Fortia-FBK at SemEval-2017 Task 5: Bullish or Bearish? Inferring Sentiment towards Brands from Financial News Headlines
Youness Mansar, Lorenzo Gatti, Sira Ferradans, Marco Guerini, Jacopo, Staiano

TL;DR
This paper presents a neural network-based method using affective lexica and word embeddings to accurately determine bullish or bearish sentiment in financial news headlines, achieving top results in a SemEval challenge.
Contribution
It introduces a novel CNN architecture combining affective lexica and word embeddings for sentiment analysis in financial headlines, outperforming previous approaches.
Findings
Achieved best performance in SemEval 2017 Task 5 subtask 2
Demonstrated effectiveness of combining affective lexica with CNNs
Validated approach on financial news sentiment classification
Abstract
In this paper, we describe a methodology to infer Bullish or Bearish sentiment towards companies/brands. More specifically, our approach leverages affective lexica and word embeddings in combination with convolutional neural networks to infer the sentiment of financial news headlines towards a target company. Such architecture was used and evaluated in the context of the SemEval 2017 challenge (task 5, subtask 2), in which it obtained the best performance.
Click any figure to enlarge with its caption.
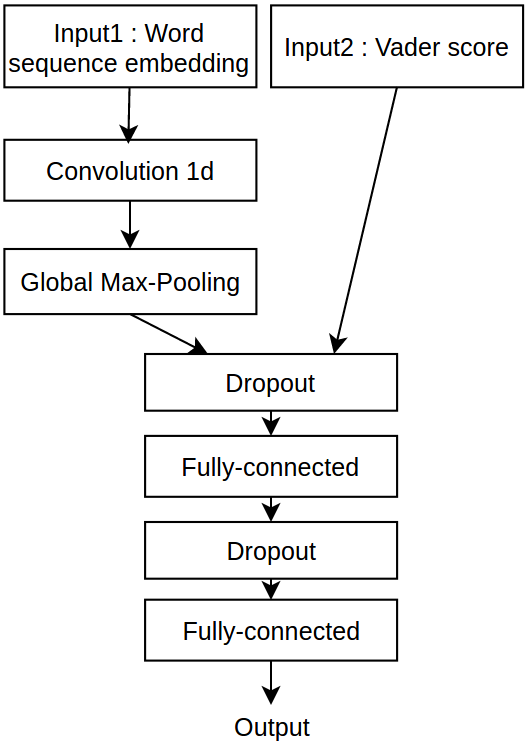 Figure 1
Figure 1| Algorithm | meanstd |
|---|---|
| Full | 0.701 0.023 |
| No embeddings | 0.586 0.017 |
| No pre-processing | 0.648 0.022 |
| Algorithm | Test scores |
|---|---|
| Full | 0.745 |
| No embeddings | 0.660 |
| No pre-processing | 0.678 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Fortia-FBK at SemEval-2017 Task 5:
Bullish or Bearish?
Inferring Sentiment towards Brands from Financial News Headlines
Youness Mansar⋆, Lorenzo Gatti∘, Sira Ferradans⋆, Marco Guerini∘, and Jacopo Staiano⋆
⋆Fortia Financial Solutions, Paris, France
∘Fondazione Bruno Kessler, Povo, Italy
{youness.mansar,sira.ferradans,jacopo.staiano}@fortia.fr
{l.gatti,guerini}@fbk.eu
Abstract
In this paper, we describe a methodology to infer Bullish or Bearish sentiment towards companies/brands. More specifically, our approach leverages affective lexica and word embeddings in combination with convolutional neural networks to infer the sentiment of financial news headlines towards a target company. Such architecture was used and evaluated in the context of the SemEval 2017 challenge (task 5, subtask 2), in which it obtained the best performance.
1 Introduction
Real time information is key for decision making in highly technical domains such as finance. The explosive growth of financial technology industry (Fintech) continued in 2016, partially due to the current interest in the market for Artificial Intelligence-based technologies111F. Desai, “The Age of Artificial Intelligence in Fintech” https://www.forbes.com/sites/falgunidesai/2016/06/30/the-age-of-artificial-intelligence-in-fintech S. Delventhal, “Global Fintech Investment Hits Record High in 2016” http://www.investopedia.com/articles/markets/061316/global-fintech-investment-hits-record-high-2016.asp.
Opinion-rich texts such as micro-blogging and news can have an important impact in the financial sector (e.g. raise or fall in stock value) or in the overall economy (e.g. the Greek public debt crisis). In such a context, having granular access to the opinions of an important part of the population is of key importance to any public and private actor in the field. In order to take advantage of this raw data, it is thus needed to develop machine learning methods allowing to convert unstructured text into information that can be managed and exploited.
In this paper, we address the sentiment analysis problem applied to financial headlines, where the goal is, for a given news headline and target company, to infer its polarity score i.e. how positive (or negative) the sentence is with respect to the target company. Previous research Goonatilake and Herath (2007) has highlighted the association between news items and market fluctiations; hence, in the financial domain, sentiment analysis can be used as a proxy for bullish (i.e. positive, upwards trend) or bearish (i.e. negative, downwards trend) attitude towards a specific financial actor, allowing to identify and monitor in real-time the sentiment associated with e.g. stocks or brands.
Our contribution leverages pre-trained word embeddings (GloVe, trained on wikipedia+gigaword corpus), the DepecheMood affective lexicon, and convolutional neural networks.
2 Related Works
While image and sound come with a natural high dimensional embedding, the issue of which is the best representation is still an open research problem in the context of natural language and text. It is beyond the scope of this paper to do a thorough overview of word representations, for this we refer the interest reader to the excellent review provided by Mandelbaum and Shalev (2016). Here, we will just introduce the main representations that are related to the proposed method.
Word embeddings.
In the seminal paper Bengio et al. (2003), the authors introduce a statistical language model computed in an unsupervised training context using shallow neural networks. The goal was to predict the following word, given the previous context in the sentence, showing a major advance with respect to n-grams. Collobert et al. Collobert et al. (2011) empirically proved the usefulness of using unsupervised word representations for a variety of different NLP tasks and set the neural network architecture for many current approaches. Mikolov et al. Mikolov et al. (2013) proposed a simplified model (word2vec) that allows to train on larger corpora, and showed how semantic relationships emerge from this training. Pennington et al. Pennington et al. (2014), with the GloVe approach, maintain the semantic capacity of word2vec while introducing the statistical information from latent semantic analysis (LSA) showing that they can improve in semantic and syntactic tasks.
Sentiment and Affective Lexica.
In recent years, several approaches have been proposed to build lexica containing prior sentiment polarities (sentiment lexica) or multi-dimensional affective scores (affective lexica). The goal of these methods is to associate such scores to raw tokens or tuples, e.g. lemma#pos where lemma is the lemma of a token, and pos its part of speech.
There is usually a trade-off between coverage (the amount of entries) and precision (the accuracy of the sentiment information). For instance, regarding sentiment lexica, SentiWordNet Esuli and Sebastiani (2006), Baccianella et al. (2010), associates each entry with the numerical scores, ranging from 0 (negative) to 1 (positive); following this approach, it has been possible to automatically obtain a list of 155k words, compensating a low precision with a high coverage Gatti et al. (2016). On the other side of the spectrum, we have methods such as Bradley and Lang (1999), Taboada et al. (2011), Warriner et al. (2013) with low coverage (from 1k to 14k words), but for which the precision is maximized. These scores were manually assigned by multiple annotators, and in some cases validated by crowd-sourcing Taboada et al. (2011).
Finally, a binary sentiment score is provided in the General Inquirer lexicon Stone et al. (1966), covering 4k sentiment-bearing words, and expanded to 6k words by Wilson et al. (2005).
Turning to affective lexica, where multiple dimensions of affect are taken into account, we mention WordNetAffect Strapparava and Valitutti (2004), which provides manual affective annotations of WordNet synsets (anger, joy, fear, etc.): it contains 900 annotated synsets and 1.6k words in the form lemma#PoS#sense, which correspond to roughly 1k lemma#PoS entries.
AffectNet Cambria and Hussain (2012), contains 10k words taken from ConceptNet and aligned with WordNetAffect, and extends the latter to concepts like ‘have breakfast’. Fuzzy Affect Lexicon Subasic and Huettner (2001) contains roughly 4k lemma#PoS manually annotated by one linguist using 80 emotion labels. EmoLex Mohammad and Turney (2013) contains almost 10k lemmas annotated with an intensity label for each emotion using Mechanical Turk. Finally, Affect database is an extension of SentiFul Neviarouskaya et al. (2007) and contains 2.5k words in the form lemma#PoS. The latter is the only lexicon providing words annotated also with emotion scores rather than only with labels.
In this work, we exploit the DepecheMood affective lexicon proposed by Staiano and Guerini (2014): this resource has been built in a completely unsupervised fashion, from affective scores assigned by readers to news articles; notably, due to its automated crowd-sourcing-based approach, DepecheMood allows for both high-coverage and high-precision. DepecheMood provides scores for more than 37k entries, on the following affective dimensions: Afraid, Happy, Angry, Sad, Inspired, Don’t Care, Inspired, Amused, Annoyed. We refer the reader to Staiano and Guerini (2014); Guerini and Staiano (2015) for more details.
The affective dimensions encoded in DepecheMood are directly connected to the emotions evoked by a news article in the readers, hence it seemed a natural choice for the SemEval 2017 task at hand.
Sentence Classification.
A modification of Collobert et al. (2011) was proposed by Kim Kim (2014) for sentence classification, showing how a simple model together with pre-trained word representations can be highly performing. Our method builds on this conv-net method. Further, we took advantage of the rule-based sentiment analyser VADER Hutto and Gilbert (2014) (for Valence Aware Dictionary for sEntiment Reasoning), which builds upon a sentiment lexicon and a predefined set of simple rules.
3 Data
The data consists of a set of financial news headlines, crawled from several online outlets such as Yahoo Finance, where each sentence contains one or more company names/brands.
Each tuple (headline, company) is annotated with a sentiment score ranging from -1 (very negative, bearish) to 1 (very positive, bullish). The training/test sets provided contain 1142 and 491 annotated sentences, respectively.
A sample instance is reported below:
Headline: “Morrisons book second consecutive quarter of sales growth”
Company name: “Morrisons”
Sentiment score: 0.43
4 Method
In Figure 1, we can see the overall architecture of our model.
4.1 Sentence representation and preprocessing
Pre-processing.
Minimal preprocessing was adopted in our approach: we replaced the target company’s name with a fixed word <company> and numbers with <number>. The sentences were then tokenized using spaces as separator and keeping punctuation symbols as separate tokens.
Sentence representation.
The words are represented as fixed length vectors resulting from the concatenation of GloVe pre-trained embeddings and DepecheMood Staiano and Guerini (2014) lexicon representation. Since we cannot directly concatenate token-based embeddings (provided in GloVe) with the lemma#PoS-based representation available in DepecheMood, we proceeded to re-build the latter in token-based form, applying the exact same methodology albeit with two differences: we started from a larger dataset (51.9K news articles instead of 25.3K) and used a frequency cut-off, i.e. keeping only those tokens that appear at least 5 times in the corpus222Our tests showed that: (i) the larger dataset allowed improving both precision on the SemEval2007 Affective Text Task Strapparava and Mihalcea (2007) dataset, originally used for the evaluation of DepecheMood, and coverage (from the initial 183K unique tokens we went to 292K entries) of the lexicon; (ii) we found no significant difference in performance between lemma#PoS and token versions built starting from the same dataset..
These word-level representation are used as the first layer of our network. During training we allow the weights of the representation to be updated. We further add the VADER score for the sentence under analysis. The complete sentence representation is presented in Algorithm 1.
4.2 Architectural Details
Convolutional Layer.
A 1D convolutional layer with filters of multiple sizes {2, 3, 4} is applied to the sequence of word embeddings. The filters are used to learn useful translation-invariant representations of the sequential input data. A global max-pooling is then applied across the sequence for each filter output.
Concat Layer.
We apply the concatenation layer to the output of the global max-pooling and the output of VADER.
Activation functions.
The activation function used between layers is ReLU Nair and Hinton (2010) except for the out layer where tanh is used to map the output into [-1, 1] range.
Regularization.
Dropout Srivastava et al. (2014) was used to avoid over-fitting to the training data: it prevents the co-adaptation of the neurones and it also provides an inexpensive way to average an exponential number of networks. In addition, we averaged the output of multiple networks with the same architecture but trained independently with different random seeds in order to reduce noise.
Loss function.
The loss function used is the cosine distance between the predicted scores and the gold standard for each batch. Even though stochastic optimization methods like Adam Kingma and Ba (2014) are usually applied to loss functions that are written as a sum of per-sample loss, which is not the case for the cosine, it converges to an acceptable solution. The loss can be written as :
[TABLE]
where and are the predicted and true sentiment scores for batch , respectively.
The algorithm for training/testing our model is reported in Algorithm 2.
5 Results
In this section, we report the results obtained by our model according to challenge official evaluation metric, which is based cosine-similarity and described in Ghosh et al. (2015). Results are reported for three diverse configurations: (i) the full system; (ii) the system without using word embeddings (i.e. Glove and DepecheMood); and (iii) the system without using pre-processing. In Table 1 we show model’s performances on the challenge training data, in a 5-fold cross-validation setting.
Further, the final performances obtained with our approach on the challenge test set are reported in Table 2. Consistently with the cross-validation performances shown earlier, we observe the beneficial impact of word-representations and basic pre-processing.
6 Conclusions
In this paper, we presented the network architecture used for the Fortia-FBK submission to the Semeval-2017 Task 5, Subtask 2 challenge, with the goal of predicting positive (bullish) or negative (bearish) attitude towards a target brand from financial news headlines. The proposed system ranked 1st in such challenge.
Our approach is based on 1d convolutions and uses fine-tuning of unsupervised word representations and a rule based sentiment model in its inputs. We showed that the use of pre-computed word representations allows to reduce over-fitting and to achieve significantly better generalization, while some basic pre-processing was needed to further improve the performance.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Baccianella et al. (2010) S. Baccianella, A. Esuli, and F. Sebastiani. 2010. Senti Word Net 3.0: An enhanced lexical resource for sentiment analysis and opinion mining. In Proceedings of LREC 2010 . Valletta, Malta, pages 2200–2204.
- 2Bengio et al. (2003) Yoshua Bengio, Réjean Ducharme, Pascal Vincent, and Christian Jauvin. 2003. A neural probabilistic language model. Journal of machine learning research 3(Feb):1137–1155.
- 3Bradley and Lang (1999) M.M. Bradley and P.J. Lang. 1999. Affective norms for English words (ANEW): Instruction manual and affective ratings. Technical Report C-1, University of Florida .
- 4Cambria and Hussain (2012) Erik Cambria and Amir Hussain. 2012. Sentic computing . Springer.
- 5Collobert et al. (2011) Ronan Collobert, Jason Weston, Léon Bottou, Michael Karlen, Koray Kavukcuoglu, and Pavel Kuksa. 2011. Natural language processing (almost) from scratch. Journal of Machine Learning Research 12(Aug):2493–2537.
- 6Esuli and Sebastiani (2006) A. Esuli and F. Sebastiani. 2006. Senti Word Net: A publicly available lexical resource for opinion mining. In Proceedings of LREC 2006 . Genova, IT, pages 417–422.
- 7Gatti et al. (2016) Lorenzo Gatti, Marco Guerini, and Marco Turchi. 2016. Senti Words: Deriving a high precision and high coverage lexicon for sentiment analysis. IEEE Transactions on Affective Computing 7(4):409–421.
- 8Ghosh et al. (2015) Aniruddha Ghosh, Guofu Li, Tony Veale, Paolo Rosso, Ekaterina Shutova, John Barnden, and Antonio Reyes. 2015. Semeval-2015 task 11: Sentiment analysis of figurative language in twitter. In Proceedings of the 9th International Workshop on Semantic Evaluation (Sem Eval 2015) . pages 470–478.