A Model of Risk and Mental State Shifts during Social Interaction
Andreas Hula, Iris Vilares, Peter Dayan, P.Read Montague

TL;DR
This paper enhances the I-POMDP framework to better model social risk, trust dynamics, and emotional responses like irritation in repeated trust games, providing insights into social behavior and disorders.
Contribution
It introduces improved inference methods for I-POMDPs, modeling social risk-aversion and irritation, and applies them to analyze human behavior in trust games.
Findings
Identified social risk-aversion in control players.
Modeled irritation and anger affecting cooperation.
Demonstrated relevance in healthy and patient cohorts.
Abstract
Cooperation and competition between human players in repeated microeconomic games offer a powerful window onto social phenomena such as the establishment, breakdown and repair of trust. This offers the prospect of particular insight into populations of subjects suffering from socially-debilitating conditions such as borderline personality disorder. However, although a suitable foundation for the quantitative analysis of such games exists, namely the Interactive Partially Observable Markov Decision Process (I-POMDP), computational considerations have hitherto limited its application. Here, we improve inference in I-POMDPs in a canonical trust game, and thereby highlight and address two previously unmodelled phenomena: a form of social risk-aversion exhibited by the player who is in control of the interaction in the game, and irritation or anger exhibited by both players. Irritation…
Click any figure to enlarge with its caption.
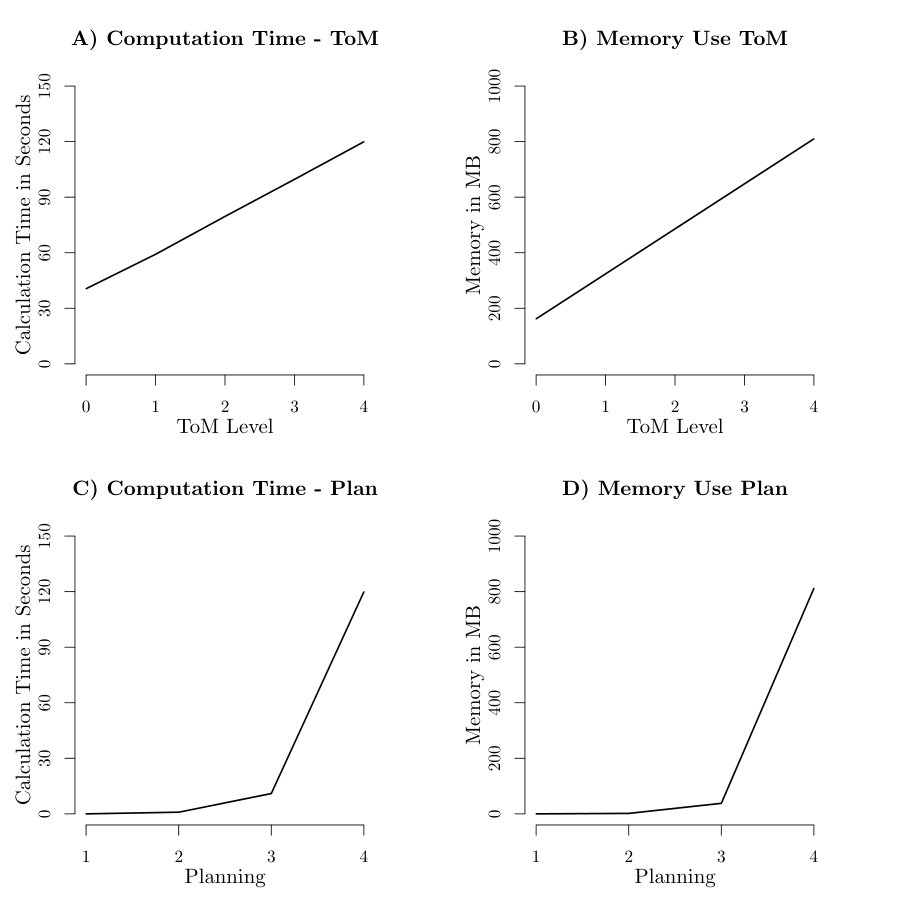 Figure 1
Figure 1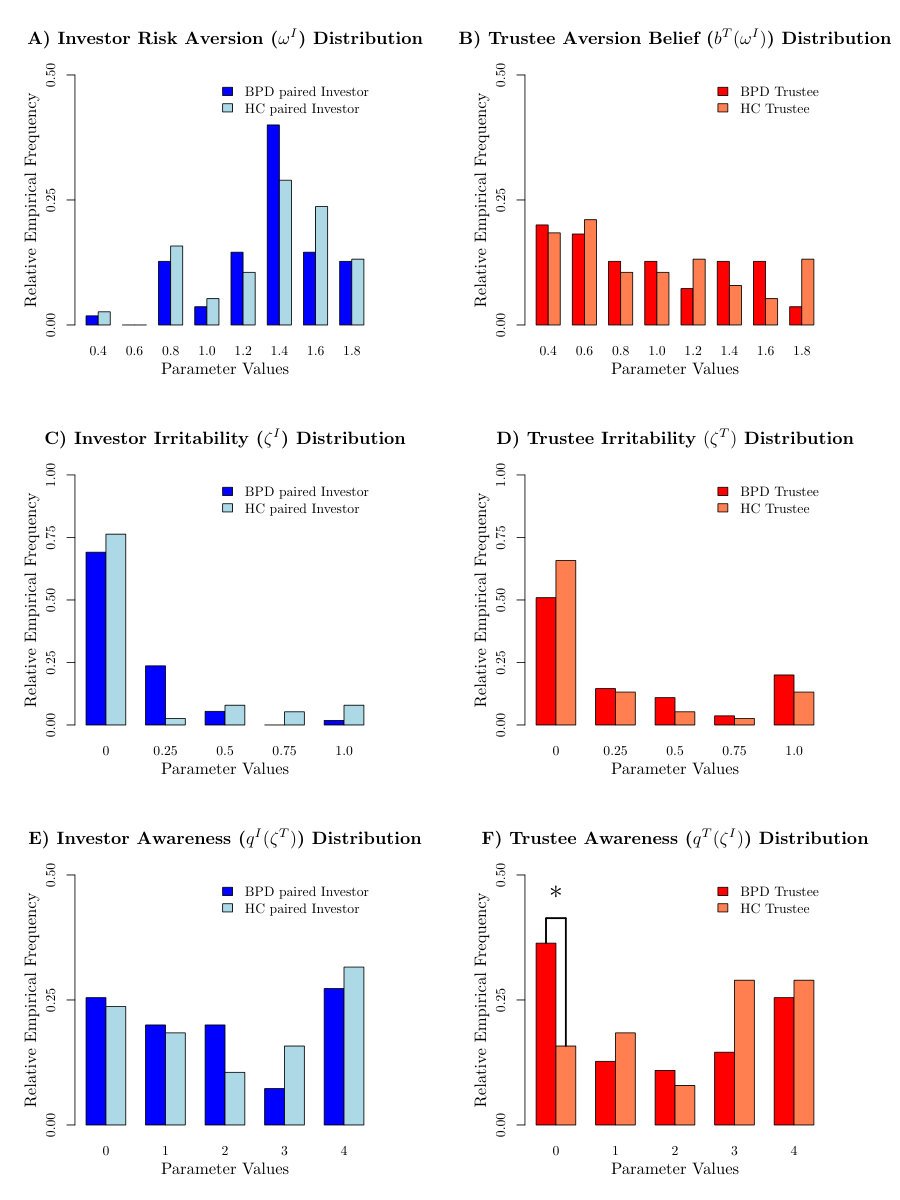 Figure 2
Figure 2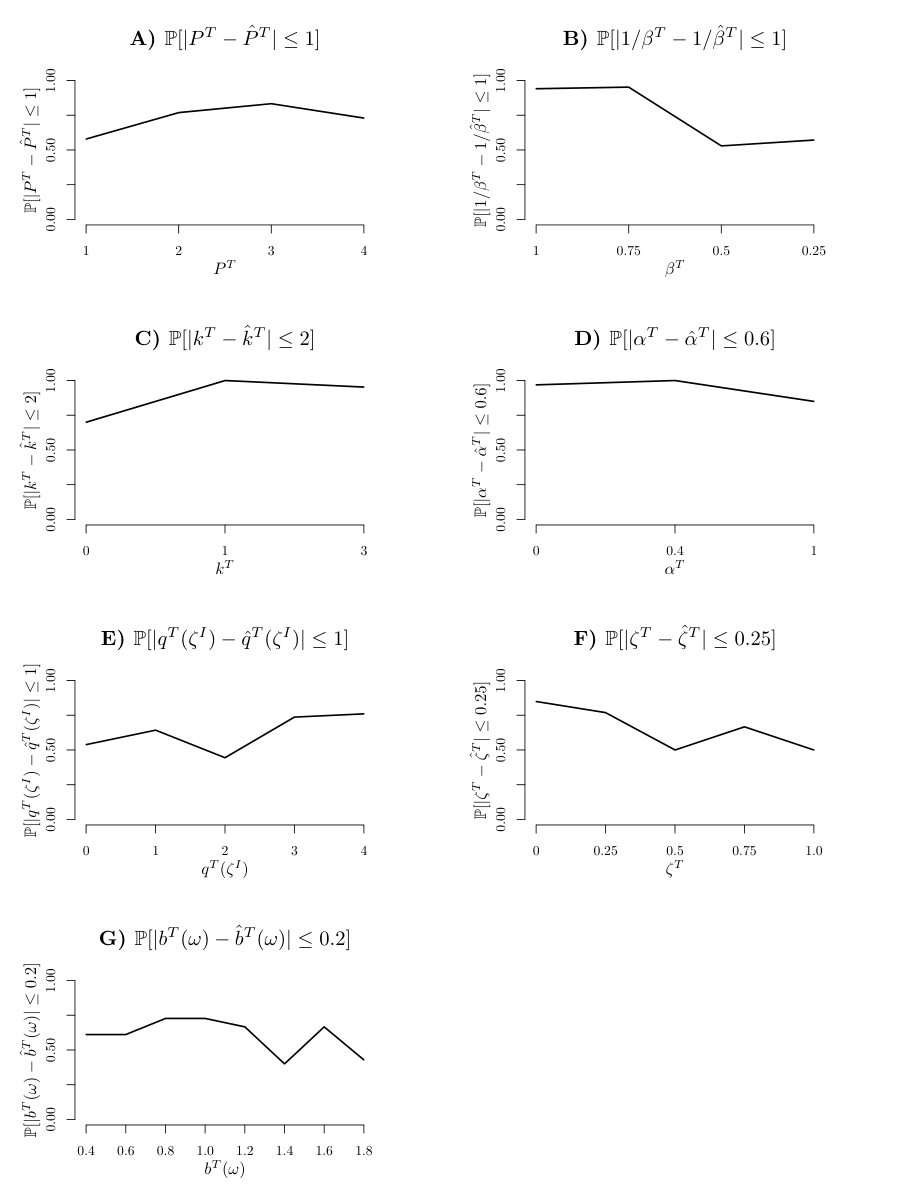 Figure 10
Figure 10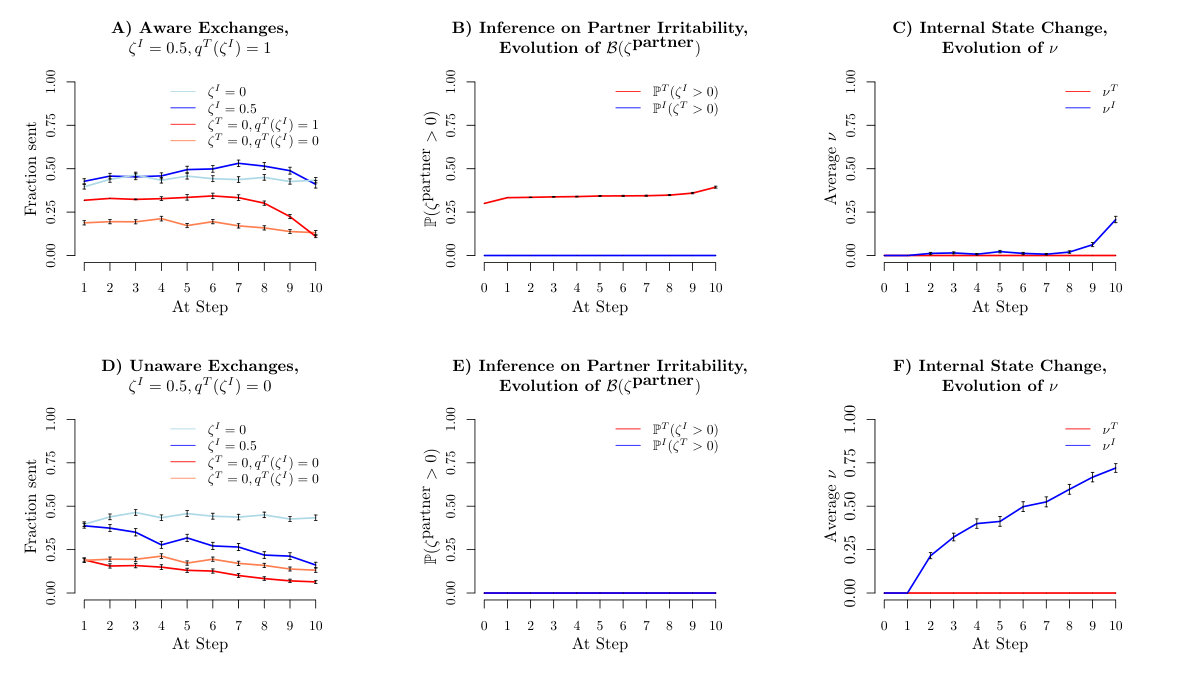 Figure 7
Figure 7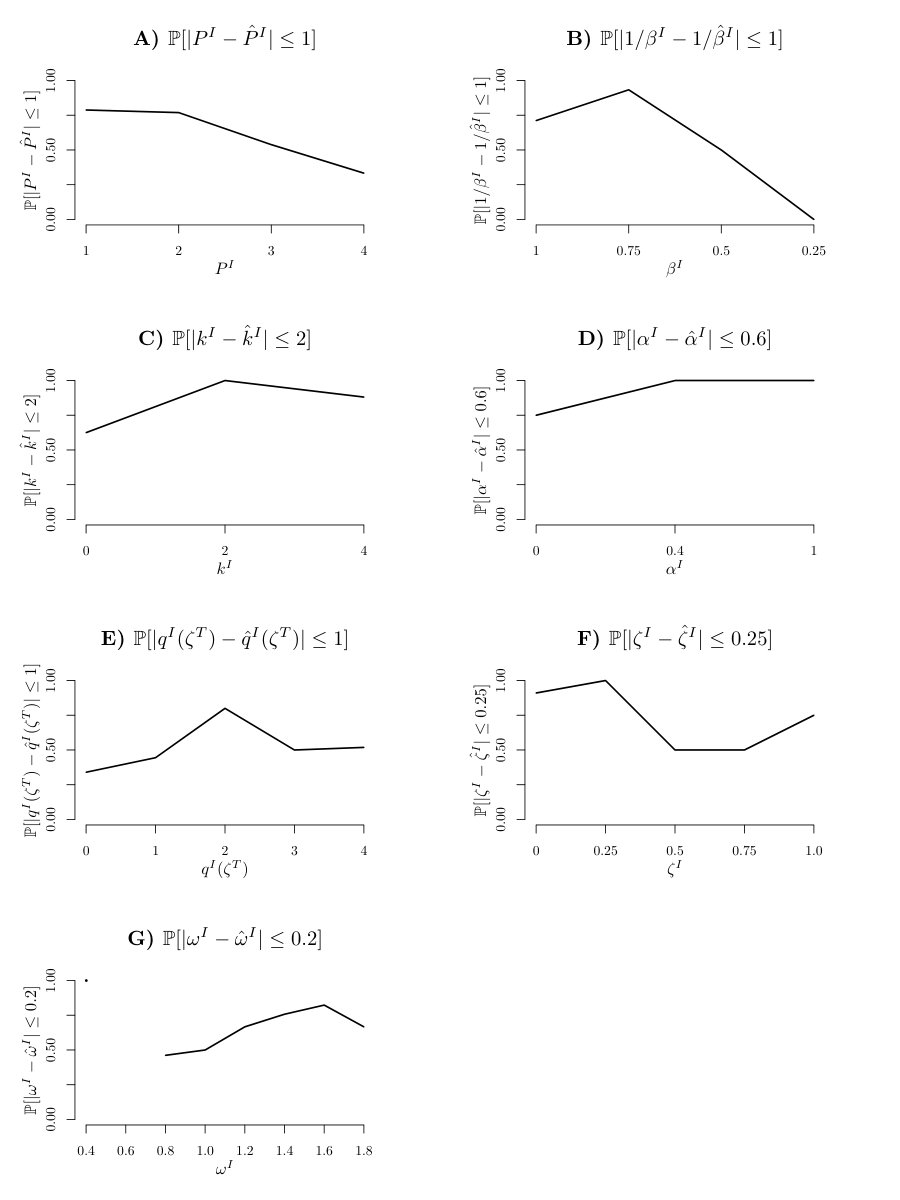 Figure 9
Figure 9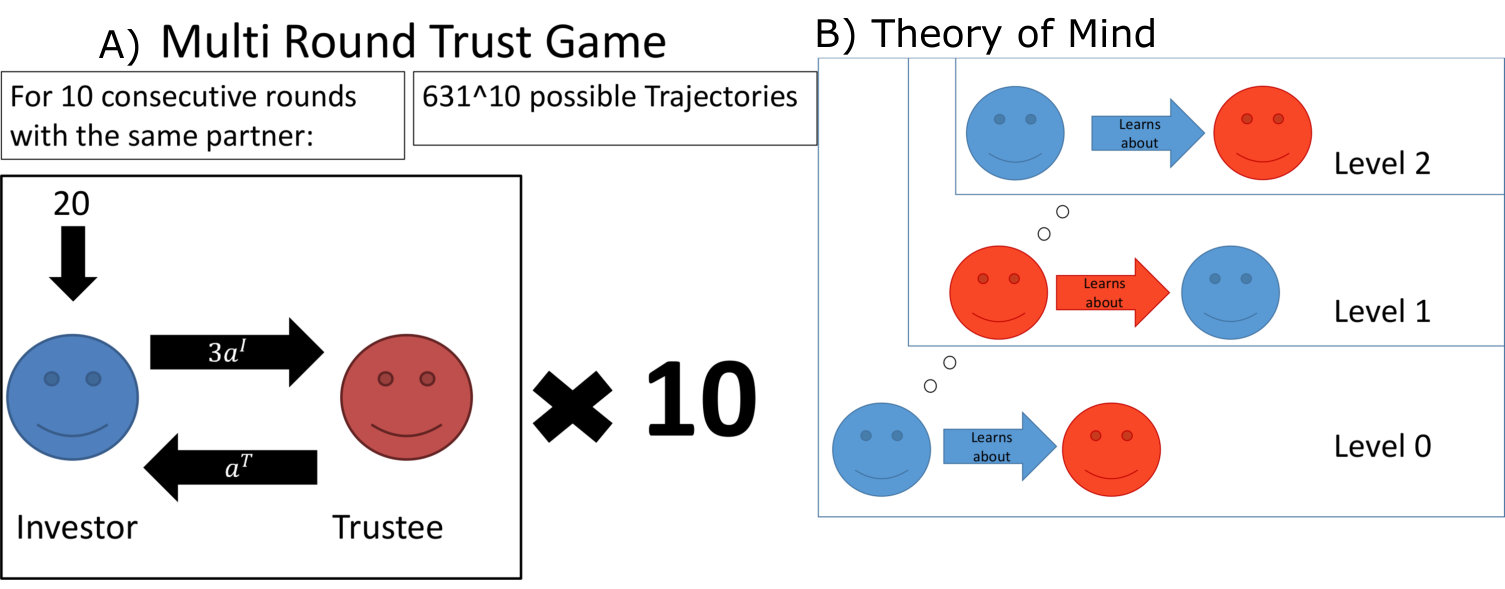 Figure 1
Figure 1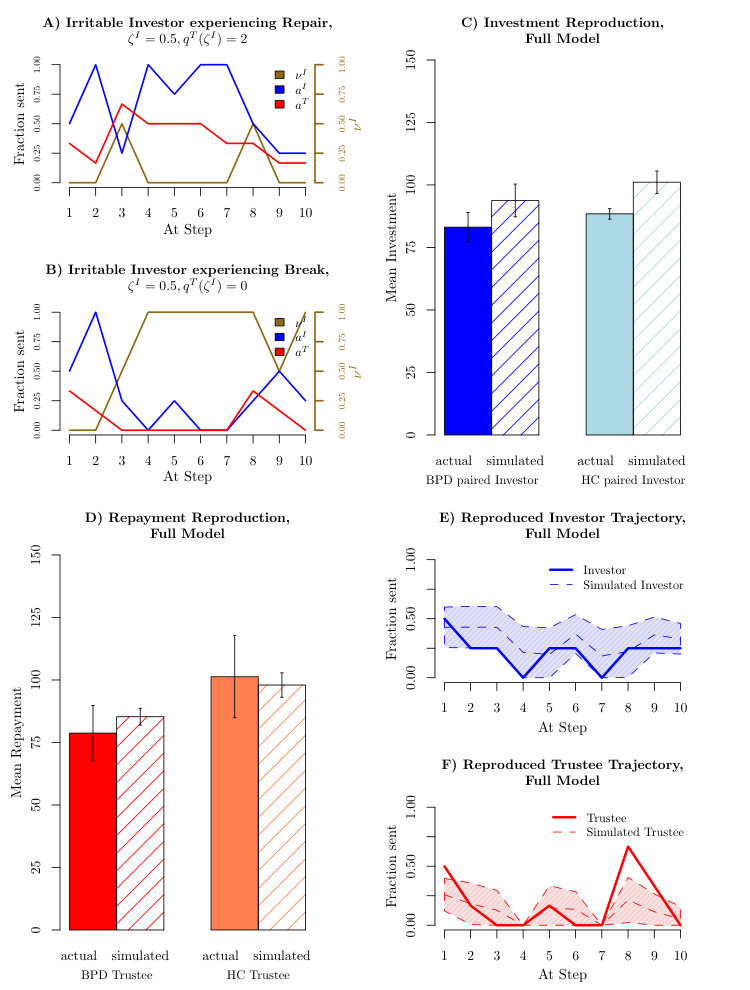 Figure 2
Figure 2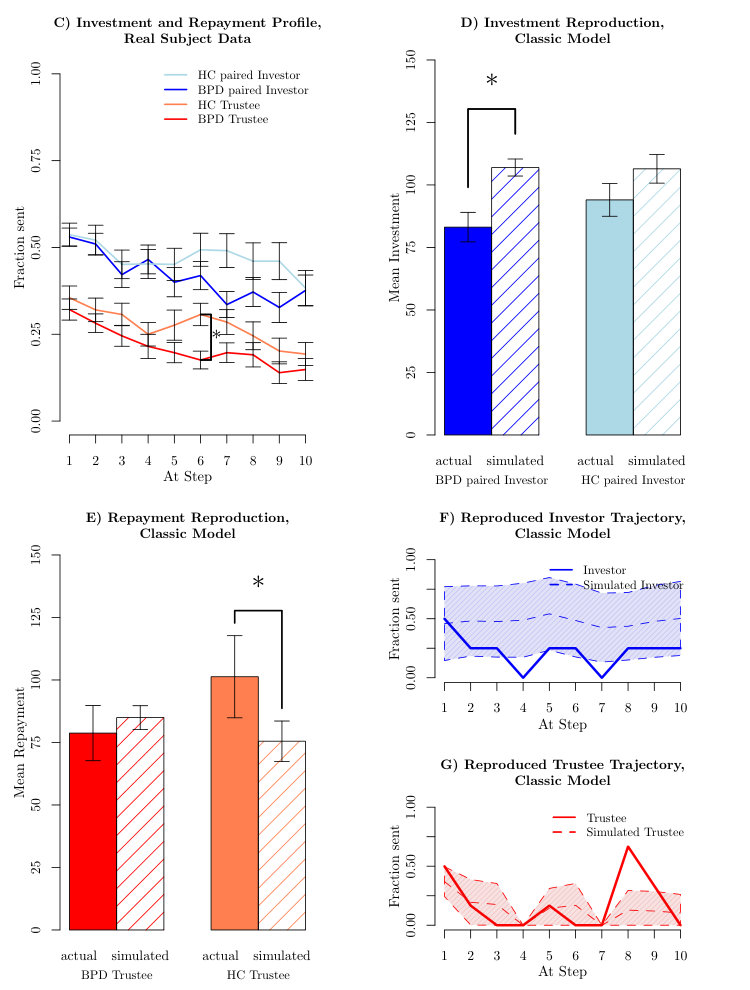 Figure 2
Figure 2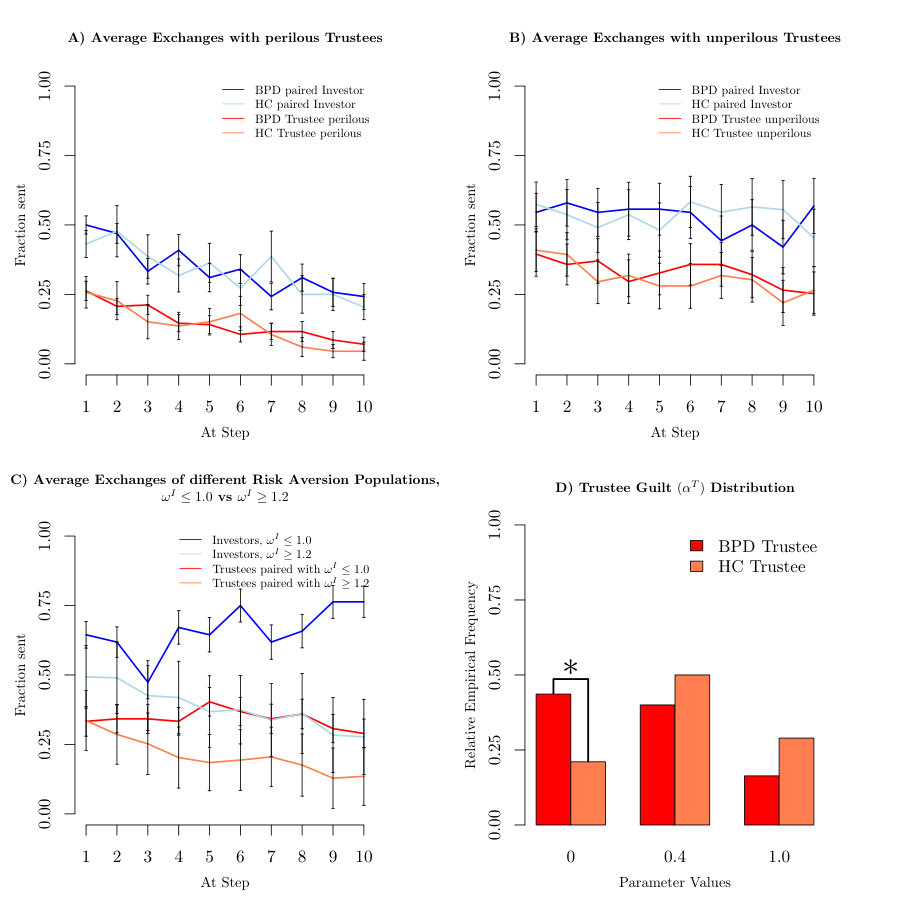 Figure 9
Figure 9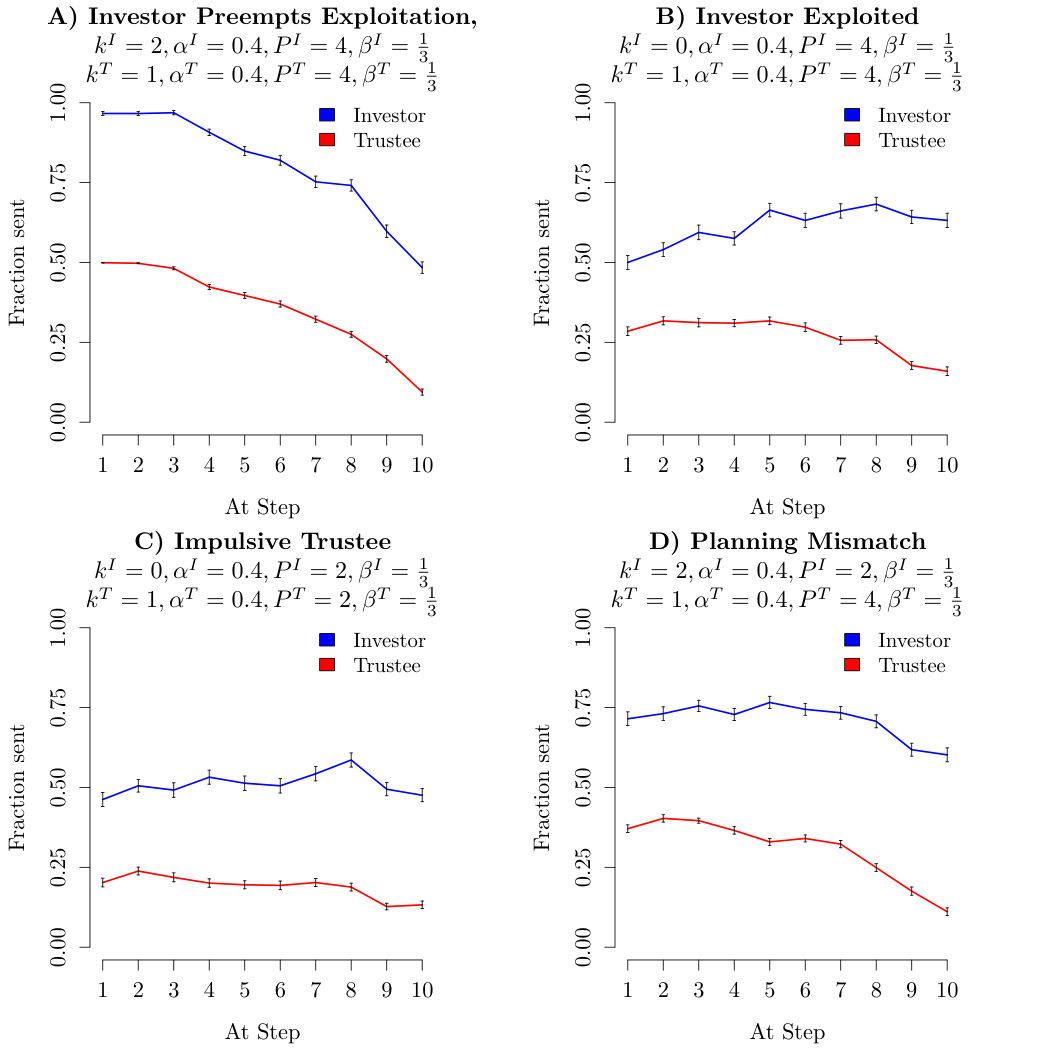 Figure 10
Figure 10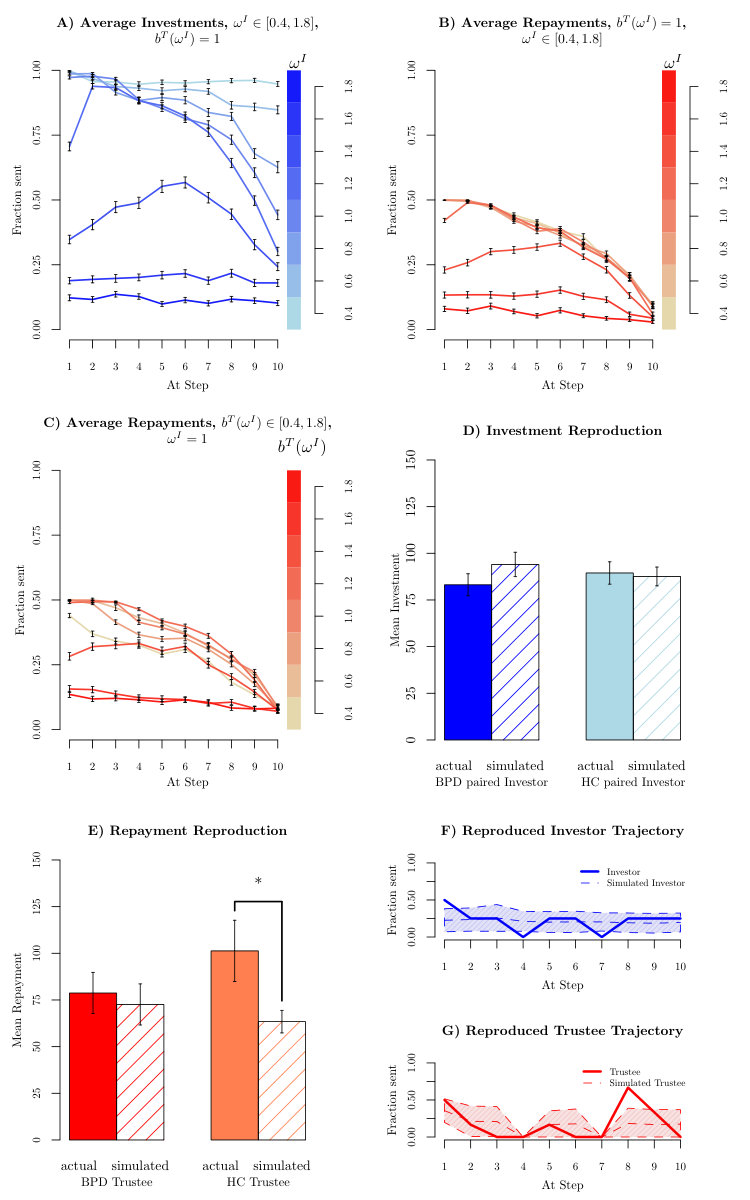 Figure 11
Figure 11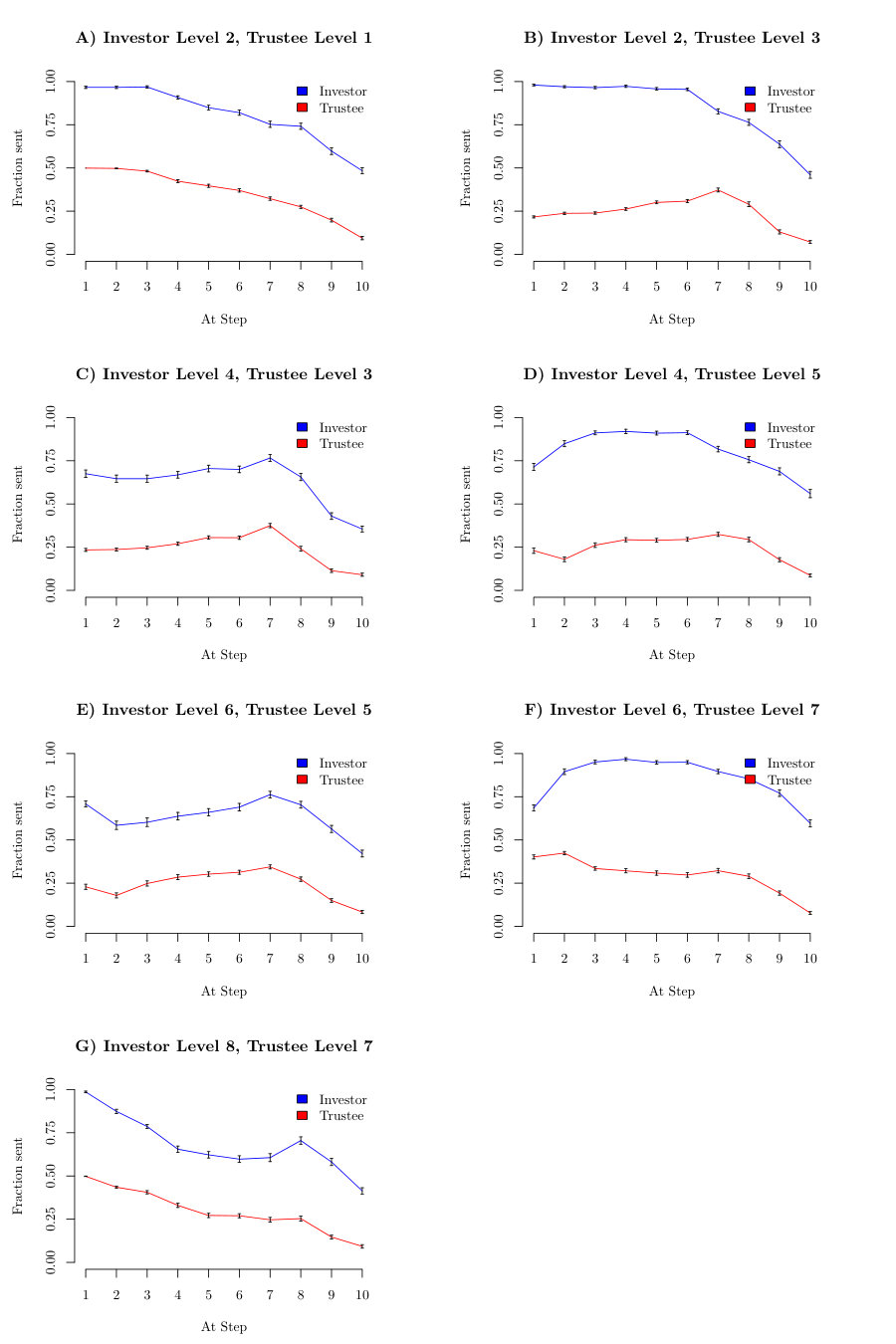 Figure 12
Figure 12Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
A Model of Risk and Mental State Shifts
during Social Interaction
Andreas Hula
Wellcome Trust Centre for Neuroimaging, London, United Kingdom
Iris Vilares
Wellcome Trust Centre for Neuroimaging, London, United Kingdom
Peter Dayan
Gatsby Computational Unit, University College London, London, United Kingdom - Wellcome Trust Centre for Neuroimaging, London, United Kingdom
P. Read Montague
Wellcome Trust Centre for Neuroimaging , London, United Kingdom - Human Neuroimaging Laboratory, Virginia Tech Carilion Research Institute, Roanoke, VA, United States - Department of Physics, Virginia Polytechnic Institute and State University, Blacksburg, VA, United States
Abstract
Cooperation and competition between human players in repeated microeconomic games offer a powerful window onto social phenomena such as the establishment, breakdown and repair of trust. However, although a suitable starting point for the quantitative analysis of such games exists, namely the Interactive Partially Observable Markov Decision Process (I-POMDP), computational considerations and structural limitations have hitherto limited its application, and left unmodelled some critical features of behavior in a canonical trust task. Here, we extend the I-POMDP framework and also improve inference. This allowed us to address two phenomena: a form of social risk-aversion exhibited by the player who is in control of the interaction in the game, and irritation or anger, seen as a shift of their internal state, exhibited by both players. Irritation arises when partners apparently defect, and it potentially causes a precipitate breakdown in cooperation. Failing to model one’s partner’s propensity for it leads to substantial economic inefficiency. We illustrate these behaviours using evidence drawn from the play of large cohorts of healthy volunteers and patients.
1 Introduction
Assessing the internal characteristics of another person is a fundamental requirement for success in human social decision making. Neither people’s self-reports, nor any current measurement device provides complete, veridical, information about another person’s state. Nevertheless, we are typically quite adept at inferring the preferences and intentions of others and even at manipulating their states, in both cases over the course of multi-round interactions. One way to formalize this capacity is via the so-called interactive Partially Observable Markov Decision Process (I-POMDP; [Gmytrasiewicz and Doshi, 2005]). This is a regular Markov Decision Process (see [Puterman, 2005]) augmented with (a) partial observability (see [Kaelbling et al., 1995]) about the characteristics of a partner; and (b) a notion of cognitive hierarchy (see [Costa-Gomes et al., 2001, Camerer et al., 2004]), associated with the game theoretic interaction between players who model each other.
In recent work, we used approximate inference methods in the I-POMDP to capture the effect of an other-regarding utility preference (namely guilt) in modeling behaviour in a popular multi-round trust task (MRT) [King-Casas et al., 2008, Chiu et al., 2008, Ray et al., 2008, Xiang et al., 2012, Hula et al., 2015]. This model offered powerful accounts of both the behavior of subjects, and also aspects of their neural activity [Ray et al., 2008, Xiang et al., 2012].
However, a detailed inspection of the residual errors revealed two key characteristics that were missing from the model: social risk aversion and irritation. Here we formalize both, including extending the I-POMDP framework to encompass the possibility that players might change their internal states as a result of interactions. We thereby fit subjects’ choices much more closely.
First, investors are dominant in the MRT, in that they can still make substantial sums of money based on initial endowments in each round without investing anything. Perhaps as a result of this, we observed that some investors apparently treat a portion of their endowment as being exclusively theirs; only risking the remainder in the social exchange. This is a form of social preference that is absent in the Fehr-Schmidt model of other-regarding preferences that we adopted as our baseline model [Fehr and Schmidt, 1999]. Here, we treat it explicitly as a form of (social) risk aversion, a factor that has previously been considered in terms of this task [Houser et al., 2009].
A second, and more complicated, failure of the existing model is that sample investment profiles are generally too homogeneous. That is, as pointed out in some of the early neuroeconomics studies of the MRT [King-Casas et al., 2008], cooperation between the players can readily break down in the face of apparent defection; with coaxing then being necessary to reestablish it (especially on the part of trustees). Such phenomena appear particularly prevalent in play involving subjects suffering from psychiatric conditions such as borderline personality disorder (BPD) (see for instance [King-Casas et al., 2008]). This condition is frequently characterised by difficulties in maintaining social relationships, sudden ruptures in trust, and social withdrawal or aggression (see [Lieb et al., 2004, Fonagy and Bateman, 2006]).
We therefore augmented the model with a form of irritation. When irritated, subjects can exhibit substantially different rules of behaviour, for instance being unwilling to cooperate at all, and reducing their depth of interpersonal reasoning. This leads to breakdowns in cooperation. To predict what might happen in response to their own choices, and thus, if beneficial to them, to prevent a breakdown, subjects need to model the possibility of such a shift in their partner’s state. They can then change their behavior prospectively.
As originally defined however, the I-POMDP framework explicitly excluded the possibility of one agent’s actions changing the decision making preferences of the other agents (see p. [Gmytrasiewicz and Doshi, 2005]). This non-manipulability assumption is also in keeping with the conventional Bayes-Nash model [Harsanyi, 1967], in which nature allocates an agent’s preference type before interactions start, and other agents merely make inferences about that type based on their observations. We extended the I-POMDP framework to encompass the possibility of internal state shift manipulations, and indeed that other agents may be aware or unaware of the possibility of such shifts or the exact actions that might trigger them. This then gives rise to much richer dynamics and more intricate manipulations during social exchange.
Our form of irritation fits somewhat better with the parameterized I-POMDP model of [Wunder et al., 2011]. This allows players to have multiple potential policies or strategies about which their opponents make interactive inferences. However, although this framework can accommodate non-stationarity in the choice of strategy (players moving from being non-irritated to being irritated and vice-versa, as a result of their opponent’s actions), it was originally designed with stationarity in mind. By contrast, our interpretation of a discrete internal state shift is critical for analyzing non-stationary human behaviour, in a manner that could for instance be used in functional magnetic resonance imaging (fMRI) analyses.
We generated simulated data using our extended model to show how the inclusion of these dimensions of social manipulation affects the course and understanding of human social exchange, and to validate parameter identifiability. We then demonstrated how the new mechanisms allow us to account for behaviour that appeared anomalous according to our previous model. Finally, we discuss how this can further the study of BPD and other disorders.
1.1 Trust Task
The multi round trust task (see [King-Casas et al., 2005, Xiang et al., 2012, Hula et al., 2015], based on [McCabe et al., 2001]) (see figure 1A) is a paradigmatic social exchange game. It involves two people, one playing the role of an “investor” the other that of a “trustee”, over sequential rounds. Quantities pertaining to the investor and trustee are denoted by superscripts “I” and “T” respectively. The participants played at the same time but did not know or meet each other at any point.
Both players know all the rules of the game. In each round, the investor receives an initial endowment of monetary units. The investor can send any units of this amount to the trustee. The experimenter triples this quantity and then the trustee decides how much (an amount ) to send back to the investor. This amount must be between 0 points and the whole amount that she receives. The repayment by the trustee is not increased by the experimenter. After the trustee’s action, the investor is informed, and the next round starts. On each round the financial payoffs of the two actors can be calculated: for the investor this is:
[TABLE]
For computational simplicity, the model treated the possible choices on a coarser grid, allowing for five investor actions and five corresponding trustee reactions. The five investor actions correspond to investing [math], , , or or of their endowment, while the trustee responses correspond to the return of [math], , , or of the received amount. The case in which the investor gives [math] is special, since the trustee has no choice but to return [math]. We round real subject actions to the respective nearest grid point.
The Nash equilibrium (based on pure monetary outcomes) for this game mandates a trivial interaction. That is because, in the last round, the investor should never invest anything, since the trustee could defect without punishment. Thus the interaction progressively unravels. Real subject behaviour in the game is quite different, and typically leads to substantial investments and returns.
1.2 Generative Model
A generative model of the multi round trust task was introduced in [Hula et al., 2015]; we enrich it here. Those of the parameters that we also assume subjects to infer about each other over the course of interaction are called “intentional”; the other parameters are inferred by the experimenter through the process of fitting the choices (using maximum likelihood), but are merely assumed by the subjects and are constant throughout the experiment. Full details of the model can be found in the supplementary material (in section S.1) here and in [Hula et al., 2015].
In the original model, there was a single intentional parameter, namely guilt . This denotes the sensitivity of one player to inequality in their favour, as in the Fehr-Schmidt model of inequity aversion [Fehr and Schmidt, 1999]. Subjects were assumed to use Bayesian inference to infer their partners’ guilt over the course of the interaction. This is possible since a high guilt () partner will provide high investments or returns and appear persistently cooperative, while a low guilt () partner is likely just to maximise their own winnings (and so only cooperate for Machiavellian reasons).
Next, a player could be aware that their partner was also learning about them, a recursive concept formalized as computational theory of mind (ToM) or reasoning level , and depicted in figure 1B. A level [math] investor learns about the trustee, but treats her as being random rather than intentional. A level investor treats the trustee as being level [math], implying that the trustee is assumed to learn about a non-intentional investor. A level investor treats the trustee as being level , implying that the trustee is assumed to know that the investor is learning about them too. This continues recursively. One consequence of the interplay of I-POMDP modeling and the asymmetric nature of the game is that only even levels yield new insight into investor behaviour, and only odd levels into that of the trustee [Hula et al., 2015]. In the original model, computational considerations restricted the theory of mind to for the investor and for the trustee. In the MRT, levels of ToM higher than of ToM do not appear to yield qualitatively new behavioural patterns (see supplementary material S.2), and so we extended consideration to levels for investors and for trustees.
Finally, subjects were classified according to their planning capacity , which quantifies how many steps of the future of the interaction they take into account when assessing the consequences of their actions. In the original model, this could take the values . However, it turns out that play for has very similar features to that of , involving exploitation of the partner and inhomogeneous effects caused by the horizon of the game (see supplementary material S.3). Therefore, to liberate the computational capacity to model an additional intentional parameter, we restricted to .
Choices were assumed to be made through a stochastic policy on the basis of expected value action values (calculated in the manner of [Bellman, 1952]) through the medium of a logistic softmax (see [McKelvey and Palfrey, 1992, Gläscher et al., 2010, Huys et al., 2011]). The inverse temperature parameter of the softmax that was fixed at in the original model, was here fit using values . Note the relatively large numerical values of investment and return, which is why the inverse temperatures may seem relatively small compared with other studies.
To gauge the differences between models with different numbers of parameters, we used the Bayesian Information criterion (BIC), which penalizes the number of parameters used to fit each subject according to the number of data points obtained in each exchange. It is defined using the negative loglikelihood (NLL) at the best fitting parameters for each subject under the given model .
[TABLE]
In the multi round trustgame , due to the choices per subject. The correction factor is for small [Draper, 1995].
The parameters of the final model can be seen in table 1.
Table of Parameters
Parameter
Values
Concept
Guilt
Measure of tendency to try and reach a fair outcome.
Plan
Number of steps likely planned ahead.
Theory of Mind
or
number mentalisation steps.
Inverse Temperature
Certainty of own choice preference.
Risk Aversion (Belief) ()
Value of money kept over (potential) money gained.
Irritability
Tendency to retaliate on worse than expected partner actions.
Irritation Belief
Initial belief on likelihood of the partner being irritable.
2 Materials and Methods
2.1 Ethics Statement
Informed consent was obtained for all research involving human participants, and all clinical investigation was conducted according to the principles expressed in the Declaration of Helsinki. The procedures were approved by the Institutional Board of Baylor College of Medicine.
2.2 Subject Data
We use the data set shown in [King-Casas et al., 2008], consisting of healthy investors, paired with trustees, of which were BPD diagnosed trustees (BPD Group, ”BPD”) and were healthy trustees, matched in age, gender, IQ and socio-economic status (SES) with the BPD trustee group (healthy control group, ”HC”). The precise demographics can be found in [King-Casas et al., 2008].
2.3 Technical Data
Programs were run at the local Wellcome Trust Center for Neuroimaging (WTCN) cluster using Intel Xeon E312xx (Sandy Bridge) processor cores clocked at GHz; no process used more than GB of RAM. We used R [R Core Team, 2013] and Matlab [MATLAB, 2010] for data analysis and the boost C++ libraries [Boost-Libraries, 2014] for code generation.
2.4 Algorithmic Change
The approach in [Hula et al., 2015] utilized a sampling based method to explore the decision tree during planning in the trust game, drawing from approximate solution methods for tree search from machine learning (see [Auer et al., 2002a, Auer et al., 2002b] [Kocsis and Szepesvári, 2006][Silver and Veness, 2010]). However, if lower levels of calculation are all part of the same hierarchy, as well as kept in memory and so are immediately available for higher level calculations, then the problem scales linearly in the theory of mind level parameter, rather than exponentially (as for other computational approaches to I-POMDPs [Gmytrasiewicz and Doshi, 2009], p. , ). This trade off of memory for computation is only practical if the planning horizon is reduced to at most steps into the future. A more detailed discussion of the used algorithm can be found in the supplementary material S.7.
The net result is that it takes less than minutes per generated step interaction, to calculate deterministically (i.e., avoiding approximations from the stochasticity of Monte Carlo-based tree evaluation) a step exchange of a level investor with a level trustee, both having horizons of steps. This comes at the cost of having to commit Gb of RAM to the tree calculation.
3 Results
We start by illustrating the failures of the existing model of the task. These motivate the changes that we then describe.
3.1 Model Failure
Figure 1C shows the average investments and returns in the data from [King-Casas et al., 2008]. The dark blue and dark red lines in figure 1C show the respective average investments and returns for healthy investors playing BPD trustees. The lighter blue and red lines show average investments and returns for healthy investors and healthy trustees who matched the BPD trustees in socio-economic status (SES), IQ, age and gender. Investments averaged about half the initial endowment and evolved over trials. In the second half of the game, investors paired with BPDs invested considerably less than investors paired with healthy trustees. This effect was a central topic in [King-Casas et al., 2008], and was explained by BPD trustees not heeding warning signals from their investor partners, indicating investor dissatisfaction with the BPD patients’ lack of reciprocation. The significant difference (, two sided t-test, Bonferroni corrected for time step comparisons, indicated by an asterisk in figure 1C in trustee reciprocation at step also indicates the time at which the average investment trajectories have persistently diverged. This gave rise to the difference in early vs late investment between the two groups that was reported in [King-Casas et al., 2008].
The solid bars in figure 1D show the average total investments in the real data for the two groups. These differ significantly at in a two sided t-test, as reported in [King-Casas et al., 2008]. The hatched bars show the result of generating data from the model in [Hula et al., 2015] (using the extensions discussed above to higher theory of mind and lower maximal planning). Model data is generated for each dyad, using that dyad’s best fitting parameters. The model overestimates the investments of the BPD-paired investors by about
Figure 1E demonstrates a similar issue for the modelled trustees. The solid bars show the returns of the control and BPD trustees; these again differ significantly at . Further, the simulated HC trustees (hatched bars) return significantly less than the actual HC trustees. Although it may seem that the simulated BPD trustees return similar proportions to the actual BPD trustees, this actually flatters the model, since this repayment is based on the over-generous model investment (the hatched bars in part B) rather than the true, more miserly, investment.
A second model failure concerns the detailed dynamics of investment across the task. The solid lines in figure 1F;G show a selected sample interaction between a healthy investor (figure 1F) and a BPD trustee (figure 1G). The trustee provides a poor return in trial , and is met by zero investment in trial . The same pattern repeats in trials and . The trustee is then far more generous in trial ; this then coaxes (to adopt a term from [King-Casas et al., 2008]) the investor to continue investing, though after breaks, the investors is unwilling to much increase their investment above a low level. The trustee then defects on trial , returning nothing. [King-Casas et al., 2008]’s conclusion was that a significant portion of the BPD group lacked mechanisms that could consistently repair the faltering interactions that occur when subjects become what we will describe as being irritated. Thus tentative ruptures (in the form of drops in investment level) turned into complete breaks, with the investor using their position of power in the game to punish the trustee.
The dashed lines in figure 1F;G show the result of simulating trajectories using parameters fit to the actual data, and also making predictions at each step based on the actual investments and returns of the dyad prior to each step (explaining why the model return is also [math] on trials and ). The shaded areas show the empirical standard deviations - which are evidently very wide. In fact, the specific reductions are not only absent in the averages; the modelled investment following the trustee’s defection on trials and decreased to [math] on only % and % of the sample runs; compared with the collapse to [math] apparent in the actual data.
We addressed these sources of model failure by introducing two new parameters, associated with risk aversion and irritation.
3.2 Risk Aversion
The investor is in charge in the MRT, since she could simply keep her endowment on each round. It has been noted since the advent of this kind of trust game in [McCabe et al., 2001] that a lack of investment could represent a social form of risk aversion rather than a lack of trust; see [Houser et al., 2009]. This could account for differences in levels of investment regardless of the cooperativity of either partner.
We parameterize such risk aversion as a multiplicative factor in the payoff functions, increasing or decreasing the evaluation of money that the investor keeps for herself compared to the money returned by the trustee:
[TABLE]
with (in steps of ). The trustee is subordinate in the task, and so does not have a risk parameter of their own. Instead, the trustee makes an assumption about the investor’s degree of risk aversion, at one of the above mentioned values. We capture intentional aspects of trust through guilt, and so treat risk aversion as a non-intentional parameter. However, in keeping with [Harsanyi, 1967], both players are assumed to be consistent, with the investor believing the trustee to know her risk aversion, and to know that she believes this; and the trustee believing that the investor believes this too. We write for the trustee’s belief about the investor’s value of .
Depending on the trustee’s belief , there will be either earlier or later attempts at exploitation. If , then the trustee infers the investor will keep investing, even if the trustee has been relatively uncooperative (i.e. the investor will be risk-seeking). Conversely, if , then the trustee will infer that any investment is contingent on their behavior, and there could be negative consequences of poor return. For values , the trustee expects the investor to invest so little that building up trust will not be worthwhile in the first place. In this case, the interaction will rupture.
Illustrations can be found in the supplemental material S.4, along with additional detail on the workings of this parameter.
Including risk aversion allows the model to account for the behavioural data much more proficiently, with the average Investor NLL improving from to . The average trustee NLL improves from to . The average BIC for the investors improves from to , and for the trustees, from to .
3.3 Irritation
We explained the breakdown in cooperation evident in figure 1F;G as arising when the participants become irritated. Formalizing this leads to four considerations: (i) what do subjects do differently when irritated; (ii) what leads a subject to become irritated; (iii) how can irritation be repaired; (iv) and what do subjects know about their own irritability? We offer a highly simplified characterization of all four of these. Individual interactions in the round MRT are too short to license more complex treatments.
Definition 1** (Irritability).**
We define the irritated state as associated with planning , guilt , temperature and complete disregard of beliefs about the other player that have hitherto been established. Additionally, for investors, the value of the risk aversion under irritation () is bounded below at i.e. , since otherwise “irritated” investors may not show punishing behaviour. We model the players’ policy as being a mixture between irritated and the nonirritated choices, with irritation weight
[TABLE]
A participant’s irritation weight is assumed to start at , and to increase when their partner’s action (investment or return) falls short of the value expected on the basis of the current model they have of the partner (including the partner’s potential irritation):
[TABLE]
Definition 2** (Intentional Inference about Irritation).**
Players maintain and update beliefs about the partner’s irritability in exactly the same way as about the partner’s guilt: that is, they employ a Dirichlet prior on a multinomial distribution over five possible irritation values (dubbed respectively “nonirritable” and four different“irritable” types in the following) and use the same approximate inference rule as is used for guilt.
However, unlike guilt, which we imagine is a characteristic that varies continuously amongst our participants, we consider a discrete set of possible prior beliefs about irritability. That is, irritability awareness is treated as an additional discrete new parameter (). The investor’s value determines prior weights of his belief over the trustee’s actual irritability . The trustee’s value determines prior weights of her belief over the investor’s actual irritability . These priors are intended to cover a suitable range of possibilities; as noted, the MRT involves too few choices to license a richer depiction.
Table of Irritation Inference settings
[TABLE]
Table 2 lists the four particular prior beliefs over the values of irritation. Players range from being ignorant about the possibility that their partners might be irritable, through stages of optimism that they are not, realism that they could be, pessimism that they likely are and fatalistic that they certainly are.
Finally, although we assume that players infer both their partner’s inequality aversion and their partner’s irritability level during the interaction, we do not allow subjects to consider their own future irritation. This follows [Loewenstein, 2005]’s observations of subjects’ inability whilst engaging in ’cold’ cognition to contemplate the possibility of ’hot’ cognition.
A detailed example of the general workings of irritation in the case of a single trajectory with potentially aware participants () is shown in figure 2A. The golden line depicts the evolution of the irritation weight . At step , a subpar repayment by the trustee was introduced by fiat to irritate the investor (the expected repayment by the trustee would have been 50%). The investor’s irritation duly rose to . At this point the trustee’s belief about the investor’s irritability is still at , as they have not observed the investor’s response to their action. At step the investor retaliated against the earlier defection of the trustee. The aware trustee thus updated their irritation beliefs, inferring that the investor was more likely to be irritable (at a marginal probability of ). Noting the potential cost to the interaction of further irritating the investor, the trustee ensured a better than expected response in the next interaction at step . Not only did the trustee repair the interaction, they also ensured that they did not further irritate the investor, at least until the very end of the interaction, as can be seen in the remainder of figure 2A, from step . This exactly captures the “coaxing”-type repair mechanism that [King-Casas et al., 2008] suggested to explain differences in investment behaviours elicited by healthy control and BPD trustees.
Figure 2B shows the consequence of a lack of irritation inference in the presence of an irritable investor. The players had the same parameter values as in figure 2A, except for being irritability ignorant (). After the same two initial actions (again introduced by fiat), without a notion of the partner being irritable, the trustee missed the chance to repair the interaction at step and the investor’s irritability weight rose to . From this point on the investments stayed low and the trustee did not placate the investor, thus receiving only a paltry total income. Both players failed to extract anything like the full return available from the experimenter.
Quantitative effects of irritability on the group level can be found in the supplementary material S.5.
Figures 2C;D show that including these various features removes the discrepancies between data generated from the full model and the subject data. There is no longer a significant difference between generated and original investments or repayments. The complete model predicts of the investor choices (chance is ) or equivalently an average NLL of on investor choices (form ) and an average NLL of or of choice predicted for trustee choices (from ). The final average BIC for the investors is and for the trustees is .
Figure 2E;F demonstrates that the model qualitatively captures ruptures and repair occurring in real interactions, with the investment decreasing to [math] on % of the sample runs on trials and . Further, the spread of the predictions is greatly reduced from those in figure 2E;F. The investor NLL of this interaction improves from to , while the trustee improves from NLL to an NLL of (with ).
3.4 Behavioural Analysis
The main intent of refining the model was to use it to make inferences about the two investor and two trustee groups that generated the data. In the supplemental material S.6, we show that such inferences are legitimate in that the parameters are broadly identifiable in self-generated data.
The distributions of the new parameters (risk aversion, irritability, awareness) across the groups are shown in figure 3A-F. We extend a finding reported in [Hula et al., 2015], namely that even in the extended model, the average guilt in BPD trustees is significantly (, , uncorrected for multiple comparisons) lower in BPD trustees compared to matched (in IQ and socio-economic status) healthy controls. This can be traced back to a significantly(, -test for equal proportions, uncorrected for multiple comparisons) higher proportion of guilt subjects. Additionally, the irritation ignorant awareness setting () is significantly (, -test for equal proportions, uncorrected for multiple comparisons) more common in BPD trustees, compared to HC trustees.
We therefore considered a model-based characterization of the subjects in which we combined together the two key differences between HC and BPD trustees in the model: trustees who are either totally guilt-less () or who are irritation unaware (), or both. Either of these leads to trustees who will attempt to exploit the investor, and so create problems in the context of an interaction in which latter is in charge. We describe these trustees as being ’perilous’.
This group turns out to be present at a significantly (, -test for equal proportions) higher proportion () in the BPD group of [King-Casas et al., 2008], compared with the HC group (), the difference remaining significant () even when Bonferroni correcting for the ( parameters plus the proportion tests and the derived “perilous group” hypothesis) comparisons that we undertook.
Figure 4 shows investment and repayment profiles for dyads in [King-Casas et al., 2008] including perilous (A) and non-perilous (B) trustees. Not only are these interaction profiles evidently different (confirmed in two-sided t-tests at , Bonferroni corrected for the time points), but also having adjusted for this by sorting healthy controls and BPD trustees according to perilousness, there is no longer a difference between the average investment and return profiles for BPD versus HC dyads ( using an uncorrected two-sided t-test).
Figure 4C compares investment and return profiles for investors with little () or substantial risk aversion (). Splits based on trustee risk aversion profiles do not appear significantly different (which is also a testament to the dominant role of the investor) and are not shown here. Finally, figure 4D shows the distributions over the guilt parameters for BPD and HC trustee subjects.
4 Discussion
Our previous model of the complex collections of choices apparent in the multiround trust task did a generally good job at accounting for many aspects, and generated prediction errors and other parametric regressors that unearthed various key neural processes. However, on closer inspection, it failed to characterize aspects of behaviour at two disparate timescales: a persistent reluctance of the dominant party to submit a portion of their endowment to the potentially fickle trustee in the game; and temporary breakdowns in cooperation and consequent repair. We therefore enriched our model in these two respects, parameterizing risk aversion (a factor that had previously been suggested as potentially corrupting the measurement of trust with this task [Houser et al., 2009]), and irritation.
Despite its formal appeal, the I-POMDP model has not been extensively used to characterize game theoretic interactions between players. One obvious reason for this is its apparent computational cost. Here we showed that it is perfectly possible to perform approximate I-POMDP inferencee in a relatively complicated model with two intentional dimensions and various other parameters. This augurs well for the future, given the importance and richness of social interactions in both economic decision-making, and as a psychological biomarker in psychiatric conditions.
Our extension of the I-POMDP framework to allow internal state shifts (and agents that may be aware of such shifts) adds a crucial layer of flexibility to these approaches. We illustrated this using irritation as an elemental emotional process. This captured the rupture and repair of cooperation, along with the associated threats of these. In the same way that the possibility of punishment or defection maintains cooperative behaviour in tasks such as the public goods game, the possibility of rupture encourages healthy participants to be beneficent. We hope that similar mechanisms will also be useful to describe strategic interactions in other tasks. We will also use it to guide the analysis of functional brain imaging data.
This model of irritation departs from conventional models of intentional inference in one important way. In repeated social exchange tasks, it is conventional to model one’s partner’s preferences, which, in Bayes-Nash terms, concerns properties of their utility functions. Indeed, this is exactly how earlier studies on the multi round trust game framed the social exchange [Ray et al., 2008, Koshelev et al., 2010, Xiang et al., 2012, Hula et al., 2015]. Here, however, we considered simultaneous intentional inference about both a utility and a policy (as in [Wunder et al., 2011]) that the player would adopt (indeed, a policy that it would be hard to justify in pure utility terms, given the costs of breaking cooperation). We include the possibility of one agent’s actions changing the intentional state of another agent, thus extending beyond the non manipulability assumption in [Gmytrasiewicz and Doshi, 2005] and providing a tracktable time series of irritation/state shifts (see figure 2AB). This non-stationarity could be accommodated within the parameterized I-POMPDs of [Wunder et al., 2011], using a specially-fashioned extension of the intentional state space.
A richer palette of such internal state-shifting default behaviors might also prove important in other tasks. Note, though, that it is not yet clear that a suitable notion of equilibrium can be defined (for instance, as the theory of mind level of the players tends to infinity). The combination of Kuhn’s theorem [Aumann, 1964] (since our players have perfect recall) and Harsanyi’s treatment of mixed strategies [Harsanyi, 1973] might be a starting point for such a treatment.
Our approach to irritability was chosen for its simplicity within the existing model. Further work on a more substantial body of human data will be necessary to fine-tune the dynamics of irritation in social exchange. One first step might be to use the model as part of an optimal experimental design framework to realize a computer-based opponent that could extract the most out of each available choice. At present, the relatively small number of actions in our version of the trust task, together with the possibility that the human partners fail to irritate each other even when they are irritable, leaves little room for further sophistication. Given a better understanding of irritation in the model, it would then be possible to refine the concept itself.
The ultimate model has the uncomfortable characteristic of employing parameters to account for the choices of each subject. However, the parameters interact in complex ways in the model, which is why they can generally be reliably inferred, as apparent in the confusion matrices in the Supplementary materials.
Finally, the model provides a generative approach to the way that patients with Borderline Personality Disorder play in the multi round trustgame, as reported in [King-Casas et al., 2008]. This approach yields a particular type of trustee, who are perilous for the interaction; this type was overrepresented in the BPD sample. After taking proper account of this subtype, we found equal average behaviours in BPDs and HCs. Thus this subgroup (which is also present in the HC group, albeit to a lesser extent) could help separate out a clinical phenotype that is separate from those sufferers of BPD who are less susceptible to the breakdown of trust. Such a separation might yield clearer clinical and neurological characterisations. It would be most interesting to look for, and analyze the clinical correlates of, types analagous to perilousness for players who are in control of interactions, like the investors here.
5 Acknowledgements
We thank Terry Lohrenz and Michael Moutoussis for helpful discussions and Tobias Hauser and Michael Moutoussis for comments on the manuscript. Special thanks go to the IT support staff at the Wellcome Trust Center for Neuroimaging and Virgina Tech Carilion Research Institute. The authors gratefully acknowledge funding by the Wellcome Trust (Read Montague) under a Principal Research Fellowship, the Kane Foundation (Read Montague) and the Gatsby Charitable Foundation (Peter Dayan). Andreas Hula is supported by the Principal Research Fellowship of Professor Read Montague.
S Supplementary Material
S.1 The Multi Round Trustgame Model
An I-POMDP generative model for the trust task was proposed in [Ray et al., 2008, Xiang et al., 2012] and substantially refined in [Hula et al., 2015]. The proximal cause of behaviour is a set of reward expectations for taking a given action after having experienced a history of events in the game. Here the agent was supposed to learn about the other agent from this history , following Bayes rule from a given initial belief system. These are assumed to generate choices using a softmax rule (something that is known to all parties) [Xiang et al., 2013, Gläscher et al., 2010, Huys et al., 2011, McKelvey and Palfrey, 1998]
[TABLE]
where is called the inverse temperature parameter and controls how diffuse are the probabilities. The policy
[TABLE]
can be obtained as a limiting case for .
The generative model parameterized the interaction using three non-intentional parameters: inverse temperature, theory of mind level and planning horizon; along with guilt as an intentional parameter (which is subject to intentional reasoning). A limited range of values was assumed for each parameter, covering the observed behaviour.
The inverse temperature in the softmax decision making mechanism could take values .
The theory of mind (ToM) level (see [Costa-Gomes et al., 2001]) encodes how many recursive steps an agent uses in their intentional model of the partner i.e. a level [math] only learns about the partner, a level knows that the partner is learning about them and so forth. Participants know their own levels () and assume that their partners play at one level lower (so the investor thinks the trustee has level ; the trustee thinks the investor has level ).
Recursion starts with a minimal model, dubbed , assumed to play a static strategy based on immediate preference (see [Hula et al., 2015]). For consistency, this implies that the level models do not themselves hold intentional models of their partners anymore, but act as in a non-intentional environment. An alternative approach to levels of thinking would be akin to the cognitive hierarchy, suggested in [Camerer et al., 2004], allowing higher level agents to maintain beliefs about multiple possible partner levels below them, instead of fixing the partner model at one less than their own level.
Based on the observation [Hula et al., 2015] that only even investor levels and odd trustee levels produce distinct behaviours, we consider for investors and for trustees (the original model was restricted to the first two in each set).
The planning horizon is the number of steps of future interaction taken into account in determining . We consider (the original model considered ; however, behaviour for is very similar to , since implies in this type of model-interaction, and lowers memory costs considerably). A discussion of why we consider this level of planning sufficient can be found below.
The intentional parameters quantify guilt (see [Fehr and Schmidt, 1999]), and change subjects’ utility functions from those described above for the investor to
[TABLE]
and for the trustee to
[TABLE]
High guilt means that every point of advantageous inequality in payoffs diminishes the utility of the outcome by i.e. there is no felt benefit from having a larger payoff than the partner. A low guilt of [math] means that only raw outcome maximization is relevant to the agent, while is a more measured, but mostly self-interested agent.
Agents know their own guilt; but adopt a multinomial distribution on the possible guilt values of their partner, with a Dirichlet prior on probabilities of the multinomial distribution. Thus the initial belief state () is a symmetric Dirichlet-Multinomial distribution,
[TABLE]
The level agent assumes equal probability for all partner guilt states and neither learns nor plans for the partner’s decisions, only using immediate expected utilities. However, the more complex agents learn and make recursive inferences about their partners. To be consistent with [Xiang et al., 2012], the posterior distribution is approximated as a Dirichlet-Multinomial distribution with the parameters of the Dirichlet prior being updated to
[TABLE]
In sum, a baseline for any I-POMDP model is random choice, defined by a probability of percent for each possible action. In likelihood terms, over the interactions in the multi round trust game this would correspond to a negative loglikelihood (NLL) of nats. The parameters characterizing a subjects’ play under the given model were determined by minimizing the NLL under the generative model .
S.2 Theory of Mind Limitation
In figure S1, we display average interactions of investor and trustees, with basic parameters: , , and various theory of mind levels. Investors and Trustees are always one level apart. In the left column the investor has the higher level and in the right column the trustee has the higher level. Since their guilt is the trustee will try to exploit the investor. In the left column the investor is of a higher level and therefore sees through the trustee’s deception and lowers the investment. In the right column the trustee is of higher level and successfully exploits the investors. From the level investor (figure S1C)) the behaviours do not appear to be qualitatively different anymore, except for minor differences in rates of increase of decline, which can be accounted for by the new parameter of risk aversion and inverse temperature (see the main text). Therefore we restricted our data fit to a maximum ToM level of .
S.3 Planning
In this section, we confirm that we can recover the paradigmatic behaviours of [Hula et al., 2015] with planning as well as we could with planning in the earlier work. The essential behaviours can be seen in figure S2A-D. Figure S2A is based on a level investor and a level trustee, with and and : The trustee tries to build up trust and then exploit the investor. The investor being level is not deceived by the trustee and reduces their investment, as the trustee defects, thus preempting exploitation. Conversely in figure S2B, the investor is level [math] and , with the other parameters being the same. In this case, the trusee successfully builds trust in the first few exchanges and later on exploits the investor, who keeps giving till the very last exchanges, believing the trustee to trustworthy. In figure S2C the “impulsive” behaviour of [Hula et al., 2015] is repoduced: It shows the average exchanges of a level [math] investor and a level trustee, with and and . The planning horizon leads the trustee to exploit the investor too early, therefore earning much less than in the case of figure S2B, despite being also of higher level than the investor and having a matched planning horizon. Finally, figure S2D demonstrates the importance of the planning horizon by showing average exchanges of a level investor and a level trustee, with and and but : Although the investor is of a higher level, the longer planning/more consistent trustee successfully deceives them, with the light drop off in investments in the end being more due to horizon effects than to the investor looking through the trustee’s deception.
We do not present the fully cooperative (guilt ) case as well as the fully greedy case (both partners guilt [math]) since those are essentially unrelated to depth of planning.
In the face of these reproductions, we can conclude that all paradigmatic behaviours of [Hula et al., 2015] can just as well be produced with planning as with planning .
S.4 Risk Aversion
The effect of risk aversion in shifting investment levels can be seen in figures S3A;B. These depict the average investment (A) and repayment (B) trajectories over simulated exchanges in which a trustee with (i.e., who believes the investor to have ) interacts with investors of varying actual values (other parameters are given in the caption). Cooperative trustee actions early in the game can make the investor overcome moderate levels of risk aversion (the curve for merges with the curve for in the early trials). Higher risk aversion levels () delay the positive effects of cooperation, such that it increases from a low initial level until step , but then drops abruptly due to horizon effects and trustee defection. For the highest risk aversion levels in figure S3A, inference about other parameters may be hampered. That is, if investments stay low throughout, risk aversion might become nearly the only parameter that can be inferred with certainty. This implies a constraint on any further statistical treatment of behavioural data or derived quantities, such as model-based fMRI analysis.
Figure S3C depicts the effect of the risk aversion belief on the trustee, with the investor now being fixed at (and not shown). For , it can be seen that trustees make early attempts to exploit investors they think are not risk averse, since they assume the investor is still more likely to invest in them than to defect. However, they then defect rather quickly. As the trustee’s belief approaches the utilitarian setting , she becomes more cooperative and for a longer time period into the game, since this is necessary to keep the investments of the utilitarian investor going. Given a high setting of the trustee returns little, as they consider the likelihood of the investor to keep investing in them to be low and thus see no gain from building up cooperation.
As figures S3D;E demonstrate, the investment can on average be well reproduced after including risk aversion in the model, although there remains a significant under-reciprocation on the part of the generated HC trustee, compared with the real exchange data. Further, figure S3FG demonstrates that despite an improvement in fit (NLL for the investor goes from to with ; for trustee the NLL goes from to with ), this model remains incapable of capturing the transient rupture and - by extension - repair that we examined in figure 2D. Again, the modelled investor decreased their investment to [math] on only % of the sample runs on trials and , compared with the collapse in the actual investment.
S.5 Quantitative Illustration of Irritability
Figure S4 shows the effect of irritability and irritability inference on average behaviours over simulated exchanges. As is also evident in figure 2, these averages blur the precise times at which the ruptures happen, but show the consequences in terms of net cooperation. In both cases (A-C; D-F), the trustee is more sophisticated than the investor () , the investor is either irritable or non-irritable, but unaware; the trustee is nonirritable (other parameters are listed in the caption). The difference between the figures is that the trustee is aware in figure S4A-C, but unaware in figure S4D-F.
Figure S4A show average investment and returns when the trustee is aware for an irritable (dark) and non-irritable (light) investor. The trustee’s awareness enables her to keep the investment at almost the same level in both cases. This arises from the excess return that she provides. Thus, as in figure 2F, trustees who realize that their investors are irritable will delay exploitation to the late rounds of the game. For the case of the irritable investor, figure S4B shows the average evolution of the inference about partner irritability. The trustee becomes aware that their partner is likely irritable after the first retaliation (as in the particular case in figure 2F). The average internal state of the same investor and trustee can be seen in figure S4C. Overall the irritation weight of the investor is kept low by an aware trustee, who can repair the interaction if needed. The value of irritability between investor and trustee is not symmetric in this example, so that the trustee may reliably repair or fail to repair without being themselves subjected to the effects of irritation. We note that the investor is driven up to near equally high investments in the non-irritable case in figure S4A compared to that in the irritable case of figure S4A, despite the trustee actually returning less. This is because the level trustee knows exactly what actions they need to take in order to confuse the inference of the level investor (i.e. what responses the investor will consider unlikely). By contrast, the level trustee in figure S4A accounts for potential irritability right away and thus has to “play along” with the investor ’s expectations and is less effective in tricking their inference.
By contrast, figure S4D shows that if the trustee is unaware, then there can be ruptures of cooperation that become apparent even at the group average level. The evolution of the beliefs about irritation is nugatory, as can be seen in figure S4E. Figure S4F shows how the irritation weight reaches high values quickly, only occasionally being reduced by chance repair.
S.6 Parameter Recoverability
The ultimate model is rather complicated. This raises the concern that the same behaviour might result from radically different settings of the parameters, implying that we would not be able to draw stable or meaningful conclusions from fitting behaviour. Indeed, we have already observed that certain settings will make it impossible to make inferences about some parameters – thus, playing with a highly risk averse investor will give no opportunity for a trustee to express her individual characteristics.
To examine this, we assessed parameter recoverability. That is, we used the parameters obtained from ML estimation on the participants (note that not all values were represented in the population – is absent, for instance), generated new data ab initio from the model, fitted the new data, and quantified any discrepancies between the original and recovered parameters. Figures S5 and S6 show the probability of recovering either the actual or a neighboring parameter value for investor and trustee respectively.
It is apparent that the model has some significant purchase on all the parameters. However, some parameters are much harder to estimate than others. There are perhaps four most egregious forms of confusion. First, irritable subjects can be inferred as being non-irritable (figures S5F; S6F). This occurs if the remaining randomness of the interaction in the model is such that the investor’s irritation is not excited. Indeed, the task was not designed with irritation in mind, and so players are not forced or encouraged to irritate each other.
Second, the investor’s awareness is not very reliably recovered (figure S5E). It is slightly better recovered for the trustee (figure S6E), who faces a more stringent challenge to keep the investor trusting them.
Thirdly, the inverse temperatures of generated investor trajectories tend to be overestimated (figure S5B). This is not surprising since the preferred actions will be the same for several temperature settings, thus requiring several “unlikely” actions to identify a lower in investors.
Finally, there is a tendency to missestimate the risk aversion belief of the trustee, for high settings of , as the parameter apparently has less influence on trustee choice, than it does for the investor, who is in control of the interaction (see figure S6G). This effect may be driven by the fact that the trustees estimated to have such high beliefs were also estimated to be considerably more irritable and thus the ensuing breaks might have confounded the inference about the risk aversion belief or vice-versa per chance lower repayments could have been interpreted as irritability. Globally, irritability is under rather than overestimated, however we can not rule out a particular interaction for high subjects.
Also, many parameter values which are less reliably recovered are also the less common values in the estimated data to begin with, thus making their recovery subject to a higher volatility by means of lower numbers.
S.7 Algorithmic Representation
We outline the algorithm through which we achieve linear running time in the theory of mind level for the given I-POMDP problem (under no environmental uncertainty i.e. the only source of uncertainty being the future partner actions).
The components used in the calculation are the observation-action history h (encoding actions taken a and observations made o in temporal sequence, as indicated by a time subindex), the target theory of mind level k, the remaining steps till the time horizon P, the reward expectation E, the material reward r(a,o, ) of observing o after action a, the probability p(o) of observing upon taking action at history for a given intentional model , the utility of future steps U and importantly the level “default” choice making model/policy , that starts the hierarchy. Furthermore, let Ah be the number of possible actions at history , h, a be the number of possible observations after taking action a at history h, U(o) be the utility of observation to the agent and E be the number of elements of the vector E. Additionally, denotes the belief state of the agent at history h, the probability distributions on the possible partner types, with denoting a concrete intentional model and denoting the number of intentional models that an agent holds and denotes the probability of under the given Belief state . denotes the intentional model that the agent themselves is using (in this concrete case, their utility and irritability) and denotes the irritation policy, with denoting the irritation weight under a given current model.
The target of the algorithm 1 (procedure ToM-HIERARCHY) is to calculate, for a given number of future steps P, all encountered histories h and ToM-levels k, the action probabilities (h,P,k, , ) for all possible actions. This is accomplished by means of action values/conditional reward expectations Q(h, P, k,, ) obtained by means of dynamic programming/the Bellman equation (procedure BELLMAN). Probabilities are assumed to be obtained via a logistic softmax with the action values as input (procedure PROB). The values crucially depend on the probabilities of partner actions (at level k-1) h , a , P, k (procedure OBSERVATION). “Partner-Irritation” denotes the current irritation state of the partner (as by the mechanism in the main text) under a given intentional model.
The algorithm starts from levels , if they are an even number of levels apart from the target level . The reason for this is, that an agent at level models their partner at level and this partner in turn models the agent at level .
The well known Bellman equation allows to calculate current action preferences based on potential future outcomes, which in our case crucially depend on the choice preferences of the partner Q(h, a , P, k ) and the resulting likelihood h , a , P, k of choosing a response (which is included in the observation o) to the action a of the agent. So in one Bellman calculation, both the choice preference of the agent level and the partner model at are being calculated.
Essentially now the partner model at depends only on the choice preferences of the (and lower) agent models, which at that point have been fully calculated and stored. In turn the level agent can be fully calculated from the level response preferences alone, leading to the stated linear complexity in .
The principles behind this algorithm are not limited to exact calculations (which may be forbiddingly expensive in larger problems). Instead the procedure could be combined with approximate solutions methods if one utilizes a “convergence criterion” for each levels’ calculations, before moving to the next “level-layer”. One potential complication to be aware of in this case, is that higher level simulations may choose very different action paths, therefore necessitating a return to lower level calculations, if the resulting history was not sufficiently explored at the lower level. This may incur additional costs, compared to a pure linear increase in running time as is the case for the exact calculation.
The various critical scalings are shown in figure S7A-D: Figure S7A;B show the linear growth of computation time and memory respectively with (maximal) theory of mind level (including all lower-level calculations and tree storage). Conversely, figure S7C shows the exponential rise in time for calculating a level investor, level trustee interaction at different planning horizons. Similarly, the exponential growth of memory use in the planning horizon for a level investor, level trustee can be seen in figure S7D.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[Auer et al., 2002 a] Auer, P., Cesa-Bianchi, N., and Fischer, P. (2002 a). Finite time analysis of the multiarmed bandit problem. Machine Learning , 47(2-3):235–256.
- 2[Auer et al., 2002 b] Auer, P., Cesa-Bianchi, N., Freund, Y., and Schapire, R. (2002 b). The nonstochastic multiarmed bandit problem. SIAM Journal on Computing , 32:48–77.
- 3[Aumann, 1964] Aumann, R. (1964). Mixed and behavior strategies in infinite extensive games. Advances in Game Theory, Annals of Mathematics Studies , 52:627–650.
- 4[Bellman, 1952] Bellman, R. (1952). On the Theory of Dynamic Programming. Proc. Natl. Acad. Sci. USA .
- 5[Boost-Libraries, 2014] Boost-Libraries (2014). http://www.boost.org .
- 6[Camerer et al., 2004] Camerer, C., Ho, T., and Chong, J. (2004). A cognitive hierarchy model of games. Q J Econ , 119:861–898.
- 7[Chiu et al., 2008] Chiu, P., Kayali, M., Kishida, K., Tomlin, D., Klinger, L., and Montague, P. (2008). Self responses along cingulate cortex reveal quantitative neural phenotype for high-functioning autism. Neuron , 57:463–473.
- 8[Costa-Gomes et al., 2001] Costa-Gomes, M., Crawford, V., and Broseta, B. (2001). Cognition and behavior in normal-form games: An experimental study . Econometrica , pages 1193–1235.