Distributed Voting/Ranking with Optimal Number of States per Node
Saber Salehkaleybar, Arsalan Sharif-Nassab, S. Jamaloddin Golestani

TL;DR
This paper introduces a scalable distributed algorithm for multi-choice voting and ranking in networks, using a minimal and optimal number of node states, with proven efficiency and complexity analysis.
Contribution
It presents a novel distributed voting/ranking algorithm that is simple, scalable, and uses an optimal number of states, with proven optimality in ranking and conjectured optimality in voting.
Findings
Algorithm uses only K×2^{K-1} states for voting.
Time complexity is O(log(n)) in complete graphs.
Number of states is proven optimal for ranking.
Abstract
Considering a network with nodes, where each node initially votes for one (or more) choices out of possible choices, we present a Distributed Multi-choice Voting/Ranking (DMVR) algorithm to determine either the choice with maximum vote (the voting problem) or to rank all the choices in terms of their acquired votes (the ranking problem). The algorithm consolidates node votes across the network by updating the states of interacting nodes using two key operations, the union and the intersection. The proposed algorithm is simple, independent from network size, and easily scalable in terms of the number of choices , using only nodal states for voting, and nodal states for ranking. We prove the number of states to be optimal in the ranking case, this optimality is conjectured to also apply to the voting case. The time complexity of the algorithm is…
Click any figure to enlarge with its caption.
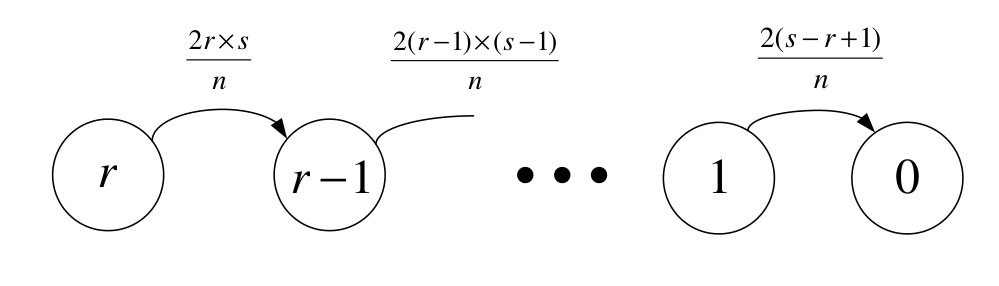 Figure 1
Figure 1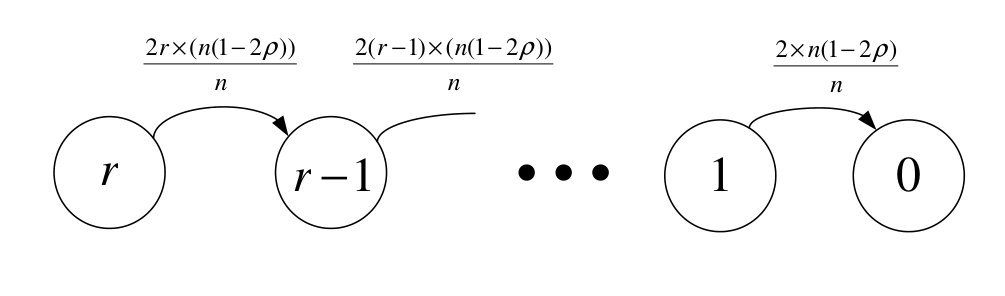 Figure 2
Figure 2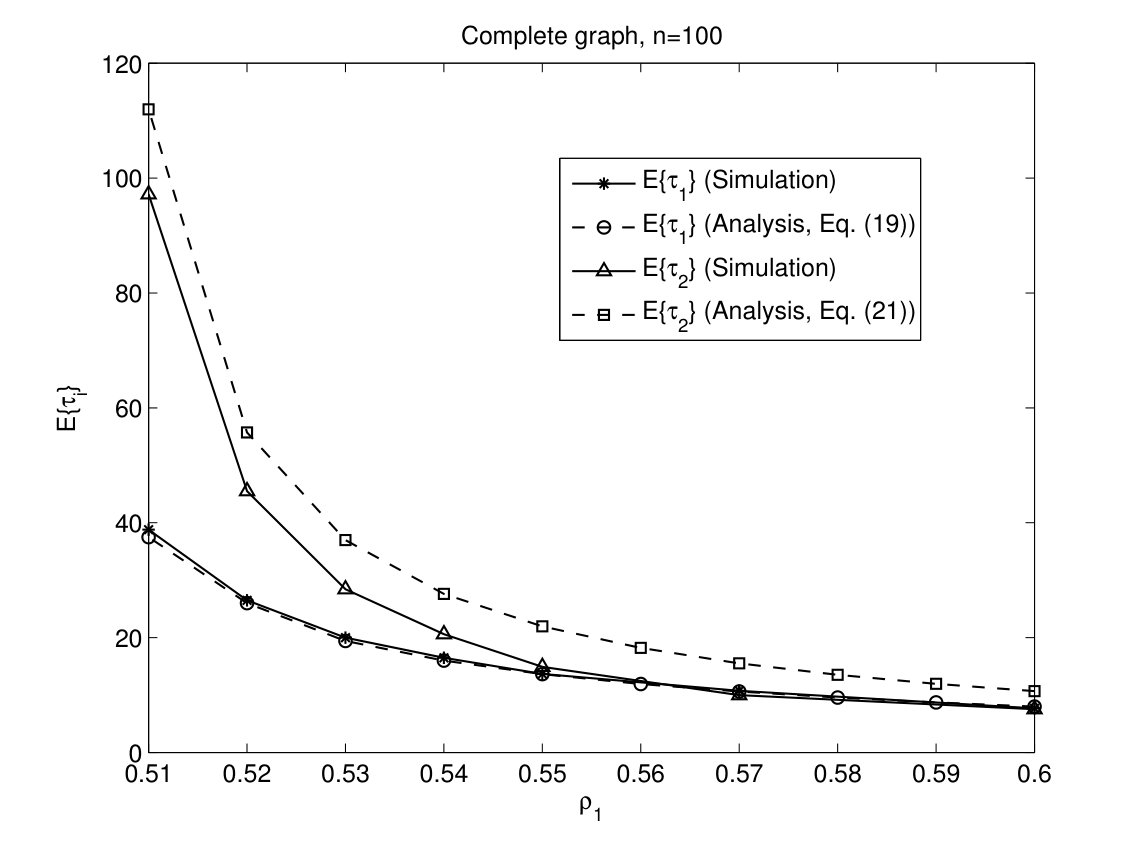 Figure 3
Figure 3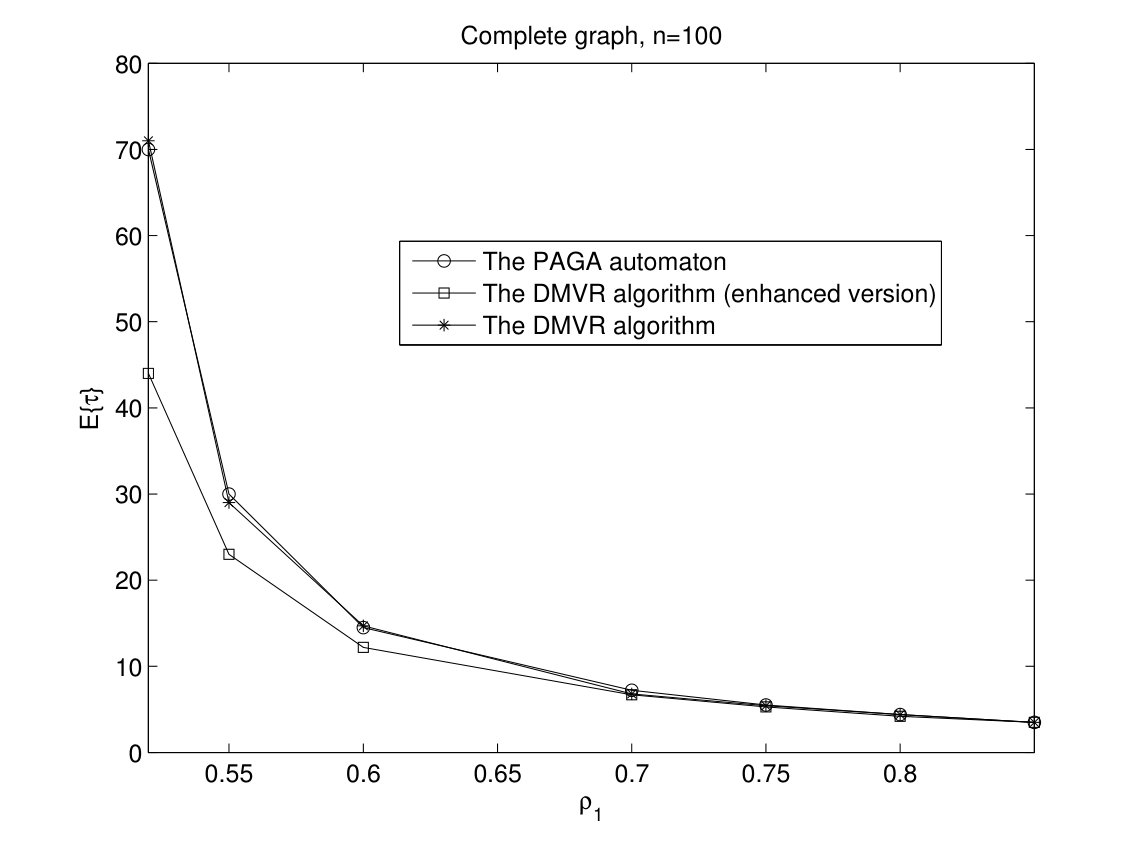 Figure 4
Figure 4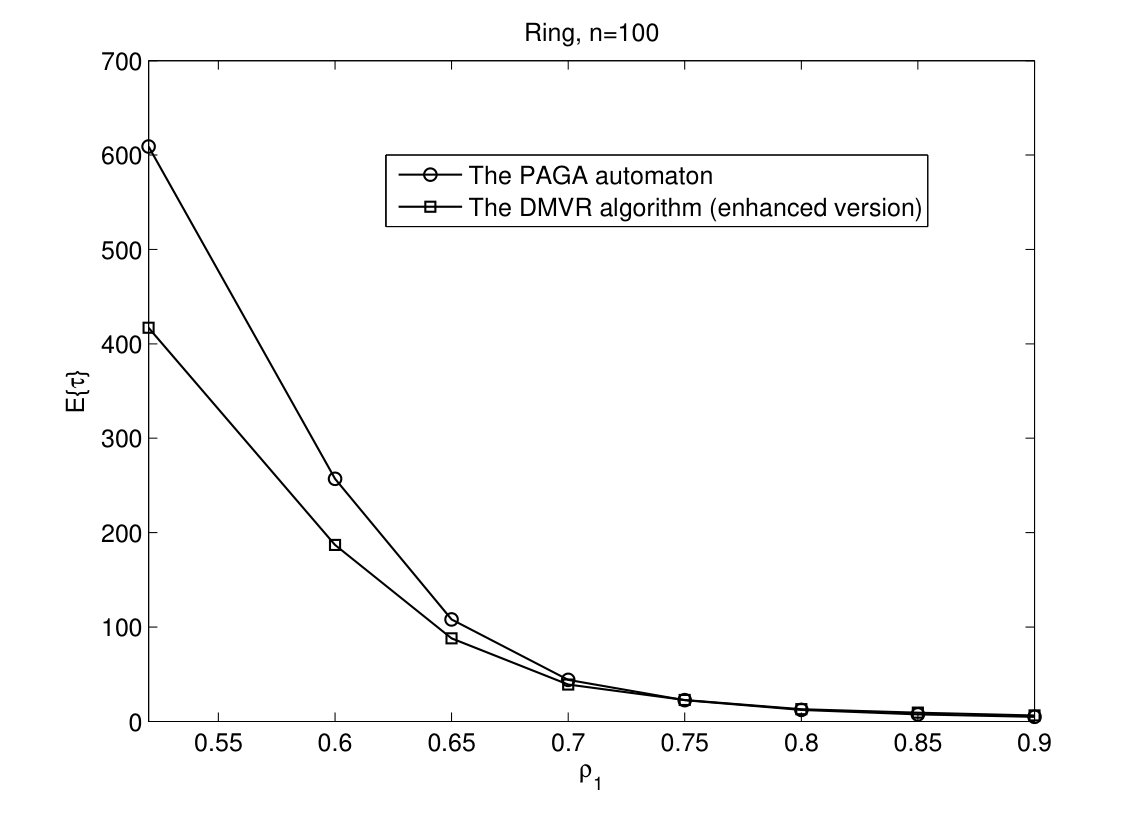 Figure 5
Figure 5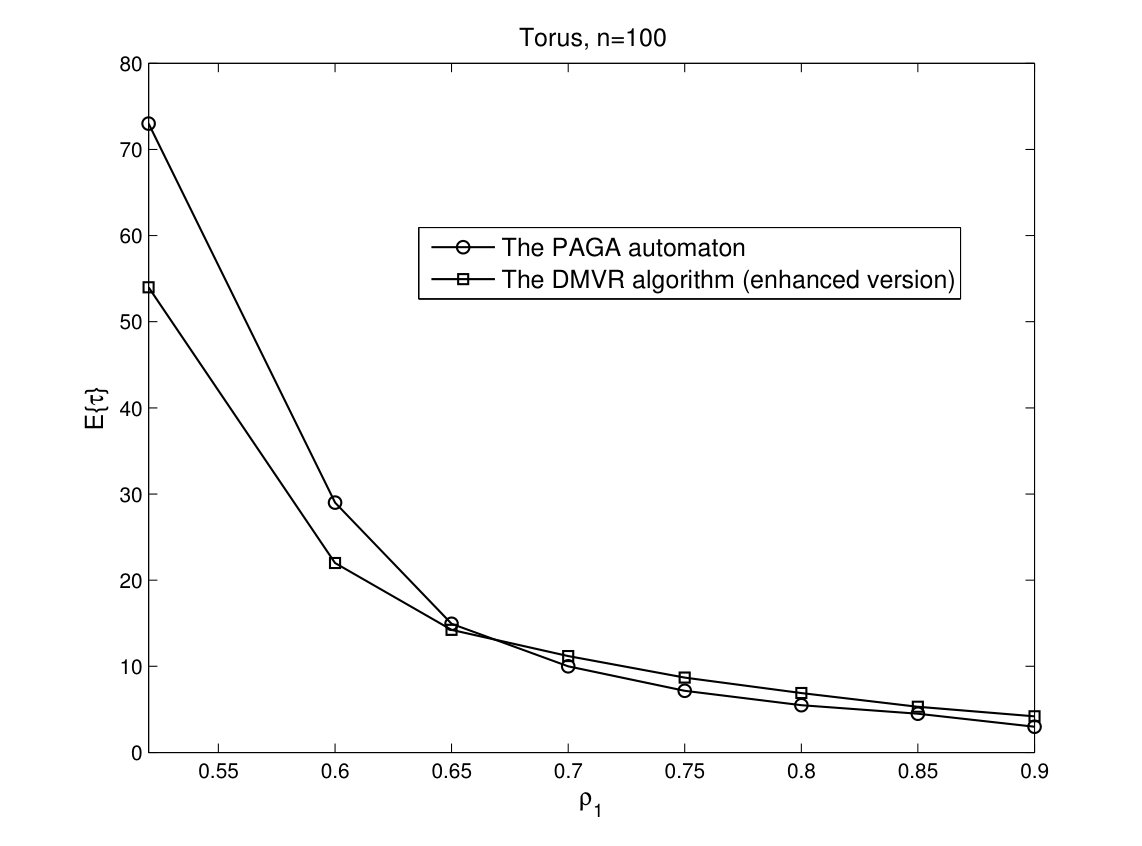 Figure 6
Figure 6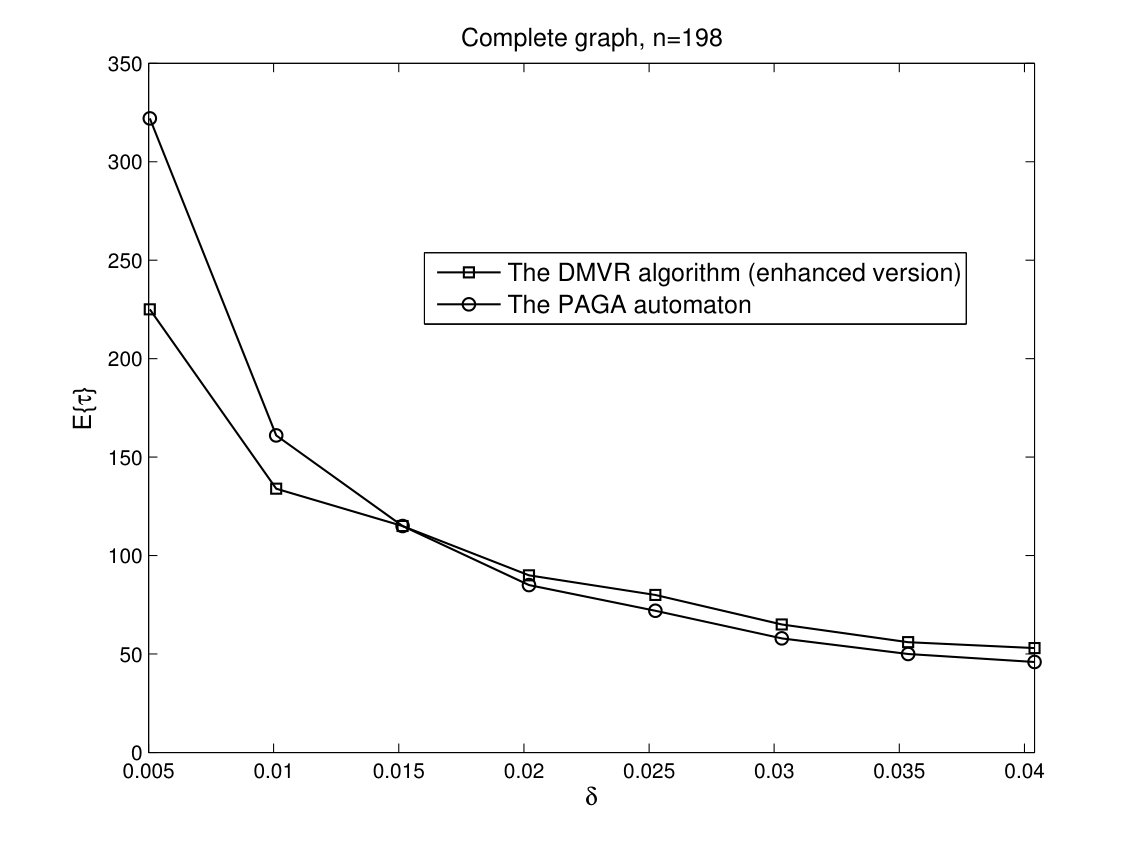 Figure 7
Figure 7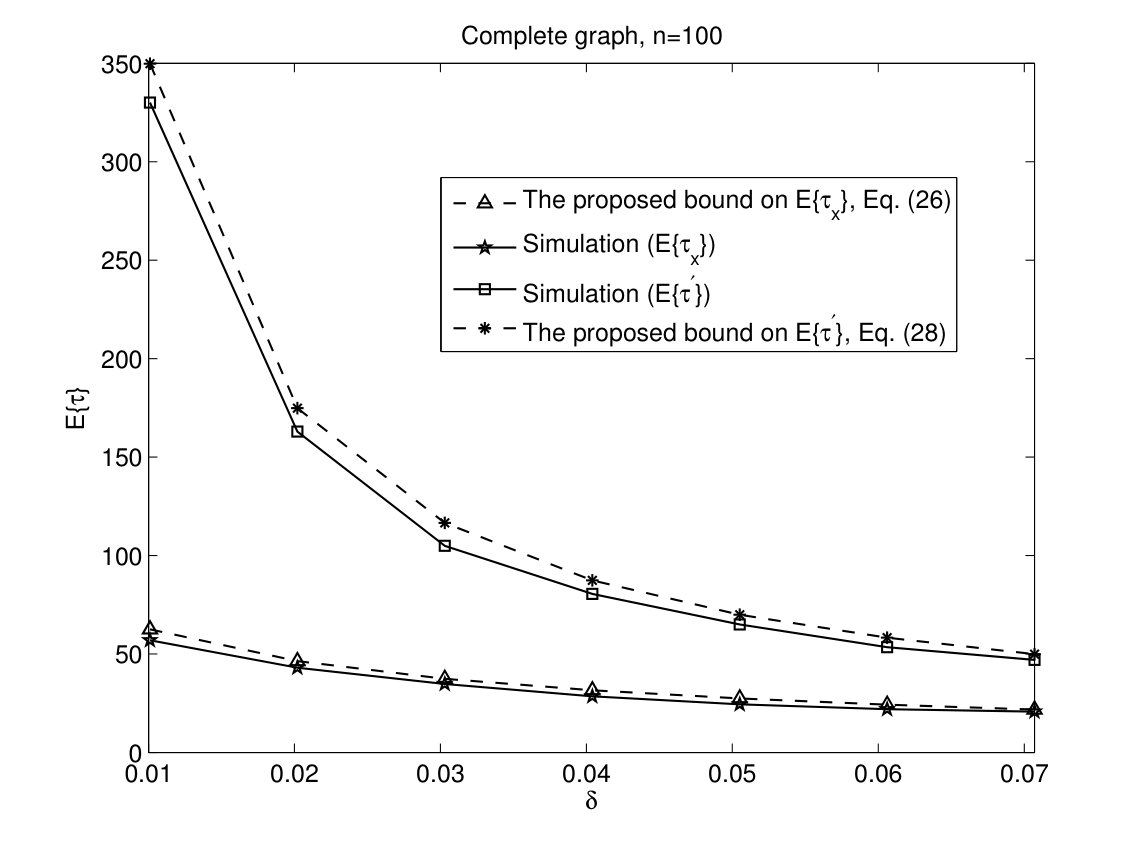 Figure 8
Figure 8Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsInternet Traffic Analysis and Secure E-voting · Distributed systems and fault tolerance · Cooperative Communication and Network Coding
Distributed Voting/Ranking with Optimal Number of States per Node
Saber Salehkaleybar*, Member, IEEE*, Arsalan Sharif-Nassab, and S. Jamaloddin Golestani*, Fellow, IEEE*
Dept. of Electrical Engineering, Sharif University of Technology, Tehran, Iran
Emails: [email protected], [email protected], [email protected]
Abstract
Considering a network with nodes, where each node initially votes for one (or more) choices out of possible choices, we present a Distributed Multi-choice Voting/Ranking (DMVR) algorithm to determine either the choice with maximum vote (the voting problem) or to rank all the choices in terms of their acquired votes (the ranking problem). The algorithm consolidates node votes across the network by updating the states of interacting nodes using two key operations; the union and the intersection. The proposed algorithm is simple, independent from network size, and easily scalable in terms of the number of choices , using only nodal states for voting, and nodal states for ranking. We prove the number of states to be optimal in the ranking case; this optimality is conjectured to also apply to the voting case. The time complexity of the algorithm is analyzed in complete graphs. We show that the time complexity for both ranking and voting is for given vote percentages, and is inversely proportional to the minimum of the vote percentage differences among various choices.
I Introduction
One of the key building blocks in distributed function computation is “Majority Voting”. It can be employed as a subroutine in many network applications such as target detection in sensor networks [1, 2], distributed hypothesis testing [3], quantized consensus [4], voting in distributed systems [5], and molcular nanorobots [6]. In the distributed majority voting, each node chooses a candidate from a set of choices and the goal is to determine the candidate with the majority vote by running a distributed algorithm. As an example in target detection [1], wireless sensors combine their binary decisions about the presence of a target through majority voting, and send a report to the fusion center if the majority is in favor of presence.
The majority voting problem for the binary case has been extensively studied in cellular automata (CA) literature. In [7], it has been shown that there is no synchronous deterministic two-state automaton that can solve binary voting problem in a connected network. Several two-state automata have been proposed for the ring topology [8, 9], the most successful of which can get the correct result in nearly of initial configurations of selected votes [10]. In order to circumvent the impossibility result of [7], asynchronous and probabilistic automata have also been presented in CA community [11, 12, 13]. However, none of them can obtain the correct result with probability one [14]. Using a different approach, binary voting problem can be solved by a randomized gossip algorithm [15] that computes the average of initial node values. The drawback of this approach is that the number of required states in its quantized version [16] grows linearly in terms of the network size [14].
In applying gossip algorithms to the implementation of binary majority voting, node does not need to come up with the exact average of the node values; it suffices to determine interval to which the average node values belongs. From this observation, Bénézit et al. [17] proposed an elegant solution based on an automaton, with the state space , which resembles the idea in [16]. The initial state of nodes voting for “0” or “1” is [math] or , respectively. When two neighbor nodes get in contact with each other, they exchange their states and update them according to a transition rule. It can be shown that the states of all nodes would be in the set at the end of the algorithm, if the choice “0” is in majority. Otherwise, the state of all nodes would belong to the set . In [14], a Pairwise Asynchronous Graph Automata (PAGA) has been used to extend the above idea to the multiple choice voting problem, and sufficient conditions for convergence are stated. This approach results in a 15-state automaton and a 100-state automaton for the ternary and quaternary voting problems, respectively. For majority voting with more than four choices, pairwise and parallel comparison among the choices, has been proposed [14], requiring number of states in terms of the number of choices, . At the end, authors posed a few open problems. One of the main problems is whether voting automata exist for any number of multiple choices without running multiple binary or ternary voting automata in parallel? Furthermore, what is the minimum number of states of a possible solution?
In more recent works [18, 19, 20, 21], it has been shown that the majority vote can be obtained with high probability if the initial votes are sufficiently biased to the majority or the network size is large enough. However, none of these works can guarantee convergence to the correct result.
A generalization of the distributed voting problem, is the distributed ranking problem in which the goal is to rank all the choices in terms of the number of votes, each get from different network nodes [20]. In this paper, we propose a Distributed Multi-choice Voting/Ranking (DMVR) Algorithm for solving the majority voting and ranking problems in general networks. The proposed algorithm may also be applied where each node is allowed to vote for more than one choice. Our main contributions are summarized as follows:
- •
Our proposed DMVR algorithm provides a simple and easily scalable approach for distributed voting and ranking that works for any number of choices, requiring and number of states for the voting and ranking problems, respectively. For instance, the number of required states is for ternary voting, and for quaternary voting, compared to respectively and states in the case of PAGA algorithm [14]. Furthermore, unlike the randomized gossip algorithms [16, 15], the number of states is independent from the network size.
- •
We establish a lower bound on the number of required states in any ranking algorithm, and show that the DMVR algorithm achieves this bound. Compared to the existing algorithms, the state of the DMVR algorithm can be encoded by roughly bits.
- •
In complete graphs, we analyze the time complexity of the DMVR algorithm for the ranking problem. We will show how the time complexity is related to the percentage of nodes voting for different choices. Besides, we propose a modification for speeding up the DMVR algorithm for the majority voting problem.
The remainder of this paper is organized as follows: In Section II, the DMVR algorithm for majority voting and ranking is described. Section III studies the convergence of the DMVR algorithm. Furthermore, the number of states of the DMVR algorithm is analyzed in both cases of voting and ranking. Section IV is devoted to analyze the time complexity of the DMVR algorithm in complete graphs. In Section V, simulation results are provided. Finally, we conclude the paper in Section VI.
II The Distributed Multi-choice Voting/Ranking (DMVR) algorithm
II-A Problem Statement
Consider a network with nodes. The topology of the network is represented by a connected undirected graph, , with the vertex set , and the edge set , such that if and only if nodes and can communicate directly. Furthermore, it is assumed that each node is equipped with a local clock which ticks according to a Poisson process with rate one. Initially, each node chooses a choice from a set of choices . Let be the number of nodes that select the choice and . In the majority voting problem, the goal is to find the choice in majority, i.e. the choice satisfying . In the ranking problem, the desired output is a permutation, of such that .
II-B Description of the DMVR algorithm
A value set is associated with each node at time . At , the only member of is the selected choice of node . In the process of the algorithm, always remains a subset of . The algorithm essentially performs two function. One function of the algorithm deals with consolidating node choices across the network. This function utilizes two key operations, the union and the intersection, in order to update the value sets and of nodes and , when they interact. The second part of the algorithm has to do with disseminating the consolidated result of part one throughout the network. For reasons to be clarified later, the above two functions of the algorithm are executed in parallel, not sequentially. The second function of the algorithm operates on a collection of sets , , at each node . We collectively refer to the sets , , of node as memory of it. Each is a subset of . Unlike the dissemination function, the consolidation function is identical for the voting and ranking. In the following, we describe the dissemination function for the more general case, i.e. for the ranking case, the dissemination for the voting case being a special and simplified version of it.
When node ’s clock ticks at time , it chooses one of the neighbor nodes, say node , randomly. Then, nodes and update their value sets and memories according to the following transition rules:
[TABLE]
where there is no memory updating if . Furthermore, we have: for , .
When the algorithm converges111In Section III, Theorem 1, we will describe when the algorithm eventually converges to the correct result., each node can obtain the correct ranking as follows222 The “” is the set-theoretic difference operator, i.e. for any sets and .:
[TABLE]
In the case of the majority voting problem, it suffices to keep the memory at each node . We denote by when the DMVR algorithm is executed for the majority voting problem. The description of the DMVR Algorithm is given in Algorithm 1.
Suppose that . It is not difficult to show that the updating rule in (1) has the following properties:
- •
Define the size of choice as: . The size of every choice is preserved during the updates.
- •
We have . If , the two nodes just exchange their value sets.
- •
The quantity strictly increases if . Otherwise, it remains unchanged.
III Convergence Analysis
In this section, we will show that the DMVR algorithm converges to the correct solution for the majority voting and ranking problems. First, we study how value sets consolidate and get in a convergence set, by defining a Lyapunov function. Then, we discuss how memory updating can disseminate the correct result in parallel to value set updating. Next, we merge value sets and memories of the DMVR algorithm in order to reduce memory usage in both majority voting and ranking problems. At the end, we prove that the proposed implementation is optimal in terms of the required number of states for the ranking problem.
III-A Consolidation of Value Sets
In this part, we analyze how value sets consolidate in the network until the state of the system gets in a convergence set.
Definition 1**.**
Let the network state vector at time be defined as . The set of all state vectors with the following property is called the convergence set and is denoted by :
[TABLE]
Example 1**.**
Consider a network of nodes and three possible choices . Assume that . The state vector cannot be in the set since . However, the state vector is a member of the convergence set.
Lemma 1**.**
If at time , then , .
Proof:
Assume that the state vector is in . If two nodes and get in contact with each other at any time , then according to Definition 1, the outputs of transition, i.e. the sets and would be or . Since we know that , is also in . Thus, the proof is complete. ∎
Definition 2**.**
The Lyapunov function is defined as follows:
[TABLE]
Lemma 2**.**
If two nodes and contact with each other at time , and , then there would be a reduction in the Lyapunov function .
Proof:
Suppose that , , and . The change in the Laypunov function is:
[TABLE]
which is strictly less than zero for all . ∎
Definition 3**.**
Let . We denote the time that the state vector hits the set for the first time by , i.e.:
[TABLE]
Definition 4**.**
Let be a random walk on the network starting from node . We define to be the first time visits node :
[TABLE]
and the worst case hitting time, , is defined as follows:
[TABLE]
Lemma 3**.**
There exists such that:
[TABLE]
where is defined in (8).
Proof:
Consider two random walks and on the network starting from nodes and , respectively. We define the coalescing time of two random walks as follows:
[TABLE]
It follows from Markov inequality that:
[TABLE]
If , then there exist , such that . The corresponding random walks meet each other (or some other intermediate such value sets) up to time with probability at least , which results in reduction of according to Lemma 2. Otherwise, is in the set .
∎
Lemma 4**.**
The state vector hits the set in bounded time with probability one.
Proof:
We know that the Lyapunov function is lower bounded by zero. According to Foster’s criteria (see [22], page 21) and Lemma 3, it follows that:
[TABLE]
∎
III-B Dissemination of Result in Memories
In this part, we show how memory updating disseminates the correct result in the network. Without loss of generality, in the remainder of this paper, we assume that .333We assume that . Otherwise, we can reduce the problem to the case with fewer choices. By slight modifications, the DMVR algorithm can also work for the cases where we have choices with equal size.
Definition 5**.**
Assume that the state vector gets in at time . We define the vector as follows:
[TABLE]
and r_{k}(t)=\big{|}\left\{i\big{|}|v_{i}(t)|=k\right\}\big{|}.
Theorem 1**.**
The vector defined in (2), gives the correct ranking of choices in a finite time with probability one.
Proof:
From Lemma 4, we know that the state vector eventually gets in the set at time . For a choice , let be the smallest index such that . According to the definition of the convergence set and the preservation property, we know that: . Hence, we have: . Thus, based on assumption , the only possibility is: and , for all . Since , there exists at least one value set , in the network. The value sets take random walk in the network and set the memories to for all . Let be the time that , . Based on the definition of , we have: . Hence, all nodes obtain the correct ranking after time . ∎
From above theorem, gives the choice in majority. Hence, the DMVR algorithm can solve the majority voting problem by just updating .
Remark 1**.**
In the proposed solution, each node can also vote for more than one choice. To do so, it is sufficient to initialize the value set of each node to the union of its preferred choices. In this general case as well, the DMVR algorithm gives the correct ranking based on the size of choices.
III-C State-optimal Implementation of DMVR Algorithm
For the case of majority voting, the state of node is the pair where the sets and have and possible states, respectively. Thus, the total number of states is . However, we can implement the DMVR algorithm with fewer states by adding the following rules:
- •
If the output of updating rule, , is the empty set, we replace it by the set .
- •
If , we select a random member and change to . Otherwise, remains unchanged. Then, the state of node is saved in the form of \big{(}m_{i}(t^{+}),v_{i}(t^{+})\backslash m_{i}(t^{+})\big{)}.
When , there is at least one value set in the network. When this value set meets a new node with , it updates to and will never be changed after that. Because when . For a fixed , the number of possible states for is . Consequently, the total number of states reduces to . As an example, in the ternary voting, we have the following 12 states:
[TABLE]
Thus, the number of states for ternary voting is 12 compared to 15 for the PAGA automaton [14] and it is equal to 32 for quaternary voting while the number of states for the PAGA is 100.
In the case of ranking problem, we replace the value set and memories by an ordered -tuple , which is a permutation of the set along with an integer which we perceive as a pointer to an entry of . At the beginning of the algorithm, each node puts its preferred choice in the first entry of , and sets an arbitrary permutation of other choices in the remaining entries. It also sets . Let be a -tuple containing the first entries of and be the set representation of it without any order. For a set , we define as a permutation of that preserves the order of entries in accordance with . Now, assume that two nodes and get in contact with each other at time , and let . Then, we apply the following updating rule:
[TABLE]
where , . We also set and . It is not difficult to verify that this form of implementing the DMVR algorithm can solve the ranking problem by the same arguments in Theorem 1.
From the above implementation, we can run the DMVR algorithm for the ranking problem with states where the terms and are the possible values of the pointer and the ordered tuple , respectively.
Example 2**.**
Suppose that . Two examples for the updating rule in (15) are given as follows:
[TABLE]
where the arrow symbol points the -th entry of .
The following theorem proposes a lower bound for the required number of states of any ranking algorithm. This bound meets the required number of states of the DMVR algorithm, proving optimality of it for the ranking problem.
Theorem 2**.**
Any algorithm that finds the correct ranking in a finite time with probability one over arbitrary network topology, requires at least number of states per node.
Proof:
It is enough to show that the theorem applies in complete graphs. Suppose that the ranking problem can be solved by running algorithm at each node in a finite time. Consider that each node has a state . Let integer corresponds to the ranking . We define a class of states, , as a set of states which nodes associate with ranking . Algorithm is said to converge to ranking at time if . We denote members of the class by where . Let be the set of initial configurations that are consistent with the ranking , i.e.:
[TABLE]
Let be the number of nodes in whose state is . In complete graphs, the whole information of can be represented by the set . Thus, the class corresponds to a subset of the following set:
[TABLE]
Let be the set of vectors that are achievable from the initial configuration .
Lemma 5**.**
Consider two initial configurations , . Then, we have: .
Proof:
By contradiction. Suppose that there exists . We run algorithm in a complete graph with nodes for two different initial configurations of nodes . The algorithm should give the correct result for any scheduling of local clocks at nodes. Consider a scheduling which only clocks of nodes in the set are ticking up to time and the states of these nodes become . Now, suppose that a centralized algorithm want to obtain correct ranking by just looking at states of nodes in and votes of nodes in . Algorithm finds the ranking of votes of nodes in by the vector . But the centralized algorithm still needs to obtain all differences , . Otherwise, it cannot rank votes of nodes in the whole network correctly. However, the two different initial configurations are mapped to the same state vector . Consequently, the algorithm cannot recover the correct initial configuration which is a contradiction. Thus, the proof of lemma is complete. ∎
We know that . Furthermore, we have:
[TABLE]
Let which maps to . According to Lemma 5, the mapping should be invertible. For sufficiency large , this can occur only if . Consequently, it can be concluded that each class has at least members and total number of states is at least . ∎
IV Time Complexity
In this section, we first analyze the time complexity of the DMVR algorithm for the binary voting problem in complete graphs. Then, we study the multiple choice case and derive a tight bound on the running time of the DMVR algorithm for the ranking problem. At the end, we propose a method to speed up the DMVR algorithm in majority voting problem.
IV-A Binary Voting Case
In order to study the time complexity of the DMVR algorithm, we divide its execution time into two phases:
- •
First phase (extinction of ): This phase starts at the beginning of the algorithm and continues until none of the value sets are . We denote the finishing time of this phase by .
- •
Second phase (dissemination of in memories): This phase follows the first phase and it ends when memories of all nodes are . The execution time of this phase is represented by .
IV-A1 Time complexity of the first phase
For the binary case, the transition rule of DMVR algorithm is exactly the same as the PAGA algorithm. In [23], an upper bound, , is given for the PAGA algorithm in complete graphs where . Here, we propose exact average time complexity for the first phase. Suppose that the number of nodes voting for , are and at the beginning of the algorithm. We denote the sets of nodes having value sets and at time by and , respectively. Consider the Markov chain in Fig. 1. The state , , represents the number of nodes whose value sets are . Suppose that the state of Markov chain is at time . The chain undergoes transition from state to if one of nodes in the set gets in contact with one of nodes in , which occurs with rate . After updating the value sets, both and will decreased exactly by one. Let be the sojourn time in state . Hence, we have:
[TABLE]
in terms of time units. Thus, the average running time of the first phase is: time units. Furthermore, we can obtain the variance of as follows:
[TABLE]
IV-A2 Time complexity of the second phase
At the beginning of the second phase, the number of nodes in is and all the remaining nodes have the value sets or . Furthermore, the memories of all of these nodes are in extreme case. Consider the Markov chain in Fig. 2. The state , represents the number of nodes having value sets or with memory . We denote the set of such nodes by . There is a reduction in if and only if a node in gets in contact with a node in . If , then with rate , there is a transition from state to state . Let be the sojourn time in state . Then, we have:
[TABLE]
Thus, we can conclude that the time complexity of the DMVR algorithm is:
[TABLE]
IV-B Multiple Choice Voting Case
Consider two choices and . From the state vector , we define a new state vector by projecting the value set of each node on , i.e. . Thus, the projected state vector represents the path of execution in a binary voting with just two choices . We define to be the convergence set of the projected system as follows:
[TABLE]
Lemma 6**.**
Let and be the time that the state vectors and hit their corresponding convergence sets. Then, we have: .
Proof:
First, we prove that . If , then for all :
[TABLE]
Now, we show that . Consider any two nodes and at time . Without loss of generality, assume that . We will show that . By contradiction, suppose that there exists a choice such that and . Now, consider any choice . Since , the state vector has already hit its convergence set. This occurs if and only if and . Hence, we can conclude that . However, it means that which is a contradiction. ∎
From (19) and (20), and can be obtained by substituting with and , respectively.
Lemma 7**.**
(Order Statistics [24]) Let denote random variables (not necessarily independent or identically distributed) with means and variances . Let . Then, we have:
[TABLE]
Now, we can give an upper bound on from above lemma:
[TABLE]
where .
After the state vector gets in the convergence set, we should still wait to copy vector in memories of all nodes. At time , the number of nodes with the value state is , . Let be the set of such nodes and be the time until memories ’s of all nodes are set to . When a node contacts with any node in , its memory will be set to . With the same arguments in previous part, we have:
[TABLE]
Thus, an upper bound on can be obtained from order statistics:
[TABLE]
where . From the bounds in (26) and (28), we can conclude that the time complexity of the DMVR algorithm is .
IV-C Speeding up the DMVR algorithm for majority voting problem
The execution time of the DMVR algorithm can be divided into two phases: The first phase starts at time zero and it ends when the state vector gets in the convergence set . Afterwards, the second phase starts and it terminates when all nodes’ memories are set with the majority vote. In order to speed up the second phase, we add the following rule when two nodes and contact with each other at time :
1:if then
2: Generate from Bernoulli distribution with success probability .
3: if then
4: ,
5: else
6: .
7: end if
8:end if
It is worth mentioning that the added rule is executed from the beginning of the algorithm. The idea behind this rule is that even nodes with the value sets other than the majority vote, cooperate in spreading the majority vote in the memories of all nodes. We call the proposed solution as the enhanced version of the DMVR algorithm. Simulation results show that the enhanced version of the DMVR algorithm can speed up the DMVR algorithm in complete graph, torus, and ring networks.
Lemma 8**.**
Each node converges to the majority vote in a finite time with probability one by running the enhanced version of the DMVR algorithm.
Proof:
Let be the time that the state vector gets in the convergence set. Since then, the only value set with size one in the network would be . Consider the vector . We define the Lyapunov function , , as follows:
[TABLE]
Suppose that two nodes and get in contact with each other at time . Let be the vector of length with all entries equal to . Then, we have:
[TABLE]
where . Hence, by the same arguments in Lemma 3, we conclude that converges to vector with probability one. ∎
V Simulations
In this section, we evaluate the time complexity of the DMVR algorithm through simulations and compare it with PAGA automaton in binary and ternary voting. Furthermore, we study the proposed time complexity bounds in complete graphs. Each point in simulations is averaged over 1000 runs.
We compare the proposed bounds on and derived in (19) and (21) with simulation results for binary voting in Fig. 3. As it can be seen, the bound is exact as we expected while there is a constant gap between simulation and analysis for .
In Fig. 4, the time complexities of DMVR algorithm, its enhanced version, and the PAGA automaton are depicted versus . Since the transition rule of DMVR algorithm is identical to the PAGA automaton in binary case, the performance of two algorithms are very close to each other. However, the enhanced version of DMVR algorithm outperforms the other two algorithms as gets close to 0.5. In Fig. 5, we can also see this trend in ring and torus networks.
For ternary voting problem, we consider the percentage of initial votes in the form of where . In Fig. 6, time complexities of enhanced version of the DMVR algorithm and the PAGA automaton are given for , . As it can be seen, the enhanced version of the DMVR algorithm outperforms the PAGA automaton for small .
At the end, we compare the bounds for and derived in (26) and (28) for the ranking problem with three votes. In Fig. 7, bounds from order statistics have a small gap with simulation results and they can predict the behaviour of the DMVR algorithm accurately based on the percentage of initial votes.
VI Conclusions
In this paper, we proposed the DMVR algorithm in order to solve the majority voting and ranking problems for any number of choices. The DMVR algorithm is a simple solution with bounded memory and it is optimal for the ranking problem in terms of number of states. Furthermore, we analyzed time complexity of the DMVR algorithm and showed that it relates inversely to . As a future work, it is quite important to obtain the minimum required number of states for solving majority voting problem. We conjecture that the DMVR algorithm is an optimal solution for majority voting problem, i.e. at least states are required for any possible solution.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] N. Katenka, E. Levina, and G. Michailidis, “Local vote decision fusion for target detection in wireless sensor networks,” Signal Processing, IEEE Transactions on , vol. 56, no. 1, pp. 329–338, 2008.
- 2[2] M. S. Ridout, “An improved threshold approximation for local vote decision fusion,” Signal Processing, IEEE Transactions on , vol. 61, no. 5, pp. 1104–1106, 2013.
- 3[3] J. B. Rhim and V. K. Goyal, “Distributed hypothesis testing with social learning and symmetric fusion,” Signal Processing, IEEE Transactions on , vol. 62, no. 23, pp. 6298–6308, 2014.
- 4[4] S. Kar and J. M. Moura, “Distributed consensus algorithms in sensor networks: Quantized data and random link failures,” Signal Processing, IEEE Transactions on , vol. 58, no. 3, pp. 1383–1400, 2010.
- 5[5] D. Angluin, J. Aspnes, Z. Diamadi, M. J. Fischer, and R. Peralta, “Computation in networks of passively mobile finite-state sensors,” Distributed computing , vol. 18, no. 4, pp. 235–253, 2006.
- 6[6] Y.-J. Chen, N. Dalchau, N. Srinivas, A. Phillips, L. Cardelli, D. Soloveichik, and G. Seelig, “Programmable chemical controllers made from dna,” Nature nanotechnology , vol. 8, no. 10, pp. 755–762, 2013.
- 7[7] M. Land and R. Belew, “No two-state ca for density classification exists,” Physical Review Letters , vol. 74, no. 25, pp. 5148–5150, 1995.
- 8[8] D. Peleg, “Local majority voting, small coalitions and controlling monopolies in graphs: A review,” in Proc. of 3rd Colloquium on Structural Information and Communication Complexity , 1997, pp. 152–169.