DOPE: Distributed Optimization for Pairwise Energies
Jose Dolz, Ismail Ben Ayed, Christian Desrosiers

TL;DR
This paper introduces a distributed optimization method using ADMM for pairwise energy functions in vision, enabling parallel computation and handling non-submodular potentials effectively.
Contribution
It presents a novel distributed ADMM framework that decomposes pairwise energy optimization into parallel sub-problems with a new consistency constraint, applicable to non-submodular functions.
Findings
Improves efficiency of pairwise energy optimization in vision tasks.
Effectively handles non-submodular potentials.
Demonstrates benefits over serial algorithms like BK in experiments.
Abstract
We formulate an Alternating Direction Method of Mul-tipliers (ADMM) that systematically distributes the computations of any technique for optimizing pairwise functions, including non-submodular potentials. Such discrete functions are very useful in segmentation and a breadth of other vision problems. Our method decomposes the problem into a large set of small sub-problems, each involving a sub-region of the image domain, which can be solved in parallel. We achieve consistency between the sub-problems through a novel constraint that can be used for a large class of pair-wise functions. We give an iterative numerical solution that alternates between solving the sub-problems and updating consistency variables, until convergence. We report comprehensive experiments, which demonstrate the benefit of our general distributed solution in the case of the popular serial algorithm of Boykov and…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3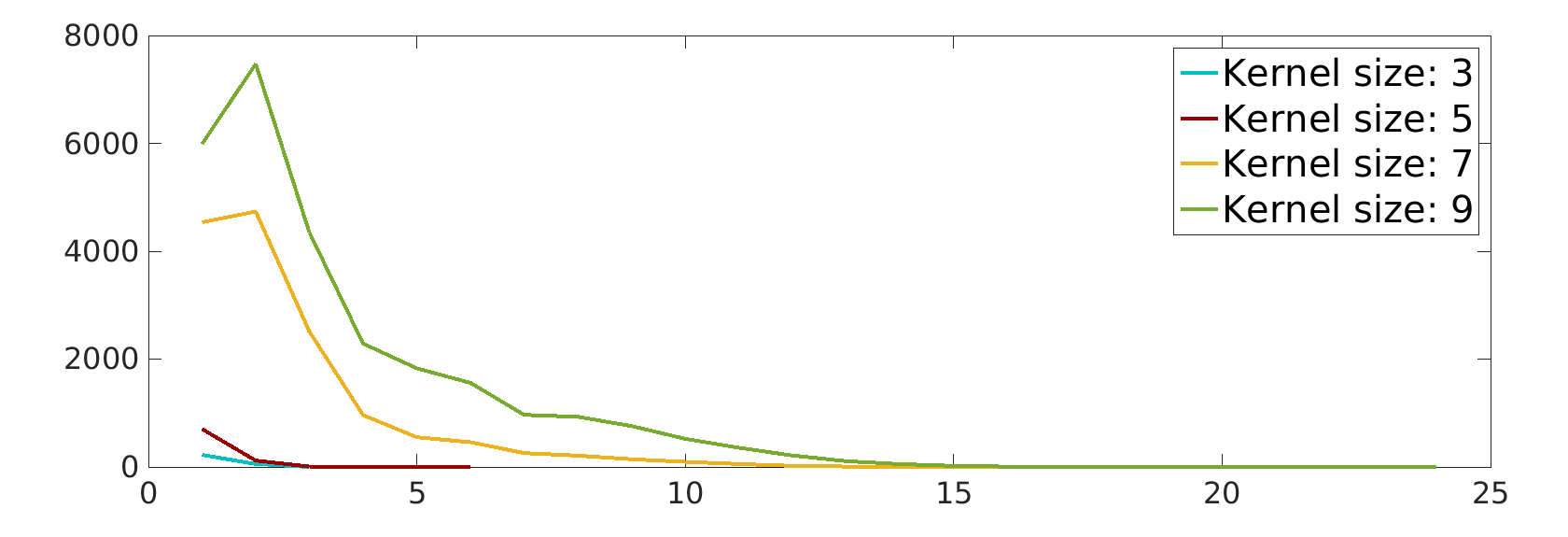 Figure 4
Figure 4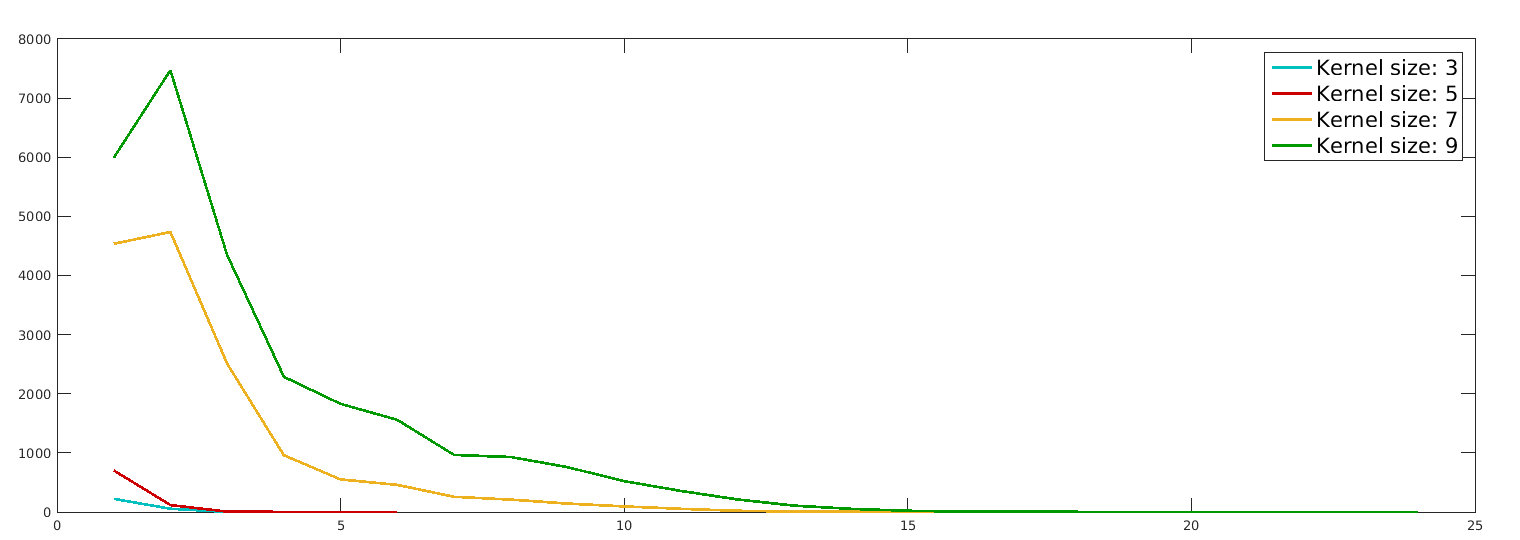 Figure 5
Figure 5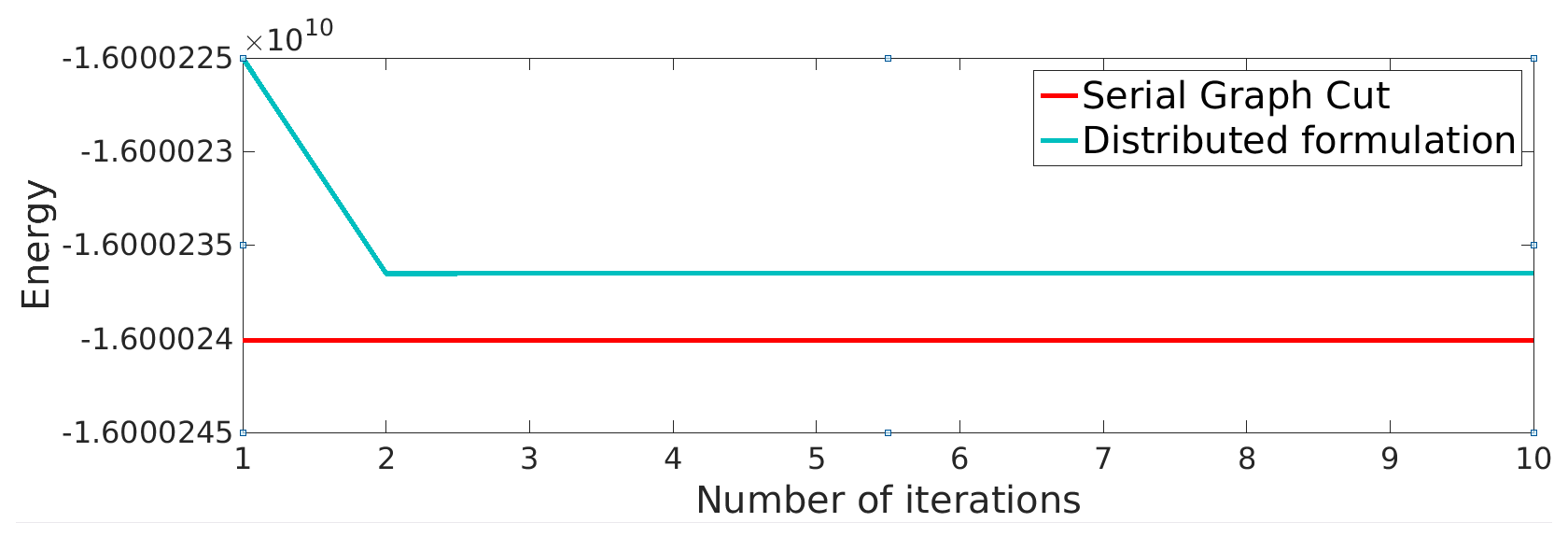 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9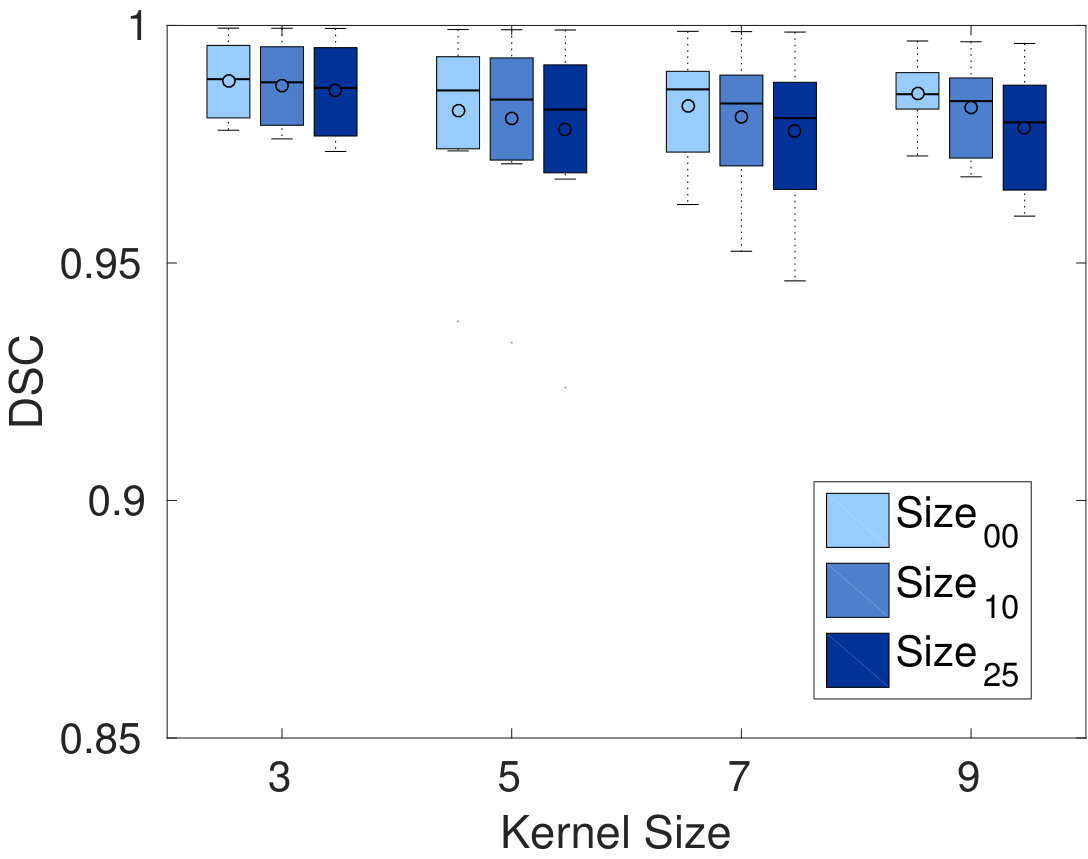 Figure 10
Figure 10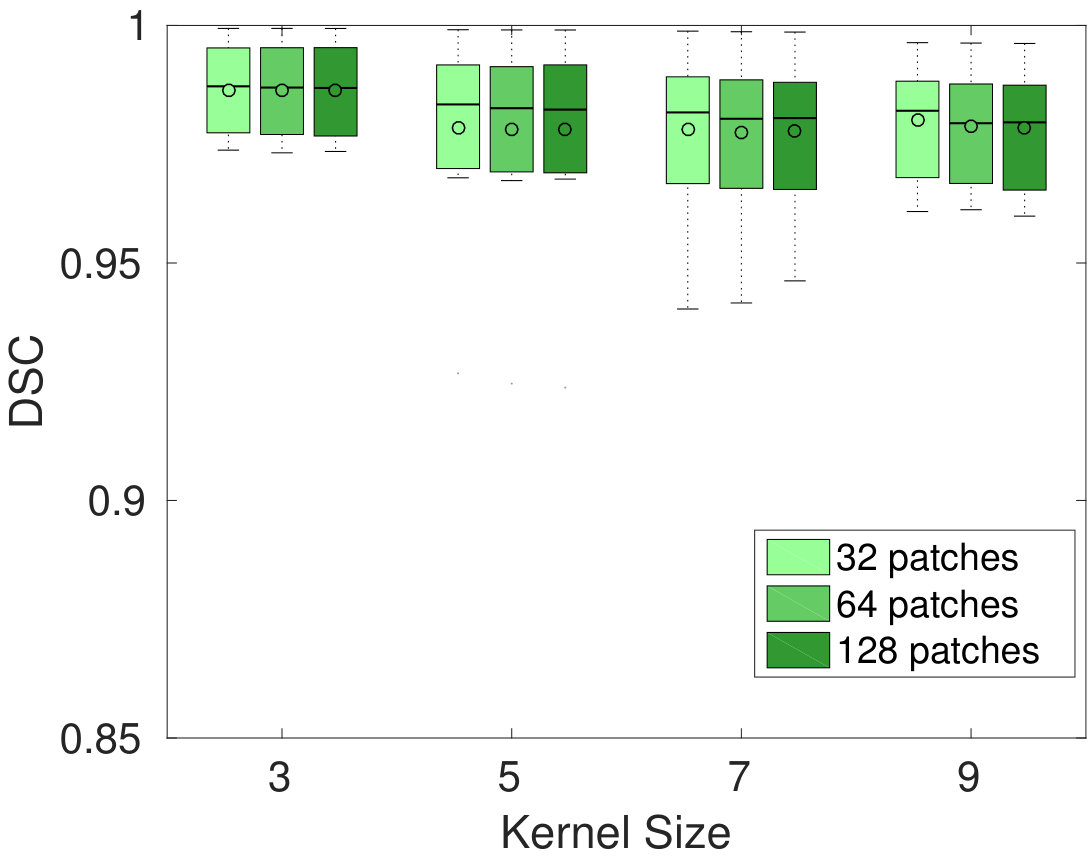 Figure 11
Figure 11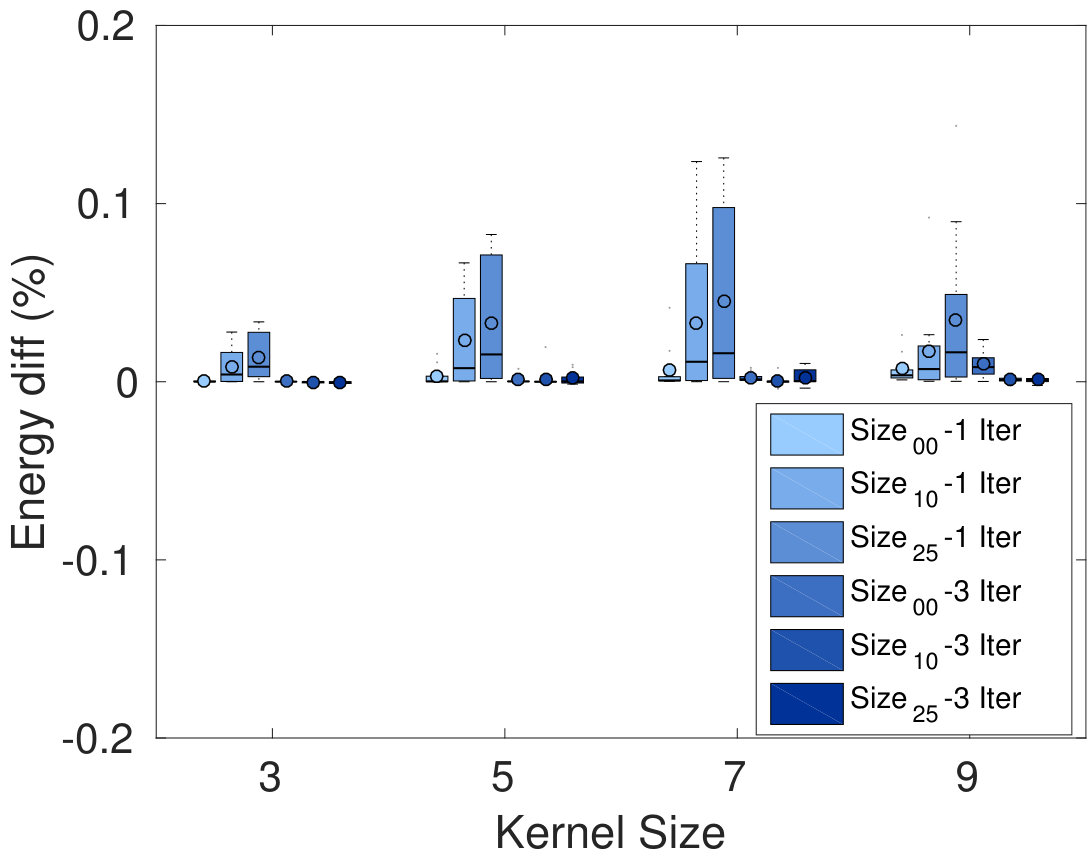 Figure 12
Figure 12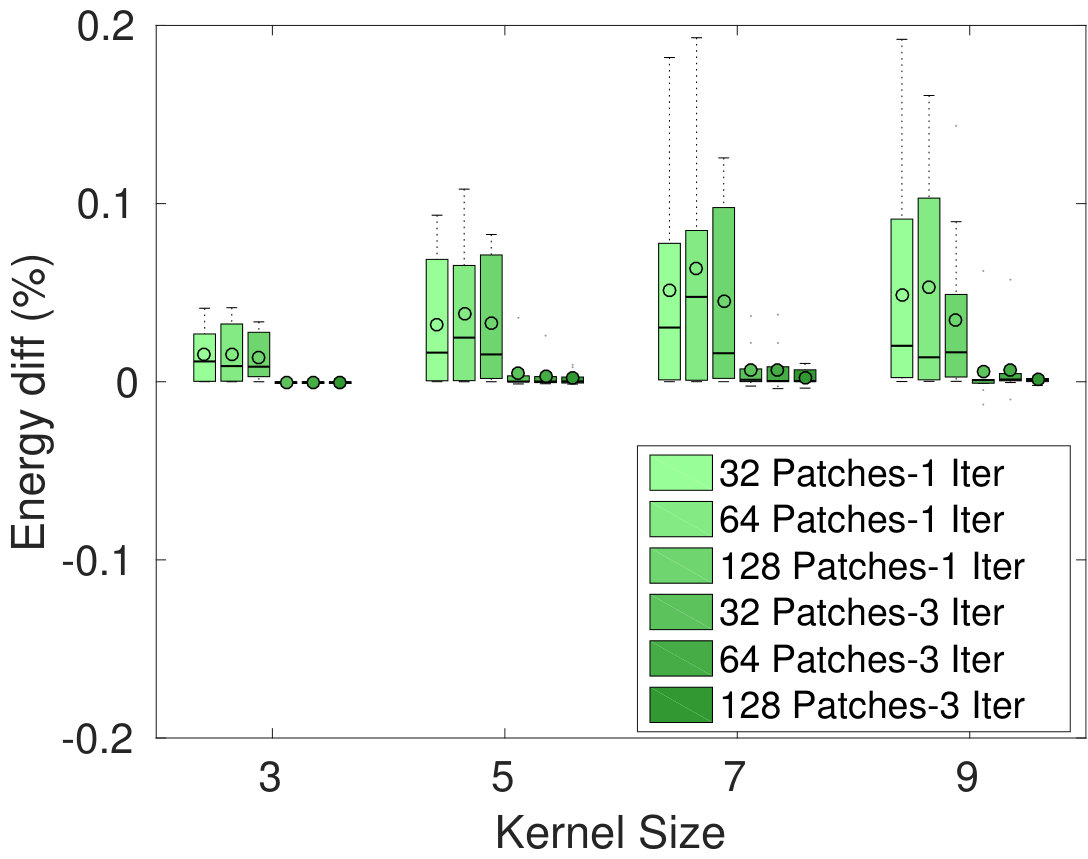 Figure 13
Figure 13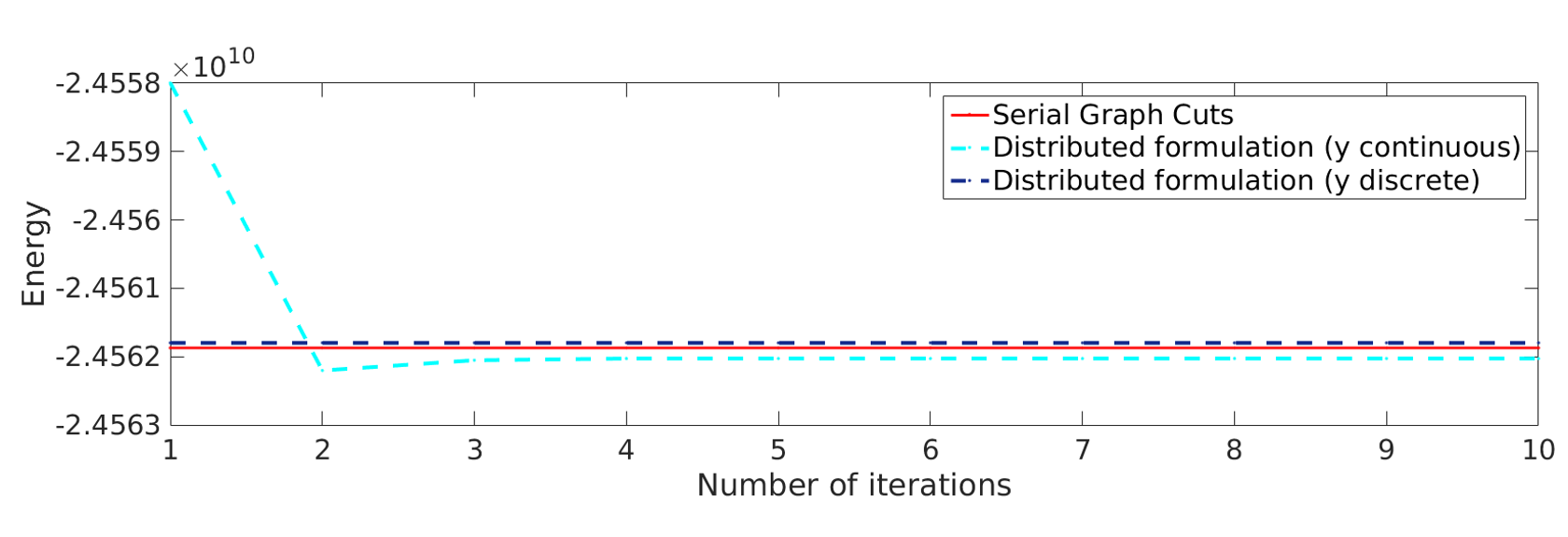 Figure 14
Figure 14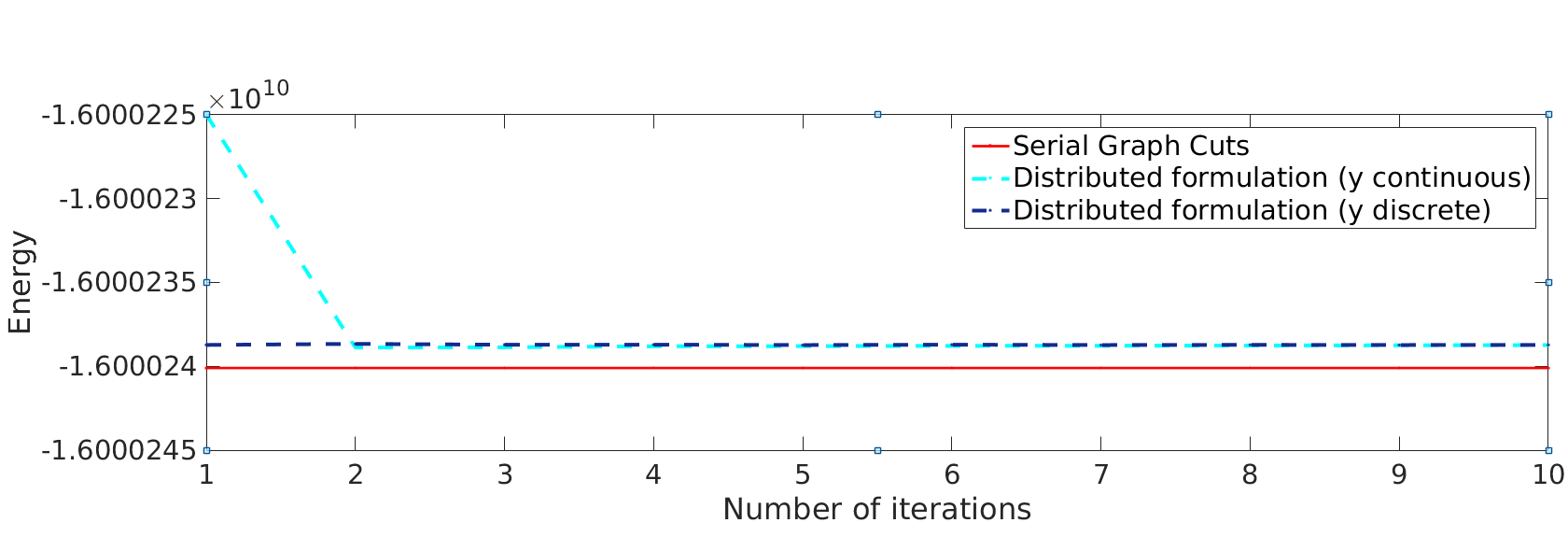 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23 Figure 24
Figure 24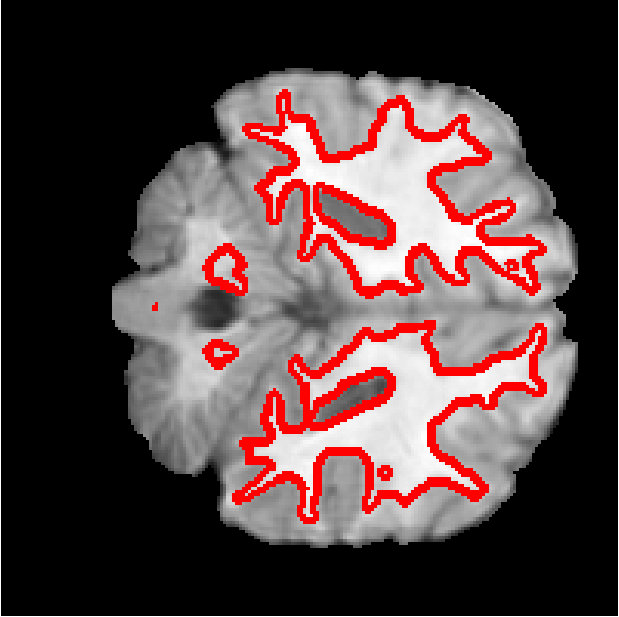 Figure 25
Figure 25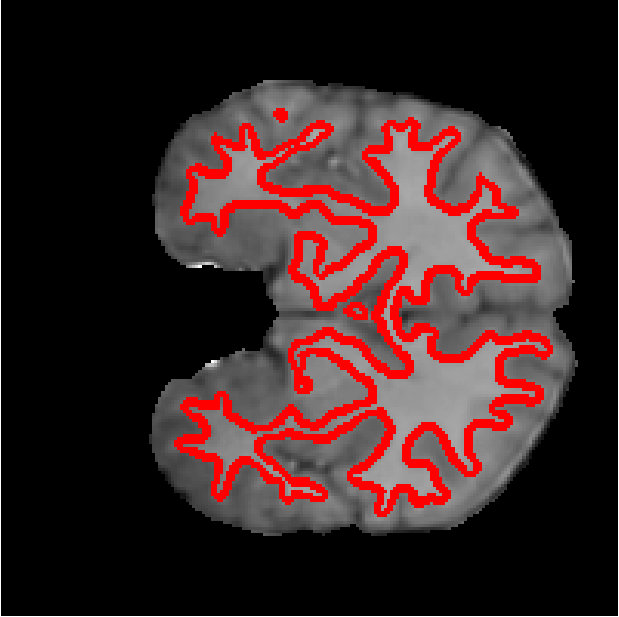 Figure 26
Figure 26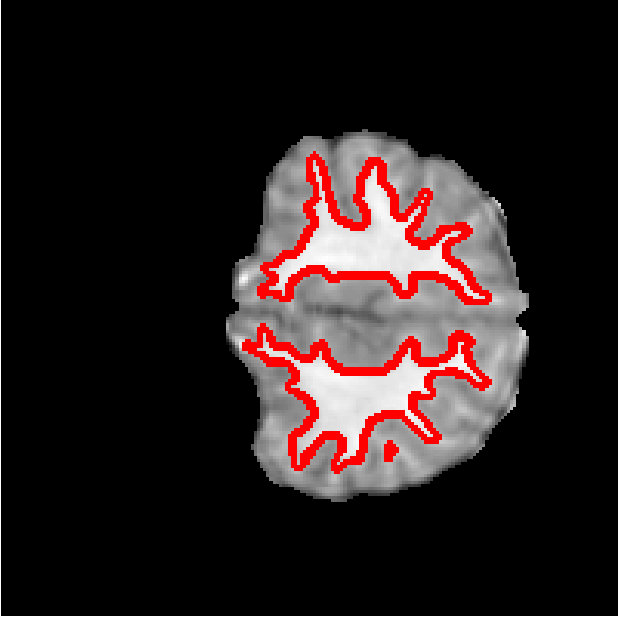 Figure 27
Figure 27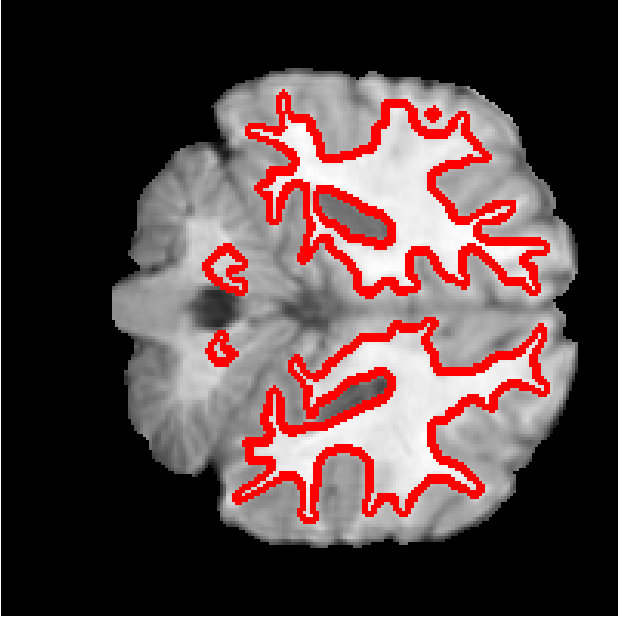 Figure 28
Figure 28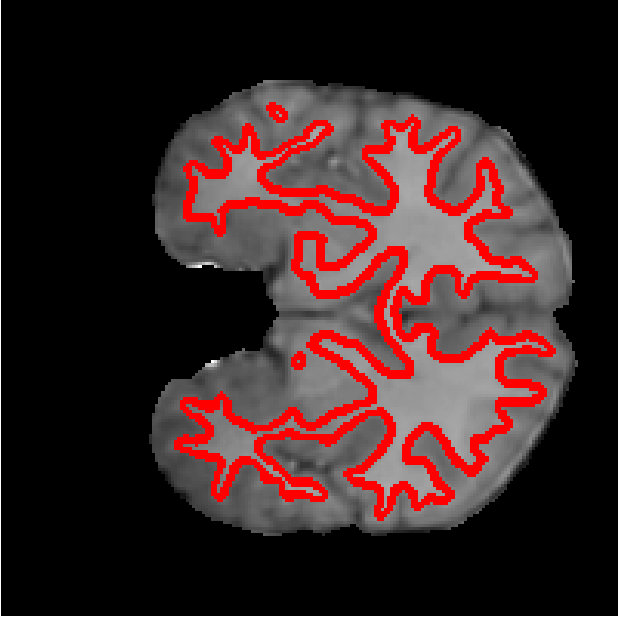 Figure 29
Figure 29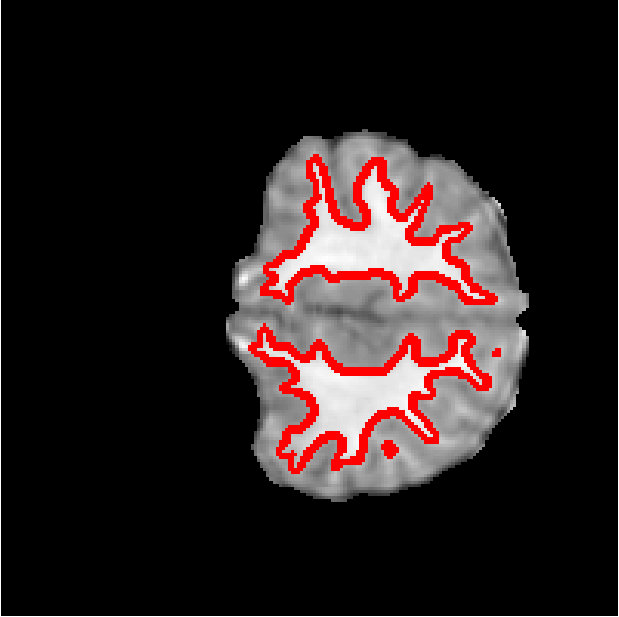 Figure 30
Figure 30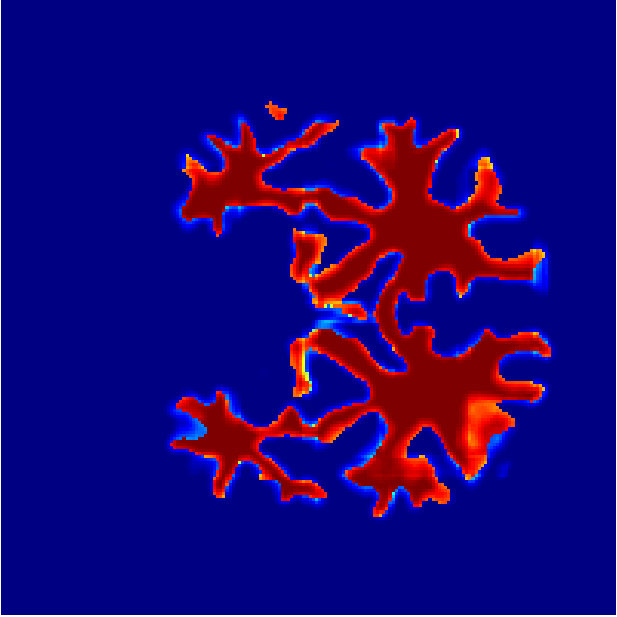 Figure 31
Figure 31 Figure 32
Figure 32 Figure 33
Figure 33 Figure 34
Figure 34 Figure 35
Figure 35 Figure 36
Figure 36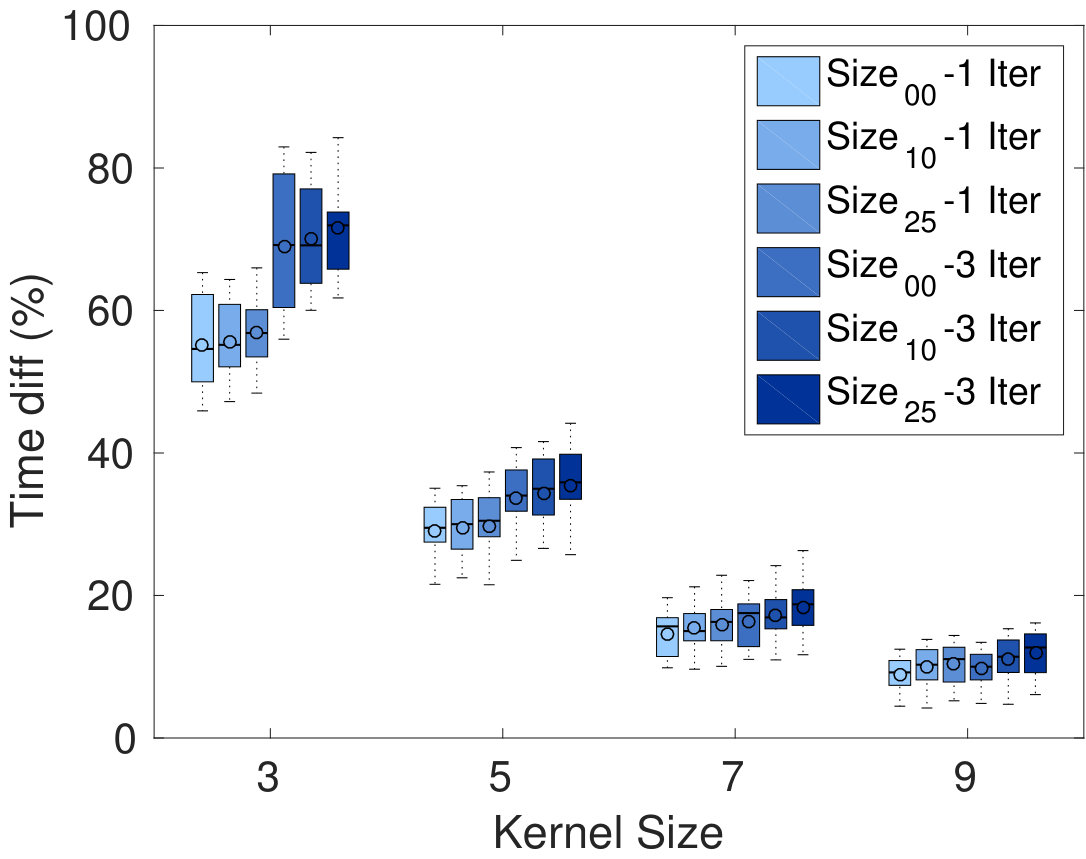 Figure 37
Figure 37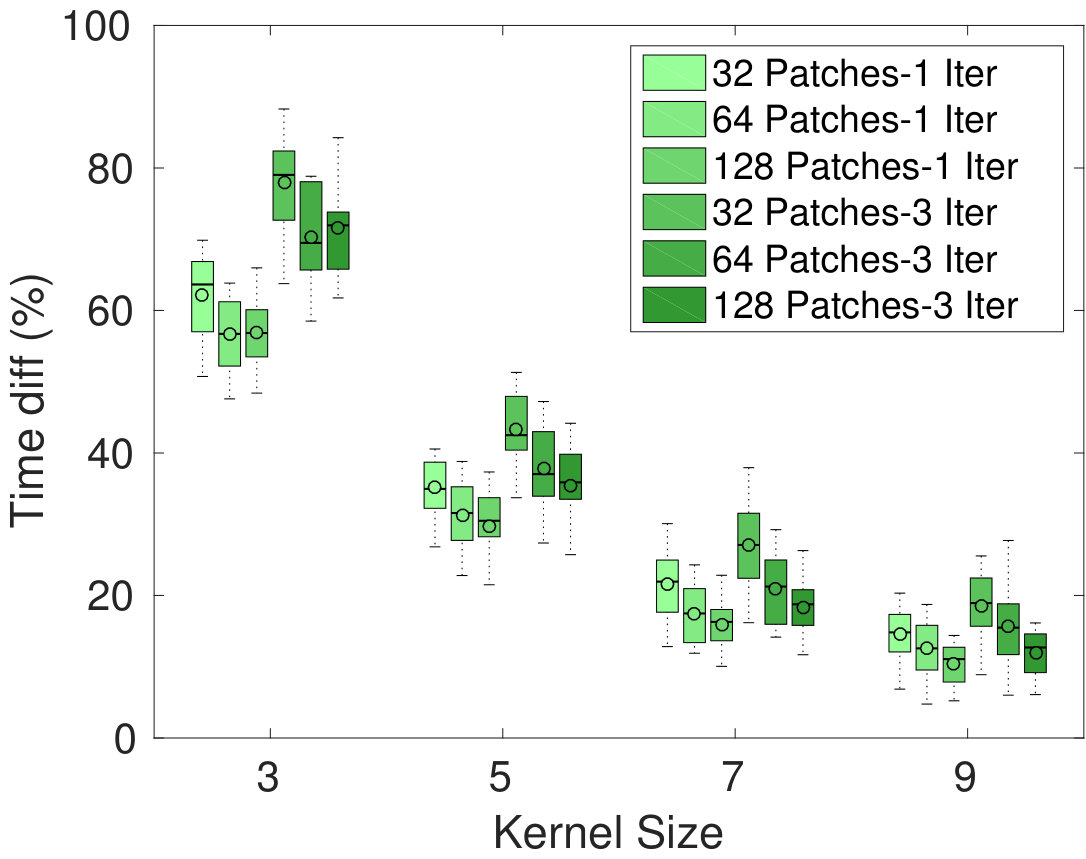 Figure 38
Figure 38 Figure 39
Figure 39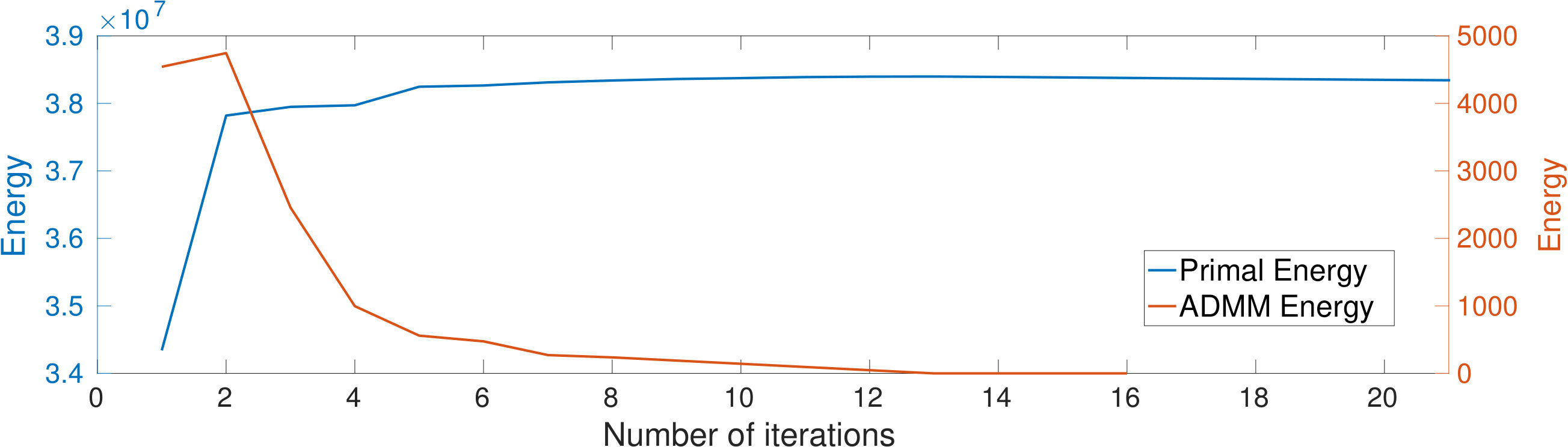 Figure 40
Figure 40| LSA-TR [10] |
|
|||
|---|---|---|---|---|
| Energy | 1.0906 104 | 1.1115 104 | ||
| Time | 174 s | 53 s |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSparse and Compressive Sensing Techniques · Medical Image Segmentation Techniques · Advanced Neural Network Applications
DOPE: Distributed Optimization for Pairwise Energies
Jose Dolz
Ismail Ben Ayed
Christian Desrosiers
Laboratory for Imagery, Vision and Artificial Intelligence
Ecole de Technologie Superieure, Montreal, Canada
Abstract
We formulate an Alternating Direction Method of Multipliers (ADMM) that systematically distributes the computations of any technique for optimizing pairwise functions, including non-submodular potentials. Such discrete functions are very useful in segmentation and a breadth of other vision problems. Our method decomposes the problem into a large set of small sub-problems, each involving a sub-region of the image domain, which can be solved in parallel. We achieve consistency between the sub-problems through a novel constraint that can be used for a large class of pairwise functions. We give an iterative numerical solution that alternates between solving the sub-problems and updating consistency variables, until convergence. We report comprehensive experiments, which demonstrate the benefit of our general distributed solution in the case of the popular serial algorithm of Boykov and Kolmogorov (BK algorithm) and, also, in the context of non-submodular functions.
1 Introduction
A mainstay in computer vision, regularization serves a breadth of applications and problems including segmentation [27, 29], optical flow [18], shape fitting [17], stereo matching [15], deconvolution [10], high-dimensional clustering [28], among many others [3, 13]. For instance, in the discrete setting, segmentation problems are commonly stated as optimizing a regularization-based functional111We give a binary (two-region) segmentation functional for simplicity but the discussion extends to multi-region segmentation. of the following general form [1, 4, 16]:
[TABLE]
where is the image domain and is a binary vector indicating a possible foreground-background segmentation: if pixel belongs to the foreground class, otherwise . controls the relative importance of each term. The first term is a sum of unary potentials typically defined via log posteriors:
[TABLE]
with denoting the feature vector of pixel (e.g., color). The second term in (1) is a general form of pairwise regularization. The second-order Potts model [4] is an important example of pairwise regularization, and is very popular in computer vision: given a neighborhood for pixel , and [math] elsewhere. In this case, is a penalty for assigning different labels to neighboring pixels and . Such a penalty can be either a constant, in which case the regularization term measures the length of segment boundary, or a decreasing function of feature (e.g., color) difference , which attracts the segment boundary towards strong feature edges [4]. Potts regularization belongs to an important family of discrete pairwise functions, submodular functions222A function defined over a pair of discrete binary variables is submodular if and only if ., which were instrumental in the development of various efficient computer vision algorithms. The global optimum of a function containing unary and submodular pairwise potentials can be computed exactly in polynomial time using graph cut (or max-flow) algorithms [5]. Other examples of pairwise terms of the general form in (1) include non-submodular functions, which arise in problems such as curvature regularization [10, 22], surface registration [13], deconvolution [10] and inpainting [13]. It also includes dense (fully connected) models [16], where pairwise penalties are not restricted to neighbouring pixels. These are only few examples of pairwise-function problems widely used in combination with popular optimization techniques such as LP relaxation [13] or mean-field inference [1, 16]. Finally, it is worth mentioning that total-variation (TV) terms can be viewed as the continuous counterpart of Potts regularization, and were the subject of a large number of vision works in recent years [7, 23, 24, 30].
Recently, there have been significant research efforts focusing on designing parallel (or distributed) formulations for optimizing pairwise functions [1, 19, 25]. Distributing computations would be beneficial not only to high-resolution images and massive 3D grids but also to difficult high-order models [11, 14, 26], which require approximate solutions solving a large number of problems of the form (1). For instance, continuous convex relaxation techniques have been gaining popularity recently due to their ability to accommodate parallel implementations [7, 23, 24, 30]. Unfortunately such techniques are restricted to TV regularization terms. Mean-field inference techniques [1, 16] also attracted significant attention recently as they can be parrallelized, albeit at the cost of convergence guarantees [1].
In the context of submodular functions, several studies focused specifically on parallel formulations of the max-flow/graph-cut algorithm of Boykov and Kolmogorov (BK algorithm) [5], which has made a substantial impact in computer vision. The BK algorithm yields a state-of-the-art empirical performance for typical vision problems such as 2D segmentation. Even though this augmenting path algorithm is serial, it uses heuristics that handle efficiently sparse 2D grids, outperforming top parallel push-relabel max-flow algorithms [8]. Unfortunately, distributing the computations for the BK algorithm is not a trivial problem333Augmenting-path max-flow algorithms are based on global operations and, therefore, do not accommodate parallel/distributed implementations, and the efficiency of the algorithm may decrease when moving from 2D to 3D (or higher-dimensional) grids. Therefore, parallel/distributed computations for this algorithm would be of substantial benefit to the community, and several works addressed the problem [2, 19, 25]. For instance, the method in [19] investigated a bottom-up approach to parallelize the BK algorithm using two subsequent phases: the first stage partitions the graph into several sub-graphs and processes them in parallel, whereas the second stage gradually merges the subgraphs so as to involve longer paths, until a global minimum is reached. Unfortunately, this technique requires a shared-memory model, which does not accommodate distributed computations. The method in [25] wrote the max-flow (graph cut) problem as a linear program, and viewed the objective function as a sum of two functions, each involving a sub-graph. Then, they used a dual decomposition formulation to process each of the two sub-graphs independently. However, it is not clear how to split the problem into a large number of sub-graphs (for faster computations) as this would increase exponentially the number of constraints (w.r.t. the sub-graphs). The method in [2] proposed a linear program formulation of the BK algorithm, via a minimization statement. Solving the problem via Newton iterations yields matrix-vector multiplications, which can be evaluated in parallel. This method, however, is not significantly faster than the serial BK algorithm [25].
In general, the existing distributed/parallel formulations for optimizing pairwise functions are technique-specific. For instance, the methods in [2, 19, 25] were tailored for the BK algorithm, and it is not clear how to extend these methods beyond the context of max-flow formulations and submodular functions. In this study, we formulate an Alternating Direction Method of Multipliers (ADMM), which systematically distributes the computations of any technique for optimizing pairwise functions, including non-submodular potentials. Our method decomposes the problem into a large set of small sub-problems, each involving a sub-region of the image domain (i.e., block), which can be solved in parallel. We achieve consistency between the sub-problems through a novel constraint that can be used in conjunction with any functional of the form (1). We give an iterative numerical solution that alternates between solving the sub-problems and updating consistency variables, until convergence. Our method can be viewed as a variant of the alternating projections algorithm to find a point in the intersection of two convex sets and, therefore, is well suited to distributed convex optimization. We report comprehensive experiments, which demonstrate the benefit of our general solution in the case of the popular BK algorithm and, also, in the context of non-submodular functions.
2 Formulation
Let be the vector of unary penalties and the matrix of pairwise penalties . It is easy to show that the general segmentation problem in (1) can be expressed in matrix form as follows:
[TABLE]
Here, is the Laplacian matrix corresponding to , and is a diagonal matrix such that .
Let us divide a large image into blocks () that can overlap, which allows pixels of image to be simultaneously located in multiple blocks. Let denote the segmentation vector of block . Our goal is to reformulate problem (3) in a way that the tasks of segmenting blocks are not directly coupled, thus allowing them to be performed simultaneously. To achieve this, we connect them through the segmentation vector of the whole image , by imposing linear constraints , , where is a matrix selecting the pixels of block .
Given the segmentation vectors of each block, global segmentation can be expressed using the following proposition.
Proposition 1**.**
If each pixel of belongs to at least one block, i.e. , and , , then the following relationship holds:
[TABLE]
Here, is a diagonal matrix such that is the number of blocks containing pixel . In short, this proposition states that, if the block segmentation vectors are consistent (i.e., pixels have the same label across blocks containing them), then is simply the mean label of pixel within the blocks containing this pixel. This property also applies when relaxing the integer constraints on , allowing us to develop an efficient optimization strategy.
In the following theorem, we show that segmentation problem (3) can be reformulated as a sum of similar sub-problems, one for each block , connected together through a relaxed global segmentation vector .
Theorem 1**.**
Denote as and the unary and binary potential weights of block , adjusted to consider the occurrence of pixels in multiple blocks. Moreover, let be the diagonal matrix such that , and be the Laplacian of . If , then problem (3) can be reformulated as
[TABLE]
where and .
Proof.
See details in Appendix A. ∎
We solve problem (1) with an ADMM approach. Moving constraints , into the functional via augmented Lagrangian terms [12] (with multiplier ) gives:
[TABLE]
In this equation, augmented Lagrangian parameter controls the trade-off between the original functional and satisfying the constraints. In general, ADMM methods are not overly sensitive to this parameter and converge if is large enough [6]. In practice, is initialized using a small value and increased at each iteration by a given factor. To solve problem (6), we note that the functional is convex with respect to each parameter , and . We thus update these parameters alternatively, until convergence is reached (i.e., the constraints are satisfied up to a given ).
Given , the segmentation vectors of each block can be updated independently, in parallel, by solving the following problem:
[TABLE]
Using the fact that for binary vector , we reformulate the problem as:
[TABLE]
Notice that for fixed, this block problem corresponds to a sum of unary and pairwise potentials. Therefore, as discussed in the introduction, it can be solved with one of the popular techniques444The choice depends on the form of the matrix of pairwise potentials., e.g., the BK algorithm [5]
Once all block segmentation vectors have been computed, we can update the global segmentation by solving the following problem:
[TABLE]
Since we have relaxed the integer constraints on , this corresponds to a unconstrained least-square problem, whose solution is given by:
[TABLE]
Note that since is diagonal, computing its inverse is trivial.
Finally, the Lagrangian multipliers are updated as in standard ADMM methods:
[TABLE]
The pseudo-code for implementing our Dope method is given in Algorithm 1. In a first step, the algorithm computes the unary and pairwise potentials of the global image, and divides the image into possibly overlapping blocks , , based on a given partition scheme. For each block , the algorithm pre-computes parameters , , , and . Note that these parameters can be computed in parallel. In the main loop, the algorithm then simultaneously recomputes segmentation vectors of each block, and uses them to update the global segmentation vector . This process is repeated until constraints linking the block segmentation to the global segmentation are satisfied, up to a given . As mentioned earlier, the algorithm’s convergence is facilitated by increasing the ADMM parameter by a factor of at each iteration.
3 Experiments
The main goal of our experiments is to demonstrate that our Dope formulation can distribute the computations of powerful serial algorithms without affecting the quality of the energies at convergence. First, we prove that our formulation can achieve segmentation results consistent with the popular serial graph cut (sGC) algorithm of Boykov-Kolmogorov [5], while allowing distributed computations. We illustrate the usefulness of our method on the task of segmenting high-resolution 2D multi-channel images (Section 3.1) and 3D MRI brain volumes (Section 3.2) using the second-order Potts model, and compare its accuracy, obtained energies and efficiency to those corresponding to sGC. The consistency between our method’s segmentation and sGC is measured using Dice score coefficient (DSC) and relative energy differences:
[TABLE]
where is the energy of serial GC and is the energy given by our distributed regularization formulation.
Another objective of these experiments is to assess the impact of our method’s parameters on computation time and segmentation accuracy. In particular, we evaluated how the partitioning scheme (i.e., block size and overlap) affects the method’s performance. If blocks are small, a greater level of parallelism can be achieved, but segmentation consistency across blocks might be harder to satisfy. Conversely, using larger blocks with more overlap encourages global consistency of the segmentation, but might increase the run times. In our experiments, we considered three partitioning schemes, dividing images into , or even-sized blocks. For each of these, we tested three levels of overlap. In the first one, denoted by , images were split into non-overlapping blocks covering the whole image (i.e., each pixel/voxel is in exactly one block). The size of these blocks was then increased by 10% and 25%, leading to larger blocks with greater overlap. We denote these two overlapping partitions by and , respectively. Furthermore, we investigated the impact of neighbourhood size (i.e., the number of non-zero pairwise potentials ) on segmentation performance. Using larger neighbourhoods, as defined by the kernel, can lead to a finer segmentation but significantly increases run times. Kernel sizes of 3, 5, 7 and 9 pixels/voxels were considered in our experiments. We used square kernels for 2D images, and spherical kernels in the 3D setting. The regularization parameter was selected per image (typically, its values are proportional to image size). Note that the same was used for computing the energy of both our method and sGC. Finally, the ADMM parameter was initialized to for 2D images and for 3D volumes, and increased by a factor of at each iteration.
Finally, we report curvature regularization experiments to show the use of our formulation in the case of non-submodular pairwise functions (Section 3.3). These experiments involve distributing the computations of the trust region (LSA-TR) method in [10], a serial non-submodular optimizer that recently obtained competitive555LSA-TR outperforms significantly popular non-submodular optimization techniques such as TRWS and QPBO; See the comparative energy plots in [10]. performances in a wide range of applications (deconvolution, inpainting, among others). This shows that our formulation can be readily used in these applications.
Our method was implemented in Matlab R2015b, and all experiments were performed on a server with the following hardware specifications: 64 Intel(R) Xeon(R) 2.30GHz CPUs with 8 cores, and 128 GB RAM. For sGC, we used the publicly available B-K Matlab tool666http://vision.csd.uwo.ca/code/, which implements the max-flow algorithm. In the next sections, we present the results obtained for high resolution 2D multi-channel images, 3D MRI data and a squared curvature regularization example.
3.1 High-resolution 2D multi-channel images
We first tested our method on 10 high-resolution 2D multi-channel images, with resolution ranging between 20003000 and 26003900 pixels. As in [4], we drew seeds to generate color model priors for the foreground and background regions (see Fig. 1). The k-means algorithm [21] was employed to group foreground/background seed pixels into clusters, which were then used to compute the log posteriors of unseeded pixels.
Figure 2 gives the average relative energy difference (%), relative time difference and Dice similarity coefficient (DSC) between the segmentation of our Dope method and sGC, computed over the 10 images. In the left-side plots, the number of blocks was set to 128, but we varied the size of these blocks and the kernel. Conversely, the right-side plots compare our method with sGC for various numbers of blocks and kernel sizes, while keeping the block size fixed to . Values are reported for one and three ADMM iterations of our method. While a more detailed analysis is presented below, we found that three iterations were often sufficient to achieve convergence in the case of 2D images (e.g., see Fig. 1). We observe that energy differences are quite small in all tested configurations, with values around 0.1% for one ADMM iteration and 0.01% for three ADMM iterations. With respect to block size, we observe no difference between the tested configurations, for the same number of ADMM iterations. For a single ADMM iteration, increasing the overlap seems to result in higher energy differences. However, these differences disappear when using three iterations, suggesting that having a greater overlap requires more iterations to converge.
As expected, segmentation times varied proportionally to the number and size of blocks. However, doubling the number of blocks did not lead to reduction in processing time by the same factor. This is in part due to pre-processing operations, such as computing the unary and pairwise potentials for the whole image, which need to be performed regardless of the image partitioning scheme used. Another trend that can be observed is that the speed-up provided by our method increases with the kernel size. Thus, for kernel sizes of 7 or more, our method obtained nearly identical segmentation results up to 5 times faster than sGC. Additionally, allowing the algorithm to run three iterations did not increase run times significantly for larger kernels, suggesting that most operations are performed in pre-processing steps.
In terms of segmentation consistency, it can be seen that our Dope method obtains segmentation results quite similar to those of sGC, with DSC values above 0.99. In most cases, increasing the number of blocks decreases DSC values, although this difference is not significant. A similar effect can be observed when employing larger blocks and kernels. Overall, the segmentation results obtained by our method are consistent with those of sGC, for all tested configurations.
Figure 1 gives two examples of segmentations obtained by sGC and our Dope method. The first column shows the image to be segmented with foreground/background scribbles, whereas the second and third columns give the segmentation result of sGC and our method, respectively. The evolution of the segmentation energy is also shown in Figure 1 (right). We observe that our approach converges rapidly, requiring only two iterations to achieve near-zero energy differences.
3.2 3D MRI volumes
Segmentation efficiency is particularly important in the case of 3D volumes, where computational and memory requirements often exceed the capacity of current methods. As a second experiment, we tested our Dope method on a 3D MRI brain volume of size 200200100. For this experiment, we considered the task of segmenting sub-cortical brain regions, and used the soft probability map generated by a 3D convolutional neural network [9] 777https://github.com/josedolz/LiviaNET as unary potentials in the energy function.
Figure 3 shows the energy related to the augmented Lagrangian terms in Eq. (6), for a partitioning composed of 128 blocks with , and kernel sizes corresponding to 3, 5, 7 and 9. Recall that this energy corresponds to segmentation consistency across different blocks. We observe that the number of iterations required to achieve convergence increases with kernel size, probably due to the broader interaction between blocks for larger kernels. However, our method converged in less than 10 iterations, for all kernel sizes. These observations are confirmed by Figure 4, which also shows the variation of segmentation energy (unary and pairwise potentials) when employing 128 blocks with and a kernel of size 7. We notice that the segmentation energy increases with the number of iterations. This can be explained by the fact that this energy is computed using the integer-relaxed segmentation vector , which gets increasingly restricted to a binary solution over time. Segmentation convergence is illustrated in Fig. 5, which shows the evolution of for a random 2D slice of the volume.
Analyzing detailed results, we see that mean relative energy differences increase with kernel size, ranging from 0.1 for kernels of size 3 to 2.5 when employing kernel of size 9. Moreover, for a fixed kernel size, having a greater overlap leads to smaller energy differences (e.g., energy difference of 1.5 for compared to 2.25 for , for a kernel size of 9 and 128 blocks). This suggests the greater usefulness of having overlapping blocks in the segmentation of 3D volumes. However, when overlap is allowed, larger block sizes reported slightly higher energy differences. As was the case for 2D image segmentation, the speed-up of our Dope method depends on kernel size and the block number/size. Hence, for 64 blocks with and kernel size of 7, our method was about 3 times faster than sGC, while a speed-up of was achieved using 128 blocks with and a kernel size of 9. For segmentation consistency, DSC values ranged from 0.95 to 0.99 in all tested configurations. While a few iterations were sufficient for small kernels, larger kernels required more iterations to converge.
Figure 6 shows the segmentation of white matter tissues in three axial slices, obtained by our Dope method using 128 blocks with and kernel size of 7 (left column) and sGC (middle column). Segmentation differences are shown in the rightmost column. It can be observed that the two segmentations are very similar, with a DSC equal to 0.9638 and an energy difference of only . In Figure 7, we illustrate 3D segmentation results by showing the surface of the left and right putamen regions, extracted by our method and sGC. Note that, in this case, the probability maps of these specific regions were used as unary potentials in the energy function.
3.3 Curvature regularization
We demonstrated that our general formulation can distribute the computations of a powerful serial sub-modular optimization algorithm (i.e., BK) without affecting the quality of the energies at convergence. In this section, we report a curvature regularization experiment to illustrate how our method can also distribute the computations of non-submodular optimization techniques. Specifically, we focused on distributing the computations of the stat-of-the-art LSA-TR method in [10].
Table 1 reports the energies obtained by LSA-TR non-submodular optimization [10] and a distributed version based on our Dope formulation. To obtain these energies, we employed the squared curvature model and the Picasso’s ink drawing used in [22]. Fig. 8 depicts the results of this experiment. Notice that, by distributing the computations of LSA-TR with our Dope formulation, we obtained a very similar result while reducing computation time.
4 Conclusion
In this work, we have formulated a general Alternating Direction Method of Multipliers (ADMM) technique that systematically distributes computations in the context of pairwise functions. Our method is scalable, allowing computations for large images by decomposing the problem into a large set of small sub-problems that can be solved in parallel. Unlike existing approaches, which distributes computation to a restricted number of cores [20], our algorithm can be easily adapted to the number of available cores. As shown in the results, another advantage of our technique is that it requires a small number of iterations to converge: about 3 iterations for high-definition 2D images and 5-10 iterations for 3D volumes. This allows our method to obtain segmentation results consistent with those of sGC, while allowing distributed computations.
While our experiments have focused on a standard Potts model, one of the main benefits of our formulation lies in its generality. This generality has been proven by distributing the computations in the context of a non-submodular function. Thus, our approach is not technique-specific, and can be applied to a wide variety of pairwise potentials, including dense (or fully connected) models. In future work, we plan to extend our method to such models, e.g., the dense pairwise potentials in [16], and to the case of multi-label segmentation.
Appendix A Proof of Theorem 1
Using relationship (4) in Eq. (3), and relaxing the integer constraints on , general segmentation problem (3) can be reformulated as:
[TABLE]
where and The unary term can be simplified by defining vectors , and then the problem can be written as:
[TABLE]
We notice that the segmentation vectors of each block are still coupled in the right-most term of this new cost function. In order to segment each block independently, we thus split this term in two: the cost of assigning labels to pixels in the same block and in different blocks:
[TABLE]
Using the fact that , we can then reformulate the problem as:
[TABLE]
Moreover, since , the problem becomes:
[TABLE]
Let , we can therefore simplify the cost function as follows:
[TABLE]
where, again has to be equal to and While the blocks are now only coupled via , we need to further modify the cost function since the right-most term is not a Laplacian. Using the fact that , where is a diagonal matrix such that , we obtain that:
[TABLE]
Let denote the pairwise potentials of block , adjusted to consider the occurrence of pixels in multiple blocks, and let be the diagonal matrix such that . We have:
[TABLE]
where is the Laplacian of . Let , we then use the fact that to reformulate the problem as:
[TABLE]
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] P. Baque, T. M. Bagautdinov, F. Fleuret, and P. Fua. Principled parallel mean-field inference for discrete random fields. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages 5848–5857, 2016.
- 2[2] A. Bhusnurmath and C. J. Taylor. Graph cuts via l 1 1 {}_{\mbox{1}} norm minimization. IEEE Trans. Pattern Anal. Mach. Intell. , 30(10):1866–1871, 2008.
- 3[3] A. Blake, P. Kohli, and C. Rother. Markov Random Fields for Vision and Image Processing . MIT press, 2011.
- 4[4] Y. Boykov and G. Funka Lea. Graph cuts and efficient N-D image segmentation. International Journal of Computer Vision , 70(2):109–131, 2006.
- 5[5] Y. Boykov and V. Kolmogorov. An experimental comparison of min-cut/max-flow algorithms for energy minimization in vision. IEEE Transactions on Pattern Analysis and Machine Intelligence , 26(9):1124–1137, 2004.
- 6[6] N. B. Bras, J. Bioucas-Dias, R. C. Martins, and A. C. Serra. An alternating direction algorithm for total variation reconstruction of distributed parameters. IEEE Transactions on Image Processing , 21(6):3004–3016, 2012.
- 7[7] A. Chambolle and T. Pock. A first-order primal-dual algorithm for convex problems with applications to imaging. Journal of Mathematical Imaging and Vision , 40(1):120–145, 2011.
- 8[8] A. Delong and Y. Boykov. A scalable graph-cut algorithm for N-D grids. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2008.