A Method to Guarantee Local Convergence for Sequential Quadratic Programming with Poor Hessian Approximation
Tuan T. Nguyen, Mircea Lazar, Hans Butler

TL;DR
This paper introduces a simple method to ensure local convergence of SQP algorithms even when using poor Hessian approximations, addressing practical computational challenges.
Contribution
It proposes a novel approach that guarantees local convergence of SQP with low-quality Hessian approximations, which was not previously established.
Findings
The method guarantees local convergence despite poor Hessian approximations.
Numerical example demonstrates the effectiveness of the proposed approach.
Abstract
Sequential Quadratic Programming (SQP) is a powerful class of algorithms for solving nonlinear optimization problems. Local convergence of SQP algorithms is guaranteed when the Hessian approximation used in each Quadratic Programming subproblem is close to the true Hessian. However, a good Hessian approximation can be expensive to compute. Low cost Hessian approximations only guarantee local convergence under some assumptions, which are not always satisfied in practice. To address this problem, this paper proposes a simple method to guarantee local convergence for SQP with poor Hessian approximation. The effectiveness of the proposed algorithm is demonstrated in a numerical example.
Click any figure to enlarge with its caption.
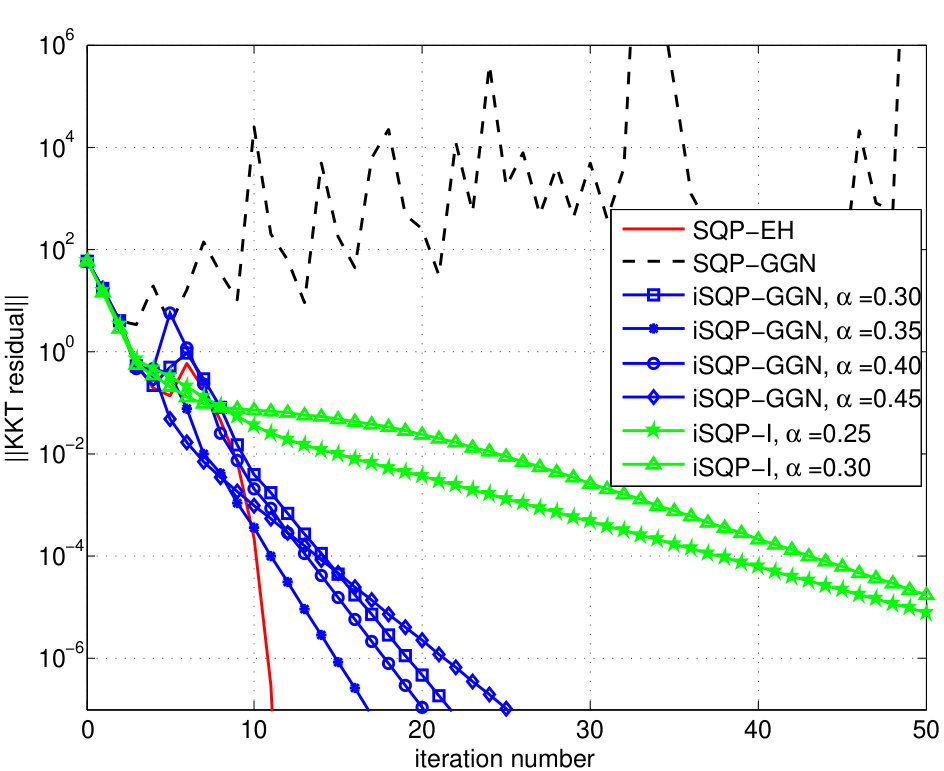 Figure 1
Figure 1| Method | Number of | Computation |
|---|---|---|
| iterations | time (ms) | |
| SQP-EH | ||
| iSQP-GGN, | ||
| iSQP-GGN, | ||
| iSQP-GGN, | ||
| iSQP-GGN, | ||
| iSQP-I, | ||
| iSQP-I, |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Optimization Algorithms Research · Sparse and Compressive Sensing Techniques · Advanced Control Systems Optimization
A Method to Guarantee Local Convergence for Sequential Quadratic Programming with Poor Hessian Approximation
Tuan T. Nguyen, Mircea Lazar and Hans Butler The authors are with the Department of Electrical Engineering, Eindhoven University of Technology, P.O. Box 513, 5600 MB Eindhoven, The Netherlands. E-mails: {t.t.nguyen,m.lazar,h.butler}@tue.nl
Abstract
Sequential Quadratic Programming (SQP) is a powerful class of algorithms for solving nonlinear optimization problems. Local convergence of SQP algorithms is guaranteed when the Hessian approximation used in each Quadratic Programming subproblem is close to the true Hessian. However, a good Hessian approximation can be expensive to compute. Low cost Hessian approximations only guarantee local convergence under some assumptions, which are not always satisfied in practice. To address this problem, this paper proposes a simple method to guarantee local convergence for SQP with poor Hessian approximation. The effectiveness of the proposed algorithm is demonstrated in a numerical example.
I INTRODUCTION
Sequential Quadratic Programming (SQP) is one of the most effective methods for solving nonlinear optimization problems. The idea of SQP is to iteratively approximate the Nonlinear Programming (NLP) problem by a sequence of Quadratic Programming (QP) subproblems [1]. The QP subproblems should be constructed in a way that the resulting sequence of solutions converges to a local optimum of the NLP.
There are different ways to construct the QP subproblems. When the exact Hessian is used to construct the QP subproblems, local convergence with quadratic convergence rate is guaranteed. However, the true Hessian can be indefinite when far from the solution. Consequently, the QP subproblems are non-convex and generally difficult to solve, since the objective may be unbounded below and there may be many local solutions [2]. Moreover, computing the exact Hessian is generally expensive, which makes SQP with exact Hessian difficult to apply to large-scale problems and real-time applications.
To overcome these drawbacks, positive (semi-) definite Hessian approximations are usually used in practice. SQP methods using Hessian approximations generally guarantee local convergence under some assumptions. Some SQP variants employ iterative updates scheme for the Hessian approximation to keep it close to the true Hessian. Broyden-Fletcher-Goldfarb-Shanno (BFGS) is one of the most popular update schemes of this type [3, 4]. The BFGS-SQP version guarantees superlinear convergence when the initial Hessian estimate is close enough to the true Hessian [1]. Another variant which is very popular for constrained nonlinear least square problems is the Generalized Gauss-Newton (GGN) method [5, 6]. GGN method converges locally only if the residual function is small at the solution [7]. Some other SQP variants belong to the class of Sequential Convex Programming (SCP), or Sequential Convex Quadratic Programming (SCQP) methods, which exploit convexity in either the objective or the constraint functions to formulate convex QP subproblems [8, 9]. SCP methods also have local convergence under similar assumption of small residual function. However, these assumptions are not always satisfied in practice, resulting in poor Hessian approximation and thus no convergence is guaranteed.
This paper proposes a simple method to guarantee local convergence for SQP methods with poor Hessian approximations. The proposed method interpolates between the search direction provided by solving the QP subproblem and a feasible search direction. It is proven that there exists a suitable interpolation coefficient such that the resulting algorithm converges locally to a local optimum of the NLP with linear convergence rate. A numerical example is presented to demonstrate the effectiveness of the proposed method.
The idea of interpolating an optimal search direction with a feasible search direction was proposed in our previous work for quadratic optimization problems with nonlinear equality constraints [10]. The method proposed in [10] was applied effectively to a practical application in commutation of linear motors [11]. This paper extends the idea to general nonlinear programming problems.
The remainder of this paper is organized as follows. Section II introduces the notation used in the paper. Section III reviews the basic SQP method. Section IV presents the proposed algorithm and proves the optimality property and local convergence property of the algorithm. An example is shown in Section V for demonstration. Section VI summarizes the conclusions.
II NOTATION
Let denote the set of natural numbers, denote the set of real numbers. The notation denotes the set . Let denote the set of real column vectors of dimension , denote the set of real matrices. For a vector , denotes the -th element of . The notation denotes the zero matrix and denotes the identity matrix. Let denote the 2-norm. The Nabla symbol denotes the gradient operator. For a vector and a mapping
[TABLE]
Let denote the open ball .
III THE BASIC SQP METHOD
This section reviews the basic SQP method. Consider the nonlinear optimization problem with nonlinear equality constraints:
Problem III.1** **(NLP)
[TABLE]
where , and . Here, is the number of optimization variables and is the number of constraints. In this paper, we are only interested in the case when the constraint set has an infinite number of points, i.e. , since the other cases are trivial. Furthermore, let us assume that the columns of are linearly independent at the solutions of the NLP.
For ease of presentation, in this paper we only consider equality constraints. The method can be extended to inequality constraints using an active set strategy or squared slack variables [1, Section 4].
First, let us define the Lagrangian function of the NLP Problem III.1
[TABLE]
where is the Lagrange multipliers vector. The Karush-Kuhn-Tucker (KKT) optimality conditions of Problem III.1 are
[TABLE]
where and are the Jacobian matrices of and . Note that and .
The solution of the optimization problem is searched for in an iterative way. At a current iterate , the next iterate is computed as
[TABLE]
where is the search direction. In SQP methods, the search direction is the solution of the following QP subproblem
Problem III.2** **(QP Subproblem)
[TABLE]
where we introduce the following notation for brevity
[TABLE]
Here, is either the exact Hessian of the Lagrangian , or a positive (semi-) definite approximation of the Hessian. Similar to [1], to guarantee that the QP subproblem has a unique solution, we assume that the matrices satisfy the following conditions:
Assumption III.3
The matrices are uniformly positive definite on the null spaces of the matrices , i.e., there exists a such that for each
[TABLE]
for all which satisfy
[TABLE]
Assumption III.4
The sequence is uniformly bounded, i.e, there exists a such that for each
[TABLE]
The KKT optimality conditions of the QP subproblem III.2 are
[TABLE]
or equivalently
[TABLE]
It should be noted that is positive (semi-) definite and is not necessarily invertible, but the matrix is invertible due to Assumption III.3 [12, Theorem 3.2]. Therefore, the KKT condition (6) has a unique solution
[TABLE]
For convergence analysis, it is convenient to have an explicit expression of . Since is positive semidefinite and is positive deinite on the null space of , there exists a constant such that [13, Lemma 3.2.1]
[TABLE]
Let us define
[TABLE]
We have that and are positive definite due to Assumption III.3. It holds that [14, Chapter 6]
[TABLE]
The solution can then be written in an explicit form
[TABLE]
where
[TABLE]
Notice that is a generalized right inverse of , i.e. .
It should be noted that if is nonsingular then can also be written as
[TABLE]
where
[TABLE]
In this case, both (10) and (11) give the same solution.
If is the exact Hessian then the basic SQP method is equivalent to applying Newton’s method to solve the KKT conditions (2), which guarantees quadratic local convergence rate [15, Chapter 18]. When an approximation is used instead, local convergence is guaranteed only when is close enough to the true Hessian. The readers are referred to [1, Section 3] for more details on local convergence of SQP.
IV PROPOSED METHOD
This section proposes a simple method to guarantee local convergence for SQP with poor Hessian approximation. The proposed method interpolates between an optimal search iteration, without local convergence guarantee, and a feasible search iteration with guaranteed local convergence.
The search direction can be viewed as the optimal direction which iteratively leads to the optimal solution of the NLP, if the iteration converges. However, local convergence is not guaranteed if is a poor approximation of the true Hessian.
To guarantee local convergence with poor Hessian approximation, we propose a new search direction which is the interpolation between the optimal search direction and a feasible search direction , i.e.
[TABLE]
where . The feasible search direction only searches for a feasible solution of the set of constraints, but its local convergence is guaranteed. The idea of this proposed interpolated update is to combine the optimality property of the SQP update and the local convergence property of the feasible update.
The feasible search direction can be found as a solution of the linearized constraints
[TABLE]
Since , there is an infinite number of solutions for (13). Two possible solutions are
[TABLE]
where is the Moore-Penrose generalized right inverse of [16], i.e.
[TABLE]
We propose the following feasible search direction
[TABLE]
It can be verified that is a solution of (13) as follows
[TABLE]
It has been proven that the feasible updates (14), (15) and (16) converge locally to a feasible solution of the constraints [17, 18].
It is worth mentioning that using the search direction in (15) can also guarantee local convergence for the interpolated update. However, this search direction results in the presence of the term in the interpolated update (12), which unnecessarily increases the computational load. Therefore, the search direction in (16) is proposed to help eliminate the unnecessary term from the interpolated update (12).
Substituting (10) and (16) into the interpolated update (12) results in
[TABLE]
For brevity, let us denote as follows
[TABLE]
In what follows we will prove the optimality property and the local convergence property of the proposed search iteration (18).
Theorem IV.1
If the iteration (18) converges to a fixed point , then satisfies the KKT optimality conditions (2).
Proof.
Let us denote
[TABLE]
From (5), (13) and (12), it follows that
[TABLE]
By definition, is a fixed point of the proposed iteration (18) if
[TABLE]
As a result we have
[TABLE]
Substituting (22) into (16) results in
[TABLE]
It follows from (12), (21) and (23) that
[TABLE]
[TABLE]
From (22) and (25), it can be concluded that satisfies the KKT optimality conditions (2). ∎
Next, we will prove local convergence of the proposed iteration. Let us assume that the approximations satisfy the following condition
Assumption IV.2
There exists a such that for each
[TABLE]
The following proposition will be used in the proof.
Proposition IV.3
Let be a convex set in which is differentiable and is Lipschitz continuous for all , i.e. there exists a such that
[TABLE]
Then
[TABLE]
A proof of Proposition IV.3 can be found in [18].
Theorem IV.4
Let be a bounded convex set in which the following conditions hold
- (i)
and are Lipschitz continuous and continuosly differentiable, 2. (ii)
and are Lipschitz continuous and bounded, 3. (iii)
is bounded, 4. (iv)
there exists a solution of the KKT optimality conditions (2) in .
Then there exist a and a such that and iteration (18) converges to for any initial estimate .
Proof.
Let us consider two cases
- •
is linear.
- •
is nonlinear.
- Case 1: in the first case when is linear, for any iterate we can write
[TABLE]
Since satisfies (20), it follows that
[TABLE]
Therefore, we have that for all . The interpolated update is then reduced to
[TABLE]
Let us denote
[TABLE]
[TABLE]
We have is positive definite due to Assumption III.3. It follows that is positive definite, due to the facts that the inverse of a positive definite matrix is positive definite, and that every principal submatrix of a positive definite matrix is positive definite [14, Chapter 8]. As a result we have
[TABLE]
This shows that is a descent direction that leads to a decrease in the cost function . In addition, since for all , we have that is also a feasible direction. Therefore, there exits a stepsize such that the iteration (30) converges [15, Chapter 3].
- Case 2: let us now consider the case when is nonlinear. Since the nonlinear constraints are solved by successive linearization (20), we can assume that the solution is reached asymptotically, i.e. as and for all . We have
[TABLE]
The second equality in (34) was obtained due to equation (20).
Let us consider the first term on the right hand side of (34). Here, is the orthogonal projection onto the null space of [14, Chapter 6]. It holds that
[TABLE]
A proof of (35) can be found in [10]. It follows that
[TABLE]
The equality holds if and only if is in the null space of , which is equivalent to
[TABLE]
This shows that the equality holds if and only if is an exact solution of the constraints. This contradicts the assumption that for all . Therefore, there exists a constant such that
[TABLE]
Next, let us consider the second term on the right hand side of (34). Observe that by (19), the definition of the matrix inverse and the strict positive definiteness of , each element of is obtained by adding, multiplying and/or division of real-valued functions. Division only occurs due to the inverse of , via the term . This allows the application of Theorem 12.4 and Theorem 12.5 in [19], to establish Lipschitz continuity in of , from Assumptions III.4 and IV.2 and the conditions that and are Lipschitz continuous and bounded for all . Note that although the theorems in [19] consider functions from to , the same arguments apply to functions from to , by using an appropriate, norm-based Lipschitz inequality. As a result we have
[TABLE]
where .
For the third term on the right hand side of (34), due to the condition that is bounded and Proposition IV.3, we have
[TABLE]
where .
From (34), (38), (39) and (40), it follows that
[TABLE]
where . We have for any that satisfies
[TABLE]
From (18), (21) and (22), it follows that
[TABLE]
Due to the Lipschitz continuity of and , we have
[TABLE]
where . If is close enough to such that
[TABLE]
then
[TABLE]
Next, we will prove that if
[TABLE]
then
[TABLE]
Indeed, if (47) holds then due to (41) we have
[TABLE]
This leads to
[TABLE]
We have proven that if (47) holds then (48) holds. Since (46) also holds for any which satisfies (45), it follows by induction that
[TABLE]
Therefore, it follows from (41) that
[TABLE]
Therefore, algorithm (18) converges, and by Theorem IV.1, it converges to a KKT point, for any initial estimate , where
[TABLE]
and any which makes . ∎
It can be seen from (52) that the proposed algorithm has a linear convergence rate.
Remark IV.5
The explicit expression (10) is of interest for convergence analysis. For implementation, instead of (10), the SQP search direction can also be computed as
[TABLE]
Note that (54) differs from (10) in implementation, but they both give the same solution. In this case, using the feasible search direction in (15) for the interpolated iteration is more convenient. It can be proven in a similar way that the optimality property and local convergence property hold for the resulting interpolated iteration (12).
The proposed method can be applied to any positive (semi) definite Hessian approximations which satisfy Assumptions III.3, III.4, IV.2. Popular Hessian approximations such as GGN, or any constant Hessian approximation satisfy these conditions. It is worth noting that the simple identity approximation also satisfies the mentioned conditions.
The proposed method therefore can be useful in some of the following situations. When the exact Hessian is indefinite or is too expensive to compute and the search iteration using Hessian approximations fails to converge, the proposed method can be used to enforce convergence. For large-scale cases when even Hessian approximations are computationally costly, the simple identity Hessian approximation can be used together with the proposed interpolation method. This results in the same search iteration as proposed in [20, 21], although the iteration and convergence therein were derived in a different way. Furthermore, if the cost function is just the 2-norm and the identity Hessian approximation is used then the proposed algorithm recovers the algorithm in our previous work [10]. It should be noted, however, that the identity Hessian approximation may result in a slower convergence rate compared to other Hessian approximations, as can be seen in the example in Section V.
V NUMERICAL EXAMPLE
This section presents a numerical example to verify the performance of the proposed algorithm. Let us consider the test problem 77 in [22].
Problem V.1
[TABLE]
The initial estimate is and . This is a nonlinear equality constrained least square problem with nonzero residual.
In nonlinear constrained least square problems, the cost function has the least square form
[TABLE]
where . A popular Hessian approximation for this type of problems is the GGN approximation
[TABLE]
It is well known that the SQP method with GGN Hessian approximation, also called the GGN method, converges locally if the residual function is small at the solution [7].
In this example, we test the exact Hessian SQP method (SQP-EH), the GGN method (SQP-GGN), the proposed interpolated method with GGN Hessian approximation (iSQP-GGN), and the proposed interpolated method with identity Hessian approximation (iSQP-I). The optimization algorithms are programmed in Matlab and tested on a 2.4GHz computer. The measure of convergence is the 2-norm of the KKT matrix (2), which is called the KKT residual. The optimization algorithms terminate when the KKT residual is less than .
The test results are as follows. The SQP-EH method converges quadratically as expected. The SQP-GGN method does not converge. The iSQP-GGN method converges linearly. This demonstrates that the proposed interpolation scheme can guarantee convergence for the GGN Hessian approximation. The iSQP-I method also converges linearly, but at a slower rate. This is expected since the GGN approximation is a better approximation than the identity matrix. The convergence rate of the methods are shown in Fig 1. The interpolation coefficients shown here are among the ones that result in fastest convergence rates for each method.
The SQP-EH method, the proposed iSQP-GGN and iSQP-I methods converge to the same solution , which is the same with the solution mentioned in [22].
The number of iterations and computation times are summarized in Table I. It is observed that the SQP-EH method requires the least number of iterations, as it converges quadratically. The iSQP-GGN method with needs a larger number of iterations, but the total computation time is lower, since it requires less computation per iteration. This demonstrates that with a suitable choice of , the proposed method can be more efficient than the SQP-EH method, especially in large-scale cases when computation of the exact Hessian can be very expensive.
Examples of large-scale problems are nonlinear model predictive control (NMPC) problems. In [20, 21], the iSQP-I method, which is called projected gradient and constraint linearization method therein, is shown to outperform some commercial solvers when applying it to the NMPC problem for an inverted pendulum. The results of the example above suggest that with a suitable choice of the Hessian approximation, e.g. GGN approximation, the proposed method may even perform better, given the special sparse structure of the NMPC problem. Demonstrating this will be a subject of our future research.
VI CONCLUSIONS
This paper proposed a method to guarantee local convergence for SQP with poor Hessian approximation. The proposed method interpolates between the SQP search direction and a suitable feasible search direction, in order to combine the optimality property and the local convergence property of the two search directions. It was proven that the proposed algorithm converges locally at linear rate to a KKT point of the nonlinear programming problem. The effectiveness of the method was illustrated in a numerical example.
In this paper we only consider the local convergence property. For future work, we will extend the convergence result to global convergence using an augmented Lagrangian merit function [23].
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] P. T. Boggs and J. W. Tolle, “Sequential quadratic programming,” Acta Numerica , vol. 4, p. 1–51, 1995.
- 2[2] P. E. Gill, M. A. Saunders, and E. Wong, On the Performance of SQP Methods for Nonlinear Optimization . Cham: Springer International Publishing, 2015, pp. 95–123.
- 3[3] M. J. D. Powell, A fast algorithm for nonlinearly constrained optimization calculations . Berlin, Heidelberg: Springer Berlin Heidelberg, 1978, pp. 144–157.
- 4[4] R. Fletcher, Practical Methods of Optimization; (2Nd Ed.) . New York, NY, USA: Wiley-Interscience, 1987.
- 5[5] H. G. Bock, Recent Advances in Parameter identification Techniques for O.D.E. Boston, MA: Birkhäuser Boston, 1983, pp. 95–121.
- 6[6] H. G. Bock, E. Kostina, and J. P. Schlöder, Direct Multiple Shooting and Generalized Gauss-Newton Method for Parameter Estimation Problems in ODE Models . Cham: Springer International Publishing, 2015, pp. 1–34.
- 7[7] M. Diehl, “Real-time optimization for large scale nonlinear processes,” Ph.D. dissertation, Universität Heidelberg, Germany, 2001.
- 8[8] Q. T. Dinh, C. Savorgnan, and M. Diehl, “Adjoint-based predictor-corrector sequential convex programming for parametric nonlinear optimization,” SIAM Journal on Optimization , vol. 22, no. 4, pp. 1258–1284, 2012.