Hierarchical Surrogate Modeling for Illumination Algorithms
Alexander Hagg

TL;DR
This paper introduces a hierarchical surrogate modeling approach for evolutionary illumination algorithms, enabling efficient representation of diverse optimal regions by decomposing training data and using ensemble models.
Contribution
It proposes a novel hierarchical segmentation method to improve surrogate modeling in illumination algorithms, addressing the challenge of representing many diverse optimal regions.
Findings
Enhanced surrogate model accuracy for diverse solutions
Reduced computational complexity through hierarchical segmentation
Improved performance in illumination tasks
Abstract
Evolutionary illumination is a recent technique that allows producing many diverse, optimal solutions in a map of manually defined features. To support the large amount of objective function evaluations, surrogate model assistance was recently introduced. Illumination models need to represent many more, diverse optimal regions than classical surrogate models. In this PhD thesis, we propose to decompose the sample set, decreasing model complexity, by hierarchically segmenting the training set according to their coordinates in feature space. An ensemble of diverse models can then be trained to serve as a surrogate to illumination.
Click any figure to enlarge with its caption.
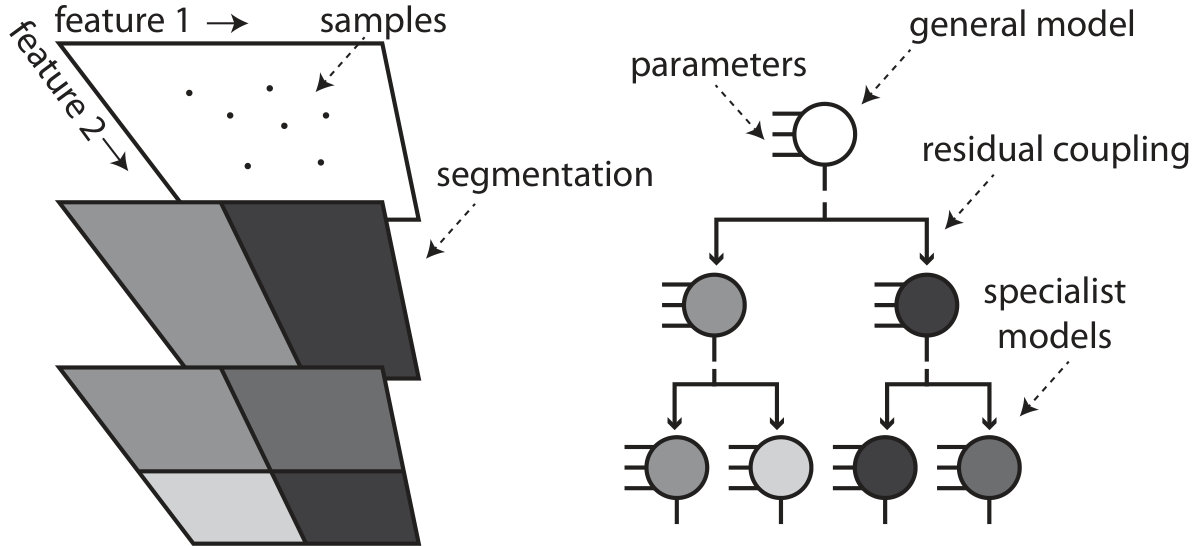 Figure 1
Figure 1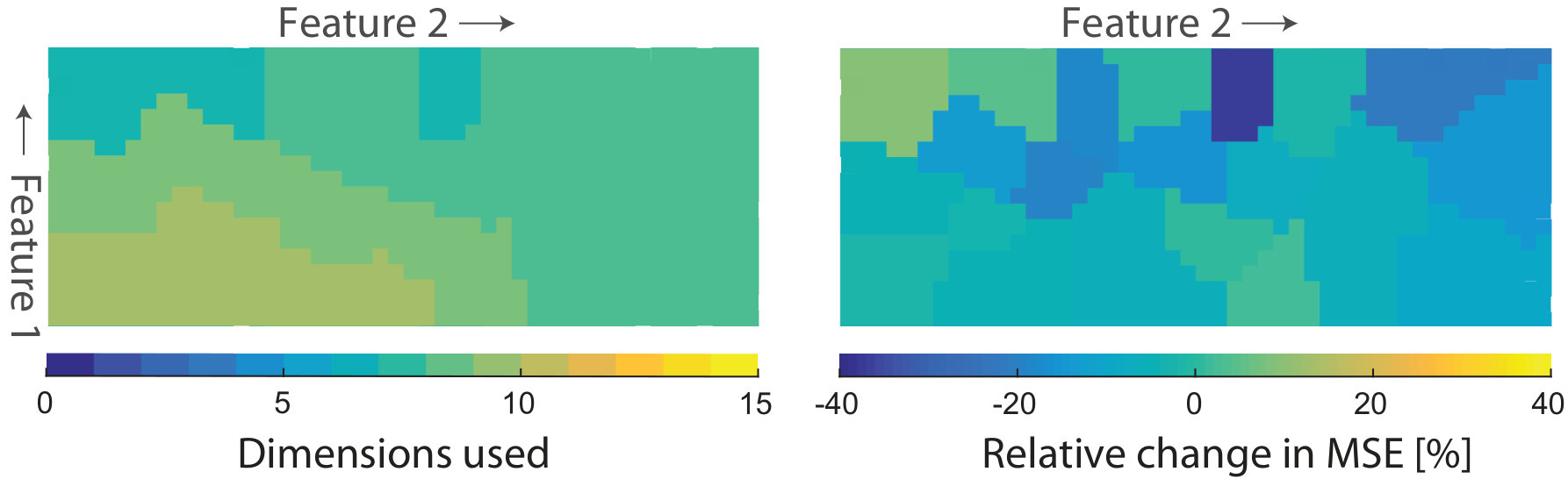 Figure 2
Figure 2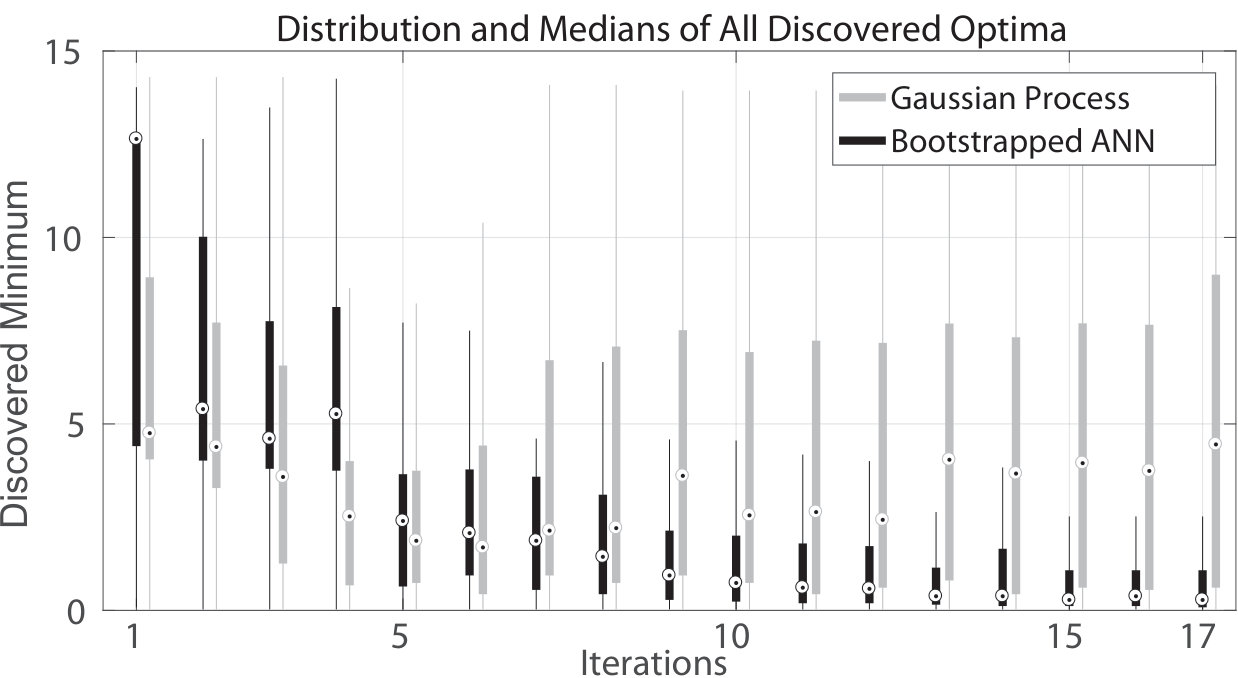 Figure 3
Figure 3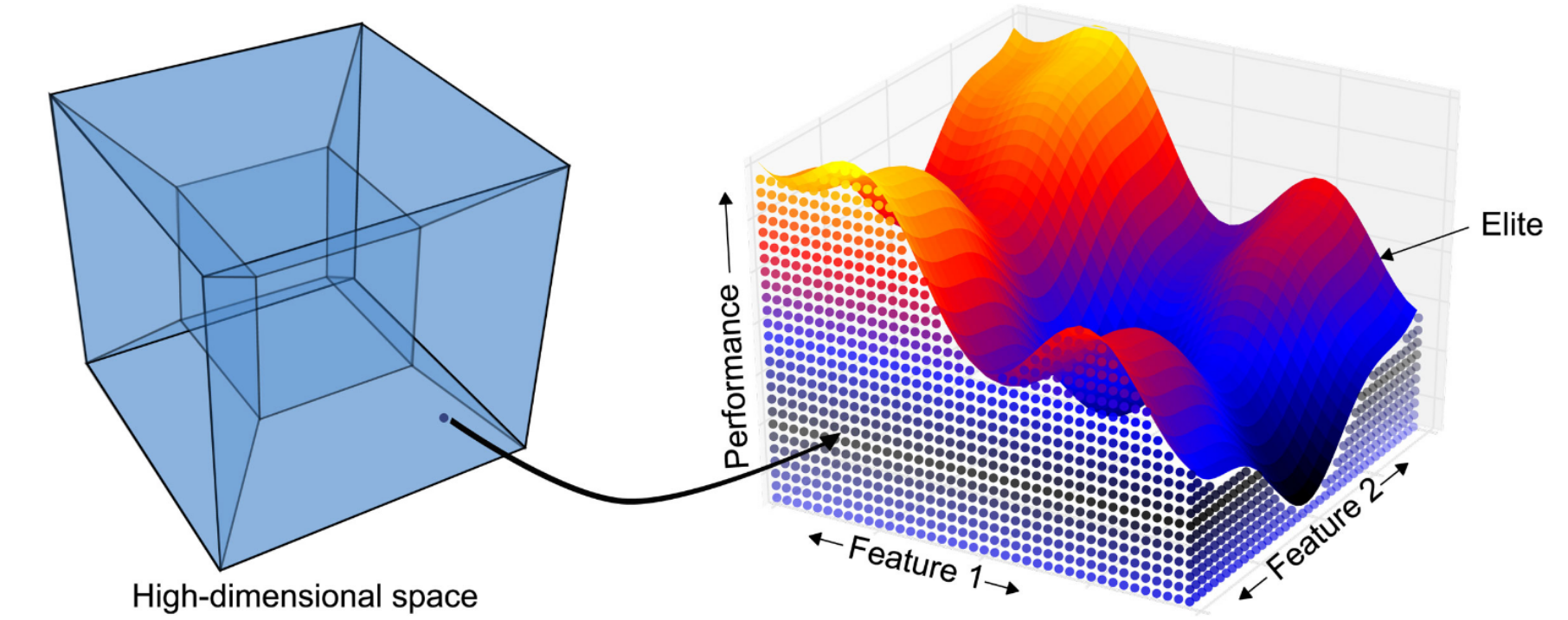 Figure 4
Figure 4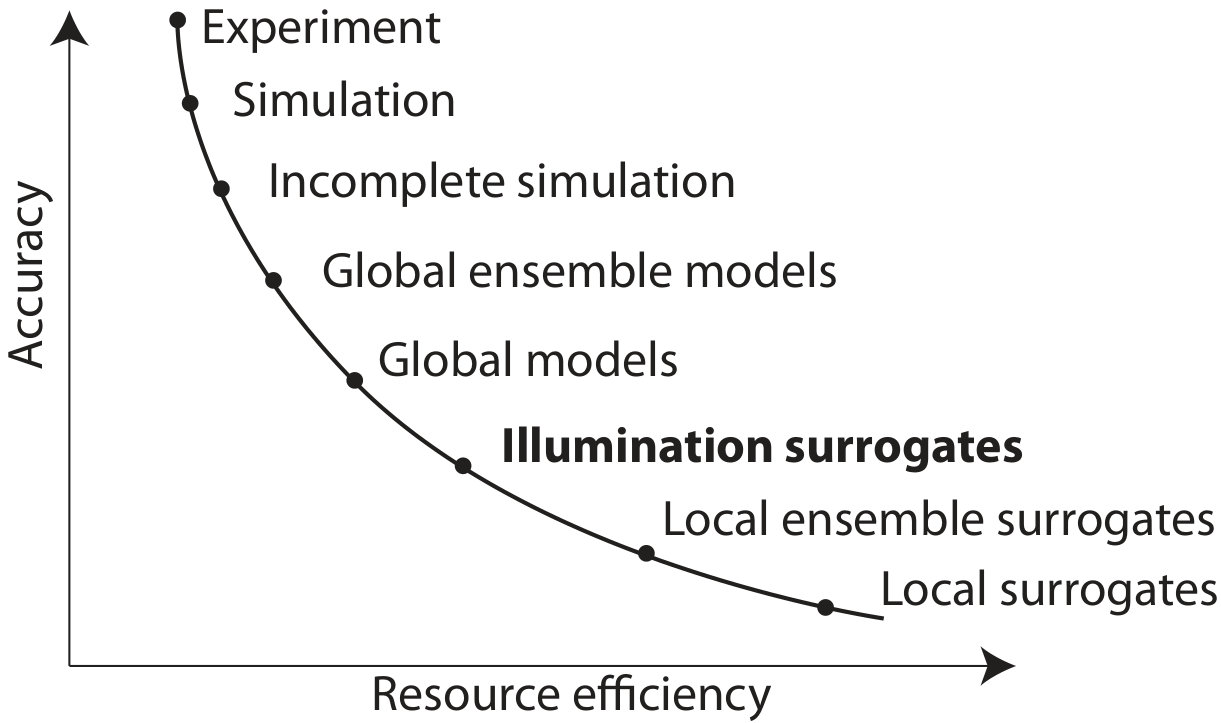 Figure 5
Figure 5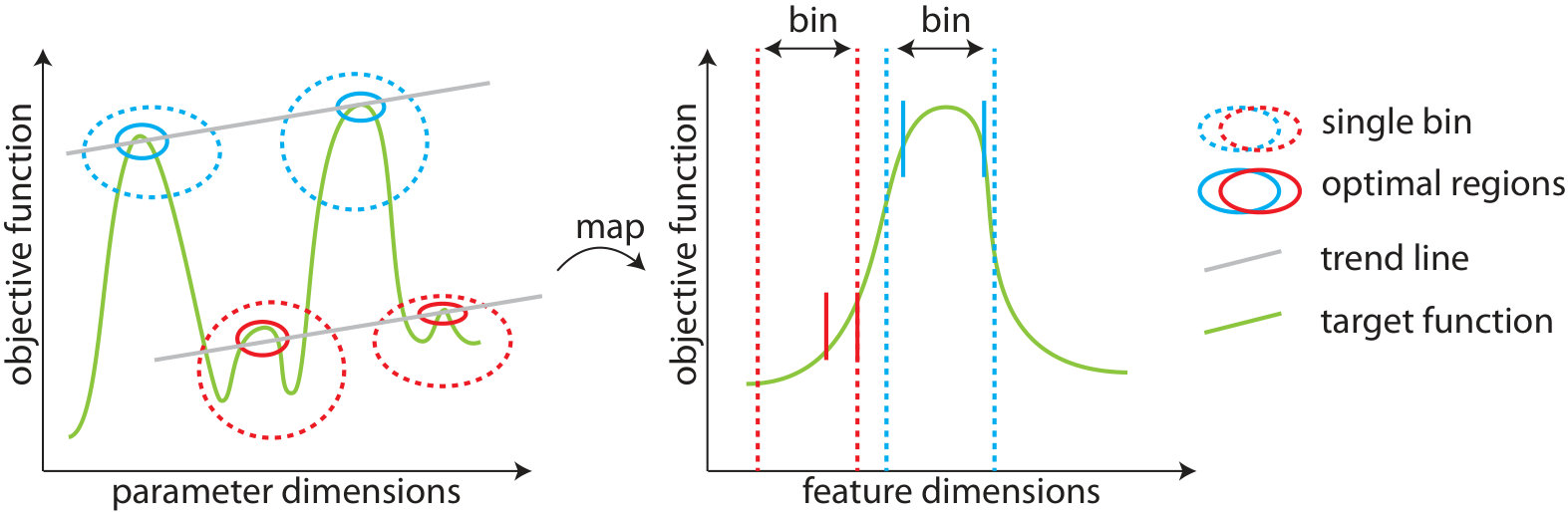 Figure 6
Figure 6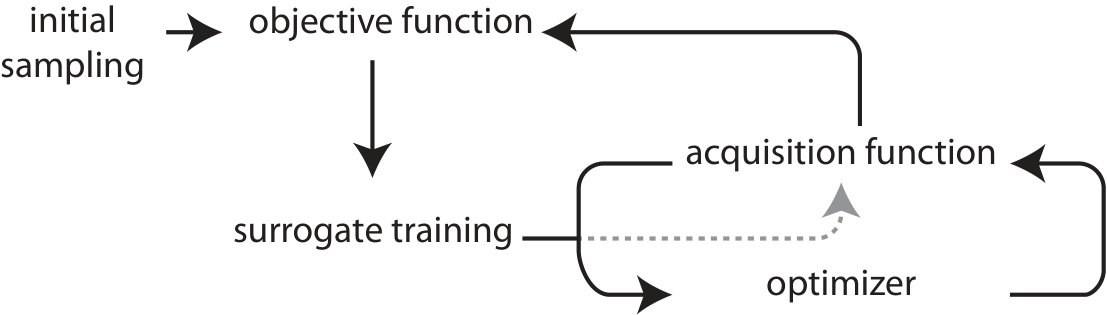 Figure 7
Figure 7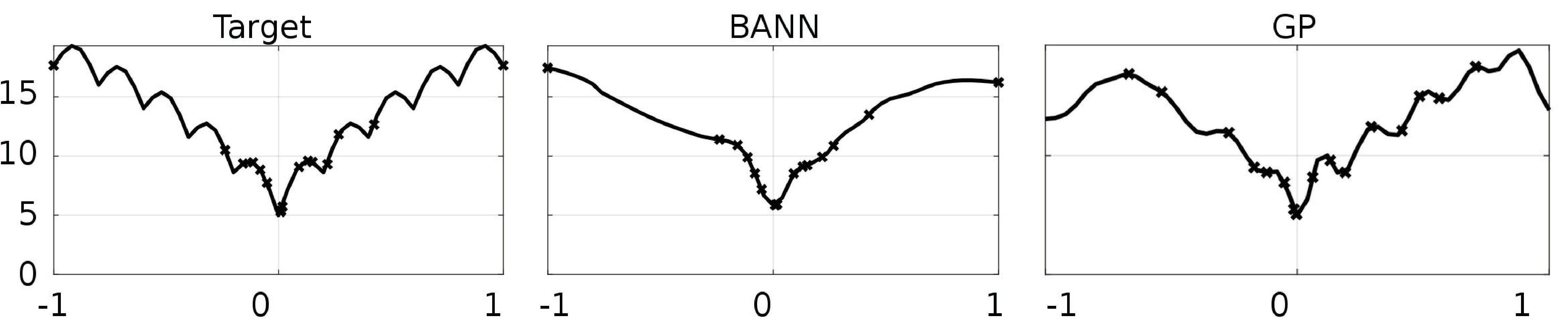 Figure 8
Figure 8Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Multi-Objective Optimization Algorithms · Evolutionary Algorithms and Applications · Metaheuristic Optimization Algorithms Research
Hierarchical Surrogate Modeling for Illumination Algorithms
Alexander Hagg
Bonn-Rhein-Sieg University of Applied SciencesGrantham-Allee 20BonnGermany53757
(2017)
Abstract.
Evolutionary illumination is a recent technique that allows producing many diverse, optimal solutions in a map of manually defined features. To support the large amount of objective function evaluations, surrogate model assistance was recently introduced (Gaier et al., 2017). Illumination models need to represent many more, diverse optimal regions than classical surrogate models. In this PhD thesis, we propose to decompose the sample set, decreasing model complexity, by hierarchically segmenting the training set according to their coordinates in feature space. An ensemble of diverse models can then be trained to serve as a surrogate to illumination.
surrogate modeling, evolutionary illumination, bagging
††copyright: rightsretained††doi: XX.XXX/XXX_X††isbn: XXX-XXXX-XX-XXX/XX/XX††conference: the Genetic and Evolutionary Computation Conference 2017; July 15–19, 2017; Berlin, Germany††journalyear: 2017††price: 15.00
1. Introduction
Computer-automated design was first introduced in 1963 by Kamentsky and Liu (Kamentsky and Liu, 1963), who created a computer program to design character recognition logic based on the processing of data samples. Many applications and methods have since been developed. Today, optimization of high-dimensional problems, such as in computational fluid dynamics (Emmerich and Naujoks, 2004) or robotics (Cully et al., 2015), can be extremely expensive in terms of computational effort.
To decrease the necessary effort to optimize an expensive objective function, approximative models are used to serve as a surrogate for these simulations. Surrogate-assisted optimization (SAO) is a technique which, supported by models from machine or statistical learning, is typically used when the objective function is complex, data is scarce or evaluation of potential solutions is expensive. A surrogate model only needs to learn an approximation of the objective function, also called the response surface, close to optimal solutions. In evolutionary optimization (EO) specifically, the approximation accuracy requirement devolves to a ranking accuracy requirement. The model only needs to accurately compare solutions.
The necessary number of evaluations can be further reduced by using Bayesian optimization (BO) (Brochu et al., 2010). The technique uses a prior over the objective function and evidence from known samples to select the best next observation based on a utility function, also called an acquisition function. This function balances exploration, sampling from uncertain areas, and exploitation, choosing samples that are most likely to perform well.
Both techniques, surrogate-assistance and the acquisition function, are used for data efficient learning. In this paradigm, learning requires a modeling technique that can not only accurately predict the objective function, but also estimate its prediction confidence.
SAO is used to find a single solution, or a Pareto front of solutions in multi-objective optimization. To find more interesting designs or design principles, illumination algorithms, introduced by Mouret et al. (Mouret and Clune, 2015), are used to explore the relationship between user-defined features and the maximal performance. For example, if an engineer wants to design a car, the relationship between the volume of the car’s luggage space and its turning radius can be illuminated. The engineer can use this feature relationship as a basis for design decisions. The method needs many evaluations of the objective function, which can be greatly reduced using surrogate-assisted illumination (SAIL), which was introduced by Gaier et al. (Gaier et al., 2017).
2. Surrogate-Assisted Optimization
The SAO process is depicted in Figure 1. Initial training of the surrogate model is performed on a small training set, which is evenly spread over parameter space. The expensive objective function is used to retrieve samples’ fitness value. Then, a surrogate model is created based on the initial sample set.
The surrogate model is updated in an on-line learning strategy. The optimization strategy is used to explore the model to find optimal solutions. In Bayesian optimization this is not done directly. To acquire new samples, the model’s confidence about its prediction is included. A common acquisition function is upper confidence bound (UCB) sampling (Auer, 2003). Here, the uncertainty of the model is added to the predicted fitness to overestimate the solution’s objective performance. The weighting of fitness and confidence controls the exploratory and exploitative behavior of the optimizer. This helps lowering regret: even if the sample is not of high fitness, the model will benefit from this additional knowledge.
Because Gaussian process (GP) models are effective with small sample sets and include an uncertainty measure, they are often used in optimization (Emmerich and Naujoks, 2004; Rasmussen and Williams, 2006; Brochu et al., 2010; Jin, 2011; Cully et al., 2015; Gaier et al., 2017). A GP describes a random distribution of functions which are defined by the mean function m and the covariance function k. GP models are interpolative. The predicted value depends on the proximity to a known sample and its value, which is defined by the covariance function.
Optimization performance does not depend on the surrogate model’s prediction accuracy alone. Depending on the chosen optimization technique, overfitting of the surrogate model can have an adverse effect on the convergence speed of the optimizer. As can be seen in Figure 2, in gradient based approaches, a model which does not fit the data perfectly can offer a smoother, easier traversable response surface, a phenomenon also called the blessing of uncertainty, which is described in work by Ong et al. (Yew-Soon Ong et al., 2006). The same is valid in EO but to a lesser degree. Even though EO only depends on rank comparisons between solutions, they still depend on a virtual gradient, which is induced by the fact that solutions are only mutated in small steps. Local optima can still lead the algorithm into traps, leading to longer convergence times (Yew-Soon Ong et al., 2006).
EO have shown to be better at divergent search than classical, gradient-based approaches (Črepinšek et al., 2013). Whereas exploitation of existing knowledge to improve solutions is an aspect that is central to both fields, many EO techniques exist that focus on exploration of the solution space, also known as novelty search. All techniques benefit from surrogate models that are not too accurate, creating a smoother objective function for the optimizer.
3. Surrogate Assisted Illumination
In recent work, Mouret and Clune introduced (Mouret and Clune, 2015) a new divergent optimization technique, MAP-Elites, which can illuminate the relationship between features and their impact on optimal solutions. The technique is a mixture of optimization and novelty search. Solutions are mapped from their high-dimensional parameter space onto a lower-dimensional map of features (Figure 3). The space is discretized into bins, niches in which individuals are similar with respect to the selected features.
To initialize MAP-Elites, a set of random solutions is first evaluated and assigned to bins. If a bin is empty, the solution is placed inside. If another solution is already occupying the bin, the new solution replaces it if it has a higher fitness, otherwise it is discarded. As a result, each bin contains the best solution found so far (elite). To produce new solutions, parents are chosen randomly from the elites, then mutated and evaluated, and finally assigned to a bin based on their feature values. Child solutions have two ways of joining the breeding pool, either by discovering an unoccupied bin or out-competing an existing solution for its bin. By repeating this process, the feature space gets increasingly explored, resulting in an increasingly optimal collection of solutions.
The technique allows engineers to generate a large number of optimal solutions that can be used to easily switch strategies in robotics control (Cully et al., 2015) or to model the optimal solutions in a feature space (Gaier et al., 2017).
SAIL is an extension to this algorithm. Gaier et al. (Gaier et al., 2017) use a GP model to support the illumination process by UCB sampling to add knowledge to the surrogate model during optimization. The GP model needs to predict the objective function based on all 11 dimensions of the parameter space. In the evaluation case that was defined, optimization of a 2D airfoil, the number of dimensions and samples is not very large. When optimizing 3D shapes however, the dimensionality can easily go up to 88 or 96 dimensions (Hasenjäger et al., 2005; Brezillon and Dwight, 2009).
4. Surrogate Methods and their Deficits
In many aspects, SAIL is very similar to SAO. Both are online methods that require a retrainable model. They can both benefit from models that annotate their prediction with a confidence interval. In both cases, the amount of samples needed for an accurate model should be minimal, as evaluations are usually expensive. Finally, they both benefit from smooth models.
On top of this, SAIL needs millions of comparisons, depending on the map’s resolution, many more than most SAO methods. In SAO, the training of the surrogate is often more expensive than evaluation, but since SAIL needs to evaluate the model more often, models with low evaluation times are beneficial to the computational requirements of the optimization process.
Another difference is the fact that SAIL is divergent and finds many, diverse optima. Locally accurate surrogate models could be too expensive to accurately model for example the optimal regions for 64x64 bins. In this case, 4096 local models would have to be trained. Also, since the diversity of the training set is high and bins are defined by non-linear features, the optimal regions within the bins do not necessarily belong to a continuous optimal region in the objective function (Figure 4). In this simplified example, notice that samples belonging to the same bin can belong to different regions in parameter space. Within each bin, the surrogate model only needs to be accurate towards the more optimal solutions, but this region can consist of solutions from multiple regions in parameter space. A single surrogate model would have to learn the high-order polynomial (green), although for rank comparisons in illumination it can be sufficient to learn linear trend lines (gray).
Training a global model that approximates the entire objective function is not feasible in optimization, as samples are expensive and we will not be able to create sufficient samples to train such a high-dimensional model. A contradiction seems to have opened up. On one hand, in order to have models that allow comparing all individuals in a bin, a local model could be trained that specializes on this task. On the other hand, tractability will be lost if every bin gets its own local model. We therefore need to train models that are more general than local surrogates but less complex than global models, placing illumination surrogates between the two techniques in terms of accuracy and efficiency (Figure 5).
SAIL will push GP to its limits in terms of computational complexity when applied to real world problems. Training complexity is ( number of samples) for training and for prediction (Quiñonero-Candela and Rasmussen, 2005). Optimized versions exist, reducing the complexity to for training and for prediction by reducing the number of interpolation points using pseudo-inputs (Snelson and Ghahramani, 2006).
Ensemble methods, like bootstrapped artificial neural networks (BANN) (Breiman, 1996), can provide confidence measures as well, by training a homogeneous set of models. The ensemble’s prediction is calculated by taking the mean of all its members. A confidence measure is obtained by evaluating the variation in member predictions.
In a preliminary investigation, we compared GP with a BANN (trained with Levenberg-Marquardt (Levenberg, 1944)) using a hill climber to optimize a 1D Ackley function. The hill climber was initialized from 10 fixed equidistant starting locations in every run in order to show how a naive optimization algorithm would perform from any starting position. The experiment was replicated 100 times. Figure 6 shows all optima that were found. Although the GP-assisted runs converge quicker than the BANN, most runs do not reach the global optimum. The median and variance of the discovered minima is much larger than the ones found using BANN-assisted hill climbing. This is due to the BANN model being much smoother, as was shown in Figure 2. GP-assisted illumination might not benefit as much from the blessing of uncertainty as do more global models like artificial neural networks (ANN).
5. Proposal
In order to support illuminating a high-dimensional search space, we propose to segment the objective function into simpler functions, along the same feature dimensions used by the illumination algorithm. This decomposition can simplify the modeling process, by allowing the optimal region in a bin, which can be disparate in parameter space, to be approximated by lower complexity models.
Figure 7 shows a preliminary result on modeling 2D airfoils, produced by MAP-Elites. The airfoils are defined by 15 parameters, typical airfoil features are used for the map, and the objective function is the aerodynamic drag coefficient of the airfoils. The sample set is segmented using unbiased k-means. The dimensionality in every segment is reduced using principal component analysis and dimensions which explain less than 1% of total variation removed. ANN surrogates are trained to predict the drag coefficient. The segmentation leads to a varying dimensionality reduction (left) in all segments. In many segments, the error, compared to the error of a flat model trained on all samples, is reduced as well.
Hypothesis 1.
Using segmentation of training samples in feature space, decomposing the problem of modeling the objective function can lead to dimensionality reduction, simplifying training.
Using separate surrogates for all training set segments might be too naive, as some bins could be described by the same model and some bins might need complex models that cannot be trained with only a small amount of samples. By using a hierarchical decomposition, we can create more general models, those that are trained on large, continuous regions of the fitness space, as well as more specialized models, reusing samples in many ways. This idea is borrowed from deep learning and other hierarchical approaches in computer vision (Behnke, 2003). Figure 8 shows how a hierarchical decomposition of the map could be directly mapped onto a surrogate model structure. In the example above (Figure 7), every submodel on layer is connected to their parent models using residual coupling (He et al., 2016): models are trained to predict the discrepancy between the parent model and samples’ true values.
An open question is whether to use a direct coupling between models, or to separately train models on various-sized sample subsets. In SAO and SAIL, training models is relatively cheap, because we do not have many samples. We are also willing to invest some time to reduce the amount of necessary real fitness evaluations. By training models on many subsets of the training data, we can maximize model diversity. We can use these diverse models to create a (hierarchical) ensemble, similar to bagging, whereby multiple models are trained to decrease the total prediction variance (Breiman, 1996). Gu (Gu, 2016) showed that diverse, heterogeneous ensembles often show a significantly higher accuracy than the base classifiers on their own.
Hypothesis 2.
Hierarchical decomposition of training samples can be used to train a diverse ensemble of surrogate models, allowing us to learn complex structure by using many shallow models.
The large set of diverse models can be used to extract confidence intervals, but it is unclear how to combine the predictions from ensemble members in a hierarchy. Whereas in normal ensemble learning, we can straightforwardly look at the prediction variance over all members to construct confidence intervals, this might not be the best option for hierarchical ensembles. Specialist members are expected to be more accurate than the more general models. We can therefore make a more informed weighting of models’ prediction, putting different confidence levels to models in different layers of the hierarchy.
Hypothesis 3.
Confidence intervals can be determined from a model hierarchy in a more informed way than by direct variance estimation.
The working hypotheses do not include a specific modeling technique. In order to evaluate them, we will look at three main techniques: backpropagation training (Levenberg-Marquardt), GP models and neuroevolution. In the latter case, by training a diverse, large number of ANNs on hierarchical training segments, we mimic the mini-batch training method that was introduced by Morse et al. (Morse and Stanley, 2016). This technique showed that neuroevolution can rival stochastic gradient descent training on large training problems.
We aim to increase the surrogate’s accuracy and the diversity of illuminated solutions in a data efficient learning context by using hierarchical surrogate models. By combining hierarchical surrogate modeling and ensemble techniques, we reuse samples in multiple ways, increasing the probability that an accurate surrogate is found. We further reduce illumination convergence time by using smoother surrogate models. Finally, we hope to contribute a data efficient model which can be used in SAO, as well as in SAIL.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1(1)
- 2Auer (2003) Peter Auer. 2003. Using Confidence Bounds for Exploitation-Exploration Trade-offs. Journal of Machine Learning Research 3 (2003), 397–422.
- 3Behnke (2003) Sven Behnke. 2003. Hierarchical Neural Networks for Image Interpretation .
- 4Breiman (1996) Leo Breiman. 1996. Bagging Predictors. Machine Learning 24, 421 (1996), 123–140.
- 5Brezillon and Dwight (2009) Joël Brezillon and Richard P. Dwight. 2009. Aerodynamic Shape Optimization Using the Discrete Adjoint of the Navier-Stokes Equations: Applications Toward Complex 3D Configutations. (2009).
- 6Brochu et al . (2010) Eric Brochu, Vlad M. Cora, and Nando de Freitas. 2010. A Tutorial on Bayesian Optimization of Expensive Cost Functions, with Application to Active User Modeling and Hierarchical Reinforcement Learning. (2010).
- 7Črepinšek et al . (2013) Matej Črepinšek, Shih-Hsi Liu, and Marjan Mernik. 2013. Exploration and Exploitation in Evolutionary Algorithms: A Survey. Comput. Surveys 45, 3 (2013), 35:1–35:33.
- 8Cully et al . (2015) Antoine Cully, Jeff Clune, Danesh Tarapore, and Jean-Baptiste Mouret. 2015. Robots that can adapt like animals. Nature 521, 7553 (2015), 503–507.