A randomized primal distributed algorithm for partitioned and big-data non-convex optimization
Ivano Notarnicola, Giuseppe Notarstefano

TL;DR
This paper introduces a simple, randomized primal distributed algorithm for large-scale, partitioned, non-convex optimization problems in network settings, demonstrating convergence and effectiveness through theoretical analysis and simulations.
Contribution
It proposes a novel asynchronous, randomized primal algorithm for distributed non-convex optimization that converges to stationary points, suitable for big-data network applications.
Findings
Algorithm converges to stationary points in non-convex settings.
Effective in asynchronous gossip communication environments.
Numerical simulations confirm theoretical convergence results.
Abstract
In this paper we consider a distributed optimization scenario in which the aggregate objective function to minimize is partitioned, big-data and possibly non-convex. Specifically, we focus on a set-up in which the dimension of the decision variable depends on the network size as well as the number of local functions, but each local function handled by a node depends only on a (small) portion of the entire optimization variable. This problem set-up has been shown to appear in many interesting network application scenarios. As main paper contribution, we develop a simple, primal distributed algorithm to solve the optimization problem, based on a randomized descent approach, which works under asynchronous gossip communication. We prove that the proposed asynchronous algorithm is a proper, ad-hoc version of a coordinate descent method and thus converges to a stationary point. To show the…
Click any figure to enlarge with its caption.
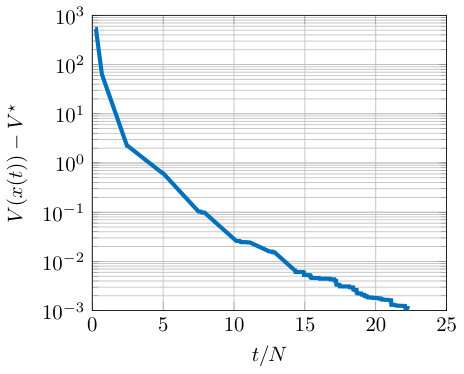 Figure 1
Figure 1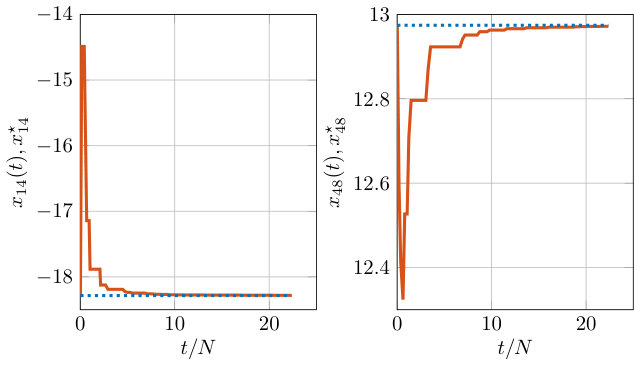 Figure 2
Figure 2Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStochastic Gradient Optimization Techniques · Sparse and Compressive Sensing Techniques · Distributed Control Multi-Agent Systems
A randomized primal distributed algorithm
for partitioned and big-data non-convex optimization
Ivano Notarnicola and Giuseppe Notarstefano Ivano Notarnicola and Giuseppe Notarstefano are with the Department of Engineering, Università del Salento, Via Monteroni, 73100 Lecce, Italy, [email protected]. This result is part of a project that has received funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement No 638992 - OPT4SMART).
Abstract
In this paper we consider a distributed optimization scenario in which the aggregate objective function to minimize is partitioned, big-data and possibly non-convex. Specifically, we focus on a set-up in which the dimension of the decision variable depends on the network size as well as the number of local functions, but each local function handled by a node depends only on a (small) portion of the entire optimization variable. This problem set-up has been shown to appear in many interesting network application scenarios. As main paper contribution, we develop a simple, primal distributed algorithm to solve the optimization problem, based on a randomized descent approach, which works under asynchronous gossip communication. We prove that the proposed asynchronous algorithm is a proper, ad-hoc version of a coordinate descent method and thus converges to a stationary point. To show the effectiveness of the proposed algorithm, we also present numerical simulations on a non-convex quadratic program, which confirm the theoretical results.
Index Terms:
primal, non-convex, proximal, asynchronous, randomized, coordinate, big-data, partitioned.
I Introduction
In several network scenarios optimization problems arise in which an aggregate cost function, sum of local cost functions, needs to be minimized in a distributed way. A typical approach in distributed optimization is to develop algorithms in which the processors in the network reach consensus on a minimizer of the problem. However, when the dimension of the decision variable depends on the number of agents in the network the consensus approach gives rise to algorithms which scale badly with the network size. Enforcing consensus on the entire vector of decision variables is not necessary in many important applications, since the nodes are interested in computing only part of the decision vector, namely only some local variables of interest. In this paper we consider a partitioned problem set-up in which the aggregate function is the sum of local functions, each one depending only on a portion of the decision vector. For this set-up our goal is to design a distributed algorithm in which the nodes compute only a local portion of interest of the entire solution vector, so that the whole minimizer can be obtained by stacking together the local portions.
This partitioned set-up has been introduced in [1] where a distributed ADMM-based algorithm is proposed. In [2] some concrete motivating scenarios are described for the same set-up and a dual decomposition algorithm is proposed. In both the above references the algorithms are designed for a synchronous network with a fixed communication graph. In [3], an analogous problem formulation is considered within a parallel context. The authors propose a coordinate descent method and derive its convergence rate. In [4] the authors propose a distributed algorithm for a partitioned quadratic program under lossy communication. A distributed ADMM-based algorithm with applications in MPC is proposed in [5] to deal with an unconstrained optimization problem with local domains which is related to the set-up in this paper.
Usually, distributed approaches need a common clock (e.g., because a diminishing (time-varying) step-size is used). We want to avoid this limitation designing an asynchronous, event-triggered protocol based on local and independent timers, [6]. A Newton-Raphson consensus strategy is proposed in [7] to solve unconstrained, convex optimization problems under asynchronous, symmetric gossip communications. In [8] a self-triggered communication protocol is considered. Based on an error condition a distributed, continuous-time algorithm is developed. In [9] an asynchronous ADMM-based distributed method is proposed for a separable, constrained optimization problem with a convergence rate . A distributed, asynchronous algorithm for constrained optimization based on random projections is proposed in [10].
The asynchronous, distributed algorithm we design in this paper is based on a (randomized) coordinate descent method. In [11] the coordinate method for huge scale optimization has been introduced. This powerful approach has been extended to deal with (convex) composite objective functions and parallel scenarios, see [12, 13, 3]. In [14] a coordinate approach to solve linearly constrained problems has been proposed. Using a coordinate ADMM-based approach, in [15] a distributed, asynchronous algorithm is developed.
Regarding non-convex optimization problems, in [16], the authors extend the coordinate approach to large-scale non-convex optimization proving the rate of convergence of their algorithms. A parallel algorithm based on local strongly convex approximations is exploited in [17] to cope with non-convex optimization problems. The latter approach has been extended to a distributed context in [18]. In [19], the authors proposed an auction-based distributed algorithm for non-convex optimization.
As main paper contribution we propose an asynchronous, distributed algorithm to solve partitioned, big-data non-convex optimization problems. The proposed primal algorithm is based on local updates involving the minimization of a strongly convex, quadratic approximation of the objective function. Each node constructs this approximation by exchanging information only with neighboring nodes. The updates at each node are regulated by a local timer that triggers independently from the ones of the other nodes. We prove the convergence in probability of the distributed algorithm by showing that it is equivalent to a generalized coordinate descent method for the minimization of non-convex composite functions. The generalized coordinate descent algorithm extends the one proposed in [16] and thus represents a side interesting result.
The paper is organized as follows. In Section II we present the problem set-up. In Section III we propose our algorithm and prove its convergence in Section IV. Finally, in Section V we show some simulations.
Notation
Consider a vector partitioned in block-components as follows
[TABLE]
where, for all , we have and . Moreover, consider a block decomposition of the identity matrix , where for all each . Then we can write and . For a function , we denote the “partial” gradient of with respect to .
II Optimization problem set-up
We consider a network of nodes which can interact according to a fixed, undirected communication graph , where is the set of edges. That is, the edge models the fact that node and can exchange information. We denote by the set of neighbors of node in the fixed graph , i.e., , and by its cardinality. Here we assume that the graph contains also self-edges, so that contains also .
We want to stress that the fixed graph only models, for each node, the set of possible neighbors the node can communicate with. On top of this graph, we will consider an asynchronous communication protocol described later.
We start by a common set-up in distributed optimization, i.e., the minimization of a separable cost function composed by two contributions, i.e., , where and , with . Usually this composite structure of the objective functions, is used to split the effective cost into a smooth part (modeling some local objective) and a (possibly) non-smooth one being a regularization term or a constraint.111A constraint is modeled by setting , with and otherwise.
In this paper we consider problems in which the composite function has a partitioned structure, that we next describe. Let the decision variable be partitioned as stated in (1), then the sub-vector with , represents the relevant information at node . Each local objective has a sparsity consistent with the interaction graph, namely, for , the function depends only on the component of node and of its neighbors. To highlight this property we let and write . Also, each function depends only on the component , i.e., .
In light of the described structure, the problem we aim at solving in a distributed way can be written as
[TABLE]
where node knows only the functions and . We call this problem partitioned (due to the structure of the functions and ) and big-data (since the dimension of the decision variable depends on the number of nodes).
Note that, in this partitioned scenario, network structure and objective function are inherently related. That is, nodes that share a variable are neighbors in the communication graph. As pointed out in the introduction this set-up appears in several interesting applications [2]. In the following assumptions we state the main properties of problem (2).
Assumption II.1**.**
For all , is a smooth function of . In particular, has block-coordinate Lipschitz continuous gradient, i.e., for all there exists constants such that for all and it holds
[TABLE]
where is a suitable matrix such that is a vector in with -th block-component equal to and all the other ones equal to zero.
In light of Assumption II.1, it is easy to show that the following lemma holds.
Lemma II.2**.**
Let Assumption II.1 hold, then the aggregate function has block-coordinate Lipschitz continuous gradient. In particular, for all , the partial gradient has Lipschitz constant given by .
Proof.
The proof follows straight by simply writing the norm of the aggregate cost and then bounding each term of its gradient by using its block Lipschitz constant. ∎
Remark II.3**.**
Note that one can assume directly that is Lipschitz continuous, but while the condition we impose can be checked in a distributed way, the weaker one needs a global knowledge of the cost .
Assumption II.4**.**
For all , the function is a proper, closed, proper, convex function.
We stress that we have not assumed any convexity condition on , thus optimization problem (2) is non-convex in general. Finally, we state the following assumption which is quite standard for non-convex scenarios.
Assumption II.5**.**
The cost of problem (2) is a coercive function.
Assumption II.5 guarantees that at least a local minimum for problem (2) exists.
Figure 1 visualizes the sparsity structure for a function partitioned according to a path graph of nodes. Each -th column shows the variables on which depends, while along each -th row it is possible to see in which functions a variable appears. It is worth noticing that the sparsity in the -th row shows the consistency that needs to be maintained among neighboring nodes on variable .
III Distributed optimization algorithm
In this section we present our asynchronous distributed algorithm.
In order to develop our algorithm, we need to introduce some technical tools: (i) the asynchronous communication protocol necessary to manage the overall behavior of the algorithm, and (ii) the local approximation model that each node will use to perform its local (descent) update.
We consider an asynchronous communication protocol where each node has its own concept of time defined by a local timer , which randomly and independently of the other nodes triggers when to awake itself. The timers trigger according to exponential distributions with a common parameter. We denote a realization drawn by node . Between two triggering events the node is in an idle mode, i.e., it continuously receives messages from neighboring nodes and updates some internal variables. When a trigger occurs, it switches into an awake mode in which it updates its local variable and transmits the updated information to its neighbors. A formal discussion on this protocol is given in [6].
The proposed distributed algorithm is based on local quadratic, strongly-convex approximations of the cost function that each node computes.
Formally, each node constructs the following local approximation of the entire cost function at a fixed (neglecting the constant term which does not affect the optimization),
[TABLE]
with a symmetric, positive definite matrix satisfying the following assumption.
Assumption III.1**.**
For any and it holds that .
Intuitively Assumption III.1 guarantees the strong convexity of . The role of the Lipschitz constant in the bound will be clear in the analysis of the algorithm given in Section IV.
Informally, the asynchronous distributed optimization algorithms is as follows. A node takes care of modifying the variable . We denote the current state of node , which is the estimated optimal value of the variable . Consistently we denote the vector of states of nodes in .
When a node wakes up, it updates its state by moving in the direction obtained from the minimization of its local approximation , being the current value of the decision variable. Then, it sends to each neighbor the updated and . When in idle, node is in a listening mode. If an updated is received from a neighbor no computation is needed. If is also received ( was an awake node) the following happens. Node updates the partial gradients of its local function according to the new , and sends back the updated partial gradients to its neighbors. In order to highlight the difference between updated and old variables at node during the awake phase, we denote the updated ones with a “” symbol, e.g., as .
We want to stress two important aspects of the idle/awake cycle. First, these two phases are regulated by local timers without the need of any central clock. Second, when in idle a node only receives messages and from time to time evaluates a partial gradient, which takes a negligible time compared to the computation performed in the awake phase.
The distributed algorithm is formally reported in the table below (from the perspective of node ).
We point out some aspects involving the local approximation (3) that each node uses in its local computations.
First, it is worth noting does not depend on the entire state , but only on , and therefore is constructed by node by using only information from its neighbors. Moreover, node does not needed the expression of neighboring cost functions to build , but only the gradients . In some special cases (discussed in the following paragraph), could include second order information of , , i.e., , that should be sent together with the gradients.
Second, different choices for the weight matrix are allowed. By exploiting the block Lipschitz continuity of the gradient of , a first simple choice is to set for all and . Motivated by existing works in the literature, e.g., [17], non diagonal choices for are reasonable: for instance, assuming , one can select a second order approximation, i.e., set for a sufficiently large for all . As mentioned above this information can be constructed in a distributed manner.
Third and final, recalling the definition of the proximal operator of a closed, proper, convex function given by \mathbf{prox}_{\alpha,\varphi}(v):=\mathop{\rm argmin}_{x}\big{(}\varphi(x)+\frac{1}{2\alpha}\|x-v\|^{2}\big{)} with , we have that for the update law described in (4)-(5), can be rephrased in term of proximal operators and, thus, leading to a distributed coordinate proximal gradient method. On this regard it is worth noting that our algorithm, with a general expression for , can be written in terms of a generalized, weighted version of the proximal operator as follows. Given a positive definite matrix , we define
[TABLE]
thus, the iteration (4)-(5) can be recast as
[TABLE]
IV Convergence analysis of the Partitioned Coordinate Descent distributed
algorithm
In this section we prove the convergence in probability of the proposed algorithm.
First, it is worth pointing out that being the algorithm asynchronous, for the analysis we need to carefully formalize the concept of algorithm iterations. We will use a nonnegative integer variable indexing a change in the whole state of the distributed algorithm. In particular, each triggering will induce an iteration of the distributed optimization algorithm and will be indexed with . We want to stress that this (integer) variable does not need to be known by the agents. That is, this timer is not a common clock and is only introduced for the sake of analysis.
Theorem IV.1**.**
Let Assumptions II.1, II.4, II.5 and III.1 hold true. Then, the Partitioned Coordinate Descent distributed algorithm generates a sequence (obtained stacking the nodes’ states) such that the random variable converges almost surely, i.e., there exists a random variable such that
[TABLE]
Moreover, any limit point of is a stationary point of problem (2) and, thus, satisfies its first order optimality condition, i.e., there exists a subgradient of at such that .
IV-A Coordinate descent method for composite non-convex minimization
In this subsection we consider a more general composite optimization problem and prove a result that is instrumental to the convergence proof of our distributed algorithm. We introduce a generalization of the algorithm proposed in [20, 13, 16] based on the quadratic approximation introduced in (3). We present the algorithm for problem (2), but we want to stress that the algorithm can be applied to a general function with block-Lipschitz continuous gradient. This will be clear from the analysis.
We consider a coordinate descent method based on selecting a random block-component, say , of at each iteration and updating only through a suitable descent rule. The descent step is based on the quadratic approximation of the cost function given in (3). The coordinate descent method is formally summarized in the table below.
In the following we present results for the theoretical convergence of the generalized coordinate descent algorithm.
Lemma IV.2**.**
Let Assumption II.1, II.4, III.1 hold. Let be the random sequence generated by Generalized Coordinate Descent Algorithm, then for all it holds
[TABLE]
Proof.
From Assumption II.1 (Lipschitz continuity of ), we can write the well-known descent lemma (see [21, Proposition A.24]), for all and for all
[TABLE]
with introduced in the Notation paragraph.
Since satisfies Assumption III.1, then we can generalize the above descent condition by introducing a uniform bound depending on the Lipschitz constant of block , i.e.,
[TABLE]
Due the partitioned structure of , the explicit expression of actually depends only on , , thus the latter condition can be further rephrased as
[TABLE]
with defined as in (3).
Consider a descent direction computed as in (7), then satisfies the first order necessary condition of optimality for problem (7)
[TABLE]
where is a particular subgradient of .
Starting form equation (9) with the following identification and , and adding and subtracting the term we obtain
[TABLE]
where we used the convexity of , the optimality condition (10) and the uniform bound in Assumption III.1. ∎
Theorem IV.3**.**
Let Assumptions II.1, II.4, II.5 and III.1 hold true. Then, the Generalized Coordinate Descent Algorithm generates a sequence such that the random variable converges almost surely. Moreover, any limit point of is a stationary point of and, thus, satisfies the first order necessary condition for optimality for problem (2), i.e., there exists a subgradient of at such that
[TABLE]
Proof.
The result is proven by following the same line as in [16, Theorem 1] where the generalized Lemma IV.2 is used in place of [16, Lemma 3]. ∎
IV-B Proof of Theorem IV.1
Our proof strategy is based on showing that the iterations of the asynchronous distributed algorithm can be written as the iterations of an ad-hoc version of the coordinate descent method for composite non-convex functions given in Section IV-A.
Timer model and uniform node extraction. Since the timers trigger independently according to the same exponential distribution, then from an external, global perspective, the induced awaking process of the nodes corresponds to the following: only one node per iteration wakes up randomly, uniformly and independently from previous iterations. Thus, each triggering, which induces an iteration of the distributed optimization algorithm and is indexed with , corresponds to the (uniform) selection of a node in that becomes awake. We denote the extracted node. Notice that node changes the value of its state while all the other states are not changed by the algorithm.
State consistency (inductive argument). Next we show by induction that if all the nodes have a consistent and updated information before a node gets awake, then the same holds after the update. By consistent we mean that for a variable , all the nodes in have the same state . By updated we mean that each node has an updated value of the gradients , . First, node changes only its state relative to the variable . This variable is shared only with neighbors , which receive the new state after the update. As regards the gradients, the ones affected by the change of the variable are , with . Notice that these gradients are only used by nodes . But after the broadcast performed by , each idle receives the updated , updates the gradients, and sends them to its neighbors . The variables and gradients for the rest of the nodes in the network are not changed by the update of node .
Coordinate descent equivalence and convergence. Finally, we simply notice that, thanks to the consistency argument just shown, steps (4)-(5) correspond to steps (7)-(8). Thus, we have shown that our distributed algorithm implements the centralized coordinate method and therefore inherits its convergence properties. By invoking Theorem IV.3, the proof follows.
V Numerical simulations on a non-convex constrained quadratic program
In this section we present a numerical example showing the effectiveness of the proposed algorithm.
We consider an undirected connected Erdős-Rényi random graph , with parameter , connecting nodes and we test the distributed algorithm on a partitioned non-convex constrained quadratic program in the form
[TABLE]
where each for all and each cost matrix is only symmetric (not positive definite). We construct as the difference between a positive definite matrix and a suitable scaled version of the identity matrix. Finally, each function denotes the indicator function of the segment , i.e., we constrain each to lie into an interval. We set and for all .
Problem (11) fits our set-up described in Section II by defining
[TABLE]
and
[TABLE]
Moreover, we use the local approximation as in (3) with with for all .
In Figure 2 we plot the evolution of two selected components of the decision variable at each iteration (defined as discussed in Section IV), i.e., , . The horizontal dotted lines represent the centralized solution. Since the algorithm is asynchronous and based on a coordinate approach, we plot the rate of convergence with respect to the normalized iterations in order to show the effective behavior with respect to the global time.
In Figure 3 we show the difference, in logarithmic scale, between the cost at each iteration and the value of attained at the limit point of (proven to be a stationary point).
VI Conclusions
In this paper we have proposed an asynchronous, distributed algorithm to solve partitioned, big-data non-convex optimization problems. The main idea is that each node updates its local variable by minimizing a suitable, local quadratic approximation of the cost, built via an information exchange with neighboring nodes. We prove the convergence of the distributed algorithm by showing that it corresponds to a proper instance of a coordinate descent method.
Acknowledgments
The authors would like to thank Angelo Coluccia e Massimo Frittelli for their help and suggestions.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] T. Erseghe, “A distributed and scalable processing method based upon admm,” IEEE Signal Processing Letters , vol. 19, no. 9, pp. 563–566, 2012.
- 2[2] R. Carli and G. Notarstefano, “Distributed partition-based optimization via dual decomposition,” in IEEE 52nd Annual Conference on Decision and Control (CDC) , 2013, pp. 2979–2984.
- 3[3] I. Necoara and D. Clipici, “Parallel random coordinate descent method for composite minimization: Convergence analysis and error bounds,” SIAM Journal on Optimization , vol. 26, no. 1, pp. 197–226, 2016.
- 4[4] M. Todescato, G. Cavraro, R. Carli, and L. Schenato, “A robust block-Jacobi algorithm for quadratic programming under lossy communications,” in IFAC-Papers On Line , vol. 48, no. 22. Elsevier, 2015, pp. 126–131.
- 5[5] J. F. Mota, J. M. Xavier, P. M. Aguiar, and M. Puschel, “Distributed optimization with local domains: Applications in MPC and network flows,” IEEE Transactions on Automatic Control , vol. 60, no. 7, pp. 2004–2009, 2015.
- 6[6] I. Notarnicola and G. Notarstefano, “Randomized dual proximal gradient for large-scale distributed optimization,” in IEEE 54th Conference on Decision and Control (CDC) , 2015, pp. 712–717.
- 7[7] F. Zanella, D. Varagnolo, A. Cenedese, G. Pillonetto, and L. Schenato, “Asynchronous Newton-Raphson consensus for distributed convex optimization,” in 3rd IFAC Workshop on Distributed Estimation and Control in Networked Systems , 2012.
- 8[8] D. V. Dimarogonas, E. Frazzoli, and K. H. Johansson, “Distributed event-triggered control for multi-agent systems,” IEEE Transactions on Automatic Control , vol. 57, no. 5, pp. 1291–1297, 2012.