Stress Testing German Industry Sectors: Results from a Vine Copula Based Quantile Regression
Matthias Fischer, Daniel Kraus, Marius Pfeuffer, Claudia Czado

TL;DR
This paper introduces a vine copula-based quantile regression method for stress testing industry sectors, demonstrating its robustness and ability to model nonlinear dependencies in German PD data, with significant implications for financial risk assessment.
Contribution
It presents a novel application of vine copula-based quantile regression for stress testing, highlighting its advantages over traditional methods in capturing complex sector interdependencies.
Findings
Stressed automobile sector significantly impacts the German economy.
Vine copula quantile regression outperforms classical linear and expectile regression.
Method demonstrates robustness and handles nonlinearities effectively.
Abstract
Measuring interdependence between probabilities of default (PDs) in different industry sectors of an economy plays a crucial role in financial stress testing. Thereby, regression approaches may be employed to model the impact of stressed industry sectors as covariates on other response sectors. We identify vine copula based quantile regression as an eligible tool for conducting such stress tests as this method has good robustness properties, takes into account potential nonlinearities of conditional quantile functions and ensures that no quantile crossing effects occur. We illustrate its performance by a data set of sector specific PDs for the German economy. Empirical results are provided for a rough and a fine-grained industry sector classification scheme. Amongst others, we confirm that a stressed automobile industry has a severe impact on the German economy as a whole at different…
Click any figure to enlarge with its caption.
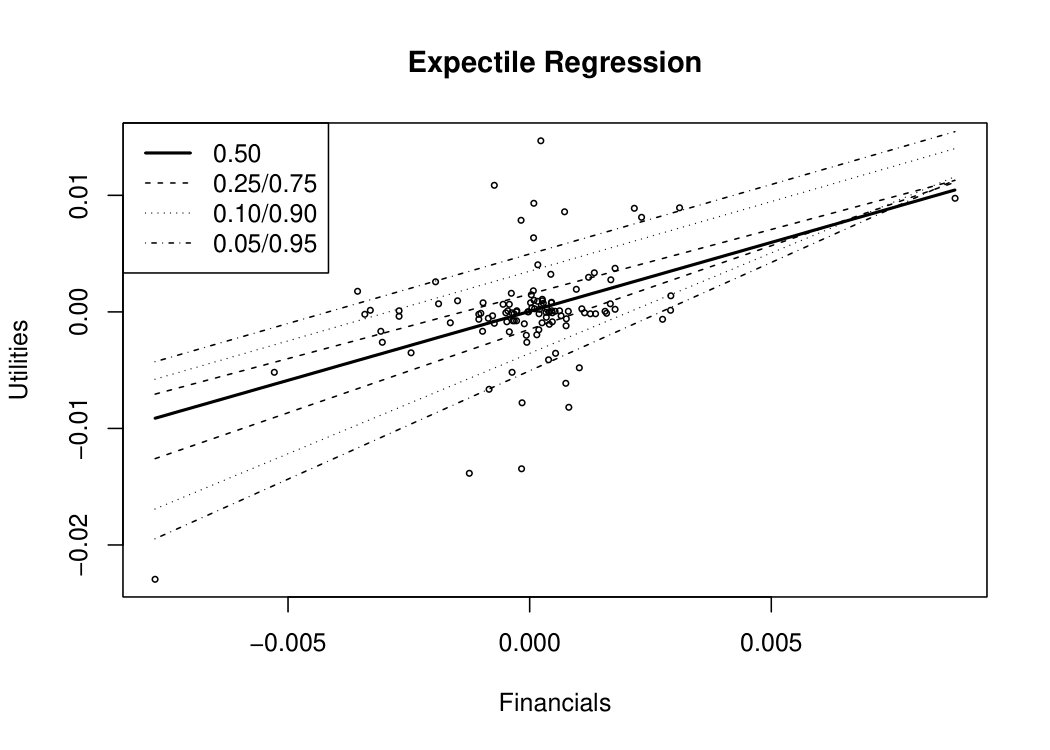 Figure 1
Figure 1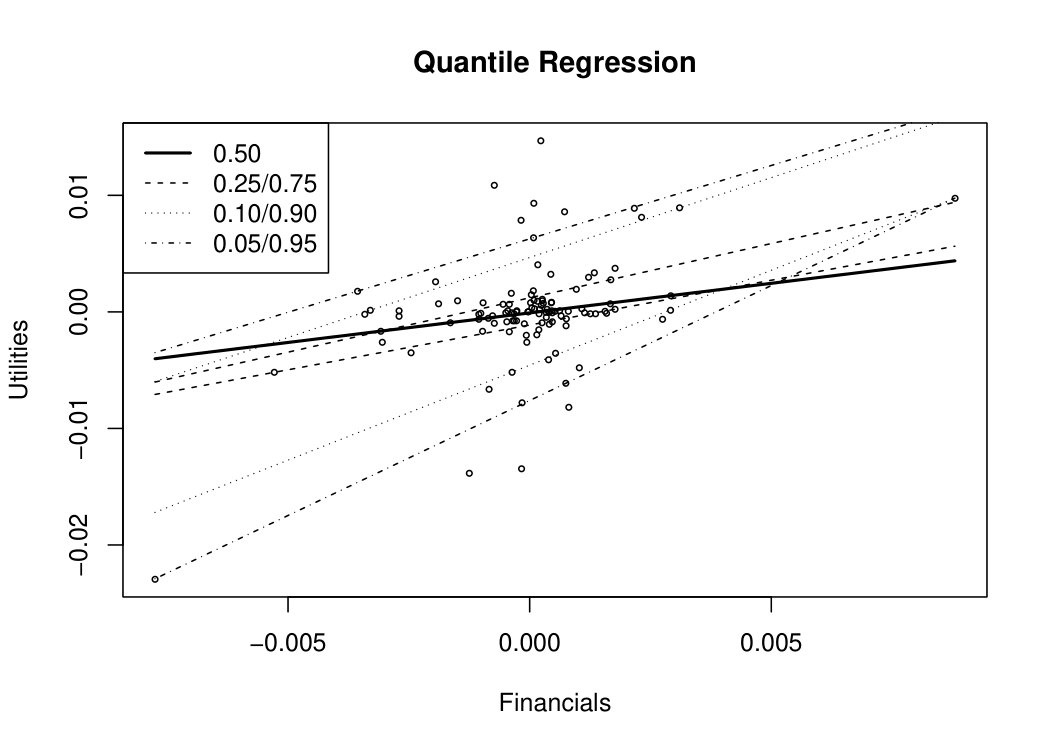 Figure 2
Figure 2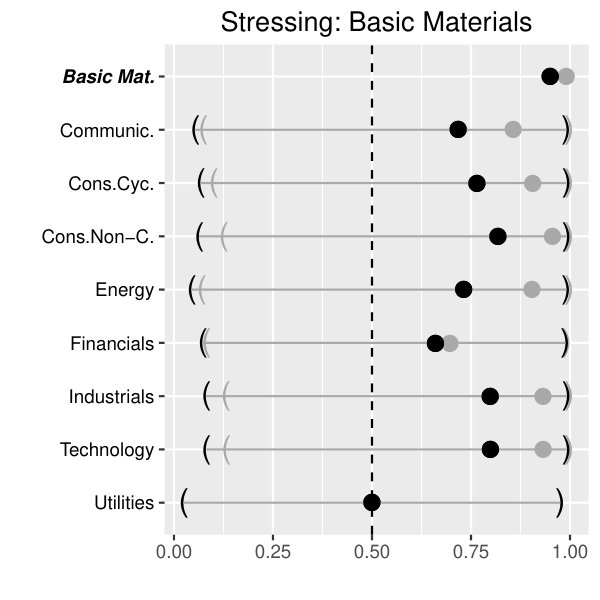 Figure 3
Figure 3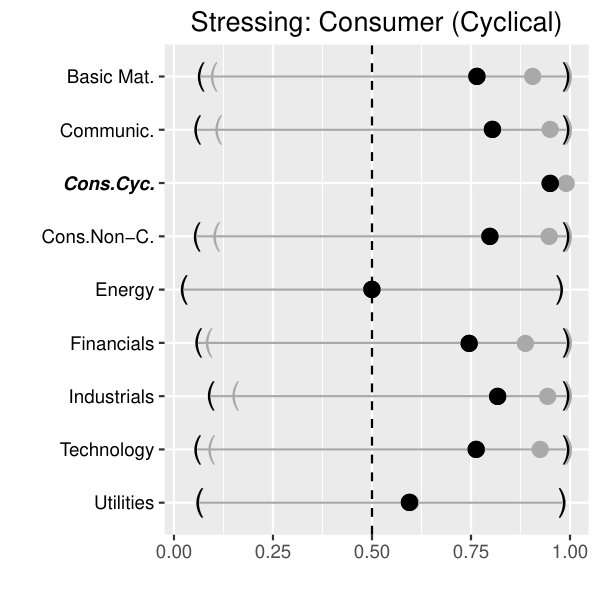 Figure 4
Figure 4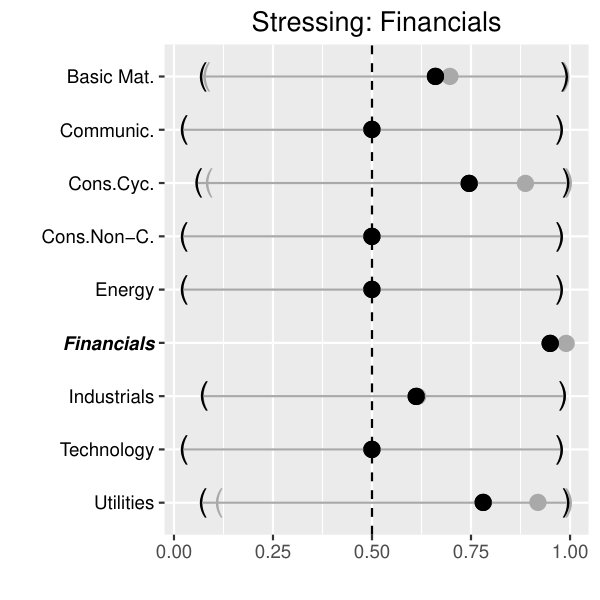 Figure 5
Figure 5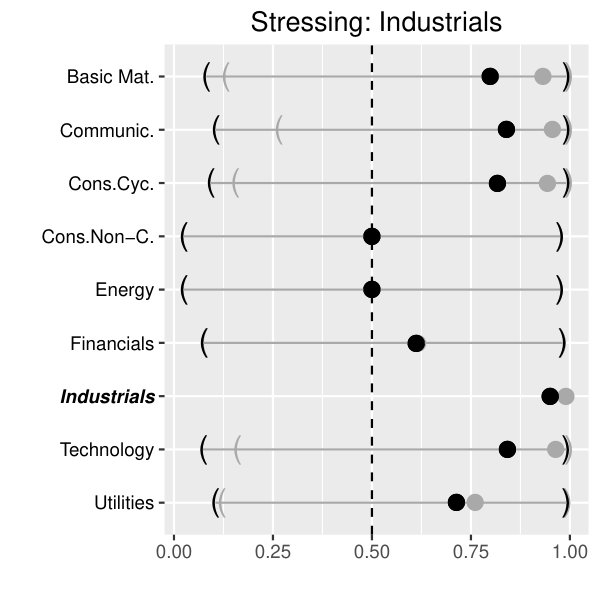 Figure 6
Figure 6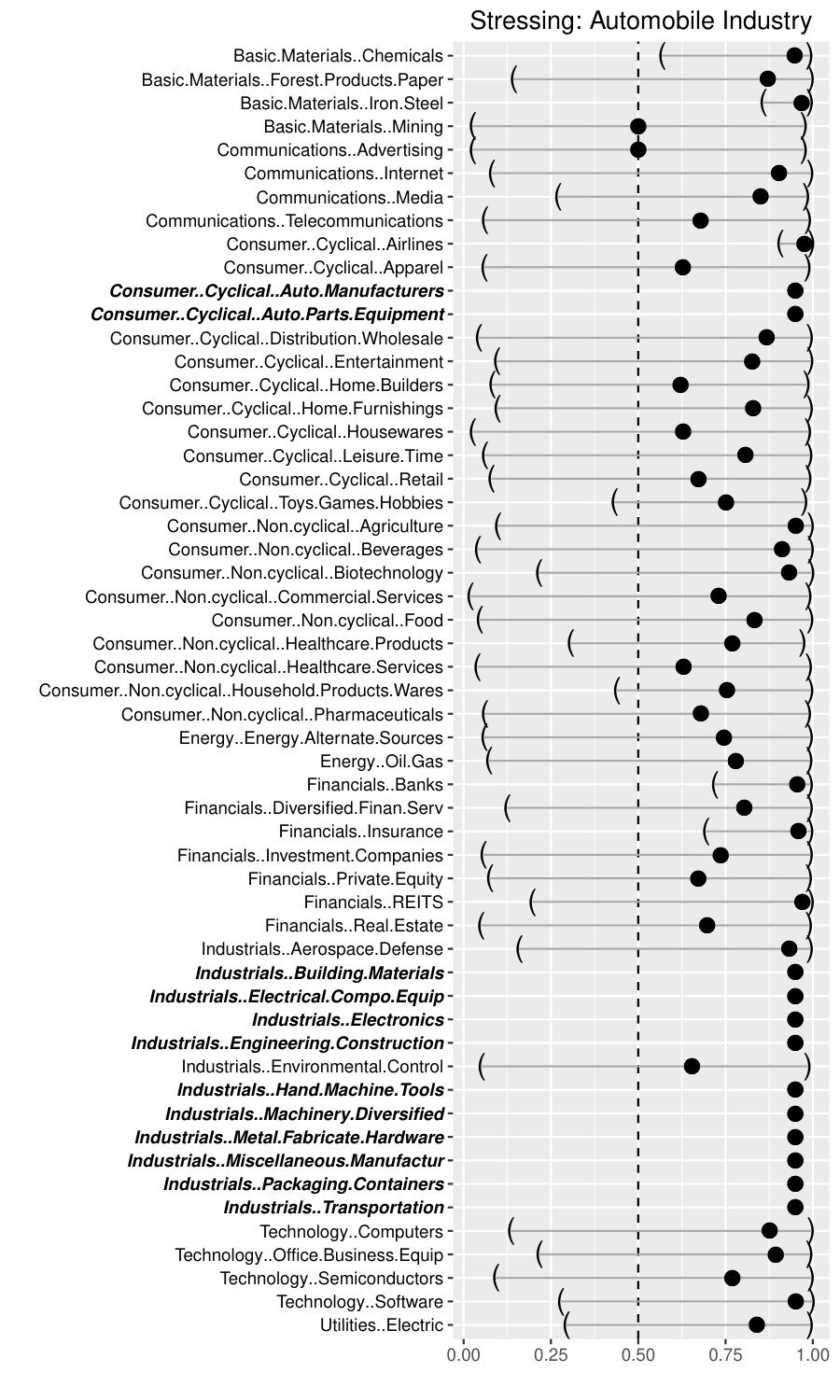 Figure 7
Figure 7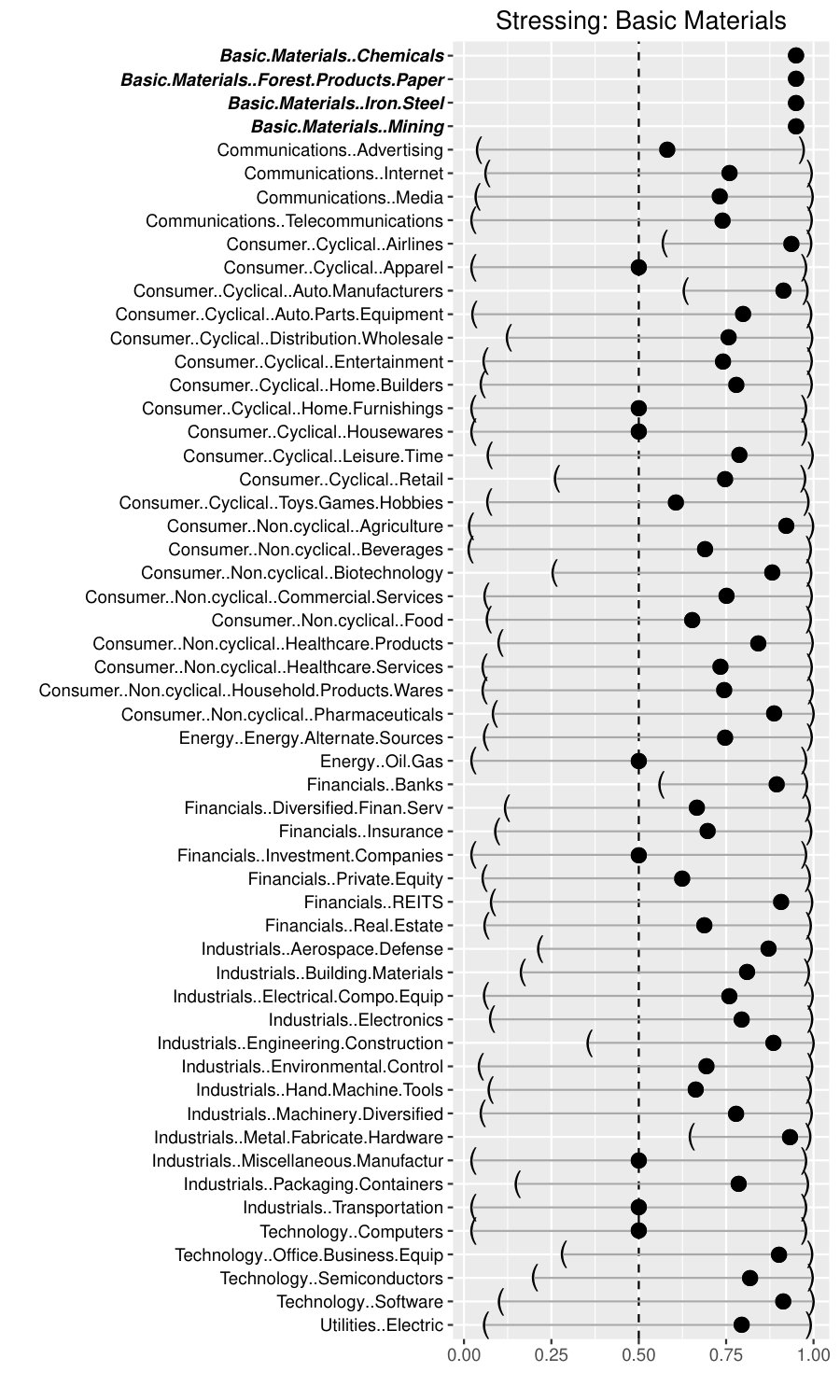 Figure 8
Figure 8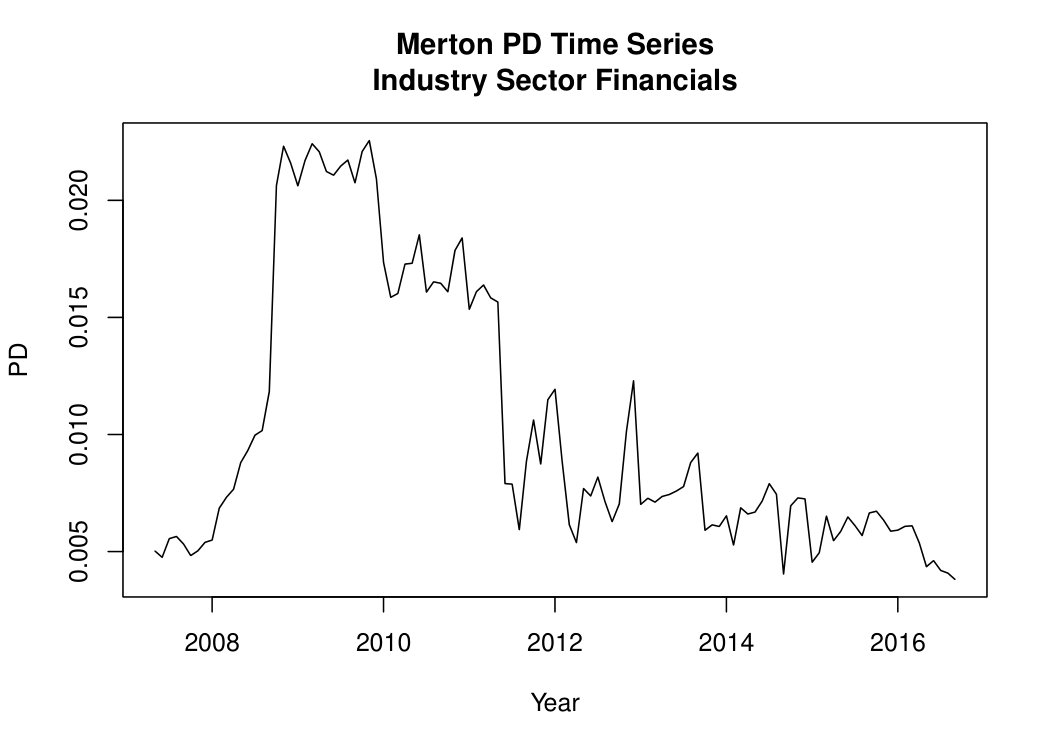 Figure 9
Figure 9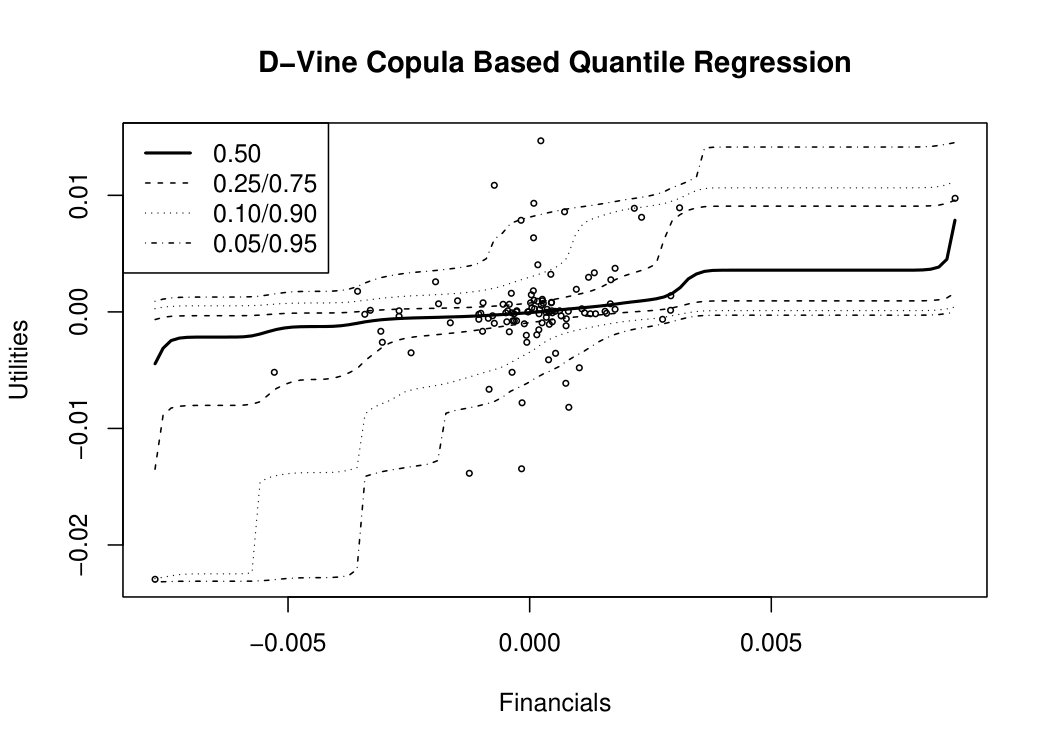 Figure 10
Figure 10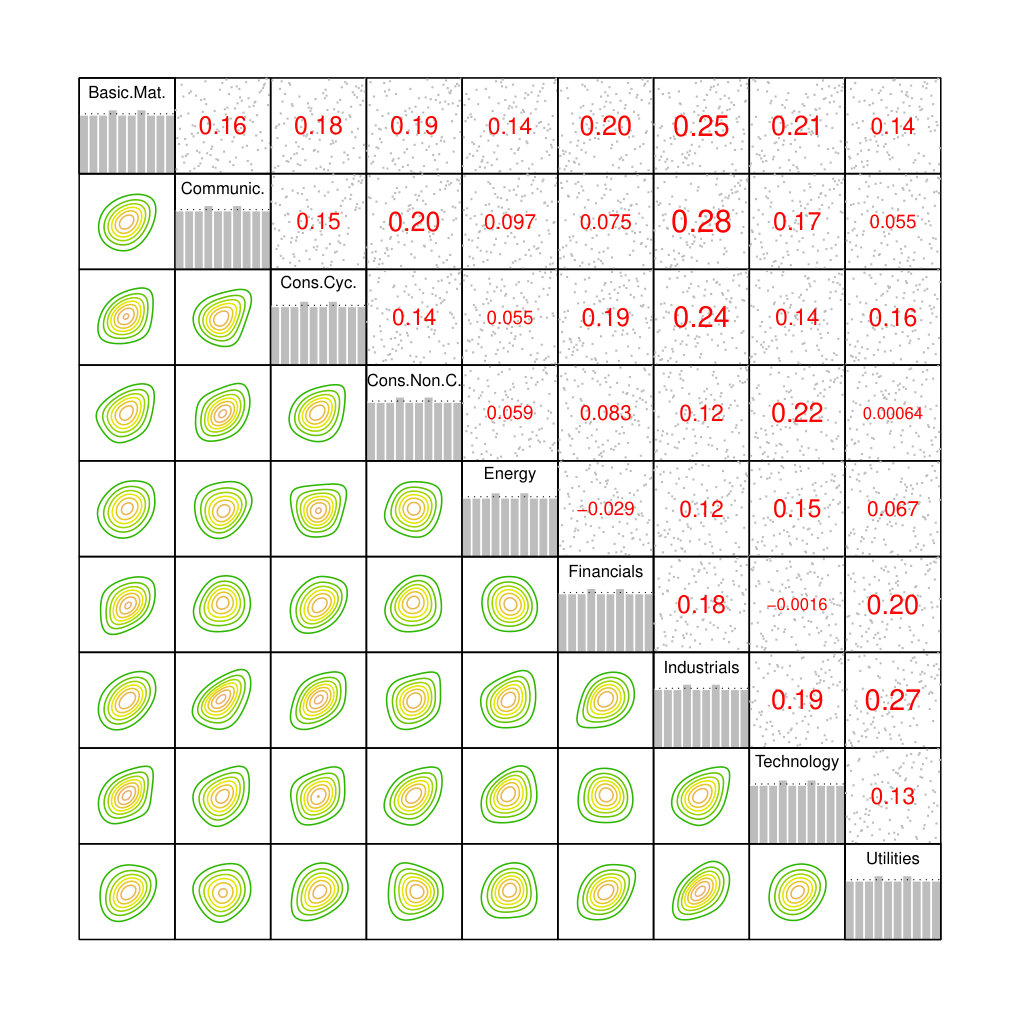 Figure 12
Figure 12Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMonetary Policy and Economic Impact · Credit Risk and Financial Regulations · Financial Risk and Volatility Modeling
\newaliascnt
thmdummy \aliascntresetthethm
\newaliascntdefidummy \aliascntresetthedefi
\newaliascntlemdummy \aliascntresetthelem
\newaliascntcordummy \aliascntresetthecor
\newaliascntpropdummy \aliascntresettheprop
\newaliascntexadummy \aliascntresettheexa
\newaliascntalgdummy \aliascntresetthealg
\newaliascntremdummy \aliascntresettherem
\newaliascntbspdummy \aliascntresetthebsp
Stress Testing German Industry Sectors:
Results from a Vine Copula Based Quantile Regression
Matthias Fischer111Lehrstuhl für Statistik und Ökonometrie, Lange Gasse 20, 90403 Nürnberg; [email protected], Daniel Kraus222Zentrum Mathematik, Technische Universität München, Boltzmanstraße 3, 85748 Garching; [email protected], Marius Pfeuffer333Corresponding author, Lehrstuhl für Statistik und Ökonometrie, Lange Gasse 20, 90403 Nürnberg; [email protected] and Claudia Czado444Zentrum Mathematik, Technische Universität München, Boltzmanstraße 3, 85748 Garching; [email protected]
Abstract
Measuring interdependence between probabilities of default (PDs) in different industry sectors of an economy plays a crucial role in financial stress testing. Thereby, regression approaches may be employed to model the impact of stressed industry sectors as covariates on other response sectors. We identify vine copula based quantile regression as an eligible tool for conducting such stress tests as this method has good robustness properties, takes into account potential nonlinearities of conditional quantile functions and ensures that no quantile crossing effects occur. We illustrate its performance by a data set of sector specific PDs for the German economy. Empirical results are provided for a rough and a fine-grained industry sector classification scheme. Amongst others, we confirm that a stressed automobile industry has a severe impact on the German economy as a whole at different quantile levels whereas e.g., for a stressed financial sector the impact is rather moderate. Moreover, the vine copula based quantile regression approach is benchmarked against both classical linear quantile regression and expectile regression in order to illustrate its methodological effectiveness in the scenarios evaluated.
Keywords: stress testing; quantile regression; vine copulas; expectile regression
1 Motivation
Generally speaking, stress testing identifies potential vulnerabilities of financial institutions under hypothetical or historical scenarios. Financial institutions typically perform stress tests to assess possible short-term losses resulting from various types of risk (e.g., credit risk, market risk, operational risk). The history of stress tests in the banking industry dates back to the early 1990s, where large banks started to initiate internal stress exercises. In 1996, the Basel Capital Accord was amended which requires banks to conduct stress tests and determine their ability to respond to market events. However, up until 2007, stress tests were typically performed only by the banks themselves, for internal self-assessment. Beginning in 2007, regulatory institutions became interested in conducting their own stress tests to ensure the effective operation of financial institutions. Since then, stress tests have been routinely performed by financial regulators in different countries or regions, to ensure that the banks under their authority are engaging in practices likely to avoid negative outcomes. Recently, the European Banking Authority (EBA) published the results of the 2016 EU-wide stress test of 51 banks. The aim of this stress test was to assess the resilience of EU banks to adverse economic developments. Similarly, the Federal Reserve Board currently published the scenarios to be used by banks and supervisors for the 2017 Comprehensive Capital Analysis and Review (CCAR) and Dodd-Frank Act stress test exercises. The focus within this work is on stress testing credit risk and losses associated therewith. Typically, the loans portfolios of the banking sector consist of financial obligations to counterparties from different business lines. Hence, the key source of credit risk in that portfolio is that a counterparty may default, which would result in losses for the bank. Secondly, one has to be aware of (industry/country) sector risk which means that multiple clients within an industry sector default because of structural weaknesses within this sector. Finally, even counterparties from different sectors may tend to default together in economic downturns, e.g., if only one (industry/country) sector enters a crisis and these sectors are highly correlated with the other. In all cases, the primary interest lies in the explanation (in a first step) and the initiation of stress (in a second step) of the counterparties’ probability of default (PD).
In this context, quantile regression (QR) is an increasingly important empirical tool in economics and other sciences for analyzing the impact a set of regressors (e.g., macro-economic variables) has on the conditional distribution of an outcome (here: PD). Extremal QR, or QR applied to the tails, is also very helpful in the context of stress testing. The quantile regression method is used to estimate parameters in accordance with the distribution of a dependent variable. One could use high quantile values of these distributions such as the 95th percentile value for a period in which large stresses occur. For a period in which no stresses are exerted on the economy, normal parameters estimated by the least square method might come to application.
Extremal QR was applied by Koenker and Xiao, (2002), Schechtman and Gaglianone, (2012), Covas et al., (2014) and Ong, (2014) within a macro-credit risk link context, i.e., connecting PDs and macro-economic variables. In contrast to these studies, we apply extremal QR to investigate how crises (in the sense of higher PDs) in industry sectors are connected to other industry sectors. Above that, we circumvent the disadvantages of classical QR, namely the occurrence of so-called quantile-crossings and apply D-vine copula based quantile regression as recently advocated by Kraus and Czado, 2017a , instead. Against this background, the outline of this work is as follows: Section 2 briefly reviews D-vines and D-vine copula based regression. Section 3 is dedicated to the empirical study which relies on (averaged) default probabilities of 9 different German industry sectors and selected subgroups. After a brief description of the underlying data set, the data transformation to the copula scale and the resulting data structure is discussed. A D-vine based copula regression is performed and highlights are presented. Finally, we illustrate its superiority to alternative approaches such as traditional quantile regression and expectile regression. Section 4 concludes.
2 A short review on D-vines and D-vine copula based quantile regression
Copulas are important and useful tools to model the dependence between financial variables. They allow separate considerations of marginal distributions and dependencies due to Sklar’s Theorem (Sklar,, 1959), which states that the joint distribution of a continuous random vector can be expressed in terms of its marginal distributions , , and its unique copula through the relationship
[TABLE]
This facilitates flexible modeling of multivariate distributions, since the marginals and the dependence function can be modeled separately. Another consequence of Sklar’s Theorem is that, as long as the interest lies in the dependence between random variables, one can consider the probability integral transformed random variables , , which are uniformly distributed. We say that these variables and their realizations are on the copula scale. Thorough introductions to copulas are given in Joe, (1997) and Nelsen, (2006).
In high dimensions many parametric copula models lack flexibility. For example, the exchangeable Archimedean copulas only have one or two dependence parameters and elliptical copulas always exhibit symmetric dependencies in the tails. Vine copulas overcome these shortcomings by breaking down the modeling of a multivariate copula to the fitting of several bivariate copulas (Bedford and Cooke,, 2002; Aas et al.,, 2009; Fischer et al.,, 2009). E.g., in three dimensions a vine copula density decomposition is given by
[TABLE]
where the three pair-copulas , and can be modeled separately, each with its own parametric copula family and dependence parameter(s). The arguments of the conditional copula , namely and , are obtained by taking derivatives, i.e., , . Note that choosing only bivariate Gaussian copulas in the decomposition always results in a multivariate Gaussian copula. Thus, vine copulas can be seen as a generalization of Gaussian copulas.
To conduct statistical inference it is usually assumed that the conditional copula does not depend on , i.e., . This so-called simplifying assumption has been inspected by many researchers (see e.g., Stöber et al.,, 2013; Spanhel and Kurz,, 2015; Killiches et al.,, 2017). While there exist cases where it is a model restriction, empirical studies show that the assumption is not a severe restriction for financial data sets (Kraus and Czado, 2017b, ).
A special subclass of vine copulas that we will use to model the dependence between default probabilities of German industry sectors are D-vine copulas. The decomposition of a -dimensional simplified D-vine copula density can be seen as a generalization of Equation (missing) 2.1 and is given by
[TABLE]
Thus, modeling a -dimensional D-vine copula consists of fitting bivariate parametric copulas, so-called pair-copulas. The arguments of the pair-copulas are obtained from a recursive formula given in Joe, (1997) using the specified pair-copulas.
For the purpose of stress testing we are interested in estimating conditional quantiles of a response variable conditioned on predictor variables :
[TABLE]
Given a fully specified D-vine copula with response as first variable, the conditional copula quantile function can be analytically expressed only using the pair-copulas of the D-vine (see Kraus and Czado, 2017a, ).
The only question remaining is how to fit the D-vine to given copula data, such that predictions of its conditional quantile functions are optimal. Kraus and Czado, 2017a propose an algorithm, which sequentially adds covariates to the D-vine that improve the model fit (measured in terms of the log-likelihood of the conditional density ) the most. This is done until none of the remaining covariates is able to improve the model fit. Thus, the algorithm facilitates an automatic forward covariate selection. The authors further demonstrate that D-vine copula based quantile regression outperforms traditional quantile regression methods established in the literature regarding prediction accuracy.
3 Data description and empirical results
3.1 Original data set
For parameter estimation, a data pool with German exchange traded corporates is used. Based on a standard Merton model (see Merton,, 1974), the original time series consist of one-year PDs between May 2007 and September 2016. The PDs which are available monthly over the time horizon and on company level are averaged on sector level, using a market-based classification scheme, similar to the GICS and ICB systems with 9 industry sectors (Basic Materials, Communications, Cyclical Consumer Goods & Services, Non-cyclical Consumer Goods & Services, Energy, Financials, Industrials, Technology, Utilities) and several industry groups for a finer classification scheme. More precisely, PD’s within a Merton setting estimate the probability that a firm will default over a specified period of time (here: one year). As usually, “default” is defined as failure to make scheduled principal or interest payments. In the Merton setting, a firm defaults when the market value of its assets falls below its liabilities payable. Hence, the relevant drivers are the current market value of the firm, the level of the firm’s obligations and the vulnerability/sensitivity of the market value to large changes. Exemplarily, Figure 1 illustrates the “PD history” for Financials with significant peaks caused by the last financial crisis from 2007 to 2008.
3.2 Time dependencies and transformation to copula scale
We consider the monthly differences of the aggregated sector PDs on a rough as well as on a more detailed level. The differenced data series are stationary and do not exhibit any autocorrelation or volatility clustering. Therefore, no ARMA-GARCH models are necessary to account for time dependencies.
Next, we transform the differenced (aggregated) data to the copula scale by applying the probability integral transform using the empirical cumulative distribution function as marginal distribution functions. The corresponding contour plots and Kendall’s values are displayed in Figure 2.
The dependencies are weak to medium and mostly positive, at first glance. The Industrials sector seems to have the strongest interdependencies with the other ones. The empirical copula density contours suggest that the dependencies are quite asymmetric, such that Gaussian copulas or elliptical copulas in general would not provide reasonable fits. Some pairs seem to exhibit tail dependence (e.g., Industrials and Technology). The histograms of the marginals displayed on the diagonal naturally are flat after transforming the observations with their empirical distribution function.
3.3 Selected results of the D-vine copula based quantile regression
We perform stress tests similar to the ones described in Kraus and Czado, 2017a . Large values (i.e., close to 1) of the variables on the copula scale correspond to large differences in the sector PDs. Therefore, inducing stress on an industry sector will be treated as setting the value of the respective industry sector covariate to a predetermined quantile level , usually . Then we use D-vine quantile regression to examine the effect of the stressed companies (covariates) on the other companies (responses). The predicted quantile will give information on how strongly the response companies are affected by the stress scenario. E.g., large deviations of the conditional predicted mean from the unconditional median of 0.5 imply strong effects of the stress scenario.
3.3.1 Results for stressing at 95% and 99% on aggregated data
At first we present the results on the aggregated data, stressing one sector at stress levels (black) and (gray). For reasons of brevity, our focus lies on the sectors Basic Materials (upper left panel of Figure 3), Cyclical Consumer Goods (upper right panel of Figure 3), Financials (lower left panel of Figure 3) and Industrials (lower right panel of Figure 3).
As expected, the effect on the conditional quantile functions strongly depends on the specific (stressed) sector and - to some minor extent - on the concrete stress level.
Across all sectors under consideration, Energy seems to be quite resistant against local sector crises. The same holds for the Utilities sector if we restrict ourselves to crises arising from Basic Materials and Cyclical Consumer Goods. On the other hand, sector crises arising from Basic Materials and Cyclical Consumer Goods spread over to most of the other sectors beside the Utilities sector. This does not hold for Financials and Industrials. In particular, stressing the sector Financials mainly affects the sector Cyclical Consumer Goods and Utilities. Above that, a simulated crisis in the Industrial sector has a significant impact on the segments Basic Materials, Communications, Cyclical Consumer Goods and Technology.
3.3.2 Selected scenarios on detailed level
Next, we focus on an industry classification scheme consisting of 55 sub-sectors in order to perform stress tests and analyze stress effects on a more granular scale. For instance, specific sub-sectors can now be isolated in order to check which of the other sub-sectors are affected and how strong these effects can be expected. However, it should be mentioned that the number of companies which are used to calculate averaged (sub-)sector PD’s decreases with increasing granularity which also implies decreasing statistical precision of the estimators. As before, we consider the probability integral transforms of the differenced time series data.
Again, we restrict ourselves to two arbitrarily selected industry sectors out of the four sectors discussed above: Basic Materials and the Automobile Industry.
Generally, the Basic Materials sector is a category that accounts for companies involved with the discovery, development and processing of raw materials. The sector includes the mining and refining of metals (iron and steels), chemical producers and forestry products. As known from the theory, the Basic Materials sector is sensitive to changes in the business cycle. Similar to the proceeding in 3.3.1, we do not vary the stress impulse within the sub-sectors of Basic Materials keeping it constant at 95% and hence solely focus on the impact on other sub-sectors. In this case, a more granular insight is gained. For instance, the overall impact on Communications was observed on a medium level. On a more granular level and with reference to the left panel of Figure 4, the sub-sector Advertising turns out to be stress resistant.
Alternatively, the initial stress may start from a single sub-sector. This effect is exemplarily illustrated in the right panel of Figure 4, where we refined the previously conducted general scenarios of Cyclical Consumer Goods and Industrials of 3.3.1 by only inducing stress on the sector Automobile Industry represented by the sub-sectors Auto Manufacturers, Auto Parts & Equipment, and several sub-sectors of the Industrials sector (see the sub-sectors written in bold and italics in the right panel of Figure 4). The Automobile Industry is probably one of the most important German industry sectors. In 2014, for instance, three of the four biggest German companies (ordered by sales volume) were producing automobiles (Volkswagen AG, Daimler and BMW). Against the current economic and political background, short-term or medium-term turmoils might result from the upcoming new American protectionism related to the discussions on the introduction of possible trade barriers imposed by the newly elected US government, but also if we consider the innovative processes and services related to electric mobility or the increasing interconnection between IT technology and car construction. As expected, we observe that this stress scenario has a severe impact on the entire German economy. 28 out of the remaining 43 sub-sectors exhibit a predicted conditional median greater than 75%, 12 sub-sectors are strongly affected with conditional medians greater than 90% and 7 (Iron and Steel, Airlines, Agriculture, Banks, Insurance, REITS and Software) even exceed the stress level of 95%.
Despite looking at response industry sectors and covariates simultaneously, we also examined the impact of lagged covariates. However, these turned out to not have a relevant influence on the response industry sectors, neither as single covariates nor in combination with non-lagged variables. This might be due to the fact that the sector PDs are derived from equity data and financial markets anticipate future depreciations in current stock prices.
3.4 Results from alternative approaches
In order to motivate the use of copula based quantile regression, we would like to point out some results from alternative approaches. Conditional quantiles
[TABLE]
can also be linearly modeled by traditional quantile regression, see e.g., Koenker, (2006) and for an example Figure 5 where the method is applied to the differenced time series of response sector Utilities and the covariate Financials. However, as the conditional quantiles at different levels and are estimated independently it can occur that for given covariate realizations and levels , can have a larger value than , an effect known as quantile crossing. Whereas different approaches have already been proposed to combat quantile crossing, see e.g., He, (1997), Dette and Volgushev, (2008) or Bondell et al., (2010), the novel D-vine copula based quantile regression of Kraus and Czado, 2017a also ensures that this effect is prevented.
Expectile regression might be an alternative to quantile regression and has gained increasing attention in the recent literature, see e.g., Waltrup et al., (2015). Based on replacing the L1 weighting scheme for conditional quantiles by an L2 metric, expectiles
[TABLE]
can be bijectively linked to conditional quantiles and also uniquely determine a distribution function. Same as for quantile regression, expectile regression can lead to crossing of estimated curves, see the middle panel of Figure 5. Even though this problem is in practice less likely for expectile regression than for quantile regression, see e.g., Schnabel, (2011), similar methods as for regularizing traditional quantile regression can be applied to prevent this effect. Although expectile regression implies some advantages such as computational efficiency, it still bears the problem of weak interpretability. Except for the % expectile which can be interpreted as a mean parameter, all other expectiles do not follow an intuitive interpretation in contrast to quantiles. As a consequence, modeling the % expectile is equivalent to applying a traditional linear model.
Due to the intuitive interpretability of quantiles and the robustness of the median, we favor quantile regression over expectile regression in this work. Moreover, following the criticism in Bernard and Czado, (2015) that conditional quantiles are only linear given very strong assumptions on the underlying copula of the response and covariate variables as well as the quantile crossing problem, we identify the D-vine copula based quantile regression approach as a suitable method for our stress test, see the lower panel of Figure 5.
4 Summary and Outlook
This work evaluates the mutual impact of industry sector specific stress in the German economy using D-vine copula based quantile regression. Concerning simultaneous consideration of covariate and response variables, we illustrate the impact of sector stress arising from Basic Materials, Cyclical Consumer Goods or Industrials on the other industry segments. Above that, our analyses confirm that the Automobile sector strongly influences the whole economy. We also identify that a stressed Financials sector has only moderate influence on the other German industry. Similarly, lagged covariate segments exhibit only minor impact on their response sectors as well. We identify D-vine copula based quantile regression as a preferable method for conducting industry sector stress tests as it accounts for the nonlinearity properties of conditional quantiles and prevents quantile crossing effects. Moreover, in contrast to modeling conditional expectiles, conditional quantiles allow for an intuitive interpretation and have better robustness properties.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Aas et al., (2009) Aas, K., Czado, C., Frigessi, A., and Bakken, H. (2009). Pair-copula constructions of multiple dependence. Insurance, Mathematics and Economics , 44:182–198.
- 2Bedford and Cooke, (2002) Bedford, T. and Cooke, R. M. (2002). Vines: A new graphical model for dependent random variables. Annals of Statistics , 30:1031–1068.
- 3Bernard and Czado, (2015) Bernard, C. and Czado, C. (2015). Conditional quantiles and tail dependence. Journal of Multivariate Analysis , 138:104–126.
- 4Bondell et al., (2010) Bondell, H. D., Reich, B. J., and Wang, H. (2010). Noncrossing quantile regression curve estimation. Biometrika , 97(4):825–838.
- 5Covas et al., (2014) Covas, F. B., Rump, B., and Zakrajšek, E. (2014). Stress-testing US bank holding companies: A dynamic panel quantile regression approach. International Journal of Forecasting , 30(3):691–713.
- 6Dette and Volgushev, (2008) Dette, H. and Volgushev, S. (2008). Non-crossing non-parametric estimates of quantile curves. Journal of the Royal Statistical Society: Series B , 70(3):609–627.
- 7Fischer et al., (2009) Fischer, M., Köck, C., Schlüter, S., and Weigert, F. (2009). An empirical analysis of multivariate copula models. Quantitative Finance , 9(7):839–854.
- 8He, (1997) He, X. (1997). Quantile curves without crossing. The American Statistician , 51(2):186–192.