Token-based Function Computation with Memory
Saber Salehkaleybar, S. Jamaloddin Golestani

TL;DR
This paper introduces a token-based distributed function computation algorithm with memory that accelerates meeting times of tokens and reduces complexity compared to previous methods, with proven theoretical improvements and robustness enhancements.
Contribution
The paper presents the TCM algorithm, a novel token-based approach with a chasing mechanism that improves meeting times and complexity over the CRW algorithm in various network topologies.
Findings
TCM reduces time complexity by at least √(n/log n) in Erdös-Renyi and complete graphs.
In torus networks, TCM reduces time complexity by log(n)/log(log n).
Simulation shows at least constant factor message complexity improvement.
Abstract
In distributed function computation, each node has an initial value and the goal is to compute a function of these values in a distributed manner. In this paper, we propose a novel token-based approach to compute a wide class of target functions to which we refer as "Token-based function Computation with Memory" (TCM) algorithm. In this approach, node values are attached to tokens and travel across the network. Each pair of travelling tokens would coalesce when they meet, forming a token with a new value as a function of the original token values. In contrast to the Coalescing Random Walk (CRW) algorithm, where token movement is governed by random walk, meeting of tokens in our scheme is accelerated by adopting a novel chasing mechanism. We proved that, compared to the CRW algorithm, the TCM algorithm results in a reduction of time complexity by a factor of at least …
Click any figure to enlarge with its caption.
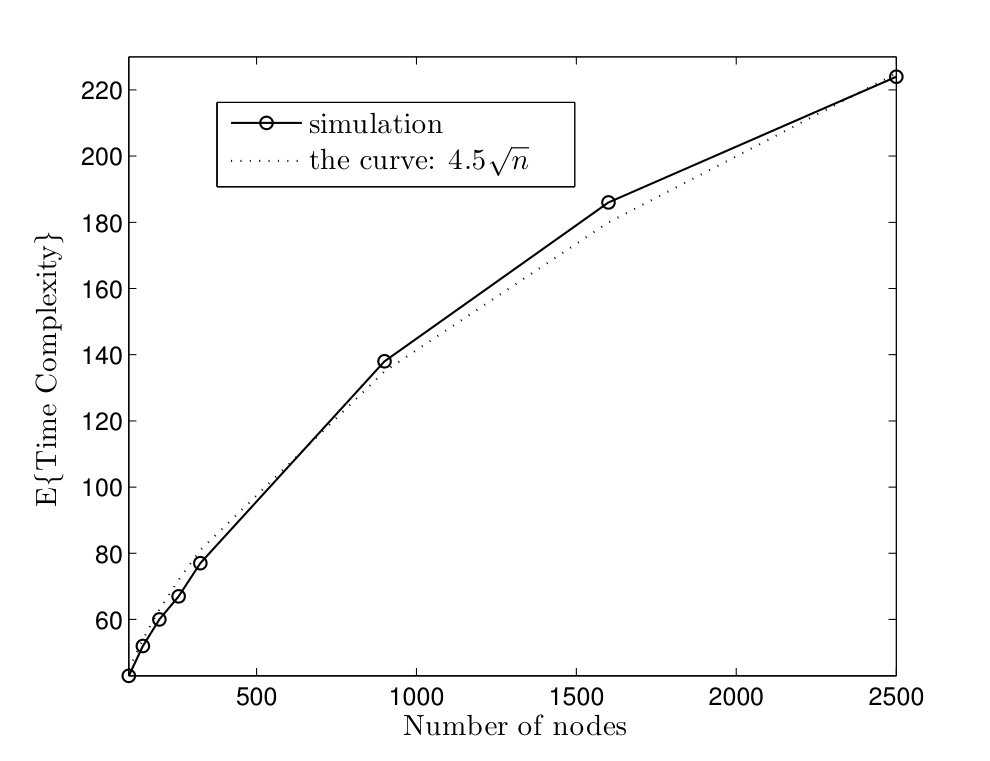 Figure 1
Figure 1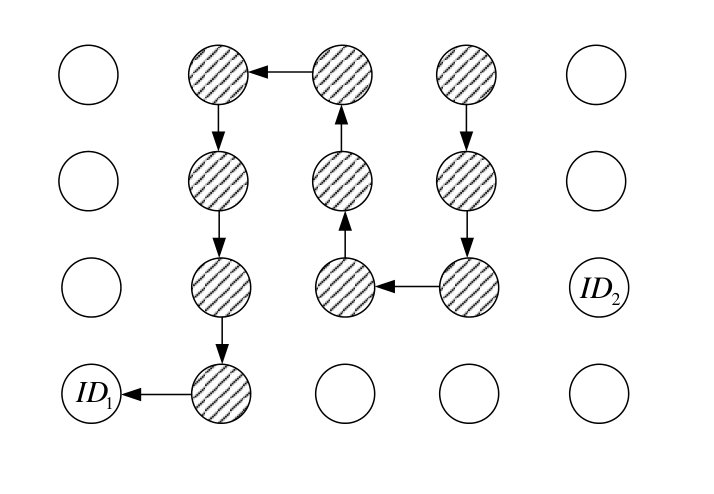 Figure 10
Figure 10 Figure 11
Figure 11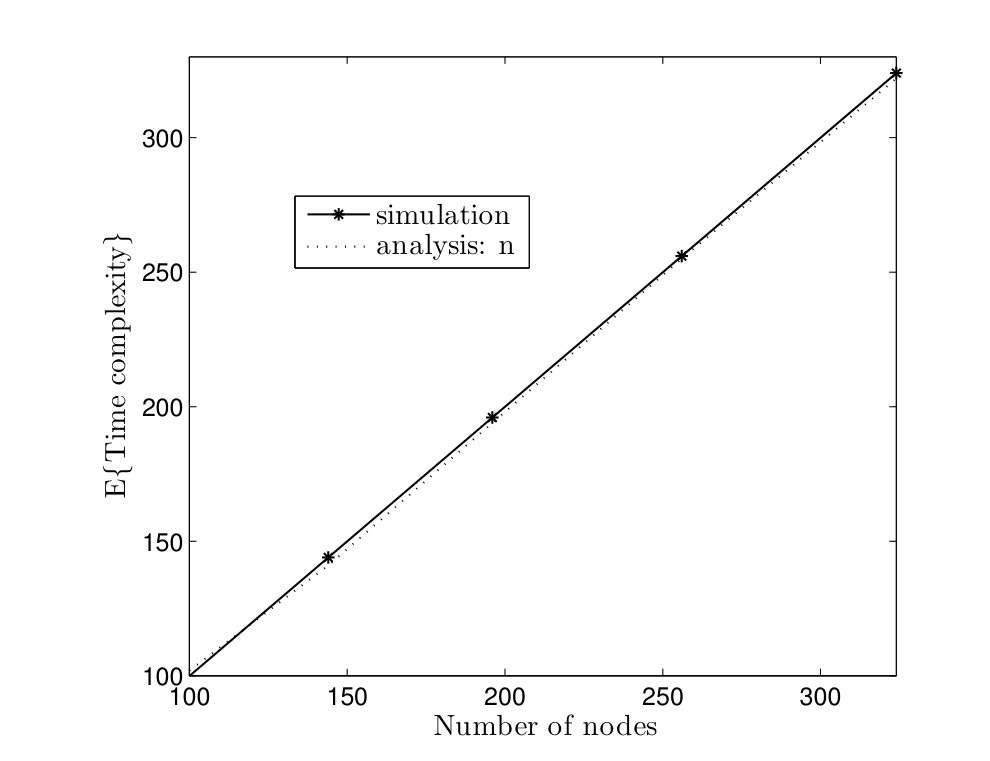 Figure 2
Figure 2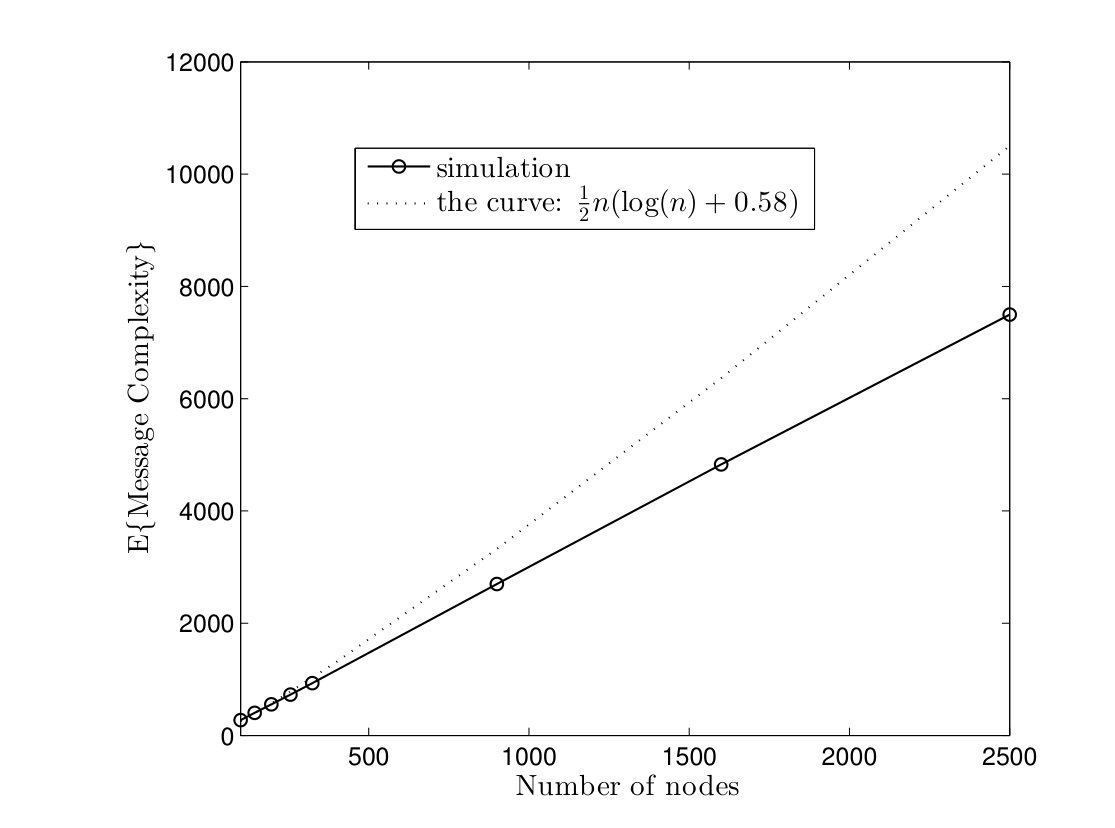 Figure 3
Figure 3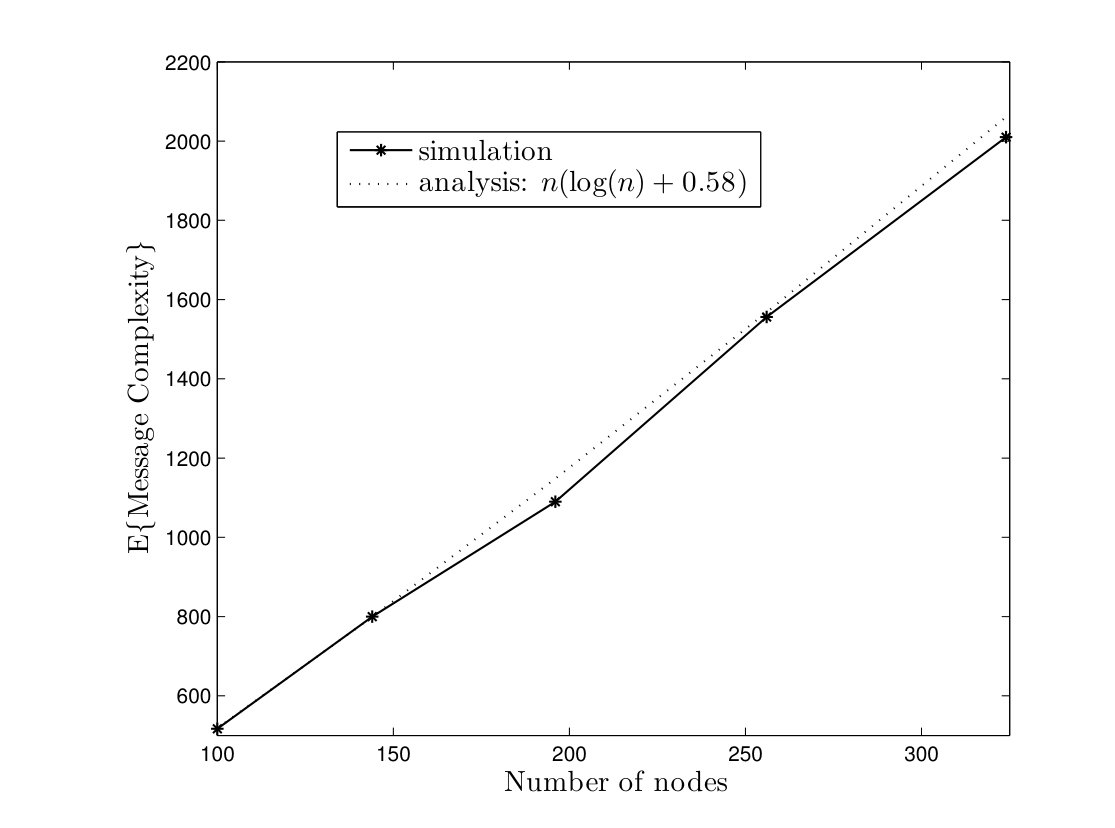 Figure 4
Figure 4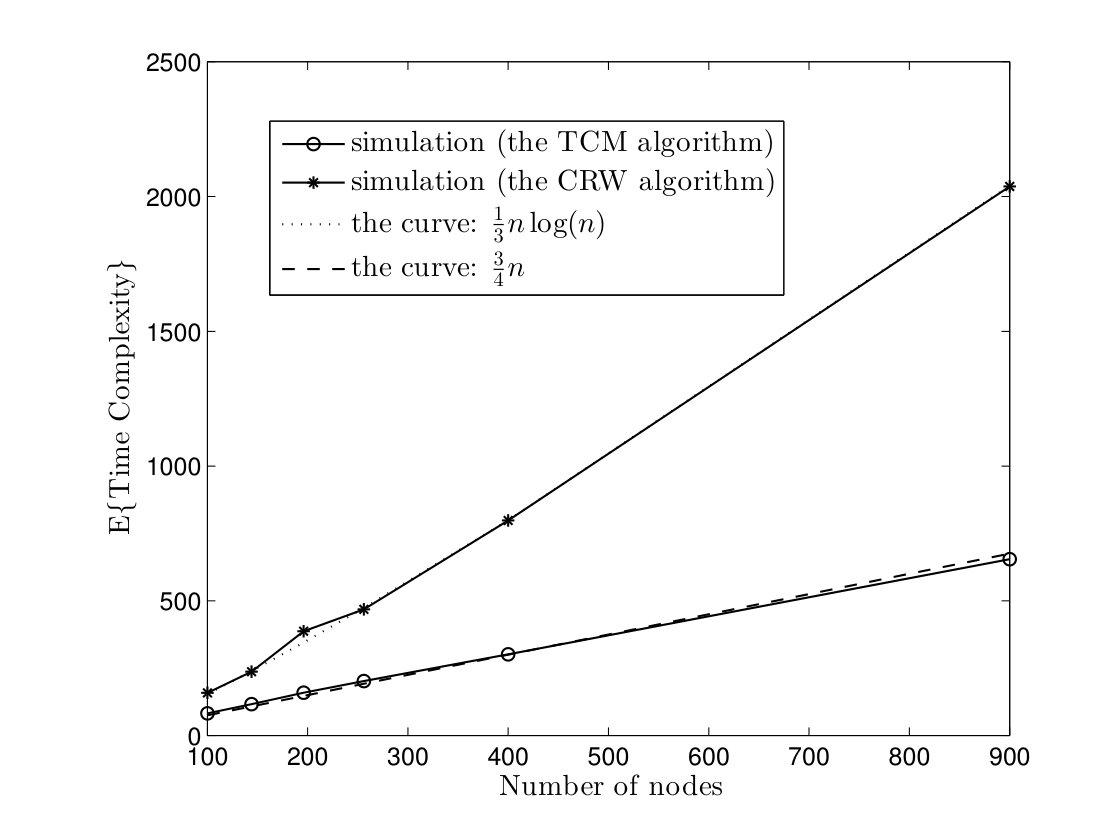 Figure 5
Figure 5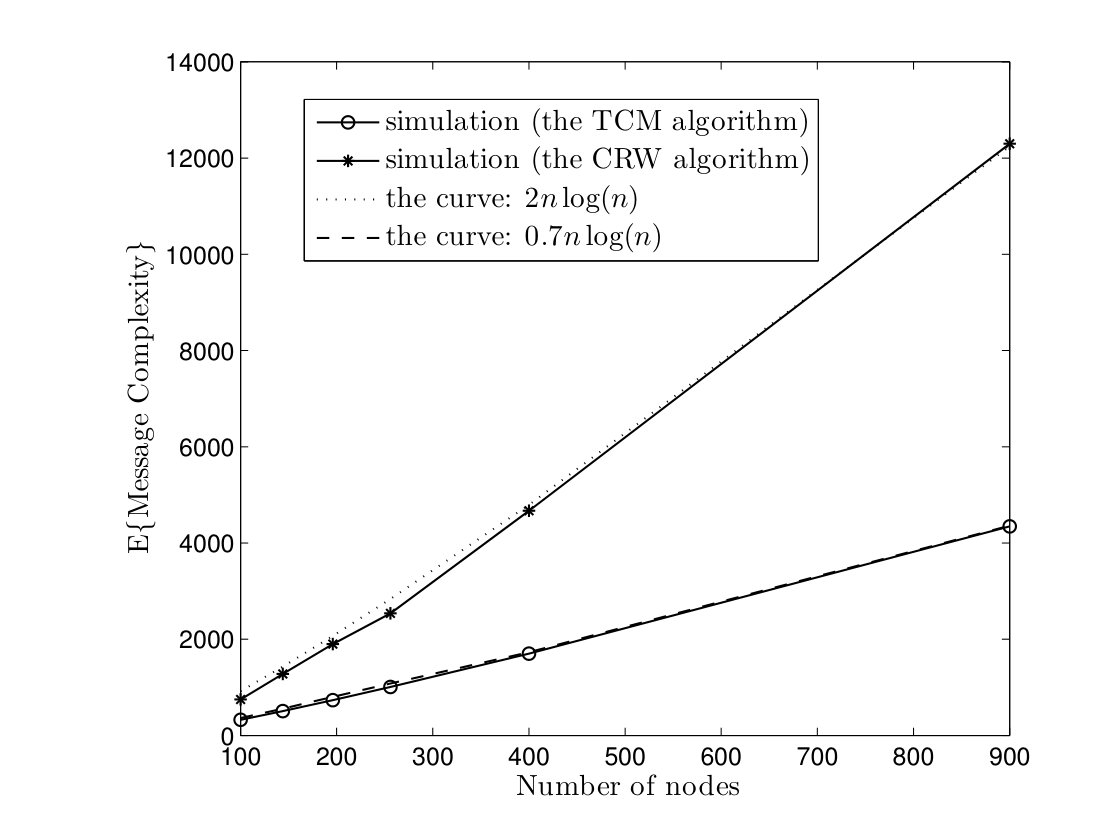 Figure 6
Figure 6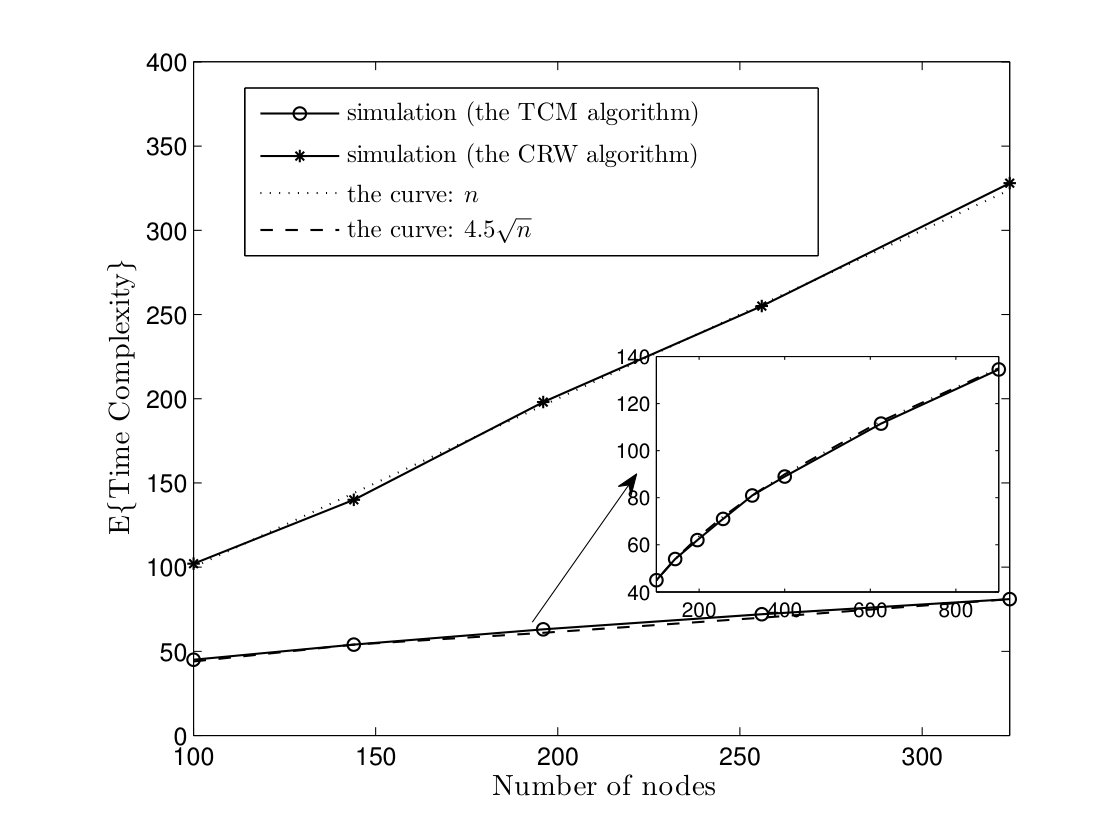 Figure 7
Figure 7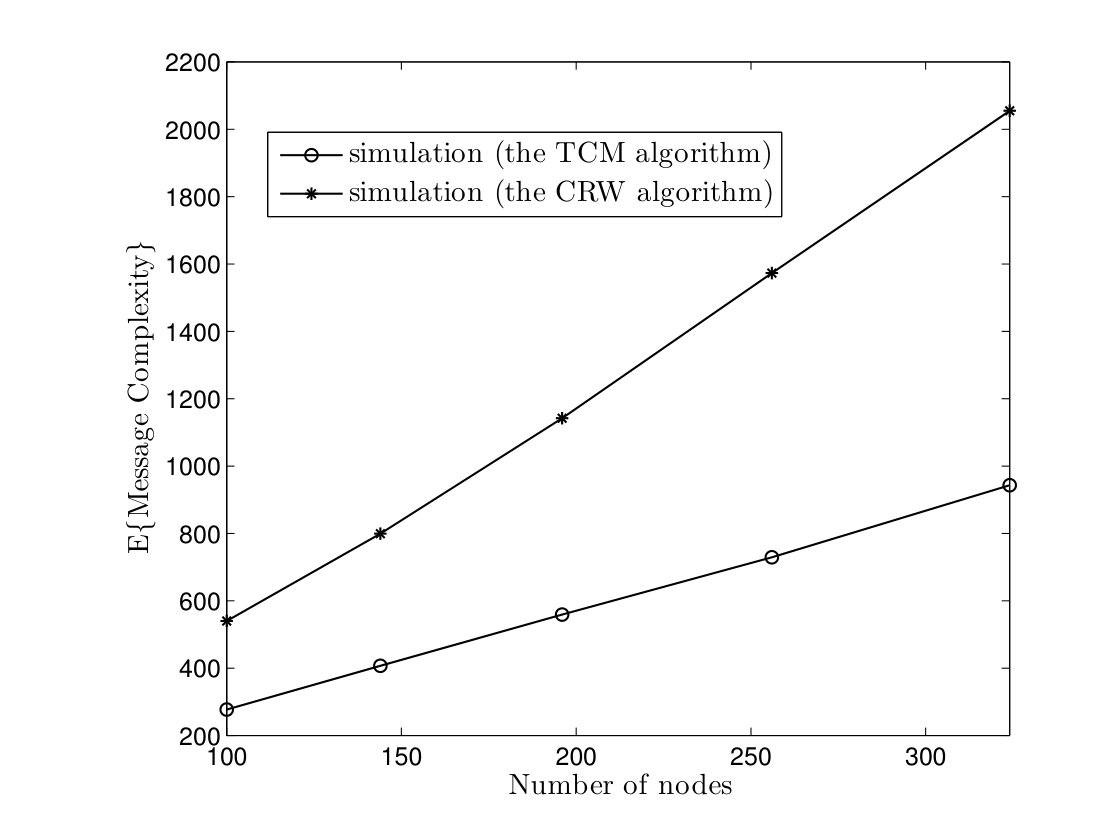 Figure 8
Figure 8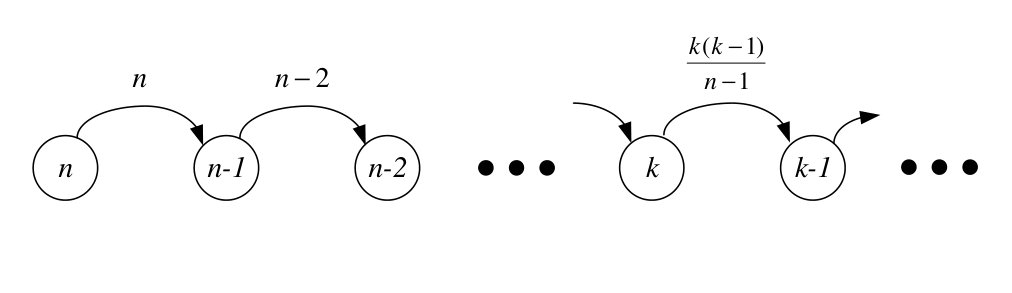 Figure 11
Figure 11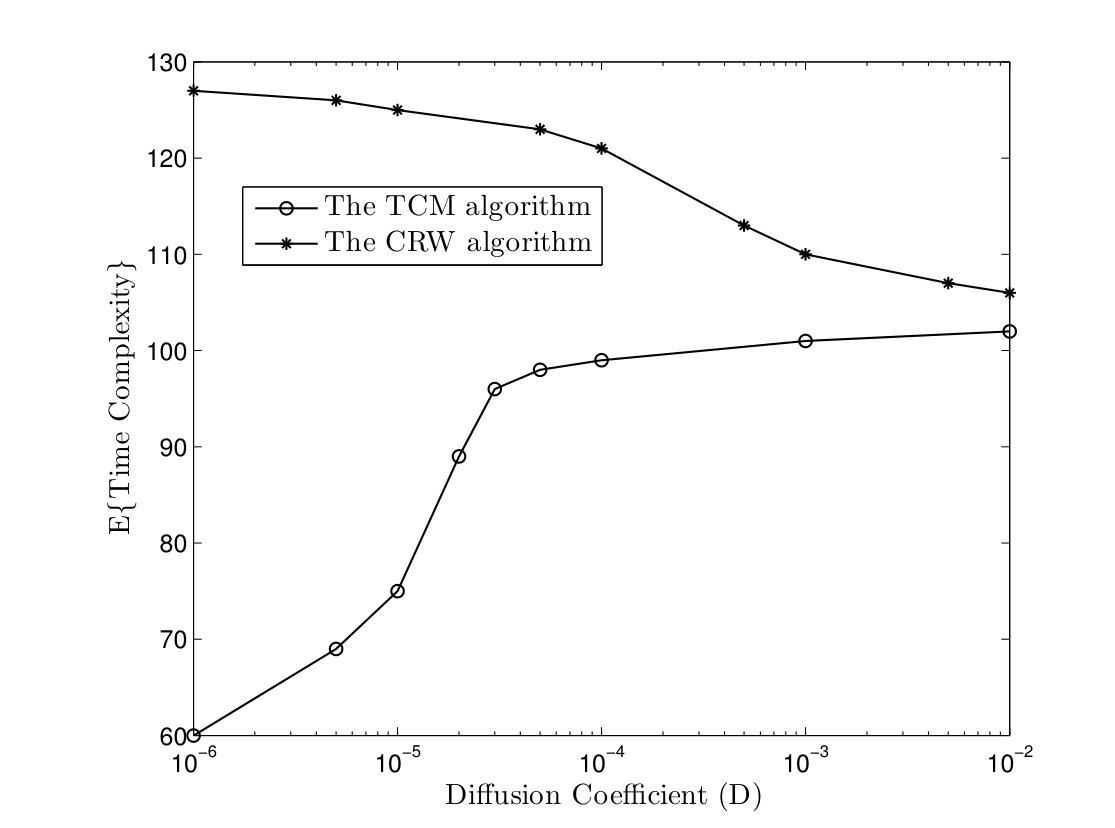 Figure 12
Figure 12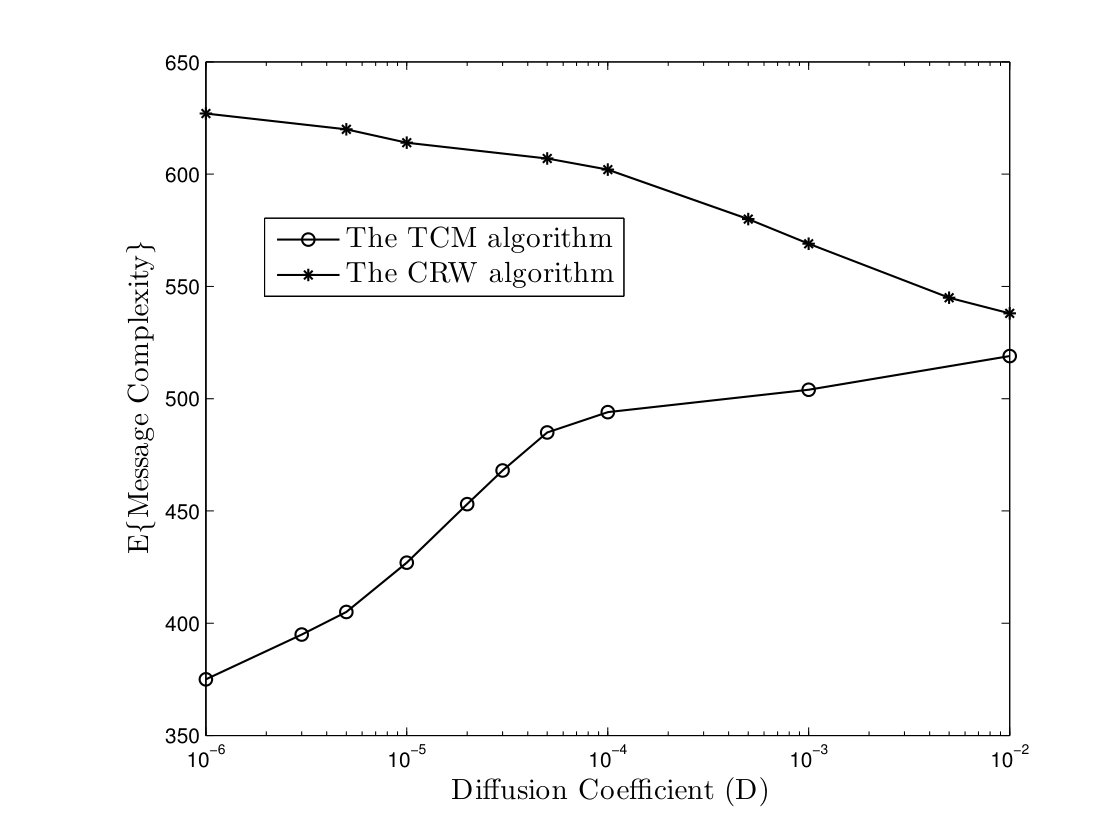 Figure 13
Figure 13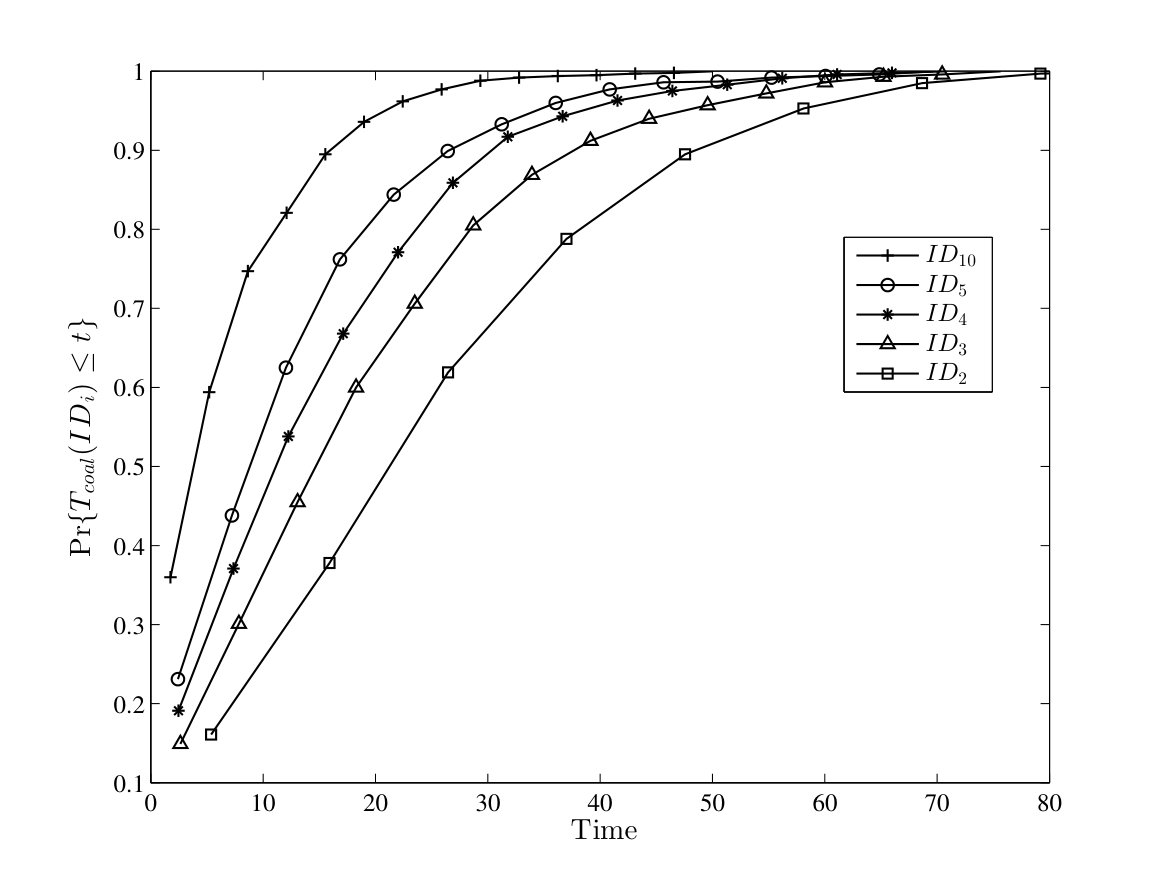 Figure 14
Figure 14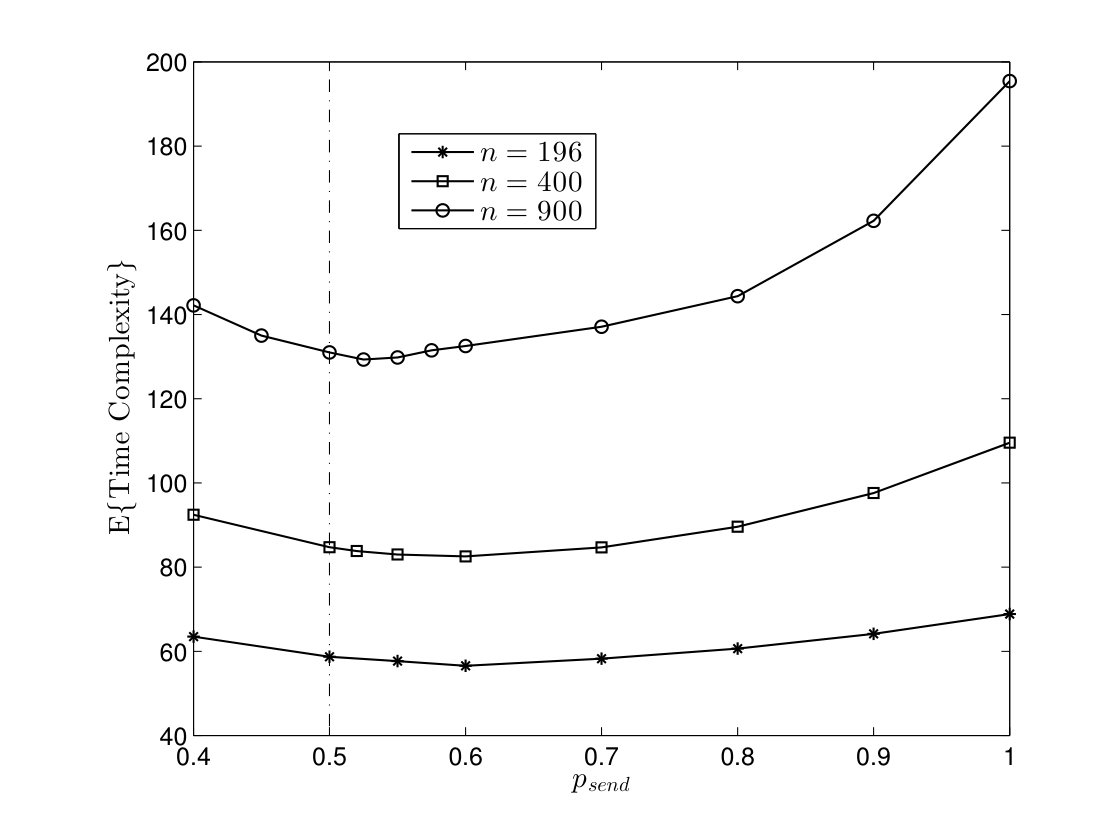 Figure 15
Figure 15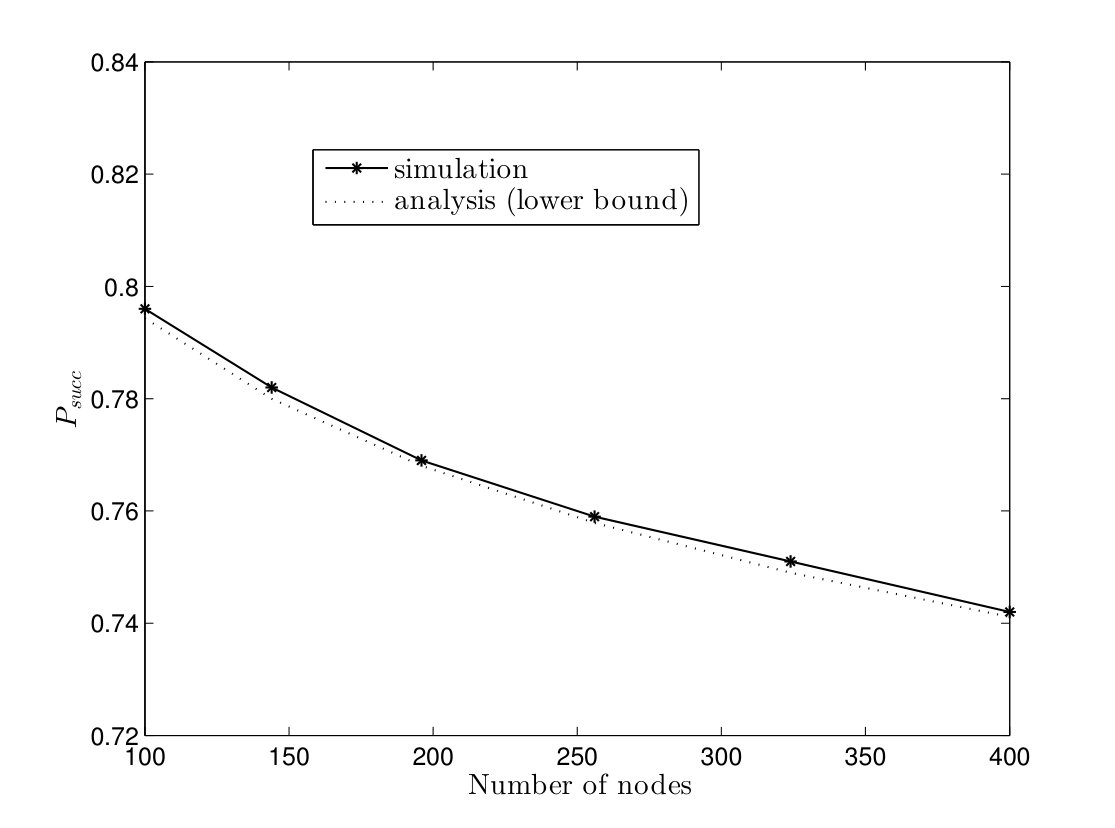 Figure 16
Figure 16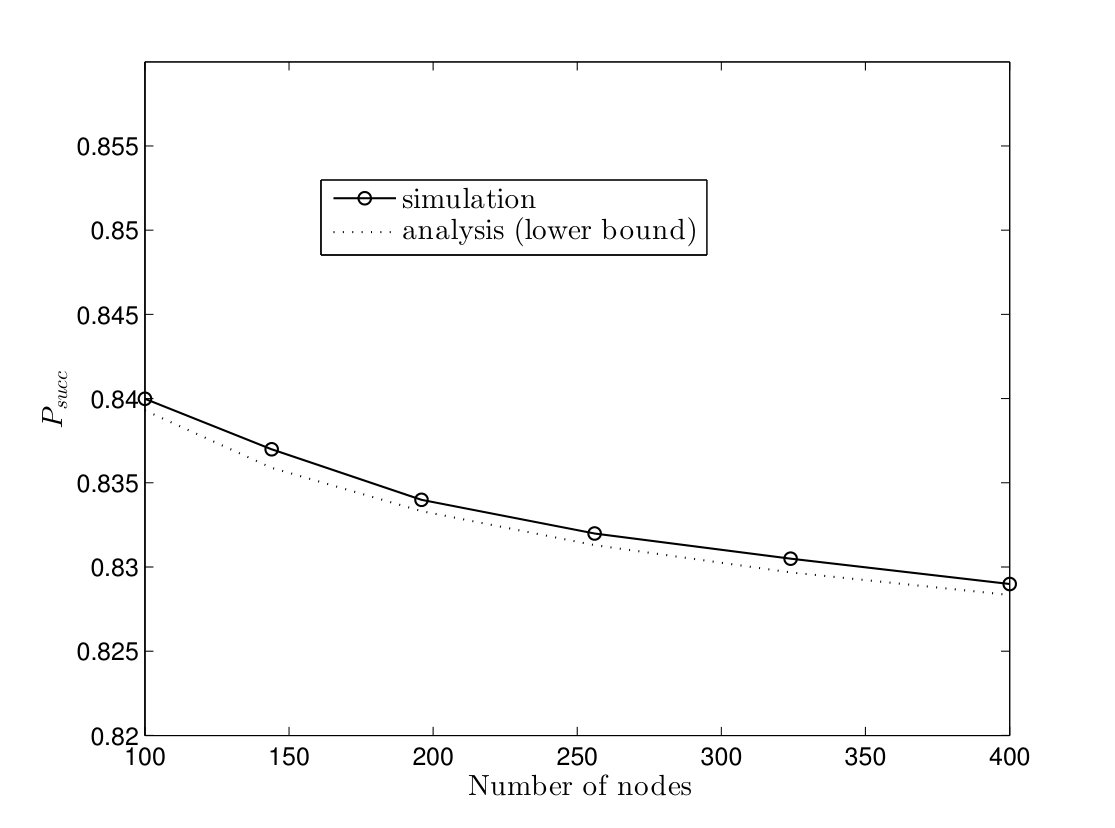 Figure 17
Figure 17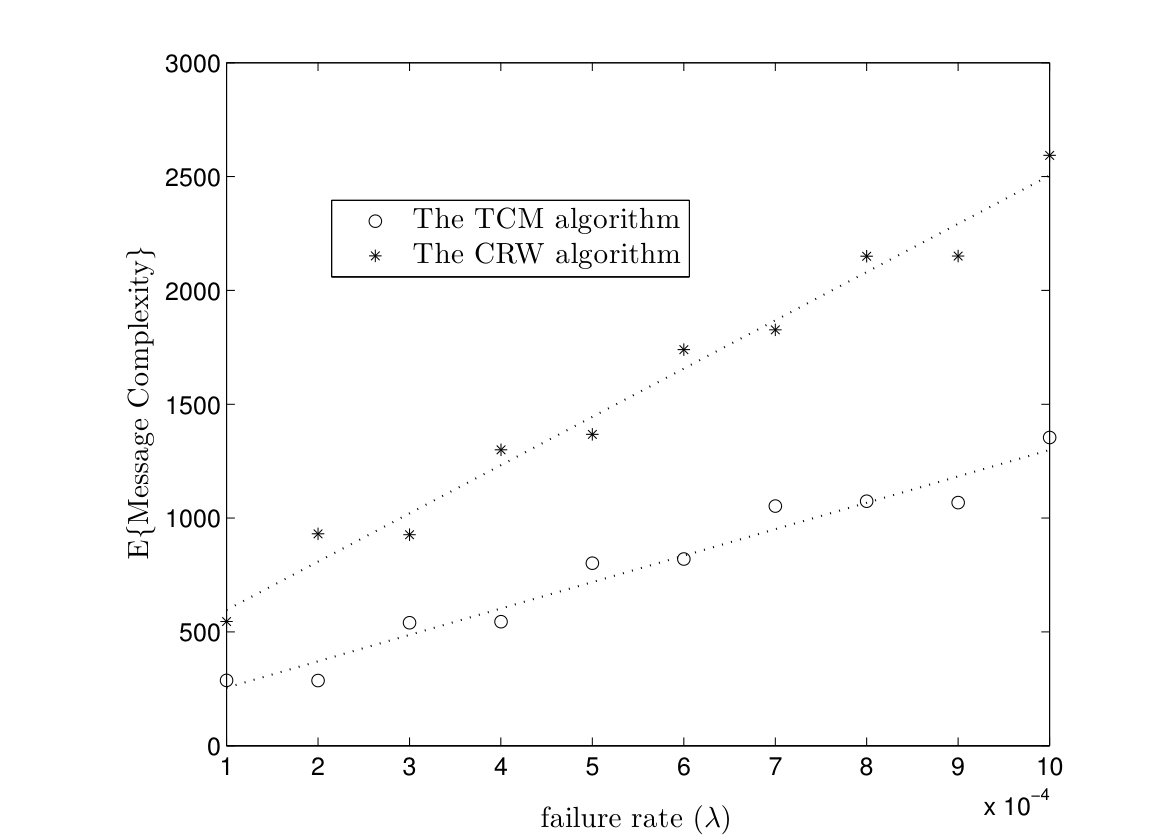 Figure 18
Figure 18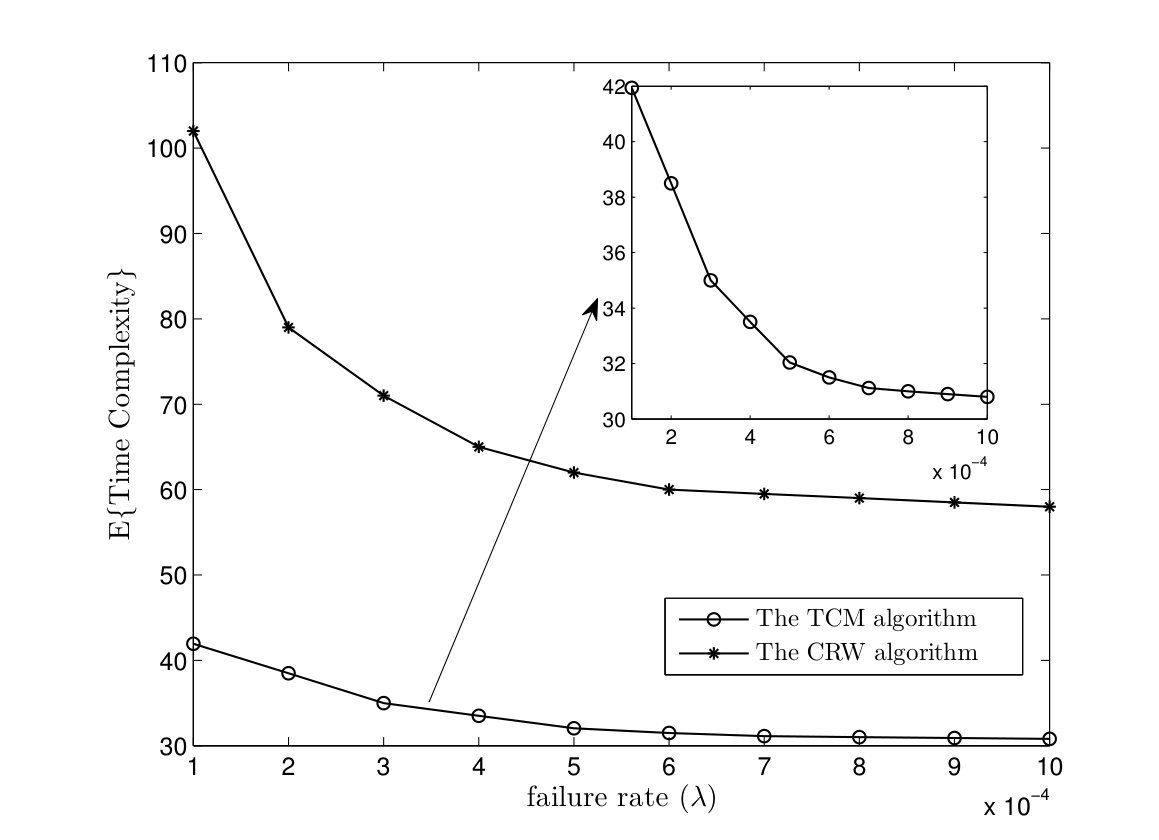 Figure 19
Figure 19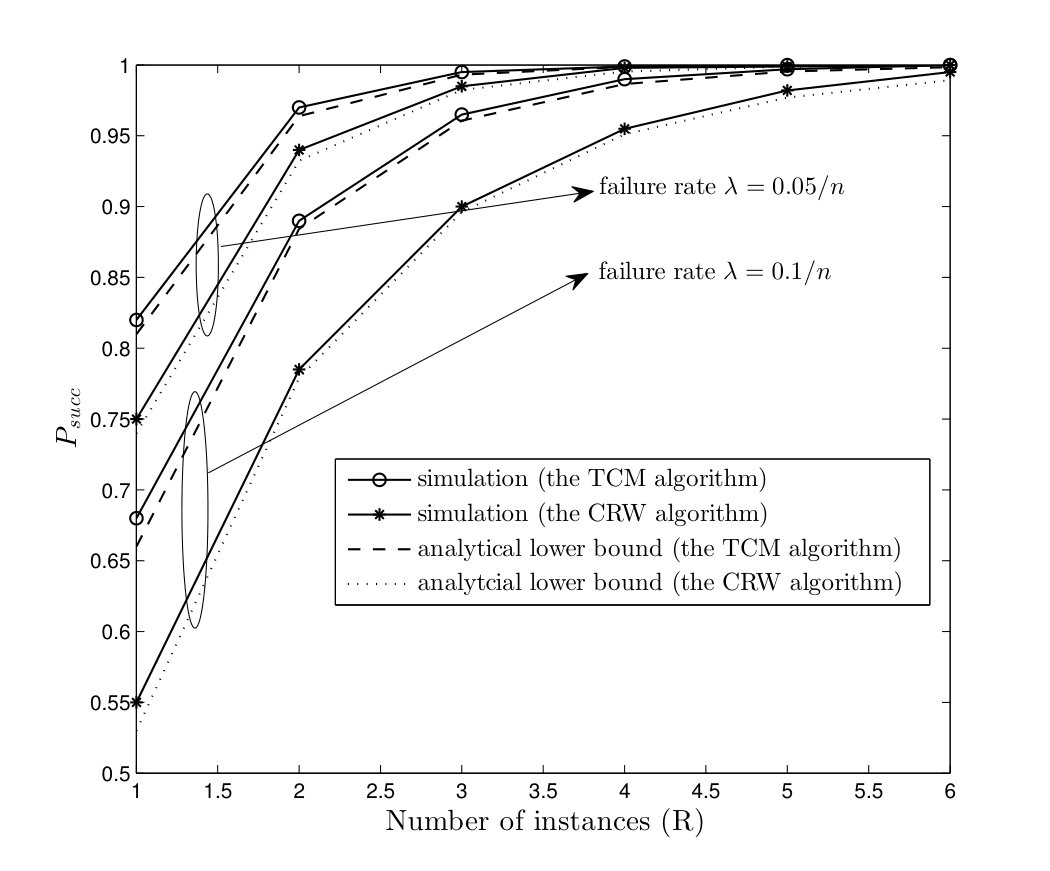 Figure 20
Figure 20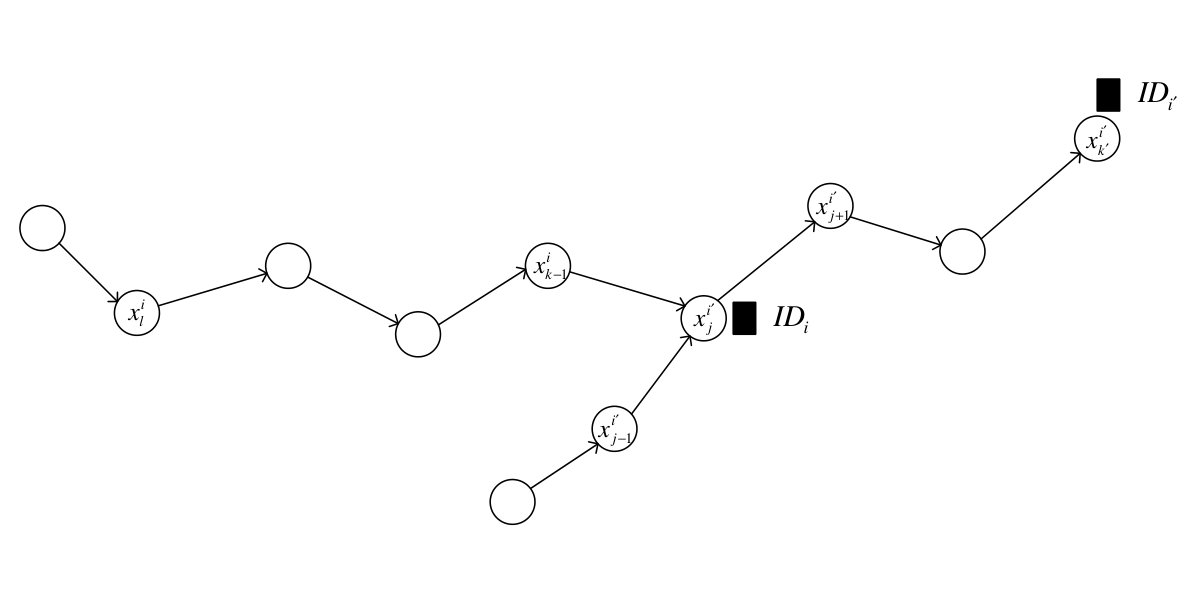 Figure 21
Figure 21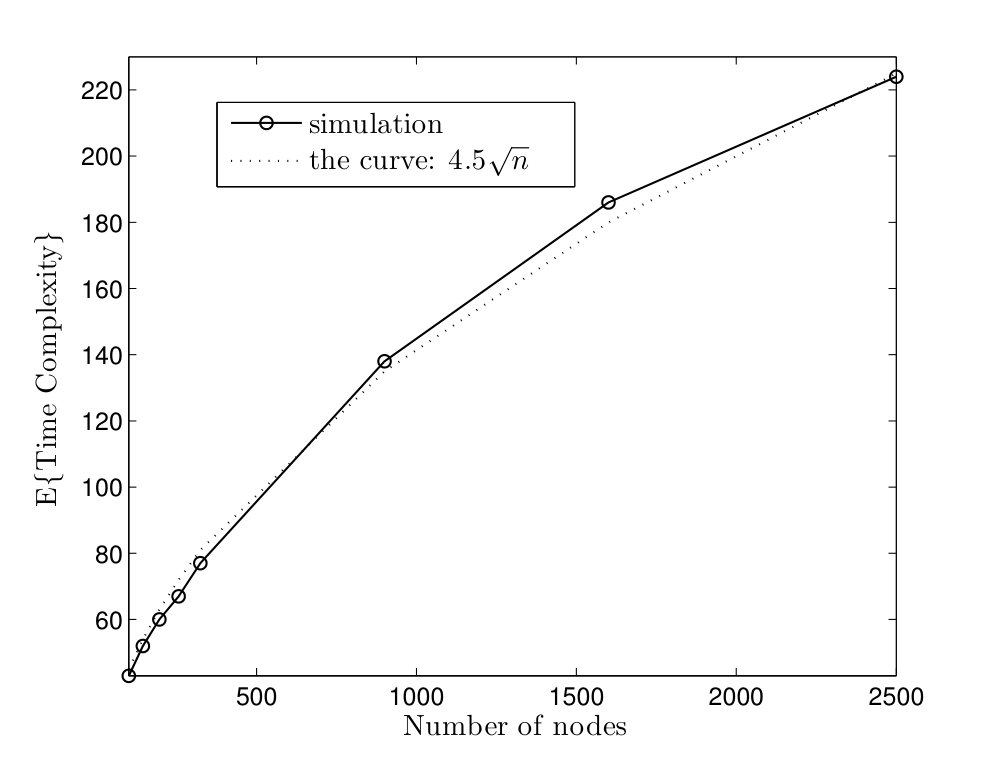 Figure 1
Figure 1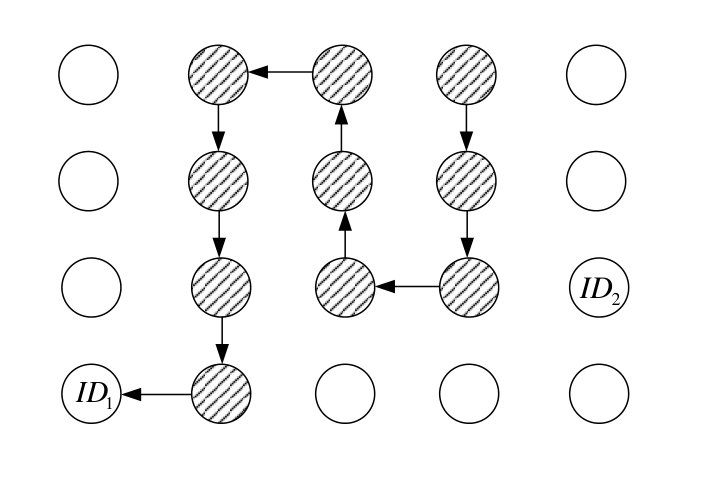 Figure 10
Figure 10 Figure 11
Figure 11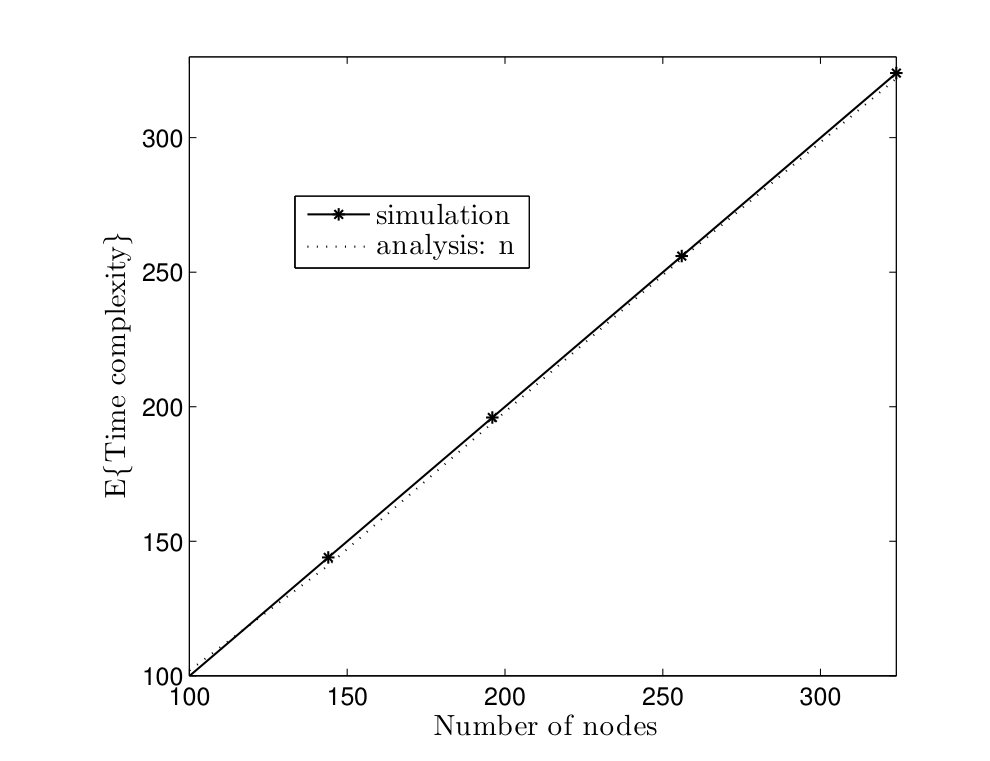 Figure 2
Figure 2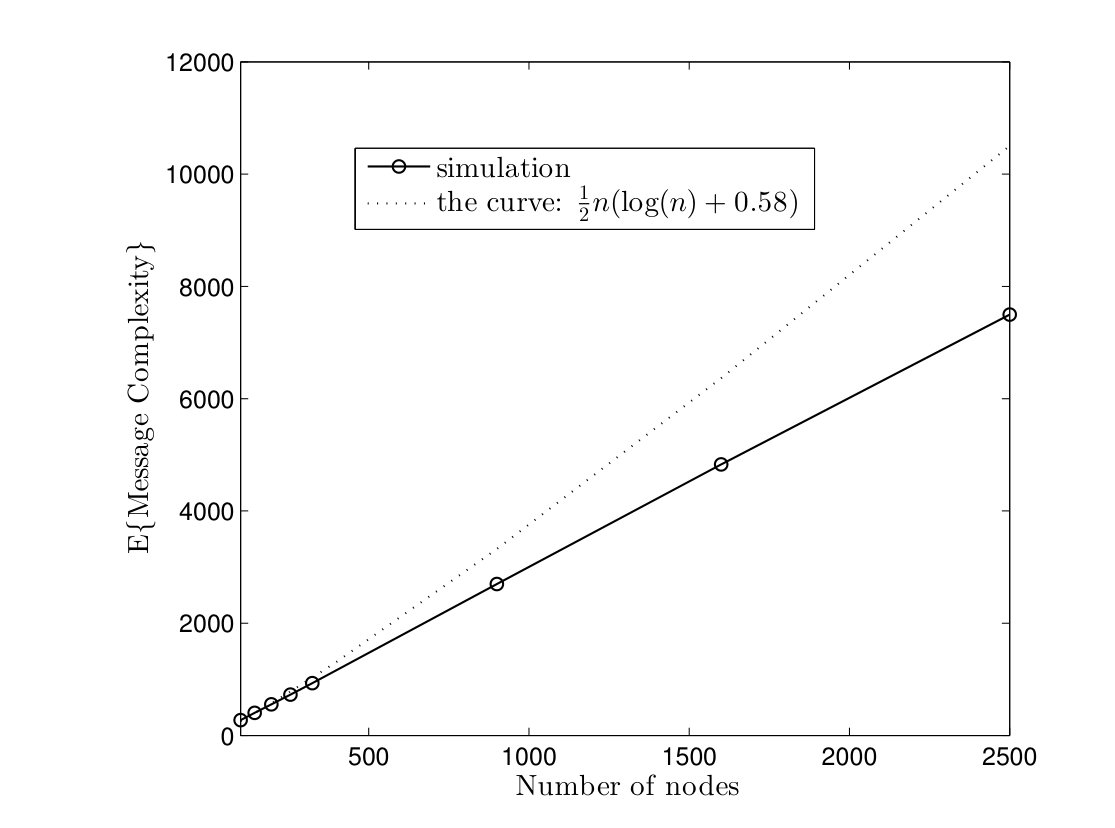 Figure 3
Figure 3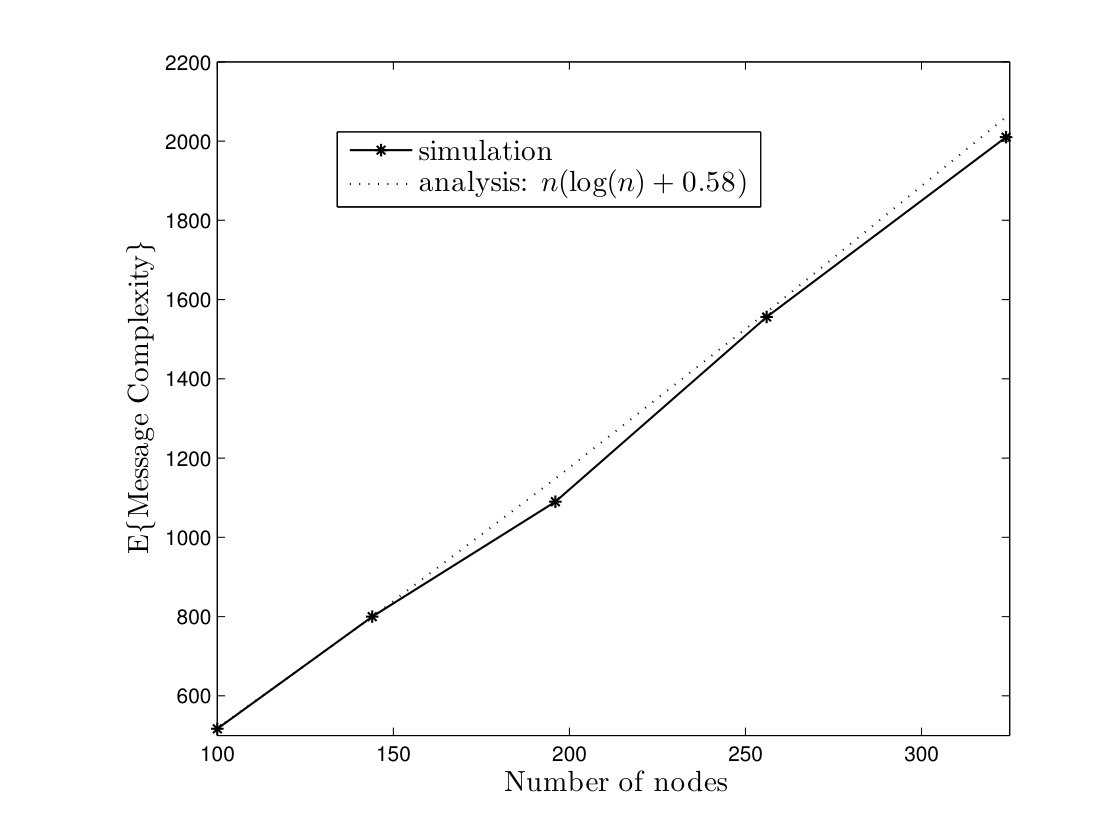 Figure 4
Figure 4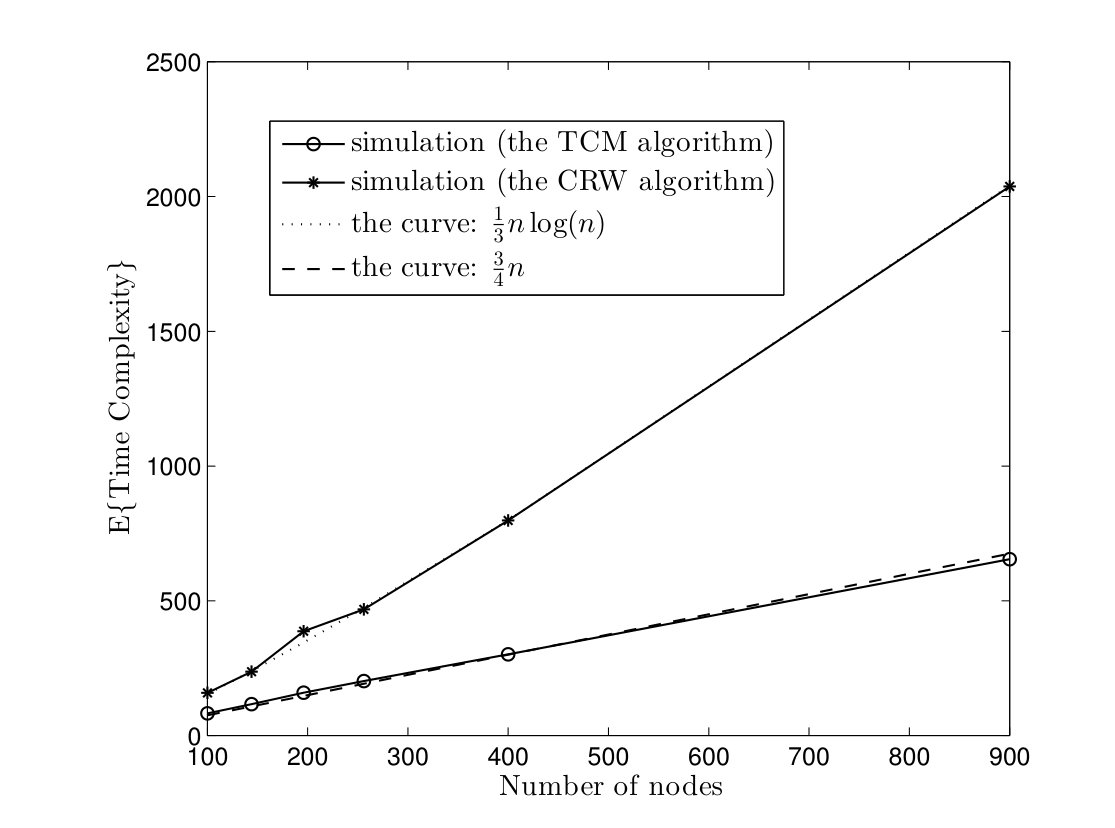 Figure 5
Figure 5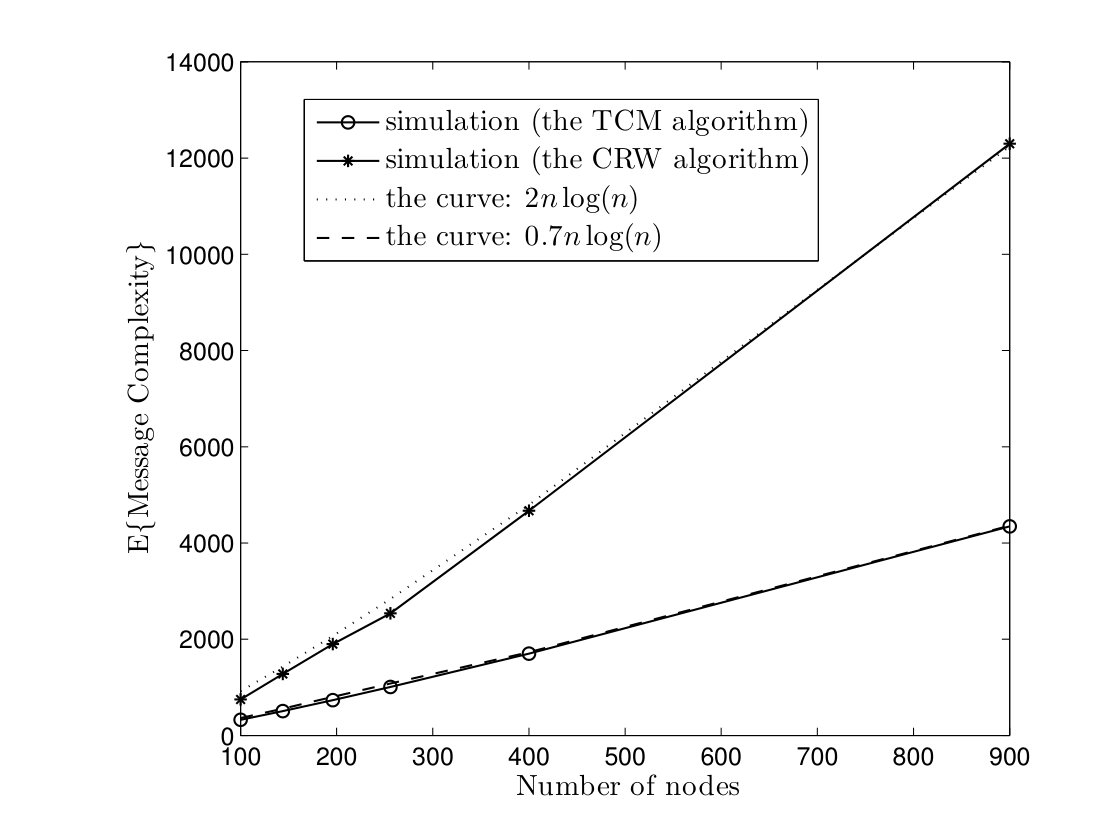 Figure 6
Figure 6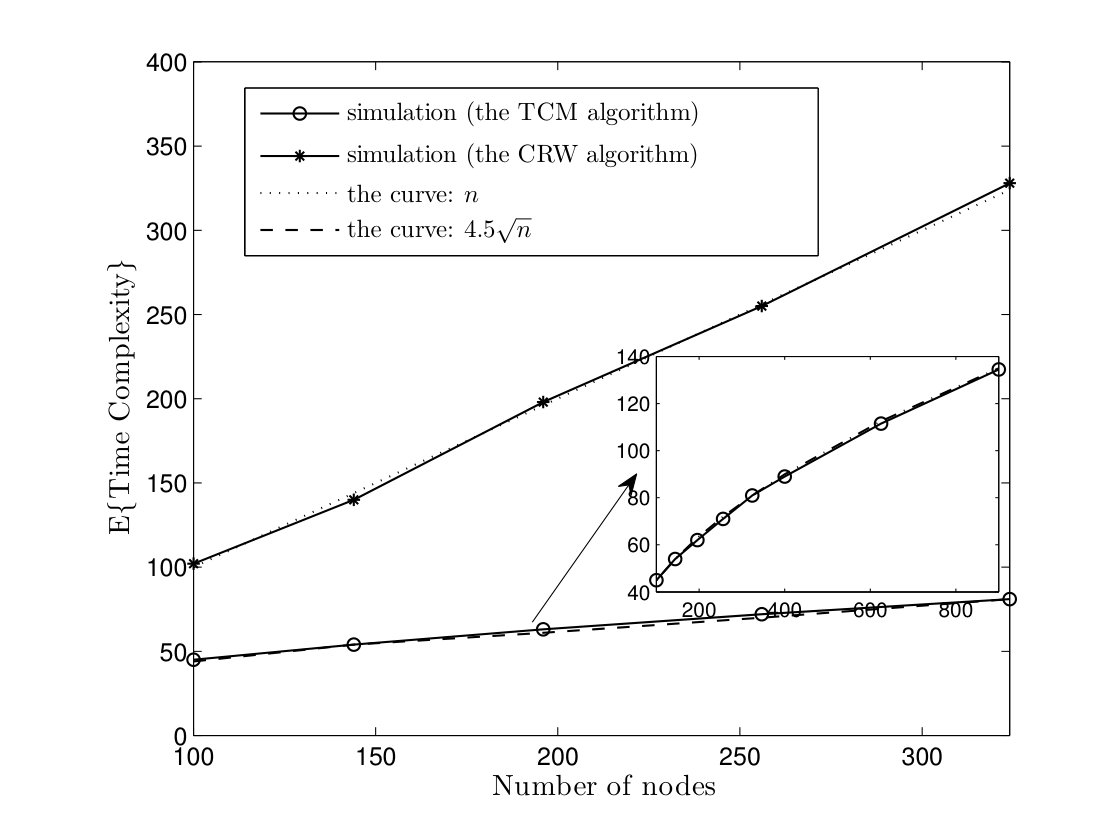 Figure 7
Figure 7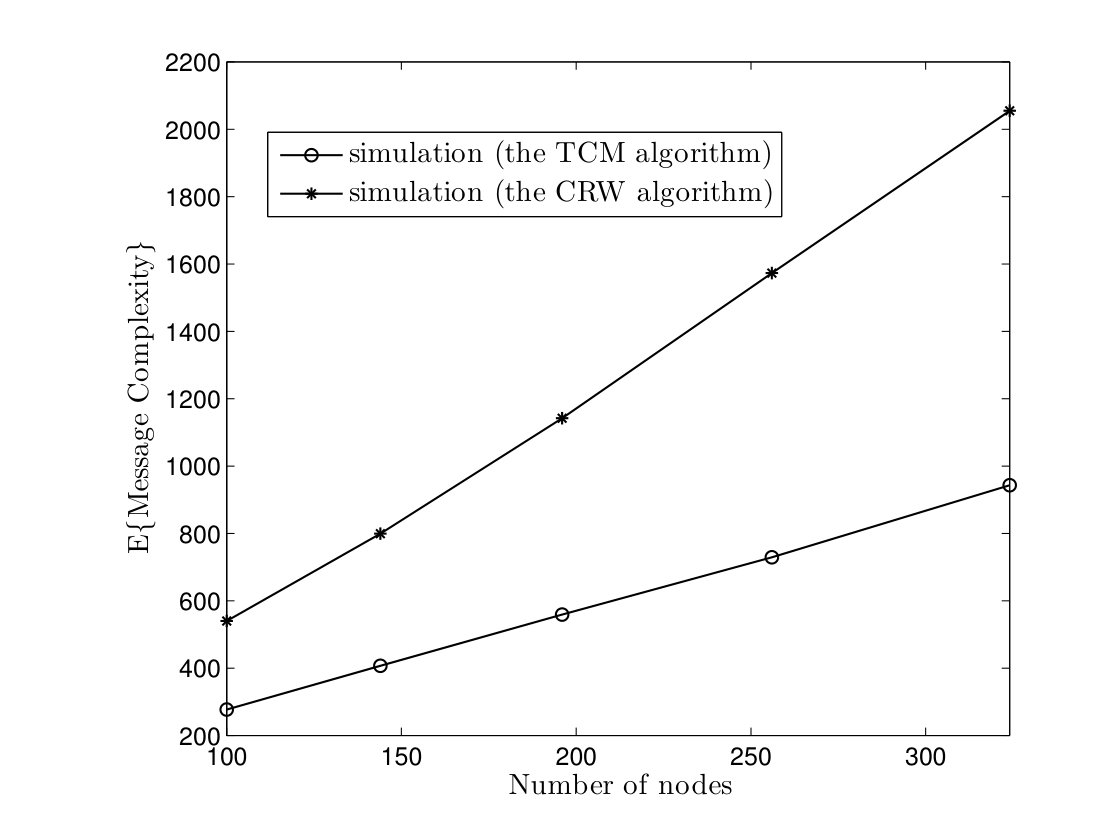 Figure 8
Figure 8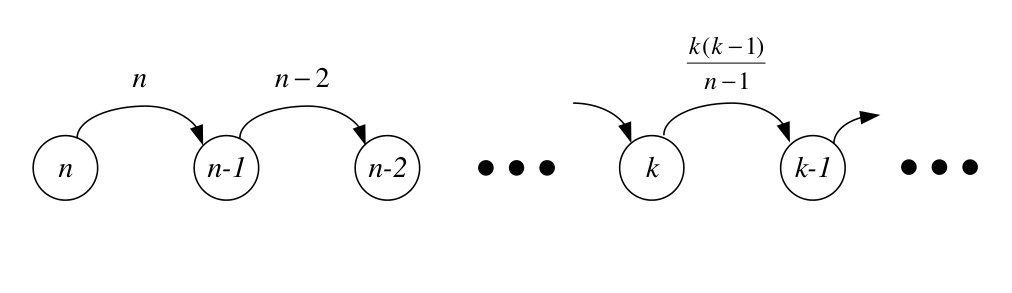 Figure 32
Figure 32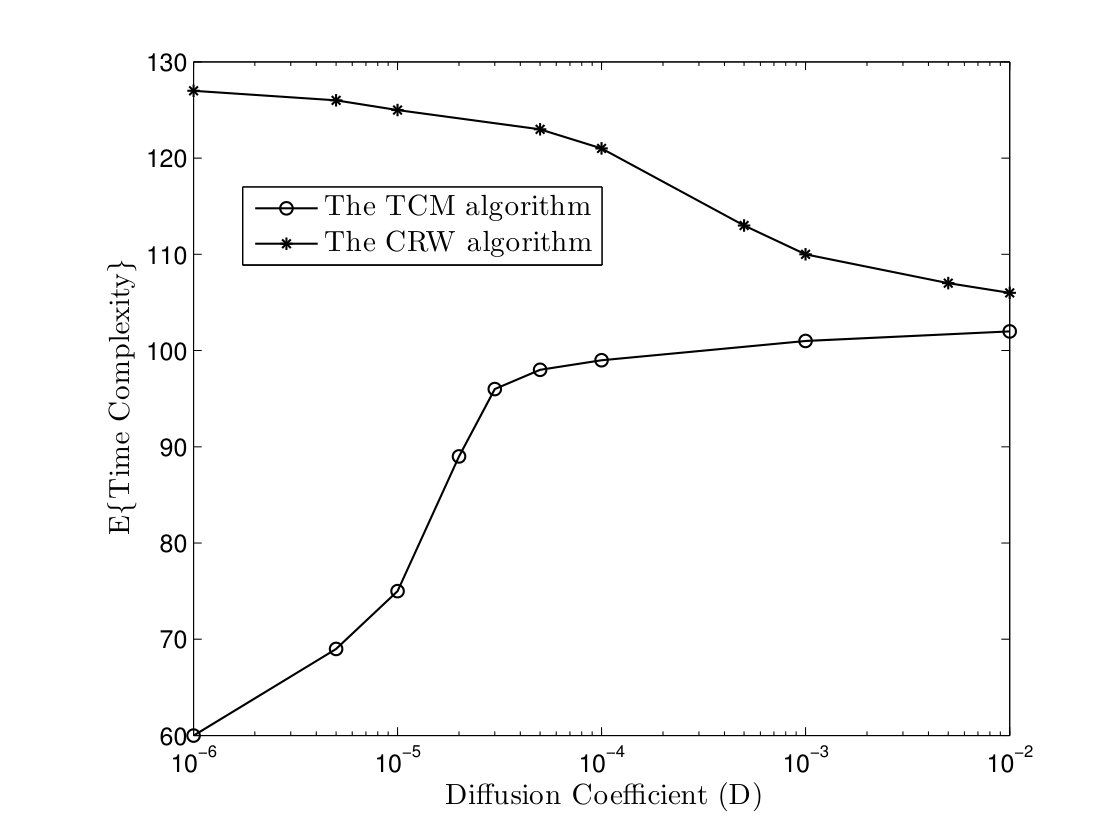 Figure 33
Figure 33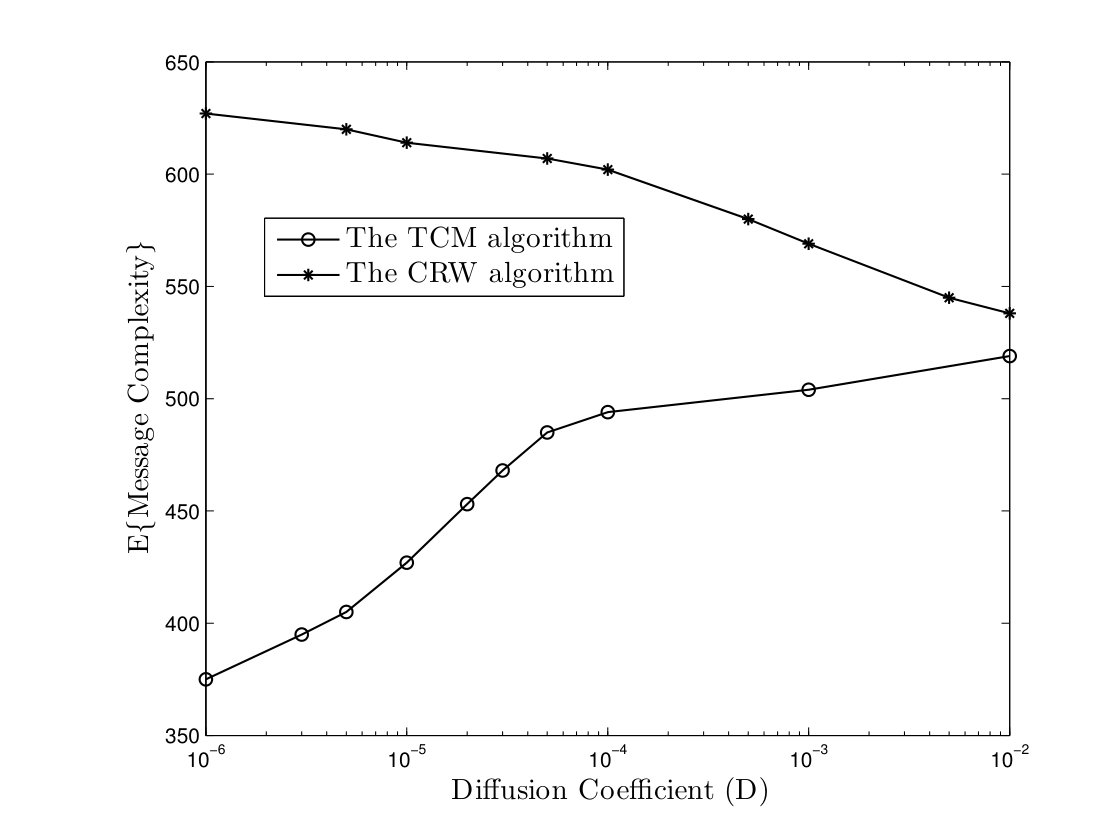 Figure 34
Figure 34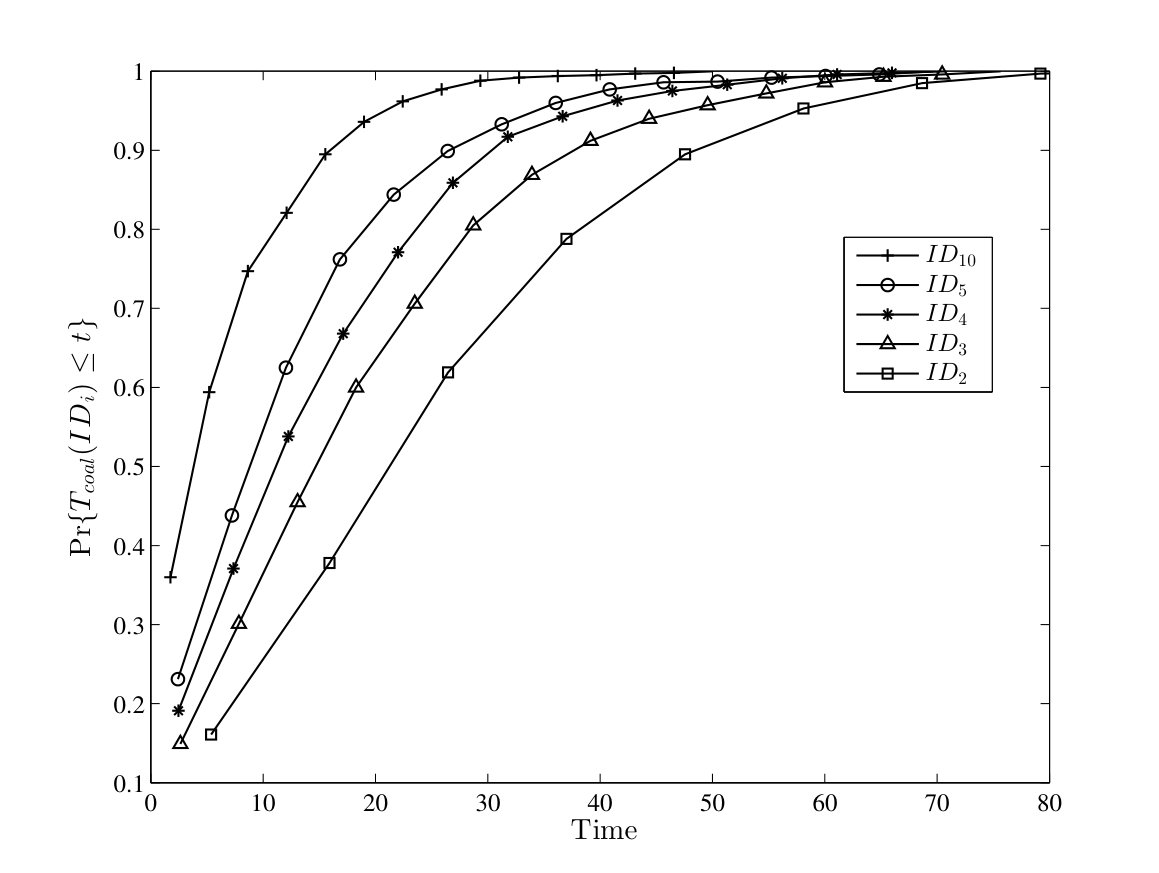 Figure 35
Figure 35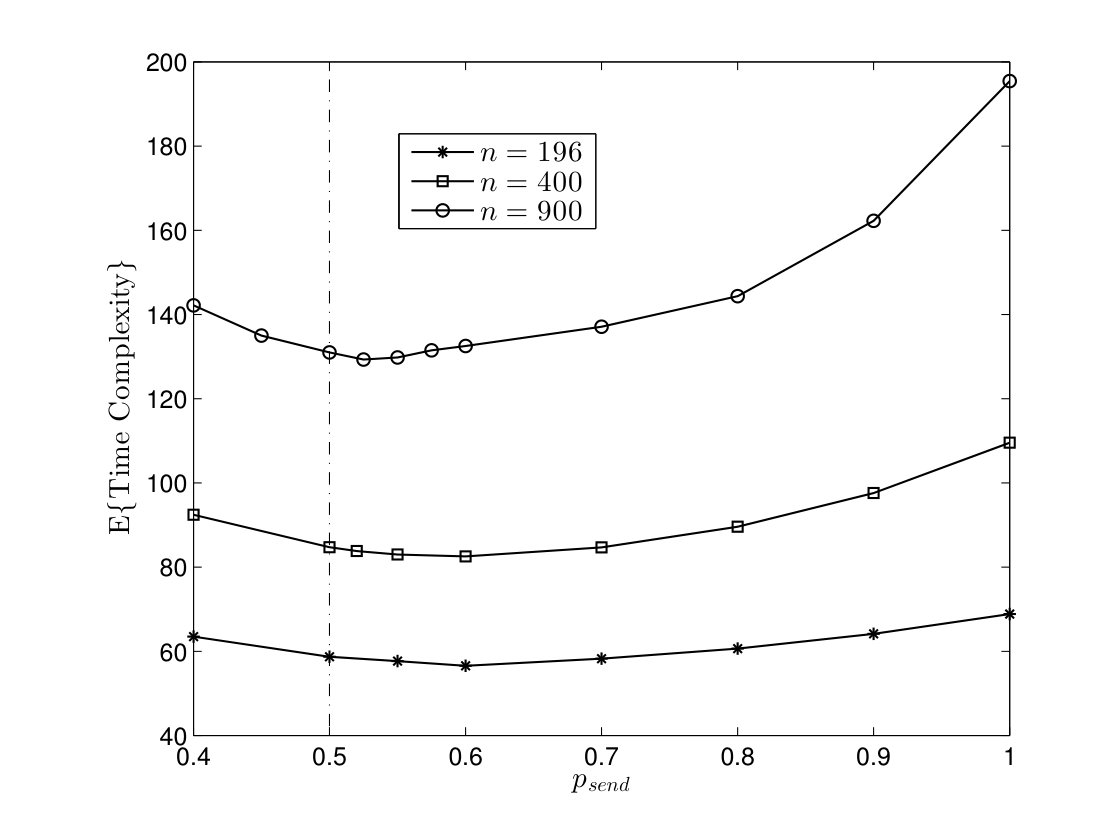 Figure 36
Figure 36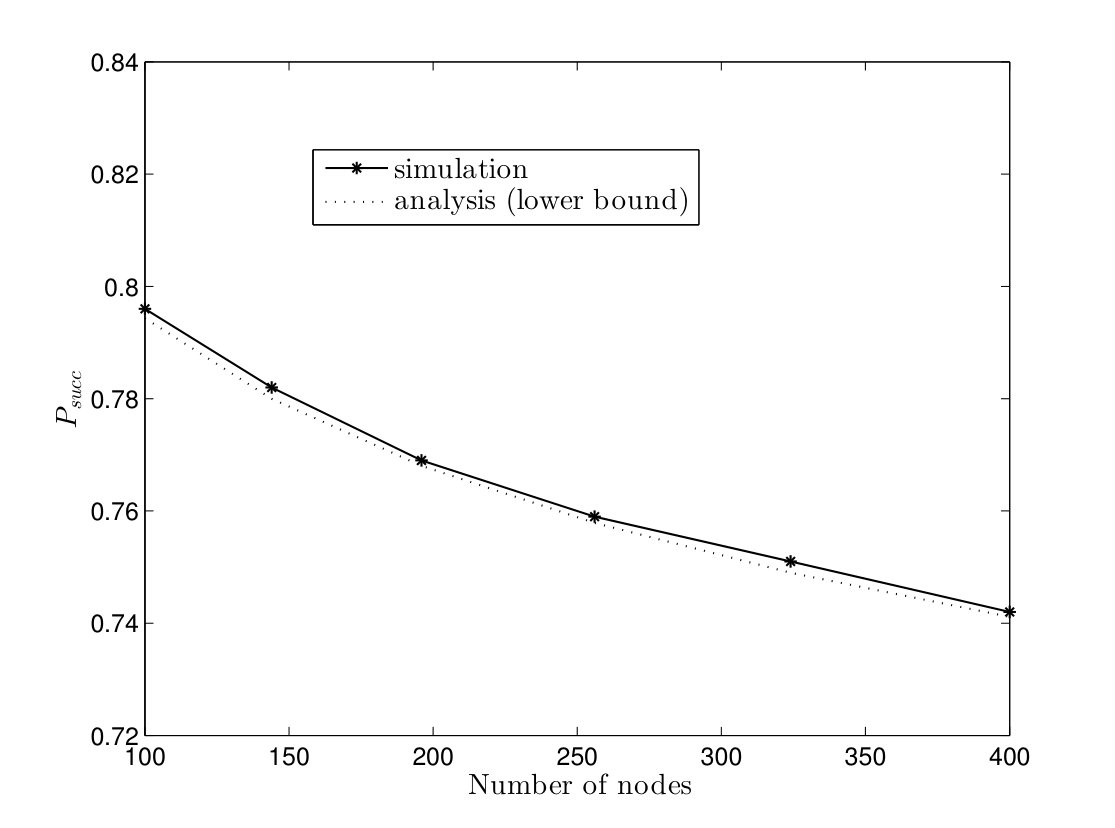 Figure 37
Figure 37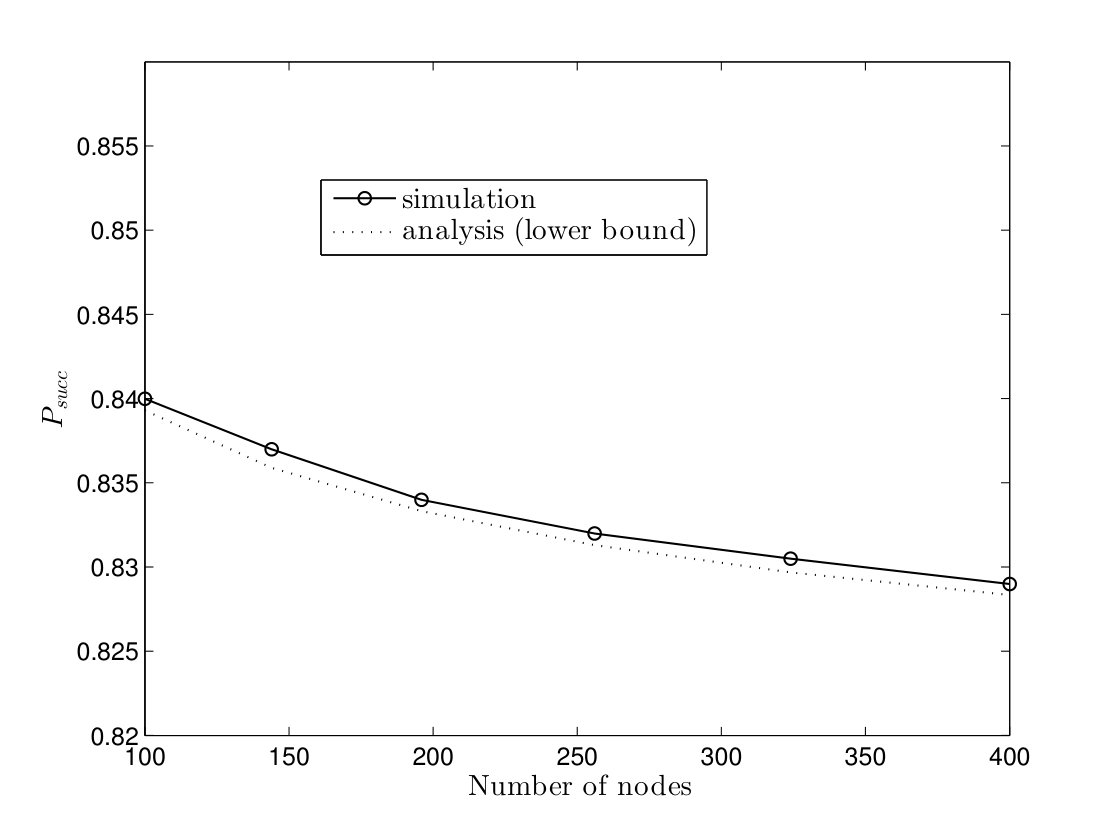 Figure 38
Figure 38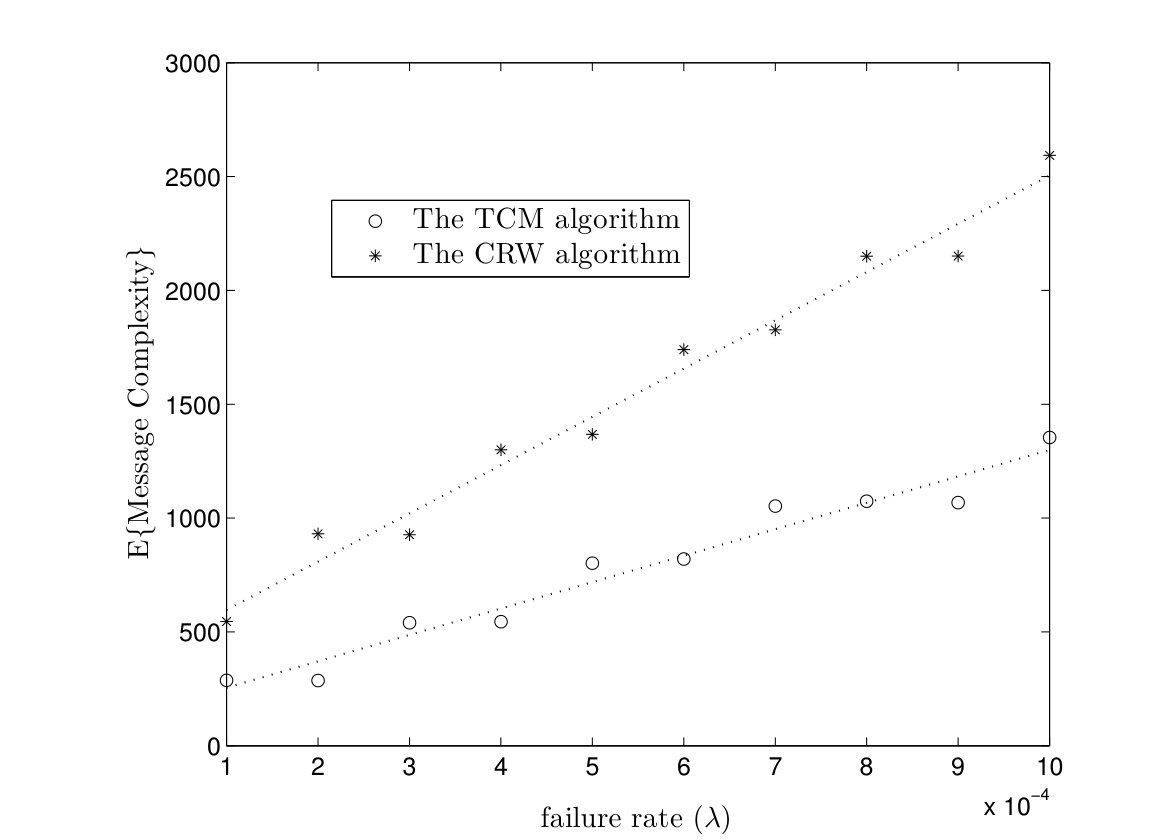 Figure 39
Figure 39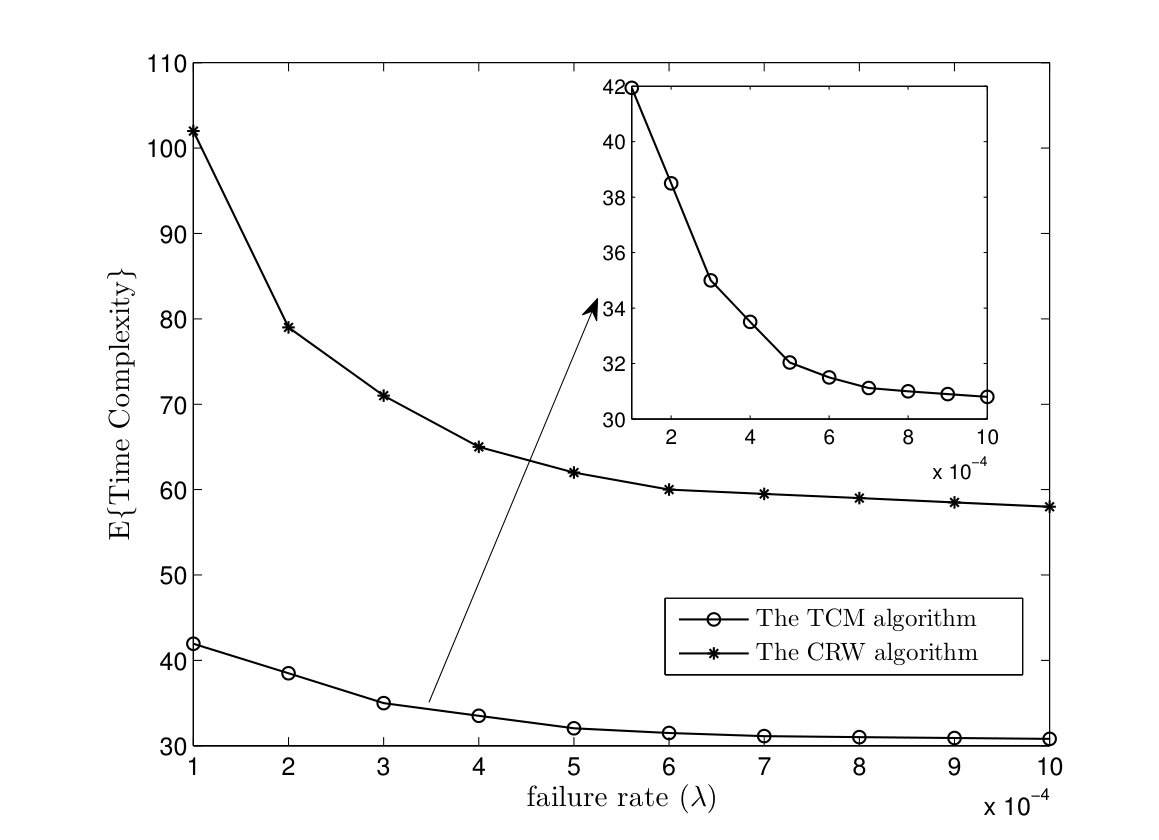 Figure 40
Figure 40Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsDistributed systems and fault tolerance · Advanced Memory and Neural Computing · Parallel Computing and Optimization Techniques
Token-based Function Computation with Memory
Saber Salehkaleybar*, Student Member, IEEE*, and S. Jamaloddin Golestani*, Fellow, IEEE*
Dept. of Electrical Engineering, Sharif University of Technology, Tehran, Iran
Emails: [email protected], [email protected]
Abstract
In distributed function computation, each node has an initial value and the goal is to compute a function of these values in a distributed manner. In this paper, we propose a novel token-based approach to compute a wide class of target functions to which we refer as “Token-based function Computation with Memory” (TCM) algorithm. In this approach, node values are attached to tokens and travel across the network. Each pair of travelling tokens would coalesce when they meet, forming a token with a new value as a function of the original token values. In contrast to the Coalescing Random Walk (CRW) algorithm, where token movement is governed by random walk, meeting of tokens in our scheme is accelerated by adopting a novel chasing mechanism. We proved that, compared to the CRW algorithm, the TCM algorithm results in a reduction of time complexity by a factor of at least in Erdös-Renyi and complete graphs, and by a factor of in torus networks. Simulation results show that there is at least a constant factor improvement in the message complexity of TCM algorithm in all considered topologies. Robustness of the CRW and TCM algorithms in the presence of node failure is analyzed. We show that their robustness can be improved by running multiple instances of the algorithms in parallel.
I Introduction
Distributed function computation is an essential building block in many network applications where it is required to compute a function of initial values of nodes in a distributed manner. For instance, in wireless sensor networks, distributed inference algorithms can be executed by computing average of the sensor measurements as a subroutine. Examples of distributed inference in sensor networks include transmitter localization [1], parameter estimation [2], and data aggregation [3]. As another application, consider a network with processors in which each processor has a local utility function and the goal is to obtain the optimal solution of sum of the utility functions subject to some constraints. This problem has frequently arisen in network optimization algorithms such as distributed learning [4], link scheduling [5], and network utility maximization [6]. All these algorithms utilize a distributed sum or average computation subroutine in solving the optimization problems.
Consider the problem of computing a target function in a network with nodes, where is the initial value of node . A common approach is based on constructing spanning trees [7, 8]. In this solution, the values would be sent toward the root where the final result is computed and sent back to all nodes over the spanning tree. Although the spanning tree-based solution is quite efficient in terms of message and time complexities, it is not robust against network perturbations such as node failures or time-varying topologies. For example, the final result may be dramatically corrupted if a node close to the root fails.
To overcome the above drawback of spanning tree-based solutions, recent approaches take advantage of local interactions between nodes [9]. In these approaches, each node which has a value, chooses one of its neighbors, say node ; The two nodes then update their values based on a predefined rule function which is determined by the target function (see Lemma II.1). By iterating this process in the entire network, the target function is computed in a distributed manner. Let and be the current values of nodes and , respectively. Two possible options for executing the rule function are:
[TABLE]
where and are the updated values of nodes and , respectively. The value is the identity element of the rule function , i.e. for any value .
The first option in (1) corresponds to the class of distributed algorithms commonly called gossip algorithms [9]. The main advantage of these algorithms is that they are robust against network perturbations due to their simple structure. However, this robust structure is obtained at the expense of huge time and message complexities [9]. For the first option, various updating rule functions have been proposed for specific target functions like average [10], min/max, and sum [11]. For instance, the updating rules and can be used to compute average and min functions, respectively.
The second updating option can compute a wide class of target functions including the ones computable by gossip algorithms (see Lemma II.1) and it is much more energy-efficient than the gossip algorithms [12]. This approach can be easily implemented by a token-based algorithm: Suppose that each node has a token at the beginning of the algorithm and passes its initial value to its token. A node is said to be inactive when it does not have a token. If the local clock of an active node like ticks, it chooses a random neighbor node, like node , and sends its token carrying its value. Upon receiving the token, node updates its value, and becomes active (if it is not already)111In case of computing the sum function, the updating rule function is and the identity element is equal to zero.. Then, node sets its own value to , and becomes inactive. From token’s view, each token walks in the network, randomly, until it meets another token. The two tokens will then coalesce and form a token with an updated value. This process continues until the result is aggregated in one token. Finally, the last active node can broadcast the result by a controlled flooding mechanism222In section II, we will explain how the last active node broadcasts the final result.. This computation scheme is called Coalescing Random Walk (CRW) algorithm after the coalescing random walks [13].
The CRW algorithm offers comparable performance to spanning tree-based solutions in terms of message complexity [12], making it much more energy-efficient than the gossip algorithms. However, it is still slow due to deficiency in token coalescence when only a few tokens remain in the network. Hence, authors in [12], modified the CRW algorithm in order to improve its running time. In the modified algorithm, which we call the truncated CRW algorithm, at some point of time, the execution of the CRW algorithm is terminated and each active node broadcasts the value of its token via a controlled flooding mechanism, leaving the completion of the computation to each network node. However, this solution does not lead to a significant improvement in time or message complexity [12].
In this paper, we propose a mechanism to speed up the coalescence of tokens. Suppose that each token has a unique identifier (UID) besides its carried value. In the proposed mechanism, each node registers the maximum UID of tokens seen so far, and the outgoing edge taken by the token with the maximum UID. When a token enters a node previously visited by a token with higher UID, it follows the registered outgoing edge. Otherwise, it will go to a random chosen neighbor node, according to a predefined probability. Figure 1 illustrates a scenario where two tokens are left in the network and show how coalescing is expedited in the proposed scheme. Since nodes memorize the outgoing edge of a token with maximum UID they have seen, we call the proposed scheme “Token-based function Computation with Memory” (TCM) Algorithm.
It is interesting to mention an analogy between this scheme and cosmology. Think of tokens in the network as cosmic dusts in space. Accordingly, the process of function computation is like forming a planet from cosmic dusts. By running the TCM algorithm, tokens with small UID (light dusts) are trapped in the set of nodes visited by tokens with higher UID (in the gravitational field of heavy dusts). The coalescing process continues until a single token is left, similar to birth of a planet.
The main contributions of the paper are as follows:
- •
We show that the proposed TCM algorithm, by accelerating coalescing of tokens, reduces the average time complexity by a factor in complete graphs and Erdös-Renyi model compared to the CRW algorithm and its truncated version. Furthermore, there is at least factor improvement in torus networks. Simulation results show that the TCM algorithm also outperforms the CRW algorithm in terms of message complexity.
- •
In CRW and TCM algorithms, the final result may be corrupted if an active node fails. Hence, it is quite important to study the robustness of these algorithms under node failures. In this regard, we evaluate the performance of CRW and TCM algorithms based on a proposed robustness metric. We show that the robustness can be substantially improved by running multiple instances of the TCM and CRW algorithms in parallel. We prove that, for the CRW algorithm, the required number of instances in order to tolerate the failure rate in complete graphs, is of the order . While the TCM algorithm needs to run only instances in parallel.
- •
We study the performance of TCM and CRW algorithms under random walk mobility model [14]. Simulation results show that both algorithms can compute the class of target functions defined in Lemma II.1 successfully even in high mobility conditions.
The remainder of the paper is organized as follows: In Section II, the TCM algorithm is described. In Section III, the performances of TCM and CRW algorithms are analyzed and compared for different network topologies. In Section IV, we study the robustness of both algorithms in complete graphs. In Section V, the performances of TCM and CRW algorithms are evaluated through simulations and then compared with analytical results. Finally, we conclude with Section VI.
II The TCM algorithm
II-A System model
Consider a network of nodes, where each node has an initial value and the goal is to compute a function of initial values in a distributed manner. The topology of the network is represented by a bidirected graph, , with the vertex set , and the edge set , such that if and only if nodes and can communicate directly. We index ports of node with , where is the degree of node .
It is assumed that the function is symmetric for any permutation of the set , i.e. . This means that it does not matter which node of the network holds which part of the initial values.
II-B Description of the TCM algorithm
Assume that a UID is assigned to each node .333One can use randomized algorithms to assign UIDs. Each node randomly chooses an integer number in the set . From birthday problem [15], it can be shown that each node gets a UID with high probability if is large enough. Furthermore, each node can encode its UID with bits. At the beginning of the algorithm, each node has a token to which it passes its UID and initial value. It is also assumed that each node has an independent clock which ticks according to a Poisson process with rate one. Let the value and UID of the token at node be and , respectively. We denote the token at node by the vector . The role of parameter will be explained in the next part.
The TCM algorithm computes the target function by passing and merging tokens in the network. When a node does not have a token, it becomes inactive until a neighbor node gets in contact with it. Let be the maximum UID of the tokens, node has seen so far. Algorithm 1 describes how and when an active node sends or merges tokens. The subroutine Send() is executed by each tick of local clock while the subroutine Receive() is activated upon receiving a token from some neighbor node.
Suppose that the local clock of active node ticks. Node decides to send the token to a neighbor node. In this respect, we make distinction between two cases:
Case 1- : In this case, node decides to pass the token to a random neighbor node with probability . Thus, node waits for number of clock ticks on average before sending out the token. To implement the waiting mechanism, node will exit the subroutine Send() with probability , each time its clock ticks (line 6). Otherwise, it chooses a random port , sets the to , and sends the token on that port (lines 7-8).
Case 2- : In this case, node sends the token on the port with probability one.
Now, suppose that node receives a token . If node is inactive, then the received token remains unchanged. Otherwise, it will coalesce with the token at nodes and the token with greater UID remains in the network (line 15). Then, the parameters , , and are updated to , , and , respectively (lines 16-18). The updating rule function is determined by the target function as explained in Lemma II.1. Furthermore, the value is the identity element of the rule function , i.e. for any value .
From top view, each token walks randomly in the network until it enters a node visited by a token with higher UID (Case 1). Then, it follows a path to meet the token with higher UID (Case 2). We call the walking modes in the first and second cases the random walk and chasing modes, respectively. In the random walk mode, a token walks with the lower speed . Thus, it can be followed by tokens with lower UID more quickly.
II-C Termination of the TCM algorithm
The process in Algorithm 1 continues until a few tokens remain in the network. In order to terminate the algorithm, we consider two options:
- •
Option 1- Assume that the exact network size, , is known by all nodes. Furthermore, each node has a parameter , beside its initial value which is equal to one at the beginning. The sum of parameters can be computed in parallel to the target function. If the parameter in an active node reaches , it can identify itself as the unique active node in the network. Then, it broadcasts the output of the TCM algorithm to all nodes by controlled flooding, further explained below.
- •
Option 2- Suppose that there exists an upper bound on the network size. Then, the execution time of the TCM algorithm can be adjusted to a time such that, on average, at most a constant number of active nodes remain after time . Afterwards, each active node broadcasts the value of its token including the UID. All nodes can obtain the final result by combining values received from the active nodes. In analyzing the performances of CRW and TCM algorithms, we consider the first option.
In controlled flooding, an active node sends the value and UID of its token to all neighbor nodes. Each node , upon receiving this message from a node for the first time, forwards it to all its neighbor nodes except node . Since each message is transmitted on each edge at most twice, the time and message complexities of controlled flooding are and , respectively444In complete graphs, we can employ gossip algorithm proposed in [16] to broadcast the output with time and message complexities of the order and , respectively..
The allocation of memory at node would be: where the possible values of the first three entries are in the set . Thus, the TCM algorithm requires at most bits more storage capacity compared to the CRW algorithm. The next Lemma identifies the class of target functions which can be computed by the TCM algorithm.
Lemma II.1**.**
The TCM algorithm can compute a collection of symmetric functions if there exists an updating rule function such that for any permutation of the set , we have: , , .
Proof.
The proof is the same as Lemma 3.1 in [12]. ∎
A wide class of target functions fulfil these requirements such as min/max, average, sum, and exclusive OR. For instance, updating rule functions , , and are used for computing sum, minimum, and exclusive OR functions, respectively. The average function can also be computed by dividing the output of the sum function by the network size which is obtained by summing parameter of nodes in parallel to computing the sum function.
III Performance Analysis of the CRW and TCM Algorithms
In this section, we study the performances of CRW and TCM algorithms in complete graphs, Erdös-Renyi model, and torus networks. The considered network topologies may resemble different practical networks. For instance, the topology of a wireless network, in which all stations are in transmission range of each other, is typically modelled by a complete graph. A peer-to-peer network such that all nodes can communicate with each other in the overlay network, is another example of complete graphs. As we explain later, the Erdös-Renyi model is frequently used as a model to represent social networks. Furthermore, torus network is a simple structure widely used to model distributed processing systems with grid layout or grid-based wireless sensor networks.
As a prelude to analyze the performance of the TCM algorithm, we first present an analysis of time and message complexities of the CRW algorithm for complete graphs, although the CRW algorithm is already analyzed in [17]. Then, we study time complexity of the TCM algorithm in complete graphs. We also give a naive analysis of message complexity of the TCM algorithm in complete graphs and time/message complexity of both algorithms in Erdös-Renyi model and torus networks. The summary of time and message complexities for the TCM algorithm and the CRW/truncated CRW algorithms are given in Table 1. In complete graphs and Erdös-Renyi model, the TCM algorithm reduces the time complexity at least by a factor . In the case of torus networks, there is an improvement at least by a factor with respect to the CRW algorithm. Furthermore, the message complexity of the TCM algorithm is at most the same as the CRW and truncated CRW algorithms. Simulation results show that there is at least a constant factor improvement in the message complexity by employing the TCM algorithm in all considered topologies.
In analyzing the CRW and TCM algorithms, we assume that each token is transmitted instantaneously. Furthermore, passing a token is counted as sending one message in the network.
III-A Time and message complexities of the CRW algorithm on complete graphs
Let and be the average time and message complexities of the CRW algorithms, respectively. Next theorem gives a tight bound on and .
Theorem III.1**.**
The average time and message complexities of the CRW algorithm in complete graphs are of the orders and , respectively.
Proof.
We can represent the process of token coalescing by a Markov chain with the number of active nodes remaining in the network defined as the state (see Fig. 2). The chain undergoes transition from state to state if a token chooses an active nodes for the next step, which occurs with rate . Let be the sojourn time in state . Then the average time complexity is:
[TABLE]
Besides, in state , on average, messages are transmitted before observing a coalescing event. Therefore, the average message complexity would be555 where is the Euler-Mascheroni Constant.:
[TABLE]
∎
Thus, the average time and message complexities of CRW algorithm are of the orders and , respectively.
III-B Time complexity of TCM algorithm on complete graphs
Let the UIDs of the tokens at the beginning of the algorithm be denoted as . Without loss of generality, assume that . Throughout this section, we also assume that .
Definition III.1**.**
Let , , denote the time that token coalesces with a token with a larger UID. Thus, the algorithm running time would be: .
In the TCM algorithm, token walks randomly in the network. In each step, it chooses a random node from the whole set of network nodes except the node where it is currently presented. After taking steps, the average number of visited nodes by token would be: .
Definition III.2**.**
We call the set of nodes visited by token during its first movements the event horizon of , and denote it by .
Notice that, in the TCM algorithm, when a token gets in the event horizon of token , it cannot escape and will eventually coalesce with token . We borrowed the term event horizon from general relativity, where it refers to “the point of no return”.
Lemma III.1**.**
The size of event horizon of token after taking steps, i.e. , is at least with probability greater than where constant .
Proof.
See Appendix A in the supplemental material. ∎
Now, we can obtain an upper bound on the average time complexity of the TCM algorithm, from Lemma III.1.
Theorem III.2**.**
In complete graphs, the average time complexity of TCM algorithm is of the order .
Proof.
For a complete proof, see Appendix B in the supplemental material. Here, in order to provide better insight about the algorithm, we present a naive analysis, that is based on a modified model of the network, where Poisson assumption for clock ticks is relaxed. Instead, we adopt a slotted model for time, where each token in the chasing mode, takes one step in each time slot. Furthermore, in the random walk mode, we replace the assumption of with sending token every other slot. Tokens which are scheduled to move in a time slot, take steps in a random order.
In our analysis, we utilize the following inequality that we trust is correct, based on intuition and simulation verification:
[TABLE]
As an example, simulation results are given for a network with nodes in Fig. 3.
First, we derive an upper bound on the probability that the token gets in the event horizon of after time slot . According to the simplified timing model, token moves at even time slots and token tries to get in the event horizon of token at the same time slots. In order to obtain the upper bound, we wait for time slots to have a big enough event horizon of token . Since the size of event horizon in the next time slots is equal or greater than the one at time slot , the probability of not hitting the event horizon in time interval is less than . By bounding from below (see Lemma III.1), we have for :
[TABLE]
where the last inequality is obtained by replacing , for .
When token reaches the event horizon of token at time slot , it takes at most another time slots to coalesce with token . Because the size of is at most and the relative velocity of two tokens is . From this fact, we have: . From (5), we can obtain the following:
[TABLE]
Now, an upper bound can be derived on the average time complexity:
[TABLE]
(a) From the inequalities in (4) and (6).
(b) Due to for .
From (7), we conclude that the average time complexity is of the order . Comparing with the CRW algorithm, the TCM algorithm improves the time complexity with at least a factor of .
∎
III-C Message complexity of TCM algorithm on complete graphs
In this part, we give a naive analysis of the message complexity of TCM algorithm in complete graphs. To obtain the bound on message complexity, we will show that the average number of messages sent in the TCM algorithm until observing a coalescing event, is less than the case for the CRW algorithm.
Proposition III.1**.**
The average message complexity of the TCM algorithm is of the order in complete graphs.
Proof.
Assume that clock of an active node ticks at time and tokens remain in the network. Suppose that token is in node . The token may be in two different modes: Walking randomly or following another token with higher UID. In the first mode, it will choose any node like with probability . Thus, the probability of coalescing is:
[TABLE]
where is an indicator parameter which is equal to one if node is active at time and otherwise, it is zero. But the expected number of active nodes excluding node is: . Hence, the probability of coalescing in this mode is .
In the second mode, token follows another token with higher UID and decided to go to a neighbor node, let say node . We know that there exist tokens excluding token which walk randomly or follow another token on a trajectory of a random walk. Thus, node is active with probability at least . Following the same arguments in analyzing the message complexity of the CRW algorithm, the message complexity is of the order .
∎
III-D Time and message complexities of TCM and CRW algorithms in Erdös-Renyi model
In some network applications, it is required to compute a specific function in social networks, such as majority voting [18]. Hence, it is quite important to study the performances of TCM and CRW algorithms in these scenarios. Erdös-Renyi model is frequently used as a simple model to represent social networks [19]. In this part, we use this model to give a naive analysis on the time and message complexities of TCM and CRW algorithms in social networks.
In Erdös-Renyi model, there exists an edge between any two nodes with probability . It can be shown that the graph is almost certainly connected, if [20]. The next two propositions give upper bounds on the time and message complexities of CRW and TCM algorithms.
Proposition III.2**.**
In the Erdös-Renyi model, the average time and message complexities of CRW algorithm are of the order and , respectively.
Proof.
Assume that tokens remain in the network. Consider token walks randomly until it meets another token. In each step, it may be located in any node. From the token’s view, it seems that edges are randomly established with probability in each step. Suppose that token is in node at time . It will choose an active node with probability, :
[TABLE]
where is the degree of node excluding an active node . The first term in summation shows the probability of having an edge between two nodes and . The second term represents the probability that node has number of neighbor nodes excluding the node and the last term is the probability that node chooses active node from the set of its neighbor nodes. From Jensen’s inequality and convexity of function over , we have: . It can be easily verified that for . Following the same arguments in analyzing the performance of CRW algorithm in complete graphs, we can deduce that the time and message complexities are of the order and , respectively. ∎
Proposition III.3**.**
In the Erdös-Renyi model, the average time and message complexities of TCM algorithm are of the orders and , respectively.
Proof.
Suppose that the token is in random walk mode. In each step, it visits each node with probability for large enough . Intuitively, we still have the same bounds on the probabilities , . By the same arguments for the case of complete graphs, the time and message complexities are of the order and , respectively. ∎
III-E Time complexity of TCM algorithm on torus networks
In this part, we give a naive analysis on the time complexity of TCM algorithm in torus networks. We will show that the average running time of the algorithm is of the order . To obtain the bound, we first need to review two lemmas about single random walks.
Lemma III.2**.**
[21]** Consider a discrete torus. Let be the average time for a single random walk to hit the set of nodes contained in a disc of radius around a point starting from the boundary of a disc of radius around . Then, we have: .
Lemma III.3**.**
[22]** Let be the number of nodes visited by a single random walk on after steps. Then, we have: and variance .
Proposition III.4**.**
In torus networks, the average time complexity of the TCM algorithm is of the order .
Proof.
Consider the token . From Lemma III.3, number of nodes are visited on average by token after steps. To simplify the analysis, we approximate the region of visited nodes with a disc of radius on a unit torus (see Fig. 4). Hence, after steps, radius of the disc would be where . Furthermore, any other token () walks randomly or follows another token on a trajectory of a random walk. Hence, from Lemma III.2, token hits the disc after average time units if it does not coalesce with any other token during this time interval. Following that, at most time slots are required to reach token . Therefore, the time complexity is of the order . ∎
IV Robustness Analysis
In this section, we study the robustness of CRW and TCM algorithms. In the literature of distributed systems, identifying robust algorithms is done mostly from a qualitative rather than quantitative perspective. For instance, there is a common belief that gossip algorithms have a robust structure against network perturbations such as node failures or time-varying topologies [9]. Nevertheless, this advantage is achieved by huge time and message complexities [9].
To the best of our knowledge, there exist a few works [23, 24] on analyzing the robustness of distributed function computation (DCF) algorithms. One of the main challenges is that it is difficult to devise a well defined robustness metric. Despite the challenges, there exist some methodologies for defining a robustness metric in a computing system [25, 26]. Here, we follow the same approach in these methodologies. To do so, three steps should be taken:
-
First, a metric should be considered for the system performance. In our case, we consider it as the probability of successful computation at the end of the algorithm, i.e. \Pr\{v_{i}=f(v_{1}^{0},\cdots,v_{n}^{0}),\forall i\in\{1,\cdots,n\},\mbox{ node i has not failed}\} where is the output of node . Note that the correct result is a function of initial values of whole nodes.
-
In the second step, network perturbations should be modelled. In the CRW and TCM algorithms, the final result may be corrupted if an active node fails. Thus, studying the impact of such event on the robustness of these algorithms is quite important. In order to model node failures, we assume that each node may crash according to exponential distribution with rate . Therefore, the average lifespan of a node is . As a result, at most number of nodes fail on average. We assume that the expected number of crashed nodes during the execution of the algorithm is at most a small fraction of network size, i.e. where .
-
At the end, it should be identified how much perturbation the algorithm can tolerate such that the performance metric remains in an acceptable region. For this purpose, we define the following robustness metric.
Definition IV.1**.**
The robustness metric, , is defined by the following equation:
[TABLE]
Intuitively, the robustness metric shows maximum failure rate which an algorithm can tolerate such that the probability of successful computation is greater than a desired threshold, . In order to execute CRW and TCM algorithms in the presence of node failure, it is assumed that each token chooses a random neighbor node for the next clock tick, if the contacting node at the current moment has been failed.
IV-A Robustness of CRW algorithm in complete graphs
We first derive the probability that node is active at time , i.e. .
Lemma IV.1**.**
In the non-failure scenario, node is active at time with probability .
Proof.
We use the mean field theorem to calculate the probability (for more on mean field theorem, see [27]). Due to symmetry property of the complete graphs, each node is active at time with the same probability . Thus, the portion of active nodes will decrease with rate . Therefore, we have: . By solving the differential equation and considering the fact that , we have: and where is the the number of active nodes at time . ∎
Lemma IV.2**.**
In the CRW algorithm, the probability of successful computation is greater than for the node failure rate .
Proof.
The function computation is successful iff none of active nodes fail up to time .666In controlled flooding mechanism, the value of last active node is broadcasted to all nodes. Thus, node failures have negligible impact on the final result in this phase and we neglect it in our analysis. Let be the event that none of active nodes fails in the time interval . Thus, the probability , satisfies the following equation:
[TABLE]
(a) From property of exponential distribution considered in modelling node failures.
(b) We assume that is not affected by missing a small fraction of nodes.
Therefore, we have:
[TABLE]
By solving the above differential equation, we have: . Hence, we can obtain a lower bound on the probability of successful computation, , as follows:
[TABLE]
The above inequality holds due to Jensen’s inequality and considering the fact that function is convex. ∎
After some manipulations, it can be easily verified that: . Hence, the single CRW can tolerate failure rates of order . But, how can we improve the performance of this algorithm such that it tolerates failure rates of order ? One effective solution is to run multiple CRWs in parallel. More specifically, we run instances of CRW algorithm denoted by ; As a result, if an active node fails in some instances of the CRW algorithm, it might be inactive in the other instances and those instances survive from that node failure.
In order to run multiple instances of the algorithm, tokens carry the index of the corresponding instance in the execution of the algorithm and can only coalesce with token of the same index. At the end of the algorithm, nodes decide on the output of an instance which includes as many values as possible in computing the target function. To do so, we can assume that each node has a count parameter which is equal to one at the beginning of the algorithm (see section II). The sum of these count parameters is obtained alongside computing the target function of initial values for each instance of the algorithm. Nodes decide on the output of instance with maximum count parameter.
Lemma IV.3**.**
To tolerate the failure rate of and get the correct result with probability , the number of instances of the CRW algorithm should be greater than:
[TABLE]
Proof.
Assuming that the multiple instances are approximately independent and considering and Lemma IV.2, the probability of successful computation of the target function with instances of CRW algorithm is greater than:
[TABLE]
∎
Corollary IV.1**.**
The CRW algorithm is robust against failing fraction of nodes by running instances of CRW algorithm in parallel. Thus, the message complexity is of the order . Since , this solution imposes low message overhead.
IV-B Robustness of TCM algorithm in complete graphs
To study the robustness of TCM algorithm, we first need to obtain the average percentage of active nodes at time . However, deriving for TCM algorithm in complete graphs is not an easy task as the one for the CRW algorithm. Since it is required to compute the following sum:
[TABLE]
where obtaining (or even bounds on them) is quite challenging. In order to simplify the analysis, we consider a form of function where and . The reason for choosing this form is that the average running time is of the order and it can also be fitted properly to the simulation results777From simulation results, the root mean square error (RMSE) of fitted function is less than for all .. According to this assumption, we can derive the probability of successful computation by the following lemma.
Lemma IV.4**.**
The probability of successful computation by TCM algorithm is greater than in complete graphs where .
Proof.
By the same arguments in the proof of Lemma IV.2, we have:
[TABLE]
Since is convex and non-increasing and is concave (), the is convex. Hence, we have from Jensen’s inequality:
[TABLE]
where . ∎
Corollary IV.2**.**
From Lemma IV.4, we can see that is at least for a single TCM algorithm. Similar to the CRW algorithm, we can run multiple instances of TCM algorithm in parallel to improve its robustness. In order to tolerate the failure rate of , the required number of instances running in parallel should be of the order .
V Simulation Results
In this section, we evaluate the performances of TCM and CRW algorithms through simulation. Simulation results are averaged over 10000 runs for both algorithms in complete graphs, torus networks, and Erdös-Renyi model.
In Fig. 5, average time complexities of TCM and CRW algorithms are given for complete graphs. In the TCM algorithm, is set to . As it can be seen, simulation results are close to our analysis. Furthermore, the TCM algorithm outperforms the CRW algorithm by a scale factor . For instance, for , the average time complexities of TCM and CRW algorithms are and time units, respectively. Hence, the amount of improvement is . In Fig. 6, the average message complexities of TCM and CRW algorithms are depicted in complete graphs. As it can be seen, the average message complexity of TCM algorithm is always less than half of the one for the CRW algorithm.
In order to study the effect of parameter on the running time of TCM algorithm, the average time complexity is plotted versus for the complete graphs in Fig. 7. Intuitively, the event horizon of token grows with a pace inversely proportional to . On the other hand, the relative velocity of two tokens is approximately related to . Thus, the average time complexity increases as goes to zero or one. Furthermore, the optimal gets close to as network size increases.
In Fig. 8, we evaluate the average time and message complexities of TCM and CRW algorithms in torus networks. We can see that TCM algorithm has at least a gain of in time complexity and a scale factor of in message complexity. In Fig. 9, the average time and message complexities of TCM and CRW algorithms are depicted in Erdös-Renyi model. According to Fig. 9(a), the TCM algorithm has an improvement in time complexity by a factor . Furthermore, the average message complexity of TCM algorithm is approximately half of the CRW algorithm.
In Fig. 10, the probability of successful computation by running one instance of TCM and CRW algorithms are depicted in the case of complete graphs. The failure rate is set to . For the TCM algorithm, is approximately equal to for different values of in the range . Besides, results from analysis are close to it by an offset of . In the case of CRW algorithm, results from the simulation and the analysis are also close to each other. For this algorithm, is greater than for various values of in the range .
In Fig. 11(a), the message complexities of the TCM and CRW algorithms are plotted versus failure rate in a complete graph with nodes. The number of parallel instances is determined such that the probability of successful computation is equal to . As it can be seen, it is required to run a few more instances of the TCM and CRW algorithms to tolerate higher failure rate. Furthermore, message complexity of the TCM algorithm is less than the one for the CRW algorithm. In Fig. 11(b), the time complexities of both algorithms are given versus failure rate. For higher failure rate, we need to run more instances of the TCM/CRW algorithm to have . On the other hand, executing multiple instance of the algorithms improves the time complexity. Since the target function is computed if any of the instances is terminated successfully.
In Fig. 12, the probabilities of successful computation of the TCM and CRW algorithms are plotted versus number of multiple instances in a complete graph with nodes for the failure rates . It can be seen that the analytical lower bounds in (12) and (17) are close to simulation results. Furthermore, goes to one in all cases when number of instances are executed in parallel. Thus, the proposed solution makes both algorithms robust against node failures by running a few number of instances in parallel as we expected from Corollaries IV.1 and IV.2.
Studying the impact of dynamic topologies on the performance of distributed algorithms is quite important. Here, we evaluate the performance of TCM and CRW algorithms under node mobility. There exist different mobility models in the literature of mobile ad hoc networks [14]. In the simulations, we consider the Random Walk (RW) mobility model which is frequently used in determining the protocol performance and it can mimic movements of mobile nodes walking in an unpredictable way [14].
Initially, suppose that nodes are located randomly over a square of unit area. Let be the location of node at time . In the RW mobility model, the differences and are two independent normally distributed random variables with zero mean and variance where is the diffusion coefficient [28]. Thus, the mean square displacement of a node is related to the parameter . In particular, the probability of large displacement increases as diffusion coefficient grows. We assumed that if a node reaches the boundary of simulated area, it will be bounced off the boundary according to the same angle. Furthermore, two nodes are neighbor if the distance between them is less than a fixed transmission range. The transmission range is set to a value such that the graph remains connected with high probability for the static case, i.e. [29].
In the TCM algorithm, we assume that each node registers the UID of the node that the token passed to it. Whenever an active node should send a token to a node which is not in its transmission range any more, it will pass its token to a random neighbor node. In Fig. 13, the time and message complexities of TCM and CRW algorithms are depicted versus the parameter in a network with nodes. It is noteworthy that both algorithms can compute the class of target functions defined in Lemma II.1 successfully even in high mobility networks. Furthermore, the time and message complexities of TCM algorithm increases as the parameter grows while node mobility improves the performance of CRW algorithm. In fact, higher mobility weakens the advantage of chasing mechanism. On the other hand, it gives an opportunity to a completely randomized solution, i.e. the CRW algorithm, to reduce the coalescing time of distant tokens. Nevertheless, simulation results show that the TCM algorithm outperforms the CRW algorithm in both time and message complexities.
VI Conclusions
In this paper, we proposed the TCM algorithm to compute a wide class of target functions (such as sum, average, min/max, XOR) in a distributed manner. In complete graph and Erdös-Renyi model, we showed that it reduces running time at least by factor with respect to completely randomized solution, i.e. the CRW algorithm, and there is at least a factor of improvement in torus networks. We defined a robustness metric to study the impact of node failures on the performance of CRW and TCM algorithms. The TCM and CRW algorithms can tolerate the failure rate of by running and instances in parallel, respectively. Furthermore, simulation results showed that both algorithm can compute the target functions successfully even in high mobility conditions.
VII Appendix A
Proof of Lemma III.1:
The pdf of can be approximated with Gaussian distribution where and [29]. After some manipulations, we have:
[TABLE]
where . Hence, the size of the set , is greater than with probability at least .
VIII Appendix B
Proof of Theorem III.2:
Consider token (). Let be the node visited by token at -th step and be the history of the corresponding walk. We define the walk taken by token as weakly self-avoiding walk, provided that:
[TABLE]
for some where . Thus, in a weakly self-avoiding walk, token visits new nodes with higher probability than the visited nodes.
Lemma VIII.1**.**
In the TCM algorithm, the path traced by token () is a weakly self-avoiding walk.
Proof.
Suppose that the token enters a node visited by some other token with higher UID. Let be the maximum UID, node has seen so far. Furthremore, assume that token is in steps and has visited node in -th step for the last time, i.e. . We denote the chasing and random walk modes of token by and , respectively. Now, for a given history , we have:
[TABLE]
Suppose that token was in -th step when token was leaving node (see Fig. 14). We prove that token will not visit nodes in the set in the next step. By contradiction, assume that there exists where . However, we have:
[TABLE]
due to the fact that token is chasing token . For , the above equation asserts that token revisited node in some step later than which is contradiction.
We know that token was eventually in the random walk mode in -th step. Hence, each node in the set is selected with probability in the -th step. Consequently, we have:
[TABLE]
From (20) and (22), it can be concluded that:
[TABLE]
Thus, the proof is complete.
∎
Assume that if token coalesces with token (where ), it virtually sticks to token . Now, if token meets another token, say with higher UID, token and all tokens attached to it, stick to token . This process continues until token hits the event horizon of by itself or another token. We denote the time for token to hit the event horizon of token by . Furthermore, let be the set of nodes visited by token up to time .
Token takes steps in the network according to a Poisson process with rate (assuming that ). At each step, it chooses one of nodes except its current node with probability . Thus, each node (excluding the initial node having token ) is not visited by token up to time with probability independently from other nodes. Hence, the pdf of the number of visited nodes at time is:
[TABLE]
for .
Lemma VIII.2**.**
We have the following probabilistic bound on the number of visited nodes by token at time :
[TABLE]
where .
Proof.
From (24) and the proposed upper bound for binomial distribution in [30], we have:
[TABLE]
where , and . Besides, we have:
[TABLE]
From above equation, it can be easily seen that for . Therefore, the proof is complete. ∎
Lemma VIII.3**.**
Let be the number of steps taken by token in time interval . Then, we have the following bound:
[TABLE]
where .
Proof.
The random variable is a Poisson process with rate at least . Thus, we have from the Chernoff bound:
[TABLE]
The proof is complete. ∎
Remark VIII.1**.**
By the same arguments in Lemma VIII.3, it can be shown that: where .
Given a time , we say that the event occurs if . Let and define . We have:
[TABLE]
(a) The first sum is given according to the union bound. The second sum is greater than the probability of having where and are the probabilities of choosing a node from the set and , respectively.
(b) From Lemma VIII.1, the path traced by token () is a weakly self-avoiding walk. Thus, we have: .
(c) The sum has greater value for larger and smaller . We can obtain this inequality by bounding the probability and from Lemma VIII.2 and Remark VIII.1, respectively.
(d) From Strling’s approximation, the probability is in the order of . Thus, it is less than for large enough .
Lemma VIII.4**.**
Assume that the event occurs. Then, the probability of not hitting the event horizon of token by token after is less than the following:
[TABLE]
Proof.
Suppose that the event occurs at time . Thus, the size of the the set , , will be greater than as far as token does not hit it. Hence, the probability of not hitting the event horizon of in time interval is less than . By bounding from below (see Lemma VIII.3), we have:
[TABLE]
∎
Lemma VIII.5**.**
Suppose that token hits the event horizon of token at time . Then, it will coalesce with token in next time units with probability greater than where and .
Proof.
In worst case scenario, the event horizon of token is a line with length and token hits end of the line at time . Thus, token reaches token at time given in the following equation:
[TABLE]
Let us define random variable , which is the difference of two independent Poisson random variables and with rates and , respectively. Hence, the random variable has Skellam distribution and we have:
[TABLE]
Since token takes at most steps in time interval with probability , we have:
[TABLE]
∎
Corollary VIII.1**.**
From Lemmas 31 and VIII.5, we have:
[TABLE]
Now, we can obtain an upper bound on the average time complexity:
[TABLE]
(a) Regardless of the event , token covers the complete graph in time units on average [13]. Thus, any token () will coalesce with it in at most time units on average. Hence, we have: . Besides, we know that according to (30).
(b) According to union bound.
(c) From Corollary 36.
(d) From the fact that for .
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] J. Almodovar and J. Nelson, “A gossip-based distributed processing algorithm for multiple transmitter localization,” in Statistical Signal Processing Workshop (SSP), 2012 IEEE , 2012, pp. 169–172.
- 2[2] A. Chiuso, F. Fagnani, L. Schenato, and S. Zampieri, “Gossip algorithms for simultaneous distributed estimation and classification in sensor networks,” Selected Topics in Signal Processing, IEEE Journal of , vol. 5, no. 4, pp. 691–706, 2011.
- 3[3] L. Necchi, A. Bonivento, L. Lavagno, A. Sangiovanni-Vincentelli, and L. Vanzago, “E 2rina: an energy efficient and reliable in-network aggregation for clustered wireless sensor networks,” in Wireless Communications and Networking Conference, 2007.WCNC 2007. IEEE , 2007, pp. 3364–3369.
- 4[4] G. Mateos, J. A. Bazerque, and G. B. Giannakis, “Distributed sparse linear regression,” Signal Processing, IEEE Transactions on , vol. 58, no. 10, pp. 5262–5276, 2010.
- 5[5] L. Hyang-Won, E. Modiano, and B. Long, “Distributed throughput maximization in wireless networks via random power allocation,” Mobile Computing, IEEE Transactions on , vol. 11, no. 4, pp. 577–590, 2012.
- 6[6] A. Nedic and A. Ozdaglar, “Distributed subgradient methods for multi-agent optimization,” Automatic Control, IEEE Transactions on , vol. 54, no. 1, pp. 48–61, 2009.
- 7[7] N. Lynch, Distributed algorithms . Morgan Kaufmann, 1996.
- 8[8] R. Sappidi, C. Rosenberg, and A. Girard, “Computing statistical functions in wired networks,” Selected Areas in Communications, IEEE Journal on , vol. 31, no. 4, pp. 731–742, 2013.