Restoration of Atmospheric Turbulence-distorted Images via RPCA and Quasiconformal Maps
Chun Pong Lau, Yu Hin Lai, Lok Ming Lui

TL;DR
This paper introduces a novel method combining RPCA and quasiconformal maps to effectively restore high-quality images from sequences distorted by atmospheric turbulence, addressing both geometric distortion and spatial-temporal blur.
Contribution
The proposed algorithm uniquely integrates RPCA and quasiconformal maps for turbulence distortion correction, providing a new approach to image restoration in challenging atmospheric conditions.
Findings
Effective reduction of geometric distortion and blur.
Restoration of image details and improved visual quality.
Validated on synthetic and real turbulence-distorted videos.
Abstract
We address the problem of restoring a high-quality image from an observed image sequence strongly distorted by atmospheric turbulence. A novel algorithm is proposed in this paper to reduce geometric distortion as well as space-and-time-varying blur due to strong turbulence. By considering a suitable energy functional, our algorithm first obtains a sharp reference image and a subsampled image sequence containing sharp and mildly distorted image frames with respect to the reference image. The subsampled image sequence is then stabilized by applying the Robust Principal Component Analysis (RPCA) on the deformation fields between image frames and warping the image frames by a quasiconformal map associated with the low-rank part of the deformation matrix. After image frames are registered to the reference image, the low-rank part of them are deblurred via a blind deconvolution, and the…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4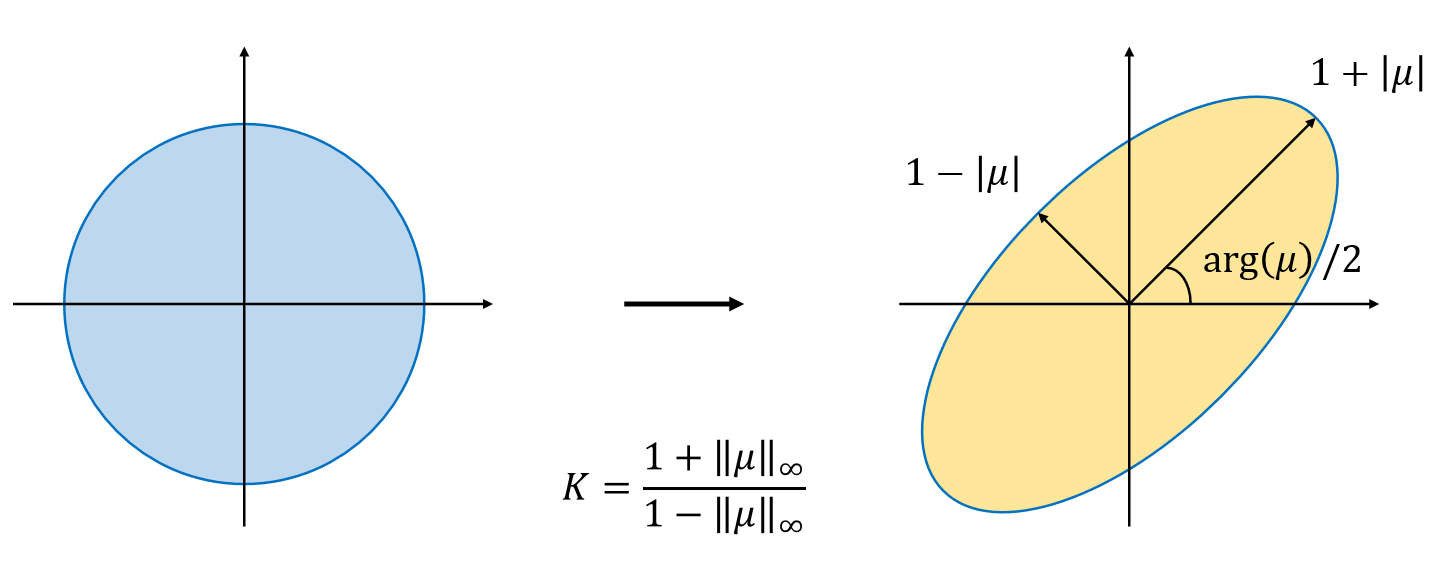 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23 Figure 24
Figure 24 Figure 25
Figure 25 Figure 26
Figure 26 Figure 27
Figure 27 Figure 28
Figure 28 Figure 29
Figure 29 Figure 30
Figure 30 Figure 31
Figure 31 Figure 32
Figure 32 Figure 33
Figure 33 Figure 34
Figure 34 Figure 35
Figure 35 Figure 36
Figure 36 Figure 37
Figure 37 Figure 38
Figure 38 Figure 39
Figure 39 Figure 40
Figure 40| Sequence | SGL | Centroid | Two-stage | NDL | Proposed |
|---|---|---|---|---|---|
| Car | 21.1054 | 29.3143 | 26.1112 | 29.1757 | 31.7101 |
| 0.7086 | 0.8842 | 0.7994 | 0.8703 | 0.9162 | |
| Carfront | 16.7093 | 19.5172 | 15.3815 | 19.9009 | 24.0959 |
| 0.6801 | 0.8163 | 0.5448 | 0.8136 | 0.9137 | |
| Desert | 20.8255 | 27.7507 | 25.2696 | 22.9450 | 31.2749 |
| 0.6985 | 0.8837 | 0.7886 | 0.7563 | 0.9385 | |
| Road | 23.9782 | 30.0300 | 26.5800 | 27.4061 | 33.8682 |
| 0.7638 | 0.8608 | 0.7827 | 0.8036 | 0.9063 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Restoration of Atmospheric Turbulence-distorted Images via RPCA and Quasiconformal Maps
Chun Pong Lau, Yu Hin Lai and Lok Ming Lui
Abstract
We address the problem of restoring a high-quality image from an observed image sequence strongly distorted by atmospheric turbulence. A novel algorithm is proposed in this paper to reduce geometric distortion as well as space-and-time-varying blur due to strong turbulence. By considering a suitable energy functional, our algorithm first obtains a sharp reference image and a subsampled image sequence containing sharp and mildly distorted image frames with respect to the reference image. The subsampled image sequence is then stabilized by applying the Robust Principal Component Analysis (RPCA) on the deformation fields between image frames and warping the image frames by a quasiconformal map associated with the low-rank part of the deformation matrix. After image frames are registered to the reference image, the low-rank part of them are deblurred via a blind deconvolution, and the deblurred frames are then fused with the enhanced sparse part. Experiments have been carried out on both synthetic and real turbulence-distorted video. Results demonstrate that our method is effective in alleviating distortions and blur, restoring image details and enhancing visual quality.
Index Terms:
Image restoration, Atmospheric turbulence, Robust Principal Component Analysis, Quasiconformal Theory
1 Introduction
The problems of restoring a clear image from a sequence of turbulence-degraded frames are of high research interest, as the effect of geometric distortions and space-and-time-varying blur would significantly degrade image quality. Under the effects of the turbulent flow of air and changes in temperature, density of air particles, humidity and carbon dioxide level, the refractive index changes accordingly and light is refracted through several turbulence layers [1] [2]. Therefore, when we want to capture images in locations where the temperature variation is large, for instance, deserts, roads with tons of vehicles, objects around flames, or from a long distance to perform long-range surveillance or to take pictures of the moon, rays from the objects would arrive at misaligned positions on the imaging plane, and thus distorted images are formed. Moreover, for a high-resolution video, even if the global oscillation of an image frame is not too large, the deformation of the objects in that image can be large. For example, in Figure 1, the left image is an observed frame from a high-resolution mildly distorted video, while the right image is the same image zoomed in on a distorted object.111The image is from http://seis.bris.ac.uk/~eexna/download.html. If we just consider the zoomed part in the video, the deformation would be large. In general, there are two types of approaches to deal with the problem, one being hardware-based adaptive optics techniques [3] [4] and the other being image-processing-based methods [5] [6] [7] [8] [9]. In this paper, we focus on an image-processing-based method to restore the image. Since we are working on a sequence of distorted images or turbulence-degraded video, we assume the original image is static and the image sensor is also fixed. In order to model this problem, the mathematical model in this paper is based on [11, 10],
[TABLE]
where and are the captured frame at time , the true image, and the sensor noise respectively. The vector lies in the two-dimensional Euclidean space. represents the blurring operator, which is a space-invariant diffraction-limited point spread function (PSF). is the deformation operator, which is assumed to deform randomly. Note each of the sequences and are assumed to be identically distributed random variables, and the subscripts indicate the different actual outcomes that these variables turn out to be at different time instants.
Atmospheric turbulence has two main degradations on images: geometric distortion and blur. In this paper, we propose a new framework to stabilize a severely distorted video and reconstruct a sharp image with fine details. First, we propose an iterative scheme to optimize an energy model to subsample sharp and mildly distorted video frames, and obtain a comparatively sharp reference image at the same time. This speeds up the computation and extracts the useful information from the original video. We then apply 2-step stabilization to stabilize the subsampled video with Beltrami coefficients, which further suppresses the distortion and replaces some comparatively blurry images with sharper ones by image warping using optical flow and RPCA. After that, we register the stabilized video with respect to the reference image by optical flow. Furthermore, we separate the video into a low-rank part and a sparse part by RPCA. On one hand, we apply blind deconvolution to deblur the low-rank part; on the other hand, we extract texture patches in the sparse part by adaptive thresholding, apply guided filtering to enhance the texture patches, and eventually fuse the low-rank and sparse parts together to obtain the final image.
2 Previous work
Since the video frames are corrupted by both blur and geometric distortion, it is difficult to deal with them simultaneously, especially in the scenario where a large portion of the images are severely degraded. The registration process is furthered complicated by the lack of a good reference frame for the observed image sequence. Meinhardt-Llopis and Micheli [12] proposed a reference extraction method which was coined the centroid method. In its scheme, the deformation fields between each pair of images are computed via optical flow and are assumed to have zero mean. This is equivalent to assuming the ground truth to be the temporal deformation mean of the frames. Next, every image is warped with the mean vector field to obtain a centroid image with respect to each image. Finally, the temporal mean of the centroids is taken to be the resultant image, in which the geometric deformations in the images are approximately cancelled out. In [13], Micheli et al. used a dynamic texture model to learn the parameters and put them into a Kalman filter model to get a blurry image. Finally, they used a Non-local Total Variation (NLTV) model to deblur and obtain a clear image. The assumption that the ground truth is the temporal deformation mean does not hold realistically. While the centroid method usually gives a good reference image, they cannot fully resolve the distortion, especially in the case that a large portion of the images are severely degraded. As the mean of the norms of deformation fields of the images increases, the deviation of the mean deformation of the images from the underlying model mean is amplified, and thus the resultant centroid images (and their temporal mean) remain distorted. Also, the temporal averaging makes the temporal mean of centroids contain features that appear in only a few frames, and thus ghost artifacts are formed.
Another method is the “lucky frame” approach [14], which selects the sharpest frame from the video. This method is motivated by statistical proofs [15] that given sufficient video frames, there is a high probability that some frame would contain sharp texture details. Since in practice it is difficult to assume one can find a frame which is sharp everywhere, Aubailly et al. [17] proposed the Lucky-Region method, which selects at each patch location the sharpest patch across the frames and fuses them together. Anantrasirichai et al. [18] adopted this idea and introduced frame selection prior to registration. However, the cost function introduced was coarse, and the selection was done in one step by sorting. As a result, some of the selected frames geometrically differ significantly from the reference image. In addition, the cost function assumed the reference image (i.e. the temporal intensity mean over all frames) to accurately approximate the underlying true image, which is usually not the case. Another similar approach was proposed by Roggemann [19], where a subsample is selected from images produced by adaptive-optics systems to produce a temporal mean with higher signal-to-noise ratio.
As atmospheric turbulence can severely distort video frames, even if a satisfactory reference image is acquired, the video may not be registered well onto it. A feasible approach to enable registration is to stabilize the video and reduce the deformation between each frame and the reference image. Lou et al. [16] proposed to stabilize video by sharpening each frame via spatial Sobolev gradient flow, and temporally smoothing the video to reduce interframe deformation. However, the distribution of the image intensities is not preserved under Sobolev gradient sharpening, and temporally smoothing produces ghost artifacts.
Zhu et al. [11] proposed a B-spline nonrigid registration algorithm to tackle distortion, and a patch-wise temporal kernel regression based near-diffraction-limited (NDL) image restoration to sharpen the image. Finally, they use blind deconvolution algorithm to deblur the fused image. However, NDL will further blur the image and produce some defects on the fused image. Then Furhad et al. proposed a frame selection criterion which is based on sharpness, in which they perform some preprocessing to filter out heavily blurred frames. They then propose spatiotemporal kernel regression to fuse the image. However, if sharp but severely distorted frames exist, they may be selected as deformation is not considered. Then the filtered image sequence will contain some distorted frames, which will degrade the reference image and hence the final output.
Recently, Robust Principal Component Analysis (RPCA) is another tool to tackle the problem of atmospheric turbulence. He et al. [20] proposed a low-rank decomposition approach to separate the registered image sequence into low-rank and sparse parts. The former has less distortion, but is blurry and few detail texture image; on the other hand, the latter contains texture information but is noisy. Blind convolution is applied on the low-rank part to obtain a deblurred result, which is combined with the enhanced detail layer to get the final result. Xie et al. [21] proposed a hybrid method, which assigns the low-rank image to be the initial reference image. The reference is then improved by solving a variational model, and the frames are registered to the reference image. However, as the deformation between the reference image and the observed frames may be large, direct registration may produce errors.
3 Contributions
3.1 Frame sampling
In a turbulence-distorted video sequence of a stationary object and camera, all the frames are geometrically deformed and blurry. In order to remove the distortion by atmospheric turbulence, a good reference image is needed to obtain accurate deformation fields between the reference image and the observed frames. On the other hand, not all of the frames are useful to extract a good reference and provide useful information for image fusion. As a result, we propose subsampling the original video to obtain useful frames. The proposed algorithm can obtain a sharper and less deformed reference image and a good subsampled video by optimizing an energy model, which balances the number of subsampled frames and the quality of the reference image.
3.2 Internal stabilization
Suppose we have an image sequence in which a majority of frames are mildly deformed from each other, but the deformation of the remaining frames from the majority is significant. We propose extracting the low-rank part of the deformation fields among the frames via Robust Principal Component Analysis, in which the outlier deformation fields and error produced in the deformation estimation are diminished and reoriented. The frames are then warped with the adjusted fields, which aligns them well while avoiding heavy influence from outlier deformations.
3.3 Absorbing stabilization
Given an image sequence in which each frame is at most mildly deformed from each other, and additional frames which are deformed more severely, the latter can be stabilized by registering each of its frames to the aligned sequence. This allows for the incorporation of sharp but heavily deformed frames, which provides more texture details for image fusion afterwards.
The mathematical background and implementation details of the above methods will be elaborated in the following sections.
The remainder of this paper is organized as follows. The mathematical background of the employed conformal geometry techniques and Robust Principal Component Analysis is described in Section 4. The numerical scheme is described in detail in Section 5. The performance of the method is evaluated on six sets of videos/images and is compared with other techniques in Section 6. Finally, Section 7 presents the conclusions of the paper.
4 Mathematical Background
4.1 Quasiconformal map
Quasiconformal maps are a generalization of conformal maps. They are orientation preserving homeomorphisms between Riemann surfaces with bounded conformality distortion.
Definition 4.1**.**
Let be a continuous function with continuous partial derivatives defined via , , with
[TABLE]
is quasi-conformal provided that it satisfies the Beltrami equation,
[TABLE]
for some complex-valued Lebesgue measurable function satisfying is called the Beltrami coefficient (BC) of .
Given an orientation preserving homeomorphism , we can find the corresponding BCs from the Beltrami equation:
[TABLE]
The Jacobian of is related to :
[TABLE]
Since is an orientation preserving homeomorphism, and everywhere. Hence, we must have . For any closed subset of , .
Theorem 4.2** (measurable Riemann mapping theorem).**
Suppose is Lebesgue measurable and satisfies ; then there is a quasiconformal homeomorphism from onto itself, which is in the Sobolev space and satisfies the Beltrami equation in the distribution sense. Furthermore, by fixing 0, 1, and , the associated quasiconformal homeomorphism is uniquely determined.
Then a homeomorphism from or onto itself can be uniquely determined by its associated BC. Under this setting, if we are given a motion vector field between two frames, we can calculate the BC of the map. Conversely, we can also calculate the motion vector field if we have the associated BC.
4.2 Linear Beltrami Solver
Lui et al. [22] proposed a linear algorithm, called Linear Beltrami Solver, to reconstruct a quasiconformal map from its associated Beltrami coefficient on the rectangular domain in . Let , we have
[TABLE]
where and u and v satisfy some boundary conditions. In the discrete case, solving the above elliptic PDEs (3) can be discretized as solving a sparse symmetric positive definite linear system. Readers can refer to [22] for details.
4.3 Optical Flow
Suppose we have a sequence of images, we can use optical flow to estimate the motion vector field between two images using the intensity difference between two images. Intuitively, optical flow is our visual sense of motion. Mathematically, for a three-dimensional case (with two spatial dimensions and a temporal dimension), a pixel at location with intensity will be moved by and between the two image frames, and the following brightness constancy constraint can be given:
[TABLE]
By Taylor expansion, we have
[TABLE]
So we have . Thus, we have . This is an equation in two unknowns and cannot be solved as such. This is known as the aperture problem of the optical flow algorithms.
4.3.1 Large Displacement Optical Flow
In the paper, we will use Large Displacement Optical Flow to calculate the deformation fields between two image frames. We give a brief review on it.
Large Displacement Optical Flow [23] is a coarse-to-fine variational framework for optical flow estimation between two image frames that incorporates descriptor matches in addition to the standard brightness and gradient constancy constraints. is denoted as the displacement field between two images and . Descriptor matches are obtained by matching densely sampled HOG descriptors in the two images with approximate nearest neighbour search.
is obtained by minimizing the energy functional:
[TABLE]
Here, and are the two input images, is the sought optical flow field, and denotes a point in the image. In the above equation, the first two terms represent intensity and gradient constancy, the third term is the robust smoothness constraint and the last term biases the displacement field towards the confident descriptor matches . is a delta function indicating whether a descriptor match is available in the location and is the confidence of the match. Descriptor matches are obtained by matching densely sampled HOG descriptors in the two images. With the Large Displacement Optical Flow, we can calculate the motion vector field between two images even if the deformation between the two frames is relatively large. Readers can refer to [23] for details.
4.4 Low rank decomposition
In mathematics, the low-rank approximation is a minimization problem, in which the cost function measures the fit between a given matrix (the data) and an approximating matrix (the optimization variable), subject to the constraint that the approximating matrix has reduced rank.
Suppose we have a matrix . our goal is to decompose into , where is the low-rank matrix and is the sparse matrix. We can obtain by
[TABLE]
where represents the number of non-zero entries in the matrix . Although the above problem follows naturally from our problem formulation, the cost function is highly non-convex and discontinuous, and the equality constraint is highly non-linear. Therefore, Candes et al. [24] suggest that the above problem can be efficiently solved, under quite general conditions, by replacing the cost function,
[TABLE]
where represents the nuclear norm of (the sum of its singular values), represents the 1-norm of (the sum of absolute values of its entries), and is a positive weighting factor. We call the above convex program Robust Principal Component Analysis (RPCA). For low-rank decomposition in this paper, we apply the algorithm of the Exact Augmented Lagrange Multiplier Method (EALM) [25], where the above convexified optimization problem is solved by Augmented Lagrange Multiplier method with the augmented problem .
5 Proposed Algorithm
In this section, we describe our proposed algorithm in detail. Our algorithm can be divided into three main stages (see Figure 2), namely,
- Reference image extraction and subsampling, 2. Stabilization and 3. Image fusion.
5.1 Reference image extraction and subsampling
To restore a turbulence-degraded video, a suitable reference image capturing the geometric structures of objects in the image frames is crucial. With a good reference image, the geometric deformation under turbulence can be accurately estimated through image registration between the reference image and image frames. The extraction of the reference image certainly relies on the image frames of the video. However, under turbulence distortions, not all image frames are useful for extracting a reference image. For example, image frames with large geometric deformations and blurs will not provide accurate information to extract the reference image. Therefore, it calls for developing an algorithm to simultaneously subsample useful frames from the video and extract the reference image from the subsampled frames.
We propose an iterative algorithm to subsample frames of the video and extract an accurate reference image by considering an optimization problem. Useful image frames should be sharp and less distorted. On the other hand, if more frames that are useful are subsampled, more information can be used to extract the reference image. Therefore, it is necessary to design an algorithm that optimizes between the number of frames and the usefulness of these subsampled frames.
Denote the image frames of a turbulence-degraded video by , where denotes a pixel in the image domain . Our goal is to search for an optimal subsample of indices , such that a good reference image can be extracted from . To achieve this goal, we first need to quantitatively measure the sharpness and geometric distortion of an image frame. The sharpness of an image can be measured by
[TABLE]
where is the Laplacian operator. In essence, is the convolution of with the Laplacian kernel, which captures the features or edges of objects in the image (see Figure 5). The magnitude of is higher for sharper images. Hence, is larger for sharper images. For example, Figure 5(b) and (d) show the Laplacian image of a sharp image (Figure 5(a)) and a blurry image (Figure 5(c)) respectively. The magnitude in intensities of Figure 5(c) is obviously larger than that of Figure 5(d). Hence, provides an effective measurement for the sharpness of an image. For the ease of implementation, we usually normalize to the range of .
Next, we need to quantitatively measure the geometric distortion. An intuitive way to measure the geometric distortion between two images is to estimate the deformation field between them. However, it involves high computational costs to compute the image correspondences. To alleviate this issue, we propose to measure the geometric distortion between two images by measuring their dissimilarities in intensities at every pixel. If two images are similar in intensities, it requires less deformation to transform one image to another. Common measures of dissimilarity include the sum of squared differences , the sum of absolute differences and the weighted sum of absolute and gradient differences . In this paper, we adopt the sum of squared differences as the dissimilarity measure.
Now, in order to obtain an optimal subsample of the image frames as well as the optimal reference image , we propose to maximize the following energy functional:
[TABLE]
where measures the sharpness and the geometric distortion from the potential reference image of the subsampled frames . The term will be defined later. Here, is a parameter balancing the first and second terms in the energy functional. The first term is an increasing function in the cardinality of , which aims to subsample as many useful frames as possible for the extraction of the reference image. Note that a concave increasing function is chosen, as a marginal increase in the size of the subsample has reduced effect on the accuracy of the extracted reference image as the number of subsampled frames increases. Therefore, by maximizing the energy functional with the two combined terms, our model simultaneously searches for a good reference image together with a maximal subsample of sharp frames, whose geometric distortions from the reference image are small.
Next, we proceed to define . Using the measures of sharpness and geometric distortion described above, can be formulated as follows:
[TABLE]
where is a positive constant for controlling the importance of sharpness of the image frames. The first term measures the geometric distortion of from . Clearly, is small if the subsampled frames are sharp and their geometric distortions from are small.
To increase the energy functional , the following strategy can be applied. Fixing , we consider the following optimization problem:
[TABLE]
Suppose . Then, solves the optimization problem (9). In practice, we compute the finite sequence and pick the largest . Then, and solve our proposed optimization model.
Now, to solve the optimization problem (11), an alternating minimization scheme is applied. Supposed and are fixed, and an initial subsampling with is arbitrary chosen. The iterative scheme can then be described as follows:
Fixing , we minimize over . Note that and can both be easily calculated for each . Denote by . Arrange such that:
[TABLE]
Then, is the required minimizer. We set and compute . 2. 2.
Next, fixing , we minimize over . Note that the second term is a constant since is fixed. We only need to find that minimizes . By differentiating with respect to , the minimizer is given by the temporal mean of :
[TABLE]
We then set .
Repeat step 1 and step 2 above until the difference between the energies at the current and previous steps is smaller than some hyperparameter . Note that is always lower than , as each step in the alternating scheme forces the energy to drop or remain the same. Figure 4 illustrates the optimization of .
The overall algorithm is summarized in Algorithm 1.
5.2 Stabilization
After the video is subsampled, sharp image frames with comparatively smaller geometric distortions remain. The subsampled frames can further be stabilized by warping each image frame via a suitable deformation field. As a result, a significant amount of geometric deformations can be removed. The stabilization involves two procedures (see Figure 6), namely, (1) Internal stabilization and (2) Absorbing stabilization. We will describe each procedure in detail.
5.2.1 Internal stabilization
Although a subsample of frames has been chosen in the previous step by minimizing geometric deformation, one may still not assume the subsampled frames are free of deformation and blur, if most frames of the original sequence are severely distorted. As a result, they cannot be registered properly. Unsatisfactory registration will seriously influence the fusion of the images. In order to reduce the error of registration, we propose a stabilization method which further suppresses the distortion. See Figure 7.
Let be the subsampled frames obtained from the previous step. Our goal is to obtain a new image sequence from with less oscillation, such that each new frame is closer to the ground truth image .
Suppose the reference image from the previous step is close to . Then, an intuitive way to stabilize can be done by warping each frame by the registration map from to . More specifically, we obtain by
[TABLE]
This approach to stabilize the video is effective if the reference image and video frames are both sharp and mildly distorted. In our case, since the video is severely distorted by turbulence, both the extracted reference image and the subsampled frames may suffer from various levels of blur and geometric distortion. Then objects in the reference image may be too blurry or occluded for optical flow algorithms to establish correct correspondences. As a result, this simple method to stabilize the video by registering each frame to the reference image is not applicable. To alleviate this issue, a remedy is to consider the deformation map from to . It is much less likely that a particular object is blurred or occluded in each of the frames . By incorporating data from all of , we can avoid the aforementioned errors while reducing geometric distortions.
Our goal is to extract an accurate estimation of the deformation map from each frame to the reference image. The registration map can be represented by the deformation field , where
[TABLE]
Similarly can be represented by a vector field , where
[TABLE]
Since the reference image is the temporal mean of the subsampled frames, the temporal mean of the deformation fields is usually small. Mathematically, one can assume that
[TABLE]
Then the following proposition is a useful observation for the extraction of from .
Proposition 1**.**
Suppose \Bigg{\|}\dfrac{\sum\limits_{i=1}^{T_{\text{samp}}}\overrightarrow{V^{i}_{\text{ref}}}}{T_{\text{samp}}}\Bigg{\|}_{\infty}\leq\varepsilon. Let . Then , i.e. .
Proof.
[TABLE]
∎
This proposition gives guidance on how one can estimate with from . Pick a pixel of the reference image . Due to the turbulence, the position of is warped to in causing geometric deformation in the image frames. To remove the geometric deformation, one can warp the point by to a new position . According to the proposition, is close to the original position of in the reference image . Hence, the geometric deformation can be suppressed.
On the other hand, by triangle inequality, it is easily to observe that
[TABLE]
Thus, the new image sequence after warping has small oscillation provided that is small, where is the warping operator and .
This method has also been applied in [12],[27], and has shown itself to be effective for suppressing geometric distortion, provided that the deformation field is small and the video is not too blurry.
However, in some cases, a few of the image frames will contain deformations that differ significantly from the remaining majority of frames. These outlying deformed frames may originate from incorrect registration via optical flow, or from subsampled frames which have relatively larger displacement from the reference image. Since the centroid method simply calculates the mean of the motion vector fields, if there are some outlier deformations, the centroid method will also capture those deformations and hence the shape of those small deformed frames will be deformed. To solve the problem, we propose to apply RPCA on the deformation fields to suppress the outlier deformations. See Figure 8.
For every frame , we calculate the deformation fields from the fixed frame to the other frames. Denote vectorized as . Define
[TABLE]
, where contains the horizontal displacement vectors, and contains the vertical displacement vectors.
We then apply RPCA to decompose each of into low-rank and sparse parts:
[TABLE]
Denote
[TABLE]
where are deformation fields each of size . By the above argument, in the presence of outlier deformation fields, we obtain the stabilized deformation field in the mean of . When the deformation fields exhibit an overall pattern, the RPCA algorithm extracts the part that resembles the other fields in the low-rank part, whereas the outlying part is captured in the sparse matrix. However, when there is no such pattern, then the low-rank part extracted by RPCA will not correspond to any useful pattern. We identify the absence of a general pattern by observing the number of non-zero entries in the sparse part by RPCA. If too many non-zero entries are present, we resort to applying centroid method.
[TABLE]
On the other hand, warping an image with a non-bijective deformation field may often cause unnatural artifacts. Since the object and the camera are static, we can require that the deformation field is bijective. We can easily enforce the bijectivity constraint by smoothing out the Beltrami coefficient, and guarantee the warped image is fold-free. By Beltrami equation (2), we can calculate , the Beltrami representation of for each . Then we restrict by thresholding it, i.e.
[TABLE]
As seen in Figure 3, at each position where the Beltrami representation is thresholded, the orientation (i.e. arg()/2) of local deformation is preserved.
Then we can reconstruct the deformation field with the Linear Beltrami Solver:
[TABLE]
by enforcing boundary conditions. Then we warp with for each to obtain stabilized ,
[TABLE]
Then we obtain a stabilized image sequence in which distortion is suppressed.
5.2.2 Absorbing stabilization
In the subsampling stage, we choose images which are both sharp and at most minorly distorted. As a result, some of the sharp images whose pixels are severely displaced are discarded. It would be useful if we can make use of those sharp but severely deformed video frames, because they may contain textures which are sharper than any Internal stabilized frame. However, we need to align them onto the same positions and shapes to fuse them. As those sharp frames are geometrically dissimilar to the reference image, estimating the deformation fields between them and the reference by optical flow would likely produce errors, especially if features are not detected in some frames due to occlusion or blurring. As such, warping them leads to large registration errors. On the other hand, we have acquired a stabilized video whose frames have little deformation from the reference image. Features are unlikely to be occluded or blurred out in all of these stabilized frames. Thus we can make use of the ample information in the stabilized sequence to stabilize the sharp and severely deformed images, and transform them to be minorly deformed. See Figure 9.
Suppose we have an Internal stabilized sequence and the sharpest frames in the original sequence, denoted by . Denote the subsampled sequence by . We aim to make use of as many sharp frames in as possible. We propose to replace the Internal stabilized frames whose corresponding subsampled frames are not in with frames in . The latter frames are not aligned well with . Their geometric distortions from have to be suppressed prior to registration. We name this procedure Absorbing stabilization, as it absorbs sharp frames into the subsample.
Absorbing stabilization is carried out in a similar manner with Internal stabilization. The only difference is that Internal stabilization acts on an element of the subsample with respect to which it is stabilized, whereas the “absorbed” sharp frames in are not elements of either the subsampled sequence or the stabilized sequence. Denoting the deformation field from sharp frame to by ,
[TABLE]
5.2.3 Registration
From subsection 3.1, we obtain a reference image , whose geometric structure is similar to the underlying truth. Suppose now we have Absorbing stabilized sequence and . Note that the geometric deformation of the Absorbing stabilized sequence is now suppressed and thus the error of the registration can be reduced. Applying Large Displacement Optical Flow, we have vector fields from each Absorbing stabilized frame to . By Beltrami equation (2), we can calculate , the Beltrami representation of for each . Then we restrict by thresholding it, i.e.
[TABLE]
We can obtain
[TABLE]
by enforcing boundary conditions. Then we warp with for each to obtain registered ,
[TABLE]
Then we obtain a registered image sequence .
5.3 Image fusion
5.3.1 Detail extraction
From the above we now have a stabilized-then-registered sequence at hand. As there are blurry regions in each frame but at different spatial locations, we aim to extract information from each frame to produce an image as sharp and with as many texture details as possible. We adopt a modified version of the image fusion scheme from [20]. Figure 10 illustrates the process of Detail extraction.
In [20], patches on the adaptive-thresholded sparse part are added together with weights to form a detail layer. The weights are obtained by smoothing the binary patches with guidance from their corresponding selected sharp patch, i.e.
[TABLE]
where is a guided filter.
The detail layer is then obtained by the weighted sum
[TABLE]
Since the patch size can be large, the 1-positions in the binary image may be relatively close, and the patches may spatially overlap each other. As seen in our experiments, the fused detail intensities go out of bounds if there is overlap among the patches. See Figure 11. As a remedy, instead of a weighted sum, we first multiply each patch with its corresponding weight , and then pick for each spatial position the intensity with the highest absolute value amongst the patches, i.e.
[TABLE]
where . The detail layer with weight is held on to be fused in the next section.
5.3.2 Deblurring
While deblurring an image, the texture details are often overly sharpened, producing undesired artifacts. In accordance with [20], after RPCA is applied for detail extraction, the texture details are captured in the sparse part. Therefore, the low-rank part keeps the coarse structure and is blurry. Thus blind deconvolution [26] is directly implemented on the low-rank part , which is then fused with the texture detail layer
[TABLE]
Degradation caused by blur is generally modelled as follows,
[TABLE]
where is the blurred image, is the latent sharp image, h is the blur kernel. The blind deconvolution algorithm can be regarded as the following:
[TABLE]
where and are the regularization terms used to restrain and based on their prior knowledge. The sparse regularization term in [26] is defined as
[TABLE]
where and are the image gradients of F in horizontal and vertical directions respectively, and is defined as
[TABLE]
Here, are fixed parameters. Sparsity is also imposed to regularize the blur kernel as follows:
[TABLE]
For the details for solving the optimization problem (28), we refer the reader to [26].
6 Experimental Result and Discussion
In this section, detailed experimental justification of the proposed method will be illustrated. Firstly, we show the improvement of the reference image compared to several methods. Then, we show the importance of subsampling the video sequence, which not only obtains a better reference image but also reduces the computation time. Next, the advantages of stabilization are illustrated by comparing to those registering the frames alone. Finally, both qualitative and quantitative measures are used to evaluate the performance of the proposed algorithm comparing with several state-of-the-art methods. Peak Signal to Noise Ratio (PSNR) and Structural Similarity Index (SSIM) are computed to assess the quality of the restored images objectively.
For all experiments, the parameters and in the energy model (9) in the subsampling stage are in the range of and respectively. For the registration stage, the parameters of the Large Displacement Optical Flow [23] used are the default setting. For our modified version of the image fusion scheme from [20], we perform adaptive thresholding by assigning 1 to entries whose absolute difference with the norm of the mean of the window centered at itself is greater than a threshold taken from the range , and 0 elsewhere. The patch size is taken to be 7, and the weight in unsharp masking is taken to be 1.7. The fusion weight applied on the detailed layer is in the range of . For the deblurring stage, we apply blind deconvolution to obtain the final output. Two separate sets of parameters are used for the synthetic image sequences and real sequences. In the synthetic experiments, the blur kernel is set to be , the noise level is chosen within the interval , the deblurring weight is set to be 0.02 and all other parameters are set to default. The details of the parameters can be found in [26] and its project page.222http://www.cse.cuhk.edu.hk/leojia/programs/deblurring/deblurring.htm For real sequences, we set the same parameters to (7,9,0.03,0.2) to obtain the outputs. The proposed algorithm is implemented in Matlab with MEX and C++. All the experiments are executed on an Intel Core i7 3.4GHz computer.
The proposed method is compared with four representative methods: Sobolev gradient-Laplacian method [16] (SGL), Centroid method [12] (Centroid), the data-driven two-stage approach for image restoration [28] (Two-stage) and near-diffraction-limited-based image restoration for removing turbulence [11] (NDL). For the Two-stage method, it was originally applied to restore a sharp image from an underwater video which was distorted by water waves. As videos degraded by water turbulence are generally treated as if under large distortion with mild blur, Two-stage still gets reasonable results and thus the comparison is valid. The codes of SGL [16], Two-stage [28] and NDL [11] are provided by the respective authors, and the parameters used are default setting.
6.1 Quality of subsampled reference image
The visual quality of the reference images obtained by the proposed algorithm, temporal averaging, the temporal average of the low-rank and the centroid method [12] are compared qualitatively in this subsection. The reference images are shown in Figure 13: the first column (a) are the observed image from ’Chimney’ and ’Desert’ sequences while the other four columns are the reference images generated by temporal mean (b), mean of low rank (c), centroid method (d) and proposed algorithm (e). In the Chimney sequence, the subsampled reference image is sharper and preserves more details than the other three methods. This is because the subsampled sequence only consists of sharp and mildly distorted images, and hence the obtained reference image is clearer. For the other methods, the blurry and severely deformed frames are also taken into account so the reference image is corrupted. For an even more severely turbulence-degraded video (Desert sequence), the blurring effect is more noticeable. For the mean of the low-rank part, the general geometric structure is extracted and so sharp edges are preserved. However, most texture details will go to the sparse part, so the details are removed. For the centroid method, the texture details are kept as every image is warped by an average deformation field, and there is no direct manipulation on image intensities except interpolation. However, since the centroid method is based on the strong zero-mean assumption of the deformation fields between ground truth and the distorted sequence, which does not usually hold for turbulence-distorted video, the geometric structure may not be well kept. For the proposed method, the reference image is reconstructed from a good subsampled sequence, which minimizes the energy (9) considering similarity and sharpness and improves iteratively. As a result, the edges are sharp, the geometric structure is preserved and the texture details are kept. The energy plot of (9) is shown in Figure 14. The PSNR of the reference images also justify the result.
6.2 Importance of subsampling
In this subsection, we will illustrate the importance of subsampling. We compare the fusion results with and without subsampling. We register each video sequence to their corresponding reference image, which is the temporal mean of the sequence. Then fusion is applied to the two registered video sequences. Visual comparison and quantitative measures will be used to justify the result. Comparing (c) to (d) in Figure 15, noticeable artifacts can be observed in the edges of the wheel and the overall image is also blurry. In contrast, comparing to the fusion result of the original video, the wheel in the subsampled sequence is free of artifacts, is sharper and has clearer edges. This observation can be explained by two factors:
Since the subsampled video is obtained by maximizing the energy that depends on the number of frames in the subsampled sequence, their similarity to the reference image, and their sharpness, the subsampled image frames mainly consist of comparatively sharp and less deformed image frames. Fewer noisy components are included in the sparse part in the fusion stage, and hence the result has a sharper edge and richer texture details are preserved. 2. 2.
Since the reference image is constructed by a sharper and mildly distorted video sequence, the reference image is sharper and better preserves geometric structure. This has been justified in subsection 6.1. Therefore the alignments of the registered frames are more accurate, and the frames are thus more similar to the reference image. Therefore, the fusion artifacts due to poor registration become insignificant.
6.3 Importance of stabilization
This subsection demonstrates the importance of stabilization by applying low-rank decomposition on the deformation fields. Since stabilization is mainly used for enhancing the registration results, some fusion results will be shown, and the performance will be evaluated by visual comparison and PSNR. We will show the importance of the stabilization by comparing the fusion results with and without stabilization. Figure 19 shows the fusion result of the subsampled Car sequence with stabilization and that without stabilization, which is (b) in Figure 15. The details are kept in a vivid way as the registration is more accurate and so the fusion is more satisfactory. Also, the details are sharper as absorbing stabilization is applied. (See zoomed parts in Figure 19). The stabilization plays an important role in the proposed algorithm and makes a significant improvement because the geometric deformation of the video frames is further suppressed before registration. Therefore, the registration error can be reduced. Moreover, the Absorbing stabilization stabilizes the sharp but severely distorted frames. As a result, more texture details are kept in the fusion stage and thus the PSNR of the fusion result using stabilization is higher.
On the other hand, the proposed stabilization scheme can be treated as a preprocessing step for registration. To illustrate this idea, we incorporate the stabilization scheme with the symmetric constraint-based B-spline registration proposed by Zhu and Milanfar [11]. This method is a common tool to tackle the turbulence-degraded video and gives satisfactory registration results in most cases. However, if the turbulence is strong in the sense that the frames are very blurry and severely distorted, the method may not obtain a good result.The registration results along with their corresponding fusion results are shown in Figure 16 and Figure 18. As shown in Figure 16, the registration results are improved significantly in the sense that the textures are not distorted (zoomed part (f) and (h)) and the edges are sharp (zoomed part (j) and (l)) after applying stabilization. As a result, the fusion result has also shown a significant improvement by stabilization in Figure 18.
6.4 Simulated Experiment
To quantitatively evaluate the performance of the proposed algorithm, several sets of video sequences (namely Desert and Road) are generated with severe simulated turbulence distortions. Each frame of the simulated sequences is generated from a single image by randomly selecting positions, and considering an image patch centered at each chosen position. A uniform motion vector patch with the same size of the image patch is generated, whereas the vector is randomly generated from a normal distribution for 2-vectors. Each vector patch is then smoothed with a Gaussian kernel and entrywise multiplied with a distorting strength value. The overall motion vector field is then generated by adding up the vector patches wherever overlapping. The image is then warped by the generated motion vector field. Note that the distortion effects are accumulated where the patches overlap. For each image frame, a Gaussian blur is applied to make them blurry. In the simulated experiments, the chosen patch size is , and the mean of the Gaussian kernel is slightly shifted for each image patch. See Figure 12. The Desert and Road sequences consist of frames each, among which 70 frames are degraded under severe distortion and the rest are deformed relatively mildly. The distorting strengths of severely distorted frames are in the range of while those of mildly distorted frames are in . The Carfront sequence is a data set obtained from [18] which contains mildly distorted frames when compared with the Desert and Road sequences. Note that the Carfront sequence is cropped from the original sequence. The Car sequence contains frames, among which only 15 are mildly distorted frames and the others are severely distorted. The distorting strengths of the mildly distorted frames and the severely distorted frames are in the ranges of and respectively. It serves as an extreme test case where most of the frames are severely degraded. I gives the PSNR and SSIM values for all restoration results of five different restoration algorithms. Each sequence has two rows, where the first row denotes the PSNR values and the second row denotes the SSIM values.
6.4.1 Mildly distorted sequences
The Carfront sequence contains mildly distorted frames only and all the turbulence strength of images are similar. The restoration results of the Carfront sequence are shown in Figure 17. Since the deformations among Carfront frames are small, the restoration result of Centroid method and proposed algorithm are comparable. For the Carfront sequence, Centroid keeps the geometric structure well but the result is blurry. The shape of the restored image by SGL is slightly distorted and the intensities are unnatural. Two-stage distorts the image in a ripple-like pattern. NDL also keeps the structure relatively well but some artifacts are produced. The proposed algorithm keeps both the geometric structure and local details well.
6.4.2 Strongly distorted sequences
The majority of the frames in the Desert and Road sequences are strongly distorted, whereas the remaining are mildly distorted. The restoration results of the sequences are shown in Figure 21 and Figure 22. Since the deformations among Desert and Road frames are large, the restoration result of the proposed algorithm differs from existing methods. As the imaged objects are significantly displaced across frames, the temporal smoothing effect of the centroid method produces noticeable blur. This is more observable in the Desert experiment, where the many vertical edges are obscured by the blur, whereas in the Road sequence, thin strips parallel to the road are also diminished. A similar temporal smoothing effect manifests in SGL as overlapping shadowy artifacts. Intensity overshoots and jagged edges are observed in the results by NDL, likely because symmetric constraint-based B-spline registration cannot handle random discontinuous displacements across the temporal domain. In comparison, the proposed algorithm preserves clear edges and texture details. It is because the mildly distorted and sharp frames are selected and a good reference iamge is obtained in the subsampling stage. As a result, the proposed algorithm outperforms existing methods.
6.4.3 Extreme case: severely distorted sequence
Most of the frames in the Car sequence are severely distorted, even more so than the Desert and Road sequences. Moreover, the distortions of the mildly distorted frames in the Car sequence are stronger than those in the Desert and Road sequences. The restoration results are shown in Figure 20. The result produced by the centroid method is fairly blurry, and its intensity contrast is significantly lower than other methods. Besides the intensity overshoots, several regions of the SGL result are noticeably deformed. The NDL result has fewer deformed regions, but it is relatively blurry, and straight edges are not preserved as well as the other methods. The proposed algorithm preserves geometric structure well and produces a clear image with minimal artifacts. The reason of the proposed algorithm outperforming the other methods in this extreme case is that the stabilization stage further suppresses the geometric deformation of the subsampled sequence. Therefore, a better registration result is achieved.
6.5 Real experiments
We have also tested our proposed method on two real turbulence-distorted sequences, namely the Chimney and Water Tower sequences. A point of interest of real sequences is that among the two detriments of atmospheric distortion, blur is much more prominent than geometric deformation. The restoration results of the sequences are shown in Figures 23 and 24.
As texture details in real sequences are mostly blurred, the ability of reconstruction schemes to extract sharp details is particularly crucial. In the presence of severely blurred frames, the Two-stage method cannot preserve texture details of both sequences and produces blurry results, as seen in Figure 23(l),(s) and Figure 24(l),(s). The temporal averaging in the centroid method also smooths out edges and sharp features as seen in Figure 23(k),(r). In this aspect, the Sobolev gradient-Laplacian method and near-diffraction limited method performs better, and reconstructs results with sharp details. However, due to varied reasons, the overall intensity distribution of their results differ from that of the original sequence. As a result, the pixel intensities of their results look unnatural. This is exemplified by the presence of dark strips in Figure 23(j),(m),(q),(t) and Figure 24(j),(q). The proposed algorithm produces images with relatively clear details, and preserves the intensity distribution of the original frames.
On the other hand, the severity of geometric deformation in real sequences cannot be underestimated, as exemplified by Figure 23(b). An ideal reconstruction scheme must accurately resolve such distortion. In lieu of an absent ground truth image, we compare the reconstructed results to the satisfactory original frame Figure 23(a). The near-diffraction limited method result show noticeable structure difference from Figure 23(a). The zoomed part Figure 23(m) shows vertical stretching, and Figure 23(t) highlights an additional kink on the right. The Two-stage reconstructed result is too blurry to identify the geometric structure within. In comparison, our proposed method preserves the geometric structure as well as the Sobolev gradient-Laplacian method and the centroid method.
In both of the above aspects, the proposed method is among the top performers.
7 Conclusion
The proposed algorithm produces better-aligned images compared to existing schemes when geometric deformation is severe. In addition, depending on the purpose of the reader, our algorithm can be partially implemented to suit their needs. For instance, to extract a stabilized video sequence from a distorted video sequence, the Deformation Removal algorithm can be applied. If computational time is essential and the need for sharpness is relaxed, the references extracted in subsection 5.1 would suffice. This enables near real-time stabilization of geometrically deformed video. Moreover, the stabilization scheme can be used as a prepossessing of registration and obtain a better registration result.
However, due to the severity of distortions in the observed frames, a feature-matching optical flow scheme is required to obtain reliable deformation fields. In addition, numerous optical flow operations are required to obtain deformation fields. As a result, the algorithm is computationally expensive. We encourage interested readers to improve the algorithm and suggest suitable optical flow schemes.
Acknowledgments
The image used for generating the Car sequence is a resized version of the Car image retrieved from the RetargetMe benchmark for image retargeting by Rubinstein, Gutierrez, Sorkine-Hornung and Shamir. The Carfront sequence is retrieved from the project webpage of [18]. The image used for generating the Desert sequence is retrieved from WallpapersWide.com, whereas the image used for generating the Road sequence is by Dave and Les Jacobs for Blend Images and Getty Images. The Chimney sequence is produced by Hirsch and Harmeling from Max Planck Institute for Biological Cybernetics, whereas the Water Tower sequence is produced by Prof. Mikhail A. Vorontsov from the Intelligent Optics Lab of the University of Maryland. Both are recovered from [11]’s project webpage. The code for RPCA is from [29]. The code for optical flow is from [23]. The authors would like to thank the above persons for allowing them to use the video, pictures and algorithms in their experiments. Lok Ming Lui is supported by HKRGC GRF (Project ID: 402413).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] M. C. Roggemann, B. M. Welsh and B. R. Hunt, Imaging Through Turbulence , 1st ed., CRC Press, 1996.
- 2[2] R. E. Hufnagel and N. R. Stanley, “Modulation Transfer Function Associated with Image Transmission through Turbulent Media”, J. Optical Soc. Amer. , vol. 54, no. 1, pp. 52–61, 1964, 10.1364/JOSA.54.000052.
- 3[3] Pearson, James E. ”Atmospheric turbulence compensation using coherent optical adaptive techniques.” Applied optics 15.3 (1976): 622-631.
- 4[4] R. K. Tyson, Principles of Adaptive Optics , Academic Press, 1998.
- 5[5] M. Shimizu, S. Yoshimura, M. Tanaka and M. Okutomi, “Super-Resolution from Image Sequence under Influence of Hot-Air Optical Turbulence”, Proc. IEEE Conf. Comput. Vis., Pattern Recog. (CVPR) , June 2008, 10.1109/CVPR.2008.4587525.
- 6[6] D. Li, R. M. Mersereau and S. Simske, “Atmospheric Turbulence-Degraded Image Restoration Using Principal Components Analysis”, IEEE Trans. Geosci. Remote Sens. , vol. 4, no. 3, July 2007, 10.1109/LGRS.2007.895691.
- 7[7] M. A. Vorontsov, “Parallel image processing based on an evolution equation with anisotropic gain: integrated optoelectronic architectures”, J. Optical Soc. Amer. A , vol. 16, no. 7, pp. 1623–1637, July 1999, 10.1364/JOSAA.16.001623.
- 8[8] S. Seitz and S. Baker, “Filter Flow”, Proc. 2009 12 th Int. Conf. Comput. Vis. (ICCV) , Oct. 2009, 10.1109/ICCV.2009.5459155.