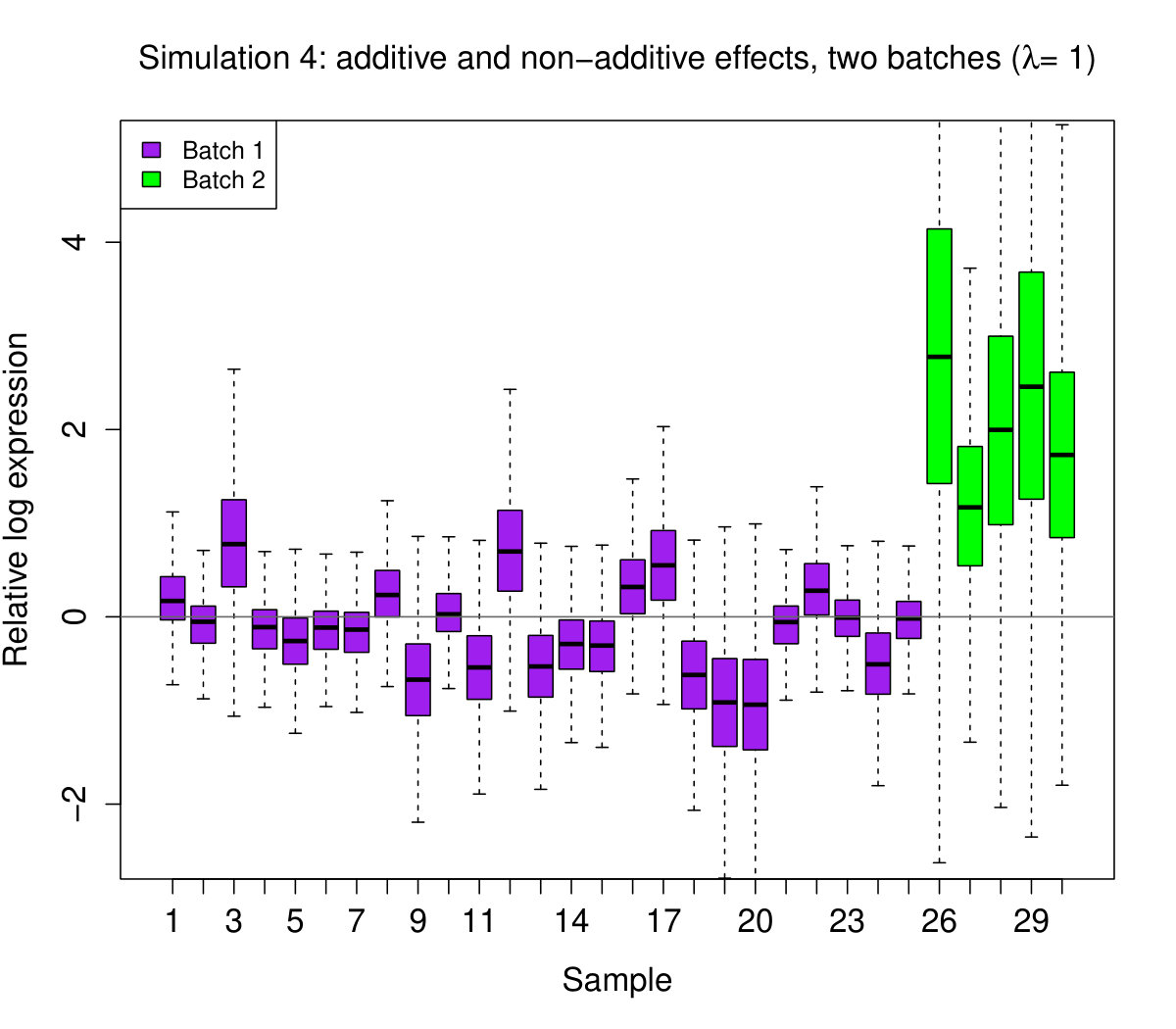 Figure 7
Figure 7Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
RLE Plots: Visualising Unwanted Variation
in High Dimensional Data
Luke C. Gandolfo111Bioinformatics Division, The Walter and Eliza Hall Institute of Medical Research, Melbourne, Victoria, 3070, Australia. 222School of Mathematics and Statistics, University of Melbourne, Melbourne, Victoria, 3070, Australia. and Terence P. Speed11footnotemark: 1 22footnotemark: 2
Abstract
Unwanted variation can be highly problematic and so its detection is often crucial. Relative log expression (RLE) plots are a powerful tool for visualising such variation in high dimensional data. We provide a detailed examination of these plots, with the aid of examples and simulation, explaining what they are and what they can reveal. RLE plots are particularly useful for assessing whether a procedure aimed at removing unwanted variation, i.e. a normalisation procedure, has been successful. These plots, while originally devised for gene expression data from microarrays, can also be used to reveal unwanted variation in many other kinds of high dimensional data, where such variation can be problematic.
1 Introduction
Relative log expression (RLE) plots are a simple, yet powerful, tool for visualising unwanted variation in high dimensional data. They were originally devised for analysing data from gene expression studies involving microarrays, e.g. see Bolstad et al., (2005) and Brettschneider et al., (2008). Such studies generate high dimensional data: expression levels (i.e. activity levels) of many thousands of genes are measured simultaneously using a microarray (one for each studied individual). Studies often involve many individuals and therefore many microarrays. Unfortunately, the data generated is often affected by unwanted variation, i.e. variation caused by technical factors and not by the biology of interest. There are many causes of such variation (see Scherer,, 2009). For example, batches of samples may be processed in different laboratories which operate at different temperatures leading to variation between the batches, i.e. a so-called batch effect. Moreover, the temperature of a particular laboratory may be quite variable throughout the day leading to additional variation within a batch. In any particular study, however, the physical causes of such variation will typically be unknown. This unwanted variation can be so large that comparing gene expression values between samples, often the main objective of such a study, can no longer be sensibly done; doing so can lead to false positives, false negatives, or both. Thus, it is crucially important to be able to detect the presence of unwanted variation. This is what RLE plots were devised to do.
Because of their ability to detect unwanted variation, RLE plots are particularly useful for assessing whether a normalisation procedure, i.e. a procedure aimed at removing unwanted variation, has been successful: a “bad” plot would suggest a failure to normalise (e.g. see Gagnon-Bartsch and Speed,, 2012). RLE plots, while originally devised for microarray data, can also be used to reveal unwanted variation in many other kinds of high dimensional data, e.g. metabolomic, proteomic, and RNA sequencing data, to name a few.
Our aim here is to provide a detailed examination of these plots, with the aid of examples and simulation. We begin by explaining what an RLE plot is, then we describe what it can reveal. We then discuss a number of important points to keep in mind when interpreting the plot. To make our discussion concrete we frame it in terms of one kind of data: microarray data. Nearly everything we say applies mutatis mutandis to other kinds of high dimensional data.
2 What is an RLE plot?
We suppose that our microarray expression data (after log transformation) is organised into a matrix with rows, each representing a microarray sample, and columns, each representing the expression measurements for a particular gene across the samples. Let be the log expression for gene in sample , and let denote the th column of the matrix . An RLE plot is constructed as follows:
For each gene , calculate its median expression across the samples, i.e. , then calculate the deviations from this median, i.e. calculate , across the s. 2. 2.
For each sample, generate a boxplot of all the deviations for that sample.
We use the median, a robust measure of centre, to protect against outliers.
To furnish an example we consider data from a study by Vawter et al., (2004). The aim of this study was to find genes that are expressed differently between the brains of men and women. The study design is briefly summarised as follows (the full details need not concern us). Brain tissue samples were obtained (post-mortem) from 5 men and 5 women, with tissue taken from three distinct brain regions of each person, producing 30 tissue samples. Each of these samples were split into three portions, thereby producing three identical groups of 30 samples, and each group was sent to a different laboratory to be analysed with one of two types of microarray. Data for this study is available on Gene Expression Omnibus (GSE2164).
For our purposes we restrict our attention to a small subset of 27 samples: these were all the samples analysed with the same kind of microarray (the Affymetrix HG-U95A microarray, measuring the expression of 12,626 genes), but processed at two different laboratories (24 at University of Michigan, 3 at UC Davis). We henceforth refer to this as the gender data. We processed the data, performing background correction and summarisation (but not the default quantile normalisation), with the RMA package (Irizarry et al., 2003), then generated an RLE plot using the steps described above (see Figure 1). For contrast, we also generated standard boxplots of the data by skipping the first of the above steps.
3 What can RLE plots reveal?
3.1 RLE plots can reveal unwanted variation
The most obvious feature an RLE plot reveals is sample heterogeneity. For example, the plot for the gender data shows large differences between samples. A deeper interpretation of an RLE plot can be made if we assume the following:
- (A)
Expression levels of a majority of genes are unaffected by the biological factors of interest.
This is often a plausible assumption. In the gender study, for example, it is plausible to assume that only a minority of genes will be expressed differently between men and women for the same brain region. The same applies to different brain regions in the same individual, male or female.
In ideal circumstances, i.e. where no unwanted variation is present, under assumption (A) the log expression measurements for a majority of genes would simply consist of a mean plus a random variation about that mean: , where has zero mean and constant variance (depending on the gene ) across the samples. Since , by subtracting the median when constructing an RLE plot, we would obtain
[TABLE]
i.e. we remove the variation between genes, leaving only the variation between samples. So, in ideal circumstances, an RLE plot would only display s: the boxplots would be roughly centred on zero and would roughly be the same size. Thus, under (A), sample heterogeneity is a sign of unwanted variation.
The RLE plot for the gender data is far from the above ideal, and so reveals substantial unwanted variation. We see unwanted variation both between and within batches as indicated by the varying position and widths of the boxplots. Note that the substantial within batch variation, between the Michigan samples, is only dimly apparent from the standard boxplots, but is brought into sharp relief in the RLE plot. Also note that variation, in the form of varying boxplot widths, is only revealed in the RLE plot. In the standard boxplots, this variation is obscured by the variation between genes; it is only revealed by removing the between gene variation in the construction of an RLE plot.
3.2 Simulated data
We have seen that “bad” RLE plots reveal unwanted variation in two ways: varying boxplot position and varying boxplot width. What kinds of effects, in a statistical sense, produce these features in a plot? To help answer this question we use simulation. We simulate log expressions , for gene in sample , under the following model:
[TABLE]
where and are additive gene and sample effects, respectively, is a non-additive effect, and is a random error. We will use a simple multiplicative form for the non-additive effect:
[TABLE]
where and are the means over and , respectively, and is a constant. This form for is the kind discussed by Tukey, (1949) and Mandel, (1969, 1971). Note that by subtracting row and column means in the product we obtain a non-additive effect which is “orthogonal” to the additive effects. Also note that, while can take any value, below we simply use it as an indicator to switch the non-additive effect “on” or “off”. Using (1), we simulate as follows:
For each gene , simulate . 2.
For each sample , simulate . 3.
For a fixed gene , for each sample simulate , where we simulate .
This model implies that mean expression varies across genes, and each gene varies differently across samples. We can obtain a batch effects by assigning different values of to different batches of samples. Note that we require , i.e. the variation across samples is typically less than the variation between genes, since this is usually a property of real microarray data.
With this model, we simulate four different data sets each with samples and genes:
Additive effects only: and for all . 2. 2.
Additive effects only, in two batches: for , for , and for all . 3. 3.
Additive and non-additive effects: and for all . 4. 4.
Additive and non-additive effects, in two batches: for , for , and for all .
In all instances, we set . The latter two parameters give , as required. We then generate RLE plots for each data set (see Figure 2).
These results show, perhaps not surprisingly, that shifting boxplots are produced by additive sample effects. However, perhaps more surprisingly, we see that additive sample effects are not sufficient to produce variation in the boxplot widths; this feature only appeared when non-additive sample effects were present. We do not claim that these are the only kinds of statistical effects that produce “bad” RLE plots – there are clearly others. These effects, however, seem to be some of the most important, as we will see next.
3.3 Real data
Can additive and non-additive sample effects help explain “bad” RLE plots for real data? The answer is “yes”, in many instances. Take, for example, the gender data again. Let be the matrix containing the gender data, where is the log expression for gene in sample . First, we try removing the additive sample effect by calculating , where the dot indicates averaging over the subscript replaced by the dot. The RLE plot for (see Figure 3a) suggests that additive sample effects provide an explanation for much of the variation in boxplot position.
To investigate the non-additive effects we examine the following residual, which is the standard estimate for the non-additive component of a linear model:
[TABLE]
Following Mandel, (1969, 1971), we can partition the non-additive component of the data by applying the singular value decomposition (SVD) to the matrix , whose entries are these residuals. First observe that the SVD of can be written as a sum of (rank 1) matrices:
[TABLE]
where is the rank of , is the th singular value, and and are th left and right singular vectors, respectively. Now observe that the entries of these matrices have the form , i.e. a product with one factor indexed by , the other indexed by , all scaled by . In other words, we have decomposed the non-additive component of the data into a sum of non-additive effects of simple multiplicative type. So, by subtracting matrices from we can remove non-additive sample effects from the data, in addition to the additive sample effect removed previously. Given this, define as follows:
[TABLE]
where . We generate RLE plots of for (see Figure 3b).
We see that as increases the RLE plots approach their ideal appearance: the boxplots line up around zero and become roughly the same size. This suggests that non-additive sample effects provide the rest of the explanation for the variation in boxplot position and much of the explanation for the variation in boxplot widths.
Since additive and non-additive sample effects are not the only kinds of statistical effects that can conceivably produce “bad” RLE plots, we do not wish to claim that these effects provide the only explanation for the features seen in the RLE plot for the gender data, only that they provide a possible explanation.
4 Discussion
We commented in the introduction that RLE plots are particularly useful for assessing whether a normalisation procedure, i.e. a procedure that attempts to remove unwanted variation, has been successful; a “bad” plot indicates a failure to normalise. It is important to note, however, that achieving an ideal RLE plot after applying a normalisation procedure does not necessarily mean the procedure has succeeded. The procedure may have succeeded in removing the unwanted variation, but may have also removed the biological signal of interest, i.e. the differences in expression of a minority of genes. An RLE plot cannot diagnose whether the signal of interest has been removed, only whether significant unwanted variation remains; the plot cannot tell if the baby has been thrown out with the bath water. For example, the procedure of simply removing additive and non-additive effects from the gender data clearly removed a large amount of unwanted variation, as evidenced by the series of RLE plots, but we most likely also removed much of the signal of interest. Removing unwanted variation without also removing the signal of interest is a more sophisticated enterprise (for one approach, see Gagnon-Bartsch and Speed,, 2012). Thus, “bad” looking RLE plots are usually strong evidence that a normalisation procedure has failed, but “good” looking RLE plots are only weak evidence that a procedure has succeed, in the sense of not also removing signal of interest. Strong evidence that a procedure has succeeded needs to be obtained from other sources, e.g. -value histograms, positive control gene rankings, comparison with previous results, and, best of all, experimental validation (see Gagnon-Bartsch and Speed,, 2012).
Lastly, we mention two important points about assumption (A), i.e. that expression of a majority of genes are unaffected by the biological factors of interest. Firstly, this assumption is not always needed to infer the presence of unwanted variation from an RLE plot. Large differences between replicate samples are an immediate sign of unwanted variation. In the gender study, for example, samples 5 and 26 are from the same individual and brain region; nominally, the samples are identical. The large disparity between the two can only be explained by unwanted variation, most likely resulting from being analysed at different laboratories.
Secondly, assumption (A) is not always safe to make. There may be instances where different biological factors of interest elicit a shift in the expression levels of a large majority of genes. In that case, a bad RLE plot might not be a reliable sign of unwanted variation, but a sign of a genuine shift in expression levels for some of the samples. Thankfully, however, these instances are rare, and when they do occur the effect is often expected.
5 Conclusion
We have seen that RLE plots, i.e. boxplots of deviations from gene medians, provide a simple, yet powerful, tool for detecting and visualising unwanted variation in high dimensional microarray data, the presence of which is often problematic. The only assumption we need to interpret sample heterogeneity in an RLE plot as a sign of unwanted variation is that expression levels of a majority of genes are unaffected by the biological factors of interest. We noted, however, that while this assumption is often plausible, it is sometimes not safe to make, and sometimes not even needed. We have seen that RLE plots can reveal unwanted variation in two ways, i.e. varying boxplot position and varying boxplot width, and that additive and non-additive sample effects can produce these features, although additive effects alone cannot produce variation in boxplot width. We showed how simulated data with these effects produce these features, and that these effects provide an explanation of these features for real data. We have emphasised that due to their ability to detect unwanted variation, RLE plots are particularly useful for assessing whether a normalisation procedure has been successful, with a “bad” plot usually suggesting that the procedure has failed. However, we cautioned that while bad looking RLE plots are excellent evidence that a normalisation procedure has failed, good looking RLE plots are only weak evidence that a procedure has succeeded, in the sense of not also removing signal of interest. Although our discussion has been framed in terms of microarray expression data, the original context in which RLE plots were devised, we hope we have conveyed how RLE plots might be useful for revealing unwanted variation in many other kinds of high dimensional data, where such variation can be problematic.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Bolstad et al., (2005) Bolstad, B., Collin, F., Brettschneider, J., Simpson, K., Cope, L., Irizarry, R., and Speed, T. (2005). Quality assessment of affymetrix genechip data. In Bioinformatics and computational biology solutions using R and bioconductor , pages 33–47. Springer.
- 2Brettschneider et al., (2008) Brettschneider, J., Collin, F., Bolstad, B. M., and Speed, T. P. (2008). Quality assessment for short oligonucleotide microarray data. Technometrics , 50(3):241–264.
- 3Gagnon-Bartsch and Speed, (2012) Gagnon-Bartsch, J. A. and Speed, T. P. (2012). Using control genes to correct for unwanted variation in microarray data. Biostatistics , 13(3):539–552.
- 4Irizarry et al., (2003) Irizarry, R. A., Bolstad, B. M., Collin, F., Cope, L. M., Hobbs, B., and Speed, T. P. (2003). Summaries of Affymetrix Gene Chip probe level data. Nucleic acids research , 31(4):e 15.
- 5Mandel, (1969) Mandel, J. (1969). The partitioning of interaction in analysis of variance. Journal of Research of the National Bureau of Standards, Series B , 73:309–328.
- 6Mandel, (1971) Mandel, J. (1971). A new analysis of variance model for non-additive data. Technometrics , 13(1):1–18.
- 7Scherer, (2009) Scherer, A. (2009). Batch effects and noise in microarray experiments: sources and solutions . John Wiley & Sons.
- 8Tukey, (1949) Tukey, J. W. (1949). One degree of freedom for non-additivity. Biometrics , 5(3):232–242.